Login impossible suite à l'upgrade vers Fedora 32 5 Oct 2020 11:47 AM (4 years ago)
J’ai récemment mis à jour ma distibution Linux Fedora vers la version 32.
La manipulation en elle-même est très simple et parfaitement décrite sur cette page : https://fedoramagazine.org/upgrading-fedora-31-to-fedora-32/
Par contre, j’ai eu quelques soucis lorsque j’ai voulu m’authentifié : j’étais systématiquement redirigé vers l’écran de login, sans message d’erreur.
Je vais vous décrire ici les manipulations réalisées pour revenir à la normale.
Contexte
Comme je l’indiquais, j’ai mis à jour ma distribution Fedora vers la version 32.
Tout s’est déroulé correctement, aucun problème majeur rencontré.
Le système a redémarré correctement et j’ai pu m’authentifier une première fois.
Par contre, je me suis rendu compte que je ne disposais plus de l’affichage habituel, en particulier, la barre des fenêtres en bas de l’écran n’apparaissait plus.
En fouillant un peu, je me suis rendu compte que toutes les extensions Gnome étaient désactivées.
Je les ai donc toutes réactivées via l’application Ajustement.
L’affichage était de nouveau conforme à mes attentes et j’ai pu travailler sur mon PC sans problème.
Problème
Mais, lorsque j’ai voulu accéder à mon poste quelques jours après, impossible de m’authentifier.
Lorsque je validais mon mot de passe, l’écran se figeait quelques instants et j’étais redirigé vers l’écran de sélection de compte.
Aucun message d’erreur, pas d’explication.
Je me suis alors connecté avec un autre compte sur le poste, pour lequel je n’avais pas réactivé les extensions Gnome.
En recherchant quelques minutes, j’ai rapidement compris que le problème venait bien de l’activation des extensions.
Solution
Voici ce qu’il faut faire pour pouvoir de nouveau accéder à votre compte et réactiver les extensions.
Retrouver l’accès au compte
Dans un premier temps, connectez-vous avec un compte utilisateur non impacté par ce problème.
Si besoin, créez-en un nouveau.
Ouvrez un terminal et saisissez la commande ci-dessous pour vous connecter avec le compte défaillant :
su - nom_du_compteEnsuite, il faut désactiver les extensions avec la commande suivante :
gsettings set org.gnome.shell disable-user-extensions trueVous pouvez-maintenant fermer le terminal et la session en cours puis vous connectez avec le compte initialement impacté.
Activer les extensions
Le problème suit à la mise à jour vient du fait que la version 32 de Fedora utilise un nouveau système permettant de gérer les extensions.
Cette information est indiquée sur cette page https://fedoramagazine.org/whats-new-fedora-32-workstation/, au paragraphe New Extensions Application.
Comme indiqué, il faut maintenant installer le package gnome-extensions-app.
sudo dnf install gnome-extensions-appVous pouvez ensuite démarrer l’application Extensions et activer les extensions que vous souhaitez.










Configurer AWS Beanstalk pour exécuter une application Laravel 9 Jun 2020 7:27 PM (4 years ago)
Le déploiement d’une application Laravel sur la plateforme Linux 2 d’AWS Beanstalk nécessite quelques paramétrages supplémentaires.
Nous allons voir dans cet article comment les mettre en place.
En effet, bien que la documentation officielle soit très complète (https://docs.aws.amazon.com/fr_fr/elasticbeanstalk/latest/dg/php-laravel-tutorial.html), il manque quelques précisions au moment où j’écris cet article.
Contexte
Je ne reviendrai pas ici sur la création d’une application Laravel, la documentation et très complète en ligne.
De même, pour le déploiement dans Beanstalk, vous pouvez vous référer à la documentation officielle : https://docs.aws.amazon.com/fr_fr/elasticbeanstalk/latest/dg/php-laravel-tutorial.html
Pour rédiger cet article, j’ai utilisé la version 7 du framework Laravel.
Dans Beanstalk, j’ai utilisé la plateforme suivante :
Plateforme: PHPBranche de plateforme: PHP 7.3 running on 64bit Amazon Linux 2Version de plateforme: 3.0.2
Il s’agit bien ici de la version 2 de la plateforme Linux. Celle-ci utilise Nginx, alors que la version 1 utilise Apache (cet article ne s’applique pas dans ce dernier cas).
Vous pourrez trouver les informations sur les plateformes PHP ici : https://docs.aws.amazon.com/elasticbeanstalk/latest/platforms/platforms-supported.html#platforms-supported.PHP
Problème
Si vous déployez votre application Laravel directement sur cette version 2 de la plateforme, les redirections ne seront pas possibles puisque Nginx n’est pas configuré pour les prendre en compte (contrairement à Apache, via les fichiers .htaccess).
Le but est donc de configurer notre environnement pour permettre les redirections vers le fichier index.php.
Pour cela, je me baserai sur :
- La documentation Laravel pour le déploiement dans Nginx : https://laravel.com/docs/7.x/deployment#nginx
- La documentation AWS pour étendre la plateforme : https://docs.aws.amazon.com/fr_fr/elasticbeanstalk/latest/dg/platforms-linux-extend.html (section Configuration du proxy inverse)
Solution
Je suppose que le paramétrage pour utiliser le répertoire /public comme racine a été faite comme indiqué dans la documentation : https://docs.aws.amazon.com/fr_fr/elasticbeanstalk/latest/dg/php-laravel-tutorial.html#php-laravel-tutorial-configure
Le principe est d’ajouter à la configuration Nginx la redirection vers le fichier index.php pour que le framework Laravel gère les différentes routes.
Pour cela, il faut créer le fichier .platform/nginx/conf.d/elasticbeanstalk/laravel.conf à la racine de votre projet.
Le nom du fichier n’a pas d’importance, mais il faut respecter les règles suivantes :
- Le fichier doit être créé dans l’arborescence
.platform/nginx/conf.d/elasticbeanstalk/ - L’extension du fichier doit être
.conf
Ce fichier doit contenir :
location / {
try_files $uri $uri/ /index.php?$query_string;
}Vous pouvez bien entendu ajouter les configurations supplémentaires que vous souhaitez, le but ici est de gérer les redirections.
Il ne vous reste plus qu’à déployer votre application dans Beanstalk.
Installer l'extension MongoDB pour PHP dans Amazon Web Service 9 Jun 2020 12:10 PM (4 years ago)
L’installation d’une extension PHP dans Amazon Web Service Elastic Beanstalk n’est pas aussi simple qu’il y paraît, en particulier pour MongoDB.
La documentation à ce sujet n’est d’ailleurs pas à jour (au moment où j’écris cet article) : https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/php-configuration-phpini.html
Nous allons voir comment procéder.
Contexte
Je tiens à préciser que j’écris cet article alors que je découvre les services offerts par AWS (Amazon Web Service).
Il est possible que ce que je décrive ne convienne pas aux puristes.
Dans cet article, il s’agit plus d’un retour d’expérience d’un débutant qui souhaite tester le déploiement d’une application PHP dans AWS Elastic Beanstalk avec la possibilité de se connecter à un replicaset MongoDB.
Je ne m’attarderai pas sur l’utilisation d’AWS, la documentation officielle est très complète.
Version officielle
Dans la documentation en ligne, il est indiqué qu’un simple fichier de configuration suffit.
Pour cela, dans l’application, il faut créer le fichier .ebextensions/mongodb.config à la racine.
files:
"/etc/php.d/99-mongodb.ini" :
mode: "000644"
owner: root
group: root
content: |
extension=mongodb.soPour ma part, impossible de disposer de la connectique à MongoDB de cette façon.
J’ai fait l’essai avec un projet simple ne contenant qu’un fichier phpinfo.php, la catégorie MongoDB n’était pas affichée.
Celle que j’ai utilisée
Après plusieurs recherches, voici la solution que j’ai retenue (et qui fonctionne pour mon besoin).
Il faut toujours créer le fichier .ebextensions/mongodb.config à la racine du projet.
Mais celui-ci exécutera la commande permettant d’installer l’extension via PECL :
commands:
install_mongodb_driver:
test: "php -r \"exit(extension_loaded('mongodb') ? 1 : 0);\""
command: pecl install mongodb-1.7.4Le fichier décrit la commande install_mongodb_driver (vous pouvez choisir le nom qui vous convient).
Elle sera exécutée si le résultat de l’instruction test est 0 (code de sortie de la commande qu’elle indique).
La ligne command utilise la commande PECL pour installer l’extension (ici en version 1.7.4).
Il suffit d’adapter la version de l’extension à votre besoin.
Vous pouvez vous référer au référentiel officiel pour identifier la version qui correspond à votre projet : https://pecl.php.net/package/mongodb
Lorsque votre application est déployée, vous disposez de l’extension MongoDB.
Les raccourcis vi à connaître 19 Apr 2020 12:04 PM (5 years ago)
L’outil vi est un éditeur de texte dépourvu d’interface graphique disponible sous Linux.
Il est souvent de cauchemar des personnes qui doivent l’utiliser, mais est très puissant.
Nous allons voir dans cet article les commandes les plus utiles.
Les commandes listées ici sont les plus utiles à mon sens. Il y en a énormément d’autres. N’hésitez pas à effectuer quelques recherches complémentaires.
Démarrer
Pour éditer un fichier ou en créer un, vous pouvez utiliser la commande suivante :
vi chemin/vers/mon/fichier.txtQuitter
| Raccourci | Description |
|---|---|
:q<Entrée> |
Quitte vi sans sauvegarde (quit, quitter) |
:q!<Entrée> |
Force vi à quitter sans sauvegarde (en ignorant les modifications éventuelles) |
:wq<Entrée> |
Enregistre les modifications et quitte vi (write / quit, écrire / quitter) |
:x<Entrée> |
Identique à :wq<Entrée> |
Se déplacer
| Raccourci | Description |
|---|---|
0 |
Déplace le curseur au début de ligne courante |
$ |
Déplace le curseur en fin de ligne courante |
w |
Déplace le curseur au début du mot suivant |
b |
Déplace le curseur au début du mot précédent |
:0<Entrée> ou 1G |
Déplace le curseur au début de la première ligne du fichier |
:n<Entrée> ou nG |
Déplace le curseur au début de la ligne numéro n |
:$<Entrée> ou G |
Déplace le curseur au début de la dernière ligne du fichier |
Insérer
| Raccourci | Description |
|---|---|
i |
Active le mode insertion de texte au niveau du curseur (insert, insérer) |
I |
Active le mode insertion de texte en début de ligne (Insert, Insérer) |
a |
Active le mode insertion de texte un caractère après le curseur (append, ajouter) |
A |
Active le mode insertion de texte en fin de ligne (Append, Ajouter) |
o |
Insère une ligne après le curseur et passe en mode insertion (open, ouvrir) |
O |
Insère une ligne avant le curseur et passe en mode insertion (Open, Ouvrir) |
<Esc> |
Quitte le mode insertion |
Supprimer
| Raccourci | Description |
|---|---|
x |
Supprime le caractère au niveau du curseur |
nx |
Supprime n caractères à partir du curseur |
dw |
Supprime le mot à partir du curseur (delete word, supprimer mot) |
dnw |
Supprime n mots à partir du curseur (delete n words, supprimer n mots) |
D |
Supprime jusqu’en fin de ligne, à partir du curseur |
dd |
Supprime la ligne courante |
ndd ou dnd |
Supprime n lignes à partir de la ligne courante |
Remplacer
| Raccourci | Description |
|---|---|
rx |
Remplace le caractère au niveau du curseur par la lettre x |
Rphrase<Esc> |
Remplace les caractères à partir du curseur par phrase |
cwphrase<Esc> |
Remplace le mot à partir du curseur par phrase (change word, remplacer mot) |
cnwphrase<Esc> |
Remplace n mots à partir du curseur par phrase (change n words, remplacer n mots) |
Cphrase<Esc> |
Remplace tous les caractères jusqu’en fin de ligne par phrase |
ccphrase<Esc> |
Remplace la ligne courante par phrase |
nccphrase<Esc> ou cncphrase<Esc> |
Supprime n lignes à partir de la ligne courante par phrase |
Copier / coller
| Raccourci | Description |
|---|---|
Y ou yy |
Copie la ligne sur laquelle le curseur est positionné |
nY |
Copie n lignes |
P |
Colle les lignes copiées avant le curseur |
p |
Colle les lignes copiées après le curseur |
Annuler
| Raccourci | Description |
|---|---|
u |
Annule la dernière modification (undo, défaire) |
U |
Annule toutes les modifications de la ligne courante |
Rechercher
| Raccourci | Description |
|---|---|
/motif |
Recherche motif en avant |
?motif |
Recherche motif en arrière |
n |
Répète la dernière recherche en avant |
N |
Retourne au résultat précédent |
Définir les paramètres WI-FI d'un Raspberry Pi Zero W sans périphérique 18 Apr 2020 12:07 AM (5 years ago)
Le Raspberry Pi Zero W est la version mini de la célèbre carte Raspberry Pi.
La lettre W indique qu’il dispose de la connectivité WI-FI.
Nous allons voir dans cet article comment définir les paramètres réseau sous Raspbian sans avoir à connecter clavier / souris / écran.
Cette configuration fonctionne également avec le Raspberry PI 3 Model B+.
Prérequis
Pour pouvoir profiter de votre mini ordinateur en WI-FI, il vous faut :
- Un raspberry Pi Zero W
- Une carte MicroSD avec un adaptateur
- Une alimentation MicroUSB
Il est important que le Raspberry soit un Zero W. Sans ce dernier W, vous n’aurez pas le module WI-FI natif.
Côté logiciel, vous aurez besoin de :
- Un outil de transfert d’image OS : j’utilise Etcher sous Linux. Il est également disponible pour Windows et Mac.
- Un éditeur de texte : l’éditeur de base de votre ordinateur suffit amplement.
- Un outil de connexion SSH : je suis adepte des lignes de commandes, mais vous pouvez utiliser Putty.
Préparation de l’image
Pour faire fonctionner votre Raspberry, il faut télécharger au préalable le système Raspbian : https://www.raspberrypi.org/downloads/.
Ensuite, le “transfert” du système choisi sur la carte MicroSD (ou flashage de la carte MicroSD) se fait en utilisant le logiciel listé ci-dessus.
Je ne détaillerai pas la procédure pour flasher la carte MicroSD ici. De nombreux sites en parlent très bien et les manipulations sont très simples.
Configuration du réseau WI-FI
Insérez la carte MicroSD dans son adaptateur pour pouvoir y accéder sur votre poste.
Placez-vous à la racine de la carte nommée boot puis créez le fichier wpa_supplicant.conf.
Ensuite éditez ce fichier et renseignez les paramètres de votre réseau WI-FI comme ci-dessous :
country=FR
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
update_config=1
network={
scan_ssid=1
ssid="Mon_Réseau_Wifi"
psk="le_mot_de_passe_de_mon_réseau"
key_mgmt=WPA-PSK
}Les valeurs à renseigner dépendent évidemment de votre configuration :
country: code du pays sur 2 lettres (https://fr.wikipedia.org/wiki/ISO_3166-1)ctrl_interface: permet l’utilisation dewpa_cliupdate_config: précise que les changements faits via la ligne de commande seront sauvegardésscan_ssid: indique que votre réseau WI-FI peut être masquéssid: nom du réseau WI-FIpsk: mot de passe pour se connecter au réseaukey_mgmt: sécurité du réseau
Plus d’informations sur la syntaxe et autres paramètres du fichier sont disponibles sur https://linux.die.net/man/5/wpa_supplicant.conf.
Et la sécurité dans tout ça !
En effet, le mot de passe est écrit en clair dans le fichier. On a connu mieux.
Je vous expliquerai comment remédier à ce problème à la fin de cet article.
Activation du SSH
Pour pouvoir se connecter au Raspberry en SSH, il faut l’activer.
Rien de plus simple, il suffit de créer un fichier vide nommé ssh à la racine de la carte MicroSD boot (au même emplacement que le fichier wpa_supplicant.conf).
Faites bien attention qu’il n’y ait aucune extension au fichier ssh lorsqu’il est créé.
Démarrage du Raspberry
Toutes les configurations sont maintenant terminées (n’oubliez pas de sauvegarder les fichiers).
Vous pouvez éjecter la carte MicroSD de votre ordinateur et l’insérer dans le Raspberry.
Mettez-le sous tension et attendez quelques minutes que la procédure de démarrage se termine.
Et voilà !
Votre Raspberry est connecté à votre réseau WI-FI.
Pour trouver son adresse IP, vous aurez plusieurs solutions :
- Utiliser l’interface de votre box / routeur
- Utiliser un outil pour scanner votre réseau (je n’en utilise pas, mais une petite recherche sur Internet vous donnera une liste de logiciels)
Il vous suffit ensuite de vous connecter en SSH pour vérifier que tout fonctionne correctement.
Les identifiants par défaut sont :
- login =
pi - mot de passe =
raspberry
Sécuriser la configuration
Comme nous l’avons vu lors de la configuration du réseau, le mot de passe est écrit en clair dans le fichier wpa_supplicant.conf.
Nous allons voir comment corriger cela.
Sous Linux
Si votre ordinateur est sous Linux, vous pouvez réaliser cette manipulation avant le premier démarrage de votre Raspberry.
Dans un terminal, saisissez la commande suivante :
wpa_passphrase Mon_Réseau_WifiRenseignez votre mot de passe puis appuyez que la touche Entrée.
Vous obtenez alors la configuration de base pour votre réseau :
network={
ssid="Mon_Réseau_Wifi"
#psk="le_mot_de_passe_de_mon_réseau"
psk=a69c58a517d7f9d20bcc0a49c60be5b87c27349d05bbf998076b70196af53b62
}Il ne vous reste plus qu’à :
- Recopier simplement cette configuration dans le fichier
wpa_supplicant.conf - Supprimer la ligne en commentaire avec le mot de passe en clair
- Compléter la configuration avec d’autres paramètres : pays, scan…
Sous Windows
Lorsque le Rapberry est démarré, connectez vous en SSH.
Une fois connecté, comme ci-dessus, exécutez la commande suivante :
wpa_passphrase Mon_Réseau_WifiSaisissez le mot de passe lorsque vous y êtes invités.
Éditez le fichier /etc/wpa_supplicant/wpa_supplicant.conf et remplacez le mot de passe par celui encrypté retourné par la commande précédente.
Redémarrez le Raspberry.
Tester unitairement un service Angular 3 Apr 2020 1:02 PM (5 years ago)
Les tests unitaires représentent une part importante du développement.
Si vous êtes adeptes du TDD (Test Driven Development), je ne vous apprendrai pas leur utilité.
Dans cet article, je vais vous présenter comment tester un service Angular.
En particulier, si votre service nécessite l’injection d’un autre service, vous verrez comment réaliser ce qu’on appelle un mock.
Prérequis
Si vous souhaitez réaliser les exercices au fur et à mesure de la lecture de cet article, vous devez disposer des outils suivants installés sur votre poste :
| Outil | Version |
|---|---|
| NodeJS | 10.19.0 |
| NPM | 6.14.3 |
| Angular | 9.1.0 |
Si ce n’est pas le cas, vous pouvez vous référer à la documentation officielle de chacun.
Le code source complet des exemples ci-dessous est disponible sur GitHub : https://github.com/benjaminprevot/2020-04-03-tester-unitairement-un-service-angular
Rappels
Test unitaire
Pour simplifier, les tests unitaires permettent de valider une partie précise de votre programme.
En particulier, ils évitent les régressions lors du cycle de développement.
Intégrés dans une chaîne d’intégration continue, ils représentent une étape importante de la validation du code source.
Mock
Les mocks sont des objets dits “simulés”.
Ils permettent de gérer le comportement d’une instance en forçant sont comportement.
Lors de la mise en place de tests unitaires, ils sont très utiles pour définir un comportement immuable dans le temps d’objets qui sont utilisés au sein de votre code.
Cela évite des comportements imprévisibles qui fausseraient les résultats des tests.
Création de l’application
Passons maintenant à la pratique.
Tout d’abord, nous allons créer une nouvelle application Angular pour vous guider dans la mise en place des tests unitaires.
Pour cela, vous devez ouvrir un terminal de commande et vous positionnez dans le répertoire de travail.
Dans mon cas, je me place dans le répetoire workspace de mon répertoire personnel, sous Linux.
cd ~/workspaceEnsuite, la création de l’application mon-application se fait via la commande ci-dessous :
ng new mon-applicationQuelques questions vous serons posées, leurs réponses n’ont pas d’importance ici.
Lorsque l’exécution est terminée, il faut maintenant se placer dans la répertoire de l’application (c’est dans ce répertoire que les commandes suivantes seront lancées).
cd mon-applicationNotre appliation est maintenant créée et prête à être testée.
Création du service
Nous allons maintenant créer le service et le test unitaire correspondant.
Pour cela, Angular met à disposition une commande permettant de créer le fichier contenant la définition du service et le fichier pour le test unitaire correspondant.
ng generate service MonServiceJe ne rentrerai pas dans le détail de cette commande, vous pouvez vous référer à la documentation officielle pour plus de détails : https://angular.io/cli/generate#service
Dans le répertoire src/app, nous disposons de 2 fichiers supplémentaires :
mon-service.ts: définition de notre servicemon-service.spec.tx: test unitaire de notre service
Par défaut, le test unitaire contient le code pour vérifier que le service est correctement créé.
Exécution des tests unitaires
Pour lancer les tests unitaires, il faut utiliser la commande suivante :
ng testVous verrez alors les différentes étapes de compilation et l’exécution des tests.
Une fenêtre de votre navigateur s’ouvre avec un rapport d’exécution.
En particulier, la liste des tests unitaires et leur état est disponible.
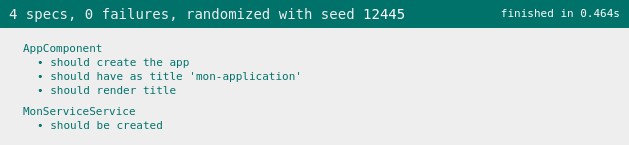
Les autres informations de ce rapport ne nous intéressent pas ici.
Comme vous avez pu le remarquer, la console est “bloquée”.
En effet, la commande précédente lance un processus permettant de rafraichir le rapport au fur et à mesure que le code est modifié.
Nous pouvons maintenant faire évoluer le service et compléter les tests.
Ajout d’un nouveau test unitaire
Afin respecter le principe du TDD, nous allons ajouter un test vérifier le résultat de notre service.
Pour cela, nous allons vérifier que l’appel à la fonction get de notre service retourne la valeur Hello World!.
Il faut alors éditer le fichier src/app/mon-service.spec.tx.
Nous rajoutons le bloc suivant :
it('should return a promise of "Hello World!" when get is called', (done) => {
service.get().then(result => {
expect(result).toEqual('Hello World!');
done();
});
});Je ne rentrai pas dans le détail de la syntaxe.
Petites précisions sur ce test :
- Le résultat de la fonction
getest en fait de typePromise<string>. C’est pourquoi, il faut utiliserthen()afin de s’abonner au résultat. - L’exécution est asynchrone, il faut mettre en place le paramètre
doneet notifier de la fin de l’exécution du test viadone().
Si vous enregistrer cette modification, le rapport des tests n’est pas mis à jour puisqu’il y a une erreur dans la console.
error TS2339: Property 'get' does not exist on type 'MonServiceService'.En effet, nous appelons la fonction get() dans le test unitaire alors qu’elle n’est pas définie dans le service.
Nous allons maintenant la mettre en place pour pouvoir faire fonctionner le test.
Création de la fonction get()
Ouvrez maintenant le fichier src/app/mon-service.ts.
Pour définir la fonction get(), il suffit de rajouter le code ci-dessous :
get(): Promise<string> {
return null;
}Cette fois, notre code compile et le rapport des tests est mis à jour.
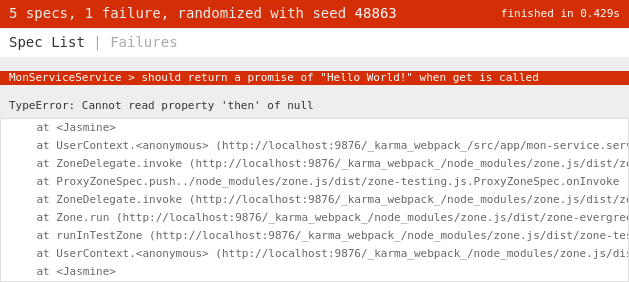
Nous obtenons une erreur indiquant que notre résultat est null.
C’est bien ce que nous avons écrit.
Implémentation basique
Afin de faire fonctionner notre service, nous allons remplacer la déclaration de la fonction.
Pour l’instant, nous allons utiliser retourner Hello World! à chaque appel de la fonction.
get(): Promise<string> {
return Promise.resolve('Hello World!');
}Lorsqu’on enregistre les modifications, il n’y a plus d’erreur dans la console et le rapport est à jour indiquant que tous les tests ont réussi.
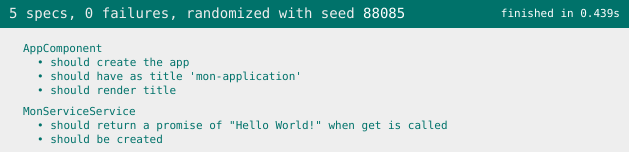
Nous allons améliorer un peu notre service afin qu’il appelle une API et retourne le résultat.
Mock d’un appel d’API
Comme précédemment, nous allons d’abort améliorer notre test unitaire.
Notre service va appeler une API, mais nous n’allons pas réellement réaliser l’appel HTTP.
En effet, il faudrait mettre un place un serveur web dédié au test et il s’agirait plus d’un test d’intégration que d’un test unitaire.
Notre but ici est de vérifier que le résultat de l’API est bien retourné par notre service.
Nous allons donc mettre un place un mock de l’API afin de simuler son comportement.
L’appel de l’API sera fait via HttpClient.
Déclaration du mock
Tout d’abord, nous allons déclarer le mock au début du bloc describe.
let httpClientMock: jasmine.SpyObj<HttpClient>;N’oubliez pas d’ajouter l’import de HttpClient.
import { HttpClient } from '@angular/common/http';Instanciation du mock
Nous ajoutons maintenant un block beforeEach pour instancier le mock.
beforeEach(() => {
httpClientMock = jasmine.createSpyObj('HttpClient', [ 'get' ]);
});On indique ici que nous allons réaliser un mock de type HttpClient pour la fonction get.
Il est possible d’instancier le mock directement au moment de la déclaration.
J’ai une préférence pour le faire dans un bloc beforeEach afin de réinitialiser le mock à chaque test.
Ajout du provider
Il faut maintenant indiquer que le mock doit être utilisé lors de l’injection.
Pour cela, il faut modifier l’appel à la méthode configureTestingModule.
TestBed.configureTestingModule({
providers: [
{ provide: HttpClient, useValue: httpClientMock }
]
});Ainsi, à chaque injection de HttpClient, c’est notre mock qui sera pris en compte.
Amélioration du test unitaire
Nous modifions maintenant notre test afin de :
- Simuler le comportement de l’appel à l’API
- Vérifier que le résultat de cet appel est retourné par notre service
On remplace le test précédent par ce code :
it('should return a promise of "Résultat API" when get is called', (done) => {
httpClientMock.get.withArgs('/api').and.returnValue(of('Résultat API'));
service.get().then(result => {
expect(result).toEqual('Résultat API');
done();
});
});Il faut également ajouter l’import
import { of } from 'rxjs';La ligne concernant le mock simule l’appel à la fonction get lorsqu’elle est appelée avec le paramètre /api pour qu’elle retourne Résultat API.
En sauvegardant, on obtient une erreur indiquant que le résultat n’est pas celui attendu.
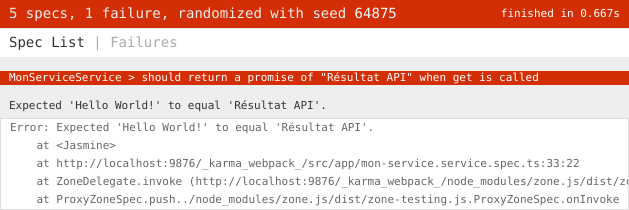
En effet, nous n’avons pas changé l’implémentation de notre service.
Il retourne toujours Hello World! alors que nous attendons Résultat API.
Correction de l’implémentation
Nous allons maintenant utiliser HttpClient dans notre service.
Dans notre service, nous ajoutons l’injection de HttpClient en modifiant le constructeur :
constructor(private httpClient : HttpClient) { }N’oubliez par l’import
import { HttpClient } from '@angular/common/http';Enfin, il faut remplacer la fonction get() comme ci-dessous :
get(): Promise<string> {
return this.httpClient.get<string>('/api').toPromise();
}On précise ici que nous appelons l’API /api et que nous retournons son résultat sous forme de Promise.
En sauvegardant, on obtient le rapport suivant :
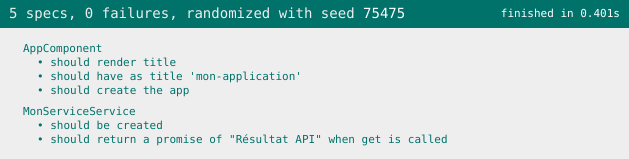
Conclusion
Nous avons vu ici comment tester un service Angular et réaliser un mock.
Pour HttpClient, Angular met à disposition un module de testing intégré. Le but ici est de donner une façon de faire qui peut être appliquée quelque soit le type souhaité.
Je vous mets à disposition les sources complètes sur GitHub : https://github.com/benjaminprevot/2020-04-03-tester-unitairement-un-service-angular
Filtrer les expressions régulières dans Jekyll 30 Mar 2020 12:10 PM (5 years ago)
Jekyll est un générateur de site web statique.
Il permet, par exemple, de transformer vos fichiers écrits avec Markdown en un blog.
Un de ses avantages est de pouvoir étendre les fonctionnalités de bases.
Dans cet article, je vais vous partager un plugin que j’ai trouvé pour gérer les expressions régulières.
Contexte
Par défaut, Jekyll offre de nombreux filtres : https://shopify.github.io/liquid/filters/
Il est possible de :
- Calculer la valeur absolue d’une valeur numérique : abs
- Transformer la première lettre d’une phrase en majuscule : capitalize
- Encoder une chaîne de caractères dans une URL : url_encode
- …
Besoin
Les filtres disponibles par défaut permettent de gérer la majorité des cas.
Cependant, j’ai rapidement eu besoin de gérer les chaînes de caractères plus complexes.
Les expressions régulières étaient alors nécessaires, mais non disponibles de base.
Il faut donc étendre les fonctionnalités offertes par Jekyll.
Plugin
Il est possible d’ajouter des plugins personnels facilement.
Pour cela, il suffit d’ajouter un peu de code Ruby dans le répertoire _plugins.
Dans notre cas, le fichier _plugins/regex-filter.rb contient le code ci-dessous :
module Jekyll
module RegexFilter
def replace_regex(input, reg_str, repl_str)
re = Regexp.new reg_str
# This will be returned
input.gsub re, repl_str
end
end
end
Liquid::Template.register_filter(Jekyll::RegexFilter)Ce code a été trouvé sur le forum stackoverflow : Jekyll filter for regex substitution in content?
Je ne suis pas un expert en Ruby, mais il est facilement compréhensible que ce code remplace l’expression régulière passée en paramètre par la dernière valeur de la fonction.
Utilisation
Pour activer ce filtre, il faut utiliser le nom de la fonction comme filtre.
Par exemple, le code ci-dessous supprimera le préfixe http:// ou https:// :
{{ url | replace_regex: "^https?://", "" }}Il vous suffit maintenant de créer le fichier _plugins/regex-filter.rb et d’utiliser le filtre pour gérer les expressions régulières.
Installation de Magento 2 Community Edition 29 Mar 2020 3:19 AM (5 years ago)
La plateforme Magento met à disposition une solution de E-Commerce basée sur le Framework PHP Zend.
Elle offre de nombreuses fonctionnalités de base, mais peut également être étendue par un système de modules / thèmes…
Afin de connaître un peu mieux cette plateforme, j’ai voulu la tester sur mon poste.
Malheureusement, tout n’a pas fonctionné du premier coup.
Dans cet article, je vais vous lister les problèmes rencontrés et les solutions mises en place.
Les solutions utilisées ici sont uniquement à but de tests. Pour la mise en production, il faut vous référer à la documentation officielle.
Installation de l’environnement
Pour faire fonctionner Magento, j’ai choisi d’installer :
En fonction de votre système d’exploitation, référez-vous à la documentation officielle pour l’installation et le démarrage.
Lorsque tout était prêt, j’ai téléchargé la version Community Edition 2.3.3 sur la page dédiée : https://magento.com/tech-resources/download
Il suffit de décompresser l’archive dans le répertoire adéquat du serveur Apache, puis, dans un navigateur, se connecter à http://localhost.
L’assistant d’installation vous guidera à chaque étape.
C’est alors que les problèmes ont commencé…
Extensions PHP manquantes
Ma première erreur a été d’oublier certaines extensions PHP.
En effet, dès le début de l’installation, une vérification des extensions PHP requises est faite et un rapport indique celles manquantes.
La liste complète des extensions est disponible ici : https://devdocs.magento.com/guides/v2.3/install-gde/system-requirements-tech.html#required-php-extensions
Il faut alors les installer et/ou les activer.
Ressources et administration indisponibles
Le second problème rencontré s’est produit à la fin de l’installation.
En voulant tester l’accès au site, les différentes ressources (styles, scripts…) n’étaient pas disponibles.
Pire pour l’administration, totalement inaccessible.
J’ai trouvé la solution sur le forum de Magento : Unable to access Magento admin page.
Pour corriger, il faut configurer le serveur Apache pour qu’il gère les fichiers .htaccess.
Dans le fichier /etc/apache2/httpd.conf, il faut trouver remplacer AllowOverride None par AllowOverride All.
Transfert d’images impossible
Lorsque l’installation est terminée, il était alors possible d’utiliser le site, de le configurer…
Un dernier problème est apparu : impossible de transférer des images dans l’administration.
Le message File validation failed apparaissait à chaque tentative.
Idem, la solution a été trouvée sur le forum de Magento : File validation failed
J’ai édité le fichier /var/www/localhost/htdocs/vendor/magento/framework/File/Uploader.php.
Il a fallu remplacer le code
/**
* Return file mime type
*
* @return string
*/
private function _getMimeType()
{
return $this->fileMime->getMimeType($this->_file['tmp_name']);
}par
/**
* Return file mime type
*
* @return string
*/
private function _getMimeType()
{
return $this->_file['type'];
}Conclusion
Finalement, les problèmes ont rapidement été corrigés en effectuant quelques recherches.
Les documentations, articles… sont nombreux.
Utiliser le bouton Aqara WXKG11LM dans Jeedom 4 Mar 2020 11:34 AM (5 years ago)
Aqara est une gamme de produits domotiques.
J’ai été séduit par ses prix attractifs et son intégration dans Jeedom.
Le bouton WXKG11LM m’a permet de déclencher un scénario.
Mais son intégration n’a pas fonctionné au premier essai…
Contexte
J’ai créé des scénarios dans Jeedom pour la gestion de mes volets.
La mise en place du bouton WXKG11LM m’a permis de déclencher :
- l’ouverture des volets d’une partie du rez-de-chaussée
- l’ouverture de tous le volets du rez-de-chaussée
- la fermeture de tous les volets de la maison
Configuration
Pour intégrer le bouton WXKG11LM, j’ai utilisé le plugin MQTT couplé au projet Zigbee2mqtt.

Vous pouvez vous référer à la documentation du projet pour plus de détails : Pairing devices
Pour déclencher un scénario lors d’un clic simple du bouton, il suffit de définir l’événement provoqué avec la valeur #[Parent][Bouton][click]#==”single”
Pour un double clic, il faut utiliser la valeur #[Parent][Bouton][click]#==”double”
Configuration supplémentaire
Les informations saisies précédemment permettent de déclencher les actions, mais ce n’est pas suffisant.
En effet, les données pour la clic sur le bouton sont considérées comme des “informations” dans Jeedom et non comme des “actions”.
Par défaut, s’il y a une répétition de la valeur, seule la première est prise en compte.
Concrétement, s’il y a un clic simple sur le bouton, l’événement est interprété.
Si, quelques instants plus tard, un autre clic simple est réalisé, l’événement n’est pas pris en compte.
Comme il s’agit d’une information, il n’y a pas de “changement d’état”, l’action correspondante n’est pas déclenchée.
Solution
Pour remédier à ce “problème”, il faut indiquer à Jeedom de prendre en compte la répétition d’information.
Il faut alors se rendre dans la configuration de l’objet correspondant dans le plugin MQTT.
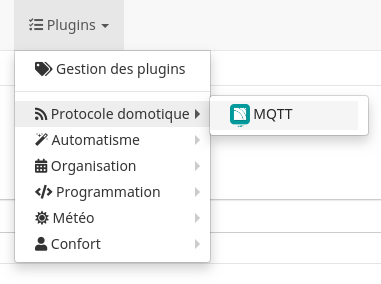
Puis, sélectionnez l’objet correspondant au bouton et l’onglet Commandes.
Dans la ligne click, cliquez sur l’icône  .
.
Dans l’onglet Configuration, sélectionnez Toujours répéter pour le champ Gestion de la répétition des valeurs.
Sauvegardez les informations saisies.
Ainsi, à chaque clique sur le bouton, l’événement sera interprété et l’action déclenchée.
Flasher une clé USB CC2531 avec un Raspberry Pi 24 Feb 2020 11:37 AM (5 years ago)
Récemment, je me suis enfin lancé dans la domotique.
Et comme j’aime mettre les mains dans la cambouis, j’ai opté pour la solution Jeedom sous Raspberry Pi.
Afin de réduire les coups, les capteurs de la marques Aqara semblent répondre à mes besoins.
Pour les utiliser, il me fallait une dongle Zigbee.
Dans cet article, je vais ajouter quelques précisions sur comment flasher une clé USB CC2531 avec un Raspberry Pi.
Contexte
Pour pouvoir utiliser le protocle Zigbee sur ma box Jeedom, j’ai choisi le projet Zigbee2mqtt.
Outre le fait qu’il me permettait de diminuer mes dépenses, j’ai été séduit par sa mise en place simple, sa documentation complète et les nombreux appareils compatibles.
Pour tout configurer, il suffit de suivre les instructions décrite sur la page Running Zigbee2mqtt.
Mais avant l’installation, il faut disposer d’une clé USB CC2531 et la flasher afin qu’elle soit reconnue.
La suite de cet article décrit comment s’y prendre.
Matériel
Voici à quoi ressemble une clé USB CC2531 :

Pour la flasher, il vous faudra également le câble adéquat pour la connecter au Raspberry :

Initialement, j’ai essayé sans ce câble, mais j’ai très vite compris qu’il allait me simplifier la vie et éviter de casser la clé.
Lorsque vous êtes en pocession de tout ce matériel, le flashage avec le Raspberry peut commencer.
Flashage
Le projet Zigbee2mqtt dispose d’une page décrivant comment flasher la clé USB avec un Raspberry : Alternative flashing methods.
Je ne vais pas rentrer dans les détails, cette page est très bien faite.
Par contre, je vais apporter quelques précisions.
Lorsque vous testez que la clé est correctement reconnue via la commande
cd flash_cc2531
./cc_chipidLe résultat n’est pas forcément celui indiqué sur le site.
L’identifiant peut contenir d’autres lettres, le but est surtout de vérifier qu’il n’est pas égal à 0000 ou ffff.
Si la valeur est incorrecte, vous pouvez essayer en précisant une valeur au paramètre -m.
Pour ma part, j’ai pu obtenir une valeur correcte pour l’identifiant en saisissant la commande suivante :
./cc_chipid -m 81La valeur 81 est propre à ma clé, il faudra peut-être que vous essayiez avec une autre.
Notez bien la valeur utilisée, elle sera utile pour les autres commandes.
En effet, dans la suite de la procédure, il faudra ajouter ce paramètre à toutes les commandes utilisées pour flasher la clé.
Ainsi, j’ai pu finaliser le guide avec les commandes suivantes :
./cc_erase -m 81
./cc_write -m 81 CC2531ZNP-Prod.hexEt voilà, après quelques instant, la clé est prête.
Notez bien que la valeur 81 est propre à mon cas, cette valeur sera peut-être différente pour vous.
Vous pouvez ensuite continuer l’installation de Zigbee2mqtt en vous référant à la page Running Zigbee2mqtt.
Embellir un meuble Ikea avec des caches vis marbrier 8 Aug 2018 1:13 PM (6 years ago)
La mode est au vintage, on ne peut le nier, c’est la grande tendance.
J’ai aussi succombé au chant des sirènes et j’ai voulu customiser un meuble Ikea pour lui donner une petite touche d’ancien.
Dans cet article, je vais vous expliquer ce que j’ai fait pour cacher les vis d’assemblage avec des cache vis marbrier.
Pour commencer, si vous ne savez pas ce qu’on appelle des caches vis marbrier (je ne le savez pas non plus avant la métamorphose de mon meuble), il s’agit de ceci :

Comme vous pouvez le voir, le principe est simple : vous passer la vis dans l’anneau.
Une fois celle-ci vissée dans la surface souhaitée, il suffit ensuite de visser la partie conique sur l’anneau.
Mais, pour les meubles Ikea, la chose n’est pas aussi simple.
Vous vous en doutez, il existe différentes tailles de vis et donc différentes tailles pour les caches vis marbrier.
Pas de chance, les vis d’assemblage pour les meubles Ikea ne semblent pas standard (je me trompe peut-être, mais passé plusieurs heures à chercher sur Internet, j’ai renoncé) pour avoir des caches vis à prix raisonnable.
Pour pallier à ce “problème” et réduire la facture, j’ai finalement acheté des caches vis plus petits et les ai collés sur la tête de vis.

Il faut cependant vérifier que l’orifice de l’anneau est au moins égal à l’encoche de la vis.
Le but est de coller l’anneau du cache sur la tête de vis et faire en sorte qu’il soit possible de passer l’outil pour visser, comme sur la photo ci-dessous.

Sous un autre angle :

Lorsque la colle est complétement sèche, vous pouvez alors revisser votre meuble.

Et pour finir, la partie conique peut être mise en place.

Pour ma part, j’ai voulu donné un côté un peu plus sympa au meuble Kallax sur lequel repose ma platine vinyle.

Externaliser les composants 'composite' de JSF 2.0 8 Feb 2011 12:49 PM (14 years ago)
Nous avons vu dans un article précédent comment créer des composants ‘composite’ avec JSF 2.0 : JSF 2.0 et les composants ‘composite’.
Cependant, ces composants étaient directement inclus dans le projet, ce qui ne permet pas de les réutiliser.
Nous allons voir comment mettre en place un projet contenant nos composants afin de pouvoir les réutiliser par la suite.
Environnement
Pour cet article, j’ai utilisé la version 3 de GlassFish et son implémentation de JSF 2.0.
Les développements sont réalisés dans Eclipse 3.6.1 avec un JDK 1.6.
Mise en place du projet
Nous allons tout d’abord mettre en place le projet contenant les composants.
Pour cela, un simple projet Java dans Eclipse fera l’affaire.
L’arborescence est la suivante :
JsfComponent
|- META-INF/
| |- resources/
| | |- tag/
| | | |- hello.xhtml
| |- faces-config.xml
|- .classpath
|- .projectLe sous-répertoire tag représente l’identifiant de notre librairie de composants.
Le fichier hello.xhtml représente le composant.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:composite="http://java.sun.com/jsf/composite">
<h:head>
</h:head>
<h:body>
<composite:interface>
<composite:attribute name="nom" required="true" />
</composite:interface>
<composite:implementation>
<h1>Hello #{cc.attrs.nom}!</h1>
</composite:implementation>
</h:body>
</html>Le fichier faces-config.xml ne contient que la balise racine ; mais il doit être présent pour que le composant soit réutilisable.
<?xml version="1.0" encoding="UTF-8"?>
<faces-config
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-facesconfig_2_0.xsd"
version="2.0">
</faces-config>Comme vous pouvez le voir, tous les fichiers doivent se situer dans le répertoire META-INF.
Génération de la librairie
Pour créer l’archive dans Eclipse, nous allons utiliser la méthode d’export mise à notre disposition.
Pour cela, faites un clique droit sur le projet, puis Export… > Java > JAR file.
Dans la fenêtre, décocher les cases correspondant à .classpath et .project.
Renseignez le chemin et le nom du fichier JAR à générer, puis cliquez sur le bouton Finish.
Nous disposons maintenant de l’archive contenant notre composant réutilisable.
Utilisation du composant
Pour tester notre composant, nous allons créer un projet Web dynamique dans Eclipse.
Puis, il faut déplacer l’archive que nous avons générée à l’étape précédente dans le répertoire lib du projet.
Il faut maintenant faire appel à notre composant.
Pour cela, il suffit de déclarer le namespace dans la page XHTML.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:tag="http://java.sun.com/jsf/composite/tag">
<h:head>
</h:head>
<h:body>
<f:view>
<tag:hello nom="Benjamin" />
</f:view>
</h:body>
</html>La déclaration se fait simplement via l’instruction xmlns:tag="http://java.sun.com/jsf/composite/tag.
Le tag ci-dessus (en fin d’URI) correspond à l’identifiant de notre librairie de composants (= le sous-répertoire contenant notre composant).
L’utilisation est identique à celle de la déclaration “classique” de composants.
Effet de coin de page en CSS 3 28 Oct 2010 11:24 AM (14 years ago)
De nombreux sites ont mis en place un effet de coin de page (Peel effect en anglais) pour des publicité, donner des informations complémentaires…
Vous pouvez en voir des exemples ici :
- http://www.smple.com/pagePeel/
http://www.sohtanaka.com/web-design/examples/peeling-effect/(je me suis d’ailleurs inspiré de cette démo pour rédiger cet article)
Comme vous l’aurez remarqué, cet effet est mis en place en utilisant une animation Flash ou du JavaScript.
Nous allons voir dans cet article comment réaliser le même effet en CSS 3 sans script complémentaire.
Arborescence du site
Avant toute chose, voici comment sont ordonnés les fichiers.
- img : répertoire contenant les images
- index.php : fichier principal contenant la structure HTML
- style.css : feuille de style
Mise en place de la structure HTML
Dans un premier temps, nous allons mettre en place notre page HTML afin de définir les différents composant dont nous avons besoin.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<link href="style.css" media="screen" rel="stylesheet" type="text/css" />
</head>
<body>
<a href="http://benjaminprevot.fr/" id="peel">
<img src="img/corner.png" />
</a>
<div id="header">
<span class="title">Peel effect</span>
</div>
</body>
</html>Cette page contient un lien (id="peel") représentant notre coin de page cliquable ; il aura comme arrière-plan l’information que nous souhaitons mettre en place.
L’image qu’il contient est en fait le coin de page plié.
Définition des styles
Maintenant, il faut mettre en forme notre page.
Pour cela, il faudra placer le coin de page en haut à droite.
body, html {
background: #f5f5ff;
font: normal normal normal 11px/20px Verdana, sans-serif;
height: 100%;
margin: 0;
padding: 0;
width: 100%;
}
#header {
background: #145eb1 url(img/header.png) repeat-x scroll 0 0;
height: 200px;
}
#header .title {
color: #ffffff;
font: normal normal bold 2em Verdana, sans-serif;
line-height: 200px;
}
#peel {
background: transparent url(img/text.png) no-repeat scroll 100% 0;
position: absolute;
right: 0;
text-decoration: none;
top: 0;
width: 50px;
height: 50px;
box-shadow: -5px 5px 5px rgba(0, 0, 0, 0.3);
transition: height 0.3s ease-out 0, width 0.3s ease-out 0;
-moz-box-shadow: -5px 5px 5px rgba(0, 0, 0, 0.3);
-moz-transition: height 0.3s ease-out 0, width 0.3s ease-out 0;
-o-transition: height 0.3s ease-out 0, width 0.3s ease-out 0;
-webkit-box-shadow: -5px 5px 5px rgba(0, 0, 0, 0.3);
-webkit-transition: height 0.3s ease-out 0, width 0.3s ease-out 0;
}
#peel:hover {
height: 300px;
width: 300px;
}
#peel img {
border: none;
height: 100%;
width: 100%;
}Nous définissons la nouvelle taille du lien lorsque le curseur le survole.
L’image adaptera sa taille automatiquement et dévoilera alors le contenu.
L’ajout de transition permet de donner plus de fluidité à l’effet.
Managed Bean avec les annotations JSF 2.0 18 Jul 2010 4:59 AM (14 years ago)
La version 2.0 de JSF a apporté de nombreuses nouveautés.
Parmi elles, l’utilisation des annotations pour la déclaration des Managed Beans.
Nous allons mettre en place un exemple simple - compteur de clique sur un bouton - pour illustrer cette nouvelle utilisation.
Environnement
Pour cet article, j’ai utilisé l’implémentation 2.0 de JSF sur un serveur GlassFish 3.
- Eclipse 3.5 Galileo
- GlassFish 3
- JDK Sun 1.6
- JSF 2.0
Création du projet et configuration
Pour la mise en place, vous pouvez vous reporter aux chapitres Création du projet et Configuration de l’article JSF 2.0 et les composants ‘composite’.
Dans la vue Navigator, voici l’arborescence :
JSFManagedBean
|- .settings/
|- build/
|- src/
|- WebContent/
| |- META-INF/
| |- WEB-INF/
| |- compteur.xhtml
|- .classpath
|- .projectCréation du Managed Bean
Dans un premier temps, nous allons mettre en le Managed Bean.
Les versions 1.x de JSF imposaient de déclarer nos objets dans un fichier de configuration : faces-config.xml.
Il est toujours possible de le faire dans la version 2.0 mais le but de cet article est de montrer l’utilisation des annotations.
Pour cela, créez une classe fr.benjaminprevot.jsf.bean.CompteurBean dans le répertoire src du projet.
package fr.benjaminprevot.jsf.bean;
import javax.faces.bean.ManagedBean;
import javax.faces.bean.SessionScoped;
/**
* @author Benjamin PREVOT
*/
@ManagedBean
@SessionScoped
public class CompteurBean {
private int compteur = 0;
public int getCompteur() {
return compteur;
}
public void incrementer() {
compteur++;
}
}Comme vous pouvez le voir, nous utilisons 2 annotations pour définir notre Managed Bean :
@ManagedBean: déclare la classe comme définissant un Managed Bean@SessionScoped: définit le scope de notre Bean ; ici, il aura une portée session
Vous trouverez plus de détails ici : http://java.sun.com/javaee/javaserverfaces/2.0/docs/managed-bean-api/index.html.
Dans cette classe, nous avons défini un attribut compteur qui comptera simplement le nombre de cliques sur un bouton.
Vous pouvez remarquer que l’accesseur à cet attribut est aussi déclaré ; pour accéder à une propriété d’un Manager Bean, vous devez impérativement définir les getters / setters nécessaires ; un attribut n’est jamais lu / modifié directement.
Enfin, la méthode incrementer permet d’ajouter un au compteur courant.
Utilisation du Managed Bean
Nous allons maintenant mettre en place une page compteur.xhtml dans le répertoire WebContent du projet.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:tag="http://java.sun.com/jsf/composite/tag">
<h:head>
<title>Compteur</title>
</h:head>
<h:body>
<f:view>
<h:outputText value="Nombre de cliques : #{compteurBean.compteur}" />
<h:form>
<h:commandButton action="#{compteurBean.incrementer}" value="Incrémenter" />
</h:form>
</f:view>
</h:body>
</html>Dans un premier temps, nous affichons la valeur du compteur (<h:outputText value="Nombre de cliques : #{compteurBean.compteur}" />).
Pour accéder au Managed Bean, il suffit d’utiliser les Expression Language (#{...}) et d’utiliser le nom de la classe (minuscule pour la première lettre).
Vous pouvez remarquer que nous utilisons le nom de l’attribut pour le lire ; comme je vous l’indiquais précédemment, il faut pour cela que le getter existe.
Ensuite, nous définissons un bouton qui va appeler la méthode incrementer : <h:commandButton action="#{compteurBean.incrementer}" value="Incrémenter" />.
N’oubliez pas de l’entourer de la balise <h:form> pour que l’action fonctionne.
Test
Vous pouvez maintenant déployer l’application et démarrer le serveur.
Dans un navigateur, utilisez l’adresse http://localhost:8080/JSFManagedBean/compteur.jsf.
Une page contenant le message Nombre de cliques : 0 apparaît avec un bouton Incrémenter.
En cliquant sur le bouton, vous pourrez alors voir le compteur augmenter.
JSF 2.0 et les composants 'composite' 17 Jul 2010 12:17 PM (14 years ago)
Comme nous l’avons vu dans Premiers pas avec JSF, nous pouvons créer facilement des applications Web grâce au framework JSF.
Mais vous voudrez sûrement créer vos propres composants afin de définir votre bibliothèque d’éléments réutilisables.
Nous allons voir comment l’implémentation de JSF 2.0 va nous permettre de mettre en place ces composants rapidement.
Pour cela, les tags composite seront très utiles.
Environnement
Pour cet article, j’ai utilisé l’implémentation 2.0 de JSF sur un serveur GlassFish 3.
- Eclipse 3.5 Galileo
- GlassFish 3
- JDK Sun 1.6
- JSF 2.0 (Mojarra :
https://javaserverfaces.dev.java.net/)
Création du projet
Nous créons tout d’abord un projet Web dynamique (Dynamic Web Project) sous Eclipse : JSFCreationComposant.
Dans la vue Navigator, voici l’arborescence :
JSFCreationComposant
|- .settings/
|- build/
|- src/
|- WebContent/
| |- META-INF/
| |- resources/
| |- WEB-INF/
| |- index.xhtml
|- .classpath
|- .projectPréparation
Dans un premier temps, il faut mettre en place les librairies JSF.
Pour cela, vous pouvez télécharger les JAR nécessaires à l’adresse suivante : https://javaserverfaces.dev.java.net/ ; dans la rubrique Downloads, choisissez la version 2.0.
Copiez les librairies dans le répertoire lib du projet.
Configuration
Éditez le fichier web.xml pour indiquer que toutes les requêtes *.jsf devront être interprétées par la servlet FacesServlet.
<?xml version="1.0" encoding="UTF-8"?>
<web-app
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:web="http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
id="WebApp_ID"
version="2.5">
<display-name>JSFCreationComposant</display-name>
<servlet>
<display-name>JSF Servlet</display-name>
<servlet-name>Faces Servlet</servlet-name>
<servlet-class>javax.faces.webapp.FacesServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>Faces Servlet</servlet-name>
<url-pattern>*.jsf</url-pattern>
</servlet-mapping>
</web-app>La configuration est maintenant terminée.
Création de la page
Créez une page index.xhtml dans le répertoire WebContent du projet.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:h="http://java.sun.com/jsf/html">
<h:head>
<title>Hello Word!</title>
</h:head>
<h:body>
<f:view>
Hello World!
</f:view>
</h:body>
</html>Vous pouvez alors déployer l’application et démarrer le serveur.
Pour tester l’application, saisissez l’adresse suivante : http://localhost:8080/JSFCreationComposant/index.jsf.
Création du composant
Nous avons mis en place l’application, maintenant, nous allons créer un composant permettant de saluer une personne en affichant le message Hello Benjamin! (le prénom sera un paramètre).
Pour commencer, créez le répertoire tag dans le répertoire resources.
Puis créez le fichier hello.xhtml : ce fichier contiendra le corps de notre nouveau composant.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:composite="http://java.sun.com/jsf/composite">
<h:head>
<title>Hello tag</title>
</h:head>
<h:body>
<composite:interface>
<composite:attribute name="nom" required="true" />
</composite:interface>
<composite:implementation>
Hello #{cc.attrs.nom}!
</composite:implementation>
</h:body>
</html>Comme vous pouvez le remarquer, ce fichier est composé des mêmes éléments qu’une page XHTML classique.
Les informations dans la partie head ne seront pas affichées lors du rendu du composant, en particulier l’élément title.
La représentation de notre composant se situe dans l’élément body :
composite:interface: définit comment le composant doit être utilisé, en particulier la liste des attributscomposite:implementation: définit le composant proprement dit
Vous pourrez trouver plus d’informations ici : http://java.sun.com/javaee/javaserverfaces/2.0/docs/pdldocs/facelets/index.html.
Dans notre exemple, le composant ne comporte qu’un seul attribut - nom - obligatoire (required="true").
Le composant permettra d’afficher le message Hello {nom}!.
Comme vous pouvez le remarquer, la valeur de l’attribut nom est récupérée par Expression Language : #{cc.attrs.nom}.
Utilisation du composant
Pour utiliser notre nouveau composant, il faut modifier le fichier index.xhtml comme suit :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:tag="http://java.sun.com/jsf/composite/tag">
<h:head>
<title>Hello Word!</title>
</h:head>
<h:body>
<f:view>
<tag:hello nom="Benjamin" />
</f:view>
</h:body>
</html>La modification se fait en 2 étapes :
- Ajout du namespace tag :
xmlns:tag="http://java.sun.com/jsf/composite/tag" - Appel du composant :
<tag:hello nom="Benjamin" />
Vous pouvez alors redéployer l’application et tester : http://localhost:8080/JSFCreationComposant/index.jsf.
Le message Hello Benjamin! s’affiche alors à l’écran.
Il vous suffit alors de modifier la valeur de l’attribut nom pour personnaliser le message.
Premiers pas avec JSF 14 Jul 2010 12:31 PM (14 years ago)
Java Server Faces (JSF) est un framework Java / J2ee basé sur des composants permettant le développement d’applications Web.
Pour présenter cet outil, nous allons mettre en place un simple Hello World.
Bien sûr, il ne s’agit que d’un exemple afin d’avoir un point de départ pour une application plus évoluée.
Environnement
Nous travaillerons sous Eclipse et déploierons l’application sous Tomcat.
Voici la configuration utilisée pour ce tutoriel :
- Eclipse 3.5 Galileo
- Tomcat 6.0.20
- JDK Sun 1.6
- JSF 1.2
Création du projet
Pour démarrer, il faut créer un projet Web Dynamique (Dynamic Web Project) sous Eclipse.
Nous le nommerons PremiersPasAvecJSF.
Dans la vue Navigator, le projet se présent comme ci-dessous :
PremiersPasAvecJSF
|- .settings/
|- build/
|- src/
|- WebContent/
| |- META-INF/
| |- WEB-INF/
| | |- lib/
| | |- web.xml
|- .classpath
|- .projectPréparation
Nous allons maintenant mettre en place les librairies nécessaires au projet.
Pour cela, nous aurons besoin de télécharger les fichiers JAR nécessaires sur le site du projet : https://javaserverfaces.dev.java.net/.
Nous utiliserons jsf-api.jar et jsf-impl.jar ; pour cela, copier ces 2 fichiers dans le répertoire lib du projet.
Il est possible qu’une exception soit levée au moment de l’exécution si votre serveur ne dispose pas des librairies JSTL.
Si c’est le cas, vous pourrez télécharger les JAR à cette adresse : https://jstl.dev.java.net/.
Il vous suffira alors de copier ces fichiers dans le répertoire lib.
Configuration
Il faut tout d’abord mettre en place la configuration dans le fichier web.xml afin que les requêtes soient interprétées par la servlet JSF FacesServlet.
Pour cela, nous déclarons dans un premier la servlet :
<servlet>
<display-name>JSF Servlet</display-name>
<servlet-name>faces</servlet-name>
<servlet-class>javax.faces.webapp.FacesServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>Ensuite, nous déclarons le mapping afin d’indiquer que toute requête se terminant par jsf sera gérée par la servlet :
<servlet-mapping>
<servlet-name>faces</servlet-name>
<url-pattern>*.jsf</url-pattern>
</servlet-mapping>Mise en place de la JSP
Nous allons maintenant écrire la page (JSP) permettant d’afficher notre texte.
Pour cela, nous créons un fichier hello.jsp dans le répertoire WebContent du projet.
<%@ taglib uri="http://java.sun.com/jsf/core" prefix="f" %>
<%@ taglib uri="http://java.sun.com/jsf/html" prefix="h" %>
<f:view>
<h:outputText value="Hello World avec JSF!" />
</f:view>Vous pouvez remarquer que nous utilisons 2 types d’éléments :
f:view: conteneur de tous les éléments JSFh:outputText: permet d’afficher du texte
JSF met à disposition 2 librairies de tags :
core: tags définissant les éléments indépendant du rendu (HTML ou autre)html: tags définissant les éléments HTML
Vous pourrez trouvez plus de détails sur ce site : http://java.sun.com/javaee/javaserverfaces/2.0/docs/pdldocs/facelets/index.html.
Test
Vous pouvez maintenant déployer le projet dans votre serveur (ici, Tomcat 6) et tester en utilisant l’url http://localhost:8080/PremiersPasAvecJSF/hello.jsf.
En effet, pour appeler la JSP que nous avons créées, il suffit d’appeler cette JSP en remplaçant l’extension (jsp) par jsf.
Vous devez alors voir une page affichant Hello World avec JSF!.
Sécurité
Ouvrons une petite parenthèse sur la sécurité et, en particulier, sur l’accès direct aux JSP.
En effet, comme nous avons placé les JSP dans le répertoire WebContent du projet, elles sont directement accessibles par l’utilisateur.
Pour remédier à cela, il suffit d’interdire l’appel direct aux JSP dans le fichier web.xml.
<security-constraint>
<web-resource-collection>
<web-resource-name>no-jsp-access</web-resource-name>
<url-pattern>*.jsp</url-pattern>
</web-resource-collection>
<auth-constraint>
<description>No direct access to JSP</description>
</auth-constraint>
</security-constraint>web.xml
Pour finir, voici le fichier web.xml complet tu projet.
<?xml version="1.0" encoding="UTF-8"?>
<web-app
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:web="http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
id="WebApp_ID"
version="2.5">
<display-name>PremiersPasAvecJSF</display-name>
<servlet>
<display-name>JSF Servlet</display-name>
<servlet-name>faces</servlet-name>
<servlet-class>javax.faces.webapp.FacesServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>faces</servlet-name>
<url-pattern>*.jsf</url-pattern>
</servlet-mapping>
<security-constraint>
<web-resource-collection>
<web-resource-name>no-jsp-access</web-resource-name>
<url-pattern>*.jsp</url-pattern>
</web-resource-collection>
<auth-constraint>
<description>No direct access to JSP</description>
</auth-constraint>
</security-constraint>
</web-app>Liens utiles
Créer et déployer une application avec Java Web Start 29 Jun 2010 11:40 AM (14 years ago)
« Java Web Start est un outil informatique de déploiement de logiciels fondés sur la technique Java. » (Wikipedia)
Nous allons voir comment mettre en place et déployer une application écrite avec Swing et déployée grâce à Java Web Start. Pour cela, nous écrirons une application simple permettant d’afficher Hello World!.
Préparation
Cet article a été rédigé en utilisant la configuration suivante :
- Windows Vista édition Familiale Premium
- Eclipse 3.5
- Java 1.6
- Apache 2.2
Création de l’application
Comme je vous l’indiquais en introduction, nous allons mettre en place une application simple permettant d’afficher Hello World!, développée en Swing.
Pour cela, nous créons une classe Main qui sera notre écran principal.
package fr.benjaminprevot.jws;
import java.awt.BorderLayout;
import javax.swing.JFrame;
import javax.swing.JLabel;
/**
* @author Benjamin PREVOT
*/
public class Main extends JFrame {
private static final long serialVersionUID = -1852233155700440419L;
public Main() {
setDefaultCloseOperation(DISPOSE_ON_CLOSE);
setLayout(new BorderLayout());
setResizable(false);
setSize(400, 300);
setTitle("Hello");
JLabel label = new JLabel("Hello World!");
label.setHorizontalAlignment(JLabel.CENTER);
add(label, BorderLayout.CENTER);
}
public static void main(String[] args) {
new Main().setVisible(true);
}
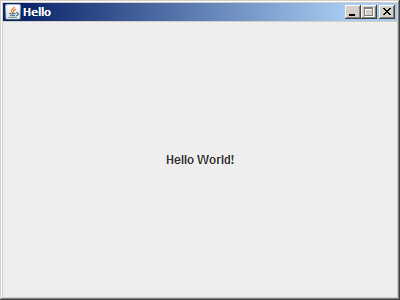
}Nous ne nous attarderons pas sur le code de cette classe qui n’est pas l’objet de l’article.
Si l’on exécute ce code, nous obtenons une fenêtre comme celle-ci :
Mise en place d’une tâche Ant
Il nous faut maintenant déployer l’application sur notre serveur Web.
Pour cela, nous utiliserons une tâche Ant afin de créer notre archive Jar et la copier dans notre serveur.
Le script créer le fichier Jar dans le répertoire build de notre projet.
Ce fichier sera ensuite copier dans le dossier W:/web/htdocs/jws qui est accessible via l’URL http://localhost/jws/.
Les propriétés du script sont stockées dans un fichier build.properties.
bin.dir=${basedir}/bin
build.dir=${basedir}/build
dest.dir=W:/web/htdocs/jws
jar.file=jws.jarVoici le script Ant que j’ai utilisé pour réaliser les opérations décrites ci-dessus :
<project basedir="." default="all" name="JWS">
<property file="build.properties" />
<target name="clean">
<delete dir="${build.dir}" />
<delete file="${dest.dir}/${jar.file}" />
</target>
<target name="init">
<mkdir dir="${build.dir}" />
</target>
<target name="jar">
<jar destfile="${build.dir}/${jar.file}">
<fileset dir="${bin.dir}" />
</jar>
</target>
<target name="copy">
<copy file="${build.dir}/${jar.file}" todir="${dest.dir}" />
</target>
<target name="all" depends="clean,init,jar,copy" />
</project>Le script supprime d’abord les fichiers qui ont déjà été mis en place, puis crée les répertoires nécessaires, crée le fichier Jar et le recopie vers notre serveur Web.
Pour pouvoir lancer le script complet, il suffit d’exécuter la tâche all.
Création du fichier JNLP
Notre fichier Jar est maintenant accessible via notre serveur Apache.
Il faut maintenant créer un fichier de déploiement : JNLP - Java Network Launching Protocol.
Ce fichier est en fait une description XML des propriétés de démarrage de notre application.
Nous le créerons (index.jnlp) dans le même répertoire que notre archive : W:/web/htdocs/jws.
Voici le fichier JNLP mis en place pour notre exemple :
<?xml version="1.0" encoding="utf-8"?>
<jnlp spec="1.0+" codebase="http://localhost/jws/" href="index.php">
<information>
<title>JWS</title>
<vendor>Benjamin PREVOT</vendor>
<homepage href="http://localhost/jws/" />
</information>
<resources>
<j2se version="1.6+" href="http://java.sun.com/products/autodl/j2se" />
<jar href="jws.jar" />
</resources>
<application-desc main-class="fr.benjaminprevot.jws.Main" />
</jnlp>Comme vous pouvez le voir, nous spécifions :
- Le titre de l’application
- L’auteur
- L’adresse de la page d’accueil
- La version minimale de Java pour pouvoir lancer l’application
- Le nom de l’archive (le fichier Jar que nous avons créé avec la tâche Ant)
- La classe à exécuter pour lancer l’application
Il s’agit d’un fichier simple pour notre exemple.
Il est possible d’ajouter d’autres archives nécessaires à l’exécution de l’application, des images, des resources, s’il faut créer un raccourci sur le bureau, si l’application peut être lancée en mode offline…
Vous pourrez trouver la référence complète sur les fichiers JNLP sur cette page : http://java.sun.com/javase/6/docs/technotes/guides/javaws/developersguide/syntax.html.
Lancement de l’application
Pour exécuter notre application, il suffit maintenant d’appeler notre fichier JNLP dans un navigateur : http://localhost/jws/index.jnlp.
Si une fenêtre apparaît pour ouvrir ou enregistrer le fichier, il faut choisir de l’ouvrir en utilisant le lanceur Java Web Start.
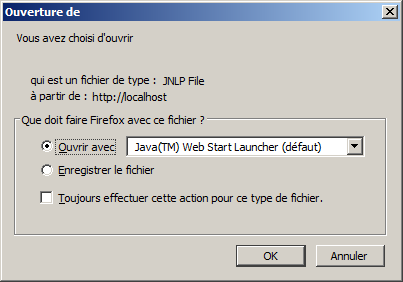
Votre application est alors démarrée.
Gérer l'affichage en colonnes des PDF avec iText 19 Jun 2010 4:00 PM (14 years ago)
iText est une librairie Java permettant de générer des documents PDF : http://itextpdf.com/.
Nous allons voir comment gérer l’affichage par colonne avec la classe MultiColumnText : http://api.itextpdf.com/com/itextpdf/text/pdf/MultiColumnText.html.
Pour cela, nous afficherons un long texte (Lorem ipsum dolor sit amet…) sur 3 colonnes par page.
Préparation
La version de la librairie iText utilisée est 5.0.2. Vous pourrez la télécharger sur le site officiel : http://itextpdf.com/.
Le texte que nous utiliserons a été généré à partir du site http://www.lipsum.com/ (9 paragraphes).
Ce texte est enregistré dans le fichier C:/lipsum.txt.
Création de la classe Java
Pour réaliser notre test, nous créons une classe Java appelée Columns.
package fr.benjaminprevot.itext;
/**
* @author Benjamin PREVOT
*/
public class Columns {
private String pathname;
private String filename;
/**
* Constructeur
*/
public Columns(String pathname, String filename) {
this.pathname = pathname;
this.filename = filename;
}
}Cette classe contient 2 attributs :
pathname: chemin vers le fichier contenant le texte à afficher (C:/lipsum.txt dans notre cas)filename: chemin vers le fichier PDF à générer
Pour l’instant, notre classe ne contient que ses attributs et un constructeur.
Nous allons tout d’abord lui ajouter une fonction permettant de charger les paragraphes à partir d’un fichier.
Chargement du texte
Une méthode sera dédiée à la lecture du texte à afficher.
Elle retournera une liste de chaînes de caractères qui représenteront les paragraphes.
/**
* Charge le texte à afficher à partir d'un fichier.
*
* @param pathname Chemin complet vers le fichier
* @return Une liste de paragraphes à afficher
* @throws FileNotFoundException Si le fichier n'existe pas
* @throws IOException Si une exception I/O est générée
*/
public List<String> getText(String pathname) throws FileNotFoundException, IOException {
// Fichier contenant le texte
File file = new File(pathname);
// Reader pour lire le contenu du fichier
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
// Initialisation de la liste
List<String> list = new ArrayList<String>();
// Lecture du fichier
while (reader.ready()) {
list.add(reader.readLine());
}
// Retour du contenu
return list;
} finally {
// Fermeture du reader
if (reader != null) {
reader.close();
}
}
}Nous passerons rapidement sur cette fonction qui n’est pas très compliquée (lecture du fichier, enregistrement des lignes dans une liste, retour de la liste).
Génération du PDF
Pour finir, nous créerons une méthode qui va générer le fichier PDF contenant le texte lu à partir du fichier.
La présentation se fera sous forme de 3 colonnes par page.
/**
* Création du fichier PDF.
* @throws DocumentException Si une exception est générée dans le Document
* @throws FileNotFoundException Si le fichier n'est pas trouvé
* @throws IOException Si une exception I/O est générée
*/
public void generate() throws DocumentException, IOException {
// Fichier PDF
File file = new File(filename);
// Si le fichier existe déjà, il est supprimé
if (file.exists()) {
file.delete();
}
// Flux de sortie
OutputStream os = null;
// Création du document iText
Document document = null;
try {
os = new FileOutputStream(file);
document = new Document(PageSize.A4, 20, 20, 20, 20);
// Lien entre le document et le flux de sortie
PdfWriter.getInstance(document, os);
// Ouverture du docuement pour écriture
document.open();
// Création d'un object MultiColumnText permettant de gérer l'affichage par colonne
MultiColumnText mct = new MultiColumnText();
// Définition des colonnes : 3 colonnes espacées de 10 unités
mct.addRegularColumns(document.left(), document.right(), 10f, 3);
// Affichage des paragraphes
List<String> list = getText(pathname);
for (String s : list) {
mct.addElement(new Paragraph(s));
}
document.add(mct);
} finally {
if (document != null) {
// Fermeture du document et enregistrement dans le fichier columns.pdf
document.close();
}
if (os != null) {
// Fermeture du flux de sortie
os.close();
}
}
}Nous ne attarderons pas sur la création du document PDF en lui-même.
Pour plus de détails, vous pouvez vous référer au site officiel : http://itextpdf.com/examples/index.php?page=chapters.
La partie qui nous intéresse pour l’affichage par colonne correspond à l’utilisation de la classe MultiColumnText.
Après l’instanciation (MultiColumnText mct = new MultiColumnText()), nous définissons les propriétés de l’affichage en colonne (mct.addRegularColumns(document.left(), document.right(), 10f, 3)).
Nous utilisons la méthode addRegularColumns qui permet une répartition régulière des colonnes.
- 1er paramètre : position à gauche
- 2ème paramètre : position à droite
- 3ème paramètre : espacement entre les colonnes
- 4ème paramètre : nombre de colonnes
Pour plus de détails sur cette méthode, vous pouvez vous référer à la documentation officielle : http://api.itextpdf.com/com/itextpdf/text/pdf/MultiColumnText.html#addRegularColumns(float, float, float, int).
Exécution du code
Notre classe est maintenant terminée, nous pouvons la tester.
public static void main(String[] args) throws Exception {
new Columns("C:/lipsum.txt", "C:/columns.pdf").generate();
}Vous pourrez alors voir le résultat dans le fichier C:/columns.pdf. Le code complet de la classe, le contenu du fichier à afficher et le résultat sont ici : http://demo.benjaminprevot.fr/gerer-laffichage-en-colonnes-des-pdf-avec-itext/source.zip.
Produire un WebService SOAP avec Zend Framework 16 Jun 2010 12:46 PM (14 years ago)
Plusieurs méthodes existent pour créer des WebServices SOAP.
- Contract First ou Top-Down : le fichier WSDL est écrit en premier, puis l’implémentation.
- Code First ou Bottom-Up : l’implémentation est d’abord faite, puis le fichier WSDL est généré à partir du code écrit.
Il est souvent recommandé d’utiliser la première méthode, mais rédiger un fichier WSDL peut vite devenir compliqué (même si de plus en plus d’outils aide à sa réalisation).
Nous allons voir dans cette article comment mettre en place la 2ème méthode.
Pour réaliser les exemples ci-dessous, j’ai utilisé la version 1.10.3 du framework de Zend que vous pouvez télécharger ici : http://framework.zend.com/download/archives.
Création de la classe de service
Avant de commencer l’implémentation avec le framework Zend, nous allons mettre en place une classe qui regroupera les différentes méthodes qui seront exposées via notre WebService.
Cette classe sera enregistrée dans un sous-répertoire des controllers (services) dans le fichier MonWebService.php.
<?php
class MonWebService {
// ...
}
?>Nous allons simplement définire une fonction qui fera l’addition de 2 entiers passés en paramètres.
Bien entendu, il est possible de définir autant de méthodes qu’on le souhaite.
La classe est alors codée comme suit :
<?php
class MonWebService {
/**
* Addition de 2 entiers
* @param integer $a
* @param integer $b
* @return integer
*/
public function add($a, $b) {
return $a + $b;
}
}
?>Vous pouvez remarquer le commentaire de la fonction : il sera repris lors de la génération du fichier WSDL. N’oubliez pas de l’adapter à vos besoins.
En fait, en respectant la syntaxe PHP docblock, le fichier WSDL généré pour typer les paramètres et les valeurs de retours des fonctions exposées.
Mise en place du controller
Nous allons maintenant définir le controller qui permettra de retourner la WSDL et de traiter les requêtes SOAP.
Pour cela, nous créons un controller appelé WsController avec une seul action index.
<?php
require_once APPLICATION_PATH . '/controllers/services/MonWebService.php';
class WsController extends Zend_Controller_Action {
public function indexAction() {
if (is_null($this->getRequest()->getParam('wsdl'))) {
// Traitement de la requête
$server = new Zend_Soap_Server('http://monserveur/ws/?wsdl');
$server->setClass('MonWebService');
$server->handle();
} else {
// Retour de la WSDL
$wsdl = new Zend_Soap_AutoDiscover();
$wsdl->setClass('MonWebService');
$wsdl->handle();
}
exit;
}
}
?>Nous vérifions si l’utilisateur a demandé la WSDL (présence du paramètre wsdl) ou a fait un requête.
Ainsi, pour afficher la définition du WebService, il suffit d’appeler l’adresse http://monserveur/ws/?wsdl.
Pour exécuter le WebService, l’adresse à appeler est http://monserveur/ws/.
Test du WebService
Pour tester notre WebService, plusieurs méthodes sont possibles.
Personnellement, j’utilise le logiciel soapUI : https://www.soapui.org/.
Pour ceux qui ne souhaitent pas télécharger cet outil, nous allons mettre en place un controller permettant d’appeler notre WebService.
Création du controller
Dans un premier temps, nous allons créer un controller appelé WsClientController :
<?php
class WsClientController extends Zend_Controller_Action {
public function indexAction() {
// Récupération des 2 paramètres
$a = $this->getRequest()->getParam('a');
$b = $this->getRequest()->getParam('b');
// Appel du WebService
$client = new Zend_Soap_Client('http://monserveur/ws/?wsdl');
$result = $client->add($a, $b);
// Passage des informations à la vue
$this->view->a = $a;
$this->view->b = $b;
$this->view->result = $result;
}
}
?>Comme vous pouvez le remarquer, l’appel du WebService se fait en 2 étapes :
- La création du client
Zend_Soap_Client - L’appel de la méthode directement sur l’instance du client
Ce code ne tient pas compte de l’existence des paramètres, de leur type…
Il s’agit simplement d’un test pour valider le bon fonctionnement de notre WebService.
Création de la vue
Il nous faut maintenant afficher le résultat.
<h1>
<?php printf('%s + %s = %s', $this->a, $this->b, $this->result) ?>
</h1>Nous affichons simplement la formule mathématique et le résultat.
Test
En appelant l’adresse http://monserveur/wsclient?a=1&b=2, on obtient 1 + 2 = 3.
Le résultat de l’addition a bien été calculé par le WebService.
Erreurs rencontrées
SOAP extension is not loaded
L’extension PHP permettant de gérer les appels SOAP n’est pas activée dans le fichier de configuration.
Il faut éditer le fichier php.ini et activer php_soap.dll ou php_soap.so.
Styliser les légendes de vos images avec CSS 3 29 Apr 2010 7:28 AM (15 years ago)
Lorsque l’on affiche des images sur un site, il est toujours utile d’ajouter divers informations (source, lieu…) pour le visiteur.
Mais comment ajouter une légende aux photos sans surcharger l’interface ?
Le but de cet article sera de réaliser un effet similaire à celui-ci : http://thirdroute.com/projects/captify/.
Et encore une fois, CSS 3 va nous aider à mettre en place ce que nous souhaitons, sans JavaScript.
Mise en place du document HTML
Comme à l’accoutumée, nous commençons par le code HTML.
<ul id="pictures">
<li class="legend-top">
<img alt="landscape001.jpg" src="landscape001.jpg" />
<span>Légende en haut</span>
</li>
<li class="legend-top">
<img alt="landscape002.jpg" src="landscape002.jpg" />
<span>Légende en haut</span>
</li>
<li class="legend-bottom">
<img alt="landscape003.jpg" src="landscape003.jpg" />
<span>Légende en bas</span>
</li>
<li class="legend-bottom">
<img alt="landscape004.jpg" src="landscape004.jpg" />
<span>Légende en bas</span>
</li>
</ul>Il s’agit d’une simple liste contenant les images <img /> et les légendes <span />.
Pour chaque image, nous précisons si la légende sera afficher en bas (classe legend-bottom) ou en haut (classe legend-top).
Style de la liste
D’abord, le style de la liste.
#pictures {
list-style: none outside none;
margin: 0 auto;
padding: 0;
width: 640px; /* Nous affichons les images sur 2 colonne, la largeur est égale à 2 fois la largeur pour chaque image */
}
#pictures li {
border: 5px solid #fff; /* Ajout d'une bordure blanche */
float: left;
height: 225px; /* Hauteur de l'image */
margin: 5px;
overflow: hidden;
position: relative;
width: 300px; /* Largeur de l'image */
}Style de éléments
Nous mettons maintenant en place le style pour chaque élément de la liste :
#pictures li img {
z-index: 10;
}
#pictures li span {
background: rgba(0, 0, 0, 0.5); /* Les légendes auront un arrière-plan noir avec une opacité de 50% */
color: #fff;
display: block;
font-weight: bold;
height: 30px;
left: 0;
line-height: 30px;
padding: 5px 10px;
position: absolute;
text-shadow: 2px 2px #333;
width: 280px;
z-index: 20;
}Comme vous pouvez le remarquer, nous utilisons une propriété de CSS 3 pour définir la couleur d’arrière-plan.
Pour plus de détails, vous pouvez vous référer au site du W3C : http://www.w3.org/TR/2008/WD-css3-color-20080721/#rgba-color.
Nous ajoutons aussi un effet d’ombre sur le texte avec la propriété text-shadow : http://www.w3.org/TR/css3-text/#text-shadow.
Il faut maintenant mettre en place les styles spécifiques pour les légendes du bas et du haut.
#pictures li.legend-bottom span {
border-top: 10px solid rgba(255, 255, 255, 0.2);
bottom: -50px;
transition: bottom 0.3s ease-in-out;
-moz-transition: bottom 0.3s ease-in-out;
-o-transition: bottom 0.3s ease-in-out;
-webkit-transition: bottom 0.3s ease-in-out;
}
#pictures li.legend-bottom:hover span {
bottom: 0;
}
#pictures li.legend-top span {
border-bottom: 10px solid rgba(255, 255, 255, 0.2);
top: -50px;
transition: top 0.3s ease-in-out;
-moz-transition: top 0.3s ease-in-out;
-o-transition: top 0.3s ease-in-out;
-webkit-transition: top 0.3s ease-in-out;
}
#pictures li.legend-top:hover span {
top: 0;
}Nous définissons les positions pour les légendes ainsi que les transitions pour l’affichage.
Les informations sur la propriété transition sont regroupées sur cette page : http://www.w3.org/TR/css3-transitions/.
Vous pouvez voir le résultat sur la démo en ligne.
Créer une galerie photos avec CSS 3 27 Apr 2010 4:00 PM (15 years ago)
Toujours à la recherche de solutions permettant de réaliser des effets avec CSS 3, je me suis penché sur la création d’une galerie photos sans JavaScript.
Le but va être de réaliser un ensemble d’aperçus de photos comme sur ce site : http://www.sohtanaka.com/web-design/fancy-thumbnail-hover-effect-w-jquery/.
Bien entendu, JavaScript interdit ;)
Mise en place de la structure HTML
Avant toute chose, nous allons définir la structure de notre fichier HTML.
<ul id="thumbs">
<li><a href="#"><img alt="landscape001.jpg" src="landscape001.jpg" /></a></li>
<li><a href="#"><img alt="landscape002.jpg" src="landscape002.jpg" /></a></li>
<li><a href="#"><img alt="landscape003.jpg" src="landscape003.jpg" /></a></li>
<li><a href="#"><img alt="landscape004.jpg" src="landscape004.jpg" /></a></li>
<li><a href="#"><img alt="landscape005.jpg" src="landscape005.jpg" /></a></li>
<li><a href="#"><img alt="landscape006.jpg" src="landscape006.jpg" /></a></li>
<li><a href="#"><img alt="landscape007.jpg" src="landscape007.jpg" /></a></li>
<li><a href="#"><img alt="landscape008.jpg" src="landscape008.jpg" /></a></li>
<li><a href="#"><img alt="landscape009.jpg" src="landscape009.jpg" /></a></li>
</ul>Il s’agit tout simplement d’une liste de photos (les aperçus) : la galerie.
##Mise en page
Il faut maintenant positionner notre galerie.
Pour cela, nous optons pour une disposition de 3 photos par ligne.
Le code CSS ci-dessous va nous y aider :
#thumbs {
list-style: none outside none; /* On supprime le style de la liste par défaut */
margin: 0 auto; /* La galerie est centrée horizontalement */
padding: 0;
width: 480px;
}
#thumbs li {
float: left;
height: 112px;
margin: 0;
padding: 5px;
position: relative;
width: 150px;
z-index: 10;
}
#thumbs li:hover {
z-index: 100; /* Nécessaire pour Firefox */
}
#thumbs li img {
border: 5px solid #fff;
z-index: 100;
transition: transform 0.25s ease-in-out;
-moz-transition: -moz-transform 0.25s ease-in-out;
-o-transition: -o-transform 0.25s ease-in-out;
-webkit-transition: -webkit-transform 0.25s ease-in-out;
transform: scale(0.75); /* On réduit l'image à 75% */
-moz-transform: scale(0.75);
-o-transform: scale(0.75);
-webkit-transform: scale(0.75);
}Nous obtenons alors une galerie photos centrer horizontalement, avec 3 colonnes.
Au passage, nous réduisons la taille des images à 75% et nous définissons la transition qui sera appliquée au survol du curseur.
Pour plus d’informations sur les propriétés CSS, vous pouvez vous référer au site du W3C :
transform: http://www.w3.org/TR/css3-2d-transforms/transition: http://www.w3.org/TR/css3-transitions/
Effet au survol du curseur
Le but est maintenant de définir le style lorsque le curseur se positionne au dessus de l’image souhaitée.
Pour cela, nous ajoutons le code ci-dessous :
#thumbs:hover li img {
opacity: 0.5; /* Au survol de la galerie, toute les images auront une opacité de 50% */
}
#thumbs li:hover img {
opacity: 1; /* L'image survolée aura une opacité de 100% */
z-index: 100;
transform: scale(1); /* On affiche l'image à sa taille normale */
-moz-transform: scale(1);
-o-transform: scale(1);
-webkit-transform: scale(1);
box-shadow: 1px 1px 10px #000; /* On ajoute une ombre */
-moz-box-shadow: 1px 1px 10px #000;
-o-box-shadow: 1px 1px 10px #000;
-webkit-box-shadow: 1px 1px 10px #000;
}Les effets au survol du curseur sont obtenus en utilisant la pseudo-class :hover.
Pour les détails sur la propriété box-shadow, vous pouvez consulter le site http://www.w3.org/TR/2005/WD-css3-background-20050216/#the-box-shadow.
Créer un effet de slide avec CSS 3 sans JavaScript 26 Apr 2010 4:00 PM (15 years ago)
Nous avons souvent vu des librairies JavaScript permettant de réaliser des effets de slide :
- http://jqueryui.com/demos/effect/
http://demos.mootools.net/Fx.Slidehttp://labs.adobe.com/technologies/spry/samples/effects/slide_sample.html
Avec les nouvelles spécifications CSS 3, il est maintenant possible de mettre en place cet effet facilement sans aucun code JavaScript.
Nous allons voir comment mettre en place un effet identique à ceci : http://www.incg.nl/blog/2008/hover-block-jquery/.
Préparation de la structure HTML
Nous allons tout d’abord mettre en place un bloc global contenant nos éléments glissants :
<div id="slides">...</div>Chaque élément glissant sera de la forme suivante :
<div>
<p>Mon texte</p>
<img alt="Mon image" src="chemin/image.jpg" />
</div>Déclaration du style CSS
La structure est maintenant créée, il faut définir le style permettant de positionner l’image au dessus du texte et ajouter l’effet souhaité.
Pour cela, nous appliquons d’abord un style au bloc.
#slides div {
background: #fff;
height: 225px; /* Égal à la hauteur de l'image */
margin: 10px;
overflow: hidden;
position: relative;
width: 300px; /* Égal à la largeur de l'image */
}La taille du bloc doit être identique à celle de l’image.
Il faut maintenant positionner l’image au dessus du texte, pour cela, nous utilisons un positionnement absolu.
#slides div img {
left: 0;
position: absolute;
top: 0;
}Ajout de l’effet Slide
Nous allons maintenant définir l’effet de glissement au passage du curseur sur le bloc.
Pour cela, les nouvelles propriétés CSS 3 vont nous aider.
#slides div:hover img {
transform: translateY(-225px); /* Valeur négative égale à la hauteur de l'image */
-moz-transform: translateY(-225px);
-o-transform: translateY(-225px);
-webkit-transform: translateY(-225px);
}Ce code permet d’appliquer un nouveau comportement à l’image lorsque le curseur de la souris se positionne au dessus du bloc (div:hover).
Pour plus de détails sur la propriété transform, vous pouvez vous référer à l’adresse suivante : http://www.w3.org/TR/css3-2d-transforms/.
Comme vous l’avez remarqué, certaines propriétés commencent pas -moz, -o et -webkit ; cela permet aux différents navigateurs (Firefox, Opera et Safari) d’interpréter ces données.
Si l’on teste ce code, nous avons bien une image positionnée au dessus du texte, mais aucun effet au passage du curseur.
Pour cela, il faut modifier la partie div img comme ci-dessous :
#slides div img {
left: 0;
position: absolute;
top: 0;
transition: transform 0.5s ease-in-out;
-moz-transition: -moz-transform 0.5s ease-in-out;
-o-transition: -o-transform 0.5s ease-in-out;
-webkit-transition: -webkit-transform 0.5s ease-in-out;
}Nous avons ajouté un effet de transition.
Ainsi, nous indiquons que la propriété pour laquelle il y aura un effet est transform (voir le bloc CSS div:hover img), cet effet s’étendra sur 0,5 seconde et utilisera la fonction de calcul ease-in-out.
Pour plus de détails, vous pouvez vous référer au site du W3C : http://www.w3.org/TR/css3-transitions/.
En testant ce code, nous obtenons un glissement vers le haut lorsque le curseur entre dans le bloc, l’image dévoile ainsi le texte.
Comme vous le voyez, aucun code JavaScript n’a été utilisé pour mettre en place un effet de glissement.
L’inconvénient de cette méthode est qu’elle n’est applicable que pour les navigateurs supportant les propriétés de transformation 2D et les transitions définies par CSS 3.
Il est bien entendu possible de réaliser des glissements dans les directions que l’on souhaite, pour cela, vous pouvez vous reporter à la démonstration ci-dessous.
Trier une liste de chaînes de caractères en Java 10 Mar 2010 11:58 AM (15 years ago)
Trier une liste de chaînes de caractères en Java est très simple : la classe java.util.Collections dispose de la méthode static sort.
Par contre, il ne faut pas oublier que le tri dépend de la langue.
Considérons la liste de caractères suivante :
List<String> list = new ArrayList<String>();
list.add("a");
list.add("z");
list.add("\u00E0"); // à
list.add("\u00E9"); // ä
list.add("\u00E5"); // å
list.add("\u00E6"); // æ
list.add("\u00E4"); // é
list.add("\u00F8"); // ö
list.add("\u00F6"); // øUtilisation de la méthode sort
Si on effectue le tri comme suit
Collections.sort(list);On obtient le résultat suivant :
a z à ä å æ é ö øTous les caractères spéciaux sont situés après la lettre z.
Or, cet ordre n’est pas correct si l’on souhaite trier selon l’ordre de la langue danoise.
Solution
Pour pouvoir utiliser la langue correcte, il faut considérer la classe java.text.Collator qui permet de tenir compte de la locale.
Pour effectuer le tri en Danois, le code devient alors
Locale locale = new Locale("da", "DK");
Collections.sort(list, Collator.getInstance(locale));On obtient le résultat suivant
a à é z æ ä ø ö åOn remarque que le tri n’est pas effectué de la même façon.
Finalement, pour une application multilingue, effectuer un tri n’est pas si trivial.
Installer MySQL en tant que service Windows 28 Feb 2010 1:14 PM (15 years ago)
L’installation du serveur de base de données MySQL en tant que service Windows peut poser certains problèmes. Nous allons voir les manipulations à réaliser pour mettre en place rapidement la configuration nécessaire.
Prérequis
Cet article a été réalisé sous l’environnement suivant :
- Windows Vista édition Familiale Premium
- MySQL 5.0.27 (version Without installer)
Installation de MySQL
Avant toute chose, il vous faut télécharger la version sans installeur de MySQL à l’adresse suivante : http://dev.mysql.com/downloads/mysql/5.0.html#win32 ; choisissez la version Without installer.
Une fois le téléchargement terminé, dézippez simplement le contenu de l’archive dans le répertoire de votre choix ; pour notre exemple, nous travaillerons dans le répertoire C:\database. Le chemin vers MySQL est alors C:\database\mysql-5.0.27.
Fichier de configuration
Il nous faut maintenant créer un fichier de configuration afin de préciser les paramètres utilisés lors du démarrage du serveur de base de données. Nous placerons le fichier de configuration dans le répertoire MySQL.
Pour cela, créez le fichier my.ini dans le répertoire C:\database\mysql-5.0.27 ; nous créerons un fichier minimum, le but de cet article n’étant pas de décrire en détails la configuration de MySQL ; pour plus d’informations, http://dev.mysql.com/doc/refman/5.0/fr/option-files.html.
Voici un exemple de fichier de configuration :
[mysqld]
basedir=C:/database/mysql-5.0.27
datadir=C:/database/mysql-5.0.27/data
default-character-set=utf8basedir: précise le chemin vers le répertoire de MySQLdatadir: répertoire où les données seront stockéesdefault-character-set: jeu de caractères utilisé pour la base de données
MySQL est maintenant configurer, nous allons maintenant installer le service Windows.
Installation du service
Pour installer notre service Windows, lancez une console : Démarrer > Exécuter… Saisissez cmd puis cliquez sur OK.
Placez-vous dans le sous-répertoire bin de MySQL :
c:
cd \database\mysql-5.0.27\binIl est important de vous placez dans ce répertoire pour créer le service, sinon Windows ne trouvera pas le chemin vers l’exécutable nécessaire pour lancer MySQL.
Exécutez maintenant la commande suivante :
mysqld --install MySQL5 --defaults-file=C:\database\mysql-5.0.27\my.iniArrêtons-nous sur les options utilisées
install: précise le nom du service ; dans notre cas MySQL5defaults-file: indique le chemin vers le fichier de configuration que nous avons créons plus haut
Si le service a été installé correctement, le message Service successfully installed. est affiché.
Démarrage du service
Toujours dans la console, saisissez la commande suivante pour démarrer le service que nous venons d’installer :
net start MySQL5Si le service démarre correctement, les lignes suivantes sont affichées :
Le service MySQL5 démarre.
Le service MySQL5 a démarré.Première connexion
Nous allons maintenant nous connecter pour vérifier que la base de données fonctionne. Pour nous connecter, tapez la commande suivante :
mysql -u rootCette commande permet de vous connecter à la base de données en tant qu’utilisateur root. Si la connexion est réussie, le serveur de base de données est installé correctement.
Pagination d'un tableau avec Mootools 28 Feb 2010 1:05 PM (15 years ago)
Nous allons voir comment mettre en place rapidement un système de pagination pour les tableaux réutilisable et non intrusif avec le framework Javascript Mootools.
Prérequis
Pour pouvoir mettre en place la pagination du tableau, nous utiliserons la librairie MooTools que vous pouvez télécharger sur le site officiel https://mootools.net/. Cet article a été écrit en utilisant la version 1.6.0 de MooTools.
Création de la classe Pagination
Nous allons créer une classe qui va nous permettre de manipuler un tableau afin de gérer la pagination. Pour cela, nous utilisons la syntaxe que MooTools a mise à notre disposition.
Tout d’abord, créons le gabarit de la classe dans le fichier /js/pagination.js :
var Pagination = new Class({
// Le contenu de notre classe
});Le but de cet article n’étant pas de décrire le fonctionnement de MooTools pour créer des classes, vous pouvez vous reporter à la documentation du site officiel : https://mootools.net/core/docs/1.6.0/Class/Class.
Mise en place du constructeur
Maintenant, il faut définir le constructeur afin de pouvoir utiliser notre classe :
var Pagination = new Class({
options: {
currentPage: 0,
lines: 5
},
initialize: function(table, options) {
this.table = table;
this.setOptions(options);
}
});
Pagination.implement(new Options);Attardons-nous un moment sur ces nouvelles informations.
Dans options, nous définissons 2 valeurs :
currentPage: le numéro de la page affichée à l’écran ; par défaut, elle vaut 0 (la première page)lines: le nombre de lignes affichées dans une page ; par défaut, 5 lignes par page
Dans la méthode initialize (le constructeur), nous récupérons 2 paramètres :
table: la table HTML pour lequel nous mettons en place la paginationoptions: des options supplémentaires que nous souhaitons renseigner, comme le nombre de ligne par page ou la page courante par défaut
Comme ci-dessus, nous ne nous attarderons pas sur la syntaxe de implement ; pour plus de détails, https://mootools.net/core/docs/1.6.0/Class/Class#Class:implement.
Initialisation et affichage
Nous allons maintenant créer 2 méthodes afin de
- initialiser et de calculer certaines valeurs que nous utiliserons dans notre code
- afficher / masquer les lignes du tableau
Initialisation des données
Lors de l’initialisation, nous stockons 2 informations importantes : les lignes du tableau et le nombre de pages maximum.
Ces informations sont calculées dans la méthode _init suivante :
_init: function() {
this.rows = $ES('tbody tr', this.table);
this.countPages = Math.ceil(this.rows.length / this.options.lines);
}La première ligne permet de récupérer les lignes contenues dans le tableau.
La seconde calcule le nombre de pages maximum.
Affichage / masquage des lignes
Pour gérer l’affichage des lignes du tableau, nous créons une autre fonction :
_display: function() {
this.rows.each(function(row, index) {
if (index < this.options.lines * this.options.currentPage) {
row.setStyle('display', 'none');
} else if (index > this.options.lines * (this.options.currentPage + 1) - 1) {
row.setStyle('display', 'none');
} else {
row.setStyle('display', 'table-row');
}
}.bind(this));
}Cette fonction itère sur toutes les lignes du tableau et gère l’affichage / le masquage des lignes en fonction de la position de chacune dans le tableau : si la ligne fait partie de la page courante, elle est affichée (row.setStyle('display', 'table-row')), sinon elle est masquée (row.setStyle('display', 'none')).
Premiers appels
Maintenant que nos 2 méthodes sont définies, il faut les appeler dans le constructeur afin d’initialiser la pagination ; le constructeur devient :
initialize: function(table, options) {
this.table = table;
this.setOptions(options);
this._init();
this._display();
}Navigation entre les pages
En l’état, il est possible d’utiliser notre classe de pagination, mais vous pouvez remarquer qu’il est encore impossible de naviguer entre les différentes pages. Nous allons donc écrire 5 nouvelles méthodes :
goToPage: permet d’accéder directement à une page précisepreviousPage: va à la page précédente de la page courantenextPage: va à la page suivante de la page courantefirstPage: va à la première pagelastPage: va à la dernière page
Comme vous pouvez vous en douter, nous écrivons d’abord la méthode goToPage afin de la réutiliser dans les autres méthodes de navigation :
goToPage: function(page) {
if (page < 0 || page > this.countPages - 1) return;
this.options.currentPage = page;
this._display();
}Cette méthode prend en paramètre le numéro de la page vers laquelle il faut aller (n’oubliez pas que la numérotation commence à 0) ; elle vérifie que le paramètre est correct et affiche la page demandée.
Pour définir les 4 autres méthodes, il suffit d’appeler goToPage :
previousPage: function() {
this.goToPage(this.options.currentPage - 1);
},
nextPage: function() {
this.goToPage(this.options.currentPage + 1);
},
firstPage: function() {
this.goToPage(0);
},
lastPage: function() {
this.goToPage(this.countPages - 1);
}Utilisation de la classe
Nous avons terminé l’écriture de la classe Pagination. Maintenant, il suffit de créer un objet de type Pagination et d’appeler les différentes méthodes que nous avons écrites.
Un petit exemple valant mieux qu’un long discours, voici comment utiliser notre classe.
Création du tableau HTML
Pour pouvoir réaliser la pagination, nous devons d’abord créer notre table en utilisant la balise <tbody> :
<table id="acteurs">
<thead>
<tr>
<th>#</th>
<th>Prénom</th>
<th>Nom</th>
<th>Rôle</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>Kad</td>
<td>Merad</td>
<td>Philippe Abrams</td>
</tr>
<tr>
<td>2</td>
<td>Dany</td>
<td>Boon</td>
<td>Antoine Bailleul</td>
</tr>
<tr>
<td>3</td>
<td>Zoé</td>
<td>Félix</td>
<td>Julie Abrams</td>
</tr>
<tr>
<td>4</td>
<td>Philippe</td>
<td>Duquesne</td>
<td>Fabrice Canoli</td>
</tr>
<tr>
<td>5</td>
<td>Line</td>
<td>Renaud</td>
<td>Madame Bailleul</td>
</tr>
<tr>
<td>6</td>
<td>Michel</td>
<td>Galabru</td>
<td>Le grand oncle de Julie</td>
</tr>
<tr>
<td>7</td>
<td>Stéphane</td>
<td>Freiss</td>
<td>Jean</td>
</tr>
<tr>
<td>8</td>
<td>Guy</td>
<td>Lecluyse</td>
<td>Yann Vandernoout</td>
</tr>
<tr>
<td>9</td>
<td>Anne</td>
<td>Marivin</td>
<td>Annabelle Deconninck</td>
</tr>
<tr>
<td>10</td>
<td>Patrick</td>
<td>Bosso</td>
<td>Le gendarme</td>
</tr>
<tr>
<td>11</td>
<td>Zinedine</td>
<td>Soualem</td>
<td>Momo</td>
</tr>
<tr>
<td>12</td>
<td>Jérôme</td>
<td>Commandeur</td>
<td>Inspecteur Lebic</td>
</tr>
</tbody>
</table>Nous ne nous attarderons pas sur la syntaxe de la table.
Nous allons maintenant ajouter des liens permettant de naviguer :
<div id="actions">
<a href="#" id="premiere">Premiére page</a>
<a href="#" id="precedente">Page précédente</a>
<a href="#" id="suivante">Page suivante</a>
<a href="#" id="derniere">Dernière page</a>
</div>Utilisation de la classe Pagination
Maintenant, il faut importer les fichiers Javascript nécessaires. Pour cela, il suffit d’ajouter les lignes suivantes dans le head de votre page HTML :
<script type="text/javascript" src="js/mootools.js"></script>
<script type="text/javascript" src="js/pagination.js"></script>Enfin, nous allons instancier notre objet afin de pouvoir naviguer ; toujours dans le head de votre page, vous pouvez ajouter les lignes suivantes :
<script type="text/javascript">
window.addEvent('domready', function() {
var pagination = new Pagination('acteurs', {
currentPage: 2,
lines: 3
});
$('precedente').addEvent('click', function(event) {
new Event(event).stop();
pagination.previousPage();
});
$('suivante').addEvent('click', function(event) {
new Event(event).stop();
pagination.nextPage();
});
$('premiere').addEvent('click', function(event) {
new Event(event).stop();
pagination.firstPage();
});
$('derniere').addEvent('click', function(event) {
new Event(event).stop();
pagination.lastPage();
});
});
</script>Voyons un peu ce que ce code fait :
Tout d’abord, il attend que le DOM soit prêt pour pouvoir créer notre objet : window.addEvent('domready', function() {...}). Pour plus de détails sur cette syntaxe, référez-vous à la page https://mootools.net/core/docs/1.6.0/Utilities/DOMReady#Window-Event:-domready.
L’objet pagination est instancié et fait référence à la table acteurs ; de plus, il précise que la page par défaut est la 2 et qu’il faut afficher 3 lignes par page.
Ensuite, on ajoute les actions sur les liens pour naviguer.
Et voilà, notre tableau est maintenant paginé.
Utiliser Apache en frontal de Tomcat 28 Feb 2010 12:48 PM (15 years ago)
Cet article va vous expliquer comment connecter le serveur HTTP de Apache avec Tomcat.
Cela permettra de :
- répartir les charges entre les 2 serveurs
- utiliser les fonctionnalités du serveur Apache comme l’url rewriting
- gérer le SSL
- …
Environnement
L’article a été réalisé sous l’environnement suivant :
- Windows XP
- Apache HTTP 2.0.59
- Apache Tomcat 5.5.20
Pour faire le lien entre les 2 serveurs, il vous faudra télécharger sur le site Tomcat Connector le module mod_jk pour Apache : http://www.apache.org/dist/tomcat/tomcat-connectors/jk/binaries/. Dans notre cas, vous devez choisir le fichier situé dans le répertoire win32/jk-x.y.zz nommé mod_jk-apache-2.0.xx.so.
Configuration de mod_jk
Pour configurer le module de Apache, nous allons créer un fichier dans le répertoire conf du serveur Apache. Dans notre cas, nous allons l’appeler workers.properties.
Dans ce fichier, nous allons ajouter les lignes suivantes :
worker.list=default
worker.default.type=ajp13
worker.default.host=127.0.0.1
worker.default.port=8009Un peu d’explication sur les parmètres que nous venons de saisir :
worker.list: définit le nom de la liste de paramètres qui sera utilisée. Comme vous pouvez le remarquer, le nom de la liste spécifiée fait partie des noms de paramètres suivantsworker.default.type: le type de worker utilisé pour faire le lien entre Apache et Tomcat ; la valeur de ce paramètre doit être l’une des suivantes : ajp13, ajp14, jni, lb ou status ; par défaut, il s’agit de ajp13worker.default.host: le nom ou l’adresse IP du serveur Tomcatworker.default.port: indique le port
Installation de mod_jk
La mise en place du module mod_jk est très simple :
- Copiez le fichier mod_jk-apache-2.0.xx.so que vous avez téléchargé dans le répertoire modules de votre distribution du serveur Apache
- Éditez le fichier conf.httpd du répertoire conf
- Recherchez le groupe de ligne commençant par
LoadModule - Ajoutez à la fin de ce groupe de lignes l’instruction suivante
LoadModule jk_module modules/mod_jk-apache-2.0.xx.so - Ajoutez à la fin du fichier les lignes suivantes
JkWorkersFile "W:/Apache2/conf/worker.properties"
JkLogFile "W:/Apache2/logs/mod_jk.log"
JkLogLevel warning
JkMount /monApplication default
JkMount /monApplication/* defaultArrêtons nous un instant sur les dernières lignes que nous venons d’ajouter :
JkWorkersFile: indique le chemin vers le fichier de configuration, workers.properties, que nous avons créé (n’oubliez pas de préciser votre chemin)JkLogFile: le chemin vers le fichier de log (idem que précédemment, il faut utiliser vos propres paramètres)JkLogLevel: le niveau de log à partir duquel les informations seront enregistrées dans votre fichier de logJkMount: indique le lien entre votre application J2EE installée dans le Tomcat (monApplication) et le worker que vous avez défini
Démarrage des serveurs
Vous pouvez maintenant démarrer votre serveur Tomcat puis votre serveur Apache. Pour tester le bon fonctionnement de votre configuration, après le démarrage de vos serveur, il vous suffit de démarrer votre navigateur Web préféré et de saisir l’adresse http://localhost/monApplication ; vous devriez alors avoir accès à votre application J2ee.