[Akitando] #32 - Como eu aprendi Inglês? E entendendo "padrões"! 11 Dec 2018 10:00 AM (6 years ago)
Disclaimer: esta série de posts são transcripts diretos dos scripts usados em cada video do canal Akitando. O texto tem erros de português mas é porque estou apenas publicando exatamente como foi usado pra gravar o video, perdoem os errinhos.
Descrição no YouTube
Errata a 25:16 a legenda está "colégio" mas é "faculdade" :-)
Novamente um episódio que ficou um pouco longo então será o único desta semana.
Desta vez quero explorar como eu aprendi inglês e aproveitar pra explicar porque é tão importante inglês na nossa área e também porque NÃO é tão complicado como muita gente pensa. Trabalhoso, sim. Caro ou complicado, não.
Uma tangente neste assunto será tocar no que muita gente pensa sobre "padrões" e o erro nesse pensamento. Fiquem ligados!
Links:
- Off Topic: Somos Matematicamente Ignorantes (http://www.akitaonrails.com/2008/03/01/off-topic-somos-matematicamente-ignorantes)
- [Off-Topic] A Revolta de Atlas: Dinheiro é a raíz de todo o mal? (http://www.akitaonrails.com/2011/02/03/off-topic-a-revolta-de-atlas-dinheiro-e-a-raiz-de-todo-o-mal)
- Descartes' Error: Emotion, Reason, and the Human Brain (https://www.amazon.com.br/Descartes-Error-Emotion-Reason-Human/dp/014303622X)
Script
Olá pessoal, Fabio Akita
Já que eu tenho falado sobre estudo acho que vale a pena entrar no tema do temeroso Inglês. Todo programador sabe que deveria já saber inglês mas fica empurrando, empurrando, até o dia que começa a perder oportunidades, e aí percebe como já é tarde demais.
Vamos dizer o óbvio: pare com as justificativas, qualquer razão que você está usando pra não evoluir no inglês não é nada mais, nada menos, que puro … bullshit, a fucking big pile of turd.
Ah, isso é imperialismo, temos que ser patriotas, valorizar a língua nacional, bla bla bla mi mi mi fuck you se você diz imbecilidades como essa.
Tamos entendidos? Então vamos avançar
(...)
TUDO que sai de mais importante na área de tecnologia sai primeiro em INGLES. Sabe o que acontece se você depende de material em português? Você precisa esperar essa tecnologia ganhar público, alguém se arriscar a traduzir material em português e publicar aqui. E todo mundo sabe que todo projeto open source, principalmente nas primeira iterações, muda o TEMPO TODO.
Ou seja, do ponto de vista de retorno financeiro, Não é um bom negócio publicar livros de versões 1.0 de projetos open source porque o 2.0 vai sair em 6 meses e o livro vai ter pouco tempo de vida. Livro técnico é absolutamente chato de escrever - eu sei, eu já escrevi um. Especialmente porque se você demora muito, tem que ficar revisando todos os capítulos anteriores quando sai um update. E depois que publica ainda tem que ficar correndo atrás se sai outros updates que quebram os exemplos que você colocou no livro, ou seja, é um puta trampo de manter o livro atualizado ao mesmo tempo que o software ainda está inacabado e evoluindo.
Mundo open source é assim mesmo. E se por acaso um novo projeto consegue ganhar o seu público de early adopters e começa a ter demanda, sabe quem ganha mais dinheiro? Quem aprendeu sobre o software antes mesmo de ter saído a versão 1.0. Depois que saiu a versão 4, 5 etc que já tem livro, já tem curso, já tem toneladas de screencast, é quando o taxa/hora vale menos, 2x, 5x, 10x menor do que era pago pra quem se arriscou e aprendeu na versão 0.1 alfa.
Vocês já entenderam uma coisa meio óbvia? As pessoas ficam procurando “o que a maioria das pessoas está fazendo”. Eu penso assim: puts, se a maioria das pessoas tá fazendo uma coisa, é porque essa coisa vale muito pouco e nunca vão me pagar muito, justamente porque tem um milhão de indianos que vão cobrar 10x menos que eu pra fazer a mesma coisa.
Claro, o mais seguro é primeiro ir atrás de alguma coisa bem óbvia. Por isso eu falei no episódio de “O que devo estudar” pra ir num Java, C# ou PHP da vida. Mas qual o próximo passo? Ora, quem ganha mais na indústria? As moscas brancas. Os cisnes negros. Mas é muito raro você escolher, conscientemente, a tecnologia que ainda vai se popularizar, e acertar em cheio. Precisa de muita experiência pra isso, e mesmo assim você pode estar errado.
Se eu fosse resumir, você precisa saber duas coisas importantes: história e línguas. Mas não do jeito que você pensa. Todo mundo fica atrás só dos headlines, da notícia de hoje. Eu estou mais interessado em juntar as peças das notícias de ontem, de 1 ano atrás e de 1 década atrás. Eu fico constantemente comparando essas coisas. Não tem uma receita, mas quanto mais você estuda a história da sua área, mais você vai entendendo pra onde as coisas tem mais probabilidade de ir. Isso se chama reconhecimento de patterns, vou voltar nisso no fim do vídeo.
Agora, finalmente, línguas, que é o tema de hoje. Existem dezenas de formas de fazer isso e de novo, não vou dizer o óbvio. O óbvio está em todos os canais de YouTube de línguas e uma rápida procurada no Google vai te trazer uma tonelada de cursos online. Baixa lá o Duolingo e Just fucking do it!
Mas o que eu quero fazer é explicar como Eu encaro o aprendizado de qualquer coisa usando meu aprendizado de inglês como exemplo.
Sabe que tipo de pessoa aprende coisas mais rápido? Uma criança. Todo mundo já ouviu falar que toda criança é uma esponja, que aprende tudo que você ensina pra elas? Eu sempre ouvi falar isso e como toda cagação de regra que eu ouço eu parei pra pesquisar e refletir sobre isso.
Eu me considero uma criança em muitos aspectos, até hoje. Uma delas é que eu não tenho muito apego a nada. Portanto eu tenho muito pouco a perder. E isso é uma criança: ela não nada pra perder, ou melhor, ela nunca parou pra considerar que tem coisas pra perder, e por isso não tem medo de arriscar nada. Tudo pra ela é uma oportunidade, lembra que eu venho repetindo muito isso nos episódios anteriores?
No caso de línguas, todo adulto começa pensando que tem muito a perder. O adulto começa a pensar no que os outros vão pensar, como os outros vão julgar. Será que vão dizer que estou demorando muito pra aprender e acharem que sou devagar? Será que vão dizer que eu não consigo falar e achar que sou incapaz? Será que vão ficar tirando sarro de mim e vou virar a piada do grupo? Daí você pára e pensa, se vou aprender tem que ser sério! Se é pra ser sério, precisa ser num curso top. Só que curso top é caro e eu não tenho dinheiro agora, e se for pra pagar caro precisa reservar muito tempo senão não compensa. Hm, como não tenho nem dinheiro e nem tempo, vamos deixar pro próximo semestre que aí vai dar tempo de guardar dinheiro e organizar minha vida pra ter tempo …. Daí passa seis meses e o que acontece? Nada.
Agora tente se lembrar de você quando criança ou qualquer criança que você conheça, seu sobrinho, seu filho, seu neto? Aos 2 anos de idade, quantos cursos top de português ela fez? Quantas horas em salas de aula com professores especializados ela fez? Quantas certificações em cursos especiais ela tirou?
Não é possível que você nunca tenha pensado que em 2 anos, uma criança sai do zero pra razoavelmente fluente numa língua, o suficiente pra você entender sentenças inteiras e em mais 2 anos ela tá quase tão fluente quanto você (ou melhor, se bobear). Obviamente, não adianta falar com ela de coisas técnicas específicas, falar em bolsa de valores, física, engenharia, tudo vocabulários que ela não vai saber. Mas largue essa criança num shopping center e certamente ela vai conseguir se comunicar com tudo mundo. E se ela não entender alguma coisa? Ela vai perguntar e perguntar e perguntar, até ficar satisfeita com a resposta, que é exatamente o que VOCÊ não faz.
Não subestime esse processo. Todo mundo quer esse processo na verdade, por isso você vai fazer intercambio. Todo mundo tem essa intuição de que se você fizer uma imersão num país estrangeiro, você vai magicamente, aprender mais rápido. Qualquer metodologia que te incentive a se concentrar acima do normal num período limitado de tempo funciona da mesma forma, indo pro exterior ou não. Ir pro exterior pra mim é mais status do que necessidade. Mas claro, se puder, com certeza vá, a experiência maior é a vivência mais do que o estudo. Trabalhe num bar, pague seu curso e passe 1 ano morando fora. Você provavelmente não ia precisar ver meus vídeos se tivesse feito isso :-)
Claro, você precisa ter um mínimo de estrutura. Nem que seja as porcarias de aulas de inglês que tivemos na nossa escola, que ensinou só o basicão do verbo To Be e meia dúzia de palavras. Mas isso deve ser o suficiente.
Eu mencionei num dos vídeos que quando eu comecei a fazer faculdade, meu inglês não era fluente. Eu lia devagar e não tinha nenhuma fluência pra falar, nem pra arriscar frases. O que me motivou foi no primeiro de aula o professor listar livros estrangeiros na bibliografia e eu ter colegas de classe que já tinham morado fora ou feito intercambio e estavam na minha frente. Eu já disse também que é o tipo de coisa que me deixa motivado a correr atrás.
E foi exatamente o que eu fiz. E aprendizado é que nem dieta, ou você faz all-in, sem compromisso, ou não faz. Do, or do not, there is no fucking try.
Vamos lá, assim como 99% da população, eu só comprava livros e revistas em português, eu só assistia filme dublado ou com legenda, eu ouvia música mas sequer prestava atenção nas letras e eu evitava tudo que tinha inglês. Eu fiz aqueles cursos de bairo, no caso Fisk, mas eu desisti porque não via evolução. Era essa minha situação no ano em que entrei na faculdade. Eu nunca fiquei 100% perfeito na fluência, mas ouçam vocês mesmos:
Ok, so I spent the next 10 years under lockdown. In my mind, I have decided that just enrolling in an ordinary English course would be too damn slow. I am not advocating that classes are not good, it's just not right for someone like me, I am a stubborn son of a bitch that wants to dictate my own pace, which is usually faster than average.
Moreover, I wanted to speak as close to a native American as I possibly could without having to live there. What if I consumed the exact same things every day as if I was living in a USA city somewhere?
If I moved there, there wouldn't be any Portuguese resources anywhere. So I'd be forced to browse in the web in English, go to Barnes & Noble and buy English-only books and magazines. I'd like to go to the Chinese Theater in LA to watch the blockbuster premieres, all in English.
So, it was only a matter of emulating the exact same environment in my own routine. I never bought or read a single book or magazine in Portuguese ever again. I spent a good portion of my small salary by importing computer books. I was paying 5x more buying magazines such as Wired, or PC Magazine. I rented movies at Blockbuster, and I had to put a box in front of the TV set to hide the Portugues subtitles. And fortunately, I am the kind of nerd that watches the favorite movies many times over.
Did you read my blogs and facebook or twitter timelines? To this day, more than 20 years later, I keep writing in English as much as I can. This procedure became my routine. To this day, I avoid consuming Brazilian sources, it's just a habit. I don't read Brazilians books, I don't watch Brazilians tv-shows. It's considered normal nowadays to not watch the open TV because of Netflix, but I have been doing that since the mid-'90s. Let's say I was ahead of this curve by at least a decade. YouTube, Netflix, Amazon Kindle, just made my life easier.
When I was in college, I did all my programming in English. It always felt wrong to mix Portuguese variable names with English-based statement syntax. It's just wrong. Don't do it. If for nothing else, only realize that if you use Portuguese, you won't ever be able to open source it. I am not saying that you should open source everything, but why are you closing that door so soon? And you can't ever hire programmers from other countries to help out either. Writing code in Portuguese limits the reach of that code.
I spent around 5 or 6 years consistently doing precisely that. From my first year in college to the dotcom era. Remember that PSN dotcom I mentioned I worked for? So they wanted me to fly to their Florida office to get acquainted with the other developers. This was 2001, and it was the very first time I set foot in the USA.
Remember when I mentioned that you want to be ready when the opportunity arises? That's precisely my point. If I had procrastinated, I would have missed that chance.
And let me tell you: no amount of theory will save you in practice. I realized my limitations when I arrived there. Jesus Christ, the freaking Cubans, and their Spanish-mixed English are stupidly hard to understand. And I had people from Texas in the office, also a crazy difficult accent to follow. I think I can deal with them way better today, but for my very first attempt, I had to ask people to repeat slowly many times. And don't think for a second that I didn't.
Over the years, I met people that have been teaching me. And this is super important. You feel ashamed when someone tries to correct your misspellings. And you lose an opportunity. Whenever someone corrects me, I engage. I say "hey thanks, so, is this the correct way, let me try again," and if the person is willing, we end up spending a few minutes with training. That's how I finally figured out the proper way of saying tree and three, and words like three, there, those, there. That was an afternoon coffee with a friend of mine from the USA.
Remember when I mentioned children? The sad thing about adults is that we lose our inner child. Learning is essentially letting your adult self aside and bring back the curious child back. Never feel ashamed, never hold your questions back. Children are interested, their parents even get upset when children ask too many questions. Let them. This is the only way to learn stuff: to question everything, no matter how silly it sounds. The only dumb thing is not to ask questions.
And again, will it be worth it? Will you ever be able to speak fluently like a native American? You could. It all depends on training and commitment. As you can tell by now, I can't. This is the closest I could get.
The interesting thing you don't think about? The Americans don't care. They can tell I'm not a native. But I'm understandable, and that's enough. In their minds what they immediately think is: "damn, this guy speaks better English than I could ever speak any other language." That's right, most Americans only speak English, they respect anyone that can speak more than one language, and they appreciate you even more for being understandable to them.
Americans are used to different accents, they have Latinos, people from Mexico, Republica Dominicana, they have Chinese, they have Italians, and so on and so forth. There are dozens of dialects and accents throughout the country.
And if you add English from Great Britain, the Netherlands, Australia, it's all different. Your particular accent, my own accent, doesn't sound nearly as bad as you think it does.
You are an adult, what the heck are you ashamed for? Mockery? Oh, come on. This is bullshit. The only reason you're not studying and doing your best right now is your own laziness. You're just lazy, admit it. It's pathetic. If you really wanted you could start right now, for zero bucks. Change your Operating System default language to English - seriously, I have a hard time with Windows in Portuguese because I can't find anything, I am used to English and the order of things in English. Then, erase all your Portuguese bookmarked websites. Change the default language of your web browser to English. None of this cost any money.
Install tools like Grammarly to correct your terrible written English. Read as much as you can, every day, in English. Listen to as much as you can. I subscribe to hundreds of English-only YouTube channels, I have zero Portuguese channels. Netflix? Start with subtitles in English - it's so awesome that there is this option; if only I had it my VHS days. When you go rewatch a movie you like, turn the subtitles off. And instead of not paying attention because you feel uncomfortable, do the opposite, pay extra attention, pause the video whenever you learn a new word. Get your smartphone and Google it. The tools we have today make the learning process so much easier. I do that myself. For example, I just learned a new word that I never used before: "unrequited," which means "unreturned, like a feeling not reciprocated," and that was from Woody Allen's Cafe Society movie. Old movies always teach me words I never used.
As a disclaimer, also keep in my that I always read a scripted text in my channel, and this section was no exception ;-)
Now, let me switch back to Portuguese!
Eu acho que eu soou diferente quando eu falo em inglês e português, porque você não pode falar inglês com o mesmo ritmo que fala português do mesmo jeito que seria bizarro você cantar, por exemplo, um Fly me to the Moon do Frank Sinatra com ritmo de Funk. Pensa como fica. Você precisa respirar diferente. E é mais fácil “ver” isso quando assiste séries e filmes, comece a prestar atenção na linguagem corporal dos atores. Eu já fiquei horas fazendo careta pra TV pra imitar a posição da boca e o jeito de inspirar e expirar as palavras. E sobre respiração, uma coisa que eu vejo 90% das pessoas fazendo errado: fale as palavras até o fim, não tente conectar uma palavra na outra como fazemos falando português corrido. Fale inglês como um gaúcho ou sulista fala português, pausado, correto, palavras até o fim, com pausa. Só isso já é meio caminho andado pra ser entendido.
Mas se você não está convencido, vou dizer uma última coisa que eu acho muito importante, inclusive tem a ver com programação. No mundo da programação, você frequentemente vê o povo falando de padrões de programação ou padrões de arquitetura.
Quando alguém fala “padrão” parece dizer no sentido de “é a melhor forma” de fazer alguma coisa. E isso está errado. Em inglês temos 3 palavras diferentes: standard, default e pattern. Os 3 traduzem em português pra padrão, mas eles querem dizer 3 coisas completamente diferentes.
O que você pensa por padrão, normalmente é o que o americano pensa quando diz “standard”. Um standard a ser seguido.
Ou você tem default, que é a escolha padrão, ou quando você não escolhe, o que é escolhido é o default.
Finalmente, pattern é simplesmente alguma coisa que aparece várias vezes. Pode ser certo ou errado. Um pattern pode simplesmente indicar uma tendência. Por exemplo, se todo mundo resolver começar a usar calça vermelha. Isso é uma moda, posso dizer que é um pattern. Ou dizer que toda boa pizza “costuma” ter queijo, é um pattern. Mas não é um padrão ou 100% das pizzas precisariam ter queijo. Entendem a diferença?
Por isso, toda vez que em programação você ver algum livro ou matéria falando em “padrão de arquitetura”, não pense que esse deve ser O jeito certo de fazer. É só um jeito que, naquele momento que o texto foi escrito, o autor viu com alguma frequência, o suficiente pra chamar de pattern. Em 1 ano pode já estar obsoleto porque assim como tendências, patterns também ficam velhos, outros patterns aparecem.
Se você parar pra entender o básico sobre como o cérebro funciona, do ponto de vista neurológico, um de nossos melhores mecanismos é nossa habilidade de aprender e detectar patterns. É parte do que chamamos de instinto, quando sentimos que vamos ser atacados, e fugimos sem pensar. Ou mesmo quando vemos textos como este:
(.... texto bagunçado)
Nós não lemos palavras de letra em letra, nós identificamos o pattern e vamos lendo em clusters, às vezes pulamos uma sentença inteira se for um cliche ou um chavão. Porque o pattern economiza nosso processamento, é meio como uma rede neural artificial funciona, ou o que chamamos hoje de machine learning, é basicamente identificação de patterns.
Patterns também tem efeitos colaterais, é de onde temos as ilusões de ótica por exemplo, onde vemos patterns que não existem ou patterns que nos confundem:
(... ilusao de otica)
Psicologicamente é de onde vem muito de nossas neuroses e até mesmo teorias da conspiração que é basicamente vermos patters que não existem, adicionar causalidade a coisas que não tem correlação. Tudo é parte dessa identificação de patterns.
Quando aprendemos inglês nos inserindo no ambiente como eu fiz artificialmente, mesmo que eu não entenda tudo que estou lendo ou ouvindo, se eu praticar deliberadamente a repetição, eu eventualmente vou “sentir” quando algo soa correto ou não. Eu não lembro a regra gramatical. Quando eu leio uma frase eu sei que “soa estranho” ou não. I won’t do it, ou I’m not gonna do it, são literalmente a mesma coisa, mas naturalmente eu digo um ou outro sem pensar muito. E eu argumentaria que pro dia a dia, isso é um bom nível, quando você naturalmente fala uma frase de acordo com o contexto da conversa sem precisar conscientemente pensar na construção dessa frase, que é exatamente como você fala sua língua nativa: você não precisa fazer um esforço consciente muito grande pra simplesmente falar.
Em resumo, o que normalmente chamamos de Padrão não é Standard. É Pattern. E você saberia disso se lesse os livros em Inglês, em vez das traduções em português, onde é impossível traduzir o contexto exatamente como o autor gostaria. Toda tradução perde parte do sentido, não importa quão bom seja o tradutor, especialmente porque algumas coisas tem carga filosófica ou cultural que não tem como traduzir.
Um dos exemplo que eu mais gosto é quando traduzem “making money” pra “ganhar dinheiro”. Tecnicamente está correto. Você diz: “I’m going to work to make money” que traduziria pra “Eu vou trabalhar pra ganhar dinheiro”. Em português a frase implica que sua opção é trocar seu trabalho por dinheiro, em inglês não se diz “ganhar”, se diz “make” que é “fazer”, a frase em inglês implica a opção de você produzir onde antes não existia alguma coisa, que é a essência de empreender.
E na minha cabeça essa é uma das maiores diferenças culturais dos Estados Unidos pra qualquer outro lugar do mundo: lá, filosoficamente falando, o objetivo era construir e criar onde nada existia antes. No resto do mundo é dividir e tomar o que existe, ganhar o dinheiro, ganhar as terras, ganhar o poder, não construir.
E com isso eu espero que tenha conseguido explicar o que eu acho sobre aprendizado e em particular o que eu acho que pode ajudar na sua jornada pra aprender outra língua. Eu fiz mais ou menos a mesma coisa pra aprender Japonês. Em ambos os casos eu fiz sim curso, até o básico e saí do curso, aqueles cursos de bairro sabe? Como auto-didata eu acho que não fui tão ruim, o que vocês acham? E quais são as suas histórias não convencionais de como aprenderam línguas? Não deixe de compartilhar nos comentários abaixo, se gostaram mande um joinha, compartilhe com seus amigos, assine o canal e clique no sininho. A gente se vê, até mais.









Estimates are Promises - A Better Metaphor 26 Jun 2017 12:44 PM (7 years ago)
If you didn't know, I am frequently answering questions over Quora. Follow me there, so far I wrote almost 600 answers, many of which resemble my longest blog posts here.
One of the most popular answer regards the subject of "What is the hardest thing you do as a software engineer?". I wrote a similar answer in Brazilian Portuguese in the post "Estimativas são Promessas. Promessas devem ser cumpridas.".
In a nutshell, you can never give an estimate that is "correct". If you could, it would not be an "estimate", it would be a "prediction".
Let us assume that we have neither precognition powers nor magic crystal balls to tell us the future.
To estimate something is to "guess" the value of something. It's always a guess. It's the same thing as a valuation. And as any guess, it can never be deemed "correct". It's just a likely candidate among an infinite range of possible values.
There is zero connection between a guess and the outcome. Understand this simple truth: saying something can happen does not MAKE it happen.
Estimating tomorrow's weather as rainy does not MAKE it rain. Estimating the results of the Super Ball does not MAKE it happen. Therefore, there is zero correlation between an estimate and the actual outcome.
I stated in the aforementioned articles that "Estimates are Promises". The intention was to provoke a reaction as most people assume that estimates can never be promises exactly because of what was just explained.
What makes promises special is that once you promise something it is expected that you ACT upon realizing it.

No one that has no "skin in the game" should give estimates.
If you're not an active player in the game, you should not give any guesses. The same way no one makes promises for someone else.
Can you actually make credible promises and meet them? Yes, you can, but first, you must understand a few more truths about reality.
You probably already saw many articles explaining many methodologies and project management techniques. I believe most of them succeed in explaining the Whats and the Hows, but as usual, they all fail in explaining the Whys.
Why do we need those methodologies? Why are they even needed? Why do they work? What are the hidden mechanisms that they put in motion?
What makes Agile techniques different from your usual Homeopathy or budget Self-Help cliché?
It's always all about Paretto
There is no such thing as a precise project scope. There is a limit to add details after which you just get diminishing returns.
The most precise level of detail one feature scope can have is the actual coding of the feature. This is important: the lines of code from programming is NOT the outcome. The execution of that code in runtime is what end users will actually experience.
The programming itself is the ACTUAL blueprint. The diagrams, the use cases, the user stories or any other non-programming before that is just draft, a mere sketch.
A naive architect or designer might think that the detailed diagrams or use case documents, fancy powerpoint slides, have the same worth as an engineering blueprint. But they do not: they're the equivalent sketch in a napkin. Volatile, mostly worthless actually.

"But isn't the programming the same as the construction phase itself, laying bricks on top of bricks?¨ - NO, this is not what a programmer does. The brick work is the task of the so-called language interpreter or the compiler spitting out the binary that executes.
This is the metaphor that make non-programmers crazy: in engineering, the construction itself is the most expensive and time consuming parts. In programming, the blueprinting (the coding) is the expensive part, and the "construction" is actually trivial (just compiling the code, which is automatic).
The same way, a project scope is just a set of sketches. We should dump the notion that there will ever exist a "complete" scope of a project. There is no way to say "100% of the scope" or "closed scope", because a software project scope is, by definiton, always incomplete.
Moreover, I will argue that approximately 80% of this so called "scope" - what I prefer to call sketch - is mostly worthless to most of the end users activities (the admin section, institutional pages that no one reads, complicated signing up processes, etc).
This is why every feature list MUST be prioritized. You usually can get by with 20% of the features (this is roughly what people mean when they say "MVP or "most viable product"). Release as early as you can, get user feedback and refine the rest of the "sketch" you call backlog.
So, instead of aiming for an all-or-nothing proposition of having to find stupid ass complex equations to figure out a "precise" estimate for an incomplete sketch, assume you can actually deliver EARLY, the first 20% that actually matters and figure out the rest in iterations.
Oh yeah, this is what we call "Agile" by the way.
Agile is about Risk Management
People assume Agility is about project management in terms of managing the "project management" instruments themselves: the backlog, the rituals, the metrics.
Having Agile-like instruments don't make you Agile.
Being Agile is keeping Risk under control.
Instead of thinking about projects as an all-or-nothing endeavor. You must start thinking about it as an investor would think about his portfolio of stocks. You don't expect the entire portfolio to yield profits, you actually assume that some stock will underperform. You just don't know which, so you dillute your risk.

Trying to predict the stock market is an exercise in futility.
Trying to predict the precise implementation of a project - specially the long ones - is also an exercise in futility.
So you must deal with uncertainty the correct way: by becoming Antifragile.
"Some things benefit from shocks; they thrive and grow when exposed to volatility, randomness, disorder, and stressors and love adventure, risk, and uncertainty. Yet, in spite of the ubiquity of the phenomenon, there is no word for the exact opposite of fragile. Let us call it antifragile. Antifragility is beyond resilience or robustness. The resilient resists shocks and stays the same; the antifragile gets better" - Nassim Taleb
Instead of the preposterous exercise in futility of trying to predict uncertainty and random events you do the reasonable thing: you assume Black Swans exist and you can't predict them. So you prepare for the uncertainty in the only reasonable way: by not trying to predict them.
Expose the small mistakes early, correct them often. Implementing everything in a black-box and do a Big Bang deployment is the easiest path to failure. Delivering often, exposing the bugs and fixing them constantly is accepting that mistakes will happen and gaining strength in the process as you go.

A Better Metaphor

Imagine that you - the non-programmer client or you, the programmer that has no clue how to explain the process to your non-programmer client - have an iron ore furnace to manage.
Thing about those furnaces is that if you heat it too much, they can explode in your face. If you cool it down too much, the ore will harden.
Your job is to add coal to the furnace. You decide in which rate. If you go too fast it gets exploding hot. If you go too slow you may extinguish the fire and lose your furnace.
Now, try to make an estimate of a constant intake of coal to keep your furnace in good shape.
You can't.
The easiest way out is to install a thermometer that keeps track of the current temperature of the furnace.
You're safe within a certain margin of temperatures and you speed up or slow down the coal intake by check the thermometer all the time.
ALL THE FREAKING TIME.

This is what Agile-based "Velocity" (or any of the fancier Monte Carlo simulations) actually is: a thermometer.
If the Velocity is too high, your team is probably working either extra time or delivering lower quality code. This will backfire because either your team will burn out too fast or the code is accumulating technical debt too fast and you won't be able to pay back. Velocity will drop to a halt if you keep this high (furnace explode).
If the Velocity is too low, your team is slacking off, your backlog is a useless piece of shit that no one can understand even after 10 hour meetings, or you already left the Velocity get too high and now you're paying back technical debt or your team is dead after burn out (fire extinguised).
You want to keep Velocity steady, constant. This is what being Agile is all about: keeping an eye on the thermometer and responding.
The Triforce of Projects

Welcome to the Iron Triagle of Project Management.
Repeat after me: if I want to lock down the time, the cost, and the scope, I am a moron.
Repeat again.
You should lock down time and cost, and if you read this far, you know you can never lock down "scope", you can just make it fat (and not necessarily more valuable). This is why I always say that the very definition of a Product Manager or Product Owner is to be the bastion of ROI (Return on Investment).
Now, why?
Because the Iron Triangle has the following corollary:

- If you want it fast and good, it can't be cheap
- If you want it fast and cheap, it can't be good
- If you want it good and cheap, it can't be fast
This is a Law, you can't fiddle with it. Pick your choice.

How do I keep Promises then?
Now, with those 3 truths in hand:
- You can't have your lunch and eat it too (cheap, fast, and good)
- You're managing the temperature of the furnace
- You only need 20% of the "sketch" you call "scope"
Yes, any experienced developer can give you a "ballpark" estimate. A ballpark goes like this:
- 1 month (maybe 1 month and a half, but definitely less than 2)
- 3 months (it's more than 2 months, less than 6 months)
- 6 months (it's more than 4 months, less than 9 months)
- it's more than 6 months, probably less than 1 year
Don't even try to granulate more than that. It's useless.
Lock the time. And lock the cost (that being the amount of developers times the hourly rate times the total amount of estimated hours). That's it.
Now jot down what the client call "scope" as user stories in a backlog and have him prioritize it.
Start the iterations. After each iteration release to a staging environment. Non-programmers, beware: ALWAYS make sure whoever programmer you hire to ALWAYS deliver testable versions of the delivered stories to a publicly available URL that you can actually visit and test.
If your programmer refuses to do that or give excuses: FIRE HIM.
If your programmer or company or whatever promises you a certain "closed scope" price, promises to do everything and you believe them, you're too gullible.
Do you think it's funny to play this stupid game of "I'll pretend to tell you that I know the truth and you will pretend that you believe what I tell you."

No serious professional has time to play stupid games and the only honest thing anyone can say about any software project is: "given my experience I believe the ballpark for this kind of project is within X months, given the Y and Z assumptions".
Now, you don't have to believe him. You just need to start checking the thermometer. Any non-programmer will be able to assess the quality of the delivery based on the frequent deliveries of the prioritized features.
"But what if after 2 weeks I don't like the results?" Easy: FIRE HIM.
And sometimes "firing" is not even the correct word. Sometimes the relationship is difficult and the best thing to do is to go separate ways.
You need to accept losing 2 weeks - or any short period of time - as part of the Risk Management. It's better to accept losing 2 weeks worth of your project budget than having to blindly believe someone for 6 months and having to lose the entire project budget and some more.
Paretto again: Agility is about Risk Management. You accept that losing 20% of your budget is ok. And you play with that. But that's also okay, because you only actually need a bit more than 20% of the sketchy scope you have.
See what I just did with the Math here?
We stop playing around the pretend game and actually manage the risks of the project. You collaborate on the equivalent thermometer which is a combination of the prioritized backlog (the scale), the velocity (the temperature), and you keep an eye on the partial deliveries on the staging environment.
Conclusion
So yes, Estimates should be taken as seriously as Promises. You can give reasonable Estimates granted that you can manage the Risks and the Client accepts the rules of the game (there is no "closed, complete, scope", and "priorities first", and "testing and accepting delivered features every week").
The idea behind Promises is that you have to MANAGE in order to meet them. The best way to do that is to frequently stop, re-assess and then keep going. It feels like you're wasting time, but you're actually saving yourself from wasting time.
If you don't have a skin in the game, back off.
Velocity is meant to be kept steady. Not always increasing. Not always volatile and unpredictable. Keep velocity in a predictable rate and use the variance as indication of being too fast or too slow, adjust the other variable, measure again and go. Just like a furnace thermometer.
There are several versions of "thermometers" from Joel Spolsky's Evidence Based Scheduling all the way to fancy Monte Carlo simulations and other stochastic processes (they are all thermometers and NOT estimation tools).
What stops you from doing that is using the wrong metaphors and the wrong references.
Instead of trying to find equivalent metaphors in the construction business, factories and other "hard"-ware assemblies, you should look elsewhere, where you will find other "soft"-ware processes.
Musicians have deadlines. Painters have deadlines. Choreographers have deadlines. Sports have deadlines. Research laboratories have deadlines. How do they meet them? By constantly checking the current state and comparing to the goals, assessing if what they are doing is actually working and changing what doesn't work.

Hollywood has deadlines. They have far worse variables to control than any software project you might ever encounter, and they manage to deliver. And profit.
And accept that you can't control all variables, so stop trying. Think of it as the financial markets. One day you have Ethereum skyrocketting 4,000% and the very next day you have it falling down to ashes in a flash-crash.
Don't aim to become resistent or resilient. Prepare to become Antifragile.
Ex Manga Downloadr - Part 7: Properly dealing with large Collections 16 Jun 2017 10:10 AM (7 years ago)
In my previous post I was able to simplify a lot of the original code through the use of Flow. But the downside is that the running time actually increased a lot.
José Valim kindly stepped in and posted a valuable comment, which I will paste here:
Have you tried reducing the
@max_demandinstead?@max_demandis how much data you exchange between stages. If you set it to 60, it means you are sending 60 items to one stage, 60 items to the other and so on. That gives you poor balancing for small collections as there is a chance all items end-up in the same stage. You actually want to reducemax_demandto 1 or 2 so each stage gets small batches and request more than needed. Another parameter you usually tune is thestages: ...option, you should set that to the amount of connections you had in poolboy in the past.However, I believe you don't need to use Flow at all. Elixir v1.4 has something called
Task.async_streamwhich is a mixture of poolboy + task async, which is a definitely better replacement to what you had. We have added it to Elixir after implementing Flow as we realized you can get a lot of mileage out ofTask.async_streamwithout needing to jump to a full solution like Flow. If usingTask.async_stream, themax_concurrencyoption controls your pool size.
And, obviously, he is right. I misunderstood how Flow works. It's meant to be used when you have a bazillion items to process in parallel. Particularly processing units that can have high variance and, hence, a lot of back-pressure not only because there is a lot of items to process, but because their running times can vary dramatically. So, it's one of those cases of having a canon, but I only have a fly to kill.
What I wasn't aware is the existence of Task.async_stream and it's companion Task.Supervisor.async_stream if I need to add more control.
Let's backtrack a bit.
Dealing with collections in Elixir
Erlang is a beast. It provides all the building blocks of a real-time, highly-concurrent, operating system! Really, what it provides out of the box is way more than any other language/platform/virtual machine, ever. You don't get that much for free on Java, or .NET or anything. You have to assemble the pieces manually, spend hundreds of hours tweaking, and still pray a lot to have everything working seamlessly.
So, you have distributed systems to build? There is no other option, really. Do Erlang, or suffer in hell.
Then, Elixir steps this up a notch creating a very reasonable and simple to use standard library that makes the coding part actually enjoyable. This is a killer combo. You need to do the next Whatsapp? You need to do the next Waze? You need to rebuild Cassandra from scratch? You need to create stuff like Apache Spark? Do Elixir.
In Erlang, you need to solve everything using GenServer. It's a neat abstraction from OTP. You are required to understand OTP intimately. There is no shortcut here. There is no Erlang without OTP.
That said, you can start simple and scale without so much hassle.
Usually, everything starts with Collections, or more correctly, some kind of Enumeration.
Just like my simple Workflow.pages/1 function which iterates through a list of chapter links, fetch each link, parse the returning HTML and extracts the collection of page links within that chapter, reducing the sub-lists into a full list of page links.
If I know the collection is small (less than 100 items, for example) I would just do this:
1 2 3 4 5 6 |
def pages({chapter_list, source}) do pages_list = chapter_list |> Enum.map(&Worker.chapter_page([&1, source])) |> Enum.reduce([], fn {:ok, list}, acc -> acc ++ list end) {pages_list, source} end |
And that's it. This is linear. It will sequentially process just one link at a time. The more chapter links, the longer it will take. Usually I want to process this in parallel. But I can't fire a parallel process for each chapter link, because if I receive 1,000 chapter links and fire them all, it will be a Denial of Service and I will certainly receive hundreds of time outs.
You can run into 2 main problems when you need to iterate through a big collection.
If your collection is humongous (imagine a gigabyte long text file that you need to iterate line by line). For that you use
Streaminstead ofEnum. All functions look almost exactly the same, but you will not have to load the entire collection into memory and you will not keep duplicating it.If your processing unit takes a long time. Now that you solved not blowing off your memory usage, what if you have slow jobs while iterating through each item in the collection? That's our case, where the collection is rather small, but the processing time is long as it's fetching from an external source on the internet. It can take milisseconds, it can take a few seconds.
One way to control this is through the use of "batches", something along these lines:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def pages({chapter_list, source}) do pages_list = chapter_list |> Enum.chunk(60) |> Enum.map(&pages_download(&1, source)) |> Enum.concat {pages_list, source} end def pages_download(chapter_list, source) results = chapter_list |> Enum.map(&Task.async(fn -> Worker.chapter_page([&1, source]) end)) |> Enum.map(&Task.await/1) |> Enum.reduce([], fn {:ok, list}, acc -> acc ++ list end) {pages_list, source}, results end |
This is just for the example, I have not compiled this snippet to see if it works, but you get the idea of chunking the big list and processing each chunk through Task.async and Task.await.
Again, for small lists, this should be ok (thousands) and where each item does not take too much to process.
Now, this is not very good. Because each chunk must finish before the next chunk begins. Witch is why the ideal solution is to keep a constant amount of jobs running at any given time. To that end, we need a Pool, which is what I explained in Part 2: Poolboy to the rescue!.
But implementing the proper way to keep the pool entirely filled requires some boring juggling between Poolboy transactions and Task.Supervisor.async. Which is why I was interested in the new Flow usage.
The code does come clean, but as I explained before, this is not the proper use case for Flow. It's better you have to iterate over tens of thousands of items or even infinite (you have a incoming traffic of requests in need of parallel processing, for example).
So, finally, there is a compromise. The solution between the simple Task.async and Flow is Task.async_stream which works like a pool implementation, where it keeps a max_concurrency of jobs running in a stream. The final code becomes way more elegant like this:
1 2 3 4 5 6 7 |
def pages({chapter_list, source}) do pages_list = chapter_list |> Task.async_stream(MangaWrapper, :chapter_page, [source], max_concurrency: @max_demand) |> Enum.to_list() |> Enum.reduce([], fn {:ok, {:ok, list}}, acc -> acc ++ list end) {pages_list, source} end |
And this is the final commit with the aforementioned changes.
Conclusion
The implementation with Task.async_stream is super simple and the times finally became the same as before.
1 |
84,16s user 20,80s system 138% cpu 1:15,94 total |
Way better than the more than 3 minutes it was taking with Flow. And this is not because Flow is slow, it's because I was not using it correctly, probably shooting a big chunk into a single GenStage and creating a bottleneck. Again, only use Flow if you have enough items to put hundreds of them into several parallel GenStages. We are talking about collections with tens of thousands of items, not my meager pages list.
There is a small tweak though. To fetch all chapter and page links I am using a max_concurrency of 100. Timeout is the default at 5000 (5 seconds). That works because the returning HTML is not so big and we can parallelize that much on a high bandwidth connection.
But the images downloading procedure at Workflow.process_downloads I had to cut max_concurrency in half and increase the timeout up to 30 seconds to make sure it wouldn't crash.
Because this is a simple implementation there is no crash recovery and no retry routine. I would have to replace this implementation with Task.Supervisor.async_stream to regain some control. My original implementation was more cumbersome but I had places to add retry mechanisms. So again, it's a compromise between ease of use and control, always. The more control you have, the worse the code becomes.
This is a simple example exercise, so I will keep it at that for the time being.
Ex Manga Downloadr - Part 6: The Rise of FLOW 13 Jun 2017 10:59 AM (7 years ago)
It's been way more than a year since I posted about my pet project Ex Manga Downloadr. Since then I just did small updates to keep up with the current Elixir and libraries versions.
As a quick recap, the exercise is that I want to web scrap from MangaReader.net, a bunch of images, organized in pages and chapters, and in the end it should compile organized PDFs so I can load them on a Kindle device.
Web scrapping, is a simple loop of HTTP GETs over a ton of URLs, scrapping the HTML, and fetching more URLs to download.
In many simple languages, people usually solve this naively in 2 ways:
- A simple nested loop. One single thread, sequencial fetches. So if you have 5,000 links and each links takes 10 seconds to fetch, it's basically 10 * 5,000 = 50,000 seconds, which is a stupid long time.
- A simple spawn of processes, fibers, threads or parallel I/O in a reactor, all at once. An attempt to paralelize all fetches at once.
Everybody probably agree that the first option is stupid. Now, the second one is tricky.
The tricky part is CONTROL.
Anyone in Go would say "oh, this is easy, just put a loop and spawn a bunch of goroutines" or anyone in Node.js would say "oh, this is easy, just put a loop, make the fetch - they all will run asynchronously - and add callbacks, a basic async/await."
They're not wrong, but this is still too naive an implementation. It's trivial to trigger hundreds or thousands of parallel requests. Now, what happens if one fails and you have to retry? What happens if the MangaReader has a throttling system that will either start cutting down connections or timing them out? Or if your internet bandwidth is just not enough, and after a certain amount of requests you start having diminishing returns and time outs?
The message is: it's damn trivial to spawn parallel stuff. it's damn complicated to control paralle stuff.
This is why, in my first implementation in Elixir, I introduced a complicated implementation using a combination of a custom GenServer, Elixir's own Task infrastructure for async/await pattern, and Poolboy to control the rate of the parallelism. This is how you control the bottleneck out to slow resources: using pools and queues (which is why every good database has a connection pool, remember C3P0?)
This is one snippet of my older implementation:
1 2 3 4 5 6 7 |
def chapter_page([chapter_link, source]) do Task.Supervisor.async(Fetcher.TaskSupervisor, fn -> :poolboy.transaction :worker_pool, fn(server) -> GenServer.call(server, {:chapter_page, chapter_link, source}, @genserver_call_timeout) end, @task_async_timeout end) end |
Yes, it's very ugly, and there are boilerplates for the GenServer, the custom Supervisor to initialize Poolboy and so on. And the higher level workflow code looks like this:
1 2 3 4 5 6 7 |
def pages({chapter_list, source}) do pages_list = chapter_list |> Enum.map(&Worker.chapter_page([&1, source])) |> Enum.map(&Task.await(&1, @await_timeout_ms)) |> Enum.reduce([], fn {:ok, list}, acc -> acc ++ list end) {pages_list, source} end |
So, inside the Worker module each public method wraps the GenServer internal calls into a Task async and in the collection iteration we add Task.await to actually wait for all parallel calls to finish, so we can finally reduce the results.
Elixir now comes with this very interesting GenStage infrastructure that promises to replace GenEvent and the use case is when you have a producer-consumer situation with back-pressure. Basically when you have slow endpoints and you would end up having to control bottlenecks.
Then, Flow is an easier high abstraction that you can use almost the same way you would use Enum in your collections, but instead of sequential mapping, it takes care of parallel traversing and control of batches. So the code is very similiar but without you having to control the parallelization controls manually.
This is the full commit where I could remove Poolboy, remove my custom GenServer, reimplement the Worker as simple module of functions and then the workflow could get rid off the async/await pattern and use Flow instead:
1 2 3 4 5 6 7 8 9 |
def pages({chapter_list, source}) do pages_list = chapter_list |> Flow.from_enumerable(max_demand: @max_demand) |> Flow.map(&MangaWrapper.chapter_page([&1, source])) |> Flow.partition() |> Flow.reduce(fn -> [] end, fn {:ok, list}, acc -> acc ++ list end) |> Enum.to_list() {pages_list, source} end |
The only boilerplate left is the Flow.from_enumerable() and Flow.partition() wrapping the Flow.map, and that's it!
Notice I configured @max_demand to be 60. You must tweak it to be larger or smaller depending on your internet connection, you have to experiment it. By default, Flow will trigger 500 processes in parallel, which is way too much for a web scrapping on a normal home internet connection and you will suffer diminishing returns. That's what I had to do previously with Poolboy, by initiating a pool of around 60 transactions at most.
Unfortunately not everything is as straight forward as it seems. Running this new version on the test mode I get this result:
1 |
58,85s user 13,93s system 37% cpu 3:13,78 total |
So a total time of more than 3 minutes, using around 37% of the available CPU.
My immediate previous version using all the shenanigans of Poolboy, Task.Supervisor, GenServer, etc still gives me this:
1 |
100,67s user 20,83s system 152% cpu 1:19,92 total |
Less than HALF the time, albeit using all my CPU cores. So my custom implementation still uses my resources to the maximum. There is still something in the Flow implementation I didn't quite get right. I already tried to bump up the max_demand from 60 up to 100 but that didn't improve anything. Leaving it to the default 500 slows everything down to more than 7 minutes.
All in all, at least it makes the implementation far easier on the eyes (hence, way easier to maintain), but either the Flow implementation has bottlenecks or I am using it wrong at this point. If you know what it is, let me know in the comments section below.
THE CONF Initiative 20 Oct 2016 6:00 AM (8 years ago)
Obs: se você é brasileiro, leia esta versão em Português.
Update 04/04/2017: Most of the event infrastructure and suppliers are contracted, the event is a GO! And the Call for Papers is up until May, submit your talk proposals as soon as possible.
Update 12/09/2016: We confirmed the dates of Sep 29-30 of 2017 at Centro de Convenções Rebouças. Reserve the dates in your calendar!
I was the main curator and organizer of all Rubyconf Brasil events and I have been doing Ruby related events and talks in Brasil for the past 10 years. My last Rubyconf Brasil in 2016 had almost 1,200 attendees coming from all over the country.
I also did talks in international events such as Locos x Rails 2009, Railsconf 2010, RubyKaigi 2011, Toster 2012, Bubbleconf 2012, and others. In smaller scale I travelled all over Brasil doing more than 150 talks as well.
My main goal was to foster a healthy Brazilian Ruby community as well as help growing a better class of local software developers.
But I still have an annoying scratching itch that never went away.
When I decided to organize a Ruby-centric event in Brazil, 10 years ago, my main concern was if the subject would be interesting enough to have momentum. I had a personal goal in mind: a Railsconf-comparable conference, reaching for 1,000 attendees, consistently happening for 10 years.
The initial goal was reached a few years ago, since at least 2013 when we reached the magic 1,000 number and 2016 reached my personal number "10" conferences in a row.
But the format of Brazilian tech events still gives me that itch.
To put it in perspective, some big conferences attract people from all over the world. Notable examples are Railsconf, OSCON, Microsoft Build, QCon NY, QCon SF, ApacheCon, LinuxCon, Apple WWDC, Google I/O, etc.
Some of them for obvious reasons. If you want to know the hottest news on Apple, you have to attend WWDC. Many of those example have exclusive content from the organizer's companies such as Facebook or Google.
Other conferences attract people due to their roster of speakers' reputations. And in turn they attract more speakers that want to be in that roster. It's maybe the case of OSCON, or QCon.
Conundrum
This section can become quite confusing so I will try to be as much direct and to point as I can. I will narrow down the narrative to Brazil, but the same argument can be applied to any country in Latin America. Please, bear with me.
First of all, our conferences are all presented in Brazilian Portuguese, exclusively to a Brazilian audience.
To increase their reputation, big events here bring "international" guest speakers - and by "international" I mean "from out of Latin America", such as USA, Europe.
The local audience go to those event sometimes just because of the quality of those guests.
The untold truth is that most of those guests wouldn't come out of their own volition without an invitation and financial incentives. But those same speakers usually compete to speak in USA or European events. I am not criticizing them! This is a natural consequence and I would do the same if I were them.
This is the symptom of how Brazilian events are made. They are very well done and effective for the intended audience: Brazilians. Simultaneously making them not attractive for everybody else.
It's a matter of economics, because it's expensive to come here, the visa process for americans is annoying, and they get better exposition on a more diverse event that understands English.
At the same time, we have several great Brazilian developers applying to speak at american or european events to gain more exposure, exactly for the same reasons: our Brazilian events lack in audience reach because they are mostly made just for Brazilians.
Only Brazilians speak Brazilian Portuguese.
The international audience is not aware of the quality of our Brazilian speakers because we are not doing a good job advertising that!
One first step to remedy this situation is to try something never attempted here: to create a Brazilian conference where the main language of presentation is English. Surprisingly, I believe this doesn't sound like a big deal for anyone, anywhere in the world, but for Brazilians!
This won't increase the ammount of international speakers wanting to come here, and this is not the goal.
The goal is to create an Internationally Recognizable stage for our highly-skilled developers to speak up to a larger audience. This audience would be able to watch them either coming here or online. Because no american will ever try to watch a Brazilian recorded talk that is spoken in Portuguese, but they will have no problem watching a Brazilian speaking in English.
Not only our conferences are not attractive for English-speaking audiences, but they are not attractive even for our fellow neighbors in Argentina, Colombia, Chile, Uruguay, Paraguay, etc.
Brazil is a big Portuguese-speaking island surrounded by Spanish-speaking countries in a globalized English-speaking world.
We can do better.
From Brazil, to the World
The real change is to create an internationally visible stage in Brazilian soil.
And for that we could try to create the very first Latin American Tech Conference entirely in English. I never attended FOSDEM but I heard that attendees there speak Dutch, French, German but most content is presented in English exactly for that diversity. Europeans are certainly better adjusted to multiple languages than Brazilians are. We live in a globalized and diverse world, and like it or not, the technology lingua-franca is English.
Brazil, and Latin America in general, has many talented and hard-working developers competing in the international arena. Many core contributors to big open source projects, many programmers working in renowed companies, and even CTOs to USA and European companies are from Brazil.
For example, did you know that former Director of Engineering of SoundCloud in Berlin and now Director of Engineering at DigitalOcean NY is a Brazilian? Actually his own team there has a dozen of Brazilians. Did you know that Godaddy has a Brazilian as VP of Software Engineering? You have Brazilian engineers working at Heroku, Gitlab, startups such as Doximity, Pipefy. And that's not even counting the big Brazilian tech companies such as Nubank, the flagship all-online credit card and one of the largest successful cases of Clojure in the world. Elixir, the language that is conquering hearts and minds, again invented and built by a Brazilian living in Poland. Xamarin, one of the major catalysts for Microsoft into the OSS world is founded by a Mexican, and it has important Brazilian engineers. Crystal, the brand new language that promises to bring Ruby-like enjoyment to the low-level compiled world was invented and built by an Argentinian. If you're a Rails developer you definitely used Devise in your projects, one of the most ubiquitous library in the Rails community, made and maintained by brazilians. And I can go on and on.
I am not saying that worldwide speakers would flock to come here, that's not even the point. But I know that many tech companies throughout the world are in need to hire great developers, wherever they are.
This is one of the many things foreigners don't know about Latin American software developers: we are literally on par with anyone from anywhere in the world. You just need to know where to look.
We are not low-quality cheap labor.
We are near-shore, top-quality, skillful and educated software engineers. And this is not hubris.
But we are doing a very poor job at advertising that to the world.
Most conferences in Brazil are in Brazilian-Portuguese only, with a couple of foreigner guest speakers (usually requiring some form of translation). They are made exclusively to showcase technology and brands to a beginner-level audience, but they don't do a lot to showcase our potential to that international arena.
What if one event made in Brazil finally raises that bar, presenting our cream of the crop, in English?
Would that alienate the Latin American audience? I don't think so. I have been experimenting in the last couple of years and my event alone, Rubyconf Brazil, didn't have any simultaneous translations. An audience of almost 1,000 attendees listened to English-only speakers without any problems whatsoever.
Heck, our guests that came from Argentina presented in English in a Brazilian conference!
This is the result of years of having hundreds of screencasts and events recorded made available on YouTube! Thousands of hours of online classes over Code School, Code Academy and many others. Hundreds of ebooks from Pragmatic Programmer and other publishers. Brazilians are consuming all that for years, and by the way, did you know that one of the top instructors at Code School is a Brazilian?
There are dozens of great small to big tech conferences all over the continent, introducing technology to many young people wanting to learn more. They are doing a fantastic job already. But there is still a big gap between those events and the worldwide arena of international events, and I think this proposal is one step in the direction to finally close this gap.
It's about damn time we bring more attention to that fact in a conference that welcomes anyone from anywhere in the world.
So the first criteria for such an event is that every speaker presents in English, where all recorded material is available and accessible to anyone in the world.
Code-Only aNd Fun - No-Frills
I believe a conference should have focus.
Any event that tries to squeeze everything in ends up having their identities diluted so much that every tech event becomes similar to every other tech event.
Instead, I'd rather have an event for programmers, made by programmers, with a focus on programming and creativity by means of software. I'd like to have a mostly technical event, with the main goal of showcasing the Latin America capacity.
So the second criteria would be for the speakers to send proposals focused on code. Preferably open source code of his own authorship, but subjects around software development at the very least. No propaganda to advertise services or products. No self-help topics. I want to focus around the craft of software.
One example of interesting code would be something such as Sonic Pi a live coding music synth DSL written in Ruby. How about Ruby 2600, an Atari emulator written in Ruby by Brazilian developer Chester? Or this presentation about interface testing with Diablo 3 again presented by fellow Brazilian developer Rodrigo Caffo at Rubyconf 2012? Or this talk about Sprockets by another fellow Brazilian developer and Rails Core Committer Rafael França, presented at RailsConf 2016? Or this talk about Crystal presented by fellow Argentinian developer Ary Borenszweig in Prague last year?
And out of the Ruby world, there are many great examples in communities as diverse as Python, Javascript, Go, and so on.
Part of this concept came to me while watching Koichi Sasada's keynote at Rubyconf Brazil 2014. Koichi is a Japanese Ruby Core Committer and he mentioned his concept of "EDD: Event Driven Development", meaning that he speeds up prior to speaking at important conferences.

Many developers begin new open source code or speed up their contributions near to presenting at events. It's a positive cycle. This kind of event I am proposing could be a catalyst to exactly this kind of positive cycle in Latin America. Code that leads to more Code.
So the main criteria would be Code Only aNd Fun!
"THE CONF" Initiative
Every new implementation should start small, and a code-only event should also have it's Beta stage.
My initial criteria:
- Code-Only
- And Fun, of course, or "No-Frills" if you prefer.
- All in English, All inclusive for everybody from anywhere.
- Mainly (but not exclusively) focused around great Latin American developers.
The Target: realistically it will be primarily targetting Brazilians (and I hope, some of our Latin American friends) locally, and the International audience of software developers, at least online. I believe it may be an event for around 300 attendees, maybe around 20 speakers. If we can gather at least that, it would be a superb first step.
The Goals: to create a Latin American stage to showcase our skills, in practice, to the world. Less non-Latin American speakers at first, no sponsored talks to sell products. Mostly Code.
If I am not mistaken this would be the very first Latin American conference, with Latin American speakers, with the mission of eventually becoming an Internationally Recognizable conference. One that would primarily attract and bring together communities all over Latin America and that eventually becomes recognized by the worldwide community of developers and enterprises looking to hire our great developers or companies, no matter where they are.

If you like the idea and want to participate, start following @theconfbr Twitter account and the Facebook page. This is basically the very first "draft" of the idea and this is the time to send suggestions. The more support I see, the easier it will be to decide to go forward or not.
I still don't have a date, but if the idea shows potential and people support it, I'd like to aim for the 3rd quarter of 2017. Show your support, send your suggestions, this will help me make a decision and how to best implement it.
Ex Pusher Lite - Part 2 - First Working Core! 14 Dec 2015 8:04 AM (9 years ago)
In Part 1 I basically started with Daniel Neighman's tutorial.
In Part 2 I will add the proper mechanisms to make a minimal core that is actually useful and deploy it to Heroku. In order to do that I need to implement the following:
- a simple Administration authentication (a hardcoded admin_username and admin_password will do for now)
- an admin restricted "/api/admin/apps" endpoint to manage new Applications. Each Application should have a randomly generated key and secret.
- the existing "/events" endpoint from Part 1 should be moved to "/api/apps/:app_id/events" and have access restricted to the authentication of the key and secret of the Application identified as "app_id".
- for now, the Event will just broadcast to the appropriate topic. We want to be able to broadcast to everyone from an Application as well to specific topics within the Application scope.
As usual, the code for this section will be tagged as v0.2 in both the client demo and server-side Github repositories.
The App Resource
If this project of ours is to behave like Pusher.com, we need a way to create new "Applications". Each client connecting to this service will be bound to this Application. Events should be restricted to the Application boundary. This is how we will isolate different clients connecting to the same server. So you can have one core serving several different web applications.
Once a new application is created, the client/consumer web app will have the pair of key and secret tokens that it will use to connect both the server-side triggers as well as the client-side Websocket listeners.
As a disclaimer, at this stage of development I will not implement any sophisticated authentication system such as OAuth2 or JWT. I will save this for posts to follow. For now I will use the Application's key and secret just as simple username and password in an HTTP Basic Auth. This should be good enough for our purposes for the time being.
So, the very first step is to create such an "Application" resource and we can resort to Phoenix's built-in JSON scaffold generator:
1 |
mix phoenix.gen.json App apps name:string slug:string key:string secret:string active:boolean |
Most tutorials will show you the "phoenix.gen.html" generator, which behaves like Rails's "scaffold", generating HTML templates for each of the CRUD verbs. This is similar but it skips HTML and assumes this is going to be a JSON CRUD API.
We need to manually update the "web/router.ex" file like this:
1 2 3 4 5 6 7 8 |
# web/router.ex scope "/api", ExPusherLite do pipe_through :api post "/apps/:app_slug/events", EventsController, :create scope "/admin" do resources "/apps", AppController, except: [:new, :edit] end end |
The "EventsController" is the one we implemented in Part 1 and that we will overhaul during this Part 2.
The generator gave us this new "AppController", and similarly to Rails' routes, the DSL is remarkably similar here. If you're a Railer I bet you can instantly recognize the routes this DSL is generating.
The generator also created a proper migration for us:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# priv/repo/migrations/20151210131528_create_app.exs defmodule ExPusherLite.Repo.Migrations.CreateApp do use Ecto.Migration def change do create table(:apps) do add :name, :string add :slug, :string add :key, :string add :secret, :string add :active, :boolean, default: false timestamps end create index(:apps, [:name], unique: true) create index(:apps, [:slug], unique: true) end end |
Again, remarkably similar to ActiveRecord's Migration DSL. Migrations behave as you expect. You must run:
1 2 |
mix ecto.create # if you haven't already mix ecto.migrate |
This App resource will need the ability to create slugs out of the names (which we will use as "app_id") and also generate random key and secret values. So we must add these dependencies to the "mix.exs" file:
1 2 3 4 5 6 |
# mix.exs defp deps do [..., {:secure_random, "~> 0.2.0"}, {:slugger, "~> 0.0.1"}] end |
The final App model is quite long, so I will break it down for you:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# web/models/app.ex defmodule ExPusherLite.App do use ExPusherLite.Web, :model alias ExPusherLite.Repo schema "apps" do field :name, :string field :slug, :string field :key, :string field :secret, :string field :active, :boolean, default: true timestamps end @required_fields ~w(name) @optional_fields ~w() ... |
This block declares the model Schema. Be careful if you generate a migration and then change its fields settings: you must remember to update the schema in the model. In my first attempt I didn't include the "slug" field, so I rolled back the database migration (with "mix ecto.rollback"), changed the migration to add the "slug" field and re-ran the "ecto.migrate" task.
I was puzzled with the model not picking up the new field; after some time I remembered that Ecto models don't attempt to fetch the real database schema and generate accessors dynamically, instead it relies on the explicitly declared schema block as shown above. After I added the new "slug" field in the schema block, then the model would properly use the new field.
1 2 3 4 5 6 7 8 9 |
# web/models/app.ex ... def get_by_slug(slug) do Repo.get_by!(__MODULE__, slug: slug, active: true) end def hashed_secret(model) do Base.encode64("#{model.key}:#{model.secret}") end ... |
These are just helper functions to use in the AppController. The odd bit might be "MODULE" but this is just a shortcut for the atom representation of the current module, which is "ExPusherLite.App". This is how you make a simple query to the model, it resembles Rails' "App.get_by(slug: slug, active: true)".
In Elixir convention, Ecto has functions with and without bangs ("get_by!" and "get_by"). If you want to catch an error you use the version without bangs and it will return either a "{:ok, result}" tuple or a "{:error, result}" and you can pattern match them. Or you can use the bang version and it will raise an exception. Depends on what you want to do.
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# web/models/app.ex ... def changeset(model, params \\ :empty) do model |> cast(params, @required_fields, @optional_fields) |> validate_length(:name, min: 5, max: 255) |> unique_constraint(:name) |> generate_key |> generate_secret |> slugify |> unique_constraint(:slug) end ... |
Second only to the Schema block I mentioned above, this "changeset/2" function is the most important part of a Model.
In Rails you just have the concept of a "Model" which is considered "Fat" because it deals with database operations, business logic and framework hooks all in the same place. In Phoenix you have to deal with at least 3 different concepts:
- You have a Repo, which receives a Changeset and uses it to insert or update the designated rows in the database table. You will see "Repo.get" or "Repo.insert", not "App.find" or "App.save".
- Then you have the Changeset which are just Elixir Maps (the ones with the syntax "%{key => value}"). It's just a Hash, a Dictionary, a collection of key-value pairs. A Repo accepts Maps for its operations.
- Finally, you have the Model which actually give meaning and context to the raw Changesets. And the function "changeset/2" above is the one responsible for receiving a raw Map, piping it through a validation and transformation chain and return a valid Changeset for the Repo to use.
So, in a controller you will usually find code like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# web/controllers/app_controller.ex ... def create(conn, %{"app" => app_params}) do changeset = App.changeset(%App{}, app_params) case Repo.insert(changeset) do {:ok, app} -> conn |> ... {:error, changeset} -> conn |> ... end ... |
This is how you create a new, validated, changeset and then pass it to the Repo, treating the results in a pattern match block. Just compare the above changeset line with the beginning of the "changeset/2" function:
1 2 3 4 5 6 |
... def changeset(model, params \\ :empty) do model |> cast(params, @required_fields, @optional_fields) |> validate_length(:name, min: 5, max: 255) ... |
It maps the "%App{}" empty record to the "model" argument and the "app_params" that comes from the request (a map of the format "%{name => 'foo', active: => 'true'}") to the argument "params". Then it pipes the model and params to the "cast/4" function which will copy the values from the params map to the model map/changeset. And it keep passing the resulting changeset to the following functions, such as "validated_length/3" below, and so on. If the chain ends with no exceptions, you end up with a clean, validated changeset that you can just pass to the Repo to blindly insert to the database.
In the above implementation we are chaining filters to generate the key, secret and slug, and this is the implementation as private functions:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# web/models/app.ex ... defp generate_key(model) do if get_field(model, :key) do model else model |> put_change(:key, SecureRandom.uuid) end end defp generate_secret(model) do if get_field(model, :secret) do model else model |> put_change(:secret, SecureRandom.uuid) end end defp slugify(model) do if name = get_change(model, :name) do model |> put_change(:slug, Slugger.slugify_downcase(name)) else model end end end |
The logic is set so new key/secret are generated only if the fields are empty and a new slug is generated only if the name has changes. And this is it, I told you the model code would be a bit large. You can see how to use the Slugger and SecureRandom libraries we added in the "mix.exs" before.
I also want to add the equivalent of a Rails seed file to create a test application so it's easier for new comers to know what to do. Phoenix has seeds and you can implement it like this:
1 2 3 4 5 6 7 |
# priv/repo/seeds.exs alias ExPusherLite.App alias ExPusherLite.Repo # not using the App.changeset should just avoid all validations and generations Repo.insert! %App{ slug: "test-app", name: "Test App", key: "test-app-fake-key", secret: "test-app-fake-secret", active: true } |
Remember how I detailed the role of the "changeset/2" function in creating a clean and validated changeset, which is just a Map? You can skip that function altogether and hand craft your own final Map and pass it to the Repo. The Repo doesn't care if this is a valid Map or not it will just try to insert it into the database regardless. And in this case the App Model avoids us to hardcode keys and secrets, so this is how we do it in a seed file.
We can just run it directly like this:
1 |
mix run priv/repo/seeds.exs |
The AppController just need 2 changes. The first is to search the App through the slug field instead of the default 'id' field. This is simple enough, we just replace all calls to "app = Repo.get!(App, id)" to "app = App.get_by_slug(id)", which is why we implemented this function in the model above.
The second thing is Authentication.
Adding Authentication
Now that we have an App model that can generate secure random UUIDs for key and secret, I will add a second level of authentication for administrators to be able to create such Apps.
For that I will just hard-code a secret in the config file of the application itself to serve as a development default. Like this:
1 2 3 4 5 6 7 |
# config/config.exs ... config :ex_pusher_lite, :admin_authentication, username: "pusher_admin_username", password: "pusher_admin_password" ... import_config "#{Mix.env}.exs" |
You must add this block before the "import_config" function. Then you can override those values in the "config/prod.secret.exs" file, for example, like this:
1 2 3 4 5 |
# config/prod.secret.exs ... config :ex_pusher_lite, :admin_authentication, username: "14e86e5fee3335fa88b0", password: "2b94ff0f07ce9769567f" |
Of course, generate your own pair of secure username and password and replace it in the production environment if you intend to actually use this. For Heroku, we will still have to tweak this further, so keep this in mind.
Just to make the process easier, I also added the following helper function:
1 2 3 4 5 6 7 8 9 |
# lib/ex_pusher_lite.ex ... # Return this applicaton administration Basic HTTP Auth hash def admin_secret do admin_username = Application.get_env(:ex_pusher_lite, :admin_authentication)[:username] admin_password = Application.get_env(:ex_pusher_lite, :admin_authentication)[:password] secret = Base.encode64("#{admin_username}:#{admin_password}") end end |
This is how you fetch the configuration values. I am generating a simple Base64 encoded string out of the username concatenated with the password with a comma, which is what Basic HTTP Auth requires. I will use this admin hash for the "AppController" and each client must provide the key/secret in its own App instance to be able to trigger the "EventsController".
For both controllers I will create a single Authentication Plug, like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# lib/ex_pusher_lite/authentication.ex defmodule ExPusherLite.Authentication do import Plug.Conn alias ExPusherLite.App def init(assigns \\ [admin: false]), do: assigns def call(conn, assigns) do token = if assigns[:admin] do ExPusherLite.admin_secret else params = fetch_query_params(conn).params params["app_slug"] |> App.get_by_slug |> App.hashed_secret end "Basic " <> auth_token = hd(get_req_header(conn, "authorization")) if Plug.Crypto.secure_compare(auth_token, token) do conn else conn |> send_resp(401, "") |> halt end end end |
As I explained in previous articles, a Plug is like a chainable Rails Middleware or even a Rack application. It must have a single "call/2" that receives a Plug.Conn structure and returns it back, allowing to form a chain/pipeline of Plugs.
We check if we want to compare with the Admin token or the App token and then retrieve the Basic HTTP authorization token that's in the HTTP request connection structure (we retrive individual header values through the "get_req_header/2" function). Finally we make a secure compare between the tokens.
To enable this plug in the controllers we just add it like this:
1 2 3 4 5 6 7 |
# web/controllers/app_controller.ex defmodule ExPusherLite.AppController do use ExPusherLite.Web, :controller alias ExPusherLite.App plug ExPusherLite.Authentication, [admin: true] ... |
1 2 3 4 5 6 |
defmodule ExPusherLite.EventsController do use ExPusherLite.Web, :controller - plug :authenticate + plug ExPusherLite.Authentication ... |
In Part 1 we had a simpler "plug :authenticate" in the EventsController. We can remove it and also the "authenticate/2" function. We just refactored it into a better function that also serves administration authentication now, but the idea is the same.
This is it: the basics for API authentication. Again, this is not the best solution as the username/password pair goes in the URL and it's open to man-in-the-middle attacks. SSL only encrypts the HTTP body but the URL is still open.
For example, if an administrator wants to create a new application, he must do the following:
1 |
curl --data "app[name]=foo-app" http://pusher_admin_username:pusher_admin_password@localhost:4000/api/admin/apps |
And this would be one example of the resulting JSON representation of the new app:
1 |
{"data":{"slug":"foo-app","secret":"8ef69064-0d7e-c9ef-ac14-b6b1db303e7a","name":"foo-app","key":"9400ad21-eed8-117a-bce5-845262e0a09e","id":5,"active":true}}%
|
With this new key and secret in hand, we can update our client demo to make use of the new app.
Configuring the Client Demo
We must start by adding the proper Application details in the ".env" file:
1 2 3 4 5 |
PUSHER_URL: "localhost:4000" PUSHER_APP_ID: "foo-app" PUSHER_KEY: "9400ad21-eed8-117a-bce5-845262e0a09e" PUSHER_SECRET: "8ef69064-0d7e-c9ef-ac14-b6b1db303e7a" PUSHER_CHANNEL: "foo-topic" |
We must also tweak the "config/secrets.yml" to reflect the new metadata (development, test, and production must follow this):
1 2 3 4 5 6 7 8 |
development: secret_key_base: ded7c4a2a298c1b620e462b50c9ca6ccb60130e27968357e76cab73de9858f14556a26df885c8aa5004d0a7ca79c0438e618557275bdb28ba67a0ffb0c268056 pusher_url: <%= ENV['PUSHER_URL'] %> pusher_app_id: <%= ENV['PUSHER_APP_ID'] %> pusher_key: <%= ENV['PUSHER_KEY'] %> pusher_secret: <%= ENV['PUSHER_SECRET'] %> pusher_channel: <%= ENV['PUSHER_CHANNEL'] %> ... |
And we can create an initializer to make it easier to use this metadata properly:
1 2 3 4 5 6 7 8 9 10 11 12 |
# config/initializers/pusher_lite.rb module PusherLite def self.uri key = Rails.application.secrets.pusher_key secret = Rails.application.secrets.pusher_secret app_id = Rails.application.secrets.pusher_app_id url = Rails.application.secrets.pusher_url uri = "http://#{key}:#{secret}@#{url}/api/apps/#{app_id}/events" URI.parse(uri) end end |
Again, the Rails app will trigger the ExPusherLite server using the Basic HTTP Auth. Do not be fooled into thinking this is "secure", it just "feels a bit secure through obscurity". You have been warned, wait for the next articles on this subject. But this is usable in controlled environments.
To finalize the upgrades, we must change the client-side access to the new metadata, first changing the application layout:
1 2 3 4 5 6 7 |
<!-- app/views/layouts/application.html.erb --> ... + <meta name="pusher_host" content="<%= Rails.application.secrets.pusher_url %>"> - <meta name="pusher_key" content="<%= Rails.application.secrets.pusher_key %>"> + <meta name="pusher_app_id" content="<%= Rails.application.secrets.pusher_app_id %>"> <meta name="pusher_channel" content="<%= Rails.application.secrets.pusher_channel %>"> ... |
The javascript "index.es6" fetches from this meta headers, so we must change them there:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# app/assets/javascripts/application/pages/home/index.es6 ... let guardianToken = $("meta[name=guardian-token]").attr("content") let csrfToken = $("meta[name=guardian-csrf]").attr("content") + let pusherHost = $("meta[name=pusher_host]").attr("content") - let pusherKey = $("meta[name=pusher_key]").attr("content") + let pusherApp = $("meta[name=pusher_app_id]").attr("content") let pusherChannel = $("meta[name=pusher_channel]").attr("content") - let socket = new Socket("ws://localhost:4000/socket", { + let socket = new Socket(`ws://${pusherHost}/socket`, { params: { guardian_token: guardianToken, csrf_token: csrfToken } }) socket.connect() // Now that you are connected, you can join channels with a topic: - let channel = socket.channel(pusherChannel, {}) + let channel = socket.channel(`public:${pusherApp}`, {}) channel.join() .receive("ok", resp => { console.log("Joined successfully", resp) }) .receive("error", resp => { console.log("Unable to join", resp) }) - channel.on("msg", data => { + channel.on(`${pusherChannel}:msg`, data => { let new_line = `<p><strong>${data.name}<strong>: ${data.message}</p>` $(".message-receiver").append(new_line) }) + + channel.on("msg", data => { + let new_line = `<p><strong>Broadcast to all channels</strong>: ${data.message}</p>` + $(".message-receiver").append(new_line) + }) } |
One important modification from Part 1 is that the WebSocket host was hardcoded to "localhost" and here we are making it configurable through the meta tags. Right now, for localhost tests, we are using the plain "ws://" protocol but when we deploy to Heroku we will change it to "wss://" for SSL. Same thing for the "PusherLite" initializer. Keep that in mind.
Now it's subscribing to a different format of topic/channel. In Part 1 it would be something like: "public:test_channel" now we are listening to "public:foo-app", so the application is the Websocket subscription "topic".
Then we are changing the socket listener to listen for 2 different events. The first one is in the format "test_channel:msg". So this is how we must now send messages to an specific "channel" within an "app/topic".
And last we still listen to the old "msg" event, but this serves as a "broadcast" event for all connected clients subscribed to this particular "foo-app" Application. Now web clients can listen to specific "channels" within the "app" but also receive system wide "broadcast" messages. This is a big improvement and it didn't require much on the Javascript side.
But what more does it take to make this "channel-only and broadcast" system work? First, we start changing the web form to allow a user to choose between sending a channel-only message or a broadcast, like this:
1 2 3 4 5 6 7 8 |
<!-- app/views/home/index.html.erb --> ... <%= f.text_field :name, placeholder: "Name" %> <%= f.text_field :message, placeholder: "Message" %> + <%= f.check_box :broadcast %> <%= f.submit "Send message", class: "pure-button pure-button-primary" %> </fieldset> ... |
Now the EventsController must accept this new parameter:
1 2 3 4 5 6 |
# app/controllers/events_controller.rb ... def event_params params.require(:pusher_event).permit(:name, :message, :broadcast) end end |
Finally, the Model must use this new information before posting to the ExPusherLite server:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# app/models/pusher_event.rb class PusherEvent include ActiveModel::Model attr_accessor :name, :message, :broadcast validates :name, :message, presence: true def save topic = if broadcast == "1" "#general" else Rails.application.secrets.pusher_channel end Net::HTTP.post_form(PusherLite.uri, { "topic" => topic, "event" => "msg", "scope" => "public", "payload" => {"name" => name, "message" => message}.to_json }) end end |
I am just assuming a hard-coded "#general" string to serve as the broadcast trigger for the server. Now we must make the server accept this new protocol schema, so let's go back to Elixir.
First we must start with the counterpart for the previous POST trigger, ExPusherLite.EventsController:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# web/controllers/events_controller.ex defmodule ExPusherLite.EventsController do use ExPusherLite.Web, :controller - plug :authenticate + plug ExPusherLite.Authentication - def create(conn, params) do - topic = params["topic"] - event = params["event"] + def create(conn, %{"app_slug" => app_slug, "event" => event, "topic" => topic, "scope" => scope} = params) do message = (params["payload"] || "{}") |> Poison.decode! - ExPusherLite.Endpoint.broadcast! topic, event, message + topic_event = + if topic == "#general" do + event + else + "#{topic}:#{event}" + end + ExPusherLite.Endpoint.broadcast! "#{scope}:#{app_slug}", topic_event, message json conn, %{} end ... |
The first difference is that I am pattern matching from the arguments directly to the "topic" and "event" variables. This function is also aware of the "#general" string the client can send to indicate an app-wide broadcast. And the new topic is the concatenation of "topic" and "event" to allow for "channel-only" messages.
To connect this all to the WebSocket handler, we must make the following changes:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# web/channels/room_channel.ex - def handle_in("msg", payload, socket = %{ topic: "public:" <> _ }) do - broadcast socket, "msg", payload + def handle_in(topic_event, payload, socket = %{ topic: "public:" <> _ }) do + broadcast socket, topic_event, payload { :noreply, socket } end - def handle_in("msg", payload, socket) do + def handle_in(topic_event, payload, socket) do claims = Guardian.Channel.claims(socket) if permitted_topic?(claims[:publish], socket.topic) do - broadcast socket, "msg", payload + broadcast socket, topic_event, payload { :noreply, socket } ... |
Now, the Channel does not pattern match on a specific event, it let it through without further validation, trusting that the EventsController is doing the right thing. I will come back to this piece for improvements in the future, possibly.
Deploying our first Phoenix app to Heroku!
In this section we will just follow the official documentation, so read it if you want more details.
Let's get started:
1 2 |
heroku apps:create your-expusherlite --buildpack "https://github.com/HashNuke/heroku-buildpack-elixir.git" heroku buildpacks:add https://github.com/gjaldon/heroku-buildpack-phoenix-static.git |
I am naming the application "your-expusherlite" but you should change it to your own name, of course. And the rest of the configuration data are all examples that you must change for you own needs.
Heroku relies on environment variables. So we start by erasing "config/prod.secret.exs" and change "config/prod.exs" to look like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
config :ex_pusher_lite, ExPusherLite.Endpoint, http: [port: {:system, "PORT"}], url: [scheme: "https", host: "your-expusherlite.herokuapp.com", port: 443], force_ssl: [rewrite_on: [:x_forwarded_proto]], cache_static_manifest: "priv/static/manifest.json", secret_key_base: System.get_env("SECRET_KEY_BASE") # Configure your database config :ex_pusher_lite, ExPusherLite.Repo, adapter: Ecto.Adapters.Postgres, url: System.get_env("DATABASE_URL"), pool_size: 20 config :ex_pusher_lite, :admin_authentication, username: System.get_env("PUSHER_ADMIN_USERNAME"), password: System.get_env("PUSHER_ADMIN_PASSWORD") # remove this line: # import_config "prod.secret.exs" |
Now we must configure the environment variavles "SECRET_KEY_BASE", "PUSHER_ADMIN_USERNAME" and "PUSHER_ADMIN_PASSWORD". Use the included "mix phoenix.gen.secret" to generate those.
1 2 3 |
heroku config:set SECRET_KEY_BASE="`mix phoenix.gen.secret`" heroku config:set PUSHER_ADMIN_USERNAME="FPO0QUkqbAP6EGjElqBzDQuMs8bhFS3" heroku config:set PUSHER_ADMIN_PASSWORD="n78DPGmK3DBQy8YAVyshiGqcXjjSXSD" |
Then it's just a matter of waiting for the good old "git push heroku master" to finish compiling everything in the first time. And because this is the first deploy you should not forget to run "heroku run mix ecto.migrate" to create the database table.
Now, if I did everything right, as an Administrator that knows the above hardcoded secrets I should be able to create a new Application like this:
1 |
curl --data "app[name]=shiny-new-app" https://FPO0QUkqbAP6EGjElqBzDQuMs8bhFS3:n78DPGmK3DBQy8YAVyshiGqcXjjSXSD@your-expusherlite.herokuapp.com/api/admin/apps |
And this is the result I got!
1 |
{"data":{"slug":"shiny-new-app","secret":"42560373-0fe1-506e-28ca-35ab5221fb3d","name":"shiny-new-app","key":"958c16e7-ab93-dac0-0fc6-6cb864e26358","id":1,"active":true}}
|
Great, now that we have a valid Application key and secret we can configure our Rails Client Demo and deploy it to Heroku as well.
Deploying the Rails Client to Heroku
This is a simple Rails application, we can just create the app and deploy right away:
1 2 3 4 5 6 7 |
heroku create your-expusherlite-client heroku config:set PUSHER_URL=your-expusherlite.herokuapp.com heroku config:set PUSHER_APP_ID=shiny-new-app heroku config:set PUSHER_KEY=958c16e7-ab93-dac0-0fc6-6cb864e26358 heroku config:set PUSHER_SECRET=42560373-0fe1-506e-28ca-35ab5221fb3d heroku config:set PUSHER_CHANNEL=shiny-new-topic git push heroku master |
I'm assuming the readers of this post already know how to configure a Rails app properly for Heroku. Just to mention it, I configure this app with the 12 factor and Puma gems and added a proper Procfile. Another very small change was changing the "pusher_lite.rb" initializer to create a URI with "https" because the ExPusherLite we deployed to production requires SSL by default.
There is one more caveat. Being led by experienced web programmers, they made sure that, unlike this bare bone exercise here, the Phoenix framework itself is secure. One such example is to disallow Websocket connections from different hosts.
Out of the box, the "phoenix.js" Socket will fail connection when we try to connect from the "your-expusherlite-client.herokuapp.com" Rails app host to the Phoenix app in "your-expusherlite.herokuapp.com" with the following error:
1 |
WebSocket connection to 'wss://your-expusherlite.herokuapp.com/socket/websocket?guardian_token=N_YCG6hGK7…iOlsicHVibGljOioiXX0._j6s2LiaKde9rBhnTMxDkm0XV5u89pNh1AdLFY6Rlt8&vsn=1.0.0' failed: Error during WebSocket handshake: Unexpected response code: 403 |
And in the Phoenix log we will see this very helpful message:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[error] Could not check origin for Phoenix.Socket transport.
This happens when you are attempting a socket connection to
a different host than the one configured in your config/
files. For example, in development the host is configured
to "localhost" but you may be trying to access it from
"127.0.0.1". To fix this issue, you may either:
1. update [url: [host: ...]] to your actual host in the
config file for your current environment (recommended)
2. pass the :check_origin option when configuring your
endpoint or when configuring the transport in your
UserSocket module, explicitly outlining which origins
are allowed:
check_origin: ["https://example.com",
"//another.com:888", "//other.com"]
|
Unless you know what a Cross-Site Web Socket Hijacking you will prefer to keep the default settings as they are. In a green-field Phoenix app, the Web part will connect to the Web Socket in the same app and, therefore, in the same host, so this is not an issue.
In this case I am making a separated micro-service to mimick Pusher.com behavior so it should be able to accept Web Socket connections from different hosts.
If you control the applications being created, you will likely prefer to make the "check_origin" setting read from your database for the exact hosts. As a feature for next time I could add a "host" field in the "App" model and use it to validate connections in the transport configuration. For the time being I will just make it accept any hosts:
1 2 3 4 5 6 7 8 9 10 |
# web/channels/user_socket.ex defmodule ExPusherLite.UserSocket do use Phoenix.Socket ## Channels channel "*", ExPusherLite.RoomChannel ## Transports transport :websocket, Phoenix.Transports.WebSocket, check_origin: false ... |
And this is it! Now the Rails app should be able to connect and send messages! And you should be able to create any number of new apps and connect all of them to this same service.

Conclusion
Right now, we have a functional, albeit bare-bone, Pusher.com clone that will work for any number of use cases where Pusher.com would be used.
As I warned many times before, the security part is still flaky and needs working. I will still extend on what Daniel began with Guardian to authenticate Web Socket users to private channels as well. And the core should also receive auditing and reporting capabilities (to be able to report usage, number of active connections, throughput of events, keep at least a short history of events so new connections can retrieve the last sent messages, and so on).
But from here it's a matter of adding features to an already working core. And this is nothing more than Phoenix out-of-the-box without too much added on top of it! It says a lot of the current state of maturity of this very capable framework.
In terms of performance, for this very simple example, I spinned up 1 free Heroku dyno for each app.
The Rails app is able to respond to the front-end user interface in around 2ms. And the Sucker Punch job - which does the heavy HTTP POST to ExPusherLite - takes in the order of 30ms or less.
The Phoenix server receives the HTTP POST and performs the broadcast in around less than 6ms. Also quite fast. The times will vary a lot because I believe the free dyno is not only slow but also stays in highly shared metal boxes, getting impact from other neighbor apps running in the same box.
Because we already have an administrative API to create and manage apps (create new ones, delete, update, etc) we can already create a separated application in any other framework to make a dashboard for admins or for a self-serving front-end for developers to register new apps and receive key/secret pair to add in their own applications.
Both the ExPusherLite server and the demo client are deployed in Heroku and you can test the client right now clicking here. The admin keys are different from what I showed in this post, of course, so you won't be able to create new apps, but you can deploy it yourself to your own environment.
Ex Pusher Lite - Part 1: Phoenix Channels and Rails apps 9 Dec 2015 11:39 AM (9 years ago)
Finally, after a lengthy exercising period (and plenty of blogging!) I will start implementing the Elixir app I wanted from the very beginning.
As a Rails developer there are a few things we can't do in Rails. One of them is to deal with real-time messaging.
Rails 5 will bring Action Cable, and it might be good enough for most cases. It uses Faye, which in turn is based on Eventmachine. You can implement a good enough solution for Websockets using Faye in your Rails 4.2 app right now.
Another option is to avoid the trouble altogether and use a messaging service. One option I always recommend for zero friction is to use Pusher.com.

The Basics
You will want to clone from my example repository, like this:
1 2 3 4 |
git clone https://github.com/akitaonrails/pusher_lite_demo cd pusher_lite_demo git checkout tags/v0.1 -b v0.1 bundle |
This is a very very simple implementation of a real-time, websocket-based, chat using Pusher. The idea goes like this:
We start by having a front-end Form to send messages
1 2 3 4 5 6 7 8 9 |
<!-- app/views/home/index.html.erb --> <%= form_for @event, url: events_path, remote: true, html: {class: "pure-form pure-form-stacked"} do |f| %> <fieldset> <legend>Send your message remotely</legend> <%= f.text_field :name, placeholder: "Name" %> <%= f.text_field :message, placeholder: "Message" %> <%= f.submit "Send message", class: "pure-button pure-button-primary" %> </fieldset> <% end %> |
It's using Rails built-in jQuery support for Ajax posting the form to the "EventsController#create" method:
1 2 3 4 5 6 7 8 9 10 |
# app/controllers/events_controller.rb class EventsController < ApplicationController def create SendEventsJob.perform_later(event_params) end def event_params params.require(:pusher_event).permit(:name, :message) end end |
Just to annotate the process, the "routes.rb" looks like this:
1 2 3 4 5 6 |
# config/routes.rb Rails.application.routes.draw do resources :events, only: [:create] root 'home#index' end |
The HTML layout looks like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
<!-- app/views/layout/application.html.erb --> <!DOCTYPE html> <html> <head> <title>Pusher Lite Demo</title> <meta name="viewport" content="width=device-width, initial-scale=1"> <meta name="pusher_key" content="<%= Rails.application.secrets.pusher_key %>"> <meta name="pusher_channel" content="<%= Rails.application.secrets.pusher_channel %>"> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track' => true %> <%= javascript_include_tag 'application', 'data-turbolinks-track' => true %> <script src="//js.pusher.com/3.0/pusher.min.js"></script> <%= csrf_meta_tags %> </head> <body> <div class="pure-menu pure-menu-horizontal"> <span class="pure-menu-heading">Pusher Client Demo</span> ... </div> <div class="pure-g-r"> <div class="pure-u-1-3 message-form"> <%= yield %> </div> <div class="pure-u-1-3 message-receiver"> </div> </div> </body> </html> |
This layout imports the default "application.js" which configures Pusher, establishes the Websocket connection and subscribes to messages on a specific topic with specific events:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// app/assets/javascript/application.js //= require jquery //= require jquery_ujs //= require turbolinks //= require_tree . $(document).on("page:change", function(){ var pusherKey = $("meta[name=pusher_key]").attr("content"); var pusher = new Pusher(pusherKey, { encrypted: true }); var pusherChannel = $("meta[name=pusher_channel]").attr("content"); var channel = pusher.subscribe(pusherChannel); channel.bind('new_message', function(data) { var new_line = "<p><strong>" + data.name + "<strong>: " + data.message + "</p>"; $(".message-receiver").append(new_line); }); }); |
It gets the configuration metadata from the layout meta tags which grabs the values from "config/secrets.yml":
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
development: secret_key_base: ded7c4a2a298c1b620e462b50c9ca6ccb60130e27968357e76cab73de9858f14556a26df885c8aa5004d0a7ca79c0438e618557275bdb28ba67a0ffb0c268056 pusher_url: <%= ENV['PUSHER_URL'] %> pusher_key: <%= ENV['PUSHER_KEY'] %> pusher_channel: test_chat_channel test: secret_key_base: f51ff494801ff0f9e1711036ef6f2f6f1e13544b02326adc5629c6833ae90f1a476747fae94b792eba8a444305df8e7a5ad53f05ea4234692ac96cc44f372029 pusher_url: <%= ENV['PUSHER_URL'] %> pusher_key: <%= ENV['PUSHER_KEY'] %> pusher_channel: test_chat_channel # Do not keep production secrets in the repository, # instead read values from the environment. production: secret_key_base: <%= ENV["SECRET_KEY_BASE"] %> pusher_url: <%= ENV['PUSHER_URL'] %> pusher_key: <%= ENV['PUSHER_KEY'] %> pusher_channel: <%= ENV['PUSHER_CHANNEL'] %> |
And as I'm using dotenv-rails, the ".env" looks like this:
1 2 3 |
PUSHER_URL: "https://14e86e5fee3335fa88b0:2b94ff0f07ce9769567f@api.pusherapp.com/apps/159621" PUSHER_KEY: "14e86e5fee3335fa88b0" PUSHER_CHANNEL: "test_chat_channel" |
Pusher is configured in the server-side through this initializer:
1 2 3 4 5 |
# config/initializers/pusher.rb require 'pusher' Pusher.url = Rails.application.secrets.pusher_url Pusher.logger = Rails.logger |
Finally, the "EventsController#create" actually do an async call to a SuckerPunch job:
1 2 3 4 5 6 7 8 |
class SendEventsJob < ActiveJob::Base queue_as :default def perform(event_params) @event = PusherEvent.new(event_params) @event.save end end |
By the way, as a segway, SuckerPunch is a terrific solution for in-process asynchronous tasks. It's a better option to start with it without having to implement a separated system with Sidekiq workers.
Once you have larger job queues or jobs that are taking too long, then go to Sidekiq. If you use ActiveJob, the transition is as simple as changing the following configuration line in the "config/application.rb" file:
1 |
config.active_job.queue_adapter = :sucker_punch
|
This job just calls the "save" method in the fake-model "PusherEvent":
1 2 3 4 5 6 7 8 9 10 11 12 13 |
class PusherEvent include ActiveModel::Model attr_accessor :name, :message validates :name, :message, presence: true def save Pusher.trigger(Rails.application.secrets.pusher_channel, 'new_message', { name: name, message: message }) end end |
As it's a very simple, the Gemfile is equally simple:
1 2 3 4 |
gem 'pusher' gem 'dotenv-rails' gem 'purecss-rails' gem 'sucker_punch' |
So what it does is very simple:
- The application loads Pusher and the necessary configuration.
- When the user goes to "http://localhost:3000" he is presented with the message Form.
- When the user posts the message, it ends in "EventsController#create", which calls SuckerPunch's "SendEventsJob", instantiates a new "PusherEvent" model with the received form params and finally triggers the message to the Pusher server.
- The same form page also loads the Pusher javascript client and connects to the "test_chat_channel" topic and listens to the "new_message" event, which is the same thing the "Pusher.trigger" call sends together with the form message params.
- The Pusher server broadcasts the received trigger message to all subscribed Websocket clients.
- The Pusher javascript client in the user's browser receives the new message and just formats the message and appends to the "message-receiver" div HTML block in the same page.
Pusher has support for authenticated users, private channels and more, but this is 80% of the usage for most cases. You can implement this as a chat system, a notification system, or anything like that.
Your Rails app sets up the front-end HTML/Javascript to connect to Pusher, listening to certain topics and events and the same Rails app triggers Pusher in the server-side, posting new messages. Pusher receives messages and broadcasts to the clients that subscribes to its topics. That's it.
Ex Pusher Lite - Part 1: Initial Phoenix-based Pusher replacement
My original idea was to make a drop-in replacement for the Pusher server, using the same Pusher client, but for now it was not easy to do so.
Instead, this Part 1 will focus on implementing an initial server ExPusherLite server that also receives events triggered by the same Rails server-side controller process and broadcasting to the same Rails front-end component through WebSockets.
I followed Daniel Neighman tutorial. I had to do a few adjustments to have it working (and as this is still Part 1, it's not a complete solution yet!)
You can close the initial version from my other Github repository like this:
1 2 3 |
git clone https://github.com/akitaonrails/ex_pusher_lite cd ex_pusher_lite mix deps.get |
The tutorial implemented initial setup for Guardian and Joken for JSON Web Tokens. I am still getting used to how channels are implemented in Phoenix.
It already comes pre-configured with a single socket handler that multiplexes connections. You start through the EndPoint OTP application:
1 2 3 4 5 6 |
# lib/ex_pusher_lite/endpoint.ex defmodule ExPusherLite.Endpoint do use Phoenix.Endpoint, otp_app: :ex_pusher_lite socket "/socket", ExPusherLite.UserSocket ... |
This application is started by the main supervisor in "lib/ex_pusher_lite.ex". It points the endpoint "/socket" to the socket handler "UserSocket":
1 2 3 4 5 6 7 8 9 10 11 |
# web/channels/user_socket.ex defmodule ExPusherLite.UserSocket do use Phoenix.Socket ## Channels channel "*", ExPusherLite.RoomChannel ## Transports transport :websocket, Phoenix.Transports.WebSocket # transport :longpoll, Phoenix.Transports.LongPoll ... |
The "channel" function comes commented out, so I started by uncommenting it. You can pattern match the topic name like "public:*" to different Channel handlers. For this simple initial test I am sending everything to the "RoomChannel", which I had to create:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
defmodule ExPusherLite.RoomChannel do use Phoenix.Channel use Guardian.Channel # no auth is needed for public topics def join("public:" <> _topic_id, _auth_msg, socket) do {:ok, socket} end def join(topic, %{ claims: claims, resource: _resource }, socket) do if permitted_topic?(claims[:listen], topic) do { :ok, %{ message: "Joined" }, socket } else { :error, :authentication_required } end end def join(_room, _payload, _socket) do { :error, :authentication_required } end def handle_in("msg", payload, socket = %{ topic: "public:" <> _ }) do broadcast socket, "msg", payload { :noreply, socket } end def handle_in("msg", payload, socket) do claims = Guardian.Channel.claims(socket) if permitted_topic?(claims[:publish], socket.topic) do broadcast socket, "msg", payload { :noreply, socket } else { :reply, :error, socket } end end def permitted_topic?(nil, _), do: false def permitted_topic?([], _), do: false def permitted_topic?(permitted_topics, topic) do matches = fn permitted_topic -> pattern = String.replace(permitted_topic, ":*", ":.*") Regex.match?(~r/\A#{pattern}\z/, topic) end Enum.any?(permitted_topics, matches) end end |
This is all straight from Daniel's original tutorial, the important bit for this example is the first "join" function, the others deal with permissions and authentication that came through a JWT claim. I will deal with this in Part 2.
To make this work, I had to add the dependencies in "mix.exs":
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# mix.exs defmodule ExPusherLite.Mixfile do use Mix.Project ... defp deps do [{:phoenix, "~> 1.0.3"}, {:phoenix_ecto, "~> 1.1"}, {:postgrex, ">= 0.0.0"}, {:phoenix_html, "~> 2.1"}, {:phoenix_live_reload, "~> 1.0", only: :dev}, {:cowboy, "~> 1.0"}, {:joken, "~> 1.0.0"}, {:guardian, "~> 0.7.0"}] end ... end |
And add the configuration at "config.exs":
1 2 3 4 5 6 7 8 9 10 |
# config/config.exs ... config :joken, config_module: Guardian.JWT config :guardian, Guardian, issuer: "ExPusherLite", ttl: { 30, :days }, verify_issuer: false, serializer: ExPusherLite.GuardianSerializer, atoms: [:listen, :publish, :crews, :email, :name, :id] |
Now I have to add a normal HTTP POST endpoint, first adding it to the router:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# web/router.ex defmodule ExPusherLite.Router do use ExPusherLite.Web, :router pipeline :browser do plug :accepts, ["html"] plug :fetch_session plug :fetch_flash #plug :protect_from_forgery plug :put_secure_browser_headers end ... scope "/", ExPusherLite do pipe_through :browser # Use the default browser stack get "/", PageController, :index post "/events", EventsController, :create end |
Notice that I totally disabled CSRF token verification in the pipeline because I am not sending back Phoenix CSRF token from the Rails controller. Now, the "EventsController" is also almost all from Daniel's tutorial:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# web/controllers/events_controller.ex defmodule ExPusherLite.EventsController do use ExPusherLite.Web, :controller plug :authenticate def create(conn, params) do topic = params["topic"] event = params["event"] message = (params["payload"] || "{}") |> Poison.decode! ExPusherLite.Endpoint.broadcast! topic, event, message json conn, %{} end defp authenticate(conn, _) do secret = Application.get_env(:ex_pusher_lite, :authentication)[:secret] "Basic " <> auth_token = hd(get_req_header(conn, "authorization")) if Plug.Crypto.secure_compare(auth_token, Base.encode64(secret)) do conn else conn |> send_resp(401, "") |> halt end end end |
I had to change the authenticate function a bit because either I didn't understood Daniel's implementation or it expected something different. But in this version I am just expecting a simple Basic HTTP Authentication "authorization" header which is a string with the format "Basic [base64 username:password]". Look how I am pattern matching the string, removing the Base64 and "secure comparing" it (a constant-time binary compare to avoid timing attacks, this comes built-in with Phoenix).
This is a simple authentication technique for the Rails controller to POST the message trigger just the same as in the Pusher version.
And this is it, this is all it takes for this initial Phoenix-based Pusher replacement.
Ex Pusher Lite - Part 2: Changing the Rails application
Now that we have a bare bone Phoenix app that we can start through "mix phoenix.server" and make it available at "localhost:4000" we can start changing the Rails application.
As I said in the beginning, my original wish was to use the same Pusher javascript client but change the endpoint, turns out it's more difficult than I thought, so I will start by removing the following line from the application layout:
1 |
<script src="//js.pusher.com/3.0/pusher.min.js"></script> |
We can get rid of the Pusher gem in the Gemfile and the "pusher.rb" initializer as well.
Now, a replacement for the "pusher.min.js" is Phoenix own "phoenix.js" that comes bundled in "deps/phoenix/web/static/js/phoenix.js". The problem is that it is an ES6 javascript source that Phoenix passes through Brunch to be transpiled back to ES5 in every Phoenix application.
But I am copying this file directly to the Rails repository at "app/assets/javascripts/phoenix.es6". I could change it to ES5 but I decided to go the more difficult path and just add Babel support to Rails Asset Pipeline using Nando's very helpful tutorial on the subject.
The gist goes like this, first we add the dependencies in the Gemfile:
1 2 3 4 5 6 7 8 9 10 |
# Use SCSS for stylesheets #gem 'sass-rails', '~> 5.0' gem 'sass-rails', github: 'rails/sass-rails', branch: 'master' gem 'sprockets-rails', github: 'rails/sprockets-rails', branch: 'master' gem 'sprockets', github: 'rails/sprockets', branch: 'master' gem 'babel-transpiler' ... source 'https://rails-assets.org' do gem 'rails-assets-almond' end |
Babel needs some configuration:
1 2 3 4 5 6 7 8 |
# config/initializers/babel.rb Rails.application.config.assets.configure do |env| babel = Sprockets::BabelProcessor.new( 'modules' => 'amd', 'moduleIds' => true ) env.register_transformer 'application/ecmascript-6', 'application/javascript', babel end |
And for some reason I had to manually redeclare application.js and application.css in the assets initializer:
1 2 3 |
# config/initializers/assets.rb ... Rails.application.config.assets.precompile += %w( application.css application.js ) |
We need Almond in order to be able to import the Socket module from the Phoenix javascript package. Now, we change the "application.js":
1 2 3 4 5 6 7 8 |
//= require almond //= require jquery //= require jquery_ujs //= require turbolinks //= require phoenix //= require_tree . require(['application/boot']); |
It require an "app/assets/javascripts/application/boot.es6" file, this is straight from Nando's tutorial:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
import $ from 'jquery'; function runner() { // All scripts must live in app/assets/javascripts/application/pages/**/*.es6. var path = $('body').data('route'); // Load script for this page. // We should use System.import, but it's not worth the trouble, so // let's use almond's require instead. try { require([path], onload, null, true); } catch (error) { handleError(error); } } function onload(Page) { // Instantiate the page, passing <body> as the root element. var page = new Page($(document.body)); // Set up page and run scripts for it. if (page.setup) { page.setup(); } page.run(); } // Handles exception. function handleError(error) { if (error.message.match(/undefined missing/)) { console.warn('missing module:', error.message.split(' ').pop()); } else { throw error; } } $(window) .ready(runner) .on('page:load', runner); |
And it relies on attributes in the body tag, so we change our layout template:
1 2 3 |
<!-- app/views/layouts/application.html.erb --> ... <body data-route="application/pages/<%= controller.controller_name %>/<%= controller.action_name %>"> |
I didn't mention before but I also have a "HomeController" just to be the root path for the main HTML page, it has a single "index" method and "index.html.erb" template with the message form. So I will have the need for an "application/pages/home/index.es6" inside the "app/assets/javascripts" path:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import {Socket} from "phoenix" export default class Index { constructor(root) { this.root = root; } setup() { // add event listeners console.log('-> Setting up Pusher Lite socket') let guardianToken = $("meta[name=guardian-token]").attr("content") let csrfToken = $("meta[name=guardian-csrf]").attr("content") let pusherKey = $("meta[name=pusher_key]").attr("content") let pusherChannel = $("meta[name=pusher_channel]").attr("content") let socket = new Socket("ws://localhost:4000/socket", { params: { guardian_token: guardianToken, csrf_token: csrfToken } }) socket.connect() // Now that you are connected, you can join channels with a topic: let channel = socket.channel(pusherChannel, {}) channel.join() .receive("ok", resp => { console.log("Joined successfully", resp) }) .receive("error", resp => { console.log("Unable to join", resp) }) channel.on("msg", data => { let new_line = `<p><strong>${data.name}<strong>: ${data.message}</p>` $(".message-receiver").append(new_line) }) } run() { // trigger initial action (e.g. perform http requests) console.log('-> perform initial actions') } } |
This bit is similar to the Pusher javascript handling, but we are getting a bit more information from the meta tags, the "guardian-token" and "guardian-csrf" tokens. Because I was following Daniel's tutorial I also changed the name of the event from "new_message" to just "msg" and the topics now need to have a "public:" prefix in order for the Phoenix's RoomChannel handler to match the public topic name correctly.
First things first. In order for this new javascript to have the correct tokens I had to add the following helper in the views layout:
1 2 3 4 5 |
... <%= csrf_meta_tags %> <%= guardian_token_tags %> </head> ... |
And this "guardian_token_tags" is again straight from Daniel's tutorial:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
module GuardianHelper ISSUER = "pl-web-#{Rails.env}" DIGEST = OpenSSL::Digest.new('sha256') def guardian_token_tags token = Base64.urlsafe_encode64(SecureRandom.random_bytes(32)) [ "<meta content=\"#{jwt(token)}\" name=\"guardian-csrf\" />", "<meta content=\"#{token}\" name=\"guardian-token\" />", ].shuffle.join.html_safe end private def jwt(token) JWT.encode(jwt_claims(token), Rails.application.secrets.pusher_key, 'HS256') end def jwt_claims(token) { aud: :csrf, sub: jwt_sub, iss: ISSUER, iat: Time.now.utc.to_i, exp: (Time.now + 30.days).utc.to_i, s_csrf: guardian_signed_token(token), listen: jwt_listens, publish: jwt_publish, } end def jwt_sub return {} unless current_human.present? { id: current_human.id, name: current_human.full_name, email: current_human.email, crews: current_human.crews.map(&:identifier), } end def jwt_listens listens = ['deploys:web', 'public:*'] listens.push('private:*') if current_human.try(:in_crew?, :admins) listens end def jwt_publish publish = ['public:*'] publish.push('private:*') if current_human.try(:in_crew?, :admins) publish end def guardian_signed_token(token) key = Rails.application.secrets.pusher_key signed_token = OpenSSL::HMAC.digest(DIGEST, key, token) Base64.urlsafe_encode64(signed_token).gsub(/={1,}$/, '') end end |
I had to tweak it a bit, specially to get the proper keys from the "secrets.yml" file which now looks like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
development: secret_key_base: ded7c4a2a298c1b620e462b50c9ca6ccb60130e27968357e76cab73de9858f14556a26df885c8aa5004d0a7ca79c0438e618557275bdb28ba67a0ffb0c268056 pusher_url: http://<%= ENV['PUSHER_KEY'] %>:<%= ENV['PUSHER_SECRET'] %>@<%= ENV['PUSHER_URL'] %> pusher_key: <%= ENV['PUSHER_KEY'] %> pusher_secret: <%= ENV['PUSHER_SECRET'] %> pusher_channel: "public:test_chat_channel" test: secret_key_base: f51ff494801ff0f9e1711036ef6f2f6f1e13544b02326adc5629c6833ae90f1a476747fae94b792eba8a444305df8e7a5ad53f05ea4234692ac96cc44f372029 pusher_url: http://<%= ENV['PUSHER_KEY'] %>:<%= ENV['PUSHER_SECRET'] %>@<%= ENV['PUSHER_URL'] %> pusher_key: <%= ENV['PUSHER_KEY'] %> pusher_secret: <%= ENV['PUSHER_SECRET'] %> pusher_channel: "public:test_chat_channel" # Do not keep production secrets in the repository, # instead read values from the environment. production: secret_key_base: <%= ENV["SECRET_KEY_BASE"] %> pusher_url: http://<%= ENV['PUSHER_KEY'] %>:<%= ENV['PUSHER_SECRET'] %>@<%= ENV['PUSHER_URL'] %> pusher_key: <%= ENV['PUSHER_KEY'] %> pusher_secret: <%= ENV['PUSHER_SECRET'] %> pusher_channel: <%= ENV['PUSHER_CHANNEL'] %> |
My local ".env" file looks like this:
1 2 3 4 |
PUSHER_URL: "localhost:4000" PUSHER_KEY: "14e86e5fee3335fa88b0" PUSHER_SECRET: "2b94ff0f07ce9769567f" PUSHER_CHANNEL: "public:test_chat_channel" |
This bit needs more working, I know. I just copied Pusher's key and Pusher's password as KEY and SECRET. This is the bit I mentioned I tweaked in the RoomChannel's authenticate function in the Phoenix side.
Now that I have this in place, I have to change the "PusherEvent" model to trigger the message from the form to the Phoenix's EventsController, like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# app/models/event.rb require "net/http" require "uri" class PusherEvent include ActiveModel::Model attr_accessor :name, :message validates :name, :message, presence: true def save uri = URI.parse("#{Rails.application.secrets.pusher_url}/events") Net::HTTP.post_form(uri, { "topic" => Rails.application.secrets.pusher_channel, "event" => "msg", "payload" => {"name" => name, "message" => message}.to_json }) end end |
As I am doing this through SuckerPunch, I am using plain old "Net::HTTP.post()" to post the message to the Phoenix "/events" endpoint. Phoenix will properly authenticate because the "pusher_url" is sending the "PUSHER_KEY:PUSHER_SECRET" as HTTP Basic Auth. It will end up in the "authorization" header and Phoenix will properly authenticate the server side, then it will broadcast to the WebSocket connections subscribed to the topic.
The new javascript will subscribe to the "public:test_chat_channel" topic and listen to the "msg" event. Once it receives the payload, it just formats the message and, again, appends to the same place in the "message-receiver" div tag.
Conclusion: Further Work
So, with this we have exactly the same behavior than the Pusher version, but now it's under my control.
The idea is for the Phoenix app to have apps, a real authentication for different apps. Then every Rails app I do can just connect to this same Phoenix service.
The next steps include properly implementing the Guardian/JWT pieces, then I can jump to private channels support and add HTTP APIs to list channels in apps and users online in channels.
I will then create a second companion Rails app as an administration dashboard to consume those APIs and be able to create or revoke apps and basic maintenance and reporting. This should be a good enough replacement for a Pusher-like messaging solution that is really fast.
Erlang's Ping Pong (tut15) in Clojure and Elixir 9 Dec 2015 7:42 AM (9 years ago)
This is a very short post just because I thought it was fun. I was reading this very enlightening article on Clojure's Quasar/Pulsar compared to Erlang and how they are trying to plug the holes on the JVM shortcomings.
When you're learning Erlang through its official documentation, the first thing you build in the chapters on Processes is a very simple Ping Pong code that looks like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
-module(tut15).
-export([start/0, ping/2, pong/0]).
ping(0, Pong_PID) ->
Pong_PID ! finished,
io:format("ping finished~n", []);
ping(N, Pong_PID) ->
Pong_PID ! {ping, self()},
receive
pong ->
io:format("Ping received pong~n", [])
end,
ping(N - 1, Pong_PID).
pong() ->
receive
finished ->
io:format("Pong finished~n", []);
{ping, Ping_PID} ->
io:format("Pong received ping~n", []),
Ping_PID ! pong,
pong()
end.
start() ->
Pong_PID = spawn(tut15, pong, []),
spawn(tut15, ping, [3, Pong_PID]).
|
It's not pretty, it's Prolog-ish. The Clojure article claims how close they got with lightweight threads (true green threads) and this is the same exercise done in Clojure:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
(defsfn pong []
(if (== n 0)
(do
(! :pong :finished)
(println "ping finished"))
(do
(! :pong [:ping @self])
(receive
:pong (println "Ping received pong"))
(recur (dec n)))))
(defsfn pong []
(receive
:finished (println "Pong finished")
[:ping ping] (do
(println "Pong received ping")
(! ping :pong)
(recur))))
(defn -main []
(register :pong (spawn pong))
(spawn ping 3)
:ok)
|
People that like the Lisp-y aesthetics of programming directly in the AST representation through the structure of parenthesis based blocks will find this very pretty.
I personally spent years looking into code like this (Common Lisp, Elisp, Scheme, etc) and I still can't get used to it. Once you have a competent editor such as Emacs, that can deal with the proper parenthesis handling, it's easier, yes, but I still can't find the joy in doing this kind of hackish syntax.
Elixir is not just a new syntax on top of Erlang, as the great book Metaprogramming Elixir will teach you, it opens up the entire Erlang BEAM AST through the usage of the quote/unquote mechanics, making programming directly into the AST through "Hygienic Macros" a breeze. It's really the best of both worlds of having a modern, good looking, joyful syntax and the same power a Lisp-y language gives you in terms of well behaved macros.
Now, this is the same example as above, in Elixir:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
defmodule ExPingPongTut15 do def ping(0, pong_pid) do send pong_pid, :finished IO.puts("ping finished") end def ping(n, pong_pid) do send pong_pid, {:ping, self} receive do :pong -> IO.puts("Ping received pong") end ping(n - 1, pong_pid) end def pong do receive do :finished -> IO.puts("Pong finished") {:ping, ping_pid} -> IO.puts("Pong received ping") send ping_pid, :pong pong() end end def start do pong_pid = spawn(fn -> pong end) spawn(fn -> ping(3, pong_pid) end) end end |
Because of the power of pattern matching in the functions arguments signature, you can define 2 separated functions, avoiding the "if" as in the Clojure example. Of course, because it's Clojure and it has a complete macro system, and because it's core.match has the proper pattern matching mechanisms, you can emulate the same thing through external libraries such as defun though.
This was just a simple exercise, I hope it shed some light on the basic similarities between these 3 languages. And as "ugly" as Erlang may feel, I still feel more comfortable with its quirks then nested parenthesis.
Ex Manga Downloadr - Part 5: Making it more robust! 6 Dec 2015 12:20 PM (9 years ago)
And there I go again. I know some of you may be bored by this tool already, but as a playground project, I still want to make this a good code. But there are 2 big problems right now.
When I was testing only with MangaReader.net as a source, everything worked almost flawlessly. But adding MangaFox in Part 3, with its more restrictive rules towards scrapper tools like mine (timing out more frequently, not allowing too many connections from the same place, etc), the process just kept crashing and I had to manually restart it (the resuming features I added in Part 4 payed off, but it's not a reliable tool anymore).
To recap, the Workflow just organizes each step of the process. It's functions are similar to this:
1 2 3 4 5 6 |
def process_downloads(images_list, directory) do images_list |> Enum.map(&Worker.page_download_image(&1, directory)) |> Enum.map(&Task.await(&1, @await_timeout_ms)) directory end |
It deals with a large list, maps over each element sending it to a Worker function to run, like this:
1 2 3 4 5 6 7 |
def page_download_image(image_data, directory) do Task.async(fn -> :poolboy.transaction :worker_pool, fn(server) -> GenServer.call(server, {:page_download_image, image_data, directory}, @genserver_call_timeout) end, @task_async_timeout end) end |
It returns an asynchronous Task waiting for 2 things: for Poolboy to release a free process to use, and for the Worker/GenServer function to finish running inside that process. As I explained in Part 2 this is so we can limit the maximum number of connections to the external source. If we didn't have this restriction, sending tens of thousands of asynchronous requests at once, the external source would just fail them all.
First thing to bear in mind is that a "Task.async/2" links itself to the caller process, so if something goes wrong, the parent process dies as well.
The correct thing to do is to add a Task.Supervisor and make it deal with each Task child. To do that, we can just add the Supervisor in our supervised tree at "pool_management/supervisor.ex":
1 2 3 4 5 6 7 8 9 |
defmodule PoolManagement.Supervisor do use Supervisor ... children = [ supervisor(Task.Supervisor, [[name: Fetcher.TaskSupervisor]]), :poolboy.child_spec(:worker_pool, pool_options, []) ] ... end |
And we can replace the "Task.async/2" calls to "Task.Supervisor.async(Fetcher.TaskSupervisor, ...)" like this:
1 2 3 4 5 6 7 |
def page_download_image(image_data, directory) do Task.Supervisor.async(Fetcher.TaskSupervisor, fn -> :poolboy.transaction :worker_pool, fn(server) -> GenServer.call(server, {:page_download_image, image_data, directory}, @genserver_call_timeout) end, @task_async_timeout end) end |
This still creates Tasks that we need to await on, and as before, if the function inside crashes, it still brings down the main process. Now my refactoring found a dead end.
This is the 2nd problem I mentioned in the beginning of the article: a flaw in my design.
Instead of just mapping through each element of a large list, I should have created an Agent based GenServer to keep the list as the state and make the the entire Workflow system a new supervised GenServer. If fetching one URL crashed the GenServer, its supervisor would restart it and pick up the next element in list.
But, as I am in no mood for this refactoring right now (it's Sunday afternoon) I will concentrate on a quick fix (yes, jerry-rigged patch), just so the function in the async call does not raise exceptions.
OMG! It's a Try/Catch block!
Turns out that everything I run inside the Poolboy processes are HTTP get requests through HTTPotion. Fortunately I had already refactored every HTTPotion get call into a neat macro:
1 2 3 4 5 6 7 8 9 10 11 |
defmacro fetch(link, do: expression) do quote do Logger.debug("Fetching from #{unquote(link)}") case HTTPotion.get(unquote(link), ExMangaDownloadr.http_headers) do %HTTPotion.Response{ body: body, headers: headers, status_code: 200 } -> { :ok, body |> ExMangaDownloadr.gunzip(headers) |> unquote(expression) } _ -> { :err, "not found"} end end end |
Now I only need to replace 1 line in this macro:
1 2 |
- case HTTPotion.get(unquote(link), ExMangaDownloadr.http_headers) do + case ExMangaDownloadr.retryable_http_get(unquote(link)) do |
And define this new retryable logic in the main module:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
defmodule ExMangaDownloadr do require Logger # will retry failed fetches over 50 times, sleeping 1 second between each retry @max_retries 50 @time_to_wait_to_fetch_again 1_000 ... def retryable_http_get(url, 0), do: raise "Failed to fetch from #{url} after #{@max_retries} retries." def retryable_http_get(url, retries \\ @max_retries) when retries > 0 do try do Logger.debug("Fetching from #{url} for the #{@max_retries - retries} time.") response = HTTPotion.get(url, ExMangaDownloadr.http_headers) case response do %HTTPotion.Response{ body: _, headers: _, status_code: status } when status > 499 -> raise %HTTPotion.HTTPError{message: "req_timedout"} _ -> response end rescue error in HTTPotion.HTTPError -> case error do %HTTPotion.HTTPError{message: message} when message in @http_errors -> :timer.sleep(@time_to_wait_to_fetch_again) retryable_http_get(url, retries - 1) _ -> raise error end end end ... end |
I strongly stated that in Elixir we should not use "try/catch" blocks, but there you have it.
This is the consequence of the flaw in my initial Workflow design. If I had coded the Workflow module to be a GenServer, with each list managed by an Agent, each failed HTTPotion call would allow the supervisor to restart it and try again. Without resorting to the ugly "try/catch" code.
Maybe this will force me to write Part 6 as being the code to remove this ugly try/catch later, so consider this a Technical Debt to make everything work now so we can refactor later and pay the debt back.
"HTTPotion.get/2" calls can raise "HTTPotion.HTTPError" exceptions. I am catching those errors for the time being, matching the messages against a list of errors I had already, sleeping for a certain amount of time (just a heuristic to see if the external sources respond better that way) and I recurse to itself through a limited number of "retries", until it reaches zero, in which case it may even be the case that the internet connection is down or some other severe error that we would not be able to recover soon.
With this code in place, now even fetching from MangaFox, without tweaking down the POOL_SIZE, will run until the end, and this solves my needs for now. If anyone is interested in suggesting a better, GenServer based Workflow design, I would really appreciate a Pull Request.
Cheers.
Ex Manga Downloadr - Part 4: Learning through Refactoring 3 Dec 2015 10:40 AM (9 years ago)
Yesterday I added Mangafox support to my downloader tool and it also added a bit of dirty code into my already not-so-good coding. It's time for some serious cleanup.
You can see everything I did since yesterday to clean things up through Github's awesome compare page
First things first: now the choice to have added a reasonable amount of tests will pay off. In this refactoring I changed function signatures, response formats, moved a fair amount of code around, and without the tests this endeavor would have taken me the entire day or more, rendering the refactor efforts questionable to begin with.
At each step of the refactoring I could run "mix test" and work until I ended up with the green status:
1 2 |
Finished in 13.5 seconds (0.1s on load, 13.4s on tests) 12 tests, 0 failures |
The tests are taking long because I made a choice for the MangaReader and Mangafox unit tests to actually go online and fetch from the sites. It takes longer to run the suite but I know that if it breaks and I didn't touch that code, the source websites changed their formats and I need to change the parser. I could have added fixtures to make the tests run faster, but the point in my parser is for them to be correct.
Macros to the Rescue!
Each source module has 3 sub-modules: ChapterPage, IndexPage and Page. All of them have a main function that resembles this piece of code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
defmodule ExMangaDownloadr.Mangafox.ChapterPage do require Logger ... def pages(chapter_link) do Logger.debug("Fetching pages from chapter #{chapter_link}") case HTTPotion.get(chapter_link, [headers: ["User-Agent": @user_agent, "Accept-encoding": "gzip"], timeout: 30_000]) do %HTTPotion.Response{ body: body, headers: headers, status_code: 200 } -> body = ExMangaDownloadr.Mangafox.gunzip(body, headers) { :ok, fetch_pages(chapter_link, body) } _ -> { :err, "not found"} end end ... end |
(Listing 1.1)
It calls "HTTPotion.get/2" sending a bunch of HTTP options and receives a "%HTTPotion.Response" struct that is then decomposed to get the body and headers. It gunzips the body if necessary and goes to parse the HTML itself.
Similar code exists in 6 different modules, with different links and different parser functions. It's a lot of repetition, but what about making the above code look like the snippet below?
1 2 3 4 5 6 7 8 9 |
defmodule ExMangaDownloadr.Mangafox.ChapterPage do require Logger require ExMangaDownloadr def pages(chapter_link) do ExMangaDownloadr.fetch chapter_link, do: fetch_pages(chapter_link) end ... end |
(Listing 1.2)
Changed 9 lines to just 1. And by the way, this same line can be written like this:
1 2 3 |
ExMangaDownloadr.fetch chapter_link do fetch_pages(chapter_link) end |
Seems familiar? It's like every block in the Elixir language, you can write it in the "do/end" block format or the way it really is under the covers: a keyword list with a key named ":do". And the way this macro is defined is like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
defmodule ExMangaDownloadr do ... defmacro fetch(link, do: expression) do quote do Logger.debug("Fetching from #{unquote(link)}") case HTTPotion.get(unquote(link), ExMangaDownloadr.http_headers) do %HTTPotion.Response{ body: body, headers: headers, status_code: 200 } -> { :ok, body |> ExMangaDownloadr.gunzip(headers) |> unquote(expression) } _ -> { :err, "not found"} end end end ... end |
(Listing 1.3)
There is a lot of details to consider when writing a macro and I recommend reading the documentation on Macros. The code is basically copying the function body from the "ChapterPage.pages/1" (Listing 1.1) and pasting into the "quote do .. end" block (Listing 1.3).
Inside that code we have "unquote(link)" and "unquote(expression)". You also must read the documentation on "Quote and Unquote". It just expands this "external" code inside the macro code to defer execution until the macro quote code is actually executed, instead of running it at that exact moment. I know, tricky to wrap your head around this the first time.
The bottom line is: whatever code is inside the "quote" block will be "inserted" where we called "ExMangaDownloadr.fetch/2" in the "pages/1" function in Listing 1.2, together with the unquoted code you passed as a parameter.
The resulting code will resemble the original code in Listing 1.1.
To make it simpler, if you were in Javascript this would be a similar code:
1 2 3 4 5 6 |
function fetch(url) { eval("doSomething('" + url + "')"); } function pages(page_link) { fetch(page_link); } |
"Quote" would be like the string body in an eval and "unquote" just concatenating the value you passed inside the code being eval-ed. This is a crude metaphor as "quote/unquote" is way more powerful and cleaner than ugly "eval" (you shouldn't be using, by the way!) But this metaphor should do to make you understand the code above.
Another place I used a macro was to save the images list in a dump file and load it later if the tool crashes for some reason, in order not to have to start over from scratch. The original code was like this:
1 2 3 4 5 6 7 8 9 10 11 |
dump_file = "#{directory}/images_list.dump" images_list = if File.exists?(dump_file) do :erlang.binary_to_term(File.read!(dump_file)) else list = [url, source] |> Workflow.chapters |> Workflow.pages |> Workflow.images_sources File.write(dump_file, :erlang.term_to_binary(list)) list end |
(Listing 1.4)
And now that you understand macros, you will understand what I did here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
defmodule ExMangaDownloadr do ... defmacro managed_dump(directory, do: expression) do quote do dump_file = "#{unquote(directory)}/images_list.dump" images_list = if File.exists?(dump_file) do :erlang.binary_to_term(File.read!(dump_file)) else list = unquote(expression) File.write(dump_file, :erlang.term_to_binary(list)) list end end end ... end defmodule ExMangaDownloadr.CLI do alias ExMangaDownloadr.Workflow require ExMangaDownloadr ... defp process(manga_name, directory, {_url, _source} = manga_site) do File.mkdir_p!(directory) images_list = ExMangaDownloadr.managed_dump directory do manga_site |> Workflow.chapters |> Workflow.pages |> Workflow.images_sources end ... end ... end |
And there you have it! And now you see how "do .. end" blocks are implemented. It just passes the expression as the value in the keyword list of the macro definition. Let's define a dumb macro:
1 2 3 4 5 6 7 |
defmodule Foo defmacro foo(do: expression) do quote do unquote(expression) end end end |
And not the following calls are all equivalent:
1 2 3 4 5 6 7 8 |
require Foo Foo.foo do IO.puts(1) end Foo.foo do: IO.puts(1) Foo.foo(do: IO.puts(1)) Foo.foo([do: IO.puts(1)]) Foo.foo([{:do, IO.puts(1)}]) |
This is macros combined with Keyword Lists which I explained in previous articles and it's simply a List with tuples where each tuple has an atom key and a value.
More Macros
Another opportunity to refactor were the "mangareader.ex" and "mangafox.ex" modules that were just used in the unit tests "mangareader_test.ex" and "mangafox_test.ex". This is the old "mangareader.ex" code:
1 2 3 4 5 6 7 8 9 |
defmodule ExMangaDownloadr.MangaReader do defmacro __using__(_opts) do quote do alias ExMangaDownloadr.MangaReader.IndexPage alias ExMangaDownloadr.MangaReader.ChapterPage alias ExMangaDownloadr.MangaReader.Page end end end |
And this is how it was used in "mangareader_test.ex":
1 2 3 4 |
defmodule ExMangaDownloadr.MangaReaderTest do use ExUnit.Case use ExMangaDownloadr.MangaReader ... |
It was just a shortcut to alias the modules in order to use them directly inside the tests. I just moved the entire module as a macro in "ex_manga_downloadr.ex" module:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
... def mangareader do quote do alias ExMangaDownloadr.MangaReader.IndexPage alias ExMangaDownloadr.MangaReader.ChapterPage alias ExMangaDownloadr.MangaReader.Page end end def mangafox do ... end defmacro __using__(which) when is_atom(which) do apply(__MODULE__, which, []) end end |
And now I can use it like this in the test file:
1 2 3 4 |
defmodule ExMangaDownloadr.MangaReaderTest do use ExUnit.Case use ExMangaDownloadr, :mangareader ... |
The special "using" macro is called when I "use" a module, and I can even pass arguments to it. The implementation then uses "apply/3" to dynamically call the correct macro. This exactly how Phoenix imports the proper behaviors for Models, Views, Controllers, Router, for example:
1 2 3 |
defmodule Pxblog.PageController do use Pxblog.Web, :controller ... |
The macros are open in a Phoenix file and available in the "web/web.ex" module, so I just copied the same behavior. And now I have 2 less files to worry about.
Tiny refactorings
In the previous code I used the "String.to_atom/1" to convert the string of the module name to an atom, to be later used in "apply/3" calls:
1 2 3 4 5 6 |
defp manga_source(source, module) do case source do "mangareader" -> String.to_atom("Elixir.ExMangaDownloadr.MangaReader.#{module}") "mangafox" -> String.to_atom("Elixir.ExMangaDownloadr.Mangafox.#{module}") end end |
I changed it to this:
1 2 |
"mangareader" -> :"Elixir.ExMangaDownloadr.MangaReader.#{module}" "mangafox" -> :"Elixir.ExMangaDownloadr.Mangafox.#{module}" |
It's just a shortcut to do the same thing.
In the parser I was also not using Floki correctly. So take a look at this piece of old code:
1 2 3 4 5 6 7 8 9 |
defp fetch_manga_title(html) do Floki.find(html, "#mangaproperties h1") |> Enum.map(fn {"h1", [], [title]} -> title end) |> Enum.at(0) end defp fetch_chapters(html) do Floki.find(html, "#listing a") |> Enum.map fn {"a", [{"href", url}], _} -> url end end |
Now using the better helper functions that Floki provides:
1 2 3 4 5 6 7 8 9 10 |
defp fetch_manga_title(html) do html |> Floki.find("#mangaproperties h1") |> Floki.text end defp fetch_chapters(html) do html |> Floki.find("#listing a") |> Floki.attribute("href") end |
This was a case of not reading the documentation as I should have. Much cleaner!
I did other bits of cleanup but I think this should cover the major changes. And finally, I bumped up the version to "1.0.0" as well!
1 2 3 4 5 |
def project do [app: :ex_manga_downloadr, - version: "0.0.1", + version: "1.0.0", elixir: "~> 1.1", |
And speaking of versions, I'm using Elixir 1.1 but pay attention as Elixir 1.2 is just around the corner and it brings some niceties. For example, that macro that aliased a few modules could be written this way now:
1 2 3 4 5 |
def mangareader do quote do alias ExMangaDownloadr.MangaReader.{IndexPage, ChapterPage, Page} end end |
And this is just 1 feature between many other syntax improvements and support for the newest Erlang R18. Keep an eye on both!
The Obligatory "Flame War" Phoenix vs Node.js 3 Dec 2015 5:01 AM (9 years ago)
I’ll warn you upfront: this will be a very unfair post. Not only am I biased for disliking Javascript and Node.js, but at this moment, I am very excited and fascinated by Elixir and Erlang.
Comparisons are always unfair. There is no such a thing as a “fair” synthetic benchmark comparison, the author is always biased towards some targetted result. It’s the old pseudo-science case of having a conclusion and picking and choosing data that backs those conclusions. There are just too many different variables. People think it’s fair when you run it in the same machine against 2 “similar” kinds of applications, but it is not. Please don’t trust me on this as well, do your own tests.
All that being said, let’s have some fun, shall we?
The Obligatory “Hello World” warm-up
For this very short post, I just created a Node.js + Express “hello world,” I will point to its root endpoint, Express, rendering a super simple HTML template with one title and one paragraph.
For Elixir, I just bootstrapped a bare-bone Phoenix project and added one extra endpoint called “/teste” in the Router. This endpoint will call the PageController, then the “teste” function, and render an EEX template with the same title and paragraph as in the Express example.
Simple enough. Phoenix does more than Express, but this is not supposed to be a fair trial anyway. I chose Siege as the testing tool for no particular reason. You can pick the testing tool you like the most. I am running this over my 2013 Macbook Pro with 8 cores and 16GB of RAM, so this benchmark will never max out my machine.
The first test is a simple run of 200 concurrent connections (the number of CPUs I have) firing just 8 requests each for 1,600. First, the Node.js + Express results:
The first run already broke a few connections, but the 2nd run picked up and finished all 1,600 requests. And this is the Phoenix results:
As you can see, Node.js has the upper hand in terms of the total time spent. One single Node.js process can only run one single real OS thread. Therefore it had to use just a single CPU core (although I had 7 other cores to spare). On the other hand, Elixir can reach all 8 cores of my machine, each running a Scheduler in a single real OS thread. So, if this test was CPU bound, it should have run 8 times faster than the Node.js version. As the test is largely a case of I/O bound operations, the clever async construction of Node.js does the job just fine.
This is not an impressive test by any stretch of the imagination. But we’re just warming up.
Oh, and by the way, notice how Phoenix logs show the request processing times in MICROseconds instead of milliseconds!
The Real Fun
Now comes the real fun. In this second run, I added a blocking “sleep” call to both projects, so each request will sleep for one full second, and this is not absurd. Many programmers will use poor code that blocks for that time, process too much data from the database, render templates that are too complex, and so on. Never trust a programmer to do the right best practices all the time.
Then, I fire up Siege with ten concurrent connections and just one request each, for starters.
This is why in my previous article" Why Elixir?" (http://www.akitaonrails.com/2015/12/01/the-obligatory-why-elixir-personal-take), I repeated many times how “rudimentary” a Reactor pattern-based solution is. It is super easy to block a single-threaded event loop.
If you didn’t know that already, how does Node.js work? In summary, it is a simple infinite loop. When a Javascript function runs, it blocks that event loop. The function has to explicitly yield control back to the loop for another function to have a chance to run. I/O calls take time and just sit back idly waiting for a response, so it can yield control back and wait for a callback to continue running, which is why you end up with the dreaded “callback pyramid hell”.
Now, with what I explained in all my previous articles, you may already know how Elixir + Phoenix will perform:
As expected, this is a walk in the park for Phoenix. It doesn’t have a rudimentary single-thread loop waiting for the running functions to yield control back willingly. The Schedulers can forcefully suspend running coroutines/processes if they think they are taking too much time (the 2,000 reductions count and priority configurations), so every running process has a fair share of resources to run.
Because of that, I can keep increasing the number of requests and concurrent connections, and it’s still fast.
In Node.js, if a function takes 1 second to run, it blocks the loop. When it finally returns, the next 1-second function can run. That’s why if I have ten requests taking 1 second each to run, the entire process will linearly take 10 seconds!
Which obviously does not scale! If you “do it right,” you can scale. But why bother?
“Node” done right
As a side note, I find it ironic that “Node” is called “Node.” I would assume that connecting multiple Nodes that communicate with each other should be easy. And as a matter of fact, it is not.
If I had spun up 5 Node processes, instead of 10 seconds, everything would take 2 seconds as five requests would block the 5 Node processes for 1 second, and when returned, the next five requests would block again. This is similar to what we need to do with Ruby or Python, which have the dreaded big Global Interpreter Locks (GIL) that, in reality, can only run one blocking computation at a time. (Ruby with Eventmachine and Python with Tornado or Twisted are similar to Node.js implementation of a reactor event loop).
Elixir can do much better in terms of actually coordinating different nodes, and it is the Erlang underpinnings that allow highly distributed systems such as ejabberd or RabbitMQ to do their thing as efficiently as they can.
Check out how simple it is for one Elixir Node to notice the presence of other Elixir nodes and make them send and receive messages between each other:
Yep, it is this simple. We have been using Remote Procedure Calls (RPC) for decades; this is not new. Erlang has implemented this for years, and it is built-in and available for easy usage out-of-the-box.
On their websites, ejabbed calls itself a “Robust, Scalable, and Extensible XMPP Server,” and RabbitMQ calls itself “Robust messaging for applications.” Now we know they deserve the labels “Robust” and “Scalable.”
So, we are struggling to do things that have been polished and ready for years. Elixir is the key to unlocking all this Erlang goodness right now. Let’s just use it and stop shrugging.
Ex Manga Downloadr - Part 3: Mangafox Support! 2 Dec 2015 9:27 AM (9 years ago)
I thought Part 2 would be my last article about this tool, but turns out its just too much fun to let it go easily. As usual, all the source code is on my Github repository. And the gist of the post is that now you can do this:
1 2 3 |
git pull mix escript.build ./ex_manga_downloadr -n onepunch -u http://mangafox.me/manga/onepunch_man/ -d /tmp/onepunch -s mangafox |
And there you go: download from Mangafox built-in! \o/
It starts when I wanted to download manga that is not available at MangaReader but exists under Mangafox.
So, the initial endeavor was to copy the MangaReader parser modules (IndexPage, ChapterPage, and Page) and paste them at a specific "lib/ex_manga_downloadr/mangafox" folder. Same thing done to the unit tests folder. Just a matter of copying and pasting the files and change the "MangaReader" module name to "Mangafox".
Of course the URL formats are different, the Floki CSS selectors are a bit different, so that's what have to change in the parser. For example, this is how I parse the chapter links from the main page at MangaReader:
1 2 3 4 |
defp fetch_chapters(html) do Floki.find(html, "#listing a") |> Enum.map fn {"a", [{"href", url}], _} -> url end end |
And this is the same thing but for Mangafox:
1 2 3 4 5 |
defp fetch_chapters(html) do html |> Floki.find(".chlist a[class='tips']") |> Enum.map fn {"a", [{"href", url}, {"title", _}, {"class", "tips"}], _} -> url end end |
Exactly the same logic but the pattern matching structure is different because the returning HTML DOM nodes are different.
Another difference is that MangaReader returns everything in plain text by default, but Mangafox returns everything Gzipped regardless if I send the "Accept-Encoding" HTTP header (curiously, if I retry several times it changes behavior and sometimes send plain text).
What I did different was to check if the returned %HTTPotion.Response{} structure had a "Content-Encoding" header set to "gzip" and if so, gunzip it using the built-in Erlang "zlib" package (nothing to import!):
1 2 3 4 5 6 7 |
def gunzip(body, headers) do if headers[:"Content-Encoding"] == "gzip" do :zlib.gunzip(body) else body end end |
I would've preferred if HTTPotion did that out of the box for me (#OpportunityToContribute!), but this was easy enough.
Once the unit tests were passing correctly after tuning the scrapper (HTTPotion requests) and parser (Floki selectors) it was time to make my Worker aware of the existence of this new set of modules.
The Workflow module just call the Worker, which in turn does the heavy lifting of fetching pages and downloading images. The Worker called the MangaReader module directly, like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
defmodule PoolManagement.Worker do use GenServer use ExMangaDownloadr.MangaReader require Logger ... def chapter_page(chapter_link) do Task.async fn -> :poolboy.transaction :worker_pool, fn(server) -> GenServer.call(server, {:chapter_page, chapter_link}, @timeout_ms) end, @transaction_timeout_ms end end ... def handle_call({:chapter_page, chapter_link}, _from, state) do {:reply, ChapterPages.pages(chapter_link), state} end ... end |
That "use ExMangaDownloadr.MangaReader" statement up above is just a macro that will alias the corresponding modules:
1 2 3 4 5 6 7 8 9 |
defmodule ExMangaDownloadr.MangaReader do defmacro __using__(_opts) do quote do alias ExMangaDownloadr.MangaReader.IndexPage alias ExMangaDownloadr.MangaReader.ChapterPage alias ExMangaDownloadr.MangaReader.Page end end end |
So when I call "ChapterPages.pages(chapter_link)" it's a shortcut to use the fully qualified module name like this: "ExMangaDownloadr.MangaReader.ChapterPages.pages(chapter_link)".
An Elixir module namespace is just an Atom. Nested module names have the full, dot-separated name, prefixed with it's parent. For example:
1 2 3 4 5 6 7 8 |
defmodule Foo do defmodule Bar do defmodule Xyz do def teste do end end end end |
You can just call "Foo.Bar.Xyz.teste()" and that's it. But there is a small trick. Elixir also transparently prefixes the full module name with "Elixir". So in reality, the full module name is "Elixir.Foo.Bar.Xyz", in order to make sure no Elixir module ever conflicts with an existing Erlang module.
This is important because of this new function I added to the Worker module first:
1 2 3 4 5 6 |
def manga_source(source, module) do case source do "mangareader" -> String.to_atom("Elixir.ExMangaDownloadr.MangaReader.#{module}") "mangafox" -> String.to_atom("Elixir.ExMangaDownloadr.Mangafox.#{module}") end end |
This is how I map from "mangafox" to the new "ExMangaDownloadr.Mangafox." namespace. And because of the dynamic, message passing nature of Elixir, I can replace this code:
1 2 3 |
def handle_call({:chapter_page, chapter_link}, _from, state) do {:reply, ChapterPages.pages(chapter_link), state} end |
With this:
1 2 3 4 5 6 |
def handle_call({:chapter_page, chapter_link, source}, _from, state) do links = source |> manga_source("ChapterPage") |> apply(:pages, [chapter_link]) {:reply, links, state} end |
I can now choose between the "Elixir.ExMangaDownloadr.Mangafox.ChapterPage" or "Elixir.ExMangaDownloadr.MangaReader.ChapterPage" modules, call the pages/1 function and send the same argument as before. I just have to make sure I can receive a "source" string from the command line now, so I change the CLI module like this:
1 2 3 4 5 6 7 8 9 10 11 |
defp parse_args(args) do parse = OptionParser.parse(args, switches: [name: :string, url: :string, directory: :string, source: :string], aliases: [n: :name, u: :url, d: :directory, s: :source] ) case parse do {[name: manga_name, url: url, directory: directory, source: source], _, _} -> process(manga_name, url, directory, source) {[name: manga_name, directory: directory], _, _} -> process(manga_name, directory) {_, _, _ } -> process(:help) end end |
Compared to the previous version I just added the ":source" string argument to the OptionParser and passed the captured value to process/4. I should add some validation here to avoid strings different than "mangareader" or "mangafox", but I will leave that to another time.
And in the Workflow module, instead of starting from just the manga URL, now I have to start with both the URL and the manga source:
1 2 3 4 |
[url, source] |> Workflow.chapters |> Workflow.pages |> Workflow.images_sources |
Which means that each of the above functions have to not only return the new URL lists but also pass through the source:
1 2 3 4 5 6 |
def chapters([url, source]) do {:ok, _manga_title, chapter_list} = source |> Worker.manga_source("IndexPage") |> apply(:chapters, [url]) [chapter_list, source] end |
This was the only function in the Workflow module hardcoded to MangaReader so I also make it dynamic using the same manga_source/2 function from the Worker, and notice the return value being "[chapter_list, source]" instead of just "chapter_list".
And now, I can finally test with "mix test" and create the new executable command line binary with "mix escript.build" and run the new version like this:
1 |
./ex_manga_downloadr -n onepunch -u http://mangafox.me/manga/onepunch_man/ -d /tmp/onepunch -s mangafox |
The Mangafox site is very unreliable to several concurrent connections and it quickly timeout sometimes, dumping ugly errors like this:
1 2 3 4 5 |
15:58:46.637 [error] Task #PID<0.2367.0> started from #PID<0.124.0> terminating
** (stop) exited in: GenServer.call(#PID<0.90.0>, {:page_download_image, {"http://z.mfcdn.net/store/manga/11362/TBD-053.2/compressed/h006.jpg", "Onepunch-Man 53.2: 53rd Punch [Fighting Spirit] (2) at MangaFox.me-h006.jpg"}, "/tmp/onepunch"}, 1000000)
** (EXIT) an exception was raised:
** (HTTPotion.HTTPError) connection_closing
(httpotion) lib/httpotion.ex:209: HTTPotion.handle_response/1
|
I did not figure out how to retry HTTPotion requests properly yet. But one small thing I did was add an availability check in the Worker module. So you can just re-run the same command line and it will resume downloading only the remaining files:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
defp download_image({image_src, image_filename}, directory) do
filename = "#{directory}/#{image_filename}"
if File.exists?(filename) do
Logger.debug("Image #{filename} already downloaded, skipping.")
{:ok, image_src, filename}
else
Logger.debug("Downloading image #{image_src} to #{filename}")
case HTTPotion.get(image_src,
[headers: ["User-Agent": @user_agent], timeout: @http_timeout]) do
%HTTPotion.Response{ body: body, headers: _headers, status_code: 200 } ->
File.write!(filename, body)
{:ok, image_src, filename}
_ ->
{:err, image_src}
end
end
end
|
This should at least reduce rework. Another thing I am still working on is this other bit at the main "CLI.process" function:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
defp process(manga_name, url, directory, source) do File.mkdir_p!(directory) dump_file = "#{directory}/images_list.dump" images_list = if File.exists?(dump_file) do :erlang.binary_to_term(File.read(dump_file)) else list = [url, source] |> Workflow.chapters |> Workflow.pages |> Workflow.images_sources File.write(dump_file, :erlang.term_to_binary(list)) list end images_list |> Workflow.process_downloads(directory) |> Workflow.optimize_images |> Workflow.compile_pdfs(manga_name) |> finish_process end |
As you can see the idea is to serialize the final images URL links to a file using the built-in serializer ":erlang.binary_to_term/1" and check if that dump file exists, and deserialize with ":erlang.term_to_binary/1" before fetching all pages all over again. Now the process can resume directly from the process_downloads/2 function after.
Mangafox is terribly unreliable and I will need to figure out a better way to retry timed out connections without having to crash and manually restart from the command line. It's either a bad site or a clever one that shuts down scrappers like me, although I am guessing it's just a bad infrastructure on their side.
If I downgrade from 50 process to 5 in the pool, it seems to be able to handle it better (but the process slows down, of course):
1 2 3 4 5 6 |
pool_options = [
name: {:local, :worker_pool},
worker_module: PoolManagement.Worker,
size: 5,
max_overflow: 0
]
|
If you see time out errors, change this parameter. MangaReader still supports 50 or more for concurrency.
And now you know how to add support for more manga sources. Feel free to send me a Pull Request! :-)
The Obligatory "Why Elixir?" Personal Take 1 Dec 2015 6:26 AM (9 years ago)
So, I've been studying and exercisizing quite a bit with Elixir. José Valim recently announced the new features of the upcoming Elixir 1.2. The language design is already elegant, lean, and it keeps gradually polishing itself.
First and foremost, I am a Web Applications Developer. I deal with Ruby on Rails applications and infrastructure. So, I am not a Desktop developer, a Mobile developer, Games developer or a Tools developer. This is very important to get out of the way right from the start.
And by the way, as I will focus my programming efforts more and more into Elixir, and it does not mean I am "switching" from Ruby to Elixir. I don't need to make exclusive choices, and in my mind, at least for a period of time, Rails joining forces with Phoenix will be a very difficult to beat combo for my web development strategies.
I know, Phoenix is built like Rails so why not just switch altogether: because most content-based sites don't need the concurrency aspects of Phoenix, and I said "for a period of time" because Rails still has a humongous ecosystem with more mature gems that make development easier and faster. This can change in the future, but for now the combo makes sense as I can build a normal website in Rails as I would normally do (with Devise, ActiveAdmin, Spree or whatever) and add Phoenix for stuff like WebSockets (real-time notifications, real-time chatting, background jobs that can be run more efficient than Sidekiq, etc).
This article will summarize my personal take on 2 fronts:
As anything that I want to argue about, this is lengthy, but it wouldn't be nice to just state something without further elaboration. In this quest for understanding, I may have confused a bit or two, so let me know in the comments section below if there are things to fix or to explain in more detail.
Let's get started.
Other Developer Roles than just the Web
In a Desktop environment, you will definitely want to make a combination of Node-Webkit with native libraries. If you're in specific corporate environments, you won't have any more choices than plain WFC based .NET development of Java Swing. Your options have been set for quite some time, and even Visual Basic.NET still has its place. Specific toolchains will be dictated by Microsoft and Oracle/Java Community Process
In Linux environments you will still use wrappers around GTK+, Qt ot similar toolkits. There is not a lot of ways around this.
If you're a Mobile-first developer, you do need to learn your way into Swift and Objective-C (to some extent) for iOS and the specific Java flavor for Android's Dalvik/ART. But I will argue that you have a lot to gain in native development if you use RubyMotion. Or, you can simply keep following Facebook's React Native endeavor. There's a lot of fragmentation in this environment, you can do as little as possible with Web Mobile and Phonegap/Cordova, and build compelling apps with tools such as Ionic Framework. The only consensus is that if you really want to build the advanced next gen stuff, you want to dive deep into the native frameworks each platform has to offer.
If you're a Game Developer you want to be as close to the metal as possible. It's definitelly feasible to write perfectly playable mobile games using any number of Javascript libraries together with HTML 5's technologies such as the Canvas and WebGL. But for the next gen blockbuster you will either use mature engines such as Unity or Unreal or even build your own if you're really invested in this field. This will require you to actually know your way into C/C++ programming. Really depends on how deep you want to go down the rabbit hole.
If you're a Tools Developer you will have the benefits from both old and new generation of languages. If you're closer to the Linux Kernel you will really need C/C++ in your baggage. But for the new generation of light containers (LXC), Docker, you can benefit from Go, an application development environment suited to make life easier than having to handle C/C++ idiosyncrasies. Rust is another great new choice to make it easier to - among other things - to write memory-leak free small libraries and tools (I am mentioning that in particular because it's important for languages like Ruby or Python to be able to add performance by binding to C-based native libraries and Rust make this task easier).
Different languages have different teams and different long term goals, which is why it's not apples and oranges to compare languages. Go, for instance, is heavier than Rust, but both are good for command-line tools, specialized daemons, and in the case of Go, networking-heavy and concurrency-heavy endeavors.
In my eyes, Go is a "better" Java or C++. And don't interpret this wrong: Java is still a very fine language and platform. There is hardly anything that come close to the maturity of the JVM and the extensive ecosystem behind it. I would not think for a second in trying to rewrite complex systems written in Java such as the Lucene library or Elasticsearch/SOLR solutions, for example.
But the power of Standard Java is difficult to unleash without some warming up for the HotSpot to pick up steam. It makes it not a great solution for command-line tools. But now you have a good middle ground with Go. You also don't have a good time embedding Java into other platforms, and then you would need to go back to C, but now you have another good middle ground with Rust.
If you want to unleash different programming models, specially those more suited to concurrent abstractions such as the Hoare's CSP like Actor model, you can try Scala with Akka (which is now the standard actor library) and Clojure's Pulsar/Quasar. Akka and Quasar are the ones that come "close" (but can never match) Erlang's built-in OTP platform.
For the Web at large, you can do just fine with the current (ever changing, unstable) Node.js ecosystem, Python (Django, Plone), Ruby (Ruby on Rails, Sinatra), PHP (Zend, Laravel), even Perl has it's place. Combined with mature services in different platforms (Elasticsearch in Java, PostgreSQL in C, RabbitMQ in Erlang), any big and complex Web Application can be written with any number of best-of-breed tools and combinations that best suit your needs.
This is an unfair, short overview, of course. I didn't cover every aspect of computer science or industry. There are several other active and useful languages such as Lua, Haskell, Fortran, Ada, Julia, R, The message being: you don't need to choose a single language, it will really depend on what you're going to deliver. And a true craftsman will master many tools to the the job done in the best way possible.
"Functional" Concepts that Really Matter
I wrote about my opinions on the current surge in the so called Functional style of programming. I recommend you read it before continuing.
There are some aspects that are adamant if you really want to go beyond the academic research and into the real world of productivity.
Immutability and Opaque Message Passing are VERY important
In order for computation to be fast, we are used to share data between routines. We move pointers around and change data in place.
It's not particularly fast to make things immutable and not shared. The more you make data mutable and the more you share, the harder it is to make your code run concurrently.
It is an important trade-off: if you see mutable data and shared state, you're optimizing for performance.
One can't say that a language is essentially good or bad for having mutable or immutable data. But for what it's worth, my personal opinion is that it's harder to convince users to follow conventions like "share a little as possible, mutate as little as possible." Most will not even know about it if it's not built-in and enforced. I prefer having immutability enforced by default.
In Erlang, data is immutable. Similar to Java it pass values by reference in routine calls (it is not copying values between calls, as many misunderstand it).
And in the case of recursion it optimizes through Tail Cail Optimization to make it faster. By the way, this is one optimization that the Java VM just can't quite do it yet. Clojure needs special 'recur' and 'trampoline' calls, for example. Scala can rewrite the tail recursion to a loop in compile time, with the '@tailrec' annotation. Erlang has its own traps as well, so not so black and white at the moment.
In Erlang, as I explained before, you run functions within completely isolated processes. If the function recurs or blocks, it stays isolated. Processes can only communicate by sending (immutable and opaque) messages to each other. Messages get queued in a "run queue" or "mailbox" and the function can choose to receive and respond to those messages. That's it.
So, you can pass values by reference between routines, or you can share data in a third party process as the mediator of data. One such infrastructure built-in to Erlang is the ETS, the Erlang Term Storage, which is part of the so called OTP platform. Think of ETS as a very simple and very fast built-in key value storage like Memcached. You use it for the same use cases as a cache and it's as simple as just doing this:
1 2 3 |
table = :ets.new(:my_fancy_cache, [:set, :protected]) :ets.insert(table, {"some_key", some_value}) :ets.lookup(table, "some_key") |
Many might argue that Erlang's rigid process isolation and communication strictly restricted to opaque message passing are overkill and that you can pass by using something akin to Clojure's MVCC Software Transaction Memory, or STM. You do have STM in Erlang, with the other built-in OTP tool, built on top of the ETS, called Mnesia. It offer the equivalent of ACID database transactions in-memory. It's not a new concept, but STM is not available as a language feature and it's still uncertain if it really is a good choice to have it.
An inspired result, I believe, from Clojure's choice of having transactional memory with history queue and snapshot isolation is shown in its crown jewel, Datomic. The idea is not revolutionary by any stretch of the imagination as you have many other prior art such as RethinkDB, CouchDB, and extensions for existing databases. Good for a service, still I don't think it's a good thing to share state, even if you have a transactor around that state. Erlang's immutability with rigid process isolation still has no match.
Coroutines and Schedulers
You already know sub-routines, you do it all the time by partitioning large portions of code into smaller functions or methods that call each other. You may already know about a specialized kind of Coroutines in the form of Fibers (as first implemented in Windows circa 1997).
Fibers offer a way for your current function execution to "yield" back to its caller, preserving its current state, and then the caller can "resume" the suspended Fiber to continue its execution from where it last yielded. This allows for non-preempted, cooperative multitasking. We have Fibers in Python, Ruby, and other languages and it allows the creation of constructions like Generators. Even Javascript can have some form of Fibers if you add libraries like node-fibers:
1 2 3 4 5 6 7 8 9 |
var Fiber = require('fibers'); function sleep(ms) { var fiber = Fiber.current; setTimeout(function() { fiber.run(); }, ms); Fiber.yield(); } |
The call to 'yield' suspends the current execution until the function in the 'setTimeout' is called. Then it calls 'run', which resumes the previously yielded function. This is still "rudimentary" compared to coroutines: because the function itself has to yield control out to the reactor event loop, in the case of a Node.js application. If you don't, you will block the event loop in a single threaded Node.js process, and therefore you block everything until the function finishes, defeating the whole purpose. And this is one of those "conventions" that "good" programmers should follow, but most will forget.
Fibers are useful to make it less ugly to program in a rudimentary Reactor environment, where you depend on callbacks calling callbacks and you end up with the anti-pattern of callback pyramid of doom. With Fibers you can program as you would in a synchronous imperative language transforming this ugly Javascript code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
function archiveOrders(date, cb) { db.connect(function(err, conn) { if (err) return cb(err); conn.query("selectom orders where date < ?", [date], function(err, orders) { if (err) return cb(err); helper.each(orders, function(order, next) { conn.execute("insert into archivedOrders ...", [order.id, ...], function(err) { if (err) return cb(err); conn.execute("delete from orders where id=?", [order.id], function(err) { if (err) return cb(err); next(); }); }); }, function() { console.log("orders been archived"); cb(); }); }); }); } |
Into this more manageable thing:
1 2 3 4 5 6 7 8 9 10 11 |
var archiveOrders = (function(date) { var conn = db.connect().wait(); conn.query("selectom orders where date < ?", [date]).wait().forEach(function(order) { conn.execute("insert into archivedOrders ...", [order.id, ...]).wait(); conn.execute("delete from orders where id=?", [order.id]).wait(); }); console.log("orders been archived"); }).future(); |
The entire Promises, Futures debacle depends in part on proper Fibers. Javascript, being a very poor design, does not come with anything built-in and hence the proliferation of Fibers, Deferreds, Promises, Futures implementations that can never reach neither consensus nor people actually using them at large.
So, Fibers are ok. Coroutines are better because you have multiple points of suspending a function and more. And even better, in Erlang one doesn't need to even think about rudimentary Reactor loops (yes, reactors are a rudimentary construction for concurrency when you have no other good choice): it has transparent asynchronous calls. Everything in Erlang is asynchronous and non-blocking but you don't deal with callback pyramids because there is something better underneath: the Scheduler.
By the way, I find it very frustrating that Go's "goroutines" are not proper "coroutines".
For each Erlang process with SMP (symmetric multiprocessing) support there will be one real thread per CPU core available in your system, and for each thread there will be one single Scheduler to manage the internal green threads (processes) and run-queue.
As a programmer, I don't have to "remember" to yield control back to a passive event loop. The scheduler will take care of balancing computation time to each concurrent process. If a process is taking too long the Scheduler can choose to suspend it and give time to other routines. Erlang defines a "reduction" and that there are different priority levels of functions. If a function takes more than 2,000 reductions, the Scheduler can choose to suspend it. If you have 8 CPU cores, but the computation on the processes are not heavy, the VM can choose to just use 1 or 2 Schedulers and leave the other 6 idle so the hardware can turn the cores off to save energy (!!). Yep, Erlang is even Eco Friendly!
And we need to repeat this again: because each process is rigidly isolated, with immutable data and no shared state, it's easier to suspend a running process. In the case of the JVM this is usually implemented by raising checked exceptions and have everybody implement some Suspendable interface. It can be done using this 3rd party Java continuation library where you yield by raising an Exception (!) Nasty stuff.
Rust is still implementing something for coroutines as well, but still nothing as mature. But again, coroutines is just part of the story, you would need a heavier system with userland schedulers for it to make sense. Go is better candidate to incorporate such a system in its runtime, but it also come short on being able to implement all this. There is Suture, an attempt to have some of OTP in Go, but it can't be done. Even Akka, the first mainstream OTP clone for Scala, can't come close because of the JVM shortcomings. Clojure with Pulsar/Quasar, come closer, but not there yet.
Now, the Erlang Scheduler is not only capable of suspending and resuming processes but it also takes care of message passing between them. So each Scheduler has its own run-queue to queue and dispatch messages. Again, because data is immutable, you only need some form of locking when you want another Scheduler (in another real thread) to take over a few processes in order to balance processing between cores. Erlang support SMP since OTP R12B (we are at R18 right now, and still evolving).
Most languages still rely on the OS real threads preemptive model to do multitasking. And this is heavy and slow because of all the context switching involved and all the locking logic most programmers will do wrong (the best practice for concurrency is: do not use threads, chances are you will screw up). Again, we make the right assumptions first: programmers can't do proper multithreading, so let a Scheduler do it, when necessary, and avoiding slow OS context switching as much as possible. Suspendable green threads combined with a userland Scheduler coordinating cooperative switching is a way faster and safer choice.
If you want to learn more about coroutines this Lua Paper on the subject explains in more details what I just elaborated:
Implementing a multitasking application with Lua coroutines is straightforward.Concurrent tasks can be modeled by Lua coroutines. When a new task is created, it is inserted in a list of live tasks. A simple task dispatcher can be implemented by a loop that continuously iterates on this list, resuming the live tasks and removing the ones that have finished their work (this condition can be signalled by a predefined value returned by the coroutine main function to the dispatcher). Occasional fairness problems, which are easy to identify, can be solved by adding suspension requests in time-consuming tasks.
Static vs Dynamic Typing is still controversial
We saw a heavier movement from bureacratic static typed systems (mainly Java prior to 6, C# prior to 4, C++) to purely dynamic languages such as Perl in the late 80's, Python in the late 90's, Ruby in mid 2000's. We tried to go from "making the compiler happy" to "making programmers happy", which makes more sense if you ask me.
Scala, Groovy, Haskell, Swift brought a very practical middle ground with Hindley-Milner derived Type Inference systems, in a way that we can code kinda like in dynamic languages but with the compiler doing more work to infer types for us before generating the final executable bytecode.
But there is a big catch: it's very difficult to hot swap code inside the runtime if you have static signatures. I'm not saying that it is impossible, but a lot more difficult. You do can reload code in Java (one example being Spring Loaded) or Haskell (there is a hotswap plugin and other alternatives). You don't do granular reloads in a statically typed language because if you want to change the signature of a method, you have to change the graph that depends on that signature. It's doable, albeit, cumbersome.
In Erlang, because there is no such hard dependencies, and again because of inherent advantages of it only having immutable data with no shared state, and dependencies limited to opaque message passing, you can granularly reload one single module and most important of all: you can implement simple callbacks to transform the old state of a process into a new state structure, because just reloading the code is half the story if you will have hundreds of old processes restarting into the new code but having to deal with previous state. In an Erlang GenServer, you just implement this single callback:
1 |
code_change(OldVersion, CurrentState, _Extra) -> {ok, NewState}. |
So, while Type Inference is a nice middle ground, the flexibility of Dynamic Typing goes beyond being easy for programmers to use. As with Python, Ruby, Javascript, Perl and other dynamic typed languages, you will want to cover your code with proper test suites - which should not be optional in strong typed languages anyway. There is no doubt a compiler's static analysis help a lot, but it's my personal take that dynamic typing allows me more flexibility.
Fault Tolerance: Don't fear your code
With Dynamic Typing we will end up again in the endless discussion of "programmers never do it right, we need a compiler to enforce static rules". And you are almost right: programmers screw up, but a compiler will not save you day anyway, and worst: it might give you a false sense of security. There is no worse security hole than false sense of security. A test suite is way better to assert proper implementation, and it's still no hard guarantee.
I said that this is controversial, as a more rigid static typing system is more productive than having to unit tests every input and output types of every function. But if you thought that, you're at least wrong in that this is not what unit tests are for: it's for testing unit behaviors, in spite of what the types are. Testing types is what we call "chicken typing" and it's another form of defensive programming. You must test for behavior, not for stuff that a compiler would check. And again, having the static typing hinges my flexibility because now I have to constantly fight the typing, add more boilerplate, and ultimately if the behavior is wrong, the code is wrong, despite the type checks.
For a system to be "tolerant to buggy code or uncaught failures" is the opposite of littering your code with guarding statements like "try/catch" or "if err == x" or having some form static level checking with Result monads (that most people will just unwrap anyway). Guards can only go so far. And yes, this is anedoctal as there is not statistics that "everybody will unwrap" and most good programmers won't, but if experience tells me one thing is that bad programmers will fall for "try/catch" the whole thing when they don't know what to do anyway.
You need a system that allows any buggy code to fail and not crash the environment around it, which would bring it into an inconsistent, corrupt, state.
The problem with faulty code is that it leaves the state in a position where it has nowhere else to go. And if this state is shared, you leave every other bit of code in a position where they can't decide where to go next. You will need to shut everything down and restart from the last known good state. Almost all "continuous delivery" workflows are implemented around restarting everything.
Instead of having to bring everything down in case you forget to try/catch something, you can rely on Erlang's underpinnings of not sharing state, having immutable data, and - most importantly - having the rigidly isolated lightweight process system to make the process that is holding the faulty code to shut down and warn it's Supervisor. This is the general idea behind the so called OTP in Erlang.
The idea of a Supervisor is to have a small process that monitors other processes. The Supervisor has as little code as possible in order to rarely (or never) fail (the best kind of code is "no code"). Once a faulty process crashes because of uncaught exception or other underterministic reasons, it sends a notification message to the Supervisor run-queue mailbox, and then die cleanly. The Supervisor then chooses what to do based on it's underlying restart strategy.
Let's say you have a list of URLs you're scrapping. But you didn't anticipate dirty structures in your parsing logic. The process doing the scrapping crashes and dies. The Supervisor is notified and choose to restart the process, giving the new process the previous state - the URL list - and now that the faulty URL is not there anymore, the new process can happily continue the job with the next URL in the list.
This is a simple example of the dynamic between the Erlang VM, the Supervisor and its children workers. You can go further and have several Applications, which in turn start up new Supervisors, which in turn start up children processes. And you have a Supervisor Tree that can trap exits and restart granular bits of your runtime code without bringing the rest of the system into an inconsistent state.
Such is the beauty of the rigid process isolation concept.
Every I/O in the system is wrapped in Ports, which obeys Async/callback logic transparently without you having to create pyramids of callbacks. The process consuming such ports just gets suspended by the Scheduler until the Async call returns and it can resume work. No callback pyramid hell. No need for rudimentary Fiber implementations to allow for rudimentary Promises/Futures systems. Just coroutines inside processes that can be suspended and resumed by the Scheduler. Less opportunities for programmer errors to stack up.
So, a programmer will forget to code every possible branch of execution and because he knows that, the very worst thing that can happen is not if he forgets an uncaught exception, but if he decides to program deffensivelly and add general conditions to trap any error and never raise it. You've seen it before, when you find code that is trapped inside generic try/catch blocks, trying to avoid every error possible. But what really happens is that the system may not crash but your logic and your processing is faulty at its core. And you won't find about it, because it doesn't crash, therefore no one is ever notified! You will not end up with less bugs, you will end up with a mountain of logic bugs that are never noticed because they are all swallowed!!
This is the core of Fault Tolerance: do not fear Erlang, fear the programmers! Instead, we should do what Joe Armstrong presented in his seminal paper "Making reliable distributed systems in the presence of software errors". This is both a detailed guide into Erlang and OTP but also his arguments on how to write fault tolerant systems by making the programmer write code as clearly as he originally intended, without the need to be defensive, with the confidence that if he misses something, OTP will be there to catch it and not let the system die, but instead to give a chance to fix it and reload it without disrupting other good parts of the system.
This is the ultimate goal of good programming: not being deffensive, not putting try/catch everywhere because you're afraid.
Summary
This short summary is the reason why Erlang sounds very compelling for my Web Development needs, or for any scalable complex system, at least for me.
Every other language had to make trade-offs. Every new language on top of the JVM has to deal with limitations inherent to how the JVM was originally architected. Rust still can build better abstractions, but it's scope is for smaller tools and libraries, not distributed complex systems. Yes, eventually it can do whatever C/C++ can do, and Mozilla is actually basing the core of its next generation browser core on Rust. This will bootstrap better higher level libraries and frameworks, the same way Apple using Objective-C created the entire set of Core frameworks that make implementing complex applications much easier.
Go made a choice for keeping familiarity with its C++ inheritance. Of course, it has tons of useful features, in particular the built-in goroutines that make concurrent coding much easier than in previous languages.
Haskell is too strict for most programmers (yes, Monads, still difficult for the average programmer to fully grasp) and despite contraty opinions, to me it still feel like it appeal more to researchers than everyday developers. Other dynamic languages such as Ruby, Python, may still go the way of Erlang with Ruby adding some immutability (in 2.3 with immutable String by default), but it's still a long way to go.
Erlang has everything, as Joe Armstrong envisioned a fault tolerant system to be. It started as an exercise implemented in Prolog in 1986. It migrated from the previous JAM compiler to the current BEAM VM in 1998. It added SMP around 2008. It has been gradually evolving, polishing its rough edges, being really battle tested in really mission critical systems for decades. It's ready for us, right now.
It has Fault Tolerance guaranteed by the principles of immutable data, no shared state, pure opaque message passing, and suspendable processes, all managed by Schedulers. This guarantees that faulty routines can crash one single process but not the entire system and definitely not bringing state of other process to inconsistent, corrupted, states.
Then you can instrument your virtual machine and check that Supervisors are restarting children more than you want and decide to fix the buggy code. And once you do, you can choose not to shut down and restart the entire system to reload the code fixes, you can do it granularly, on the fly, with running processes that will pick up the fixes once the Supervisor restarts it. The granular hot swap of code is guaranteed because there is no hierarchy of types to care about.
And because you have proper coroutines with no hierarchy of shared state dependencies, you can have asynchronous exceptions that can forcefully shut down processes without creating side effects to other running processes. A Supervisor may choose to restart its entire children list when one of its child crashes and another of its child depended on that previous process. You can switch from "one for one" restart strategy to "one for all" (like the Musketeers).
There is only one problem with Erlang: it was not designed for "programmer happiness", a concept we got used to have for granted because of Ruby and newer languages.
Erlang has its roots in Prolog and it shows. Once you step up and really dive deep exercising with the language you can possibly get used to it. But if you came from more modern dynamic languages such as Ruby, Python, Groovy, you will definitely miss the comfortable modern constructions.
Elixir is the missing piece, the Philosopher's Stone if you will, that can unlock all the 30 years of refinements, maturity, industry battle tested technologies in large scales, to the average programmer.
It brings many modern construct such as making macros easier in order to allow for Domain Specific Languages, having testable comments in your code, adding a more modern standard library that is easily recognizable from a Ruby or Clojure point of view, polymorphism through Protocols, and so on.
This is one example of Elixir straight from its source code tests:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
Code.require_file "../test_helper.exs", __DIR__ defmodule Mix.ArchiveTest do use MixTest.Case doctest Mix.Archive test "archive" do in_fixture "archive", fn -> File.write ".elixir", "~> 1.0.0" Mix.Archive.create(".", "sample.ez") archive = 'sample.ez' assert File.exists?(archive) assert has_zip_file?(archive, 'sample/.elixir') assert has_zip_file?(archive, 'sample/priv/not_really_an.so') assert has_zip_file?(archive, 'sample/ebin/Elixir.Mix.Tasks.Local.Sample.beam') assert has_zip_file?(archive, 'sample/ebin/local_sample.app') end end defp has_zip_file?(archive, name) do {:ok, files} = :zip.list_dir(archive) Enum.find(files, &match?({:zip_file, ^name, _, _, _, _}, &1)) end end |
Code that can be written like this automatically makes me grin.
This is the perfect combination. Again, it is not without shortcomings. Erlang is by no means a fast language. It is way faster than Ruby, Python, or other interpreted languages. It can be made a bit faster with native compilation through the HIPE compiler, but still nowhere near the speeds of Go, Rust, or any Java derivative such as Scala, Groovy or Clojure.
So, if you really need raw power of computation, you will want Go or Java. Again, I'm not saying there are only those 2, but it's the usual choices if you don't want to go down to C/C++. Haskell has terrific performance, but it's learning curve is less than stellar.
Erlang is a whole system, it has its own scheduling system, it controls living, breathing processes that each has its own garbage collector, it controls system signal trapping and so on. It was designed to be a full server. It is much smaller than a full blown Java Enterprise Edition container, so small that you can actually package command line tools that do start up fast enough. But this is not the sweet spot. For that purpose you will better off with Go or even Rust.
For the same reasons it was not made to be an embeddable language the way Lua is. It was not made to create libraries that can be easily linked to via FFI or C-like function exports, the way Rust can.
There are ways to create desktop-class applications, specially with cross-platform wxWidgets, the way the built-in Observer intrumentation application is done, but Erlang was not built to be a desktop toolkit.
Also because it prioritizes correctness, rigidly isolated processes communicating just by opaque messages, immutable and non-shared states, it means that Erlang is not suited to hard data science processing. So I doubt it's the best choice for Big Data analytics, DNA sequencing and other hard stuff that tools like Julia, R, Fortran, are better choices. It's not the same thing to say that it can't be a good database core, Riak and CouchDB proved that already. But complex queries on top of high volumes of data is not the sweet spot as well.
So, Erlang is good for distributed systems, with high concurrency of opaque message exchange and proxing. The exact scenario where the Web is. Web Applications heavy load of throughput that need real time chats and notifications, heavy and time consuming payment transactions, gathering of data from many sources in order to reduce them to consumable HTML or JSON responses.
But for the average Web developer (and by "average" I mean minimally able to architect the kinds of complex systems we deal with everyday in web development, not simple static website contruction), Erlang was a real challenger, and now we can have the comfort of a real modern language with hints of Ruby and Clojure, without the complexities of strong typing but with the security of its built-in Fault Tolerance constructions in order to deliver highly reliable, highly scalable, modern Web applications.
"Yocto Services"! And My First Month with Elixir! 25 Nov 2015 11:04 AM (9 years ago)
Wow, for the past month (almost, from Oct 27 to Nov 25) I decided that it was past time to dive deep and actually learn Elixir. I did just that, I am still a beginner but I feel very confident that I can tackle Elixir based projects now.
For my learning process:
- I read the entire oficial Elixir Documentation;
- I read the entire Dave Thomas' Programming Elixir book;
- I watched almost all Elixir Sips screencats
- I read the entire Benjamin Tan Wei Hao's The Little Elixir & OTP Guidebook book;
- I did a number of tutorials and exercises, and
And finally, I documented everything I learned almost every day in the following articles:
- How Fast is Elixir/Phoenix?
- Personal Thoughts on the Current Functional Programming Bandwagon
- Phoenix Experiment: Holding 2 Million Websocket clients!
- My first week learning Elixir
- Ex Manga Downloader, an exercise with Elixir
- Ex Manga Downloadr - Part 2: Poolboy to the rescue!
- Phoenix "15 Minute Blog" comparison to Ruby on Rails
- Observing Processes in Elixir - The Little Elixir & OTP Guidebook
- ExMessenger Exercise: Understanding Nodes in Elixir
- Elixir 101 - Introducing the Syntax
Yes, I am prolific, and highly focused. I did the learning and writing all within less than a month (it would've been less if I could have used night time and weekends). So I'd say that the average developer would take at least 3 to 4 months to cover the same material.
Initial Thinking: Yocto Services!
For good of for worse, we are in the dawn of the Micro Services architecture. In summary it's fragmenting your monolith into smaller applications that responds to HTTP based endpoints - that people call "APIs" - and that are responsible for a very narrow set of responsabilities. Then you create a "front-end" web application that will consume those services, such as analytics, payment methods, user authentication directories, and so on.
This is no novelty, of course, having HTTP APIs that return JSON structures is just a fancier way of doing the same, good, old Remote Procedure Calls, or RPCs, a technology we have for decades to interconnect clients and servers in a network. But I digress.
If this is what people call "Micro" services, I think of Elixir processes as "Yocto" Services! (Milli > Micro > Nano > Pico > Femto > Atto > Zepto > Yocto, by the way - I may have just invented a new term here!)
I described a bit of the Processes infrastructure, how to spawn them, how to exchange messages between them, and how to link them together. So, go read my previous post if you haven't already.
Inside an Elixir app you will find many processes, some from the VM running the show and some from your own app. If you architected it correctly, you've implemented an OTP application, with proper groups of Supervisors and Children, all organized in a Supervision Tree. A small worker dies, its supervisor knows how to deal with it.
Now, here's the mental model: think of an Elixir process as a tiny micro-service - a Yocto service, if you will! - inside your application, . In a Phoenix application, for example, you don't import a "database library" you actually spin up a "Database Service" (which is an Ecto Repo) that runs in parallel with the Endpoint application that responds to HTTP requests coming from the internet. The code in your controllers and models "consume" and send messages to the Ecto Repo "Service". This is how you can visualize what's going on.
I have shown the Observer in the previous article as well. You will find a large tree if you open it up inside the IEx shell of a Phoenix application:

In summary you will find the following section in the Pxblog Phoenix App Supervision Tree:
1 2 3 4 5 6 7 8 |
Pxblog.Supervisor
- Pxblog.Endpoint
+ Pxblog.Endpoint.Server
+ Pxblog.PubSub.Supervisor
* Pxblog.PubSub
* Pxblog.PubSub.Local
- Pxblog.Repo
+ Pxblog.Repo.Pool
|
This is the Pxblog I explained in the Phoenix and Rails comparison article I published a few days ago.
I still didn't read the source code of Phoenix, but if I am interpreting the Observer correctly, the Endpoint.Server controls a pool of processes that are TCP listeners that the application is ready to accept requests from, concurrently, with overflowing to accept more connections (I believe it's a pool implementation like Poolboy, which I explained in Part 2 of the Ex Manga Downloader article).
Then, you have the PubSub.Supervisor and PubSub.Local applications that I believe support the WebSocket channels.
The Repo alone controls 10 initial processes in its pool, possibly a database connection pool. Notice how Endpoint and Repo groups are in parallel branches in the supervision tree. If Repo fails for some external database problems, the Endpoint group does not have to fail. This is what's declared in the Pxblog Application definition at lib/pxblog.ex:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
defmodule Pxblog do
use Application
# See http://elixir-lang.org/docs/stable/elixir/Application.html
# for more information on OTP Applications
def start(_type, _args) do
import Supervisor.Spec, warn: false
children = [
# Start the endpoint when the application starts
supervisor(Pxblog.Endpoint, []),
# Start the Ecto repository
worker(Pxblog.Repo, []),
# Here you could define other workers and supervisors as children
# worker(Pxblog.Worker, [arg1, arg2, arg3]),
]
# See http://elixir-lang.org/docs/stable/elixir/Supervisor.html
# for other strategies and supported options
opts = [strategy: :one_for_one, name: Pxblog.Supervisor]
Supervisor.start_link(children, opts)
end
...
end
|
See how it defines Endpoint and Repo under the Pxblog.Supervisor.
I can go on and forcefully kill the entire Pxblog.Repo node from the Supervision Tree using the Observer, like I did in the previous article, and the proper strategy kicks in, the Phoenix Supervisor successfully restarts the Repo, and no one will ever notice something crashed underneath.

From the IEx I can still make more calls to the Repo like this and it it responds as if it had never crashed:
1 2 3 4 5 6 7 8 9 |
iex(4)> Pxblog.Repo.all(Pxblog.User)
[debug] SELECT u0."id", u0."username", u0."email", u0."password_digest", u0."inserted_at", u0."updated_at" FROM "users" AS u0 [] OK query=78.2ms queue=3.2ms
[%Pxblog.User{__meta__: #Ecto.Schema.Metadata<:loaded>,
email: "akitaonrails@me.com", id: 1,
inserted_at: #Ecto.DateTime<2015-11-20T14:01:09Z>, password: nil,
password_confirmation: nil,
password_digest: "...",
posts: #Ecto.Association.NotLoaded<association :posts is not loaded>,
updated_at: #Ecto.DateTime<2015-11-20T14:01:09Z>, username: "akitaonrails"}]
|
And the way I think about this is: my IEx shell is sending a message to the Yocto Service called Pxblog.Repo (in reality it's forwarding messages to the database adapter that then checks out a process from the pool). Just like I would consume external Micro Services through HTTP APIs.
So the landscape of your application is comprised of a series of processes and groups of supervised processes all working to compose a larger structure. As I said in previous articles, should one group of process collapse, its Supervisor kicks in, traps the error and uses its strategy to, for example, restart all of its children processes, bringing the app to a consistent state once more, and without you having to restart the entire Elixir application.
So each process can be a full blown Yocto Service, running online and waiting for other services to consume it, such as the Repo's workers.
Divide and Conquer
Again, as a disclaimer, I am still new to Elixir but the way I find easier to understand it, is like this:
If you must deal with external resources, be it a File, or a Network Connections, or anything outside of the Erlang VM, you will want it to be a GenServer.
Then, if you have a GenServer, you want to start it up under a Supervisor (usually, the simple boilerplate that defines the children and restart strategy).
The number of GenServer processes you want to start up depends on how many parallel processes you want to have running. For example, if it is a database service, there is no point in starting up more than the available number of maximum connections your database allows. If you have several files to process, you want at most the number of available files or - in practice - just a few process to deal with batches of files. You will usually want a pool of GenServer processes, and in this case you want to use Poolboy.
One GenServer may call other GenServers. You don't want to use a try/catch exception handling mechanism because you just need the particular GenServer process to crash if something goes wrong: if the file is corrupted or doesn't exist or if the network goes unstable or disconnects. The Supervisor will replace that process with a new GenServer process in its place and refill the Pool if needed.
You can make GenServers talk remotely using the Node feature I explained 2 posts ago, with the ExMessenger example. Then it would be like a normal Micro Services architecture, but where the inside Yocto Services are actually doing the talking.
Any transformation with no side-effects (transforming a simple input into a simple output), like getting an HTML body string and parsing into a List of tuples, can be organized in a normal Module. Refer to libraries like Floki, to see how they are organized.
Each Erlang VM (called BEAM) is a single OS process, that manages a single real thread per CPU core available in your machine. Each real thread is managed by its own BEAM Scheduler, which will slice processing time between the lightweight processes inside.
Each BEAM process has its own mailbox to receive messages (more correctly called a run-queue). I/O operations such as file management will run asynchronously and not block the schedule, which will manage to run other processes while waiting for I/O.
Each BEAM process also has its own separated heap and garbage collector (a generational, 2 stage copy collector). Because each process has very little state (variables in a function) each garbage collector stop is super short and runs fast.
So, each BEAM VM can be thought of as an entire application infrastructure, with many Yocto Services available for your application to call.
And as I said in the previous article, each BEAM VM can remotelly call other BEAM VMs and exchange messages between them as if they were in the same VM. The semantics are almost the same and you have distributed computing the easier way.
Erlang implemented a fantastic set of primitives that quickly scale as large as you want or need, with the proper wirings to not let you down. And Elixir fixes the only problem most people have with Erlang: it's old Prolog-inspired weird syntax. Elixir is a thin and effective coat of modern language design, partly inspired by Ruby (although not a port by any means, it's still Erlang underneath).
I hope this series helped shed some light on why Elixir is the best choice among the new generation of high concurrency enabled languages and I also hope I made myself clear on why just high concurrency is not enough: you want high reliability as well. And in this aspect, the OTP architecture, built-in with Erlang, has no competition.
Elixir 101 - Introducing the Syntax 25 Nov 2015 10:25 AM (9 years ago)
I've been posting a lot of articles in the last few weeks, check out the "Elixir" tag to read all of them.
Many tutorial series start introducing a new language by its syntax. I subverted the order. Elixir is not interesting because of its syntax. Erlang is interesting all by itself, because of its very mature, highly reliable, highly concurrent, distributed nature. But its syntax is not for the faint of heart. It's not "ugly", it's just too different for us - from the C school - to easily digest. It derives from Prolog, and this is one small example of a Prolog exercise:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
% P03 (*): Find the K'th element of a list. % The first element in the list is number 1. % Example: % ?- element_at(X,[a,b,c,d,e],3). % X = c % The first element in the list is number 1. % element_at(X,L,K) :- X is the K'th element of the list L % (element,list,integer) (?,?,+) % Note: nth1(?Index, ?List, ?Elem) is predefined element_at(X,[X|_],1). element_at(X,[_|L],K) :- K > 1, K1 is K - 1, element_at(X,L,K1). |
Erlang has a similar syntax, with the idea of phrases divided by commas and ending with a dot.
José Valim played very smart: he chose the best of the available mature platforms and coated it with a layer of modern syntax and easier to use standard libraries. This is the same problem implemented in Elixir:
1 2 3 4 5 6 |
defmodule Exercise do def element_at([found|_], 1), do: found def element_at([_|rest], position) when position > 1 do element_at(rest, position - 1) end end |
If I copy and paste the code above in an IEx shell I can test it out like this:
1 2 |
iex(7)> Exercise.element_at(["a", "b", "c", "d", "e"], 3) "c" |
This simple exercise shows us some of the powerful bits of Erlang that Elixir capitalizes upon, such as pattern matching and recursion.
First of all, every function must be defined inside a module, which you name with the defmodule My.Module do .. end. Internally it becomes the atom "Elixir.My.Process". Nesting modules is just a larger name concatenated with dots.
Then you can define public function with the def my_function(args) do .. end block which is just a macro to the same def my_function(args), do: ... construct. Private methods are declared with defp.
A function is actually identified by the pair of its name and its arity. So above we have element_at/2 which means it accepts 2 arguments. But we have 2 functions with the same arity: the difference is the pattern matching.
1 |
def element_at([found|_], 1), do: found |
Here we are saying: the first argument will be an array, decompose it. The first element of the array will be stored in the "found" variable, the rest "_" will be ignored. And the second argument must be the number "1". This is the description of the so called "pattern", it should "match" the input arguments received. This is "call-by-pattern" semantics.
But what if we want to pass a position different than "1"? That's why we have this second definition:
1 |
def element_at([_|rest], position) when position > 1 do |
Now, the first argument again need to be an array, but this time we don't care about the first element, just the rest of the array without the first element. And any position different than "1" will be stored in the "position" variable.
But this function is special, it is guarded to only allow a position that is larger than 1. What if we try a negative position?
1 2 3 |
iex(8)> Exercise.element_at(["a", "b", "c", "d", "e"], -3)
** (FunctionClauseError) no function clause matching in Exercise.element_at/2
iex:7: Exercise.element_at(["a", "b", "c", "d", "e"], -3)
|
It says that none of the clause we passed doesn't match any of the defined ones above. We could have added a third definition just to catch those cases:
1 |
def element_at(_list, _position), do: nil |
Adding the underscore "_" before the variable name is the same as having just the underscore but we are naming it just to make it more readable. But any arguments passed will just be ignored. And this is the more generic case if the previous 2 don't match.
The previous line is the same as writing:
1 2 3 |
def element_at(_list, _position) do nil end |
I won't dive into macros for now, just know that there is more than one way of doing things in Elixir and you can define those different ways using Erlang's built-in support for macros, dynamic code that is compiled in runtime. It's the way of doing metaprogramming with Elixir.
Now, going back to the implementation, the first function still can look weird, let's review it:
1 2 3 |
def element_at([_|rest], position) when position > 1 do element_at(rest, position - 1) end |
What happens is: when we call Exercise.element_at(["a", "b", "c", "d", "e"], 3) the first argument will pattern match with [_|rest]. The first element "a" is disposed and the new list ["b", "c", "d", "e"] is stored as "rest".
Finally, we recurse the call decrementing from the "position" variable. So it becomes element_at(["b", "c", "d", "e"], 2). And it repeats until position becomes "1", in which case the pattern matching falls to the second function defined as:
1 |
def element_at([found|_], 1), do: found |
In this case the rest of the array is pattern matched and the first element, "c" is stored in the "found" variable, the rest of the array is discarded. It only got here because the position matched as "1", and so it just returns the variable "found", which contains the 3rd element of the original array, "c".
This is all nice and fancy, but in Elixir we could just have done this other version:
1 2 3 |
defmodule Exercise do def element_at(list, position), do: Enum.at(list, position) end |
And we are done! Several tutorials will talk about how recursion and pattern matching to decompose lists solve a lot of problems, but Elixir gives us the convenience of treating lists as Enumerables and provide us a rich Enum module with very useful functions such as at/2, each/2, take/2, and so on. Just pick what you need and you're managing lists like a boss.
Oh, and by the way, there is something called a Sigil in Elixir. Instead of writing the List of String explicitly, we could have done it like this:
1 2 |
iex(8)> ~w(a b c d e f) ["a", "b", "c", "d", "e", "f"] |
Or, if we wanted a List of Atoms, we could do it like this:
1 2 |
iex(9)> ~w(a b c d e f)a [:a, :b, :c, :d, :e, :f] |
Lists, Tuples and Keyword Lists
Well, this was too simple. You really need the idea of pattern matching and basic type in your mind to make it flow. Let's get another snippet from the Ex Manga Downloadr:
1 2 3 4 5 6 7 8 9 10 11 |
defp parse_args(args) do parse = OptionParser.parse(args, switches: [name: :string, url: :string, directory: :string], aliases: [n: :name, u: :url, d: :directory] ) case parse do {[name: manga_name, url: url, directory: directory], _, _} -> process(manga_name, url, directory) {[name: manga_name, directory: directory], _, _} -> process(manga_name, directory) {_, _, _ } -> process(:help) end end |
The first part may puzzle you:
1 2 3 4 |
OptionParser.parse(args, switches: [name: :string, url: :string, directory: :string], aliases: [n: :name, u: :url, d: :directory] ) |
The OptionParser.parse/2 receives just 2 arguments: 2 arrays. If you come from Ruby it feels like it's a Hash with optional brackets, translating to something similar to this:
1 2 3 4 5 |
# this is wrong OptionParser.parse(args, { switches: {name: :string, url: :string, directory: :string}, aliases: {n: :name, u: :url, d: :directory} } ) |
This works in Ruby but it is not the case in Elixir, there are optional brackets but not where you think they are:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# this is the correct, more explicit version OptionParser.parse(args, [ { :switches, [ {:name, :string}, {:url, :string}, {:directory, :string} ] }, { aliases: [ {:n, :name}, {:u, :url}, {:d, :directory} ] } ] ) |
WHAT!?!?
Yep, the second argument is actually an array with elements that are Tuples paired with an atom key and value, and some of the values are themselves arrays with tuples.
in Elixir, Lists are what we usually call an Array, a Linked-List of elements. Linked-Lists, as you know from your Computer Science classes, are easy to insert new elements and remove elements.
in Elixir, Tuples are immutable fixed lists with fixed positions, with elements delimited by the brackets "{}"
If the previous example was just too much, let's step back a little:
1 2 3 4 5 6 |
defmodule Teste do def teste(opts) do [{:hello, world}, {:foo, bar}] = opts IO.puts "#{world} #{bar}" end end |
Now we can call it like this:
1 2 |
iex(13)> Teste.teste hello: "world", foo: "bar" world bar |
Which is the same as calling like this:
1 2 |
iex(14)> Teste.teste([{:hello, "world"}, {:foo, "bar"}])
world bar
|
This may confuse you, but it's very intuitive. You can just think of this combination of Lists ("[]") with Tuple elements containing a pair of atom and value ("{:key, value}") to behave almost like Ruby Hashes being used for optional named arguments.
Then, we have the Pattern Match section in both previous examples:
1 2 3 4 5 6 7 8 |
case parse do {[name: manga_name, url: url, directory: directory], _, _} -> process(manga_name, url, directory) {[name: manga_name, directory: directory], _, _} -> process(manga_name, directory) {_, _, _ } -> process(:help) end |
And
1 |
[{:hello, world}, {:foo, bar}] = opts
|
The last example is just decomposition. The previous example is pattern match and decomposition. You match based on the atoms and positions within the tuples within the list. You match from the more narrow case to the more generic case. And in the process, the variables in the pattern are available for you to use in the matching case clause.
Let's understand the meaning of this line:
1 |
{[name: manga_name, url: url, directory: directory], _, _} -> process(manga_name, url, directory)
|
It is saying: given the results of the OptionParser.parse/2 function, it must be a tuple with 3 elements. The second and third elements don't matter. But the first element must be a List with at least 3 tuples. And the keys of each tuples must be the atoms :name, :url, and :directory. If they're there, store the values of each tuples in the variables manga_name, url, and directory, respectivelly.
This may really confuse you in the beginning, but this combination of a List of Tuples is what's called a Keyword List and you will find this pattern many times, so get used to it.
Keyword List feel like a Map, but a Map has a different syntax:
1 2 |
list = [a: 1, b: 2, c: 3] map = %{:a => 1, :b => 2, :c => 3} |
This should summarize it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
iex(1)> list = [a: 1, b: 2, c: 3]
[a: 1, b: 2, c: 3]
iex(2)> map = %{:a => 1, :b => 2, :c => 3}
%{a: 1, b: 2, c: 3}
iex(3)> list[:a]
1
iex(4)> map[:a]
1
iex(5)> list.a
** (ArgumentError) argument error
:erlang.apply([a: 1, b: 2, c: 3], :a, [])
iex(5)> map.a
1
iex(6)> list2 = [{:a, 1}, {:b, 2}, {:c, 3}]
[a: 1, b: 2, c: 3]
iex(7)> list = list2
[a: 1, b: 2, c: 3]
|
Keyword Lists are convenient as function arguments or return values. But if you want to process a collection of key-value pairs, use a dictionary-like structure, in this case, a Map. Specifically if you need to search the collection using the key. They look similar but the internal structures are not the same, a Keyword List is not a Map, it's just a convenience for a static list of tuples.
Finally, if this pattern matches the parse variable passed in the case block, it executes the statement process(manga_name, url, directory), passing the 3 variables captured in the match. Otherwise it proceeds to try the next pattern in the case block.
The idea is that the "=" operator is not an "assignment", it's a matcher, you match one side with the other. Read the error message when a pattern is not matched:
1 2 |
iex(15)> [a, b, c] = 1 ** (MatchError) no match of right hand side value: 1 |
This is a matching error, not an assignment error. But if it succeeds this is what we have:
1 2 3 4 5 6 |
iex(15)> [a, b, c] = [1, 2, 3] [1, 2, 3] iex(16)> a 1 iex(17)> c 3 |
This is a List decomposition. It so happens that in the simple case, it feels like a variable assignment, but it's much more complex than that.
Pipelines
We use exactly those concepts of pattern matching on the returning elements from the HTML parsed by Floki in my Manga Downloadr:
1 2 |
Floki.find(html, "#listing a") |> Enum.map(fn {"a", [{"href", url}], _} -> url end) |
The find/2 gets a HTML string from the fetched page and matches against the CSS selectors in the second argument. The result is a List of Tuples representing the structure of each HTML Node found, in this case, this pattern: {"a", [{"href", url}], _}
We can then Enum.map/2. A map is a function that receives each element of a list and returns a new list with new elements. The first argument is the original list and the second argument is a function that receives each element and returns a new one.
One of the main features of the Elixir language that most languages don't have is the Pipe operator ("|>"). It behaves almost like UNIX's pipe operator "|" in any shell.
In UNIX we usually do stuff like "ps -ef | grep PROCESS | grep -v grep | awk '{print $2}' | xargs kill -9"
This is essentially the same as doing:
1 2 3 4 5 |
ps -ef > /tmp/ps.txt
grep mix /tmp/ps.txt > /tmp/grep.txt
grep -v grep /tmp/grep.txt > /tmp/grep2.txt
awk '{print $2}' /tmp/grep2.txt > /tmp/awk.txt
xargs kill -9 < /tmp/awk.txt
|
Each UNIX process can receive something from the standard input (STDIN) and output something to the standard output (STDOUT). We can redirect the output using ">". But instead of doing all those extra steps, creating all those extra garbage temporary files, we can simply "pipe" the STDOUT of one command to the STDIN of the next command.
Elixir uses the same principles: we can simply use the returning value of a function as the first argument of the next function. So the first example of this section is the same as doing this:
1 2 |
results = Floki.find(html, "#listing a") Enum.map(results, fn {"a", [{"href", url}], _} -> url end) |
In the same ExMangaDownloadr project we have this snippet:
1 2 3 4 5 6 7 8 9 10 11 |
defp process(manga_name, url, directory) do File.mkdir_p!(directory) url |> Workflow.chapters |> Workflow.pages |> Workflow.images_sources |> Workflow.process_downloads(directory) |> Workflow.optimize_images |> Workflow.compile_pdfs(manga_name) |> finish_process end |
And we just learned that it's the equivalent of doing the followng (I'm cheating a bit because the 3 final functions of the workflow are not transforming the input "directory", just passing it through):
1 2 3 4 5 6 7 8 9 10 11 |
defp process(manga_name, url, directory) do File.mkdir_p!(directory) chapters = Workflow.chapters(url) pages = Workflow.pages(chapters) sources = Workflow.images_sources(pages) Workflow.process_downloads(sources, directory) Workflow.optimize_images(directory) Workflow.compile_pdfs(directory, manga_name) finish_process(directory) end |
Or this much uglier version that we must read in reverse:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
defp process(manga_name, url, directory) do File.mkdir_p!(directory) finish_process( Workflow.compile_pdfs( Workflow.optimize_images( Workflow.images_sources( Workflow.pages( Workflow.chapters(url) ) ) ), manga_name ) ) end |
We can easily see how the Pipe Operator "|>" makes any transformation pipeline much easier to read. Anytime you are starting from a value, passing the results through a chain of transformation, you will use this operator.
Next Steps
The concepts presented in this article are the ones I think most people will find the most challenging upon first glance. If you understand Pattern Matching, Keyword Lists, you will understand all the rest.
The official website offers a great Getting Started that you must read entirely.
From intuition you know most things already. You have "do .. end" blocks but you still don't know that they are just convenience macros to pass a list of statements as an argument inside a Keyword List. The following blocks are equivalent:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
if true do a = 1 + 2 a + 10 end if true, do: ( a = 1 + 2 a + 10 ) if true, [{:do, ( a = 1 + 2 a + 10 )}] |
Mind blowing, huh? There are many macros that add syntactic sugar using the primitives behind it.
On the most part, Valim made the powerful Erlang primitives more accessible (Lists, Atoms, Maps, etc) and added higher abstractions using macros (do .. end blocks, the pipe operator, keyword lists, shortcuts for anonymous functions, etc). This precise combination is what makes Elixir very enjoyable to learn. It's like peeling an onion: you start with the higher abstractions and discover macros of simpler structures underneath. You see a Keyword List first and discover Lists of Tuples. You see a block and discover another Keyword List disguised with a macro. And so on.
So you have a low curve of entry and you can go as deep as you want in the rabbit hole, until the point you're extending the language.
Elixir provides a very clever language design on top of the 25 year old mature Erlang core. This is not just clever, it's the intelligent choice. Keep learning!
ExMessenger Exercise: Understanding Nodes in Elixir 25 Nov 2015 6:19 AM (9 years ago)
I was exercising through this 2014's old blog post by Drew Kerrigan where he builds a bare bones, command line-based, chat application, with a client that send messages and commands to a server.
This is Elixir pre-1.0, and because it's an exercise I refactored the original code and merged the server (ex_messenger) and client (ex_messenger_client) projects into an Elixir Umbrella project and you can find my code on Github here.
If you have multiple applications that work together and share the same dependencies you can use the Umbrella convention to have them all in the same code base. If you mix compile from the umbrella root, it compiles all the apps (which are independent Elixir mix projects as well), it's just a way to have related apps in the same place instead of in multiple different repositories.
The code shown here is in my personal Github repository if you want to clone it.
Nodes 101
Before we check out the exercise, there is one more concept I need to clear out. In the previous article I explained about how you can start processes and exchange messages and how you can use the OTP GenServer and Supervisor to create more robust and fault tolerant processes.
But this is just the beginning of the story. You probably heard how Erlang is great for distributed computing as well. Each Erlang VM (or BEAM) is network enabled.
Again, this is one more concept I am still just beginning to properly learn, and you will want to read Elixir's website documentation on Distributed tasks and configuration, that does an excellent job explaining how all this works.
But just to get started you can simply start 2 IEx sessions. From one terminal you can do:
1 2 3 4 5 6 |
iex --sname fabio --cookie chat Erlang/OTP 18 [erts-7.1] [source] [64-bit] [smp:4:4] [async-threads:10] [kernel-poll:false] Interactive Elixir (1.1.1) - press Ctrl+C to exit (type h() ENTER for help) iex(fabio@Hal9000u)1> |
And from a different terminal you can do:
1 2 3 4 5 6 |
iex --sname akita --cookie chat Erlang/OTP 18 [erts-7.1] [source] [64-bit] [smp:4:4] [async-threads:10] [kernel-poll:false] Interactive Elixir (1.1.1) - press Ctrl+C to exit (type h() ENTER for help) iex(akita@Hal9000u)1> |
Notice how the IEx shell shows different Node names for each instance: "fabio@Hal9000u" and "akita@Hal9000u". It's the sname concatenated with your machine name. From one instance you can ping the other, for example:
1 2 |
iex(akita@Hal9000u)2> Node.ping(:"fabio@Hal9000u") :pong |
If the name is correct and the other instance is indeed up, it responds the ping with a :pong. This is correct just for nodes in the same machine, but what if I need to connect to an instance in a remote machine?
1 2 3 4 |
iex(akita@Hal9000u)3> Node.ping(:"fabio@192.168.1.13") 11:02:46.152 [error] ** System NOT running to use fully qualified hostnames ** ** Hostname 192.168.1.13 is illegal ** |
The --sname option sets a name only reachable within the same subnet, for a fully qualified domain name you need to use the --name, for example, like this:
1 |
iex --name fabio@192.168.1.13 --cookie chat |
And for the other node:
1 |
iex --name akita@192.168.1.13 --cookie chat |
And from this second terminal you can ping the other node the same way as before:
1 2 |
iex(akita@192.168.1.13)1> Node.ping(:"fabio@192.168.1.13") :pong |
And you might be wondering, what is this "--cookie" thing? Just spin up a third terminal with another client name, but without the cookie, like this:
1 |
iex --name john@192.168.1.13 |
And if you try to ping one of the first two nodes you won't get a :pong back:
1 2 |
iex(john@192.168.1.13)1> Node.ping(:"fabio@192.168.1.13") :pang |
The cookie is just an atom to identify relationship between nodes. In a pool of several servers you can make sure you're not trying to connect different applications between each other. And as a result you get a :pang. Instead of an IP address you can use a fully qualified domain name instead.
And just by having the node "akita@" pinging "fabio@" we can see that they are aware of each other:
1 2 |
iex(fabio@192.168.1.13)2> Node.list [:"akita@192.168.1.13"] |
And:
1 2 |
iex(akita@192.168.1.13)2> Node.list [:"fabio@192.168.1.13"] |
If one of the node crashes or quits, the Node list is automatically refreshed to reflect only nodes that are actually alive and responding.
You can check the official API Reference for the Node for more information. But this should give you a hint for the next section.
Creating a Chat Client
Back to the exercise, the ExMessenger server has "ExMessenger.Server", which is a GenServer and the "ExMessenger.Supervisor" that starts it up. The ExMessenger.Server is globally registered as :message_server, started and supervised by the "ExMessenger.Supervisor".
The "ExMessengerClient" starts up the unsupervised "ExMessengerClient.MessageHandler", which is also a GenServer, and globally registered as :message_handler.
The Tree for both apps look roughly like this:
1 2 3 4 5 |
ExMessenger
- ExMessenger.Supervisor
+ ExMessenger.Server
ExMessengerClient
- ExMessengerClient.MessageHandler
|
We start them separately, first the message server:
1 2 |
cd apps/ex_messenger iex --sname server --cookie chocolate-chip -S mix run |
Notice that for this example we are starting with a simple name "server", for the local subnet, and a cookie. If will respond as "server@Hal9000u" (Hal9000u being my local machine's name).
Then, we can start the client app:
1 2 |
cd apps/ex_messenger_client server=server@Hal9000u nick=john elixir --sname client -S mix run |
Here we are setting 2 environment variables (that we can retrieve inside the app using System.get_env/1) and also setting a local node name "client". You can spin up more client nodes using a different "sname" and a different "nick" from another terminal, as many as you want, linking to the same "server@Hal9000u" message server.
I'm starting up like this instead of a command line escript like I did in the ExMangaDownloadr because I didn't find any way to set the --sname or --name the same way I can set --cookie using Node.set_cookie. If anyone knows how to set it up differently, let me know in the comments section down below.
Notice that I said "linking" and not "connecting". From the "ExMessengerClient" we start like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
defmodule ExMessengerClient do use Application alias ExMessengerClient.CLI alias ExMessengerClient.ServerProcotol def start(_type, _args) do get_env |> connect |> start_message_handler |> join_chatroom |> CLI.input_loop end ... end |
The get_env private function is just a wrapper to treat the environment variable "server" and "nick" that we passed:
1 2 3 4 5 6 7 8 |
defp get_env do server = System.get_env("server") |> String.rstrip |> String.to_atom nick = System.get_env("nick") |> String.rstrip {server, nick} end |
Now, we try to connect to the remote server:
1 2 3 4 5 6 7 8 9 10 11 |
defp connect({server, nick}) do
IO.puts "Connecting to #{server} from #{Node.self} ..."
Node.set_cookie(Node.self, :"chocolate-chip")
case Node.connect(server) do
true -> :ok
reason ->
IO.puts "Could not connect to server, reason: #{reason}"
System.halt(0)
end
{server, nick}
end
|
The important piece here is that we are setting the client's instance cookie with Node.set_cookie/1 (notice that we didn't pass it in the command line options like we did with the server instance). Without setting the cookie the next line with Node.connect(server) would fail to connect, as I explained in the previous section.
Then, we start the "ExMessengerClient.MessageHandler" GenServer, linking with the Message Server instance:
1 2 3 4 5 |
defp start_message_handler({server, nick}) do
ExMessengerClient.MessageHandler.start_link(server)
IO.puts "Connected"
{server, nick}
end
|
The Message Handler GenServer itself is very simple, it just sets the server as the state and handle incoming messages from the server and prints out in the client's terminal:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
defmodule ExMessengerClient.MessageHandler do use GenServer def start_link(server) do :gen_server.start_link({ :local, :message_handler }, __MODULE__, server, []) end def init(server) do { :ok, server } end def handle_cast({ :message, nick, message }, server) do message = message |> String.rstrip IO.puts "\n#{server}> #{nick}: #{message}" IO.write "#{Node.self}> " {:noreply, server} end end |
Going back to the main "ExMessengerClient" module, after starting the (unsupervised) GenServer that receives incoming messages, we proceed to join the pseudo-chatroom in the server:
1 2 3 4 5 6 7 8 9 10 11 12 |
defp join_chatroom({server, nick}) do
case ServerProcotol.connect({server, nick}) do
{:ok, users} ->
IO.puts "* Joined the chatroom *"
IO.puts "* Users in the room: #{users} *"
IO.puts "* Type /help for options *"
reason ->
IO.puts "Could not join chatroom, reason: #{reason}"
System.halt(0)
end
{server, nick}
end
|
I defined this "ServerProcotol" module which is just a convenience wrapper for GenServer.call/3 and GenServer.cast/2 calls, to send messages for the remote GenServer called :message_server:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
defmodule ExMessengerClient.ServerProcotol do def connect({server, nick}) do server |> call({:connect, nick}) end def disconnect({server, nick}) do server |> call({:disconnect, nick}) end def list_users({server, nick}) do server |> cast({:list_users, nick}) end def private_message({server, nick}, to, message) do server |> cast({:private_message, nick, to, message}) end def say({server, nick}, message) do server |> cast({:say, nick, message}) end defp call(server, args) do GenServer.call({:message_server, server}, args) end defp cast(server, args) do GenServer.cast({:message_server, server}, args) end end |
Pretty straight forward. Then, the main ExMessengerClient calls the recursive input_loop/1 function from the CLI module, which just receives user input and handles the proper commands using pattern matching, like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
defmodule ExMessengerClient.CLI do alias ExMessengerClient.ServerProcotol def input_loop({server, nick}) do IO.write "#{Node.self}> " line = IO.read(:line) |> String.rstrip handle_command line, {server, nick} input_loop {server, nick} end def handle_command("/help", _args) do IO.puts """ Available commands: /leave /join /users /pm <to nick> <message> or just type a message to send """ end def handle_command("/leave", args) do ServerProcotol.disconnect(args) IO.puts "You have exited the chatroom, you can rejoin with /join or quit with /quit" end def handle_command("/quit", args) do ServerProcotol.disconnect(args) System.halt(0) end def handle_command("/join", args) do ServerProcotol.connect(args) IO.puts "Joined the chatroom" end def handle_command("/users", args) do ServerProcotol.list_users(args) end def handle_command("", _args), do: :ok def handle_command(nil, _args), do: :ok def handle_command(message, args) do if String.contains?(message, "/pm") do {to, message} = parse_private_recipient(message) ServerProcotol.private_message(args, to, message) else ServerProcotol.say(args, message) end end defp parse_private_recipient(message) do [to|message] = message |> String.slice(4..-1) |> String.split message = message |> List.foldl("", fn(x, acc) -> "#{acc} #{x}" end) |> String.lstrip {to, message} end end |
And this wraps up the Client.
Creating a Chat Server
The Chat Client sends GenServer messages to a remote {:message_server, server}, and in the example, server is just the sname "server@Hal9000u" atom.
Now, we need this :message_server and this is the "ExMessenger.Server" GenServer:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
defmodule ExMessenger.Server do use GenServer require Logger def start_link([]) do :gen_server.start_link({ :local, :message_server }, __MODULE__, [], []) end def init([]) do { :ok, HashDict.new } end ... end |
And this is it, when the "ExMessenger.Supervisor" starts this GenServer it register globally in this instance as :message_server. And this how we address messages from what we called "clients" (the ExMessengerClient application).
When the ExMessengerClient calls the ServerProtocol.connect/1, it sends the {:connect, nick} message to the server. In the Server we handle it like this:
1 2 3 4 5 6 7 8 9 10 11 12 |
def handle_call({ :connect, nick }, {from, _} , users) do cond do nick == :server or nick == "server" -> {:reply, :nick_not_allowed, users} HashDict.has_key?(users, nick) -> {:reply, :nick_in_use, users} true -> new_users = users |> HashDict.put(nick, node(from)) user_list = log(new_users, nick, "has joined") {:reply, { :ok, user_list }, new_users} end end |
First, it checks if the nick is "server" and disallows it. Second, it checks if the nickname already exists in the internal HashDict (a key/value dictionary) and refuses if it already exists. Finally, in third, it puts the pair of nickname and node name (like "client@Hal9000u") in the HashDict and broadcasts through the log/3 private function to all other nodes in the HashDict dictionary.
The log/3 is just to create a log message concatenating the nick names of all clients and printing it out, then broadcasting this to the Message Handler of all the clients listed in the HashDict:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
defp log(users, nick, message) do user_list = users |> HashDict.keys |> Enum.join(":") Logger.debug("#{nick} #{message}, user_list: #{user_list}") say(nick, message) user_list end def say(nick, message) do GenServer.cast(:message_server, { :say, nick, "* #{nick} #{message} *" }) end def handle_cast({ :say, nick, message }, users) do ears = HashDict.delete(users, nick) Logger.debug("#{nick} said #{message}") broadcast(ears, nick, message) {:noreply, users} end |
Up to this point it just casts a message to itself, the {:say, nick, message} tuple, that is handled by the GenServer and calling the broadcast/3 function defined like this:
1 2 3 4 5 6 7 8 9 10 11 12 |
defp broadcast(users, nick, message) do Enum.map(users, fn {_, node} -> Task.async(fn -> send_message_to_client(node, nick, message) end) end) |> Enum.map(&Task.await/1) end defp send_message_to_client(client_node, nick, message) do GenServer.cast({ :message_handler, client_node }, { :message, nick, message }) end |
It maps the list of users and fire up an asynchronous Elixir Task (that is itself just a GenServer as I explained before in the Ex Manga Downloader series). Because it's a broadcast it makes sense to make all of them parallel.
The important bit is the send_message_to_client/3 which casts a message to the tuple { :message_handler, client_node } where "client_node" is just "client@Hal9000u" or any other "--sname" you used to start up each client node.
Now, this is how the clients send GenServer message calls/casts to {:message_server, server} and it send messages back to {:message_handler, client.
This is not your traditional TCP Client/Server example!
Now, we are calling the "ExMessenger.Server" a Chat "Server" and the "ExMessengerClient" a Chat "Client". Although we have been calling them as "Server" and "Client" they don't refer to the usual "TCP Server" and "TCP Client" examples you may be familiar with!
The ExMessenger.Server is indeed a Server (an OTP GenServer) but the ExMessengerClient.MessageHandler is also a Server (another OTP GenServer)! But because they both have Node behavior, it's more like they are 2 peer-to-peer nodes instead of your old school, simple client->server relationship. They can have client behavior (the Server sends messages to the MessageHandler) and server behavior (the Server receiving messages from ExMessengerClient).
Let this concept sink in for a moment, built-in with the language you get a full blown, easy to use, peer-to-peer network distribution model. You don't need to have one single node to be elected as the sole "node", you could have all nodes in a ring to coordinate between them, avoiding single points of failure.
I believe this is maybe how Erlang based services such as ejabberd and RabbitMQ work.
In the case of ejabberd, I can see that it keeps the state of the cluster in Mnesia tables (Mnesia being one other component of OTP, it's a distributed NoSQL database built-in!) and it indeed use the Node facilities to coordinate distributed nodes:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
...
join(Node) ->
case {node(), net_adm:ping(Node)} of
{Node, _} ->
{error, {not_master, Node}};
{_, pong} ->
application:stop(ejabberd),
application:stop(mnesia),
mnesia:delete_schema([node()]),
application:start(mnesia),
mnesia:change_config(extra_db_nodes, [Node]),
mnesia:change_table_copy_type(schema, node(), disc_copies),
spawn(fun() ->
lists:foreach(fun(Table) ->
Type = call(Node, mnesia, table_info, [Table, storage_type]),
mnesia:add_table_copy(Table, node(), Type)
end, mnesia:system_info(tables)--[schema])
end),
application:start(ejabberd);
_ ->
{error, {no_ping, Node}}
end.
|
This is how a snippet of pure Erlang source code looks like, by the way. You should have enough Elixir in your head right now to be able to abstract away the ugly Erlang syntax and see that it's a case pattern matching on the {_, :pong} tupple, using Node's ping facilities to assert the connectiviness of the node and updating the Mnesia table and other setups.
Also in the source code of the RabbitMQ-Server you will find a similar thing:
1 2 3 4 5 6 7 8 9 10 11 |
become(BecomeNode) ->
error_logger:tty(false),
ok = net_kernel:stop(),
case net_adm:ping(BecomeNode) of
pong -> exit({node_running, BecomeNode});
pang -> io:format(" * Impersonating node: ~s...", [BecomeNode]),
{ok, _} = rabbit_cli:start_distribution(BecomeNode),
io:format(" done~n", []),
Dir = mnesia:system_info(directory),
io:format(" * Mnesia directory : ~s~n", [Dir])
end.
|
Again, pinging nodes, using Mnesia for the server state. Erlang's syntax is uncommon for most of us: variables start with a capitalized letter (we intuitively think it's a constant instead), statements end with a dot, instead of the dot-notation to call function from a module it uses a colon ":", different from Elixir the parenthesis are not optional, and so on. Trying to read code like this show the value of having Elixir to unleash Erlang's hidden powers.
So, up to this point, you know how internally processes are spawn, how they are orchestrated within the OTP framework, and now how they can interact remotely through the Node peer-to-peer abstraction. And again, this is all built-in to the language. No other language come even close.
Observing Processes in Elixir - The Little Elixir & OTP Guidebook 22 Nov 2015 7:57 AM (9 years ago)
In my journey to really understand how a proper Elixir application should be written I am exercising through Benjamin Tan Wei Hao's excelent The Little Elixir & OTP Guidebook. If you're just getting started, this is a no-brainer: buy and study this guidebook. Yes, it will help if you already read Dave Thomas' Programming Elixir book first.
In my Ex Manga Downloadr Part 2 article I explored adding better process pool control using the excelent and robust Poolboy library. One of the guidebook main exercises is to build a simpler version of Poolboy in pure Elixir (Poolboy is written in good, old, Erlang).
This main goal of this article is to introduce what Fault Tolerance in Erlang/Elixir mean and it is also an excuse for me to show off Erlang's observer:

Yes, Erlang allows us to not just see what's going on inside its runtime environment but we can even take action on individual Processes running inside it! How cool is that?
But before we can show Fault Tolerancy and the Observer I need to explain what Processes are, and why they matter. You must understand the following concepts to successfully understand Elixir programming:
- You don't have "objects", which are runtime instances of classes (or prototipical objects, which are copies of other objects). Instead of "Classes" you have collections of functions organized in modules, without dependency in internal state. And instead of "objects" we have, roughly speaking, "processes". For example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
defmodule MyProcess do def start do accepting_messages(0) end def accepting_messages(state) do receive do {:hello, message} -> IO.puts "Hello, #{message}" accepting_messages(state) {:counter} -> new_state = state + 1 IO.puts "New state is #{new_state}" accepting_messages(new_state) _ -> IO.puts "What?" accepting_messages(state) end end end |
- We can execute a function inside another process. This is how we can spawn a brand new, concurrent, lightweight process:
1 2 |
iex(2)> pid = spawn fn -> MyProcess.start end #PID<0.87.0> |
When the accepting_messages/1 is called, it stops at the receive/0 block, waiting to receive a new message. Then we can send messages like this:
1 2 |
iex(3)> send pid, {:hello, "world"} Hello, world |
It receives the {:hello, "world"} atom message, it pattern matches the value "world" into the message variable, and concatenates the "Hello, world" string, which it prints out with IO.puts/1 and recurse to itself again. We call the receive/0 block again, and block, waiting for further messages:
1 2 3 4 5 6 7 8 9 10 11 |
iex(4)> send pid, {:counter} New state is 1 {:counter} iex(5)> send pid, {:counter} New state is 2 {:counter} iex(6)> send pid, {:counter} New state is 3 {:counter} iex(7)> send pid, {:counter} New state is 4 |
We send the {:counter} message to the same process pid again and when it receive this message, it gets the state value from the function argument, increments it by 1, prints out the new state, and calls itself again passing the new state as the new argument. It blocks again, waiting for further messages, and for each time it receives the {:counter} message, it increases the previous state by one again and recurses.
This is basically how we can maintain state in Elixir. If we kill this process and spawn a new one, it restarts with zero (which is what the start/0) function does.
So, while you don't have "objects" you do, however, have Processes. Superficially, a process behaves like an "object". Careful not to think that a Process is like a heavyweight Thread though. Erlang has its own internal scheduler that controls the concurrency of parallels and you can load as many as 16 billion lightweight processes if your hardware allows it. Threads are super heavy, Erlang processes are super light.
As we saw in the example, each process has its own internal mechanism to receive messages from other processes. Those messages accumulate in an internal "mailbox" and you can choose to receive and pattern match through those messages, recursing to itself again in order to receive new messages if you want.
Processes can be linked to or monitor other processes, for example, within an IEx shell, we are within an Elixir process, so we could do:
1 2 3 4 5 6 7 8 |
iex(1)> self #PID<0.98.0> iex(2)> pid = spawn fn -> MyProcess.start end #PID<0.105.0> iex(3)> Process.alive?(pid) true iex(4)> Process.link(pid) true |
With self we can see that the current process id for the IEx shell is "0.98.0". Then we spawn a process that calls Myprocess.start/0 again, it will block in the receive call. This new process has a different id, "0.105.0".
We can assert that the new process is indeed alive and we can link the IEx shell with the "0.105.0" pid process. Now, whatever happens to this process will cascade to the shell.
1 2 3 4 5 6 7 |
iex(5)> Process.exit(pid, :kill) ** (EXIT from #PID<0.98.0>) killed Interactive Elixir (1.1.1) - press Ctrl+C to exit (type h() ENTER for help) /home/akitaonrails/.iex.exs:1: warning: redefining module R iex(1)> self #PID<0.109.0> |
And indeed, if we forcefully send a kill message to the "0.105.0" process, the IEx shell is also killed in the process. IEx restarts and its new pid is "0.109.0" instead of the old "0.98.0". By the way this is one way a process is different from a normal object. It behaves more like an operating system process where a crash in a process does not affect the whole system as it does not hold external shared state that can corrupt the system's state.
The important concept is that we now have a mechanism to define a Parent Process (IEx in this example) and Children processes linked to it.
- Parent processes don't need to stupidly suicide itself because their children screwed up. Instead, they can trap exits and decide what to do later:
1 2 3 4 5 6 7 |
iex(2)> Process.flag(:trap_exit, true) false iex(3)> pid = spawn_link fn -> MyProcess.start end #PID<0.118.0> iex(4)> send pid, {:counter} New state is 1 {:counter} |
First, we declare that the IEx shell will trap exists and not just die. Then we spawn a new process and link it. The spawn_link/1 function has the same effect of spawn/1 and then Process.link/1. We can send a message to the new pid and check that it is indeed still working.
1 2 3 4 5 6 7 |
iex(5)> Process.exit(pid, :kill) true iex(6)> Process.alive?(pid) false iex(7)> flush {:EXIT, #PID<0.118.0>, :killed} :ok |
Now we forcefully kill the new process again, but IEx does not crash this time, as it is explicitly trapping those errors. If we check the killed pid, we can assert that it is indeed dead. But now we can also inspect IEx's own process mailbox (in this case, just flushing whats queued in the inbox) and see that it just received a message saying that its child was killed.
From here we could make IEx process treat this message and decide to just mourn for its deceased child and commit suicide itself, or move on and spawn_link a new now. We have choice in the face of disaster.
OTP Workers
Letting aside the grim metaphor, we learned that we have Parent and Child processes, but more importantly they can fit the roles of Supervisors and Workers that are supervised, respectivelly.
Workers is where we put our code. This code can have bugs, it can depend on external stuff that can make our code crash for unexpected reasons. In a normal language we would start using the dreaded try/catch blocks, which are just ugly and wrong! Don't catch errors in Elixir, just let it crash!!
As I explained in my previous article, everything in Elixir ends up being a so called "OTP application". The example above is just a very simple contraption that we can expand upon. Let's rewrite the same thing as an OTP GenServer:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
defmodule MyFancyProcess do use GenServer def start_link(_) do GenServer.start_link(__MODULE__, 0, name: __MODULE__) end ## Public API def hello(message) do GenServer.call(__MODULE__, {:hello, message}) end def counter do GenServer.call(__MODULE__, :counter) end ## GenServer callbacks def init(start_counter) do {:ok, start_counter} end def handle_call({:hello, message}, _from, state) do IO.puts "Hello, #{message}" {:reply, :noproc, state} end def handle_call(:counter, _from, state) do new_state = state + 1 IO.puts "New state is #{new_state}" {:reply, :noproc, new_state} end end |
This new MyFancyProcess is essentially the same as MyProcess but with OTP GenServer on top of it. There are Public API functions and GenServer callbacks.
Benjamin's book go to great lenghts to detail every bit of what I just implemented. But for now just understand some basics:
The module does "use GenServer" to import all the necessary GenServer bits for your convenience. In essence one of the things it will do is create that receive block we did in the first version to wait for messages.
The start_link/1 function will create the instance of this GenServer and return the linked process. Internally it will call back to the init/1 function to set the initial state of this worker. This is a flexible language, we have multiple ways of doing the same thing, and this is good, having just a single way of writing code is boring.
The convention is to have one public function that calls the internal handle_call/3 (for synchronous calls), handle_cast/2 (for asynchronous calls), and handle_info/2. You could just call handle_call from the outside, but it's just ugly, so you will find this convention everywhere.
Once we have this in place, we can start calling it directly:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
iex(11)> MyFancyProcess.start_link(0) {:ok, #PID<0.261.0>} iex(12)> MyFancyProcess.hello("world") Hello, world :noproc iex(13)> MyFancyProcess.counter New state is 1 :noproc iex(14)> MyFancyProcess.counter New state is 2 :noproc iex(15)> MyFancyProcess.counter New state is 3 :noproc |
And this is much cleaner than the version where we manually spawn_link and send messages to a pid. This is all handled nicely by the GenServer underneath it. And as I said, the results are the same as the initial crude MyProcess example.
In fact, this convention does make us type a lot of boilerplate many times over. There is a library called ExActor that grealy simplifies a GenServer implementation, making our previous code become something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
defmodule MyFancyProcess do use ExActor.GenServer, initial_state: 0 defcall hello(message), state do IO.puts "Hello, #{message}" noreply end defcall counter, state do new_counter = state + 1 IO.puts "New state is #{new_counter}" new_state(new_counter) end end |
This is way cleaner, but as we are just using IEx, I'm not using this version for the next section, stick with the longer version of MyFancyProcess listed in the beginning of this section!
OTP Supervisor
Now that we have a worker, we can create a Supervisor to supervise it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
defmodule MyFancySupervisor do use Supervisor def start_link do Supervisor.start_link(__MODULE__, []) end def init(_) do children = [ worker(MyFancyProcess, [0]) ] opts = [strategy: :one_for_one] supervise(children, opts) end end |
This is just a simple boilerplace that most Supervisors will have. There are many details you must learn, but for this article's purposes the important bits are, first, the definition of the children specification, saying that this Supervisor should start the MyFancyProcess GenServer instead of us having to MyFancyProcess.start_link manually. And the second important bit is the opts list which defines the strategy of :one_for_one, meaning that if the Supervisor detects that the child has died, it should restart it.
From a clean IEx, we can copy and paste both the MyFancyProcess and MyFancySupervisor above and start playing with it in the IEx shell:
1 2 3 4 5 6 7 8 9 10 11 |
iex(3)> {:ok, sup_pid} = MyFancySupervisor.start_link {:ok, #PID<0.124.0>} iex(4)> MyFancyProcess.hello("foo") Hello, foo :noproc iex(5)> MyFancyProcess.counter New state is 1 :noproc iex(6)> MyFancyProcess.counter New state is 2 :noproc |
This is how we start the Supervisor and you can see that right away we can start sending messages to the MyFancyProcess GenServer because the Supervisor successfully started it for us.
1 2 3 4 |
iex(7)> Supervisor.count_children(sup_pid) %{active: 1, specs: 1, supervisors: 0, workers: 1} iex(8)> Supervisor.which_children(sup_pid) [{MyFancyProcess, #PID<0.125.0>, :worker, [MyFancyProcess]}] |
Using the Supervisor PID that we captured right when we started it, we can ask it to count how many children it is monitoring (1, in this example) and we can ask the details of each children as well. We can see that the MyFancyProcess started with the pid of "0.125.0"
1 2 3 4 |
iex(9)> [{_, worker_pid, _, _}] = Supervisor.which_children(sup_pid) [{MyFancyProcess, #PID<0.125.0>, :worker, [MyFancyProcess]}] iex(14)> Process.exit(worker_pid, :kill) true |
Now, we can grab the Worker pid and manually force it to crash as we did before. We should be screwed, right? Nope:
1 2 3 4 5 6 7 8 9 |
iex(15)> Supervisor.which_children(sup_pid)
[{MyFancyProcess, #PID<0.139.0>, :worker, [MyFancyProcess]}]
iex(16)> MyFancyProcess.counter
New state is 1
:noproc
iex(17)> MyFancyProcess.counter
New state is 2
:noproc
|
If we ask the Supervisor again for the list of its children, we will see that the old "0.125.0" process did indeed vanish but a new one, "0.139.0" was spawned in its place by the Supervisor strategy of :one_for_one as we defined before.
We can continue making calls do the MyFancyProcess but you will see that the previous state was lost and it restarts from zero. We can add state management in the GenServer using a number of different persistent storages such as the built-in ETS (think of ETS as a built-in Memcache service), but I think you get the idea by now.
Graphically visualizing Processes
This entire article was motivated by just this simple thing in Benjamin's book: by the end of page 139 of the book you will have built a very simple pool system that is able to start 5 process in the pool, guarded by a supervisor. And from there he goes on to show off the Observer.
Erlang has a built-in inspector tool called Observer. You can use the Supervisor built-in functions to inspect processes as I demonstrated before, but it's much cooler to see it visually. Assuming you installed Erlang Solutions propertly, in Ubuntu you have to:
1 |
wget https://packages.erlang-solutions.com/erlang-solutions_1.0_all.deb && sudo dpkg -i erlang-solutions_1.0_all.deb |
Only then, you can start the observer directly from the IEx shell like this:
1 |
:observer.start |
And a graphical window will show up with some stats first.

This is very powerful becuase you have insight and control over the entire Erlang runtime! See that this status window even show you "uptime", it's line a UNIX system: it is made to stay up no matter what. Processes have its own garbage collector and they all behave nicely towards the entire system.
You can hook a remote Observer to remote Erlang runtimes as well, if you were wondering. Now you can jump to the Applications tab to see how the "Pooly" exercise looks like with 5 children under its pool:

Because those children are supervised with proper restart strategies, we can visually kill one of them, the one with the pid labeled "0.389.0":
And as the Observer immediatelly shows, the Supervisor took action, spawned a new child and added it to its pool, bringing the count back to 5:

This is what Fault Tolerance with proper controls mean by using OTP!
With the bits I explained in this article you should have enough concepts to finally grasp what the Erlang's high reliabiliby fuzz is all about. The basic concepts are very simple, to hook your application to OTP is also a no-brainer, what OTP has implemented under the hood is what makes your application much more reliable.
There are clear guidelines on how to design your application. Who supervises what. What should happen to the application state if workers are restarted? How you divide responsabilities between different groups of Supervisor/Children?
Your application is supposed to look like a Tree, a Supervision Tree, where failure in one leaf does not bring the other branches down and everything knows how to behave and how to recover, elegantly. It's really like a UNIX operating system: when you kill -9 one process, it doesn't bring your system down, and if it's initd monitored service, it gets respawned.
Most important: this is not an optional feature, a 3rd party library, that you choose too use. It's built-in in Erlang, you must use it if you want to play. There is no other choice and this is the best choice. Any such pattern that is not implemented in a concurrent language, to me, represents a big failure of the language. This is Elixir's strength.
This is high level control you won't find anywhere else. And we still didn't even talk about how OTP applications can exchange messages across the wire in really distributed systems, and how the Erlang runtime can reload code while an application is running, with zero downtime, akin of what IEx itself is capable of and how Phoenix allow development mode with code reloading! OTP gives all this for free, so it's well worth learning all the details.
We went through processes, pids, send a kill message to a process, trap exits, parent having child processes. Feels very similar to how UNIX works. If you know UNIX, you can easily grasp how all this fit together, including Elixir pipe operator "|>" compared to UNIX's own pipe "|", it's similar.
Finally, The Little Elixir & OTP Guidebook is a very easy to read, very hands-on small book. You can read it all in a couple of days and grasp everything I quickly summarized here and much more. I highly encourage you to buy it right now.
Ex Manga Downloadr - Part 2: Poolboy to the rescue! 19 Nov 2015 7:35 AM (9 years ago)
If you read my previous article I briefly described my exercise building a MangaReader downloader. If you didn't read it yet, I recommend you do so before continuing.
In the mid-section of the article I described how I was still puzzled on what would be the best way to handle several HTTP requests to an unstable external source where I can't control timeout or other network problems.
A big Manga such as Naruto or Bleach have dozens of chapters with dozens of pages each, accounting for thousands of necessary HTTP requests. Elixir/Erlang do allow me to fire up as many parallel HTTP requests as I want. But doing that makes the HTTP requests timeout very quickly (it's like doing a distributed denial of service attack against MangaReader).
By trial and error I found that firing up less than a 100 HTTP requests at once allows me to finish. I capped it down to 80 to be sure, but it really depends on your environment.
Then I had to manually chunk my list of pages to 80 elements and process them in parallel, finally reducing the resulting lists into a larger list again to pass it through to the next steps in the Workflow. The code gets convoluted like this:
1 2 3 4 5 6 7 8 9 10 11 |
def images_sources(pages_list) do pages_list |> chunk(@maximum_fetches) |> Enum.reduce([], fn pages_chunk, acc -> result = pages_chunk |> Enum.map(&(Task.async(fn -> Page.image(&1) end))) |> Enum.map(&(Task.await(&1, @http_timeout))) |> Enum.map(fn {:ok, image} -> image end) acc ++ result end) end |
Now I was able to reimplement this aspect and the same code now looks like this:
1 2 3 4 5 6 |
def images_sources(pages_list) do pages_list |> Enum.map(&Worker.page_image/1) |> Enum.map(&Task.await(&1, @await_timeout_ms)) |> Enum.map(fn {:ok, image} -> image end) end |
Wow! Now this is a big improvement and it's way more obvious what it is doing.
Best of all: downloading a Manga the size of Akira (around 2,200 pages long) took less than 50 seconds. And this is not because Elixir is super fast, it's because MangaReader can't keep up if I extend the Pool size. It's hitting at a constant rate of 50 concurrent connections!
This just makes my 4 cores machine, sitting down over a connection of 40Mbs use less than 40% ~ 30% of CPU and using no more than around 3,5 Mbs. If MangaReader could keep up we could easily fetch all pages 2 or 3 times faster without breaking a sweat.
It was fast with the previous strategy, but I guess it got at least twice as fast as a bonus. But how did I accomplish that?
Open Telecom Platform
In the previous article I also said that I didn't want to dive into "OTP and GenServers" just yet. But if you're a beginner like me you probably didn't understand what this means.
OTP is what makes Erlang (and consequently, Elixir) different from pretty much every other language platform but, maybe, Java.
Many new languages today make it do many tasks in parallel through convoluted Reactor patterns (Node.js, EventMachine/Ruby, Tornado/Twisted/Python, etc) or through (cleaner) green threads (Scala, Go).
But none of this matters. It's not difficult to launch millions of lightweight processes, but it is not trivial to actually CONTROL them all. It doesn't matter how fast you can exhaust your hardware if you can't control it. Then you end up with millions of dumb minions wreaking havoc without an adult to coordinate them.
Erlang solved this problem decades ago through the development of OTP, initially called Open Systems, within Ericsson in 1995. By itself OTP is a subject that can easilly fill an entire fat book and you will still not be able to call yourself an expert.
Just so I don't get too boring here:
- Start with this very brief summary;
- Then read Elixir's tutorial on Supervisors and the page on Processes first if you haven't already;
- Finally, you can go further with The Elixir & OTP Guidebook from Manning Publications.
Now, below is my personal point of view. As I am a beginner myself, let me know in the comments section below if I got some concept wrong.
OTP is a collection of technologies and frameworks. The part that interests us the most is to understand that this is a sophisticated collection of patterns to achieve the Nirvana of highly reliable, highly scalable, distributed systems. You know? That thing every new platform promises you but fails to actually deliver.
For our very simple intents and purposes, let's pick up what I said before: it's trivial to fire up millions of small processes. We call them "workers". OTP provides the means to control them: Supervisors. And then it also provides the concept of Supervisor Trees (Supervisors that supervise other Supervisor). This is the gist of it.
Supervisors are responsible for starting up the workers and also to recover from exceptions coming from the workers (which is why in Erlang/Elixir we don't do ugly try/catch stuff: let the error be raised and caught by the Supervisor). Then we can configure the Supervisor to deal with faulty worker by, for example, restarting them.
We already touched this OTP stuff before. An Elixir Task is just a high level abstraction. It internally starts its own supervisor and supervised to monitor over asynchronous tasks.
There are so many subjects and details that it's difficult to even get started. One concept that is important to know is about state. There is no global state! (Yay, no Javascript globals nightmare.) Each function has its own state and that's it. There is no concept of an "object" that holds state and then methods that can modify that state.
But there is the concept of Erlang processes. Now, a process do have state, it's a lightweight piece of state that exists only in runtime. To execute a function in a separated, parallel process, you can just do:
1 2 |
iex> spawn fn -> 1 + 2 end #PID<0.43.0> |
Different from an object, a process does not have a set of methods that access its inner "this" or "self" states. Instead each process has a mailbox. When you start (or "spawn" in Erlang lingo) a new process, it returns a pid (process ID). You can now send messages to the process through its pid. Each process has a mailbox and you can choose to respond to incoming messages and send responses back to the pid that sent the message. This is how you can send a message to the IEx console and receive the messages in its mailbox:
1 2 3 4 5 6 7 |
iex> send self(), {:hello, "world"} {:hello, "world"} iex> receive do ...> {:hello, msg} -> msg ...> {:world, msg} -> "won't match" ...> end "world" |
In essence, it's almost like an "object" that holds state. Each process has its own garbage collector, so when it dies it's individually collected. And each process is isolated from other processes, they don't bleed state out, which makes them much easier to reason about.
The Getting Started page on Processes from the Elixir website show examples of what I just explained and I recommend you follow it throughly.
In summary, a process can hold internal state by locking indefinitely waiting for an incoming message in its mailbox and then recursing to itself! This is a mindblowing concept at first.
But, just a simple process is just too dawn weak. This is where you get OTP's GenServer, which is a much more accomplished process. OTP exposes Behaviours for you to implement in order to add your own code but it takes care of the dirty infrastructure stuff so you don't have to.
Deferring the Heavy Workflow calls to a Worker
All that having being said, we know that in the Workflow we implemented before, we have trouble with the Page.image/1 and Workflow.download_image/2 functions. This is why we made them asynchronous processes and we wait for batches of 80 calls every time.
Now, let's start by moving away this logic to a GenServer Worker, for example, in the ex_manga_downloadr/pool_management/worker.ex file:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
defmodule PoolManagement.Worker do use GenServer use ExMangaDownloadr.MangaReader @timeout_ms 1_000_000 @transaction_timeout_ms 1_000_000 # larger just to be safe def start_link(_) do GenServer.start_link(__MODULE__, nil, []) end def handle_call({:page_image, page_link}, _from, state) do {:reply, Page.image(page_link), state} end def handle_call({:page_download_image, image_data, directory}, _from, state) do {:reply, Page.download_image(image_data, directory), state} end end |
I first moved the Workflow.download_image/2 to Page.download_image/2 just for consistency's sake. But this is a GenServer in a nutshell. We have some setup in the start_link/1 function and then we have to implement handle_call/3 functions to handle each kind of arguments it might receive. We separate them through pattern matching the arguments.
As a convention, we can add public functions that are just prettier versions that call each handle_call/3:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def page_image(page_link) do Task.async fn -> :poolboy.transaction :worker_pool, fn(server) -> GenServer.call(server, {:page_image, page_link}, @timeout_ms) end, @transaction_timeout_ms end end def page_download_image(image_data, directory) do Task.async fn -> :poolboy.transaction :worker_pool, fn(server) -> GenServer.call(server, {:page_download_image, image_data, directory}, @timeout_ms) end, @transaction_timeout_ms end end |
But we are not just calling the previous handle_call/3 functions. First there is the Task.async/1 we were already using in the Workflow functions to make the parallel batches. But inside the Task calls there is this other strange thing: :poolboy.
Controlling Pools of Processes through Poolboy
The entire OTP ordeal I wrote here was just an introduction so I could show off Poolboy.
Repeating myself again: its trivial to fire up millions of processes. OTP is how we control failures to those processes. But there is another problem: the computation within each process may be so heavy we can either bring down the machine or, in our case, do a Distributed Denial of Service (DDoS) against poor MangaReader website.
My initial idea was to just do parallel requests in batches. But the logic is convoluted.
Instead, we can use a process pool! It queues up our requests for new processes. Whenever a process finishes it is returned to the pool and a new computation can take over the available process. This is how pools work (you probably have an intuition of how it works from traditional database connection pools). Pools and queues are useful software constructs to deal with limited resources.
By doing this we can remove the chunking of the large list into batches and do it like we would process every element of the large list in parallel at once, repeating again the initial version:
1 2 3 4 5 6 7 8 9 |
pages_list |> chunk(@maximum_fetches) |> Enum.reduce([], fn pages_chunk, acc -> result = pages_chunk |> Enum.map(&(Task.async(fn -> Page.image(&1) end))) |> Enum.map(&(Task.await(&1, @http_timeout))) |> Enum.map(fn {:ok, image} -> image end) acc ++ result end) |
Now, removing the chunking and reducing logic:
1 2 3 4 |
pages_list |> Enum.map(&(Task.async(fn -> Page.image(&1) end))) |> Enum.map(&(Task.await(&1, @http_timeout))) |> Enum.map(fn {:ok, image} -> image end) |
And finally, replacing the direct Task.async/1 call for the GenServer worker we just implemented above:
1 2 3 4 |
pages_list |> Enum.map(&Worker.page_image/1) |> Enum.map(&Task.await(&1, @await_timeout_ms)) |> Enum.map(fn {:ok, image} -> image end) |
Now, Poolboy requires will require a Supervisor that monitors our Worker. Let's put it under ex_manga_downloadr/pool_management/supervisor.ex:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
defmodule PoolManagement.Supervisor do use Supervisor def start_link do Supervisor.start_link(__MODULE__, []) end def init([]) do pool_options = [ name: {:local, :worker_pool}, worker_module: PoolManagement.Worker, size: 50, max_overflow: 0 ] children = [ :poolboy.child_spec(:worker_pool, pool_options, []) ] supervise(children, strategy: :one_for_one) end end |
More OTP goodness here. We had a rogue Worker, now we have a responsible Supervisor deferring responsability to Poolboy. We start with a pool that can hold a maximum of 50 process within (without overflowing). This number comes from trial and error again. And the Supervisor will use a strategy of :one_for_one, which means that if the Worker dies it restarts it.
Now, we must add Poolboy to the mix.exs as a dependency and run mix deps.get to fetch it:
1 2 3 4 5 6 7 |
defp deps do [ ... {:poolboy, github: "devinus/poolboy", tag: "1.5.1"}, ... ] end |
In the same mix.exs we make the main Application (surprise: which is already a supervised OTP application) start the PoolManagement.Supervisor for us:
1 2 3 4 |
def application do [applications: [:logger, :httpotion, :porcelain], mod: {PoolManagement, []}] end |
But we also need to have this PoolManagement module for it to call. We may call it pool_management.ex:
1 2 3 4 5 6 7 |
defmodule PoolManagement do use Application def start(_type, _args) do PoolManagement.Supervisor.start_link end end |
Summary
Let's summarize:
- the ExMangaDownloadr application will start up and fire up the PoolManagement application;
- the PoolManagement application fires up the PoolManagement.Supervisor;
- the PoolManagement.Supervisor fires up Poolboy and assigns PoolManagement.Worker to it, configuring it's pool size to 50 and responding to the pool name :worker_pool
- now we start to fetch and parse through the Manga's chapters and pages until the ExMangaDownloadr.Workflow.images_sources/1 is called;
- it will call the PoolManagement.Worker.page_image/1 function which in turn fires up a Task.async/1, calling :poolboy.transaction(:worker_pool, fn -> ... end);
- if a process is available in Poolboy's pool it starts right away, otherwise it awaits for a process to become available, it will wait until the @transaction_timeout_ms timeout configuration.
- the process maps the entire pages_list, creating one async Task for each page in the list, we end up with a ginourmous list of Task pids, then we Task.await/2 for them all to return.
Now, this application is much more reliable and faster as it fires up a new HTTP connection as soon as the first one responds and it return the process back to the pool. Instead of firing up 80 connections at a time, in batches, we start with 50 at the same time and then we fire up one at a time for each process returned to the pool.
Through trial and error I set the @http_timeout to wait at most 60 seconds. I also set the timeout_ms which is the time to wait for the GenServer worker call handle to return and transaction_timeout_ms which is the time Poolboy awaits for a new process in the pool, both to around 16 minutes (1,000,000 ms).
This is putting 25 years of Erlang experience in the Telecom industry to good use!
And to make it crystal clear: OTP is the thing that sets Erlang/Elixir apart from all the rest. It's not the same thing, but it's like if the standard would be to write everything in Java as an EJB, ready to run inside a JEE Container. What comes to mind is: heavy.
In Erlang, an OTP application is lightweight, you can just build and use it ad hoc, without bureacracy, without having to set up complicated servers. As in our case, it's a very simple command line tool, and within it, the entire power of a JEE Container! Think about it.
Ex Manga Downloader, an exercise with Elixir 18 Nov 2015 10:26 AM (9 years ago)
Update 11/19/15: In this article I mention a few doubts I had, so read this and then follow through Part 2 to see how I solved it.
As an exercise (and also because I'm obviously an Otaku) I implemented a simple Elixir based scrapper for the great MangaReader website. One can argue if it's ok to scrap their website, and one might also argue if they providing those mangas are ok in the first place, so let's not go down this path.
I had an older version written in Ruby. It still works but it's in sore need of a good refactoring (sorry about that). The purpose of that version was to see if I could actually do parallel fetching and retry connections using Typhoeus.

As I've been evolving in my studies of Elixir that tool felt like a great candidate to test my current knowledge of the platform. It would make me test:
- Fetch and parse ad hoc content through HTTP (HTTPotion and Floki).
- Test parallel/asynchronous downloads (Elixir's built-in Task module).
- The build-in command line and option parser support.
- Basic testing through ExUnit and mocking the workflow (Mock).
The exercise was very interesting, and a scrapper is also an ideal candidate for TDD. The initial steps had to go like this:
- Parse the main manga page to fetch all the chapter links.
- Parse each chapter page to fetch all the individual pages.
- Parse each page to parse the main embedded image (the actual manga page).
For each of those initial steps I did a simple unit test and the IndexPage, ChapterPage and Page modules. They have roughly the same structure, this is one example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
defmodule ExMangaDownloadr.MangaReader.IndexPage do def chapters(manga_root_url) do case HTTPotion.get(manga_root_url, [timeout: 30_000]) do %HTTPotion.Response{ body: body, headers: _headers, status_code: 200 } -> {:ok, fetch_manga_title(body), fetch_chapters(body) } _ -> {:err, "not found"} end end defp fetch_manga_title(html) do Floki.find(html, "#mangaproperties h1") |> Enum.map(fn {"h1", [], [title]} -> title end) |> Enum.at(0) end defp fetch_chapters(html) do Floki.find(html, "#listing a") |> Enum.map fn {"a", [{"href", url}], _} -> url end end end |
Here I am already exercising some of Elixir's awesome features such as pattern matching the result of the HTTPotion.get/2 function to extract the body from the returning record.
Then I pass the HTML body to 2 different functions: fetch_manga_title and fetch_chapters. They both use the Floki package which can use CSS selectors to return a List. Then I need to walk through the list (using Enum.map/2 for example) and pattern match on it to extract the values I need.
Pattern Matching is one of the most important concepts to learn about Elixir/Erlang. It's different from simply assigning a value to a variable, it can be used to dismount a structure into its components and get their individual parts.
Then I just went through building the skeleton for the command line interface. This is already explained in other tutorials such as this and this, so I won't waste time explaining it again. At the core I needed to have the following workflow:
- Starting from the Manga main URL at MangaReader, extract the chapters
- Then loop through the chapters and fetch all the pages
- Then loop through the pages and fetch all the image sources
- Then loop through the images and download them all to a temporary directory
- Then sort through files in the directory and move them to sub-directories of 250 images each (I think it is a good size for each volume)
- Finally, resize and convert all the images of each sub-directory into a PDF file for my Kindle to consume.
This workflow is defined like this:
1 2 3 4 5 6 7 8 9 10 11 12 |
defp process(manga_name, url, directory) do File.mkdir_p!(directory) url |> Workflow.chapters |> Workflow.pages |> Workflow.images_sources |> Workflow.process_downloads(directory) |> Workflow.optimize_images |> Workflow.compile_pdfs(manga_name) |> finish_process end |
This is one place where the pipeline notation from Elixir really shines. It's much better than having to write this equivalent:
1 |
Workflow.compile_pdfs(Workflow.optimize_images(directory)) |
This notation is just syntatic sugar where the returning value of the previous statement is used as the first argument of the following function. Combine that with other syntatic sugars such as parenthesis being optional (just like beloved Ruby) and you have a clear exposure of "transforming from a URL into compiled PDFs".
I separated the Workflow into its own module and each step is very similar, each taking a list and walking through it. This the simplest of them:
1 2 3 4 5 6 |
def pages(chapter_list) do chapter_list |> Enum.map(&(Task.async(fn -> ChapterPage.pages(&1) end))) |> Enum.map(&(Task.await(&1, @http_timeout))) |> Enum.reduce([], fn {:ok, list}, acc -> acc ++ list end) end |
If you're new to Elixir here you will find another oddity, this "&(x(&1))", this is just a shortcut macro to this other similar statement:
1 2 3 4 5 |
Enum.map(fn (list) -> Task.async(fn -> ChapterPage.pages(list) end) end) |
Enum is one of the most useful modules you need to master. If you come from Ruby it feels like home, you must learn all of its functions. You're usually having to transform one collection into another, so it's important to study it throughly.
A few problems understanding parallel HTTP processing (W.I.P.)
Then there is this Task.async/await deal. If you're from a language that have Threads, it's quite similar: you start several different Threads and await for all of them to return before continuing. But a Task in Elixir is not a real thread, it's "green thread" or, in Erlang lingo, a very lightweight "process". Erlang uses processes for everything, thus does Elixir. Under the hood, the "Task" module encapsulates the entire OTP framework for supervisors/workers. But instead of having to deal right now with OTP GenServer I decided to go the simpler route for now, and the "Task" module accomplishes just that.
Then, I ended up with a problem. If I just kept going like this, spawning hundreds of async HTTP calls, I quickly end up with this exception:
1 2 3 4 5 6 7 8 9 |
17:10:55.882 [error] Task #PID<0.2217.0> started from #PID<0.69.0> terminating
** (HTTPotion.HTTPError) req_timedout
(httpotion) lib/httpotion.ex:209: HTTPotion.handle_response/1
(ex_manga_downloadr) lib/ex_manga_downloadr/mangareader/page.ex:6: ExMangaDownloadr.MangaReader.Page.image/1
(elixir) lib/task/supervised.ex:74: Task.Supervised.do_apply/2
(elixir) lib/task/supervised.ex:19: Task.Supervised.async/3
(stdlib) proc_lib.erl:240: :proc_lib.init_p_do_apply/3
Function: #Function<12.106612505/0 in ExMangaDownloadr.Workflow.images_sources/1>
Args: []
|
That's why there is @maximum_fetches 80 at the top of the Workflow module, together with this other odd construction:
1 2 3 4 5 6 7 8 9 10 11 |
def images_sources(pages_list) do pages_list |> chunk(@maximum_fetches) |> Enum.reduce([], fn pages_chunk, acc -> result = pages_chunk |> Enum.map(&(Task.async(fn -> Page.image(&1) end))) |> Enum.map(&(Task.await(&1, @http_timeout))) |> Enum.map(fn {:ok, image} -> image end) acc ++ result end) end |
This gets a huge list (such as all the pages of a very long manga like Naruto), breaks it down to smaller 80 elements list and then proceed to fire up the asynchronous Tasks, reducing the results back to a plain List. The chunk/2 private function just get the smaller size between the list length and the maximum fetches value.
Sometimes it breaks down if the maximum is larger, sometimes it doesn't, so my guess is my code not dealing with network instabilities (with some retry logic) or even the MangaReader site queueing up above my designated timeout (which I set to 30 seconds). Either way, keeping the maximum value lower than 100 seem to be a good balance without crashing the workflow down.
This is one part I am not entirely sure what to do to deal with uncertainties in the external website not responding or network falling down for a little while. HTTPotion has support for asynchronous calls, but I don't know what's the difference between using that or just making synchronous calls within parallel processes with Task, the way I'm doing. And in either case, they are supervised workers, how do I handle the exceptions, how should I implement logic to retry the call once it fails? If anyone has more knowledge about this, a comment below will be really appreciated.
Finally, there is one dirty trick under the reason of why I like to use MangaReader: it's very friendly to scrappers because on each page of the manga the image is annotated with an "alt" attribute with the format "[manga name] [chapter number] - [page number]". So I just had to reformat it a bit, adding a pad of zeroes before the chapter and page number so a simple sort of the downloaded files will give me the correct order. MangaFox is not so friendly. This is how to reformat it:
1 2 3 4 5 6 7 8 |
defp normalize_metadata(image_src, image_alt) do extension = String.split(image_src, ".") |> Enum.at(-1) list = String.split(image_alt) |> Enum.reverse title_name = Enum.slice(list, 4, Enum.count(list) - 1) |> Enum.join(" ") chapter_number = Enum.at(list, 3) |> String.rjust(5, ?0) page_number = Enum.at(list, 0) |> String.rjust(5, ?0) {image_src, "#{title_name} #{chapter_number} - Page #{page_number}.#{extension}"} end |
Once I have all the images, I spawn another external process using Porcelain to deal with shelling out to run ImageMagick's Mogrify and Convert tools to resize all the images down to 600x800 pixels (Kindle Voyage resolution) and pack them together into a PDF file. This results in PDF files with 250 pages and around 20Mb in size. Now it is just a matter of copying the files to my Kindle through USB.
The ImageMagick code is quite boring, I just generate the commands in the following format for Mogrify:
1 |
"mogrify -resize #{@image_dimensions} #{directory}/*.jpg"
|
And compile the PDFs with this other command:
1 |
"convert #{volume_directory}/*.jpg #{volume_file}"
|
(By the way, notice the Ruby-like String interpolation we're used to.)

Technically I could copy the MangaReader module files into a new MangaFox module and repurpose the same Workflow logic once I tweak the parsers to deal with MangaFox page format. But I leave that as an exercise to the reader.
The MangaReader module tests do real calls to their website. I left it that way on purpose because if the test fails it means that they changed the website format and the parser needs tweaking to conform. But after a few years I never saw they changing enough to break my old Ruby parser.
Just as a final exercise I imported the Mock package, to control how some inner pieces of the Workflow implementation returns. It's called Mock but it's more like stubbing particular functions of a module. I can declare a block where I override the File.rename/1 so it doesn't actually try to move a file that doesn't exist in the test environment. This makes the test more brittle because it depends on a particular implementation, which is never good, but when we are dealing with external I/O, this might be the only option to isolate. This is how the Workflow test was done. Again, if there is a better way I am eager to learn how, please comment down below.
This is how a unit test with Mock looks like, stubbing both the HTTPotion and File modules:
1 2 3 4 5 6 7 8 9 |
test "workflow tries to download the images" do with_mock HTTPotion, [get: fn(_url, _options) -> %HTTPotion.Response{ body: nil, headers: nil, status_code: 200 } end] do with_mock File, [write!: fn(_filename, _body) -> nil end] do assert Workflow.process_downloads([{"http://src_foo", "filename_foo"}], "/tmp") == [{:ok, "http://src_foo", "/tmp/filename_foo"}] assert called HTTPotion.get("http://src_foo", [timeout: 30_000]) assert called File.write!("/tmp/filename_foo", nil) end end end |
Conclusion
This has been a very fun experience, albeit very short, and good enough to iron out what I have learned so far. Code like this make me smile:
1 |
[destination_file|_rest] = String.split(file, "/") |> Enum.reverse |
The way I can pattern match to extract the head of a list is a different way of thinking. Then there is the other most important way of thinking: everything is a transformation chain, an application is a way to start from some input argument (such as a URL) and go step by step to "transform" it into a collection of PDF files, for example.
Instead of thinking on how to architect classes and objects, we start thinking about what is the initial arguments and what is the result I want to achieve, and go from there, one small transformation function at a time.
The Workflow module is an example. I actually started writing everything in a single large function in the CLI module. Then I refactored into smaller function and chained them together to create the Workflow. Finally, I just moved all the functions into the Workflow module and called that from the CLI module.
Because of no global state, thinking in smaller and isolated small functions, both refactoring and test-driven development are much smoother than in OOP languages. This way of thinking is admitedly slow to get a grip, but then it starts to feel very natural and it quickly steers your way of programming into leaner code.
And the dynamic aspects of both Erlang and Elixir make me feel right at home, just like having an "improved Ruby".
The code of the downloader is all on Github, please fork it.
I am eager to exercise more. I hope this motivates you to learn Elixir. And if you're already an advanced programmer in Elixir or Erlang, don't forget to comment below and even send me a Pull Request to improve this small exercise. I am still a beginner and there is a lot of room to learn more. All contributions are greatly appreciated.
My first week learning Elixir 3 Nov 2015 4:07 AM (9 years ago)
I set myself to try to learn enough Elixir to be comfortable tackling some small projects. After 1 entire week studying close to 6 hours a day (around 42 hours) I'm still not entirely comfortable but I think the main concepts were able to sink in and I can fully appreciate what Elixir has to offer.
This is not my first time touching Erlang though. I was fortunate enough to be able to participate in a small workshop at QCon San Francisco 2009 with no other than Francesco Cesarini. Thanks to him I was able to understand some of Erlang's exquisite syntax, the correct concept of Erlang processes, how immutability and pattern matching governs their programming flow. It was very enlightening. Unfortunately I couldn't see myself doing Erlang full time. I just hoped those mechanisms were available in a language such as Ruby ...
Between 2007 and 2009 Erlang had a new renaissance between the languages aficionados because of the "Programming Erlang" book released by The Pragmatic Programmers, written by no other than Joe Armstrong himself, the Erlang's creator. Dave Thomas tried to push Erlang a lot in 2007, but even he wasn't able to sell Erlang's powerful engine because of the strange presentation of the syntax.
After 2009, José Valim had a long run to release the controversial Rails 3.0 big rewrite (which was fortunately a success) and he decided to step aside and try something else. His own research led him to Erlang for the reasons I mentioned above, but he decided that he could solve the "quirk syntax" problem. You can see some of this very first talks about Elixir in the Rubyconf Brasil 2012 and 2013 recordings. The very early beta was released in 2012 and he finally released the stable 1.0 in 2015. Chris McCord was able to release Phoenix stable soon after.
When I first heard about this, Elixir found its place under my radar. I didn't jump right in though, between 2009 and 2015 we had a surge in "functional programming" interest because of the Javascript renaissance, the release of Scala, Go Lang, Clojure, the promise of Rust, and so on. So I waited, carefully following every one of them.
Then, 2014 came and suddenly everybody else found out about Erlang, with their spartan infrastructure that enabled Whatsapp to serve half a billion users with absurdly low costs and made Facebook buy them for a hefty USD 19 billion! We all knew about the Whatsapp case since at least 2011 but it was not until 2014 that everybody noticed. But not even this was able to steer Erlang to the fore front just yet.
When Elixir stable was released this year, followed by Phoenix stable, I knew it was time for me to start investing some quality time with it. Erlang's core sell itself: everybody else is doing concurrency by means of immutability and lightweight threads (or green threads, NxM strategy between green threads and real threads). It is actually quite trivial to max out the machine just shooting up millions of light processes nowadays. What makes it difficult is to create a system that has the potential to actually achieve 99.9999999% reliability. Spawning processes is easy, how do you coordinate them in the same machine? How do do you coordinate them between different machines? How do you update a living system without bringing it down? How do you handle failures? How to you supervise everything?
These are the questions that Erlang solved decades ago (20 years ago) with the now famous OTP, Ericsson's Open Telecom Platform. Something that was created to meet the performance and reliability needs of telecommunications in large scales. When we say it like this it feels that it will be a royal pain to learn, something akin to the JEE (Java Enterprise Edition), but worse.
And I can tell you that to learn enough OTP to be productive is actually very easy (you won't achieve the legendary 99.9999999% reliability out of the blue, but you'll be able to build something reliable enough). Think of it as a collection of half a dozen modules, with a couple of function interfaces to implement, a few words of configuration and you're basically done. It's so easy and lightweight that in fact many small libraries are written with OTP in mind and it's easy to just "plug and play". It's not a heavyweight server-side only thing.
To harness that power you will need to learn Elixir, unofficially, a language that has an uncanny resemblance to Ruby, built to spill out Erlang bytecode for its BEAM virtual machine. You can't find a better combination.
One Week
Having said all that, let's cut to the chase. You definitely want to get acquainted with the Functional Programming concepts such as immutability, higher order functions, pattern matching. I made a list of links for those concepts in my previous post, I recommend you read it.
Assuming you're already a programmer in a dynamic language (Ruby, Python, Javascript, etc) and you want the fast crash course. Start buying "Programming Elixir" by Dave Thomas and actually do each piece of code and the exercises in order. It's a book so easy to read that you will be able to finish it in less than a week. I did it in 3 days. The Elixir-Lang official website has a very good documentation as well and they link many good books you want to read later.
Then subscribe to Josh Adam's Elixir Sips. If you're a Rubyist, it's like watching Ryan Bates Railscasts from the beginning all over again. Although it's more akin to Avdi Grimm's RubyTapas show, with very short episodes just for you to have your weekly fix on Elixir.
You can watch some of the episodes for free in low resolution, but I highly recommend you subscribe and watch the HD versions. It's well worth it. But about the episodes, there are more than 200 episodes. I've watched more than 130 in 12 hours :-) So I figure I would take another 2 days to watch everything.
You should definitely watch everything if you can, but if you can't, let me list the ones I think are the essentials. First of all, keep in mind that Josh has been doing this for quite a while, when he started Elixir was version 0.13 or below and Erlang was version 17 or below.
For example, episode 171 - Erlang 18 and time highlights the new Time API. You must know about this. Episode 056 - Migrating Records to Maps shows a new feature in Erlang 17 and Elixir where it makes Maps more preferable than the previous Records. Maps are explained in episodes 054 and 055. If you learn the Phoenix web framework, it used the ORM Ecto underneath and Ecto models are Maps, so you must know this.
It means that the first 180 episodes, at least, are using previous versions of Erlang, Elixir, Phoenix, etc and you must keep in mind that new versions will have different APIs. This was one of the reasons I waited for the stable releases, because it was only natural that projects evolve and take time to have stable APIs and chasing several moving targets is really difficult for the uninitiated.
Having said that, watch this list first:
- 001 - Introduction and Installing Elixir.mp4
- 002 - Basic Elixir.mp4
- 003 - Pattern Matching.mp4
- 004 - Functions.mp4
- 005 - Mix and Modules.mp4
- 006 - Unit Testing.mp4
- 010 - List Comprehensions.mp4
- 011 - Records.mp4
- 012 - Processes.mp4
- 013 - Processes, Part 2.mp4
- 014 - OTP Part 1_ Servers.mp4
- 015 - OTP Part 2_ Finite State Machines.mp4
- 016 - Pipe Operator.mp4
- 017 - Enum, Part 1.mp4
- 018 - Enum, Part 2.mp4
- 019 - Enum, Part 3.mp4
- 020 - OTP, Part 3 - GenEvent.mp4
- 022 - OTP, Part 4_ Supervisors.mp4
- 023 - OTP, Part 5_ Supervisors and Persistent State.mp4
- 024 - Ecto, Part 1.mp4
- 025 - Ecto, Part 2_ Dwitter.mp4
- 026 - Dict, Part 1.mp4
- 027 - Dict, Part 2.mp4
- 028 - Parsing XML.mp4
- 031 - TCP Servers.mp4
- 032 - Command Line Scripts.mp4
- 033 - Pry.mp4
- 041 - File, Part 1.mp4
- 042 - File, Part 2.mp4
- 044 - Distribution
- 045 - Distribution, Part 2
- 054 - Maps, Part 1.mp4
- 055 - Maps, Part 2_ Structs.mp4
- 056 - Migrating Records To Maps.mp4
- 059 - Custom Mix Tasks.mp4
- 060 - New Style Comprehensions.mp4
- 061 - Plug.mp4
- 063 - Tracing.mp4
- 065 - SSH.mp4
- 066 - Plug.Static.mp4
- 067 - Deploying to Heroku.mp4
- 068 - Port.mp4
- 069 - Observer.mp4
- 070 - Hex.mp4
- 073 - Process Dictionaries.mp4
- 074 - ETS.mp4
- 075 - DETS.mp4
- 076 - Streams.mp4
- 077 - Exceptions and Errors.mp4
- 078 - Agents.mp4
- 079 - Tasks.mp4
- 081 - EEx.mp4
- 082 - Protocols.mp4
- 083 - pg2.mp4
- 086 - put_in and get_in.mp4
- 090 - Websockets Terminal.mp4
- 091 - Test Coverage.mp4
- 106 - Text Parsing.mp4
- 109 - Socket.mp4
- 112 - Benchfella.mp4
- 113 - Monitoring Network Traffic.mp4
- 124 - Typespecs.mp4
- 125 - Dialyzer.mp4
- 126 - Piping Into Elixir.mp4
- 127 - SSH Client Commands.mp4
- 131 - ExProf.mp4
- 132 - Randomness in the Erlang VM.mp4
- 135 - Benchwarmer.mp4
- 138 - Monitors and Links.mp4
- 139 - hexdocs.mp4
- 141 - Set.mp4
- 142 - escript.mp4
- 144 - Erlang's
calendarmodule.mp4 - 145 - good_times.mp4
- 153 - Phoenix APIs and CORS.mp4
- 155 - OAuth2_ Code Spelunking.mp4
- 156 - Interacting with Amazon's APIs with erlcloud.mp4
- 157 - Playing with the Code Module Part 1 - eval_string.mp4
- 159 - Simple One for One Supervisors.mp4
- 160 - MultiDef.mp4
- 171 - Erlang 18 and Time.mp4
- 172 - Arc File Uploads.mp4
- 174 - ElixirFriends_ Saving Tweets with Streams and Filters.mp4
- 175 - Pagination with Ecto and Phoenix using Scrivener.mp4
- 176 - Prettying Up ElixirFriends.mp4
- 178 - Memory Leaks.mp4
- 179 - Rules Engine.mp4
- 180 - Collectable.mp4
- 182 - Phoenix API.mp4
- 183 - React with Phoenix.mp4
- 184 - React with Phoenix Channels.mp4
- 185 - Mix Archives.mp4
- 186 - Automatically Connecting Nodes.mp4
- 187 - Compiling a Custom AST Into Elixir Functions.mp4
- 190 - Testing Phoenix Channels.mp4
- 193 - Linting with Dogma.mp4
- 194 - Interoperability_ Ports.mp4
- 196 - Crashing the BEAM.mp4
- 200 - Custom Types in Ecto.mp4
- 201 - Tracing and Debugging with erlyberly.mp4
- 202 - Exception Monitoring with Honeybadger.io.mp4
- 203 - plug_auth.mp4
- 204 - Behaviours.mp4
This is roughly half of what's available in Elixir Sips. All the other episodes are also interesting, but if you're just getting started, this list should be enough to wet your fingers in the language.
Railers will enjoy Phoenix and the ecosystem that is growing around it. You can already authenticate through OAuth2, do pagination will_paginate style with Scrivener, file uploads carrierwave style with Arc, deploy to Heroku.
For more exercises, you can easily connect to HTTP endpoints using HTTPoison, parse HTML with Floki, parse JSON with Poison. For more libraries, you can follow this Github page called Awesome Elixir which lists many new Elixir packages that you can use. But make sure you walk yourself through the basic concepts first. Elixir has a Rake-like task management system with built-in Mix, you can add dependencies in a Gemfile-like file called Mix.exs, which every projects has. You can add dependencies through Github urls or from Hex.pm which is like Rubygems.org.
In this learning process, the concepts that I find more important to learn first are:
- Elixir basic syntax and concepts (pattern matching, loops through recursion, immutable state, primitive types including Maps, the pipe operator)
- The concept of processes, nodes, and intercommunication between processes and nodes, including Monitors and Links.
- OTP Basics, learn what GenServer, GenEvent, GenFSM are.
After you learn that you can figure out how to build OTP applications and do something practical for the Web using Phoenix, particularly you will want to learn everything about Phoenix's Channels, the infrastructure for robust, fast and highly concurrent WebSockets.
This is it. This is my first week learning Elixir, and my next step is to train myself by doing more exercises and also learning more about Phoenix. Even though Phoenix is inspired by Rails, it is not a clone, it has its own set of unique concepts to learn and this is definitely going to be a very interesting ride.
If you have more tips and tricks for beginners, feel free to comment below.
Phoenix Experiment: Holding 2 Million Websocket clients! 29 Oct 2015 5:28 AM (9 years ago)
Update: 11/04/15 As I said in the article below, Gary Rennie, one of the people doing the experiment finally posted a very detailed account of how they were able to achieve this incredible milestone. Read all about it here
If you still don't follow the Phoenix Framework (Web framework written in Elixir) creator, Chris McCord, you should. In the last week he has been experimenting how far Phoenix can go. He was able to set up a commodity Rackspace server with 40 cores and 128GB of RAM (although it seems he only needed less than 90GB) and 45 other servers to create an astounding 2 million clients with long running Websocket connections and broadcasting messages to all of them at once!
The thread is very interesting so I decided to compile the most interesting bits directly from his Twitter feed. Take a close look!
Chris or someone from the team will probably report the details about this experiment soon, but because of those testings and benchmarks Phoenix master already got some bottleneck fixes and it is pretty ready for prime time! If you were not aware he is writing a book about Phoenix for The Pragmatic Programmer and I recommend you buy the beta as well.
To give some perspective, Websocket connections will probably sit idle and no real app will broadcast to all users at once all the time, this experiment is trying to exercise the most out of the metal. One comparison would be this Node.js experiment holding 600k connections in a small machine but CPU load going up faster. Apples to Oranges comparison, but just to keep perspective.
10/20/15
josevalim: 128k users connected. @chris_mccord broadcasts a message to all in the channel, @TheGazler receives it immediately on the other side.
chris_mccord: @j2h @josevalim @TheGazler yep! 4 cores, 16 gb memory. Single machine
10/21/15
chris_mccord: Heres what a Phoenix app & server look like with 128000 users in the same chatroom. Each msg goes out to 128k users!
10/22/15
chris_mccord: @andrewbrown @josevalim it’s basically this app with some optimizations on phx master
10/23/15
chris_mccord: We just hit 300k channel clients on our commodity 4core 16gb @Rackspace instance. 10gb mem usage, cpu during active run < 40% #elixirlang
chris_mccord: @chantastic @bcardarella +1 to prag book. My RailsConf Elixir workshop also might be a nice companion to the book
10/24/15
chris_mccord: @SkinnyGeek1010 these are 300k individual ws connections (joining a single channel)
chris_mccord: Calling it quits trying to max Channels– at 333k clients. It took maxed ports on 8 servers to push that, 40% mem left. We’re out of servers!
chris_mccord: @bratschecody 300k on a single server, with connections pushed from 8 servers
chris_mccord: To be clear, it was a single 4core server, 16gb. Traffic was pushed from 8 servers to open 333k conns. Out of ports, need more servers
chris_mccord: @perishabledave 30-40% under active load. Once 333k established, idle.
10/25/15
chris_mccord: @eqdw I’m sold on EEx. But Phoenix has template engines with 3rd party haml/slim options
10/26/15
bratschecody: Whenever @chris_mccord speaks it's how they've increased clients a single Phoenix server is handling. 128k, 300k, 330k, 450k. DON'T STOP MAN
chris_mccord: @gabiz we also improved our arrival rate by 10x, now reliably establishing conns at 10k conn/s . Next up is reducing conn size
chris_mccord: Consider what this kind of performance in a framework enables. With Pusher you pay $399/mo for 10k conns. This box is $390/mo for 450k conns
chris_mccord: I’m sure comparable hardware on AWS is even cheaper
10/27/15
chris_mccord: On a bigger @Rackspace box we just 1 million phoenix channel clients on a single server! Quick screencast in action:
chris_mccord: @AstonJ accordingly to recent tests, ~ 2 million uses 58GB
chris_mccord: @perishabledave 40core / 128 gb. These runs consumed 38gb, cpu was very under-utilized. Ran out of ports, so spinning up more boxes
chris_mccord: Thanks to @mobileoverlord and @LiveHelpNow , they are spinning up 30 more servers to help us try for 2 million channel clients on one server
chris_mccord: @AstonJ just standard box with ulimit and file descriptors set higher
chris_mccord: @cbjones1 @Rackspace we are, but we using 45 separate servers to open the connections :)
chris_mccord: @cbjones1 @Rackspace 65k ports per remote ip right?
10/28/15
chris_mccord: Final results from Phoenix channel benchmarks on 40core/128gb box. 2 million clients, limited by ulimit
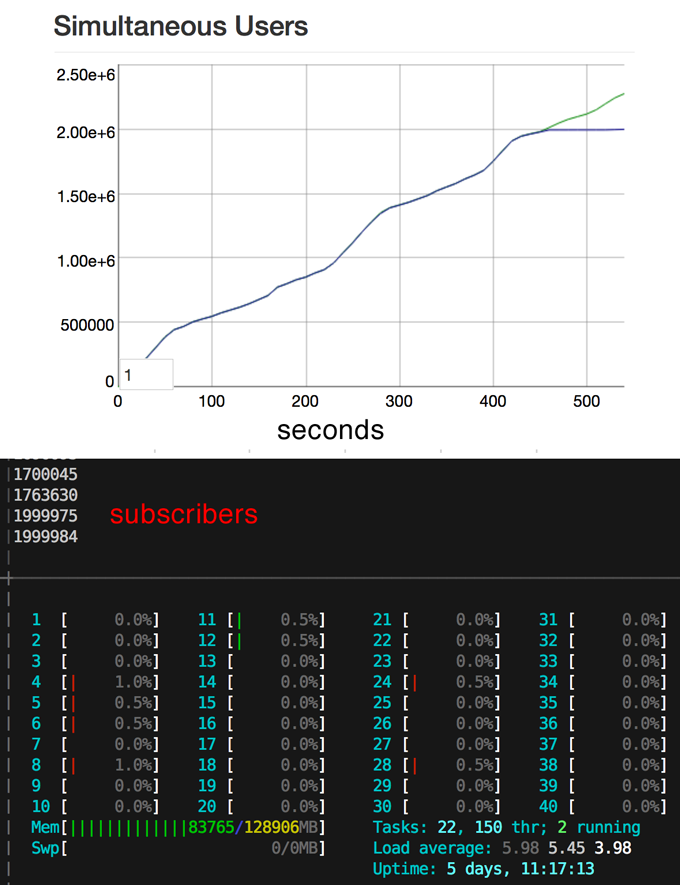
chris_mccord: The chat app had 2M clients joined to one topic. We sharded pubsub & broadcasts go out in 1-3s. The app is totally snappy at these levels!
chris_mccord: @ashneyderman will publish writeup soon. Only knobs were about a dozen sysctrl/ulimit max files/ports. Stock ubuntu 15.10 otherwise
chris_mccord: One surprising thing with the benchmarks is how well stock ubuntu + dozen max limit options supports millions of conns. No kernel hack req’d
joeerl: @chris_mccord So now you understand why WhatsApp used Erlang :-) - obvious really.
chris_mccord: @lhoguin @felixgallo @joeerl @rvirding I accidentally forgot to set the ulimit higher than 2M, and we’re out of time on the servers now
chris_mccord: @lhoguin @felixgallo @joeerl @rvirding we had 45 tsung clients with capacity to send 2.5M. Every indication says it would’ve been just fine
chris_mccord: @felixgallo @lhoguin @joeerl @rvirding now that we know the gotchas, pretty quick turnaround (few hours with svr setup, coordinating nodes)?
chris_mccord: @felixgallo @lhoguin @joeerl @rvirding @ErlangSolutions devil is in the details tho. We find a bottleneck at 2.25M & spend 48 hours+ fixing
chris_mccord: @mentisdominus it’s a different story when we broadcast to 2M subscribers

Personal Thoughts on the Current Functional Programming Bandwagon 28 Oct 2015 11:14 AM (9 years ago)
Today, Git is unanimously the only best way to manage source code. Back in 2009, when it was still gaining traction, there were some detractors. Some would say that they wouldn't use Git because it was written in C, instead of C++. To that, Linus Torvalds famously retorted:
*YOU* are full of bullshit.
C++ is a horrible language. It's made more horrible by the fact that a lot of substandard programmers use it, to the point where it's much much easier to generate total and utter crap with it. Quite frankly, even if the choice of C were to do *nothing* but keep the C++ programmers out, that in itself would be a huge reason to use C.
To this day, many still try to reason against Linus' arguments. I am of the opinion that one of the reasons Git and the Linux kernel are good is exactly because of the choice of C (and, for better or worse, the bullying culture of their benefactor dictator, Linus).
Languages have features, they have ancestors, they are imbued with some sense of philosophy and purpose. Because of that it's easy to see why young people choose languages in an attempt to fit in to some group. It's not so much because a language has some style of syntax or because it's insanely fast or because it's elegantly implemented.
Some people like Google and feel more compelled to justify their choice of Go. Some people like Apple and feel more compelled to justify their choice of Swift or Objective-C. Some people are naturally more academic, and don't feel so much the need to justify their choice of Haskell - which, by the way, has an unofficial motto of "Avoid success at any costs."
In particular, young programmers feel the need to justify their choices using some sort of logical reasoning. Trying to explain language choices because of features is a fallacy. You don't need to explain why you listen to Bruno Mars, if you like him just do. You don't need to explain why you eat Thai food, if you like it just do.
Which is why, most blog posts and articles trying to justify the choice of a language or tool are very unreliable: because they can't escape being biased. There is no logical reasoning that can unambiguously define one language as the winner over other languages. Any language that is in use today has applications, some more than others, of course.
Easier said then done, I know. Bear with me.
Each new generation struggles to find identity, they have the need to not just follow what the previous generation left behind.
And we, programmers, are naturally averse to "legacy" anyway. It's in our DNA to try to rewrite history every time. It's easy to write new stuff, it's very difficult to make something that lasts. Because of that, many of us go back to the longer past in order to justify our new choices as "rediscoveries". It may be one reason the Lisp people are so persistent.
The Hype
You don't only have a dozen languages to fight against if you're a language extremist. You have hundreds.
There are not only imperative, object-oriented, funcional paradigms in programming. There are many more paradigms.
It's rare to have a language that implements only one paradigm, most languages are multi-paradigm.
Functional paradigm - the current new kid on the block - is not the best. It's just another paradigm. Electing one over the other is denying a long history of computer science research and achievements.
Why the current trend in functional languages? Because it is a departure from the previous generation, very compelling for new folk trying to make a dent in history.
It makes you feel special to be able to discuss about functional purity, monad vs unique type, and other oddities. That's all there is to most of the discussions.
- You have the credibility track of a Paul Graham's essays.
- You have the coincidental choice of Javascript gaining sudden traction and having some functional aspects.
- You start realizing that managing mutable state generates a lot of hassles and make parallel programming difficult and then realize that some functional languages offer immutable state and that triggers an epiphany.
- You hear stories, Bank Simple using some Clojure, a Clojure-based machine learning startup, Prismatic, getting a hefty Series A, or the amazing story of the small Erlang-based startup, Whatsapp, being bought by USD 19 billion. How can you not pay attention?
Some Benefits
The functional style of programming, of dealing with the transformation pipeline of immutable things without shared state, do actually improve our way of thinking about problem resolutions. But so does any other programming paradigm. Declarative programming, for example, where you define computation logic without defining a detailed control flow leading to SQL, regular expressions.
There are indeed benefits of so many discussions around functional programming. At the very least the new generation is getting the chance to grasp old and really useful concepts such as:
- First Class Functions - when there is no restrictions on how a function can be created and used.
- Higher Order Functions - a function that can take a function as an argument and return functions.
- Lexical Closures or just Closures - the definition is bit difficult but it's usually there when you can define a function within a function.
- Single Assignment (from which you can have Immutability) - when a variable is assigned once, at most.
- Lazy Evaluation - when execution is deferred until really necessary.
- Tail Call Optimization (Tail Recursion) - in practice, if the last expression of a recursive function is itself, it can just jump back to the beginning instead of creating a new stack frame overhead.
- List Comprehensions - creating lists based on existing lists. Python programmers are more acquainted with the term, at least.
- Type Inference (Hindley-Milner Type System) - in practice it allow you to write code without having to declare static types all the time and leave it to the compiler to infer the correct types. Gives the best of both dynamic and static world.
- Pattern Matching - dispatching mechanism to choose between variants of a function (which is also important for Logic Programming and to differentiate between declarative and imperative paradigms)
- Monadic Effects - now, this is one of the most difficult concepts to really understand.
Dynamic languages such as Ruby, Python, Javascript already made us comfortable with the notions of first class functions, higher order functions, closures, list comprehensions. Existing languages such as Java and C# have been deploying some of those features such as closures, comprehensions.
Type Inference has been quickly gaining adoption since at least 2004 when Scala, Groovy, F# brought it to mainstream discussion. Then C# 3.0+ adopted it, now Rust, Swift were designed with it in mind.
We are used to String Patterns because of Regular Expressions, but the Pattern Matching paradigm feels alien at first. Erlang is probably the most recognizable language that uses it, and now Elixir and Rust sport this feature and you should start to paying attention.
There are many more concepts but the list above should be a fair enough list. But out of all of them the most difficult to wrap one's head around is Monads. A Monad can be defined as a functional design pattern to describe a computation as a sequence of steps.
Pure functional languages are supposed to not have side-effects. This simple statement can spur quite a lot of heated discussions. You will come into contact with other concepts such as referential transparency (where you can safely replace an expression with its value). You will probably hear about how purely functional languages wrap side-effects such as I/O consequences using Monads, and that there are several different kinds of Monads (Identity, Array, State, Continuation, etc).
Regardless of Haskell Monads and the intricasies of the mathematics behind it, you have probably already bumped into Monads one way or the other. One could argue that Javascript Promises is a kind of Monad. And you also have ML inspired Option Types which are of the same family of Haskell's Maybe Monads.
Rust is all built around the Option Monad (also known as Maybe Monad, from Haskell, but the ML language came before and named this pattern as 'Option'). Even Java 8 recently obtained this new feature and named it Optional. In Swift it's also named Optional. It's the best way we know today to deal with errors, vastly superior than dealing with returning error codes, or (argh), raising exceptions or dealing with Null.
Ruby is known as a multi-paradigm object-oriented and functional language, an amalgam between Smalltalk and Lisp, and the next version 3.0 will probably see the official inclusion of an optional operand inspired by the #try method we already use for safe method chaining. And we might also see immutable strings, making it easier to write more functional constructs while being more efficient for the garbage collector to boot.
Conclusion
Functional programming is not the end game for programming paradigms. It's a hell of a good one, and the current needs fit in nicely with the aforementioned techniques. But don't be fooled, we have been scaling very large applications that lasted years with no functional language features. C, C++, COBOL, ADA, have been driving very large systems for decades. Functional is great to have, but it's not utterly necessary if we didn't.
We are in need of transforming large amounts of data points into more useful aggregates, we are in need to reason about those transformations a bit better and be able to execute volumes of small transformations in parallel and in distributed infrastructures. Functional techniques reasoning do help.
Haskell is widely acclaimed as the language that represents the functional programming ideals. But it is meant to be an academic language, a compilation of the best research in the field. It's supposed to not be mainstream, but to give an implementation for those more inclined to dive deeper into the rabbit hole. There were many older languages that preceded it and you could be interested such as ISWIM, Miranda, ML, Hope, Clean. Haskell kind of compiles the best of them in one place.
Clojure is trying to bring those functional concepts to the Java world. The Java legacy integration is one of its strength but also the source of its weaknesses. It stil remains to be seen how far it can go.
Elixir is my personal bet as it drives the industrial strength battle tested Erlang to the forefront. It's undeniably a Ruby for the functional world. It's actor model is what inspired what you have today in Scala/Akka. Go's goroutines and channels are a close match.
Many other languages are receiving the functional sugar coating these days. Javascript and Ruby have some of the functional features mentioned above. Java and C# didn't have functional influences in their inceptions so they are receiving a few features just to remain competitive. But even without being a pure functional language, many of those features have been adapted and implemented in one way or another.
In the near future we will probably have more hybrid languages leading the pack. Go, Swift and Rust are good examples of modern and very young languages that get inspiration in many different paradigms. They avoid pureness in order to be actually accessible to more developers. Pureness ends up alienating most people. We will find the more mainstream languages somewhere in the middle.
In the meantime, by all means, do dive deeper into the functional programming concepts, they are quite interesting and finally today we can have more practical applications instead of just academic experimentation. But don't try to make a cult out of this, this is not a religion, it's just one small aspect of the computer science field and you will benefit if you incorporate this with other aspects to have a better picture of our field.
How Fast is Elixir/Phoenix? 27 Oct 2015 10:23 AM (9 years ago)
I like to know what my tools are capable of, because that says how and where I can use them. I will not bore you by stating how awesome Elixir and Erlang are. You've heard/read it before.
I will also not bore you with "15 minute blog" tutorials as there are many out there already.
Instead, I'd like to show what Phoenix - the Rails-like web framework written in Elixir - is capable of.
You can make the same simulation as I did by repeating the following steps:
- Install Elixir and Phoenix
- Generate a skeleton Phoenix app with a simple Post model
- Create a Heroku app and add the necessary buildpacks
- Deploy the app to Heroku and run the migration
- Open a remote console to Heroku and run the following to load the database with sample data:
1 2 3 4 |
(1..1000) |> Enum.map(fn (n) -> %{title: "title #{n}", body: to_string(n)} end) |> Enum.map(fn (params) -> Blog.Post.changeset(%Blog.Post{}, params) end) |> Enum.each(fn (changeset) -> Blog.Repo.insert(changeset) end) |
Feeling strange? Read the Programming Elixir book as soon as possible!
If you're a Rails developer, this is the equivalent of doing:
1 |
(1..1000).each { |n| Post.create title: "title #{n}", body: n } |
Before anyone starts, No: Ruby is not better or Elixir is not worse because of this particular difference in lines of code, do not let this illusion fool you here or in any other language comparison.
Now we can fire up Blitz.io (load testing tool). The default settings of the free plan will simulate increasing the number of concurrent users from 1 all the way to 250. Blitz's default timeout is 1 second which is not a lot for web applications under heavy load, you can increase it up to 20 seconds just to be safe.
We will test the "/posts" endpoint, which will fetch 1,000 rows from the database (and it will suffer from bottlenecks in query processing time and the restricted amount of concurrent connections that the free Postgresql plan allows).
I ran this simulation several times and this is the result:

Through the console a single request, rendering those 1,000 rows, is taking around 150ms end to end (fast!):
1 2 |
[info] GET /posts [info] Sent 200 in 152ms |
But when we put it under heavy traffic the response time go all the way up to 15 seconds. The app keeps up and responds all requests without dropping any of them. It takes more and more time because of the length of the request queue and aforementioned database bottlenecks.
This is expected because we are running on the slowest possible options on Heroku: the free tiers. The web dynos run in shared machines with possible heavy neighbors and the free database does not give any guarantees. So the Phoenix app is having to really struggle to deal with the ridiculous amount of traffic without a lot of resources to back it up. The free Postgresql database is probably the cause of most of the bottlenecks and increase in response time.
For example, if we remove the database from the equation and just return the default homepage (which I tweaked to render an additional random number, in order to know that it's not cached in any way) gives a very different result:

It's still on the same free small web dyno, and it's rendering and returning a very simple 2.2kb HTML, compared to the previous 560 kb posts page.
It averages out to around 17ms for the entire roundtrip but the actual processing time of the page inside the dyno, as stated by the logs, is this:
1 2 |
[info] GET / [info] Sent 200 in 389µs |
This is microseconds, a fraction of a milisecond, which is crazy fast. Response times still bump up a bit and goes all the way to 25ms, which is still very fast. Many things may be responsible for the bumps but I would bet it is heavier neighbors in the same machine making our tests dirty. We can't avoid it in a cloud environment but it's not bad.
Of course, in real world applications I would be careful to not ever have stupid endpoins returning half a megabyte worth of HTML and holding the database waiting for hundreds of rows that could be easily cached in-memory or even in memcached. This is a synthetic, very naive test just to see how far it can go. We just saw 2 extremes: an almost-static tiny page rendering and a stupid heavy rendering. A custom app, correctly done, will fall in between those.
This is speed that can't be ignored. It feels strange in the beginning, but Elixir quickly reminds you of the joys of programming in Ruby for the first time. Combined with the heavyweight industrial strength of Erlang's OTP underpinnings, and the above results, I can easily recommend Phoenix for any number of microservices. It's the best place to start testing in production as soon as possible and check how productive it can be.
I'm very interested in exploring OTP more, so you can expect me writing somemore about it in the future.
Dynamic Site as fast as a Static Generated One with Raptor 20 May 2015 6:51 AM (9 years ago)
If you ask what's the best way to do a fast content site, many people will point you to Jekyll or a similar tool.
The concept is simple: nothing will be faster than a statically generated website. But writing a complete website statically is not viable because you will be repeating HTML code for headers, footers, sidebars, and more across all pages. But current tools such as Markdown, SASS, Sprockets (or Gulp/Grunt tasks if you're using a Javascript clone of Jekyll) will make it a whole lot easier to properly structure, organize and separate concerns on what are reusable snippets and what is just content. Then it will "compile" the content and the snippets into complete HTML pages ready to just transfer to any web server.
Because it's already static files, the web server doesn't need to reverse proxy to an application server or have any other kind of dynamic processing, just serve the files as it would serve any other asset. And this is Fast.
If you're doing a personal blog, a simple and temporary hotsite, something that you know won't change too much, and if you're a developer, this is possibly the way to go: fire up Jekyll, write your content in Markdown, compile, copy assets to S3 or Github Pages, and you're up.
Problem is: what if I want more from my content web site? What if I don't want to have developer tools around to compile my pages and I just want a plain simple Administrative section to edit my content? What it I want to mix a static content section with my dynamic web application (an ecommerce, social network, etc)?
Then I have to use Rails and Rails is very slow compared to a static web site. Or is it?

I've fired up Blitz.io to a small Heroku website (Free Plan, 1 dyno) with Heroku Postgresql and Memcached Cloud. The code for this test web site is on my Github account and it's a plain Rails 4.2 project with Active Admin and all the perks of having a Rails based code structure.
So, the graphs on the left side of the image is Blitz.io hitting hard on the poor small Heroku dyno more than 7,000 times in 60 seconds and getting a response of 12ms in average for the 404.html static page. This is quite good and it's the fastest you will get from a single 512Mb web dyno. More importantly: it keeps quite consistent even increasing the number of concurrent simulated users hitting the same page without ever timing out or erroring out.
Now, the surprise: the graphs on the right side is content generated in Rails and served through Raptor (Passenger 5). It's the same Blitz.io default configuration running almost 7,300 requests within 60 seconds, increasing from 1 up to 250 concurrent simulated users and receiving no timeouts or errors with an average response time of around 20ms!
That's not too shabby! More importantly is the similarity between the 2 sets of graphs: it means that response time does not increase with the added concurrent users and more simultaneous requests over time, so it means that this setup scales!
Yes, Rails can Scale!
How is it done?
So, this is obviously a very specific situation: replacing a statically generated website with a dynamic web app that outputs static content. There are different moving parts to consider.
The very first trick to consider: generate proper Etags:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
class PagesController < ApplicationController def index @pages = fetch_resources if stale?(resources_etag(@pages)) respond_to do |wants| wants.html end end end def show @page = fetch_resource(params[:id]) fresh_when last_modified: @page.updated_at.utc, etag: "#{deploy_id}/#{@page.cache_key}", public: true end ... end |
This is what's done in the PagesController. Learn more about the #stale? and #fresh_when methods that set proper Cache-Control, Last-Modified, Age and Etag HTTP headers.
The idea is simple: if the generated content does not change between requests, the application does not have to process all the views and helpers and models to output the very same HTML again. Instead, it will simply stop processing at that point and return a simple HTTP 304 Not Modified header to the browser.
Now, even if this works, each user will have to receive a complete HTTP 200 response with the generated HTML. So if 250 users connect, at least 250 HTML responses will have to be generated so the next request will get only the HTTP 304 response. That's where Passenger 5 (a.k.a. Raptor) kicks in!
It has an internal small cache to keep tabs on the content and cache control headers. So, after the 1st user requests the page, it gets cached. The next users and requests will get the stale content from the cache instead of having Rails regenerate it. In practice it's almost as if Passenger is serving a static file which is why performance and throughput behaviors are quite similar in the graphs.
There is another problem: to check if a content is fresh or not, it needs to check the source content itself: the database data. And fetching from the database to check it is slow and doesn't scale as well.
One workaround is to cache this information in a faster storage, such as Memcached:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
class PagesController < ApplicationController ... private def fetch_resources cache_key = "#{deploy_id}/pages/limit/10" Rails.cache.fetch(cache_key, expires_in: 1.day) { Page.recent.limit(10) } end def resources_etag(pages) recent_updated_at = pages.pluck(:updated_at).max || Time.current etag = "#{deploy_id}/pages_index/#{recent_updated_at.iso8601}" { last_modified: recent_updated_at.utc, etag: etag, public: true } end def fetch_resource(id) cache_key = "#{deploy_id}/page/#{id}" Rails.cache.fetch(cache_key, expires_in: 1.hour) { Page.friendly.find(id) } end end |
This is what those methods do in the PagesController. The index action is trickier as it's just a list of pages. I can cache the 10 most recent items. I can generate the etag based on the item that was most recently updated. I can combine those two. It depends on how often you change your content (most static web sites don't add new content all the time, if you're a heavily updated website you can decrease the expiration time for 1 hour instead of 1 day, and so on).
For the show action it's more straightforward as I can just cache the single resource for an hour or any range of time and that's it. Again, it depends on how often you change this kind of content.
Now, the controller won't hit the database all the time. It will hit Memcached instead. Because Memcached Cloud or Memcachier are external services, it's out of the Heroku dyno premises so it will have network overhead that can go all the way to 30ms or more. Your mileage may vary.
After the content is fetched from the cache, it generates the ETags to compare with what the client sent through the If-None-Match header. Notice that I'm customizing the etag with something called deploy_id. This is a method defined in the ApplicationController like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
class ApplicationController < ActionController::Base protect_from_forgery with: :exception private def deploy_id if Rails.env.production? ENV['DEPLOY_ID'] || '0' else rand end end end |
It's an environment variable. Because the Etag only checks if the content changed, what if I change my stylesheets or anything about the layout or HTML structure? Then the client won't receive this change. Because I only make those changes through a new deployment to Heroku I can also manually change it (or add a Capistrano task, or something similar for automation). Then all Etags will change at once, forcing Rails to generate the new pages and cache them again. This is the fastest way if you want to invalidate all the cache at once.
The important part is for Passenger to receive a Cache-Control: public to kick in its internal cache. Beware that you can't cache everything, only what's publicly visible. If you have authenticated areas, you don't want to cache those as the content will probably be different for different users. In that case you will need to know about Fragment Caching and other techniques to cache snippets within the logged in pages.
The best thing is that you can rely on Rails alone to serve both blazing fast public pages that don't need a separated pipeline to generate static files and the usual dynamic stuff you love to do.
Extras
I won't add details here because the code I made available on Github already shows how it's done but this is the extra stuff I'd like to highlight:
- ActiveAdmin is the best administration engine out there for your projects, use it.
- Bourbon together with Neat and Bitters is the best option to fast and clean stylesheets. Avoid Bootstrap if you can.
- FriendlyId is still the best way to generate slugs for your resources, don't write yet another slug generator from scratch.
- Redcarpet is still the best Markdown processor.
- Rouge is the surprise: it's far better than the good old CodeRay or Python's Pygments for code syntax highlighting. It's compatible with Pygments CSS themes and it's easily pluggable with Redcarpet, making it a nice combo.
Conclusion
Making a fast web site is a matter of understanding the basics of the HTTP protocol and taking advantage of web servers' ability to deliver cached content. The more you cache, the better!
There are more to come from the Passenger camp, they're researching ways to cache content based on user's profiles. Serving speficic cached content for anonymous users and different content for Administrators, for example. You should check it out and contribute if you can.
You can also serve a generic cached page through this method and use Javascript to fetch small snippets to fill in specific user content as well, such as Notification badges or something similar, so you can still take advantage of a full page cache and have some user-specific dynamic content.
And before someone asks, yes I tried Puma with Rack::Cache in the Web App. In the Blitz.io test, it blows up fast, timing out and erroring out all request after a while as its request queue blow up. Seems like the time to fetch from Memcached over the network is too much for it's queues to hold and getting all the way down to Rack::Cache was not fast enough as well. I've replaced Puma for Raptor and took off Rack::Cache and the results were dramatically better in this particular scenario. But by all means, more tests and data would be welcome.
Now it's up to your creativity: once you get this concept you can bend it to your needs. Do you have any other suggestion or technique? Comment down below and share! And as the example site code is available I'll be more than happy to accept Pull Requests to improve it.
[Off-Topic] First Time in São Paulo, What to do? 24 Aug 2014 12:17 PM (10 years ago)
TL;DR: This is the Google Maps with all the places I mention in this post already set up in layers over the city.

If you read my mini City Guide from last year you're probably already acquainted with the Geography of the place. It's always important to be aware of your surroundings when you're in a foreign land.
Now you're here, you don't have a lot of time to randomly explore. And that would not be efficient anyway because São Paulo is humongous in size. I live here all my life, almost 4 decades, and I didn't explore everything yet.

But if you're near a Subway station (Metro) you're in luck as many of the staples of the city are at walking distance from the many stations or not far with Taxi from one of the stations. So let me pinpoint a few must-go places.
For the Feijoada you will go to Bolinha and for great Barbecue you will choose Vento Haragano or Fogo de Chão. Unfortunately none of them are at walking distance from Paulista Ave, but they are close by Taxi and I recommend you do so. They are definitely not on the cheap side, but if you're here, you should try our best.
Another staple of São Paulo: it's intense night life. You will want to try it at least once. After sunset, all kinds of tribes spread around the city. If you're staying in the Paulista Ave, you're already next to some of those places: Augusta St.
At Augusta and nearby streets such as Bela Cintra, you will find Beco 203 if you like disco, rock, some alternative bands and indie music. FunHouse, if you're young as the population is just above teenagers. D-Edge is a 3 story high warehouse with great decoration, rock and international DJ's. Lab Club for pop, electronic, and enjoy the molecular drinks.

If you're looking for the popular Brazilian country music, Sertanejo, try Villa Country and Wood's. Now, if you want something more VIP, go to Club A or Pink Elephant. If you like GLS parties, you want to go to The Week, Bubu Lounge or A Lôca.
Just don't party too hard on the conference days :-)
So, you did party hard. Now it's time to fix your hangover. And for that, I recommend you go to Bella Paulista which is a 24-hours super bakery with everything you need, from bread, to sandwitches, soups, and everything to calm you down.

If you're more on the intellectual side, you're also in luck, because MASP - The São Paulo Art Museum is right around the corner, together with Casa das Rosas, for literature and poetry, and finally Itaú Cultural, a reference in terms of culture and research, with many expositions you can visit, do check it out.

There are theaters around but unfortunately you would need to understand Brazilian Portuguese to appreciate it, such as Comedians Comedy Club.
Now, you can go to Old Downtown to appreciate some of the classics. First stop is very early in the morning at Metro São Bento. From there you can reach Mercado Municipal, our humongous central market, to try fresh ingredients, spices, and everything a high end, high quality, one of a kind market has to offer. Definitely visit it if you can, try the sandwitches and other food there. You can learn a lot about the culture of anyplace by visiting its central market.

Then, go to Metro Estação da Luz, from there you can go visit Museu da Língua Portuguesa. It's the only museum in the world dedicated entirely to a language. This will enlight you a lot about our Portuguese language. And right next to it you can go to Pinacoteca to enjoy some more great art.

If you're into History, go to Metro Ipiranga and get a bus or taxi to the Parque da Independência and at the same place the Museu Paulista - and unfortunately, as of now, the place is closed for restoration. Check their website for updates.

If you're staying during the weekend, I recommend going to Metro Liberdade on Sunday. Liberdade is the Asian neighborhood of São Paulo. Some may be surprised that it's smaller than you might think given how well known the place is. The main places are near the Metro and the Galvão Bueno Ave. There are several japanese restaurants, stores that sell japanese ingredients and foods and Sunday they have an outdoor fair. Quite hidden around there you can also find the Busshinji Temple and the Museu Histórico da Imigração Japonesa, the museum about the century old immigration of Japanese to Brazil.
Now, if you're into being healthy, going to relax in a park is another great option. Again, right next to Paulista Ave, you will find Parque Trianon. But of course, the staple of the city is Parque do Ibirapuera. You can go to Metro Vila Mariana and get a bus or taxi to the park. It's huge, although just half the size of New York's Central Park. But you will find museums, expositions and other activities around, it also rents bikes so you can have a ride inside the park if you want.

To wrap it up, night is approaching, the sun is setting down, so you will go to Metro Vila Madalena which is the traditional region for bars and bohemians. Bar Astor, Boteco São Bento, Bar Filial. Particularly you want to go straight to Aspicuelta Street where you will find many of the great bars next to each other such as Melograno Bar, Mercearia São Pedro, Salve Jorge, São Cristóvão.
There are several places I didn't even attempt to mention such as Memorial da América Latina, Berrini, Cidade Jardim, Edifício Itália, Museu do Teatro Municipal, Edifício Matarazzo, Pateo do Colegio, Espaço Cultural Catarse, Centro Cultural Fiesp, Instituto Cervantes, Teatro Eva Herz, Galeria Vermelho, Mosteiro de São Bento, 25 de Março and so many more places.

If you're staying at least 2 weeks you can attempt to go to more places. São Paulo is known for it's dozens of malls as well, they are literally everywhere and it's easy to find as everybody knows where they are. But the items in this list are not so well known even for people that live here, so they're interesting to go visit.
Do you have any other questions? Leave a comment below. And if you're from São Paulo and want to add more tips, also leave a comment below.
[Off-Topic] #noEstimates Debunked 7 Oct 2013 6:35 AM (11 years ago)
Update: One thing I forgot to mention. If you didn't want to read all this or if you disagree altogether. Ask yourself: you don't want due dates. So are you willing to give up your salary due date as well? Why can't you estimate what to deliver and your client has to pay you regardless? Let's make this even: you do #noEstimates if, and only if, you are willing to #noSalary. Your employer shaw withhold your payment until you deliver, and in this scenario your payment must be depreciated the longer it takes. Unfortunately labor law doesn't allow that. But it would be an interesting scenario.
There's been a lot of people currently talking about #noEstimates. I've read most of the arguments in its favor and you can Google it easily enough so I won't make any extensive references to any of them. The gist of it is that estimates will never be good enough, the more specification and planning you do seems to never increase the quality of the estimates, specially because in a dynamic market specification change too often and the more estimation efforts you do, the more the waste. And because estimates seems to be such a waste why not get rid of them altogether?
Feels like a noble idea, specially for software developers. Software is maleable, it's abstract, it just feels like it doesn't fit traditional notions of project management. And while we are at it, why not get rid of the entire notion of projects as well? And hence, another trend just emerged: the #noProjects.
My intention here is not to answer each of their arguments, that's not the point. What I will do is explain why the entire idea is absurd in the first place. So let's get to the basics first.
One thing that I advocate since at least 2008 is the idea of project management and markets in general through the models of Complex Adaptive Systems, Chaos Theory and Evolutionary Biology. I've been largely influenced by the ideas of Nassim Nicholas Taleb and his magnum opus "The Black Swan". It's an incredible idea that the markets are not bound by linear paths, but by chaotic agents that influence a complex system. All companies are managed to deal with averages, with limited sigmas as margins of operational error. But once something big, a "Black Swan", such as the 2008 economic crisis arrives, most are not prepared to deal with it, no models are able to predict it, and the whole system shuts down and collapse.
If you're unfamiliar with the idea, Google it for a moment and you will understand that companies, markets and people relationships in general, are dynamic systems that conform to evolutionary biology rules. Decentralized systems seems to be the way to go. And those concepts influence many of the Lean movements we see today. So, yes, I am very well aware of those effects.
But as a summary, the whole gist of it is: the ones with the most chance of survival in such a complex system are the ones that are the most adaptable, not the ones that strictly conform to plans. Conforming to long term plans and sticking to it with rigidity is the easy way to fall down when Black Swans happen.
That said, it made me think about another concept: Einstein's General Theory of Relativity. In modern cosmology it superceded the Theory of Newton. When I first learned about it my main thought was: if Newton is "wrong", why aren't we using Relativity to calculate everything in our day-to-day lives? The answer is that Newton's theory is only "wrong" if you define it as the being able to calculate everything, but it isn't. It can't be applied to the very very large, gravitational calculation, galaxy level calculations. But, if you limit it to Earth like sizes, where we are calculating the path of an airplane, the trajectory of a bullet, etc, it is still applicable, as the margins of error are negligible. So in the day-to-day operations, we can reduce the problems to Newton and not use General Relativity. This is an oversimplification, of course, but bear with me.
The same applies to companies. We are all bound to Power Law distributions, Evolutionary Biology, the relentless forces of Chaos that make everything behave like Complex Adaptive Systems. But in a constrained environment I will argue that we can reduce the calculation back to Bell Curves. This is the most difficult to "prove" so I will not attempt it right now but the following explanation may get you there.
Let's define what a company is: it's a set of operations. Operations are repetitive activities. So you have activities such as "pay a supplier", "send a purchase order", "process the payroll", "transport products", etc. The set of all those activities define what a company is.
The whole idea of a company is to perform those operations in the most efficient way possible. You do that by continuously refining the process in small steps or by means of a breakthrough, changing the entire way you do a particular operation. For example, back in the day, there were entire groups of people dedicated to fill in paper forms and organize them to make information flow within a company. With the emergence of digital systems, ERPs, all that paperwork is not necessary today. We were able to get rid of an entire profession of typewriters and we added efficiency and more precision to the system. Breakthroughs are usually the digital automation of manual labor or getting rid of a process altogether.
To accomplish such breakthroughs there are Projects. Projects are temporary endeavors where a group of people concentrate to achieve some pre-established goal. Projects usually have a fixed starting and due date, a fixed budget, and a fixed amount of people involved.
And here we arrive to the Estimation part: all projects want to achieve some goal. In the particular case of a software project, we implement software code that is meant to achieve that goal. To achieve a goal we come up with software features and we break them down into Use Cases, User Stories, Requirements or any artifact meant to describe what is to be built. And then we estimate how much resources (time, money, people) are necessary to implement each of those pieces and integrate them together in a "solution" that solves the problem and achieves the goal.
What software developers complain is that it is not possible to estimate those pieces with precision and projects will always be delivered late and overbudget. So the best idea is to not estimate and simply start coding and delivering value as soon as possible and consider it done only when its done.
Some software developers get so fed up of this whole notion that they want to leave their companies to start their own tech startups where they will be able to do whatever they want without any controls. Then they look up for investors because they need a lot of money and a lot of time. Of course they do. What they don't realize is that EVERYBODY needs a lot of money and a lot of time. And investors know this: the idea is irrelevant, execution is key. The people that deserve more money and more time are exactly those that can pressure themselves into delivering underbudget and ahead of everybody. Just doing something and not being worried about constraints is exactly the affairs of the mediocre. And mediocre don't deserve anything.
Now back to basics: we have something called Economy exactly because resources are not infinite. Everything that has value has a price, be it a physical product or working hours.
Understand this: in the services business (where we software developers are all in, regardless if you're an employee, a co-founder, etc) value has only two variables: quality and efficiency. We tend to regard quality as the only thing that matters. Worse: we tend to regard what we think as quality as the only thing that matters.
This brings us back to CONTEXT. Most programmers are bad at estimates. And the root reason is because they are usually utterly incompetent with understanding context. As someone with a Math background I read all articles about processes, methodologies and stuff like "#noEstimates" as "formulas".
Formulas alone don't mean anything. Any mathematician knows that you have to define a Domain and an Image, the source and the destination of the all inputs and all outputs. For example, if I show a formula such as "f(x) = 1 / x" you might argue that this is an invalid and wrong formula as I can't divide if x is zero, for example. But if I say that the Domain is every Natural number but zero, now this is a totally valid formula for the Image of the Rationals.
So, when someone says "#noEstimates" it begs the question: on which Domain and for what Image? This is the origin of the discussion for most of the statements made in the Internet: people will argue for or against an idea because each is in a different Domain. That's the same for Agile in general, Lean Startups, Lean Manufacturing, etc. They usually only define practices, procedures, formulas, but they rarely define Domain and Image. This makes a confusion and loses the point.
What I will define, though, is that Projects are necessary everytime there is a defined goal to be achieved. This is the domain. And I will also state that when people state "#noEstimates" they are not in the Domain of Projects but of "Ongoing Operations". Actually, this is where Lean Manufacturing in general lies as well. I have explained Operations above, and this is where small improvement steps (Kaizen) emerges. Sometimes the feedback loop from an operation gives enough input to justify a Project to make a larger step and a breakthrough.
Projects, on the other hand, continues to be a temporary endeavor. The whole idea is to establish the boundaries, such as time and cost constraints. And we come back to the original question: but it is impossible to predict the efforts necessary for something as maleable as software development.
First of all, yes, it is impossible to predict with exact precision. Again, let's define it: it's impossible to predict a number with zero margin of error. Estimation is prediction with margins of error. And why is that some projects cost more than twice as much and take twice as much time as the estimation?
More often than not, because the team is incompetent, that's 90% of the cases. The problem is not the estimation, it's the execution. Estimation is the establishment of an expectation. Expectations must be managed. An estimation is only good if the context is taken into consideration. Most people don't like to estimate because "what if" scenarios. What if the client change his mind? What if we find a difficult obstable? What if a meteor strike the Earth and all living creatures perish? We can't manage "what if", what we can manage is what we know and create constraints. Project constraints start with its goal. To accomplish those goals we also establish the rules of engagement: the premises. Without goals and without premises there is no game.
None of those guarantees a Prediction. An estimation is only as good as the execution. Now we have to manage it. Everybody has to manage it. It's no good if you define clear rules and all of a sudden you see a programmer doing nothing and when you ask him why he is doing nothing his answer is "oh, because I emailed the client about some requirements and he never replied back so I was waiting". And when you ask "and did you try calling him?", usually the answer is "No, I didn't". There is no amount of processes, methodologies that can "fix" an incompetent employee. Lack of technical skills can be fixed. Bad faith cannot.
The ones advocating #noEstimates can argue that they are not like that and I can believe it. But 90% of the projects that failed had employees like that. Programmers tend to put the blame on the client, the bosses, the market, but never themselves. And as a programmer I will argue that the reason most projects fail has nothing to do with changing requirements, limited time, but with lazy employees. Want to make projects go right? Start with Human Resources first, then go find methodologies and practices.
The problem with all methodologies not stating the Domain under which their formulas work is that most people don't realize that the Domain start with "having competent, committed and skilled employees". Most adopt methodologies with the hope that they will turn incompetent employees into competent, and that just doesn't happen.
With that out of the way, why do we need estimates? Or more generally, why do we need constraints? Because that's the core of value of any system. Nature puts pressure on any living species: changing climate, limited food supplies, predators. The species that are most adaptable evolves, the ones that can't adapt perishes.
When someone says "it's impossible to do X", that's probably the most valuable goal to pursue. Because the whole statement is: "it's impossible to do X with what we know today". It was impossible to go around the globe in 24 hours, it's not anymore. It was impossible to communicate with the other side of the globe in real time, it's not anymore.
Constraints are the foundation of innovation. If I had to define innovation I'd say that "it's the process by which you accomplish something that was deemed impossible before".
If you have infinite resources, or if you just don't need to worry about constraints (that's what happens in bubbles), you don't innovate. This is so important that I will repeat it:
Innovation is the byproduct of Constraints.
We estimate based on past knowledge. If we can't out perform our past selves, how incompetent are we? I mean, we can argue that software is not predictable, and I agree. But making mistakes of orders of magnitude in recreating similar software only smells incompetence to me. Most of the software we produce are not brand new ideas, breakthrough new algorithms. They are really mostly the same: content websites, ecommerce, elearning, social networks, social commerce, forums, polls. Unless you work in research programs, what other kinds of different software did you do lately?
Estimation is rarely the problem. All estimation comes from a set of premises. Not managing those premises is the problem. If requirements change, this is not a problem. We can always manage that. We can't manage accumulated problems in the last day of the project. And usually the case is that programmers defer dealing with problems. Again this is not a problem with estimation, it's a problem with Human Resources.
Meritocracy only exists in a system of scarcity, where one stands out against another compared to a constraint. In a system where there is only abundance, there is no need to innovate, there is no need for merit. Companies that just received a humongous amount of cash will invariably show symptoms of laziness, not innovation. The confusion arrives because some of the "practices" being stated derive from this temporary unreal situation of a bubble, and can't withstand the pressure of time. Give it enough time and you will realize "why did we, with so much cash and so much time, accomplished so little, and the other small tech startup, with so limited resources was able to outperform us?". And this is the answer of why a Yahoo! buys a Tumblr, why a Facebook buys an Instagram, why a Google buys a Waze.
If you advocate #noEstimation, why not go a step further and advocate #noWork? It's just one step further.
Rubyconf Brasil 2013: Meet Luis Cipriani 27 Aug 2013 5:00 AM (11 years ago)

If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th. The countdown is reaching its end! Only 2 days to go! Register while there is still time!
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. Several great established companies and tech startup are supporting the conference sending great developers.
Meet Twitter, which I believe needs no introduction. Luis Cipriani recently joined them as Brazil Partner Engineer, after a long run at Abril Publishing in its R&D department. He is an specialist in many technologies but particularly APIs and web infrastructure.
Don't miss his talk precisely at 1:15PM of the second day of the event. Let's get to know more about him:
"Your talk is APIs and infrastructure, stuff that most web developers don't fully understand although they should, can you explain what some of the requirements are to understand what you're going to talk about?"
Cipriani: HTTP Caching is a subject that all Rails developers will need to deal some day, the great thing about it is that you can learn and get experience incrementally, applying the basic HTTP headers is enough to have a relevant result and as you want to have more control over the way your resources are being cached or expired, more advanced techniques are just there to learn. But I recommend that the audience have at least basic knownledge in HTTP protocol to enjoy more the other insights I'll show.
"Many developers would love to become as experienced and fluent in Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a Ruby beginner?"
Cipriani: First and most important, don't believe that you are a great developer, even if someone told you so. Always feel unconfortable about not having a deeper knowledge about some technology or language, and reserve some time to try new things. Also, learn to contribute and listen carefully to feedbacks from the community. Make something useful for you or someone else that solves a real problem, this gives motivation to continue doing great stuff.
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
Cipriani: The world is still having lots of difficulties to deal with the massive stream of information being produced by companies, social networks, sensors, etc. So I think that any technology or general initiative that proposes itself to help to solve this problem will get a lot of attention and investiments around the world. And among these technologies are some areas of Computer Science such as Semantic Web, Machine Learning, Information Management/Retrieval and Distributed Database Systems.

Rubyconf Brasil 2013: Meet Carlos Galdino 26 Aug 2013 4:20 AM (11 years ago)

If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th. The countdown is reaching its end! Only 3 days to go! Register while there is still time!
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. Several great established companies and tech startup are supporting the conference sending great developers.
Meet Plataformatec a Brazilian consulting shop specialized in Ruby on Rails and known for famous open source projects such as Devise and Simple Forms. Carlos Galdino is a software developer at Plataformatec.
Don't miss his talk precisely at 4:00PM of the first day of the event. Let's get to know more about him:
"Your talk is about Rubinius, one of the alternative implementations for Ruby, can you explain what some of the requirements are to understand what you're going to talk about?"
Galdino: I'd say that the most important thing the audience should have is to be curious about how things work under the hood, otherwise it'd be boring for them. I'm going to give an overview about how an implementation of a language, in this case Rubinius as the implementation and Ruby as the language, which concepts are present and how they're tied up. So, if you ever wanted to know what happens to the code you write after writing it, you should attend the talk.
"Many developers would love to become as experienced and fluent in Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a Ruby beginner?"
Galdino: Never stop learning. Always be curious about things and how they work. Another thing that I think is extremely important is to be open-minded, you shouldn't only read and learn about Ruby or Rails. Try to read about completely different subjects, subjects that you might don't use in a daily basis. It'll help you when deciding something because you'll have different perspectives.
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
Galdino: Functional Programming. After being the next big thing for decades, I think its time has finally come. You see everyday more and more people excited and talking about it. We've reached a point where you can't ignore concurrency and parallelism, and functional languages make easier to deal and even avoid some common problems that appear when dealing with such things in languages like Ruby, Java and others.

Rubyconf Brasil 2013: Meet William PotHix 23 Aug 2013 7:20 AM (11 years ago)

If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th. The countdown is quickly approaching it's destiny, only 6 days to launch!
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. Several great established companies and tech startup are supporting the conference sending great developers.
William Molinari, also known as PotHix, works for Locaweb building their Cloud Computing technologies.
Don't miss his talk precisely at 4:00PM of the second day of the event. Let's get to know more about him:
"Your talk is about how you used Ruby to build Locaweb's Cloud offerings, many still think that Ruby is only good for web applications and they don't know how much it's used in the infrastructure as well, can you explain what some of the requirements are to understand what you're going to talk about?"
PotHix: This talk will show how we used Ruby and Rails to build an app to deal with hypervisors, firewalls, dhcp and some other network tasks. You don't need any advanced knowledge in Ruby. Some knowledge about Rails or networking in general will help you benefit more from the talk but it would be great to have an intermediate knowledge of Ruby and the basics of networking.
"Many developers would love to become as experienced and fluent in Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a Ruby beginner?"
PotHix: Something that helped me a lot when learning Ruby was being in touch with good Ruby developers, attend to local user groups (Guru-SP in this case) and attend to online free courses (like rubylearning.org). Learn new languages and try different programming situations and exercises also helps a lot to understand the ways we can choose to solve a problem.
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
PotHix: I'm not using it directly but I believe in Docker potential to build and manage different environments. I think we'll have a lot of interesting softwares build on to of it and flynn.io looks a good example.
%20and%20attend%20to%20online%20free%20courses%20(like%20%3Ca%20href%3D%22http://rubylearning.org%22%3Erubylearning.org%3C/a%3E).%20Learn%20new%20languages%20and%20try%20different%20programming%20situations%20and%20exercises%20also%20helps%20a%20lot%20to%20understand%20the%20ways%20we%20can%20choose%20to%20solve%20a%20problem.%3C/p%3E%0A%0A%3Cp%3E%22There%20are%20so%20many%20new%20technologies,%20best%20practices%20and%20so%20on%20being%20released%20all%20the%20time.%20In%20your%20personal%20opinion,%20and%20maybe%20related%20to%20your%20current%20field%20of%20work,%20what%20are%20some%20of%20the%20trends%20in%20technology%20that%20you%20think%20we%20should%20be%20paying%20attention%20for%20the%20near%20future?%22%3C/p%3E%0A%0A%3Cp%3E%3Cstrong%3EPotHix:%3C/strong%3E%20I'm%20not%20using%20it%20directly%20but%20I%20believe%20in%20%3Ca%20href%3D%22https://github.com/dotcloud/docker%22%3EDocker%3C/a%3E%20potential%20to%20build%20and%20manage%20different%20environments.%20I%20think%20we'll%20have%20a%20lot%20of%20interesting%20softwares%20build%20on%20to%20of%20it%20and%20%3Ca%20href%3D%22http://flynn.io%22%3Eflynn.io%3C/a%3E%20looks%20a%20good%20example.%3C/p%3E)
Rubyconf Brasil 2013: Meet Bruno AbstractJ 23 Aug 2013 6:40 AM (11 years ago)
If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th. The countdown is quickly approaching it's destiny, only 6 days to launch!
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. Several great established companies and tech startup are supporting the conference sending great developers.
Meet JBoss, today a division of Redhat, both of them are very recognized brands in the Java and Open Source fields.
Bruno Oliveira, also known as AbstractJ, works implementing the AeroGear product for JBoss, he is a former Caelum teacher and developer and he has been collaborating in the open source community.
Don't miss his talk precisely at 2:00PM of the first day of the event. Let's get to know more about him:
"Your talk is about cryptography done right in Ruby, this is a very compelling subject that all programmers should understand specially considering the recent discussions around privavy and information security, can you explain what some of the requirements are to understand what you're going to talk about?"
Bruno: Cryptography can be a tough topic, specially for newcomers. Try doing it blindly without background knowledge and you can easily get into serious trouble, or even get fired. Please don't expect deep complex math or anything like that, since I don't consider myself a crypto analyst and this isn't the presentation goal. As long as you're interested in learning few tricks you'll be fine.
My main goal at RubyConf Brazil is to discuss cryptography for mere mortals, non-experts, developers like you and me. As a consequence, I'll be covering basic concepts, common mistakes, how complex the existing APIs are (with good reason) and how Krypt can potentially narrow the gap between simple and safe. I'll also be covering controversial topics like privacy on the internet in general.
"Many developers would love to become as experienced and fluent in Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a Ruby beginner?"
Bruno: I've started my career as a sysadmin a long time ago, I was paranoid about infrastructure security, firewalls, DMZs and honeypots, and before I even realized I was programming to solve my day-to-day issues. The early days were hard ones, and involved a lot of reading; the nice thing is that all my early security experience came to be very useful nowadays. Take this advice: the best thing you can do is to learn from your previous experiences, whether they are bad or good.
It doesn't matter whether you're a Ruby, Rails, Java, Python programmers, the most important thing is having no fear of learning, change, or leaving your comfort zone. If you are working at a dead-end job where you stopped learning new stuff a long time ago, just quit. Quoting Johnny Cash "Success is having to worry about every damn thing in the world, except money" - it's more common than you think to give up a good salary to have the opportunity to learn and improve your skills.
Another tip is: while reading a hundred of books is important, never downplay contributing to open source projects. There's a lot of experienced programmers out there, sharing their code at GitHub, how about getting together and hacking some code? I think the best way to learn is having your code torn into pieces by others; it doesn't matter if your code is good or bad, being a good developer is about overcoming the fear of making mistakes and learning from them instead; as a bonus you'll improve your english skills.
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
Bruno: We have been living in a critical moment with the recent privacy scandals, security became a hot topic and suddenly every application or framework now has "military-grade security". Don't buy into the hype! Instead, try to understand the basics of cryptography, keep up with CVEs and NIST. Another good place to go a little deeper on the topic is to take a look on some security libraries like libsodium and Blake2.
Rubyconf Brasil 2013: Meet Danilo Sato 22 Aug 2013 7:08 AM (11 years ago)

If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th. The countdown continues, only 7 days to launch!
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. Several great established companies and tech startup are supporting the conference sending great developers.
Meet Thoughtworks one of the most recognizable brands in the international consulting market.
Danilo Sato works for Thoughtworks for 5 years, dealing with international projects and evangelizing Agile and Lean methodologies.
Don't miss his talk about Object Oriented Programming precisely at 11:00AM of the first day of the event. Let's get to know more about him:
"Your talk is about a subject that most feel like they understand but they usually don't, which is object oriented programming, can you explain what some of the requirements are to understand what you're going to talk about?"
Danilo: You probably have already heard or learned a little about Object-Orientation. That should be enough prior experience to understand my talk. Having worked with Rails might help understand some of the examples, but I won't assume you have in-depth knowledge on the subject. The topics I want to cover will be applicable to Ruby in general, as well as other OO languages you might have to work with.
"Many developers would love to become as experienced and fluent in Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a Ruby beginner?"
Danilo: I think one of the easy pitfalls in our industry is to be close-minded about which technology you work with. The software industry changes all the time, new languages, libraries, frameworks are created, evolve, get in and out of fashion. It's very easy to find a comfort zone and not worry about everything else, but you risk becoming obsolete or locked-in to an old technology if you're not constantly challenging yourself to learn new things.
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
Danilo: Just like in fashion, technology evolves but also have cycles. I would say that instead of focusing only on the next new trend, there are lots to learn from studying the past. We like to learn the same lessons over and over again, and my talk will touch on a core skill that I think won't go away: software design. Investing in learning about software design is something that will pay off when you move to a new language, when you learn a new framework, and when you're building an application for your client. To me this is a core skill to invest in.

Rubyconf Brasil 2013: Meet Eduardo Shiota 19 Aug 2013 7:45 AM (11 years ago)

If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th. The countdown begins, 10 days to launch!
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. Several great established companies and tech startup are supporting the conference sending great developers.
Meet Baby.com.br a Brazilian e-commerce geared toward the baby products. It's under the umbrella of venture capitals such as Monashees and Accel Partners, and they have a big Ruby development team.
Eduardo Shiota works for Baby for a while, he is responsible for usability and front-end development. Because he studied both Arts and Computer Science, he has a unique point of view that binds both worlds.
Don't miss his talk precisely at 10:15AM of the first day of the event. Let's get to know more about him:
"Your talk is about Modular and Event-Driven Architecture in Javascript, can you explain what some of the requirements are to understand what you're going to talk about?"
Shiota: If you're starting with Front-end or just JavaScript development now, it's important to know that the language is much more than jQuery, visual effects, and DOM manipulation. Having this concept in mind and the desire to understand the fundamental concepts of the language are enough to take in the content of this talk, and apply it on a daily basis.
"Many developers would love to become as experienced and fluent in Javascript and Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a beginner?"
Shiota: It's pretty easy to get stuck on basic Front-end development, doing one-file-huge JavaScript solutions, and simply slicing PSDs into CSS. You have to take it to the next level. Ask yourself "How can I make this better? How can I make this reusable? How can I test this? How can I make this easily understandable and modifiable?". Search for the answers. Read a LOT of books, like Eloquent JavaScript, JavaScript: The Good Parts, and JavaScript Patterns. Subscribe to JavaScript Weekly e BrazilJS Weekly. Watch a lot of JavaScript talks on YouTube. Write some simple games or quizzes. Try some new methods. Have fun. =)
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
Shiota: We're living a boom of JS MV* frameworks, languages that are compiled to JavaScript, like CoffeeScript and TypeScript, and the growth of the Node.js community. It's important to not stick to just a single solution or library, stay in touch with the growth of the language as a whole, and know which topic is worth digging deeper. Keep yourself up to date on ECMAScript 6 "Harmony"'s progress, and every update on modern browsers APIs.
%3C/p%3E%0A%0A%3Cp%3E%22There%20are%20so%20many%20new%20technologies,%20best%20practices%20and%20so%20on%20being%20released%20all%20the%20time.%20In%20your%20personal%20opinion,%20and%20maybe%20related%20to%20your%20current%20field%20of%20work,%20what%20are%20some%20of%20the%20trends%20in%20technology%20that%20you%20think%20we%20should%20be%20paying%20attention%20for%20the%20near%20future?%22%3C/p%3E%0A%0A%3Cp%3E%3Cstrong%3EShiota:%3C/strong%3E%20We're%20living%20a%20boom%20of%20JS%20MV*%20frameworks,%20languages%20that%20are%20compiled%20to%20JavaScript,%20like%20CoffeeScript%20and%20TypeScript,%20and%20the%20growth%20of%20the%20Node.js%20community.%20It's%20important%20to%20not%20stick%20to%20just%20a%20single%20solution%20or%20library,%20stay%20in%20touch%20with%20the%20growth%20of%20the%20language%20as%20a%20whole,%20and%20know%20which%20topic%20is%20worth%20digging%20deeper.%20Keep%20yourself%20up%20to%20date%20on%20ECMAScript%206%20%22Harmony%22's%20progress,%20and%20every%20update%20on%20modern%20browsers%20APIs.%3C/p%3E)
Rubyconf Brasil 2013: Your first time in São Paulo, Brazil 15 Aug 2013 12:00 PM (11 years ago)
Update (08/24/2014): I just posted a companion article for this one, highlighting the tourist points of the city.
Update (02/2014): this article was written for Rubyconf Brazil 2013, so don't be confused by the context.
Rubyconf Brasil is quickly approaching, don't miss it on August 29, 30. Register today at the website. Several speakers will be coming to Brazil, don't miss your chance to get to know Hal Fulton, Hongli Lai, Laurent Sansonetti, Kevin Tripplet, Jaime Andrés, Dávila, Ben Langfeld, Pablo Astigarraga.
I understand that it can be intimidating to come to Brazil for the first time so I decided that it could be a good idea to draft a few important things to keep in mind while staying around here.
First things First (TL;DR)
The weather is quite cool these days, it's Winter in Brazil and although it's not as cold as in North Europe it's a good idea to bring some extra coats if you're not used to a cold weather. On the other hand, the weather can change quite dramatically in a few days here in São Paulo. For example, right now it's around 12 degrees Celsius (or around 54 Fahrenheit), going down to less than 9C (48F) at night. But it seems like it's possible to go up to almost 30C (86F) during the conference days, so come prepared, specially if you are staying for an entire week or more.
DO NOT FORGET TO BRING A UNIVERSAL POWER PLUG ADAPTER!!
This is very important: until 2011 we had outlets that were compatible to the USA and some European power plugs. After that the country changed to a (worse in my opinion) new standard that is completely incompatible with any other plugs. Some good hotels have adapters for foreigners but I wouldn't count on that. When you land at the airport you can buy them at the duty free stores, just don't forget or you will be out of juice for your devices!
Speaking of which, another thing that is quite useful is to find a telecomunications store at the airport (Claro, Vivo, Oi, Tim) or in any mall or big commercial area (Paulista Ave. has some). Buy a pre-paid SIM card for your smartphone, with 3G enabled - and test it in the store!. It will be a whole lot easier to navigate through out the city that way. Whenever I go to other countries that is the first thing I try to do. Also make sure to have some friends or acquaintances in your contact list in case you have any emergencies or even get lost in the city.
You most probably don't speak Brazilian Portuguese. The first thing to know is that it's not nearly the same as Spanish. It's very difficult to find people that can speak fluent English, but be assured that most people here will try their hardest to understand you. Friendliness is definitely something you can count on. Speak slowly and the clearest that you can to make yourself understood. In public transportation and taxi cabs that's going to be bit different as workers under our traffic stress aren't particularly friendly, so be patient.
About taxi cabs, when you arrive at the airport you may be approached by private drivers. DO NOT TAKE THEM. Use an official taxi company at the airport exit. It's easy to make the distinction as the official taxi are all standardized and you will see staff organizing the lines. Pay the fare at the taxi booth inside the airport with a pre-determined price. Even while walking around the city, always get a cab from an official line. You may want to try apps such as 99Taxi while in the city.
By the way, Google Maps works great around here, even to know subway time schedules. Waze also works great.
BRAZIL IS NOT VIOLENT!! (in general)
Regardless of what you may have heard or read in news channels, Brazil in general is not a violent country. Not even in São Paulo, our largest and crowdest city. It doesn't mean that it's not there, just don't go look for it. Keep in mind a few useful rules: don't make it easy for pickpockets. If you leave your bag in the floor, unattended, you may not find it there later.
There is a popular saying here "a oportunidade faz o ladrão" that can be roughly translated as "opportunity makes thieves". It's not properly translated culturally wise but I think you got it. Just make sure to not have all your money in your wallet in the backpocket of your pants. It's wise to distribute it in your pockets, specially if you decide to wander around some of the rougher areas of the city (more on that below).
It's totally safe for you to walk around by yourself. Avoid "showing off" while in busy areas. Speaking in your shiny brand new smartphone while walking around crowded streets may not be a good idea. If you're in a taxi cab, stuck in a traffic jam, don't be playing with your tablet while having your window wide open. Be aware of your surroundings. That being said, there's no need to be paranoid. In 6 years of receiving foreign speakers at Rubyconf, not once I have heard of anything that happened to any of our speakers or to anyone else for that matter. I myself have lived more than 3 decades here and I've been robbed once a decade.
Rubyconf will be near one of the landmarks of this city: Paulista Avenue. If your hotel is nearby it's a good area to be because it's the easiest way to access most of what's important in the city. If you're not near the conference venue and not near a subway station be prepared to get some heavy traffic. Rush hours in São Paulo start around 8AM until 10AM and then from 5PM until 9PM. And I mean much-worse-than-Manhatan levels of traffic jams. So be organized and wake up early. If you're 5 miles away or more from the conference, calculate at least 1 hour in traffic.
Business hours in São Paulo start at 9AM and ends at 6PM. Banks open at 10AM and close at 4PM. Shopping Centers and other stores and restaurants are usually open at least until 10PM, lot's keep working until after midnight. Night life in São Paulo is particularly busy. You will find drugstores, markets, convenience stores, and several busineses that go on for 24 hours.
Understanding the City: A Geography Overview
With the most important points being said, let's focus on location. As the wise would say, "location, location, location."
First and foremost, some may find this confusing because "São Paulo" can refer to 3 different things: the state, the capital city of the state, the big metropolitan area also known as "Greater São Paulo" which is a group of 39 municipalities around São Paulo City.
The metropolitan area is humongous. The Greater São Paulo has no less than 20 million people. São Paulo City alone has more than 11 million. We are talking about the 6th most densely populated area in the planet. If we expand to the Campinas city through Jundiaí city, this area has 12% of the country population. In terms of size, we are talking about something the size of the entire country of Lebanon or Jamaica.
Even with this size, one thing you will notice right away is that our public transportation is surprisingly lacking given that the GDP of this area alone was more than USD 300 billion (2011).
It's important to understand the geographic map. The map below shows the Greater São Paulo metropolitan group:

São Paulo City is the big grey area in the middle. When you land here, you will be at Guarulhos International Airport (GRU) in Guarulhos City, which is outside of São Paulo. It's one of the green cities in the north. You will have to go through a 40 to 50 minutes ride (without traffic) to go downtown.
Now, let's zoom in the grey area from the previous map:

Our city is roughly divided in 5 zones: North, South, East, West and Center or what I prefer to call "Old Downtown". This is 11 million people city but you will never have to go out of the area I circled in red, mainly near Old Downtown and what I personally call "New Downtown".
Let's zoom in a little bit the area surrouding the red circle:

There is this river named "Tietê" that cuts through the city. It creates this "semi-island" that we call "Expanded Downtown". Inside the island are the areas I called "Old Downtown" and "New Downtown". The Paulista Avenue roughly divides those 2 areas. The old one more up north and the other more south.
The red lines are the main avenues that connect the city traffic. Line number 4 in the map is the Paulista Avenue. The blue line is what we call the "Marginal", it's a large road that surround this Expanded Area and follow the Tietê River course. Although it's one single continuous wide road, it has 2 names: Marginal Tietê at the north half and Marginal Pinheiros at the south half.
So you will be most of the time around Red Line Line 4 (from the map above), the Paulista Avenue, located within the Expanded Area, surrounded by the Marginais. You will probably go through the Marginal when you come from the Guarulhos Airport (which would be way north outside of the map).
Remember I mentioned much-worse-than-Manhatan traffic jams? This is a snapshot of the traffic layer of the São Paulo Expanded Area around 5:30PM on a Thursday just so you have an idea of what I mean:

I call this traffic map "São Paulo bleeding".
I hope you're still with me in the Geography lesson. Now let's get more practical: subway lines!
I will overlay the metro lines on top of the map above so you have an idea:
Now the cleaner map (click the image to see the larger version):
And now the abstract representation to make it easier to navigate (again, click the image for the larger version):

You will most certainly not go away from the area cropped in the image above, the green line, which go under the Paulista Avenue. So you guessed it: from Paulista Avenue you have easy access to many of the interesting places in the city.
We have several ways to go through the public transportation, but the easiest way is to know that you can buy individual tickets inside the subway station. Always buy at least 2 so you have your way back guaranteed. It's the cheapest and faster way to navigate through the city. Use taxi cabs to go from a subway station to where you want to go and then back. Using a taxi for tourism is the easiest way to go bankrupt fast, because they aren't cheap, specially with heavy traffic.
Conclusion
This should cover the basics to understand the city. The São Paulo page at Wikipedia does a great job of explaining more details about the city, tourism and recreation options. There is also this Wikitravel Page that might help.
Most people will be staying at the Pergamon Hotel. It's at walking distance from the conference venue (Frei Caneca Theater), but you will probably want to get a taxi to go to Paulista Avenue, it's less than 5 min by car. And the Frei Caneca St. is parallel to Augusta St. which is very well known for it's active nightlife, if you like it.
Unfortunately we don't have anything that comes close to Yelp! around here. Don't be shy, if you don't know anyone from here, use the conference to get to know more people. Brazilians are really very friendly and they will be more than willing to explain a lot more and give great recommendations.
Don't stay just in the hotel. This is a great opportunity to get to know a new place, different people and culture. Pay special attention to the Old Downtown, the historic center and contrast it with the "New Downtown" where you will find the luxurious neighborhood of Jardins and the Tech neighborhoods of Vila Olímpia and Brooklin. Get in touch with the Brazilian Ruby community beforehand to schedule visits to startups and other companies.
Don't be a stranger, this is a city and a community that wants to exchange experiences and knowledge. Welcome to São Paulo!
Rubyconf Brasil 2013: Meet Hongli Lai 14 Aug 2013 12:41 PM (11 years ago)

If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th.
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. Several great established companies and tech startup are supporting the conference sending great developers.
Meet Phusion the group of computer scientists from the Netherlands that first made Ruby on Rails deployment really easy. Most people won't remember but prior to 2007 it was pretty painful to deploy a Rails application. Zed Shaw brought us Mongrel. But it was not until Phusion released Passenger that we started to speed up to the point where Ruby web deployment became the gold standard.
Hongli Lai is coming here for the second time, he was in the very first Rails Summit Latin America 2008 together with his partner Ninh Bui. Since then they have been evolving the Passenger technology, making it work with Apache, NGINX and in several different customizations and scenarios.
Don't miss his closing keynote about Passenger precisely at 4:45PM of the first day of the event. Let's get to know more about him:
"Your talk is about the upcoming Phusion Passenger 4, can you explain what some of the requirements are to understand what you're going to talk about?"
Hongli: To understand the talk, you should have a basic understanding on how to deploy a Rails application. For example, past experience with using Phusion Passenger, Unicorn, Puma or Thin will be very helpful. You don't have to understand it very deeply, because the talk is designed to be easy to follow even for beginners. A part of the talk, especially the optimization and tweaking part, will be more advanced, but I will structure them in such a way so that beginners can follow it as well.
"Many developers would love to become as experienced and fluent in Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a Ruby beginner?"
Hongli: I believe the best way to become good is to get a lot of practice. I do not believe in talent, but I do believe in hard work. I think I am at the place I am now because I've been developing software for more than a decade. For the first few years, my code sucked and I didn't really understand what I was doing. It was only after years of experience that I began to produce good code.
In the beginning, I was self-taught. Self-teaching can get you very far, but there are certain mathematical and formal foundations that are best learned at a university. In that regard, my computer science education has helped me a lot, although I could never have reached my current level without a lot practical experience as well.
Finally, it is a good idea to be curious about other people's work. You will learn a lot by studying others' design and code, both with regard to what to do and what not to do. It is also a good idea to be open minded, and not to jump to conclusions too quickly. What at first glance appears to be a bad piece of code written by someone else may have legitimate reasons for being like that. It is important to understand those reasons.
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
Hongli: I do not believe you should pay too much attention to trends. Trends come and go, and a lot of the current trends are just modifications of past trends. Furthermore, not all trends may be useful to you in their raw form. Instead of following a trend, you should understand the core reasons behind the trend, and adopt those instead.
That being said, there are several trends which I believe are good trends to follow and which I believe are timeless:
Automated testing. You should definitely have automated tests, which have saved me time and time again in the past. Having a good test suite gives you confidence and reduces developer anxiety (fear of breaking something), which allows you to develop faster. There are several styles in area the automated testing, e.g. TDD and BDD. I belong to none of them, but I take ideas from all of them and apply them where I think makes sense.
Continuous integration. Instead of having long development cycles, and integrating developer branches after a long time, or releasing software to staging after a long time, you should do it short intervals. This will give you more confidence, reduces developer anxiety and will allow you to release to production with less hassle. Continuous integration implies automated testing. A CI tool such as Travis or Apachai Hopachai is indispensable.
Operational automation. If a task takes too many steps, or if it's too mentally draining (which makes it easy to introduce human errors), consider automating the task as much as possible so that you only have to enter one command to get it done. There are two trends which are strongly related to this core idea:
The devops movement. Compared to traditional sysops, which performs a lot of tasks by hand, the devops moment seeks to automate as much as possible. You describe your cluster configuration in code, and a tool such as Chef, Puppet or Ansible builds the cluster for you. It changes the game so much if you can run a single command to rebuild your entire server cluster, instead of manually installing and configuring software every time.
Virtualization of the development environment. This is like devops for development environments instead of for production environments. Instead of letting your developers build their development environment manually (installing a compiler, installing git, installing MySQL, editing your software's config files, etc), you describe the environment in code and let a tool such as Vagrant (in combination Chef, Puppet or Ansible) build it for you. All developers will have a consistent development environment, and they can set up a new one quickly whenever they switch machines. When done properly, no human error will be possible.
Rubyconf Brasil 2013: Jaime Andrés Dávila 13 Aug 2013 1:58 PM (11 years ago)

If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th.
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. Several great established companies and tech startup are supporting the conference sending great developers.
Meet Neo, they call themselves a "global product innovation company". They are spread all over the world and have several well known names involved, such as Eric Ries, Ian McFarland, Evan Henshaw-Plath, Jim Weinrich and many more.
Jaime Andrés Dávila works at the Uruguay branch of Neo, formerly known as Cubox. He is a prolific software developer that proposed a unique approach to explain a recently well discussed design pattern, DCI, with something intriguing: semiotics.
Don't miss his talk precisely at 1:15PM of the second day of the event. Let's get to know more about him:
"Your talk is the design pattern known as DCI, one that has been recently discussed quite a lot. If someone is just beginning with Ruby, can you explain what some of the requirements are to understand what you're going to talk about?"
Jaime: Probably the most important thing to understand is the concept of "design patterns" not the specifics of every pattern, but the "reason to exist", why patterns are important, why not a single pattern is the silver bullet for everything and as an specific topic, the MVC concept.
Related to semiotics, it doesn't matter if you don't have any experience, I'm going to start from scratch and just give some details on the specific part that's important for us, in this case DCI; however if you are interested in this kind of lecture we could have a good talk about social fields.
"Many developers would love to become as experienced and fluent in Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a Ruby beginner?"
Jaime: Just keep reading, keep learning and keep enjoying every moment in front of your computer. One of the most important things someone has told me is "don't be afraid to say I don't know".
Oh!!! and commitment with your work: if you decide to do something, don't quit, just stay there until you're satisfied with your work, that way you'll learn to be professional and specially you'll learn to be proud of your work.
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
Jaime: OWA (one window app), it's not just the concept, it's the way that should be implemented, JS has proved it's a great and complex language so learn some of the main frameworks like angularjs, emberjs, backbonejs.
Hypermedia API, even there's a lot information about it, I think it's still not fully implemented so there's still a lot of space to improve and learn.
,%20it's%20not%20just%20the%20concept,%20it's%20the%20way%20that%20should%20be%20implemented,%20JS%20has%20proved%20it's%20a%20great%20and%20complex%20language%20so%20learn%20some%20of%20the%20main%20frameworks%20like%20angularjs,%20emberjs,%20backbonejs.%3C/p%3E%0A%0A%3Cp%3EHypermedia%20API,%20even%20there's%20a%20lot%20information%20about%20it,%20I%20think%20it's%20still%20not%20fully%20implemented%20so%20there's%20still%20a%20lot%20of%20space%20to%20improve%20and%20learn.%3C/p%3E)
Rubyconf Brasil 2013: Meet Caike Souza 11 Aug 2013 5:00 AM (11 years ago)

If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th.
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. Several great established companies and tech startup are supporting the conference sending great developers.
Meet Envylabs a very well known Ruby shop based in Orlando, Florida. They are also well known for the CodeSchool e-learning website, where you can learn a lot about everything you need to know to become a good web developer including courses in Ruby, Git, Javascript and much more.
Carlos Souza, also known as Caike, is a Brazilian programmer who moved to Orlando to work for Envylabs a few years ago. He works as a programmers for Envylabs as well as a teacher for CodeSchool and he is coming back to Brazil to share his experiences.
Don't miss his talk precisely at 2:00PM of the first day of the event. Let's get to know more about him:
"Your talk is about joining ongoing Rails projects, which may be difficult sometimes. If someone is just beginning with Ruby, can you explain what some of the requirements are to understand what you're going to talk about?"
Caike: This talk is for anyone who has jumped into existing Rails project, either at a new job or contributing to open source. If you've ever joined a Rails project started by someone else, it's likely that you've run into issues with setting up your environment, getting the app to run properly on your machine, deploying it to production for the first time and other blockers that got in the way of writing new features or fixing bugs.
My goal is to show some techniques that can help reduce the overhead of joining an existing Rails project.
"Many developers would love to become as experienced and fluent in Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a Ruby beginner?"
Caike: The tip I have is to never stop learning new things, but at the same time to learn how to be comfortable with the unknown. There are times out there that you will have to take a leap of faith and just assume things work the way they do. Some people have a hard time accepting that, but the sooner you realize that it's ok to not know about absolutely everything, the easier it will be to actually get things done.
Also, the best way to write good code is to read good code. There are many open source projects out there and amazingly talented developers behind them, so use the source! :)
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
Caike: Definitely ed tech (educational technology) is a big thing that's revolutionizing the education field and I feel we are about to see even greater things in the near future. It's great to see new ways of using technology to facilitate learning and not only enabling people to get jobs, but more importantly, enabling them to discover new passions.
%3C/p%3E%0A%0A%3Cp%3E%22There%20are%20so%20many%20new%20technologies,%20best%20practices%20and%20so%20on%20being%20released%20all%20the%20time.%20In%20your%20personal%20opinion,%20and%20maybe%20related%20to%20your%20current%20field%20of%20work,%20what%20are%20some%20of%20the%20trends%20in%20technology%20that%20you%20think%20we%20should%20be%20paying%20attention%20for%20the%20near%20future?%22%3C/p%3E%0A%0A%3Cp%3E%3Cstrong%3ECaike:%3C/strong%3E%20Definitely%20ed%20tech%20(educational%20technology)%20is%20a%20big%20thing%20that's%20revolutionizing%20the%20education%20field%20and%20I%20feel%20we%20are%20about%20to%20see%20even%20greater%20things%20in%20the%20near%20future.%20It's%20great%20to%20see%20new%20ways%20of%20using%20technology%20to%20facilitate%20learning%20and%20not%20only%20enabling%20people%20to%20get%20jobs,%20but%20more%20importantly,%20enabling%20them%20to%20discover%20new%20passions.%3C/p%3E)
Rubyconf Brasil 2013: Meet Pablo Astigarraga 9 Aug 2013 4:00 AM (11 years ago)

If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th.
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. Several great established companies and tech startup are supporting the conference sending great developers.
Meet Vivid Cortex a MySQL monitoring and analysis tools as a service. They just raised $2M to further improve their technology. Pablo Astigarraga is coming to speak at the event, more specifically about a subject that most people think they know but they actually don't: the classic Model-View-Controller (MVC) design pattern.
Don't miss his talk precisely at 1:15PM of the first day of the event. Let's get to know more about him:
"Your talk is about the MVC pattern and it's history, an important concept to be mastered by every Ruby on Rails or even Javascript programmer. If someone is just beginning with Ruby, can you explain what some of the requirements are to understand what you're going to talk about?"
Pablo: My talk is much more about the design pattern itself than about the particular implementation of Rails, so while having basic familiarity with Rails or any other MVC framework will probably be helpful but you don't really need it in order to follow the talk. The aim of the talk itself is to give some insight on how this particular design pattern has developed over the years and what are the problems it solves well and the problems that we aren't quite certain of how to approach yet, so hopefully it should add to whomever does software on the web these days.
"Many developers would love to become as experienced and fluent in Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a Ruby beginner?"
Pablo: Good question. I think the only real pitfall in the way of becoming a good developer is complacence. If we as developers keep an open mind and remember to always be playful, passionate and informed about our craft we'll become good at it, the scary thought is that in order to keep being good developers we need to never stop learning stuff, but that's kind of awesome, too.
In the end the only things we need are practice and willingness. :)
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
Pablo: Hum, I think the platform as a service world is becoming super interesting. Sure: Heroku paved the way a few years ago by being all magical about their deploys, but now that they've open sourced their buildpack tool Docker it's super easy to set up your own PaaS with projects like Dokku, I have this on my own VPS and I am able to deploy Ruby (and many more) apps with zero configuration simply by doing a git push to it, this is the future for all deploys, I think, and I love it.
%20design%20pattern.%3C/p%3E%0A%0A%3Cp%3EDon't%20miss%20his%20talk%20precisely%20at%201:15PM%20of%20the%20first%20day%20of%20the%20event.%20Let's%20get%20to%20know%20more%20about%20him:%3C/p%3E%0A%3Cp%3E%22Your%20talk%20is%20about%20the%20MVC%20pattern%20and%20it's%20history,%20an%20important%20concept%20to%20be%20mastered%20by%20every%20Ruby%20on%20Rails%20or%20even%20Javascript%20programmer.%20If%20someone%20is%20just%20beginning%20with%20Ruby,%20can%20you%20explain%20what%20some%20of%20the%20requirements%20are%20to%20understand%20what%20you're%20going%20to%20talk%20about?%22%3C/p%3E%0A%0A%3Cp%3E%3Cstrong%3EPablo:%3C/strong%3E%20My%20talk%20is%20much%20more%20about%20the%20design%20pattern%20itself%20than%20about%20the%20particular%20implementation%20of%20Rails,%20so%20while%20having%20basic%20familiarity%20with%20Rails%20or%20any%20other%20MVC%20framework%20will%20probably%20be%20helpful%20but%20you%20don't%20really%20need%20it%20in%20order%20to%20follow%20the%20talk.%20The%20aim%20of%20the%20talk%20itself%20is%20to%20give%20some%20insight%20on%20how%20this%20particular%20design%20pattern%20has%20developed%20over%20the%20years%20and%20what%20are%20the%20problems%20it%20solves%20well%20and%20the%20problems%20that%20we%20aren't%20quite%20certain%20of%20how%20to%20approach%20yet,%20so%20hopefully%20it%20should%20add%20to%20whomever%20does%20software%20on%20the%20web%20these%20days.%3C/p%3E%0A%0A%3Cp%3E%22Many%20developers%20would%20love%20to%20become%20as%20experienced%20and%20fluent%20in%20Ruby%20as%20you%20are.%20What%20have%20been%20some%20of%20the%20pitfalls%20you%20had%20to%20overcome%20in%20order%20to%20become%20a%20great%20developer?%20Any%20good%20tips%20for%20a%20Ruby%20beginner?%22%3C/p%3E%0A%0A%3Cp%3E%3Cstrong%3EPablo:%3C/strong%3E%20Good%20question.%20I%20think%20the%20only%20real%20pitfall%20in%20the%20way%20of%20becoming%20a%20good%20developer%20is%20complacence.%20If%20we%20as%20developers%20keep%20an%20open%20mind%20and%20remember%20to%20always%20be%20playful,%20passionate%20and%20informed%20about%20our%20craft%20we'll%20become%20good%20at%20it,%20the%20scary%20thought%20is%20that%20in%20order%20to%20keep%20being%20good%20developers%20we%20need%20to%20never%20stop%20learning%20stuff,%20but%20that's%20kind%20of%20awesome,%20too.%3C/p%3E%0A%0A%3Cp%3EIn%20the%20end%20the%20only%20things%20we%20need%20are%20practice%20and%20willingness.%20:)%3C/p%3E%0A%0A%3Cp%3E%22There%20are%20so%20many%20new%20technologies,%20best%20practices%20and%20so%20on%20being%20released%20all%20the%20time.%20In%20your%20personal%20opinion,%20and%20maybe%20related%20to%20your%20current%20field%20of%20work,%20what%20are%20some%20of%20the%20trends%20in%20technology%20that%20you%20think%20we%20should%20be%20paying%20attention%20for%20the%20near%20future?%22%3C/p%3E%0A%0A%3Cp%3E%3Cstrong%3EPablo:%3C/strong%3E%20Hum,%20I%20think%20the%20platform%20as%20a%20service%20world%20is%20becoming%20super%20interesting.%20Sure:%20Heroku%20paved%20the%20way%20a%20few%20years%20ago%20by%20being%20all%20magical%20about%20their%20deploys,%20but%20now%20that%20they've%20open%20sourced%20their%20buildpack%20tool%20%3Ca%20href%3D%22http://www.docker.io/%22%3EDocker%3C/a%3E%20it's%20super%20easy%20to%20set%20up%20your%20own%20PaaS%20with%20projects%20like%20%3Ca%20href%3D%22https://github.com/progrium/dokku%22%3EDokku%3C/a%3E,%20I%20have%20this%20on%20my%20own%20VPS%20and%20I%20am%20able%20to%20deploy%20Ruby%20(and%20many%20more)%20apps%20with%20zero%20configuration%20simply%20by%20doing%20a%20git%20push%20to%20it,%20this%20is%20the%20future%20for%20all%20deploys,%20I%20think,%20and%20I%20love%20it.%3C/p%3E)
Rubyconf Brasil 2013: Meet Hal Fulton 8 Aug 2013 4:00 AM (11 years ago)

If you didn't register yet, don't miss this opportunity. Go to the official website to register as soon as possible. The conference will commence on August 29th.
This is the 6th consecutive year that Locaweb and myself are organizing yet another great Rubyconf in Brazil. For some years I wanted to bring one of the most influencial authors in my library: Hal Futon, author of The Ruby Way, one of the best books to learn Ruby.
Finally, he will be here! He will be the keynote speaker to open the second day of the conference on August 30rd. So don't miss the opportunity to meet him. Let's get to know some more about him before the event.
"Your talk is about External DSLs, an important concept to be mastered by every Ruby programmer. If someone is just beginning with Ruby, can you explain what some of the requirements are to understand what you're going to talk about?"
Hal: This talk isn't specifically relevant to Rails, although there certainly are areas in which a "custom" parsing solution is needed. You'd be more likely to use this material if you are developing libraries, tools, or plugins. If you're a beginner in Ruby, you can still understand the topic. It helps if you have some genuine background in computer science (or at least have an understanding of what "parsing" really means).
"Many developers would love to become as experienced and fluent in Ruby as you are. What have been some of the pitfalls you had to overcome in order to become a great developer? Any good tips for a Ruby beginner?"
Hal: Everyone's pitfalls will be different. One of my biggest weaknesses is the "fear of complexity." This is why, although I am a Ruby expert, I am still a newbie in Rails myself. (Yes, they are different! Ruby existed more than 10 years before there was any "Ruby on Rails.")
My best advice is:
Read books. Read a LOT of books. Not just how-to books, but theory-based books and the classics such as Refactoring by Martin Fowler and Object-Oriented Software Construction by Bertrand Meyer. And (as one of my college computer science textbooks recommended) read Zen and the Art of Motorcycle Maintenance.
Take actual coursework if you can. There is no substitute for having a human teacher who can answer questions.
Read other people's code, especially the "best" developers you can find.
Pair-program whenever you can. Even if the other person is less skilled than you, you will still learn from the experience.
Contribute to open-source projects as you find the time and the skill.
Experiment! Try the tools and libraries and techniques that you read about. Write little tools for your own use. Imitate other people's ideas and try to improve on them.
"There are so many new technologies, best practices and so on being released all the time. In your personal opinion, and maybe related to your current field of work, what are some of the trends in technology that you think we should be paying attention for the near future?"
Hal: Such a hard question! :) Obviously mobile technology is getting more and more important. Inter-operating and syncing between different devices and applications is a growing concern.
As for what specific technologies we should watch -- that is an even harder question. No one can see the future. In 2006, I thought RSS was going to be very important; but it did not grow as much as I expected.
A friend gave me a rule to follow: Wait until you hear of a new piece of technology for the third time -- then go and read about it.
Also, I tend to favor more "open" solutions where technology is concerned (although we can't dismiss some of the less-open tech such as Apple's iOS).
.%3C/p%3E%0A%0A%3Cp%3E%22Many%20developers%20would%20love%20to%20become%20as%20experienced%20and%20fluent%20in%20Ruby%20as%20you%20are.%20What%20have%20been%20some%20of%20the%20pitfalls%20you%20had%20to%20overcome%20in%20order%20to%20become%20a%20great%20developer?%20Any%20good%20tips%20for%20a%20Ruby%20beginner?%22%3C/p%3E%0A%0A%3Cp%3E%3Cstrong%3EHal:%3C/strong%3E%20Everyone's%20pitfalls%20will%20be%20different.%20One%20of%20my%20biggest%20weaknesses%20is%20the%20%3Cem%3E%22fear%20of%20complexity.%22%3C/em%3E%20This%20is%20why,%20although%20I%20am%20a%20Ruby%20expert,%20I%20am%20still%20a%20newbie%20in%20Rails%20myself.%20(Yes,%20they%20are%20different!%20Ruby%20existed%20more%20than%2010%20years%20before%20there%20was%20any%20%22Ruby%20on%20Rails.%22)%3C/p%3E%0A%0A%3Cp%3EMy%20best%20advice%20is:%3C/p%3E%0A%0A%3Col%3E%0A%3Cli%3E%3Cp%3ERead%20books.%20Read%20a%20LOT%20of%20books.%20Not%20just%20how-to%20books,%20but%20theory-based%20books%20and%20the%20classics%20such%20as%20%3Ca%20href%3D%22http://www.refactoring.com/%22%3ERefactoring%3C/a%3E%20by%20Martin%20Fowler%20and%20%3Ca%20href%3D%22http://www.amazon.com/dp/0136291554%22%3EObject-Oriented%20Software%20Construction%3C/a%3E%20by%20Bertrand%20Meyer.%20And%20(as%20one%20of%20my%20college%20computer%20science%20textbooks%20recommended)%20read%20%3Ca%20href%3D%22http://www.amazon.com/Zen-Art-Motorcycle-Maintenance-Inquiry/dp/0060589469%22%3EZen%20and%20the%20Art%20of%20Motorcycle%20Maintenance%3C/a%3E.%3C/p%3E%3C/li%3E%0A%3Cli%3E%3Cp%3ETake%20actual%20coursework%20if%20you%20can.%20There%20is%20no%20substitute%20for%20having%20a%20human%20teacher%20who%20can%20answer%20questions.%3C/p%3E%3C/li%3E%0A%3Cli%3E%3Cp%3ERead%20other%20people's%20code,%20especially%20the%20%22best%22%20developers%20you%20can%20find.%3C/p%3E%3C/li%3E%0A%3Cli%3E%3Cp%3EPair-program%20whenever%20you%20can.%20Even%20if%20the%20other%20person%20is%20less%20skilled%20than%20you,%20you%20will%20still%20learn%20from%20the%20experience.%3C/p%3E%3C/li%3E%0A%3Cli%3E%3Cp%3EContribute%20to%20open-source%20projects%20as%20you%20find%20the%20time%20and%20the%20skill.%3C/p%3E%3C/li%3E%0A%3Cli%3E%3Cp%3EExperiment!%20Try%20the%20tools%20and%20libraries%20and%20techniques%20that%20you%20read%20about.%20Write%20little%20tools%20for%20your%20own%20use.%20Imitate%20other%20people's%20ideas%20and%20try%20to%20improve%20on%20them.%3C/p%3E%3C/li%3E%0A%3C/ol%3E%0A%0A%0A%3Cp%3E%22There%20are%20so%20many%20new%20technologies,%20best%20practices%20and%20so%20on%20being%20released%20all%20the%20time.%20In%20your%20personal%20opinion,%20and%20maybe%20related%20to%20your%20current%20field%20of%20work,%20what%20are%20some%20of%20the%20trends%20in%20technology%20that%20you%20think%20we%20should%20be%20paying%20attention%20for%20the%20near%20future?%22%3C/p%3E%0A%0A%3Cp%3E%3Cstrong%3EHal:%3C/strong%3E%20Such%20a%20hard%20question!%20%20:)%20%20Obviously%20mobile%20technology%20is%20getting%20more%20and%20more%20important.%20Inter-operating%20and%20syncing%20between%20different%20devices%20and%20applications%20is%20a%20growing%20concern.%3C/p%3E%0A%0A%3Cp%3EAs%20for%20what%20specific%20technologies%20we%20should%20watch%20--%20that%20is%20an%20even%20harder%20question.%20No%20one%20can%20see%20the%20future.%20In%202006,%20I%20thought%20RSS%20was%20going%20to%20be%20very%20important;%20but%20it%20did%20not%20grow%20as%20much%20as%20I%20expected.%3C/p%3E%0A%0A%3Cp%3EA%20friend%20gave%20me%20a%20rule%20to%20follow:%20Wait%20until%20you%20hear%20of%20a%20new%20piece%20of%20technology%20for%20the%20%3Cem%3Ethird%20time%3C/em%3E%20--%20then%20go%20and%20read%20about%20it.%3C/p%3E%0A%0A%3Cp%3EAlso,%20I%20tend%20to%20favor%20more%20%22open%22%20solutions%20where%20technology%20is%20concerned%20(although%20we%20can't%20dismiss%20some%20of%20the%20less-open%20tech%20such%20as%20Apple's%20iOS).%3C/p%3E)
[Off-Topic] Blogs are Obsolete. What's Next? 4 May 2013 9:46 AM (11 years ago)
Up until now I have almost 900 blog posts written over a period of 7 years. Some of those posts already "expired" as the piece of information got obsolete. Many of those are still very relevant and useful today.
People that have been following my blog for the past 7 years had the chance of reading most of those articles. But what about the new people? It's very hard to explore old good articles around a pool of almost 900.
Every blog still follows the very same structure: they are sorted by date in descending order, they show up one at a time in a long stream. Only new posts (or those manually chosen) show up at the top. As soon as I post a new article, the previous one become less relevant. If the blog is paginated, last month's posts will be buried and hidden in previous pages. Most people don't navigate to previous pages nor go through tags (which only help so far).
People looking for some specific pieces can search them through Google (or internal Search if I implement one).
A blog is structured in a way that old posts must remain less relevant and more difficult to find. It's a good enough structure for a news feed. If you write columns, opinions, research, timeless material in general, it's a horrible structure.
We've seen a plethora of blog engines around but they are all exactly the same: a post has many comments, new posts go first in the feed, old posts go to hidden pages in a precarious pagination system.
Several other things have been tried already, none of them succeeded in solving this issue. Tags, featured articles, hierarchical categories, random visualizations of old posts in the main page. None solve the problem of discoverability of old still-relevant posts for new readers.
Maybe this is an unsolvable problem and I don't have a good idea to move forward with this structure. So I'm interested in seeing if anyone else tried to tackle this problem with a different perspective or if new approaches are emerging in this field. Please comment below if you've seen new ideas coming out.
Post.order("created_at DESC").page(params[:page]) is history. What's next?

%20show%20up%20at%20the%20top.%20As%20soon%20as%20I%20post%20a%20new%20article,%20the%20previous%20one%20become%20less%20relevant.%20If%20the%20blog%20is%20paginated,%20last%20month's%20posts%20will%20be%20buried%20and%20hidden%20in%20previous%20pages.%20Most%20people%20don't%20navigate%20to%20previous%20pages%20nor%20go%20through%20tags%20(which%20only%20help%20so%20far).%3C/p%3E%0A%3Cp%3EPeople%20looking%20for%20some%20specific%20pieces%20can%20search%20them%20through%20Google%20(or%20internal%20Search%20if%20I%20implement%20one).%3C/p%3E%0A%0A%3Cp%3EA%20blog%20is%20structured%20in%20a%20way%20that%20old%20posts%20must%20remain%20less%20relevant%20and%20more%20difficult%20to%20find.%20It's%20a%20good%20enough%20structure%20for%20a%20news%20feed.%20If%20you%20write%20columns,%20opinions,%20research,%20timeless%20material%20in%20general,%20it's%20a%20horrible%20structure.%3C/p%3E%0A%0A%3Cp%3EWe've%20seen%20a%20plethora%20of%20blog%20engines%20around%20but%20they%20are%20all%20exactly%20the%20same:%20a%20post%20has%20many%20comments,%20new%20posts%20go%20first%20in%20the%20feed,%20old%20posts%20go%20to%20hidden%20pages%20in%20a%20precarious%20pagination%20system.%3C/p%3E%0A%0A%3Cp%3ESeveral%20other%20things%20have%20been%20tried%20already,%20none%20of%20them%20succeeded%20in%20solving%20this%20issue.%20Tags,%20featured%20articles,%20hierarchical%20categories,%20random%20visualizations%20of%20old%20posts%20in%20the%20main%20page.%20None%20solve%20the%20problem%20of%20%3Cstrong%3Ediscoverability%3C/strong%3E%20of%20old%20still-relevant%20posts%20for%20new%20readers.%3C/p%3E%0A%0A%3Cp%3EMaybe%20this%20is%20an%20unsolvable%20problem%20and%20I%20don't%20have%20a%20good%20idea%20to%20move%20forward%20with%20this%20structure.%20So%20I'm%20interested%20in%20seeing%20if%20anyone%20else%20tried%20to%20tackle%20this%20problem%20with%20a%20different%20perspective%20or%20if%20new%20approaches%20are%20emerging%20in%20this%20field.%20Please%20comment%20below%20if%20you've%20seen%20new%20ideas%20coming%20out.%3C/p%3E%0A%0A%3Cp%3E%3Ctt%3EPost.order(%22created_at%20DESC%22).page(params%5B:page%5D)%3C/tt%3E%20is%20history.%20What's%20next?%3C/p%3E%0A%0A%3Cp%3E%3Cimg%20src%3D%22https://akitaonrails.s3.amazonaws.com/assets/image_asset/image/345/obsolete.jpg%22%20alt%3D%22Obsolete%22%20/%3E%3C/p%3E)
_Why, Ruby Dramas, and Dynamiting Courtlandt 7 Sep 2012 9:37 AM (12 years ago)

I recently wrote an article named _Why Documentary at Rubyconf 2012, Denver reminding people about this person that called himself "_Why", who decided to vanish in August of 2009, taking all his work with him, essentially committing virtual suicide.
It has attracted lots of trolls and haters at the comments section, more discussion than I anticipated, questioning why we praise someone that was crazy enough to destroy all his work, that is obviously not a good role model, and that compared to other titans of programming has done little and with less quality?
Then, today I heard about this website about Ruby Dramas - that I'm not linking. I don't know the author and I even think this is just for fun, but the reactions from the trolls and haters aren't. Essentially it links a few of what we call "Ruby Dramas", the discussions that trolls and haters call a waste of time, a demonstration of the immaturity and childish behavior of Ruby programmers.
In 2006, Kathy Sierra wrote an article called Dilbert and the zone of mediocrity where she asserts that if you want to be successful, then you don't want to just please everybody in order to make all of them just like you. You do things in a way that people will love you, but knowing that the consequence is that many others will certainly hate you in the process. It's an all of nothing proposition, if you just make efforts for everybody to like you, you are just being mediocre.
There's a catch. It's not that you make things in order to make people love you. It's just that you should to things in a way that You Love It.
What are trolls and haters? In essence, they come back to you everytime because they care about some of the same things that you do. But they are not producers, they are looters, plunders. What they are actually saying is: "You're so good, please me, I want the successful ones to please me, because I can't do what you do, as the weaker one, I deserve to be pleased."
Such is the mentality of altruism and collectivism: people that have less, that can achieve less, deserve what successful people produced, and the successful people must feel guilt for being so much better. The horrible Robin Hood philosophy.
I will allow myself for some philosophical liberty and the use of metaphors to illustrate my point. I have never talked to other Rubyists that knew _Why personally, so I hope they don't get offended if my personal view differs, but again, this is just my personal opinion.
I learned recently that coincidentally the name "Why, the Lucky Stiff" is mentioned in Ayn Rand's famous masterpiece The Fountainhead. -- by the way, as not being a native american, I was just told that this was a very common expression back in the day. But I couldn't resist leaving this coincidence noted anyway :-)
This novel illustrates the ideal vision of Ayn Rand's Objectivism philosophy. It tells the story of the ideal man: Howard Roark, a talented architect that lives for the passion of his creative skills. He bows to no one, even if it means his own destruction. He lives by his moral principles of voluntary trade and individual achievement.
Objectivism is the foundation of a more pure version of Capitalism (not the version we current live in), where individual man make voluntary agreements only.
So, the trolls and haters, in The Fountainhead, are personified by the looters such as the Peter Keatings and Ellsworth Tooheys of the world.
Spoiler Alert!! (do not go forward if you prefer to read the book)
Summarizing, in the book Roark ends up in a project called Courtlandt, a huge complex for the poor and destitute, where no other architect was able to design a complex that would be within requirements and budget. Only Roark was able to solve the puzzle and he agrees to deliver if, and only if, his work is not modified by any means.
When he does deliver, the other architects think they have a say in his designs and they modify it according to a committee that think they know better for "the greater good". When Roark knows about it, and see his creation being built in a way that he did not want, he decided to dynamite and bring it down.
He goes to court and this is his defense:
Read the full novel version of this remarkable defense speech.
Again, as a metaphor, I can't help myself to picture _Why in Howard's shoes, talking to his detractors, the trolls and haters, the ones naming the so called "Ruby Dramas", the looters, the ones that think they know about "the greater good".
Some people question why does "_Why" evoke such "irrational worship" when in the end of the day he didn't even do so much coding, and his coding was not exactly good enough (according to their own views, of course).
My personal pet theory is exactly because _Why embodies Howard Roark ideals. He is an artist, just like Roark. He did things in ways that surprised people. He created, he produced, he remained an independent mind. But some contract was breached. I don't know what it is, maybe the agreement was exactly that: "leave me alone", "do not come after my personal identity", "do not tell how I should do my work".
So when the Tooheys ran over him, he literally dynamited Courtlandt. It was his work, his terms, his choice. And his individual choice was to do what Roark defended:
“I am an architect. I know what is to come by the principle on which it is built. We are approaching a world in which I cannot permit myself to live.
“Now you know why I dynamited Cortlandt.
“I designed Cortlandt. I gave it to you. I destroyed it.
“I destroyed it because I did not choose to let it exist. It was a double monster. In form and in implication. I had to blast both. The form was mutilated by two second-handers who assumed the right to improve upon that which they had not made and could not equal. They were permitted to do it by the general implication that the altruistic purpose of the building superseded all rights and that I had no claim to stand against it.
“I agreed to design Cortlandt for the purpose of seeing it erected as I dedigned it and for no other reason. That was the price I set for my work. I was not paid.
So Kathy Sierra was right: if you do something remarkable, that you love, some will also love it, and others will denounce and hate it. Trolls are like leeches, they come crawling fast pursuing other people's success in order to feed from it. They do it not by producing, but by evoking the altruistic principles, all against the individual. And this is the evil in our society: we should be able to understand that individual achievement is not to be shared. An individual that achieved success by his own merits deserve every penny of it without the need to feel guilty.
Trolls and Haters name things such as "Ruby Dramas" because they want your attention. They want the people they quote to be available to please them. And they can't be pleased, so it's an impossible proposition. Trolls exists just for the sake of trolling. That's what Kathy may not have realized when she first wrote her essay: yes, success will attract the haters, but not because they care about what was achieved and want to protect it, but because - like leeches - they want to benefit without producing, on the principle that successful people must please those who cannot achieve.
Roark said: "We are approaching a world in which I cannot permit myself to live", and so _Why deleted his work, even though many others contributed to it. Again, there was a breach of contract and again I quote Roark:
“I did not receive the payment I asked. But the owners of Cortlandt got what they needed from me. They wanted a scheme devised to build a structure as cheaply as possible. They found no one else who could do it to their satisfaction. I could and did. They took the benefit of my work and made me contribute it as a gift. But I am not an altruist. I do not contribute gifts of this nature.
“It is said that I have destroyed the home of the destitute. It is forgotten that but for me the destitute could not have had this particular home. Those who were concerned with the poor had to come to me, who have never been concerned, in order to help the poor. It is believed that the poverty of the future tenants gave them the right to my work. That their need constituted a claim on my life. That it was my duty to contribute anything demanded of me. This is the second-hander’s credo now swallowing the world.
“I came here to say that I do not recognize anyone’s right to one minute of my life. Nor to any part of my energy. Nor to any achievement of mine. No matter who makes the claim, how large their number or how great their need.
“I wished to come here and say that I am a man who does not exist for others.
“It had to be said. The world is perishing from an orgy of self-sacrificing.
“I wished to come here and say that the integrity of a man’s creative work is of greater importance than any charitable endeavor. Those of you who do not understand this are the men who’re destroying the world.
“I wished to come here and state my terms. I do not care to exist on any others.
And the point of this article is not to idealize _Why, just to state what it means to value individual achievement.
So, many people see value in _Why, enough to forgive him for destroying his Courtlandt and praise him as an inspiration. The trolls and haters are furious, of course, just like Ellsworth Toohey was. It doesn't matter the volume or even the quality of his work. It could've been 6 lines of code, but if those 6 lines have meant plenty to a lot of people, he would still be remembered. Such is the nature of creation.
We can't get rid of the trolls and haters. I myself know that for everything I do that people love, I know some of the haters by name and address. They are there, sneaking, crawling. But it doesn't matter, because I don't do what I do for their sake, I do for my own. And if you're a person that produces, you should too.
And if anything, to me personally, that's what _Why symbolizes. I don't think we are praising just his person, but what he represented: being a creative individual producing for his own sake.
_Why Documentary at Rubyconf 2012, Denver 2 Sep 2012 7:54 PM (12 years ago)
Update: This article generated some heat. I've published another post with some of my thoughts about the subject later.
RubyConf Brazil 2012 has just finished but the US Rubyconf 2012 will begin on November 1-3, 2012, at Denver, Colorado. While I was finishing my post about the event, I came across this trailer for Why's Documentary, to be released during the US Rubyconf, if I understood correctly.
Now, if you're new to the Ruby ecosystem, you may have not heard about this character named "Why, The Lucky Stiff". I think 2 of the best articles about him were written by a fellow Brazilian Rubyist, Diogo Terror to Smashing Magazine in 2010, titled _Why: A Tale Of A Post-Modern Genius and Annie Lowrey for Slate Where’s _why?.
He inspired an entire first generation of Rubyist around the turn of the century. He wasn't just a programmer, he was a craftsman, literally. The only one I accept calling himself an "artist" within our programming world. His most famous work is the book Why's Poignant Guide to Ruby used by many famous Rubyists you know when they first found about Ruby.
Then in August 19, 2009 he vanished.
Some say that great men are recognized only after their passing ("You either die a hero, or live long enough to see yourself becoming the villain"). Maybe his last stroke of genius was to commit "virtual suicide", by erasing every digital trace of his existence - he actually deleted all his work, his projects, his source codes that were available online. Thanks to technologies such as Git (by the way, this was a great showcase of the recovering capabilities of distributed versioning systems) almost all of the deleted material was recovered and you can find them in places such as here. But the fact that he disappeared and his whereabouts are still unknown kept the myth going and 3 years later he is still remembered.
In 2007 I was conducting a series of interviews with several famous Rubyists of our community. And of course, I did send an email to Why himself. And he responded in a very unexpected way. I think it's time to disclose the unabridged content of the email so you understand his exotic personality.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
Date: Thu, 19 Apr 2007 17:38:59 -0500 From: why the lucky stiff <why@whytheluckystiff.net> To: fakita@bccl.com.br Subject: SPAM: Re: Invitation for an Interview for Brazilian Blog On Wed, Apr 18, 2007 at 10:28:25AM -0300, Fabio Akita wrote: > First of all let me introduce myself, my name is Fabio Akita, I've written > the first brazilian Rails book called "Repensando a Web com Rails". I have a > very well known blog in Brazil called "Akita on Rails": It is great to meet you, Fabio. I love accomplished Brazilians and try to fill my life with any kind of Brazilian I can find. I also try to drink milk from a bag as often as I can. Do you like apricots? I like mediterranean apricots only. But I am willing to entertain new forms of apricot, as they become available. > I adore your work! I love creative stuff and you're an artist. I appreciate your remarks, but I have a hard time believing that anyone would like my art. I will definitely die without recognition and few will ever see the work I do. But I like it that way a lot!! One of the worst things a person can get in life is recognition. But a scalp rash is very, very bad as well. I have had some serious scalp rashes and I also have thrown up blood quite a few times along the way. > So here goes the invitation: would you be available for an interview to my > blog? We could do the usual way via Skype or Gtalk where I can record the > chat. Nothing formal or fancy, just a conversation between two tech geeks > that anyone could enjoy. I'm afraid I am currently in hiding, my friend Fabio. As you may know, I am operating as a freelance professor right now. I am unaccredited, unlicensed with an ill-advised curriculum. There are no international laws protecting freelance professors from imprisonment and deportation, so am I forced into hiding. Fortunately, I have found a rather remarkable hiding place which is quite safe and has very colorful wallpaper and animal pelts. I also cannot do interviews unless they are submitted in handwriting. I also cannot respond to interviews in anything but handwriting. There are several reasons for this rule, but the foremost reason is that I like making people do unnecessary and frivolous things. And forcing interviews to be handwritten is way too unnecessary and frivolous for me to pass up, oh Fabio can't you see that!! Anyway, it is a pleasure to know you. I hope a free cart of food and cheese and DVDs and satin robes and super-long sofas comes crashing into your house today!! It will all be free and courtesy of a steep incline somewhere at a higher elevation. _why |
Unfortunately I didn't pursue this enough, I was actually planning on sending the interview questions to him, handwritten. :-) In retrospect, I wish I had, it would've been fun.
And that was Why, an icon for the Ruby community, an original character that can't be copied or replaced and we are very lucky for having here. Explore his material, learn his style, transmit his message of education, entertainment, friendliness, mastery and craftsmanship.
Ruby is Beautiful? What is Beauty? 2 Sep 2012 4:46 PM (12 years ago)
If you're a Rubyist you know the meme that "Ruby allows you to write beautiful code".
Several within the community have tried to define what "Beautiful Ruby Code" is, and even though most were successful showing us really beaultiful code, I don't think I saw someone actually being able to communicate the concept of "Beauty" yet.
Comes TED. If you know me, you know that I've been completely addicted to it for years now, all themes of TED inspires me. And tonight, while having dinner, I watched the great Richard Seymour (no, he is not a programmer) talking about this very subject and I was blown away.
Find the video below, but let me add a few words of my own. Specially in our small world of programmers and technologists, we have lots of discussions around "Form" vs "Function", as if we should choose one over the other, or as if we should balance one against the other.
I'm of the same opinion as Richard that it is not a "Form" VS "Function". The correct way of thinking is: "Form" IS "Function". Another thing is that you don't evaluate something as beautiful, you don't analyse it, you don't rationalize beauty, you feel beauty.
And your reaction to beauty is directly related to what you know, to what you have experienced. If you haven't lived, if you haven't learned, you won't find beauty. Back to programming, it's impossible for someone that just started to learn how to write software, or even someone that already did a few small projects to understand the concept of "beauty". It's only after some time, some experience and some learning that they will start to grasp what beauty possibly feels like.
With that comment, please watch Richard Seymour (if you want subtitles for your native language, go to original site so you can choose subtitles):
Knowledge and Experience is everything. Ignorance doesn't know beauty.
Registration are Open for Rubyconf Brazil 2012 11 Jul 2012 9:13 AM (12 years ago)

Registrations are open through the official Rubyconf Brazil 2012 website. The opening price is BRL 150, roughly USD 75 that you can pay through Paypal. If your company is going to sponsor your registration, ask the person in charge to register himself as a company. After registration he can subscribe many people and pay just once.
Time goes by very fast and who would say that one day we would be opening the 5th consecutive Ruby conference in Brasil? It feels like it was yesterday that Locaweb offered his mighty to support Rails Summit Latin America 2008. Locaweb, the largest web hosting company in Latin America, continues to be a fundamental support without which it would be much too difficult to organize an 800 attendees, conference in 2 consecutive days, with 2 parallel tracks, and real-time audio translation from Portuguese to English and vice-versa.
This year we will have 33 speakers and 11 of those coming from all over the world. This includes well known name such as Bruce Williams, from LivingSocial.com; John Nunemaker, from Github.com; Josh Kalderimis, from TravisCI fame; and several great names from the Brazilian community such as José Valim, Nando Vieira, Carlos Brando, and several others. We will have a wide range of subjects from best practices and architecture, tooling and platforms (Adhersion, Puppet), Java integration (JRuby, Torquebox), games, web design and UX, and much more. This is the denser Rubyconf Brazil in terms of talks, more than 30 so far!
The date and venue are set for August 30rd and 31st, in São Paulo, Brazil, at Frei Caneca Convention Center. Check out information regarding venue at the official website. It will be a Thursday and Friday so set your schedule to stay here during the weekend and enjoy more about the city and the community.
This is the space to increase your network, get to know new and potential growing markets, meet entrepreneurs and investors. Technology, markets and communities will be together in this great event.
If you have any questions, please get in touch
,%20Java%20integration%20(JRuby,%20Torquebox),%20games,%20web%20design%20and%20UX,%20and%20much%20more.%20This%20is%20the%20denser%20Rubyconf%20Brazil%20in%20terms%20of%20talks,%20more%20than%2030%20so%20far!%3C/p%3E%0A%3Cp%3EThe%20date%20and%20venue%20are%20set%20for%20%3Cstrong%3EAugust%2030rd%20and%2031st%3C/strong%3E,%20in%20S%C3%A3o%20Paulo,%20Brazil,%20at%20Frei%20Caneca%20Convention%20Center.%20Check%20out%20information%20regarding%20venue%20at%20the%20official%20website.%20It%20will%20be%20a%20Thursday%20and%20Friday%20so%20set%20your%20schedule%20to%20stay%20here%20during%20the%20weekend%20and%20enjoy%20more%20about%20the%20city%20and%20the%20community.%3C/p%3E%0A%3Cp%3EThis%20is%20the%20space%20to%20increase%20your%20network,%20get%20to%20know%20new%20and%20potential%20growing%20markets,%20meet%20entrepreneurs%20and%20investors.%20Technology,%20markets%20and%20communities%20will%20be%20together%20in%20this%20great%20event.%3C/p%3E%0A%3Cp%3EIf%20you%20have%20any%20questions,%20please%20%3Ca%20href%3D%22mailto:rubyconf@locaweb.com.br%22%3Eget%20in%20touch%3C/a%3E%3C/p%3E)
[Off-Topic] Reading with subtitles over Kanjis in Japanese webpages 8 May 2012 5:36 AM (12 years ago)
This is something I just stumbled upon and because it’s tricky to install the first time I decided to grab the pieces that make it work. It’s so useful I had to post about it.
If you’re learning Japanese this will definitely prove to be an invaluable tool. I am Japanese but I didn’t payed attention to proper Kanji training when I was a child. It shows now, as I can read Kanji only to what would be considered below high-school level in Japan. Still very useful, but it means I can’t read most websites in Japanese fast enough.
I’ve known of a Firefox add-on I’m very fond of for a long time now called Rikaichan. When enabled, you have hover your mouse over the kanji text and it will popup a box with the translation. You must install the Firefox add-on in the previous link and a proper dictionary to your native language from Rikaichan’s webpage. And that’s it.

But if you like to read Manga (Japanese Comics), you’re probably familiar with “Furigana”, which is kind of like “subtitling” over the Kanjis with Hiragana or Katakana, which are the Japanese syllabus based alphabets (the first for Japanese only words, the second for foreign words). That makes reading and understanding the more difficult Kanjis super easy and way faster than hovering over the Kanjis or plain old looking manually into the dictionary for each ideogram.
A normal snippet of a Japanese webpage looks like this:

But with Furigana Inserter the same snippet looks like this:

To install it, first you install the add-on. Then you have to install the HTML Ruby add-on as well. Finally, you have to install this dictionary. It’s a 7-zip file you must decompress and manually drag it over Firefox to install.
If you’re on a Mac, I’m assuming you know what Homebrew is and already have that installed. Because then you can install Mecab like this:
1 2 |
brew install mecab brew install mecab-ipadic |
Finally, it seems like you must manually make Furigana Inserter aware of Mecab by adding a symlink into its extension folder:
1 |
ln -s /usr/local/lib/libmecab.dylib ~/Library/Application\ Support/Firefox/Profiles/454dy2eg.default/extensions/furiganainserter@zorkzero.net/mecab/libmecab.dylib |
Understand that the Firefox Profile folder will have a different name in your computer. The one in the example is in my Mac. Open the terminal and tab to autocomplete each folder as you type and it should work just fine.
Restart Firefox, right-click in Japanese pages and you will have a “Enable Furigana” option waiting for you. Rikaichan seems to misbehave when hovering over Furigana enabled Kanji, so you may need to disable Furigana to use Rikaichan. But it’s a good compromise and may open a whole lot of new content in Japanese for us to consume.
One reason to use Firefox.
,%20you%26%238217;re%20probably%20familiar%20with%20%26%238220;Furigana%26%238221;,%20which%20is%20kind%20of%20like%20%26%238220;subtitling%26%238221;%20over%20the%20Kanjis%20with%20Hiragana%20or%20Katakana,%20which%20are%20the%20Japanese%20syllabus%20based%20alphabets%20(the%20first%20for%20Japanese%20only%20words,%20the%20second%20for%20foreign%20words).%20That%20makes%20reading%20and%20understanding%20the%20more%20difficult%20Kanjis%20super%20easy%20and%20way%20faster%20than%20hovering%20over%20the%20Kanjis%20or%20plain%20old%20looking%20manually%20into%20the%20dictionary%20for%20each%20ideogram.%3C/p%3E%0A%3Cp%3EA%20normal%20snippet%20of%20a%20Japanese%20webpage%20looks%20like%20this:%3C/p%3E%0A%3Cp%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2012/5/8/Screen%2520Shot%25202012-05-08%2520at%252010.17.14%2520AM_original.png?1336483852%22%20alt%3D%22%22%20/%3E%3C/p%3E%0A%3Cp%3EBut%20with%20%3Ca%20href%3D%22https://addons.mozilla.org/pt-BR/firefox/addon/furigana-inserter/%22%3EFurigana%20Inserter%3C/a%3E%20the%20same%20snippet%20looks%20like%20this:%3C/p%3E%0A%3Cp%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2012/5/8/Screen%2520Shot%25202012-05-08%2520at%252010.17.25%2520AM_original.png?1336483884%22%20alt%3D%22%22%20/%3E%3C/p%3E%0A%3Cp%3ETo%20install%20it,%20first%20you%20install%20the%20%3Ca%20href%3D%22https://addons.mozilla.org/pt-BR/firefox/addon/furigana-inserter/%22%3Eadd-on%3C/a%3E.%20Then%20you%20have%20to%20install%20the%20%3Ca%20href%3D%22https://addons.mozilla.org/firefox/addon/html-ruby/%22%3E%3Cspan%3EHTML%3C/span%3E%20Ruby%3C/a%3E%20add-on%20as%20well.%20Finally,%20you%20have%20to%20install%20this%20%3Ca%20href%3D%22http://code.google.com/p/itadaki/downloads/detail?name%253Dfuriganainserter-dictionary-1.2.7z%22%3Edictionary%3C/a%3E.%20It%26%238217;s%20a%207-zip%20file%20you%20must%20decompress%20and%20manually%20drag%20it%20over%20Firefox%20to%20install.%3C/p%3E%0A%3Cp%3EIf%20you%26%238217;re%20on%20a%20Mac,%20I%26%238217;m%20assuming%20you%20know%20what%20%3Ca%20href%3D%22https://github.com/mxcl/homebrew%22%3EHomebrew%3C/a%3E%20is%20and%20already%20have%20that%20installed.%20Because%20then%20you%20can%20install%20Mecab%20like%20this:%3C/p%3E%3Ctable%3E%3Ctr%3E%0A%20%20%3Ctd%20title%3D%22double%20click%20to%20toggle%22%20ondblclick%3D%22with%20(this.firstChild.style)%20%7B%20display%20%3D%20(display%20%3D%3D%20'')%20?%20'none'%20:%20''%20%7D%22%3E%3Cpre%3E%3Ca%20href%3D%22https://www.akitaonrails.com/english%23n1%22%20name%3D%22n1%22%3E1%3C/a%3E%0A%3Ca%20href%3D%22https://www.akitaonrails.com/english%23n2%22%20name%3D%22n2%22%3E2%3C/a%3E%0A%3C/pre%3E%3C/td%3E%0A%20%20%3Ctd%3E%3Cpre%3Ebrew%20install%20mecab%0Abrew%20install%20mecab-ipadic%0A%3C/pre%3E%3C/td%3E%0A%3C/tr%3E%3C/table%3E%0A%3Cp%3EFinally,%20it%20seems%20like%20you%20must%20manually%20make%20Furigana%20Inserter%20aware%20of%20Mecab%20by%20adding%20a%20symlink%20into%20its%20extension%20folder:%3C/p%3E%3Ctable%3E%3Ctr%3E%0A%20%20%3Ctd%20title%3D%22double%20click%20to%20toggle%22%20ondblclick%3D%22with%20(this.firstChild.style)%20%7B%20display%20%3D%20(display%20%3D%3D%20'')%20?%20'none'%20:%20''%20%7D%22%3E%3Cpre%3E%3Ca%20href%3D%22https://www.akitaonrails.com/english%23n1%22%20name%3D%22n1%22%3E1%3C/a%3E%0A%3C/pre%3E%3C/td%3E%0A%20%20%3Ctd%3E%3Cpre%3Eln%20-s%20/usr/local/lib/libmecab.dylib%20~/Library/Application%5C%20Support/Firefox/Profiles/454dy2eg.default/extensions/furiganainserter@zorkzero.net/mecab/libmecab.dylib%0A%3C/pre%3E%3C/td%3E%0A%3C/tr%3E%3C/table%3E%0A%3Cp%3EUnderstand%20that%20the%20Firefox%20Profile%20folder%20will%20have%20a%20different%20name%20in%20your%20computer.%20The%20one%20in%20the%20example%20is%20in%20my%20Mac.%20Open%20the%20terminal%20and%20tab%20to%20autocomplete%20each%20folder%20as%20you%20type%20and%20it%20should%20work%20just%20fine.%3C/p%3E%0A%3Cp%3ERestart%20Firefox,%20right-click%20in%20Japanese%20pages%20and%20you%20will%20have%20a%20%26%238220;Enable%20Furigana%26%238221;%20option%20waiting%20for%20you.%20Rikaichan%20seems%20to%20misbehave%20when%20hovering%20over%20Furigana%20enabled%20Kanji,%20so%20you%20may%20need%20to%20disable%20Furigana%20to%20use%20Rikaichan.%20But%20it%26%238217;s%20a%20good%20compromise%20and%20may%20open%20a%20whole%20lot%20of%20new%20content%20in%20Japanese%20for%20us%20to%20consume.%3C/p%3E%0A%3Cp%3EOne%20reason%20to%20use%20Firefox.%3C/p%3E)
[Journey to Japan #3] Exclusive Video Interviews 27 Nov 2011 7:40 PM (13 years ago)
It’s been a while since I’ve written about my Ruby Kaigi 2011 trip. Since then I’ve been really busy and I left out lots of great material shamelessly accumulating dust in my hard drive, but no more. Today I was finally able to edit some of that and upload the interviews I have recorded with some of the most well known Japanese Ruby contributors. Wonderful people that I was lucky to meet and that were very friendly to me and eager to tell their stories.
These are the first versions of the edited videos, I still didn’t have time to add English subtitles, but I wanted to upload them as soon as possible so the Japanese community could check them out first. I will try to add the subtitles in the following days (help would be appreciated). The Matz interview in particular has the worst audio as we were in the middle of an after-party in a small bar with very bad acoustics, so I apologize for its quality, I hope you can get most out of it.
Alencar Koga helped me out a lot during the interviews. Coincidentally he is a Brazilian just like me, but he’s been living in Japan for a long time and was able to build a great career, being now the CTO of MTI Japan, one of the largest mobile app developers in the country. Akira Matsuda also helped me a lot, and he is also a very well known Rubyist in Japan. Both were edited out of the videos to make them shorter to watch. I appreciate their help a lot as they will be very useful when I do the English subtitles.
The first three videos were recorded at the after-party in the first day of Ruby Kaigi. I have to admit that I was not in my best shape after having a few drinks and after a full day of event :-) By the way, the second and third video interviews were introduced by me in Brazilian Portuguese instead of English, so forgive me for my confusion. All of them have myself making questions in English and the guests replying back in Japanese. Only the Matz interview is all in English.
Shintaro Kakutani-san was the first one I’ve interviewed, being one of the main organizers of the event and a long time Ruby evangelist in Japan. He is a very active community leader, helping maintain the Japanese Ruby ecosystem.
The second one was Gotou Yuzou-san, he is one of the oldest Ruby Core Committers being the author of both Webrick and OpenSSL. He wrote a few books about Ruby in Japan and he works for the Tokyo branch of Nacl, the company from Matsue that has been contributing to Ruby since the beginning, hiring Matz as a fellow researcher.
The third one was recorded when the party was over. I was able to reach the couple Yasuko and Koichiro Ohba. Yasuko-san is well known being the president of the consulting company EveryLeaf. She employs several Ruby developers and does Ruby related projects and now mobile development as well. She is an example of entrepreneurship in the community. Koichiro-san works for a Heroku-like company in Japan, managing Cloud based infrastructure using JRuby technology. He contributes and evangelizes JRuby, specially in terms of documentation, localization (internationalization, etc).
On the second day of the event I was able to catch up with Nobuyoshi Nakada-san. He is “the” oldest Ruby Core Contributor, and he probably touched every single part of Ruby. He is also known as “the patch monster” as he seems to be a coding machine, being more active through out the last 15 years than Matz himself. He deserved to be the first one Matz chose to follow him at SalesForce.com.
Finally, at the Heroku Drink up in the last day of the event, I was finally able to grab Matz himself for an interview. Having been continuously and consistently on this road for that last few years, you can imagine how thrilled I was for having being able to interview Matz himself in person, at my home land in Japan. But as I’ve warned before, the audio is not good because of all the noise. At least Matz can speak English so everybody will be able to get most of this one.
Enjoy them all. This is for all of my friends in Japan! Thanks again for the hospitality.
RubyConf Brazil 2011 is coming! 18 Sep 2011 8:41 PM (13 years ago)
I have just released the beta version of the RubyConf Brazil website. The registration process is about to be released in the next few days but you can already check out the contents of the website.
This is the 4th year we are organizing this great conference and I’d like to invite you all to come again and visit Brazil. RubyConf Brazil is going to be great, last year we had more than 700 attendees and we will keep the same format of two intense days with two parallels tracks going on with real-time translations for everybody to enjoy!
So open up your schedule and make reservations for November 3 and 4 to come to São Paulo, Brazil.
I will keep on updating the website in the next few days, some slots in the program are being confirmed, so keep on looking for news.
And by the way, this time I decided to change the website process and make it public. All the source code is available for you to fork at Github. So if you want to contribute, tweak something that’s broken in someone’s web browser, add relevant content, or if you’re a speaker you can keep your audience engaged by adding more information about yourself and your talk. I have even added Disqus-based comments in every page so people can interact and collaborate.
Come check it out!
[Journey to Japan #2] The Final RubyKaigi 5 Aug 2011 4:13 AM (13 years ago)
I hope you enjoyed my first article in the series Exploring Tokyo City. Now let me tell my impressions of the RubyKaigi Conference itself.

What many may not know is that RubyKaigi is in its 6th iteration and it has always been organized by volunteers effort. Their leader is Masayoshi Takahashi-san. He is also the founder of Nihon Ruby-no-kai (Japan Ruby Group) which also helds the e-zine Rubyist Magazine. You should check those resources out to see what the Japanese Rubyists are doing. Great resource.

The main group seems to surround around Takahashi-san and then Shintaro Kakutani-san who works for Eiwa System Management and he is the main Ruby Evangelist in Japan, doing talks all around the country, helping create and organize Regional RubyKaigi, translating books such as the recently released Agile Samurai (from Pragmatic Programmers). As an Evangelist myself, I have to honestly say that Kakutani-san puts me to shame (which inspires me to try harder!). He is doing a remarkable work and if you didn’t know him, you should.

The Program Chair for the conference is no other than Dr. Koichi Sasada, PhD in Information Science and Engineering from The University of Tokyo, he runs the Sasada Labs researching on programming languages and its processors. Oh, and did I mention that he is the creator and current maintainer of “YARV”, the Ruby 1.9 series’ heart? You can read a small interview with him from the Rails Magazine.
There are several individual contributors for RubyKaigi that you really should spend some time knowing about. They are very active and very committed. “Friendship”, “effort”, “unity” and most specially “respect”, were words that came to mind knowing some of them.

The Program
Being honest, I can speak a bit of Japanese, but just casually, so I can’t understand more advanced techie-vocabulary, my skills are poor like that, I apologize.
So, it’s a bit difficult to understand some of the most interesting talks presented by Japanese speakers. But they had a nice and geeky workaround. Both halls had the main big screen for the slide projections and also two vertically oriented, narrower screens for Twitter stream projection at the left-hand side (#kaigi1 for the Big Hall and #kaigi2 for the Small Hall – which was not that “small”) and IRC streams on the right-hand side.

This is a clever idea for community driven real time translation. When a foreigner speaker is presenting on stage, the staff would write translations of some of the key phrases at the official IRC stream and anyone could contribute tweeting at an specific hall room channel, which shows in the other screen.
More than that, there was another staff volunteer, Makoto Inoue who helped us, foreigner speakers to place proper Japanese subtitles in our English-written slides, which really helps a lot. I will come back to Makoto in the last section, hold on.
Unfortunately, though it does help, it’s still difficult to follow more technical talks, such as the talk about ThreadGroup class that I tried to attend. But again, this is something that I want to try in our own RubyConf Brazil. Here in Brazil, because we have Locaweb organizing the difficult logistics of the event, we’re able to contract professional narrators to deliver voiced real-time English to Brazilian Portuguese and vice-versa through wireless earphones, and I can say that this is an expensive investment. I’ll talk more about RubyConf Brazil in another article.
Thanks to Dr. Koichi Sasada and the staff, the program is very well balanced. They had,
Hard-core tech-talks such as:
- The Real Time Profiler for Ruby
- Dynamic Component System and Memory Reduction of VM for Embedded Systems
- Parallel World of CRuby’s GC
- How to read JIS X 3017
- CRuby lock design improvement and why it sucks

Business oriented case talks such as:
- Large-scale web service and operations with Ruby
- Issues of Enterprise Rubyist
- Critical mission system implemented in Ruby
Community oriented and motivational talks such as:
A bit less hard-core tech-talks such as:
- Advancing Net::HTTP
- Drip: Persistent tuple space and stream
- Actors on stage
- Use rails_best_practices to refactor your rails codes
- MacRuby on Rails
- Writing custom DataMapper Adapters

And finally some Agile related talks that most should be used to see by now such as:
- Efficient JavaScript integration testing with Ruby and V8 engine
- 5 years know-how of RSpec driven Rails app. development
- BDD style Unit Testing
- Toggleable Mocks and Testing Strategies in a Service Oriented Architecture
And there are many more that you must see. And speaking of which there are even a KaigiFreaks (probably a homage to the venerable Confreaks that you all know and love) volunteers staff group dedicated to stream videos of the conference in real time, record, edit and then organize and merge volunteer-made English subtitles. Editing video is a laborious work and to have volunteers doing it, I really applaud this wonderful volunteer group.
You want more? Lot’s of session video recordings are already available. You can watch the Japanese sessions from the Main Hall Room and from the Secondary Hall Room. This is huge, I just wish RubyConf Brazil video recording contractors could be this efficient! But hang on, this year we will improve on the video services as well.
Opening Keynote – Bridging the Gap
Aaron Patterson, our friendly @tenderlove delivered a great opening keynote. It’s very interesting because you all know that he’s probably the only person that is both a Ruby Core and Rails Core committer, moreover, having the opportunity to talk to him a few times makes me feel like he really “understands” the Japanese-ways. Watch him talk:
[16M01] Ruby Ruined My Life. (en) from ogi on Vimeo.
The gist of his talk was about the differences in organization between the Ruby and Rails Core teams. The Ruby Core Team is sort of role oriented, where each committer usually has very specific responsabilities, being the maintainer of certain features of Ruby. There’s even the important role of a “Release Manager” currently held by ms. “Yuki Sonoda”, a.k.a. @yugui, who’s been doing a great job. You can see the list of maintainers in the official Wiki.
Aaron himself is responsible for the YAML parser, Psych, Fiddle, DL. He notes that this kind of organization makes you take more care when messing around someone else’s area. It’s not a deterrent, but you have to be more careful. On the other hand, there are areas that are lacking a full time maintainer. And the other thing is that the release cycle is long, so it takes time for changes and even fixes to reach a broader audience sooner.

The Rails Core, on the other hand, doesn’t have very specific roles, so everybody kind of “owns” everything. But the side-effect is that at the same time no one is actually “responsible” for any particular part. They don’t have a release manager, for example, so there’s no one actively organizing what’s missing to close a release. Again, you saw Rails 3.1 Release Candidate being announced at RailsConf back in May and we’re closing July without a final 3.1 release.
But he’s not stating that one of them is better than the other but instead that they can learn from each other. For example, he made the case that the Ruby Core could be less ceremonious about commits and specially about reverts, people should be able to touch the code without getting afraid of offending anyone. And also that the Ruby Core could put more thought in deciding what should be maintained inside Ruby’s subversion repo and what should be removed and maintained separately as gems, to make it easier for parallel features to evolve independently.
Watch his presentation, he goes on several ideas and also talks about DTrace, other tech stuff and lot’s of funny jokes.
[TL;DR] The Language Barrier
Aaron reminded us again that many people still complain that there are two distinct Ruby development mailing lists, ruby-core and ruby-dev. The first in English, the other in Japanese. A few paranoid developers even go crazy enough to think that there are some kind of “conspiracy” going on in the Japanese list, stuff that’s decided without never showing up in the English list. As Aaron said, there’s no such thing going on.
The more usual complaint is always the same “why don’t the Japanese people communicate in English?” And again, the old bad habit of “taking things for granted”. The ignored reality is that the Japanese people, in general, doesn’t have good English skills. It’s not arrogancy, lack of effort, it’s a simple lack of skills.
I’m from Brazil and here people don’t usually speak good English as well. For me, it feels like Brazilians and Japaneses have a similar level of English understanding. It’s very frustrating. But on the other hand, it’s also frustrating to see Americans taking for granted that everybody else in the world understands English. It reminds me of that memorable scene from the fantastic movie Inglourious Basterds where Diane Kruger’s character Bridget von Hammersmark sarcasticaly says:

Gotta love Tarantino :-)
I can’t tell the American’s reaction to that scene, but I’m pretty sure everybody else had a good laugh. Now, seriously, I shouldn’t laugh because we usually only speak Brazilian-Portuguese, which is a language that almost no other country use. The same for Japanese. But the sarcasm was just to raise the discussion.
It doesn’t feel good when a foreigner expects us to talk his language instead of the other way around. But it’s also not good that we don’t increase our efforts to learn more languages, like Europeans seem to do. I’ll talk more about this in another article.
That said, my point is that there are too many assumptions in communications, and I don’t mean only different grammar or vocabulary. More importantly, there are particular protocols in each culture that we also take for granted and expect that everybody else will comply. But communication between people from different cultures can lead to a lot of misunderstandings. Being geeky, it’s the same as an MSN Client trying to connect to an XMPP-based server :-)
After lunch we had the Ruby Core Team on stage discussing what’s going on in the current Ruby development afairs. Sonoda-san confirmed 1.9.3 for August, with not so many new features, more bug fixes, security updates, stability in general. But they presented a few small controversial features. One in particular was interesting.

We have the private class method to hide particular methods in Ruby. Now they have implemented private_constant to hide class and module names that we don’t want exposed publicly. It’s an interesting feature, though it annoyed some, like Yehuda, a bit.
It was fun (not in the bad sense, please) to see him raise his hand in the Q&A session and state that the Ruby Core could discuss a bit more about new features like that with the other library developers before releasing them. The Japanese Ruby Core team didn’t fully understand what he said at first. Then Matz attempted to translate what he said, but they were still puzzled, until Matz added that it was more of a statement than a question. So the Ruby Core made that “ah, got it!” face and moved on, but Yehuda kept waiting for some answer, kind of feeling ignored maybe.
Again, it’s not my intention to make plain fun out of this, and this was just my personal understanding. But it was an example of a situation where people try to communicate without using the same language and the same protocols. After the session, I was shortly talking to Aaron, Yehuda showed up, and he said that he was actually waiting for some discussion, and we tried to explain that it sounded more like a statement, which is why they didn’t address it.
The Ruby Core Team
Another interesting thing that was not entirely news, but I wasn’t aware of, was the introduction of Shota Fukumori-kun, @sora_h on Twitter. With only 14 years old, he is the youngest Ruby Core committer. He did some work on making the Ruby test suite run in parallel if multiple cores are available. Sounds easy when I explain like this, but it is not. He made several other contributions to Ruby and other open source projects, take a look at his website. I am more and more amazed by the amount of very young developers exposing themselves all around the world. I wonder if this is starting a new trend. Just pay attention and keep looking.
The sense of humor of the Ruby Core was also interesting to see. Yuki Sonoda-san with her kind of serious posture were making lots of small jokes and comments, kind of breaking the ice between the developers on stage. She inquired Matz if they would have a 1.9.4. She complained, kidding, that she wouldn’t like to deal with the maintenance of 1.9.2, 1.9.3 and even 1.9.1 that’s still supported, plus a future 1.9.4. Matz made a funny troubled face and played with the option to delegate it to Shyouhei Urabe-san, one of the maintainers of the 1.8 series. As Sonoda-san moves to 1.9.3 maybe Urabe-san could also graduate from 1.8 to 1.9. They made some fun out of releasing 2.0 instead of 1.9.4 as well. Matz agreed for a while, Sasada-san was against, and they didn’t settle on 2.0 just yet. Just a humorous session between the core developers. But don’t expect 2.0 any time soon.

The only other news around Ruby is that Kirk Haines, the brave maintainer of the venerable 1.8.6 version said that there will be just one more release in the next couple of months to close most outstanding bugs remaining, then 1.8.6 will finally reach its end of life. Rest in piece!
And the last bit is that Ruby will change its license to become BSDL + Ruby. There’s a discussion around this topic if you are interested in license stuff.
Other Sessions
As I’ve mentioned before, RubyKaigi had a very balanced program with several different themes for everybody. I want to congratulate everybody for a very well thought out mix of sessions. As usual, I had the same dilemma that I have in every conference I attend, I either miss sessions because I’m tweaking my slides until the last minute or I’m trying to meet new people, record interviews, do networking.
Thankfully people more disciplined than me not only attended most sessions but also described them (please, send comments with links to other blogs with reports from the Kaigi). One of them is Stoyan Zhekov who wrote three articles, for Day 1, for Day 2 – Part 1 and Day 2 – Part 2.
If you understand Japanese or if you want to test the strengths of Google Translator, you can read the huge report in the Gihyo website made reports for Day 1, Day 2 and Day 3. It’s 21 pages long! (And I’m on Page 4 of the Day 3 Report, yay!) I also recommend that everybody keep an eye on the RubyKaigi 2011 website because I’m sure they will also post links to the slides in Slideshare. And you already have all the video recordings from this year and the previous years as well, so save some time to watch as many as you can.
Books on Sale
I don’t know if this is something that every RubyKaigi had, but they have set a small book selling booth with several nice titles. They were releasing a few new titles at the Kaigi, so they also had a book signing session in the lunch interval where Matz signed several books. The other day, Takahashi-san, Morohashi-san and Matsuda-san signed their brand new book as well. They released books for Rails 3 and Ruby 3 Recipes.

That was great, I had my book signed by all four of them (yay!). And they have several books about Ruby, some books are very specific such as an entire book just on dRuby, another specific for Mac desktop app development with Ruby. They also have several translated books from The Pragmatic Programmers such as The Agile Samurai, by Kakutani-san. Agile is growing bigger in Japan, still far from mainstream, but people are interested.

(TL;DR) Lightning Talks
Special remarks goes for the YamiRubyKaigi (something like “Dark RubyKaigi”) and the next two Lightning Talk sessions. Because it was three days long, there were plenty of time for several quick (5 min long) talks. I was surprised by how many people did talk about many different – and sometimes just funny – subjects. That’s something that unfortunately in Brazil, we are still lacking behind, I have a hard time with lightning talk sessions because they usually have very few people willing to talk and usually the topics are still basic in content. After seeing so many lightning talk sessions from RailsConf and RubyKaigi, I know that we still have work to do here.
A few highlights and examples from those lightning talks are:
- Zenpre a web tool to make it easy to upload your slides at Slideshare, prepare a UStream transmission and make an online video + slides presentation.
- ODBA or “Object Database Access” which defines itself as an unobtrusive Object Cache system for transparent object persistence.
- Rios Proxy a framework for command line interface tools.
- ActiveLDAP is a Rails 3.1 compatible library to access LDAP directories.
There are several other interesting talks that I recommend you to watch. Some are just funny, some are motivational, but it can’t be denied that 39 lightning talks (17 YamiRubyKaigi Talks, 11 lightning talks on the 2nd day, 11 lightning talks on the 3rd day), accounting for around 3 hours and 15 minutes of content is a lot. Congratulations to the community for spending time assembling slides and interesting content and showing up on stage to present them.
And as I promised to my new good friends from Australia, Andy Kitchen and Jonathan Cheng, I will give my support to their brand new and revolutionary software development technique, introduced at YamiRubyKaigi, that would make even Kent Bech rethink his concepts! :-) I present to you: V.D.D
Now seriously, putting some thought in this subject, I always wondered how come I see lots of people lining up to talk at US conferences such as RailsConf and now I saw lots of people again lining up to talk at RubyKaigi. Here in Brazil I usually have a hard time coming up with enough interesting talks to fill one single session.
It’s just another speculative theory of mine. In the US there are several smaller Ruby user groups that keep meeting with certain frequency, such as the Seattle.rb group. I speculate that people start “training” there, showing small talks in front of small audiences, testing the acceptance of their content, then they attend larger conferences. In Japan, the Ruby Evangelist Kakutani-san and Rails Evangelist Matsuda-san have been raising regional “kaigis”, groups, such as Asakusa.rb, inspired by the US user groups. Again, this model helps to raise good speakers, providing space for practice in front of smaller audiences, and only then going to larger conferences.
In Brazil, the Ruby community started late, developed fast, and all of a sudden we already had a large conference such as Rails Summit, breaking an important period of time where the regional communities could grow and mature. We now do have regional communities, but few of them actually gather together, presenting ideas in front of each other with frequency. Most smaller communities only meet online at mailing lists. So most people never presented to smaller audiences, never got feedback, and couldn’t know if their content is engaging or not.

My recommendation: regional communities are awesome, if you’re from some place in the world where they don’t exist, please start one. It always starts like this: with one person, perhaps two, for some time you will feel very small, but persistency and consistency will attract people and all of a sudden you are a few dozen. And you’re practicing social skills, testing ideas, getting direct feedback.
In São Paulo, there are companies such as Caelum Training Center which always supported small communities. They provide a monthly space in their facilities so the regional Ruby group can gather and present their ideas at least once every month. One can tell the difference in quality of speakers that have been training in groups like this. It doesn’t matter if it’s not perfect, because it’s not supposed to be. You exercise precisely because you’re still not good. I have presented almost 100 times at events, and I’m still very bad at several points that I need to improve. Perfection comes with practice. And practice comes with repetition and feedback. Regional user groups are a great place for people to practice.
Closing Keynote
Matz closing keynote was particularly interesting. It was the first time I’ve seen him talking live, and it’s the first time I’ve seen him speak about anything different than Ruby 2.0 or RiteVM. He talked about 4 different topics, first about his career, then about pendulums, about PG and the next 100 years, exactly as the title of his talk describes. In general, it was his vision about the future.
[18M10] Pendulum, PG, and the hundred year language from rubykaigi on Vimeo.
As you all know, Matz is now a member of Heroku. He’ll have official support to hire some Ruby committers and assemble a full time team to maintain the development of the Ruby platform. He confirmed that he’ll not move to San Francisco and that the pace of development of Ruby should not change that much, at least not at first. He’ll do his work as he has always done it, from Matsue, his home town, and he’ll remain a fellow researcher at NaCl, the Japanese company where he has been working for from the last 10 years or so.
The first developer hired to be a full time employee on that team was the remarkable mr. Nakata Nobuyoshi, the top committer, surpassing even Matz in commits into the Ruby trunk, and one of the oldest and most senior developer of Ruby. Great choice, and expect to watch an interview I recorded with him. He has been contributing on his free time from the last 15 years, a very committed developer that you rarely see nowadays.

Then Matz explained that Japanese programmers like to build their own small languages, something like a hobby. Lightweight Language events have been going on for a long while now. Even highschool students attempt to build their own languages. And he’s been seeing lots of attempts in several places. It would be interesting if the next mainstream language comes out of this. But he also mentioned one of his personal characteristics: “負けず嫌い”, meaning that he hates to lose. Speaking just like this it may sound kind of harsh, but it just means that he is not the kind of person that will sit tight and wait. He will always be looking for new ways to improve his language design. He welcomes the challenge with open arms, that’s what he means, in general terms.
He actually first mentioned that he is “大人げない” literally meaning “immature” but more like “not acting like an adult is supposed to” or just being plain “childish”. It was fun when he dived into the “PG” section of his talk, mentioning the famous essayist and entrepreneur Paul Graham, whose fantastic essays are a must-read to every serious programmer. Matz reminded that Paul Graham created a Lisp-ish language called Arc, but it was not very popular. But imagining the 100 year language, we can improve on current languages, to get to the taste of Paul Graham’s. And there’s this Lisp-ish language called Ruby, invented by a guy named Matz, and this language is popular. So, maybe as a language designer, Matz is better than Paul Graham?? Of course he was kidding, but it was very interesting to listen Matz himself saying this particular remark, showing his “大人げない” and “負けず嫌い” sides.

He kept saying about his thoughts of the 100 year language, that something like Ruby would still be around. With the current trend of hardware evolution following Moore’s Law, we would not build languages just for the purpose of raw performance, but for the purpose of being hospitable by humans. So his last remark for the future generations was “大人げない大人になろう”, literally meaning “Be immature adults” or also “don’t become too serious” or an even better analogy is Steve Job’s remark at the famous 2005 Stanford Commencement Address, where he closed saying “Stay Hungry, Stay Foolish”. It’s a similar advice.
Just before that, he mentioned again that “Rivals are always welcome, of course” … “But I will crush you!” :-) Again, don’t take this seriously, it was explicitly intended to sound comical.
And it was interesting because for the longest time people in the Ruby community have been hearding the meme “Matz is nice and so we are nice.” I don’t recall where this started, but I think everybody that has been at the community for some time knows this. Which is why it was fun to see this other “dark side” from Matz, being “immature” and “hating to lose”. This is great, I think that this side doesn’t contradict the other, it’s just that we can be fiercer without losing kindness.

(TL;DR) The Last RubyKaigi
As I’ve mentioned before, this big event is all organized by the sheer will and effort of a group of very dedicated volunteers. They join every year, for the last 6 years, to put together this great event. You can feel that it’s different from a company-organized event such as RailsConf or RubyConf Brazil. Don’t get me wrong, the quality is on par or superior in many aspects. It’s the mood that is different.
After Matz closing keynote, Takahashi-san made a small closing speech. He thanked all the sponsors, the attendees, and the volunteer staff. It was very nice to see all of them gathering on the stage. I had no idea that the staff group was so large. I felt very humbled by that sight and they deserved the applauses.
But this year’s conference was born from a seed planted last year. I don’t know how far have Takahashi-san and the other leaders thought about this, but if it’s half of what I speculate, I think it’s a bold move.
Before I start, let me introduce you to another Ruby developer from Japan, Makoto Inoue. This year he volunteered to help the foreigner speakers to have their slides translated to japanese, to make it easy on the real time translators during the talks (Thanks for the help, Makoto-san!). He started his Ruby career because of Rails a few years ago and now he got himself a good position at New Bamboo, in London, the company that also delivered the very awesome Pusher service.
Makoto attended last year as well and wrote his thoughts in two articles that you should read before going on (Part 1, Part 2). In the second part he mentions another article originally wrote by Shyouhei Urabe, a Ruby Core developer. This article is titled RubyKaigi must die and it seemed to have inspired Takahashi-san on the theme for RubyKaigi 2011. Because I feel it’s important to point out, I will quote the article here:

1: The quality of RubyKaigi is unnecessarily high
The fee of Ruby Kaigi (JPY 6000 for 3 days) is way too low considering average conference fees, yet the quality is too high. We should think about how come this is possible. It looks to me that it is relying too much on volunteers. It is as if we are burning the motivation of these volunteers as fuel. I am worried that people get burnt out, and nothing is going to be left in the end. I don’t think buying someone’s motivation by money (= paying money to stuff, or hiring professional event company) is necessarily bad, especially if it helps to sustain the community.
To be frank, there is no structure for RubyKaigi to continue. This is because we were not sure if the Kaigi will continue when we first started. We thought “just give a try”. We continued because its continuous good response, but this is not sustainable.
2: RubyKaigi should be starting point, not the goal
The initial purpose of Ruby Kaigi was to find people (who have contributed to Ruby , or use Ruby for interesting ways) and put spotlight on them. There must be so many Rubyists who kept low profile unless attended Ruby Kaigi. I do agree that it’s a great thing, but that should not be the start point. RubyKaigi is almost like a cradle for Rubyist, but that’s not the end goal. I feel that the number and quality of theses people start outweighing RubyKaigi and RubyKaigi will become constraints to people as it grows.
How can we avoid this? We need some sort of scale up/out strategy such as increasing the capacity of the Kaigi, do it more frequently, or incorporate RubyKaigi as sustainable organisation, but not sure if there are anyone who want to do that. Then the alternative goes to “Stop it!!”.
3: Isn’t RubyKaigi creepy?
I was expecting that someone is going to say this at some point. Why you guys always mentions “Love” or “Feels” good, and everybody gets so moved? That’s so creepy. You need to calm down a bit. Isn’t it abnormal? If you start hearing something sounds smooth, that means there are something else behind.
To say brutally frank, RubyKaigi is an instrument for a few leading people to agitate other people, and this is so called “cult”. It may not be that bad. Having said that, I am insider of the community (NOTE: The author is one of the Ruby core committers), so even I may underestimate this phenomenon.
This is dangerous, because it is a sign of temporarily fever and people soon go away when the hype goes. It’s nice that Ruby becomes so popular, but we have to think about how to have sustainable community, so the further fever should stop. It’s now time to cool down a bit.
That’s all. If you keep saying “It is too hard (to organise)” or “(RubyKaigi organisation) is so fragile”, then you should stop now. RubyKaigi is not all of your life, isn’t it?
So at the closing speech from RubyKaigi 2010, they announced that 2011 would be The Final RubyKaigi. The idea is close this cycle, reorganize and come back. Takahashi-san will found a proper organization to be the stewardship of an yet unnamed new conference that will come back probably in 2013. So 2012 will be the first gap in 6 years of RubyKaigi. It is still unknown how this will be reorganized, but it seems clear that it’s not the end.

Don’t take everything literally, those are wise word that deserve some reflection. So pay attention.
It’s already a great achievement to be able to deliver six consecutive conferences like this. I was involved in three consecutive conferences of similar sizes and I can appreciate the effort. I said it’s a bold move because it takes courage to dismantle something like this. Once you start and you really like it, it’s difficult to let go. But on the other hand you need to step up to the next level once you reach the first ceiling, and I think RubyKaigi served its purpose.
In the US, Chad Fowler, Rich Kilmer, David Black organized the first RubyConf back in 2001 and just after that they founded RubyCentral, a non-profit organization, to organize the next conferences and support regional events. It was very “American” and a smart move that payed off in spades, specially with the following support from O’Reilly and other companies. They are delivering the 11th RubyConf and they just delivered the 6th RailsConf. The “founding fathers” of the American Ruby Community were able to foster a sustainable ecosystem. I’ll come back to this subject in another article.

There are several similarities in the Japanese and Brazilian Ruby communities, there are specific challenges and there are lots of things that I have personally learned in my trip. I will share some of those insights in my next articles, for now I will wrap up my impressions of this Final RubyKaigi by saying that it succeeded in going beyond my expectations and I really appreciate all the effort spent by the staff in putting this great conference together, and I wish them luck in coming back.
Congratulations!
[Journey to Japan #1] Exploring Tokyo City 25 Jul 2011 9:54 PM (13 years ago)
This is the first article in a series that will use the Japanese RubyKaigi trip as the background – and a kind of excuse – for something else entirely that I’ll attempt to achieve, though I am not sure if I will be able to succeed.
If you don’t know me, my name is Fabio Makoto Akita. Fabio is my Brazilian first name. Makoto is my Japanese first name (considered a middle name in the Western world) and Akita is my family name. I am a 3rd generation Brazilian-Japanese born and raised in Brazil. Many people in Japan asked me about this, hence the explanation here.

Brazil is an Emerging and Developing Country, former Third World. Some assume that the Brazilian culture is very much similar to the US culture, being from the same Western world and having some of the same European roots. And that Japan has a very different culture from both, being from the Far East, the Orient.
Ruby is one of the few open source projects that I am aware of that has a strong US derived community and at the same time another strong Japanese one.
(TL;DR) Disclaimer

I was raised with a very strong Japanese foundation, but at the same time strongly influenced by the Brazilian culture that surrounds my Japanese family stronghold. I was shaped in a country that consumes and incorporates many aspects of the US culture although little to nothing of its inner philosophies.
Thus I’m in the fortunate position of having being raised in both Western and Eastern cultures at the same time. It’s usually not a big deal for most, even for other Japaneses raised outside of Japan. But at least for me, it means that I don’t take anything for granted. Explaining will be a difficult challenge, so just assume that decision-making is more difficult for people like me.
I’m not a professional in the field of Social Anthropology. Sometimes I’ll have to victimize myself relying on exaggerated Reductionism. Do take everything you read with a grain of salt. I won’t state “absolute” truths, just conclusions and explanations based on different points of view that are neither good or bad, just different. Try to refrain yourself to think in terms of “right” and “wrong” and instead try to understand the subject at hand.
What I’m asking is not trivial. Do not take anything for granted, assume that you’re always influenced from your own culture’s point of view. It necessarily carries lots of prejudices that will lead to biased conclusions, some of them known as common sense. Also do assume that I do understand the side-effects of tools such as reductionism, empiricism and plain old speculation. I’ll assume smart readers.
The challenge for this series and the goal I’ll pursue is to write in order for Brazilians, North Americans and Japaneses to understand, already with the assumption that each has its own outstanding culture.
(TL;DR) The Decision to Depart
As a Japanese myself, you can imagine that visiting my family’s country of origin for the first time carries a strong personal importance. At the same time I’m of the kind that enjoys travelling only when there’s an outstanding purpose for me to accomplish.

I would restrain my desire to visit Japan until I had some purpose. Back in 2007, I still didn’t have it. I could go and tell people there that “I intend to make contributions in the future to help the Brazilian Ruby community.”
Who cares anyway? The road to hell is paved with good intentions. Results will always overshadow any good intention. I knew it would take a few years but everything worthwhile takes time to accomplish.
Four years have passed since I decided to become a Ruby evangelist, and I finally had something to share, so I decided that it was time. But 2011 has been a very heavy year for me in terms of volume of work, in a positive way. Thus I only started preparing for RubyKaigi around the end of June. I casually sent an email on June, 22nd to Japan’s top Rails Evangelist, Akira Matsuda saying that I might go.

That kickstarted another thread with him and Japan’s Top Ruby Evangelist Shintaro Kakutani saying that one of the international speakers wouldn’t be able to go, so there would be an available 30min slot in one of the parallel tracks. That’s how I ended up as a speaker! This is a good example of Serendipity.
At that time I was buried in work so the visa process had to wait (yep, Brazilians need visas in several countries). My flight was booked to depart on July 12th, Tuesday, and I was only able to go to the Japanese Consulate on July 4th. If anything went wrong, I wouldn’t have any more time to retry. It only served visa requests on Mondays, Wednesdays and Fridays and only from 9AM to 11AM. To make things even more exciting, I was anxiously waiting at the consulate’s office on the 4th and the last required document was hand-delivered to me at 10:55AM, at the 11th hour ! But I digress.

Attending RubyKaigi for the first time, being able to visit Japan for the first time and still be able to talk to the Japanese community felt just like a perfect wrap up for my personal journey. It was a long and very difficult one, but very worthwhile.
Apologize
Four years since I’ve decided to evangelize Ruby, I knew what I wanted to talk about. It was named Personal Dilemma: How to work with Ruby in Brazil?. That would be on July 18th. The video recording of my session was already made available (thanks to the efficient RubyKaigi staff). Please take a look and give feedback, it always helps.
There was one mistake in the introduction of my talk, where I speak in Japanese. I meant to say “I’d like to thank Yukihiro Matsumoto and the Ruby Core, although they may not be here” but I actually said “… although maybe not necessary.” How come!? By making the mistake of saying “iranai” instead of “irarenai” or simply “inai” so I apologize for that, I hope people that understand Japanese can tell that it was a mistake from the context.

A Brazilian-Japanese Meets Japan
Before the heavier philosophy and cultural discussion that I want to attempt, let me start light with a simple report of my first visit to Japan.
I travelled to Japan on July 12th. Because Japan is 12 hours ahead of Brazil and because the total time of the travel would take more than 28 hours (11:30 hours from São Paulo, Brazil to Frankfurt, German; 6 hours waiting at Frankfurt; and finally another 11 hours to Narita, Japan), I would only arrive on July 14th.
The coincidence is that my birthday was on July 13th, which I basically spent at the airport of Frankfurt. I think that by now you all understand that I was receiving a very big birthday gift. Absolutely no complains, but as a bonus the flight from Frankfurt to Narita was pretty empty and I was actually the only passenger on my seat row! So I was able to have all 3 seats just for me. Very lucky, really appreciated that.

I landed at Narita International Airport at 3PM on July 14th. It is Winter here in Brazil but Summer in Japan, and it was a very nice, hot, sunny day at Narita. I am of the kind that never counts the chickens before they hatched. I was holding my breath since my company agreed to sponsor my trip and until I cleared the Immigration process and put my feet in Japanese soil, only then I was able to finally relax. So you can imagine how stressful were the days prior to my travel. Anything could go wrong: the visa could not have been approved – as I explained before -, I could have had trouble in the German Immigration, I could have had trouble in the Japanese Immigration. When too many uncontrollable variables can go wrong, you have to plan very carefully and never put your guard down until every risky step has been securely completed. Assuming nothing will go wrong, being overconfident, is what will lead you to fail. Murphy is one busy fellow that never ever rests, so can’t you.
Now, a big tip if you intend to visit Japan for the first time: do not get a taxi cab to Tokyo. Narita and Tokyo are around 1 hour apart. In Brazil, we have a very sad public transportation system, the Guarulhos International Airport in São Paulo is located in the city of Guarulhos, less than an hour from São Paulo City, so we usually get a taxi cab. But taxis are very expensive in Japan. My mistake of getting a cab from Narita to the neighborhood of Ikebukuro cost me more than 20,000 yen, more than USD 260! That is twice what I would pay in Brazil for a similar distance.

There is a much nicer solution: the Skyliner, a very fast, comfortable and reliable train line that can take you straight from the Airport Lobby directly to many main train stations in Tokyo, from where you can reach virtually anyplace in the city. And it will cost you 10 times less than the taxi. But, I was tired, I was thinking like a Brazilian, and totally ignored the possibility of the Airport having such an efficient train line a few meters away from the arrival gate.
(TL;DR) Adapting to Japan
I stayed at an inexpensive hotal called Oh-Edo at Toshima-ku in Ikebukuro. I was a bit surprised that my room was very small compared to Brazilian standards – a normal size by Japanese standards I think. Remember, real estate in Tokyo is expensive. More than that, the population density is overwhelming. As a comparison Tokyo has more than 32 million people in an area of 8,000 km2 and my home city of São Paulo has 18,8 million people in a similar area of 8,400 km2. So, twice the density in average!
July 14th was Thursday and I arrived at evening. After I dropped all my luggage and rested a bit, I decided to explore the Ikebukuro neighborhood. As an explanation for my background, I have spent several years of my childhood learning Japanese, absorbing the culture and even the pop culture. It was very common for the São Paulo Japanese community to import VHS tapes with several Japanese TV shows, dramas, movies, music show all recorded. So every week we would go to a rental store (there were a few well known in São Paulo in the 80’s and 90’s) and watch a few tapes through out the week. We had a gap of around a month, I think, which was the average time spent for ship delivery.

More than that, specially through the 90’s I was an avid manga and anime fan. So I also consumed several hundreds of volumes of manga written in Japanese and another hundreds of hours of animes. The sheer volume of content that I was able to consume in more than 10 years meant that I almost knew every aspect of Tokyo city and its surroundings without never been there. I knew all in theory, it was time to experience in practice. But it means that I had almost no impacts or shocks whatsoever. It was a process of validation of knowledge more than anything which I believe is different from what a non-Japanese person would feel being there.
While many people would think that this is a lot and I was probably very dedicated, this would not be true. Many Japanese from the 2nd or 3rd generation, raised around the 80’s and early 90’s would show the same behavior. I would even guess that I am under the average of Japanese knowledge if you compare many from my generation. There are several Brazilian-Japanese that can read, write and speak flawless college-level Japanese, which is not my case.

Another thing is that I have not been practicing my Japanese for several years now. My Kanji skills are bad, possibly remembering less than 300, which is less than what a 3rd grade student has to learn. To be able to read a newspaper, for example, one has to know at least 2,000 Kanjis. This means that I was able to behave, listen and speak properly – although with a flaky vocabulary at times – but I wasn’t able to read every sign in the streets and stores. Some key signs have English subtitles, making it a bit easier.
If I remember correctly, Tokyo was not a planned city, so there is no logical organization as the city grew organically. But some common features of the major neighborhoods is that there are some main large avenues surrounded by grids of very narrow streets (no sidewalks, barely large enough for one car). Buildings are very near to one another, giving a very compact feeling to city blocks. The buildings that are not in the main avenues are usually very narrow as well. This is the result of the sheer population density; it simply can’t waste any space at all. If you have the chance go visit the Odaiba neighborhood – unfortunately I didn’t have time to go there myself – but it is built over the sea, showing how the city is looking for ways to find more space where there are none.

Another thing that confuses foreigners is that in Western countries the address system usually has streets and avenues with names and each house or building with a number in a linear ascending order.
For example, the Oh-Edo Hotel is located at Tokyo-gun, Toshima-ku, Ikebukuro, 2-68-2. Sounds weird? Addresses in most parts of the Japan, on the other hand, are described from the name of the municipality (Tokyo-gun), the ward (Toshima-ku) than 3 numeric identifiers divided by district (2-choume), the city block (68-ban), the house number (2-go) which, by the way, is not in any particular recognizable order, most probably numbered by order of construction within the block.
So, without a map one can’t navigate through the city. So another tip is that I was fortunate enough to have printed the Google Map’s map of my hotel, which the taxi driver was able to use to come close to the hotel area and, even with this, we had to stop to ask for directions. So, do buy a City Guide with maps of the main regions so you won’t be completely lost! And every time you want to go to a new location, print a Google Maps’ map or ask someone to write a map in a piece of paper. You won’t be able to go blindly to new locations within the city trusting only in the Western logic of street names, linear numbers, crossings, etc.
The Ikebukuro area seems to be a very famous one, with several commercial blocks and a mix of convenience stores, restaurants, game centers, small night clubs, karaokes, a very busy area at night as well. Everything was at a comfortable walking distance from my hotel.
Transportation and Entertainment Efficiency
The primary way of transportation within Tokyo is definitely their super efficient railway system. According to Wikipedia there are an staggering amount of 882 interconnected rail stations in the Tokyo Metropolis, 282 of which are Subway stations. It is estimated some 20 million people use rail as their primary means of transport (not trips) in the metropolitan area daily. In comparison, the entire country of Germany, with the highest per-capita railway use in Europe, has 10 million daily train riders.

At São Paulo we only have 62 stations, where 3.6 million people ride daily. I am personally ashamed to present this aspect of my city to foreigner friends. The public transportation problem is nothing short of awful. For Brazilians, a railway system the size of the Japanese one is something only imaginable in science fiction. It was really overwhelming to enter the huge Ikebukuro station for the first time and feel lost, as a small lab rat in a maze looking for the exit.
The only thing that I knew was that from the Ikebukuro station I would be able to find the Yamanote Line, which goes to several landmark neighborhoods such as Akihabara and Shibuya, which I intended to visit on Friday, 15th. I didn’t locate them in the map at first glance, but talking to the station clerk (and this is where speaking Japanese is really helpful). Most Japanese understand a bit of English but they can’t speak in a very fluent or understandable way (more on that later). If I walked near the walls I would see the many many line maps and I would eventually find it but it was easier when he explained me that I should look for the JR Line. Instead of “Yamanote” which is the Line name, the signs pointed to the private company maintainer name, the “JR”, which is short for East Japan Railway Company. So whenever you see JR in the station signs, they refer to the Yamanote, which is a circular line that goes through several well known locations within the most busy area of Tokyo.

First, I went to Shibuya, which has several clothing stores, malls, restaurants. A good place for shopping. By the way, several of the main train stations have malls built over them, they definitely want you to consume. And another thing you will notice is the sheer volume of visual noise all over the buildings, several colorful and giant advertising outdoors spread out over the city making for a very colorful and busy landscape. This is similar to some busy places of New York City for example.
Contrast that to my home city of Sao Paulo, the 4th largest metropolis in the world. In 2007 our mayor banned all outdoor advertising. It was quite a successful programs, the publicity market complained but other than that people accepted it. Most will say that the city looks much cleaner now and I agree, though it’s a bit sad that it’s now quite greyish and boring at the same time. It doesn’t help that contrary to Tokyo we have few trees and green areas, limited to small patches of vegetation and a few parks in the city.

Speaking of which, it reminds me of the problem of urban pollution. We suffer a lot in Sao Paulo where we even have a common saying that “in Sao Paulo people can ‘see’ the air they breath”, quite literally true as you can see a yellowish heavier pollution layer in the horizon covering the city. I personally felt like the air in Tokyo was much cleaner than I’m used to. Probably not as good as in rural areas, but for a metropolis as big as Tokyo I think they are holding up pretty well.
Next step was Akihabara, or just “Akiba”. If you want electronics and geeky entertainment, that’s the place to go. It is a huge area filled with electronic stores, manga stores, several “maid cafes”. Remember to bring your passport for the duty free discounts.

As a curiosity, Japan has a large music industry. But the Japanese take the word “industry” quite literally in which they actually mass-produce idol singers. Head-hunting self-made talents is still done but it’s usually more difficult and takes longer. Instead, they will make market research, design a long term plan, make huge auditions to find potential young candidates that can be inserted into the process, raised, given special education, singing classes, dancing classes and turned into professional idols. Robots could almost replace them and no one would notice.
(TL;DR) AKB48
Wait a minute; they are actually going that path!

From Akiba you will find AKB48, one of the most radical “entertainment products” that I’ve seen this industry deliver. It’s a huge group with 48 idols divided into Teams A, K and B. They even have Trainee idols! The idea is to enable fans to have a closer contact with their idols in their own theater at Akiba, therefore having many idols help them to better distribute the schedule. The idea seems to have fans more engaged in the future of the group, almost like a next generation reality show, one that has been going for more than 6 years already.
AKB48 is in the Guinness World Records as the largest pop group ever – obviously. That’s an idea that I can understand, from an Asian context, but I can’t see it delivered overseas outside of Asia (Korea, China have similar “tastes” for pop idols). It’s so radical that they even created a computer generated idol mixing features of the body and face of some of the real idols from the group. The fans were shocked when she was identified as not being a real person! Go figure!
Watch the TV commercial featuring the new idol:
Were you able to identify which one was the CG model? Now take a look at the making of:
Back to the Tour
I have digressed a bit, so back to the report. Friday ended, not Saturday marks the beginning of RubyKaigi, which would take place at Nerima Culture Center. Looking the maps I figured out that I could take the Seibu-line from Ikebukuro station directly to Nerima, so there I went. A less than 15 min ride in the train left me right across the street from the conference center, piece of cake.
I will leave the RubyKaigi specific report for the next article, so I will keep talking about my city tour for now.
So, while I was attending the conference I didn’t visit any other places. One curiosity was that on Monday 18th, the day I would deliver my talk, I went to the Ikebukuro station to get the Seibu line train. I was kind of tired because I was working on the final tweaks for my slides at morning, so I didn’t realize that the train was taking a long time to get to the destination. It was supposed to be a 15 min ride.
Then, I was looking out the window and realized that the city was getting less and less crowded, fewer buildings, less people. I was heading to the suburbs! I jumped off at the next station, at Musashi-sakai I guess. Quiet place, felt almost like countryside. I looked more carefully at the line map and realized that there were at least 6 different train routes served by the same Seibu line! So I got another one to go back to Nerima. That whole trip took me more than an hour, but it was worth the learning. So be very careful: every line can have trains go around different routes, they are all named properly, it’s just a matter of paying attention.

By the way, for foreigners it helps a lot that inside the train, there’s always recordings saying what’s the name of the next station, what other lines cross the same station in case you need to change lines, which side of the train will open for exit, and they say it in both Japanese and English. Also, most maps have Japanese and English written versions.
Even the ticket selling machines have options for English menus and options. You just have to look at the map and find your station. There will be number codes next to each station name. That’s the price of the ticket. Then in the ticket machine you touch the button with that price and insert the coins or bills. It’s usually around the 130-190 yen range for most stations.
If you decide to change lines in the middle of the route to go to another station, there will be machines to adjust fares. Save the ticket after you enter the train, you will need it to exit in the other station or to adjust the price or you can talk to the clear next to the exit passages to adjust fares. Japanese citizens usually have rechargeable smart cards called Suica and others such as Pasmo and Toica. Japan has dozens of different smart card systems that you will see written in many places inside the stations, trains, buses.
Last Few Days

The next day after the conference I visited Ueno an area that is neighbor to Akihabara. Shintaro Kakutani-san was very kind to let me visit his workplace at Eiwa System Management. After that Akira-san guided me to the Tokyo branch of NaCl, the consulting company where Matz himself work. Finally, I went to Hatsudai, near the Shinjuku area, to meet Alencar Koga, a Brazilian-Japanese living and working in Japan for almost 20 years. He guided me through MTI the company he works for and that created famous mobile products such as Music.jp, Japan’s second largest music distributor. I’ll talk a bit more about them in my next article.

The Hatsudai station is particularly interesting. I think it’s not within the major stations such as Shinjuku, Ueno or Ikebukuro, but it has a great architecture, very large, and it is next to the Tokyo Opera City Tower that you can access straight up from the station and which serves several business companies such as MTI and even the Japanese Apple branch.

Next day, Wednesday 20th, would be my last day in Tokyo. I wanted to visit a few key places so I headed straight to Asakusa. Careful not to mistake it for “Akasuka”. I wanted to see the famous Kiryuu-zan Sensou-ji, the oldest temple in Tokyo. You know me for not being a religious person, but it was not the reason I wanted to go there. I respect history, specially my ancestor’s history. It was a very powerful and emotional moment for me to see the temple with my own eyes and just stay there, standing still.



There was also this large red box where people go to throw in some coins and worship or make requests. I did throw a few coins but then the only thing that came to my mind was not a request, but a few words of appreciation and acknowledgment, that’s all.

It was a cloudy and rainy day but it didn’t annoy me at all because it actually added up to my feeling of relaxation and calm, especially in the temple. After that I headed to Ginza, which is said to be one of the most luxurious places in Tokyo, specially if you have lots of money to spend. It is akin to New York’s 5th Avenue. As any other district in Tokyo, there were a few large avenues surrounding the same compact blocks behind with the same very narrow streets.



Unfortunally I didn’t have enough time to visit it thoroughly. So I just walked through one of the main avenues taking pictures. It’s very overwhelming. Each big brand has its own big façade in a big building – I don’t know if they own the entire building or only the facade – but you will be able to recognize several of them, such as Tiffany, Prada, Salvatore Ferragamo, Abercrombie and more. If you intend to visit Tokyo, reserve an entire day just for Ginza, it’s well worth it. Actually, the ideal trip would be to reserve at least half a day for each major district in Tokyo. That can easily fill up an entire month of vacation there.
I couldn’t stay more at Ginza because it was almost dusk, and with a cloudy weather it would get dark fast. I wanted to visit the Tokyo Tower before that so I could take at least a few visible pictures.

I had a Tokyo City Guide book with me at all times which was very helpful. But the guide did have one mistake: it said that in order to visit Tokyo Tower I should go to Roppongi. But asking the station clerks they said that I actually had to go to Kamiyacho station! Thinking about it, I think the rationale of the book authors was that Kamiyacho seems to be an small area not worth having a whole chapter in the book. So the next important area is Roppongi, then they just added Tokyo Tower there. Again, that’s why you should not rely on just one foreigner source of information. Asking the local people is always the best and Japanese are always very helpful and kind.

When I arrived at Kamiyacho through the subway, it was raining, it was also getting dark fast, but I was able to arrive to Tokyo Tower very fast, walking just half a kilometer. Now, the tower is beautiful. You pay a small fare to be able to get in and ride the elevator to the observatory station, 135m up. The Tower itself has 333m, making it 10m higher than the Eiffel Tower. I visited the 1st and 2nd observatory floors but unfortunally I didn’t have much time to visit the top Special Observatory. But it was good enough; it was much more interesting than I thought it would be. The observatory is pretty large; they have gift stores and a very cozy cafeteria in the 1st floor from where you can take a cup of coffee while admiring Tokyo’s aerial view through the large windows.



In the 1st floor there’s this Club 333 where all Wednesdays and Thursdays they will have small shows. I was able to see a live music show by indie singers where they made several cover performances such as Nate James’ Impossible song.

At the base of the tower there is this three store building with another cafeteria, even a McDonald’s, and several souvenir shops (Japanese love souvenirs, which we call “omiyage” and “meibutsu”).

There were even a small gallery with an ancient Tokyo theme, having paintings by Tomonori Kogawa. If you think those paintings remind you of anime, you’re right as he worked as an animator for famous studio Sunrise in the 80’s. There were several items and explanation texts as well. Many foreigners will probably recognize a Geisha but not many will realize that even Geishas obeyed a very rigid hierarchy system! Respect for hierarchy is very serious up to this day and it’s ingrained within the Japanese culture.


As I’ve said, I am an avid Manga fan. So the Tokyo Tower was the background for several of my favorite titles, such as Clamp’s Rayearth, so more than a tourist landmark that provides good pictures, I like to think of it as having a more personal meaning, as it showed up many times in my youth.


Small Consideration about Sushi
Finally, I left Kamiyacho and headed to Roppongi. There I took a few pictures of the famous Roppongi Hills, a very ambitious piece of engineering. A huge complex for offices, shops, theaters, and more. I only saw its façade, and again didn’t have time for a full tour inside. But it is surely a huge complex, where the subway station has corridors going straight inside the complex.


At Roppongi I met Koga-san again for dinner. We casually found a sushi restaurant and as I didn’t have sushi yet, I thought it would be a good opportunity to try. Koga-san recommends going to Tsukigi where you can find the “Tokyo Metropolitan Central Wholesale Market”. This is the place to find the most fresh fish in Tokyo, thus it is also the place you will probably find the finest sushi and sashimi available. That said, it was already late at night so I decided to stay at Roppongi where I was certain that the “average” sushi would be much better than the finest sushi in Brazil. And I was right!

Sushi and sashimi in most places of the Western world (North and South America), are just crap. Western people underestimate sushi altogether. It is a simple delicacy that takes years to master, exactly because it is so simple. Simplicity means that you can’t fake it: it’s either well done or a disaster. And I can only find bad sushi in America, no matter where I go. There are very few good ones, for sure, but rare. So it was an absolute pleasure for me to taste such a good sushi. It was the very first time I tasted “real” sushi. You must order “Oh-Toro” the fatty cut of the tuna fish and the most delicious ingredient in sushi. A good Oh-Toro literally “dissolves” in your mouth. Absolutely delicious. Can’t find enough words to describe it, you have to go taste it to understand.

Pro tips: Never ever fill up a dish with lots of shoyu (soy-sauce). It’s an absolute sin to dunk the rice part entirely into it. You’re supposed to taste the fish and the rice, not the soy. You only need a small touch of shoyu in the fish part. So you have to turn the sushi upside down when touching the soy dish. That’s very difficult to do with ohashi (chopsticks), but nigiri-sushi was meant to be hold with your fingers, this is the correct way of eating sushi. And good sushi is made to be eaten in just one bite. Put it all in your mouth! You also don’t need extra wasabi in the shoyu dish as the sushi chef is supposed to put the correct amount between the fish and rice roll. And this rice roll is supposed to be small, solid and not break apart easily. And no, cream cheese and all those “fancy” ingredients are not real sushi.

Now you know that you’ve been eating crap sushi and in the wrong manner. I always get very frustrated every time I hang out with friends to a sushi restaurant, so I am just expressing my many years of frustration in those last few paragraphs. It had to be said.
(TL;DR) Some Personal Aspects I Like
Anyway, Tuesday and Wednesday were cloudy and rainy days, but that was good because the weather was so hot. Friday night, 15th, I experienced my very first earthquake shake. I was reading a magazine in my bed and I felt a slow movement, at first I thought that maybe I was fainting but a few seconds later I saw that the walls and ceiling were actually moving. It was a very weak earthquake that lasted for only a few seconds. Only enough time for to me sit down in the bed and wonder if I should go underneath the table. While I was trying to figure out what to do, it stopped. It was quite fun, I never thought I would be able to feel a real earthquake. Brazil has no natural offenses such as earthquakes, hurricanes, tsunamis or anything like this.
Then, on the early morning of Wednesday 20th, they said there was a Typhoon striking Japan as well, but I overslept and by the time I woke up it has gone already. You have to reflect on this: Japan is a very small country, with less than 380,000 km2. Mato Grosso, the 6th largest state of the 27 in Brazil, has roughly 360,000 km2. My state of Sao Paulo has 248,000 km2.
Worse than that, 10% of the active volcanoes in the world are located in Japan. According to Wikipedia there are at least 1,500 earthquakes registered every year. There are minor tremors happening everyday somewhere in the country.
A reflection that always comes to my mind is that natural hazards such as that make a population much stronger and disaster tolerant. Because of so many natural disasters in Japan such as earthquakes, typhoons, tsunamis and even the so discussed Fukushima disaster recently, it really makes for a very strong population. For example, because of the so frequent earthquakes, Japan is the leading researcher in prediction of earthquakes and on advanced civil engineering that allows hem to build skyscrapers that can literally shake several meters without crashing down.
Human beings will always attribute a higher value to things they don’t have. So for a Japanese, living in a natural hazard free place, with large open areas with vegetation and forests, places to plant fruits and vegetables, where the weather is warm and cozy, is nothing more than a far dream.
For Brazilians, on the other hand, this is the reality. And we take it for granted exactly because we have no idea what natural hazards of those magnitudes are. The same thing can be said for war. I am being over simplistic, I know, but peace is usually highly valued for those that experienced times of violent warfare. People that were born and raised in peaceful times will not give it enough value.
“Value” is given to stuff that are rare. If you have too much of anything, you don’t feel like it’s worth much because you take it for granted. Something to reflect about, but again, I digress.

From the photos you can see that Japanese streets are very clean and organized. Even the inside and hidden streets are very clean. The main avenues rarely have bubble-gum marks in the asphalt, indicating that people don’t spit them in public. You shouldn’t even smoke in public places, so you won’t see cigarettes butts in the streets. There are usually reserved areas near the stations called “smoking areas”. You can only smoke at those areas or within shops or special closed smoking rooms with proper ventilation and air filters, and this allows for a very clean landscape.


There was this one thing that I knew Japanese had and that I know you will laugh when I tell you, but keep reading. It’s the Washlets ! It is a special toilet seat. In the Western world we clean ourselves using our hands with toilet paper and throw it in the toiler trashcan. Think about this: we bring our hands very close to very dirty material. We dispose that dirty paper in the trashcan where it can accumulate for a few days in the bathroom. It’s not exactly a heath hazard, but it just feels dirty. So this special seat will spill a jet of warm water directly at your anus, cleaning it up before you get toilet paper to dry it. I don’t know about you, but it feels much cleaner that way. Virtually every modern Japanese building and house will have this Washlet available.

If you’re a foreigner be aware of those. It is not unheard of foreigners pressing the water spray button without knowing about it and getting surprised by this warm strong jet of water all over him. I don’t know if it’s a common feature of all of them, but they also constantly flush it automatically. As I mentioned, real estate in Japan is ridiculously expensive exactly because there is so little land to share. So normal Japanese houses are also ridiculously small, narrow. Just so you have an idea, larger districts such as Ikebukuro, Shibuya have capsule hotels. Instead of you renting a room in a hotel to spend the night, you can rent a sleeping capsule, which you can rent to spend the night in case you missed the last train back. It is very small, you can only stay laid down inside.
It is also not rare for a small residence to not have a bathroom at all, so the building will have a shared bathroom. And you can only have a shower at public bath houses (sentou) nearby. But as you may think, this is not considered something “low” or only for the “poor”. It is a quite normal thing. As I will repeat many times, do not judge someone elses culture by your own standards.
And this is not to say that every Japanese has perfect cleaning habits, they don’t. Public areas can even be cleaner than their own houses. The reasoning that I speculate is that if you have a small house, you’re single, and you usually don’t take any guests inside, you will probably not clean it up well enough. On the other hand, the façade of your house is visible to anyone and you don’t want to be perceived as someone with poor cleaning habits, so you will keep that part cleaner.
(Cultural note: this article is huge, I know, but I can bet money that the only thing some of my fellow Brazilians will comment is this toilet section, such is the nonsense of the Latino-way).
Japanese people are very aware of their public image and they will keep it always clean, both physically clean, but also in terms of politeness and formality. Japanese people are much more formal than Western people, even in small circles of close friends. They won’t assume a higher level of liberty between each other unless explicitly said so.
When I visited MTI with Koga-san, we went to a nearby Pub. There we found some of his co-workers. So, Koga-san bought 2 bottles of beer for everybody. Even though they know each other and are considered colleagues or friends, because Koga-san has a respectable position in the company, they made a lot of ceremony and thanked him a lot, more than we usually see within western people groups. Another curiosity, in bars with friends, you usually don’t fill up your own glass. It’s the duty of the person next to you to keep your glass full. And this is not to suck up, it’s just very normal daily formality. Japanese have several social protocols that they follow automatically, this being one of them.

Finally, two last things I have to report. I never felt safer in my entire life. I walked through many places all around, and I never had the feeling that I could be robbed. I could open my wallet, count money while walking, use my video camera, my phone and I never thought of anything bad happening, such is the security level in one of the largest metropolis in the world. I would never do half of what I did here in Sao Paulo, nor in New York City. I would always be looking over my shoulders, I would be careful while looking into my phone or taking pictures. This is a huge difference. I think only Canadians and some North European citizens can assert the same.
Then, there is the transportation system that I said so much about. There is one more thing: they are punctual. And I don’t mean, “more or less”, or “sometimes”, they are “perfectly punctual”. If the train is scheduled to arrive in the station at 7:37AM it will arrive at precisely 7:37AM – otherwise what would be the point of not rounding up the numbers? The margin of error is around 1 minute. I didn’t see any train getting late. Japanese people have a high pride for punctuality, and it shows. This is one of the very few places in the world where you will witness a system that actually works as promised.

If you add the relaxing feeling of security and the systems and processes that work perfectly all over the city, it physically makes you less stressed than in my city of Sao Paulo. Here I have to be constantly worried about security and I become very stressed because of traffic, late appointments and systems and services that don’t work. It’s difficult for people that don’t live in big metropolis to understand how big a difference it makes. I was very relaxed all the time in Japan, no worries whatsoever. When I came back to Sao Paulo, it all came back to me, all the worries, all the frustrations, all the stress. Painful, really.
Farewell
I wanted to stay a few more days but it was not possible. Unfortunately I didn’t have enough time to visit a few other areas that I had previously in mind, such as Harajuku. But at least I was able to visit many of the places I wanted, specially Akiba and Asakusa, which were in the top of my list.

In the last day, I got a taxi cab to Nippori station, but just because my luggage was very heavy, otherwise I would walk to Ikebukuro station then to to Nippori. From Nippori you can buy the Airport Express Skyliner ticket, it’s less than USD 20 if I’m not mistaken. It has marked seats, it’s very very comfortable and goes straight underneath the Narita Airport. It can’t be more convenient than that, I wish we had something similar in Sao Paulo.
There are several aspects of the Japanese culture that I will explain in more detail in the next articles, this was just a warp up article for what’s to come.

This wraps up my impressions of my short city tour around Tokyo. I didn’t even scratched the surface but it was a fantastic experience that I will definitely repeat in the future. I can’t recommend it much as a great tourism destination for your next vacation.
Upcoming: Journey to Japan 23 Jul 2011 4:30 PM (13 years ago)
I attended RubyKaigi 2011 and it was a very exciting trip for me. My grandparents were born in Japan, I am 3rd generation Japanese born and raised in Brazil. This was my first time visiting my grandparents home country. It was therefore the first time I decided to attend RubyKaigi, the most famous Japanese Ruby conference. And if it couldn’t be exciting enough, I was able to attend it as a speaker, the first from South America. It couldn’t be better.
I came back to Brazil yesterday and I am still recovering from the burn out of the trip. I am still thinking on how to tackle this complex subject. But I do want to tell the story and explain most of what I can.
Until then, I’ve compiled 3 small trailers to get you wondering what’s to come:
Enjoy!
[Objective-C] Distributing your Static Library 23 Apr 2011 7:46 PM (13 years ago)
If you didn’t read my last two article I recommend you do so before going any further because I am using the same pet project, ObjC Rubyfication as an example for this article. The point is: you are writing reusable code that you want in more than one project.
Most of this was based on Cocoanetics article about universal static libraries. So, if you’ve payed attention to my previous article, you saw this screenshot:

I said that I only had these targets configured: CocoaOniguruma, Kiwi, Rubyfication and RubyficationTests. But there are 3 others: CocoaOniguruma SIM, Rubyfication SIM, and Build & Merge Libraries. The reason is simple:
- The “CocoaOniguruma” Target builds the libCocoaOniguruma.a binary that’s compatible with the ARM processor for iOS
- The “CocoaOniguruma SIM” Target builds the libCocoaOnigurumaSimulator.a binary that’s compatible with the i386 processor for the local iPhone Simulator
- The “Rubyfication” Target builds the libRubyfication.a binary that’s compatible with the ARM processor for iOS
- The “Rubyfication SIM” Target builds the libRubyficationSimulator.a binary that’s compatible with the i386 processor for the local iPhone Simulator
- The “Build & Merge Libraries” Target merges the corresponding particular binaries of each target into a single Universal (Fat) Binary that we can easily distribute and reuse.
Concepts and History
Some explanation is in order. When you’re developing iOS applications, you can test it directly in your iPhone device or within the Simulator. Now, Apple was very clever: any other vendor in the market will try to first create an ARM processor emulator to run on top of your i386 processor. Then it will get all the binaries for ARM and run within this emulator. The OS itself will remain compiled for ARM processors and run within the emulator.
Now, this is dead slow, impractical. Anyone that experimented an emulation environment like this knows how ridiculous it is. Don’t confuse it for VMWare or Parallels solutions, which are fast because they are an emulated environment for the same processor, so you can run Windows on top of your Mac because the processors and operating systems now support VT-x, which means you mostly don’t have to emulate the processor. Now, every smartphone and tablet on the market uses an ARM processor, which has nothing to do with i386.
So, how did Apple delivered a super-fast iPhone/iPad emulator that runs at real-time speed on your Mac? Simple, it didn’t. It is called “Simulator” and not “Emulator” for a reason: everything that runs within the Simulator is compiled for i386, not for ARM. So what you’re running is an actual binary that runs natively over your Mac! No emulation required. The iOS is very portable. The same way Mac OS X was able to transition from the Power PC to Intel back in 2005, the iOS can do the same trick as they are basically the very same operating system.
When you choose the iPhone scheme in XCode, it compiles for ARM and uploads the bits to your iPhone device to run the application. When you choose the Simulator scheme in XCode, it compiles for i386, upload the bits in your Simulator and runs natively as any other application in your Mac.
Now, going back to the main issue: when I distribute a binary of my Static Library, I have to remember that the developer will be linking against my library to deploy for both the ARM device (iPhone/iPad) and the Simulator (i386). So I would have to deliver at least 2 binary files. But Apple is even smarter than that. Actually, NeXT was. When they first transitioned the NeXTStep operating system from Motorola to Intel processors back in the late 80’s, they created Fat Binaries, which is essentially one binary that contains both processor-specific bits in one single package. When Apple transitione from the Power PC to Intel they renamed it to Universal Binaries. And that’s essentially what we need to build now.
Operations
We now understand what a Universal Binary is. To make it easier, I right-clicked over the “Rubyfication” and “CocoaOniguruma” targets and duplicated them. They will be created as “Rubyfication copy” and “CocoaOniguruma copy”. We can change the “Product Name” in the build settings of each for a more reasonable name:

In my case I renamed them to “RubyficationSimulator” and “CocoaOnigurumaSimulator”. That will give me both “libRubyficationSimulator.a” and “libCocoaOnigurumaSimulator.a”. As you can see in the Products group:

Important: remember that the Rubyfication target had CocoaOniguruma as a target dependency. You will need to change the “Rubyfication SIM” target to point to the new “CocoaOniguruma SIM” target! The other thing is that you will need to force both new targets to compile to “Latest Mac OS X” in the “Base SDK” option in the Build Settings of each, and “32-bit Intel” in the “Architectures” build option. This will make them compile for i386 processors. The original targets should have their “Base SDK” to “Latest iOS” and “Architectures” to “Standard (armv6 armv7)”.

Now, we need to create a new target of the kind “Aggregate” :

I named it “Build & Merge Libraries”. In the “Build Phases” tab you will start with just the “Target Dependencies” phase. You just need to add the new “Rubyfication SIM” and “CocoaOniguruma SIM” targets. Then you need to add 3 more phases, one for “Run Script”, another to “Copy Files” and a last “Run Script”.

In the “Copy Files” phase I have just added all the public headers that I want to distribute together with the universal binary library. This is because the other developers will need to add those header files into their projects in order to be able to compile against my library. Now notice that I am copying them to an “Absolute Path” that states ${TARGET_BUILD_DIR}/../Rubyfication.
That’s where we come to the previous “Run Script” phase that should have the following code:
1 2 3 4 5 |
# make a new output folder
mkdir -p ${TARGET_BUILD_DIR}/../Rubyfication
# combine lib files for various platforms into one
lipo -create "${TARGET_BUILD_DIR}/../Debug-iphoneos/libRubyfication.a" "${TARGET_BUILD_DIR}/../Debug-iphonesimulator/libRubyfication.a" -output "${TARGET_BUILD_DIR}/../Rubyfication/libRubyfication-${BUILD_STYLE}.a"
|
The first thing it does it create this new “Rubyfication” directory. The second command uses the lipo command that merges 2 processor-dependent binaries into a universal binary. Pay attention to the PATHs if you’re reusing this script somewhere else. At least with XCode 4 that’s where it creates the binaries of each target:
- ${TARGET_BUILD_DIR}/../Debug-iphoneos/libRubyfication.a – the ARM version
- ${TARGET_BUILD_DIR}/../Debug-iphonesimulator/libRubyfication.a – the i386 version
- ${TARGET_BUILD_DIR}/../Rubyfication/libRubyfication-Debug.a – the resulting universal binary we created
Finally, the last “Run Script”, after the “Copy Files” phase described above, requires the following script:
1 |
ditto -c -k --keepParent "${TARGET_BUILD_DIR}/../Rubyfication" "${TARGET_BUILD_DIR}/../Rubyfication.zip"
|
It just creates a ZIP file with the universal binary library and its companion public header files. Any other developer can get this zip file, unzip it and add the files to their own projects now. If you want to find where this ZIP file is, the easiest way is to go to the project viewer (the left side pane) in XCode, open the “Products” group, right-click over the “libRubyfication.a” file (or any other resulting file) and choose “Show in Finder”. Then you can navigate one folder up in the hierarchy (to the “Products” folder) and you will see something like this:

And there you go: there’s your ZIP file with your brand new redistributable universal binary!
Using the Universal Binary
In order to demonstrate how to use this distributable ZIP file. I have created a very simple, bare-bone iOS project called ObjC_OnigurumaDemo that you can download from Github and run in your own iOS device.
As you can see in the screenshot below, I just unzipped the ZIP within a “Dependencies” folder in my iOS project and added the universal binary “libRubyfication-Debug.a” within the Library Linking Build Phase:

This allows me to just use anything from this library in my project, in particular a piece of code that uses the Oniguruma regular expressions:
1 2 3 4 5 6 7 8 9 10 11 |
- (IBAction)runRegex:(id)sender {
OnigRegexp* regex = [OnigRegexp compile:[regexPattern text]];
OnigResult* res = [regex match:[initialText text]];
NSMutableString* tmpResult = [NSMutableString stringWithString:@""];
for(int i = 0; i < [res count]; i++) {
[tmpResult appendString:@"("];
[tmpResult appendString:[res stringAt:i]];
[tmpResult appendString:@")"];
}
[result setText:tmpResult];
}
|
This demonstration application has a text-field called “initialText”, where you can type any string. Then you can prepare a Regular Expression in the “regexPattern” text-field and when you hit the “Run” button, it will trigget the action above that will run the Regular Expression againt the initial text and write the matches within parenthesis in the “result” text view. The applications looks like this:

And, voilá! Ruby 1.9-like Regular Expression, directly from Oniguruma, within an iOS Application!
[Objective-C] Categories, Static Libraries and Gotchas 23 Apr 2011 6:44 PM (13 years ago)
As some of you may know, I have this small pet project called ObjC Rubyfication, a personal exercise in writing some Ruby-like syntax within Objective-C. Most of this project uses the fact that we can reopen Objective-C standard classes – very much like Ruby, unlike Java – and insert our own code – through Categories, similar to Ruby’s modules.
The idea of this pet project is to be a Static Library that I can easily add to any other project and have all of its features. In this article I’d like to present how I am organizing its many subprojects within one project (and I am accepting any suggestions and tips to make it better as I am just learning how to organize things within Obj-C projects) and talk about a gotcha that took me hours to figure out and might help someone else.
To make this exercise even more fun, I also added a separated target for my unit testing suite (and see how XCode supports tests), then another target for the Kiwi BDD testing framework for Obj-C, and another one for CocoaOniguruma as I have just explained in my previous article.
I’ve been playing with ways of reorganizing my project and I realized that I was doing it wrong. I was adding all the source files from my “Rubyfication” target into my Specs target. So everything was compiling fine, the specs were all passing, but the way I defined dependencies was wrong. It is kind of complicated to understand at first, but it should be something like this:
- CocoaOniguruma Target: should be a static library, with no target dependencies and no binary libraries to link against, just a dependency to the standard Foundation framework. It exposes the OnigRegexp.h, OnigRegexpUtility.h and oniguruma.h as public headers.
- Kiwi Target: should be another static library, with no target dependencies and no binary libraries to link against, just having the Foundation and UIKit framework dependencies.
- Rubyfication: should be another static library, with CocoaOniguruma as a target dependency, linking against the libCocoaOniguruma.a binary and depending on the Foundation framework as well. It exposes all of its .h files as public headers.
- RubyficationTests: should be a Bundle which were created together with the Rubyfication target (you can specify whether you want a unit test target when you create new targets), with both Kiwi and Rubyfication targets as dependencies, linking against the libKiwi.a and libRubyfication.a binaries, and the Foundation and UIKit frameworks as well.
If you keep creating new targets manually, XCode 4 will also create a bunch of Schemes that you don’t really need. I keep mine clean with just the Rubyfication scheme. You can access the “Product” menu and the “Edit Scheme” option. Then my Scheme looks like this:

I usually configure all my build settings to use “LLVM Compiler 2.0” for the Debug settings and “LLVM GCC 4.2” for the Release settings (actually, I do that for precaution as I am not aware if people are actually deploying binaries in production compiled from LLVM).
I also set the “Targeted Device Family” to “iPhone/iPad” and I try to make the “iOS Deployment Target” to “iOS 3.0” whenever possible. People usually leave the default one which will be the latest release – now at 4.3. Be aware that your project may not run on older devices that way.
Finally I also make sure that the “Framework Search Paths” are pointing to these options:
1 2 |
"$(SDKROOT)/Developer/Library/Frameworks"
"${DEVELOPER_LIBRARY_DIR}/Frameworks"
|
Everything compiles just fine that way. Then I can press “Command-U” (or go to the “Product” menu, “Test” option) to build the “RubyficationTests” target. It builds all the target dependencies, links everything together and runs the final script to execute the tests (you must make sure that you are selecting the “Rubyfication – iPhone 4.3 Simulator” in the Scheme Menu). It will fire up the Simulator so it can run the specs.
But then I was receiving:
1 2 3 4 5 |
Test Suite '/Users/akitaonrails/Library/Developer/Xcode/DerivedData/Rubyfication-gfqxbgyxicfpxugauehktilpmwzv/Build/Products/Debug-iphonesimulator/RubyficationTests.octest(Tests)' started at 2011-04-24 02:16:27 +0000 Test Suite 'CollectionSpec' started at 2011-04-24 02:16:27 +0000 Test Case '-[CollectionSpec runSpec]' started. 2011-04-23 23:16:27.506 otest[40298:903] -[__NSArrayI each:]: unrecognized selector sent to instance 0xe51a30 2011-04-23 23:16:27.508 otest[40298:903] *** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '-[__NSArrayI each:]: unrecognized selector sent to instance 0xe51a30' |
It says that an instance of NSArray is not recognizing the selector each: sent to it in the CollectionSpec file. It is probably this snippet:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#import "Kiwi.h" #import "NSArray+functional.h" #import "NSArray+helpers.h" #import "NSArray+activesupport.h" SPEC_BEGIN(CollectionSpec) describe(@"NSArray", ^{ __block NSArray* list = nil; context(@"Functional", ^{ beforeEach(^{ list = [NSArray arrayWithObjects:@"a", @"b", @"c", nil]; }); it(@"should iterate sequentially through the entire collection of items", ^{ NSMutableArray* output = [[NSMutableArray alloc] init]; [list each:^(id item) { [output addObject:item]; }]; [[theValue([output count]) should] equal:theValue([list count])]; }); ... |
Reference: CollectionSpec.m
Notice that at Line 3 there is the correct import statement where the NSArray(Helpers) category is defined with the correct each: method declared. The error is happening at the spec in line 18 in the above snippet.
Now, this was not a compile time error, it was a runtime error. So the import statement is finding the correct file and compiling but something in the linking phase is not going correctly and at runtime the NSArray(Helpers) category, and probably other categories, are not available.
It took me a few hours of research but I finally figured out one simple flag that changed everything, the -all_load linker flag. As the documentation states:
Important: For 64-bit and iPhone OS applications, there is a linker bug that prevents -ObjC from loading objects files from static libraries that contain only categories and no classes. The workaround is to use the -all_load or -force_load flags.
-all_load forces the linker to load all object files from every archive it sees, even those without Objective-C code. -force_load is available in Xcode 3.2 and later. It allows finer grain control of archive loading. Each -force_load option must be followed by a path to an archive, and every object file in that archive will be loaded.
So every target that depends on external static libraries that loads Categories has to add this -all_load flag in the “Other Linker Flags”, under the “Linking” category on the “Build Settings” of the target, like this:
So both my RubyficationTests and Rubyfication targets had to receive this new flag. And not the Tests all pass flawlessly!
[Objective-C] It's a Unix System! I know this! 23 Apr 2011 5:47 PM (13 years ago)
While experimenting with ways of using Objective-C a little bit closer to how I code Ruby, there were two things that annoyed me a bit. First, Date Formatting and, second, Regular Expressions.
The Cocoa framework has both implemented as NSDateFormatter and NSRegularExpression that also happen to be available for iOS development.
You can format dates like this:
1 2 3 4 5 6 7 8 9 |
NSDateFormatter *dateFormatter = [[NSDateFormatter alloc] init]; [dateFormatter setDateStyle:NSDateFormatterMediumStyle]; [dateFormatter setTimeStyle:NSDateFormatterNoStyle]; NSDate *date = [NSDate dateWithTimeIntervalSinceReferenceDate:162000]; NSString *formattedDateString = [dateFormatter stringFromDate:date]; NSLog(@"formattedDateString: %@", formattedDateString); // Output for locale en_US: "formattedDateString: Jan 2, 2001" |
And you can use Regular Expressions like this:
1 2 3 4 5 6 7 8 |
NSError *error = NULL; NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:@"\\b(a|b)(c|d)\\b" options:NSRegularExpressionCaseInsensitive error:&error]; NSUInteger numberOfMatches = [regex numberOfMatchesInString:string options:0 range:NSMakeRange(0, [string length])]; |
But I have issues with both of these. The Ruby equivalent for the date formatting example would be:
1 2 3 |
require 'activesupport' date = Time.parse("2001-01-01") + 162000.seconds date.strftime("%b %d, %Y") |
And the regular expression example would be like this:
1 |
number_of_matches = /\W*[a|b][c|d]\W*/.match(string).size
|
There are 2 specific things that annoys me:
- that the Obj-C versions feels unnecessarily verbose. Now, I do understand that they are lower level and they will probably allow for more flexibility, but I think they should have higher “porcelain” versions, that are more straightforward.
- that in Obj-C, the Date Formatting uses the Unicode TR-35 formatting standard and that Regular Expressions uses the ICU standard that is inspired by Perl Regular Expression with support for Unicode and loosely based on JDK 1.4 java.util.regex.
So, the ideal solution for me would be:
- to have higher level versions of those features;
- to have C-compatible strftime date formatting and Ruby 1.9’s Oniguruma level regular expressions.
It’s a Unix System!
That’s when the obvious thing came to me: Objective-C is nothing more than a superset of C, so anything that is compatible with C is automatically compatible with Objective-C. More than that, the iOS is a Unix System! Meaning that it has all the goodies of Posix support.
So, how do I get C-compatible strftime? Easy:
1 2 3 4 5 6 7 8 9 10 11 12 |
#import "time.h" ... - (NSString*) toFormattedString:(NSString*)format { time_t unixTime = (time_t) [self timeIntervalSince1970]; struct tm timeStruct; localtime_r(&unixTime, &timeStruct); char buffer[30]; strftime(buffer, 30, [[NSDate formatter:format] cStringUsingEncoding:[NSString defaultCStringEncoding]], &timeStruct); NSString* output = [NSString stringWithCString:buffer encoding:[NSString defaultCStringEncoding]]; return output; } |
Reference: NSDate+helpers.m
Now follow each line to understand it:
- At line 4 it is returning the current time represented as the number of seconds since 1970. That method actually returns a NSTimeInterval which is a number that is essentially the same as the C-equivalent time_t
- At line 6 the C function localtime_r converts the unitTime number into the C-structure timeStruct
- At line 9 we call a custom method I created called formatter that just returns a strftime compatible string format. The Obj-C string (when we create using the “@” symbol) is an object that we must convert to an array of chars using the cStringUsingEncoding:. C functions don’t understand Obj-C string, hence the conversion. Then we finally call the strftime itself that will store the result in the buffer array of char that we declared before.
- At line 10 we now do the reverse and convert the resulting C-string (array of chars) back into an Obj-C String.
Now this is too nice. I have added a few other helper methods that now allows me to use it like this:
1 2 3 |
it(@"should convert the date to the rfc822 format", ^{ [[[ref toFormattedString:@"rfc822"] should] equal:@"Fri, 01 Jan 2010 10:15:30"]; }); |
Reference: DateSpec.m
And the “rfc822” string will just be internally converted to @"%a, %d %b %Y %H:%M:%S" by the formatter: selector in the NSDate class.
Now, to add Ruby 1.9-level regular expression you can go straight to the source and use the original C-based Oniguruma itself, exactly what Ruby does. There several ways to integrate a C library into your Cocoa project, but someone already did all the hard work. Satoshi Nakagawa wrote an Obj-C wrapper called CocoaOniguruma that makes it dead easy to integrate into your project.
There are several ways to integrate an external library into your project, the easier way (albeit, not exactly the best) that I am showing here is by creating a new Static Library Target within my project, called CocoaOniguruma:

It will create a new Group called CocoaOniguruma in your project. Than you just add all the files from CocoaOniguruma’s core folder to that group, select the new target and all the source files and headers will be properly added to the project, like this:

Finally, you need to go to the original main target of your application and add both the new target to the target dependencies and the binary .a file to the binary linking section, like this:

With all this set, I recommend you to explore the OnigRegexp.m and OnigRegexpUtility.m, that are Obj-C wrappers to the Oniguruma library. The author already did some very Ruby-like syntax for you to use.
I have wrapped those helpers in my own classes like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
- (NSString*) gsub:(NSString*)pattern with:(id)replacement {
if ([replacement isKindOfClass:[NSString class]]) {
return [self replaceAllByRegexp:pattern with:replacement];
} else if ([replacement isKindOfClass:[NSArray class]]) {
__block int i = -1;
return [self replaceAllByRegexp:pattern withBlock:^(OnigResult* obj) {
return (NSString*)[replacement objectAtIndex:(++i)];
}];
}
return nil;
}
- (NSString*) gsub:(NSString*)pattern withBlock:(NSString* (^)(OnigResult*))replacement {
return [self replaceAllByRegexp:pattern withBlock:replacement];
}
|
Reference: NSString+helpers.m
Which now allows me to use this nicer syntax:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
context(@"Regular Expressions", ^{ it(@"should replace all substrings that match the pattern", ^{ [[[@"hello world, heyho!" gsub:@"h\\w+" with:@"hi"] should] equal:@"hi world, hi!"]; }); it(@"should replace each substrings with one corresponding replacement in the array", ^{ NSArray* replacements = [NSArray arrayWithObjects:@"hi", @"everybody", nil]; [[[@"hello world, heyho!" gsub:@"h\\w+" with:replacements] should] equal:@"hi world, everybody!"]; }); it(@"should replace each substring with the return of the block", ^{ [[[@"hello world, heyho!" gsub:@"h\\w+" withBlock:^(OnigResult* obj) { return @"foo"; }] should] equal:@"foo world, foo!"]; }); }); |
Reference: StringSpec.m
If you’re thinking that it is strange for a snippet of Objective-C code to have keyword such as context or it, they come from Kiwi, which builds an RSpec-like BDD testing framework on top of SenTesting Kit for Objective-C development that you should definitely check out. But the code above should be easy enough to understand without even knowing about Kiwi. If you’re a Ruby developer, you will probably notice that the syntax bears some resemblance to what you’re used to already.
So, linking to existing standard C libraries or even third-party open source C libraries is a piece of cake for those simple cases, without having to resort to any “Native Interface” tunneling between virtual machines or any other plumbing. If you want C, they’re there for you to easily integrate and use.
[Off-Topic] iOS Development and Open Source Libraries 26 Mar 2011 10:59 AM (14 years ago)
I’ve been following the evolution of iOS development and I have to say that is becoming increasingly easier to assemble a quality application these days. Apple just released iOS 4.3.1 and Xcode 4.0.1. Great releases, and the new Xcode is a great step forward. I think this is the first big IDE to fully support Git as a first class citizen in the development workflow. Every serious IDE should do it and any serious developer should be comfortable with Git by now.
The new LLVM Compiler 2.0 is very impressive, it helps a lot in making memory leak free applications. By the way, I don’t buy the “it is too difficult doing memory management”, this is just saying “I’m too lazy and cheap”. Come on, there are thousands of quality apps both for OS X and iOS. Memory management is a little bit more difficult than having a full features generational garbage collector, but it’s nowhere near as difficult as some people claim it to be. Any reasonable developer should be able to accomplish this with minimum effort.
And to help even more, the community has been releasing more and more great libraries that further increase productivity. Let me list a few of my favorites:
- Flurry – it is the equivalent of Google Analytics for iOS. Everything is trackable nowadays and information such as who’s using your app, how they are using it, what are the most used and least used features, in what regions, are all important. You can use this data to further refine your app and make it even greater. It gives you SDK’s for Java ME, Blackberry, Android, Windows Phone and iOS. You have to sign up to have access to the libraries. You will register your application, and that will give it a unique application key that you have to hard code into your app and that’s it. It is literally as easy as doing:
1 2 3 4 5 6 |
#import "FlurryAPI.h"
...
- (void) applicationDidFinishLaunching:(NSNotification*) notice {
[FlurryAPI startSession:@"your_unique_app_key"];
...
}
|
And there are several other methods for you to count certain events in your app, to log page views, to log exceptions and errors, and even location. Definitely mandatory for every app.
- ASIHTTPRequest – most apps these days integrate with some web based back-end. Twitter, Facebook, LinkedIn, everything logs in into some cloud service out there to grab information and collaborate. Cocoa Touch as a rich set of networking capabilities but they are lower level than most would like it to be. It is boring to make connections in the background, track it’s success or error, trigger events and loading cues for the user and so on. Enter ASIHTTPRequest, it makes it strikingly easy to make reliable connections to any web endpoint. The documentation is good enough and the code is even easier:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
- (IBAction)grabURLInTheBackground:(id)sender
{
if (![self queue]) {
[self setQueue:[[[NSOperationQueue alloc] init] autorelease]];
}
NSURL *url = [NSURL URLWithString:@"http://allseeing-i.com"];
ASIHTTPRequest *request = [ASIHTTPRequest requestWithURL:url];
[request setDelegate:self];
[request setDidFinishSelector:@selector(requestDone:)];
[request setDidFailSelector:@selector(requestWentWrong:)];
[[self queue] addOperation:request]; //queue is an NSOperationQueue
}
- (void)requestDone:(ASIHTTPRequest *)request
{
NSString *response = [request responseString];
}
- (void)requestWentWrong:(ASIHTTPRequest *)request
{
NSError *error = [request error];
}
|
This library creates network queues and you can trigger as many connection requests as you want and it will manage the queue for you in the background. There are use case example in the documentation. With this library there is no need to use the low level base classes and you should delegate all HTTP requests to this library. Highly recommended.
- TouchJSON – if you are consuming online HTTP data, you will probably receive a JSON formatted payload (another trend these days). Now you have to parse it into meaningful Objective-C objects. It helps a lot that Objective-C is very dynamic and flexible in its type system so you are able to easily convert anything. It is a very boring process, though, so this library will help a lot. You will want to use ASIHTTPRequest to handle connecting to the server and once it returns, you can parse the response blob like this:
1 2 3 4 5 6 |
- (void)requestDone:(ASIHTTPRequest *)request
{
NSString *response = [request responseString];
NSError *theError = NULL;
NSDictionary *theDictionary = [NSDictionary dictionaryWithJSONString:response error:&theError];
}
|
Super easy. It supports deserializing a JSON string into a graph of Objective-C objects and it also supports the way back to convert objects into a JSON representation so you can POST it somewhere or just record it into a local file.
- ShareKit – it is a trend that every application content should shared. Whenever your user share something with his friends, it makes your app more well known, and is great marketing. You definitely want to make your app able to share content through email, Twitter, Facebook and other social networks. The documentation is good, the views are all customizable, and it takes responsability for all the boring details of logging in each online service and making connections and everything. And it is extensible, making it easy to add any new online service that comes up in the future. To add it into your app, follow the installation instructions, but in the end it comes down to you adding a UIBarButtonItem like this:
1 2 3 |
[[UIBarButtonItem alloc] initWithBarButtonSystemItem:UIBarButtonSystemItemAction target:self action:@selector(share)] |
And adding the event handler code:
1 2 3 4 5 6 7 8 9 10 11 12 |
- (void)myButtonHandlerAction
{
// Create the item to share (in this example, a url)
NSURL *url = [NSURL URLWithString:@"http://getsharekit.com"];
SHKItem *item = [SHKItem URL:url title:@"ShareKit is Awesome!"];
// Get the ShareKit action sheet
SHKActionSheet *actionSheet = [SHKActionSheet actionSheetForItem:item];
// Display the action sheet
[actionSheet showFromToolbar:navigationController.toolbar];
}
|
Can’t get easier than that.
- simple-iphone-image-processing – another very important feature is to deal with images. Every new smartphone has a camera these days and it is important to leverage this capability. But just taking pictures and recording its image file is not enough. You will want to further process the image to take out meaningful information. Want to be inspired? Take a look at this Sudoku application demo that uses this image processing library and you will understand what I mean. You can take a picture from any sudoku game printed in the newspaper, for example, and the application will parse the image, detect the information, and create a fully functional digital representation that can now be solved through well known algorithms. How cool is that? Now, problem is that this library is very old (last commit from 2009), so I am not sure how well it behaves in current iOS releases, and the documentation is close to none, so you will have to dig through its source code. I didn’t try it myself, I’m just adding it here as a note for myself to make further experiments.
- cocos2d – now, making simple list based applications is boring. You should consider adding a little bit of animation and interactivity into your app. You can use Apple’s standard Core Graphics and Core Animation APIs or you can go craze with cocos2d. It is an OpenGL accelerated 2D API so you can easily create great effects. You will have cross platform wrappers so you can leverage this knowledge in many platforms. There are several tutorials in the internet such as this, and this and more. Definitely worth studying.
- iPhone AR Kit – this is still now entirely mature yet – I guess – but many applications are using it and this should evolve fast in the future. The idea is to turn on the camera, process the image frames and add 2d or 3d animation on top of it, making the digital objects sort of “interact” with the real time captured background. If you use the device’s movement sensors (compass, gyroscope, accelerometer, etc) you can make really impressive applications. Definitely study this.
- Kiwi and Gh-Unit – unfortunatelly testing is not something well understood and practiced in the Objective-C community. Many rubyists that are also developing in Objective-C are trying to adopt the same practices we take for granted in the Ruby community so I hope this helps. Cocoa and Xcode do come with basic unit testing tools such as SentestingKit. There is close to zero documentation about this subject, you can look at Apple’s official logic testing article and this other blog post about it. The default tools are a bit basic though, so you will want to check out other testing frameworks such as Gh-Unit and Kiwi. In particular, Kiwi looks very impressive trying to follow a RSpec-like syntax:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
describe(@"Team", ^{
context(@"when newly created", ^{
it(@"should have a name", ^{
id team = [Team team];
[[team.name should] equal:@"Black Hawks"];
});
it(@"should have 11 players", ^{
id team = [Team team];
[[[team should] have:11] players];
});
});
});
|
Both are definitely worth checking out. And we should strive to add more technology and techniques for testing in Objective-C development. We did in the Ruby-land, there’s no reason we can’t do the same in Objective-C.
And this is it for now. There are many more great libraries and tools available and iOS is evolving fast, so this is all very exciting to follow and practice. I hope to be able to contribute back as soon as possible.
RubyConf Brazil is Coming up! 2 Sep 2010 9:34 PM (14 years ago)
We are just releasing the RubyConf Brazil official website! The conference will take place in São Paulo, Brazil, on October 26th and 27th. Come visit us in Brazil!

If you need anything, just send a message to rubyconf@locaweb.com.br.
And this year we have several news.
News
The first one is that we learned a lot from the previous Rails Summit Latin America conferences. The Locaweb events team was able to squeeze the costs without sacrificing quality and the registration price went all the way down until USD 85 only! In 2008 the price was almost 3 times higher!
The other change is that the venue changed from Anhembi Convention Center to Frei Caneca Convention Center, which can easily handle more than a thousand attendees. Besides, the nearby area is much more convenient because it is near the famous Paulista Ave, where you will find several Metro subway stations, bars, night clubs, restaurants. Check out this list of recommended hotels. And I also recommend you to come a few days before or leave a few days after the event so you have time to visit more of the city.
Speakers
This year we will have no less than 24 speakers! Engine Yard, for example, will be here with Yehuda Katz (Rails 3), Charles Nutter (JRuby), and Evan Phoenix (Rubinius). We will have several of the Brazilian Rails contributors such as José Valim and Ruby Summer of Code participants, Thiago Pradi and Ricardo Panaggio.
We will have some of the community luminaries such as David Black and Jim Weirich. Non-rubysts such as Blaine Cook will be here too, and more!

I intend to publish a few blog posts presenting more details about some of the speakers, so stay tuned! Meanwhile check out the program schedule. It can still change until the event.
Rubysts!
In the last two years we were able to gather more than 500 attendees each year. This year the goal is to bring in more than 700! You don’t want to stay out of this great summit: a great chance to get to know Brazil better and increase your social network, getting to know many great Latin American rubyists! Register now!
I will bring more news soon, stay tuned!
,%20Charles%20Nutter%20(JRuby),%20and%20Evan%20Phoenix%20(Rubinius).%20We%20will%20have%20several%20of%20the%20Brazilian%20Rails%20contributors%20such%20as%20%20Jos%C3%A9%20Valim%20and%20Ruby%20Summer%20of%20Code%20participants,%20Thiago%20Pradi%20and%20Ricardo%20Panaggio.%3C/p%3E%0A%3Cp%3EWe%20will%20have%20some%20of%20the%20community%20luminaries%20such%20as%20David%20Black%20and%20Jim%20Weirich.%20Non-rubysts%20such%20as%20Blaine%20Cook%20will%20be%20here%20too,%20and%20more!%3C/p%3E%0A%3Cp%3E%3Ca%20href%3D%22http://www.rubyconf.com.br/en/speakers%22%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2010/9/3/Screen%2520shot%25202010-09-03%2520at%25202.43.58%2520AM_original.png?1283492670%22%20alt%3D%22%22%20/%3E%3C/a%3E%3C/p%3E%0A%3Cp%3EI%20intend%20to%20publish%20a%20few%20blog%20posts%20presenting%20more%20details%20about%20some%20of%20the%20speakers,%20so%20stay%20tuned!%20Meanwhile%20check%20out%20the%20%3Ca%20href%3D%22http://www.rubyconf.com.br/en/schedule%22%3Eprogram%20schedule%3C/a%3E.%20It%20can%20still%20change%20until%20the%20event.%3C/p%3E%0A%3Ch2%3ERubysts!%3C/h2%3E%0A%3Cp%3EIn%20the%20last%20two%20years%20we%20were%20able%20to%20gather%20more%20than%20500%20attendees%20each%20year.%20This%20year%20the%20goal%20is%20to%20bring%20in%20more%20than%20700!%20You%20don%26%238217;t%20want%20to%20stay%20out%20of%20this%20great%20summit:%20a%20great%20chance%20to%20get%20to%20know%20Brazil%20better%20and%20increase%20your%20social%20network,%20getting%20to%20know%20many%20great%20Latin%20American%20rubyists!%20%3Ca%20href%3D%22https://rubyconf.locaweb.com.br/en/users/new%22%3ERegister%20now!%3C/a%3E%3C/p%3E%0A%3Cp%3EI%20will%20bring%20more%20news%20soon,%20stay%20tuned!%3C/p%3E)
Lost in Translation 29 Jul 2010 11:08 AM (14 years ago)
For the longest time, since I migrated my blog from Mephisto to Enki, I lost a few of my interviews and didn’t notice it. Fortunately I had an old backup from where I could recover all of them, so if you missed some of the interviews, here they are again:
- Dr. Nic
- Geoffrey Grosenbach
- Chad Fowler
- David Black
- Ola Bini
- Carl Youngblood
- Jamis Buck
- John Lam
- Avi Bryant
- Avi Bryant
- Adrian Holovaty
- Peter Cooper
- Hal Fulton
- Evan Phoenix
What happened to Rails Summit Latin America? 5 Jul 2010 6:04 AM (14 years ago)
Brazil went official in the worldwide Ruby on Rails conference roadmap with 2008’s “Rails Summit Latin America”. This was the very first big conference around Rails in the continent and a very successful one, gathering more than 550 attendees each year. We had more than 20 speakers, 2 full days, 2 parallel sessions with real-time translations.
Now, it is 2010, and I have decided that Rails Summit is no more …
RubyConf Latin America
… because it’s being replaced for the first edition of RubyConf Latin America! We managed to partner with Ruby Central, and they authorized the usage of the name.
We are already confirmed for October, 26th and 27th, this time at Frei Caneca Convention Center, in São Paulo, very near to the famous Paulista Ave. area.
After 2 years of experience we were able to optimize the costs even further, therefore the registration fee went down to BRL 150 (~ USD 78) with registration starting in August. We will maintain the same format with 2 full days of sessions, 2 parallel tracks, real time translation from English to Portuguese and Portuguese to English, coffee-break, the entire package. The quality will be the same.
Locaweb will keep on being the stewardship and main sponsor of the event. With 2 successful deliveries, I can’t think of a better partner. So it will be “RubyConf Latin America by locaweb, co-presented by Ruby Central”.

We just opened up a teaser website in Brazilian Portuguese at http://rubyconf.com.br but the complete site will be up soon.
Call for Proposals
Some companies already confirmed their participation in the conference: Engine Yard, Github, Opscode. So far we already have Charlie Nutter, Yehuda Katz, Evan Phoenix, Chris Wanstrath, Scott Chacon, David Black, Adam Jacob.
From now on, I am opening the Call for Proposals. As it is the first time I am doing this, it will be very informal. If you’re interested in participating send me an e-mail, to fabioakita at gmail with the following details:
- Full name
- Company
- State/City/Country
- Short bio
- Title of the talk
- Description of the talk
We will have more news soon! But you can already book flights to Brazil for the last week of October ;-)
![]()
[RailsConf 2010] - Video Interview - David Hansson 17 Jun 2010 10:05 AM (14 years ago)
One person that I didn’t have the opportunity to interview until this day was David Hansson himself. We talked briefly a few times in the past, but this was our first longer conversation.
I particularly enjoyed this interview because he was very easygoing. We discussed the Rails 3 project and what he enjoys most about it. We also talked about old stuff, such as the story of when he visited Brazil in 2005—if you didn’t know that, check it out!
Besides that, we also talked a bit about “Rework” related subjects such as people management and entrepreneurship. And I couldn’t let go of the opportunity to mention Ricardo Semler to him, of course :-)
So, a nice conversation—of around 24 minutes—with David Hansson himself is a good way to wrap up my material on RailsConf 2010. It was an excellent event with excellent people, and I hope to be able to meet you all again next year!
[RailsConf 2010] - Video Interviews - Part 2 17 Jun 2010 10:04 AM (14 years ago)
For this second part, I have reserved to talk about the winners of the Ruby Heroes Award. Since 2008, Gregg Pollack, from EnvyLabs, go upstage to deliver the award to 6 hard worker rubyists, who made a difference in the community.
Of the 6 winners, I was not able to talk with neither Xavier Noria, from Spain, nor Jose Valim, from Brazil. He was not attending the conference this year. But I still intend to record them, probably through video conference, and then add them to this gallery.
Aaron Patterson
Also known as @tenderlove, Aaron did change the parsers arena in the Ruby world with his contributions to open-source projects such as Psych, the new Ruby 1.9 YAML parser. Moreover, if you deal with XML nowadays, you’re probably using Nokogiri underneath. Before that, we only had REXML and Hpricot, but Nokogiri delivered on performance. Another project was Mechanize. Because of that, we now have great parsers for the main internet formats, especially if you consider that in Rails, the JSON parser is the YAML parser.
Gregory Brown
Also known as @seacreature and also known for Ruby Mendicant. I was used to using his Ruport project before, which leverages the ancient PDF Writer to generate PDF reports. But PDF Writer was abandoned. So Gregory decided to create a new foundation to deal with PDF, and from there, we got Prawn, a more modern and capable Ruby library. Besides that, he authored the “Ruby Best Practices” book, which I recommend to anyone interested in improving their skills with Ruby.
Nick Quaranto
Also known as @qrush, he is young and works for Thoughtbot, the company that brought many great open-source projects such as Paperclip or Shoulda. But Nick had a complaint: publishing gems through the good old RubyForge.net was a tedious process.
Github radically changed the working process with open source, but we still had to cope with the old way of publishing the gem packages. So Nick created Gemcutter.org, which evolved rapidly and ended up replacing Rubygems.org, becoming the de facto gem repository. So, GitHub + Gemcutter modernized our open-source process.
Wayne E. Seguin
This is easy: @wayneeseguin. Wayne became well known for his most recent project, the RVM. It is now possible to have many different versions and different Ruby implementations running in the same environment. We can have Ruby 1.8 and 1.9 and JRuby running along. Even better, we can configure each project with its own particular Ruby implementation. A simple “rvm ruby-1.9.2” command is enough to hot-swap environments. This changed how our projects were organized, making it an order of magnitude easier. Moreover, it made it easy to have multiple web apps that depend on different Ruby settings running side by side on the same web server. Literally worth the award.
[RailsConf 2010] - Video Interviews - Part 1 17 Jun 2010 10:03 AM (14 years ago)
As I said in the previous post, I decided to go back to my evangelism activities, running after interviews. Despite the short amount of time, around 5 hours, I was able to collect nothing less than 11 interviews.
I had some trouble in the way because my Flip Mino HD battery wasn’t able to hold. Even worst to find out that it takes many hours to fully recharge. When I was almost finished with Nick Quaranto, the Flip went down South. From then on, I used my iPhone camera.
One can’t help it, the Flip is excellent for short clips, or anything fast. But I recorded around 2 and a half hours of footage. If I could, in the future I’d like to have a real camera, with a more decent battery.
Por outro lado, nos dias do evento os palestrantes ficaram bem espalhados e não era muito simples encontrar quem você queria, mas no último dia a maioria estava por perto, o que tornou meu trabalho mais simples. Se a bateria tivesse colaborado acho que conseguiria mais 3 ou 4 entrevistas facilmente.
On the other hand, during the event it was not an easy task to locate a speaker, but in the last day most of them were around the Speaker Lounge, which made my job a bit easier. If the battery were able to hold up, I could have easily recored 3 or 4 interviews.
In this first batch we have Ben Scofield, James Golick, Carl Lerche, Ryan Bates, and Santiago Pastorino.
Ben Scofield
Ben was the Program Chair of the event, co-chairing with Chad Fowler. He was responsible for many aspects of the show, including on organizing the program schedule. They got more than 300 proposals. The challenge was to create a program that was broad enough to not alienate anyone. In general I think they succeeded. Of course, some of us are here for a long time and we wished to have more hard core stuff. Mayne in the future.
James Golick
One the most hyped subjects of the season is non-relational databases, or “NoSQL”. So I wanted opinions from people already using it in some scale. James Golick has been talking about this for a while, specially about Cassandra. The idea was not to discuss specifics on NoSQL, so in the interview I aimed for opinions, why use it, what to use, when to use them and stuff like that.
I know him since around 2008, when I started using his “Resource Controller” gem and even recorded a screencast about it. I asked him to talk a bit about that too.
Carl Lerche
He became more well known after he started working on the big refactor of Rails 3. Carl works with Yehuda at Engine Yard and he also contributed on Merb. More recently he also contributed to the Bundler project, the dependency resolution system coming up with Rails 3. In this interview he tells us more about this project and also talks about investment in open source and Ruby Summer of Code.
Santiago Pastorino
Santiago works for WyeWorks, a 4 people company in Uruguay that deliver projects for Silicon Valley companies. They are teaching us that it doesn’t matter if your country is very small, that your local market is limited, that there are near to none local rubyists around, it is still possible to do great deeds.
And Santiago decided to start working on the Rails project, in the most simple way imaginable at first: by trying to eliminate all the annoying warning messages. It sounds simple, but it is not. And bit by bit he began to learn more about the framework and how to contribute even more. Everybody should follow his foot steps.
[RailsConf 2010] - Video Interview - Robert Martin (English) 16 Jun 2010 12:27 PM (14 years ago)
Obs: for the Brazilian Portuguese version, click here.
I still didn’t finish compiling all the videos or even writing the main article of the event, but I was getting anxious to publish this video with Robert Martin, that I was able to record in Baltimore. It is a 16 min long conversation about languages, career, certifications and Agile.
On Thursday, 10th, last day of RailsConf, Robert Martin delivered the “Twenty-Five Zeros” opening keynote. You can watch it, in its entirety, below:
In summary, he explains that since it was invented, computer hardware evolved by at least 25 orders of magnitude, while programming languages probably didn’t evolve at the same rate. Probably even not at all.
“Ah, but today we have object orientation, we have closures, etc” As Bob Martin reminded us, we may have better and more convenient ways to organize code. But since Fortran, at its core, we still only do sequence, selection and iteration. Meaning, assignment, “if” conditions, “while” loops.
Besides, he also reminds us how languages always live in cycles: they are born, have a crescendo, begin to stagnate and eventually die or stop growing. That’s why it is important for programmers to understand that they need to learn new languages all the time. He is learning Clojure which he recommends and I also think it is a great suggestion.
In this interview we comment a little bit on this subject. But going deeper I was interested in hearing from him about the current state of growth of Agile methodologies, such as Scrum and the sudden interest in Certifications.
Many may know Robert Martin as the author of the Clean Code book and he reveals that he is working on another book called “Clean Coder” – I don’t know if he was kidding, but this is a good theme: a programmer can’t be just an excellent programmer and bad in communication. There are many other important skills that build a complete professional.
Finally, Bob is also known being one of the people that signed the Agile Manifesto and he tells us the story of how this came to be, how the meeting was organized, who participated and how they came up with the famous 4 values.
All in all, many insights coming from a professional that has been in the field for more than 4 decades and has certainly experienced much more than any one of us.
Chatting with Adam Jacob 18 Nov 2009 4:46 AM (15 years ago)
Configuration Management is a tricky subject. For non-starters, when you’re a developer and you have few boxes to take care of, you can usually get away with just managing them manually. People are probably just used to pop in a CD, double-click the “install” program and click “next”, “next” until the end, then you manually log in to backup (when you remember it), and sometimes you do apply some security updates when you remember about them.
But then you have more than a dozen machines, things start to get uglier, you end up making more mistakes, forgetting important steps, and all of a sudden managing machines become a nightmare. You end up being woken up in the middle of the night because you forgot to install some crucial component, and so on and so forth.
The same way you need testing, continuous integration tools when you’re a developer, you also need automated, reliable and flexible tools for the system administrator role. That’s where tools such as Chef kick in to help.
From Opscode Inc., we have Adam Jacob (CTO) and Jesse Robbins (CEO) to talk about the new contender in the automated system administration field, Chef, already in use by many companies which are striving with the cutting edge to maintain their datacenters.
AkitaOnRails: To kick start this interview, it would be great to have more background info about you guys. So, how did you end up in the configuration management space?

Adam: I’ve been a systems administrator for 13 years, and for a majority of that time I was working for companies who did a lot of mergers and acquisition work. Every couple of months we would acquire a new company, and it was my job to help figure out how to absorb those companies into the whole. I got really good at looking at an application I had nothing to do with creating, and figuring out what needed to be done to make it scale (or at least make it run.)
One thing we couldn’t do was tell the people who had built the applications that they needed to be radically altered (in many cases, they weren’t even around anymore.) What that meant in practice was we needed to have a very flexible, modular underlying architecture – everything we did had to be in service of the application, not the other way around. By necessity that meant becoming a tools developer – if we didn’t have the tools we needed, we would never be able to do the job in front of us.
Eventually I co-founded a consulting firm called HJK Solutions. We built fully automated infrastructure for startups – everything from OS installation to application deployment, all fully automated (including Identity Management, Monitoring and Trending, etc.) Over the course of the next two years we built infrastructure for 12 different startups, whose products ranged from electrical car fleet management to online dating.
So I come to configuration management through the trenches – as a line-level systems administrator trying to make my life easier, as a consultant helping others to reap the benefits, and now as a tool builder trying to move the state of the art forward.

Jesse: Jesse Robbins is CEO of Opscode (makers of Chef) and a recognized expert in Infrastructure, Web Operations, and Emergency Management. He serves as co-chair of the Velocity Web Performance & Operations Conference and contributes to the O’Reilly Radar. Prior to co-founding Opscode, he worked at Amazon.com with a title of “Master of Disaster” where he was responsible for Website Availability for every property bearing the Amazon brand. Jesse is a volunteer Firefighter/EMT and Emergency Manager, and led a task force deployed in Operation Hurricane Katrina. His experiences in the fire service profoundly influence his efforts in technology, and he strives to distill his knowledge from these two worlds and apply it in service of both.
AkitaOnRails: What’s the story behind Opscode, what’s its mission, and what’s the story for Chef’s creation?
Opscode: The story behind Opscode really starts when we met Jesse. He had written an article for O’Reilly Radar about Operations being the new secret sauce for startups. He and I met for coffee, became friends, and stayed in touch. Jesse understands operations culture at a visceral level, and he’s very well connected to a huge community of like-minded people that I didn’t even know existed.
As our consulting company grew, we reached a crossroads – we clearly had a nice business going, and it wasn’t difficult for us to find more work. What was difficult was finding people who had the skills to actually deploy a new infrastructure, and to adapt the stack we had developed for a new application. We couldn’t avoid the fact that there was a couple of weeks of very high-touch work that was required to get the entire infrastructure up and running for a new client.
We tried to recruit Jesse during this period, since he was one of those rare people who could do that initial high-touch engagement. He turned us down – primarily because he saw what we did: we could build a consulting company that was huge, but it would still be down to us in the trenches every day. Unless we could get over that hump, there were probably less stressful ways to make a living. :)
So we started looking at what was stopping us from being able to get that initial part of the engagement done as quickly as possible. What was stopping us from literally having a customer fill out a questionnaire, and letting that data drive 95% of the decisions about the infrastructure?
It turned out the answer was, in a word, “everything”. The entire stack of open source tools we were using had been built in a different era, and they saw the world through a very different lens. We needed everything to have an API, we needed everything to be more open with it’s data, and we needed everything to be flexible enough to handle the next evolution of application architectures (whatever that may be.)
Once we had that revelation, the next step was figuring out what a ‘new stack’ would really look like. If we could start from scratch, what would we take with us, and what would we leave behind? Amazon had done such a great job showing us what an API over the bootstrapping process could look like, and the kind of benefits that could be had from the approach. So assuming something like that existed for bootstrapping, what about the next layer of the stack (configuration)?
We started experimenting with Chef during this period of questioning. We started working on Chef with the goal of putting ourselves out of business – making the barrier to entry to having a fully automated infrastructure so low that any developer or systems administrator could just do it. We built a prototype, showed it to Jesse, and he agreed to come on board.
Opscode was born then, and our mission came out of those experiments: we are bringing Infrastructure Automation to the Masses. We want to tear down the barriers to entry that stop people from having really great, repeatable, automated infrastructure. Our role is to bring developers and systems administrators the best tools possible, so that they can build the systems they have always wanted.
We raised 2.5 million from DFJ in January of 2009 on that vision, and have been at it ever since.
AkitaOnRails: I’d like to say that only amateur sysadmins do everything manually, but I think most small to medium corporations at least still do everything manually or with random scripts spread all over the place. The notion of “configuration management” is still new to a lot of people. Could you briefly explain what it is, and why it is important?
Opscode: To me, “Configuration Management”, at it’s core, is all the stuff you have to do to take a system from “running an operating system” to “doing it’s job”. When a systems administrator configures a system by hand, and posts her notes on a Wiki, she’s practicing the most primitive form of Configuration Management.
Now, having those notes is better than nothing – when she needs to do that task again, she can at least go back and read them to remember what she did last time. She still has to do it over again, though – and the repetition gets tiresome. So she starts writing scripts that encapsulate that knowledge in code, so that now she only has to run a series of smaller commands.
Time passes, though, and entropy sets in. The systems begin to drift from where they were when the systems administrator wrote the scripts. Next thing you know, the scripts don’t run anymore, or if they did, the configuration they build is wrong. Our intrepid admin then starts editing the scripts, or making new ones, to deal with the system when it’s in this new state. This is the stage we call “tool sprawl” – you have a tool for each different phase of a systems observable life-cycle.
Modern configuration management tools solve this problem by providing a framework for describing the final state a system should be in, rather than the discrete steps we should take to get there at any given time. Rather than writing a script that lists the commands to install Apache, write the configuration file, and start the service, you would describe that “apache should be installed”, the configuration file “should look like this”, and the service “should be running”.
When the configuration management system runs it looks at each of these descriptions individually, and makes sure that they are in the proper state. We no longer care what the initial state of the system is – the configuration management system will only take action at each step in the process if the system is not in the state you described. If you run it again, and nothing has changed, the system takes no action. (Configuration management geeks call this property idempotence)
This means that you can describe your systems once in code, and as they change over time, simply update that code to reflect what you want the state of those systems to be. The impact of this model on the daily life a systems administrator cannot be overstated – it makes everything easier.
It also has huge impacts outside the systems administrators world. You now have a living document that describes how all your servers are configured – you can share it, you can put it in revision control, you can print it out for an auditor. Business processes that previously required manual intervention frequently can be boiled down to discrete changes. The more you work in this way, the more the impacts spread throughout the organization.
AkitaOnRails: Even though the Ruby community probably compares Chef to Puppet, I think one of the most widely used system is CFEngine2. How does Chef compare with CFEngine2?
Opscode: Cfengine 2 is where almost everyone in the configuration management world cut their teeth. Mark Burgess is responsible for the academic papers that outlined the idea that each part of the system should be idempotent, and his work in studying how real-world systems can be managed at scale has done more to impact the evolution of configuration management than any other individual.
In addition to the idea of idempotent resources, Burgess introduced the larger concept of “convergence”. The basic idea here is that if you have the description of how every finite resource should be configured, given enough time, those resources will bring the system into a compliant state. The order in which the resources run fundamentally does not matter – eventually, they will all wind up in the right place.
While this model works at a fundamental level, it has some pretty dramatic inefficiencies. Cfengine applies resources based on their type – all the files are managed at once, then all the services, then all the packages. You can control the order they are run with the ‘actionsequence’, but each system gets only one order. So if you need to have a file copied, a package installed, and a service restarted, it’s easy enough to model. When you start getting into more complex configurations, however, it becomes more and more difficult to get an actionsequence assembled that allows you to configure your entire system in a single run.
This is not a bug in Cfengine – it’s by design. Convergence is the answer – it’s okay that it has to run more than once, it will get there eventually. If you are thinking too much about the order things should happen in, you’re probably not thinking about idempotent descriptions.
In my experience, though, this was frustrating at scale. It meant that the amount of time it took to configure a system increased as the configuration became more complicated, and your ability to model complicated interactions in the system became increasingly opaque.
For the era in which it was written, this problem mattered a lot less. If it takes you 6 to 8 weeks to get a server even ordered, then another week to get it racked, stacked, and the OS installed, the fact that Cfengine needs to run 3 times to configure it doesn’t matter very much. (You have lots of bigger problems!) In a world where many of us can go from bare-metal to running operating system in 5 minutes, either via our own install systems or an API call to AWS, it starts to matter a whole lot.
Chef takes a different approach. We start with the idea of an idempotent “resource” – a package, a service, etc. We add the idea of “actions” – these are all the different states you might want to request a resource to be in. Then you put these resources into “recipes”, which are evaluated in the order they are written. You can then have recipes rely on other recipes having completed before they are run, giving you the ability to say “make sure Apache is installed before you configure my Web Application”.
The goal is that, with Chef, you can always bring the system into the proper state with a single Chef run. It sees convergence as a response to a bug – a system that is 1/2 configured is, in fact, broken. If the cause of the bug is environmental – a network service is not available, for example – then running Chef again will likely fix things. If the issue is that you haven’t specified the order that you want resources to be configured in, though, then it’s a bug in your recipes. If you can’t write a recipe to configure your system in a single Chef run, it’s a bug in Chef.
This also has side-effects for reasoning about the system at scale. Given the same configuration and attributes, Chef will always behave the same way, on every system. As you add more and more things to the system, it’s still easy to reason about when, and how, they will be configured.
Interestingly enough, Cfengine 3 implements a system that is very similar to Chef. Rather than a single global actionsequence, it uses a ‘bundlesequence’, where bundles are roughly analogous to Chef’s concept of a recipe.
Another major difference is that Chef allows you to ‘look up’ at your entire infrastructure when configuring a system. This ability comes in handy when you want to do things like configure a monitoring system, or a load balancer. You can ask Chef questions like “what are all the servers running my application in production”, and use the response to configure your system. (You can see an example of this on our blog)
From a systems architecture point of view, Chef and Cfengine are actually fairly similar. They both push the majority of the hard work of configuring a system out to the systems themselves. This is highly advantageous at scale – the Chef and Cfengine servers are really glorified file transfer systems.
We differ pretty deeply on our approach to what a language for configuration management should look like, but I’ll talk more about that in a later question.
Cfengine is at work in some of the largest data centers in the industry, and it fundamentally altered the landscape of systems management. While it’s not the tool I want anymore, you can’t understate the impact it’s had on the design of every configuration management tool that came after it – including Chef.
AkitaOnRails: Chef has a lot of components to it. Could you briefly describe all the main components that work together? The client side, the server side, cookbooks?
Opscode: Sure! The most important part of Chef is the cookbooks – they are where you actually describe your configuration. They collect recipes, and all the assets needed for the recipe to run (files, templates, etc.). Cookbooks are very often share-able, and lots of cookbooks already exist.
Chef can run your cookbooks in two modes – a client/server mode (chef-client), or a stand-alone mode (chef-solo). When you run chef-solo, you pass a URL to a tarball full of the cookbooks you want to have run. There is no more infrastructure than that – put your tarballs someplace you can download them, and go nuts.
In client/server mode, each Chef client is configured to talk to a Chef Server. The Server stores information about each client (a whole lot of it – things like IP addresses, loaded kernel modules, and more), and distributes the cookbooks they need to configure themselves. It also provides a REST API and an interactive Web UI, so you can easily alter the configuration of your systems centrally. Finally, all the data the server collects is indexed and searchable – you can then use this in your recipes to configure services that require complex, dynamic configuration. (Some examples would be dynamically discovering a master MySQL server, or finding all the memcached servers in a cluster)
AkitaOnRails: What would you say about Chef’s maturity? CFEngine has more than a decade of usage, which is difficult to beat. Would you say that it’s “mature enough”? Meaning, it’s already in production in companies of many sizes, its APIs don’t change too much and my cookbooks will probably work if I upgrade to newer version of Chef?
Opscode: Chef is a little over a year old – it was first released to the public on January 15th, 2009. Since then, 42 different developers have committed to the project, around 5 of whom work for Opscode. It’s been in production use in the Engine Yard Cloud from the day it was released. Since then, it’s seen adoption by companies and universities of all different sizes, from small startups to huge enterprises with very heavy compliance requirements.
So it’s definitely “mature enough” for real world use – lots of people are using it, and relying on it, every day. Balancing that knowledge with the reality that the project is fast moving and evolving is important, and we try and do it in a number of ways:
- The recipe syntax is considered basically “complete”. If we do make changes, they are backwards compatible to previous Chef releases. Short of something truly amazing coming along that radically alters the shape of the universe, this will remain true.
- We test a lot. Chef has over 2000 unit tests, and functional tests that cover the entirety of the REST API, and much of the individual resources (we’re aiming for 100% feature test coverage.) There are more lines of code testing chef than there are lines of code in Chef proper.
- If we do break backwards compatibility, we try and make it happen only when we bump the minor revision. If you have an 0.7.x version of Chef installed, it should always work with other versions of Chef in the same release cycle.
Most of the work in Chef currently is around adding more functionality, not in changing the way existing functionality works. It’s safe to use Chef today – in the future, you’ll just keep getting more good sauce to add to the mix, rather than having to deeply re-factor the way you do things.
Finally, the Chef Community is truly epically great – we have lots of people who are spending significant amounts of their time with Chef. Even if they aren’t contributing code, they are answering questions, they are writing documentation, they are hanging out on IRC and offering you cupcakes. It’s a group of people that are focused on solving real world problems, and helping each other to do the same. It’s by far what I’m proudest of, and I think it has a significant impact on whether Chef is ready for prime time. The bench is really, really deep.
AkitaOnRails: Chef uses Ruby directly, which some would say it’s both a blessing and a curse. It’s probably perfect for Rubists, but I feel that most sysadmins are used to Bash, Python and are not very flexible on change. Why did you choose to use Ruby instead of a simpler language?
Opscode: The answer to the question of why we use Ruby directly for the configuration language comes in two parts: why we extended a 3GL rather than build a declarative DSL or a complete modeling language, and why we chose Ruby as that 3GL.
First, why we extended a 3GL. Tools like Cfengine and Puppet build a declarative DSL for configuration management – a custom language, which provides a model within which systems administrators or software developers can work to automate their system. Other tools like Elastra’s EDML and ECML, OpsWare’s DCML, or Bcfg2 give you an XML schema to describe how the system should behave.
The issue with these approaches is that, by definition, they must build an abstraction for every task the end-user may want to perform: an impossible feat. The level of complexity inherent in automation, coupled with the inability to break out to 3GL language constructs when necessary, result in a system that can only target a subset of the total complexity, rather than enable users to find innovative solutions to their specific problems. By leveraging Ruby, adding support for other use cases is a matter of adding new sets of base classes while maintaining consistency and approachability in their interface design, because the full scope of the language is available.
Our goal with Chef was to keep the simplicity that comes from having the focus be on idempotent resource declaration, while giving you the flexibility of a full 3GL. In practical terms, anything you can do with Ruby you can do with Chef – and since Ruby is a 3GL, that amounts to essentially anything.
Larry Wall, the creator of Perl, has a quote that I love:
“For most people the perceived usefulness of a computer language is inversely proportional to the number of theoretical axes the language intends to grind.”
Since we wanted Chef to have the maximum amount of usefulness, we have actively tried to remove as many theoretical axes as possible – a belief that we can imagine the total breadth of the problem space being one of them. There is more than one way to do it with Chef, and the only valid criteria for rating the success of your automation project is whether it solves your problems in a reliable way.
In practice, you need to know very little Ruby to use Chef. Here is an example of installing the program “screen”:
1 2 3 |
package "screen" do action :install end |
The same thing in Puppet:
1 2 3 |
package { "screen":
ensure => present
}
|
And in Cfengine 2:
1 2 |
packages: screen action=install |
While all of these systems require learning the syntax, at a base level, there isn’t much difference between them in terms of raw learning required. The difference is that when you hit a limitation in Chef, you have the ability to innovate easily, and when you hit those same limitations in other tools, you do not.
We chose Ruby because of it’s fairly unique ability to create new syntax easily. Tools like Rspec are fine examples of ways you can manipulate Ruby for fun and profit that are very difficult to duplicate in other tools. We wanted to make sure that, even though you were “in” a 3GL, you didn’t have to go through any extra hoops to make the simple things work. Ruby was the language that I was comfortable enough in, that I knew had the ability, to make that a reality.
That said, one of our goals is to extend the ability to write Chef recipes into other 3GL’s. We have an example of doing this already with Perl – and we made no changes to the Chef source to accomplish it. You can see the demo here on CPAN. It works by using Chef’s JSON API to ship the compiled resources over to the Ruby library for execution, and over time we’ll be extending those interfaces. You’ll be able to have recipes written in Python interoperating with recipes written in Ruby and Perl.
AkitaOnRails: Does Chef have (or for that matter, need) something like Augeas, which Puppet is trying to support?
Opscode: Augeas is neat. Chef doesn’t have Augeas support today, and the reason is that nobody has needed it badly enough to write the integration. One reason is that, with Chef, it is quite easy to dynamically add to a resource (like, say, a template) or search for particular systems that match a criteria. This means that the use-case for Augeas (which edits files in place) is less necessary – you can often get the data you need to render a template, rather than needing to build it up over time with incremental edits.
We think this is a better practice in general, as it ensures that all the systems you are managing can always be restored to a working state from nothing but the cookbook repository. If you use Augeas to allow idempotent changes of individual lines of a configuration file, it encourages the behavior of individual administrators editing files in place, which is a configuration management anti-pattern.
AkitaOnRails: Sysadmins used to CFEngine complain about Ruby’s dependencies and overall weight. Because for Chef to run you need Ruby installed. Not all distros have Ruby in the same version (although most already migrated to 1.8.7). Then you have the problem of weight. I am not familiar with Chef, but Puppet can grow to hundreds of megabytes. What they don’t want is to have clusters of Chef machines (which, by themselves, also need maintenance, adding to the overall complexity). How do you deal with datacenters with thousands of servers? I know it’s difficult to measure precisely, but what would be a reasonable ratio between Chef servers x managed servers?
Opscode: When you are evaluating the scalability of configuration management systems, you want to look at two different axis. The horizontal one, which is the number of systems that can be managed by a single configuration management server at a particular rate of change, and the vertical, which is how much of your infrastructure can be automated by the tool.
On the vertical axis, I think Chef is the clear winner, for reasons I think are pretty well summed up by my answer to question 7. I would put Puppet second, and Cfengine last.
On the horizontal axis, Cfengine is the clear winner. It’s written in C, and it has the thinnest possible server component – it does nothing but authenticate clients and serve files, essentially. I know first hand of data-centers that are running huge numbers of servers off a single cfengine server.
One important metric to keep in mind when discussing the horizontal scalability of a configuration management solution is that the most important metric is the rate of change. All the tools we’ve been talking about are ‘pull’ based – the clients check in at an ‘interval’ with the server, and apply a ‘splay’ to ensure that not all the systems check in at once. A common out of the box configuration is an interval of 30 minutes, with a splay of 15 minutes. (This means a server checks in every 30-45 minutes, depending.) If you are comfortable increasing that interval, you will get more scalability out of fewer resources (by lowering the amount of concurrency.)
So when anyone says “I have 10 thousand servers on a single configuration management server”, ask them “at what interval?”.
Chef scales like a web application. The server itself is quite thin, and is responsible for authenticating clients, transferring files, storing node state, and providing a search interface. It scales horizontally by adding new Chef Servers as necessary. The API is RESTful, and there is no session state between the clients and the server. (At least not in Chef 0.8+) When you encounter scalability problems with Chef, the tools you apply are the same ones you apply to any well designed web application.
You asked specifically about memory utilization – Chef does quite well in this regard. Individual server processes usually are between 14-50MB resident. The client itself, running in daemon mode, is usually around 28MB resident.
In our testing, the current bottleneck in a Chef server is CPU. Chef is smart about how it handles file transfers – we only transfer files that have changed on the server. To support this we calculate a checksum for each file requested, and we currently don’t cache the results. We’re planning on fixing this for the next major release of Chef (0.8.0) which should shift the bottleneck over to RAM.
With Chef 0.7, you should be able to support thousands of clients at a half-hour interval and fifteen minute splay on reasonable commodity hardware. The changes in Chef 0.8 should bring that number up dramatically – I’ll get back to you with some benchmarks once the patches are in. :)
AkitaOnRails: Probably related to the previous question, seems like specially after Sarbanes Oxley there’s been an increasing interest in stuff such as ITIL, CoBit. Have you ever seen successful implementations of those in the Web-style infrastructure? I mean, I can see them succeeding in Banks, Aerospace and Defense, etc but I fail to see them working as advertised in a very dynamic environment such as Web services hosting. What are your experiences regarding this issue?
Opscode: Well, I think you can think of ITIL in the same way you think about the classic ‘Waterfall’ model of software development. For some kinds of projects and companies, it is essential – it’s hard to imagine working a different way. Most often these are companies with huge manufacturing or quality control concerns – medical health, aerospace, banking and finance, etc.
The same thing applies to ITIL – the larger the concern, and the more stringent the requirements, and the longer the lead time, the more the processes they describe start to make sense. Like all large process, though, they tend to de-emphasize the human element – people have roles to play, and forms to file. :)
In the Web Ops culture, things are different. I’ve never seen a successful marriage of ITIL and Web Ops, and the reason is that the domains are so very different. If there is a bug on the website, it’s better to ship the fix now than wait for a release management process to ensure that the site won’t have any more issues based on your fix, for example. It’s also a bad cultural fit – in the best Web Ops teams, the focus is heavy on communication, agility, and respect, rather than process, formalism, and tooling. The shift you start too see in the really great Web Ops companies is that their operations personel become enablers of the organization, rather than end-line blockers of change (to keep stability high.)
In general, I think the 4 steps outlined in visible ops for emergency management are not bad ones, but the devil is always in the details. The guy you should really ask about this is Jesse – he’s largely responsible for Amazon’s operational culture, and knows what it means to start hacking on that sort of thing from within huge organizations.
AkitaOnRails: Awesome, I think this is a wrap. Thank you very much for this interview!
Chatting with Luke Kanies 18 Nov 2009 4:45 AM (15 years ago)
Configuration Management is a tricky subject. For non-starters, when you’re a developer and you have few boxes to take care of, you can usually get away with just managing them manually. People are probably just used to pop in a CD, double-click the “install” program and click “next”, “next” until the end, then you manually log in to backup (when you remember it), and sometimes you do apply some security updates when you remember about them.
But then you have more than a dozen machines, things start to get uglier, you end up making more mistakes, forgetting important steps, and all of a sudden managing machines become a nightmare. You end up being woken up in the middle of the night because you forgot to install some crucial component, and so on and so forth.

The same way you need testing, continuous integration tools when you’re a developer, you also need automated, reliable and flexible tools for the system administrator role. That’s where tools such as Puppet kick in to help.
This time I’ve interviewed Luke Kanies, from Reductive Labs, former contributor to the famous CFEngine tool and creator of Puppet, one of the most acclaimed configuration management tool for 21st century datacenters.
AkitaOnRails: To kick start this interview, it would be great to have more background info about you. So, how did you end up in the configuration management field? I understand that you have a long history with CFEngine development, right?

Luke: I was a Unix admin going back to 1997, always writing scripts and tools to save myself time, and around 2001 I realized that I shouldn’t have to write everything myself – that someone somewhere should be able to save me time. After a lot of research and experimentation, I settled on Cfengine, and had enough success with it that I started consulting, publishing, and contributing to the project.
AkitaOnRails: What’s the story behind Reductive Labs, what’s its mission, and what’s the story for Puppet’s creation?
Luke: After a couple of years with Cfengine, I had a lot more insight but was frustrated because it still seemed to be too hard – no one was sharing Cfengine code, and there were some problems it made you work really hard to solve. The biggest issue, though, was that its development was very closed – it was difficult to contribute much more than just bug fixes.
I got frustrated enough that I stopped consulting and looked for other options. I worked briefly at BladeLogic, a commercial software company in this space, but in the end I decided that the insight I had and the lack of a great solution were a good enough start for a business that I decided to morph my consulting company into a software company and write a new tool.
AkitaOnRails: I’d like to say that only amateur sysadmins do everything manually, but I think most small to medium corporations at least still do everything manually or with random scripts spread all over the place. The notion of “configuration management” is still new to a lot of people. Could you briefly explain what it is, and why it is important?
Luke: It’s surprisingly difficult to describe it succintly, but for me, there are two key rules: You shouldn’t need to connect directly to a given machine to change its configuration, and you should be able to redeploy any machine on your network very quickly.
These two rules combine to require comprehensive automation and/or centralization for everything that goes into making a machine work. Annoyingly, they also immediately introduce dependency cycles, because your automation server needs to be able to build itself, which is always a bit of a challenge.
AkitaOnRails: I think one of the most widely used system is CFEngine2. How does Puppet compare with it? Meaning, what do I have as value added when switching to Puppet, and what are the known caveats?
Luke: There are multiple important functional differences. The biggest is Puppet’s Resource Abstraction Layer, which allows Puppet users to avoid a lot of the detail they don’t really care about, like how rpm, adduser, or init scripts work – they talk about users, groups, and packages, and Puppet figures out the details.
We also have explicit dependency support, which makes a huge difference – it’s easy to order related resources and restart services when their configuration files change, for instance.
The language is also a bit more powerful. Like Cfengine, we have a simple custom language, but Puppet’s language provides better support for heterogeneity, along with a composite resource construct that allows you to easily build in-language resource types like Apache virtual hosts that model more complex resources consisting of multiple simple resources.
AkitaOnRails: Puppet has a lot of components. Could you briefly describe some of the main ones that work together? The client side, the server side, recipes?
Luke: Most people use Puppet in client/server mode, where the central server is the only machine that has access to all of the code, and it runs a process capable of compiling that code into host-specific configurations. Then each machine runs a client (including the server), which then retrieves and applies that host-specific configuration. This has nice security implications because you’ve not shipped your code to every machine on your network.
If this model doesn’t work for you, though, it’s also easy to run Puppet stand-alone, where each machine has all of the code and compiles it separately. Multiple Puppet users do this for various reasons. This stand-alone ‘puppet’ executable is a standard interpreter – it can be used to run 1 line scripts or thousands of lines in a complete configuration.
Beyond this, we’ve got a few other interesting executables, such as to access our certificate authority functionality, and an interesting executable called ‘ralsh’ that provides a simple way to directly manage resources from the Unix shell, without having to write a separate script.
AkitaOnRails: What would you say about Puppet’s maturity? CFEngine has more than a decade of usage, which is difficult to beat. Would you say that it’s “mature enough”? Meaning, it’s already in production in companies of many sizes, its APIs don’t change too much and my recipes will probably work if I upgrade to a newer version of Puppet? I think the 0.x version makes some people nervous :-)
Luke: Really we should have called a version from 2007 1.0, but it’s hard to know how stable a release is going to be until it’s been out for a while. :)
It’s obviously tough to match Cfengine’s long life, although they’re somewhat forcibly migrating to Cfengine 3, which is a complete rewrite, so that maturity isn’t worth quite as much right now.
However, Puppet’s been in production usage around the world since 2006, and it’s currently used by more large companies than I could reasonably name – Twitter, Digg, Google, Sun, Red Hat, and lots more – and our community and customer base consider it to be mature. For the line came some time early last year, when I found that the vast majority of issues people had were user issues on their part, rather than some flaw or shortcoming in Puppet.
In general the APIs are quite stable, and we’ve done quite well, I think, at maintaining backward compatibility when the APIs have had to change. The point about API stability in a 1.0 release isn’t so much to differentiate it from previous efforts as to make a promise for the future. This especially matters for companies like Canonical, who want a release that they can support on Ubuntu for five years.
AkitaOnRails: Puppet has its own language and you can use Ruby for the advanced cases. It’s probably perfect for Rubists, but I feel that most sysadmins are used to Bash, Python and are not very flexible on change. Why did you choose to use Ruby instead of a more widespread language? What do sysadmins need to realize to shift paradigms?
Luke: Part of it is that most people don’t really need to know any ruby to be effective with Puppet. Sure, you can get some more power if you do, but if you’re not a language person, you’re perfectively functional with just Puppet.
Another nice thing is that we have a pretty smooth scale in terms of Ruby knowledge – you can start out writing ERB templates or five line extensions to Facter, which is our client-side querying system, and grow smoothly through to writing custom resource types.
In the end, I chose Ruby because I was most productive in it. I likely should have chosen Python, given its speed benefit and popularity at Red Hat and other places, but I found I just couldn’t write code in it. I started thinking in Ruby after only a few hours of usage, so it was impossible for me to turn away from it.
AkitaOnRails: Sysadmins used to CFEngine complain about Ruby’s dependencies and overall weight. Because for Puppet to run you need Ruby installed. Not all distros have Ruby in the same version (although most already migrated to 1.8.7). Then you have the problem of weight. Puppet can grow to hundreds of megabytes. What they don’t want is to have clusters of Puppet machines (which, by themselves, also need maintenance, adding to the overall complexity). How do you deal with datacenters with thousands of servers? I know it’s difficult to measure precisely, but what would be a reasonable ratio between Puppet servers x managed servers?
Luke: It’s as impossible to tell you how many clients a Puppet server can handle as it is to tell you how many clients a Rails server can handle – it all depends on the complexity of the tasks. Google scaled to 4500 client machines on a single server, but most people tend to add another server at around 500-1000 clients.
It’s true that it’s hard to keep memory usage down in a Ruby process, but we’ve made great strides in our recent releases by doing things like deduplicating strings in memory and being more efficient in our code paths. Really, though, we’ve spent a lot more time on features and bug fixing and less time on optimizing – until recently, we’ve been a small development team, and we just didn’t have the bandwidth for it.
Now that my company, Reductive Labs, has some investment, we’ve been able to add three full time developers, which is going to really help in this area.
As to dependencies, this is one area we break strongly from the Ruby community – we don’t require a single gem, other than our own Facter tool (and it’s usually not shipped as a gem). Rubyists tend not to worry too much about package dependencies – they just put it in vendor, as I’m fond of saying – but that doesn’t work when you have to deploy thousands of copies. So yes, you might have to install Ruby, but there won’t be any other dependencies you have to deal with, which greatly simplifies it.
It’s generally as tough to know how you’ll need to size your puppetmaster as it would be to size a web server – it depends on how complicated the workload is. In general, somewhere between 500 and 5000 clients, you’ll need to have a second server, but most people probably find it closer to 500. Really, though, if you’ve got 3000 clients hitting a service, you probably want to make it horizontally scalable for stability in additional to performance.
AkitaOnRails: Security is a big concern nowadays, Puppet was worried from the beginning on the handshake procedure between clients and server, can you describe it a little bit? Also, is there any built-in recipes for hardening machines, for example? Or at least any desires to add such tools in the future?
Luke: Puppet uses standard SSL certificates for authentication and encryption, including a certificate signing phase. By default, the client generates a key and a certificate request (CSR) and then uploads the CSR to its server. This upload, along with the later certificate download, are the only unauthenticated connections that are allowed by default.
From there, a human normally has to trigger the client’s certificate to be signed, but many organizations, including Google, automatically sign client certificates because they trust their internal network.
As to automatic hardening, there aren’t any recipes that I’m aware of right now, but it’s something that I’m definitely interested in. Years ago I was a big fan of TITAN, which is a hardening package for various *NIX platforms, and it was part of the inspiration to write Puppet – I’ve always wanted a portable, executable security policy.
AkitaOnRails: The puppetmaster uses Webrick by default, but the documentation also describes using Mongrel or Passenger. Are there any real gains in using those? Is it more for convenience or do we have performance/robustness improvements?
Luke: Holy cow Webrick is slow. It’s really fantastic for proof of concepts – get up and running in minutes. Once you get beyond that proof of concept, though, you really need to switch to Mongrel or Passenger. If you get more than one concurrent connection in webrick, your clients start to suffer, but you can scale to far more with the other solutions out there.
AkitaOnRails: Are there any clients case you are allowed to talk about? Meaning, more details on the kind of infrastructure, difficulties, caveats, best practices?
Luke: The possibilities here are pretty open ended. Google uses Puppet to maintain their corporate IT, which means they’re running it on thousands of laptops and desktops which is pretty different. MessageOne, a division of Dell, is really interesting in that their developers have to ship Puppet code to manage the applications that they ship, so if an app isn’t trimming its logs or backing itself up, it’s a bug that the app developer has to fix rather than the sysadmin. This really helps to bridge the divide between dev and ops, which has worked out really well for them.
Otherwise, there are lots of stores and best practices, but I’m afraid that would be a whole second article. :)
AkitaOnRails: I’ve seen Andrew Shaffer talk about Agile Infrastructure for a couple of years now, but I still think most IT organizations are unaware of this concept. Can you elaborate on what does it mean to be Agile outside of the development field?
Luke: I think Agile Infrastructure has even less adoption than Agile Development. The vast majority of IT shops haven’t changed practices significantly in years and are largely unprepared for the growth in server count that they’re experiencing. They mostly try to scale by adding more people, which we call the meatcloud, rather than scaling their tools and practice.
AkitaOnRails: Probably related to the previous question, seems like specially after Sarbanes Oxley there’s been an increasing interest in stuff such as ITIL, CoBit. Have you ever seen successful implementations of those in the Web-style infrastructure? I mean, I can see them succeeding in Banks, Aerospace and Defense, etc but I fail to see them working as advertised in a very dynamic environment such as Web services hosting. What are your experiences regarding this issue?
Luke: In general, I think these kinds of high-level policies are great for filings but aren’t so great for actually solving problems. The bigger a company is and the more public they are, the more likely they are to care about ITIL et al, but it doesn’t really help them solve problems outside of PR in my experience. You can be ITIL compliant and dysfunctional, or completely out of compliance but in fantastic shape. Considering that the best standards are derived from implementation and best practice, which few of these are, I don’t have a lot of hope for these being adopted by the best shops out there.
My personal experience is that very few companies ask or care about these standards, and the ones that do usually do so in a kind of checkbox way, in that they want to make sure they can check off things like CMDB but they aren’t really that concerned with the specifics.
AkitaOnRails: I think this is it! Thank you very much for this conversation!
[Rails Summit 2010] Commence Planning 29 Oct 2009 6:39 PM (15 years ago)
Railers all around the globe, I am very happy to report that the Ruby on Rails community in Brazil is growing strong. Last 13, 14th of October we had Rails Summit Latin America, with 550+ attendees we had the 2nd edition of the second largest Rails conference in the world after the official RailsConf.
This conference is possible thanks to Locaweb, the largest hosting company in South America. Together, we were able to organize two very successful events. When I started being a Rails activist back in 2006, with virtually no rubyists in Brazil, I never imagined how far we would be able to go. Now we have a healthy ecosystem, with some great recognized open source programmers, some small consultings starting to pop up, a few startups starting to show up, even some ‘enterprisey’ companies coming to adopt it. The Brazilian Rails community is a force to be reckoned.

There’s a lot more to do though, and I am again counting on the international rubyists support to keep on going. The last 2 Rails Summits were real challenges, and we will strive to continue to deliver the best conference in South America. Up to this year’s edition I had to have closed speakers list, but for 2010 I will finally be able to have an open Call for Participation, and I hope Railers all around the world show interest to come visit Brazil, get to know our beautiful country and meet our friendly people. I will let you know the details next year, as soon as I can.

Rails Summit gets inspiration from the official RailsConf. The format of the conference comprises 2 full days, with 2 parallel tracks, a Lightning Talk session, real-time translation from English to Portuguese and Portuguese to English, rooms with power plugs and ubiquitous wireless internet access. Up to this year we used the Elis Regina auditorium, inside the Anhembi Convention Center area, in São Paulo City. For next year we will move it to Frei Caneca Convention Center, which is also in São Paulo City, nearer the famous Paulista Ave. area, much more convenient to find hotels and entertainment areas. I think you will enjoy it. Prices will be around USD 140 for the same 2 full days of event. Above, you can see 2 photos from one of the other conferences that Locaweb does in the Frei Caneca Convention Center.
We recorded all the talks from this year’s edition and I will release them as soon as possible, so you can see how it was. Follow me on twitter or subscribe to this blog’s feed. I’ll keep you posted.

RailsConf 09 - Ninh Grosenbach Bui 10 May 2009 7:12 PM (15 years ago)
RailsConf is not your “normal” tech conference. You will have people ranting, doing real rocket-science and lot’s of people having real and genuine fun. We are very lucky to have people such as Geoffrey Grosenbach, Jason Seifer, Peter Cooper, Ninh Bui and so much more to remind us that there is an upper layer to technology: geeks love to have fun.
And don’t miss the awesome Rubystein, Phusion’s reimplementation of Wolsfenstein 3D in Ruby. They wanted to prove that Ruby is fast enough even to write games on it, and they succeeded in spades!
A RailsConf não é sua conferência “normal” de tecnologia. Você verá pessoas reclamando, fazendo coisas realmente avançadas e muitas pessoas genuinamente se divertindo. Somos muito afortunados em ter pessoas como Geoffrey Grosenbach, Jason Seifer, Peter Cooper, Ninh Bui e tantos outros para nos lembrar que existe uma camada ainda acima da tecnologia: geeks adoram se divertir.
RailsConf 09 - Message from Bryan Liles (TATFT) to Brazil 8 May 2009 12:26 AM (15 years ago)
Bryan Liles’ Test All The Fucking Time video really struck a cord and people have been repeating his motto ever since. He was so kind to send a message to the Brazilian programmers as well, check it out:
O vídeo do Bryan Liles, Test All The Fucking Time realmente tocou num ponto importante e as pessoas vem repetindo seu lema desde então. Ele foi muito legal em enviar uma mensagem aos programadores Brasileiros, dêem uma olhada ;-)
RailsConf 09 - Exclusive Audio Interviews 8 May 2009 12:07 AM (15 years ago)
I’ve had a great time interviewing several interesting Rubysts and Railers on their new projects. I think you will like to hear what they have to say.
My first guest was Joshua Timberman. He is a fervorous evangelist for the Chef project. Chef could be seen as a more modern Puppet, which by itself, already is a modern systems configuration manager. Chef is composed of several pieces, cookbooks and details that Joshua explains in his interview.
Download (22:24)
One project that I am particularly very interested is Spree. Sean Schofield started this Rails based e-commerce system to support developers that had to reinvent the wheel all the time, and e-commerce systems are notoriously not easy to do. Spree is a fairly complete project, with many nice features, including integration with ActiveMerchant, shipping support, tax categories and so on. I helped a bit doing the Brazilian Portuguese internationalization of the project as well. Highly recommended.
Download (22:15)
By now I think we all know New Relic, Fiveruns and Rails monitoring systems. But there are more competition coming up, from the guys of Highgroove Studios we have Scout a non-nonsense approach to Rails monitoring and data analysis. They are willing to go an step further: instead of just presenting raw data as reports, they are analyzing this data and giving you relevant recommendations so you can further optimize your application. And more than that: they are highly competitive in price. And the client agent that gathers data and send to their servers is open source and extensible through plugins, so you can add even more to what they already offer. Definitely worth checking out:
Download (13:43)
At RailsConf 2008, last year, I interviewed James Lindenbaum about Heroku. They were still in beta at that time. Now they finally released a commercial version with lots of new features. I was particularly surprised to find Ryan Tomayko at their booth, working for Heroku. I think Heroku really nailed easy deployment for Ruby applications over Amazon EC2. If you don’t want to worry about infrastructure, Heroku may be the answer:
Download (33:49)
Again, last year, everybody was blown away by the announcement of Gemstone – traditional Smalltalk software-house – showing a very preview version of Ruby actually running over a very mature Smalltalk VM. This is the Maglev project. Since then the development has been quite secretive. But they are finally disclosing more and more information on how the project is going. This year, they were able to show a small Sinatra application already running – albeit, with some tweaks. I think they are evolving very fast. Ruby is notoriously not an easy language to implement and Maglev will be incredible when released. In this interview we have Monty Williams, Peter McLain and Michael Latta discussing about the current development and future roadmap.
Download (36:42)
Finally, I think everybody knows Ilya Grigorik by now, from igvita.com. He received last year’s Ruby Hero Awards, and it was well deserved. He is one of the few developers that can tackle very advanced subjects in a way that anyone can understand. He started a new company recently and they have a very very interesting product called PostRank. The overall idea is fairly simple: they went a step further over Google’s own PageRank system. Instead of just considering link tracebacks, they now weigh in social network behavior. For example, a single Digg page traces back to a website with just one link. But this same page at Digg can have something like hundreds of comments, or “engagements” as Ilya calls it. This gives a totally different weigh to this traceback instead of just a simple link. So companies are starting to pay attention to social networks such as Digg, Reddit, Twitter and others and now Ilya comes up with the tool to deliver them the necessary metrics. I highly recommend you to test-drive this site, I think you will be impressed.
Download (21:43)
And this wraps up my series of interviews at RailsConf 2009. I wish I had more time to interview more people. There were very insightful and smart developers there, and I would have to git clone myself many times to be able to talk to all of them. I hope you enjoy this set of interviews.
RailsConf 09 - Message from Peter Cooper to Ruby Inside Brazil 7 May 2009 11:11 PM (15 years ago)
Maybe not everybody knows it but the well known Ruby Inside website now has a new branch in Brazil. It was recently released and we have a bunch of highly motivated Railers that are doing a great work posting everything that is news in the Ruby and Rails world both in Brazil and in other countries. Check it out Peter Cooper’s take on this:
Talvez nem todos saibam, but o bem conhecido site Ruby Inside agora tem uma nova filial no Brasil. Eles iniciaram recentemente e tem uma equipe de Railers muito motivados que estão fazendo um grande trabalho publicando notícias do mundo Ruby e Rails tanto do Brasil quanto de outros países. Dêem uma olhada na opinião do Peter Cooper sobre isso.
RailsConf 09 - DHH - The Secret of Productivity 7 May 2009 11:07 PM (15 years ago)
David Hansson delivered a nice keynote, showing how Rails evolved throughout the years, the criticisms, the discussions. He introduced the future Rails 3 feature set and, finally, discussed about the secret for productivity. There was nothing particularly new if you are already an Agilist, but it is always good to reinforce the basic concepts:
And don’t miss the complete keynote at railsconf.blip.tv
O David Hansson deu um excelente keynote, dentre outras coisas mostrando como o Rails evoluiu nos últimos anos, as críticas, discussões. Deu uma introdução às novas features do Rails 3 e finalmente, falou sobre qual o segredo da produtividade. Na realidade, para agilistas, não há nenhuma novidade. Mas vale a pena reforçar o conceito de qualquer maneira.
RailsConf 09 - Uncle Bob - Professionalism 6 May 2009 11:34 PM (15 years ago)
Brasileiros: tradução mais abaixo
Update 08/05: Bob Martins’ full keynote is now available at RailsConf’s Blip.TV page. Definitely go check it out!
It seems that O’Reilly promised to deliver – at the very least – the main keynote recordings, so unfortunately we will have Tim Ferris, but much fortunately we will have Uncle Bob. Definitely the best talk I’ve seen in eons. This particular snippet comes from the Q/A session, where Bob answer the question: “can you be too professional?” Where many would be discussing for hours, he was able to distill it in a very simple and elegant way. Check it out:
And the official, complete video of the keynote is already available! Kudos to the RailsConf staff for releasing it so quickly.
Parece que a O’Reilly prometeu entregar – pelo menos – as gravações dos keynotes principais, então infelizmente teremos Tim Ferris, mas muito felizmente teremos Tio Bob. Definitivamente a melhor palestra que vejo em muito tempo. Este trecho em particular é da sessão de perguntas e respostas, onde Bob responde à pergunta “podemos acabar sendo profissionais demais?” Onde muitos discutiriam por hora, ele foi capaz de destilar tudo de maneira simples e elegante. Dêem uma olhada.
Aproveitando, vejam a descrição da palestra neste blog também.
RailsConf 09 - Uncle Bob Martin 6 May 2009 5:26 PM (15 years ago)
Brasileiros: tradução mais abaixo
Today we were very fortunate to have the ending keynote by Robert Martin himself (a.k.a. Uncle Bob), from Object mentor.
I recorded most of the talk and I will publish them soon (and I still have lots of material that I was unable to compile just yet), but at the end of the talk I asked Bob to quickly give an advice to my fellow Brazilian programmers that were still unable to wrap their heads around TDD.
Hoje tivemos a sorte de ter o keynote de encerramento do dia apresentado por ninguém menos que Robert Martin (também conhecido como Uncle Bob), da Object Mentor.
Eu gravei boa parte e depois vou publicar (aliás, tenho muito material que ainda não tive tempo de compilar), mas no final eu pedi que ele rapidamente desse um conselho aos programadores Brasileiros que ainda não entenderam TDD.
Going to RailsConf 2009 2 May 2009 5:02 AM (15 years ago)

I will depart from Brazil at 10:55PM local time and should be arriving in Las Vegas tomorrow, Sunday, around 1:15PM. I will be staying at the Stratosphere Hotel, a little bit far from the Hilton.
I will not attend any of the tutorials on the first day. Maybe I will try to be at the Hilton, maybe I will try to be at CabooseConf. First thing I will try to do on Sunday is getting my Macbook Pro fixed :-) I will probably have to buy a new unit and I will spend the rest of the day restoring from my backup.
At the airport I should try to buy a pre-paid SIM card, so I can be reached more easily. But if anyone wants to get in touch with me, I think Twitter will be the easiest way. I will be checking my e-mail constantly also.
My schedule is available at Intridea or you can directly subscribe to my iCal calendar, so you may be able to reach me at the sessions, though it is uncertain that I will be actually following my own schedule :-) I have the tendency to hang out with people at random, so if I am not at the planned session, I am probably talking to people, making interviews, recording and so on.
My main goal with RailsConf is to talk to as many people as possible. The thing I like the most about this conference is the sheer ammount of insightful people and interesting talks.
%20I%20will%20probably%20have%20to%20buy%20a%20new%20unit%20and%20I%20will%20spend%20the%20rest%20of%20the%20day%20restoring%20from%20my%20backup.%3C/p%3E%0A%3Cp%3EAt%20the%20airport%20I%20should%20try%20to%20buy%20a%20pre-paid%20%3Cspan%3ESIM%3C/span%3E%20card,%20so%20I%20can%20be%20reached%20more%20easily.%20But%20if%20anyone%20wants%20to%20get%20in%20touch%20with%20me,%20I%20think%20%3Ca%20href%3D%22http://twitter.com/akitaonrails%22%3ETwitter%3C/a%3E%20will%20be%20the%20easiest%20way.%20I%20will%20be%20checking%20my%20e-mail%20constantly%20also.%3C/p%3E%0A%3Cp%3EMy%20schedule%20is%20available%20at%20%3Ca%20href%3D%22http://railsconf.intridea.com/%22%3EIntridea%3C/a%3E%20or%20you%20can%20directly%20subscribe%20to%20my%20%3Ca%20href%3D%22http://en.oreilly.com/rails2009/public/schedule/my_ical/46ebf9ee2c82e80d8ca1217bc7f04651%22%3EiCal%20calendar%3C/a%3E,%20so%20you%20may%20be%20able%20to%20reach%20me%20at%20the%20sessions,%20though%20it%20is%20uncertain%20that%20I%20will%20be%20actually%20following%20my%20own%20schedule%20:-)%20I%20have%20the%20tendency%20to%20hang%20out%20with%20people%20at%20random,%20so%20if%20I%20am%20not%20at%20the%20planned%20session,%20I%20am%20probably%20talking%20to%20people,%20making%20interviews,%20recording%20and%20so%20on.%3C/p%3E%0A%3Cp%3EMy%20main%20goal%20with%20RailsConf%20is%20to%20talk%20to%20as%20many%20people%20as%20possible.%20The%20thing%20I%20like%20the%20most%20about%20this%20conference%20is%20the%20sheer%20ammount%20of%20insightful%20people%20and%20interesting%20talks.%3C/p%3E)
QCon Special - Signing Off 22 Nov 2008 9:03 AM (16 years ago)
Myself and the Githubbers from Fabio Akita on Vimeo.
QCon is finally over, it was a great venue, great people. Thanks to Floyd, InfoQ and all the organizers and sponsors. I think it accomplished it’s goal of discussing the new trends in technology. It is clear that functional programming, non-relational databases and the Agile philosophy are the way to go.
Yesterday I had a great time with the awesome guys from Github. Chris Wanstrath, Scott Chacon and Tom Preston, together with RailsEnvy’s Jason Seifer. We discussed languages, Git, and several geeky stuff :-) Thank you guys, you’re kicking ass, keep going with the great job.

Ezra Zygmuntowicz was also really nice for inviting me to visit Engine Yard’s headquarter. It was really interesting to finally get to known them. He showed me the new service they’re building on top of Amazon Web Services, a way to easily create your own highly scalable Rails/Merb infrastructure. They are building a very slicky Dashboard so you can control all of your slices, configurations, environments. It is supposed to be released at the end of this year. I know people will love it.

Now I am preparing to check out and head to the airport, back to Brazil after a busy but very rewarding week. See you all guys at the next conference.
Cheers!
%20Thank%20you%20guys,%20you%26%238217;re%20kicking%20ass,%20keep%20going%20with%20the%20great%20job.%3C/p%3E%0A%3Cp%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2008/11/22/IMG_0100.JPG%22%20alt%3D%22%22%20/%3E%3C/p%3E%0A%3Cp%3EEzra%20Zygmuntowicz%20was%20also%20really%20nice%20for%20inviting%20me%20to%20visit%20Engine%20Yard%26%238217;s%20headquarter.%20It%20was%20really%20interesting%20to%20finally%20get%20to%20known%20them.%20He%20showed%20me%20the%20new%20service%20they%26%238217;re%20building%20on%20top%20of%20Amazon%20Web%20Services,%20a%20way%20to%20easily%20create%20your%20own%20highly%20scalable%20Rails/Merb%20infrastructure.%20They%20are%20building%20a%20very%20slicky%20Dashboard%20so%20you%20can%20control%20all%20of%20your%20slices,%20configurations,%20environments.%20It%20is%20supposed%20to%20be%20released%20at%20the%20end%20of%20this%20year.%20I%20know%20people%20will%20love%20it.%3C/p%3E%0A%3Cp%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2008/11/22/IMG_0101.JPG%22%20alt%3D%22%22%20/%3E%3C/p%3E%0A%3Cp%3ENow%20I%20am%20preparing%20to%20check%20out%20and%20head%20to%20the%20airport,%20back%20to%20Brazil%20after%20a%20busy%20but%20very%20rewarding%20week.%20See%20you%20all%20guys%20at%20the%20next%20conference.%3C/p%3E%0A%3Cp%3ECheers!%3C/p%3E)
Rails Podcast Brasil, QCon Special - Ola Bini (JRuby, Ioke) 22 Nov 2008 12:03 AM (16 years ago)
Brasileiros: clique aqui
Finally, I was able to finish all the interviews I intended. The last one was with Ola Bini. It was weird because we started recording yesterday and continued today. The problem was that my recorder died out of battery :-(

So, in the end we did a 2 part interview, with almost 1 hour each. You will agree that this is the geekiest interview ever. It was actually more of a lecture, with Ola Bini explaining every conceivable programming technique and paradigm in the book. Seriously.
We went through Lisp, Erlang, F#, Haskell, Java, Self, ML, Ruby, Python, Javascript, Io and much more. It was a very intense conversation so make yourself prepared for an overdose of language geekiness discussion.
I had 2 goals in mind with this. First, to introduce many programming concepts before talking about Ola’s new language implemented on top of the JVM: Ioke, a Io-inspired language, prototype-based, highly dynamic, based on Io, Lisp, Ruby. This language is way cool, you should experiment with it
The second goal was to show people that there is this whole world out there, outside of plain Java or C#. And another thing was to not show a white-bearded senior developer like Kent Beck or Tim Bray :-) No offense, but it is accidentally convenient for me that Ola is so young (early 20’s), because now young CS students doesn’t have the ‘age’ excuse for not knowing all of these concepts already.
So, it was a very productive interview. Download the first audio file from here and Part 2 form here.
Ola Bini (JRuby, Ioke)
Finalmente, eu consegui terminar todas as entrevistas que eu queria. A última foi com Ola Bini. Foi estranho porque começamos a gravar ontem e continuamos até hoje. O problema foi que meu gravador morreu sem baterias :-(
Então, no fim, fizemos uma entrevista em 2 partes, com quase 1 hora cada. Vocês vão concordar que esta é a entrevista mais geek já feita. Foi na realidade quase como uma aula, com Ola Bini explicando cada técnica ou paradigma de programação possível. Sério.
Fomos por Lisp, Erlang, F#, Haskell, Java, Self, ML, Ruby, Python, Javascript, Io e muito mais. Foi uma conversa intensa então prepare-se para uma overdose de discussão geek de linguagens.
Eu tinha 2 objetivos em mente. Primeiro, apresentar muitos conceitos de progamação antes de falar da nova linguagem do Ola implementada sobre a JVM: Ioke, uma linguagem inspirada no Io, baseada em protótipos em vez de classes, muito dinâmica e inspirada no Io, Lisp, Ruby. Essa linguagem é muito legal, e você deveria experimentá-la.
O segundo objetivo foi de mostrar às pessoas que existe um mundo enorme lá fora, fora dos comuns Java e C#. E outra coisa foi não mostar desenvolvedores sêniors de barba branca como Kent Beck ou Tim Bray :-) Sem ofensas, mas é acidentalmente conveniente para mim que Ola é tão jovem (perto dos 20), porque agora os estudantes de computação não tem a desculpa de “idade” por já não saber todos esses conceitos.
So, it was a very productive interview. Download the first audio file from here and Part 2 form here.
Então, foi uma entrevista muito produtiva. Faça download do primeiro arquivo de áudio daqui e a Parte 2 “daqui”::/files/ola_bini_part_2.mp3.
%26bodytext%3D%3Cp%3E%3Cstrong%3EBrasileiros:%3C/strong%3E%20clique%20%3Ca%20href%3D%22https://www.akitaonrails.com/2008/11/22/rails-podcast-brasil-qcon-special-ola-bini-jruby-ioke%23ola_bini%22%3Eaqui%3C/a%3E%3C/p%3E%0A%3Cp%3EFinally,%20I%20was%20able%20to%20finish%20all%20the%20interviews%20I%20intended.%20The%20last%20one%20was%20with%20Ola%20Bini.%20It%20was%20weird%20because%20we%20started%20recording%20yesterday%20and%20continued%20today.%20The%20problem%20was%20that%20my%20recorder%20died%20out%20of%20battery%20:-(%3C/p%3E%0A%3Cp%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2008/11/22/DSC05872.JPG%22%20alt%3D%22%22%20/%3E%3C/p%3E%0A%3Cp%3ESo,%20in%20the%20end%20we%20did%20a%202%20part%20interview,%20with%20almost%201%20hour%20each.%20You%20will%20agree%20that%20this%20is%20%3Cstrong%3Ethe%3C/strong%3E%20geekiest%20interview%20ever.%20It%20was%20actually%20more%20of%20a%20lecture,%20with%20Ola%20Bini%20explaining%20every%20conceivable%20programming%20technique%20and%20paradigm%20in%20the%20book.%20Seriously.%3C/p%3E%0A%3Cp%3EWe%20went%20through%20Lisp,%20Erlang,%20F%23,%20Haskell,%20Java,%20Self,%20ML,%20Ruby,%20Python,%20Javascript,%20Io%20and%20much%20more.%20It%20was%20a%20very%20intense%20conversation%20so%20make%20yourself%20prepared%20for%20an%20overdose%20of%20language%20geekiness%20discussion.%3C/p%3E%0A%3Cp%3EI%20had%202%20goals%20in%20mind%20with%20this.%20First,%20to%20introduce%20many%20programming%20concepts%20before%20talking%20about%20Ola%26%238217;s%20new%20language%20implemented%20on%20top%20of%20the%20%3Cspan%3EJVM%3C/span%3E:%20%3Ca%20href%3D%22http://www.infoq.com/news/2008/11/ioke%22%3EIoke%3C/a%3E,%20a%20Io-inspired%20language,%20prototype-based,%20highly%20dynamic,%20based%20on%20Io,%20Lisp,%20Ruby.%20This%20language%20is%20way%20cool,%20you%20should%20experiment%20with%20it%3C/p%3E%0A%3Cp%3EThe%20second%20goal%20was%20to%20show%20people%20that%20there%20is%20this%20whole%20world%20out%20there,%20outside%20of%20plain%20Java%20or%20C%23.%20And%20another%20thing%20was%20to%20not%20show%20a%20white-bearded%20senior%20developer%20like%20Kent%20Beck%20or%20Tim%20Bray%20:-)%20No%20offense,%20but%20it%20is%20accidentally%20convenient%20for%20me%20that%20Ola%20is%20so%20young%20(early%2020%26%238217;s),%20because%20now%20young%20CS%20students%20doesn%26%238217;t%20have%20the%20%26%238216;age%26%238217;%20excuse%20for%20not%20knowing%20all%20of%20these%20concepts%20already.%3C/p%3E%0A%3Cp%3ESo,%20it%20was%20a%20very%20productive%20interview.%20Download%20the%20first%20audio%20file%20from%20%3Ca%20href%3D%22https://www.akitaonrails.com/files/ola_bini_part_1.mp3%22%3Ehere%3C/a%3E%20and%20Part%202%20form%20%3Ca%20href%3D%22https://www.akitaonrails.com/files/ola_bini_part_2.mp3%22%3Ehere%3C/a%3E.%3C/p%3E%3Ch2%3EOla%20Bini%20(JRuby,%20Ioke)%3C/h2%3E%0A%3Cp%3EFinalmente,%20eu%20consegui%20terminar%20todas%20as%20entrevistas%20que%20eu%20queria.%20A%20%C3%BAltima%20foi%20com%20Ola%20Bini.%20Foi%20estranho%20porque%20come%C3%A7amos%20a%20gravar%20ontem%20e%20continuamos%20at%C3%A9%20hoje.%20O%20problema%20foi%20que%20meu%20gravador%20morreu%20sem%20baterias%20:-(%3C/p%3E%0A%3Cp%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2008/11/22/DSC05872.JPG%22%20alt%3D%22%22%20/%3E%3C/p%3E%0A%3Cp%3EEnt%C3%A3o,%20no%20fim,%20fizemos%20uma%20entrevista%20em%202%20partes,%20com%20quase%201%20hora%20cada.%20Voc%C3%AAs%20v%C3%A3o%20concordar%20que%20esta%20%C3%A9%20a%20entrevista%20%3Cstrong%3Emais%3C/strong%3E%20geek%20j%C3%A1%20feita.%20Foi%20na%20realidade%20quase%20como%20uma%20aula,%20com%20Ola%20Bini%20explicando%20cada%20t%C3%A9cnica%20ou%20paradigma%20de%20programa%C3%A7%C3%A3o%20poss%C3%ADvel.%20S%C3%A9rio.%3C/p%3E%0A%3Cp%3EFomos%20por%20Lisp,%20Erlang,%20F%23,%20Haskell,%20Java,%20Self,%20ML,%20Ruby,%20Python,%20Javascript,%20Io%20e%20muito%20mais.%20Foi%20uma%20conversa%20intensa%20ent%C3%A3o%20prepare-se%20para%20uma%20overdose%20de%20discuss%C3%A3o%20geek%20de%20linguagens.%3C/p%3E%0A%3Cp%3EEu%20tinha%202%20objetivos%20em%20mente.%20Primeiro,%20apresentar%20muitos%20conceitos%20de%20progama%C3%A7%C3%A3o%20antes%20de%20falar%20da%20nova%20linguagem%20do%20Ola%20implementada%20sobre%20a%20%3Cspan%3EJVM%3C/span%3E:%20%3Ca%20href%3D%22http://www.infoq.com/news/2008/11/ioke%22%3EIoke%3C/a%3E,%20uma%20linguagem%20inspirada%20no%20Io,%20baseada%20em%20prot%C3%B3tipos%20em%20vez%20de%20classes,%20muito%20din%C3%A2mica%20e%20inspirada%20no%20Io,%20Lisp,%20Ruby.%20Essa%20linguagem%20%C3%A9%20muito%20legal,%20e%20voc%C3%AA%20deveria%20experiment%C3%A1-la.%3C/p%3E%0A%3Cp%3EO%20segundo%20objetivo%20foi%20de%20mostrar%20%C3%A0s%20pessoas%20que%20existe%20um%20mundo%20enorme%20l%C3%A1%20fora,%20fora%20dos%20comuns%20Java%20e%20C%23.%20E%20outra%20coisa%20foi%20n%C3%A3o%20mostar%20desenvolvedores%20s%C3%AAniors%20de%20barba%20branca%20como%20Kent%20Beck%20ou%20Tim%20Bray%20:-)%20Sem%20ofensas,%20mas%20%C3%A9%20acidentalmente%20conveniente%20para%20mim%20que%20Ola%20%C3%A9%20t%C3%A3o%20jovem%20(perto%20dos%2020),%20porque%20agora%20os%20estudantes%20de%20computa%C3%A7%C3%A3o%20n%C3%A3o%20tem%20a%20desculpa%20de%20%26%238220;idade%26%238221;%20por%20j%C3%A1%20n%C3%A3o%20saber%20todos%20esses%20conceitos.%3C/p%3E%0A%3Cp%3ESo,%20it%20was%20a%20very%20productive%20interview.%20Download%20the%20first%20audio%20file%20from%20%3Ca%20href%3D%22https://www.akitaonrails.com/files/ola_bini_part_1.mp3%22%3Ehere%3C/a%3E%20and%20Part%202%20form%20%3Ca%20href%3D%22https://www.akitaonrails.com/files/ola_bini_part_2.mp3%22%3Ehere%3C/a%3E.%3C/p%3E%0A%3Cp%3EEnt%C3%A3o,%20foi%20uma%20entrevista%20muito%20produtiva.%20Fa%C3%A7a%20download%20do%20primeiro%20arquivo%20de%20%C3%A1udio%20%3Ca%20href%3D%22https://www.akitaonrails.com/files/ola_bini_part_1.mp3%22%3Edaqui%3C/a%3E%20e%20a%20Parte%202%20%26%238220;daqui%26%238221;::/files/ola_bini_part_2.mp3.%3C/p%3E)
Rails Podcast Brasil, QCon Special - John Straw (YellowPages.com) and Matt Aimonetti (Merb) 20 Nov 2008 9:06 PM (16 years ago)
Brasileiros: cliquem aqui

Today was a pretty busy day of interviews. This afternoon I was able to first interview John Straw. He is the responsible for what he calls The Big Rewrite project. The project about replacing 150k LOC from Java, with no tests, to around 13k LOC of Ruby on Rails, with almost 100% test coverage, and without reducing the scope. The original project was developed unders 22 months and the rewrite took place in 4 months of development, with 4 developers (though they had 4 months of preparation and planning, but still …).
In this interview he talks about the motivations, how it was with the team to move from Java to Ruby, how they chose Rails, what’s the size of their infrastructure. It is a great case study for any company using Java to be reassured that changing to Ruby will only bring you benefits.
After that I finally interviewed Matt Aimonetti. He is the main Merb Evangelist. He has a training and consulting firm in San Diego, he was also responsible for MerbCamp, the first Merb event around. And he is also one of the main contributors to Merb.

He was kind enough to spend a long time showing me the nuts and bolts of Merb. I was not aware of its current state and I have to tell you that it is pretty compelling. Very well thought out, it has everything you need to start developing web applications with almost the same easy of use and convenience of Ruby on Rails.
Among the best things I saw in Merb is: it can be pretty close to Rails, so you will feel right at home. It has “Slices” which is feature that I expected Rails to have for a long time – it works almost the same way as Engines, but it is built-in and feels much better. It has a neat feature of a “master process”, so you can instruct it to load N workers processes (such as a mongrel cluster) and it will monitor those workers, so if one goes down, the master will respawn it automatically, which is pretty convenient. And finally, it’s modularity is top-notch. It feels weird at first having lots of gems around, but it makes sense very fast.
And according to Matt, Merb is way faster than Rails – at least in a “Hello World” benchmark :-) All in all, I highly recommend it, specially if you’re already an advanced Ruby developer that wants more (or less) than Rails can offer out of the box right now.

Download John’s audio file from here and Matt’s file from here.
John Straw (YellowPages.com) e Matt Aimonetti (Merb)
Hoje foi mais um dia longo de entrevistas. Esta tarde eu entrevistei primeiro o John Straw. Ele é o responsável pelo que ele chama de A Grande Reescrita. O projeto de reescrita de 150 mil linhas de código Java, sem testes, por cerca de 13 mil linhas de código Ruby on Rails, com quase 100% de cobertura de testes (metade do código escrito são de testes), e sem reduzir o escopo. O projeto original foi desenvolvido em 22 meses e a reescrita levou 4 meses de 4 desenvolvedores (embora eles tenham gasto 4 meses de preparação e planejamento, mas mesmo assim …).
Nessa entrevista ele fala sobre as motivações, como foi com a equipe mover de Java para Ruby, como eles escolheram Rails, qual o tamanho da infraestrutura. É um grande estudo de caso para qualquer empresa usando Java para se assegurar que mudar para Ruby só vai trazer benefícios.
Depois disso eu finalmente entrevistei Matt Aimonetti. Ele é o principal evangelista de Merb. Ele tem uma empresa de treinamento e consultoria em San Diego, ele também foi responsável pelo MerbCamp, o primeiro evento de Merb. E também é um dos principais colaboradores do Merb.
Ele foi muito gentil de gastar muitas horas me mostrando os detalhes sobre o Merb. Eu não estava ciente do estado atual e tenho que dizer que está muito interessante. Muito bem pensado, ele tem tudo que você precisa para começar a desenvolver aplicações web com quase a mesma conveniência e facilidade de uso do Ruby on Rails.
Algumas das melhores coisas do Merb são: ele é bem próximo do Rails, então você vai se sentir em casa. Ele tem “Slices” que é uma funcionalidade que eu esperava em Rails por muito tempo – ele funciona quase como os Engines, mas já está pré-embutido e a sensação é muito melhor. Ele tem uma funcionalidade muito legal de “processo master”, então você pode instruí-lo para carregar N processos workers (como um cluster mongrel) e ele vai monitorar esses workers, então se um deles cair, o master irá recarregá-lo automaticamente, o que é bem conveniente. E finalmente, sua modularidade é muito boa. Parece estranho a princípio ter um monte de gems por aí, mas faz sentido bem rápido.
E de acordo com Matt, Merb é muito mais rápido do que Rails – pelo menos no benchmark de “Hello World” :-) Isso tudo dito, eu recomendo muito, especialmente se você já é um desenvolvedor Ruby avançado que quer mais (ou menos) do que o Rails pode oferecer agora.
Faça o download do arquivo de áudio do John aqui e o do Matt daqui.
Rails Podcast Brasil, QCon Special - Nick Sieger (JRuby) and Francesco Cesarini (Erlang) 20 Nov 2008 8:11 PM (16 years ago)
Brasileiros: cliquem aqui
This morning I interviewed Nick Sieger, core committer for the JRuby project. I was very interested to know more about how it is to develop Rails application using JRuby. He explained about the new connection pooling system in Rails 2.2 and other details about his work and contributions to JRuby.

Nick, Matt, Chris and Jan
After that I was able to interview Francesco Cesarini. He gave us an introductory tutorial on Erlang early this week. He’s been working with Erlang for the last 15 years and he is also writing a new book for O’Reilly, called Erlang Programming. This is a very insightful conversation on functional programming, scalability, concurrency and why all these subjects matter today and how Erlang fits in.
It was interesting because both Kent Beck and Tim Bray were talking about future trends in their keynotes and both mentioned CouchDB and Erlang as great stuff. You want to stay ahead of the curve? Learn Erlang.
The audio files will show up in the Ruby on Rails Podcast Brasil feed soon enough, but before that happens, you can download the audio files directly from here. Click here for Nick and here for Francesco.
Nick Sieger e Francesco Cesarini
Esta manhã eu entrevistei Nick Sieger um dos principais contribuidores para o projeto JRuby. Eu estava interessado em saber mais sobre como é desenvolver aplicações Rails usando JRuby. Ele explicou sobre o novo sistema de pool de conexões no Rails 2.2 e outros detalhes sobre seu trabalho e contribuições ao JRuby.
Nick, Matt, Chris e Jan
Depois disso eu pude entrevistar o Francesco Cesarini. Ele nos deu um tutorial de introdução a Erlang no começo da semana. Ele tem trabalhado com Erlang nos últimos 15 anos e também está escrevendo um novo livro para a O’Reilly chamado Erlang Programming. Foi uma excelente conversa sobre programação funcional, escalabilidade, concorrência e porque todos esses assuntos importam hoje e onde Erlang se encaixa.
Foi interessante porque ambos Kent Beck e Tim Bray falaram sobre tendências futuras em suas apresentações e ambos mencionaram CouchDB e Erlang como as grandes coisas. Quer ficar à frente da onda? Aprenda Erlang.
Os arquivos de áudio vão aparecer no Ruby on Rails Podcast Brasil, mas antes que isso aconteça, você pode fazer download dos arquivos de áudio diretamente daqui. Clique aqui para o Nick e aqui para o Francesco.
![]()
Rails Podcast Brasil, QCon Special - Jan Lehnardt and Chris Anderson from CouchDB 19 Nov 2008 3:59 PM (16 years ago)
Brasileiros: cliquem aqui

Another great day at QCon SF, and this morning I had the pleasure of interviewing both Jan Lehnardt and Chris Anderson, both committers for the extraordinary CouchDB project. And there is another nice twist to this as Chris is also the creator of the CouchRest project, the Ruby library to consume CouchDB resources that Geoffrey Grosenbach presents in his CouchDB screencast.
I’ve been saying that Functional Programming and Non-Relational Databases will be the way to go into the multi-core, multi-server parallel world. We are seeing this movement already. Sun is investing in different languages, including Clojure. Microsoft has been developing F# and will add functional aspects to C# 4.0. In the Cloud space we see Amazon with SimpleDB, Google with BigTable and Microsoft Azure with SQL Data Services: none of them are relational.

In the Ruby community we’ve been dabbling around Erlang for a while now, I’ve seen people trying out CouchDB with Ruby projects, even here in Brazil. So I think Rails/Merb + CouchRest will be a really nice way to have highly scalable applications almost “out of the box”.
We’ve been good at scaling the Web tier. We understand HTTP, we know load balancing techniques, we understand shared-nothing architectures. But there is always the last mile: the database tier. SQL Server implementations such as MySQL scales very poorly. Bi-directional replication is a pain to do, queries are not easily parallelizable. At some point you will have to leave the relational theory behind and start denormalizing like crazy. And at some other point, you might even need to shard your database. All this requires you to change your application code and everything is just one big and nasty nightmare.
Database scalability does not come for free, and one solution may be to leave RDBMS completely. I am not advocating dropping SQL for everything and going CouchDB, but instead that some Use Cases may be more well served with Documente-Oriented Databases instead.
Jan and Chris were really nice to give me the opportunity to interview them on the ins and outs of CouchDB. Bottomline: it’s good to prime time right now. New features are coming, but you can take advantage of it today. Again, the audio file will be available in the feed for the Ruby on Rails Brasil Podcast (in English), but you can download directly from here.
Entrevista com Jan Lehnardt e Chris Anderson
Outro grande dia na QCon SF, e esta manhã eu tive o prazer de entrevistar ambos Jan Lehnardt and Chris Anderson, ambos committers do extraordinário projeto CouchDB. E há mais uma coisa, o Chris é também o criador do projeto CouchRest, a biblioteca Ruby para consumir recursos CouchDB que o Geoffrey Grosenbach apresenta em seu screencast de CouchDB.
Eu venho dizendo que Programação Funcional e Bancos de Dados não-Relacionais serão a solução para um mundo multi-core, multi-server. Já estamos vendo este movimento. A Sun está investindo em diferentes linguagens, incluindo Clojure. A Microsoft está desenvolvendo F# e adicionará aspectos funcionais ao C# 4.0. No espaço de Cloud temos Amazon com SimpleDB, Google com BigTable e Microsoft Azure com SQL Data Services: nenhum deles é relacional.
Na comunidade Ruby já viemos falando de Erlang por um tempo, tenho visto pessoas testando com CouchDB em projetos Ruby, mesmo aqui no Brasil. Então eu acho que Rails/Merb + CouchRest será uma maneira muito legal de ter aplicações altamente escaláveis quase de maneira automática.
Somos bons já em escalar a camada Web. Nós entendemos HTTP, entendemos balanceamento de carga, entendemos arquiteturas shared-nothing. Mas sempre tem a última milha: a camada de banco de dados. Implementações de servidores SQL como MySQL escalam de maneira muito pobre. Replicação bi-direcional é doloroso, queries não facilmente paralelizáveis. Em algum ponto você vai precisar deixar a teoria relacional para trás e começar a denormalizar como louco. Em algum ponto, você pode até mesmo precisar de sharding. Tudo isso requer que você modifique o código da sua aplicação e tudo se torna um grande e feio pesadelo.
Escalabilidade de banco de dados não vem de graça, e uma solução pode ser deixar os bancos de dados relacionais completamente. Não estou defendendo acabar com SQL para tudo e ir para CouchDB, mas em vez disso existem Casos de Uso que podem ser melhor adequadas com bancos de dados orientados a documentos.
Jan e Chris foram muito legais de me dar a oportunidade de entrevistá-los e falar sobre os detalhes do CouchDB. Em resumo: ele já é bom para uso em produção agora mesmo. Novas funcionalidades estão chegando, mas você pode tirar vantagem dele hoje. Novamente, o arquivo de áudio estará disponível no feed do Ruby on Rails Brasil Podcast (em inglês), mas você pode fazer download diretamente daqui.
Rails Podcast Brasil, QCon Special - Yehuda Katz 19 Nov 2008 1:06 AM (16 years ago)
Brazilians: click here
Update 11/19: Seems like the zip file was corrupted, I replaced it with the mp3 file itself. Please, try downloading again.

There’s been a lot of buzz around Rails lately. In particular, DHH published a series of Rails Myths articles. The #2 Mythbuster, for instance, brought Zed Shaw back for some more though it was rectified already. But Mythbuster #4 got some replies from Yehuda Katz, the current maintainer of Merb.
The main issue is around Modularity. DHH’s point of view is that Rails is modular enough and you can let some components loose. But Yehuda’s argument is that it requires you to patch Rails in order to release it from some of its components, whereas Merb was built around the concept of modularity from the beginning. Some people got worried that another Cold War was starting but Yehuda says that this is not the case and that open discussions like these are actually good, instead of having behind the scenes nitpicks.
While in San Francisco for QCon, I was able to interview Yehuda on these matters. By the way, thanks a lot for him and Leah for the nice dinner. I think this is a pretty comprehensive overview of Merb, DataMapper, the current issues around Rails modularity.
On the other hand we had some sad news yesterday as well: Engine Yard was forced to lay off lots of Rubinius developers. Evan explained the reasons in his blog, and Yehuda states again that Engine Yard is still committed to Rubinius. Besides that, they also announced yesterday that EY will have a new line of services around Amazon Web Services, providing tuned appliances for optimal Rails deployments in the cloud.
I have all the details in this special episode of the Ruby on Rails Podcast Brasil (in English). It is not in the official website yet, but expect it to show up in the feeds by tomorrow. Meanwhile you can download it directly from this link
I’ll have more insights from QCon later this week, stay tuned.
Especial QCon – Yehuda Katz
Tem havido muito barulho em torno de Rails ultimamente. Em particular, DHH publicou uma série de artigos de Mitos de Rails. O Mythbuster nr. 2, por exemplo, trouxe Zed Shaw para mais um pouco mas parece que isso já foi retificado. Mas o Mythbuster nr. 4 recebeu respostas do Yehuda Katz, o atual mantenedor do Merb.
O problema principal é em torno de Modularidade. O ponto de vista do DHH é que Rails é modular o suficiente e você pode soltar alguns dos componentes. Mas o argumento do Yehuda é que isso requer que você faça remendos no Rails para liberá-lo de alguns componentes, onde o Merb já é construído sobre o conceito de modularidade desde o começo. Algumas pessoas ficaram preocupadas que mais uma Guerra Fria estivesse começando mas Yehuda diz que isso não é o caso e que discussões abertas como essa são na realidade boas, em vez de críticas por baixo dos panos.
Enquanto estou em São Francisco para a QCon, eu pude entrevistar o Yehuda sobre esses assuntos. Aliás, muito obrigado a ele e à Leah pelo ótimo jantar. Eu acho que isso é uma boa introdução sobre Merb, DataMapper e os problemas atuais da modularidade do Rails.
Por outro lado tivemos algumas notícias tristes hoje também: a Engine Yard foi obrigada a demitir muitos desenvolvedores de Rubinius. Evan explicou as razões em seu blog. Fora isso, eles anunciaram ontem que a EY terá uma nova linha de serviços sobre o Amazon Web Services, provendo appliances tunadas para instalação otimizada de Rails no cloud.
Tenho todos os detalhes nesse episódio especial do Ruby on Rails Podcast Brasil (em inglês). Ainda não está no website oficial, mas aguardem ele aparecer nos feeds amanhã. Por enquanto, vocês podem fazer download diretamente deste link.
Terei mais informações da QCon durante esta semana, fiquem ligados.
Rails Summit: Next Week! (photos) 6 Oct 2008 2:24 PM (16 years ago)

All right folks, do not forget: Rails Summit Latin America approaches, on the 15th and 16th next week! If you still didn’t register, click here.
Another thing: we will have a small Birds of a Feather session at the end of the first day. The idea is to have a few lightning talks. If you want to present anything, just register here. Ninh Bui, from Phusion, says he is excited to talk some more during this session :-)
We will have internet through WiFi, power plug outlets in the hall and ball rooms, so you’re welcome to get your notebooks.
And to just raise the expectations a little bit, I was able to get some 3D renderings on how the Elis Regina Auditorium will become. Check it out:




It’s gonna be an awesome event!

%26bodytext%3D%3Cp%3E%3Ca%20href%3D%22http://site.locaweb.com.br/railssummit/default.asp%22%20target%3D%22_blank%22%3E%3Cimg%20src%3D%22http://site.locaweb.com.br/images/locaweb/en_US/railssummit/banners/468x60.gif%22%20alt%3D%22Rails%20Summit%20Latin%20America%22%20title%3D%22Rails%20Summit%20Latin%20America%22%20border%3D%220%22%20width%3D%22468%22%20height%3D%2260%22%20/%3E%3C/a%3E%3C/p%3E%0A%3Cp%3EAll%20right%20folks,%20do%20not%20forget:%20%3Cstrong%3ERails%20Summit%20Latin%20America%3C/strong%3E%20approaches,%20on%20the%2015th%20and%2016th%20next%20week!%20If%20you%20still%20didn%26%238217;t%20register,%20%3Ca%20href%3D%22http://www.locaweb.com.br/railssummit-en%22%3Eclick%20here%3C/a%3E.%3C/p%3E%0A%3Cp%3EAnother%20thing:%20we%20will%20have%20a%20small%20%3Ca%20href%3D%22http://spreadsheets.google.com/viewform?key%253DpU_MriAPjg2Aio1o2Qp6-Pw%22%3E%3Cstrong%3EBirds%20of%20a%20Feather%3C/strong%3E%3C/a%3E%20session%20at%20the%20end%20of%20the%20first%20day.%20The%20idea%20is%20to%20have%20a%20few%20lightning%20talks.%20If%20you%20want%20to%20present%20anything,%20just%20%3Ca%20href%3D%22http://spreadsheets.google.com/viewform?key%253DpU_MriAPjg2Aio1o2Qp6-Pw%22%3Eregister%20here%3C/a%3E.%20Ninh%20Bui,%20from%20Phusion,%20says%20he%20is%20excited%20to%20talk%20some%20more%20during%20this%20session%20:-)%3C/p%3E%0A%3Cp%3EWe%20will%20have%20internet%20through%20WiFi,%20power%20plug%20outlets%20in%20the%20hall%20and%20ball%20rooms,%20so%20you%26%238217;re%20welcome%20to%20get%20your%20notebooks.%3C/p%3E%0A%3Cp%3EAnd%20to%20just%20raise%20the%20expectations%20a%20little%20bit,%20I%20was%20able%20to%20get%20some%203D%20renderings%20on%20how%20the%20Elis%20Regina%20Auditorium%20will%20become.%20Check%20it%20out:%3C/p%3E%0A%3Cp%3E%3Ca%20href%3D%22http://www.anhembi.com.br/anhembi/bin/view/Elis/WebHome%22%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2008/10/6/Picture_2.png%22%20alt%3D%22%22%20/%3E%3C/a%3E%3C/p%3E%3Cp%3E%3Ca%20href%3D%22http://www.anhembi.com.br/anhembi/bin/view/Elis/WebHome%22%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2008/10/6/Picture_3.png%22%20alt%3D%22%22%20/%3E%3C/a%3E%3C/p%3E%0A%3Cp%3E%3Ca%20href%3D%22http://www.anhembi.com.br/anhembi/bin/view/Elis/WebHome%22%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2008/10/6/Picture_4.png%22%20alt%3D%22%22%20/%3E%3C/a%3E%3C/p%3E%0A%3Cp%3E%3Ca%20href%3D%22http://www.anhembi.com.br/anhembi/bin/view/Elis/WebHome%22%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2008/10/6/DSC05860.JPG%22%20alt%3D%22%22%20/%3E%3C/a%3E%3C/p%3E%0A%3Cp%3EIt%26%238217;s%20gonna%20be%20an%20awesome%20event!%3C/p%3E%0A%3Cp%3E%3Ca%20href%3D%22http://www.locaweb.com.br/railssummit-en%22%3E%3Cimg%20src%3D%22http://s3.amazonaws.com/akitaonrails/assets/2008/10/2/Picture_1_1.png%22%20alt%3D%22%22%20/%3E%3C/a%3E%20%3C/p%3E)
Chatting with Joshua Peek 25 Sep 2008 9:32 PM (16 years ago)

This time I had some time with Joshua Peek. He was recently announced as a new member of the Rails Core Team.
He got the honor because of his hard work for the upcoming Rails 2.2, solving the thread-safety issue within Rails. Because of his Google Summer of Code project, guided by Michael Koziarski, they were able to make Ruby on Rails truly Thread-Safe, which could be a great boost for virtual machines with native-threading support, such as JRuby.
The interesting bit: he is just 19 years old and 4 years ago he wasn’t a programmer. He started on Ruby with Learn to Program and he is now a Rails Core member. Let’s get to know him.
AkitaOnRails: Ok, so let’s get started. First of all, it would be good to know more about yourself. Like how did you find Ruby, why you got hooked by it, and what are your “hobbies” in the tech area 
Josh Peek: Like most people, I originally found Ruby through Rails. At the time, I was only doing simple web design like html, css, js. I had no programming experience. I think I bought some php book, but I could never get into it. So I heard about this “Rails” thing and looked into it. I learned quickly that I really needed to learn how to program and learn Ruby, so I got the Pickaxe and Agile Web Development with Rails book and went from there.
AkitaOnRails: This is interesting, one of my goals of interviewing you is because I figured you are pretty young and there are lots of young programmers that feels that learning Ruby is difficult. And you say you never programmed before Ruby, so how was this learning curve for you?
Josh Peek: Yeah, I’m currently 19 and I started programming Ruby about 3 years ago. Before I read the pickaxe, I found this little Ruby programming book by Chris Pine. It was really helpful to get into programming. The hardest thing about programming for me, was wrapping my head around OOP. It’s really something you just need to work with to truly understand.
AkitaOnRails: Oh, and I forgot to ask, where are you from? Do you study CS?
Josh Peek: I’m currently living up in Chicago, IL where I attend college as well. Yes, my current major is Computer Science
AkitaOnRails: When you started programming with Rails, what were the things that most annoyed you, if any?
Josh Peek: Hmm, I can’t really think of anything that “annoyed” me. It was never a problem because you could either monkey patch the issue or fix it and get it out to the entire Rails community.
AkitaOnRails: So you started working with Rails as a freelancer? Did you build any open source gems, plugins as well?
Josh Peek: Yeah, I started as a freelancer. I technically still am. I used to publish a ton of Rails plugins. I think I went a bit overboard at first. I really don’t have any of those around anymore, but it would be fun to go through them and see how much my views on programming have changed since.
Right now, all my current plugins and code are at github.com/josh. I tend to just post any personal project I’m working on, on Github even if it’s not done or I think it will be useful at all.
AkitaOnRails: Ok, so the main dish Thread-safety! You said you were not particularly ‘annoyed’ by anything about Rails, but you decided to tackle on this challenge anyway, how did it all started?

Josh Peek: I did want to do a Google Summer of Code project for a while now. However when it came to signing up I did things really last second. I asked around the core team and a few ideas came up, one of them was thread safety.
I wasn’t really even that interested in doing it, I actually wanted to work in ActiveModel as my project. However the thread safe project was the only one that was accepted, so I was stuck with it. Before the project started, I had zero experience with threads.
I didn’t even know what a mutex was for, however I welcomed it as a learning experience.
AkitaOnRails: Maybe it would be interesting if you could give us an overview of how the Google Summer of Code works, I mean, what are their goals, how do you participate, how difficult it is. Some Brazilians are probably not familiar with it.
Josh Peek: Google Summer of Code is a program setup by Google that sponsors students to work on open source projects. The student creates a project proposal for the organization they want to work with, Ruby Central in my case, and it gets approved by them.
You also work with a mentor from the organization. Michael Koziarski (Rails Core) originally suggested that I do the project and so we “arranged” for us to work together.
At the end of the program, you submit your code and if you have completed the project you get paid $5000. And I think $500 of that goes to the open source organization.
AkitaOnRails: And you completed the project?
Josh Peek: Yes.
AkitaOnRails: Cool, and how long is the program?
Josh Peek: Around 3 months I think.
AkitaOnRails: Ok, back to the more technical stuff. There is something that bothers me a little bit. Of course it is a lot of work to make Rails thread-safe and this is something people were really looking forward to. But on the other hand, the MRI doesn’t use native threads, which essentially means that they are never truly concurrent, is that correct? Maybe other projects such as JRuby could benefit? Is there any real benefits for the MRI itself?
Josh Peek: Correct. JRuby is the only true solution if you want real thread concurrency. Ruby 1.9 does support “real” threads. However most of the internal C code is not thread-safe so there is an interrupter around those methods, but I’m hoping that maybe Ruby 2.0 will be fully thread-safe.
AkitaOnRails: You probably ran tests for both MRI and JRuby? Did you get improved performance/responsiveness because of the new thread-safe code? Or does it add up some new overhead instead?
Josh Peek: Our tests showed some slight improves in MRI, however the app we were testing was a simple test app. We didn’t have a real app we could benchmark since nothing else was thread-safe at the time. JRuby did show some nice improvements, again it wasn’t a real app though.
AkitaOnRails: Did you only aim for the thread-safe parts or did you also found and fixed other kinds of bottlenecks in the framework? You probably went through the entire code over and over and you already know it upside down, right? 
Josh Peek: I did a lot of work on preloading caches on boot up. The easy way out would be to just put a mutex around those caches and call it done. However, I had some extra time so I rewrote a ton of ActionView code.
Preloading means that we are building the cache on boot so it doesn’t need to be modified (or synchronized) while it’s serving requests and this should also benefit non threaded apps as well.
And it’s a huge win for Passenger, if you are using the copy on write feature, since caches built during Rails boot will be shared across multiple process.
AkitaOnRails: Awesome, the Phusion guys will like to hear about that. And I know some people will be lost about mutexes, could you explain a little bit about it for the audience?
Josh Peek: The big issue about running multiple threads is shared memory. If two threads try to access and modify the same object, it can cause some major problems. A “mutex” is a type of lock that “synchronizes” your threads so only one thread can access that piece of memory at a time.
However, this does have a performance impact because other threads have to stop while one is accessing the shared memory.
AkitaOnRails: I think it is awesome work, specially for JRuby. Did you talk to Charles, Nick or someone from the JRuby Core? I remember that I interviewed Charles and he said that even though they were pushing harder on the optimization of the JRuby runtime, the performance of Rails apps were not improving that much, so the next step would be to try to figure out how to modify Rails itself to behave better. Have you heard anything about this?
Josh Peek: Yes, we worked with Charles on some JRuby specific optimizations. He was a lot of help and he answered any of my questions relating to how JRuby synchronizes threads and what operations are atomic.
Nick Sieger actually volunteered (before GSoC) to tackle the ActiveRecord connection pool. Really a big thanks to Nick, I really didn’t have the experience to tackle that problem and he did a great job on it.
AkitaOnRails: Ok, even though the Ruby VM can’t have true concurrent threads, they actually have to deal with concurrent resources, in this case database connections, so a pool was necessary. Was it too much trouble to implement? Was it something that you had to do from scratch or there were prior work on connection pools for Ruby?
Josh Peek: Well, I think you better of asking Nick this question. But here is what I understand about it: The previous AR connection implementation did support threads, however it was easy to max out on the allowed number of db connections if a server got blasted.
The connection pool basically recycles old connections and prevents AR from establishing too many. You can actually set his max in your database.yml file with the “pool” option. I think the default is 3.
AkitaOnRails: And how does the mentor role work? I mean, did Koziarski guide you on specific points he wanted you to take a look on?

Josh Peek: Koz really help me stay on track. He did a lot of code auditing, and pointed out specific places I should look for problems in the large Rails code base.
AkitaOnRails: From the outside it probably feels ‘easy’ to say ‘ok, we just added thread-safety into Rails’, but this is not something like an external gem or plugin, you actually have to tackle the guts of the framework. How can you be sure you actually touched every part of the code that needed concurrency safety measures?
Josh Peek: That’s really what is hard about making code “thread safe”: there is no real way to be sure. You can write a bunch of unit tests and say ‘look, I can prove it’s fine’. However, the big issues are out of the way. From now on, we’ve decided to classify any further thread safe issues just like normal bugs.
AkitaOnRails: Do you think it is ready for prime-time? Or are you still tweaking it?
Josh Peek: I think it is ready for those people who have been waiting for a thread-safe Rails. People should start to audit and test their own apps for thread-safe issues and if something comes up, we’ll fix it in core. It’s really hard to test this stuff unless real people are testing real apps against it.
AkitaOnRails: At least, “Rails is not thread-safe” is not a good enough reason anymore to not use Rails. This should shut up a few pundits. This Rails 2.2 is going to be interesting, debunking some of these criticisms. Another one is “Rails doesn’t support i18n”, thanks to Sven. What else do you like the most about the next Rails release?
Josh Peek: My next little project within Rails is switching over to Rack. Rails 2.2 will include a Rack processor which lets your use it with any Rack server. However we are not fully switching over to Rack, yet. In 2.2 rack is opt-in.
./script/server will still run the old CGI processor. I hope to see CGI deprecated in the next release so we can be Rack only for 3.0.
AkitaOnRails: What are the benefits of going for Rack? It may not be so obvious for some people on why change code that is working already (the CGI bit).
Josh Peek: There should be some performance benefits, however that wasn’t enough to convince. Right now we have a ton of CGI hacks in Rails. This should clean up a lot of that.
What I really love is the standardized interface to Rails. This means a more universal API for writing ActionController related plugins that will work on any compatible Rack framework. I hope this means more Rails plugins will just work with Merb and vice versa.
AkitaOnRails: Having finished your GSoC project granted you the keys for the Rails official repo, is that correct? How does the Rails Core organize itself? Is each person responsible for some particular bit, or everybody else looks after everything?
Josh Peek: It seems like everyone has their own little responsibilities depending on what they were just working on. Since I just rewrote a ton of ActionView, I pretty much assume any issues or tickets related to it. I don’t think anyone has a pre-determined area though. People change their interests and that’s fine.
AkitaOnRails: But now can you ‘git push’ anything you want into Edge? And by the way, you mentioned you messed a lot with ActionView, but what exactly you changed there?
Josh Peek: Yeah, I’ve had commit access a while before the GSoC project (just before we switched to git). ActionView had to be refactored to support the preloading approach I was talking about earlier. So ERB templates are pre-compiled and cached on boot instead of at runtime.
AkitaOnRails: So, in 3 years you went from zero to Rails Core, solving the “thread-safety issue” and still having time to study and work on your freelance projects. How does it feel, looking back in retrospective? Did you ever thought you would contribute so much?
Josh Peek: 4 years ago, I really never even saw myself programming. I definitely never thought I end up on the Core Team of Rails.
AkitaOnRails: After so much you learned, what are the areas in computing that interests you the most? Web Development, any other area such as compilers, OS, etc? What do you intend to do next?
Josh Peek: I still really love Web Development. I recently tried some iPhone programming, but I’m not sure how I feel about it yet.
I’d love to try some lower level stuff. I still haven’t had a chance to use the Ruby C API, and I hear it’s really nice. Lately I’ve been doing a lot of work on a javascript project that’s soon to be announced and open sourced.
AkitaOnRails: Oh, and by the way, are you also a Mac user? :-) And I think this is it! Any other remarks about what we talked or something you would say to the Brazilian Ruby community?
Josh Peek: Yeah, I’ve been using Macs for about 6 years now. I’m not one of those people who switched after they discovered Ruby :-)
Josh Peek: And think thats pretty much it, … I was suckered into doing a talk at RubyConf this year, for the GSoC thing. So you’ll probably hear about about “thread safety” there. It’s probably the last time I’ll ever want to talk about Rails and threads again.
Thanks for the questions.
Rails Summit: now really for Latin America! 22 Aug 2008 7:15 AM (16 years ago)
Railers from outside of Brazil, I apologize for the delay but I am proud to announce that now anyone can register for our Rails Summit Latin America event. We just published the English version that accepts international credit cards.
The event will take place at São Paulo, Brazil, on October 15th-16th. The price is BRL 400 (Brazilian Real) but we are offering a promotional price of BRL 300 until September, 9th. We will have several high profile Railers from all over the world such as Chad Fowler, Obie Fernandez, the Phusion Guys, Dr. Nic, Luis Lavena and more!
We will probably provide a spanish text translation for the website later on, but you can register already and rest assured that we will have real time translation from english to spanish for the english speakers. So Brazilians should go here and everybody else should jump right into here
And please, help us promote this great event using the banners provided in the end of the registration page
%20but%20we%20are%20offering%20a%20promotional%20price%20of%20%3Cstrong%3E%3Cspan%3EBRL%3C/span%3E%20300%3C/strong%3E%20until%20September,%209th.%20We%20will%20have%20several%20high%20profile%20Railers%20from%20all%20over%20the%20world%20such%20as%20Chad%20Fowler,%20Obie%20Fernandez,%20the%20Phusion%20Guys,%20Dr.%20Nic,%20Luis%20Lavena%20and%20more!%3C/p%3E%0A%3Cp%3EWe%20will%20probably%20provide%20a%20spanish%20text%20translation%20for%20the%20website%20later%20on,%20but%20you%20can%20register%20already%20and%20rest%20assured%20that%20we%20will%20have%20real%20time%20translation%20from%20english%20to%20spanish%20for%20the%20english%20speakers.%20So%20Brazilians%20should%20go%20%3Ca%20href%3D%22http://www.locaweb.com.br/railssummit%22%3Ehere%3C/a%3E%20and%20everybody%20else%20should%20jump%20right%20into%20%20%3Ca%20href%3D%22http://www.locaweb.com.br/railssummit-en/%22%3Ehere%3C/a%3E%3C/p%3E%0A%3Cp%3EAnd%20please,%20help%20us%20promote%20this%20great%20event%20using%20the%20banners%20provided%20in%20the%20end%20of%20the%20%3Ca%20href%3D%22http://www.locaweb.com.br/railssummit-en%22%3Eregistration%20page%3C/a%3E%3C/p%3E)
Chatting with Luis Lavena (Ruby on Windows) 2 Jul 2008 9:16 AM (16 years ago)
This time I interviewed Luis Lavena. If you’re a Ruby developer working on Windows, you owe him a lot! After all he is the maintainer of One-Click Ruby Installer, the main Windows Ruby distribution. It is a lot of work to maintain such a distro and Luis explains all the hoops necessary to achieve this. The main message: we need more collaborators! Anyone can rant, but there are a few that actually step down from the pedestal and get their hands dirty.

AkitaOnRails: Ok. So, let’s start. First of all thank you for your time. This is very funny because we are like 5 hours apart. You’re in Paris right now, but I understand you were in Argentina. Can you tell us what you are doing now?
Luis Lavena: Yeah, funny indeed. Right now I’m Technical director of an interactive and design agency with offices in NY and Paris. My job is to bridge the design field with the technology one, mostly on web based application development.
I’m from Argentina, live there, family and friends. Now moved a few months to boost some developments and get first steps of the new organization in place.
I’m from a small province named Tucuman, northwest area of Argentina (1200 kms from Buenos Aires to be exact)
AkitaOnRails: Awesome, have you ever been in Brazil? Do you have contact with other Latin America Railers?
Luis Lavena: Even though Brazil is so close from Argentina I had never been there, which is bad. I have several friends that lived there over the years.
I keep in touch with several Rubists and Railers of Latin America, but most with the ones in Argentina due to several meetings we had during the years RubyArg mailing list has been working.
AkitaOnRails: I am very interested in understanding how the Railers are organizing themselves in Argentina as we, in Brazil, are a growing community as well. Do you see new programmers going straight to Rails or is it the usual move from Java/others to Rails? Are companies adopting it, or Rails (and Ruby in general) still has a long way to go there as well?
Luis Lavena: Well, there is a huge number of developers that came from Java and dotNET stuff (mostly Java) and they are playing with Rails, there is also lot of developers that do Ruby for administrative stuff or even creating games with it.
Companies that develops software still need to adopt Ruby/Rails for their business, the biggest problem with that is the lack of support shaped as companies like Sun or some consulting services for Java. (or even Microsoft).
AkitaOnRails: Going back to the past, how did you start in programming in general? Did you study computer science, or were you dragged in there in some other way? And, finally, how did you stumble upon Ruby and Rails?
Luis Lavena: It’s funny, I started programming back in 1989, playing with sprites and GOTO’s with BASIC on a Z80 computer.
I officially didn’t finish my degree on CS, since job and fun stuff distracted me away from it. I firstly meet Ruby back in 2001, loved its syntax, enjoyed it’s verbosity but it was not mature enough for my needs, at least not in Windows.
Even though I was using Python for so many years, I internally used Ruby to manage several stuff, from simple scripts to later rake tasks that helped us build our tools.
With Rails it was kind of different, since we started to look for alternatives to Zope and we bet on Rails at that time (0.10 or 0.12 at that time, if memory plays nice with me).
I can say I don’t regret the bet on Rails at that time.
AkitaOnRails: It is very interesting to see professionals like you moving out from your zone of comfort toward something ‘unknown’ as Ruby and Rails. Most programmers are very defensive and even aggressive on trying to find justifications for not using neither. Did you feel like that back then? What drove you towards Ruby?
Luis Lavena: Well, I’m used to change languages to fit my needs.
Keep in consideration that our first choice was pre-J2EE era or dotNET stuff, we analyzed which would provide us better solutions in the long run and we decided to avoid them.
Java stuff sounded at that time, and until today, expensive for business. Argentina is not a country where you will find customers with huge budgets to invoice them the cost of using tools designed for other markets.
Banks and such can pay the luxury of have everything running with J2EE, but that doesn’t work when you try to go smaller and agile. (mostly based on experiences with the market flow in Argentina).
AkitaOnRails: It is even more daunting considering that you decided that you wanted Ruby on Windows, you probably didn’t find anything reasonable and decided to tackle the problem yourself. Is that how it happened?
Luis Lavena: I’ve been forced to use Windows for many years, mostly related to hardware development in the video broadcast field. Moreover, I’m a BSD user and Linux one, even played some years with Macs and lately with OSX.
So that restriction forced me to build most of my tools around that limitation.
Ruby allowed me to enjoy that limitation by been expressive, which made me more productive in that field.
Ruby is not capable to handle my main requirements for video processing, but it still powers 70% of my environment, along with Open Source Software and Freeware.
I’ve been using Ruby for so long, that I thought the community, now that it’s growing, would maybe value the experience and the willing to help in this particular scenario.
So instead of keep scratching my itch in the shadow, I decided to contribute back and help others that search for the same stuff. So you can say I’m trying to balance my karma.
AkitaOnRails: Americans probably don’t understand this but in emerging countries such as Brazil, people don’t actually have much choice, most are not educated enough (cof english cof) and so they find lots of barriers. The last resort for everybody is Windows. I think it is the same thing in Argentina. Railers here don’t simply migrate to Macs or Linux, I would say that at least 90% of all developers are locked in to Windows for one reason or another. Is it the same in Argentina, I presume?
Luis Lavena: Even though I don’t like it, I must agree. Thankfully the Universities started to change that some years ago, giving talks and been more open to Linux community, which grew a lot.
Still, there are plenty of users and developer that are locked in to some corporate / mid-size environments or they require to run Windows for some proprietary hardware or such.
So, we (as the community) can’t get to those developers without being more open minded or provide tools that ease the path between their current environment and alternative tools.
AkitaOnRails: But for some reason there seems to be near to zero interest from the community on supporting Ruby on Windows. I mean, there are people like you, some RubyGem developers that go through all the trouble of making available a binary for win32, but it is not enough it seems. How did the One-Click Ruby Installer began, did you create it or you inherited it?
Luis Lavena: Yeah, I agree with you, but I cannot blame them, after all, everybody just scratch it’s own itch ;-)
I’ve inherited One-Click Installer from Curt Hibbs, who also inherited from Andy Hunt and other contributors.
The truth is that for many years I’ve been using my own version of Ruby, compiled in-house, so we had control over it. We didn’t patch it in any way, we like to have the whole process documented and automated, so we can take a look to the specific components updated that introduced conflicts.
One-Click Installer, on the other hand, relies on some builds made by the current ruby-core developers and maintainers, which make the process of finding the proper dependencies a bit hard. That build also imposed other problems, but that will require more time to explain
AkitaOnRails: Haha, I want to dive in to the more technical stuff so people can better understand the current situation on Windows. How different is Ruby on Windows compared to Ruby on Linux, for instance? The most obvious thing is that any Gem with C Extensions without proper binaries for Windows will fail. Trying to execute shell commands will fail and RubyInline as well. What else?
Luis Lavena: Hehe, that’s just the tip of the iceberg, let me show you one example. Let’s say that you have a package ABC that was build for your current distribution of Linux. That specific version of Linux links to a common runtime that handles the basic commands like file handling, console, etc. That is often called CRT (C Runtime) and on Linux, glibc.
So, your distro of Linux is linked to this glibc version A.B.C. If your distribution upgrades glibc version (like from 2.2 to 2.5) then you’re forced to:
- upgrade all your installed packages, or
- build everything from scratch.
I’ve even heard of some of these upgrades go so bad that users are forced to start from scratch. Windows, on the other hand, cannot break 2 billion applications just because of a change of CRT, so they keep old versions and maintain compatibility in the MSVCRT.dll file (where the base version is 6.0).
A plus for Windows is that you can have several CRT co-existing in your OS, the bad thing is that you cannot safely link to one CRT and use components that link to another version without worrying about segfaults and such stuff.
I tried to condense this information in a post some time ago. So you can see, the lack of development tools is not the worst problem dealing with Windows development.
AkitaOnRails: Interesting. And another thing is the Visual Studio compiler vs MinGW. Can you give us a glimpse on why you chose MinGW? Is it just because VS is commercial and developers would have to pay?
Luis Lavena: Visual Studio is great, but only when you can pay for it. The free versions lack some stuff that is very useful, like Profile-Guided Optimization (PGO) which is being used to build Windows binaries of Python, as an example.
The thing with VS, even the free versions, is that you’re not allowed to distribute them, I think it is even illegal to link to the download URL/page of it. So even for our automated sandbox project, Visual Studio would be required to be manually downloaded, installed and configured.
Thankfully in the latest versions you don’t need to install Platform SDK kit, which was 1GB. VS versions link only to the latest version of MSVCRT, which then force us to relink every library that ruby depends on with it (and Ruby source code depends on lots of externals).
Also, Ruby doesn’t use the safe CRT version of string copy functions, so you need to use a compiler flags just to avoid them… So after weeks of hard work getting it built with VC8 and every dependency, you end with something that performs almost the same, since there is no performance gain (but now you have less hair).
MinGW, on the other hand, was closer to a Linux environment, so most of the tools worked out of the box. The good part was that we didn’t require to build all the dependencies with it, since by default everything links with MSVCRT (the default CRT on Windows). MinGW also provides some cross-compilation tools that lets you build, using Linux environment, share libraries (dll) and executables for Windows.
I can consider that a plus, dunno what others think about it
AkitaOnRails: Wow, this is really overwhelming and I recommend anyone interested in the details to take a look at your blog. But all that said, you now have everything in place, a proper process and such, I assume. If I am a Windows C developer and I want to contribute, where should I go first, I mean, so I can know what tools to use, how to build stuff and so on?
Luis Lavena: That’s the good part! Gordon Thiesfeld and I have been working on two packages for new One-Click Installer: Runtime and Developer Kit.
Runtime ships the minimum Ruby+RubyGems so you get started, and it can also be used as modules for other installations. The DevKit provides the MinGW environment so you create Ruby extensions or even install the ones that are not pre-built for Windows but they are easy to get it.
This DevKit will not only let you get easily working with Ruby on Windows (and have access to some great and cool Rubygems) but also lets you contribute back to Ruby project. How? Easily, the Ruby Installer project (on Github) is self-hosted. What does it mean? It is possible for you to replicate our development environment anywhere, hack your changes or even debug Ruby’s own C code and contribute back to the community. We have been doing that for several months, and it’s working, how cool is that?
AkitaOnRails: That sounds awesome, I didn’t know that, and I bet lots of developers didn’t also. So I hope C developers reading this can get up to speed with this now. Another detail: RubyGems. How difficult it is to port a Gem with C Extensions to provide a Windows binary when you install it?
Luis Lavena: Oh, that requires that some developers don’t fall into platform specific tricks to make their tools work. One example, that is also a bad practice, is to use hardcoded paths…
Another one is to rely on the existence of some external tools, which sometimes are not available or developers/users didn’t install it. And I’m not talking about Linux-Windows platform issues, even between Linux distros that is a problem.
AkitaOnRails: So it is pretty much dependent on the quality of the original Gem, right? The cleaner the code the easier to port it, of course. But does your DevKit provide some shortcuts to achieve that? And what about RubyInline, does it simply break down?
Luis Lavena: Yeah, I’ve learned over the years that you shouldn’t assume anything about the environment your application is supposed to run, in that way, you avoid those mistakes.
Thankfully RubyInline is playing nice with Ruby Installer (One-Click Installer that uses MinGW) for a few versions back (Thanks goes to Ryan Davis to include those patches).
The current, VC6 build of One-Click Installer is not safe, since you need VS6 to work, which is no longer available. I’ve heard of users enjoying Sequel, Ambition and ImageScience on Windows thanks to those patches.
AkitaOnRails: Correct me if I am wrong, but isn’t it a way to embed C code snippets mixed in Ruby code? This means it will natively compile this snippet to run? How does it achieve this in a Windows environment that doesn’t have compilers by default?
Luis Lavena: We managed to sneak some patches to Hoe and RubyInline that “bundles” the pre-built extensions into the gems, so users don’t need a compiler in those cases.
Anyway, right now using VC6 build of Ruby requires man power to maintain those gems and keep up with new releases, which takes time. Up until now I was the only man in the show (since we own some VC6 licenses). Building everything for everyone is a burden I’m looking forward to drop into DevKit.
AkitaOnRails: Are you the ones maintaining the Windows versions of Gems or each Gem developer takes care of his own project? Is there a central repository for Windows-ready Gems? Is the DevKit already available, by the way?
Luis Lavena: For some projects I’m the only one maintaining gems for Windows, for others I only had contributed patches and other users manage the builds. There is no central repository for Windows gems since I want RubyForge to be the central one.
In any case, I’m pushing MinGW specific ones based on github forks here:
gem list —remote —source http://gems.rubyinstaller.org
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
The devkit is already available, but we are wrapping it into a good Windows Installer package. You can get your hands dirty and grab the sandbox project from "Github":http://github.com/luislavena/rubyinstaller to get your environment, or simply "download the packages":http://www.rubyinstaller.org/sandbox/. *AkitaOnRails:* So, as far as tools and processes are concerned you're doing a great job. But then there is the Ruby code that, by itself, is a big challenge from what I hear. You mentioned to me that it doesn't even look like C. What are the biggest problems? Technical or getting help from the Ruby-Core mailing list, or both? And what about test suites, how are you squashing compatibility bugs? *Luis Lavena:* To be honest, sometimes peeking into Ruby C code gives me headaches. There are lot of macros and definitions and macro conditions that happens in the middle of a if .. else block... The hardest part, besides tracing the bug is getting feedback from ruby-core. Several times I've "expressed":http://blog.mmediasys.com/2008/03/06/is-windows-a-supported-platform-for-ruby-i-guess-not/ my concerns about it on mailing lists, #irc and on my blog. Several times I asked if it was OK to get some errors in the unit tests of Ruby itself and sometimes got answers, but sometimes didn't. Thankfully we no longer need to base our testing quality in bundled unit tests of Ruby. We started to find issues with the Ruby implementation on Window using the Ruby Specs created by the guys at the Rubinius project and that most of the Implementations (IronRuby and jRuby) actively contribute and use as foundation of their interpreters. *AkitaOnRails:* So, speaking of which, "RubySpecs":http://blog.emptyway.com/2008/04/06/the-rubyspecs-quick-starting-guide/ how far is Ruby on Windows from passing it through? Or is it already? *Luis Lavena:* Well, that's a big tasks. First we started making MSpec to work properly on Windows, since RubySpec require some audit to remove some hardcoded paths in it. So we started to add guards around things that are not supported or don't even work on Windows in MRI. That takes longer since we need to review the results on each platform, dig into the Ruby documentation (that is sometimes lacking) or take a deep breath and look at the C code to find what is actually doing. If we had *more man power*, maybe we could finish guarding all the code and get a clear running specs on Windows. Right now there are many that just break or segfault. *AkitaOnRails:* You should document this process so people can help, if you didn't already :-) Now speaking of more practical stuff: Ruby on Windows, today, is it a viable runtime to run Rails apps on Windows? Even production apps? You worked with Zed Shaw on Mongrel for Windows, right? Did you try the newest FastCGI support from Microsoft for IIS? *Luis Lavena:* Hehee, documentation, documentation, it's totally overrated. We planned to have several screencasts in the RubyInstaller website, but it just remains as _'coming soon'_ for now. Not only you can develop Rails applications in Windows (as I do too), but I know several companies that run it side-to-side with IIS or even Tomcat. Even 2 years after Zed created it, Mongrel still rules the scene of Ruby web servers. I didn't do too much to Mongrel itself, since Zed created something that worked out of the box on Windows with small tweaks. I created something to run Mongrel as a service (mongrel_service), which helped several people to sneak in Ruby and Rails into their corporate environments, even talking to MSSQL Servers. I personally didn't test the "FCGI support on IIS":http://mvolo.com/blogs/serverside/archive/2007/02/18/10-steps-to-get-Ruby-on-Rails-running-on-Windows-with-IIS-FastCGI.aspx, but I was the one fixing it to be bundled with One-Click Installer so some users could enjoy it. We could say it works. *AkitaOnRails:* About performance, Windows seems to have an inherent condition: in the same machine when I start, let's say, a simple IRB in Windows, then I dual boot to Linux and run it, it seems to open up much faster (not exactly a scientific experiment :-). What is your experience around Ruby performance on Windows? *Luis Lavena:* There are performance issues related to the C code being generated by the compiler, and issues related to the OS and I/O handled by it. Loading IRB on Windows could be requiring RubyGems in the background, which in turn needs to scan and load all the gems specifications. I try to keep <code>RUBYOPT=rubygems</code> out of my environment variables. *AkitaOnRails:* By the way, why I have the impression that I see RUBYOPT=rubygems being recommended in every windows tutorial I see? *Luis Lavena:* <code>RUBYOPT=rubygems</code> is the part of the magic we must avoid. On Linux, if you start creating a script and you need a gem, you start with: --- ruby require 'rubygems' require 'some_gem' |
The same should be done for Windows, it is not painful, it’s good practice. RUBYOPT is a shortcut that I dislike, I haven’t seen a Linux distro that enables that by default, and I dislike that being set on Windows. (of course, that’s my personal point of view)
So to avoid falling into standard testing procedures, I keep using a simple but good sudoku solver that exercise recursion, array and conditions of the VM instead of being IO bound.
You can see that, with funny results on my blog (see “Rubinius, RubySpecs, and speed.” section of the post).
The main thing is that VC6 make it slow. Then you have I/O bound stuff (I/O stuff on Windows is not as good as Linux). I consider the default VC6 build of Ruby on Windows painfully slow. On the other hand, the MinGW one is snappier but I still think that there is a huge path for improvement.
AkitaOnRails: So, overall, Ruby on Windows is always evolving which is great, runs great on Windows, which is remarkable, but it could use some more help, right? Do you think more Windows C developers would help? I mean, adding more hands would help improve its quality?
Luis Lavena: Definitely!
AkitaOnRails: What kind of developers, I mean what one should know to help?
Luis Lavena: Dunno if Ruby “core” will accept that, I lately only hear the fork word around MRI ruby. Moreover, we can squash bugs in the Ruby for Windows implementation, but we cannot improve the quality too much since those changes would affect other platforms too.
The bad thing is that there is no clear separation by platform of specific code, everything is around a series of macros and compilation conditions that makes it hard to track (for the non-sadistic developers).
AkitaOnRails: Which reminds me of the Phusion guys with their Enterprise Edition which is a fork of MRI. Did you try to take a look on the copy-on-write GC patches from them? Maybe have it on the Windows version? Ruby on Windows itself is a ‘fork’. You end up having to synchronize your trunk with theirs, is that how it works?
Luis Lavena: Honestly I didn’t had time to look at Enterprise Edition, even though I followed all the posts and the discussion of those patches in ruby-core. The funny thing is that the latest releases of the Ruby 1.8.6 branch are giving me headaches (more than looking at the C code). They cannot even complete the self-tests and segfault with some extensions like the mysql gem.
AkitaOnRails: Yes, it has been causing a lot of fuzz around the community, and it should. Hope they can get around it soon. Well, I think I already took a lot of your time. Is there any subject you would like to tackle, or at least some message for your younger brazilian community?
Luis Lavena: Yeah, don’t be afraid to ask questions, don’t feel ashamed for using Windows as Platform. You can accomplish great applications using Windows, and you can infiltrate more easily into corporate environments with it.
AkitaOnRails: Oh, which reminds me of one last question that everybody asks me all the time – and I shall forward it to you, as you’re a Windows developer: what are your tools of choice to edit Ruby/Rails projects?
Luis Lavena: I mostly use Free or Open Source stuff, so I’ve been using Komodo Edit (not Pro) and Programmer Notepad, since sometimes I use them to work on C, FreeBASIC and Assembler code for embedded hardware.
Lately I’ve been using a lightweight Editor called Intype that ships with some bundles to mimic TextMate, but I really don’t take advantage of them. I used NetBeans for a while, but after 500MB I just closed it :-)
AkitaOnRails: Haha, and what would you recommend for a beginner Rails programmer?
Luis Lavena: To get started NetBeans is good, but with practice they will learn that even notepad is enough to code.
(PS: We are already including Enterprise patches for latest issues on MinGW build! :-)
AkitaOnRails: Haha, right. Well, I think this is it. I think this will reach a broader audience and call the attention of Windows developers out there. Thanks a lot!
Luis Lavena: Thanks to you Fabio.

Chatting with Blaine Cook (Twitter) 16 Jun 2008 7:29 PM (16 years ago)
Ruby on Rails is big. Twitter is big. And because of that they became easy targets for the media and the frustrated pundits wanting a few more pageviews. “Blaine Cook” was one of Twitter’s developers and he kindly agreed to participate on one of my interviews. And, of course, he will answer the question “Does Rails Scale?”

AkitaOnRails: So, let me first explain that my main goal when I interview high profile people like you is to bring good information for our growing Rails community in Brazil. It is always good to ask about your background, how did you get into Rails and what was your experience with it.
Blaine Cook: I started with Rails on a small personal project back in December 2004, after Evan Henshaw-Plath (rabble) got really excited about Ruby & Rails.

Shortly afterwards, I started working on Odeo. I really like Rails, and I’ve really enjoyed my experience with it. Building web-apps used to be a real pain (i.e., boring) because you ended up building the same pieces over and over again.
Rails fixed that. There were frameworks before, but Rails reframed the question in a humane way, and we see that in all the other frameworks that have been created afterwards.
AkitaOnRails: So, what were you doing before Rails then? Enterprise Java? Microsoft stuff? Other open source projects?
Blaine Cook: I mostly did PHP and Perl, in the context of open source projects and consulting jobs.
AkitaOnRails: So, Odeo and Twitter are your biggest projects in Rails then? Before digging into Twitter, can you tell us how was your work for Odeo?
Blaine Cook: Sure – Odeo was fine – the big problem there was with focus. Podcasting hadn’t been proven (and the form that podcasting takes now is much different than what people envisioned in 2004 / 2005), so it was a struggle to gain traction for the product.
We had all sorts of cool things built, many of which are just becoming products now. Things like multi-track mixing on the web, video messaging (like seesmic), etc.
AkitaOnRails: This is an interesting side-subject: podcasting. I do a Brazilian Rails podcast with a friend and nowadays people are very acquainted with podcasts. What was the vision 3, 4 years ago about what podcasting would become?
Blaine Cook: I think that’s fairly similar, but it seems like most of the traction (i.e., listeners) for podcasting is established thru radio shows that are seeking a wider distribution.
I think there was a sentiment that podcasting would be much more popular amongst bloggers in general. Everyone was going to have a podcast.
But in reality it’s a medium with far fewer publishers than blogging.

AkitaOnRails: You helped start Odeo, I mean were you one of the creators? Or were you hired to solve their problem? And why did you leave Odeo?
Blaine Cook: No – I started at Odeo a few months after development had started. I never really left Odeo – the product was sold, and the company continued on as Obvious. Twitter was a side-project at Odeo.
AkitaOnRails: Ok, and Twitter is big nowadays. Could you give us a glimpse of how the whole idea of “What are you doing” started? Did you think at that time that it would become such a success as it is now?
Blaine Cook: Twitter was started as a side project at Odeo, but really it was an idea that Jack had been kicking around in various forms for several years.
He and Noah Glass (the founder of Odeo) created a small sub-company within Odeo to work on it, in spring 2006. Initially, I hated the idea, mostly because it was intended to be SMS-only.
It’s hard to say looking back, but at the time I’d say Twitter was a long shot; I think that it was successful had a lot to do with luck and openness.
AkitaOnRails: So, maybe one of the biggest reasons for Twitter’s success was also its Achilles’ heels? I mean the paramount API based access it has today?
Blaine Cook: Yes, absolutely.
AkitaOnRails: So, getting to the hairy stuff, it quite is obvious that Michael Arrington dislikes Twitter, period. And specially he has something against you personally, at least considering the tone of his articles on Techcrunch. Can you comment on that?
Blaine Cook: Not really; I don’t know why he has a grudge. It’s mildly annoying, but in the end it makes Techcrunch look more like a gossip rag and less like a respectable news outlet, so it’s his loss.
AkitaOnRails: And not only that but it also seems that some tech related news media wants to co-relate Twitter’s instability with the fact that part of its front-end is powered by Ruby on Rails, hence the discussion “Does Rails scale?”. As a Railer this seems quite obvious that relating Rails and instability generates lots of pageviews. Do you think that’s the case?
Blaine Cook: I think that’s at least part of it. Obviously page views are a huge draw.
AkitaOnRails: Maybe it would be good for someone like you to explain to our audience the difference between ‘performance’ and ‘scalability’ as it seems that most people don’t know the difference between the two.
Blaine Cook: Performance and scalability are very different things. Performance is like the speed limit; it’s a question of how quickly you can get from point A to point B. In this case, we’re talking about how quickly you can get a page rendered and delivered to the user.
Scalability is a question of how many users you can handle. Highways intrinsically don’t scale, for example, because when they’re full, you get traffic jams. In web architectures, what we aim to provide are systems that will expand (usually by adding more hardware) to handle more traffic.
Obviously they’re related – if you have a traffic jam, then the effective speed limit is lower than the theoretical limit. But increasing the speed limit won’t make traffic jams any better.
There are a whole bunch of ways to make traffic less congested – adding more lanes to the highway, encouraging people to use public transit, or better yet encouraging people to work closer to home.
Likewise, there are many techniques for making web sites more scalable, and most of them don’t involve making things much “faster”.

AkitaOnRails: Great explanation. Twitter was involved in some not very good controversy since last year, and I think you were not involved in most of them, but maybe you could shed some light on those issues as some people don’t follow every news all the time. The first one being that interview where Alex Payne complained about Rails not supporting multiple databases. David Hansson ranted about it. Then Dr. Nic came to the beginning of a solution. Can you explain this matter for our audience?
Blaine Cook: Sure – it’s true that Rails doesn’t support multiple databases out of the box, but this is easily fixed. I think the interview with Alex didn’t get into the details very well, and mis-represented our challenges.
If it was just a matter of supporting multiple database connections, that’s something that’s easily solved. The real problem was much more complex, and had to do with custom sharding for our particular dataset.
Eran Hammer-Lahav has an excellent series (parts 1, 2, 3) in which he describes some of the challenges associated with building microblogging sites to scale.
None of the things he describes in the article are hard to do with Rails. In fact, I think that David (Hansson) is wrong when he says that Rails isn’t flexible – it’s actually much more flexible than most other frameworks.
AkitaOnRails: That’s right. And then the other recent controversy is, of course, because of TechCrunch again, where they state that Twitter only has like half a dozen servers and that’s why it falls down frequently. Can you roughly describe how is Twitter’s hardware architecture?
Blaine Cook: Twitter has a lot of servers, definitely more than half a dozen. I can’t go into more detail about the hardware setup, but I can say that the back end is an asynchronous messaging-based system. Starling (the queue server that I wrote that Twitter released in January) is the mechanism used to pass messages between processes.
The biggest problem is that Twitter deals with many, many often expensive API requests due to the frequent polling required to stay up to date with your friends’ most recent tweets. The big challenge was to come up with an inexpensive way to make those expensive API requests cheap.
We used memcache extensively, and had a whole bunch of caching in place well over a year ago, but it wasn’t enough.
AkitaOnRails: Last year Alex and Britt spoke at RailsConf I think about Scaling Rails where it felt like Twitter’s problem would end soon. It was mostly about caching and optimizations like that, and one of the main messages was “cache the hell out of it”. I saw you speaking this year about database sharding and how different it is to architect for 1k people and for 1 million people and that you can’t predict what to do before that. Twitter still goes down sometimes, so what changed between last year and now about Scaling Rails?

Blaine Cook: Yes – we knew for a long time that database sharding was important, but for various reasons weren’t able to move forward with it.
The thing with sharding is that until someone comes out with something like what Google has (and I don’t mean Bigtable), the sort of shape your application takes before sharding is very different than the shape afterwards. Sharding makes doing some things harder, and is generally expensive.
When people say “sharding” or “denormalization”, what they mean is “duplicating data in particular ways to make certain lookups faster.”
That always involves additional cost. If you’re building a new app that will either never see hundreds of thousands of users, or if you don’t know if it will or not, it’s generally not worth sinking lots of money into hardware and engineering time to build a “scalable” architecture.
The reality is that most developers know SQL and can build CGI applications using PHP or Rails or whatever, but relatively few have experience taking those straightforward, normalized data sets and breaking them up into much more complex sharded systems.
AkitaOnRails: Of course, sometimes people feel like they will actually build the ‘next’ Twitter. I interviewed Ezra, from Engine Yard, at RailsConf and he seems to acknowledge that the friends-of-friends graph is a problem so complex that whoever figures it out will make a ton of money I mean, isn’t it the case that traditional SQL designs don’t work all the time?
Blaine Cook: Of course – the question is, what else are you going to use? Google has an architecture that lets them spend infinite amounts of money to build denormalized lists of everything, and access those lists quickly. There are a number of projects – HBase, Hypertable, CouchDB, and many others – that aim to solve these problems, but none of them are ready for production use.
The reality is that 10 years ago, people were building web applications with tcsh, and now we have better tools.
AkitaOnRails: Where is Twitter hosted? For some reason I saw Engine Yard pitching a lot about scalability issues throughout the whole RailsConf this year. Do you think this whole “Rails doesn’t scale” meme is making Railers worried about future prospects? Even though it was not supposed to scare that much as we do have higher traffic websites such as Scribd and YellowPages in the top of the list – though the architectures are world apart, of course. What do you think about this issue?
Blaine Cook: I’m not sure, but I think Twitter actually does more traffic than YellowPages or Scribd; the API is a really killer.
AkitaOnRails: Ah, I see, Alexa and others don’t account for API request, right?
Blaine Cook: Twitter is hosted at NTT / Verio. I think there was a blog post about it in February. Right, Alexa doesn’t account for API / SMS / XMPP traffic at all.
As far as the perspective that Rails doesn’t scale – I think it’s an unfortunate side-effect of Twitter’s issues, to be sure, and I think some people worry about it. To put things into perspective, though, Friendster was written in Java to start, and switched to PHP. Myspace was written in ColdFusion and transitioned to ASP.NET.
When people run into problems scaling sites they often think that the language is the problem, but I think it’s rarely the case.
Ruby is slower than PHP or Java (depending on which framework you use) or, well, most languages, but it’s getting faster. And “slower” really only translates to additional cost.
AkitaOnRails: Which reminds me of the last controversy which was Twitter switching off from Rails. The case is that you already have a mixed environment, right? Most pundits think they ‘know’ how to solve Twitter’s problems, though they have absolutely no idea what they are talking about. Some blame Rails, others blame MySQL (“go to Oracle”, they say). Can you elaborate on that?
Blaine Cook: Right – the majority of our development was in Ruby / Rails, but there was code in other langauges. Python, Java, and there were some experiments with Scala. Which ignores the fact that we ran significant portions of our infrastructure on non-Ruby code – Apache, Mongrel, MySQL, memcached, ejabberd, etc. are all great applications and critical to building scalable sites.
Oracle definitely has some of these things figured out, but it’s much easier to hire for MySQL, and Oracle licensing and support fees are nothing to scoff at.
Building your architecture around a system that will only get cheaper with time, rather than more expensive, is always a good idea.
AkitaOnRails: And I have to ask, can you disclose some meaningful numbers, or orders of magnitude, such as tweets per day, average downtime, or something like this, just so we can have an idea of the size of Twitter’s problems? Coming from someone that has actually had to deal with such a huge situation – which most people probably will never have to face -, what would you say are Ruby/Rails’ strongest features for you?
Blaine Cook: Sadly, no – there are plenty of estimates on the web, most notably compete, and Dave Winer’s fan-out numbers.
I think Ruby’s best feature is that it’s fun to develop with. It never stops being fun, either. It’s an expressive and powerful language. Rails just makes web development painless, compared to doing everything by hand. That’s something that shouldn’t be underestimated, or whose value forgotten.
On top of that, they’re really flexible. We needed to build a denormalization tool, for example, and doing it in Ruby was just as easy / hard as any other language, except when it came to tying it in to the rest of the system – no search and replace, no subclassing or anything. Just turn it on, and it works.

AkitaOnRails: Finally can you tell us why you left Twitter? What are you new endeavors? Twitter survived WWDC last week which is saying a lot considering such huge events would usually bring it down in the past.
Blaine Cook: I’m moving to the UK, and Twitter is / has moved into a position where their primary focus is reliability. When I left, the hope was that their system was stabilized, and the roadmap was clear as far as putting them in a better position overall. At the time, they’d had an extended period of uninterrupted uptime, and had survived with flying colours SXSW. Unfortunately, it didn’t last, but it looks like things are better again.
I’m not yet ready to reveal what’s next, but I have a number of exciting things going on. I’ll continue maintaining Starling and xmpp4r-simple, and I’m still active with the OAuth spec. working group.
AkitaOnRails: In the end, Twitter became almost part of our culture already (at least in our tech world). People complain when it is down because now they depend on it so much. People like Michael Arrington, Robert Scoble, Leo Laporte are always complaining, saying they would move to Pownce or Jaiku, but they are still around. Do you have any guess on why Twitter users are so loyal?
Blaine Cook: Nope! I think the really rich landscape of tools that you can use to interact with Twitter on your own terms is a really big part of it. A lot of the users are personally invested, and they want to see that investment pay out.
AkitaOnRails: Ok, I think this covers everything Any closing remarks for our young Brazilian Rails community?
Blaine Cook: The web is remarkably young, and there’s plenty of space for really amazing things to happen. I’m always excited to see what people are working on, and what’s possible with this whole Internet thing. For all of Arrington’s petty and misinformed comments, I think sites like Techcrunch and Mashable and Silicon Alley Insider are interesting because they present a never ending stream of amazing things that people are building on the web.
The financial focus is unfortunate, as there are plenty of apps that survive and provide income for their founders without ever needing to scale to galactic proportions.
The bottom line is that there’s plenty to do, and don’t worry about scaling or business model or anything – unless you’re passionate about what you’re doing, none of it matters.
If you are passionate about what you’re doing, there’s a really good chance you’ll figure the details out.
AkitaOnRails: Fantastic! Thank you very much for you kindness, I am sure my audience will enjoy it. And just to let you know that we, Brazilians, do tweet a lot! :-) Thanks!
Blaine Cook: Excellent, glad to hear! No problem, thanks for being a great interviewer.

RailsConf 2008 - Memories 5 Jun 2008 4:33 PM (16 years ago)
Esta viagem foi fantástica. Eu estava consolado de que nem iria mais viajar. De repente, tive a oportunidade de dar o sangue por essa viagem. Graças ao apoio do Vinicius, e muito vai e vêm daqui até Niterói, finalmente consegui meu passaporte!

Portland é uma cidade muito bonita
A viagem de São Paulo para Portland não é nada fácil. No meu caso fiz escala em Dallas. foram 10 horas daqui até Dallas. Mais 2 ou 3 horas de lay over por lá, e mais 4 horas até Portland. É uma viagem cansativa de pelo menos 16 horas de uma ponta a outra.

A melhor coisa de Portland? O MAX!
Aliás, deixo registrado que o aeroporto Dallas/Fort Worth é algo incrível! Segundo um amigo meu, nem é o maior, mas o lugar é imenso. Sem brincadeira, para ir de um terminal a outro você pega um trem elétrico suspenso chamado Skyline! São uns seis terminais, é praticamente uma mini-cidade ali!
Chegando em Portland, o Carl já estava me esperando. E outra boa surpresa: finalmente entendi o tal do sistema MAX de trens. Uma boa parte do centro da cidade e adjacências está ligado via um sistema de trens circulares, baratos, silenciosos, limpos e normalmente vazios. No centro da cidade, inclusive, você pega o trem de graça. Graças a isso várias vezes fomos ao centro, no mall, nos happy hours. Foi muito bom.

Carl e Vinicius, todos nós no Denny’s
A cidade de Portland é fantástica, pelo menos a porção que eu vi me deixou impressionado. Tudo muito grande, amplo, limpo, civilizado, coisa que para um paulista como eu só se vê em cinema. O Oregon Convention Center é um espetáculo à parte. O lugar é ridiculamente grande, sem brincadeira, acho que não existe lugar perto desse aqui no Brasil. 2 mil pessoas se disperçam rapidamente nesse lugar, nada de empurra-empurra, nada de apertos, tudo muito civilizado.

Esses hamburgers do Denny’s são enormes!
Nada é muito longe, meu hotel ficava a poucos quarteirões a pé. Pelo mapa achei que fosse precisar de taxi, mas na realidade é muito perto. O pessoal ficou espalhado por vários hotéis, o Double Tree que era o oficial, o Red Lions, o Holiday Inn, o Hilton. O meu foi o Shilo Inn que dividi com o Carl e com o Vinicius. Mesmo não sendo um dos maiores a qualidade dele já bate muitos dos melhores daqui.

Bem que tentei usar Pownce em vez de Twitter, mas ele também não escala!
Como tudo ficava próximo ao trem, ir até o Double Tree era questão de pegar dois pontos para cima. Queria ir ao centro, bastava uns 15 minutos e já estava lá. Isso com certeza vou sentir muita falta. O tempo foi bem escasso. Eu acordava lá pelas 7:30 e ia dormir lá pelas 2:00 todo dia. O evento ia das 9:00 até umas 21:00 dependendo do dia. Daí sair pra conversar, comer, e rapidamente já estava tarde. Foi uma longa maratona. No meu caso eu não podia ficar apenas assistindo as sessões, eu queria entrevistar, conversar, fazer contatos e tudo mais. O resultado disso vocês puderam conferir nos posts anteriores. Vida de blogueiro não é fácil.

Acho que a baleia do Twitter é mais legal que o Alien do Pownce!
Como o Geoffrey também falou, a parte mais legal dessa conferência é o contato com as pessoas. Poder encontrar com nomes que são “famosos” apenas para nos certificar que elas são normais e de carne-e-osso como você. Rapidamente você se acostuma e parece que conhece aquele pessoal faz muito tempo. No meu caso, até o último dia, claro que meu cérebro já estava praticamente uma geléia, então parecia até que eu estava meio no limbo.

Eu, o Vinicius e o Carl pagando mico do lado do Jim!
Foi legal que depois das sessões oficiais, todo dia havia o Birds of the Feather. Eram sessões independentes onde juntava uma galera para falar de diversos assuntos. Não participei de nenhuma, aliás, só de uma. Depois de jantar, o Carl nos levou de volta à convenção e o pessoal estava reunido tocando e cantando. O Chad, o Jim e vários outros. Como todos já devem saber, o Carl fala português perfeitamente. E mais: ele sabe muitas músicas brasileiras. E queria nos empurrar pra cantar também! Eu estava perdido, afinal sou péssimo em música e praticamente não conheço nenhuma música nacional (sou japonês :-P ). Male, male cantamos “Garota de Ipanema”. Mas foi interessante.

Rich Kilmer, Cindy, Chad (ThoughtWorks)
Muita gente vê esse pessoal todo em fotos, em screencasts, dá para imaginar que são todos frios, sérios, sisudos. Foi uma feliz constatação ver que não são assim. Mesmo os que tem cara mais séria (como um Ezra), sempre foram muito receptivos, abertos a conversar e discutir idéias. Muitos deles foram super-extrovertidos, tiraram fotos engraçadas, participaram de entrevistas, e muito mais. Muito da imagem de ‘arrogância’ vem porque nós só lemos os blog posts, mas o David Hansson, por exemplo, é um cara muito gente fina.

Evan Phoenix, Nick Sieger, Wilson Bilkovich
Como disse antes, eu fiquei bastante surpreso de encontrar diversas pessoas de vários países que conheciam meu blog. Isso com certeza me deixou muito contente e ao mesmo tempo um pouco ansioso, pois eu não imaginava essa recepção. Mais legal ainda foi encontrar vários brasileiros perambulando por lá. Ao total acho que tinha pelo menos uma dúzia!

Eu, Peter Cooper e o Chris Wanstrath (Err the Blog/Github)
Porém, nesses quatro dias eu não estava a 110% como o David disse na sua apresentação, eu certamente estava a 150%. Eu literalmente não estava parando um segundo. Peço até desculpas porque acho que deixei muita gente falando sozinha várias vezes. Minha atenção estava muito dividida (literalmente, acho que meu cérebro não escala :-)

Toda a galera do Brasil, em peso!
De qualquer forma, tivemos algumas chances de conversar, trocar algumas idéias, almoçar ou jantar, de uma forma ou de outra nos trombávamos por lá. Pessoal da Globo.com, UOL, BlogBlogs, Improve it e vários outros. Alguns brasileiros que moram nos Estados Unidos como o Bruno Miranda e o Márcio Castilho, e assim por diante. Aliás, eu não consigo lembrar o nome de todo mundo. Galera que esteve lá, por favor, deixem seus nomes no comentário para que eu saiba quem são! Aliás, ainda estou esperando os blog posts de vocês sobre o evento!

Eu sei, eu sei, essa foto ficou ‘esquisita’, mas não podia deixar o Bruno de fora.
O Carl tem razão, só dá para dar o devido valor a uma conferência como essa estando lá. Provavelmente eu não estava dando o valor necessário, mas felizmente, devido à uma sequência de eventos positivos, acabei sendo ‘empurrado’ em direção a Portland e, com muito sucesso, passei por ela trazendo ótimas experiências.

Jim Weinrich tem que ser o cara mais simpático que existe :-)
Fiquei muito contente de ter conhecido tanta gente, espero que ano que vem mais brasileiros possam comparecer, mas no que depender de mim, farei o possível para estar lá de novo!

Jantar no domingo com o pessoal da Phusion. O comilão é Josh Goebel (Caboose/Pastie.org)
Odeio despedidas, desta vez não foi diferente. Cada um foi para seu canto, o Carl de volta a Utah, o pessoal da Phusion indo para Cupertino (!), o Vinicius indo pra Chicago e assim vai. É para isso que existem encontros como esse: para nos juntar pelo menos uma vez por ano. Eu saí de Portland na segunda-feira de manhã, cheguei na terça-feira de manhã e dormi o resto do dia, desabei! Daí quarta e quinta-feira eu me fechei no meu cubículo com o intuito de compilar tudo que eu lembrasse e todo o material que eu trouxe. Finalmente, fecho aqui meu último post nessa série da RailsConf 2008, espero que todos tenham gostado!

Andando às margens do rio que corta Portland, muito legal!
Agradecimentos a todos que me deram apoio – em especial ao Carl e ao Vinicius, sem os quais eu não teria chego lá -, à grande organização da Ruby Central, a todos os meus amigos e espero encontrar todos novamente!

Este sou eu, exatamente sobre o trilho do MAX. Akita “On” Rails!
[]’s
RailsConf 2008 - Rails Scales! 5 Jun 2008 11:41 AM (16 years ago)
Esta RailsConf 2008 foi bastante técnica. Ao contrário dos outros anos, o comentário geral foi que o nível técnico das sessões foi muito bom. Só de olhar para a agenda dá para ver isso. De cerca de 30 sessões, pelo menos metade lidava com algum aspecto de escalabilidade.

A maioria dos patrocinadores tinha alguma coisa relacionada com escalabilidade. A Engine Yard apresentou o Vertebra, a FiveRuns apresentou seu TuneUp, a New Relic tem o RPM, a RightScale tem seu sistema sobre AWS, a Morph tinha o Morph eXchange, a Heroku também tinha sua solução AWS e assim por diante.
Aliás, de uma vez por todas, porque várias pessoas me apontaram a mesma coisa: os newbies estão o tempo todo confundindo performance com escalabilidade. Uma não é dependente da outra, você pode ter algo extremamente veloz mas extremamente não escalável e vice-versa. As tecnologias em torno de Ruby e Rails não são performáticas, mas são escaláveis. Se não entendeu, leia este artigo
Dentre as diversas soluções uma das mais interessantes foi o Fuzed, uma arquitetura de cluster escrita em Erlang que suporta instalações Rails, mas pode suportar qualquer outra tecnologia. É um cluster inteligente que cuida das suas instâncias. Difícil explicar em palavras. Infelizmente ainda não tem muita informação online, mas achei a apresentação do Tom Preston e do David Fayram. O objetivo é usar YAWS e Erlang para criar uma infraestrutura que torne trivial deployments de instâncias Rails em slices EC2.

David Fayram e Tom Preston explicando Fuzed
Aliás, serviços como o AWS e o próprio cloud computing da Engine Yard foram estrelas. O mundo está se movendo em direção a cloud computing. Sistemas como Fuzed e Vertebra são literalmente os back-bones que vão orquestrar essas instâncias dinâmicas. Está ficando para trás essa idéia de arquiteturas estáticas, alguns scripts capistrano e um número fixo de mongrels. A idéia agora é ser dinâmico, fazer sistemas elásticos e flexíveis que se adaptam às condições de uso.
Assim que conseguir vou liberar as entrevistas que gravei, mas uma legal foi justamente com o James Linderbaum, CEO do Heroku. Como disse antes, eu não assisti à apresentação dele, mas o Vinicius saiu de lá bastante impressionado. Fazer deployment de uma aplicação, no Heroku, significa apenas um ‘git push’.
Sistemas como a da New Relic e FiveRuns disputam outro nicho: o de monitoramento e análise, de forma que eles conseguem dissecar sua aplicação e lhe dar recomendações e opções de otimização. Uma coisa que o Blaine Cook disse na sua apresentação foi que é impossível testar carga. Mesmo que você tenha uma suíte de testes com 100% de cobertura, uma coisa que não tem como prever é o comportamento humano. Mil pessoas se comportam muito diferente de 1 milhão de pessoas e você jamais vai saber como preparar sua aplicação para isso até chegar nesse patamar.
O que me leva de volta ao tal ‘problema’ Twitter. Conversei com o Ezra, com o Obie, e todos foram categóricos: não existe problema em escalar Rails. Não é o framework que vai fazer a diferença e sim a arquitetura total do sistema. Os gargalos começam muito antes, no banco de dados, nos discos, na rede. Todas essas empresas ganham dinheiro com isso, elas sabem exatamente do que estão falando.
Existem pessoas que “acham” que sabem como resolver o problema do Twitter, muito me admira que eles não tenham conseguido sequer fazer um Hello World num site feito em Frontpage. Acham que ‘entendem’ de banco de dados “o problema é o MySQL, óbvio.” Acham que sharding resolve todos os problemas. Em lugares como Engine Yard estamos falando de engenheiros sérios, que enfrentam esse tipo de problemas como rotina. Quando o Ezra diz que o problema é a estrutura de dados, a enorme árvore de amigos-de-amigos que existem nas redes sociais, ele tem razão.

Phusion tirando sarro dos ‘enterprisey’
O recado de todos foi muito simples: você não tem para onde fugir, se sua aplicação fizer sucesso, é muito provável que você não terá uma solução imediata nem óbvia. Serviços como Heroku podem adicionar novos slices dinamicamente, mas se você realmente fizer muito sucesso, nesse caso estamos falando de reestruturar sua aplicação.
Mas não adianta refatorar do nada, criar novos componentes que você “acha” que vão “escalar” melhor. É burrice. Quando se fala que é um erro otimizar prematuramente, não quer dizer que não se deva fazer nada. Algumas coisas são bastante óbvias e devem ser feitas, por exemplo, garantir que suas tabelas tenham os índices corretos, garantir que seus plugins, serviços não estejam gerando gigabytes de arquivos de log por hora, etc.
Porém, criar uma arquitetura maluca baseada apenas em ‘feeling’ é burrice. Use o que você tem à mão, ganhe tempo, lance cedo e torne seu produto um sucesso. Se conseguir fazer isso, aí você terá dados suficientes para começar a entender como seu aplicativo realmente se comporta. Com esses dados em mãos, aí sim deve começar o trabalho pró-ativo de otimização, refatoramento e, talvez, de reescrita de partes da aplicação.
Nenhum de vocês será um Twitter, é muito difícil. Mas existem vários casos sérios e que deram muito certo. Um case que eu gosto é o do John Straw, sobre reescrever o YellowPages.com. Esse website server 23 milhões de visitantes únicos/mês. 2 milhões de pesquisas/dia. Mais de 48 milhões de requisições/dia.
Vejam a apresentação, mas no final, sabe onde eles tiveram a maior quantidade de problemas de performance? Pois bem, justamente com o Oracle que não gosta de muitas conexões. Outra coisa foi a performance de carregamento de páginas. O problema foi mais por causa de download de imagens, css do que qualquer outra coisa. Sigam o guideline do Yahoo! sobre performance.
Outro case interessante é do TJ Murphy com seu Warbook um jogo social online em Rails para Facebook. Ele literalmente tem um negócio que fatura US$ 100 mil/mês e gasta apenas US$ 2 mil/mês em infra-estrutura. No caso específico dele, foi possível jogar quase tudo em memcache (95% dos hits) e usar bastante da elasticidade do AWS. O mais importante: medir antes de otimizar, ele fala em ferramentas: mire antes de atacar.

equipe da Engine Yard respondendo perguntas
No Hosting with Woes a equipe da Engine Yard discorreu algumas dicas sobre o que eles já viram todos os dias. Coisas como “não use Ferret, use Sphinx, confie em mim!” Algumas coisas úteis como discussões ebb x mongrel x thin. O que eles disseram faz muito sentido: tanto faz: sua aplicação precisa ser gigantesca para você começar a sentir alguma diferença. Além disso parece que neste momento o Thin não é muito bom para lidar com actions que demoram muito.
De qualquer forma, use NginX (eles não tinham visto Passenger até então :-). Num slice como da Engine Yard, 3 mongrels por CPU é mais do que suficiente, seu I/O vai embora antes da CPU. Para tarefas muito demoradas não use BackgrounDRB, ela foi feita de maneira ingênua, atualmente o melhor é usar BJ (Background Job) que é muito melhor.
Eles também falaram para parar de se preocupar com picos de Digg, TechCrunch, etc. Pelo menos sendo clientes deles, quer dizer :-) O que acontece é que em precisando de mais recursos, ele liberam no momento de pico e pronto. O mais importante é que sua aplicação seja o mais cacheado possível, se pudar colocar Page Cache mesmo na sua front-page melhor ainda. Um Digg pode chegar a dar até 10 mil visitantes no dia, um TechCrunch uns mil, um Ruby Inside/Ruby Flow, de 500 a mil. TV é diferente, um The Today Show pode levar até 100 mil visitantes e uma Fox News Business Show cerca de 2 mil conexões. O problema é que a maioria dessas visitas é ‘baixa-qualidade’, ou seja, poucos se dão ao trabalho de se registrar no seu serviço. Eles apenas atropelam e vão embora, por isso nem é relevante buscar esse tipo de audiência.
A Engine Yard estava particularmente mais engajada na missão de desmistificar os problemas de escalabilidade do Rails. O Ezra é um forte proponente nessa área e acho difícil qualquer outro Railer ter cacife suficiente para peitar alguém com a experiência que ele tem.

entrevistando James Linderbaum, CEO do Heroku
E antes que alguém se engane: o Maglev é revolucionário, sem dúvida, mas não vai resolver nossos problemas tão cedo. Ele é voltado a um nicho muito específico que depende de bancos de dados orientados a objetos. Segundo os engenheiros da Gemstone, separar o Maglev do backend OODB não será simples porque eles são intimamente conectados. Com isso você é obrigado a sempre ter um servidor rodando, mesmo que não queira ou não precise. Ainda estamos meio longe desse divisor de águas. Por enquanto, a realidade nos leva de volta ao MRI e ao JRuby, que são os dois únicos realmente production-ready. E isso não é um problema, com todas as opções, ferramentas e soluções que temos, é preciso talento para não conseguir fazer Rails escalar.
RailsConf 2008 - DHH vs Spolsky, epilogue 5 Jun 2008 9:31 AM (16 years ago)
Em 27 de setembro de 2006 eu publiquei um post chamado Flame War: Joel Spolsky VS Rails

Nessa época, Rails já estava em ritmo acelerado de crescimento desde o ano anterior. Isso com certeza ‘assustou’ muita gente e os ‘forçou’ a se posicionar. Grandes mestres como Martin Fowler já haviam demonstrado seu suporte ao Rails. Por outro lado, nomes conhecidos como Joel Spolsky deram uma cartada fora do baralho.
No meu artigo, eu descrevo os diversos posts que se sucederam naquela semana, envolvendo Joel criticando duramente o Rails e os vários posts do David contra-atacando. Depois Joel criticando a performance do Ruby e sendo contra-atacado por Avi Bryant e pelo Obie Fernandez.
Pois bem, quase 2 anos se passaram e qual não é minha surpresa ao ver na programação da RailsConf 2008 que o palestrante de abertura do evento é ninguém menos que Joel Spolsky em pessoa!?

Foi uma longa apresentação muito bem conduzida. Preciso dar o braço a torcer, o Spolsky é um orador fenomenal. Quem já preparou uma palestra sabe como a dele foi preparada com muito cuidado. Ele tomou muito cuidado para não mencionar Rails nem uma única vez.
O tema era “o que faz um produto ter sucesso?”
Ele começou comparando produtos. Um exemplo foi o iPod contra o Zune. Blue Chip contra Off Brand. Angelina Jolie contra Uma Thurman. Brad Pitt contra Ian Somerhalder. Brian e Angelina são iPods, Ian e Uma são Zunes. O tom dele foi como se quisesse dizer “eu sei, eu sei, concordo. isso é bullshitagem, um Ian mereceria ser tão famoso quanto um Brad, mas infelizmente não é assim que a vida funciona.”
Os pontos que ele explorou foram:
- Faça as pessoas felizes – Uma demonstração que achei engraçada foi que ele montou, na apresentação, uma interação com um Windows, (exagerando) sobre como é difícil conseguir extrair uma foto de uma câmera digital, com o Windows abrindo pop-ups esquisitos, pedindo CDs de instalação de drivers e falhando, etc. Ou seja, coisas que tornam as pessoas infelizes. Em seguida demonstrou 2 processos de checkout num e-commerce, no primeiro o estilo ‘quadradinho’ e pouco flexível de ‘wizards’, já o segundo – da Amazon – era uma tela onde você poderia fazer o que quisesse na ordem que quisesse. Segundo Spolsky, é preciso dar ao usuário a sensação de que ele está no controle.
- Seja obsecado com estética – ele comparou o Samsung Blackjack vs iPhone. Por exemplo, sobre a bateria não removível do iPhone. Ele mostrou como a Apple preferiu não ter um “corte” atrás do fone, ou seja, não ter uma tampa de bateria pela obsessão de ter um design limpo. Não importa que o Blackjack tem mais funcionalidades, o design do iPhone é tão perfeito que “dá a sensação que se eu engolisse ele iria escorregar direto até o fundo.”
Ele foi mais longe e viajou um pouco, falando sobre construções, prédios na França e nos Estados Unidos, e como não ter uma escada de incêndio na frente torna o design mais bonito, ou seja, na França é melhor morrer queimado do que enfeiar a fachada com uma escada. Sobre software, mostrou como coisas como Skins tornam um produto ridículo: se o software não funciona direito não é mudando sua cara que ele ficará melhor. Novamente ele parece pensar “infelizmente as pessoas preferem algo que seja bonito do que algo que funcione. Não brigue contra isso, siga o sistema.”
- Observe a Cultura do Código – ele discursa sobre percepção. Por exemplo, o Ford Explorer (SUV) contra o Toyota Camry (sedam). 88 pessoas morrem num Explorer por ano, contra 41 no Camry. Porém, a percepção é que o Explorer é mais ‘seguro’ que um Camry. Os SUVs tem ‘cantos arredondados’, airbags em todos os cantos, seguradores de copos e são altos. Eles nos enganam em nos fazer sentir seguros. Daí ele explica sobre ‘atribuição errônea’ ou seja, se você assiste um filme no cinema tomando um bom café, pode ser que diga que o filme foi bom por causa do café. Por outro lado se tomasse algo que não gostasse, diria que o filme foi ruim. Mas isso na realidade não tem a ver com a qualidade do filme, mas sim da reação fisiológica da pessoa.
No fim, parecia que ele queria dizer algo como, não importa se o Rails é bom ou não, mas as qualidades de tornar os programadores mais felizes, ser obcecado pela estética do código e toda a cultura ao redor o tornam um caso de sucesso. Independente se ele ache que Ruby seja lento ou que tecnicamente não haja muita coisa, não é ele quem vai mudar como as coisas funcionam.
Por isso mesmo acho que as reações foram adversas. O Ola Bini por exemplo, acha que não foi grande coisa. Muita gente elogiou o entrenimento, afinal o cara é muito bom apresentador. Mas muita gente também criticou, veladamente, a falta de ‘substância’.

Na mesma linha, no fim do dia, foi a vez do keynote do David Hansson. Ele também decidiu ir pela linha menos técnica e mais conceitual. Acho que ele acredita que finalmente já tem gente suficiente para falar das partes técnicas e ele pode falar sobre coisas que gosta mais. A apresentação de Rails 2, no ano passado na RailsConf Europe, foi ele mesmo quem fez. Mas a de Rails 2.1 foi terceirizada para o Jeremy Kemper, que também fez um trabalho competente.
O David começou falando sobre escolhas. Muita gente ‘reclama’ que Rails os força a fazer as coisas de uma determinada maneira, o tal ‘convention over configuration’. Porém, ele acha que as pessoas gostam mais de ter escolhas do que fazer escolhas. Na sua opinião, um dos fatores de sucesso do Rails é justamente porque ele faz as escolhas que você não quer ter que fazer e, se quiser, pode mudar. Nada impede que você faça as coisas diferentes da convenção, mas se seguí-la é provável que o padrão será o suficiente para a maioria.
Daí falou sobre o ‘surplus’ do Rails, ou o ‘extra’. Ou seja, Rails ainda é uma minoria no mundo de desenvolvimento, mesmo assim ele atrai muita atenção e felizmente hoje existem várias empresas e pessoas que vivem disso. Porém, David entende que esse surplus não vai durar para sempre.
Ele deu como exemplo a cidade de Dubai, que está usando o surplus do petróleo para se modernizar mais rápido do que o normal.
Algumas coisas podem acontecer, a competição pode ficar competente em copiar o Rails; ou algo dramaticamente melhor pode aparecer com um novo paradigma que torne o desenvolvimento ordens de grandeza melhor que o Rails; ou o próprio Rails poderia se tornar o mainstream.
Independente do que acontecer, precisamos usar esse ‘surplus’ para não ficarmos para trás. É como quem ganha uma bolada de dinheiro de uma só vez: você pode gastar tudo ou pode investir. É o que David sugere: que nós programadores temos que investir em nós mesmos.
Ele fala de como Rails ajudou muita gente. Normalmente os programadores precisam trabalhar 110% da sua capacidade, apagam incêndios todos os dias, se perdem na mecânica dessa rotina brutal, ficam fatigados, cansados, desmotivados. Agora, quem se encaminhou no mundo Rails, tem a chance de parar, pensar e agir de forma mais inteligente.
Na 37signals, por exemplo, eles estão investindo nas pessoas. Um dia útil da semana é dedicada para que eles façam o que quiser. Seja programação ou apenas um hobby que nada tem a ver com informática, como artesanato. O que eles entenderam é que iniciativas como essa tornam um programador melhor. E muita gente pode achar isso horrível, “perder 1/5 da semana em hobbies!?” Porém, criar um programador que pode render 10x mais que o normal com certeza vale perder 20% da semana.
E quando se fala em ser 10x mais produtivo não significa fazer 10x mais código. Pelo contrário, significa fazer 10x mais eficiente. Ou seja, codificar coisas que são realmente necessárias, em vez de apenas programar volumes de coisas desnecessárias. Esse é um ponto importante. Na média, um bom programador nunca será ordens de grandeza mais veloz apenas em digitação. Mas um bom programador é aquele que sabe priorizar as coisas, fazer as coisas que interessam primeiro.
Um ponto que meus amigos tiraram sarro na hora foi quando o David disse para “dormir mais!” Ok, eu admito, eu durmo muito pouco. E é claro que o David está certo, ninguém deve tentar ser um superman, eu mesmo não recomendo isso para ninguém. Já está mais do que comprovado que o nível de atenção, foco e, claro, produtividade, cai rapidamente com a falta de sono. No meu caso, minha desculpa é que além de programador eu sou um blogueiro. Vou dizer que é mais difícil ser um blogueiro do que um programador :-) Mas isso varia de pessoa para pessoas, de qualquer forma: “durmam mais!”
Algumas vezes é importante você começar um novo projeto do zero, em vez de apenas dar manutenção num sistema já existente. Ele contou como ele descobre mais sobre o próprio Rails quando pula para criar um novo produto. Ficar fazendo sempre a mesma coisa cansa, é sempre bom começar do zero de tempos em tempos.
Finalmente, outro ponto que eu gosto, compartilhe a mensagem, divida e ensine. Você sempre vai aprender mais quando ensinar. Não tem como ‘perder’ conhecimento quando se transmite conhecimento. Conhecimento gera mais conhecimento. Não deixe de compartilhar.
Portanto, o importante para todos nós entendermos é: esse ‘surplus’ do Rails não vai durar para sempre. Alguma coisa vai mudar as regras do jogo, como sempre acontece. Mas quando isso acontecer, devemos estar preparado para isso. Portanto devemos crescer enquanto programadores. Devemos abrir os horizontes para novas possibilidades, diversificar nossas capacidades, transmitir conhecimento. Enfim, nos tornarmos profissionais completos e não apenas mais um soldadinho de chumbo.

Embora nenhuma das duas palestras, tanto do David quanto do Spolsky não tenham sido técnicas, acho que foi importante porque Rails, mais do que uma tecnologia, é uma cultura. Pessoas como eles divulgam cultura e servem de modelo para todos nós. A mensagem implícita entre as duas palestras, para mim, é que briga de egos, rixas inacabáveis, inveja não declarada e coisas do tipo sempre são nocivas para os dois lados.
Quando o David convidou Spolsky ao palco e este subiu, eu vi um ciclo muito ruim se fechar. A rixa de 2006 ficou em 2006. Ambos são profissionais muito bem sucedidos em seus determinados nichos. Não há razão para haver rancor entre os dois. Tudo bem, Joel começou a disputa, David errou ao continuar. Não sei o que aconteceu por trás dos panos, mas independente do conteúdo das palestras (que no geral foram boas) o gran finale foi bom. Acho que a mensagem implícita foi mais interessante do que o que foi falado.
E isso me leva a Kent Beck, o pai do XP. O Vinicius Telles me disse que já havia assistido ele várias vezes e essa foi uma de suas melhores palestras. O desfecho David/Spolsky que eu disse acima me leva a pessoas como Kent. Um bom profissional precisa trilhar um caminho com desses dois para chegar ao nível de sabedoria de um Kent.
Ninguém é perfeito e não estou querendo dizer que Kent precisa ser endeusado, claro, mas não se pode negar que ele é uma presença forte. Ele é muito espontâneo. Não se ateve a slides. Teve meia dúzia, no máximo, na maior parte do tempo ele permaneceu sentado e contando três histórias de sua carreira. Da mesma forma como você ouviria seu avô contando sobre os bons tempos.
Um ponto que eu lembro porque achei engraçado foi sobre como ele começou com Test-Driven Development (TDD) “resolvi fazer um código que não funcionava, depois codificava o necessário para o teste passar, e fui fazendo assim. Nossa, eu tinha a sensação de estar trapaceando!”
Infelizmente eu não decorei a apresentação toda, ele falou muita coisa e respondeu a várias perguntas da platéia. Espero que alguém tenha gravado, porque o interessante é assistí-lo falar. Normalmente eu prefiro apenas fazer download do PDF e ler os bullet points. Mas no caso de pessoas como ele – que por sinal, sequer tem bullet points nos seus slides – o importante é absorver seu entusiasmo, apreciar sua história. Ali está ele, diante de nossos olhos, um dos pais das metodologias ágeis, falando com eloquência, calma, segurança.
E ele tem um ótimo senso de humor. No final, ele resolveu comentar sobre Zed Shaw. Foi algo na linha de “Entendo que esse sujeito, Zed Shaw, que chamou o Rails de Ghetto, incomodou vocês. Eu li e reli a reclamação dele. Se você considerar como um memorando de negócios, deveria ler somente os dois últimos parágrafos, afinal, qualquer memorando começa com baboseira e só nos dois últimos parágrafos é que estão as partes importantes.” Todos deram risada, claro :-)
“E lendo o final, eu entendi que esse Zed disse que o Rails precisa de um mercado transparente de serviços.” Mais risadas. “Bom, muito obrigado pela sugestão. De qualquer forma, resolvi ler de novo, retirando todos os palavrões, ameaças e coisas do tipo. O que sobrou foi que Rails precisa de um mercado transparente de serviços.” Mais risadas :-D
O cara é fantástico!
RailsConf 2008 - Rails 2.1 Released! 4 Jun 2008 2:44 PM (16 years ago)
No segundo dia, o keynote de abertura foi do Jeremy Kemper, um dos Core Mainteiners do Rails. Para mim o mais interessante foi o David Hansson explicando como ele entrou para a equipe. Lá por 2004, quando o Rails ainda era 0.7 ou 0.8, o Jeremy começou contribuindo. Mas não foi 1 ou 2 patches, foram pelo menos uns 20 patches, devidamente testados e documentados. Naquela época, quase 1/3 do código do Rails já era do Jeremy.

Achei mais interessante porque o keynote de fechamento foi uma mesa redonda com os demais do Rails Core Team, não estavam todos, mas David, Koziarski, Rick e Jeremy estavam respondendo perguntas da platéia. Uma das perguntas foi algo do tipo “Acho que REST é muito legal e tal, mas e quanto a SOAP? Acho que seria bom o ActiveWebService ser mais completo.” Eles concordam. “Alguém aí se habilita a abraçar essa gem?” O motivo é simples: eles não precisam dela, mas há quem precise. Qualquer um que precise de SOAP poderia contribuir e se tornar o mantenedor.
O próprio Jeremy, em sua apresentação, deu as boas vinda ao Pratik Naik, que resolveu abraçar a proposta de melhorar a documentação do Rails e, graças a isso, se tornou um Core Committer também.
Outra pessoa perguntou algo como “vocês do Core Team costumam observar o que os outros frameworks tem feito, por exemplo, Django, Seaside?” Todos disseram que sim, mas o David foi categórico: “eu gosto muito de Seaside, algumas idéias acabam entrando, porém o objetivo do Rails não é copiar o que os outros estão fazendo. Se você acha que Seaside vai lhe beneficiar mais, por favor, use Seaside. Não há nenhum problema nisso. Aliás, não consigo entender todos esses outros frameworks tentando clonar Rails. Se quer usar Rails, use Rails. Isso não faz sentido algum!”

Não sei se apenas com palavras consigo expressar o que eles quiseram dizer. Rails é um projeto open source que só está onde está graças à ajuda massiva da comunidade. Na apresentação do primeiro dia da “Andrea O.K. Wright”, ela discutiu sobre thread-safety. Um dos pontos que me chamou a atenção foi o projeto do Josh Peek em refatorar o código do Rails para que ele se torne verdadeiramente thread-safe. Seu mentor é o Core Maintainer Michael Koziarski. Vocês podem ver a aplicação dele aqui e o seu fork no Github.
Novamente, volto a tocar no ponto dos pundits. Existem dois tipos de pessoas, as ativas e as acomodadas. As acomodadas todos conhecemos, e normalmente conhecemos mais do que gostaríamos porque muito fazem barulho, como um bando de urubus disputando a carniça. Os ativos normalmente conhecemos pouco, pessoas como Josh. Eles fazem a diferença porque identificam problemas e automaticamente resolvem fazer alguma coisa a respeito. E normalmente são bem sucedidos!
Um exemplo disso foi o Fabio Kung, da Caelum. Ele encontrou problemas na maneira como se desenvolver com JRuby hoje: tendo que usar o Warbler para gerar arquivos .war e ficar fazendo redeployment o tempo todo. Em tempo de desenvolvimento isso é, literalmente, um saco.
O Jeremy concorda com isso. Na parte final da sua apresentação ele começou mostrando as diversas implementações de Ruby rodando Rails, incluindo Rubinius, Yarv e, claro JRuby. Mas nesse último caso ele explicou a mesma dor de cabeça de deployment e explicou como Nick Sieger (um dos Core Maintainers do JRuby) lhe indicou o projeto jetty-rails.
Daí, ele mostrou um slide com esse nome e mais, mostrou o bicho funcionando em tempo real! Mais um excelente exemplo de como os brasileiros se menosprezam, poucos acham que podem subir ao palco, mas o Fabio subiu, e com louvor, indicado pelo Jeremy e pelo Nick como uma excelente solução para JRuby. Que tal?


Quanto às novidades em si do Rails 2.1, o Jeremy foi bastante rápido e apenas pontuou as principais. Acho que todos que acompanham meu blog já sabem, uma vez que eu escrevi o tutorial completo faz algum tempo já. Aqui está a Parte 1 e aqui a Parte 2. Portanto não vou repetir tudo novamente :-)
Aliás, uma coisa que para mim foi muito gratificante, além dos brasileiros que encontrei por lá que me conheciam, ainda cruzei com diversos outros leitores, do Canadá, do México, do Uruguai, dos EUA mesmo. Foi muito engraçado porque nunca esperei que alguém lá fosse me chamar “você é o Akita?” Foi mais interessante porque encontrei com esse uruguaio na hora do almoço e ele me disse “Akita, o Obie está te procurando!” Eu pensei, “caramba! Eu é quem estou procurando ele!”
Fico muito contente que meu trabalho esteja sendo reconhecido lá fora também e espero que isso também ajude a trazer visibilidade para o Brasil. Já soube de algumas empresas e consultorias que enxergaram que podem contratar railers de boa qualidade aqui do Brasil.
E, pouco antes do último keynote, eu estava sentado no salão principal e, por coincidência, ainda consegui flagrar esta cena:

Someone reading my Rails 2.1 tutorial. Anyone knows him?
How cool is that!?
E eu quase ia me esquecendo! No evento havia um “Speaker Lounge”, uma grande sala onde os conferencistas se reuniam. Eu, claro, com minha famosa ‘cara-de-pau’ andei invadindo essa sala várias vezes. Inclusive no primeiro dia ainda almoçamos junto com o David, o Koziarski e o pessoal do Phusion:


Mas eu estou mudando de assunto! Pois bem, depois da apresentação do Rails 2.1 do Jeremy, fui falar com o Chad Fowler quando presenciei esta cena na Speaker Lounge:


Parece que deu algum pau no empacotamento do Rails 2.1 em Gems. Estavam todos do Rails Core reunidos tentando resolver o pepino, incluindo Chad e Jim Weinrich. Eu chamei essa cena de “Situation Room.” Quer algo mais cool do que ter problemas com gems e poder recorrer diretamente e ao vivo com alguns dos maiores contribuintes ao sistema de RubyGems como Chad e Jim? Muito legal!
RailsConf 2008 - Ruby Heroes Awards 4 Jun 2008 1:10 PM (16 years ago)
Uma apresentação que eu achei particularmente muito legal foi o Ruby Hero Awards. Inicialmente a idéia seria para toda a comunidade ‘votar’ em quem achavam que deveria ser o “herói do mundo Ruby”. Porém, como o Gregg me explicou, isso não seria justo pois as pessoas que já são as mais reconhecidas e populares é quem receberiam mais votos.

Em vez disso, eles escolheram um painel de pessoas que já são importantes e decidiram os nominados entre eles, o que eu particularmente achei mesmo mais justo.
Os apresentadores da noite foram ninguém menos que Gregg Pollack (RailsEnvy) e Steven Bristol (Less Everything). Eles explicaram o conceito do prêmio e encorajaram todos a almejar por isso. O prêmio em si é legal, mas o verdadeiro “prêmio” é ver uma comunidade se formar à sua volta, ajudar os outros e ser ajudado em troca. Bons programadores são bons justamente porque dividem seu conhecimento e, com isso, se tornam melhores. Isso pode vir de diversas formas, escrevendo livros, escrevendo código, escrevendo blogs, etc.
O primeiro prêmio foi para Evan Weaver, um excelente programador que contribui com o Rails, com Mongrel e hoje trabalha no Twitter, além de escrever o blog snax.

O segundo foi para ninguém menos que Tom Copeland. Já ouço alguém ao fundo perguntando, “quem?” Bem, se você já instalou pelo menos uma RubyGem na sua vida, deveria agradecer esse cara, que é o responsável pelo RubyForge! Veja o que a O’Reilly tem a dizer sobre Tom:
What do all these numbers mean? Good question. I think, at the very least, it means that the Ruby community is doing very well in terms of library development and releases. I give Tom Copeland a huge amount of credit for that, in that I think the very act of creating RubyForge fostered an atmosphere of development (collaborative or otherwise) and inspired programmers new to Ruby to take the step of releasing their own software. I can’t prove it, of course. It’s just a gut feeling I have after watching the Ruby community grow for seven years.

Vou pular o terceiro porque senão ele vai eclipsar os outros, mas o quarto foi outro bem conhecido: Ilya Grigorik. Principalmente porque seus artigos são excepcionais! Se você nunca leu seus artigos, deveria. Ele consegue pegar temas complexos e explicar de maneira que todos conseguem digerir. Algumas pessoas são excelentes programadores e colaboram com código, outras são excelentes professores e colaboram com artigos, tudo é válido.
“ ”
”
Ryan, Yehuda, Ilya, Evan, atrás de Steven
O quinto foi Yehuda Katz ele participa de tantos projetos open source que fica difícil até de começar a descrever, mas acredito que alguns dos principais são JQuery on Rails e o DataMapper que é outra boa alternativa ao ActiveRecord e já é muito usado por quem adotou Merb.
Finalmente, o sexto foi Ryan Bates e acho que ele não precisa de apresentação. De todos os ganhadores acho que ele é o único que cairia no critério de “já é reconhecido o suficiente” mas mesmo assim posso dizer que eu aplaudi de pé :-) O Ryan é um cara que mostrou que com apenas um pequeno screencast toda semana, pode ser feito uma grande diferença na comunidade. Muita gente abriu as portas ao Rails graças ao seu trabalho e, nesse caso, tenho certeza que o prêmio foi muito merecido.
Agora, quem foi o terceiro ganhador da noite?

Ele foi o responsável pelo famoso Ruby Quiz, escreveu os livros TextMate: Power Editing for the Mac, Best of Ruby Quiz. O Carl me contou sobre isso, e eu já havia ouvido falar não lembro onde, mas achamos que uma das razões porque ele escreveu, e gosta de TextMate, são as centenas de shortcuts que permitem que você seja produtivo nessa ferramenta.
E por que isso é importante para ele?
Bem, digamos que se você tivesse os problemas físicos dele, isso faria um mundo de diferença! James está numa cadeira de rodas há anos e nem por isso ele é o tipo de cara que vive deprimido e sentindo pena de si mesmo. E mesmo se o fizesse ninguém poderia culpá-lo. Em vez disso ele trabalha duro pela comunidade e nunca desistiu. Somente por isso acho que ele se encaixa numa categoria completamente diferente de heróis. Eu iria longe o suficiente para dedicar um Ruby Hero inteiro a ele. Mais um que merece aplausos em pé de todos nós, um grande exemplo de que “querer é poder.”
A principal mensagem desse award é: “Todos nós podemos ser Ruby Heroes.” O mais importante é não esperar sentado. Todos os grandes gênios, ou melhor, todos que hoje consideramos como grandes gênios, começaram exatamente como cada um de nós: da estaca zero, sem saber nada. Todos aprendemos aos poucos. Mas alguns andaram um pouco mais, fizeram um pouco mais, foram além. Todos nós deveríamos nos esforçar por esse “algo a mais”. Não importa o que seja. Talvez você seja um programador talentoso, por favor, escreva mais código. Talvez você seja um excelente comunicador, por favor, blogue, escreva tutoriais. Enfim, qualquer pequena contribuição nunca deve ser considerada ‘pequena demais’. Um único artigo pode fazer a diferença para muita gente.
Disclaimer: Mais um motivo de porque eu me irrito tanto quando vejo os reclamões gratuitos. Reclamar não é um problema, mas reclamar com o óbvio intuito de se parecer “superior” é de uma mesquinharia e de uma covardia que eu os categorizaria como sub-humanos. Pessoas que apenas querem pegar carona nos outros em vez de contribuir de verdade, movidos por pura inveja e todas as outras dezenas de qualidades que tornam uma pessoa um ser inferior. Tenham vergonha!
Parabéns ao Gregg e a todos os participantes do painel, acho que foi uma grande idéia. O Gregg também enviou e-mails acho que para vários outros que não foram os vencedores mas que receberam apoio de suas devidas comunidades. Como ele não menciona se posso ou não divulgar isso, acho que não tem nenhum problema. Muita gente votou em mim e o que posso dizer? Muito obrigado pelo suporte! Espero que eu continue ajudando e espero que todos vocês continuem a colaborar com toda a comunidade. A seguir, seguem algumas das mensagens que vocês enviaram ao Ruby Awards (sem os nomes, claro):
Because Akita is a great Rails evangelist in Brazil
He is the writer of the first Brazilian Rails book, he leads the translation to portuguese of the "Getting Real" book.
Great site about Ruby on Rails. Fabio really know what you say. He is Rail’s entusiast.
The first brazilian writer about Ruby and Rails
He translates books, records podcasts, write code, do interviews, have a great blog about Ruby
He is a hero in my country, Brazil
Site muito bom , bem atualizado
Akita is the brazilian ruby hero because he wrote the first brazilian book about RoR and he produce a lot of quality material about ruby and rails.
Fabio Akita is the most active rubist in the Brazilian community, making a lot of interesting articles, tutorials and screencasts, some of those in English too.
Fabio Akita has been a ruby an rails evangelist for years, writing on his blog and giving lectures and presentations.
The best railer brazilian.
Excellent author! Excellent content! Excellent tips!
Because the Akita is one of the pioneers of the language in Brazil, wrote the first book on the subject in our land and is always helping and encouraging community.
Fabio Akita is a great, the most active Ruby Evangelist in Brazil. His blog helps a lot the Ruby community, written in portuguese and english.
He has written the only RoR book in portuguese.
He write almost daily on his blog.
He it the co-author of the only RoR postcast in portuguese. http://rubyonrails.pro.br/podcasts
He is extremely active on the Brazilian community talking and spreading RoR to everyone.
Creator and maintener of the plugin "Acts As Replica" – http://github.com/akitaonrails/acts_as_replica/tree/master
He declares himself arrogant but he’s the pioneer brazilian ruby hero…
It’s the biggest brazilian Railer. His site helped me a lot too, and his comments in the brazilian rails list.
He write the only one rails book in portuguese. Share your discovery and studies with everyone everyday in your blog.
He made some great screencasts. And they were as free as a feather in the wind.
Great tutorials on Rails. Was a great place to go after Rails 2.0 was released to see what was new, and how to use it. The tutorials were well written, and very easy to follow. Even more impressive was that the tutorials were written in English, and Fabio does not speak English natively.
It’s Ruby Hero because he’s the main "railer" in Brazil. Write "Repensando a Web com Ruby on Rails" book; Member of RailsBrasil Podcast.
He’s a Rails pioneer in Brazil, wrote the first book about Rails in Brazilian Portuguese and is always trying to improve the Brazilian Rails community.
He’s the person who took the name to inside the country…
He is from a little group of people that are interested in creating a solid rails market in Brazil. His blog has a lot of rails tip, and great interviews with important persons of the global rails community, like DHH, Dr Nic, Geofrey, etc.
E não é só isso, hoje fui ver o Working with Rails e eu subi ainda mais de posição, indo para 11o!
“ ”
”
Acima de mim, e logo abaixo, vocês vêem que só tem pessoas geniais! Eu quase sinto que não deveria fazer parte desse grupo. Agradecimentos a todos que acreditam no meu trabalho e têm se beneficiado disso de alguma forma. Acho que me sinto um pouco como um “Ruby Hero” :-) Espero poder continuar correspondendo com as expectativas de todos (isso definitivamente coloca um grande peso nas minhas costas)!!
RailsConf 2008 - Phusion Passenger Enterprise Edition Unleashed! 4 Jun 2008 10:01 AM (16 years ago)
Uma das parcerias mais engraçadas que já fiz até então foi com o pessoal da Phusion. Desde que os entrevistei algumas semanas atrás meio que fizemos amizade e trocamos idéias o tempo todo via IM.

Desde então eles fizeram várias coisas:
- Lançaram a primeira versao do Phusion Passenger (a.k.a. mod_rails)
- Lançaram o quiz do Ruby Enterprise Edition
- Lançaram a campanha de doação para ganhar licenças Enterprise Edition.
O que vocês vão ler agora é o Inside Story de como muitas dessas coisas aconteceram :-)
Foi engraçado porque nossa comunidade brasileira foi a primeira a identificar que as licenças na realidade eram de mentira :-) Por alguma razão ninguém blogou sobre isso até agora e eu também segurei porque eles pediram (vocês não imaginam como é difícil para um blogueiro segurar uma informação como essas que vou contar!!). Se não me engano começou com o Julio Monteiro, que havia doado via duas empresas diferentes e, por isso recebeu duas vezes a licença, mas aí veio o interessante: duas licenças iguais a esta:
08abe6e5d8ae5e932e4a2808b484e41c
O script passenger-make-enterprisey mostra claramente que isso é nada mais nada menos do que o digest MD5 da string:
Saying “Rails doesn’t scale” is like saying “my car doesn’t go infinitely fast”.
Eles me contaram que estão tirando muito sarro de quem fala “Rails não escala”. É uma não-afirmação (non-statement). E ao mesmo tempo estão tirando sarro das pessoas “enterprisey” que, para considerar um produto a sério, precisam pagar por ele e receber uma “chave-secreta” que ninguém mais tem. Fala sério, ninguém suspeitou de um script “make enterprisey”?? Eu falei com o Ninh sobre isso e ele confirmou que ninguém mais tinha descoberto/publicado sobre isso.

A Phusion pegando dicas
com Jim Weinrich
Portanto, a versão 1.0.5 que estava no ar até então, obviamente, não continha o “Enterprise Edition”. Ela foi liberada primeiro para os que doaram e estavam presentes na platéia. Eles haviam prometido liberar a versão 2.0 poucas horas depois da apresentação, mas eles não só não tiveram muito tempo como também a internet no evento estava meio ‘lenta’, vamos dizer. Portanto, os que doaram antecipadamente receberam uma versão em DVD e devem ser os únicos que já puderam testar em produção. Conforme eles explicam no blog deles quem quiser já ainda não tem as gems oficiais mas já pode baixar do github deles.
Durante nossas conversas via IM surgiu a idéia de eu fazer uma aparição surpresa durante a apresentação (um cameo). Eles apresentariam o Passenger, daí abririam para uma sessão falsa de perguntas e respostas, eu levantaria a mão e eles me “escolheriam”. Nesse instante seria revelado o primeiro grande segredo:

Minha pergunta foi algo assim: “mod_rails é legal mas muitos criticam dizendo que o futuro do desenvolvimento web com Ruby requer Rack. O que vocês tem a dizer sobre isso?”
Todo mundo deu risada porque o slide seguinte foi assim:

E a resposta no slide seguinte foi: “Não, Passenger não vai suportar Rack … ", e no terceiro slide: “… porque ele já suporta!”
Poucas pessoas pessoas sabiam disso, incluindo eu e ninguém menos do que Ryan Bates que fez um screencast sobre o suporte a Rack, demonstrando neste vídeo:

Muita gente reclamou disso sobre o “mod_rails”. O próprio Ezra comentou neste post
As far as mod_rails goes… I think they made a huge mistake by not using rack as their interface, so I’d hope they will realize this and add rack support.
Parece que as preces deles foram atendidas. Esta outra discussão mostra como as pessoas assumem coisas sem saber como elas são feitas. O próprio Hongli Lai comentou que suportar Rack seria mais difícil do que Rails. Passenger não é apenas um conector burro de Apache para Rails, ele faz muito mais:
“Rails-specific framework pre-loading logic” is clearly explained in our architectural overview. It explains what it is, the motivation behind it, and how it works.
In a nutshell: it can decrease Rails spawn time by as much as 90%. On a busy web host where spawn time is normally 25 seconds, it can be brought down to 2.5 seconds. Preloading also makes memory sharing between processes possible.
Duas coisas importantes que o Passenger faz é trazer o tempo de startup uma ordem de grandeza para baixo. Isso é relevante porque num shared hosting você quer que processos que não estão sendo usados sejam derrubados para economizar memória, mas quando forem necessário você não quer que seu usuário espere mais de 20 segundos para carregar uma nova instância. O spawner deles consegue diminuir absurdamente esse tempo de loading porque ele sabe que muita coisa entre instâncias é exatamente igual e, portanto, pode ser colocado num cache. O documento de arquitetura deles explica isso em detalhes.
A segunda coisa é copy-on-write, que o Hongli já havia blogado a respeito em seu blog. Essencialmente um mongrel_cluster faz as coisas na força bruta: cada instância mongrel sobe uma cópia do framework Rails e da sua aplicação, duplicando tudo em memória. Ou seja, se você tem memória sobrando, tanto faz, mas normalmente nós queremos economizar o máximo possível.
O Passenger é esperto em relação a isso: ele sobre a primeira instância Ruby/Rails e as seguintes são forks da primeira. Se a primeira consome 50Mb de RAM da segunda em diantes se consome quase zero. Claro, à medida que a aplicação é exercitada, partes da aplicação precisará ser ‘copiada’ em outro espaço de memória isolado para que possa ser ‘sobrescrita’. Na prática, isso pode significar uma economia de pelo menos 1/3 da memória consumida total. Veja este slide sobre memória:
E não é só isso, devido às diversas otimizações que eles fizeram, isso também tornou usar Passenger mais rápido do que a concorrência. Vejam este slide sobre performance:
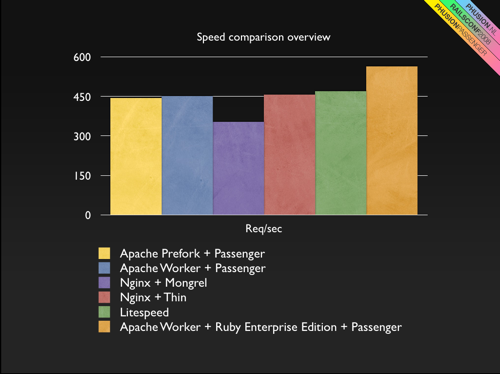
Ou seja, ele é mais rápido até mesmo do que Nginx + Thin, e mais do que isso: ele consome menos memória e roda mais rápido sobre Apache, que nunca foi um bom exemplo de baixo consumo de memória nem de performance. E ainda mais: diferente de um mongrel_cluster você não precisa limitar a quantidade de processso, não precisa se preocupar em subir uma instância caso ela dê crash por alguma razão, o Passenger faz tudo isso e com o plus de que cada nova instância que ele carrega, sobe com uma ordem de grandeza mais rápido do que a primeira, graças ao spawner.
A estratégia desses garotos foi muito boa: muita gente pediu para que eles lançassem uma versão alpha muito antes do tempo. Porém isso seria burrice, porque daí eles teriam que perder tempo com dúzias de bug reports com coisas que eles já sabiam que teriam que resolver. Daí, em vez de gastar o tempo corrigindo esses bugs, teriam que perder tempo gerenciando as pessoas.
Eles trabalharam com alguns parceiros com a Soocial, iLike, Dreamhost. Para quem usa sites sociais como Facebook já deve conhecer a iLike, que é uma aplicação Rails com mais de 20 milhões de usuários e que contabiliza centenas de milhões de page views mês e, agora, tudo rodando sobre Passenger.
Outra coisa que surgiu literalmente como uma brincadeira via IM acabou virando algo interessante na apresentação. Muitos brasileiros que me acompanham no Twitter viram quando eu lancei uma tirada que é: “A arma secreta do Python contra o Ruby: Leah Culver!” Muita gente entrou na brincadeira, o Fabio Kung não sabia sobre ela e tirou sarro no Twitter também. Foi engraçado :-)
Mas o Ninh Bui, da Phusion, também não sabia! E para os que ainda estão sem entender do que se trata, Leah Culver é praticamente uma lenda viva! Ela é uma jovem programadora de 25 anos e Líder do projeto Pownce de Kevin Rose. Sinceramente, eu nunca vi uma programadora linda como ela. Isso não existe, é praticamente uma Lei dos Programadores: “mulheres bonitas nunca serão programadoras.” Porém, ela programa em Python, e o Pownce é feito em Django.
Portanto, Ninh disse nos slides:
Sobre isso eu quero meus créditos! :-) hehehe. Na realidade eles já pretendiam colocar suporte a WSGI (que é o que o Django usa, por exemplo), mas por causa disso esse suporte ganhou nova prioridade e, em 2 dias, Passenger já suportava WSGI. Ele disse que mandou e-mail pra Leah, mas ainda não teve resposta. Boa sorte!
Claro, Passenger primariamente foi feito para suportar Rails. Diversas inteligências como o spawner, o copy-on-write, dependem exclusivamente do comportamento de dependencies do Rails. Portanto para obter os números dos slides anteriores, considere sempre Rails. Como o Hongli disse, apenas o Rack não é suficiente para ‘adivinhar’ esse tipo de detalhes.
Tanto Rack quanto WSGI ainda vão evoluir nas próximas versões, mas eles fizeram isso para demonstrar a flexibilidade da arquitetura do Passenger. Aliás, o código será finalmente aberto nos próximos dias e qualquer um poderá contribuir, pois será open source. O Hongli mesmo disse que a maior parte do source code é mais comentários e documentação do que propriamente código, portanto vocês não devem ter dificuldades em entender.
Uma das coisas que pode acontecer (ainda é uma possibilidade apenas!) é o Passenger passar a fazer parte do Mac OS X. No Leopard tanto Ruby, Rails e diversas gems já vem pré-instaladas. Mas com o Passenger, o Mac se tornaria o pacote mais simples para se desenvolver em Rails.

Eles voaram para Cupertino logo depois da RailsConf para uma reunião direto na mother-ship! Espero que boas novas apareçam em breve!
Finalmente vocês entenderam porque eu bloguei tão pouco durante a RailsConf: pela metade do evento meu notebook ficou na mão do Ninh. Isso porque ele havia lido que a alfândega americana poderia querer revistar notebooks e não devolver, então ele deixou o mac dele em casa e havia pedido se eu não emprestaria minha máquina a eles.
Eu disse que sim, mas com direito a uma entrevista exclusiva logo em seguida à apresentação. Ainda preciso compilar isso, mas eu gravei um audio podcast e o Carl gravou o vídeo dessa entrevista, que pretendemos liberar em breve.
Nesta foto vocês vêem o Gregg Pollack os entrevistando para este video :

Ninh Bui at Railsconf 2008 from Gregg Pollack on Vimeo.
Foi muito engraçado acompanhar esses garotos durante a RailsConf, eles são muito engraçados e espirituosos. O mais importante, são jovens estudantes de ciências da computação na Holanda, eles pegaram um problema que ninguém resolveu e em vez de blogar bobagens a respeito como “Ruby é uma droga porque o garbage collector deles não deixa suportar copy-on-write” ou “Apache é uma droga porque é pesado” ou “Rails é uma porcaria porque mod_ruby não funciona com ele”, etc eles pegaram todos esses problemas e codificaram uma excelente solução!
O próprio “Ruby Enterprise Edition” na realidade é um binário de Ruby customizado com os patches que modificam o GC e possibilita os ganhos de memória e performance. O instalador torna o processo transparente, copiando tudo num diretório isolado que, caso você não queira mais, pode simplesmente apagar ele fora. O Passenger pode ser configurado para usar seu Ruby padrão ou o “Ruby Enterprise”. Em breve talvez esses patches entrem no trunk do MRI mas isso ainda não aconteceu.
Tudo que eles fizeram segue o Ruby License, por isso mesmo o nome “Enterprise” é só uma brincadeira, tudo que eles fizeram sobre o Ruby precisa voltar à comunidade e é isso que vai acontecer.

Conversando com Michael Koziarski
depois da apresentação da Phusion.
No mesmo dia, no painel de fechamento, o Rails Core Team se juntou para responder perguntas da platéia. Estavam o David Hansson, o Michael Koziarski, Rick Olson e Jeremy Kemper. Durante a sessão aconteceu algo interessante: de repente o Vinicius Telles sumiu do nosso lado e eu escuto alguém falando no microfone que se parece muito com ele!!


Ele basicamente perguntou o que o Core Team achava sobre o Passenger, daí o próprio Koziarski disse que já estava usando em seus próprios sites e que estava muito contente com os ganhos de performance e redução no consumo de memória, dando um testemunho muito positivo. Não preciso dizer que o pessoal da Phusion ficou extremamente feliz por ter recebido elogios diretamente do Rails Core Team numa das apresentações com lotação quase total da platéia. Foi muito legal!
Finalmente, no final, ainda pude capturar um pequeno momento engraçado. Como eu disse antes, quem fez a doação estava presente, levou uma caixa (literalmente uma “caixa”) Enterprise, com camiseta e um DVD com a versão 2.0 do Passenger. E vejam quem estava levando uma caixa para Tim Bray:

Charles e Thomas levando Phusion Enterprise para Tim Bray :-)
Enfim, foi muito legal conhecer esse pessoal todo e acho que a apresentação do Passenger foi de longe a mais divertida da RailsConf. Talvez se não houvesse o MagLev também teria sido a mais importante, mas elas ficaram muito próximas. A diferença: Passenger funciona hoje, em produção!
My Career - Level 3 21 May 2008 6:15 AM (16 years ago)

That’s for all my friends who don’t speak portuguese. I’ve met outstanding people from all over the world who’ve been very supportive and believed in my goals since the very beginning. People like Satish Talim, Geoffrey Grosenbach and many many other visionaries. Thanks to you all and I hope you keep appreciating the efforts we’re doing here in Brazil.
So, this week I’ve had the worst/best weekend I can remember of. First of all the good stuff: last week the #1 Brazilian hosting company, Locaweb decided to support and invest on Ruby on Rails and its first move was to launch a trial period of a mod_rails based shared hosting plan. But they won’t stop there.

Last week I started conversations directly with Locaweb’s CEO and founder Gilberto Mautner and Product Director Joaquim Torres (a.k.a. Joca). Which means that Ruby on Rails is coming from both ends: the top and the bottom of the chain, recognizing the value of both the technology and the growing community in Brazil (congrats to us all!)
One of the strategy pieces is a new hiring not only to help them revert their bad reputation around the brazilian Rails community but also make them the best Rails services provider on the market. That’s a bold goal and a huge challenge. That’s where I am in, starting on mid-June, I’ll become Rails Product Manager at Locaweb with the sole mission to outdo those expectations. Not only by creating outstanding products but also helping to speed up the growth of the Brazilian Rails community.
That’s the ‘worst’ part I mentioned: on Monday I reported my leaving from Surgeworks LLC. Those who’ve been watching my career know that I spent the last year being part of the Surgeworks family with enormous proud. Since then the trust bonds grew as well as great friendships solidified, specially with our ‘commander-in-chief’ Carl Youngblood.
As a result of this excellent partnership our Brazilian crew have grown, starting with Marcus Derencius, Carlos Brando, Rodrigo Kochenburger, and Renato Carvalho. We’ve been through several projects. By now you understand why I said ‘worst’: how do I leave behind everything we’ve accomplished in the last year?
It is easy to leave a crap company, but it is impossibly difficult to leave great partnerships such as with Surgeworks. But this time I was in a crossroad, with very different paths to follow. It never was because of the easy money or any other benefit – and actually, money-wise I will still receive the same amount anyway. It’s the promise that comes with this new opportunity. Locaweb has the resources to accomplish what they intend and the order came from the top of the chain. With this promise alone I decided to step forward and accept the challenge to help both Locaweb and the Brazilian Rails community to reach such bold goals.
Repeating myself again, as always, the best piece of Ruby on Rails is its community. Specially true in Brazil. We all helped each other in one way or another. Again, I am counting on you – be from Brazil or any other country. Your collaboration is gold. I need critics – even the worst ones matter -, ideas, suggestions, feedback. What do you want me to do in order to achieve our goals?
And why I consider this important? Because it is the very first time a really big company decided to invest on Rails here in Brazil – and in Latin America for what I know. We inherit their visibility and credibility on what we’ve been doing. If we do it right, others will follow. Trainings, classes, books, products, customers and, specially, jobs right here in Brazilian soil.

When I wrote my first book in 2006, very few of us were using Rails, and almost none full-time. I wasn’t the first but the community was not one. My goal was to be able to make myself work full-time with Rails, even if I had to rise my whole market around it. That was Level 1.
In 2007, around this same time, Level 2 came to be, when I was finally able to start working full-time on Rails because of the trust Surgeworks had on me. Now, it is the turn of the tide with the arrival of Level 3, where I finally have the resources to fulfill the goal I set to myself more than 2 years ago.
I am very very thankful to Surgeworks for their unique opportunity and I still recommend them to anyone who wants to work in Rails consultancy and to any client who needs high-quality and well cared projects. I’ve spent years in Brazilian consultancies and I wouldn’t recommend any of them, actually I would highly recommend against most of those ‘big iron’ consultancies here. Surgeworks is the first I will keep actively recommending. I am still friends with all of them, including my Surgeworks coleague and partner Carlos Brando in our weekly Brazil Rails Podcast. The translation projects will keep going as before. Level 1 had a great closure as well as Level 2. Mission accomplished so far.
Now on to Level 3, are you with me? Let us all go to Level 4?

Chatting with Hongli Lai and Ninh Bui (Phusion) 6 May 2008 4:39 PM (16 years ago)

Hongli Lai and Ninh Bui, from Phusion, shaked the Rails world a few days ago. They unleashed the Holy Grail of Rails deployment: mod_rails which was received with much fanfare, and they deserved it.
They finally settled the big issue that embarrassed Railers in the past. This will also relieve dozens of hosting services that were clueless on how to solve this equation. Now, those two computer science students are above them all with this clever solution. And they have more to come.
I was very fortunate to be able to interview them. I think this is the second interview, InfoQ broke the news first with this other interview which I highly recommend to understand more of the inner gears of Passenger. They are very easy going and it was a pleasure to talk to them.

AkitaOnRails: I think the first thing I’d like to know are your backgrounds. Which one came first? mod_rails or Phusion? Meaning, did you have a company named Phusion that ended up developing mod_rails, or mod_rails was the reason to build a business around it?
Phusion: Well, as you’ve probably read by now, we’re both computer science students at the University of Twente and we’re currently in the final stages of finishing our bachelor degrees. From the beginning, we had already inferred that study can’t teach you everything, so over the years, we’ve also been doing a lot of work both commercially as well as for the open source community.
After becoming familiar with each others skills, philosophies and personal traits and from our past experience in working in IT, we thought it would be a good idea to combine our forces into a company that we could call our own, and so Phusion came to be.
So Phusion actually came before Passenger (mod_rails). More specifically, our intent was to start a company that strictly provides top-of-the-bill IT products, ideas and services to support our clients’ businesses. Passenger coincidentally happens to be our first product, and from what we’ve been hearing from both the community and companies, it seems to be perfectly in line with our company’s philosophy.
Also, after doing years of (web) development in other languages/frameworks such as PHP, J2EE, ASP.NET, etc. we’ve really come to appreciate Ruby on Rails. We think it’s really elegant and easy to use. Unfortunately deployment seemed to be out of line with the rest of the Rails experience, especially the convention over configuration part. This is why we’ve created Passenger: we want the deployment experience to be just as smooth.
AkitaOnRails: Is Phusion a consulting company or a product company? Right now you released one of the most interesting projects in Rails land so far, which is mod_rails. Now you’re preparing to release Ruby Enterprise Edition. Any new products in your pipeline that you could tell us about?
Phusion: Well, Phusion is primarily a service oriented company and we think our mission statement answers this question best:
“To exclusively provide top-of-the-line products, services and ideas, in order to support our clients’ businesses.”
If our clients’ businesses require consultancy, then we’re able to provide that as well seeing as we’ve had quite a few years of experience in that particular line of business.

In order to achieve this mission, it is crucial for us to be well-versed in a variety of skills and we’re well aware of the saying “jack of all trades, master of none”. It is for this reason that our team comprises of only highly skilled people from those parts of the industry that are of particular interest to our clients’ businesses. The reader will probably note that this allows for a dynamic configuration in organization as well as keeping the work challenging: we don’t believe in keeping people around forever for no rational reasons, so it is crucial for our employees to keep learning within our organization (hence the alias, “the computer science company”). This not only opens up a lot of doors on the innovation side, but also results in people becoming masters in several areas. So “jack of all trades, master of none” may hold true, we believe “master of a lot of areas” could just as easily hold true. Needless to say, this is crucial since computer science and IT cover such a wide area, and this particularly holds true for our clients’ businesses.
Ruby Enterprise Edition has actually been called to life as a result of Passenger: it strives to dramatically reduce memory usage of Ruby on Rails applications that are run through Passenger.
As for new products, we’re currently working on a few subscription-based web services. Our friend David Heinemeier Hansson has recently given a talk on startups which elaborates on the reasons why one would want to follow such a path. We’d highly recommend the reader to check that out and for strategic reasons, we’d like to leave it at this for now.

Hongli Lai
AkitaOnRails: For a long time the whole Rails community was rather too much comfortable with the Mongrel solution. When Zed Shaw ranted about the community, it was a wake up call and from there we saw alternatives emerging overnight such as Thin and Ebb. What did you think about that situation back then?
Phusion: From what we understand, solutions such as Mongrel, Thin and Ebb fall under the same conceptual category. That is, for the end-user, they work in a similar way, even though they are technically different. In other words, Thin and Ebb seem to be like “Mongrel, but faster/smaller”.
Passenger however has taken an approach to deployment that’s different from Mongrel et al: it intends to make deployment as simple as possible, and to lower system maintenance overhead as much as possible. For example, while Passenger handles this automatically, Mongrel, Thin and Ebb all require the administrator to manage clusters. As you’ve stated, the tech savvy have already become quite familiar with the latter, but one also needs to take the newcomers into account. For them, it’s quite an obstacle to overcome to just simply deploy an application. If we were to consider the backgrounds of these newcomers, many of them are probably already familiar with the PHP way of deployment, that is, in an upload-and-go manner. With Passenger we’ve tried to accommodate these people, as we think that this is important to the growth of the Ruby on Rails market. That doesn’t however say that we haven’t taken issues such as robustness, performance and stability into account.
As a matter of fact, independent tests have already shown that Passenger is on par or faster than the aforementioned solutions. Another problem is that shared hosts are already running Apache as their main web server, and we’ve already seen what configuration needs to be done in order to get a Mongrel cluster up and running with Apache… Needless to say, this is quite tedious and error-prone, even for many tech savvy to say the least. Passenger literally reduces this process to a matter of seconds instead of minutes. This should not only save a hosting company a great deal of time but should also keep their server administrators sane (and from our experience, they’re the last people you want to offend ;-)).
Also, setting up a Mongrel-like cluster requires quite some resources on a shared host, and it is for reasons such as these that the costs of shared Ruby on Rails hosting plans are usually higher than that of PHP hosts. Passenger however, takes on this issue as well by providing improved efficiency over the aforementioned solutions, especially in conjunction with Ruby Enterprise Edition. Early testing has already shown that the latter has resulted in a dramatic reduction in memory usage and we’ll elaborate on this soon.
If we consider these factors, it becomes apparent that Passenger (in conjunction with Ruby Enterprise Edition) has the potential to unleash a revolution within shared hosting. Not only in cost-reduction for hosting companies (and hopefully consumers), but also in increasing the popularity of Ruby on Rails.
AkitaOnRails: mod_ruby seems to be staled for a long time and needs some love. It is said that it works reasonably well for small websites but lots of ‘black magic’ in Rails makes it not suitable for mod_ruby. What makes mod_rails different than mod_ruby, in the fundamental way they operate with complex frameworks as Rails?
Phusion: We’re not really able to comment on that, because we’re not intimately familiar with mod_ruby. However, mod_ruby is not actively maintained, and there are a lot of negative comments about mod_ruby in general (such as on the Ruby on Rails wiki). It also seems that nobody really uses it. It is for these reasons that we’ve never really given mod_ruby a try.
From the aforementioned and what people often tend to forget, is that only delivering a(n excellent) product will not suffice. Marketing and promotion are really important for a product’s acceptance. We’ve not only done a lot of development, but also spent a lot of time in promoting Passenger. The fact that we’re having this interview right now is probably the result of our promotion campaign, so we’re quite happy with that. In this regard, mod_ruby doesn’t seem to be actively promoted, and perhaps this is one of the reasons why it’s relatively unknown.
AkitaOnRails: why do you think it took so long for someone to come up with a solution for an Apache module that could operate similarly to the usual mod_php or mod_python? What did you think was the most challenging aspect in the development of mod_rails?
Phusion: Well, as you’ve stated, we believe that experienced Ruby on Rails developers don’t consider deployment to be a problem; probably annoying at most. They’ve automated/standardized the deployment process for a great deal with Capistrano scripts. Newcomers however see deployment as an insurmountable problem. Consequently, we end up having a situation in which the people who can solve the problem either don’t see a problem or aren’t motivated enough to fix the problem, while the people who do see the problem cannot solve it.
Furthermore, from our personal experiences, newcomers usually want to see immediate results. It’s very demotivating for those people to continue using Ruby on Rails if they have to manage tons of obscure configurations and clusters to ‘just successfully deploy an application’. This leads to very intelligent conclusions, such as that “Ruby on Rails sucks”. ;-)
The most challenging aspect is probably cross-platform support and to elaborate on this in a nutshell:
- We have to support a whole bunch of Unix-based systems, like Linux, BSD and OS X. Passenger works on a fairly low-level (i.e. it uses advanced Unix system features), and different systems tend to behave in subtly different ways such that they can break Passenger if we’re not careful.
- A lot of challenges are created by MacOS X and Apache. There are literally tons of different ways in which Apache can be compiled and installed, and this is especially true on MacOS X. Every single Apache installation can be slightly different, and we have to support all of them. We had to write hundreds of lines of Apache auto-detection code in order to make the installation as smooth as possible. And support for OS X-specific things such as universal binaries didn’t make the challenge any easier.

Ninh Bui
AkitaOnRails: the usual Shared Hosting approach with Rails involves FastCGI, I think that’s where mod_rails will make a big impact first. In the VPS arena people are usually more comfortable just loading up a mongrel cluster, maybe a monit or god to monitor them or even use Swiftply to better control mongrel instances. There’s some tweaking involved in having permanent Ruby interpretors running, that’s mainly because of the fact that if at some point the VM needs more memory, it will allocate as much as it needs, but not return it back to the OS. Does mod_rails has some thing to avoid a monitoring system like Monit or it is still needed?
Phusion: We’ve taken this challenge into account as well. Rails applications that have been idle for a while are shut down, thereby releasing all of their resources to the operating system. Furthermore, it is possible to use Passenger in conjunction with monitoring tools such as Monit. If Monit kills a Rails process, then Passenger will automatically (re)start it when needed, as if nothing bad ever happened.
AkitaOnRails: I understand that mod_rails operates more or less like a manager for a pool of Ruby VMs. You have a minimum and maximum number of processes allowed, mod_rails starts as many as it needs depending on load and if a process is sitting idle, it will kill it after a timeout period. Most of the time a minimum amount of processes will stay running. Is that how it operates?
Phusion: It is as you describe it, with the exception that there’s no such thing as a minimum amount of processes. The reason for this is that, once an application for a certain Rails directory is spawned, that application process cannot be reused for a different Rails directory. This makes the concept of a minimum amount quite useless, except in servers that only host a single Rails application.
Of course, not having a minimum amount of processes will mean that the first request after the idle timeout will undergo a performance penalty and be slow. We’ve solved this issue by using spawner servers. Spawner servers cache Ruby on Rails framework code and application code, and they can reduce the spawn time by about 50% and 90%, respectively. You might have noticed these spawner server processes in the output of ‘ps’. The secret in reducing spawn time would lie in altering the idle timeouts of these spawner servers. We are currently working on a series of articles, in which we elaborate on the spawn times of Rails applications, what the exact roles of the spawner servers are, and how system administrators can optimize server settings to reduce spawn time.
Much of the magic that resides in Passenger still needs to be unveiled and we’ve only just started, but this is mainly for the interested people out there, i.e. the tech savvy. There is a saying in Dutch that summarizes the thought behind why we haven’t done this up till now: “Goede wijn behoeft geen krans”, which would roughly translate to that a good product does not need any supporting elaboration. A scientific publication on the other hand does need this kind of elaboration and it is also for this reason that we’re writing these articles as well.
AkitaOnRails: By staying in the same memory space as Apache itself you don’t have the overhead of a FastCGI or HTTP call over to a mongrel instance. Does this difference account for much in your benchmarks? Usually, in your experience, how much faster is mod_rails right now compared to a bare bone mongrel cluster running the same apps? Are the gainings in speed a constant or it varies enough that it is not really measurable?
Phusion: This is actually not true: the Rails processes don’t reside in the same memory space as Apache. Instead, they really are separate processes, that each can be individually shut down without affecting all the others. It is not a very good idea to embed a Ruby interpreter in Apache because of various issues, such as stability, heap fragmentation and unnecessary bloating of a process’s VM size. From what we understand, mod_ruby takes the approach of embedding Ruby inside Apache, and we suspect that this is one of the reasons why people are reporting so many problems with it.
Our own tests have shown that Passenger’s performance is faster than a Mongrel cluster behind Apache+mod_proxy_balancer. Independent tests have shown that Passenger’s performance is either on par with or slightly faster than Mongrel cluster and this seems to be perfectly in line with what we’ve been able to infer. So far we haven’t seen any tests in which Passenger is slower than a Mongrel cluster. The speed gains are not constant: they are dependent on the specific application.

Phusion folks at Fingertips
AkitaOnRails: Ruby Enterprise Edition, for what I understand, is the outcome of that ‘copy-on-write’ series we talked about. Essentially a way to patch the Ruby VM to enable a modified GC that won’t mark every object, thus allowing COW to do its work and save a considerable amount of memory. You stated 33%. I would assume that it is ‘up to 33%’, right? What’s the usual range of saved memory you experience in your tests? What affects this the most in typical Rails apps, any gotchas worth mentioning for Rails developers?
Phusion: The mentioned 33% is not a maximum, but an average. We’ve tested with real-life applications such as Typo, and so far we’ve inferred an average memory saving of 33%. The actual memory savings is dependent of the specific application so your mileage may vary.
There are no gotchas for application developers. If their application works with Passenger, then Ruby Enterprise Edition will work as well, without any need for complicated configuration options. In other words, it’s a transparent augmentation. In any case, we can guarantee you that memory usage will be no higher than when you use standard Ruby.
AkitaOnRails: I understand that you will talk more about the Enterprise Edition at RailsConf but I was hoping that you could disclose a little bit more about it. You are just finishing the second batch of donations for Enterprise licenses (I donated! :-). First things first: when are you going to release it? Is this product supposed to stay commercial only or do you intend to collaborate the GC patch back to the Ruby trunk one day?
Phusion: Thanks for donating, and as for the latter: yes, it is our intention that it will one day be merged back upstream. The alert reader will probably notice that we’ve dodged one question like Neo dodged Agent Smith’s bullets in the Matrix: skilled, except for the last bullet, that one actually hit, but enough about that ;-).
AkitaOnRails: “mod_rails” is actually the alias for “Passenger”, some people are asking if this is going to stay Rails only or if you intend to make it Rack-compatible so other frameworks as Merb and Ramaze could run under its control. Is that possible? Are you considering it?
Phusion: Let’s just say that we would prefer you to call it Passenger instead of just mod_rails eventually. ;-)
AkitaOnRails: Apache is the powerhouse for Web servers and it makes a lot of sense for an Apache module like that. Maybe I am speculating too much, but do you think it is possible to refactor it into other web server’s modules like nGinx or Litespeed? Because of the lack of a good mod_rails in the past, the Rails community drifted away to other alternatives. Is it reasonable to expect non-Apache modules?
Phusion: It’s technically possible. To keep you guys in suspense and to keep you speculating on such matters, we won’t dive into this further for the time being. ;-)

Passenger being installed!
AkitaOnRails: The way it is right now, it feels like mod_rails is a drop-in replacement for whatever strategy we had before using Apache. Are there any gotchas worth mentioning for anyone planning to migrate? I think complicated mod_rewrite rules would be the first thing?
Phusion: There’s a minor gotcha. By default we override mod_rewrite the best we can. This is because Rails project come with a .htaccess file by default, and this .htaccess contains mod_rewrite rules, which result in all requests being forwarded to CGI or FastCGI.
This is trivially solved by deleting the default .htaccess and by enabling a configuration option which tells Passenger not to override mod_rewrite. This allows the developer to use arbitrary mod_rewrite rules to his liking.
Other than that, the remaining gotcha would be that rails deployment has become quite boring thanks to Passenger, or so people say. ;-)
On a final note, we’d like to thank all you guys out there for the love and (financial) support on Passenger. We really appreciate it!
With kind regards we are, your friends at Phusion,
Hongli Lai
Ninh Bui
Chatting with Chris Wanstrath (Err the Blog/Github) 21 Apr 2008 2:12 PM (16 years ago)
Chris is a very accessible and easy-going guy, and I just got him out of AIM and started the interview right away. For those of you who never heard of ‘Chris Wanstrath’, he is also known for Err the Blog and recently as one of the guys behind the Github phenomenon.
He answered everything in color detail and we speak a lot about his open source projects, performance, scalability and, of course, lots of Git and Github stuff. Hopefully it will make people even more excited with how the Ruby/Rails community is moving things forward all the time.
aos leitores brasileiros: assim que tiver tempo irei traduzir esta entrevista.
AkitaOnRails: Ok, so, where are you from?
Chris Wanstrath: Right now I live in San Francisco but I grew up in Cincinnati, Ohio. I moved to San Francisco in 2005 to work for C|NET where I did PHP for a while on sites like gamespot.com, mp3.com, and tv.com
In 2006 I moved over to the chowhound.com site within C|NET to work on Rails, which is something I had been doing on the side for a while. While I was there P.J. Hyett and myself worked on chowhound.com then built chow.com, which we launched later that year. Then in April of 2007 we both left C|NET to form our consulting company, Err Free.
In December of 2007 we launched FamSpam, which is a site for keeping in touch with your family. It’s basically a simplified version of Google Groups with emphasis on participating in a thread at least once a week and easily finding photos or other file uploads.
While P.J. and I were working on FamSpam, Tom Preston-Werner and I were working on GitHub on the side. We started in October working nights and weekends on it. We basically wanted an easy, pretty, and feature-rich way to throw our Git repos up and share them with people. Then as we got more into it, we realized how things like the dashboard could change the way we deal with open source contributions. After that, all the social features began to fall into place. Github private beta launched in january, and in april we saw the public launch
AkitaOnRails: Wow, Cool, you are a very busy guy indeed, I want to go on in details within each topic you mentioned but first I knew you worked for C|Net because of your memcached keynotes. I have 2 questions: you were a PHP programmer, what made you switch to Ruby on Rails? And then, working for a high profile network like C|Net exposed you to very demanding public websites. How did you figured out about leveraging memcached with Rails and then your cache_fu plugin?
Chris Wanstrath: I started doing Rails at the start of 2005 and got my first PHP job in February of 2005. (before that I was doing asp and Perl, which I don’t like to talk about). So really, I never considered myself a “PHP programmer” over a Rails programmer. I really liked websites and I knew I could get paid doing PHP, so that’s what I did. In the meantime, I was constantly doing Ruby on the side.
When C|Net started doing Rails, I knew it would be a perfect fit for me. I really liked PHP and loved Gamespot, but it was just silly for me to spend all night playing with Ruby while doing PHP professionally.
In fact, one of the things that got me hired at Gamespot was my pure PHP yaml parser called SPYC (simple PHP yaml class). It was inspired (obviously) by _why’s syck yaml parser. I wanted an easy, extension-free way to deal with YAML in PHP because I was so spoiled by Ruby.
I think today the CakePHP and Symfony frameworks use it, and do their config stuff in yaml. But even when writing PHP I wanted to be writing Ruby. The main reason I picked up ruby in the first place is because I knew PHP, and I knew Perl, but I wanted something I could use to write both websites and command line scripts. Perl was great for scripts, and PHP was great for sites, but I was just tired of using them both
So while I was learning Python, Rails popped up.
As far as cache_fu goes, I was very interested in some of the “scaling” aspects of running a website while working at Gamespot.
While good OOP design and stuff like that can be learned by anyone writing enough code, you can’t really learn about scaling unless you’re working on a big website. There are just too many tricks and moving parts, and it’s too hard to simulate the load in a controlled environment.
So while at Gamespot, like I said, I tried to learn as much as possible about things like MySQL replication, clustering databases, sharding databases, and memcached based on how the smart guys at C|Net had set it all up over the years. They had a lot of machines serving a lot of traffic so it was perfect
At Chowhound, we were re-writing an old static html site in Rails and were worried about the transition from flat files to dynamic database calls and page generation. It had a fair amount of traffic from a group of rabid fans, and we knew the new “web 2.0” look of the site would not sit well with the old school users, so we at least wanted the site to be performant in order to give them one less thing to complain about. So we basically took a lot of what I had learned at Gamespot, and what information was freely available on the internet in mailing lists and discussions, and tried to do a more Rails friendly way of object caching with memcached.
Ruby is just so good at cleaning up repetition and creating friendly apis. So cache_fu does fragment caching and object caching, because in bigger sites you end up using both for different purposes which is how it was at Gamespot too, basically.
AkitaOnRails: Nice. And it is not very common for me to find people that have dealt with really big websites. Can you give us a glimpse of what kind of load your Rails apps did have to handle? Some pundits I know complain about the vanilla Rails distribution and recommend lots of tweaks like dumping ActiveRecord altogether and several other hacks. Do you have to hack Rails a lot in order to achieve the scalability you need or do you think most of it is good enough so you can avoid too much tweaking?
Chris Wanstrath: I wouldn’t really consider Chowhound to be a big Rails site anymore. Now that you’ve got scribd and twitter and friends for sale and Yellowpages, Chowhound doesn’t really make the list.
We ended up doing a lot of premature optimization on that site, and not enough real world optimization. I learned a lot of lessons there that I’ve applied to other sites along the way. However, I recently had the chance to work with the friends for sale guys on their Facebook app which gets millions of page views a day and handles an insane amount of db records.
To my knowledge, the only AR hack we did was apply Pratik Naik’s partial updates patch. This was because, with so many rows and such large indexes, you want to avoid modifying indexes when you don’t need to, so saving only the changed columns/attributes can have a real big performance gain. Luckily, partial updates are now in Rails Core.
In my experience, you spend a lot more time trying to scale SQL before you even need to address AR. And once you get to the AR part, it’s usually your application code. Fetching and saving too many records in before/after_save callbacks, full row writes like I was just describing, and generally not being a good SQL citizen. I would only ditch AR completely if I felt like I had no control over the SQL it generated. Which, as anyone knows, is not the case – you have a lot of control over it.
There are times, however, when AR is overkill and you really do need speed. On Github, we need to authenticate you every time you try and pull or push a repository over ssh. Loading an entire Rails environment, or even activerecord, was noticeably slow, so we switched to using sequel in a simple ruby script. Because we don’t need AR’s massive featureset and nice OOP capabilities for such a simple single row find, this made a lot of sense for us.
AkitaOnRails: I agree with that, that’s what I experienced too with regards to AR. So, and you’re also the author of several other famous Rails plugins like will_paginate, Ambition, the original Sexy Migrations. Can you comment briefly about each. Am I forgetting any other plugins? Some of what you did became the ‘de facto’ standards for Rails development, some people here use these plugins without really knowing you made them all.

P.J Hyett at SXSW’06
Chris Wanstrath: Err the blog is actually two people, P.J. Hyett and myself. I did not write will_paginate – P.J. wrote the original version then Mislav Marohnić re-wrote it. Mislav is now the maintainer. But I still get all the credit, which is fine by me.
As far as the other plugins go, there’s mofo, ambition, sexy migrations, cache_fu, acts_as_textiled, fixture_scenarios_builder, and gibberish.
Mofo is a microformat parser based on Hpricot. It’s up on Github and unfortunately doesn’t get enough love from me these days, but as far as I know it’s still the gold standard for microformat parsing in Ruby.
It was the first gem that I released which doubled as a Rails plugin, which is how I think most plugins should be distributed in the future. Gems already have a solid distribution system and versioning scheme, and if Github becomes a gem source then there’s almost no reason not to release plugins as gems
Sexy migrations were inspired by Hobo. Unfortunately their version was hobo-specific, so I wrote a plugin-friendly version. DHH later wrote his own version and rolled it into core, making a grand total of 3 distinct sexy migration implementations.
Gibberish is a pretty fun localization plugin I wrote pro bono for a client, just because I felt like the APIs of all the existing localization plugins were so difficult to work with. Hopefully, with the help of anyone interested, we can begin localizing Github in the near future.
Ambition was inspired by dabbling in Erlang. I read a blog post explaining that mnesia’s query syntax, which is all list comprehension (basically Ruby’s version of the Enumerable module), was made possible by the ability to walk the parse tree and build an mnesia query that way.
So I started playing with the parse_tree gem to see if I could do the same for Ruby. It’s now, of course, a full fledged framework for generating arbitrary queries for any RubyGem based on Enumerable. For simple queries, I really like treating tables as arrays, it feels very natural.
Acts_as_textiled was the first Rails plugin I released. It’s a testament to Rails that the plugin still works on edge today. The only other notable thing that Err started is the “vendor everything” term, which is now a part of Rails through config.gems.
That, and the Cheat gem (and site).

Tom Preston-Werner
AkitaOnRails: (Of course, pardon me P.J.!) And this raises another curiosity of mine: where did the name “Err” come from? It is both for Err the Blog and Err Free which is your company. And you mentioned P.J. and Tom. And you’re all full time Railers, right? How did you teamed up with them and decided starting your own company? Many times people ask me about entrepreneurship and you’re another good example.
Chris Wanstrath: “err” is kind of a play on “Typo,” which was the popular Rails blogging engine when we started our blog, so it may be kind of confusing, but I actually am cofounder of two distinct companies.
There is Err Free and Logical Awesome. Err Free is Ruby & Rails consulting and training. P.J. and I own the company, and we use it to do client work, speaking gigs, corporate training, that sort of thing. It also owns and operates FamSpam, which we use with our own families.
Logical Awesome, however, was founded by me and Tom. This is because I was developing FamSpam with P.J. and GitHub with Tom at the same time, separately. Today, however, P.J. is a part of Logical Awesome and is one of the GitHub developers.
Tom works at Powerset and doesn’t actually do much Rails for GitHub, he mainly does flash, haxe, C, css, design, and ruby. And because he’s the author of God, I make him write all the config files, too. As far as deciding to start a company, I am someone that needs to be involved in whatever I’m involved with on every level. At C|Net, there is only so much input you can have on a website that employs 30 people especially when there are dedicated product and “vision” people, whereas with Github, it’s just me Tom and P.J.
If the site is slow, confusing, sucks, or doesn’t improve your workflow, I can take responsibility for that. But if it’s fast, simple, awesome, and life changing, I get to take responsibility for that, too. Which is very rewarding.
It also means, when you’re cofounder of a mostly technical company, the discussions are a lot more logical. I saw decisions made at C|Net that directly contradicted a/b statistics we had gathered. At Logical Awesome, that would never happen. It is neither logical nor awesome. Basically: I wanted to find the ideal company so I found good people and started it.
AkitaOnRails: Ok, so we come to the main dish of the day: Github! I can’t think of a better example of an innovative product that leverages so well the power of Git. I am very curious to understand how did you come with this idea? At the same time, lots of people still can’t understand why Railers as a whole started using Git so massively all of a sudden. Mercurial, Bazaar guys are very uncomfortable. What do you think Git has that attracted Railers in flocks like that? Or at least what do you think Git has that no other have? I started evangelizing Git here in Brazil last year after listening Randall Schwartz, and recently someone asked be about what would me my pick for a Rails killer-app and Github popped out of my mind, right away. So you do have good mind share as well.

Chris Wanstrath: Github is super exciting to me because it’s really a website just for me. Tom and I are pretty similar in that we both have a fair amount of open source projects, all of which get used and patched by people we’ve never met.
Handling this the old fashion way was fine until me and P.J. started working on FamSpam… as my free time decreased, so did my ability to maintain my open source projects. And really, that’s a definite workflow problem. Sometimes when you can’t find enough time to do something, you just need to make the something take less time.
Github was literally written for chronic, god, ambition, will_paginate, and the rest of our projects. We wanted to make it dead simple for people to contribute, and really, it’s just not possible without Git.
I had started using Git right after viewing the Linus tech talk in May 2007, which is really good at explaining Git from a very high conceptual level. So when this time problem came up, I had already been using Git for a few months and Tom had serendipitously been trying to solve the same problem.
We talked after a local San Francisco Ruby meetup, at a bar of course (where all great ideas and partnerships begin), and decided to work on the problem together. I’d been playing with an err-specific Gitweb, but Github is obviously much more ambitious in its scope.
As far as the adoption of Git, I have no idea what single thing tipped it. When we began working on the app in October, we were worried about ./script/plugin and tarballs and windows and svn mirroring. we weren’t even sure we could build a business around Git, because subversion was still so utterly dominant.
As we all know, however, Git tipped at the start of 2008 and everyone somehow found the time to try it out. It maybe takes, like, two seconds to realize how much faster it is, and then a few more seconds after that to realize how much more awesome it is. So it’s not much of a surprise that it is grabbing converts.
As for the Rails community, it’s definitely because of the projects. When Merb, Rubinius, and Ruby on Rails all switch to Git, you have no choice. This is where the community is headed. As for other languages, we have a large number of non-ruby projects on Github. PHP, Java, Javascript, Lisp, Python — there are a handful of Django forks, for instance, the io and nu programming languages are also hosted on Github.
So really what it comes down to is early adopters, I think. Nu is a lisp written on Objective-C, very new and very cutting edge. The people using it right now are people who realize how powerful and awesome it is to run such a dynamic language on such a mature and stable platform. And naturally, the forward thinkers behind nu know that Git (and distributed source control) is an equally powerful, equally cutting edge concept.
With Prototype and Scripatculous moved over, and rumors of other Javascript frameworks switching, it’s only a matter of time before Git becomes even more widespread.
I think the Railers just like to blog a lot.
As far as other solutions go, it’s Rails vs Django all over again. If you use Mercurial, that’s fine. The two are so similar (yes, Git does work great on Windows) that as long as people move to distributed source control, it’s still a win.
Oh, but wait, Mercurial doesn’t have Github :-)

AkitaOnRails: There you go :-) And I wonder what were the challenges of putting something as Github together. It is not a simple Rails web app, with very fast, pure Ruby code. You’re probably dealing with thousands of system calls to Git command liners, several background jobs, maintenance, security. What do you think were the biggest challenges while assembling Github before recently releasing it to the public?
Chris Wanstrath: Well you pretty much nailed it right there… scaling Rails is the easy part. scaling sshd, Git, Git-daemon, and our background jobs is the hard part.
We call Git directly many times per page, we need to process jobs that get entered from many different places (create a repo on the website, push a repo through ssh), we need to be secure (ssl and ssh for all private repos at all times), we need to make sure it all runs fast (memcached for both Git calls and the db), we need to make sure you’re “in the loop” with a news feed aggregating information from all different sources within our system (almost 1m rows in the feed table when we launched).
So it definitely has not been easy. Not to mention that ssl is essentially the “slow flag” for http, so we need to make sure we’re going fast because things like your dashboard already have a speed handicap. As an example, sshd stores its keys in an authorized_keys file. Well, we weren’t even done with our beta yet and the keys file was over 4 megs of just plain text. So we had one of the C gurus at Engine Yard patch sshd for us to do mySQL based lookups, giving us faster searches and no pricey appending / writing of a massive file
Matthew Palmer is the said guru, and we plan to make that code open source in the near future.
We’ve also got post-receive (when you “Git push”) hooks running that we host and deliver – so if you push, we’ll POST to an arbitrary url for you with json of the commits. But you can also give us some info and we’ll post to campfire, irc, twitter, or lighthouse for you with custom payloads.
Since we have flash, flash with haxe, Python, c, ruby, bash scripts, lots of Javascript, and some forthcoming erlang under the hood, it’s definitely an interesting mix.
We are fortunate to be hosted on Engine Yard, though. If we didn’t have them we’d be screwed. Their awesome cluster setup with GFS means we can host our potentially 100s of gigs of repositories on a shared, raid’d drive with redundancy and backups. If we were running Github on a barebones VPS, I dont even know how we’d share access to those repos. It wouldn’t be fun.
They also have a lot of experts available 24/7, which is great because I have a tendency to forget to sleep and work until 7am. A lot of the pain of running a heavily unix-dependent site is taken away by those guys.

AkitaOnRails: Interesting, Erlang? I’d like to know what are you up to with it Going back, I think I saw a Rails trunk Git clone at Github way before DHH announced it a few days ago. I think it was Michael Koziarski who first did it, without much fuzz. Were you planning this together with the 37signals guys, or the switch of the Rails Core to Github was something that happened naturally? And do you have any kind of partnership with the Lighthouse guys as well, because you already have some hooks to manage Lighthouse tickets through Github commit messages, right?
Chris Wanstrath: The Erlang stuff will be very cool, I promise. We’ll make a big fuss about it when it’s ready. As far as the Rails thing goes, koz did indeed have a mirror of his Git-svn repo at Github during the beta. It was unofficial. Then in february he wrote a post explaining that the core was thinking about moving to Git.
When I saw the post I emailed him and we talked a bit about what it would take to move Rails to Github, which was obviously something I love on a huge number of levels. He said he would get back to me, and then a few weeks later the Core team contacted us and wanted to discuss the move. The rest is history.
I really respect the work the Lighthouse team does. The bug tracker is great, and the new redesign is even better, but we don’t have any official partnership with them. We wrote the post-receive lighthouse hook because we wanted it, Rails wanted it, and a huge number of our users wanted it.
AkitaOnRails: Many others started moving to Github during the Beta. I think Merb was more obvious because of Ezra’s being involved in Engine Yard. Dr. Nic started using it for the Textmate bundles. Can you point any other high profile Rails related projects hosted at Github right now?
Chris Wanstrath: Merb was actually the reason Github went into beta. We launched the beta so they could start using the site for their 0.9 rewrite of merb-core. As far as popular projects, the best thing to do is check http://Github.com/popular/watched and http://Github.com/popular/forked. Datamapper, Rspec, and Mephisto are some of the popular ones.
AkitaOnRails: Are you using vanilla Git code, or did you customize it in anyway to better fit your environment? Have you ever talked to Junio Hamano or any other Git core maintainer? With Github probably eating up a lot of your time, how is Chow and FamSpam going right now? How are you managing all those products all at once?
Chris Wanstrath: We’ve patched Git-daemon to record statistics, which we’ll soon be surfacing on the website soon in the form of better, more granular activity. You’ll be able to see how many times your project was cloned, popular projects in the last 24 hours, all time most cloned projects, that sort of thing.
We’ve emailed the core Git guys about the site, just to say thanks for writing Git and to let them know about Github, but haven’t really had an occasion to chat with them about anything in particular. If I ever run into any of them, I’ll definitely be buying them a few drinks, though.
I don’t actually work at Chow anymore. My last day at C|NET was almost exactly one year ago, so my Ruby time is spent on FamSpam, Github, open source, and doing occasional client work.
FamSpam is going well. Now that Github is launched, there are a handful of features we want to get in and all. Luckily, however, the site is very polished and has been running smoothly without the need for much intervention. What we’d really love to do, because it’s really just a great Rails-based mailing list, is try out some different concepts.
Maybe one for open source, or a version for little league teams – anyone who needs to keep in touch and have their email workflow and document sharing streamlined. For right now, however, I try to spend as much time as possible on Github. There are so many places we want to take it.
AkitaOnRails: I probably more than exceeded my interview time (sorry about that), but this conversation is super-interesting. One project I just remembered is Sake. To me Sake is very neat because many people complain about “how difficult and complex” the Git command line is, and Sake-like solutions make the workflow a lot easier. For instance, my entire Git workflow for Rails projects are only 4 small sake tasks like Git:update and Git:push. If I am not mistaken someone at Err did Sake, right? Are you still evolving it?
Chris Wanstrath: Yeah, I wrote Sake. It’s not a Rails plugin but it was written to help in Rails development. The “Git tasks” for Sake are becoming quite popular, as Git really just facilitates a better workflow. If you want to implement it, or different branches of that workflow, you can pretty easily just wrap up a few commands into a rake task or bash script.
And while bash scripts are great, sake tasks are portable. A lot of sake was inspired, very loosely, on Git – you can pull in sake tasks from any text file, whether it’s on the web or local, and sake comes with its own daemon for serving your tasks.
So you could share tasks over wifi, or something, the same way you could share Git repositories over an adhoc network. Sake is up on Github, so feel free to add features you feel should exist.
AkitaOnRails: Another thing I would like to hear your opinion about. I recently made a presentation on Rails Deployment strategies for beginners. The most common simple architecture revolves around Apache/Nginx/Litespeed + Mongrel/Evented Mongrel/Thin/Ebb. It is usually a matter of load balancing between a Web server using some kind of IPC to distribute the load back to Ruby VMs running your Rails app.
Now we have mod_Rails. What’s your opinion on having all those choices, do you have any particular recipe you like or it depends on each application’s needs? Did you have time to test mod_Rails? I think Hongli Lai is doing great stuff in regards to things like mongrel_light_cluster and his efforts on making Ruby’s GC more copy-on-write friendly, did you take a look at that?
Chris Wanstrath: The nice thing about Engine Yard is they get to take care of all that stuff for me. So while I used to spend a lot of time benchmarking and playing with different solutions, like Mongrel vs Emongrel, I just let the experts take care of it so I can focus on Github..
So no, I haven’t played with mod_Rails yet because I’m not in the situation where I could deploy it even if I wanted to use it. Which is in my opinion the best situation to be in, and pretty much the reason mod_Rails was written.
AkitaOnRails: And by the way, are you going to make any presentation at RailsConf this year?
Chris Wanstrath: I am. I’ll be talking about “Beyond cap deploy”, which will pretty much be an in-depth look at the Github architecture, and then I’ll be on a panel with Ben Curtis, Geoff Grosenbach, P.J., and Tom about being a “profitable programmer” w/ side projects.
AkitaOnRails: I am very pleased to have the opportunity to talk to you.
Chris Wanstrath: Yes, you too. Thanks!
Interviewed by FiveRuns 4 Apr 2008 8:31 AM (17 years ago)

Monday, Apr 1st, I was invited to participate in a series of interviews being published at FiveRun’s blog, called TakeFive. It was just published.
Thanks a lot for FiveRuns for choosing me, I am flattered as I don’t yet consider myself in the same luminary league as Chad Fowler, Peter Cooper, Pat Eyler, Satish Talim and all the others in the series. I hope to get up there, though :-)
This series revolves around 5 questions out of 15 that I could choose. Being prolific – as you well know – I actually answered all 15 of them. So I will publish here the remaining 10 that didn’t make into the interview. Hope you like’em.
FireRuns: What was your first “ah-ha” moment with Ruby and/or Rails and when did you know that the framework was a good fit for you (or your organization)?
AkitaOnRails: Back in 2005 I was a Java/SAP consultant creating web applications that integrates smoothly with SAP’s underlying processes and technologies. As an eager RSS reader since than, I suddenly started seeing a lot of buzz around Rails. I already knew about the Ruby language but never did anything with it, so I decided to take a closer look. Coming from a Java background, seeing Rails in action blew me away immediately. So decided to learn it, and once I got ahold of the basics I wanted to dig deeper and read the entire Rails source-code. The outcome of this journey was my book ‘Repensando a Web com Rails’, which is a comprehensive documentation of Rails written exclusively for the brazilian audience. As I was doing SAP stuff I also documented Pier Harding’s Rails connector for SAP.
FireRuns: In his RubyConf 2007 Keynote presentation Matz stated that “The suits people are surrounding us” – is this increasingly the case with the community, and what does this mean for the future of Ruby?
AkitaOnRails: Everytime I do a presentation about Ruby or Rails I emphasize that the best thing about them is not only the tecnology, but the community. The reason for Rails catching up so fast is that the community embraced it very deeply and rapidly started to fill in the several gaps. This lead to many amazing products such as RSpec. The Ruby oriented tools now surpasses those from other platforms in many ways now.
I firmly believe that adoption begins from the inside. The suits guys will not decide by themselves. The developers working inside will make the switch first and start convincing their coleagues and bosses. It is a time consuming process, but done correcly, can change the way we develop for corporations.
FireRuns: Do you have any secret techniques, tools, or other Jedi strategies that you can share with our readers?
AkitaOnRails: Unfortunately I am not in the same league as Rick Olson and other Ruby Jedi Masters. My job has been mainly trying to help our local community through information. I am a very prolific writer and I try to help the word-of-mouth process here, though we are still way behind the US in Rails adoption.
What I always recommend is to learn your tool. The first mistake many novice programmers do when they switch to Ruby is try to write in the same way they wrote C# or Java. That’s also one reason some novice programmers get frustrated because the resulting code becomes very ugly and different from those they see in the various screencasts and blogs. Buy Beginning Ruby, from Peter Cooper; The Ruby Way, the classic from Hal Fulton and watch as many Peepcode, Railscasts screencasts as possible. Learning is part of the process that makes adopting Ruby so enjoyable.
FireRuns: Where do you go for Rails-related news and insight – any particular website, blogs, forums, etc. that are of particular value?
AkitaOnRails: Of course. Actually I subscribe to a lot of RSS feeds, dozens. So the only website I go is Google Reader. Some of my favorites are Peter Cooper’s Ruby Inside, probably the best source of Rails related news. DZone, to me, is becoming more and more relevant. Some of my favorite blogs incluse Err the Blog, Josh Susser’s has_many :through, Charles Nutter’s Headius, etc. There are so many great blogs that it’s, again, difficult to list them all. Jamis Buck, Obie Fernandez, Geoffrey Grosenbach, Ezra Zygmuntowicz and so on. I usually read the digest version of the Ruby on Rails Core and Ruby on Rails Talk Google Groups as well, which are very informative.
FireRuns: Let’s talk about Rubinius – what do you see as the major advantage here, even though we’re obviously in the early stages? A test suite at last? A VM that folk can easily hack?
AkitaOnRails: As I always say in my blog, Rubinius is the technology that will become the most important one for the future of the Ruby community. Sorry Matz, but Rubinius is ‘Ruby done Right’. But don’t get me wrong, I don’t say this in a way to diminish the MRI. On the contrary, I love the MRI for what it is, but Rubinius are making all the bold decisions that will make it or break it.
I like Avi Bryant’s motto of ‘Turtles all the way’, and Rubinius represents what I would love to have: Ruby written in Ruby. Just that would be excellent. But Evan is not stopping there, he is making several breakthrough stuff in this project. For instance, I believe the Git buzz in the Rails community really started when Rubinius adopted it. The way of giving the keys to the castle to every single person that contributes is another different paradigm shift as well.
The marriage of Rubinius and Engine Yard is delivering in spades. Rubinius was also probably important to make RSpec even more well known. Now we finally have a full suite technically describing and testing the MRI that both JRuby and IronRuby are making good use of. So it should make Ruby implementations that much more compatible and well behaving.
Evan is a very clever engineer. The way he approached a new Ruby implementation using Smalltalk’s concepts is spot on. So we get the best of both world: the elegant architecture of a Smalltalk VM with the elegance of the Ruby language. It’s a win-win situation. As soon as web framework such as Rails and Merb run without modification on Rubinius, that’s when adoption rates will explode, without a doubt.
FireRuns: Is Rails still waiting for its killer app, or are we already there with Basecamp, Highrise, Twitter, Hulu, Revolution Health, etc.?
AkitaOnRails: You probably listed all the high profile Rails apps out there. Twitter is definitely a killer-app but I am not sure if it is ‘the’ killer-app. For coders, in my opinion, Github has the potential of growing to become a killer app as well. But up until this point I will be honest and say that no, we still don’t have that kind of killer app that would make people come in flocks to Rails.
FireRuns: There was a great article recently on the Rails community in Austin and the Austin on Rails user group specifically. Are you part of a local user group? Tell us about your local community, what you love about it, how it is grown, and what challenges the group sees ahead of itself, in both the near and long term.
AkitaOnRails: Yes, I subscribe to many groups though I don’t participate actively on all of them. Our local group is Rails-br at Google Groups where brazilian Railers discuss about several Rails related subjects everyday. There are a lot of noobs and we try to answer their questions and also we help each other.
It’s growing very slowly, unfortunaly. Different than the US or Europe is that Brazil is an under-developed country. As such, people here give less value to quality of life and enjoyment of their work. They want to be hired, that’s all. And right now people learn Java and C# because they need to. So Ruby adoption is very slow over here. We still wasn’t able to get enough traction to start a positive spiral. There is only my book in portuguese about Rails, the community is small, the media is also small and not paying attention, therefore companies don’t want to try Rails because of shortage of programmers, and programmers don’t want to learn Rails because there are not that many jobs. I hope we can reverse this situation soon.
FireRuns: Obie Fernandez’s new startup Hashrocket, which has been blogged about extensively, is all about being ultra-productive in 3 days. Obie has written about ultra- productivity here, but we have to ask – what are your own tips around, to paraphrase Obie and 37Signals, getting real — on steroids?
AkitaOnRails: I’ve been working with Surgeworks, which is a consulting firm, since June last year. So, I have less than a year of full time Rails experience. Before that I wasn’t doing full time Rails works. But we learned a lot and we still do a lot of mistakes, it’s part of the learning process. If someone tells you that they don’t make mistakes, they are lying.
Getting Real is about being pragmatic. It’s easier if you’re a startup, or yourself a product oriented team. But if you’re a more traditional company, the ‘Getting Real’ approach may feel too radical. It’s funny to say this, but it’s the truth. For them, low prices are higher priority than better quality. They expect Rails to deliver both very high quality and very low prices. There is a lot of convincing and explaining to be able to fully delivery Rails apps that the clients are going to really like.
To me, being a pragmatist is remembering Fred Brooks: ‘there is no silver bullet’. Rails is amazing but is no Silver Bullet either. It is a more elegant tool. But not every tool is able to fit in every job. Some projects are just not suitable for Rails, that’s a fact, but it doesn’t mean Rails is less good, on the contrary: it is great on the kinds of problems it was built to solve.
Programmers have to learn more than simply code. They have to get acquainted with processes and how companies operate. Being an offshore outsourced developer makes it even harder to use Agile methods, for example, so we have to stretch very hard to compensate for that. Communication is key. If the client is not willing to communicate, the project will fail, be it in Rails or not.
FireRuns: The Rails community at large, like many open-source communities, is in our mind very much defined by its charitable work, from the recent acts_as conference Merb/Runinius sessions, to Chad and Marcel’s yearly RailsConf testing tutorials. Is charity in many ways the glue that binds the community together? Any charitable events or initiatives that you’d like to see happen over the next year?
AkitaOnRails: What binds the community together is the common excitement around a subject: in this case Rails. As when you fall in love, passion vanishes very fast if you don’t maintain it. Events are a good way of doing that. You have two for one: you gain exposure for yourself, your project and your company and at the same time you contribute back with knowledge and guidance, helping promote the community all around the country. Whenever Ezra talks, it accumulates more positive points for Engine Yard and makes this brand that more easier to remember by all attendants. Marketing is very important.
In the US there are plenty of events already and still room for more. I would really like to see more action here in Brazil. But without sponsor and more support it is very difficult to make something on the scale of a RailsConf, which is sad. We will keep trying, though.
FireRuns: Charles Nutter recently said that “Not liking JRuby because it is written in Java is like not liking Ruby because it is written in C.” That objection put aside, what is the single greatest challenge for JRuby going forward? Peter Cooper has suggested that Ruby’s only real downside is its lethargic start-up time compared to MRI, do you agree?
AkitaOnRails: I agree with Peter about JRuby being slow to start up, but that’s something that Charles can’t do much about because the JVM behaves like that for everything, not only JRuby. The important part about JRuby is it being fully compatible with the MRI, making it easy to develop using the MRI and then deploying into a Java application server over JRuby.
Being a former Java programmer I don’t dislike. On the contrary, I think it is a great platform, with several amazing libraries and tools that the Ruby community still don’t have. Dismiss Java is a mistake, the same way it is a mistake to dismiss C: everything is written in C.
JRuby is the second most important Ruby project, Rubinius being the first. On the other hand, JRuby is more mature and available right now so you can run your Rails app inside your corporation’s Java servers. It’s very important for a niche that needs access to legacy software – lots of old Java code. It is also important for making the point that Java doesn’t need to be the sole language to run on top of the JVM and helped making Sun more flexible towards new advancements.
Chatting with Scott Hanselman 18 Feb 2008 3:45 AM (17 years ago)
This week I interviewed another person from the Microsoft camp, Scott Hanselman. I know him from his podcast Hanselminutes. In one episode he interviewed both Martin Fowler and David Hansson at last year’s RailsConf, a truly remarkable conversation.

He also posted a great screencast about Microsoft’s new alternative MVC framework and I thought it would be great to have him at my blog to talk about technology and web frameworks. As I said before I think that we should not become alienated about what’s going on in other fronts and Scott is a very forward thinking and open minded person as well.
AkitaOnRails: First of all, let me congratulate you mr. progman.exe :-) I understand that this was something you’re very excited about. Can you tell us a bit more about your transition to Microsoft and your new duties?
Scott Hanselman: I’m working for Simon Muzio who runs www.asp.net, www.iis.net and large content-packed sites like that. I like to think my job is writing a book that will never end, where that book is blog posts, articles, screencasts, videos, talks, etc. I’m a teacher at heart, so while I took the title “Community Liaison” I like “Teacher.”
AkitaOnRails: Tell us about your history. How did you start in the computer world? Did you always develop more toward Windows or did you have a background in the Unix world as well? And before you recent departure to Microsoft you worked for Corillian. What was your role there?

Scott Hanselman: This blog posts talks about my early years in school.
See that book on the right there? That’s how I learned to program. This book was THE book in 1984. I typed in the whole book on a Commodore 64.
And a VERY influential teacher that set me on the right track.
Marianne Mayfield is my fifth-grade teacher and the reason I’m in computers today. She was at my wedding, at graduations, at family events. Twenty years later and we are still close. When I was young, she recognized that I was “at risk for trouble” and sat down with my family in order to find a way to get me back on track. She saw that I was transfixed by the Apple II in our classroom and set it up so we could sneak the computer out of the school as long as it was back by Sunday Night and noone noticed.
(click links above for more details)
Scott Hanselman: I was the Chief Architect at Corillian, working with other engineers and architects throughout the company, planning, designing, coding the next generation of Corillian’s Online Banking Platform.
AkitaOnRails: I applaud your Team Hanselman campaign to help fight Diabetes. I understand that you have Diabetes as well and that, fortunately, you managed to have it under control nowadays. Can you tell us this story and the goals of your campaign?
Scott Hanselman: My personal story is here :
I currently take three shots a day of Symlin while also wearing an Insulin Pump 24-hours a day, even while I sleep. The pump saves me from an additional six shots a day, which I took for 8 years before the pump. I test my blood sugar by pricking my finger between 8 and 10 times a day – that’s about 46,500 finger pricks so far, and miles to go before I sleep.
And there’s a good explanation of diabetes here :
Here’s where the analogy gets interesting. Remember in the analogy we are flying from L.A. to New York, except we only get to check our altitude seven times. And, we only get to change altitude (take insulin) less than ten times. But, when I check my blood sugar, I’m actually seeing the past. I’m seeing a reading of what my blood sugar was 15 minutes ago. And, when I take insulin, it doesn’t start lowering my blood sugar for at least 30 minutes.
The campaign ended up raising over USD$30,000, and that money will be applied to research, education and programs surrounding diabetes.
AkitaOnRails: “What in the world were you doing at a RailsConf?” That’s what I think people from outside of the Microsoft blogosphere would ask you :-) So, are you just curious about Rails, or do you actually develop Rails-based apps? I am very interested to learn your opinions about Rails. How did you find it? What do you think is best about Rails? And more importantly, what do you think Rails could have improved?
Scott Hanselman: I’m always trying different programming languages and frameworks. I’ve been doing Rails on and off for about 18 months, but it hasn’t clicked for me yet. I’m sure it will soon. The MVC pattern is very old…I was doing it in Java over 10 years ago, and certainly the pattern goes back 30 years. I think that Rails is a good framework considering it’s young age. I think it’s Ruby that is the real magic though and I find the Ruby aesthetic to be very in line with my own.
AkitaOnRails: Then, following my biased preferences, the next article I like is your screencast over the CTP ASP.NET MVC framework. I see that this new framework resembles Rails a lot. Of course, it may just look like that because both implement MVC2. But on the other hand, it uses very similar Rails idioms everywhere. It lacks a little bit of ‘convention-over-configuration magic’ but from what I saw, it looks much better than doing conventional ASP.NET. What do you think about it? Can you summarize it a little bit for those that don’t know this product yet? And what do you think will still improve in it?
Scott Hanselman: If one points at Rails and says “that’s MVC” then everything else looks like Rails, sure. Any good MVC framework needs to not only follow the pattern as appropriate but also abstract away HTTP (assuming it’s a web framework) in a clean, but not complete, way. The ASP.NET MVC implementation still has some baggage that it will always have to carry because ASP.NET WebForms came first and wasn’t design from scratch for testability in mind. That said, it’s all about alternatives. Use the framework that makes you happy and you feel most productive in. Some fraction, maybe 20%, of ASP.NET devs will prefer MVC. Now they have a MS support choice with good integration with C# 3.0

at RailsConf’07
AkitaOnRails: And what would be tech world without discussions and flame wars? I understand that most .NET developers don’t even pay attention to Rails or other frameworks. I even heard that there are some developers questioning things like “Why yet another web framework if ASP.NET is already there?” Meaning, why reinvent the wheel and divide attentions? I particularly think that this new MVC is the way to go, but it is undeniable that the old ASP.NET has much more acceptance and support. How to reconcile both point of views?
Scott Hanselman: That’s just FUD (fear, uncertainty, and doubt). Think what they like, this Framework is just about alternatives. WebForms is great, and if you’re doing Line of Business (LOB) apps with complex grids and such, it’s not going anywhere. However, if you’re an agile shop with a penchant for TDD and have been frustrated by ViewState, then check out ASP.NET MVC. There’s nothing to reconcile. Some people take a car, some a motorcycle, and others walk. As long as you get from point A to point B and feel good about the journey.
AkitaOnRails: Speaking of flame wars, there is probably one subject that gives me the creeps: the paranoid conspiracy theories regarding Miguel de Icaza and Mono. A lot of people actually believe that Miguel is ‘selling’ part of the open source world to Microsoft. Have you ever used it? What do you hear throughout the community and what’s your opinion about this matter?
Scott Hanselman: Yes, I’ve used Mono and I think it’s a great way to get your .NET application working on Linux or Mac. I think Miguel is brilliant and a fine dancer. I hear in the community that they are happy Mono exists and that it’s available as an option.
AkitaOnRails: I will probably be cursed for this one: but I am not ‘strongly’ against Microsoft as some fundamentalists are. It is public and notorious that Microsoft is a big corporation and as such it did its share of ill conceived deeds. A lot of them were already settled in court. So, it’s more complex than people usually think. I prefer to assume that inside Microsoft there is a lot of very smart people.
Scott Hanselman: I stay out of legal stuff. Microsoft is a huge company with a lot of smart people, but it’s really many medium sized companies working together (usually). I can’t speak to “ill conceived deeds.” I can only say that I do my best every day to not be evil, as do my coworkers. There’s no evil master plan in my group.
AkitaOnRails: I particularly like the roadmap for Windows Server 2008 (with it’s minimalist approach, finally having only what you need installed). Last year you were experimenting with IIS 7 and its new FastCGI support. I think it was primarily intended for PHP support but it could theoretically handle Ruby on Rails as well. Have you tried Rails there? I think Microsoft is clearly going after the low-end with Windows Server 2008 + IIS 7, against the inexpensive Linux+Apache boxes. I think they won’t be able to reach them in terms of prices but what do you think of it as an internet service contender?
Scott Hanselman: I have little power in that arena, but every time someone will listen I’m pushing for a nice inexpensive Web Server SKU. I’m a huge fan of IIS7 and I’d like as many people as possible to check it out. I haven’t tried IIS7+Rails but I’ve heard rumors of folks getting it working.
AkitaOnRails: There are a lot of new features in .NET 3.5. LINQ is the one that interests me the most. Can you give us a brief description of why it’s so interesting? And what do you think are the best improvements of the 3.5 version? Are you already using Orcas? What’s your opinion? Oh, and are you aware of the Sapphire in Steel project?
Scott Hanselman: LINQ is interesting because it’s its own Domain Specific Language for querying objects of all kinds, and it’s living right inside VB and C#. It’s a MUCH smarter compiler and it’s a joy to work with. I’ve installed Sapphire In Steel and I know a few people who are digging it. I’m looking forward to Rails on .NET.
AkitaOnRails: One of the advantages of the Microsoft .NET strategy was being prepared since its first day to be language-agnostic. Now we have the DLR that was derived from the works in IronPython and not IronRuby. But there is yet another cool language that not many people are aware of: F#, the OCaml inspired language. Have you tried it?
Scott Hanselman: Yes, and I’ve done two podcasts on it, one with Robert Pickering, author of a book on F# and one with Dustin Campbell, an enthusiast. I’m stoked it’ll be a first-class language inside VS.

with John Lam
AkitaOnRails: I am not against technical comparisons, we have to do such things to decide our steps in projects. But I am against pointless challenges. Rails is far from perfect and I am the first say it. That said, it is great for an specific niche of web development. I usually recommend that good programmers should expand their horizons and learn as much new stuff as possible. You can’t know everything perfectly but it’s always good to be aware of the possibilities. You wrote something around these lines. What do you think about it?
Scott Hanselman: Rails is good for what it does in it’s niche. You don’t create Windows Desktop apps with Rails and that’s fine. That’s why we don’t compare Rails to WPF, we compare it to Web Frameworks. Comparison is good and there’s always good to be found on either side. I avoid flame wars as well. It’s pointless. If the shoe pinches, don’t wear it. But, try as many shoes as you can!
AkitaOnRails: Last year you wrote an interesting post about the future. Google is this big giant, Amazon released surprisingly good products in the last few months like S3, EC2, SimpleDb. I am not well aware of the current Microsoft Live’s strategy. Can you say something about where is it heading to?
Scott Hanselman: I’m not in that group so I have no insight outside of what’s already been said. However, I do still hold to my predictions in that post!
Computing will be moved into the Cloud. It’s already happening, we’re 20% there. The idea has been around since the beginning, and it will, in my opinion, continue come up until it actually happens and we build Skynet. One of these compute clouds will no doubt end up in orbit.
AkitaOnRails: And of course, I kind of ‘have’ to ask you this: do you use Windows Vista? How has it been for you given that there’s a huge underground campaign against it? Do you think it is as bad as everybody else says? I can’t comment because I never tried it outside of my virtual machine (I am a Mac guy), but they did sold 100 million licenses.
Scott Hanselman: Sure. I run Vista 64-bit on 3 machines, and Vista 32-bit on 2 machines. It was rough for the first 3 months while the driver support sucked, but now it’s fine. I’ve got 2 vista machines that haven’t been rebooted in months, just put to sleep and woken up. Once you get good video drivers, you’re usually cool.
Folks give Vista a hard time but they forget the wide range of hardware it has to run on. OS X only has to run on Macs, and a narrow range at that. Vista has to run on millions of combinations of hardware. Third Party Drivers are by FAR the thing that crashes Vista the most and it gets blamed. That’s why I run 64-bit and used only signed drivers. I’ve been thrilled with 64-bit. Works great.
AkitaOnRails: Ok, this is it :-) Thanks a lot!

Chatting with Evan Phoenix 11 Feb 2008 3:42 PM (17 years ago)

It was Avi Bryant that evangelized the neat idea of “turtles all the way”, meaning that for a language to be called ‘complete’ it should be able to extend itself. So, the ideal world would have Ruby being extended in Ruby, not in C. JRuby goes as far as it can building up a sandbox for Ruby code to run under the JVM. As cool as it is, we still rely on Java to fully extend it.
Enter Rubinius and its author Evan Phoenix, currently a full-time employee for EngineYard. Rubinius borrows heavily from Smalltalk’s concepts of a virtual machine and does as little as possible in C just for the bootstrap and all the rest is developed over pure Ruby.
Rubinius answers lots of questions about going forward over the current Ruby MRI but also raises several other questions that I hope we can nail down today in this interview with Evan himself.
So let’s get started.
AkitaOnRails: It is a tradition now in my interviews to ask about the background of the programmer. What was your path? I mean, what made you come in to the programming world and how did you get into Ruby?
Evan Phoenix: I started programming in high-school with a friend of mine. We started a small computer company doing odds and ends and I really got into it. I had gotten into Linux a few years before that, so programming became a natural extension of using Linux.
When I applied to college, I declared myself as a Computer Science major on the application, so I’ve been doing this since about then I guess.
As for Ruby, I got into it in about 2002, when I first moved to Seattle. A friend had just found it and was writing some fun stuff in it and I picked it up on his suggestion. Eventually, I found the seattle.rb, and have been working in Ruby since.
AkitaOnRails: EngineYard seems to have great faith in the future of Rubinius. How did this relationship start? Can you tell us what are EngineYard’s expectations regarding your work for them?
Evan Phoenix: The relationship started mainly with them approaching me about working for them, on Rubinius. So they saw promise in Rubinius on their own, from my presentations and such, and approached me.
Their expectations are that I make Rubinius the best Ruby VM it can be. Thats my basic mandate with them. They’re pretty much the ideal stewards of the project. They allow me to work at the pace I want, they understand the rigors of the work I’m doing, and give me a lot of freedom.
AkitaOnRails: Now let’s get into Rubinius. For non-starters how would you define Rubinius? We all know that this is an alternative Ruby implementation, so maybe it would be good to point out what makes it different than the MRI. What are the project main goals?
Evan Phoenix: One of the primary goals is to have as much of the system written in Ruby itself. With MRI, none of the core class are implemented in Ruby, all are in C. So we wanted a system that was easier to work with, and thus written in Ruby itself.
Another thing we’ve done is enrich the number of things which are objects, which adds considerable power. An easy example is the CompiledMethod class which Rubinius has. It contains the bytecode representation of a method and can be inspect, manipulated, etc, just like any other object. This opens a lot of new doors with regard to how problems can be solved.

AkitaOnRails: It is not so obvious for the brazilian audience to speak of “Squeak”, “Garnet”. Smalltalk is probably less known here than Ruby. The point is that it is well known that you were inspired by the way Squeak is implemented. This led to features like “Cuby”. Can you explain what is so great about the way Squeak is implemented and how it is helping you in the Rubinius project?
Evan Phoenix: Well, we’re currently in the process of developing Garnet/Cuby, so those tools aren’t in use really yet. But almost the entire system architecture of Rubinius is modeled off the original Smalltalk-80 Virtual Machine. It defined things like CompiledMethod, etc, which I took name for name into Rubinius.
In addition, the execution model of Rubinius is almost identical to Squeak. A good example is the way in which the system calls methods and figures out how to keep track of where to return control to when a method call returns. All that information is kept in first class objects called MethodContexts. In a language such as C, that information is stored on a processes memory stack. By keeping the data in first class objects, we’re able to query them directly to find out information about the running system. It also vastly simplifies how the garbage collector works.
AkitaOnRails: Today you have shotgun. I read somewhere that you consider it ‘cheating’ because this is not an interpreter for Ruby written in Ruby, which will lead to Cuby. It’s more kind of a bootstrapping to ease development. What’s the current state of shotgun, can we use it outside its purpose of developing Rubinius?
Evan Phoenix: Shotgun is a virtual machine written in C that provides instructions and primitive operations for running a Ruby-like language. Shotgun itself actually has no knowledge of parsing, compiling etc. It has a very simple way to load code in, and a way to execute it. You could easily write a new language which targets shotgun, in fact, Ola Bini and I have talked a few times about writing a simple lisp-style language that would run directly on shotgun.
The primitive operations it provides are kinda like syscalls in a unix system. They provide very low level operations which are built on. For example, there is an add primitive which adds to Fixnum objects together and puts the result on the stack.
AkitaOnRails: This is a personal curiosity. The MRI today uses a simple mark and sweep garbage collector (GC) whereas Java uses a highly customizable generational GC. What did you choose for memory management on the Rubinius VM?
Evan Phoenix: Rubinius uses a generational GC, combining a copy collector for the young objects, with a mark/sweep collector for the old. It’s proved to work quite well for us. The trick has been tuning how long an object exists before it is promoted to the old object space. We’ve only tuned it a little. There is a lot more work that could be put into the GC, and it’s architected to only interact with the rest of the system at a few places, so it’s logic can be completely replaced if need be without disturbing anything else.

AkitaOnRails: We have parties that favors green threads, we have parties that are all go native threads. How are you dealing with threading issues in Rubinius? Will we still have the same kind of global locking that MRI has today?
Evan Phoenix: At the moment, Rubinius only has green threads, built on the first class MethodContext objects. It currently uses libevent to allow threads to wait on IO objects quickly.
The plan (likely for 2.0) is to support native threads as well as the current green threads. You’ll be able to allocate a pool of native threads that the green threads can all share. So perhaps you have 100 green threads, you could allocate 10 native threads for them to split time between. Because of the architecture, it’s trivial to migrate a green thread between native threads.
As for the global lock on native threads, no, we don’t consider a global lock a solution for using native threads. If there is a global lock, there is no reason to use them over green threads. Because so much of Rubinius is written in Ruby, we have an easier time of figuring out how to properly lock things to keep all the objects in the system safe. We haven’t really even started this work, but it’s been talked about quite a bit.
AkitaOnRails: The current goal is probably to make Rubinius as compatible with the MRI 1.8 as possible. Did you already start any work toward YARV compatibility already? And speaking of YARV, it is the official virtual machine and bytecode compiler for the next release of Ruby. Is there any chance to make Rubinius and YARV byte-code compliant or this is not a short-term goal?
Evan Phoenix: We’re actively working toward being 1.8.6 compliant. This a big goal because there is a lot of functionality in there. We’re going to do a 1.0 release of Rubinius once it’s able to run all the specs that 1.8.6 runs and properly runs Rails 1.2, which is a good benchmark.
No, we haven’t done any work yet toward YARV compatibility, but because of how things are architected, we’ll likely just be able to have —yarv flag that you pass to Rubinius to have it use YARV compatible versions of things.
We aren’t currently working toward a common bytecode format between Rubinius and YARV, mainly because there is nothing to be gained by doing that. YARV’s bytecode format is largely internal to YARV only, last I looked, you couldn’t easily save it out to a file. Rubinius operates primarily off .rbc files, which contain a serialized CompiledMethod, and thus contain bytecodes. That being said, they are actually similar and could be unified if we saw the need to.

AkitaOnRails: Performance is always subject for a lot of discussion and it is still premature to talk about performance under Rubinius, as it is still work in progress. But I read in your blog that it is quite fast already, even surpassing MRI in many tests. How is performance evolving?
Evan Phoenix: Currently, our performance is evolving slowly. This is mainly because it’s not a priority for people writing the kernel of Rubinius (the majority of the Ruby code which makes it up). As we get closer and closer to being compliant, we’ll begin tuning things. That being said, I do write code to make Rubinius faster here and there. We went ahead and implement fast math operations to speed of the simple math that people commonly do. We have a simple profiler which can easily be turned on to give developers feedback about how their code is run.
AkitaOnRails: One of the main problems for any alternative implementation to Ruby is that it has a lot of C-based extensions, including a handful of core libraries. So if you want to stay “pure-Ruby” you have to re-implement all of them in Ruby. The JRuby guys had to go through something similar. Are there any cross-project collaborations already in this regard?
Evan Phoenix: Actually, thats not entirely true. We also saw that the landscape of Ruby includes a lot of C extensions. To make migration to Rubinius faster, we’re written a layer into Rubinius which allows all those C extensions to run (nearly) unmodified, only requiring a simple recompile. These are so that things such as ImageScience, RMagick, postgres bindings, etc can all be used under Rubinius without having to be rewritten.
AkitaOnRails: Still about C code, I know it is difficult to deliver a bytecode virtual machine and still be dependent on non-managed C code. Java has some jury rigging toward JNA, .NET as pinvoke. Do you plan something similar for Rubinius so that it can more or less easily speak with C libraries?
Evan Phoenix: We actually directly support a mechanism called FFI (Foreign Function Interface), which allows a developer to bind a C function directly as a method call. Here is a simple example:
attach_function nil, :puts, [:string], :void
end
LibC.puts “hello!”
The attach_function line is the primary interface into FFI. You simple indicate which library the function is in (in this case, nil is used because it’s include in the existing process), the name of the function (puts), the types of arguments it takes (just 1, a string), and finally, the type it returns (void, ie, nothing).
Using this, you can tie directly to C functions without having to write C wrapper code.

AkitaOnRails: You are very right when you say that formal language specs too early in the game can make it difficult to evolve the language. Ruby as been growing for 10 years now, and it feels that this is the right time to start thinking of something like this, so that we can have a baseline from where every other alternative implementation could start. Do you see any efforts towards this end?
Evan Phoenix: We’ve been actively working to develop a set of specs (in rSpec format) for 1.8. These form the primary mechanism with which we test how Rubinius is doing. These specs are being actively used by JRuby and IronRuby to test their respective Ruby environments. We’re currently in the process of moving these specs into a generic Ruby spec project to try and begin moving things toward a more formal standard.
AkitaOnRails: Another recurring question is about Rails, of course. Any new Ruby implementation today will have to face the inevitable question: does it run Rails already? :-) Rails is serving kinda like a ‘mini test suite’ and baseline for most implementations. How is Rubinius performing on this matter?
Evan Phoenix: When we run Rails, we know we’re close to a 1.0. :)
AkitaOnRails: You have a very interesting approach toward open source management: everyone that sent you a good patch gains commit access to the repository. How is this working for you? Isn’t it a bit ad hoc or people tend to follow your lead and your list of priorities?
Evan Phoenix: It’s actually working out great so far. By being spec/test oriented, new people have a place to start, either writing missing specs or making existing ones pass. Those become great intros into the whole system for them. They then begin to explore a bit more and commonly find more and more they’d love to help with. Because we have a lot of work to do in a lot of different places, people don’t have to worry about my priority list, since it’s usually involving things which others don’t need to be actively concerned with.
I really can’t say enough about the people who contribute. The one patch barrier has proved to work great because while we’ve now got over 60 committers, not once have I had to pull commit rights from someone. Sure, people mess up, but in every case, the person has corrected the behavior and/or code.
AkitaOnRails: One byproduct of this commit access approach of yours is the integration of rSpec into the Rubinius project so that you have a nice requirements tool and test suite. Do you practice Behavior Driven Development? Or this is covering just a small sub-set of the project?
Evan Phoenix: I’m largely a testing newbie, simply following the guidelines set by Brian Ford, the primary spec keeper of the project. It has proved to be a great tool for viewing how the project is progressing.
AkitaOnRails: As many other Ruby projects, Rubinius is also managed over GIT. There’s been a lot of fuzz around Git and Ruby these days. Do you think there is a new trend here? Why did you decide to go with GIT?
Evan Phoenix: Yeah, I think that GIT is picking up as a trend, because of the features it offers over subversion mainly.
The big reason we decided was it’s feature set. One big feature I love is local branches, allowing a person to manage a number of outstanding changes without trampling on each other.
We haven’t yet, but we plan to exercise the great merge / public branch capabilities.

AkitaOnRails: We heard from Ezra’s recent interviews about your new experiment on multi-VM. That would be a blessing for deployment without we having to deal with several processes in a mongrel cluster. Can you describe this feature and pin point its advantages?
Evan Phoenix: It’s pretty experimental currently, but it will only get more stable over time. The idea is that you can spin up a whole new VM in the current process. This new VM is completely separate from other VMs, living in it’s own native thread and having it’s own garbage collector, etc.
There is a mechanism for VMs to communicate with each other though, and this allows them to coordinate work. This would mean that a primary thread could accept new connections, then pass them off to a new VM to actually process. This allows you to process connections in actual parallel, in addition, because the VMs are completely separated, this even works for non-thread safe applications like Rails.
AkitaOnRails: Ezra also mentioned about a possible mod_rubinius in the making. How is it going? This definitely makes the Rubinius stack even stronger. Together with Merb, Rubinius plus multi-VM capabilities plus mod_rubinius would be a killer deployment package.
Evan Phoenix: Yes, a mod_rubinius project is just beginning. The multi-VM code and mod_rubinius overlap a bunch, so you’ll be able to have VM pools for sites, all managed through apache. We’re hoping that mod_rubinius can really simplify the Rails/Ruby deployment picture. It will operate similarly to mod_python, allowing a VM to remain running between requests, and likely even run background tasks.
AkitaOnRails: How long do you guess we are from a fully MRI-1.8 compatible release?
Evan Phoenix: We still don’t have a firm date, mainly because what fully complaint MRI-1.8 is is still unknown. We are still adding specs, working to properly define 1.8. That being said, we’re really hitting a stride and progress is advancing rapidly. We’re very close to properly running Rubygems. Ezra recently was able to run Merb on top of Rubinius, running under webrick.
I’m going to be doing a 0.9 release this week, because we’ve made so much progress since 0.8. My big hope is that by RailsConf in May, we’ll be running Rails. But don’t hold me to that. This is open source after all. :)
AkitaOnRails: Thanks, I think this is it.
Evan Phoenix: Thanks for your patience!
Chatting with Hal Fulton 9 Jan 2008 2:27 PM (17 years ago)

The Ruby Way is the undisputed must-have book in any Rubyist bookshelf. Rather than being a ‘reference’ book it explains what it takes to really dive into the intricacies and marvels of the Ruby programming style.
Today I am very happy being able to engage in a conversation with one of my favorite authors, Hal Fulton. This was a great chat and I know people will be delighted as well. He is one of the Ruby veterans and certainly has a lot of experience to share. So, let’s start:
AkitaOnRails: First of all, it is a tradition at my blog to ask for the guest’s background. How long you’ve been at the programming career? How did you first get there? What inspires you about the computer world?
Hal Fulton: I started college as a physics major, but I found that I was taking computer courses for fun. I switched to computer science and the rest was history.
Unlike most younger people now, I never was really exposed to computers until I was sixteen, because personal computers were much less common then. I was hooked right away. I saw the computer as a “magic box” that could do anything I was smart enough to instruct it to do. Really I still feel that way about it.
AkitaOnRails: This is almost a cliché already but I have to ask: you were one of the ‘first generation’ rubyist. How did you come to find Ruby and what was it that ‘clicked’ for you about the language?
Hal: I was on a contract at IBM in Austin in the fall of ‘99. In a conversation with a friend across the hall, I complained that I was never on the “ground floor” of any new technology — I was always a late adopter. And he said, “Well, you should learn Ruby then.” And I said: _"What’s that?"_ So I got on the English mailing list and started to learn Ruby (version 1.4).
My experience before was with very static languages. I had started (like many people in the earlier days) with BASIC, FORTRAN, and Pascal. Then I learned C, C++, Java, and various other things along the way. But I was never exposed much to LISP, and I never knew Smalltalk. So the whole concept of a dynamic language was a little foreign to me. I had always known that I wanted more power, but I wasn’t sure exactly what I wanted. I tried to envision macros that would give me the kind of flexibility I wanted, but it seemed like the wrong solution.
Then I learned Ruby, and I felt that I had taken not just a single leap forward, but three leaps. It was clear to me that this was very similar to what I had been looking for subconsciously.
AkitaOnRails: The Pickaxe is another must-have book, but it serves the role of a complete ‘Reference’ book whereas your book is about inner underpinnings and foundations of the language – heck, you spend 40 pages just talking about String, if this isn’t detailed enough I don’t know what would be. What was your intent when you wrote the 1st edition, how it came to be?
Hal: I met Dave Thomas and Andy Hunt online on that mailing list. At that time, their excellent book The Pragmatic Programmer had just come out, and they were working on the Ruby book. I was one of the reviewers of that book – helping to iron out little inaccuracies and problems.

A little later, Sams Publishing went looking for someone to write a book. At that time, the English mailing list had very few native speakers of English, so I had a good chance of being picked. I submitted a proposal, and they liked it.
The Pickaxe wasn’t on the shelves yet, but I had intimate knowledge of its contents. So when I put together the proposal for the book, I tried to make sure it was not in direct competition; rather, I wanted it to be complementary. If you look on the “praise page” of the first edition, there is a quote from me, saying “This is the first Ruby book you should buy.” But privately I was already thinking: “And I know what the second one should be, too.”
AkitaOnRails: As detailed and complete as you try to be Ruby has several subtleties and nuances that are hard to capture. Was there anything that you didn’t cover at that time that you would’ve like to spend more time with?
Hal: There are certainly some subtleties with classes and modules, reflection, metaprogramming, and that kind of thing, that are not mentioned or not stressed. But in general a programmer shouldn’t be “too clever” when writing code anyhow.
The most glaring omission, I think, is that there is no coverage of writing C extensions. In the first edition, I simply ran out of time, energy, and space – I couldn’t cover that. In the second edition, I omitted it because I thought the C API was going to undergo radical
changes as we approached Ruby 2.0 – more radical changes than the core classes, for example. I think this is turning out not to be true, however.
AkitaOnRails: You probably stumbled upon many Ruby students and enthusiasts that were learning Ruby through your book. By your experience, what do you think people get most amazed about the language, and what are the features that bite them initially?
Hal: I think the conciseness is one really attractive feature. Take a look at this single line of Ruby, which creates two accessors for a class:
rubyattr_accessor :alpha, :beta1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
How would you do that in C++? Well, you would declare two attributes; then you would write a pair of "reader" functions and a pair of "writer" functions. What's that, at least seven lines of code right there? But then what if you want to be able to assign different
types to these? Now you have to get into overloading. It quickly becomes a nightmare. Meanwhile, in Ruby -- it's still just one line of code.
*AkitaOnRails:* What do you like the most about Ruby that sets it apart from other similar languages?
*Hal:* One of the best features about Ruby is dynamic typing. Variables don't have types; only objects have types (or should I say, classes). Static typing was so ingrained in me that I *assumed* it was the right way. But when I gave it up, I felt as if I had removed weights that I didn't know I was wearing.
Its *regularity* is also an appealing feature. For example, a class is Ruby is in a sense a "special" thing - but not nearly so special as in (for example) C++. A class is "just an object," so you can do things to classes that you can do to other objects - such as pass them around, store them in arrays, test their values, and so on.
*AkitaOnRails:* And what would you improve if you were the guardian of it?
First of all, I'm glad I'm not the guardian of it. Matz does an excellent job, and he is much smarter than I am. I think there are some issues with reflection and dynamic programming that need to be cleaned up -- exactly how, I'm not sure.
I look forward to a truly usable virtual machine, and I look forward to some form of method combination (pre, post, wrap). I admit, though, there are small syntax and core changes I would like to make - mostly pretty minor.
For example, I've always wanted an "in" operator that would be syntax sugar for calling the include? method - for example, _"x in y"_ would mean _"y.include?(x)"_ - this operator would be essentially the same as the set membership operator in mathematics (instead of the reverse) and would sometimes make code more readable and even make parentheses unnecessary sometimes. I've used the "in" operator in Pascal since I was 18; Python has it, even SQL to an extent. I wish Ruby had it, too.
Many times I've felt a need for a data structure that would be accessed like a hash, but would preserve the order specified in the code. For example, imagine a kind of "dynamic case statement" -- we pass in possible matches and code to execute (as procs) for each of those matches. (It would have the advantage over a case statement that we can control the number of case limbs and their associated code at runtime.) Let's implement it as a method called "choose" that we call in this way:
--- rubychoose regex1 => proc { handle_case1 },
regex2 => proc { handle_case2} |
Now, what’s the problem here? The syntax fools us into thinking that regex1 somehow precedes regex2 – but when we iterate over a hash, the order is not guaranteed to be the same as in the code. (That is a property of hashes, of course, not a bug.) So we can’t control or predict the order in which these are applied. And I have found several other cases where I wanted such a thing – an associative array, a set of tuples, that had a convenient syntax for literals and had an order.
There are two usual responses to my desire for an “ordered hash.” Some people say that I’m crazy, that a hash isn’t ordered and that’s that. Some people say I could always make my own class that behaved that way – which is true, except that I wouldn’t have the convenience of representing it as a “first-class citizen” in Ruby syntax. After all, a hash “could” be represented as a second-class citizen as well – I could say
rubyHash[“a”,2,“b”,4,“c”,6]1 2 3 4 |
instead of saying:
--- ruby{"a" => 2, "b" => 4, "c" => 6} |
But I am glad for the expressiveness of the latter syntax.
AkitaOnRails: Your second edition covers Ruby 1.8. Are you researching into Ruby 1.9 (YARV) already? Being a Ruby veteran, what do you think of the directions Matz and Koichi have been choosing for the next version? Is it satisfying for you? For you, what are the good, the bad and the ugly about Ruby right now and the next version?
Hal: There have been minor points where I disagreed with Matz from time to time. But as I said, I am glad he is in charge. I like YARV from what I have seen so far. I am anxious for it to be 100% stable so that I can really get a feel for how it works.
AkitaOnRails: Your book is in the second edition, and it is a huge book, covering not only the language itself but a few 3rd party components as pdf_writer. Are you working on a 3rd edition? Maybe we will have “The YARV Way”?
Hal: I am not working on a third edition, and I think it would be very hard to write one. The second one was harder than I expected – although much content was re-used, it still had to be re-examined line by line – and more than 50 errors still crept into those 800+ pages.
I once joked that if there was a 3rd edition, it might have to be two volumes. But really, that might not be such a bad idea – basic concepts and core classes in one volume, standard and third-party libraries in the second. But that’s idle speculation. There is a kind of add-on for the book being planned – but I won’t mention that until we know more details. Ask me in a few months.
As for YARV – I think Ruby will always be Ruby. We may change the inside, but the name will remain the same for the foreseeable future.
AkitaOnRails: Around 2002 Ruby was not widely adopted and only a handful of hobbyists and enthusiasts were using and helping to improve the language. Yourself, David Black, Nathaniel Talbott, and a lot of big guns from what I call ‘the first Ruby generation’. But in 2004 came this full fledged web framework called Rails that made Ruby publicly known and acknowledged, attracting many great minds but also a lot of trolls and amateurs. I hear that some in the first generation regret it because what was once a peaceful and insightful community became very noisy. What are your thoughts about this sudden celebrity status that Ruby gained and its side-effects?
Hal: Well, Ruby isn’t a private club. I wonder if the Japanese felt any offense when Europeans and others started to be interested in it? I think that we’ve certainly lost a little bit from the old days, but I don’t waste any time thinking about it. We’ve gained quite a bit also. And it’s interesting that the “friendliness” of the community has scaled better than many of us expected. Ruby is still Ruby, and Rubyists are still Rubyists. It’s just that there are more of us now – also more projects, more activity, more opportunities. That can only be a good thing.
AkitaOnRails: Do you work with systems development in pure Ruby or do you use Ruby on Rails for web development today? What’s your occupation or day job?
Hal: I’ve done a little work with Rails here and there, but I’m more of an old-fashioned generalist. I’m not a web guy. Many younger programmers, of course, seem unaware that there is any other kind of programming to be done. But if you were writing a compiler or interpreter, a custom web server, any kind of daemon or background networking app… would you reach for your Rails book? Of course not.
I’ve done system-level work in the past, but I can’t imagine Ruby ever being appropriate for the kinds of things I did back then. For those things, we used C (the universal assembly language). In my day job, I’m happily coding Ruby every single day – telecommuting for a Dallas
company called Personifi. I’d describe my work as internal applications and tools – a lot of text analysis and indexing, a little number-crunching and a lot of word-crunching.
AkitaOnRails: Here in Brazil we have a lot of people that were initially attracted by the Rails hype machine, now they are struggling to learn the Ruby language. Metaprogramming, Closures, Mixins, make them go nuts. Do you have recommendations for new comers?
Hal: What would be a good way to start experimenting with the language? Well, you can keep a copy of The Ruby Way nearby. :-)
Really, I only have three recommendations. First of all, the mailing list or newsgroup is a powerful source of information, and there are still friendly and knowledgeable people there who will answer your questions. Second, there are millions of lines of Ruby source
out there. Study it and learn from it. Third, and most important: Just play around! You don’t really learn a language by reading about it, but by using it.
AkitaOnRails: By the way, are you already writing a new edition? :-)
Hal: I’m not, and I can’t see ahead that far. But wait six or seven months, and I do hope to have a little surprise for you…

AkitaOnRails: In the light of the current Zed episode, he said a lot of thing specifically against the Pickaxe. One of the things is his claim that the Pickaxe didn’t mention clearly all the meta-programming stuff. Then I was talking to ‘arton’ – a Ruby book author from Japan – and he reminded me: americans and japanese seem to do Ruby differently. He said that they don’t usually do all that meta-programming in the level that Rails does, for example. As you said, they don’t try to be “too clever”.
Now, I don’t want to be apologetic because I don’t think Dave needs it, but this explains a lot given that the Pickaxe mostly only had japanese sources to rely on back in 2001. I personally learned most of my Ruby reading the Rails source code at first (and books like yours later). What do you think about this? (meaning, about the Zed episode in general, and about the different american/japanese programming styles?)
Hal: As for Zed, I won’t take any sides in that discussion. Zed can say whatever he wants, and usually does. I’m sure there is some truth on both sides of any controversy.
As for metaprogramming – well, I think those capabilities are in Ruby for a reason. They are meant to be used. But any tool has both appropriate and inappropriate uses. It’s impossible to generalize and say “this is always bad,” but certainly metaprogramming can be misused.
As for Rails itself, I have no doubt there is both good and bad code in it. I suspect the developers working on it would admit as much. And it is possible that they have used “too much magic” here and there, though I couldn’t say specifically where. But could Rails exist without metaprogramming features? Not in its current sense — not in any meaningful sense, I would argue.
AkitaOnRails: I interviewed Avi Bryant, from Seaside fame, and one of his mottos is that ‘a language is not finished until it can extend itself’ or ‘turtles all the way down’ as he says. Meaning, that Ruby still relies a lot on C extensions to this day. Of course, the initial motivations for Ruby are different than Smalltalk. On the other hand people like Evan Phoenix is pursuing this very goal: make Ruby be extensible using pure Ruby. What do you think about this new direction?
Hal: I like the idea of “Ruby in Ruby” in general, though Matz does not. And I am impressed with what I have seen of Rubinius so far – I think it is an important project and will grow more important.
If it’s possible to move toward an elimination of C extensions without sacrificing speed, I suppose that’s a good thing. I am not sure if it is possible. We might at least create a “Ruby in Ruby” that does not rely directly on MRI (Matz’s Ruby Interpreter). But I don’t expect to see the “original Ruby” replaced any time soon.
AkitaOnRails: This was a very insightful conversation, thank you!
Chatting with Peter Cooper 4 Jan 2008 2:30 AM (17 years ago)
Ruby Inside is one of the greatest Ruby/Rails website available and a great source of news. Its creator is the British entrepreneur Peter Cooper, also the author of the recently published book Beginning Ruby, from Novice to Professional, an excellent source for anyone willing to learn the Ruby language.

Peter speaks about Ruby on Rails, business, novices and, as a last-minute exclusive, he comments on the recent Nuclear Zed episode that shocked a lot of people in the community. Just to clarify, Peter answered my questions before New Years Eve, it’s only the last question that was added today.
Once again, I deeply apologize the brazilian audience because I didn’t have time to translate this into Portuguese today, but I will do very soon. Stay tuned.
AkitaOnRails: For the Ruby community Peter Cooper stands for Ruby Inside. I personally enjoy reading your website as it accumulates most of the important Ruby and Rails websites out there. Let me thank you again for adding my blog to your sidebar list. But how did it start? What do you think were the most important steps you made to build its good reputation?
Peter Cooper: Ruby Inside began as a vehicle for promoting my forthcoming (now released) book, “Beginning Ruby.” The name itself came from a comment made in an interview Geoffrey Grosenbach did for the Rails podcast where someone adapted Ruby into the old “Intel Inside” slogan, which sounded like a great name for a blog covering Ruby issues. Initially, the blog was simply to promote the book, but it quickly turned into a digest of news from the whole Ruby community. I think the key to its success was that the larger Ruby blogs at the time, the O’Reilly Ruby blog being a good example, were posting less and less as their writers were getting more and more Ruby work. Ruby Inside filled a gap of providing heavily digested news from the whole Ruby community, with only one or two posts per day, allowing Ruby developers to keep up to date with things, but without having to subscribe to hundreds of blogs.
AkitaOnRails: Looking through your LinkedIn profile I see that you’ve been quite involved with internet-based business for the last 10 years. You also describe yourself as a ‘serial entrepreneur’. Entrepreneurship is something very very difficult here in Brazil, mainly because of economics and overwhelming bureaucracy involved. How difficult is it there in England to open and run your own business?
Peter: It’s very easy to start up in business in the UK. Depending on what you want to do, you can just say you’re a business right away, without filing any papers (although you do have to call the tax office to let them know!), and operate as a “sole trader.” Registering a business officially, however, is quite easy too and gives you a number of legal protections and a more professional image. Getting funding and so forth isn’t particularly easy here, compared to the UK, but if you’re willing to bootstrap, then the UK’s very good for easy banking, fast communication, and trading with the rest of the world. With the natural advantage of the English language, the US market is easy to target from the UK.
AkitaOnRails: Your other most well known products should be Code Snippets and Feed Digest. Can you introduce both of them to our Brazilian uninitiated? How did the idea occur to you? It was something like ‘scratching your own itch’ or it was something totally unrelated and maybe following some trend that you identified? What tools did you use to build them? Many people are interested to know what does it take to build a successful product. What do you think it takes to be a good internet entrepreneur?
Peter: Code Snippets was the first del.icio.us-style “tagged” public code snippet repository. In fact, I believe it was the first Rails application to use tagging at all, as I wrote the earliest code which was appropriated into a number of following tagging libraries. The site was launched in early 2005 and I sold it in February 2007 to DZone. Feed Digest is a service for mashing up, processing, and re-publishing RSS and Atom feeds into other formats, such as HTML, JavaScript, Flash, images, and so on. I sold it to a Russian company in the summer of 2007.
Both businesses / sites were a result of “scratching my own itch” as you say. I needed a system to store code snippets in a tagged way, and del.icio.us was not suitable for this, so Code Snippets came out of a 24 hour coding marathon, was publicly released, and then grew to thousands of users over time. Feed Digest evolved from an earlier service called RSS Digest that I created to scratch another itch, republishing my del.icio.us links onto the header of my blog. It grew far beyond that though, and now has over 25,000 users and serves perhaps about half a billion requests each month. I no longer own or have a direct interest in either of those projects now though, but I must be doing okay on the chart of people selling Rails apps!

AkitaOnRails: I congratulate you on your recently published book, from Apress, Beginning Ruby, from Novice to Professional. As Larry Wright states in his review, he is right that the Pickaxe is a good Reference book, but you take a different approach in being more careful about actually ‘teaching’ the environment. It does fill a gap as there are more and more people interested in learning Rails but lacking an introductory book to learn Ruby itself. Please, describe your book for our audience as I think many Brazilians don’t know about your book yet. What’s its target audience? What do you talk about?
Peter: The book is currently only available in English, unfortunately, so the US has definitely been the biggest target market so far. Content-wise, the book is very reminiscent of the “classic” programming tuition books I was brought up on in the 1980s. It takes a very “walkthrough” approach, with the installation of Ruby coming first, followed by a walkthrough of all the main concepts regarding object orientation, Ruby’s syntax, and the basic data types. Eventually, by the end of the book, the reader has gone through file operations, database usage (there’s even an SQL primer), developed a text adventure game, built a simple Rails application, and so forth. It’s very much a book you’d go through, as a beginner, from beginning to end, and then move on to more advanced books like the Pickaxe or The Ruby Way. Hopefully we will see it in Portuguese one day!
AkitaOnRails: And speaking of beginners, again I think it amusing to read at your LinkedIn profile: Does “left school at 16” count? If so, I’m in. Education is great for most, but overrated if you’re a grafter. I dropped college to work in the Internet bubble as well (though not as an entrepreneur, which I regret). I don’t recommend people to just drop college as I did, of course, this is a personal choice and everybody should take an educated decision about their own future. But there are a lot of people – at least here in Brazil – that praise certifications and diplomas much more than hands-on experience. Sure, there are very good certified developers, but there are more bad developers that actually ‘believe’ in their own certifications as a graduation for competency! I don’t see any correlation between diplomas and good developers. What is your opinion about this matter?
Peter: I have a lot of respect for people who take the academic route, and feel that in general they turn out to be better at their jobs than the less well educated. One of the downsides to being indoctrinated in academia, however, is that people with many degrees, certifications and diplomas often act like technological automatons, only understanding one course of action, not able to think dynamically on the fly, and unwilling to try radical new directions. There is a lot of room in the world for people like that, but on the other foot we also need a lot of “crazy” people who try things that initially seem idiotic or radical.
The other problem with people who brag about their certifications is that in many cases they are just proving that they managed to pass a test. Passing a test and having a lot of knowledge doesn’t necessarily mean you develop good problem solving skills or can work as a true developer, architecting solutions from scratch. For example, a builder might be excellent at building houses, but he’s likely to be very poor at actually designing buildings, which is an architect’s job. In IT, especially within smaller companies, it’s often necessary for developers to fill both architectural and development roles, and many people with certifications, but little real world experience, struggle with the design of systems.
AkitaOnRails: We are both Ruby and Rails evangelists, of course, but as myself I don’t see you as a ‘blind’ developer, meaning, the kind that needs to make everything else look bad just to justify putting Ruby up on a pedestal. I actually believe in the ‘right tool for the job’ approach. Not even DHH states that Rails is the solution for every use case. That said, I think Rails is the best approach for a niche of web development. Recently I involved myself – and I regret it – against a troll rant from a Brazilian .net advocate. I don’t dislike .net, far from that. Anyway, do you see yourself involved in rants like this? Or you do try to avoid them altogether? What is your opinion about ‘X vs Y’ type of discussions?

Peter: I think it’s possible to play interesting political games in any situation. As a regular human being I do have, of course, biases and preferences, but it’s important to recognize these for what they are and still be able to see the big picture. I believe in trying to use the right tool for the job (or, more accurately, the most efficient tool for the job – I’m not going to learn a whole new language just to solve one problem), so Ruby Inside runs on WordPress, a PHP-based weblog platform. In terms of bias, I’m certainly rather anti-Microsoft, although I do acknowledge that their approach to the development of GUI applications is light years ahead of everyone else.
I don’t try to avoid or become embroiled in X vs Y types of discussions, although I do tend to play devil’s advocate when they come up. It is important to remain as scientific and objective as possible in these situations, but I’ll certainly let a little bias show from time to time, as any human would. For example, I (and I’m far from alone on this, although a lot of people seem not to want to rock the boat publicly) am not particularly keen on David Heinemeier Hansson’s overprotection of the terms Ruby and Ruby on Rails, and especially the Rails logo to the point where he rejects the Rails logo’s usage on books that he has not personally worked on. I’m not afraid to show some bias and reference issues like these from time to time.
AkitaOnRails: This leads to another question: everyday I see people here asking us “Why should I choose Ruby on Rails over X?” Personally, I think there is no clear answer for that. Being experienced in many platforms like ASP.NET, Java, PHP, Perl, I did my choice based not only on raw performance (which Ruby lacks, for now), not even a mature library set (which is evolving fast, though). Some reasons were based solely on me being happier with this platform. I do think Ruby enables me to write more ‘beautiful’ code as Marcel Molina Jr. explains. But “Beauty is in the eye of the beholder”. What’s your take on this matter? Being an experienced programmer in other platforms, why did you choose Rails?
Peter: I was a Perl developer before I came across Ruby and Rails, and when I did see Rails, the first thing I did was try to clone it in Perl. Unfortunately, I’m definitely not in the top 10% of programmers, by any means, so my attempt was messy. I tried using Rails directly, reluctantly, with a self promise not to get suckered in to learning a whole new language, but merely to develop what I needed to develop at the time. Of course, the rest is history and I’ve been converted over to Ruby entirely, due to its consistency, ease of use, and the way it just feels like a “natural” language.
Back in 2004, Ruby’s library set was poor, RubyGems wasn’t popular, and there weren’t many books available, so it seemed like a poor choice, but these things have all changed very rapidly, and I’d say Ruby’s library set in 2007 competes very strongly with, say, Python, and while the raw numbers are behind those of Perl’s CPAN, the quality and modernity of Ruby’s libraries exceed it. Ruby is now a strong choice.
AkitaOnRails: I have to extend this theme because I think it is relevant as we see more and more switchers to Rails. I see 2 kinds of developers coming on board: the first being experienced programmers that were not satisfied with their current day-jobs and tools and wanted to try something new and refreshing. The second being novice developers that think Java or .NET have a higher learning curve than Rails. The latter worries me a little bit because some tend to think that Rails is too easy to be considered professionally and some even get frustrated in finding out that Ruby is not Basic, and you do have to make an effort to learn its way. You do training as well, what are your experience dealing with newcomers?
Peter: I have not dealt with anyone who’s completely new to Web application development, so I cannot give a strong answer. However, I certainly don’t feel that people are choosing to learn Ruby or Rails because it’s perceived as “easy.” Indeed, I think it’s the more experienced developers who consider Rails to be easy, and that’s why they’re giving it a go. Beginners tend to just go with whatever is in fashion at the time or what’s the most popular. There’s no shortage of newcomers to all of the major languages right now, it’s just that Ruby is now getting its fair share at last.
AkitaOnRails: 3 years ago the majority of developers predicted the “demise” of Rails as a viable alternative. Today we just saw Rails 2.0 out of the door and the Rails community growing faster and stronger each day. Now people do think of Rails as the contender to beat. I think this is a good thing because we tend to run faster (develop more gems, innovate more) when we are under pressure. Do you think people are accepting Rails more or do you still see barriers for Rails adoption, at least there in England or Europe in general?
Peter: I disagree with your assertion that three years ago a majority of developers predicted the demise of Rails. I think there were just a lot of defensive programmers choosing to disregard it. I also don’t think the majority of developers on other platforms see Rails as something to beat. There’s actually a lot of blindness in the branches of the programming community to the efforts being made in other branches. The majority of .Net developers don’t care about, and most likely haven’t heard of, Ruby or Rails. Developers on dying platforms, such as Cold Fusion, are more familiar with Rails, simply because they’ve been looking for alternatives, but Java and .Net are still taking on new developers at a far higher rate than Ruby and Rails. There is a large difference in what the blogs and other online media want to report and what’s actually happening out there.
AkitaOnRails: There were many things that Ruby was lacking and now we just saw Ruby 1.9 released. It is still no stable 2.0 but this is a clear sign that the language is evolving fast as a mature platform. Free performance is always welcome, but this release will break many things. Are you already using 1.9 or do you feel it’s still not ready for prime time?
Peter: I’ve played with Ruby 1.9 a bit, but I don’t routinely use it. I don’t consider myself a programmer in the academic sense. I like to be aware of, and dabble briefly with, technologies on the fringes, but I’m not one of these super-programmers who downloads, say, Erlang or Haskell and tries to learn it in a weekend. Ruby 1.8 will definitely remain my main Ruby interpreter for at least a few months yet.
AkitaOnRails: Our Brazilian community is still very young and small, I usually describe it as the US community from 2004 ~ 2005. We still didn’t reach critical mass. How are things going there at England or Europe? Is your community big enough that the market started to demand Rails related professionals already?
Peter: The market in the UK is still very small. There was literally nothing in 2005 but things have grown quickly in the last couple of years, although it’s still perhaps 1000th the size of the market for Java or .Net services. There are usually a handful of Rails related jobs floating around, but so far I’ve found that Rails is a technology that agencies are using for their clients behind the scenes, rather than something being actively demanded. I am not directly involved in the UK Ruby or Rails communities, however, so I cannot provide much more detail than this.
AkitaOnRails: This is just for amusement: if you were DHH or Matz what would you like to change in Rails or Ruby? Or maybe, where do you see both of them leading to?
Peter: If I were DHH, then Rails probably wouldn’t exist, simply because I think a lot of his excellent evangelism of Rails is driven by some craving of fame. At a more practical level, though, I would make Rails less opinionated and more customizable, simply because a lot of the opinions are too rigid to be practical in the real world. The initial opinion of relying on the database to provide information about model structure was a good one, but then along came migrations.. and suddenly we’re defining table layouts in code after all, often in many tens of different files! Why not just put the attributes into the models directly and let Rails take care of the schema changes transparently? DataMapper does this, and ActiveRecord is starting to look backwards in comparison with its bizarro approach.
On the Ruby side of things, I think Matz has done an excellent job technically, although whereas DHH scores high on the PR scale, Matz seems reluctant to promote Ruby at all. I think this is both because this sort of modesty is a honorable trait in Japanese culture, but also because Ruby is something he developed to scratch an itch, and another million or so developers using the language won’t benefit him significantly. He’s a great guy, but he lacks the craziness of Larry Wall (Perl) and the authority of Guido van Rossum (Python) and is incredibly lucky that he can rely on a very strong and vocal community to promote Ruby. One benefit of Matz’s hands-off approach is that people feel that they can take authority over various areas of the language and community for themselves without having to answer to a higher authority.
In terms of the technical side, the only thing I’d perhaps do if I were in control of the development of the Ruby language would be to make heavy pushes towards more functional constructs in Ruby 2.0. JavaScript and Perl 6 are taking strides into the world of functional programming, and Ruby needs to follow. I’d also be considering concurrency very strongly and making this a major focus for new language feature developments.
AkitaOnRails: What would be your recommendation for novice Railers here in Brazil? I mean, for those that wants to learn both Ruby and Rails but may need some guidance to start?
Peter: Well, if you can speak English, then naturally I’m going to suggest my book “Beginning Ruby” published by Apress! Unfortunately I’m not familiar with Portuguese resources for learning Ruby or Rails, although I’m sure you are! One free resource I would definitely recommend to newer developers is Chris Pine’s “Learn to Program.” It’s available as a print book, but a more raw version is available to read free online.

AkitaOnRails: Now, speaking of information, we had a very explosive new year beginning. Zed Shaw literally exploded in rants, cursing and every form of aggressive communication. As I stated in my previous article I was personally shocked at first, but I read it through – trying to filter down all the hatred, and uncivilized manners – and there’s actually some information buried there. What is your take about this episode?
Peter: Personally, I think Zed is spot on. I don’t like the way he has specifically attacked a few people personally (Kevin Clark, for example) for minor infractions. His language is harsh, and he clearly has a lot of vitriol. Behind all the swear words and chest beating, however, is a lot of truth. I sympathize with his main arguments, especially those raised in the “round two” update published on January 3rd.
Zed touches on the way some people form into elitist, ego driven gangs, such as Rails Core and the caboo.se. I was involved with the caboo.se for a while myself, and I have a great respect for many of its members (Courtenay Gasking and Amy Hoy, for example), but the whole thing stank too much of elitism to me, and I’ve distanced myself from all of this Rails related online socialization. I could recall quite a few pathetic condescending incidents from members of these communities myself, but unlike Zed I leave quietly. I think one of the biggest causes of the tension, gang-forming, and general childishness is that many of the people involved with these gangs have no social life outside of this community. This probably explains why parlor games like Werewolf and general goofery are so popular at the conferences, as opposed to, say, actually revolutionizing the field.
Lastly, Zed is spot on with his comments about the “Programming Ruby” book, more commonly known as the “Pickaxe.” I tend to remain politically correct on this subject, especially as I have a competing book, but the Pickaxe really is stunning in its mediocrity. It sells well because it has first mover advantage and name recognition, and no-one else has bothered writing a better reference book (The Ruby Way is excellent, but it’s not a reference book). For having the only printed Ruby reference book, Dave Thomas deserves credit, but it’s still mediocre.
AkitaOnRails: For the good or the bad, I have mixed feelings about this whole episode. I won’t judge anyone yet. Let’s see how it unfolds. And of course, I really appreciate Peter Cooper’s patience with me, kindly answering all my questions. Thanks a lot!
Chatting with Adrian Holovaty 31 Dec 2007 7:01 PM (17 years ago)
Traducción en Español
As I promised after the Avi Bryant interview, here’s a great conversation with Adrian Holovaty, well known creator of the Django web framework written in Python.

For me this is an important piece because I always say that technology doesn’t have to be about divorce. Technology is about integration. I am a full-time Ruby on Rails developer and evangelist, but above all, I try to be a ‘good’ programmer. And good programmers acknowledge good technology and their creators achievements. And Adrian’s Django is such a remarkable achievement that deserves the attention and success.
So, as my very first post of the year (published at 0:01hs!), I would like to celebrate the great minds of our ‘development’ community, wishing that the good developers use their time creating great technology instead of wasting it in useless flame wars.
AkitaOnRails: As I always do, let’s start by talking a little bit about yourself. How long have you been a programmer?
Adrian Holovaty: Let’s see — I’ve been tinkering with computers since I was a little boy playing with the Commodore 64 in the mid ’80s.
One early program I wrote was for the TI-85 calculator in my high-school math class. By the time I graduated, a whole bunch of students were using it, because it had all the formulas and stuff.
I didn’t take any of this stuff seriously until college, when I minored in computer science. But I didn’t end up finishing the minor, which is something I’ve always been bummed about.
My college major was journalism, as I originally wanted to be a newspaper reporter, but after I took a job with the Web site of the campus newspaper (The Maneater – best name for a newspaper ever!), I realized I would have a lot more fun working online than with a dead-tree product.
So I ended up finding a way to combine journalism/news and computer programming, and I’ve had a number of jobs doing exactly that!
AkitaOnRails: And what led you to the computer world?
Adrian: I guess it was in my upbringing, as my dad has been a computer programmer since the ’70s, back in the punchcard days. I remember seeing all sorts of those punchcards in our house when I was growing up.

AkitaOnRails: And, of course, how did you met and fell in love with Python?
Adrian: My Web development path was (I think) pretty typical, at least based on the experiences of my friends and colleagues. I originally learned how to write Perl CGI scripts in a college Web development course. Then I taught myself PHP because somebody recommended it to me.
After doing Web development with PHP for a few years, I got kind of tired of it. At that time, I was working with Simon Willison at a newspaper Web site in Lawrence, Kansas. Simon and I were both getting tired of PHP and decided to “dive into Python” (pun intended) by reading Mark Pilgrim ‘s excellent book of the same name, which was released around that time. This must’ve been late 2002.
We immediately fell in love with Python. And when I say “immediately,” I really do mean it. It was like a revelation, some sort of divine moment. It was the programming equivalent of love at first sight.
So Simon and I decided that, from then on, we were going to code everything in Python. That’s one of the perks of working for a small Web development shop — we could make those kinds of snap decisions! 
AkitaOnRails: I was first introduced to Python around 2000 as well. But it was through web development using Zope. I think it got a lot of attention at the time. Did you ever tried it?
Adrian: No, I never tried Zope. Still, to this day, I’ve never tried it. And I’ve been told that’s a good thing, because evidently it turned some people off of Python back then, for whatever reason. (Their newest version is supposed to be a ton better, but I haven’t tinkered with it, either.)
AkitaOnRails: You’re right, and it is kind of amusing because a lot of pythonists from Brazil still use Plone (I think it evolved from Zope but I didn’t try it as well). So, We all know that Django was born out of necessity when you were developing websites for World Online. Please describe how did you begin there and how is the everyday work there. Maybe what led you to Django during your work day?
Adrian: Sure! Well, generally when people think of newspapers, they think of crotchety, old-fashioned editors and reporters scribbling in paper notebooks with pencils. This Kansas newspaper that I worked at was the completely opposite of that. It’s beyond the scope of this interview, but for a number of reasons that newspaper Web site attracted (and still attracts, to this day) a really great development team – one that I would stack up against any team 10 times its size.
We were doing “Web 2.0” stuff back in 2002 and 2003, and we were building Web apps in days, not weeks or months. This was mostly due to the journalism environment – newspaper people like deadlines. 
So we were in this culture of “Web development on journalism deadlines,” and we needed some tools that let us create Web applications quickly. We looked around at some existing Python libraries at the time (2003), and we ended up deciding to write our own stuff.
We didn’t set about to make a framework – it was a very classic, clichéd path, actually! What happened was, we built a site with Python. Then we built another one, and we realized the sites had a fair amount of code in common, so we did the right thing and extracted the common bits into a library.
We kept doing this – extracting and extracting, based on each new Web application that we created – and eventually we had a framework.
AkitaOnRails: As a side-note, actually this is kind of interesting! I would love to hear what do you think World Online has that attracts good developers like yourself there! Just a summary would be ok. That’s the kind of insight brazilian companies have to learn better. Letting you do Python is probably one of them 
Adrian: Yeah, it kind of comes down to empowering the employees. My boss, who led the Web team, delegated all the technology decisions to me and Simon. That kind of culture really encourages quality work, because it makes everybody on the team more invested.


AkitaOnRails: You’re right. Traditional companies would rather have a more hierarchical (and bureaucratic) approach, with a dumb manager holding the whip. But I digress. So, I particularly dislike language x VS language y or framework a vs framework b kind of comparisons. Instead I’d like to hear what do you think is great about Python – the language and the platform – and Django. What are the features in Django that you hold dear to yourself, I mean, those bits of functionality that you actually think for yourself as ‘the’ greatest ideas?
Adrian: Well, I love abstractions – like, I suspect, any programmer. At its core, Django is just a set of abstractions of common Web development tasks. It gives me joy to create high-level abstractions, to encapsulate a large problem in such a way that is made simple.
What I really like about Django is the depth and breadth of abstractions that it provides. And in most cases (I hope!), they’re clean, easy to use and understandable.
Let me give you an example of an abstraction: creating an RSS feed.
When you create an RSS feed, you don’t want to have to deal with remembering angle brackets, and the exact formatting of the feed — you just care about the items in the feed. So Django provides a very simple library that lets you give it a bunch of items and creates a feed from them.
So that’s an obvious example, but what really excite me are the higher-level abstractions, like the concept of an “admin site.” Django comes with a completely dynamic application that makes a beautiful, production-ready CRUD site for your database. There’s no code to write – it’s only a small bit of optional configuration.
There’s also something called Databrowse, which is an abstraction of the concept “Show me my data, as intelligent hypertext.”
So whenever I’m explaining Django to someone, I always end up saying, “It’s just a bunch of abstractions of common Web development tasks” – from low-level HTTP wrapping to higher – and higher-level concepts. The higher you get, the more productive you can be. I apologize if this is too conceptual!

As for Python — what can I say? It’s gorgeous. It’s like poetry. It’s so clean, so logical, so regular, so obvious. And the import system is to-die-for.
A lot of people say Python code is easy to read/understand because of the consistent whitespace and simplicity of the language. I agree with that, but I think it’s also due to the elegant import system. Why? Because if you want to know how any Python module works, just look at the code, and look at the modules it imports. As the Zen of Python says, “Namespaces are one honking great idea – let’s do more of those!”
AkitaOnRails: Tech communities are great because they are so energetic and passionate. On one hand you have those that contribute and make the technology grow faster. On the other hand you have the pundits and trolls that like flame wars. Do you burn yourself sometimes, or do you tend to avoid this kind of discussion? Specifically, some time ago you and DHH were together at the Snakes and Rubies presentation. I think it was great because it didn’t end in yet another flame war. What’s your opinion on this kind of open (not flamed) discussion?
Adrian: The answer to this one is obvious – clearly constructive discussion is more productive.
At times, I’ve had my passion for Python/Django get the best of me, but I’ve gotten a lot better over the years. I’ve realized something: At the end of the day, what really matters is the sites people create with these tools, not the tools themselves. If you’re going to judge someone, judge the sites that person makes, instead of the tools that person uses.
These days, if I am involved in any sort of discussion like that, it’s usually to try to calm people down. 
AkitaOnRails: Well said. Going back to features, you mentioned ‘Databrowse’ before, I would like to know more about it. I think Django didn’t have it by the time I first tried it. Is it a new feature (or am I the one lagging behind?  Can you elaborate more on this construct?
Adrian: Databrowse is still quite under the radar! Here’s the use case.
Say you have a lot of data in your database, and all you want to do is look at it.
Here are your current options: You can drop into the psql or mysql prompts and run a bunch of SELECT queries, but that gets tiresome. You could run something like PHPMyAdmin, but that’s more of an administration tool than a tool for browsing. You could use some sort of external application that lets you browse your database tables, MS Access-style, but that’s in the realm of the desktop app.
Databrowse automatically creates a Web site that displays your data, so you can click around to your heart’s content.
The other thing it does is pointing out interesting, non-obvious queries. For example, if you have a table that has a DATE column in it, it will automatically create a calendar view of that table.
The point isn’t for people to use this to make public-facing sites – the point is for people to use this to explore their own data, with no effort required.
Another use case comes from the journalism world. I used to work with a guy named Derek Willis at the Washington Post newspaper. His job at the time was to acquire huge datasets and place them on the newspaper’s intranet, so that reporters could search and browse the data in their research.

Derek didn’t want to have to hand-roll a Web app each time he got a new dataset, so he used Databrowse to make intranet sites that displayed his databases — with little-to-no effort.
This comes back to what I was saying earlier about high-level abstractions. Databrowse is a particular type of abstraction, and it’s really cool that we include something like that for people to use, if they need it.
AkitaOnRails: Sounds great, I am looking forward to use it. In a degree it feels like Dabble Db – albeit inside your own app. I think you already met Avi Bryant ? I just interviewed him and it was a very insightful conversation. Have you ever tried Seaside? (out of curiosity I have a photo of you and Avi looking at his macbook sitting down in the grass, what was that?)

Adrian: Yes, it was inspired by DabbleDB – it’s essentially a very toned-down DabbleDB-ish thing for your own data. But I shouldn’t even say that, because DabbleDB is a whole universe more sophisticated than Databrowse. DabbleDB is awesome. 
Yes, I’ve met Avi a number of times and always enjoy his company. We even played some music together – he is a fantastic harmonica player!
The photo you’re referring to was taken at Foo Camp in 2007.
I haven’t tried Seaside, but it’s on my to-do list. If I were ever developing an application like DabbleDB that needed to maintain a ton of state, I would turn to Seaside first.
AkitaOnRails: I see, I feel that good musicians tend to be good programmers as well. So, my first congratulations for you is about your new book on Django that was just released. I think it is a very big milestone for the Django community. More than that you were able to make it available online under a Creative Commons license.
How did you get involved in this book? Was it difficult to convince the publisher to have the book readily available online? I ask this because at least in Brazil this is one idea that is VERY hard to push over to publishers. Tell us more about your writing experience, challenges and quirks along the way.
Adrian: Thanks very much. There’s not much to the story here – co-conspirator Jacob and I got contacted by the Apress folks, who were interested in publishing a Django book, and we did it. Well, I should amend that: It took us a long time, but we did it. 
It wasn’t difficult to convince Apress to let us make the book available online. They had previous experience doing so with Mark Pilgrim’s Dive Into Python book, and they’re generally cool people.
In retrospect, publishing the book online was a fantastic decision. Not only is the final book available online, but we made chapters available online as we wrote them, with a really nice per-paragraph commenting feature that let readers submit typos, corrections and suggestions on a very granular basis. We got a ton of fantastic feedback for which we’re immensely grateful. Having experienced this, I wouldn’t want to publish a technology book any other way.
AkitaOnRails: Now, my second congratulations is because of that Batten Award for outstanding achievement in online journalism. ChicagoCrime.org looks great and is a very good example of a mashup done right. Unfortunately our local government and public institutions have very little to almost no data available online for us to use. Where did the idea come from? How was its development?
Adrian: Thanks – and don’t let that site scare you away from visiting the beautiful city of Chicago. 

AkitaOnRails: haha, I live in São Paulo. Can’t be worse ;-)
Adrian: The idea for chicagocrime.org came when I was bumming around the official Chicago Police Department Web site and found that they publish crime data – although in an interface that’s more suited for searching than for browsing. I thought, “Wow, this is some great data!” and was writing a screen scraper within about 10 minutes.
Around that same time, I was tinkering with the Google Maps site, which had just launched, to see if I could embed Google map tiles into my own Web pages. I figured the crime data would make for a great mapping application, so I put the two together, and one of the original Google Maps mashups was born. While I was developing the site, HousingMaps.com (Craigslist + Google Maps) came out, so it beat me to the punch of being the first real Google Maps mashup – but chicagocrime.org came soon afterward.
The thing I’m most proud of is the fact that chicagocrime.org was one of the sites that influenced Google to open its mapping API. Back when HousingMaps, chicagocrime.org and the original crop of mashups came out, we were all reverse-engineering Google’s JavaScript!
AkitaOnRails: I know that you probably have 2 great passions in your career: one is Python-based development, or course, and the other is journalism (dunno the correct order here ) You’ve made yourself quite a reputation on the online media. You’re working at the Washington Post right now, is that correct? I read an article at the OJR where you explained about technology being used to empower the journalist. Do you intend to be a reporter someday or you’re more into the back-end of journalism? I think you have a strong opinion about the future of journalism in the Internet Era, don’t you?
Adrian: Well, I would say my main passion is music, but it’s hard to make a living doing that. (Django is named after the famous jazz idol Django Reinhardt)

I’m no longer working at the Washington Post. In mid 2007, I was awarded a two-year grant from the Knight Foundation to create a local-news site. So I founded EveryBlock in July. We’re a team of four people and are working hard to make a really cool application.

But, yes, going back to your question, I certainly have some strong opinions about how journalism is practiced on the Internet. This is probably out of the scope of this interview, but you can read my essay/rant awkwardly titled A fundamental way newspaper sites need to change for a taste.
AkitaOnRails: Now, that’s news to me  Didn’t know you started your own company (sorry, I still have to catch up with the Python community). Can you tell us about your new endeavor?
Adrian: Hey, I can’t blame ya – we’re staying under the radar. There’s not much to say about EveryBlock at this point other than it’s chicagocrime.org on steroids. It’s like chicagocrime, but for more cities than just Chicago and more information than just crime. 
AkitaOnRails: You should try it for Brazil :-)
Adrian: Thanks to Django’s internationalization framework, that is entirely possible. 
AkitaOnRails: Yeah, and by the way, (digressing a little) I would recommend the brazilian movie Elite Squad now that I know you’re interested in crime related data ;-)
Adrian: Noted! I’ve added “Elite Squad” to my MOVIES_TO_WATCH.TXT :-)

AkitaOnRails: Going on. Many great websites are already deployed over Django. Your own works at World Online, Washington Post being some of them. Another big name is Kevin Rose’s Pownce (the creator of Digg). You, Kevin and other influential people usually meet during conferences, don’t you? What do you think influenced him to try Django? Another great thing about Pownce has to be Leah Culver. A programmer like her is simply unheard of here in Brazil, which is a pity. You should make her the official Django cheerleader!
Adrian: I’ve never met Kevin Rose, but from what I’ve read, I believe Leah chose to use Django because either it had been recommended to her, or she liked Python, or something. I don’t know the backstory. I haven’t met Leah, either, but she was cool enough to travel to Lawrence, Kansas, for our last Django sprint a few weeks ago (which I couldn’t attend in person, unfortunately).
AkitaOnRails: It is not a rule written in stone, but in Rails community we ‘tend’ to praise Mac related tech. Of course, it is not a requirement for any language and Linux is as good. But what can I say? I am an Apple fanboy  I would like to know what’s your development environment. What tools do you use to develop your Django-based websites?
Adrian: I recently switched to a Mac after several years of using Linux on the desktop, but don’t read anything into that — I’m not a fanboy by any means, of either Linux or Mac. I miss Linux, to be honest, and in a number of ways I’ve been unimpressed by OS X’s Unix features. (Basic stuff such as readline support in the default Python is broken, etc.)
The nice things about the Mac make it worth the switch, though. Even after having used the Mac as my primary machine for 6 months, I’m still impressed that I can just close the laptop and it’ll go to sleep automatically. That never worked with Linux!
AkitaOnRails: I ask this because many people looking at Rails and Django are Java and C# programmers that are used to have a full blown IDE. I usually say that any common text editor does the job, and if you really want power vim and emacs are a perfect fit. What do you say?
Adrian: I’ve never used an IDE to program, so I’m the wrong person to ask.
Actually, I misspoke – I used an IDE-ish thing in college to program assembly. It showed the contents of the accumulators and that stuff.
AkitaOnRails: Oh, I almost forgot to ask: did you and Guido van Rossum ever met? I would like to know your opinion about the Python 3000 development. Is there anything that’s in the new version that you really anticipate?

Adrian: Yes, I’ve met Guido a number of times and was even lucky enough to have dinner with him once! It’s almost silly and unnecessary to say this, but he is incredibly smart.
I really like the new concepts and features in Python 3000, and I had the opportunity to participate in a sprint at Google Chicago a couple of months ago. My favorite feature is the migration to Unicode strings by default, because it forces the encoding issue front and center.

AkitaOnRails: Finally, what was all the fuss about Django being versioned 1.0 or jumping straight to 2.0? I didn’t follow the discussions, just read some headlines a while back. And what can people expect for the next release of Django? I understand that you don’t go big bang releases that changes the game, but what do you see getting released in the next few months in terms of new features?
Adrian: Ha – this is an amusing story. I’ve gotten worn out by people constantly asking “When is 1.0 coming out? When is 1.0 coming out?” My response always is, “Why do you need an arbitrary number assigned to the product? Many people are using the current version, so don’t hold back. Version numbers are pretty meaningless.”
So I suggested on the django-developers mailing list that we assign the version number “2.0,” as if to reinforce the fact that version numbers are indeed arbitrary. But, having given it some more thought, I’ve changed my mind on that. The amount of confusion it would cause would not be justified by the amount of rebellious pleasure I would get out of it.
As far as upcoming features, there are a number of ongoing branches of the Django codebase that will all eventually be folded into the main trunk. One is a branch called newforms-admin, which dramatically improves the amount of customization developers can make to the Django admin site. Another is queryset-refactor, which is a refactoring of our database layer, again, to make it more extensible. Other than that, there are a few small features that we need to wrap up, and it’ll be time for 1.0.
AkitaOnRails: Haha, I think you’re right, I don’t like this ‘cult of the dot-oh’ as well, it’s pretty meaningless for an open source project that’s constantly evolving. But some people do have some concerns specially in a more enterprisey-like environment. Anyway, and for those that want to see Django in action, what are the websites that you recommend people visit? Some of the Washington Post, maybe? Of course, some of the great features – as the admin site – are only for admins (duh)  But people like to see ‘living’ things instead of a bunch of tutorials.
Adrian: As an aside, I see that Rails David just wrote a rant about the same topic.
Good Django-powered sites? Let’s see – there’s Tabblo, a photo-sharing and editing site that has some really nice interactive features. There’s Curse.com, the massive online-gaming site. There’s lawrence.com, a site I helped build, which is one of the best local-entertainment sites in the world (if I may say!). And there’s a site (I forget its name) that will print a paper book from a series of Wikipedia articles that you specify – that blew my mind, the first time I saw it.
AkitaOnRails: So, I think we are done :-) That was a very pleasant conversation. I wish you have a great New Year.
Adrian: Thanks for the great questions and conversation, and happy new year!

Chatting with Avi Bryant - Part 2 22 Dec 2007 1:36 PM (17 years ago)
If you didn’t read it, take a look at Part 1 where we get to know more about Avi Bryant and his amazing product Dabble DB. In Part 2 Avi goes a little bit more in elaborating his technology opinions and points of view. It’s a very insightful reading for every programmer.
As I always say – and Avi is competent pointing out -, Ruby has its drawbacks – most of them being improved on Ruby 1.9, JRuby and Rubinius. Avi gives us good reasons why Smalltalk is yet another great platform to learn, bringing back decades of evolution and maturity. So, here goes, the unabridged version of the interview.

And stay tuned! I hope to have Evan Phoenix, Hal Fulton, Peter Cooper and Adrian Holovaty as my next guests. Lot’s of material to begin 2008 in great style.
AkitaOnRails: Some people still try to make the case in favor of Smalltalk as it being the “purest OO language out there”. Even this being a fact, do you think that this alone is compelling enough to make a case against every other language, like Ruby which is kind of a multi-paradigm language? I hope you’re not pesky about ‘language pureness’ :-)
Avi Bryant: Actually, I am pesky about it – not from an academic or aesthetic point of view, but from a pragmatic one. “Pure” languages make a lot of things easier: development tools, VMs, and infrastructure like distributed object systems or transparent persistence all get much simpler and better when you have a small, consistent language.
One experience I had, for example, was being hired to port my client library for the GOODS object database from Smalltalk to Python; I spent a huge amount of time dealing with special cases in the Python semantics (is this a class? a type? a new-style class? implemented in python or in C?) that simply never came up in Smalltalk.
Ruby does pretty well here, better than most in the scripting language space – I wouldn’t call Ruby “multi-paradigm”, by the way – but it could stand to do better.
AkitaOnRails: I think you once said that you only consider a language “finished” when it is fast enough to extend itself. This is very true for Smalltalk, Java and other platforms. Ruby is undoubtedly lacking in its current position. That was one of the reasons we now have parallel efforts like John Lam’s IronRuby, Charles and Thomas’ JRuby and Evan’s Rubinius. One of the most criticized points is that Ruby doesn’t have a formal spec for the language or its core libraries. You also said that the Java VM is not suited enough for Ruby as Strongtalk would be, for example. Does this still hold today as we see JRuby 1.1 in the horizon?
Avi Bryant: It still holds. JRuby currently seems to benchmark on par with MRI, and the best numbers from any Ruby implementation are maybe 3X MRI on average. I think we can do 25X MRI for basic language feature benchmarks (message sends, block evaluation, etc), which should be enough to make Ruby implementations of the standard libraries feasible. Even if the net result was a similarly performing system, the side benefits would be extremely valuable.

AkitaOnRails: I remember that you started the Smalltalk.rb initiative a while ago, and if I am not mistaken it was an effort to make Ruby translate into equivalent Smalltalk code so it could run in any of the available Smalltalk VM implementations out there. Is this project still going on, do you still think it is feasible to pursue such a goal?
Avi Bryant: I still think it’s a worthwhile and realistic goal. The project is still going in the sense that I’m still taking to people about how to make this happen, but I’m not able to spend time writing code for it myself at the moment. I have some reason to hope this project will progress more concretely next year, but we’ll see.
AkitaOnRails: Some time ago I read a snippet of an IRC transcript between you, Evan, Chad and even Charles. You started talking about standardizing primitives (they are C-based in MRI today). My bet is that Rubinius is the project destined to be the “next big thing” for the Ruby community. To me it seems that you and Evan collaborate a lot, is that correct?
Avi Bryant: I wouldn’t say that, but Rubinius is certainly the Ruby project that most closely aligns with my own interests and goals at the moment, and it’s great to see how much effort is being put into it. Engine Yard also deserves a lot of kudos for their financial support of the project.
I have high hopes that the work Evan and crew are doing will be of great benefit not just to Rubinius but to all of the Ruby implementations – which is why I was advocating for a standard primitive set.
AkitaOnRails: You know a lot of people, I wonder if you ever talked with Koichi Sasada himself to input some of your ideas for the YARV project as it’s going to be the “official” Ruby virtual machine out there a few months from now.
Avi Bryant: No, I don’t believe we’ve never spoken. I would certainly love to meet him some day.
AkitaOnRails: Then, we get one level up to applications. Your Seaside framework is pretty amazing. You’re very right about WebObjects as well. As a Java programmer I always pitied that it never got mainstream. Today it’s mostly relegated to Apple related websites, while lesser Java frameworks took the front. Tapestry and Cayenne are trying to top WebObjects’ features but seems they are nowhere near yet. Do you still program some Java? What are your opinion on current mainstream frameworks as Spring, JSF? For non-starters, what was it in WebObjects that makes it different than the rest?
Avi Bryant: I don’t do any work in Java any more (thankfully), so I can’t really give a qualified opinion on the state of frameworks there right now. However, the main thing I think WebObjects did right was to focus on the state and behavior of the application, rather than on the mechanics of URLs and HTML and HTTP requests.
So rather than worry about what a field was named, you would just say “this field is bound to this instance variable in my model”, and rather than worry about what URL a link went to, you’d say “this link triggers this method on my page object”.
Transitioning between pages was done by constructing a new page object and setting it up directly in Java, rather than constructing a URL that was going to be parsed to build a page. That directness and general style is something that very heavily influenced Seaside.

AkitaOnRails: Many people may not immediately understand as it as a word that is new to most of them: “continuations”. Meaning that instead of manually controlling the flow between events, with manual marshaling and unmarshaling of objects, you program as a cohesive and continuing flow. Can you explain this in a way that a novice would understand? What are the benefits and drawbacks of this approach?
Avi Bryant: Well, it’s really all about being able to get modal behavior in a web app. In a desktop application, for example, you might occasionally have a call like “file = chooseFile()” or “color = pickColor()” that opens a modal dialog, gets a result from the user, and keeps going from there.
Seaside’s use of continuations is just to allow exactly that kind of interaction in the context of the web. The tricky bit is that because of the backbutton, the user might go pick a different color from the same dialog later, and the “pickColor()” call has to return a second time. This is confusing to think about, but mostly it Just Works.
From an implementation point of view, what we’re doing is saving a copy of the stack at the point the call is made so that we can come back to it later, more than once if need be.
AkitaOnRails: You started these concepts in the Ruby land with IOWA. Once upon a time there was a framework called Borges that was also discontinued. Then Koichi mentioned taking continuation support from the next Ruby. Do you think the Ruby land is giving a step back with lack of support for continuations?
Avi Bryant: Continuations are a great abstraction, and allow a lot of interesting experimentation with language semantics. However, I wouldn’t consider it a tragedy if they disappeared from Ruby; there are more important things to worry about. From a web perspective, I think that AJAX is starting to replace a lot of the use cases where having server-side modal logic used to be important – Dabble DB, for example, barely uses Seaside’s continuation features at all.

AkitaOnRails: Your blog has a peculiar name, HREF considered harmful. You probably got your inspiration from Edsger Dijkstra/Niklaus Wirth’s Goto Statement Considered Harmful paper where Edsger made his famous case against GOTO. At the assembler level it is impossible to not JMP all the time (at least not without some macro help) but at a C level you can avoid GOTO’s altogether. Even Basic had both GOTO and GOSUB and you could just ignore the former. I am being simplistic here, but now you’re kind of saying that URLs play a similar role in a way that they disrupt the normal flow, going back in unpredictable ways and so on. On the other hand the Internet would not be what it is without URLs. How do we deal with this conundrum?

Avi Bryant: I don’t think it’s a conundrum. I think your analogy is a good one: it’s impossible to not JMP all the time, and it’s also impossible not to use URLs all the time, but we don’t have to always be aware of either one. Back when everyone wrote in assembler, people probably obsessed about having meaningful or “pretty” JMP labels the same way they obsess about having pretty URLs today. I think we need to allow ourselves to make the same leap up in abstraction level on the web that we did with higher level programming languages.
That’s not to say we should never be thinking about URLs: any website needs to export meaningful URLs to be referenced and used externally, just like any C library needs to export meaningfully labelled function names so that it can be linked into other programs. But that’s as far as it needs to go.
AkitaOnRails: Components were a big deal in the early 90’s, with RAD tools and so forth. Today it seems that they are showing up slowly, with initiatives as JSF and ASP.NET. Rails initially packed a very crude support for ‘components’ but it was dropped very early on as a bad thing (because of the jury rigged way it was implemented). Nothing new came to replace it what feels like there wasn’t enough need for it at the Rails level. On the other hand Seaside is heavy in componentization. Can you expose a little bit about the differences in this approach?
Avi Bryant: “Component” is one of those terms like “MVC” or “open” that gets used to mean so many different things it’s hard to talk seriously about it. One concrete feature of Seaside’s approach is that each piece of UI is quite independent of what other pieces of UI may be on the page.
There’s no central controller which is responsible for request processing, choosing a template, or so on – all of those responsibilities are distributed among many smaller objects. There’s also no chance of naming conflicts because you don’t directly name links or form fields, so you can have many copies of the same form/widget/etc on the same page without any confusion.
This allows a level of modularity that’s very hard to reproduce in most traditional frameworks.
AkitaOnRails: Another thing that might shock some people is that there is no traditional templating system in Seaside, no code mangling between HTML tags all over the place. Instead all HTML is abstracted in a object hierarchy that renders itself. In the Rails world there are a few alternatives that attempts some of that like HAML, Markaby. What do you think are the fundamental differences?
Avi Bryant: The HTML rendering API is a very core piece of Seaside, and a huge amount of the framework was designed with that underlying approach in mind. I think that’s the main difference when compared with HAML or Markaby, which are meant to be dropped into other frameworks.
Once you get rid of templates and switch to programmatic HTML generation, the design space just completely changes, and you need to re-evaluate almost every other decision that you made – this was a process that I went through with Seaside between the initial release, which used templates, and the 2.x versions, which don’t.
So I think we’ll have to see a framework that takes, say, Markaby as a starting point and asks “where can we go from here” before we can make any real comparisons.
with Adrian Holovaty, from Django fame
AkitaOnRails: You also touted the shared-nothing vs share-all dilemma. And you obviously have a strong case because this is not just techno-babble but you do have a successful product running on top of that vision. Do you still think it pays off to sacrifice a little bit of performance for more clean code and productivity? In a way it’s sort of what DHH himself said about Rails when people said it was slower than PHP or Perl. Actually this also has to do with your talk as being a “heretic” in a way that you’re doing things in a different way than we all are now. Can you elaborate on that?
Avi Bryant: “Share nothing” is great advice for making the maximum use of your server resources. For sites like yahoo.com or Facebook, that’s clearly very important because your business depends on serving millions of users every day.
“Share everything” is really hard on your servers, but it makes maximum use of your developer resources. For a startup like Dabble DB, where we have 4 developers, that’s really important. And since our revenue model only requires serving thousands of users every day, not millions, it’s ok to spend a little more per user on server hardware. It’s been a very worthwhile tradeoff for us.
AkitaOnRails: And speaking of DHH, you probably met in several occasions. You’re both opinionated guys with antagonist visions. Smalltalk vs Ruby. Seaside vs Rails. Share-all vs Share-nothing. One could feel tempted to draw you two as Superman vs Batman kind of dispute. Though I know that smart people don’t fight over pesky stuff. What do you think of him and his ideas, how do you think both communities could cooperate if there’s any chance for that?
Avi Bryant: I have a lot of respect for David. The only time I’ve felt antagonistic towards him was this last summer at Foo Camp. We were playing a game of Werewolf, and I was a werewolf and he was a villager. Now, as a werewolf the best thing you can do is get the person nearest you to trust you, and that happened to be DHH. And it worked – Kevin Rose was totally on to me but David managed to persuade him not to lynch me, and I ate them both and won the game. Pn3d!
Anyway. There’s probably a lesson in there somewhere. Also, in a fight between me and DHH, Neal Stephenson would win.
AkitaOnRails: Finally, Brazil still has a young and growing community. Any closing regards for our audience?
Avi Bryant: Olá and good luck! I’ve been told Rio is even more beautiful than my home of Vancouver, and I hope to visit some day.

Don’t miss the TWiT podcast interview with Avi!
Chatting with Avi Bryant - Part 1 15 Dec 2007 5:15 AM (17 years ago)
Someone once challenged all other frameworks implying that no one would get close to what we are doing in Rails … except for Avi.Seaside is such a departure from the status quo that Avi himself describes it of a ‘heretic’ framework. And he is right. He looked back in history and took what is considered ‘the’ father – and arguably ‘the’ best implementaton – of object-oriented languages: Smalltalk.
Taking clues from the venerable Apple WebObjects he set his way to implement Seaside and his very successful web product, Dabble DB. Check it out who is the man, what are his opinions and why he is so relevant to the Ruby and Rails community even though he advocates another language and another framework. Sounds strange, but when Avi speaks, you listen.

He was very kind to provide me a very long interview. It is so long I divided it in 2 parts. This is the first Part. I will release the second one in a few days. Hope you all enjoy it.
AkitaOnRails: Great. I am kind of nervous. Up until now I only interviewed Ruby and Rails advocates including Matz and DHH, this is the first time I am looking for an outside point of view.
And I know you’re very opinionated about Smalltalk and Seaside, but at the same time you have very strong binds to the Ruby community. May I start asking you more about Avi Bryant, the person? Meaning, what’s your history in the programming field?
Avi Bryant: I started programming quite young; it was something I did with my brother and father for fun, mostly writing games in C on the early Mac. As I got closer to college age, my interests turned more to theatre and film, and so when I started university it was essentially as a film major.
But in the long run computer science sucked me in, and I ended up graduating with a CS degree and working in a software engineering lab on campus. That was when I first started programming seriously, and particularly where I got especially interested in software tools.
This was around the time that the very first builds of Mac OS X – when it was essentially still just NeXTStep, without Aqua or Carbon or anything – started to become available, and since I had always programmed for the Mac I set out to learn Objective-C and Cocoa. That was my first exposure to “real” OO, and it was intoxicating.
At the same time, I was doing some web consulting on the side for some extra money, and so I was looking for a language that reminded me of Objective-C but was more dynamic and better suited for the web, and so eventually stumbled across Ruby, which fit the bill nicely.

I was still enamored with all things NeXT and Objective-C, and so when I started to work on web tools for Ruby I took NeXT’s WebObjects framework as my model, and ended up with IOWA, which is very close to being a port of WebObjects to Ruby. I presented that at the first RubyConf, which was, I think, in 2000.
RubyConf was collocated with OOPSLA that year, which I was also attending to give a talk on my research from the software engineering lab. Now, when OOPSLA started out, it was full of Smalltalkers, and even though the mainstream of OO software development – and thus the main focus of OOPSLA – moved on to Java and C#, the Smalltalkers kept coming. But instead of participating in the rest of the conference, they’d just set of a semi-official “Camp Smalltalk” with their own projector and their own schedule and hack and demo Smalltalk stuff all day.
I had of course been aware of Smalltalk, as the source of a lot of the ideas behind things I was interested in – Objective-C and Ruby, obviously, but also TDD, wikis, even the Mac to some extent – but I had never gotten anywhere with actually using it; the environments were too different, the documentation too sparse, etc.
Sitting for a day at Camp Smalltalk was the boost I needed to get past that. And once I got a taste of Smalltalk, I couldn’t let go – I started right away on a port of IOWA to Smalltalk, and convinced my next couple of clients on web projects that I should use Smalltalk instead of Ruby. This port became Seaside, and over the next several years I built up a consulting business around Seaside training and development.
Smalltalk web development may seem like a small niche to build a business around, but the fact is that nobody else was doing it at the time (for that matter, nobody else was doing web development in Ruby at the time either – that situation is a little different now.
Some people to mention in this history – Julian Fitzell was my early partner on the web projects, and we worked together on the first version of Seaside. Colin Putney was one of my early clients, who had come to me based on my work in Ruby and I had to work hard to convince to use Smalltalk; he’s now a confirmed Smalltalker and works with me on Dabble DB. Andrew Catton worked with me at the software engineering lab, and was a frequent collaborator on various other projects over the years.
A few years in, a little fed up with consulting, Andrew and I started to work on a product on the side, and that project became Dabble DB. Last summer, we were lucky enough to get funded to work on that full time, and that’s what I’ve been doing since.
AkitaOnRails: I see that you like the fact that Smalltalk is not “mainstream” in the Java-sense of the word. I can see the advantages and I agree with it. It’s like “we are a small group of very smart people”. Much like Apple’s own “Think Different” campaign. On the other hand the masses tend to like big bang marketing and support. What do you think of this culture clash? The most important part is: here in Brazil the market is very closed to non-widely-commercially-supported tech. Meaning most of them don’t like anything different than Java or .NET. How do you convince your customers about using Smalltalk – if this is actually a matter there in the US?
Avi Bryant: Yes, that’s a tricky balance. Some of the people I knew in the early days of Ruby’s popularity – post-Pickaxe, but pre-Rails – have complained about how much more popular Ruby has gotten lately, because inevitably the signal-to-noise ratio goes down on the mailing lists and at the conferences. Smalltalk doesn’t have that problem – in particular, Smalltalk has a nice mix of very experienced hackers – people like Dan Ingalls, who has been writing language implementations for more than 30 years, and has just an amazing depth of knowledge to share – and young troublemakers like myself. When you get too popular too quickly, you get a huge influx of young, inexperienced, energetic people, and the voice of experience tends to get drowned out. Not that new ideas aren’t valuable – they’re essential – but I think in this field we tend to overlook history far too much.

As for using non-standard tech, I think the best way to look at it is as a competitive advantage. Paul Graham points out that on average, startups fail, and the same could probably be said about software projects in general. So if you want not to fail, you have to do something different from the average, and using better technology is a great way to do that.
But you clearly have to be in a situation where results matter more than policy – it’s almost impossible to sell an enterprise IT department on a Smalltalk project. On the other hand, a small business owner couldn’t care less what technology you use when building a custom app for him – it’s not like he has an army of Java developers who are going to maintain it.
In general, the closer the alignment between the person who will be using the app, and the person who is writing the checks, the more they’ll care about having something that actually works, and the less about the buzzwords it involves.
That was my strategy when doing Smalltalk consulting, and that’s also our strategy with Dabble DB – we sell to users, not to CIOs.
AkitaOnRails: That’s exactly how I think. Which boils down to you having a startup. I can understand being fed up by consulting work, but what led you to choose to open your own company to sell your own products? I heard that Tim Bray is also an investor for your company? Many people wouldn’t like to lose their comfortable job positions for something as risky as this. What was the reason for this direction in your career?
Avi Bryant: When we were consulting, it became clear to Andrew and me that a) most companies, especially small businesses, couldn’t afford to hire us, and b) even those who could, they could only hire us for the very most important projects. The only way we were going to scale our business, and help as many people as possible, would be to effectively replace ourselves with software: build a product that would let them do the simple projects themselves.
We didn’t abandon everything to go and build this, however – we kept our existing clients (in fact, we took on some new ones to get a little extra capital to hire a web designer, etc), and we worked on the product on evenings and weekends, where we could.
As the product got further along, and it became more and more clear that there might be something worthwhile there, we started to work on it more in earnest, but still keeping some cash coming in with consulting.
Eventually, when the product was ready to launch, we knew we couldn’t handle Dabble DB customers at the same time as our consulting clients, and so we had to drop them entirely. That was when we took some investment from Ventures West and from Tim Bray.
So it was a fairly gradual transition, which made it a lot easier to do.

AkitaOnRails: But even then, were you doing Smalltalk/Seaside consulting only? Or you were working on different languages/frameworks for customers and Smalltalk afterwork? And for non-starters how would you briefly describe Dabble DB? I hear that you’re about to release a companion product for it, isn’t it? Can you describe them?
Avi Bryant: During that period, the consulting was all around Seaside, yes – there were some dark times earlier when I had to take some Java work :-)
Dabble DB is a hosted web app for small businesses and teams who need some kind of custom data management – maybe they need custom project management, or a custom contact database, or a custom HR application, or event planning, or just their DVD collection, but for whatever reason the off the shelf software doesn’t do what they need. Dabble lets them interactively build very rich reports on their data, with structured grouping and filtering, simple calculations and subtotals, and display it as a table, or a chart, or a map, or a calendar. You can then share these reports with people, or invite them in to enter or modify the data itself.
The companion product you’re referring to is, I think Dabble Pages. This is really just a new feature set on top of Dabble DB, which all Dabble customers get. What we’ve found is that in any organization there are usually a small number of people who want the full power of the Dabble DB user interface, and want to build new reports or add fields or restructure their data, etc. But there are also a much larger number of people who just want a simple web page where they can enter new data or view a report. So Pages lets that small core group build something for the larger group. It’s sort of like a souped up version of WuFoo or other form builders, but with Dabble DB as the administrative back-end.
It makes Dabble DB almost into a web development tool, in the sense that the administrative users really are building simple applications for the other people in their organizations – but without any whiff of programming, so of course the applications are very limited.

AkitaOnRails: Changing subjects a lil’ bit, one thing that I do admire about you is your relationship with the Ruby/Rails community. Those are different paradigms and technologies, but you never dive in flame wars like ‘Smalltalk is better than Ruby’ just for the sake of it. On the contrary, to me it feels like you do like Ruby, as you presented at RailsConf about the possibility of running Ruby empowered by a modern VM like GemStone’s. But, you did switch from Ruby to Smalltalk. What was it the ‘clicked’ for you about Smalltalk? Continuations? The whole coding-in-runtime? The tighter environment integration?
Avi Bryant: So, first of all, I very much do like Ruby, and Dabble DB includes about 3000 lines of Ruby code (I just checked) along with however much Smalltalk (and a sprinkling of Python).
What clicked about Smalltalk was a few things: one was simply the maturity, both of the community and of the technology. Smalltalk implementations have been refined over the last 25 years, and they’ve really benefited from it.
One of the major benefits, in my opinion, is that Smalltalk VMs are fast enough that it’s reasonable to implement all of the standard libraries – Array, Hash, Thread, and so on – in Smalltalk itself. So there’s no barrier where you switch from your Ruby code to the underlying C implementation; it’s “turtles all the way down”. This may not seem like a big deal but once you have it, it’s really hard to give it up.
Rubinius, of course, is moving in this direction for Ruby, and mad props to Evan and everyone else working on that project. For me, the Smalltalk environment is also key.
In some ways it’s the same things I talk about with Dabble DB: you don’t have to choose one way to organize your data, you can have one view that’s grouped by date and another filtered by customer and another where a map is the only way to understand. In Smalltalk, you don’t have to choose one file layout or order of methods and classes in your code; you’re constantly switching views on what’s basically a database of code.
My friend Brian Marick hates this, because you lose any “narrative” that might have existed by putting the code in a certain order in the file, and it’s hard to get used to, but for me, it’s the ultimate power tool for hacking on a large code-base.

That’s it for Part 1. Stay tuned for more Avi, talking about Smalltalk and Ruby on Part 2 of this interview, to be released in a few days.
Chatting with John Lam (IronRuby) 12 Nov 2007 11:37 AM (17 years ago)

It’s been a while since my last international interview, and I am back with no other than one of the responsibles for Ruby being enabled in the .NET platform. That’s correct, I’ve covering a lot about JRuby and Rubinius but we can’t neglect that one of the biggest platforms out there in the market is receiving the Ruby treatment as well. So I invited John Lam , who kindly answered several questions regarding this endeavor.
Remembering that IronRuby – named after IronPython, the first of the main open source dynamic languages built on top of .NET – is a true open source project, and also has a 3rd party addon for Visual Studio.NET, so programmers used to the VS.NET workflow can get onboard with a lower learning curve ahead of them.
Despite of opinions against Microsoft just for the sake of arguing, the fact remains that Java and .NET represent the biggest corporate development market today. And this is also a fact that the Ruby meme is spreading in a very fast way. Being built to run on top of both the JVM and the CLR represents Ruby being enabled for market niches that it wouldn’t reach otherwise, and this is huge win. I talked a little bit about this in my article (in portuguese): For myself to win, the other one has to lose. There are very intelligent people at Microsoft, John Lam being one of them.
That said, let’s get started:
AkitaOnRails: First of all, I always ask my guests about their careers: what was you path up until now? Meaning, how did you get yourself involved in computing, what drives you into it?
John Lam: I wrote a lot of software before I graduated from High School in 1986. I shipped a bunch of commercial software for the Commodore ‘platform’ (aka PET, VIC-20, C-64/128) back in the day. In 1986 I decided that there was no future in computing (which shows why folks shouldn’t take my opinions seriously :)) and decided to study the physical sciences in University. I graduated in 1995 with my doctorate in Organic Chemistry and decided that there was no future in chemistry (which, if you look at how the reverse engineering of life today is based a lot on cross-discipline interaction with other branches of life sciences, shows why folks shouldn’t take my opinions seriously :)).
Once I decided to work in computing again, I took up an obscure new development platform called Delphi which shipped in 1.0 form around the time that I re-entered the field. I spent a bunch of time working on integrating Delphi with COM, which is where I originally hung my hat. The dark side of COM pulled me into its orbit and I’ve been working on Microsoft related stuff since then.
AkitaOnRails: I see that you’re at Microsoft since January 2007, is that correct? How did you get in there, were you hired with the IronRuby project in mind? Is this your main assignment today?
John Lam: Yes, I started in January. Before joining the company, I worked on an open source bridge between Ruby and the CLR called RubyCLR. When I decided to start promoting that work at conferences, I crossed paths with the DLR team at Microsoft. Mahesh Prakriya graciously donated half of his talk at Tech Ed in 2006 so that I could talk about RubyCLR. After much hand-wringing/mind-conditioning I wound up accepting their offer to work full time on a Ruby implementation on top of the DLR and we (my wife, two kids and dog) arrived in Redmond in January.

AkitaOnRails: What was the motivations behind starting IronRuby? How did it start? Was you the original and sole developer of a .NET
implementation of Ruby?
John Lam: We want to demonstrate that the DLR is truly a multi-language dynamic language runtime, so we had to build a number of languages on top of it. Ruby certainly fit the criteria: dynamic, strong user community, lots of attention, so it made sense to implement it. IronRuby has definitely forced a lot of design changes to the DLR, making it less ‘Pythonic’ which is a good thing for other folks who are interested in building a dynamic language on top of our platform.
I’m definitely not the sole developer on IronRuby. We have two great devs working on the project: Tomas Matousek and John Messerly and they’re doing awesome work. Our tester, Haibo Luo, is doing great work to make sure that we ship a high quality implementation. Haibo’s work will be released along with IronRuby, which means that the community can also benefit from his test suite.
AkitaOnRails: Not many people here is familiar with the DLR and Silverlight, can you briefly describe them for non-starters? What makes a ‘DLR’ different from a ‘CLR’ besides jumping from “C” to “D”? :-)
John Lam: The DLR is a platform that layers on top of the CLR. This means that we can run anywhere that the CLR can run, which of course includes Silverlight. Silverlight is our cross-platform browser-based platform that runs on Windows, Mac and Linux (via the Moonlight project). We ship a cross-platform version of the CLR which means that you’ll be able to run DLR-based languages with just a 5MB initial download into your web browser.
AkitaOnRails: This is delicate: I once read Ola Bini and Charles Nutter criticizing the “Microsoft Way”, meaning that it would be extremelly hard – if not impossible – for you to write a 100% complete Ruby 1.8 implementation on top of .NET without being able to peek into the source code. The reason being the company policy toward open source licenses. Was that the case?
John Lam: I think that IronPython is the existence proof that you can build a compatible implementation of a dynamic language without looking at the original source code. In our work with IronRuby, I can tell you that not being able to look at the source code hasn’t prevented us from figuring out how Ruby accomplishes some feature – it’s all about designing the right experiments.
AkitaOnRails: I also saw that IronRuby is going to be released under open source-compatible license from Microsoft, making it probably the first trueopen source project ever from Microsoft, meaning that you would not only allow people to take a look at the source code but also to contribute back to it. How far is this?
John Lam: The Microsoft Public License was officially sanctioned by the OSI in early October. IronRuby, IronPython and the DLR are all released under this license.
We’ve already accepted contributions back in from the community, and are continuing to accept more contributions from the community.
We’re actually not the first Open Source project at Microsoft that accepts contributions back from the community. That honor belongs to the ASP.NET AJAX control toolkit which is an enormously successful project with > 1M downloads to date.

AkitaOnRails: The DLR was originally conceived as an experimental way to run Python on top of .NET. Did this make it easier for a Ruby implementation or do you feel that Python and Ruby were different enough to guarantee lots of tweaks into the DLR to make it feasible?
John Lam: It’s fair to call the original version of the DLR the “Python Language Runtime”. Adding Ruby to the mix forced a lot of additional changes to the DLR, the most significant being the refactoring of the runtime to migrate all of the Python specific idioms (which were thought to be general but turned out not to be the case) into IronPython.dll. What remains is a core which our the 4 languages developed by MSFT (IronRuby, IronPython, Managed JScript and VB) continue to use effectively today.
AkitaOnRails: Is it a goal to be 100% compatible with MRI 1.8? Or you’re going toward a sub-set of the Ruby implementation? This would make it possible to write .NET programs in Ruby, using the full set of .NET libraries and frameworks as ASP.NET, Windows.Form, LINQ, etc. Or are you planning on a full blown MRI compatible implementation, enough to be able to run an entire Rails application?
John Lam: Our #1 priority is being as compatible as possible with MRI 1.8.×. The one feature that we will not support is continuations, which is consistent with JRuby. Other than that (and in the absence of a Ruby spec), compatibility will be judged by whether we can run real Ruby applications and community developed Ruby test suites. Obviously Rails is an extremely important Ruby application, which we will absolutely run on top of IronRuby.
.NET interop is our #2 priority. We will integrate with the .NET platform, and allow you to write Ruby applications using the rich set of .NET libraries. Obviously things like Silverlight, WPF, LINQ, WinForms, and ASP.NET will be supported.
AkitaOnRails: Ruby grew as a collective and low profile effort that really exploded 3 years ago because of Rails. That’s one reason no one ever bothered to write a formal specification and test suite. You have Alioth, you have the current YARV test suite. Did you had a hard time because of this lack of formal specs? Are you in contact with people like Charles from JRuby, Koichi Sasada from YARV or Evan Phoenix from Rubinius? What do you think of all these efforts going on in parallel? Are any way in that you can contribute with one another?
John Lam: We’re using the Rubinius spec suite today, and plan on shipping it along with our sources to ensure that we catch compat bugs early in the process. I’m guilty of not participating as much as I would like to in talking more with Charlie, Evan and Koichi about collaborating on specs. We’re focused on getting the core language up and running today, and have like a lot of other fast-moving projects, been neglecting to document the things we have learned. Once the pace of the project slows down a bit, I’ll be able to spend more time engaging with the other implementers.
AkitaOnRails: Ruby has a lot of known deficiencies. Koichi is trying to improve on some of them for Ruby 1.9. How are you tackling problems like lack of native threading, simple mark and sweep garbage collector, no virtual machine and thus no byte-code compilation, performance issues, lack of native internationalization (Unicode), lots of C-based extensions.
John Lam: We get a lot of things for ‘free’ by running on top of the CLR. Native threading is supported in IronRuby. We use the CLR garbage collector, which is a world-class GC. We compile natively to IL, and our IL can be GC’d as well which is goodness for long-running server based applications. We will obviously support CLR strings, which are Unicode strings and we will also support Ruby mutable strings which are based on byte arrays. We will not support C-based extensions at all, instead we will be porting the existing C-based libraries in the Ruby Standard Libraryto C# (or Ruby).
AkitaOnRails: Are there any benchmarks comparing IronRuby with the MRI? Do you think you’re already outperforming it? Are there any issues today around Ruby performance over the DLR? Or more interestingly: is there any comparison between Ruby on DRL and C# our VB.NET over the CLR?
John Lam: We are faster than MRI in the YARV benchmarks, but that number changes daily. One great thing about our team is that we have a performance regression test suite that we regularly run across all of our code. This makes it trivial to pinpoint a build that causes a regression in performance, even if we postpone that work for a while.
We have done zero performance tuning so far; we’re just using features that exist in the DLR today, like polymorphic inline caches for efficient call-site method caching. As our implementation matures, we will tune IronRuby to perform well on application-level benchmarks (not just microbenchmarks which are useful to us but not so interesting to real customers). The DLR (and CLR) is becoming faster all the time, and any dynamic language that is built on top of the DLR will benefit from these improvements.
Obviously, languages like C# and VB.NET are faster than Ruby today. But we are confident that we can significantly narrow that gap over time.
AkitaOnRails: What about tooling? I saw you tweaked your Visual Studio.NET to have the Vibrant Ink that we – TextMate users – are used to, and it looks nice. I even saw a screenshot of code folding of Ruby inside of Visual Studio. How is its support for Ruby?
John Lam: Right now our team isn’t involved in VS integration. However, the good folks at Sapphire in Steel are doing great work at integrating IronRuby into VS.

AkitaOnRails: You mentioned in a interview about a possibility of Ruby running on top of Silverlight. How feasible this is today?
John Lam: We demonstrated IronRuby running on top of Silverlight at RubyConf. The talk should be posted soon. We’re planning on rendezvousing with Silverlight in time for their next CTP (late this year / early next year). At that time, you will be able to code in Ruby that runs in your browser.
AkitaOnRails: Microsoft is learning on how to deal with the open source community. Do you think the adoption of technologies as Python and Ruby are helping the company to understand the open source way? What do you think still have to improve? Meaning, if you could, what would you change?
John Lam: Microsoft is a big company and we’re working very hard on working together with the Open Source community. IronRuby is one of the most visible Open Source projects in the company, and we’re helping to pave the way for other teams that want to engage with the Open Source community. Change happens incrementally at big companies and it’s been fun being a part of that change!
AkitaOnRails: Silverlight was released over an open source license as well, so that the Mono guys were able to run it very quickly over Mono. Are you close to Miguel De Icaza? What do you think about Mono? An IronRuby running on top of it means a multi-platform Ruby that can run over Linux. If you ever get 100% compatibility with MRI and Rails, this means running over Apache+mod_mono on Linux and over IIS on Windows, everything developed under Orcas. Are there any plans for this kind of integration and end-to-end solution?
John Lam: Actually, Silverlight is not released under an Open Source license. The DLR, IronPython and IronRuby are all released under the Microsoft Public License, which makes it possible for Miguel and his band of merry men to just ship it on top of their Moonlight implementation.
I love how pragmatic Miguel is. We showed IronRuby running on top of Mono at RubyConf and that was largely due to the Mono team fixing a bunch of bugs at the last minute so that we could demo (thanks!). DLR + Iron* tends to push the C# and the CLR pretty hard. We’ve uncovered bugs in the Microsoft C# compiler, and we’ve uncovered bugs in gmcs under Mono as well. But thankfully, both the C# team and the Mono team have been great at fixing those bugs to unblock us.

AkitaOnRails: I think, that’s it for today. Any closing remarks for the Brazilian audience?
John Lam: Thanks for sending along a great set of questions! Good luck with your Ruby adventures and I hope you’ll have a chance to check out IronRuby in the future.