Autofac 9.1.0 12 Mar 4:00 PM (10 days ago)
Yesterday I released Autofac 9.1.0. It’s listed as a minor release - 0.X.0 semver increment - because it’s all new, backwards-compatible features, but it’s actually pretty big, I think.
AnyKey Support
Autofac now natively supports the concept of AnyKey. It behaves the same way AnyKey works in Microsoft.Extensions.DependencyInjection, but it is native to Autofac directly. The unit tests here show some very detailed examples of usage, but on a high level:
var builder = new ContainerBuilder();
builder.RegisterType<Service>().Keyed<IService>(KeyedService.AnyKey);
var container = builder.Build();
// Registering as AnyKey allows it to respond to... any key!
var service = container.ResolveKeyed<IService>("service1");
As noted, it behaves like AnyKey in Microsoft.Extensions.DependencyInjection, so there are some “rules” around when AnyKey will work and when it won’t.
- You can resolve a single instance and
AnyKeywill be a fallback. If you resolve a single instance of a service and use a key that you haven’t otherwise registered, anAnyKeyservice can provide that instance. - You can resolve a collection using
AnyKey. This allows you to get all keyed services of a certain type, but it will not include the services registered withAnyKey- only services registered with a specific key. AnyKeyworks with singletons. When you register anAnyKeyservice as a singleton, a different instance of that service will be cached for each key under which it’s resolved. Beware of this - if you’re not paying attention, it could lead to a memory leak.- Registration order is important. As always, last-in-wins. If you register a lot of
AnyKeyservices, the last one registered for the given type will be the one you get when you resolve.
Here are some examples showing usage:
var builder = new ContainerBuilder();
builder.RegisterType<Service1>().Keyed<IService>(KeyedService.AnyKey);
builder.RegisterType<Service2>().Keyed<IService>("a");
builder.RegisterType<Service3>().Keyed<IService>("b");
var container = builder.Build();
// This will ONLY get Service2 and Service3 - things registered with explicit
// keys. It will NOT return Service1, registered with AnyKey.
var allServices = container.ResolveKeyed<IEnumerable<IService>>(KeyedService.AnyKey)
// THIS WILL THROW: You can't resolve a single instance using AnyKey.
_ = container.ResolveKeyed<IService>(KeyedService.AnyKey);
// This will get you the AnyKey service because no specific keyed service was
// registered with `other-key`.
var noRegisteredKey = container.ResolveKeyed<IService>("other-key");
Again, check out the unit tests for some robust examples.
Inject Service Key Into Constructors
The new [ServiceKey] attribute allows you to inject the service key provided during resolution. This is handy in conjunction with AnyKey and is also similar to the construct in Microsoft.Extensions.DependencyInjection, but with native Autofac.
First, mark up your class to take the constructor parameter.
public class Service : IService
{
private readonly string _id;
public Service([ServiceKey] string id) => _id = id;
}
Then when you resolve the class, the service key will automatically be injected.
You can also make use of this in a lambda registration.
var builder = new ContainerBuilder();
builder.Register<Service>((ctx, p) => {
var key = p.TryGetKeyedServiceKey(out string value) ? value : null;
return new Service(key);
}).Keyed<Service>(KeyedService.AnyKey);
Metrics
Some metrics have been introduced that can allow you to capture counters on how long middleware is taking, how often lock contention occurs, and so on.
Set the AUTOFAC_METRICS environment variable in your process to true or 1 to enable this feature. You can see the set of counters that will become available here.
⚠️ This is NOT FREE. Collecting counters and metrics will incur a performance hit, so it’s not something you want to leave on in production.
General Performance Improvements
A pass over the whole system was made with an eye to trying to claw back some performance. Some additional caching was introduced to help reduce lookups and calculations of reflection data; and a few hot-path optimizations were made for the common situations.
A Personal Note
This is probably the biggest Autofac update made in quite some time - new features, some perf fixes, some metrics - and, with that, I really don’t have any active assisting project maintainers, so it was all just me. I’m pretty proud of this one. I have been suffering from maintainer burnout for a while, but I’ve got a little of my energy back lately and, honestly, it’s due to AI.
I used Codex and Claude Opus on this latest set of changes to help me out and do some of the heavy lifting. Don’t get me wrong, I reviewed all of what was output, but it was so energizing to be able to tell something else to go look for changes, dig for performance optimization opportunities, and validate them. I could create a robust set of tests (or, in some cases, adapt existing Microsoft container compatibility tests) to guide implementation and basically say, “Make it pass the tests.” I can safely say I would not have been able to deliver this new set of functionality in any near future without tools like that. Between time constraints and flagging motivation, it wouldn’t have happened.
I’m not at “just vibe code everything” level and I’m definitely not ready for Gas Town, but I see the value here and it counters some of the burnout.









Last Comic Pickup 19 Nov 2025 3:00 PM (4 months ago)
After about 31 years of being a customer of Things From Another World, I closed my comic book subscription box last night.
It feels weird.
I’ve had a comic box there longer than most of the employees have been alive. I started out at the Milwaukie, OR, location, which is just across the street from Dark Horse. (Dark Horse Comics owns TFAW, so there’s a connection.) I moved to the Beaverton, OR, location when I moved to the west side of Portland for work. Through it all I’ve gone at least once a month to pick up Daredevil, Strangers in Paradise, Sin City… lots. I’ve seen TFAW go from just a couple of stores to something like six or seven, add a full online presence, and then cut all the way back to just a couple of locations again.
I have a closet full of long boxes. The storage aspect is not awesome. But they’re my comics, and I’ve had ‘em forever, and I love ‘em.
I’d started getting some notifications from TFAW that I wasn’t subscribed to enough comics, or at least not enough that came out regularly, and I needed to either subscribe to more or close my box. I’d seen it a couple of times before and usually found something new to pick up, but lately I just haven’t wanted something new on a regular basis.
When I told the clerk I wanted to close my box, they didn’t even blink. “OK.” No hard sell, no asking me why, no attempt to retain the customer. Just, “OK.” I was like, “I’ve had a box for over 30 years, I guess I’m not subscribed to enough, but it seems weird that I’ve been a customer this long - that you’ve been getting my money for this long - and there’s not some sort of provision for that.”
“Yup,” said the clerk.
And that was it. It was very anti-climactic and, honestly, disappointing.
I took the last comic left in the box - Umbrella Academy - Plan B #3 - and left the store.
227 Trick-or-Treaters 2 Nov 2025 3:00 PM (4 months ago)
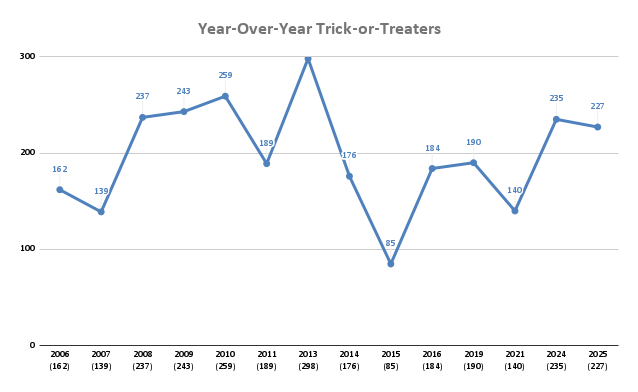
This year we had 227 trick-or-treaters. That’s a bit on the higher end for us, but not quite as many as last year.
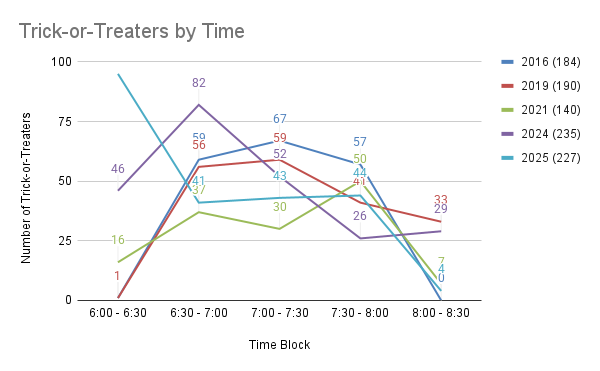
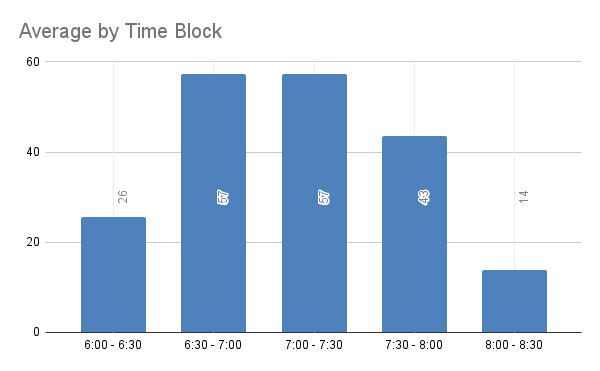
Halloween was on a Friday and it was raining pretty constantly.
As with 2024, we technically started handing out candy at 5:30 because the number of kids this year starting early was overwhelming. I’ve grouped the 5:30p to 6:00p kids (38) in with the 6:00p - 6:30p kids (57) to total 95 in the 6:00p - 6:30p time block. Given this is the second time we’ve had to start early, I wonder if I need to adjust the time capturing to start at 5:30 from here on out.
Missing/incongruous data:
- 2017 we were remodeling the house and didn’t hand out candy.
- 2018 I walked with Phoenix and the tally got lost somewhere.
- 2020 was COVID and no one handed out candy.
- 2022 we were getting our floors redone due to a leak and the whole house was torn up so we didn’t hand out candy.
- 2024 we bundled 5:30-6:00 (24) in with 6:00-6:30 (22) which affects the average for that block.
- 2025 we bundled 5:30-6:00 (38) in with 6:00-6:30 (57) which affects the average for that block.
Cumulative data:
| Time Block | ||||||
|---|---|---|---|---|---|---|
| Year | 6:00p - 6:30p | 6:30p - 7:00p | 7:00p - 7:30p | 7:30p - 8:00p | 8:00p - 8:30p | Total |
| 2006 | 52 | 59 | 35 | 16 | 0 | 162 |
| 2007 | 5 | 45 | 39 | 25 | 21 | 139 |
| 2008 | 14 | 71 | 82 | 45 | 25 | 237 |
| 2009 | 17 | 51 | 72 | 82 | 21 | 243 |
| 2010 | 19 | 77 | 76 | 48 | 39 | 259 |
| 2011 | 31 | 80 | 53 | 25 | 0 | 189 |
| 2013 | 28 | 72 | 113 | 80 | 5 | 298 |
| 2014 | 19 | 54 | 51 | 42 | 10 | 176 |
| 2015 | 13 | 14 | 30 | 28 | 0 | 85 |
| 2016 | 1 | 59 | 67 | 57 | 0 | 184 |
| 2019 | 1 | 56 | 59 | 41 | 33 | 190 |
| 2021 | 16 | 37 | 30 | 50 | 7 | 140 |
| 2024 | 46 | 82 | 52 | 26 | 29 | 235 |
| 2025 | 95 | 41 | 43 | 44 | 4 | 227 |
Our costumes this year:
- Me: PDX - the Portland International Airport
- Jenn: M3gan
- Phoenix: (Not pictured) Megara from Hercules

2025 has been rough - we had a laundry room leak with repairs that spanned from January through September, we got a new roof… there was a lot of home project stuff going on. I was entirely out of inspiration and energy, so I went simple. I made the shirt using some custom printed PDX carpet fabric I found on Etsy. On my head is a small airplane stuffy I bought off Amazon and tacked down to a headband. The scarf is something I had already. I will hopefully be more on top of things next year.
How to Reset OneDrive on Mac 5 Aug 2025 4:00 PM (7 months ago)
I really hate that OneDrive for Business names your OneDrive folder like OneDrive - Name of Your Business with a bunch of spaces and things in there. It jacks up command line stuff because ~/OneDrive - Name of Your Business doesn’t always evaluate ~ as your home drive and it cascades from there.
Instead of doing the smart thing and just creating a symbolic link to something nicer (ln -s './OneDrive - Name of Your Business' ./OneDrive) I thought I’d try to get it to sync to a different location. I really jacked it up. Uninstall/reinstall, several reboots, no luck. I had trouble formulating the right search or AI prompt to explain what I was trying to fix. I finally got the below out of a series of queries and prompts through Google Gemini, so I’m blogging it in case I need it again.
- Quit OneDrive: Select the cloud icon in the menu bar, then click Settings > Quit OneDrive.
- Locate OneDrive: Find the app in your Applications folder.
- Show Package Contents: Right-click on OneDrive and select “Show Package Contents”.
- Navigate to Resources: Go to Contents > Resources.
- Run the Reset Script: Double-click
ResetOneDriveAppStandalone.command. A terminal window will pop up and clean a lot of things. - Restart and Setup: Start OneDrive and complete the setup process.
Minor Differences in JSON Serializers in .NET/C# 27 Apr 2025 4:00 PM (10 months ago)
The move from Newtonsoft to System.Text.Json for JSON serialization in .NET is not a new thing, but there are two subtle differences that I always forget or get wrong so I figured I’d write them down so I can Google my own answer later.
This is based on .NET 8 and 9. If you come in looking at this later, they may have updated.
Dictionaries
There are Roslyn analyzers that want you to set dictionary-based properties to be get-only.
public class Model
{
public IDictionary<string, string> WhatAnalyzersWant { get; } = new Dictionary<string, string>()
}
- Newtonsoft supports this and will add the items to the existing dictionary.
- System.Text.Json does not support this and the dictionary will remain empty after serialization.
For greatest compatibility between the two frameworks, leave dictionary properties get/set and suppress the analyzer message.
Enums
I work on a lot of services where we specify camelCase style naming, including on the enum members.
To set System.Text.Json up for camelCase enums, it looks like this:
var settings = new JsonSerializerOptions
{
Converters =
{
new JsonStringEnumConverter(JsonNamingPolicy.CamelCase, true),
},
};
For Newtonsoft, it looks like this:
var settings = new JsonSerializerSettings
{
Converters =
{
new StringEnumConverter(new CamelCaseNamingStrategy()),
},
};
In addition, Newtonsoft supports using System.Runtime.Serialization.EnumMemberAttribute to specify an exact value, which will override the camelCase naming. System.Text.Json does not support this attribute.
public enum Policy
{
// Only Newtonsoft uses this attribute.
[EnumMember(Value = "ALWAYS")]
AlwaysHappens,
NeverHappens
}
In the above example…
- Newtonsoft will render
ALWAYSandneverHappens. - System.Text.Json will render
alwaysHappensandneverHappens.
Further, both frameworks allow you to mark an enum with a specific converter, which can also dictate the casing/strategy.
For greatest compatibility between the two frameworks, use the appropriate serializer settings to handle casing on your enum and don’t mark things up with any attributes related to serialization.
Goodbye, Kai 24 Apr 2025 4:00 PM (11 months ago)

On Wednesday, April 23, 2025, we had to say our final goodbyes to Kai, who was such a good boy to the very end.
We brought Kai and Stanley home in July 2008 as kittens, brothers from the same litter. Kai was always super territorial, despite being an indoor cat, and would always make sure that cat outside the window knew this was his house.
He had the longest forelegs arms I’ve ever seen on a cat. He loved to stretch out and just barely touch you.
During COVID when we were all home all the time, he became extra dependent on the humans, turning into more of a dog than a cat. He’d patrol around, sit on the floor next to you, and always want to be with the humans.
When no humans were around, he’d balance his time between being in the sun; being in bed; or cuddling with his brother, Stanley. We ran a lot of experiments trying to figure out which was more important - sun, bed, or bro. If he could be in a bed in the sun with his brother, that was the best. I think sun was probably the top ranking thing, though. He really loved being a sunny buddy.
He really wanted to drink your water out of your cup. Didn’t matter how warm it was, it was yours and that made him want it. I 3D printed some drink covers to put on top of your cup if you got up and left. He never figured out you could just flip the top off and get to the cup - it was enough to stop him. He was also a total sweet tooth - if you got some dessert, he really wanted it. We never even gave him any (he couldn’t stomach people food) but something about sweets made him immediately show up.
He never really pooped in a litter box. He’d pee in there, but he just wouldn’t poop in there. That wasn’t too horrible except in the last couple of years it stopped being solid and really was… not good. He also started losing weight, like a lot of weight. He had been a pretty stout boy for a while and by the end of his life he was close to eight pounds, just skin hanging off bones. It was sad to see him change so much.
He turned 17 earlier this month and in the past couple of months his internal health kept deteriorating. On the outside, he’d still run around and play and was active, but inside… he was not doing well. We decided it was probably time to say goodbye.
He loved getting in his carrier, which is so weird because he only ever got taken to the vet in that thing. He wasn’t a traveling cat. But even on the last day, he really wanted in there to go, which just made the trip harder.
We said goodbye to him and we miss him. His brother misses him. Love you, buddy.
%20but%20something%20about%20sweets%20made%20him%20%3Cem%3Eimmediately%3C/em%3E%20show%20up.%3C/p%3E%0A%0A%3Cp%3EHe%20never%20really%20pooped%20in%20a%20litter%20box.%20He%E2%80%99d%20pee%20in%20there,%20but%20he%20just%20wouldn%E2%80%99t%20poop%20in%20there.%20That%20wasn%E2%80%99t%20%3Cem%3Etoo%20horrible%3C/em%3E%20except%20in%20the%20last%20couple%20of%20years%20it%20stopped%20being%20solid%20and%20really%20was%E2%80%A6%20not%20good.%20He%20also%20started%20losing%20weight,%20like%20a%20%3Cem%3Elot%3C/em%3E%20of%20weight.%20He%20had%20been%20a%20pretty%20stout%20boy%20for%20a%20while%20and%20by%20the%20end%20of%20his%20life%20he%20was%20close%20to%20eight%20pounds,%20just%20skin%20hanging%20off%20bones.%20It%20was%20sad%20to%20see%20him%20change%20so%20much.%3C/p%3E%0A%0A%3Cp%3EHe%20turned%2017%20earlier%20this%20month%20and%20in%20the%20past%20couple%20of%20months%20his%20internal%20health%20kept%20deteriorating.%20On%20the%20outside,%20he%E2%80%99d%20still%20run%20around%20and%20play%20and%20was%20active,%20but%20inside%E2%80%A6%20he%20was%20not%20doing%20well.%20We%20decided%20it%20was%20probably%20time%20to%20say%20goodbye.%3C/p%3E%0A%0A%3Cp%3EHe%20%3Cem%3Eloved%3C/em%3E%20getting%20in%20his%20carrier,%20which%20is%20so%20weird%20because%20he%20only%20ever%20got%20taken%20to%20the%20vet%20in%20that%20thing.%20He%20wasn%E2%80%99t%20a%20traveling%20cat.%20But%20even%20on%20the%20last%20day,%20he%20%3Cem%3Ereally%3C/em%3E%20wanted%20in%20there%20to%20go,%20which%20just%20made%20the%20trip%20harder.%3C/p%3E%0A%0A%3Cp%3EWe%20said%20goodbye%20to%20him%20and%20we%20miss%20him.%20His%20brother%20misses%20him.%20Love%20you,%20buddy.%3C/p%3E)
Using RHEL subscription-manager in a Container Image 20 Feb 2025 3:00 PM (last year)
Scenario:
- You have a Red Hat Enterprise Linux (RHEL) subscription.
- You are building a series of containers based on RHEL, like:
- Base container with RHEL 8 and some small amount of packages.
- In a different repo, a container based on your RHEL 8 base image which adds some packages.
- Your application container, based on that second image, which adds yet other packages.
The problem: When you build these containers they all seem to be seen by the RHEL subscription-manager as the same logical machine, so you get a bunch of errors like 410 Gone when you try to register the container with the package management system.
My experience is that this is because, by default, the hostname of every container image being built is buildkitsandbox by default. This is set up by the Docker build kit. When you run subscription-manager register to attach to the subscription, depending on a few things (whether you’re using the public customer portal or an internal subscription portal, etc.) you may see registrations get stomped because the same hostname is trying to register from different places at the same time.
The answer: Set the hostname by providing the build argument BUILDKIT_SANDBOX_HOSTNAME to your container.
docker build --build-arg BUILDKIT_SANDBOX_HOSTNAME=something-unique .
Then in your container, just make sure you do some cleanup before installing things.
RUN subscription-manager clean \
&& subscription-manager register --org="XXX" --activationkey="YYY" --force \
&& yum update -y \
&& yum install -y some-package \
&& yum clean all \
&& subscription-manager unregister \
&& subscription-manager clean \
&& rm -rf /var/cache/yum /var/cache/dnf
The combination of the unique hostname and proactive cleanup should get you past the issues.
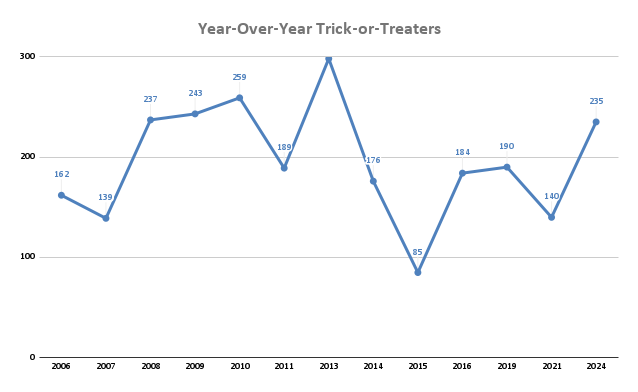
235 Trick-or-Treaters 3 Nov 2024 3:00 PM (last year)
This year we had 235 trick-or-treaters. That’s a big increase from previous years.
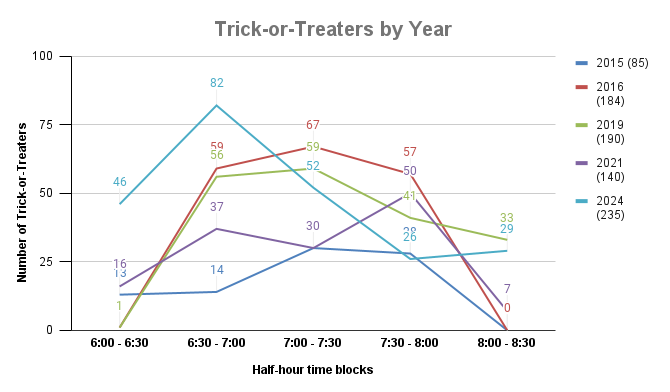
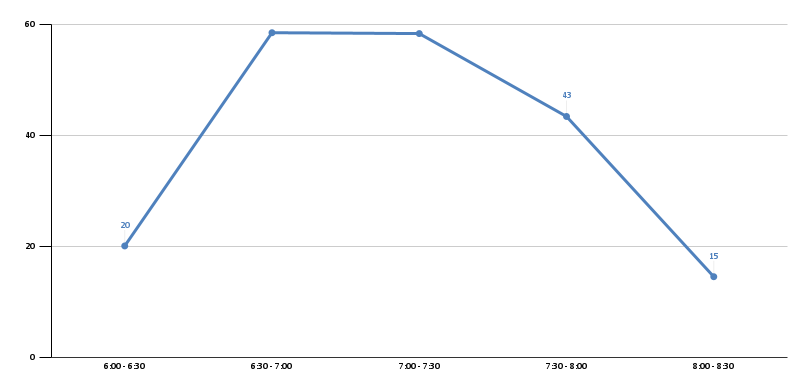
Halloween was on a Thursday and it was raining on-and-off. However, there was no school on Friday, so kids were out and prepped for staying up late on a sugar high.
We technically started handing out candy at 5:30 because the number of kids this year starting early was overwhelming. I’ve grouped the 5:30p to 6:00p kids (24) in with the 6:00p - 6:30p kids (22) to total 46 in the 6:00p - 6:30p time block. It throws the curve off a little but we’ll have to live with it.
We didn’t hand out in 2022 (we were remodeling and not home) or 2023 (COVID). It was good to be back in the swing of things. I did throw out my back a few days before, so I tallied the kids while Jenn handed out candy, but we showed up!
Cumulative data:
| Time Block | ||||||
|---|---|---|---|---|---|---|
| Year | 6:00p - 6:30p | 6:30p - 7:00p | 7:00p - 7:30p | 7:30p - 8:00p | 8:00p - 8:30p | Total |
| 2006 | 52 | 59 | 35 | 16 | 0 | 162 |
| 2007 | 5 | 45 | 39 | 25 | 21 | 139 |
| 2008 | 14 | 71 | 82 | 45 | 25 | 237 |
| 2009 | 17 | 51 | 72 | 82 | 21 | 243 |
| 2010 | 19 | 77 | 76 | 48 | 39 | 259 |
| 2011 | 31 | 80 | 53 | 25 | 0 | 189 |
| 2013 | 28 | 72 | 113 | 80 | 5 | 298 |
| 2014 | 19 | 54 | 51 | 42 | 10 | 176 |
| 2015 | 13 | 14 | 30 | 28 | 0 | 85 |
| 2016 | 1 | 59 | 67 | 57 | 0 | 184 |
| 2019 | 1 | 56 | 59 | 41 | 33 | 190 |
| 2021 | 16 | 37 | 30 | 50 | 7 | 140 |
| 2024 | 46 | 82 | 52 | 26 | 29 | 235 |
Our costumes this year:
- Me: Newt Scamander from Fantastic Beasts and Where to Find Them
- Jenn: Sally Slater, the tightrope walker from the Disney Haunted Mansion
- Phoenix: Ursula from The Little Mermaid
I made the coat and the vest for this one. I bought the wand, pants, and shirt. I’m pretty pleased with how it turned out. The coat is really warm and is fully lined - it’s not a costume pattern, it’s a historic reproduction pattern. I wore it to our usual Halloween party but couldn’t wear it all night. It was just too hot.
About halfway through making the coat I tried to push too much fabric through the serger so I broke it. It’s at the shop now. I think I threw off the timing. I also recently acquired a cover stitch machine, but I didn’t see any good places to use it on this costume. I’m excited to try it for a future project.


Using the az CLI Behind Zscaler 5 Jun 2024 4:00 PM (last year)
At work I use the az CLI behind a VPN/proxy package called Zscaler. I’m not a big fan of these TLS-intercepting-man-in-the-middle-attack sort of “security” products, but it is what it is.
The problem for me is that, if I move to a new machine, or if someone else is setting up a machine, I always forget how to make the az CLI trust Zscaler so it can function properly and not get a TLS certificate error. I’ve re-figured this out countless times, so this time I’m writing it down. It does seem to be slightly different on Mac and Windows and I’m not sure why. Perhaps it has to do with the different ways the network stack works or something.
The az CLI is Python-based so this will ostensibly work to generally solve Python issues, but I always encounter it as part of az, so I’m blogging it as such.
Zscaler does have some help for enabling trust but you sometimes have to fudge the steps, like with this.
On Mac
- Make sure you have the Zscaler certificate in your system keychain as a trusted CA. Likely if you have Zscaler running this is already set up.
- Install the latest
ca-certificatespackage or get the content from here. - Set the
REQUESTS_CA_BUNDLEenvironment variable to point at thecert.pemthat has all the CA certs in it.
This works because the Homebrew package for ca-certificates automatically includes all the certificates from your system keychain so you don’t have to manually append your custom/company CA info.
On Windows
- Go get the latest
ca-certificatesbundle from here. - Open that
cert.pemfile in your favorite text editor. Just make sure you keep the file withLFline endings. - Get your Zscaler CA certificate in PEM format. Open that up in the text editor, too.
- At the bottom of the
cert.pemmain file, paste in the Zscaler CA certificate contents, thereby adding it to the list of CAs. - Set the
REQUESTS_CA_BUNDLEenvironment variable to point at thecert.pemthat has all the CA certs in it.
Again, not sure why on Windows you need to have the Zscaler cert added to the main cert bundle but on Mac you don’t. This also could just be something environmental - like there’s something on my work machines that somehow auto-trusts Zscaler but does so to the exclusion of all else.
Regardless, this is what worked for me.
NDepend 2023.2 - This Time On Mac! 17 Dec 2023 3:00 PM (2 years ago)
It’s been a few years since I’ve posted a look at NDepend and a lot has changed for me since then. I’ve switched my primary development machine to a Mac. I don’t use Visual Studio at all - I’m a VS Code person now because I do a lot of things in a lot of different languages and switching IDEs all day is painful (not to mention VS Code starts up far faster and feels far slimmer than full VS). Most of my day-to-day is in microservices now rather than larger monolith projects.
Full disclosure: Patrick at NDepend gave me the license for testing and showing off NDepend for free. I’m not compensated for the blog post in any way other than the license, but I figured it’d be fair to mention I was given the license.
I’ve loved NDepend from the start. I’ve been using it for years and it’s never been anything but awesome. I still think if you haven’t dived into that, you should just stop here and go do that because it’s worth it.
Get Going on Mac
The main NDepend GUI is Windows-only, so this time around, since I’m focusing solely on Mac support (that’s what I have to work with!) I’m going to wire this thing up and see how it goes.
First thing I need to do is register my license using the cross-platform console app. You’ll see that in the net8.0 folder of the zip package you get when you download NDepend.
dotnet ./net8.0/NDepend.Console.MultiOS.dll --reglic XXXXXXXX
This gives me a message that tells me my computer is now registered to run NDepend console.
Running the command line now, I get a bunch of options.
pwsh> dotnet ./net8.0/NDepend.Console.MultiOS.dll
//
// NDepend v2023.2.3.9706
// https://www.NDepend.com
// support@NDepend.com
// Copyright (C) ZEN PROGRAM HLD 2004-2023
// All Rights Reserved
//
_______________________________________________________________________________
To analyze code and build reports NDepend.Console.MultiOS.dll accepts these arguments.
NDepend.Console.MultiOS.dll can also be used to create projects (see how below after
the list of arguments).
_____________________________________________________________________________
The path to the input .ndproj (or .xml) NDepend project file. MANDATORY
It must be specified as the first argument. If you need to specify a path
that contains a space character use double quotes ".. ..". The specified
path must be either an absolute path (with drive letter C:\ or
UNC \\Server\Share format on Windows or like /var/dir on Linux or OSX),
or a path relative to the current directory (obtained with
System.Environment.CurrentDirectory),
or a file name in the current directory.
Following arguments are OPTIONAL and can be provided in any order. Any file or
directory path specified in optionals arguments can be:
- Absolute : with drive letter C:\ or UNC \\Server\Share format on Windows
or like /var/dir on Linux or OSX.
- Relative : to the NDepend project file location.
- Prefixed with an environment variable with the syntax %ENVVAR%\Dir\
- Prefixed with a path variable with the syntax $(Variable)\Dir
_____________________________________________________________________________
/ViewReport to view the HTML report
_____________________________________________________________________________
/Silent to disable output on console
_____________________________________________________________________________
/HideConsole to hide the console window
_____________________________________________________________________________
/Concurrent to parallelize analysis execution
_____________________________________________________________________________
/LogTrendMetrics to force log trend metrics
_____________________________________________________________________________
/TrendStoreDir to override the trend store directory specified
in the NDepend project file
_____________________________________________________________________________
/PersistHistoricAnalysisResult to force persist historic analysis result
_____________________________________________________________________________
/DontPersistHistoricAnalysisResult to force not persist historic analysis
result
_____________________________________________________________________________
/ForceReturnZeroExitCode to force return a zero exit code even when
one or many quality gate(s) fail
_____________________________________________________________________________
/HistoricAnalysisResultsDir to override the historic analysis results
directory specified in the NDepend project file.
_____________________________________________________________________________
/OutDir dir to override the output directory specified
in the NDepend project file.
VisualNDepend.exe won't work on the machine where you used
NDepend.Console.MultiOS.dll with the option /OutDir because VisualNDepend.exe is
not aware of the output dir specified and will try to use the output dir
specified in your NDepend project file.
_____________________________________________________________________________
/AnalysisResultId id to assign an identifier to the analysis result
_____________________________________________________________________________
/GitHubPAT pat to provide a GitHub PAT (Personal Access Token).
Such PAT is used in case some artifacts (like a baseline analysis result) are
required during analysis and must be loaded from GitHub.
Such PAT overrides the PAT registered on the machine (if any).
_____________________________________________________________________________
/XslForReport xlsFilePath to provide your own Xsl file used to build report
_____________________________________________________________________________
/KeepXmlFilesUsedToBuildReport to keep xml files used to build report
_____________________________________________________________________________
/InDirs [/KeepProjectInDirs] dir1 [dir2 ...]
to override input directories specified in the
NDepend project file.
This option is used to customize the location(s) where assemblies to
analyze (application assemblies and third-party assemblies) can be found.
Only assemblies resolved in dirs are concerned, not assemblies resolved
from a Visual Studio solution.
The search in dirs is not recursive, it doesn't look into child dirs.
Directly after the option /InDirs, the option /KeepProjectInDirs can be
used to avoid ignoring directories specified in the NDepend
project file.
_____________________________________________________________________________
/CoverageFiles [/KeepProjectCoverageFiles] file1 [file2 ...]
to override input coverage files specified
in the NDepend project file.
Directly after the option /CoverageFiles, the option
/KeepProjectCoverageFiles can be used to avoid ignoring coverage files
specified in the NDepend project file.
_____________________________________________________________________________
/CoverageDir dir to override the directory that contains
coverage files specified in the project file.
_____________________________________________________________________________
/CoverageExclusionFile file to override the .runsettings file specified
in the project file. NDepend gathers coverage
exclusion data from such file.
_____________________________________________________________________________
/RuleFiles [/KeepProjectRuleFiles] file1 [file2 ...]
to override input rule files specified
in the NDepend project file.
Directly after the option /RuleFiles, the option
/KeepProjectRuleFiles can be used to avoid ignoring rule files
specified in the NDepend project file.
_____________________________________________________________________________
/PathVariables Name1 Value1 [Name2 Value2 ...]
to override the values of one or several
NDepend project path variables, or
create new path variables.
_____________________________________________________________________________
/AnalysisResultToCompareWith to provide a previous analysis result to
compare with.
Analysis results are stored in files with file name prefix
{NDependAnalysisResult_} and with extension {.ndar}.
These files can be found under the NDepend project output directory.
The preferred option to provide a previous analysis result to
compare with during an analysis is to use:
NDepend > Project Properties > Analysis > Baseline for Comparison
You can use the option /AnalysisResultToCompareWith in special
scenarios where using Project Properties doesn't work.
_____________________________________________________________________________
/Help or /h to display the current help on console
_____________________________________________________________________________
Code queries execution time-out value used through NDepend.Console.MultiOS.dll
execution.
If you need to adjust this time-out value, just run VisualNDepend.exe once
on the machine running NDepend.Console.exe and choose a time-out value in:
VisualNDepend > Tools > Options > Code Query > Query Execution Time-Out
This value is persisted in the file VisualNDependOptions.xml that can be
found in the directory:
VisualNDepend > Tools > Options > Export / Import / Reset Options >
Open the folder containing the Options File
_______________________________________________________________________________
NDepend.Console.MultiOS.dll can be used to create an NDepend project file.
This is useful to create NDepend project(s) on-the-fly from a script.
To do so the first argument must be /CreateProject or /cp (case-insensitive)
The second argument must be the project file path to create. The file name must
have the extension .ndproj. If you need to specify a path that contains a space
character use double quotes "...". The specified path must be either an
absolute path (with drive letter C:\ or UNC \\Server\Share format on Windows
or like /var/dir on Linux or OSX), or a path relative to the current directory
(obtained with System.Environment.CurrentDirectory),
or a file name in the current directory.
Then at least one or several sources of code to analyze must be precised.
A source of code to analyze can be:
- A path to a Visual Studio solution file.
The solution file extension must be .sln.
The vertical line character '|' can follow the path to declare a filter on
project names. If no filter is precised the default filter "-test"
is defined. If you need to specify a path or a filter that contains a space
character use double quotes "...".
Example: "..\My File\MySolution.sln|filterIn -filterOut".
- A path to a Visual Studio project file. The project file extension must
be within: .csproj .vbproj .proj
- A path to a compiled assembly file. The compiled assembly file extension must
be within: .dll .exe .winmd
Notice that source of code paths can be absolute or relative to the project file
location. If you need to specify a path or a filter that contains a space
character use double quotes.
_______________________________________________________________________________
NDepend.Console.MultiOS.dll can be used to register a license on a machine,
or to start evaluation. Here are console arguments to use (case insensitive):
/RegEval Start the NDepend 14 days evaluation on the current machine.
_____________________________________________________________________________
/RegLic XYZ Register a seat of the license key XYZ on the current machine.
_____________________________________________________________________________
/UnregLic Unregister a seat of the license key already registered
on the current machine.
_____________________________________________________________________________
/RefreshLic Refresh the license data already registered on the current
machine. This is useful when the license changes upon renewal.
Each of these operation requires internet access to do a roundtrip with the
NDepend server. If the current machine doesn't have internet access
a procedure is proposed to complete the operation by accessing manually the
NDepend server from a connected machine.
_______________________________________________________________________________
Register a GitHub PAT with NDepend.Console.MultiOS.dll
A GitHub PAT (Personal Access Token) can be registered on a machine.
This way when NDepend needs to access GitHub, it can use such PAT.
Here are console arguments to use (case insensitive):
/RegGitHubPAT XYZ Register the GitHub PAT XYZ on the current machine.
_____________________________________________________________________________
/UnregGitHubPAT Unregister the GitHub PAT actually registered on the
current machine.
As explained above, when using NDepend.Console.MultiOS.dll to run an analysis,
a PAT can be provided with the switch GitHubPAT.
In such case, during analysis the PAT provided overrides the PAT
registered on the machine (if any).
As usual, a great amount of help and docs right there to help me get going.
Create a Project
I created the project for one of my microservices by pointing at the microservice solution file. (Despite not using Visual Studio myself, some of our devs do, so we maintain compatibility with both VS and VS Code. Plus, the C# Dev Kit really likes it when you have a solution.)
dotnet ~/ndepend/net8.0/NDepend.Console.MultiOS.dll --cp ./DemoProject.ndproj ~/path/to/my/Microservice.sln
This created a default NDepend project for analysis of my microservice solution. This is a pretty big file (513 lines of XML) so I won’t paste it here.
As noted in the online docs, right now if you want to modify this project, you can do so by hand; you can work with the NDepend API; or you can use the currently-Windows-only GUI. I’m not going to modify the project because I’m curious what I will get with the default. Obviously this won’t include various custom queries and metrics I may normally run for my specific projects, but that’s OK for this.
Run the Analysis
Let’s see this thing go!
dotnet ~/ndepend/net8.0/NDepend.Console.MultiOS.dll ./DemoProject.ndproj
This kicks off the analysis (like you might see on a build server) and generates a nice HTML report.
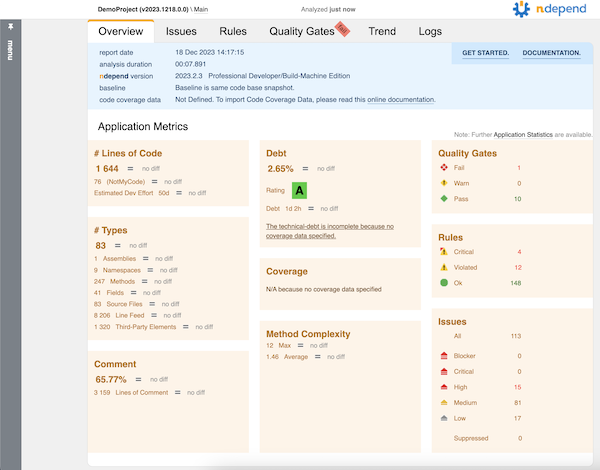
I didn’t include coverage data in this particular run because I wanted to focus mostly on the code analysis side of things.
Since my service code broke some rules, the command line exited non-zero. This is great for build integration where I want to fail if rules get violated.
Dig Deeper
From that main report page, it looks like the code in the service I analyzed failed some of the default quality gates. Let’s go to the Quality Gates tab to see what happened.
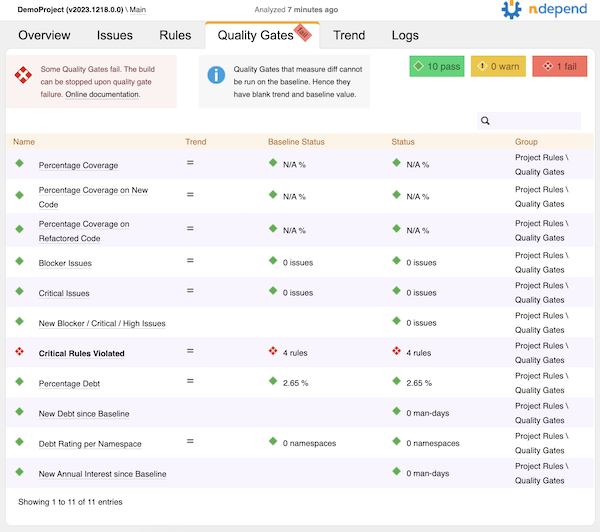
Yow! Four critical rules violated. I’ll click on that to see what they were.
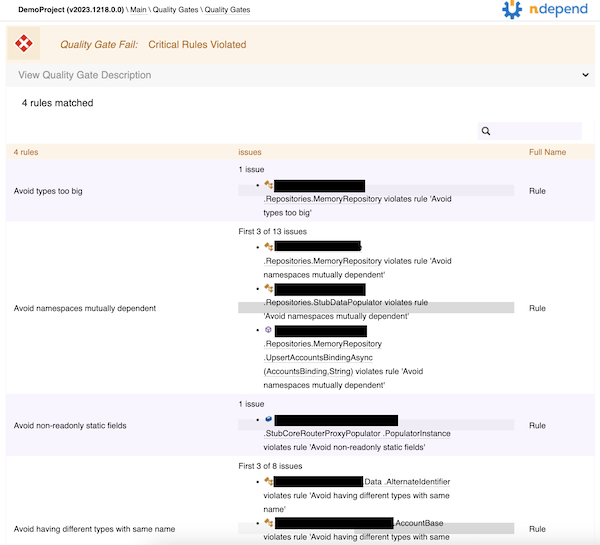
Looks like there’s a type that’s too big, some mutually dependent namespaces, a non-readonly static field, and a couple of types that have the same name. Some of this is easy enough to fix; some of it might require some tweaks to the rules, since the microservice has some data transfer objects and API models that look different but have the same data (so the same name in different namespaces is appropriate).
All in all, not bad!
I Still Love It
NDepend is still a great tool, even on Mac, and I still totally recommend it. To get the most out of it right now, you really need to be on Windows so you can get the GUI support, but for folks like me that are primarily Mac right now, it still provides some great value. Honestly, if you haven’t tried it yet, just go do that.
Room for Improvement
I always like providing some ideas on ways to make a good product even better, and this is no exception. I love this thing, and I want to see some cool improvements to make it “more awesomer.”
Installation Mechanism
I’m very used to installing things through Homebrew on Mac, and on Windows as we look at things like Chocolatey, WinGet, and others - it seems like having an installation that would enable me to use these mechanisms instead of going to a download screen on a website would be a big help. I would love to be able to do brew install ndepend and have that just work.
Visual Studio Code Support and Cross-Platform UI
There’s some integration in Visual Studio for setting up projects and running NDepend on the current project. It’d be awesome to see similar integration for VS Code.
At the time of this writing, the NDepend getting started on Mac documentation says that this is coming. I’m looking forward to it.
I’m hoping that whatever comes out, the great GUI experience to view the various graphs and charts will also be coming for cross-platform. That’s a huge job, but it would be awesome, especially since I’m not really on any Windows machines anymore.
Invoking the Command Line
The cross-platform executable is a .dll so running it is a somewhat long command line:
dotnet ~/path/to/net8.0/NDepend.Console.MultiOS.dll
It’d be nice if this was more… single-command, like ndepend-console or something. Perhaps if it was a dotnet global tool it would be easier. That would also take care of the install mechanism - dotnet tool install ndepend-console -g seems like it’d be pretty nifty.
Commands and Sub-Commands
The command line executable gets used to create projects, register licenses, and run analyses. I admit I’ve gotten used to commands taking command/sub-command hierarchies to help disambiguate the calls I’m making rather than having to mix-and-match command line arguments at the top. I think that’d be a nice improvement here.
For example, instead of…
dotnet ./net8.0/NDepend.Console.MultiOS.dll /reglic XXXXXXXX
dotnet ./net8.0/NDepend.Console.MultiOS.dll /unreglic
It could be…
dotnet ./net8.0/NDepend.Console.MultiOS.dll license register --code XXXXXXXX
dotnet ./net8.0/NDepend.Console.MultiOS.dll license unregister
That would mean when I need to create a project, maybe it’s under…
dotnet ./net8.0/NDepend.Console.MultiOS.dll project create [args]
And executing analysis might be under…
dotnet ./net8.0/NDepend.Console.MultiOS.dll analyze [args]
It’d make getting help a little easier, too, since the help could list the commands and sub-commands, with details being down at the sub-command level instead of right at the top.
Graphs in HTML Reports
Without the full GUI you don’t get to see the graphs like the dependency matrix that I love so much. Granted, these are far more useful if you can click on them and interact with them, but still, I miss them in the HTML.
Support for Roslyn Analyzers
NDepend came out long before Roslyn analyzers were a thing, and some of what makes NDepend shine are the great rules based on CQLinq - a much easier way to query for things in your codebase than trying to write a Roslyn analyzer.
It would be so sweet if the rules that could be analyzed at develop/build time - when we see Roslyn analyzer output - could actually be executed as part of the build. Perhaps it’d require pointing at an .ndproj file to get the list of rules. Perhaps not all rules would be something that can be analyzed that early in the build. I’m just thinking about the ability to “shift left” a bit and catch the failing quality gates before running the analysis. That could potentially lead to a new/different licensing model where some developers, who are not authorized to run “full NDepend,” might have cheaper licenses that allow running of CQL-as-Roslyn-analyzer for build purposes.
Maybe an alternative to that would be to have a code generator that “creates a Roslyn analyzer package” based on CQL rules. Someone licensed for full NDepend could build that package and other devs could reference it.
I’m not sure exactly how it would work, I’m kinda brainstorming. But the “shift left” concept along with catching things early does appeal to me.
Another COVID Halloween 5 Nov 2023 3:00 PM (2 years ago)
Back in 2021 we didn’t get to go to the usual Halloween party we attend due to COVID. That meant I didn’t really get to wear my Loki time prisoner costume. I decided I’d bring that one back out for this year so I could actually wear it.

This year we got to go to the party (no symptoms, even tested negative for COVID before walking out the door!) but ended up getting COVID for Halloween. That meant we didn’t hand out candy again, making this the second year in a row.
We did try to put a bowl of candy out with a “take one” sign. That didn’t last very long. While adults with small children were very good about taking one piece of candy per person, tweens and teens got really greedy really fast. We kind of expected that, but I’m always disappointed that people can’t just do the right thing; it’s always a selfish desire for more for me with no regard for you. Maybe that speaks to larger issues in society today? I dunno.
I need to start gathering ideas for next year’s costume. Since I reused a costume this year I didn’t really gather a lot of ideas or make anything, and I definitely missed that. On the other hand, my motivation lately has been a little low so it was also nice to not have to do anything.
%20but%20ended%20up%20getting%20COVID%20for%20Halloween.%20That%20meant%20we%20didn%E2%80%99t%20hand%20out%20candy%20again,%20making%20this%20the%20second%20year%20in%20a%20row.%3C/p%3E%0A%0A%3Cp%3EWe%20%3Cem%3Edid%3C/em%3E%20try%20to%20put%20a%20bowl%20of%20candy%20out%20with%20a%20%E2%80%9Ctake%20one%E2%80%9D%20sign.%20That%20didn%E2%80%99t%20last%20very%20long.%20While%20adults%20with%20small%20children%20were%20very%20good%20about%20taking%20one%20piece%20of%20candy%20per%20person,%20tweens%20and%20teens%20got%20really%20greedy%20really%20fast.%20We%20kind%20of%20expected%20that,%20but%20I%E2%80%99m%20always%20disappointed%20that%20people%20can%E2%80%99t%20just%20do%20the%20right%20thing;%20it%E2%80%99s%20always%20a%20selfish%20desire%20for%20more%20%3Cem%3Efor%20me%3C/em%3E%20with%20no%20regard%20%3Cem%3Efor%20you%3C/em%3E.%20Maybe%20that%20speaks%20to%20larger%20issues%20in%20society%20today?%20I%20dunno.%3C/p%3E%0A%0A%3Cp%3EI%20need%20to%20start%20gathering%20ideas%20for%20next%20year%E2%80%99s%20costume.%20Since%20I%20reused%20a%20costume%20this%20year%20I%20didn%E2%80%99t%20really%20gather%20a%20lot%20of%20ideas%20or%20make%20anything,%20and%20I%20definitely%20missed%20that.%20On%20the%20other%20hand,%20my%20motivation%20lately%20has%20been%20a%20little%20low%20so%20it%20was%20also%20nice%20to%20not%20%3Cem%3Ehave%3C/em%3E%20to%20do%20anything.%3C/p%3E)
Being Productive with Zero Admin on MacOS 27 Sep 2023 4:00 PM (2 years ago)
Here’s the proposition: You just got a new Mac and you need to set it up for development on Azure (or your favorite cloud provider) in multiple different languages and technologies but you don’t have any admin permissions at all. Not even a little bit. How do you get it done? We’re going to give it a shot.
BIGGEST DISCLAIMER YOU HAVE EVER SEEN: THIS IS UNSUPPORTED. Not just “unsupported by me” but, in a lot of cases, unsupported by the community. For example, we’ll be installing Homebrew in a custom location, and they have no end of warnings about how unsupported that is. They won’t even take tickets or PRs to fix it if something isn’t working. When you take this on, you need to be ready to do some troubleshooting, potentially at a level you’ve not had to dig down to before. Don’t post questions, don’t file issues - you are on your own, 100%, no exceptions.
OK, hopefully that was clear. Let’s begin.
The key difference in what I’m doing here is that everything goes into your user folder somewhere.
- You don’t have admin, so you can’t install Homebrew in its default
/usr/local/binstyle location. - You don’t have admin, so you can’t use most standard installers that want to put apps in central locations like
/Applicationsor/usr/share. - You don’t have admin, so you can’t modify
/etc/paths.dor anything like that.
Contents:
- Strategies
- Start with Git
- Homebrew
- VS Code
- Homebrew Profile
- Homebrew Formulae
- PowerShell
- Azure CLI and Extensions
- Node.js and Tools
- rbenv
- .NET SDK and Tools
- Java
- Azure DevOps Artifacts Credential Provider
- Issue: Gatekeeper
- Issue: Admin-Only Installers
- Issue: App Permissions
- Issue: Bash Completions
- Issue: Path and Environment Variable Propagation
- Issue: Python Config During Updates
- Conclusion
Strategies
The TL;DR here is a set of strategies:
- Install to your user folder.
- Instead of
/usr/local/binor anything else under/usr/local, we’re going to create that whole structure under~/local-~/local/binand so on. - Applications will go in
~/Applicationsinstead of/Applications.
- Instead of
- Use your user
~/.profilefor paths and environment. No need for/etc/paths.d. Also,~/.profileis pretty cross-shell (e.g., bothbashandpwshobey it) so it’s a good central way to go. - Use SDK-based tools instead of global installers. Look for tools that you can install with, say,
npm install -gordotnet tool install -gif you can’t find something in Homebrew.
Start with Git
First things first, you need Git. This is the only thing that you may have challenges with. Without admin I was able to install Xcode from the App Store and that got me git. I admit I forgot to even check to see if git just ships with MacOS now. Maybe it does. But you will need Xcode command line tools for some stuff with Homebrew anyway, so I’d say just install Xcode to start. If you can’t… hmmm. You might be stuck. You should at least see what you can do about getting git. You’ll only use this version temporarily until you can install the latest using Homebrew later.
Homebrew
Got Git? Good. Let’s get Homebrew installed.
mkdir -p ~/local/bin
cd ~/local
git clone https://github.com/Homebrew/brew Homebrew
ln -s ~/local/Homebrew/bin/brew ~/local/bin/brew
I’ll reiterate - and you’ll see it if you ever run brew doctor - that this is wildly unsupported. It works, but you’re going to see some things here that you wouldn’t normally see with a standard Homebrew install. For example, things seem to compile a lot more often than I remember with regular Homebrew - and this is something they mention in the docs, too.
Now we need to add some stuff to your ~/.profile so we can get the shell finding your new ~/local tools. We need to do that before we install more stuff via Homebrew. That means we need an editor. I know you could use vi or something, but I’m a VS Code guy, and I need that installed anyway.
VS Code
Let’s get VS Code. Go download it from the download page, unzip it, and drop it in your ~/Applications folder. At a command prompt, link it into your ~/local/bin folder:
ln -s '~/Applications/Visual Studio Code.app/Contents/Resources/app/bin/code' ~/local/bin/code
I was able to download this one with a browser without running into Gatekeeper trouble. If you get Gatekeeper arguing with you about it, use curl to download.
Homebrew Profile
You can now do ~/local/bin/code ~/.profile to edit your base shell profile. Add this line so Homebrew can put itself into the path and set various environment variables:
eval "$($HOME/local/bin/brew shellenv)"
Restart your shell so this will evaluate and you now should be able to do:
brew --version
Your custom Homebrew should be in the path and you should see the version of Homebrew installed. We’re in business!
Homebrew Formulae
We can install more Homebrew tools now that custom Homebrew is set up. Here are the tools I use and the rough order I set them up. Homebrew is really good about managing the dependencies so it doesn’t have to be in this order, but be aware that a long dependency chain can mean a lot of time spent doing some custom builds during the install and this general order keeps it relatively short.
# Foundational utilities
brew install ca-certificates
brew install grep
brew install jq
# Bash and wget updates
brew install gettext
brew install bash
brew install libidn2
brew install wget
# Terraform - I use tfenv to manage installs/versions. This will
# install the latest Terraform.
brew install tfenv
tfenv install
# Terrragrunt - I use tgenv to manage installs/versions. After you do
# `list-remote`, pick a version to install.
brew install tgenv
tgenv list-remote
# Go
brew install go
# Python
brew install python@3.10
# Kubernetes
brew install kubernetes-cli
brew install k9s
brew install krew
brew install Azure/kubelogin/kubelogin
brew install stern
brew install helm
brew install helmsman
# Additional utilities I like
brew install marp-cli
brew install mkcert
brew install pre-commit
If you installed the grep update or python, you’ll need to add them to your path manually via the ~/.profile. We’ll do that just before the Homebrew part, then restart the shell to pick up the changes.
export PATH="$HOME/local/opt/grep/libexec/gnubin:$HOME/local/opt/python@3.10/libexec/bin:$PATH"
eval "$($HOME/local/bin/brew shellenv)"
PowerShell
This one was more challenging because the default installer they provide requires admin permissions so you can’t just download and run it or install via Homebrew.
For this, you have one of two options:
Option 1: Use the dotnet global tool.
If you can get by on bash until the dotnet install later, you can install PowerShell as a dotnet global tool.
dotnet tool install --global PowerShell
Option 2: Manual install.
First, find the URL for the the .tar.gz from the releases page for your preferred PowerShell version and Mac architecture. I’m on an M1 so I’ll get the arm64 version.
cd ~/Downloads
curl -fsSL https://github.com/PowerShell/PowerShell/releases/download/v7.5.0/powershell-7.5.0-osx-arm64.tar.gz -o powershell.tar.gz
mkdir -p ~/local/microsoft/powershell/7
tar -xvf ./powershell.tar.gz -C ~/local/microsoft/powershell/7
chmod +x ~/local/microsoft/powershell/7/pwsh
ln -s '~/local/microsoft/powershell/7/pwsh' ~/local/bin/pwsh
Now you have a local copy of PowerShell and it’s linked into your path.
An important note here - I used curl instead of my browser to download the .tar.gz file. I did that to avoid Gatekeeper.
Azure CLI and Extensions
You use Homebrew to install the Azure CLI and then use az itself to add extensions. I separated this one out from the other Homebrew tools, though, because there’s a tiny catch: When you install az CLI, it’s going to build openssl from scratch because you’re in a non-standard location. During the tests for that build, it may try to start listening to network traffic. If you don’t have rights to allow that test to run, just hit cancel/deny. It’ll still work.
brew install azure-cli
az extension add --name azure-devops
az extension add --name azure-firewall
az extension add --name fleet
az extension add --name front-door
Node.js and Tools
I use n to manage my Node versions/installs. n requires us to set an environment variable N_PREFIX so it knows where to install things. First install n via Homebrew:
brew install n
Now edit your ~/.profile and add the N_PREFIX variable, then restart your shell.
export N_PREFIX="$HOME/local"
export PATH="$HOME/local/opt/grep/libexec/gnubin:$HOME/local/opt/python@3.10/libexec/bin:$PATH"
eval "$($HOME/local/bin/brew shellenv)"
After that shell restart, you can start installing Node versions. This will install the latest:
n latest
Once you have Node.js installed, you can install Node.js-based tooling.
# These are just tools I use; install the ones you use.
npm install -g @stoplight/spectral-cli `
gulp-cli `
tfx-cli `
typescript
rbenv
I use rbenv to manage my Ruby versions/installs. rbenv requires both an installation and a modification to your ~/.profile. If you use rbenv…
# Install it, and install a Ruby version.
brew install rbenv
rbenv init
rbenv install -l
Update your ~/.profile to include the rbenv shell initialization code. It’ll look like this, put just after the Homebrew bit. Note I have pwsh in there as my shell of choice - put your own shell in there (bash, zsh, etc.). Restart your shell when it’s done.
export N_PREFIX="$HOME/local"
export PATH="$HOME/local/opt/grep/libexec/gnubin:$HOME/local/opt/python@3.10/libexec/bin:$PATH"
eval "$($HOME/local/bin/brew shellenv)"
eval "$($HOME/local/bin/rbenv init - pwsh)"
.NET SDK and Tools
The standard installers for the .NET SDK require admin permissions because they want to go into /usr/local/share/dotnet.
Download the dotnet-install.sh shell script and stick that in your ~/local/bin folder. What’s nice about this script is it will install things to ~/.dotnet by default instead of the central share location.
# Get the install script
curl -fsSL https://dot.net/v1/dotnet-install.sh -o ~/local/bin/dotnet-install.sh
chmod +x ~/local/bin/dotnet-install.sh
We need to get the local .NET into the path and set up variables (DOTNET_INSTALL_DIR and DOTNET_ROOT) so .NET and the install/uninstall processes can find things. We’ll add that all to our ~/.profile and restart the shell.
export DOTNET_INSTALL_DIR="$HOME/.dotnet"
export DOTNET_ROOT="$HOME/.dotnet"
export N_PREFIX="$HOME/local"
export PATH="$HOME/local/opt/grep/libexec/gnubin:$DOTNET_ROOT:$DOTNET_ROOT/tools:$HOME/local/opt/python@3.10/libexec/bin:$PATH"
eval "$($HOME/local/bin/brew shellenv)"
eval "$($HOME/local/bin/rbenv init - pwsh)"
Note we did not grab the .NET uninstall tool. It doesn’t work without admin permissions. When you try to run it doing anything but listing what’s installed, you get:
The current user does not have adequate privileges. See https://aka.ms/dotnet-core-uninstall-docs.It’s unclear why uninstall would require admin privileges since install did not. I’ve filed an issue about that.
After the shell restart, we can start installing .NET and .NET global tools. In particular, this is how I get the Git Credential Manager plugin.
# Install latest .NET 8.0, 9.0
dotnet-install.sh -?
dotnet-install.sh -c 8.0
dotnet-install.sh -c 9.0
# Get Git Credential Manager set up.
dotnet tool install -g git-credential-manager
git-credential-manager configure
# Other .NET tools I use. You may or may not want these.
dotnet tool install -g dotnet-counters
dotnet tool install -g dotnet-depends
dotnet tool install -g dotnet-dump
dotnet tool install -g dotnet-format
dotnet tool install -g dotnet-guid
dotnet tool install -g dotnet-outdated-tool
dotnet tool install -g dotnet-script
dotnet tool install -g dotnet-svcutil
dotnet tool install -g dotnet-symbol
dotnet tool install -g dotnet-trace
dotnet tool install -g gti
dotnet tool install -g microsoft.web.librarymanager.cli
Java
Without admin, you can’t get the system Java wrappers to be able to find any custom Java you install because you can’t run the required command like: sudo ln -sfn ~/local/opt/openjdk/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk.jdk
If you use bash or zsh as your shell, you might be interested in SDKMAN! as a way to manage Java. I use PowerShell so this won’t work because SDKMAN! relies on shell functions to do a lot of its job.
Instead, we’ll install the appropriate JDK and set symlinks/environment variables.
brew install openjdk
In .profile, we’ll need to set JAVA_HOME and add OpenJDK to the path. If we install a different JDK, we can update JAVA_HOME and restart the shell to switch.
export DOTNET_INSTALL_DIR="$HOME/.dotnet"
export DOTNET_ROOT="$HOME/.dotnet"
export N_PREFIX="$HOME/local"
export JAVA_HOME="$HOME/local/opt/openjdk"
export PATH="$JAVA_HOME/bin:$HOME/local/opt/grep/libexec/gnubin:$DOTNET_ROOT:$DOTNET_ROOT/tools:$HOME/local/opt/python@3.10/libexec/bin:$PATH"
eval "$($HOME/local/bin/brew shellenv)"
eval "$($HOME/local/bin/rbenv init - pwsh)"
Azure DevOps Artifacts Credential Provider
If you use Azure DevOps Artifacts, the credential provider is required for NuGet to restore packages. There’s a script that will help you download and install it in the right spot, and it doesn’t require admin.
wget -qO- https://aka.ms/install-artifacts-credprovider.sh | bash
Issue: Gatekeeper
If you download things to install, be aware Gatekeeper may get in the way.
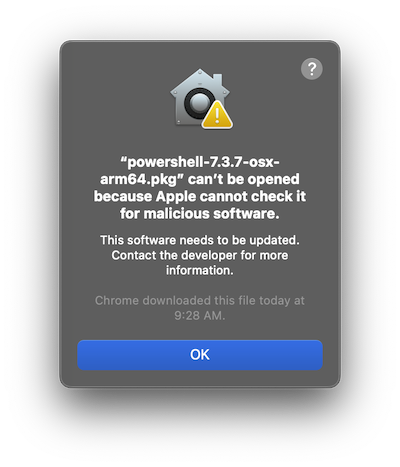
You get messages like “XYZ can’t be opened because Apple cannot check it for malicious software.” This happened when I tried to install PowerShell by downloading the .tar.gz using my browser. The browser adds an attribute to the downloaded file and prompts you before running it. Normally you can just approve it and move on, but I don’t have permissions for that.
To fix it, you have to use the xattr tool to remove the com.apple.quarantine attribute from the affected file(s).
xattr -d com.apple.quarantine myfile.tar.gz
An easier way to deal with it is to just don’t download things with a browser. If you use curl to download, you don’t get the attribute added and you won’t get prompted.
Issue: Admin-Only Installers
Some packages installed by Homebrew (like PowerShell) try to run an installer that requires admin permissions. In some cases you may be able to find a different way to install the tool like I did with PowerShell. In some cases, like Docker, you need the admin permissions to set that up. I don’t have workarounds for those sorts of things.
Issue: App Permissions
There are some tools that may require additional permissions by nature, like Rectangle needs to be allowed to control window placement and I don’t have permissions to grant that. I don’t have workarounds for those sorts of things.
Issue: Bash Completions
Some Homebrew installs will dump completions into ~/local/etc/bash_completions.d. I never really did figure out what to do about these since I don’t really use Bash. There’s some doc about options you have but I’m not going to dig into it.
Issue: Path and Environment Variable Propagation
Since you’ve only updated your path and environment from your shell profile (e.g., not /etc/paths or whatever), these changes won’t be available unless you’re running things from your login shell.
A great example is VS Code and build tools. Let’s say you have a build set up where the command is npm. If the path to npm is something you added in your ~/.profile, VS Code may not be able to find it.
- If you start VS Code by running
codefrom your shell, it will inherit the environment andnpmwill be found. - If you start VS Code by clicking on the icon in the Dock or Finder, it will not inherit the environment and
npmwill not be found.
You can mitigate a little of this, at least in VS Code, by:
- Set your
terminal.integrated.profiles.osxprofiles to pass-las an argument (act as a login shell, process~/.profile) as shown in this Stack Overflow answer. - Set your
terminal.integrated.automationProfile.osxprofile to also pass-las an argument to your shell. (You may or may not need to do this; I was able to get away without it.) - Always use shell commands to launch builds (specify
"type": "shell"intasks.json) for things instead of letting it default to"type": "process".
Other tools will, of course, require other workarounds.
Issue: Python Config During Updates
Some packages like glib have a dependency on Python for installs. However, if you have configuration settings you may need to set (for example, trusted-host), with Python being in your user folder, you may not have the rights to write to /Library/Application Support/pip to set a global config. However, sometimes these installers ignore user-level config. In this case, you may need to put your pip.conf in the folder with Python, for example ~/local/opt/python@3.12/Frameworks/Python.framework/Versions/3.12/pip.conf.
Conclusion
Hopefully this gets you bootstrapped into a dev machine without requiring admin permissions. I didn’t cover every tool out there, but perhaps you can apply the strategies to solving any issues you run across. Good luck!
Hosting Customized Homebrew Formulae 27 Sep 2023 4:00 PM (2 years ago)
Scenario: You’re installing something from Homebrew and, for whatever reason, that standard formula isn’t working for you. What do you do?
I used this opportunity to learn a little about how Homebrew formulae generally work. It wasn’t something where I had my own app to deploy, but it also wasn’t something I wanted to submit as a PR for an existing formula. For example, I wanted to have the bash and wget formulae use a different main URL (one of the mirrors). The current one works for 99% of folks, but for reasons I won’t get into, it wasn’t working for me.
This process is called “creating a tap” - it’s a repo you’ll own with your own stuff that won’t go into the core Homebrew repo.
TL;DR:
- Create a GitHub repo called
homebrew-XXXXwhereXXXXis how Homebrew will see your repo name. - Copy the original formulae into your repo. Anything with a
.rbextension will work - the name of the file is the name of the formula. - Install using
brew install your-username/XXXX/formula.rb
Let’s get a little more specific and use an example.
First I created my GitHub repo, homebrew-mods. This is where I can store my customized formulae. In there, I created a Formula folder to put them in.
I went to the homebrew-core repo where all the main formulae are and found the ones I was interested in updating:
I copied the formulae into my own repo and made some minor updates to switch the url and mirror values around a bit.
Finally, install time! It has to be installed in this order because otherwise the dependencies in the bash and wget modules will try to pull from homebrew-core instead of my mod repo.
brew install tillig/mods/gettext
brew install tillig/mods/bash
brew install tillig/mods/libidn2
brew install tillig/mods/wget
That’s it! If other packages have dependencies on gettext or libidn2, it’ll appear to be already installed since Homebrew just matches on name.
The downside of this approach is that you won’t get the upgrades for free. You have to maintain your tap and pull version updates as needed.
If you want to read more, check out the documentation from Homebrew on creating and maintaining a tap as well as the formula cookbook.
JSON Sort CLI and Pre-Commit Hook 20 Aug 2023 4:00 PM (2 years ago)
I was recently introduced to pre-commit, and I really dig it. It’s a great way to double-check basic linting and validity in things without having to run a full build/test cycle.
Something I commonly do is sort JSON files using json-stable-stringify. I even wrote a VS Code extension to do just that. The problem with it being locked in the VS Code extension is that it’s not something I can use to verify formatting or invoke outside of the editor, so I set out to fix that. The result: @tillig/json-sort-cli.
This is a command-line wrapper around json-stable-stringify which adds a couple of features:
- It obeys
.editorconfig- which is also something the VS Code plugin does. - It can warn when something isn’t formatted (the default behavior) or autofix it if you want.
- It supports JSON with comments (using
json5for parsing) but it will remove those comments on format.
I put all of that together and included configuration for pre-commit so you can either run it manually via CLI or have it automatically run at pre-commit time.
I do realize there is already a pretty-format-json hook, but the above features I mentioned are differentiators. Why not just submit PRs to enhance the existing hook? The existing hook is in Python (not a language I’m super familiar with) and I really wanted - explicitly - the json-stable-stringify algorithm here, which I didn’t want to have to re-create in Python. I also wanted to add .editorconfig support and ability to use json5 to parse, which I suppose is all technically possible in Python but not a hill I really wanted to climb. Also, I wanted to offer a standalone CLI, which isn’t something I can do with that hook.
This is my first real npm package I’ve published, and I did it without TypeScript (I’m not really a JS guy, but to work with pre-commit you need to be able to install right from the repo), so I’m pretty pleased with it. I learned a lot about stuff I haven’t really dug into in the past - from some new things around npm packaging to how to get GitHub Actions to publish the package (with provenance) on release.
If this sounds like something you’re into, go check out how you can install and start using it!
Open-GitRemote: PowerShell Cmdlet to Open Git Web View 12 Feb 2023 3:00 PM (3 years ago)
The GitLens plugin for VS Code is pretty awesome, and I find I use the “Open Repository on Remote” function to open the web view in the system browser is something I use a lot.
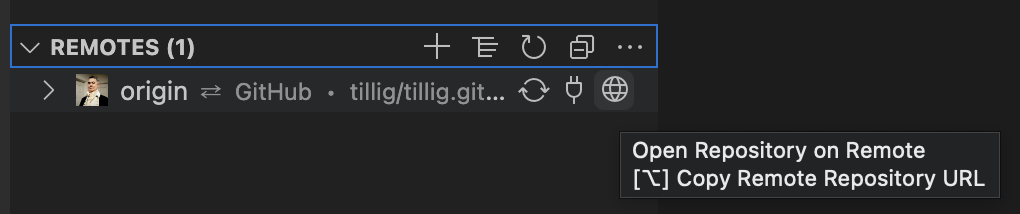
I also find that I do a lot of my work at the command line (in PowerShell!) and I was missing a command that would do the same thing from there.
Luckily, the code that does the work in the GitLens plugin is MIT License so I dug in and converted the general logic into a PowerShell command.
# Open the current clone's `origin` in web view.
Open-GitRemote
# Specify the location of the clone.
Open-GitRemote ~/dev/my-clone
# Pick a different remote.
Open-GitRemote -Remote upstream
If you’re interested, I’ve added the cmdlet to my PowerShell profile repository which is also under MIT License, so go get it!
Note: At the time of this writing I only have Windows and MacOS support - I didn’t get the Linux support in, but I think
xdg-openis probably the way to go there. I just can’t test it. PRs welcome!
%20and%20I%20was%20missing%20a%20command%20that%20would%20do%20the%20same%20thing%20from%20there.%3C/p%3E%0A%0A%3Cp%3ELuckily,%20%3Ca%20href%3D%22https://github.com/gitkraken/vscode-gitlens/blob/d1a204aa1f/LICENSE%22%3Ethe%20code%20that%20does%20the%20work%20in%20the%20GitLens%20plugin%20is%20MIT%20License%3C/a%3E%20so%20I%20dug%20in%20and%20%3Cstrong%3Econverted%20the%20general%20logic%20into%20a%20PowerShell%20command%3C/strong%3E.%3C/p%3E%0A%0A%3Cpre%3E%3Ccode%3E%23%20Open%20the%20current%20clone's%20%60origin%60%20in%20web%20view.%0AOpen-GitRemote%0A%0A%23%20Specify%20the%20location%20of%20the%20clone.%0AOpen-GitRemote%20~/dev/my-clone%0A%0A%23%20Pick%20a%20different%20remote.%0AOpen-GitRemote%20-Remote%20upstream%0A%3C/code%3E%3C/pre%3E%0A%0A%3Cp%3EIf%20you%E2%80%99re%20interested,%20I%E2%80%99ve%20%3Ca%20href%3D%22https://github.com/tillig/PowershellProfile/blob/master/Modules/Illig/Development/Open-GitRemote.ps1%22%3Eadded%20the%20cmdlet%20to%20my%20PowerShell%20profile%20repository%3C/a%3E%20which%20is%20%3Ca%20href%3D%22https://github.com/tillig/PowershellProfile/blob/master/LICENSE%22%3Ealso%20under%20MIT%20License%3C/a%3E,%20so%20go%20get%20it!%3C/p%3E%0A%0A%3Cblockquote%3E%0A%20%20%3Cp%3ENote:%20At%20the%20time%20of%20this%20writing%20I%20only%20have%20Windows%20and%20MacOS%20support%20-%20I%20didn%E2%80%99t%20get%20the%20Linux%20support%20in,%20but%20I%20think%20%3Ccode%3Exdg-open%3C/code%3E%20is%20probably%20the%20way%20to%20go%20there.%20I%20just%20can%E2%80%99t%20test%20it.%20%3Ca%20href%3D%22https://github.com/tillig/PowerShellProfile/pulls%22%3EPRs%20welcome!%3C/a%3E%3C/p%3E%0A%3C/blockquote%3E)
Halloween Force 3 Nov 2022 4:00 PM (3 years ago)
Due to some challenges with home remodeling issues we didn’t end up handing out candy this year.
We discovered a slow leak in one of the walls in our kitchen that caused some of our hardwood floor to warp, maybe a little more than a square meter. Since this was a very slow leak over time, insurance couldn’t say “here’s the event that caused it” and, thus, chalked it up to “normal wear and tear” which isn’t covered.
You can’t fix just a small section of a hardwood floor and we’ve got like 800 square feet of contiguous hardwood, so… all 800 square feet needed to be fully sanded and refinished. All out of pocket. We packed the entire first floor of the house into the garage and took a much-needed vacation to Universal Studios California and Disneyland for a week while the floor was getting refinished.
I had planned on putting the house back together, decorating, and getting right into Halloween when we came back. Unfortunately, when we got back we saw the floor was not done too well. Lots of flaws and issues in the work. It’s getting fixed, but it means we didn’t get to empty out the garage, which means I couldn’t get to the Halloween decorations. Between work and stress and everything else… candy just wasn’t in the cards. Sorry kids. Next year.
But we did make costumes - and we wore them in 90 degree heat in California for the Disney “Oogie Boogie Bash” party. So hot, but still very fun.
I used this Julie-Chantal pattern for a Jedi costume and it is really good. I’m decent at working with and customizing patterns, I’m not so great with drafting things from scratch.
I used a cotton gauze for the tunic, tabard, and sash. The robe is a heavy-weave upholstery fabric that has a really nice feel to it.

I added some magnet closures to it so it would stick together a bit nicer as well as some snaps to stick things in place. I definitely found while wearing it that it was required. All the belts and everything have a tendency to move a lot as you walk, sit, and stand. I think it turned out nicely, though.

The whole family went in Star Wars garb. I don’t have a picture of Phoenix, but here’s me and Jenn at a Halloween party. Phoenix and Jenn were both Rey, but from different movies. You can’t really tell, but Jenn’s vest is also upholstery fabric with an amazing, rich texture. She did a great job on her costume, too.


How to Manually Upgrade Rosetta 2 Nov 2022 4:00 PM (3 years ago)
Rosetta is used to enable a Mac with Apple silicon to use apps built for Intel. Most of the time, you’ll get prompted to install it the first time you need it and after that the automatic software update process will take over. However, in some environments the automatic mechanisms don’t work - maybe it’s incorrectly blocked or the update isn’t detecting things right. Here’s how to update Rosetta manually.
First, get your OS build number: 🍎 -> About This Mac -> More Info.
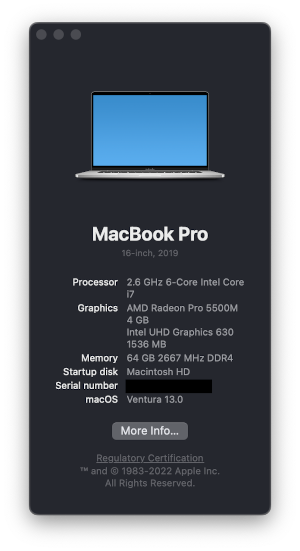
Click on the Version XX.X field and it should expand to show you the build number. It will be something like 22A380.
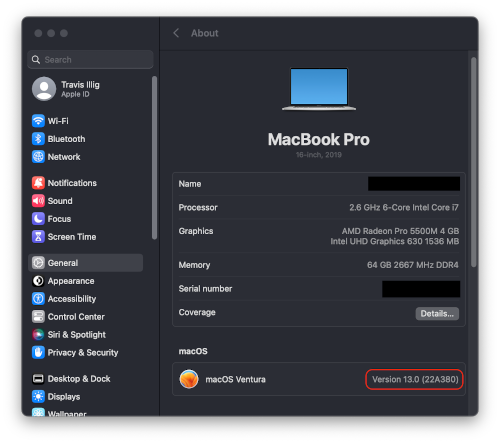
Go to the software catalog for Rosetta and search for your build number. You should see your build-specific package. The build number is in ExtendedMetaInfo:
<dict>
<key>ServerMetadataURL</key>
<string>https://swcdn.apple.com/content/downloads/38/00/012-92132-A_1NEH9AKCK9/k8s821iao7kplkdvqsovfzi49oi54ljrar/RosettaUpdateAuto.smd</string>
<key>Packages</key>
<array>
<dict>
<key>Digest</key>
<string>dac241ee3db55ea602540dac036fd1ddc096bc06</string>
<key>Size</key>
<integer>331046</integer>
<key>MetadataURL</key>
<string>https://swdist.apple.com/content/downloads/38/00/012-92132-A_1NEH9AKCK9/k8s821iao7kplkdvqsovfzi49oi54ljrar/RosettaUpdateAuto.pkm</string>
<key>URL</key>
<string>https://swcdn.apple.com/content/downloads/38/00/012-92132-A_1NEH9AKCK9/k8s821iao7kplkdvqsovfzi49oi54ljrar/RosettaUpdateAuto.pkg</string>
</dict>
</array>
<key>ExtendedMetaInfo</key>
<dict>
<key>ProductType</key>
<string>otherArchitectureHandlerOS</string>
<key>BuildVersion</key>
<string>22A380</string>
</dict>
</dict>
Look for the URL value (the .pkg file). Download and install that. Rosetta will be updated.
.%20Download%20and%20install%20that.%20Rosetta%20will%20be%20updated.%3C/p%3E)
Generate Strongly-Typed Resources with .NET Core 29 Sep 2022 4:00 PM (3 years ago)
UPDATE OCT 25 2022: I filed an issue about some of the challenges here and the weird <Compile Remove> solution I had to do to get around the CS2002 warning. I got a good comment that explained some of the things I didn’t catch from the original issue about strongly-typed resource generation (which is a very long issue). I’ve updated the code/article to include the fixes and have a complete example.
In the not-too-distant past I switched from using Visual Studio for my full-time .NET IDE to using VS Code. No, it doesn’t give me quite as much fancy stuff, but it feels a lot faster and it’s nice to not have to switch to different editors for different languages.
Something I noticed, though, was that if I updated my *.resx files in VS Code, the associated *.Designer.cs was not getting auto-generated. There is a GitHub issue for this and it includes some different solutions to the issue involving some .csproj hackery, but it’s sort of hard to parse through and find the thing that works.
Here’s how you can get this to work for both Visual Studio and VS Code.
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<!--
Target framework doesn't matter, but this solution is tested with
.NET 6 SDK and above.
-->
<TargetFrameworks>net6.0</TargetFrameworks>
<!--
This is required because OmniSharp (VSCode) calls the build in a way
that will skip resource generation. Without this line, OmniSharp won't
find the generated .cs files and analysis will fail.
-->
<CoreCompileDependsOn>PrepareResources;$(CompileDependsOn)</CoreCompileDependsOn>
</PropertyGroup>
<ItemGroup>
<!--
Here's the magic. You need to specify everything for the generated
designer file - the filename, the language, the namespace, and the
class name.
-->
<EmbeddedResource Update="MyResources.resx">
<!-- Tell Visual Studio that MSBuild will do the generation. -->
<Generator>MSBuild:Compile</Generator>
<LastGenOutput>MyResources.Designer.cs</LastGenOutput>
<!-- Put generated files in the 'obj' folder. -->
<StronglyTypedFileName>$(IntermediateOutputPath)\MyResources.Designer.cs</StronglyTypedFileName>
<StronglyTypedLanguage>CSharp</StronglyTypedLanguage>
<StronglyTypedNamespace>Your.Project.Namespace</StronglyTypedNamespace>
<StronglyTypedClassName>MyResources</StronglyTypedClassName>
</EmbeddedResource>
<!--
If you have resources in a child folder it still works, but you need to
make sure you update the StronglyTypedFileName AND the
StronglyTypedNamespace.
-->
<EmbeddedResource Update="Some\Sub\Folder\OtherResources.resx">
<Generator>MSBuild:Compile</Generator>
<LastGenOutput>OtherResources.Designer.cs</LastGenOutput>
<!-- Make sure this won't clash with other generated files! -->
<StronglyTypedFileName>$(IntermediateOutputPath)\OtherResources.Designer.cs</StronglyTypedFileName>
<StronglyTypedLanguage>CSharp</StronglyTypedLanguage>
<StronglyTypedNamespace>Your.Project.Namespace.Some.Sub.Folder</StronglyTypedNamespace>
<StronglyTypedClassName>OtherResources</StronglyTypedClassName>
</EmbeddedResource>
</ItemGroup>
</Project>
Additional tips:
Once you have this in place, you can .gitignore any *.Designer.cs files and remove them from source. They’ll be regenerated by the build, but if you leave them checked in then the version of the generator that Visual Studio uses will fight with the version of the generator that the CLI build uses and you’ll get constant changes. The substance of the generated code is the same, but file headers may be different.
You can use VS Code file nesting to nest localized *.resx files under the main *.resx files with this config. Note you won’t see the *.Designer.cs files in there because they’re going into the obj folder.
{
"explorer.fileNesting.enabled": true,
"explorer.fileNesting.patterns": {
"*.resx": "$(capture).*.resx, $(capture).designer.cs, $(capture).designer.vb"
}
}
Sonatype Nexus IQ in Azure DevOps - Illegal Reflective Access Operation 7 Sep 2022 4:00 PM (3 years ago)
Using the Sonatype Nexus IQ for Azure DevOps task in your build, you may see some warnings that look like this:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by com.google.inject.internal.cglib.core.$ReflectUtils$1 (file:/agent/_work/_tasks/NexusIqPipelineTask_4f40d1a2-83b0-4ddc-9a77-e7f279eb1802/1.4.0/resources/nexus-iq-cli-1.143.0-01.jar) to method java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain)
WARNING: Please consider reporting this to the maintainers of com.google.inject.internal.cglib.core.$ReflectUtils$1
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
The task, internally, just runs java to execute the Sonatype scanner JAR/CLI. The warnings here are because that JAR assumes JDK 8 and the default JDK on an Azure DevOps agent is later than that.
The answer is to set JDK 8 before running the scan.
# Install JDK 8
- task: JavaToolInstaller@0
inputs:
versionSpec: '8'
jdkArchitectureOption: x64
jdkSourceOption: PreInstalled
# Then run the scan
- task: NexusIqPipelineTask@1
inputs:
nexusIqService: my-service-connection
applicationId: my-application-id
stage: "Release"
scanTargets: my-scan-targets
AutoMapper, Nullable DateTime, and Selecting the Right Constructor 13 Feb 2022 3:00 PM (4 years ago)
I was doing some AutoMapper-ing the other day, converting my data object…
public class Source
{
public Source();
public string Description { get; set; }
public DateTimeOffset? ExpireDateTime { get; set; }
public string Value { get; set; }
}
…into an object needed for a system we’re integrating with.
public class Destination
{
public Destination();
public Destination(string value, DateTime? expiration = null);
public Destination(string value, string description, DateTime? expiration = null);
public string Description { get; set; }
public DateTime? Expiration { get; set; }
public string Value { get; set; }
}
It appeared to me that the most difficult thing here was going to be mapping ExpireDateTime to Expiration. Unfortunately, this was more like a three-hour tour.
I started out creating the mapping like this (in a mapping Profile):
// This is not the answer.
this.CreateMap<Source, Destination>()
.ForMember(dest => dest.Expiration, opt.MapFrom(src => src.ExpireDateTime));
This didn’t work because there’s no mapping from DateTimeOffset? to DateTime?. I next made a mistake that I think I make every time I run into this and have to relearn it, which is that I created that mapping, too.
// Still not right.
this.CreateMap<Source, Destination>()
.ForMember(dest => dest.Expiration, opt.MapFrom(src => src.ExpireDateTime));
this.CreateMap<DateTimeOffset?, DateTime?>()
.ConvertUsing(input => input.HasValue ? input.Value.DateTime : null);
It took a few tests to realize that AutoMapper handles nullable for you, so I was able to simplify a bit.
// Getting closer - don't map nullable, map the base type.
this.CreateMap<Source, Destination>()
.ForMember(dest => dest.Expiration, opt.MapFrom(src => src.ExpireDateTime));
this.CreateMap<DateTimeOffset, DateTime>()
.ConvertUsing(input => input.DateTime);
However, it seemed that no matter what I did, the Destination.Expiration was always null. For the life of me, I couldn’t figure it out.
Then I had one of those “eureka” moments when I was thinking about how Autofac handles constructors: It chooses the constructor with the most parameters that it can fulfill from the set of registered services.
I looked again at that Destination object and realized there were three constructors, two of which default the Expiration value to null. AutoMapper also handles constructors in a way similar to Autofac. From the docs about ConstructUsing:
AutoMapper will automatically match up destination constructor parameters to source members based on matching names, so only use this method if AutoMapper can’t match up the destination constructor properly, or if you need extra customization during construction.
That’s it! The answer is to pick the zero-parameter constructor so the mapping isn’t skipped.
// This is the answer!
this.CreateMap<Source, Destination>()
.ForMember(dest => dest.Expiration, opt.MapFrom(src => src.ExpireDateTime))
.ConstructUsing((input, context) => new Destination());
this.CreateMap<DateTimeOffset, DateTime>()
.ConvertUsing(input => input.DateTime);
Hopefully that will save you some time if you run into it. Also, hopefully it will save me some time next time I’m stumped because I can search and find my own blog… which happens more often than you might think.