Elasticsearch : drainer un membre du cluster 27 Oct 2016 2:00 PM (8 years ago)
Parfois il peut être intéressant de “drainer” un membre de son cluster Elasticsearch de toutes ses données, avant de réaliser une maintenance planifiée par exemple.
Vous pouvez réaliser cette action en vous basant sur l’IP du noeud, son nom ou hostname :
curl -XPUT 'localhost:9200/_cluster/settings?pretty' -d '{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "10.0.0.1"
}
}'
curl -XPUT 'localhost:9200/_cluster/settings?pretty' -d '{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "10.0.0.*"
}
}'
curl -XPUT 'localhost:9200/_cluster/settings?pretty' -d '{
"transient" : {
"cluster.routing.allocation.exclude._name" : "els01"
}
}'
curl -XPUT 'localhost:9200/_cluster/settings?pretty' -d '{
"transient" : {
"cluster.routing.allocation.exclude._hostname" : "els01.prd.sfo.domain.tld"
}
}'









Optimiser la configuration d’une carte LSI pour un RAID SSD 12 Jul 2016 2:00 PM (8 years ago)
D’après les recommandations LSI, les paramètres à utiliser pour tirer les meilleurs performances d’un RAID SSD sont :
Read Cache: DISABLED
Write Cache: WriteThrough
IO: DIRECT
En pratique :
Activer le WriteThrough
MegaCli -LDSetProp -WT -Immediate -Lall -aAll
Désactiver ReadAhead / Read Caching
MegaCli -LDSetProp -NORA -Immediate -Lall -aAll
Activer Direct IO
MegaCli -LDSetProp -Direct -Immediate -Lall -aAll
MegaCli : commandes utiles 18 Apr 2016 2:00 PM (9 years ago)
MegaCli est probablement l’un des pires utilitaires CLI jamais écrit. Voici
quelques commandes très utiles.
# Show status
MegaCli -AdpAllInfo -aAll
# Get physical drive info
MegaCli -PDList -aAll
# Get virtual disk info
MegaCli -LDInfo -Lall -aAll
# Display configuration
MegaCli -CfgDsply -aAll
# Dump eventlog events to file 'events' and open it
MegaCli -AdpEventLog -GetEvents -f events -aAll && less events
# Disable autoLearnMode for the RAID battery
echo "autoLearnMode=1" > tmp.txt \
&& MegaCli -AdpBbuCmd -SetBbuProperties -f tmp.txt -a0
# Disable cache when battery broken
MegaCli -LDSetProp NoCachedBadBBU -LALL -aALL
Warmup du cache Varnish 18 Oct 2014 2:00 PM (10 years ago)
Warmup votre cache peut être indispensable afin d’éviter un léger pic de charge inutile lorsque vous dirigez du trafic sur une instance fraichement spawn.
La première solution se base sur le sitemap de votre site. Simple,
probablement Quick & Dirty, mais efficace :
#!/usr/bin/env bash
while test -n "$1"; do
case $1 in
--sitemap|-s)
sitemap=$2
shift
;;
--http_verb|-h)
http_verb=$2
shift
;;
*)
echo "Unknown argument: $1"
exit 3
;;
esac
shift
done
tmpfile=$(mktemp /tmp/$(basename $0).XXXXXX)
sitemap=${sitemap:='http://myawesometenmillionsvisitorsmediawebsite.tld/sitemap.xml'}
http_verb=${http_verb:='GET'}
curl --silent $sitemap | grep \<loc\> | sed 's/.*<loc>//' | sed 's|</loc>||' \
>> $tmpfile
cat $tmpfile | xargs -I % -n 1 -P 16 curl -X$http_verb %
rm $tmpfileÀ noter que vous pouvez également vous en servir pour PURGE le cache en modifiant le verbe HTTP.
La seconde méthode consiste à utiliser varnishreplay :
ssh www.varnish-cache.org varnishlog -w - | varnishreplay -a localhost:6081 -r -Généralement j’utilise la première méthode tout en ajustant le trafic en adaptant le poids de ces nouvelles instances.
Reboot d’un système linux passé en “read-only” 15 Feb 2014 2:00 PM (11 years ago)
Un de vos serveurs linux est passé en read only, vous
souhaitez redémarrer le système mais la commande reboot vous retourne un
bus error. Pas de panique, essayez Magic SysRq key :
echo 1 >/proc/sys/kernel/sysrq
echo b >/proc/sysrq-trigger
En dernier recours, cette méthode est toujours mieux qu’un reboot électrique.
Enfin il est préférable de vérifier l’état de vos disques (SMART) et
contrôler l’intégrité de vos systèmes de fichiers avec fsck.
À noter que dans mon cas ce problème est survenu suite à un taux élevé d’I/O wait, sur du hardware grande série.
Un serveur HTTP en une ligne de commande 2 Dec 2013 2:00 PM (11 years ago)
Vous avez besoin de lancer un serveur HTTP “basique” de manière ponctuelle sans pour autant vous encombrer avec Apache, Nginx […] ?
Voici différentes méthodes pour y parvenir :
Avec Python
python -m SimpleHTTPServerAvec Ruby (>= 2.0.0)
ruby -run -e httpd . -p 8080Avec PHP (>= 5.4), en dernier recours ;)
php -S 127.0.0.1:8080
Détecter un disque SSD sous Linux 15 Aug 2013 2:00 PM (11 years ago)
Ayant un parc de serveurs dédiés avec des configurations matérielles diverses et variées (disques SATA, SAS, SSD …) j’ai récemment eu le besoin de déterminer si un disque est un SSD, ou pas.
L’objectif ? Créer des customs facts pour affiner la configuration de certains services comme MySQL via Puppet, enrichir mon inventaire …
Après quelques recherches je suis tombé sur cette solution :
cat /sys/block/sda/queue/rotationalLa valeur 0 est retournée pour les disques SSD, 1 pour ceux à plateaux.
Mis en pratique avec Facter, cela donne quelque chose dans ce style :
require 'facter'
Facter.add('ssd') do
confine :kernel => 'Linux'
ssd = []
Facter::value('blockdevices').split(',').each do |disk|
file = "/sys/block/#{disk}/queue/rotational"
output = Facter::Util::FileRead.read(file)
ssd.push(disk) if output.to_i == 0
end
setcode { ssd.join(',') }
endSi vous connaissez d’autres solutions, je suis preneur !
Migrer un domaine vers Amazon Route 53 31 Jul 2013 2:00 PM (11 years ago)
Màj 17/08/2013 : Route53 permet désormais d’importer ses zones.
Route 53 est le service DNS d’Amazon Webservices. Ce service est rentable, haute disponibilité et “low latency” car il utilise entre autre un réseau Anycast.
Mis à part cela, Route 53 permet surtout de faire des trucs vraiment cool comme :
-
Weighted Round RobinavecHealth checkHTTP(S) : dès que le service HTTP d’une machine est innaccessible elle est automatiquement desactivée du round robin jusqu’à son retour. -
routage du trafic vers plusieurs sites en se basant sur la latence du client : vitale lorsque vous avez plusieurs datacenter et que vous voulez que vos visiteurs soient dirigés vers celui le plus proche.
Entrons dans le vif du sujet :
-
Pour nous faciliter la vie, il existe un excellent outil nommé cli53 permettant de gérer ses Zones Route 53 via l’API d’AWS. C’est du Python, il utilise boto et le tout s’installe via
pip:pip install cli53 -
Pour ne rien perdre au passage, il est nécessaire d’extraire sa zone DNS. Généralement vous pouvez la récuperer au format texte sur l’interface de votre registrar.
Sinon vous pouvez toujours vous débrouiller avec
dig -t AXFR domain.tldsi autorisé ou au piredig -t any domain.tld. -
Créez un fichier
domain.tldavec le contenu de la zone obtenue à l’étape précédente. -
Pour que l’import fonctionne il faut que le fichier soit au format BIND. Pensez à ajouter
$ORIGIN domain.tld.au début du fichier si besoin etc … -
Ensuite il va falloir configurer
botopour que cli53 puisse discuter avec l’API d’AWS, via variables d’environnnement par exemple :export AWS_ACCESS_KEY_ID=xxx export AWS_SECRET_ACCESS_KEY=xxx -
Maintenant vous pouvez créer votre zone chez Amazon :
cli53 create domain.tldou via la console AWS -
Importez votre configuration bind
cli53 import domain.tld --file domain.tld --replace --wait -
Enfin, il ne vous reste plus qu’à déléguer votre domaine aux serveurs DNS d’Amazon. Vous pouvez obtenir la liste (4 dans mon cas) sur la console ou via la commande
cli53 info domain.tld.
Bonne migration !
J’ai changé mon nom d’utilisateur Github 21 Jan 2013 2:00 PM (12 years ago)
Tout ceux qui utilisent mes super modules Puppet ou mes autres projets hébergés sur Github ont malheureusement dû rencontrer quelques soucis.
J’ai changé mon nom d’utilisateur Benjamin-Ds en bdossantos.
Pour réparer vos submodules et remote assurez-vous d’avoir corrigé les urls
en remplaçant mon ancien nom d’utilisateur par le nouveau.
Pour rappelle cela ce passe dans les fichiers .git/config et .gitmodules :
# .gitmodules
[submodule "modules/couchdb"]
path = modules/couchdb
url = git://github.com/bdossantos/puppet-module-couchdb.git# .git/config
[submodule "modules/couchdb"]
url = git://github.com/Benjamin-Ds/puppet-module-couchdb.gitJe m’excuse pour les éventuels déploiements que j’aurais pu casser. Il faut dire que mes dépôts sont vraiment “très populaires” …
Agrégation de graphiques avec Munin 24 Aug 2012 2:00 PM (12 years ago)
Récemment j’ai eu besoin de combiner les graphiques Munin de tous mes serveurs frontaux Nginx du même pool.
Dans cet exemple je vais combiner les graphiques générés par les plugins nginx_request et if_ethX pour les serveurs s0{1..4}.domain.tld
Agrégation du nombre de requêtes/seconde (HTTP)
# file : /etc/munin/munin-conf.d/static.domain.tld
[domain.tld;static.domain.tld]
update no
contacts no
nginx_requests.graph_title Nginx requests
nginx_requests.graph_vlabel Nginx requests per second
nginx_requests.total.draw LINE2
nginx_requests.graph_args --base 1000
nginx_requests.graph_category nginx
nginx_requests.total.label req/sec
nginx_requests.total.type DERIVE
nginx_requests.total.min 0
nginx_requests.total.sum \
s01.domain.tld:nginx_request.request \
s02.domain.tld:nginx_request.request \
s03.domain.tld:nginx_request.request \
s04.domain.tld:nginx_request.requestAgrégation la bande passante de vos interfaces réseaux
# file : /etc/munin/munin-conf.d/static.domain.tld
[domain.tld;static.domain.tld]
update no
contacts no
bandwidth.graph_title Total Bandwidth in MB/s
bandwidth.graph_category Network
bandwidth.graph_vlabel MB/s
bandwidth.totalup.sum \
s01.domain.tld:if_eth0.up \
s02.domain.tld:if_eth0.up \
s03.domain.tld:if_eth0.up \
s04.domain.tld:if_eth0.up
bandwidth.totalup.label Total up Bandwidth
bandwidth.totaldown.sum \
s01.domain.tld:if_eth0.down \
s02.domain.tld:if_eth0.down \
s03.domain.tld:if_eth0.down \
s04.domain.tld:if_eth0.down
bandwidth.totaldown.label Total down BandwidthRésultats
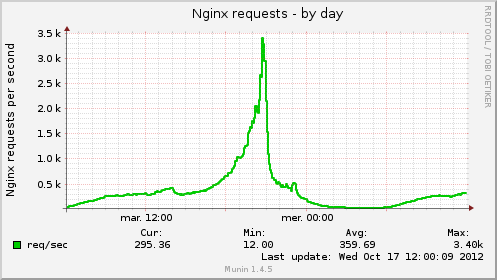
Ressources
- an evening with Munin graph aggregation
- Combiner des graphs avec Munin : température interne et externe
- How to create aggregate graphs