Your CrossFit App Doesn’t Know What You Did 8 May 4:00 PM (last month)
Your CrossFit App Doesn't Know What You Did
CrossFit apps are good at storing WOD scores, but are terrible at knowing the work you've actually done. Here's a WOD from my box:
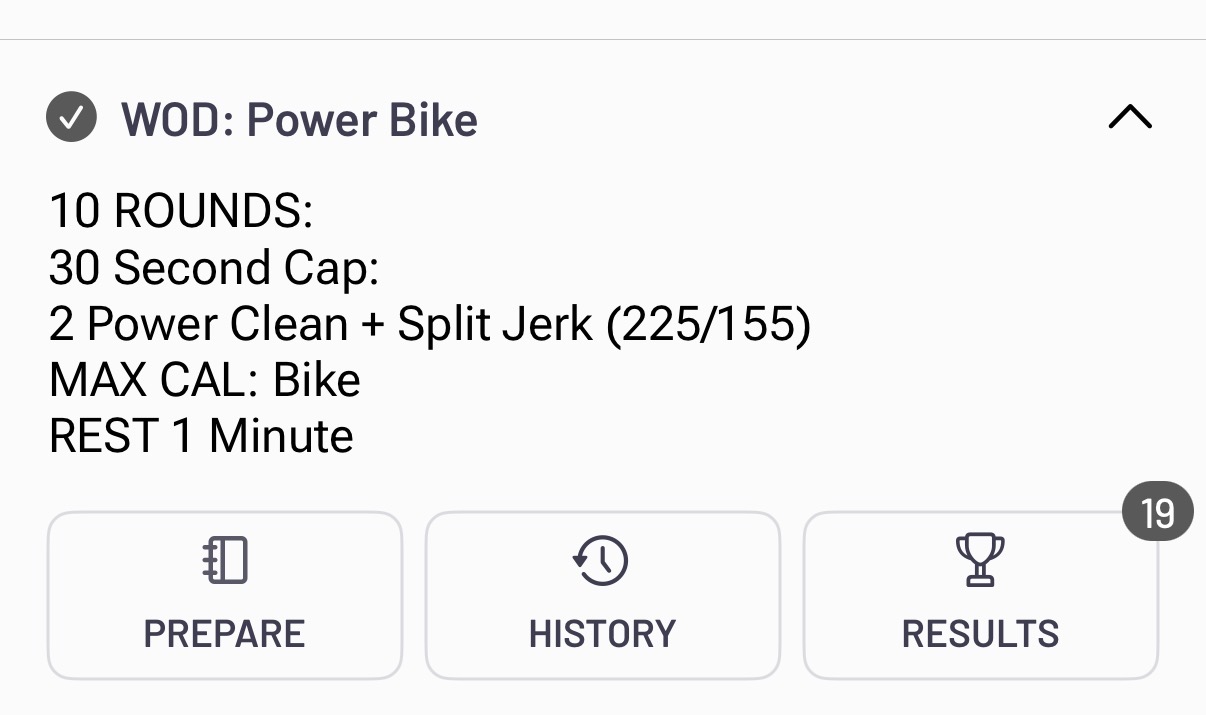
Out of 20 results, only 1 person did it RX:
Stored, not understood
In SugarWOD the only way to mark WOD as scaled is via notes. Notice how everyone wrote 155#, 145 lb, 165lb, @165, etc.
Ok, so what's the problem?
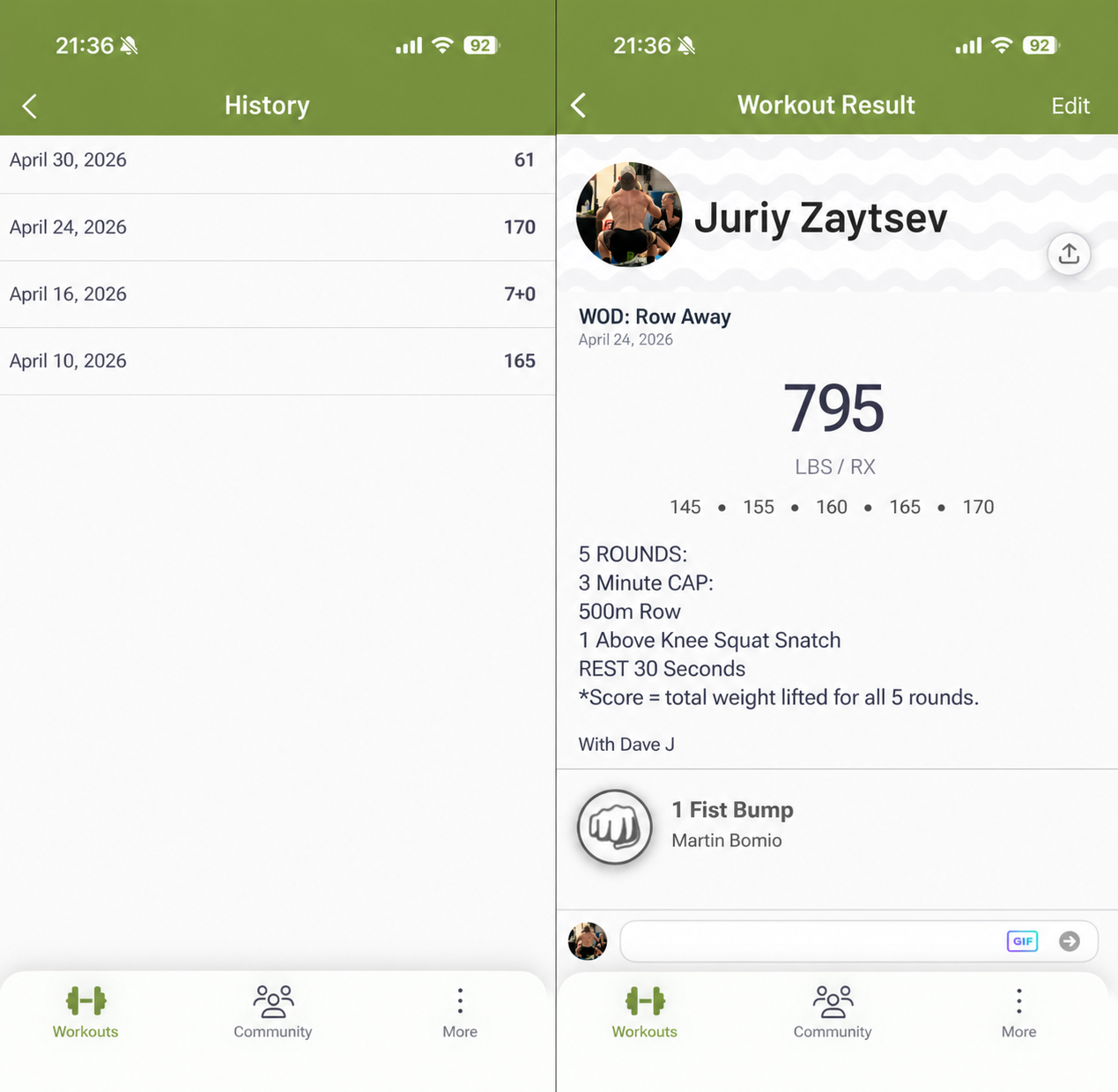
Well, the reality is that I've done 10 sets of 2 power cleans + 1 power jerk @165lb. My training log in SugarWOD, however, has no idea that this is what I've done. If I go into "History" for this WOD and click on Apr 24 I see "170" which makes me think that maybe that's the previous weight I did. But no, it brings me to a WOD where I did "1 above knee squat snatch @170lb" not "2 Power Clean + 1 Split Jerk" or even just "Power Clean + Split Jerk" or even just a standalone "Power Clean" / "Split Jerk":
It's entirely wrong and confusing. And if I go into my barbell lift history, this weight I just lifted is neither under Power Clean, nor under Clean and Jerk, nor under Split Jerk:
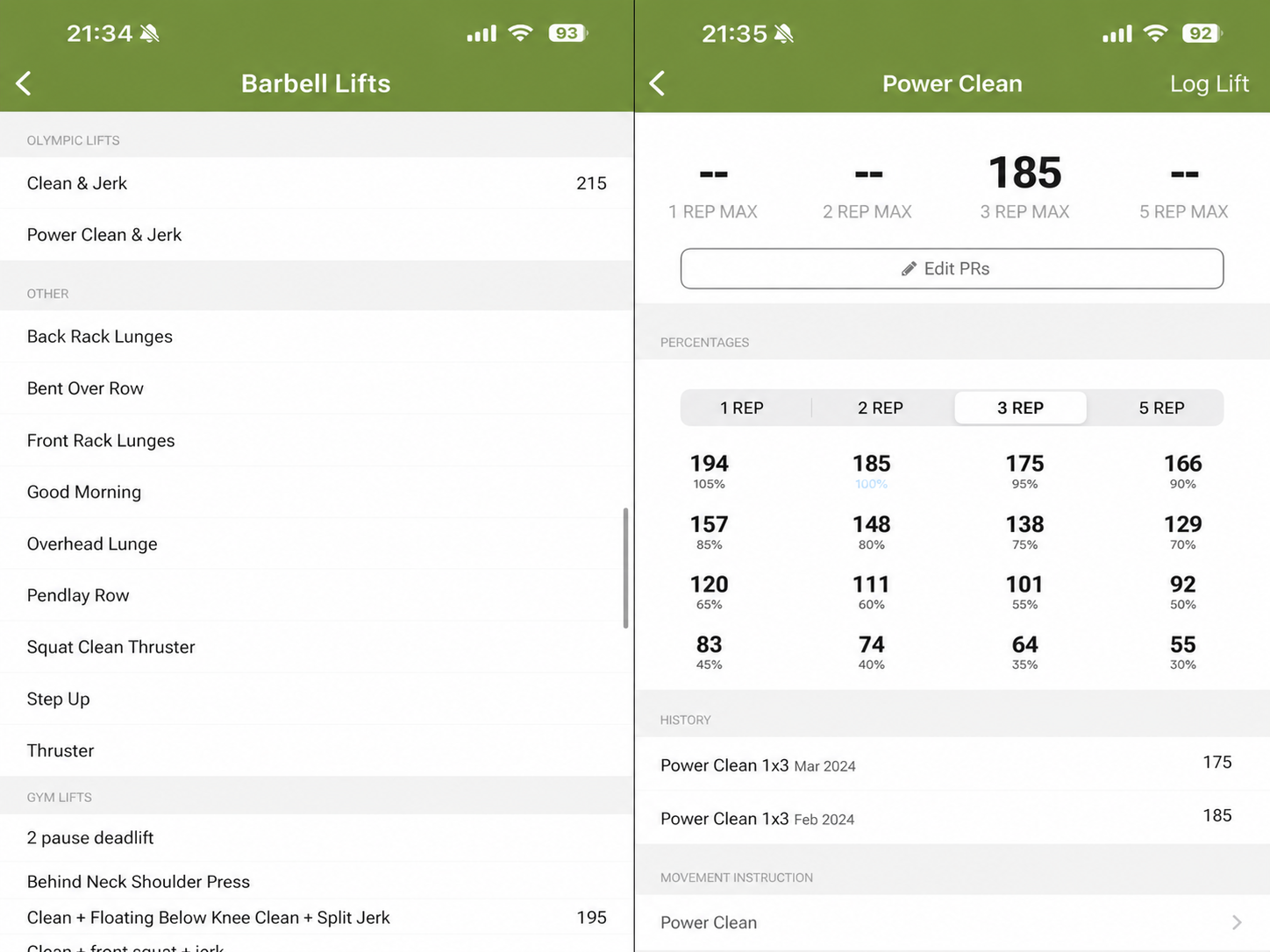
The two lonely logs for Power Clean are from Mar 2024. That's… 2 years ago. SugarWOD has no idea about countless times I've done power clean in a WOD like today.
My barbell PR history in an app simply can't be trusted.
Ok, that's SugarWOD. What about others? Of ~25 apps, only BTWB and WodUp treat scaled work as structured data — and both punt on the hard part. BTWB excludes scaled metcons from its fitness rating. WodUp tags them four ways but disqualifies any scaled benchmark from PR tracking. Everyone else — Wodify, SugarWOD, Mayhem, CompTrain, TrainHeroic, Hevy, Strong, the long tail — collapses your work into Rx/Scaled + a score + a notes field.
We were already half-right
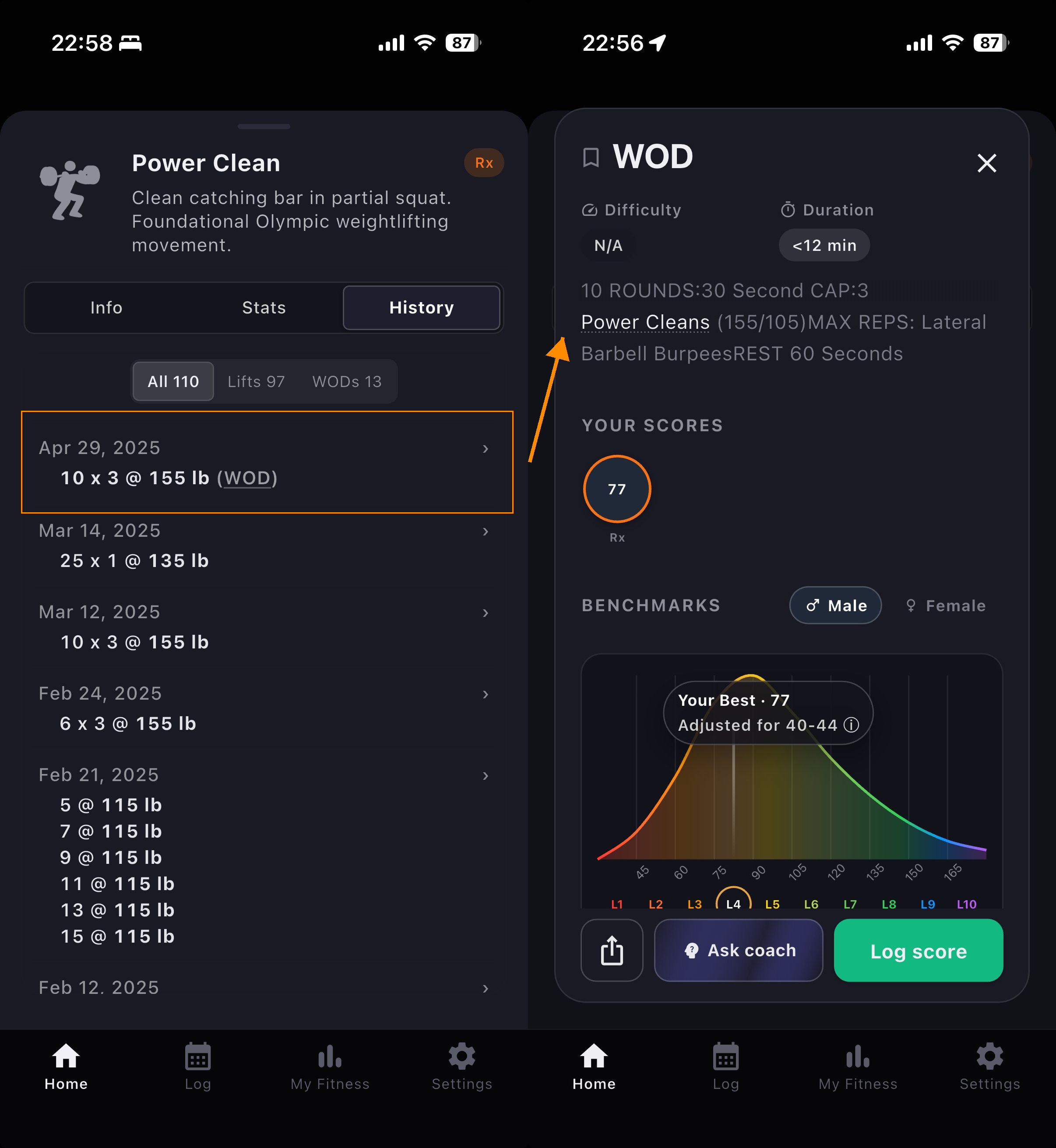
In PRzilla, we already tracked all movements correctly when logged individually or as part of a WOD. Here's a workout with Power Clean that I did in Apr 2025 which SugarWOD never showed. It's displayed in the history, alongside individual lifts:
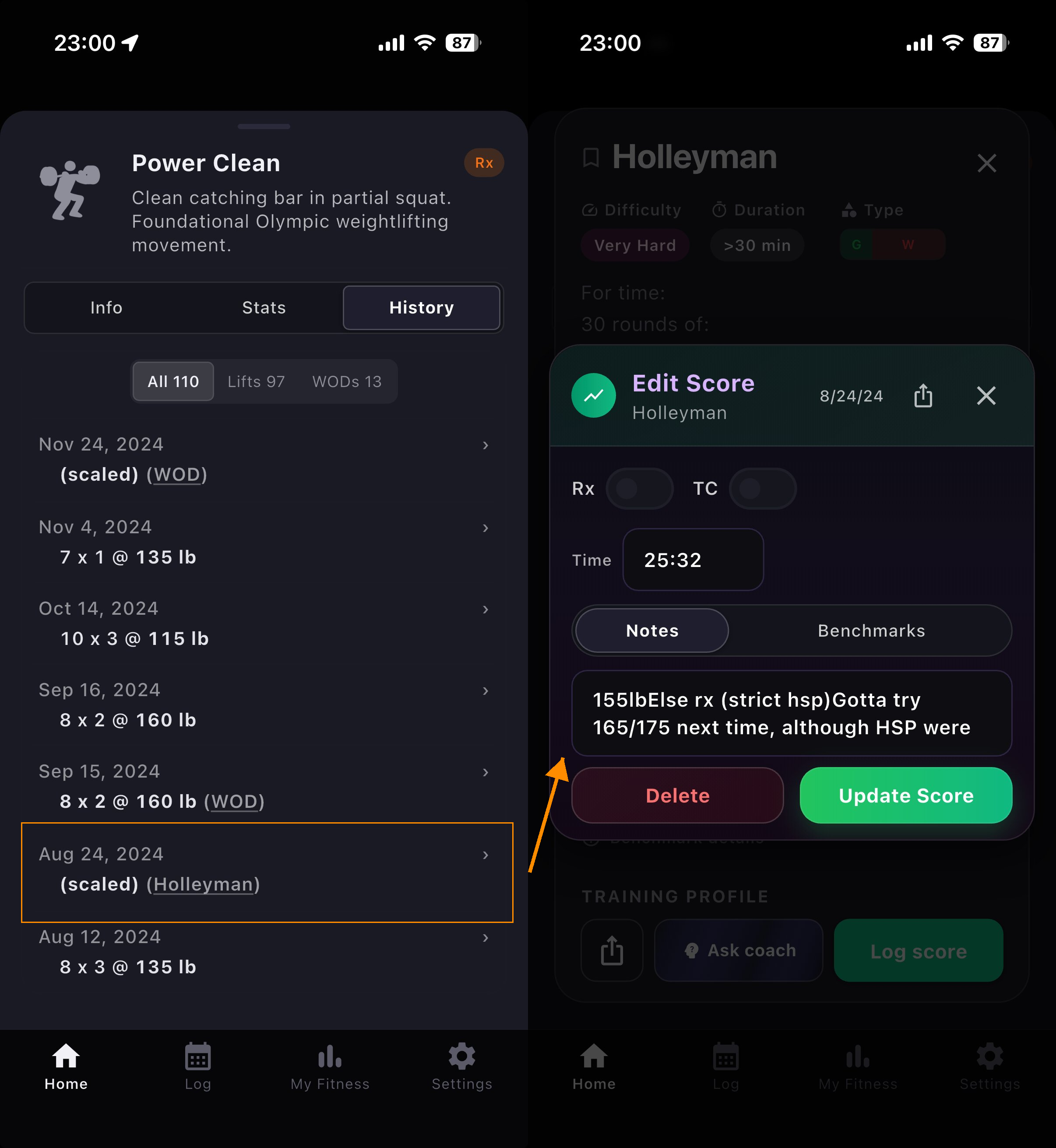
Scaled WODs like this Holleyman were part of the history too, but we didn't actually know how you scaled them outside of the notes. It would just display as "(scaled)" and not be part of any metrics:
As fast as a notes field
I always knew this is one of the most important things to have in a CrossFit app worth its salt; after many weeks of work, it's finally here.
You can now specify exactly the work you've done when logging any WOD in PRzilla. WOD's are just prescriptions. Every WOD is decomposed into movement blocks. And it's those movement blocks that define your history, stats, charts, etc. in our system.
But here's a harsh truth: the last thing athletes want to do when logging WODs is to spend few minutes tinkering with movements, sets, reps, and weights. Sweaty hands. Still breathing hard. 99% of us write "165#" and move on. That's why it was very important for me to remove as much friction when logging scaled WODs as possible.
Let's go back to the Clean & Jerk WOD. The moment I add it, PRzilla parses it into Power Clean, Split Jerk, and Air Bike; it creates all 10 sets of each, prefills first with 2 reps, second with 1 rep, and adds RX weight to both.
Because I scaled to 165lb, all I need to do is type "165" in Power Clean's topmost weight cell and click "Apply to all sets below". It takes me the same amount of time as writing "165#".
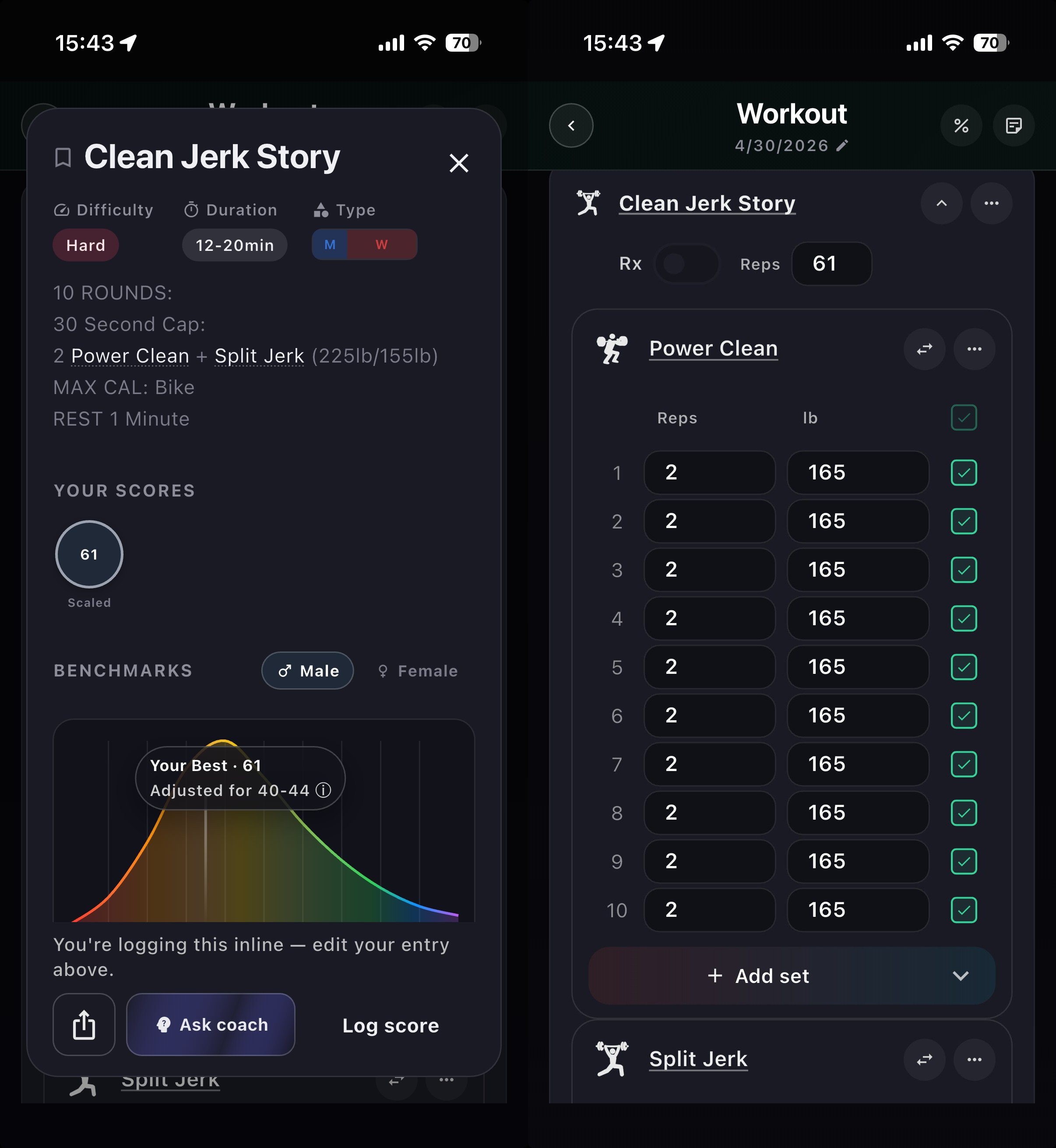
If I scaled that WOD to just power clean I can remove Split Jerk movement from the session by clicking "Delete". It's actually faster than typing "Did not do Split Jerk" in the notes. And I can replace power clean with dumbbell clean just as quickly as typing "Scaled to db cleans".
We now have the power of a full-blown workout editor within the context of one WOD. And we have minimal friction.
From score to signal
When looking at your workout session (left pic), you now see the things you've actually done and not just what was prescribed. A lot more useful metric that goes in line with the rest of the movements in a workout session. After all, we show 3 x 2 @ 275lb on Front Squats and not just "Find 2RM in 15min":
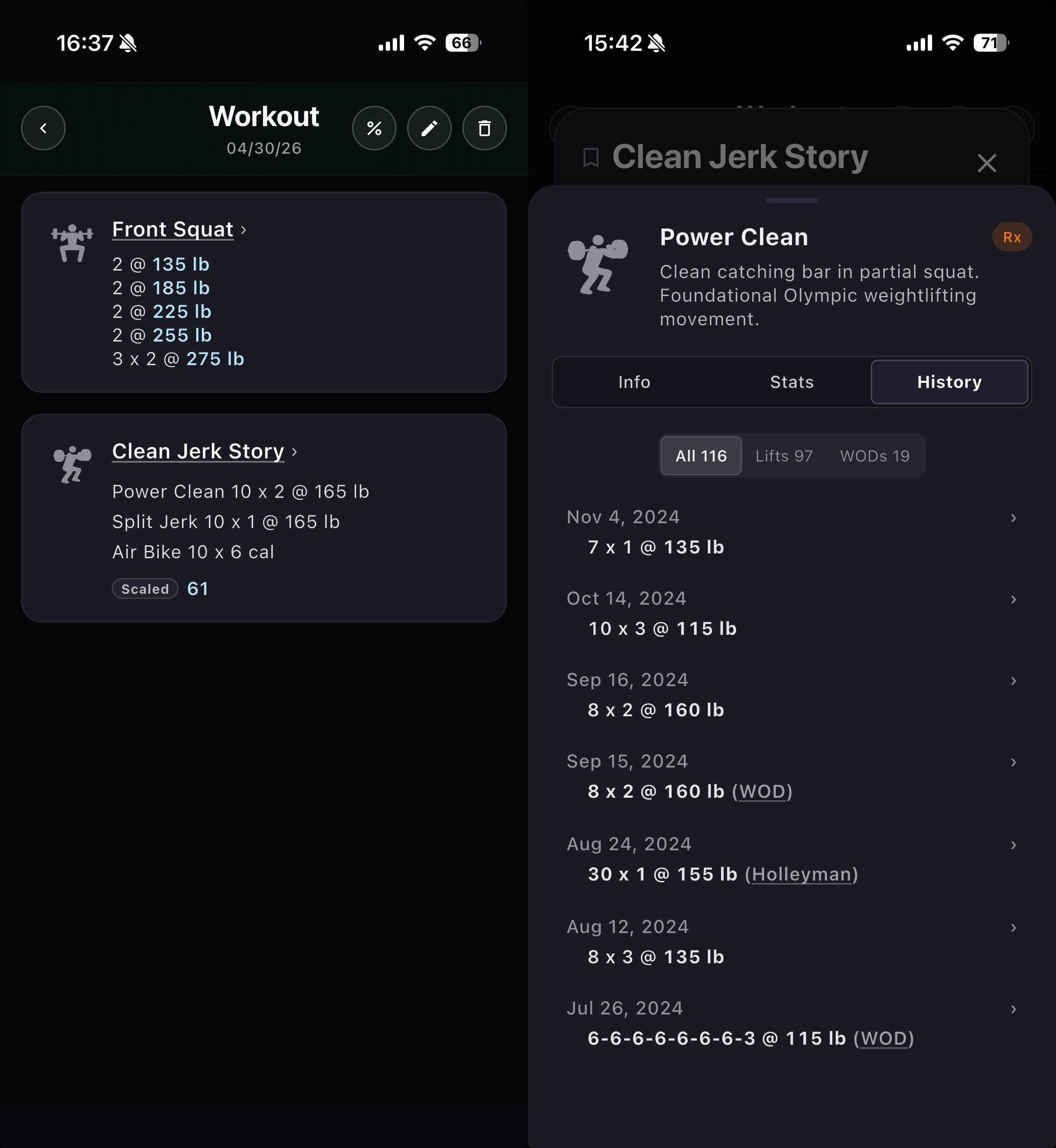
The Holleyman (right pic) is now displaying 30 x 1 @155lb because we have your actual weight as part of the WOD movements (=work performed). Seeing all the weights in a history list like this feels like a basic right in a CrossFit-aware workout tracker :)
You can't program what you can't see
Ok, charts and history lists are nice and all but… does this all really matter? I think so. Accurate training data is the foundation of your fitness training. We need to know where you stand in order to design a path forward.
If you scaled Holleyman to 185lb (and finished all 30 rounds), now we know these things:
1RM — this tells us that your max is at least 185lb without explicitly testing it.
1RM is essential for daily programming.Volume — you've done 185x30=5550lb of Power Clean in that session.
When we know your volume, we know the intensity of a given workout relative to your usual effort. If you've only ever done 1000lb of power cleans in a WOD, doing a WOD with 5000lb will wreck you for days. We can mark such WOD as high-volume for your level. A high-volume day can then either be scaled correctly or programmed in a way that doesn't interfere with other workouts in a week.Progress — Holleyman @155lb in 20min vs. Holleyman @185lb in 20min is the kind of progress you can see if we track scaled work. That's density: more work done in the same amount of time. It's important to know if you're trending up, down or plateauing.
Programming — passing your results to AI coach makes for highly relevant advice. If it knows you did 30 rounds of power cleans @185lb, it can use that to create a workout that's within your reach. It can tell you to scale up or down next time according to this weight. It can even flag less obvious things like weak squat clean in relation to power clean.
A coach who doesn't know what you lifted can't tell you what to lift tomorrow. Neither can your app. PRzilla is my attempt to fix that — give it a try.









CrossFit training in the age of AI 1 May 4:00 PM (last month)
CrossFit training in the age of AI
If you've been following this blog, you know I've spent the past year building PRzilla — from AI-powered WOD benchmarks to My Fitness visualizations that replaced a decade of spreadsheets to a full workout tracker. If you're new here, the short version: I left my tech career to build the CrossFit training app I always wanted, and it turned into something much bigger than I expected.
The native app is live — iOS and Android, 11 consecutive weekly releases and counting — and what started as a workout tracker has become an AI training companion that sits on top of your data, reads your recovery metrics, and coaches you like someone who actually knows your training history.
Here's how I got there.
Why not SugarWOD or Strong or Strava?
As I mentioned earlier, most training apps I've used are either geared towards traditional strength training (Strong/Hevy) or are Crossfit-class-centric and suck at logging any other activity (SugarWOD/Wodify/PushPress) or are too specialized and have poor workout trackers (Strava focuses on running/biking and Whoop focuses on recovery; strength logging is poor).
If I joined my gym class on Monday, I want to log whatever WOD was on a whiteboard / in SugarWOD. If on Tuesday I do an open gym instead to work on my ring muscle up practice, I want to log 3-3-3-2-2-2-2 and let it be part of my metrics. Maybe I also do an hour on a rower to work on zone 2. Or maybe I went for a run with a friend who's preparing for Hyrox or a Brooklyn half. I want to log those too. And then perhaps on Friday I'm traveling to SF and will drop into another box. The box is on a completely different programming track and often different platform like Wodify or PushPress. I want to log whatever WOD I end up doing at that gym. And even if I only ever do my gym programming via SugarWOD, what happens when I move to another area and join another box that uses different software—I'd like to keep all my history and lifts.
PRzilla solves all of this. Here's what that looks like in practice:
No longer tied to a single CrossFit box and their platform
You can log anything you want
You own your data
Camera advantage
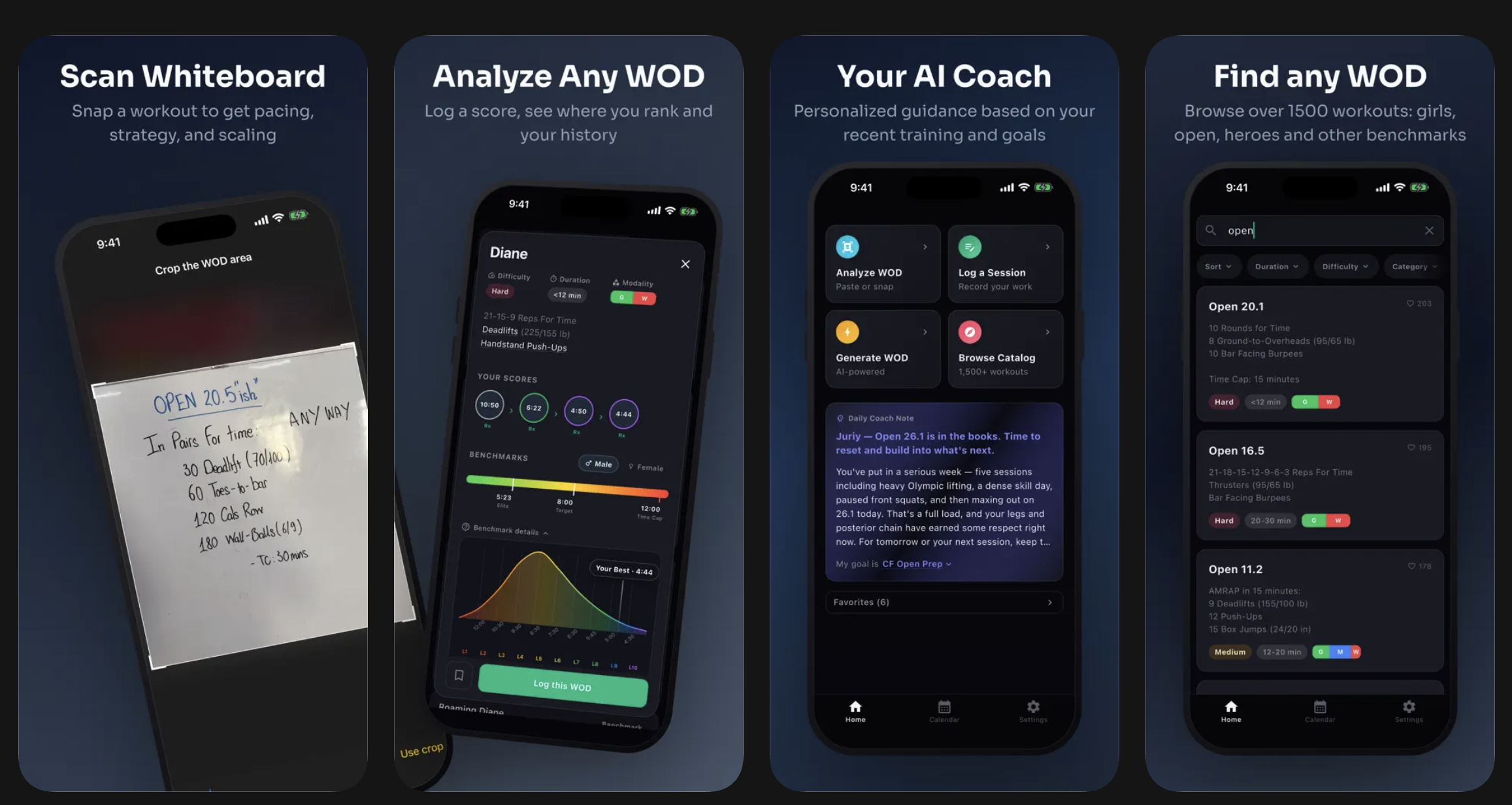
One feature I'm especially excited about is that you can snap a photo of your gym's whiteboard and the app breaks the entire training day into structured movements and WODs — matching canonical benchmarks when it recognizes them or creating a custom one when it doesn't. WODs automatically get analyzed for performance level bell curve so you can immediately see where you stand.
Here I snapped SugarWOD's whiteboard and it turned it into back squat and shoulder press as single movements (which I could then log as many sets/reps of) and it created a WOD with running and Fran-like couplet, giving me a time to shoot for:
I spent months building and refining this sophisticated workout tracker that can handle any workout. Even though I made it easy to log things, I eventually realized that training log itself is not the end goal. There are two more legs of a tripod that truly elevate training experience to the next level.
Recovery as the middle lever
Your training log is the past. Your programming is the future.
They're intimately related to each other: as a coach, I need to know what you're capable of doing in order to design a program to get you from point A (your past) to point B (your goal). Your training log is a snapshot of your abilities, strengths and weaknesses. An advanced lifter that needs to work on their positions in a snatch to bring it from 1.25x to 1.5xBW has very different movements prescribed than someone who just started training and are working on their 5x5 Back Squat progression.
However, Training Data ↔ Programming don't exist in a vacuum; the subject in the middle—you—responds to demands placed on them (=programming) positively or negatively. One way to measure how they respond to them is via your recovery metrics: HRV, RHR, Sleep hours/quality. Waking up with low HRV could be related to a hard session yesterday (it tells us that it might have been too intense for you). And it should adjust your programming accordingly (multiple hard sessions lead to overtraining).
And so I've added Apple Health integration:
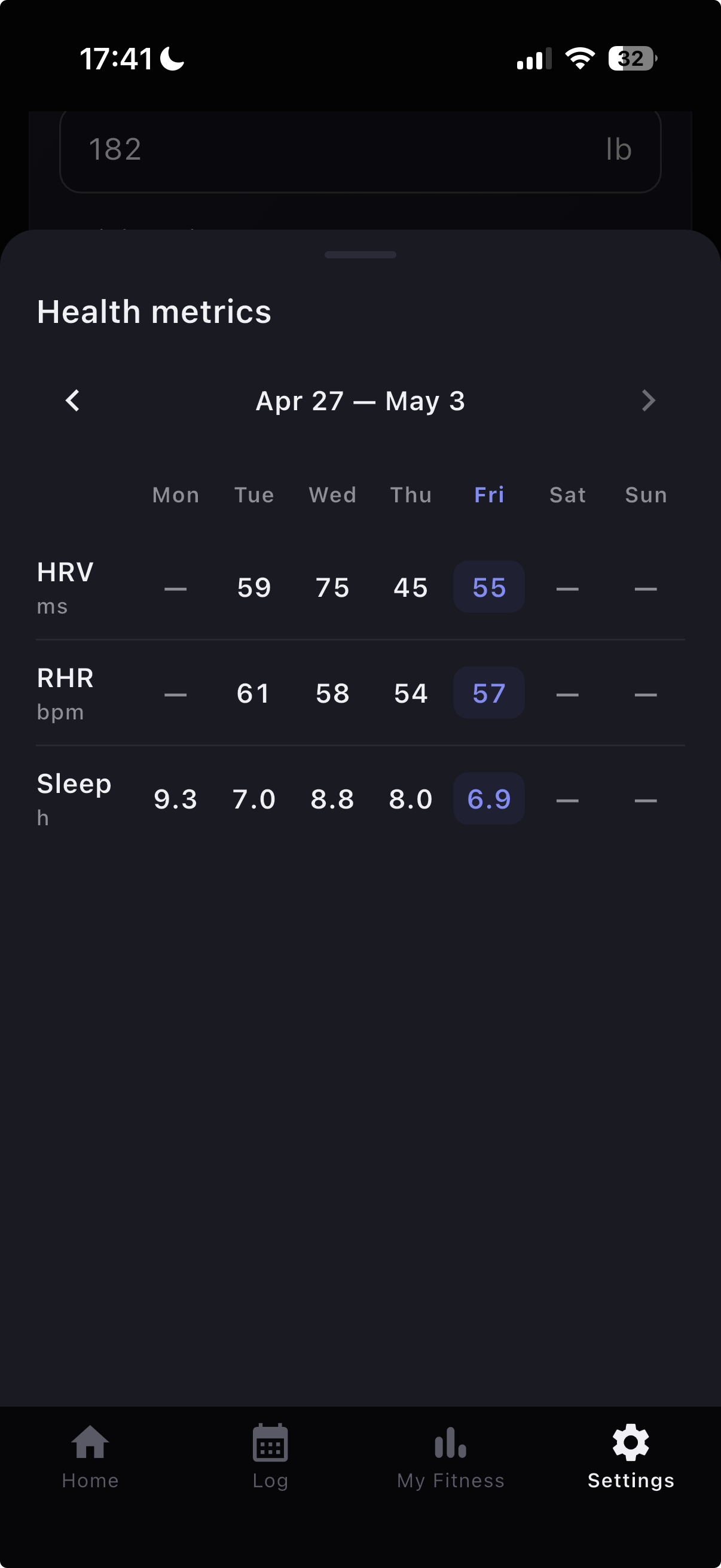
The feature is in beta but the idea is that you can now see your "readiness" day-by-day. Last week I saw my HRV drop 15ms after back-to-back heavy sessions — a clear signal I was accumulating more fatigue than I was recovering from. Without this data, I would have pushed through another hard day. With it, I dialed back to skill work and was fully recovered by Thursday.
AI as an orchestrator
A good coach would start by looking at your training history, create a program to get you from point A (your past) to point B (your goal), then adjust it in real time based on how you respond to it (your recovery metrics).
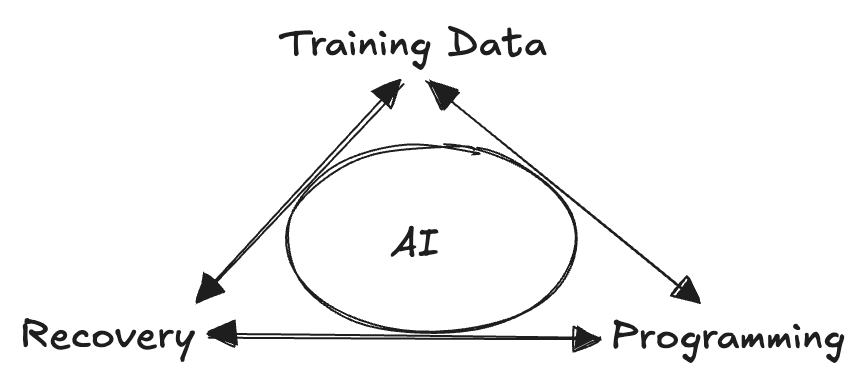
Given AI capabilities in 2026, it can do all of the above. It just needs to have access to your health and training data. It can serve as an orchestrator in the middle, carefully analyzing your past (recent training), ingesting what's present (morning readiness) and adjusting your future (today or tomorrow's workout).
Meet your personal coach; they know you better than a coach in your gym.
The coach has access to your full training history, remembers past conversations, and can search the web for workout details you mention. You don't re-explain yourself every session — it already knows your recent lifts, your weak points, and your goals.
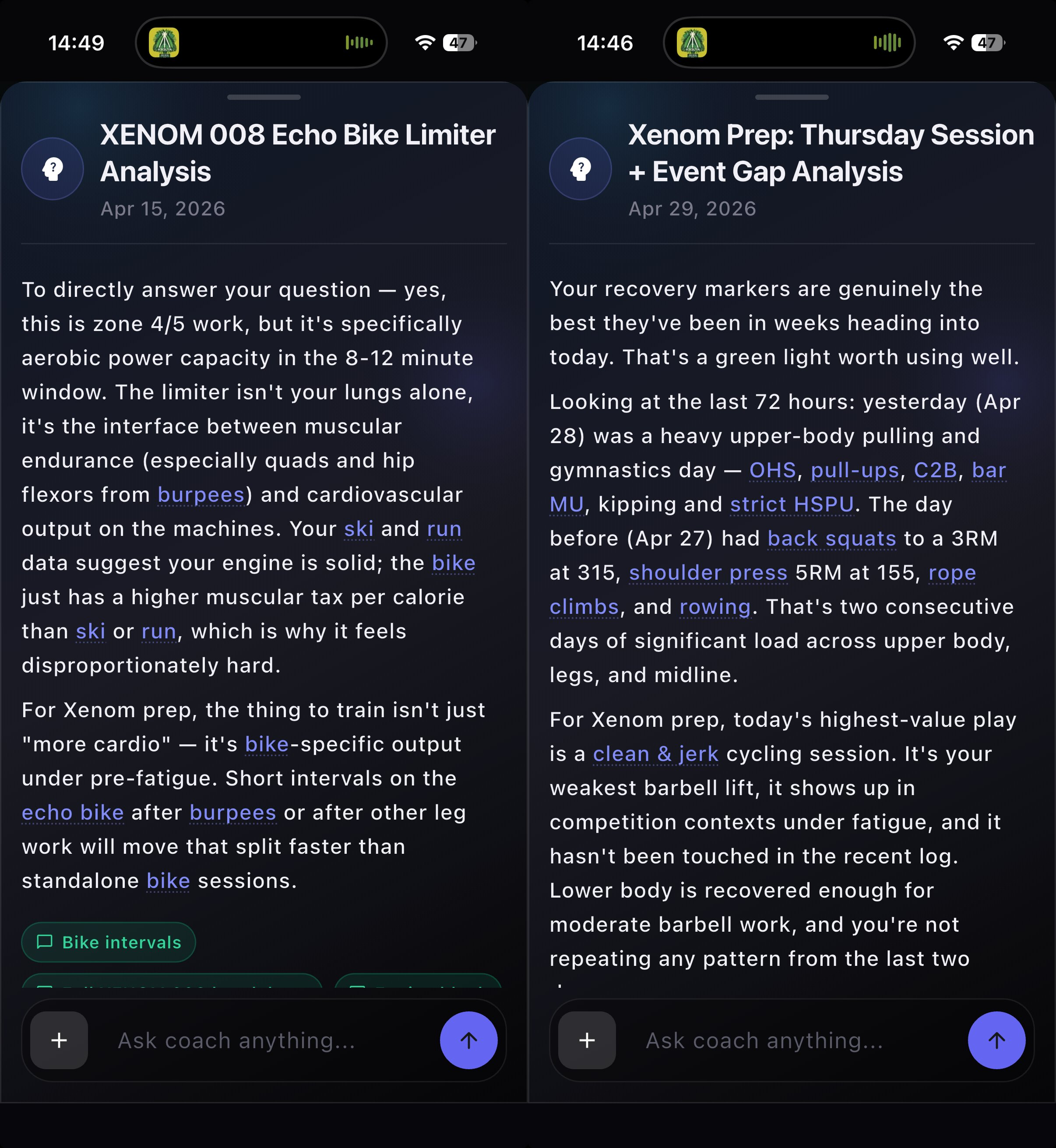
As you can see, I've been using it for my own training. My honest take, as a coach myself, is that I'm genuinely surprised at how relevant the answers are. I would say they're at ~80-90% of what a human coach would recommend; not perfect and sometimes sloppy, but very useful as a brainstorming partner if you're a high level athlete, and are very illuminating if you're a beginner.
Some things you can ask:
- "How has my squat been progressing?"
- "How should I approach this workout?" (attach a WOD from our catalog or a picture)
- "What movements have I not done much lately that decay the fastest?"
- "Help me structure this week as a best prep for QuarterFinals next week; recall that I do a long engine team WOD every Saturday"
I wanted to create a workout tracker that can handle serious training demands. I ended up with a real-time AI companion at your fingertips that can guide you like a real coach.
My fitness
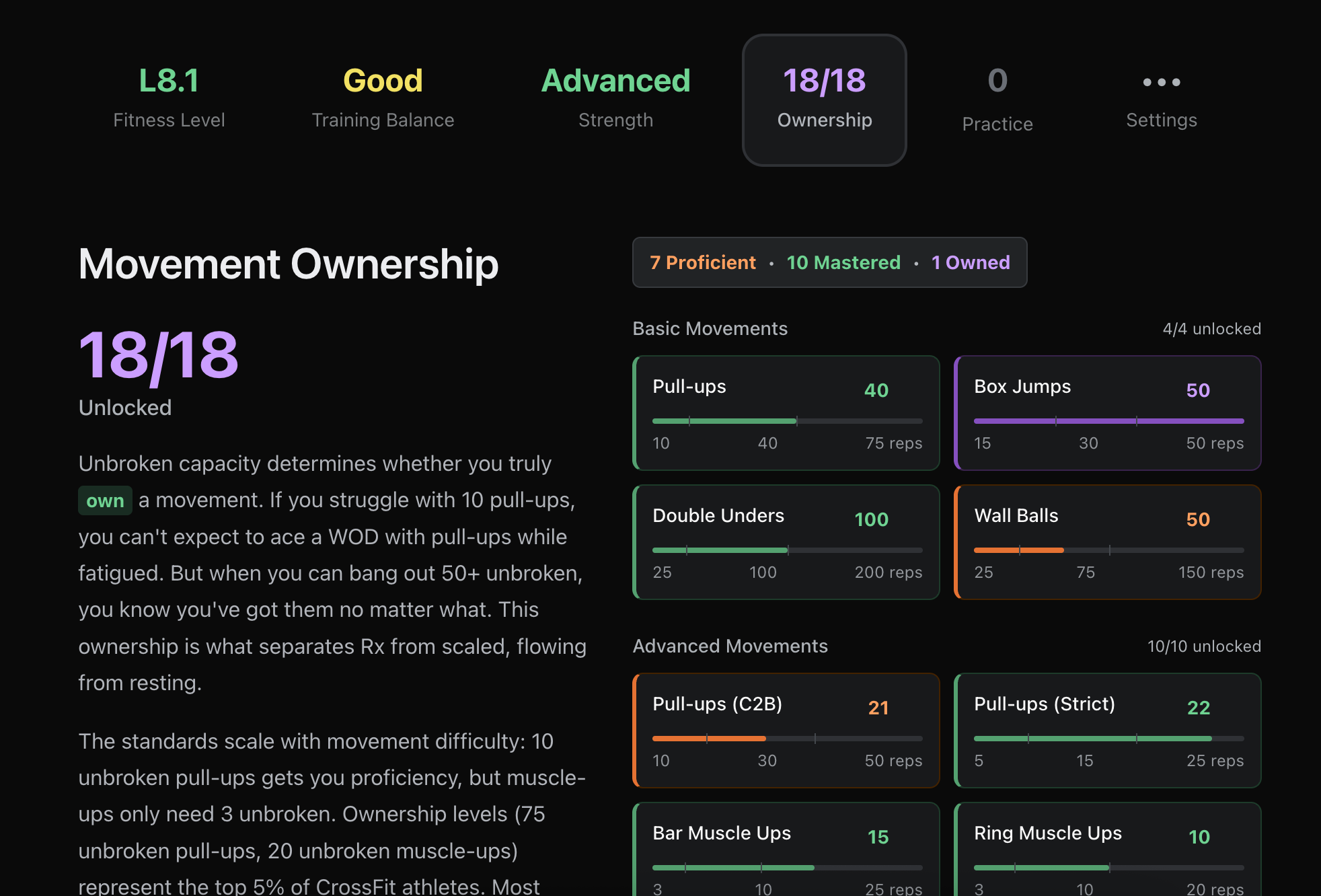
There's one more piece I haven't talked about yet. All of this data — your training history, your recovery trends, your AI coaching conversations — paints a picture of who you are as an athlete. Your fitness level across workouts. Your strength relative to established standards. How much you've actually practiced each skill over your lifetime. I've been calling this 'My Fitness' — a gamified snapshot of your athletic identity that evolves as you train. Think of it as Whoop's 'real age' but for functional fitness: one page that shows you exactly where you stand and what to work on next. You've seen it on the web and it's coming to the native app soon.
Overnight success 23 Mar 4:00 PM (3 months ago)
Overnight success
Exhibit A
"Omg, look at this beautiful design", Cat said. "Finally, someone made a beautiful period tracking app".
I was looking at a stylish "28" logo and UI with a color palette that could easily win Apple's app of the year.
It had not just tracking, but symptom logging, workouts with videos, diet suggestions and recipes; a whole ecosystem, aka cycle-syncing.
Her and I have been half-jokingly talking about creating a cycle app that doesn't suck. The app we were looking at surely looked like one: it had a ton of functionality including much-desired partner integration, the UX made sense, and a gorgeous design tied it all together.
"Wow, someone finally vibe-coded what we've envisioned", I thought.
I fired up deep research. Few minutes later it printed out something that I didn't quite expect: "Started in 2019... two founders who were working in brand..." Before my surprise could wear off, it was replaced with a familiar thought: "Overnight success doesn't exist." I've seen this so many times yet I'd still fall victim to thinking that someone just came up with something brilliant over a hackathon weekend.
Exhibit B
"Dude, you gotta teach me how to be so good at ring muscle-ups", Dee told me as I finished my 15th rep on Open 26.2. Dee was a level 2 CrossFit coach at the box I was visiting in Vietnam. The 2nd workout this year ended with a brutal set of 20 ring muscle-ups after about 12min of other shoulder-intense movements and high-skill gymnastics. Even doing 1 muscle-up was a worthy achievement and put you straight into 75th percentile.
My score put me in 90th. Out of 20 RX participants in our gym, only 2 others did better. It seemed I immediately gained respect among everyone as half of the box watched me perform perfect reps as the timer ticked down.
The next day I came across a ton of Reddit posts on Open performance frustrations. Folks were devastated with their scores.
This reminded me of my own feelings few years ago: I was doing powerlifting and bodybuilding-style training for many years. I thought I was strong and jacked and fit and all the things. Then I joined a CrossFit class and finished one of the last. In the years that followed I'd routinely perform way below what "good" meant by CrossFit standards. I was humbled again and again.
Don't just take my word for it, here are my Open results to prove it:
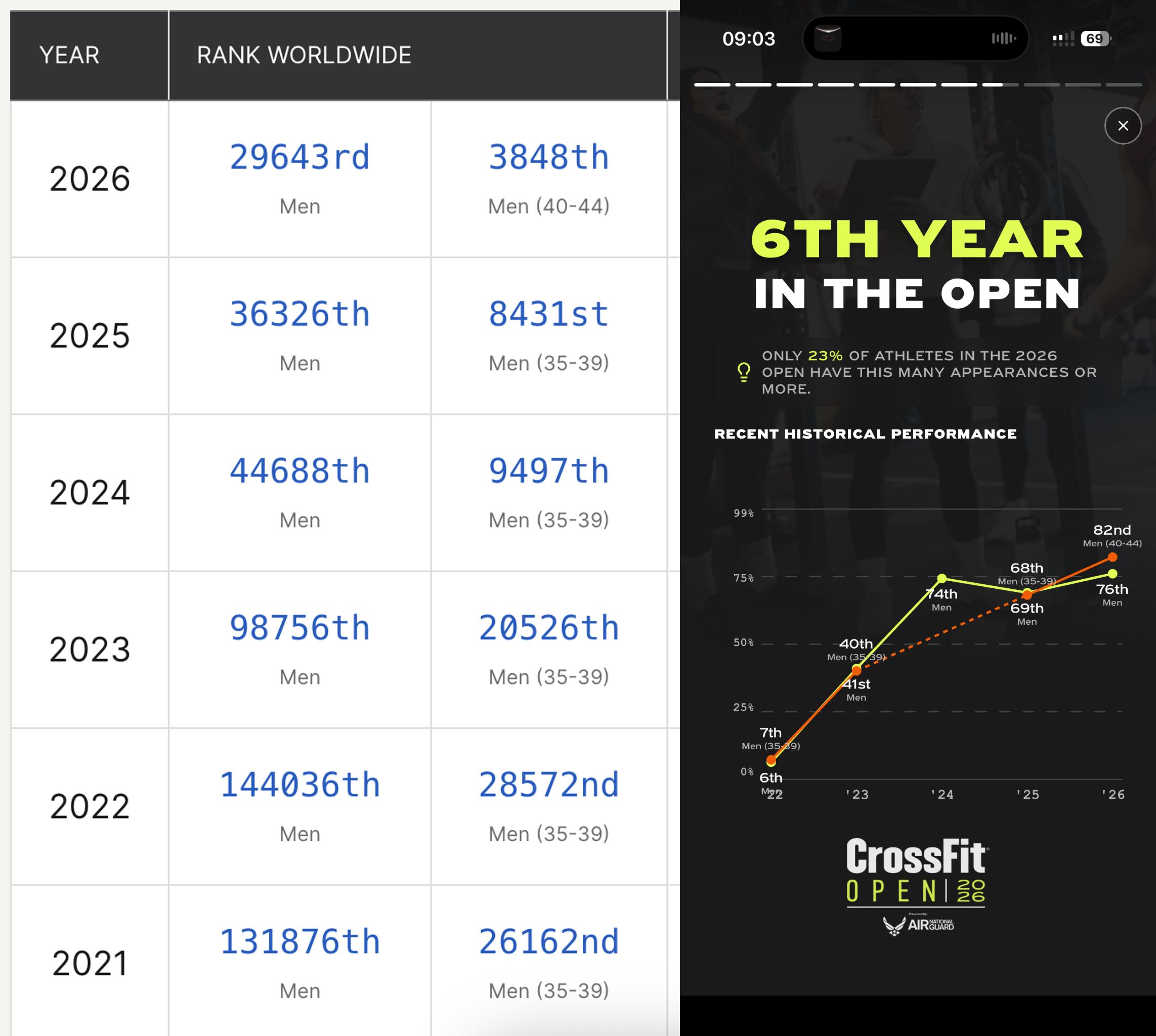
What people don't see leading up to those flawless ring muscle-ups are all the times someone practices them consistently, for weeks, months, or years. What they don't see is the slow growth from bottom 5% to top 17% over 6 years. No overnight success here either.
Exhibit C
When I started building PRzilla last year, I surveyed over a dozen of CrossFit boxes and their coaches. I wanted to see what they like/dislike about their existing platforms like Wodify or SugarWOD. One theme was common—some gyms recently switched to PushPress, a "new kid" on the block—and they were all quite happy with it. It provided a no-nonsense, all-in-one class management solution as well as social features for members. I remember checking it out couple years ago when I dropped into a box in Bangkok: clean, simple UI, modern features like a social feed. It looked a lot like what I would build.
Fast forward few months and I'm chatting with Dan Uyemura. "PushPress is 12 years old, yet I still come across affiliates who have never heard of it", Dan tells me. I want to say I'm in disbelief but, of course, I'm not. I know better. "We were at 0 profit first few years and I almost quit. And now it feels like we're only getting started."
As I'm nearing a year of working on my vision, it's easy to want to be so much further. More daily visitors, more registrations, more app installs, more features. Every day you see incredible products that were bootstrapped in "just few months", or vibe-coded in a weekend while talking to Claude on the phone from the subway.
Every day I see 2-3 apps that claim to do the same thing as what I'm building. Shouldn't I be further? Shouldn't I be better?
And so I remind myself: there's no overnight success. The grind continues. Step by step. 1% better every day.
What’s my XENOM score? 22 Mar 4:00 PM (3 months ago)
What's my XENOM score?
TLDR: xenom calculator is here
The other day I came across XENOM — a newly-founded global CrossFit competition with a known and fixed set of workouts. Think CrossFit Games but standardized to a consistent two-day event similar to HYROX. You get a score on each of the 10 workouts and your final result is the sum total.
This got me thinking: can we determine athlete's performance on this kind of event?
In HYROX world, people ask the same question: what's my estimated HYROX time if I've never run the race? Why do we care? Well, if we know user's estimated time we know their starting level, their weakest splits, best division to compete under, and—most importantly—what improvement is realistic and what exact program to follow to get better for the upcoming race. Just like to run a marathon your training would look very different if you're at 8min/mile with 10 miles weekly average or 5min/mile with 50miles/week.
I've been working on CrossFit benchmarking with AI for a long time. But the XENOM problem is different: instead of figuring out time/reps on a given workout, race estimate is asking us to map athlete performance onto a score on a different workout.
HYROX vs XENOM
So how do HYROX calculators do this? Because HYROX is a sequence of single movements, its math is a lot simpler. Take your 1km running time × 8, add time of each of the stations (rowing, wall balls, etc.), and add fatigue multipliers for each.
XENOM estimate is asking: how well would I do on 4 attempts of max snatch in 9min, on a wall walk + rope climb ladder, on a 12min WOD ending with max rep muscle-ups, on a 3km run into 2k ski, and so on.
Obviously the best way — outside of doing an entire mock race — would be to just attempt each of those workouts and plug in your results1. But in the age of modern AI and having access to your training data (like we do in PRzilla), we should certainly be able to figure this out without actual attempts.
1RM snatch (XENOM 001) is easy: just plug your best max lift. Recent snatch matters more than your all-time-best from 5 years ago.
What about more complex workouts?
Think like a coach
Putting my coach hat on, to determine the score on XENOM 002 which is an ascending ladder of 2 wall walks + 1 rope climb, 4 wall walks + 2 rope climbs, etc. for 8min, I could start by checking user's recent wall walk performance. Ok, they've done 5x5 wall walks a month ago and 3 rope climbs a couple months ago. They're capable of getting to 2+1, 4+2 and can likely get to 6+3 as well and perhaps even 8+4. I'm able to predict this because 5x5 tells me that 5 is not their true max (1RM) but likely 7-8 is.
Muscular endurance
Here's the thing: max consecutive reps are not a perfect predictor to what an athlete is able to do. Some aren't able to piece 10 wall walks in a row but they can bang out 30-45 via 10-15 sets of 3 with short rest. That's a first wrench in our calculations. I might see that you've only ever done 3 consecutive wall walks, but I don't know what your muscular endurance on them is. A classic example is Cindy — if you did 20 rounds RX I can say with high confidence that your muscular endurance is quite strong; you're able to continuously perform 5/10/15 of pull-ups/push-ups/squats for 20 minutes. Same thing with wall walks: being able to do 10 in a row is an indicator of your continuous-set endurance and proficiency in the movement... but an even better predictor could be looking at a WOD that includes plenty of wall walks like Open 21.1, 22.1, 23.3, etc.
Similar movements
As a coach, I can also look at your handstand push-up performance, either as a max-rep number or in a WOD that includes them (e.g. Diane). How about handstand walk. You can do 50ft? Your handstand endurance is generally "strong" and so your wall walk performance should be at least L5. But here's a curve ball: can you extrapolate handstand walk performance from a handstand push-up? The stabilizing muscle stamina has some overlap but you can certainly get good at handstands without ever being able to do a handstand push-up; the latter requires strength and stability throughout the entire range of motion.
WOD logging is complicated
Even if we have your training data, CrossFit-style workouts make our calculation hard because you log a score, you don't log how you performed the movements.
In a WOD that calls for 3 rounds of 20 C2B, did you do them as 5 sets of 4 because the mastery isn't quite there (e.g. ~L3 perf) or did you bang out sets of 20 (e.g. ~L8 perf) because you own them? We can somewhat extrapolate it from the total time: an athlete that's able to do easy 20 is likely to finish workout faster than the one breaking in 4 sets, but it's not a direct indicator of your movement performance.
Thankfully, when logging untimed practice (standalone movements) in PRzilla, you log them as sets and reps. This makes it easier for us to determine your max reps without a standalone test. Just like logging 3x10 bench press @185lb tells us your estimated 1RM.
There is a good opportunity for disruption here: specify sets/reps when logging WODs for that ultimate analytics.
Movement relevance
Another curveball: let's say you log 10 rounds on a WOD that's a 12min AMRAP of 5 deadlifts and 5 wall walks. This is a good indicator of your capacity but did you do 10 rounds because of deadlift strength or wall walk strength, and which percentage of each contributed to the final score? It could be 80%/20%—you're a powerlifter with 500lb deadlift who's never done handstand work; or 20%/80% — you're a gymnast who's never done deadlifts. We should be looking at a broader set of workouts: if you consistently do well on those with handstand movements, we can assume with more certainty that you're good at them.
Submaximal strength
While we know that absolute strength corresponds to being able to do more work at a given weight, can we really be sure that a person with 255lb clean will do better on Grace than a person with 205lb clean? I've seen guys in the gym who never go above 185lb but they can cycle 135lb forever, and do it fast. On the other hand, my clean is closer to 225 but my HR is through the roof after 15 singles with 135lb. In other words, you don't need to push the ceiling in order to get good at sub maximal weight endurance2.
This is why looking at a user's DT and Grace scores is as important as looking at their Clean 1RM; it shows their performance in barbell cycling, submaximal strength and endurance rather than their absolute max.
Ideal benchmarks
Why is Grace such a great benchmark? Because it asks you to perform X reps in one movement in shortest time. This is similar to a famous 30 muscle-ups for time. If we invert this into max reps in X time, you have tests like Handstand Push-ups: Max reps in 2 min. Going back to wall walks, if we know max reps athlete can complete in 2 min, that'd be one of the best proxy benchmarks for events like 002.
HYROX PFT
An interesting proxy that exists in HYROX world is their Physical Fitness Test: run 1000m, do 50 burpee broad jumps, 100 stationary lunges, 1000m row, 30 hand-release push-ups, and 100 wall balls.
15–25 min is PRO, 25–35 minutes is Open, 30–40 min is Doubles, 35–45 min is Relay.
Notice anything? PFT is similar to Grace or 30RMU's: it's a chipper of all of the HYROX movements where you perform X reps on each as quickly as you can. This is a direct indicator of strength/endurance/capacity on each of them, making your level approximation quite accurate.
XENOM PFT
So should XENOM have its own PFT? HYROX's works because it IS the race, just miniaturized. Same movements, scaled volume, done. Clean and obvious.
XENOM can't do that. Ten events, nineteen movements across three completely different fitness domains — a miniature version is just a giant chipper. Technically, it would be something like King Kong or Fight Gone Bad. Practically, you'd be testing too many things in a way that's not really representative of individual events: stimulus of a ladder is very different than a stimulus of max-weight attempts or a long endurance grinder.
We could come up with something like this: accessible to a majority of CrossFitters (no muscle-ups, no heavy snatch, no max-cal bike) but it would only be a faint projection of your overall performance.
For time:
1,000m Run
15 Thrusters (60/42kg)
15 Toes-to-Bar
1,000m Echo Ski
10 Cleans (80/55kg)
10 Handstand Push-Ups
Elite: <15 min, RX: 15–22 min, Compete: 22–32 min
XENOM calculator
In the meantime, I whipped up XENOM calculator in PRzilla.
Calculator is smart. It uses WOD scores that serve as best proxies for an event — DT, Fran, Amanda, 5k run, etc. If there are no benchmarks it analyzes your training data for relevant signals. It decays benchmarks at different rates based on scientific research: strength reduces slowly, endurance diminishes fast, and acquired skills mostly persist.
Here it's showing that I'll probably land right at that fabulous 50th percentile :) You can override each score if you performed that specific workout or feel like our projection is incorrect.
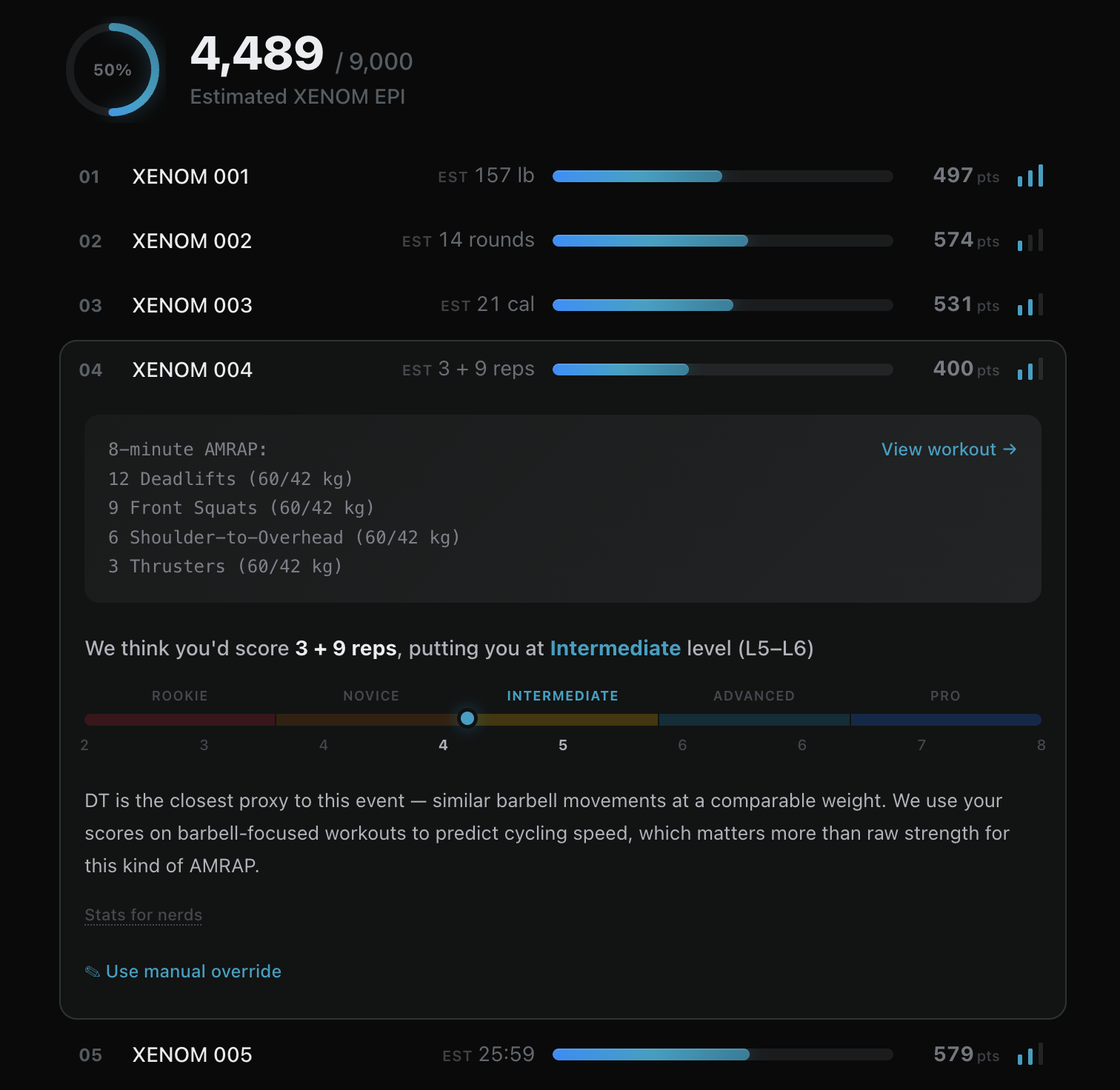
If you're logged in, it uses your existing WOD scores under the hood. If you don't have account, just plug your WOD scores manually and it'll use the exact same smart calculations. The more scores you give the more accurate final prediction is.
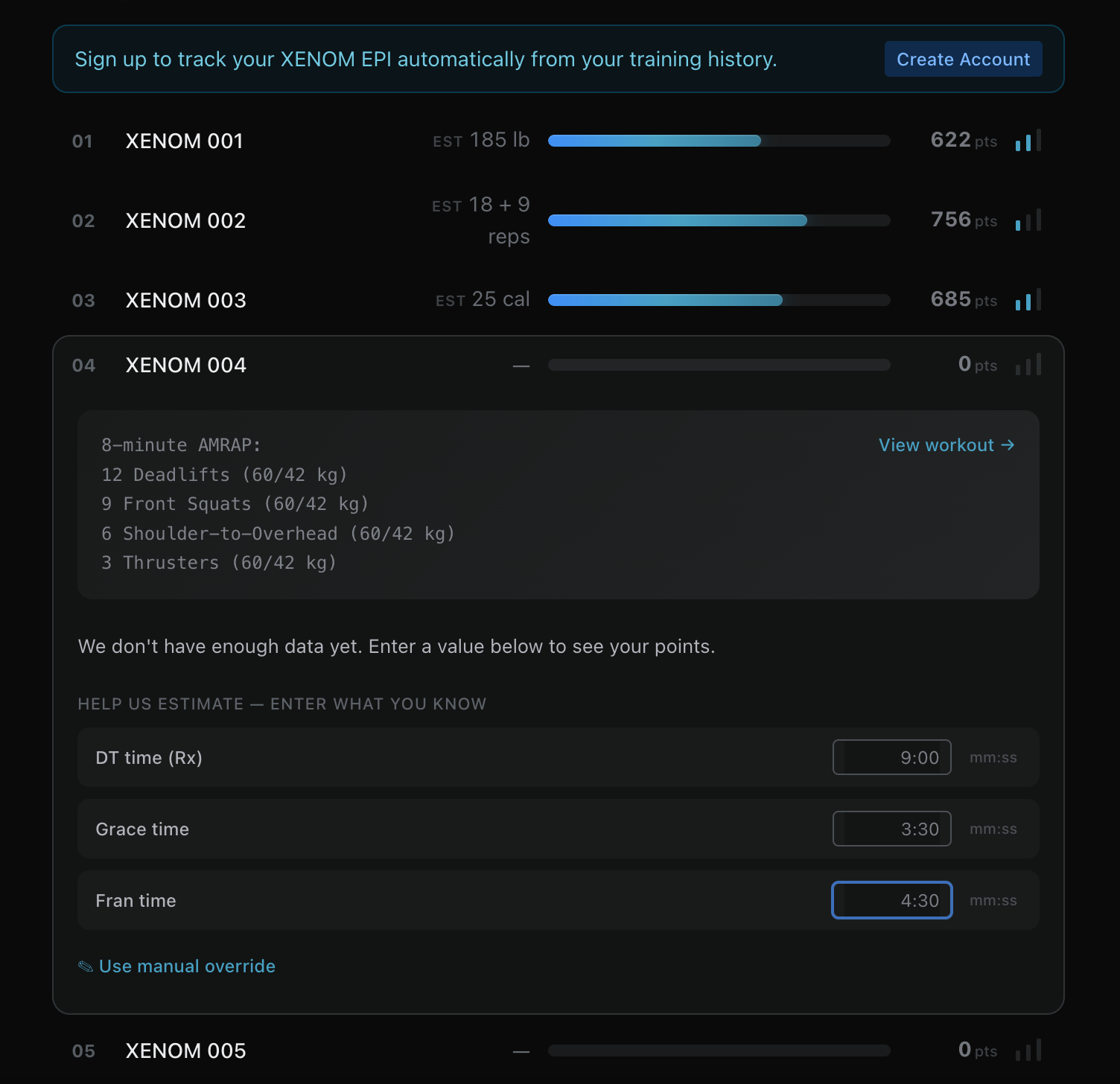
I'll be refining this calculator as we learn more about benchmarks. I'd like to add a division estimate to help folks decide what track to compete under.
AI Coach
Next version: I'd like to try feeding this through LLM asking it to reason as a coach. Coach doesn't just run formulas — they read between the lines. They notice you've been logging at 70% for two months, that your shoulder-heavy movements have quietly disappeared from your logs, that your snatch PR is from 2022 but you've been crushing Isabel lately. That kind of contextual reasoning is hard to encode in rules.
Drop me a note if you have thoughts on this or just found it useful.
Many HYROX calculators do a very simple math where they ask you to put time of each station.
For more on strength and submaximal strength, see coach Shawn's recent excellent writeup on this.
Reflections on training, 2025 → ‘26 23 Jan 3:00 PM (5 months ago)
Reflections on training, 2025 → '26
Looking back
A big shift last year has been towards skill learning and widening movement repertoire. Now that I'm 40, I can't quite recover as fast after going hard on WODs. I've also grown weary of constantly chasing higher strength numbers: squat, deadlift, clean. Most of those have plateaued years ago and now need a dedicated multi-month cycle to make meaningful progress1. And so I found that learning new movements and practicing existing ones is one way to improve fitness while giving body a break. It's also fun and rewarding as you see your quantity and quality go up.
Testing ↔ Training ↔ Recovery
I'm now increasingly seeing my time in the gym as existing in one of 3 buckets.
I'm testing if I perform a for-score workout and push myself to my max or near-max. This is the most fun one, of course; it's rewarding to end up in top 3 on a leaderboard. But it also comes with the highest cost. For muscular stamina workouts like Cindy or Eva, you're very sore for the next few days due to the density of work (volume/time). For near-max lifts, your CNS is fried and joints take a beating.
I'm training if I perform a prescribed body of work at a specific, usually RPE5-8 intensity. Training could be timed but often isn't. 40min EMOM with ~30sec rest each min is a good example. So is doing 10 sets of 3 snatches at ~75% with 1-2min rest. These are usually less fun, but they need to constitute most of the time.
I'm recovering if I consciously limit my work to a very low intensity and/or perform low-impact movements. This is where Zone 2 training comes in, such as spending 45-90min on a bike or a rower at ~130bpm (for my age). I managed to make these type of days less boring by throwing skill learning into the mix; I would do some handstand walks every 250-500m on a rower, or do 1-2 ring muscle-ups. Anything that's ~20% of your capacity and ideally bodyweight-only.
Ideal week then looks like 1-2 days of testing, 3-4 days of training, and 1-2 days of recovery. This looks easy on paper but tends to be a very delicate balancing act and is quite difficult to get perfectly right.
The moment I push my testing a bit too much, I get injured. If I don't include recovery, I stop progressing or quickly overtrain. Another takeaway: just because I can ace that workout and beat my (or other) scores, doesn't mean I should.
Old dog, new tricks
Last year I've probably spent 30% on each of the following:
High level gymnastic skills — Ring Muscle Ups and Handstand Walk
Zone 2 training
Longer/endurance-heavy WODs
RMU's and HSW were the last two pieces of the CrossFit puzzle. It was what I needed to be able to RX 99% of WODs in a typical class.
I went from being able to do 2-3 muscle-ups to hitting 10 in a row, being able to do 4-5 on any given day, and under fatigue during WODs. I even accidentally progressed to 2-3 strict ones! Handstand walks were also something I struggled to not fall just a few feet in, and now I can almost always go 50ft, confidently. The power of practice truly can not be underestimated: all I did was show up and practice every week, sometimes once, sometimes twice. In that regard, the year has been a success.
The other part was focusing on improving my endurance: weekly zone 2 training and grinding out >30min WODs. The year ended on a good note as I finally completed Eva RX at 44:04. Earlier in 2025, I've done it with 24kg bell in 40min. Even if I didn't improve in my fitness, it feels like my mental fortitude has gotten better with these grueling long workouts2; I've learned to suffer for longer and under more fatigue.
It's hard to tell if my Zone 2 training is having an actual impact on VO2 max but it certainly feels like I can sustain on med/long-duration WODs better. Running also feels the best it ever has.
Advanced lifter curse
I walked into our box yesterday and saw a "Q1 2026 Goals" board. Someone wanted to hit a 210kg squat. Below were: "3 muscle-ups", "15ft handstand walk" and a "kipping pull-up". Last year I wrote "10 RMU" and "50ft handstand walk". Few years ago I would have written 365lb (2xBW) squat or 185lb (1xBW) shoulder press; now all conquered.
I starred at the board, unsure about my next goal.
I've hit most of the things written on it and much more. It wasn't about feeling superior; I was reminded of how far I've come and how many are still on their way to reach goals that I've conquered long ago.
Do I really need to work towards hitting 15 consecutive RMUs? Or 2x50ft handstand walks, which would be a natural progression. I've hit the point of diminishing returns. Being able to walk over obstacles is a semifinals territory and isn't something I'd ever need in a regular class. To play devil's advocate, hitting strict ring muscle-up isn't something you'd need in a class either! Yet I wanted to be able to do it as a pure form of incredible upper body strength and control.
As I'm nearing 15 years into my fitness journey, all of this feels like an "advanced lifter" curse. When you've reached 90% performance on most things, the remaining 10% start to take a lot more time and the progress slows down to a crawl.
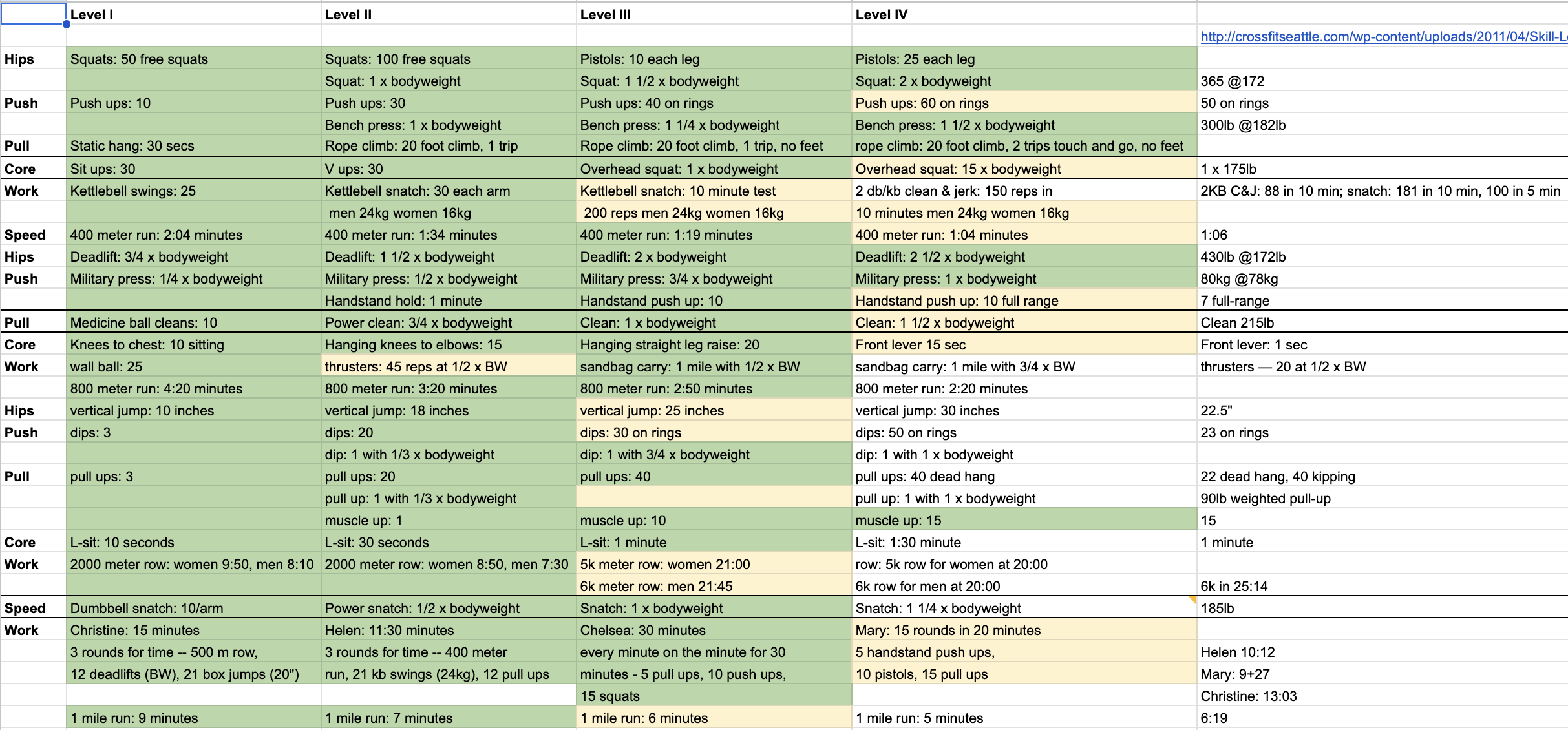
One option is to keep pushing towards Level 3 and 4 on this CrossFit standards sheet I've been using for the last few years. But while most of the Level 3 are achievable with a few month of dedicated practice, I find that many of the Level 4 would take years.
Genetics aside, the reason I hit 2.5xBW deadlift was because I powerlifted for a few years. Similarly, the only way to run 5min mile is to be… a runner. To go from my current 6:30 best (and now, likely, closer to 7:15), I'd need to start running 2-3 times a week, build capacity over a year, slowly improve speed, slowly adopt my body to volume, train the body to go that fast for that "long". You don't just run 5 min mile. You only do that if you're a runner. And so the question then becomes: do I want to put all my eggs in one basket? How would running 2-3 times a week affect my strength, my muscular endurance, my gymnastic proficiency, and other aspects of fitness?
Maintenance and aging
Biological age matters more than chronological one3, but it's hard not to think about turning 40. Relatively, my body has less work capacity than an average 30 yo athlete of the same "level". CrossFit Open also acknowledges it, putting me in a 40-45 bracket. Should the goal this year (and going forward) then just be to maintain existing fitness and avoid major regressions?
I'm already doing that intuitively. I'd make sure to squat heavy at least every other week: I'm way below my all-time-best 365lb but even hitting 300lb right now feels like a good baseline and puts me in the top 5 in the class. I might not be able to do 100 dubs like I did at one point, but comfortably banging out 30-50 goes a long way in any workout.
I realized that reaching a certain goal serves as an overextension that builds a ceiling. Hitting 10 RMU's last year was a nice goal but the ultimate "friend we've made along the way" was the fact that 3-5 started feeling like nothing. To go back to running analogy, training for a 5 min mile would create a baseline where running 7min mile feels like a child's play. I'd just need to keep that baseline by running once or twice weekly.
CrossFit Open
I ended up putting "Open 2026, do better than last year" on the whiteboard. It's a fun short-term goal that would certainly push my engine further, but I'm very much aware that Open can be easily gamed and is just a subset of overall fitness and what CrossFit wants you to achieve. Next two months I'll be focusing on frequent practice of top 5 open movements that are skill-sensitive: dubs, thrusters, muscle-ups, c2b, and rowing. I will also double-down on nausea-like WODs that Open is famous for.
Engine
I think if I were to pick one goal this year, it would be to continue building the engine (= endurance). I've built strength over many years and I've always been good at gymnastics (thanks to yoga since early age). Endurance is still lacking so I need to keep hammering >20 min WODs, more running, more hero ones.
Self-regulation
Earlier last year I did Vipassana and it was pretty life-changing. I've noticed a lot more calm during intense workouts where the feeling of "dying" (zone 4-5) still feels awful but at least it doesn't provoke as much of a panic state as it would before. I'm able to sustain in red for longer.
One of the intentions for this year is to maintain my meditation practice as it helps in both, "life" and when on the training floor.
Although I did finally hit 185lb (1xBW) snatch this year!
Another one I'm particularly proud of was 8 rounds of: 5 RMU, 7 DL (225/155), 5 Toes Through Rings, 7 Double KB Snatches (53/35), 5 HSP which I RX'd in 33:13
Whoop says I'm 4 years younger and Function Health says I'm only 30yo
CrossFit tracking app but… you’re in control? 19 Dec 2025 3:00 PM (6 months ago)
CrossFit tracking app but... you're in control?
As I was working on PRzilla — an app to track WOD scores, fitness skills and standards, I quickly realized that I needed a way to log new sessions without constantly doing a clunky, manual SugarWOD / Strong app export/import.
There was really no way around it — I had to build a "workout tracker" 🙈
The thing about most CrossFit tracking apps — SugarWOD, Wodify, PushPress — is that they're focused around gym programming. This makes sense since community is at a core of CrossFit's methodology. You sign up to the gym, attend classes, and never have to worry about what to work on, the workouts just appear in your app.
On the end of the spectrum there are apps like Strong and Hevy which are geared towards traditional strength training. They're your classic workout trackers for individuals walking into the gym, hitting 3x10 bench press and 3x15 tricep extensions because they saw it in a Men's Health magazine.

I come from the "left", which I did for many years, using Strong app since 2018 (and Fitocracy before that… RIP). Then I started doing more CrossFit-style workouts and I'm now signed up to a box that uses SugarWOD. Couple times a week I join the classes if they look fun or include something I want to work on or… I simply want to workout with friends.
As such, I'm often somewhere in the middle: I want to be able to come to the gym on Monday and log my own workout of, say, 10x3 ring muscle-up practice and 5k row that I do in between RMU's, followed by a WOD like 15min AMRAP of 1,2,3,… shuttle sprints and wall walks. And I want to come to the class on Tue and log whatever SWOD, WOD, and other things they're doing.
Now here's the crazy part — there seems to be a bizarrely large separation between these two camps. PushPress, Wodify, and SugarWOD all make it really hard to log individual movements. You're either doing Fran (and logging your score) or you're shit out of luck. Wodify and PushPress are the most restrictive — you can't even use them without a gym subscription. I get it, their business model revolves around gyms paying fees that depend on number of users. SugarWOD is a bit more relaxed in that you can switch between gyms (as long as you know their invite code).
All 3 support custom logging but it's incredibly limiting and is always tucked away behind multiple menus. This use-case isn't what they're optimizing for.
Here's Wodify help docs showing 5 step (!) process on how to log 2 sets of muscle-ups for the day.
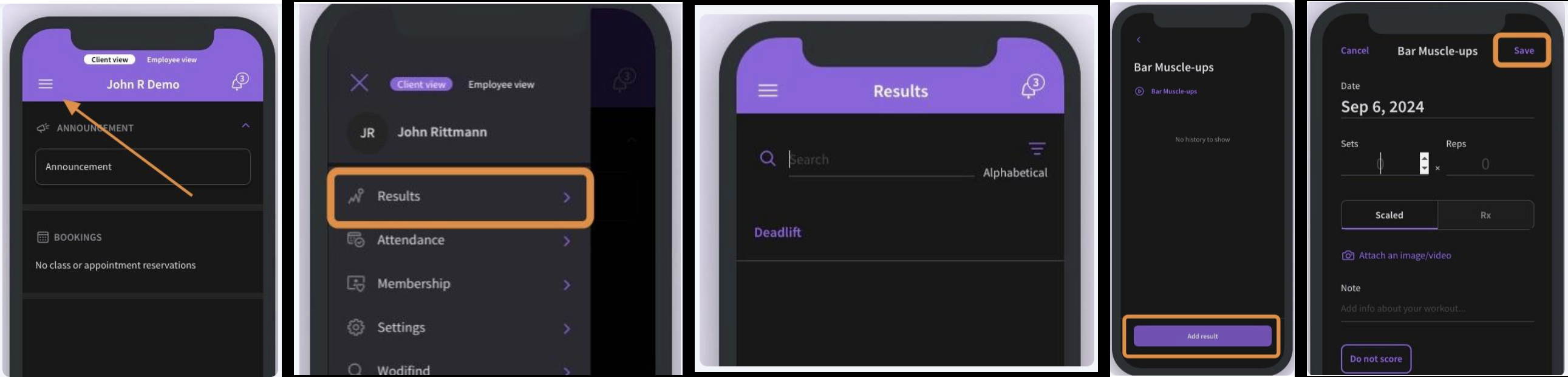
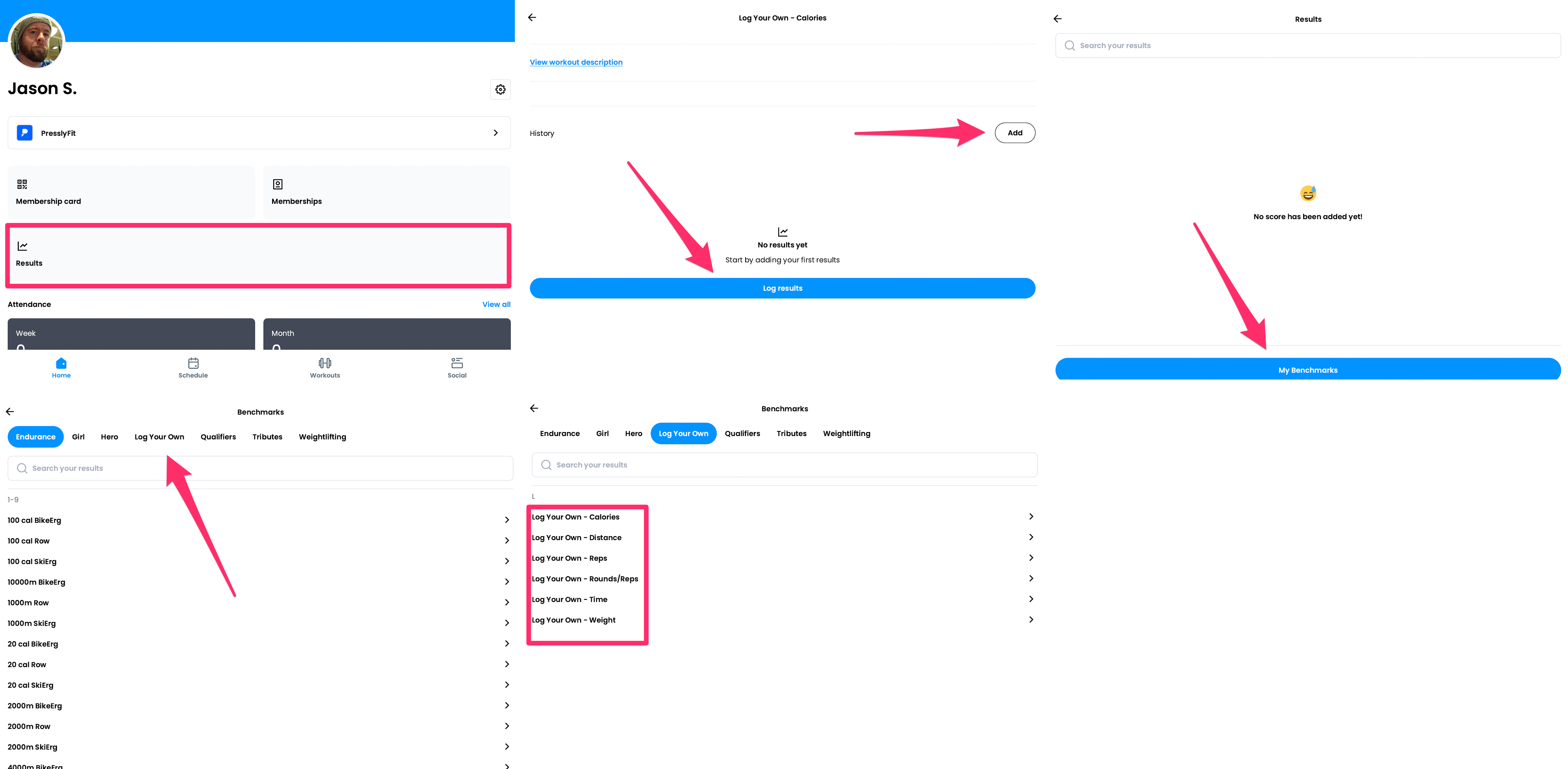
In SugarWOD, you need to click into "More" → "Logbook" → "Log a workout", then chose from a limited list of weightlifting, endurance, or gymnastics. When I say limited, it means you can't even log 10x3 of RMU (it mostly has "max reps" wods).
One exception to the rule is BTWB app that's often considered the golden standard for CrossFit tracking. That's why I put it closer to the middle in my diagram. It allows you to log individual movements as well as any WOD — custom or canonical — and it doesn't lock you into a specific affiliate.
But while its "New workout" starts off nicely with "Single Movement" (this is your classic Hevy/Strong logging) vs. "Multiple Movements" (this is your classic WOD), it quickly transforms into a clunky UI that resembles a cockpit of an airplane, drowning you in a myriad of options that are frustrating to comb through:
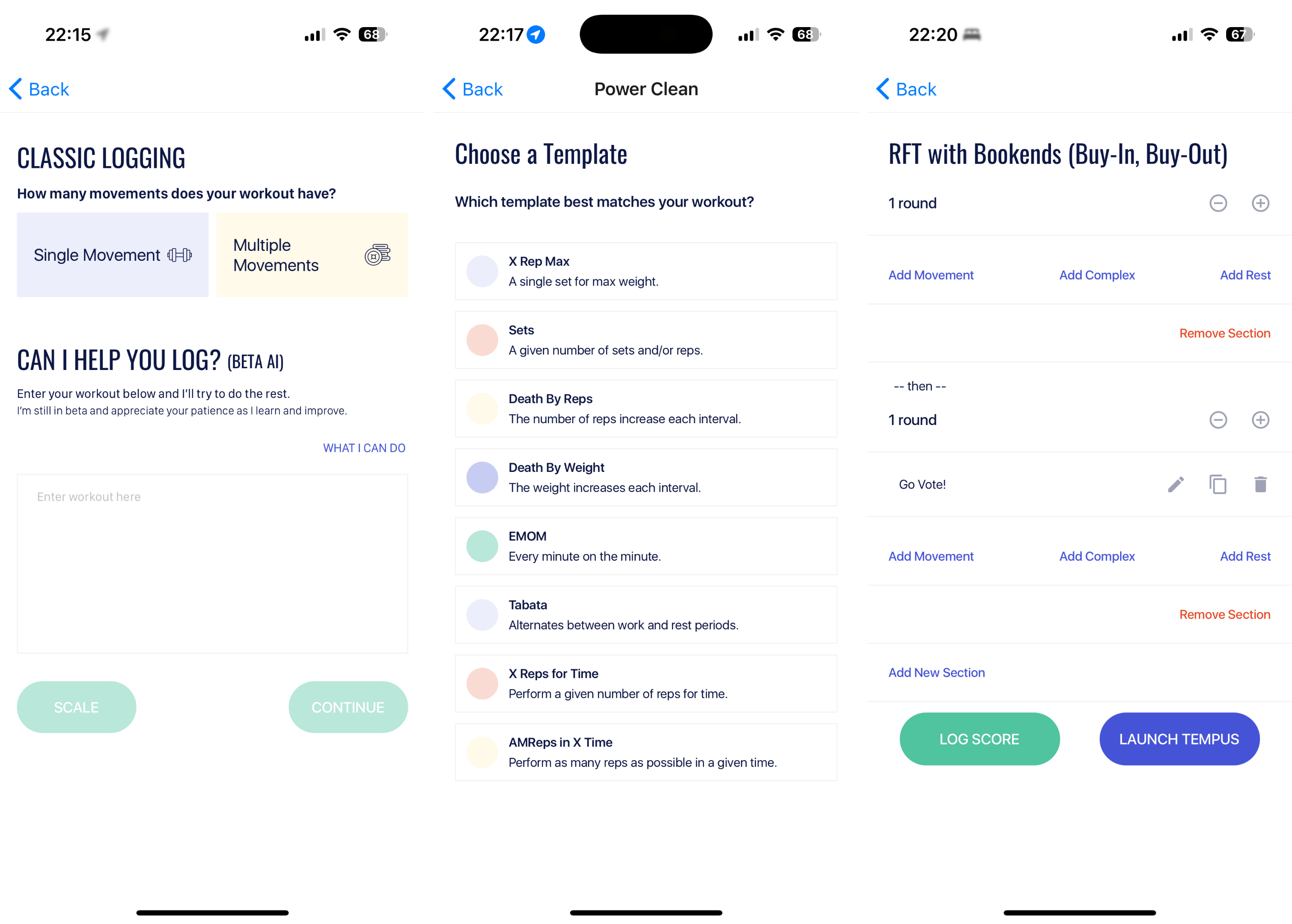
I got to the gym and I have no plan. I decide to start with some light snatches… just give me a quick way to start adding the sets. With Strong, it takes exactly 2 seconds and 3 clicks: "Start an Empty Workout" → "Add Exercises" → Type "Sna" → "Add" and you're all set.
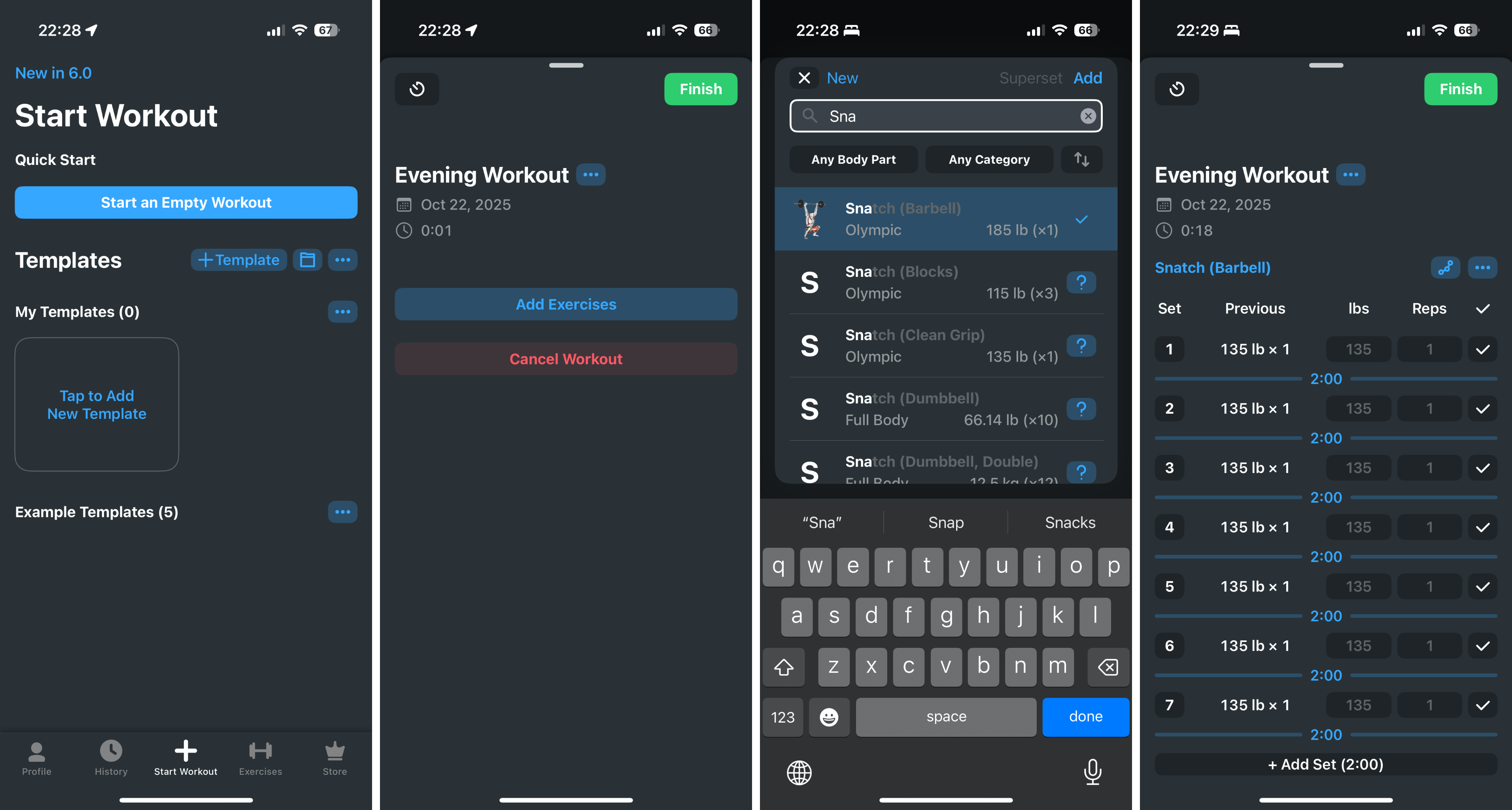
If I want to then make those sets into a WOD, perhaps there should just be a way to do that. And if instead of an individual movement I want to throw in a quick WOD next, after my untimed practice, perhaps there should just be a quick option for that; and this is where I'd chose from AMRAP, For Time, For Load, EMOM, etc.
BTWB is close but is not quite that perfect best-of-both-worlds app.
"But why" and long-term tracking
Wodify docs on how to add custom workouts list some great examples for why you'd even want to log them:

I'll add few more:
What if I'm injured and can't do today's programming?
What if I simply don't like today's programming?
What if I feel kinda off today and just want to get on a bike and do some light cardio?
What if I'm trying to get better at something so I'm substituting today's programming or supplementing it?
What if I completely switch to another affiliate programming because it serves me better?
What if I stopped coming to an affiliate and switched to a home gym? Or moved to another city or country?
BTWB is the best of all evils here, if you can get past their awkward UX. But all the other apps are simply not great options for long-term CrossFit tracking. Most importantly, it's important to be in control of your data: WOD performance and all the individual movement history.
An ideal app should allow to:
Log individual movements aka Strong/Hevy; plain sets-and-reps/time/distance, quick and easy.
Log a score for a canonical WOD (Fran, Murph, Open 21.4, etc.)
Log a score for a custom WOD (whatever you came up with — AMRAP, For Time, For Load, EMOM, etc.)
Subscribe to any box, see their programming, log their WOD's as part of your own data! This is really just 2 or 3 but the WODs (canonical or custom) are provided by the gym.
Bonus points if you can specify exactly how you scaled a WOD so that the data can be analyzed programmatically. Adding "25# db" in notes doesn't count since we can't really measure your progress and your effort!
PRzilla as a hybrid workout tracker
After couple months, I'm now pretty satisfied with the workout tracker in PRzilla. I've been using it exclusively for a few weeks and have gotten to the point where I no longer need to use any other app.
I've learned that building "simple" workout tracker isn't as trivial as I thought 😅 Despite engineering for 20 years I still grossly underestimate complexity of systems. The hardest task was figuring out active/draft vs. completed sessions as well as various constraints: there could only be 1 draft at a time, there could only be 1 workout session per day, etc.
Then there're hidden things like ranking movements in a search list so you get most relevant show up at the top. It's what separates good UX from the great one. I also use supersets almost daily so I came up with a UX to link cards together via drag and drop — something I haven't seen in other apps.
The best part about building your own app is that you control an entire experience and can "easily" implement any features you need. E.g. one idea I have is to show inline insights about workout sessions after you've done them: total volume lifted or distance ran, relative effort (based on your 1RM), milestones ("you've just reached 1000 miles cycled this year" or "this is your 2nd best consecutive ring muscle-up set"), etc. This could be shown every time you log a workout.
I can now also easily create goals and display them as progress bars. Perhaps you're working towards a 300lb bench press: we can show your progress easily. Or maybe you're working on reaching 100 muscle-up sessions this year: we can show that as well.
The things I haven't added that exist in Strong/Hevy that I might consider in the future:
Movement reordering (easy to add but it needs to work well with supersets)
Rest time between sets
Template-like logging; i.e. adding set in UI is not the same as completing it
Stay tuned on the future developments and drop me a note if you're using it and have feedback (or would like to have all of your SugarWOD data imported).
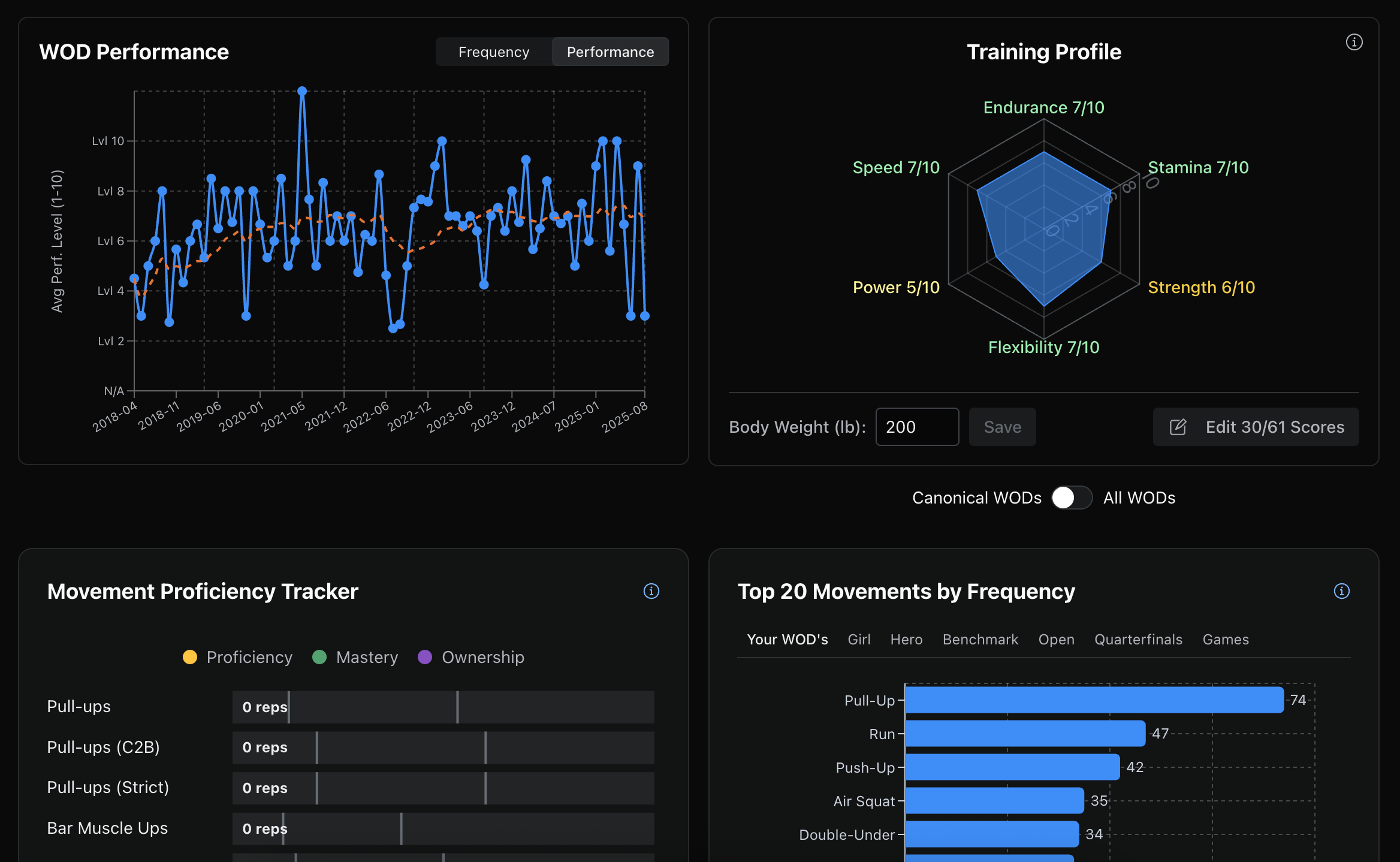
My Fitness: from spreadsheet to an app 3 Oct 2025 4:00 PM (8 months ago)
My Fitness: from spreadsheet to an app
My fitness journey—as is the case with many teenagers—began with bodybuilding. I wanted to look good. Soon after, I found StrongLifts 5x5 and got into powerlifting. It became all about numbers: getting bigger bench, bigger squat, bigger press. Yet, I’ve always been drawn to the notion of Total Athleticism, as coined by Max Shank in one of the articles on T-Nation that I used to read religiously around 20151. Having a 300 bench was cool but I didn’t want to be one of those powerlifters who had massive numbers yet couldn’t run up the stairs. I wanted to also be good at running, calisthenics, kettlebells. Eventually this brought me to “functional fitness” and, of course, CrossFit, which popularized it circa 2000.
CrossFit standards
In my fitness circles, CrossFit was still criticized for its reckless high-skill olympic movements performed at high intensity. Blame the epic fail videos of someone doing something stupid and the ignorance around the methodology. While I was on the offense about doing actual CrossFit, I loved the “variable movements” concept. I found a couple of “crossfit athlete standards” posters online and made this spreadsheet to track my progress across multiple domains. It immediately exposed all my gaps: I could squat 2x bodyweight but my snatch was at a measly 100lb and all the speed and work capacity tests were barely at level 2:
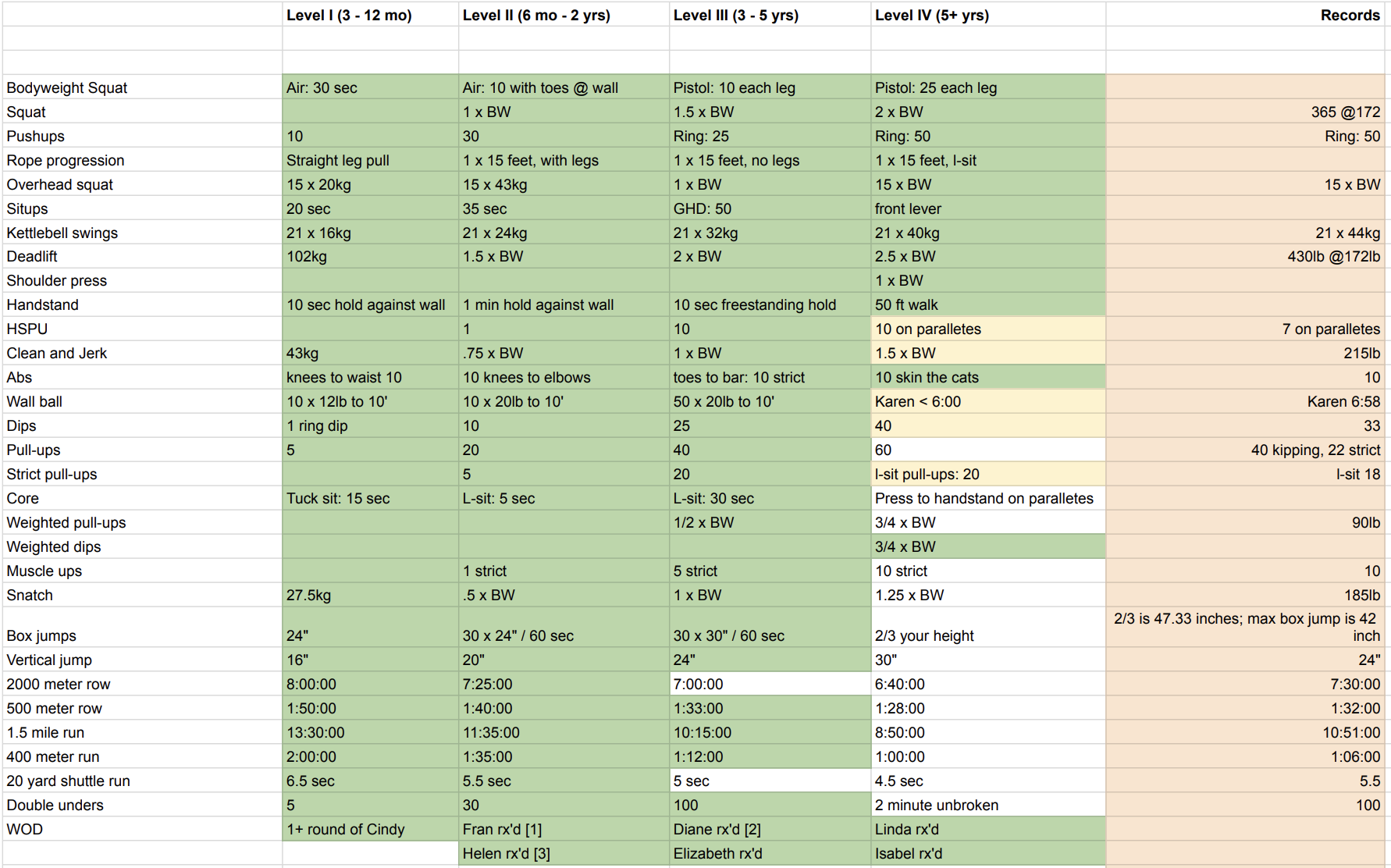
If I wanted to be an all-around developed athlete, these were the things I had to work on. The standards also served as an “objective” benchmark. To consider yourself “advanced” here’s how many pull-ups you had to be able to do; and this is how fast your 1 mile run would have to be. It gave me a concrete goal to work towards. These spreadsheets became my north star for the following few years. For a challenge junky like me, they were a perfect long-term obsession.
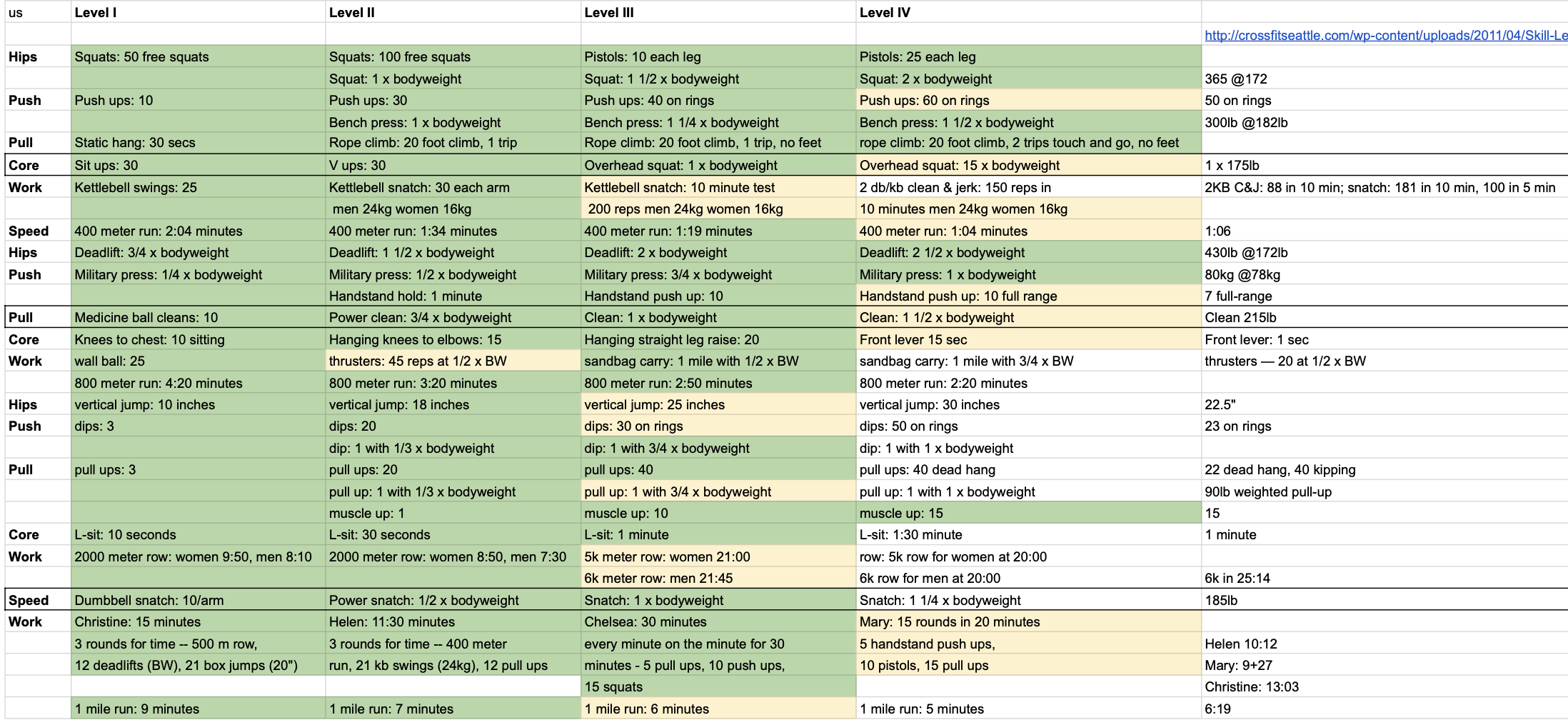
Strength and Skill
The spreadsheet overload was real. This wasn’t the first one I used. As far back as 2011, I found exrx.net Strength Standards and created this view to understand where I stand strength-wise and what to work on:
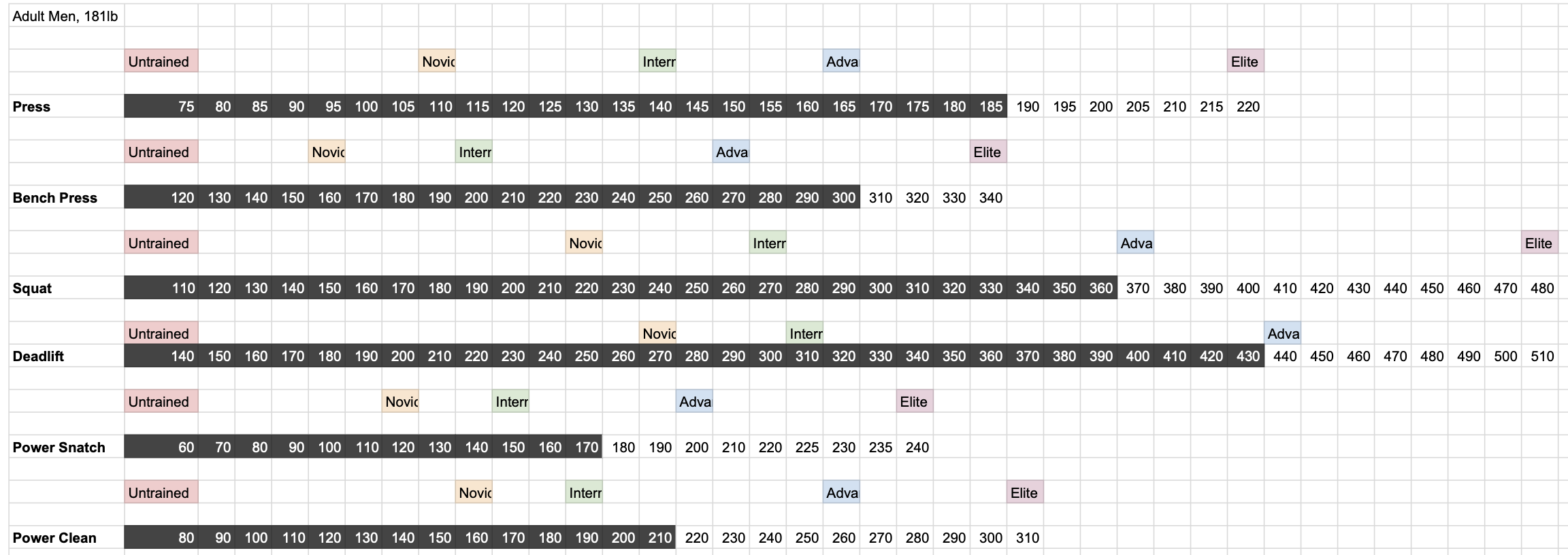
In the last couple years I started tracking my frequency and total-lifetime-session-count of certain movements I wanted to be better at — a concept I wrote about before:
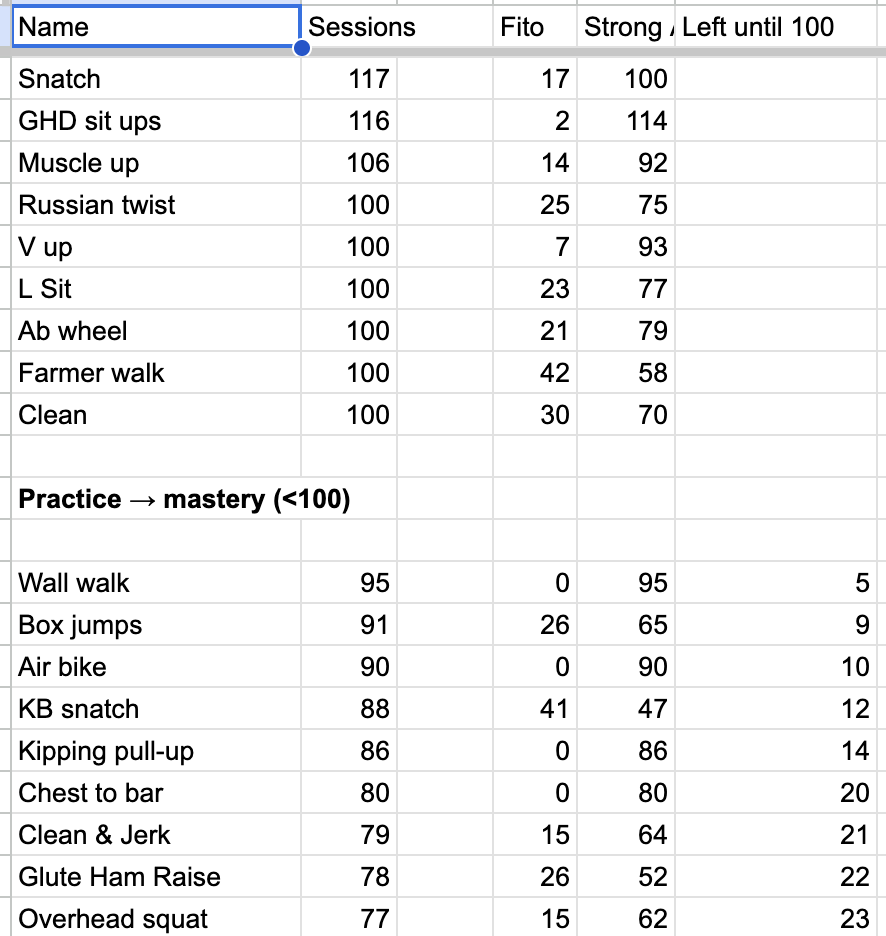
Finally, I tracked my proficiency levels on various CrossFit -specific movements as a way to advance my skill and become fluent in them during WOD’s.
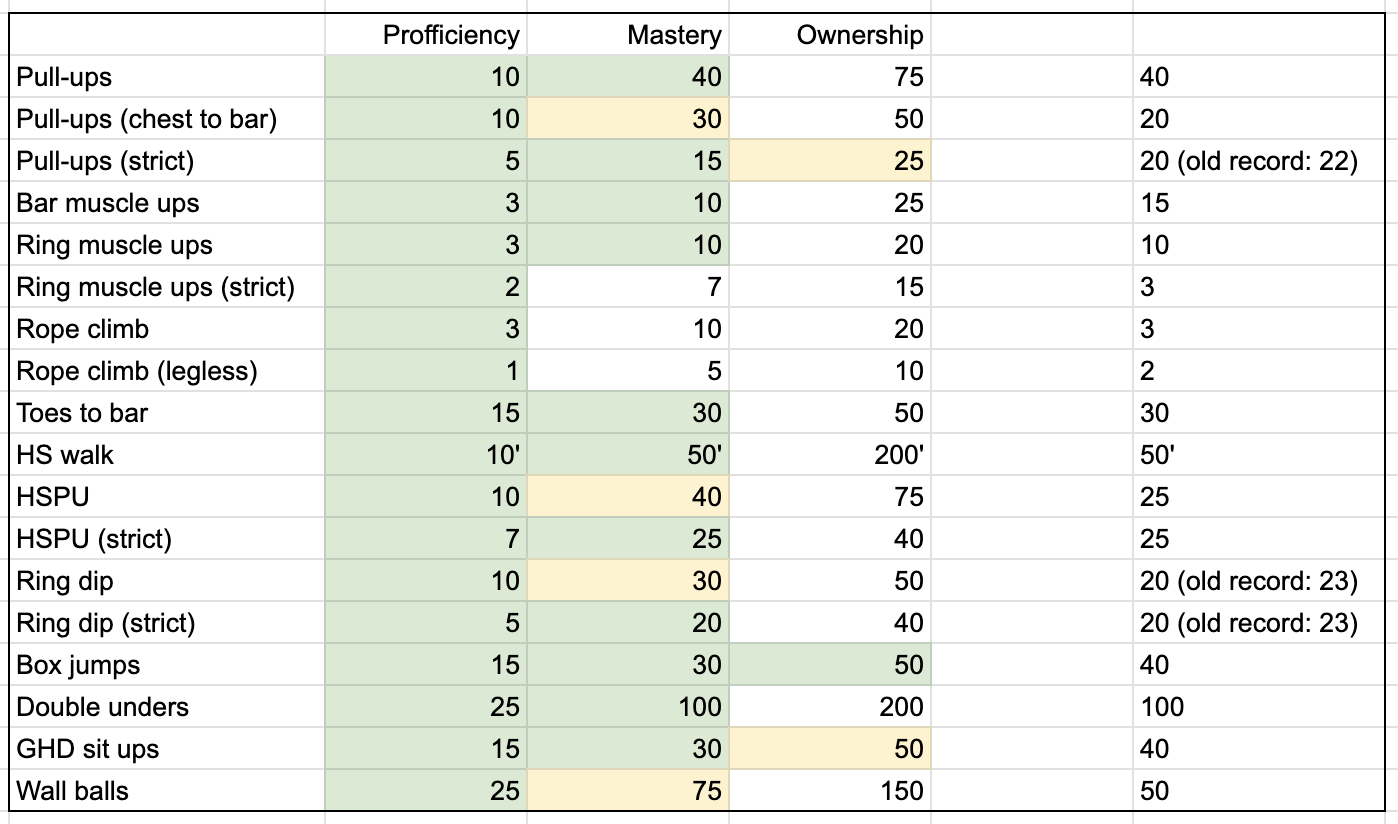
One app to rule them all
The year was 2025.
I was a software engineer.
And I would still manually update a spreadsheet with the number of times I’ve performed a certain movement that I deemed as “needed practice“.
This was embarrassing.
When I embarked on building PRzilla, I realized that perhaps this was the time to ditch manual spreadsheet tracking. I could now build an app that would have all of this backed in:
-
show your fitness level across multiple movement patterns/domains (strength, endurance, gymnastics, work capacity, etc.)
-
show your raw strength benchmarks (squat, deadlift, snatch, push press, etc.)
-
show your skill proficiency as a “lifetime sessions performed”
-
if you’ve done ring muscle-ups only 20 times in your life, you’re unlikely to be better at them vs. someone who has done them 120 times
-
-
show your skill ownership as a “max consecutive reps able to do“
-
being able to do 50 consecutive kipping pull-ups means you own them; this movement is unlikely to be your limiting factor in any WOD that has them
-
Whoop, Apple Fitness, and the rise of quantified fitness
I use Whoop and I absolutely love how it’s able to distill complex/boring HRV/RHR metrics into simple, quantified scores like recovery and strain. Whoop and Apple Fitness—that’s just as big on quantifiable fitness—were a big motivation for this app.
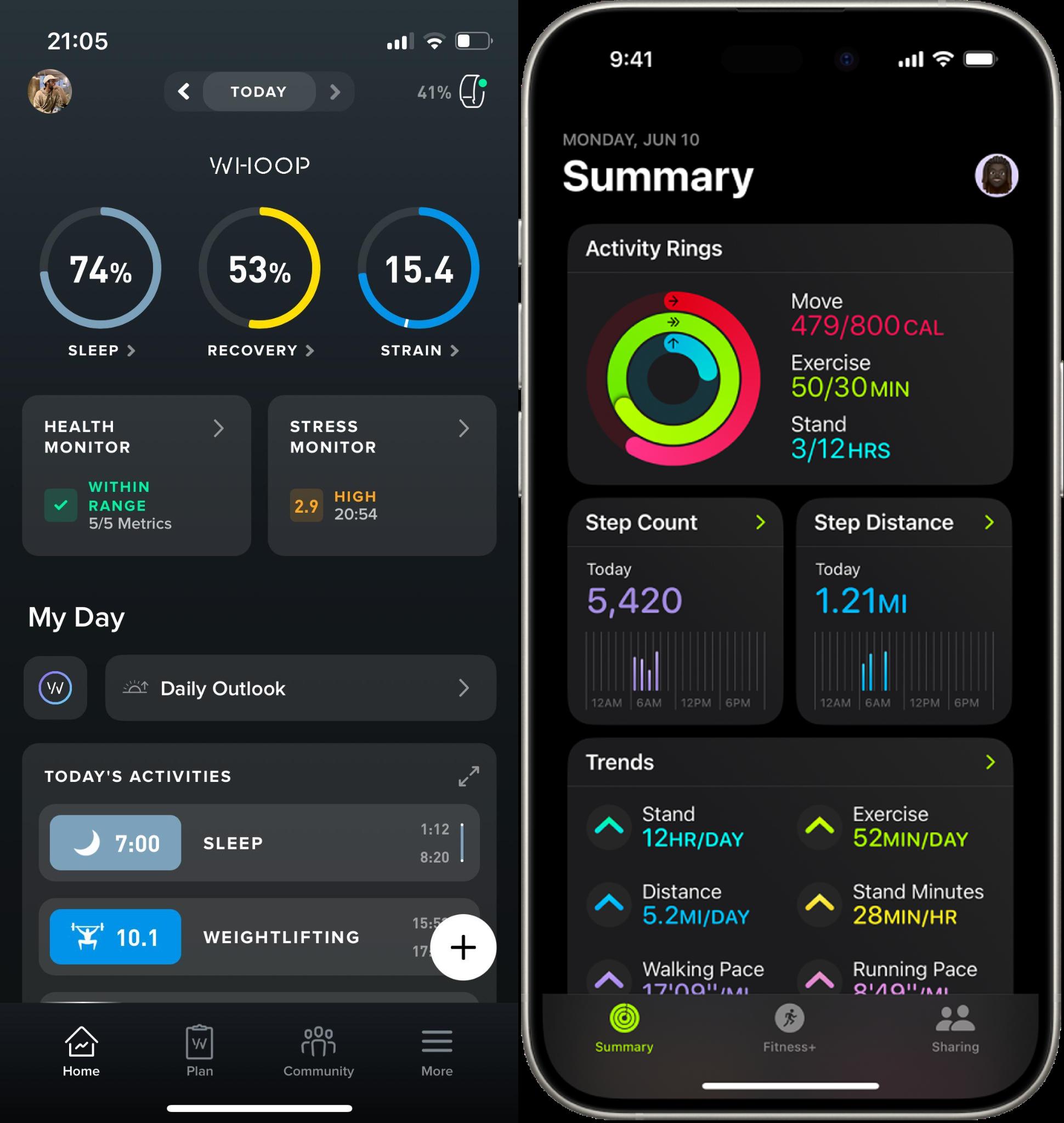
On the other hand there are apps like BTWB which is one of the most extensive Crossfit-style workout tracking tools, but I found its UI unintuitive and UX clunky:
A snapshot of your fitness
And so I turned all my spreadsheets into a simple snapshot consisting of 5 views: your level, balance, strength, ownership, and practice. These could be easily extended in the future with any other modules: time domain distribution, specific goals tracking like work capacity or endurance. Or even sport-specific ones like Hyrox.

SugarWOD parser
In order to turn all my workout data into beautiful charts, I needed to… have that data in the first place. One issue was that it was split between:
-
SugarWOD — scores of WODs prescribed by my box that I did
-
wodwell.com — common WODs that I did on my own
-
Strong app — traditional strength training workouts that are not WODs (aka sets and reps)
Importing wodwell scores was easy since it was just a map of common wod (fran, murph, etc.) to a score. Strong app export would be a lot more involved since I would have to implement sets and reps tracking (as well as workout sessions, potential rest values, and so on). So I decided to focus on SugarWOD import. And this is where the fun began.
Good news: SugarWOD allows easy export of all of you workout history.
Bad news: SugarWOD data is very… unstructured.
Thanks for reading Juriy’s Substack! Subscribe for free to receive new posts and support my work.
Here’s an example of CSV:
09/14/2022,WOD,24 Minute AMRAP:Row 240m12 Lateral Burpees over Back of Rower48 Double Unders24 Alternating Front Foot Elevated Reverse Lunges (53/35)*,3.073,3+73,Rounds + Reps,,"[{""rnds"":3,""reps"":73}]",,SCALED,As you can see, we have an arbitrary, potentially non-descriptive wod title like “WOD” plus gobbled up, plain-text description like “24 Minute AMRAP:Row 240m12 Lateral Burpees over Back of Rower48 Double Unders24 Alternating Front Foot Elevated Reverse Lunges (53/35)*” that’s missing basic formatting / newlines.
As humans, we’re able to quickly parse this into:
24 Minute AMRAP:
Row 240m
12 Lateral Burpees over Back of Rower
48 Double Unders
24 Alternating Front Foot Elevated Reverse Lunges (53/35)*Thank god we live in the age of LLM’s which are capable of reasoning through a messy jammed up text like this just like we—humans—do.
Another peculiarity was load-based entries. In SugarWOD you can program them in a workout and specify sets and reps, e.g. 5 sets of 3 snatches. Users can then log a value for each of the 5 sets. In order to present your performance on the leaderboard, SugarWOD allows coaches to specify how to score those sets — max value (who got the highest weight)? lowest value (who got the fastest row time)? sum of all values (who did the most work overall)? and so on. The export doesn’t expose this scoring criteria so parser needs to infer it based on the sets data. In the example below, we can see that the scoring was using SUM of 12 sets and so 695 is not the weight user did as a 1RM squat snatch; the real squat snatch values are in the sets field:
05/31/2024,WOD,12 ROUNDS:30 Second CAP:3 Toes to Bar2 Lateral Barbell Burpees1 Squat Snatch*REST 1 Minute.*Increase weight as able.,695,695,Load,,"[{""success"":true,""load"":55},{""success"":true,""load"":55},{""success"":true,""load"":55},{""success"":true,""load"":55},{""success"":true,""load"":55},{""success"":true,""load"":55},{""success"":true,""load"":60},{""success"":true,""load"":60},{""success"":true,""load"":60},{""success"":true,""load"":60},{""success"":true,""load"":60},{""success"":true,""load"":65}]",,RX,In this case it’s “obvious” that 695 wasn’t a 1RM snatch (current world record is 496lbs) but some cases are much less obvious so the parser needs to be very careful there.
LLM-powered pipeline
And so after many weeks of experimenting, refining, rewriting, and adjusting based on real data (thanks to amazing volunteers in my gym), I now have a pretty smart and capable pipeline that turns unstructured SugarWOD data into a structured PRzilla data:
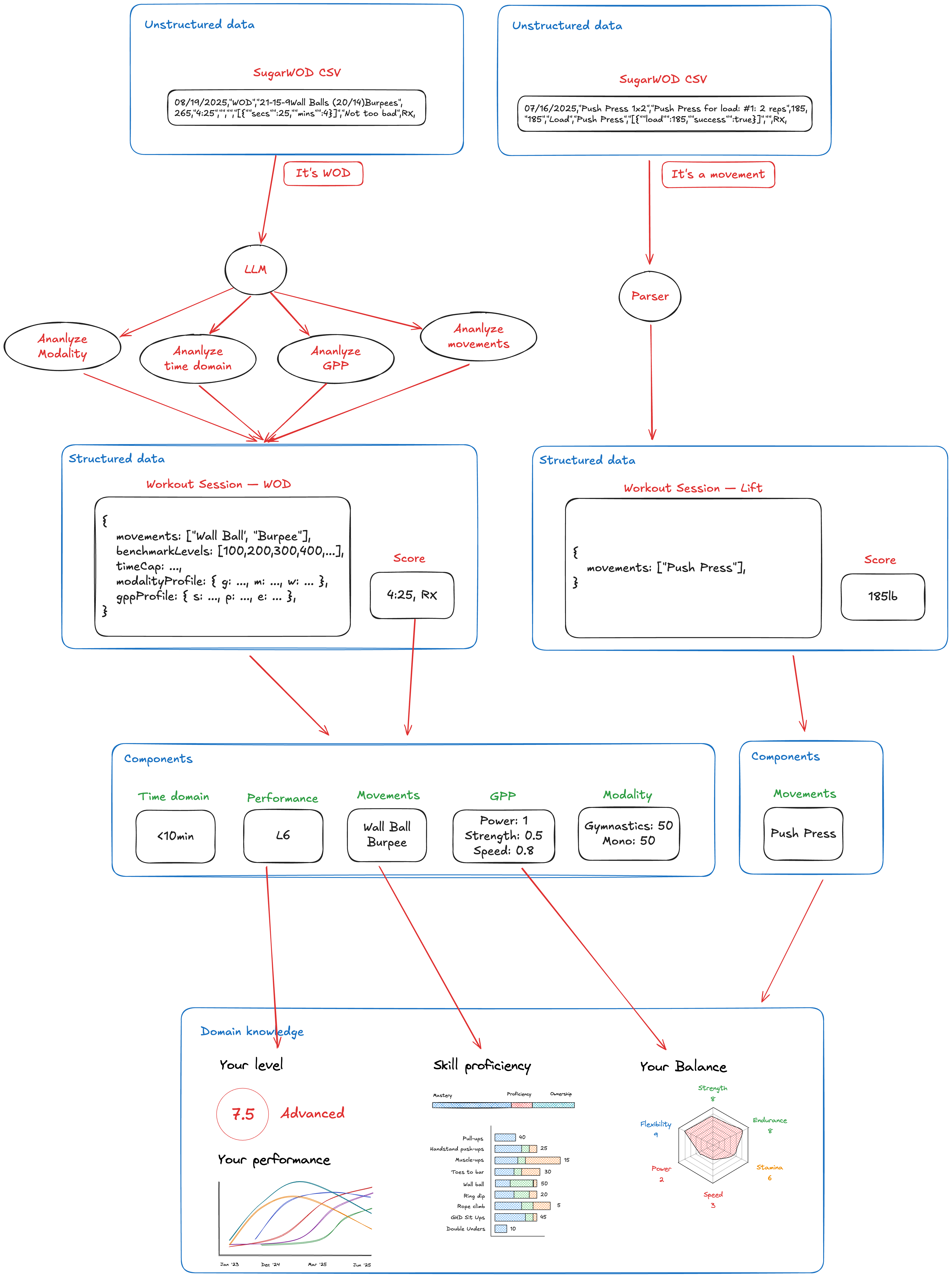
One of the biggest findings—and things that slowed me down—was realizing that a giant, monolithic LLM prompt we used to generate giant JSON with a dozen of different fields (gpp, modality, difficulty, benchmarks, classification, etc.) was taking way too much time, was way too expensive, and often produced errors as it tried to do too many things at once.
Parallelization for the win
I then switched to a series of small, targeted LLM parsers/prompts—as seen on the diagram above—for each of the metrics and ran them in parallel. The results were astonishing: faster and cheaper execution and much more accurate results. This also gave me flexibility to run only specific parsers in specific cases; e.g. when parsing your historic data we want to extract movements (to feed it into our proficiency metrics), performance levels (to understand how your fitness level progressed), time domain (to see a time domain breakdown), and so on. We don’t care about coaching/scaling/stimulus module since the workouts are in the past and users don’t need to know that! However, those modules are important for new workouts, when using analyze or generate.
Finally, it allowed me to run these parsers in parallel which meant that a WOD analysis was now taking time_of_slowest_module (usually ~12-15sec) rather than sequential SUM(module1, module2, …) that would usually take up to 40 sec!
Unstructured to structured
The end result is incredible. We’re able to turn a textual mess like this, into an actual workout and your actual performance. Here we see that 14min AMRAP was properly parsed into movements like “Wall Walk” and “Front Squat”; that it’s an endurance and stamina -heavy workout (yep!), that it’s classified as “Very Hard” and its modality are equally “Gymnastics” and “Weighlifting”. Moreover, AI determined that user’s score of 80 falls right around L3 (which we would likely adjust to L3.5 or L4 due to workout’s difficulty):
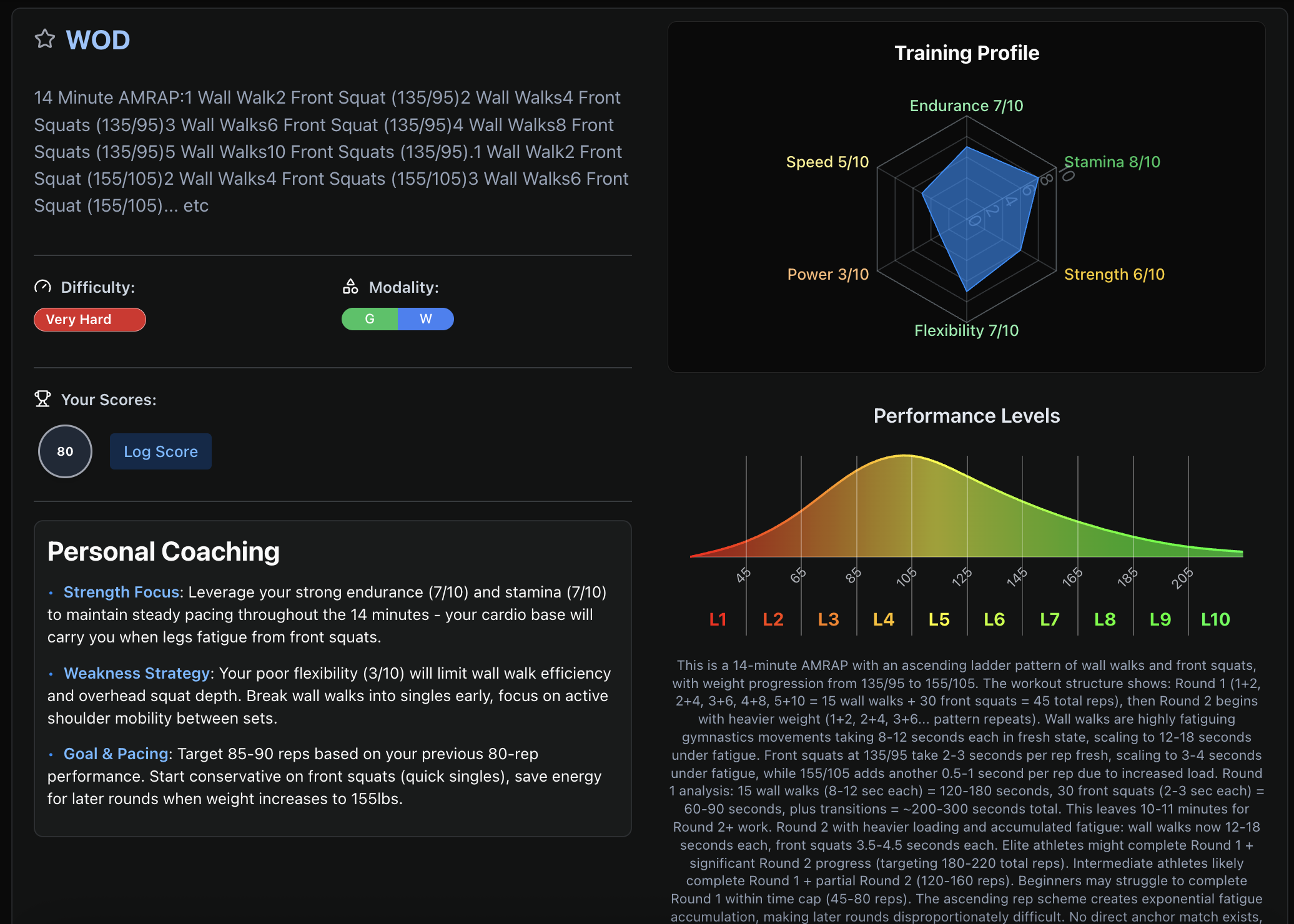
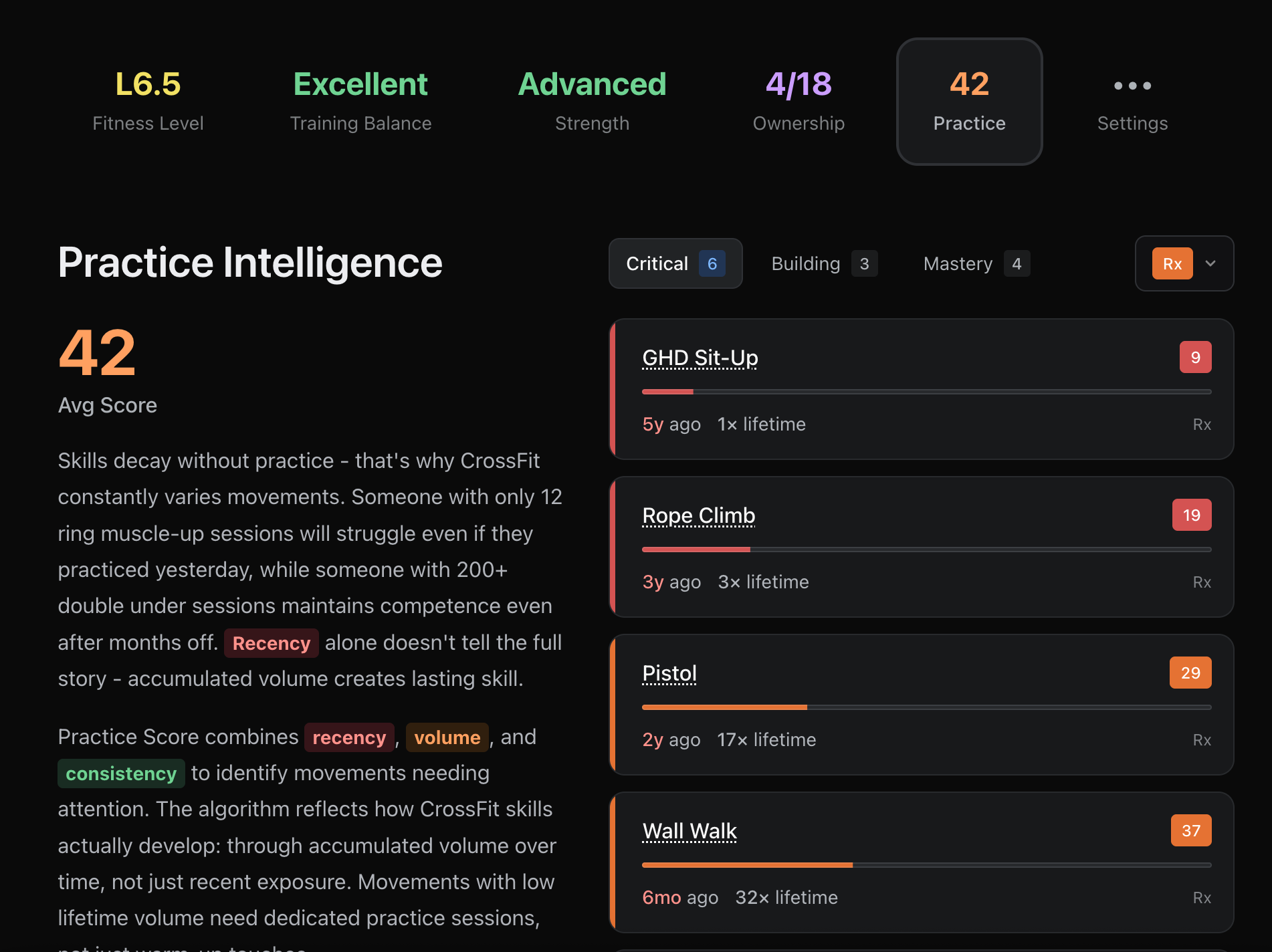
Parsing “Wall Walk” as a movement is what allows us to count that towards your practice score! Notice that we now know that you’ve done “Wall Walk” 32 times in your life with the recent one being 6 months ago.
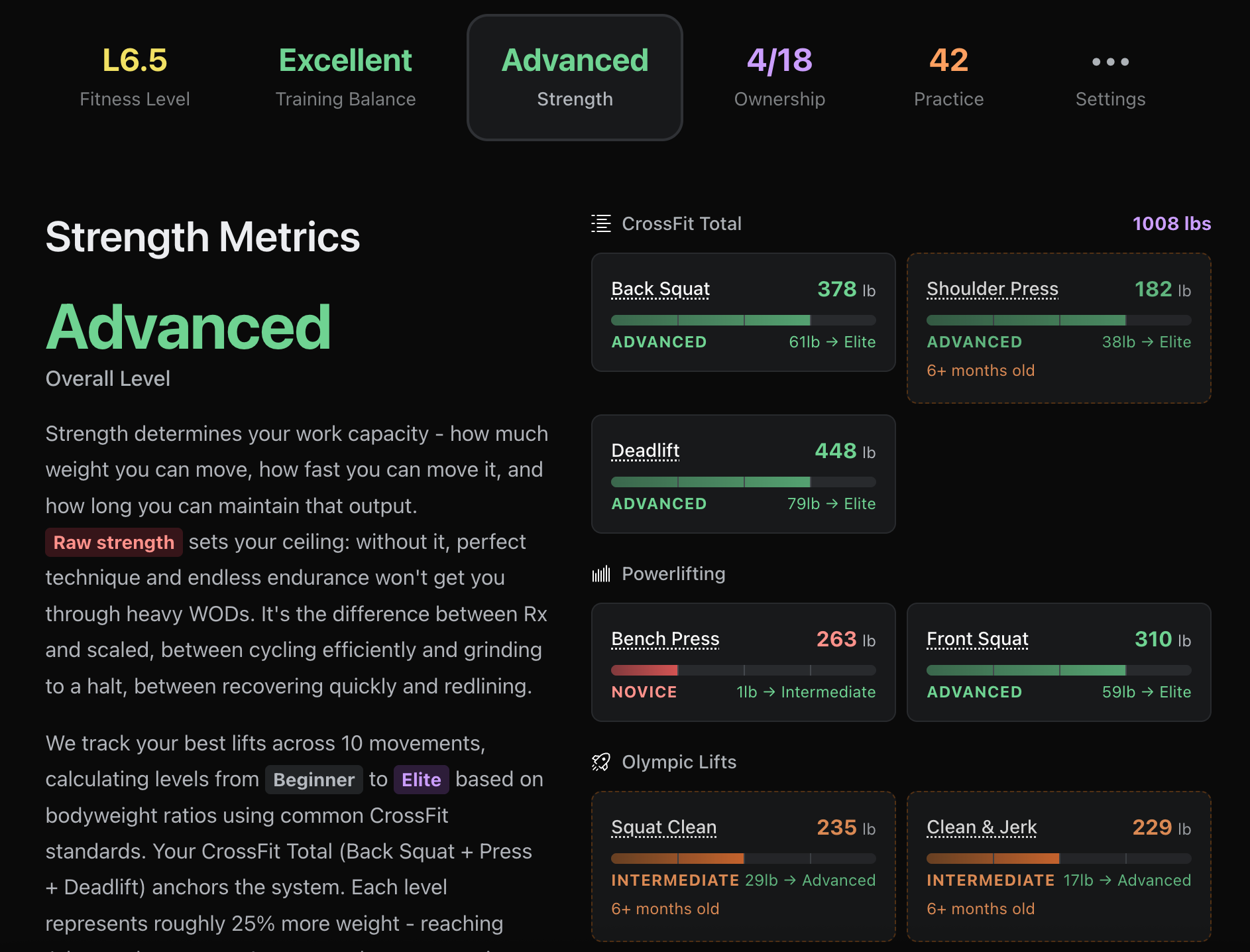
Now that we have this structured data, the possibilities—all of a sudden—are endless. We can easily, and more importantly, automatically show your strength levels: powerlifting, weightlifting, crossfit total:
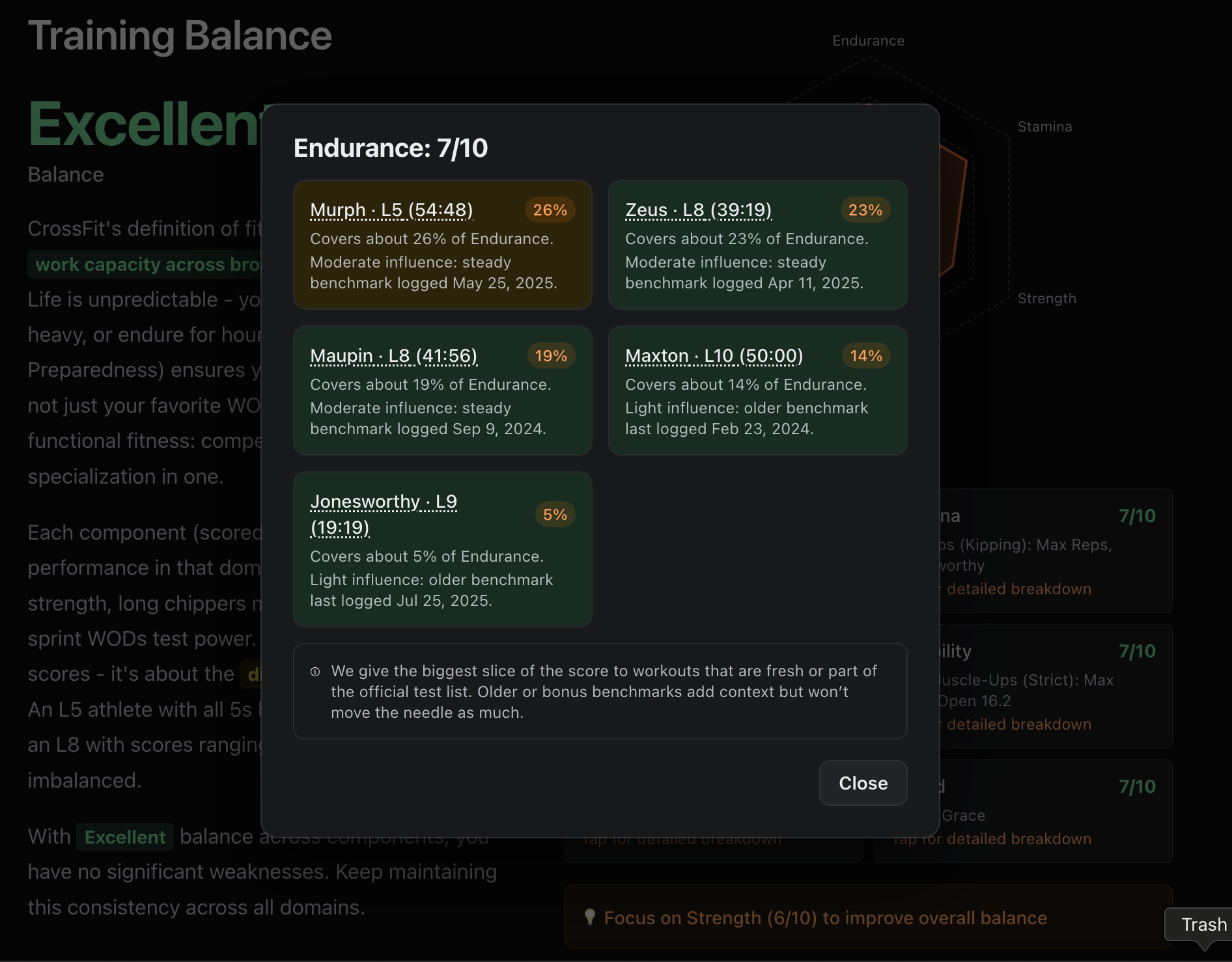
We can derive how good you are at Endurance, Stamina, Power and other GPP components based on your scores on WODs that are high in those:
Because we’ve determined time domain of all the wods you’ve ever done, we can show if you’re leaning towards shorter or longer ones. Yes, parsing 1300 entries is expensive but at least we can marvel at the end result 😅. Here is coach Mike’s real data dating back to 2018. You can see that early years prioritize short WODs (<12min) whereas last couple years the focus has shifted towards longer, HYROX-style ones:
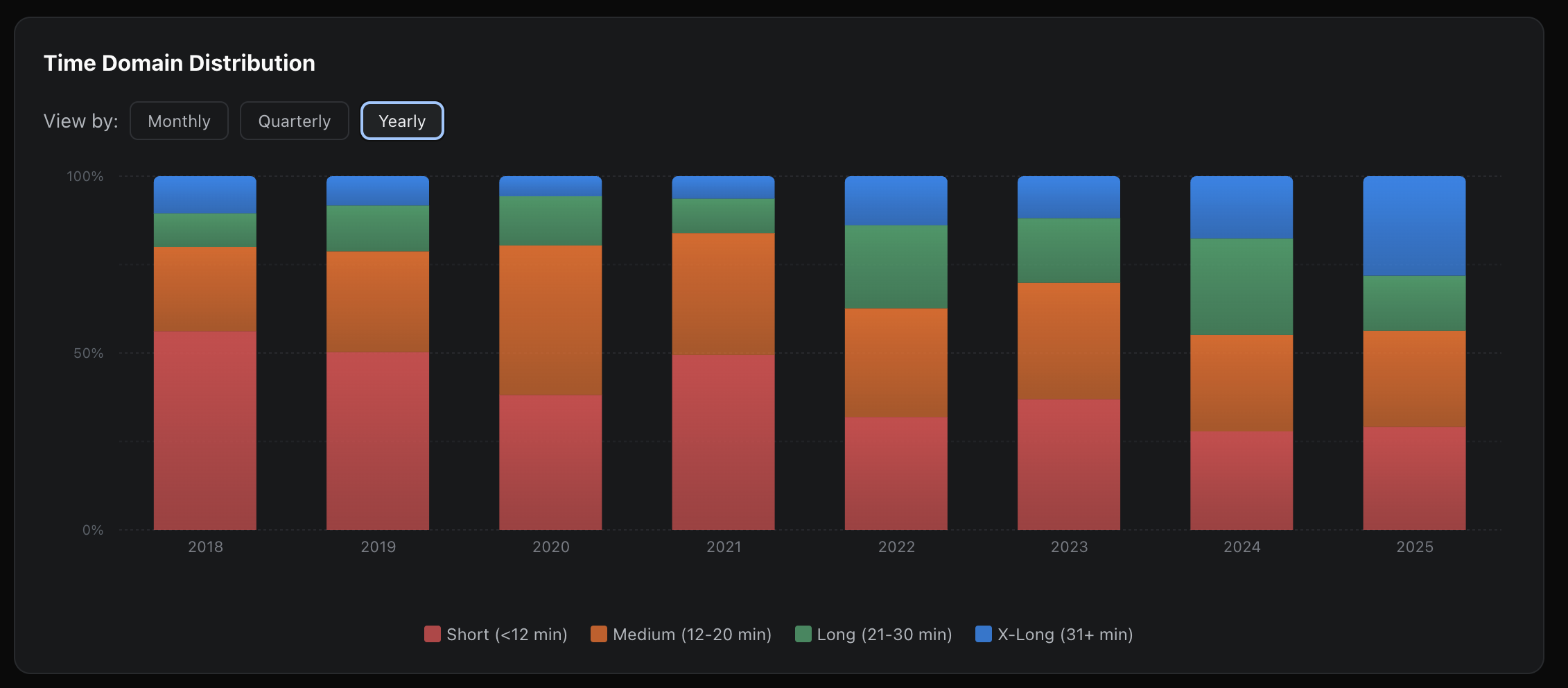
And, of course, we have ability to see all the WODs for any given movement (why it’s so important to parse those for all the custom WODs and create proper associations). Here you can see that Mike has done over 232 lifetime front squat sessions over 8 years, 157 as dedicated lifts and 75 as part of WODs:
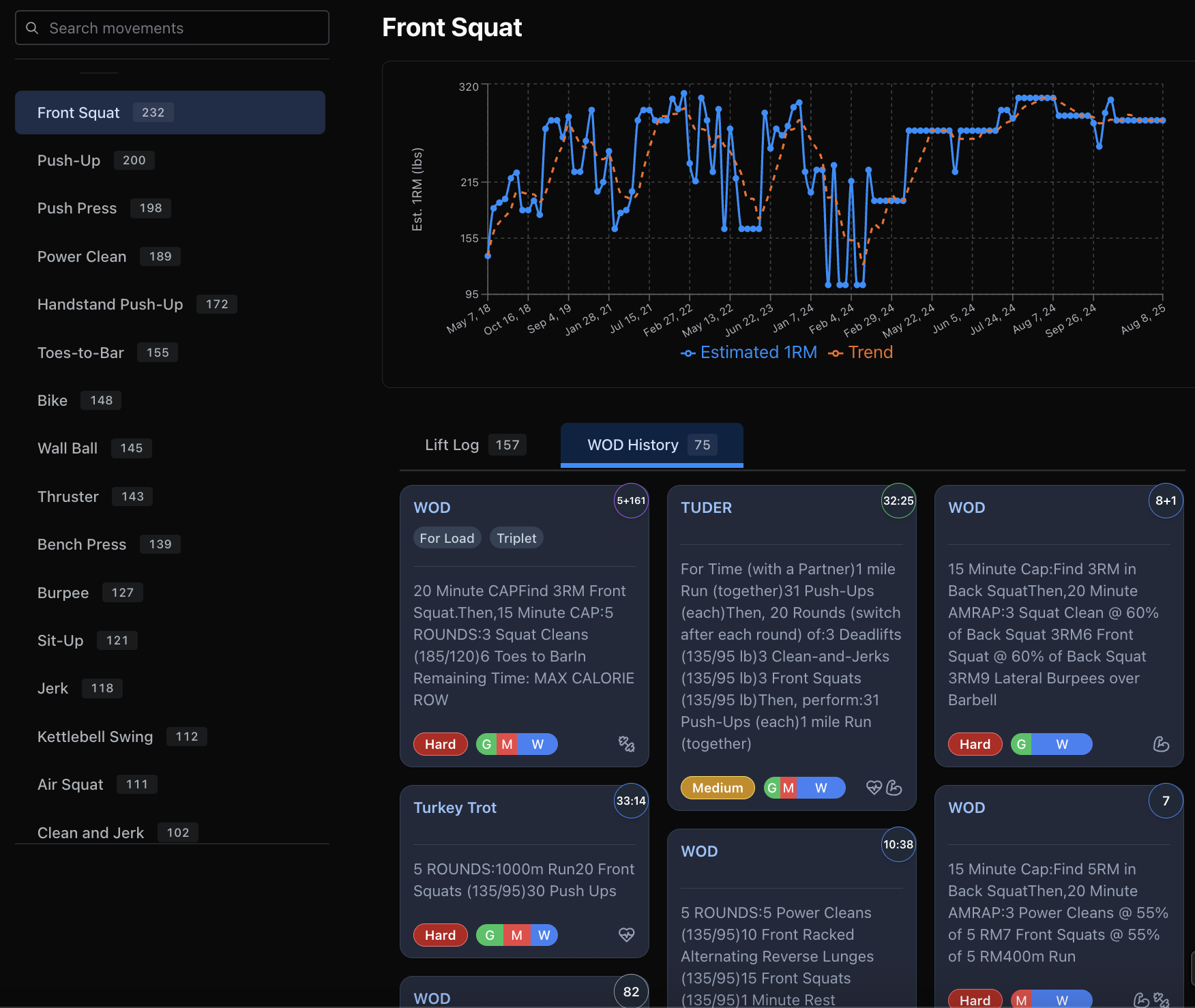
In the interest of brevity, I’ll stop right here. There are other things powering this pipeline which I’m still refining and perhaps can talk about later: male vs. female benchmarks, age-based adjustment of strength and fitness metrics, smart movement aggregation for practice skill screen, logging import errors like movements that don’t match in our DB, or a smart system of retrying LLM when parsers fail.
End goal
Now that I’ve gotten here, I can’t help but wonder: what’s next? and what’s the end goal? I can now replace spreadsheets with this app but it doesn’t solve all of my use cases. The dream would be to have an app that can track all of my workouts. This means:
-
It needs to be a native (mobile) app
-
Web apps are great but when in the gym and on the go—let’s be honest—we all prefer native apps.
-
-
Replace SugarWOD completely?
-
PRzilla is able to do this by parsing previous data but what about future one?
-
I would need to either:
-
Implement SugarWOD API integration that’s tied to a box directly.
-
Implement some sort of image recognition of a WOD (snap a TV in your box) that can then be logged directly into our system.
-
-
-
Allow custom sets and reps logging
-
This is a big one… and it would allow me to switch completely away from Strong app.
-
But first… I’ll need to port Strong app data into our system (perhaps more on that in later posts!)
-
Alex Viada came out with Hybrid Athlete around the same time.
PRzilla: CrossFit AI companion 9 Sep 2025 4:00 PM (9 months ago)
PRzilla: CrossFit AI companion
Why
When I left LinkedIn, I itched to build something in the space dear to my heart — fitness and CrossFit specifically. I also wanted a challenge of building a full-stack app, something I’ve never done before. The app would solve my pain points but I wanted to release it out there for anyone to use. This meant database, auth, users, and production-level user experience. It would be the biggest project I’ve ever done. With the rise of AI-assisted coding, it was a perfect time.
Problem
I’ve been using SugarWOD to track scores for CrossFit workouts (WODs) prescribed by my gym. But SugarWOD was never designed to be a standalone tracker: it’s missing many WODs, those that are there don’t have any info, and it doesn’t have a way to discover new ones. So I supplemented it with wodwell.com to find more workouts and track their scores.
Wodwell has its own issues: full of ads, a clunky UI, and it's slow. More importantly, I wanted to be in control of my data and wodwell has no export. It also wasn’t great that my workout history and performance data was split between two platforms.
What
All of this sounded like a perfect opportunity to build just that: a full-stack app that has an incredibly easy and fast search through a 1000 most popular WODs. It would allow to log scores for any of them, to track your progression over time, and to favorite WODs for later. As I started coding with AI, I quickly realized I could go even further: we could get insights into WODs via AI analysis (time domain, difficulty, L1-10 benchmarks, etc.)
How
Before I set out on this journey I wanted to define few foundational tenets that were non-negotiable.
AI-driven
“Vibe coding” exploded as I was starting this project. My LinkedIn feed was full with “this is incredible” and “this will never work” posts. I came across Addy’s article on Cline and decided to build this app entirely with AI as a matter of principle. No manual coding. It would be a perfect experiment since an app was not just a trivial one-pager vibe-coded in a day.
Mobile-ready
Always a fun UI challenge and is certainly a must these days unless you provide a native app. In context of CrossFit, you often need to look things up or log your scores while in the gym. Every page needed to be responsive and every UI concept needed to be adopted to small and large screens.
Dark mode
Not a terribly complicated constrain and is largely solved by using the right foundational abstractions but it does add cognitive complexity, especially if you’re working with AI, as you need to ensure it complies and uses the right tokens.
Stateful
Often overlooked aspect but it’s what separates a polished, predictable app from a clunky frustrating experience. URL’s are the source of truth. Important UI state change needs to be reflected in them. Now you have the power to reload it, bookmark it, share it, go back, and so on.
Fast
Next.js is known for SSR support out of the box; this means fast server-driven apps. This was a great opportunity for me to learn and experiment with these concepts.
Big lesson I took from introducing these in the beginning: each constrain is a liability, another dimension to your product surface. Be careful with creating too many from the start. Think iPhone and its lack of copy-paste first few years.
A feature alone is a single point or a line (1D).
- Add a "mobile-ready" constraint, and that line now exists on a 2D plane (feature x device). You have to test both states.
- Add "dark mode," and the plane becomes a 3D cube (feature x device x theme).
- Add "SSR-ready," and you're now in a 4D space.
From Zero to SaaS in 150 Days
I’ve now spent about 5 months working on this daily-ish. I learned a ton about AI assisted coding and wrote about most of it. The lessons never stop and I post them weekly on LinkedIn.
What started as a simple way to see most common WODs, quickly turned into a powerful UI that allows to find just the right workout. With the power of AI, I’ve gone deep on classifying workouts to create helpful data that doesn’t exist anywhere else out there — difficulty, modality, training stimulus, time domain, and workout characteristics via tags.
When I ask AI to summarize the complexity 1 of the app now:
PRZilla is a large-scale production web application with 123,000 lines of TypeScript code across 818 files, featuring 19 database tables, ~109 React components in 304 TSX files, and 67 tRPC API procedures. The codebase includes 1,532 test cases with 256 E2E tests across 40 test files ensuring critical user journeys, 58 service modules handling complex business logic including 6 AI-powered features, and manages 922 predefined workouts with sophisticated scoring algorithms. This represents approximately 2-3 years of full-time development effort , comparable in complexity to a mid-sized SaaS product.
It’s incredible to see the kind of power you wield with AI. The breadth and depth of functionality certainly feels like it would have taken me 2-3 years. I haven’t written any of this code and honestly can’t imagine having to ever write code manually again.
Cutting wood by hand is slow. Using an electric saw freehand is fast, but it’s how you get a crooked cut. The real leverage comes when you bolt the saw in place at a precise angle, set the exact speed, and let it execute a perfect cut in a minute.
That is exactly how I build software now. I don’t write code manually. And I don't just hand a task to an AI. Instead, I architect the system, protect it with guardrails so it stays the course, and give it specific instructions so it knows exactly the path to follow.
My role has changed: I am the architect and the guardrail engineer.
The Hard Part is Still the Hard Part
Having spent a good amount of time not only developing new features but also refactoring, redesigning UI, and fixing bugs, I can tell with good confidence: your app will not fall apart. AI is capable of 95%. The remaining 5% are complex cases that usually reside at the edges of larger system integrations OR are just complex in nature. Those would be also complex for human, likely even more so.
For example, I’ve struggled to implement a well-working lazy loading of WOD cards on the main page because there was already a complex state management of various filters that had to all work in unison and support SSR; introducing lazy loading created X^Y^Z level of state management complexity and AI struggled to keep everything together without small bugs popping up here and there.
These are the fundamentally hard issues inherent to engineering. AI offers no magic wand for challenges like:
-
The "dependency hell" of npm packages.
-
The chaos of flaky end-to-end tests.
-
Navigating features with no documentation.
AI also can’t make your app stable if the underlying structure is rotten: fragmented state, logic duplication, complex branches with subtle bugs. But it’s surprisingly good at finding those and fixing them in a heartbeat.
Code != Product
When I look at the app right now I feel like it would have taken me much less time to build the “final” version. Yet, the reality is that development works like this in non-trivial apps:
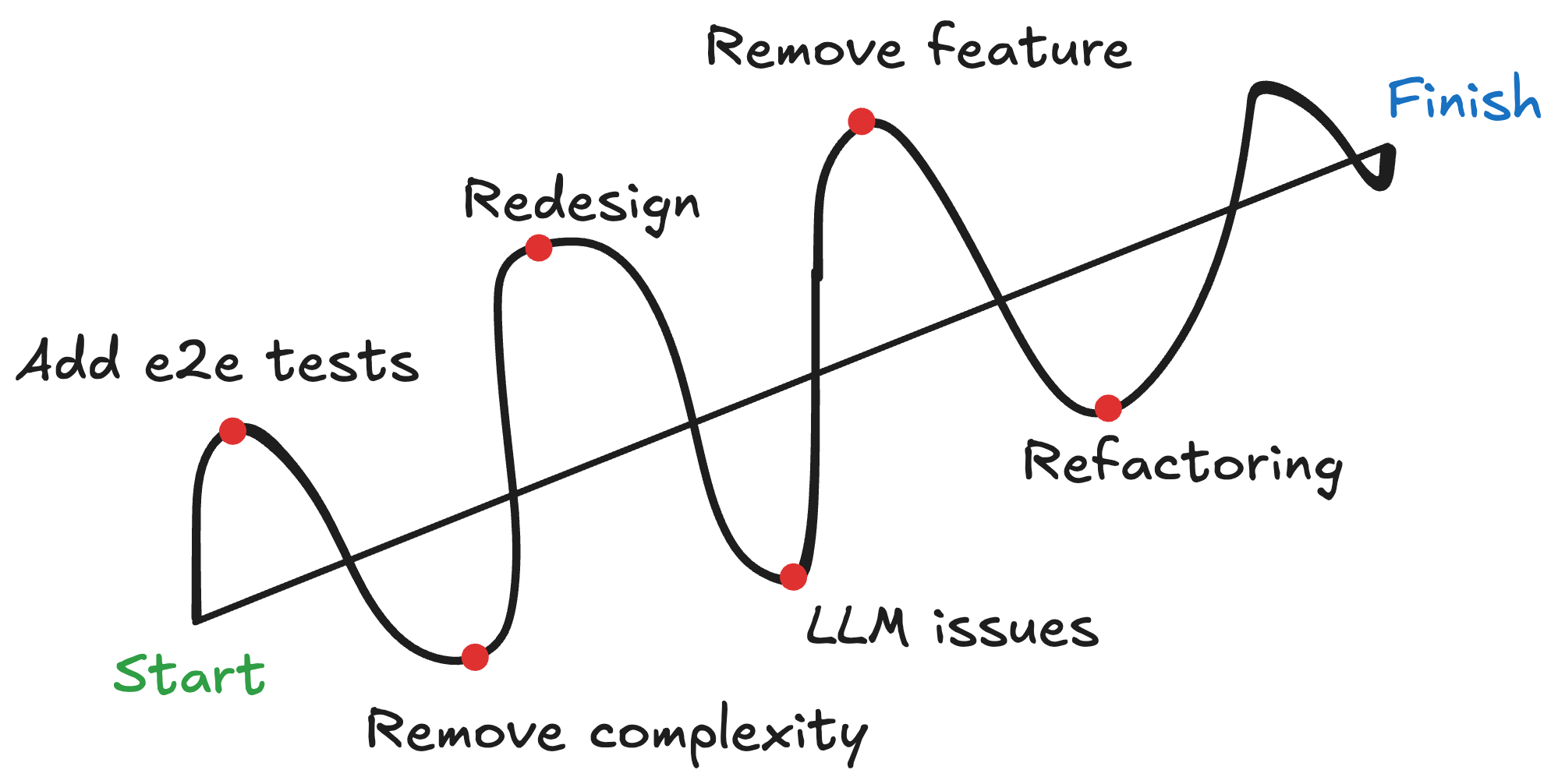
AI allows you to travel that curvy path much faster. Although you have to be careful because without proper guardrails you can start swinging too far left and right: you created too much code, too many experiments, pushed things to prod too fast, all leading to too much liability.
Production-ready
You develop a feature, you have 1 problem.
You decide to release it into production, now you have 10 problems.
Besides the app looking “good” and working “smooth”, the most important production-level aspect is making sure you don’t break things. In the last 10 years I’ve worked at big companies where, despite often being oncall, you always have dedicated SRE help. You also have a well-oiled infra machine to detect errors in prod and notify you.
Thankfully, for small full-stack apps like mine, platforms like PostHog & Sentry are incredible and provide all-in-one solutions for error monitoring (and more) with generous basic tiers.
No broken windows
I followed a pretty standard, tiered approach to release things safely:
-
TypeScript must pass
-
Linter must pass
-
Unit tests must pass
-
E2E tests must pass
-
Test locally to ensure things work
-
Always push to a branch in production (Vercel makes it easy). This is basically your staging environment since it’s hitting production DB.
-
Manually test feature in prod branch, merge into main if it works well. An even safer option would be to introduce feature flags with gradual rollouts but I didn’t want that complexity just yet.
-
Finally, watch out for spikes in errors following the rollout of a commit.
Big takeaway here was not to trust AI with E2E tests. I didn’t pay too much attention to all of the assertions at first, then quickly discovered that bugs weren’t being caught. Turns out quality of E2E assertions was subpar: tests relied only on visibility checks, many used vague assertions or hard‑coded values, and almost none validated data against the database. Tests were slow and flaky due to waitForTimeout calls and text-based or CSS-class selectors. I ended up adding lint rules (via eslint-plugin-playwright) to ensure AI doesn’t break this in the future.
Good design
I struggled with design at first but later found that it’s often a matter of the right prompt. For example, this was prompted to look like Apple Fitness / Whoop in 2025 with Sonnet 4 (which translates to clean, modern and minimal UI with oversized elements):
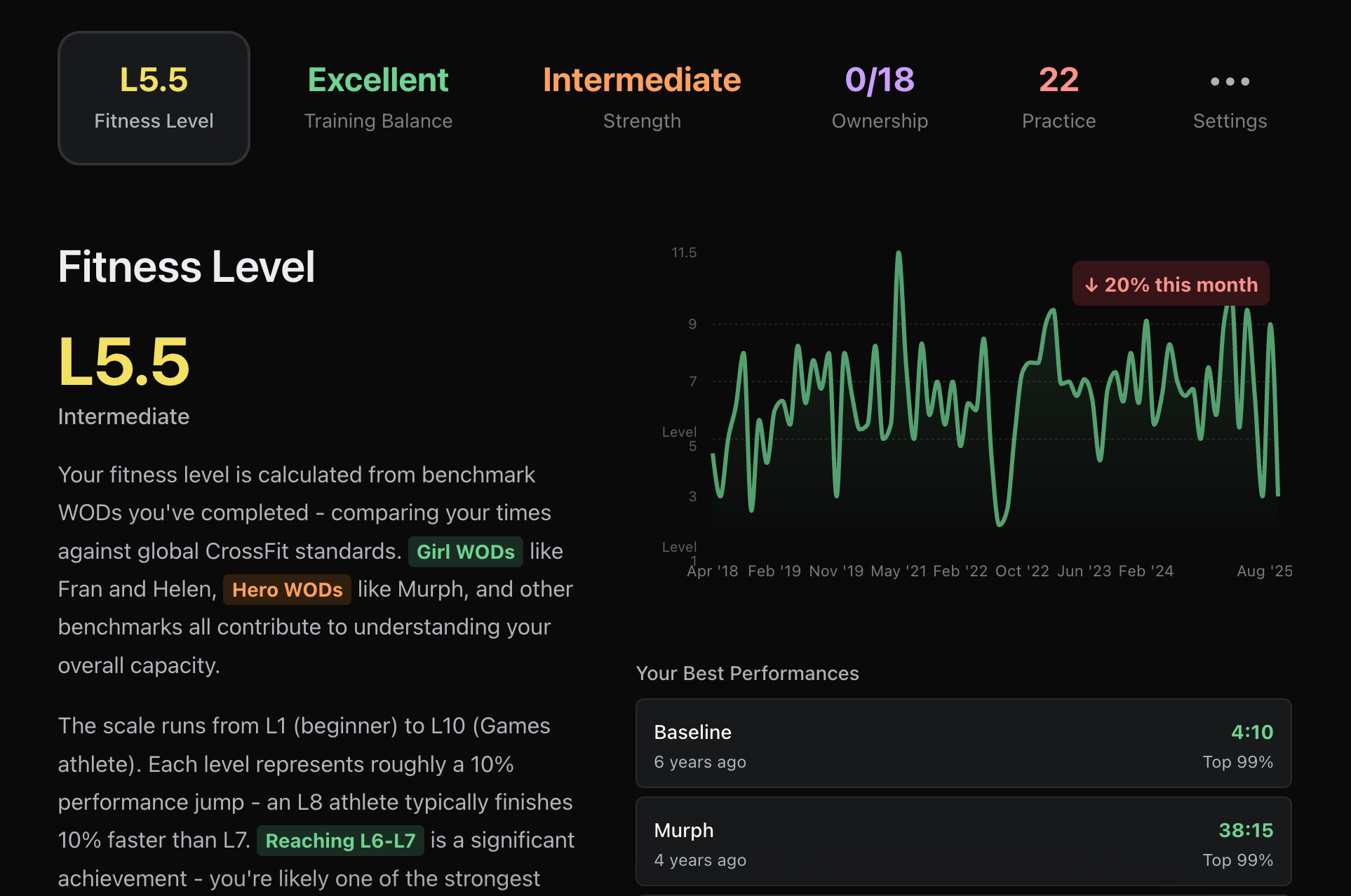
Compare to the old one:
To summarize, I think at least 80% of my time was spent on making things polished: figuring out UI/UX, refining UI/UX… endlessly, testing various permutations of an app, thinking through edge cases, ensuring it’s tested well, ensuring it’s feature-complete yet not over-engineered, documenting it well, deploying it correctly, and so on.
In the next post, I’ll dive deeper into some of the fitness-heavy concepts I’ve implemented in the app. We’ll talk more about that colorful “My Fitness” page and the complex LLM-powered pipeline that powers it!
Code metrics don't tell the whole story, but they do provide a rough idea of this app's scale. Recognizing that AI can introduce bloat, I carefully reviewed and streamlined all committed code. I estimate the result is a lean codebase with no more than 15-20% potential cruft.
The science of Vipassana 6 Jul 2025 4:00 PM (11 months ago)
The science of Vipassana

The Buddhist Framework: From Sensation to Misery
First, the Buddhist terms which come from the chain of Dependent Origination (Paṭiccasamuppāda):
Vedanā (Sensation/Feeling-Tone): This is the raw, unprocessed, pre-cognitive feeling that arises from sensory contact. It's not a complex emotion, just a simple "pleasant," "unpleasant," or "neutral" tag. It's the first flicker of experience.
Taṇhā (Craving/Aversion): This is the immediate, gut-level reaction to vedanā. If the sensation is pleasant, the mind reflexively generates a "want more" signal (craving). If it's unpleasant, it generates a "get rid of it" signal (aversion). This is the pivot point.
Saṅkhāra (Mental Formations/Conditioned Reactions): This is where the reaction deepens and solidifies. It refers to our complex, deeply ingrained habitual patterns of thought, emotion, and behavior that are triggered by craving or aversion. You are correct that they are often negative patterns, as they are reactive and automatic rather than conscious and wise.
Goenka's teaching that "craving begets craving and leads to more and more misery" is a direct description of how this chain becomes a self-perpetuating loop.
The Scientific Explanation: A Reinforcing Neurological Loop
Modern neuroscience reveals that this ancient psychological map corresponds directly to observable brain functions. The entire process can be understood as a powerful, habit-forming reinforcing feedback loop built on three key scientific concepts: Reward-Based Learning, Hebbian Plasticity, and Cortical Hijacking.
Step 1: The Sensation and the Amygdala's Alarm (Vedanā)
When a sensory input arrives, it is immediately tagged with an emotional valence by the primitive parts of the brain.
The Mechanism: Information from your senses makes a rapid first stop at the amygdala, the brain's threat and salience detector. The amygdala instantly tags the sensation: "Pleasant! Pay attention!" or "Unpleasant! Danger!" This happens in milliseconds, long before your conscious, rational brain (the prefrontal cortex) has had time to process it fully. This initial, lightning-fast tag is the biological equivalent of vedanā.
Step 2: The Dopamine Hit or the Cortisol Spike (Taṇhā)
This initial tag immediately triggers a chemical reaction that fuels craving or aversion.
The Mechanism (Craving): If the sensation is tagged "pleasant" (e.g., the taste of sugar, the "like" on social media), the brain's reward system is activated. The ventral tegmental area (VTA) releases the neurotransmitter dopamine into the nucleus accumbens. This dopamine surge doesn't just feel good; it's a powerful signal that says, "That was important! Do it again!" This is the neural basis of taṇhā (craving).
The Mechanism (Aversion): If the sensation is tagged "unpleasant" (e.g., a critical comment, physical pain), the amygdala triggers the release of stress hormones like cortisol and adrenaline. This creates a state of anxiety and vigilance, powerfully motivating you to escape the source of the feeling. This is the neural basis of taṇhā (aversion).
Step 3: Strengthening the Habit Loop (Saṅkhāra)
This is the core of the reinforcing loop. Every time you act on that dopamine-driven craving or that cortisol-driven aversion, you strengthen the neural pathway that produced it. This is a fundamental principle of neuroplasticity called Hebbian Learning, famously summarized as: "Neurons that fire together, wire together."
The Mechanism: When you repeat a behavior in response to a cue (the vedanā), the connection between the sensory neurons, the emotional/reward centers, and the motor centers in the basal ganglia (the brain's habit center) becomes faster, stronger, and more automatic.
The Reinforcing Loop in Action:
Cue: You feel an unpleasant sensation of anxiety (vedanā).
Craving: The brain craves relief from this feeling (taṇhā).
Routine: You habitually pull out your phone and scroll social media. The novelty and intermittent rewards provide small dopamine hits, temporarily overriding the anxiety.
Reward & Reinforcement: The temporary relief reinforces the entire neural circuit. The next time you feel anxious, the urge to grab your phone will be stronger and more immediate.
This is the scientific explanation for "craving begets craving." The very act of satisfying the craving digs the neurological groove of that saṅkhāra deeper, making it the brain's default response.
Step 4: The Misery of a Hijacked Brain
Over time, this reinforcing loop becomes so powerful that the prefrontal cortex (PFC)—the seat of rational thought, long-term planning, and self-control—gets "hijacked." The automatic, reactive pathways from the amygdala and basal ganglia become dominant.
The Mechanism: The brain learns that the quickest way to soothe the discomfort of craving or aversion is to perform the habitual action. This creates a state of "dopamine deficit," where you need more and more of the stimulus just to feel normal. The "misery" Goenka speaks of is the scientific state of being caught in this loop: you are constantly agitated by craving/aversion and compelled to perform actions that provide only fleeting relief, all while your capacity for conscious choice and long-term wellbeing is diminished.
The practice of Vipassana is a direct intervention in this loop. By observing the raw vedanā (the pleasant or unpleasant sensation) with mindful equanimity, you refuse to feed the next link in the chain (taṇhā). You feel the itch but don't scratch it. In neurological terms, you are activating your prefrontal cortex to consciously inhibit the automatic, reactive firing of the amygdala and basal ganglia. By repeatedly doing this, you weaken the old, reactive neural pathways and, through the same principle of neuroplasticity, begin to build a new, wiser pathway of non-reaction.
Vipassana through the modern lens 28 Jun 2025 4:00 PM (12 months ago)
Vipassana through the modern lens
I first heard about Vipassana few years ago. Also known as "10 day silent meditation", it seemed like an extreme challenge for highly spiritual people detached from the regular joys (and miseries) of life. So… not for me.
Recently, a close friend has gone through one and highly recommended it. Blame middle-life crisis, but this time I decided to give it a try. "It could be a cool new challenge", I thought. "How hard could 10 days of 'no talking' be"?
Little did I know how far off my understanding of Vipassana was and how impactful the experience would become.
Why
So why do this? I've recently gone through a major life change — "quitting" my software engineer career of almost 20 years, not really wanting to go back to work for another company, searching for a deeper meaning other than making money and climbing the career ladder, and wanting to apply myself to something more purposeful and meaningful in life (= not involving helping billion-dollar company meet earnings expectations at all costs).
Perhaps related or in parallel to that, I started noticing myself living in the past a bit too much. Thinking about how nice things were "back then", not really having anything to look forward to. I wasn't enjoying life with the same intensity I once had. My brain was getting "solidified" and wired to existing connections; I needed to shake things up deep and from the bottom up. "Grumpy old man" had to go.
Talking to squirrels
I got to the center in Delaware and learned that my next 10 days will be in the form of:
Wake up at 4am
Meditate for 6 full hours throughout the day (up to 16 if you so desire!)
Spend the other 11 hours walking and thinking (no talking, no reading, no writing, no exercise)
Sleep at 9pm
Fantastic… And so 10 days began.
During my time there I often wondered what surrounding neighbors think: a couple dozen people pacing back and forth through the park in the middle of the complex, sometimes standing still and starring into the horizon, sometimes talking to squirrels, sometimes sitting on the bench for so long — with *gasp* no phones in hand — that it would certainly be classified as "cuckoo" in the "real world".
(mental ↔ physical) training
Despite expecting some level of spirituality, I found almost none during the daily practice and discourses. Instead, it felt like we were part of an intensive training bootcamp but instead of physical exercises we were training our minds to be still, to not react, and to observe our deep body sensations. That's it!
As a fitness aficionado, this really appealed to me. It was pure work and pure science. Meditation and sensory observation was something you could progress as you would with neuromuscular adaptations, "flexing" daily to become better, and it having tangible positive effect on your well being.
I realized that as much as we need physical movement, we need mental stillness.
Move your DNA postulated that we're a function of our daily movements and daily behaviors in general. Since I read it, I started paying a lot more attention to how I move: using my left and right limbs equally, noticing tiny but deeply ingrained patterns that I could disrupt. This gave me a deeper awareness of my body. The more crude awareness came from years in the fitness realm — yoga, bodybuilding, powerlifting, martial arts, calisthenics, and CrossFit.
Yet, all of those were body awareness in motion; I lacked body awareness in stillness!
Stillness was so mentally hard for me that I had to always stuff my brain with other activities — working out, working, creating, consuming, partying — anything but the state of just being.
Thankfully, the one thing I could do was breathing well — this was the start of each meditation session and a way to get to a deeper state of interoception. I read Breathe few years ago and it forever changed my perspective on breathing. Then, Oxygen Advantage highlighted the importance of carbon dioxide tolerance and counter-intuitive shallow breathing. I've been regularly practicing breath work ever since, for calming effect and for performance enhancement.
Could it be that this interest in subtler bodily functions was perhaps my search for something else… and that's when meditation came along?
Coming home
Few days in, the thought came and sent shivers down my spine: "This is it. This boiski is coming home."
My meditation journey actually started back in 1998 and is closely connected to yoga practice that my grandma taught in Ukraine when I was just 13 years old. Grandma became somewhat of a celebrity among yogis in the post-USSR area, going from a sick math teacher at 60 years old to an incredible yoga teacher with seminars and thousands of students across the world.

Back then, I practiced yoga daily and quite seriously. I recall getting into deeper meditative states after an intense 90 min ashtanga. Teachers often talked about "Тонкий план" (astral plane in yogi lore) as something you can feel in or around your body but — being a skeptical teenager — I didn't think much of it.

As a fantasy and DnD geek, I was also fascinated with monks and how they would train their bodies and minds to exhibit unheard of feats of strength and resistance.
Then I had to stop because my first girlfriend thought I was getting a little too removed from the real world (to be fair, a 13 year old should probably live through a full range of standard earthly emotions during that age and not get too zen about life :D).

Here I was, in Delaware, 27 years later, practicing that same technique, having similar feelings in a weird circular fashion as life often appears to be.
"But 10 days is so long!"
People say day 3 and 7th are the hardest. I found that every single day was equally hard (including 10th one).
As I was there, 10 days certainly felt way too long and unnecessary. But on day 7 I got a profound realization and thought: "oh so that's why we're still here". Then same thing happened on day 9. And even on day 10. More days means you have more chances to experience wider range of emotions stemming from different thoughts and circumstances around you, either in the now — weather, food — or in a "non-existent" mind realm (past or future).
Benefits
The intended benefit of Vipassana is to learn the technique (1st-4th days), deepen it (4th-9th days), apply it in human interactions (day 10) and then take it with you to the real world via a daily practice.
The actual bouquet of benefits is much more multi-faceted. You can take advantage of each layer below individually, but together they create a powerful punch through your psyche:
Break from devices.
In the modern world of social media, severing dopamine loop is extremely impactful (see Dopamine Nation, Dopamine Detox, etc.)Break from civilization and daily stress.
I noticed that without big city noise there's a lot less anxiety. The startle reflex begets subtle bodily tension that we then carry throughout the day.Undisrupted time to process thoughts.
We rarely have dedicated time to think these days. 10-15min in a shower (look at the insights during r/showerthoughts) and perhaps a weekly 45min therapy session is all you get. Here you have hours upon hours to just think.Entering meditative state that eliminates mind chatter.
As active Beta waves diminish, they are replaced by the calmer and slower Alpha and Theta brainwaves. These are linked to creativity, enhanced learning and memory consolidation.Sensory practice during meditation.
This is the real meat of this whole experience. Who would have thought that Buddha was onto something 2500 years ago:Autonomic Nervous System Regulation: The focused attention on breath and bodily sensations sends signals to the brain that the body is safe, leading to a decrease in heart rate, blood pressure, and the production of stress hormones like cortisol.
Reduced Amygdala Reactivity: By repeatedly and non-judgmentally observing sensations in Vipassana, the practitioner learns to decouple sensory experience from habitual emotional reactions, calming the amygdala's alarm system.
Increased Interoception and Insula Activity: We're now learning that interoception has a host of health benefits such as drastic improvements in anxiety disorders.
Surrender
For me, Vipassana was also a challenge on other levels:
First time no exercise for 10 days (in my 15 years of being obsessed with training)
First time eating vegan food for 10 days (unheard of for this "foodie")
No supplements, no tracking your daily steps, no closing activity rings, no checking recovery score, no fasting timers, none of the other virtual shackles I'd always worry about.
Just pure existence disconnected from the rest of the world. This was the ultimate surrender and trust in the process. My ego fought this with such vengeance, it felt hard, dumb, scary, annoying, counter-productive, unnecessary, and yet… it just had to happen. I came out happier, more present, more driven by the process rather than the goal.
Science
In 2018, I went through a stage of binging on behavioral psychology books — Thinking, Fast and Slow, Predictably Irrational, Nudge, etc. As I was listening to Goenka talk about cycles of craving and aversion and how one begets an ever-increasing loop of misery, I couldn't help but think about all the science we know that explains the same things. The dopamine-driven reward mechanism was a great example of a reinforcing loop from Thinking In Systems and body scanning reminded me of Huberman's NSDR (aka yoga nidra) that I've already been using for short rests.
I did a deep dive into the science of Vipassana teachings and wrote a separate post about it! It's fascinating how we now have scientific backing for the entire thing.
Critique
My main critique is that there was 0 focus on movement. Walking is allowed but not encouraged. I had to stretch all the time and foam roll myself between sittings just to be able to rotate my torso. It was brutal.
I get that you're not supposed to do anything else besides meditation and just being, but some light stretches are certainly very necessary. And the amount of sitting could probably be halfed and would still have the same effect; most people zonk out during long hourly sessions — you can't scan your body for that long without a ton of experience.
The schedule (4am to 9pm) is also very extreme. I would argue that 4 hours of actual meditation a day is plenty, but they give you enough time to do it up to 16 hours if you really want to. For the purpose of learning the technique, it certainly doesn't need to be so long UNLESS it's meant to make you uncomfortable. I'm fairly certain this is one of the intentions and it certainly helps with curbing your ego.
Aftermath
Overall, this was the hardest thing I've done in a long time. And the most rewarding one. In a way, it felt like a near death experience — when you remove everything, your mind clearly understands what's important in life. I am now more present in the moment, have a lot more clarity about what I want in life, less anxiety and the need to rush somewhere in hopes of filling my brain with activities. I have a much better sense of my body which makes it easier to not react to internal or external stimulus, especially the unpleasant one. With the pleasant ones — there's a certain level of distancing where you still enjoy them but not in an all-encompassing, craving way. Truly an incredible tool in one's journey of self-exploration.