Templafy DevOps setup presentation at DevOpsDays Copenhagen 2023 10 May 2023 4:00 PM (last year)
Last week I did my [first conference talk](https://devopsdays.org/events/2023-copenhagen/program/rasmus-kromann-larsen) in a few years at DevOpsDays Copenhagen 2023. I really enjoyed the conference as well - lots of interesting people and great Open Spaces sessions that served to both connect people and also have much more in-depth conversations about audience provided topics.
My talk was a whirlwind tour of the build pipelines we use at Templafy to push our code to production. As part of the presentation I did an actual deployment to production and described what was going on and why we ended up there. Practical tips on the approaches we had taken to evolve to this place.
 Original abstract below in case it is removed from the DevOpsDays site at some point.
## The Road to Production: How our build pipelines evolved
All software must go to production to provide value and this road has a lot of different approaches. At Templafy we believe in shipping our code as quickly as possible. Over the last 3 years, we have been evolving our build pipelines to keep up with onboarding many new colleagues while reducing the risk of breakage through more tests and static analysis. Today we ship 10.000 pull requests to production per year with a dynamically scaling fleet of build agents that has more compute (240 cores and nearly 1 TB of RAM) than our actual production environment at peak.
In this talk, we will explore the problems we have faced and the solutions we picked - what worked and what did not work? Along the way there will be practical tips that can be applied at any level of build automation no matter if you are just starting out or already have an advanced setup.
The demos will be based on Azure DevOps but the problems discussed also apply to build services like GitHub Actions and others.
Original abstract below in case it is removed from the DevOpsDays site at some point.
## The Road to Production: How our build pipelines evolved
All software must go to production to provide value and this road has a lot of different approaches. At Templafy we believe in shipping our code as quickly as possible. Over the last 3 years, we have been evolving our build pipelines to keep up with onboarding many new colleagues while reducing the risk of breakage through more tests and static analysis. Today we ship 10.000 pull requests to production per year with a dynamically scaling fleet of build agents that has more compute (240 cores and nearly 1 TB of RAM) than our actual production environment at peak.
In this talk, we will explore the problems we have faced and the solutions we picked - what worked and what did not work? Along the way there will be practical tips that can be applied at any level of build automation no matter if you are just starting out or already have an advanced setup.
The demos will be based on Azure DevOps but the problems discussed also apply to build services like GitHub Actions and others.




%20in%20a%20few%20years%20at%20DevOpsDays%20Copenhagen%202023.%20I%20really%20enjoyed%20the%20conference%20as%20well%20-%20lots%20of%20interesting%20people%20and%20great%20Open%20Spaces%20sessions%20that%20served%20to%20both%20connect%20people%20and%20also%20have%20much%20more%20in-depth%20conversations%20about%20audience%20provided%20topics.%0A%0AMy%20talk%20was%20a%20whirlwind%20tour%20of%20the%20build%20pipelines%20we%20use%20at%20Templafy%20to%20push%20our%20code%20to%20production.%20As%20part%20of%20the%20presentation%20I%20did%20an%20actual%20deployment%20to%20production%20and%20described%20what%20was%20going%20on%20and%20why%20we%20ended%20up%20there.%20Practical%20tips%20on%20the%20approaches%20we%20had%20taken%20to%20evolve%20to%20this%20place.%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/devopsdays-talk.jpg%22%20/%3E%0A%0AOriginal%20abstract%20below%20in%20case%20it%20is%20removed%20from%20the%20DevOpsDays%20site%20at%20some%20point.%0A%0A%0A%23%23%20The%20Road%20to%20Production:%20How%20our%20build%20pipelines%20evolved%0A%0AAll%20software%20must%20go%20to%20production%20to%20provide%20value%20and%20this%20road%20has%20a%20lot%20of%20different%20approaches.%20At%20Templafy%20we%20believe%20in%20shipping%20our%20code%20as%20quickly%20as%20possible.%20Over%20the%20last%203%20years,%20we%20have%20been%20evolving%20our%20build%20pipelines%20to%20keep%20up%20with%20onboarding%20many%20new%20colleagues%20while%20reducing%20the%20risk%20of%20breakage%20through%20more%20tests%20and%20static%20analysis.%20Today%20we%20ship%2010.000%20pull%20requests%20to%20production%20per%20year%20with%20a%20dynamically%20scaling%20fleet%20of%20build%20agents%20that%20has%20more%20compute%20(240%20cores%20and%20nearly%201%20TB%20of%20RAM)%20than%20our%20actual%20production%20environment%20at%20peak.%0A%0AIn%20this%20talk,%20we%20will%20explore%20the%20problems%20we%20have%20faced%20and%20the%20solutions%20we%20picked%20-%20what%20worked%20and%20what%20did%20not%20work?%20Along%20the%20way%20there%20will%20be%20practical%20tips%20that%20can%20be%20applied%20at%20any%20level%20of%20build%20automation%20no%20matter%20if%20you%20are%20just%20starting%20out%20or%20already%20have%20an%20advanced%20setup.%0A%0AThe%20demos%20will%20be%20based%20on%20Azure%20DevOps%20but%20the%20problems%20discussed%20also%20apply%20to%20build%20services%20like%20GitHub%20Actions%20and%20others.%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/devopsdays-talk-2.jpg%22%20/%3E)





React, Webpack, TypeScript presentation at Vertica 31 May 2017 4:00 PM (7 years ago)
Yesterday at Vertica in collaboration with Aarhus .NET User Group I presented my talk: "ASP.NET without Razor: React, Webpack and TypeScript". Demos and slides can be found [here](https://github.com/rasmuskl/react-webpack-typescript). ## Abstract React has been gaining popularity for single page apps but how does it fit into ASP.NET web apps? How can we use it in combination with Visual Studio without turning our regular workflow upside down? At Templafy we recently migrated our existing Knockout.js frontend to React. As part of this journey, we had to decode all the node.js guides on using React and convert them into a working solution. In the end we settled on the combination of React, Webpack and TypeScript. This talk is a condensed version of our experiences. In the session we explore what React and Webpack are, how they work and how they differ from the tools we usually use in ASP.NET. We will also have a brief introduction to TypeScript and what benefits it adds. After looking at these technologies individually we will look at how they can work together in an ASP.NET web app. This will also include a closer look at the development workflow with hot reloading and the advantages and disadvantages of the entire setup.

React, Webpack and TypeScript presentation at Microsoft 3 Apr 2017 4:00 PM (8 years ago)
This Friday I gave a [repeat](https://www.meetup.com/Copenhagen-Net-User-Group/events/238615694/) of my "ASP.NET without Razor: React, Webpack and TypeScript" talk at Microsoft in Lyngby in collaboration with Copenhagen .NET User Group.
The event had around 260 atteendees and the talk was a bit shorter this time, as I only had an hour (originally the talk was around 2 hours).
It was a 2 talk event with Anders Hejlsberg following my session with a great introduction to TypeScript and where it it is headed.
 Demos and slides can be found [here](https://github.com/rasmuskl/react-webpack-typescript).
## Abstract
React has been gaining popularity for single page apps but how does it fit into ASP.NET web apps? How can we use it in combination with Visual Studio without turning our regular workflow upside down?
At Templafy we recently migrated our existing Knockout.js frontend to React. As part of this journey, we had to decode all the node.js guides on using React and convert them into a working solution. In the end we settled on the combination of React, Webpack and TypeScript. This talk is a condensed version of our experiences.
In the session we explore what React and Webpack are, how they work and how they differ from the tools we usually use in ASP.NET. We will also have a brief introduction to TypeScript and what benefits it adds. After looking at these technologies individually we will look at how they can work together in an ASP.NET web app. This will also include a closer look at the development workflow with hot reloading and the advantages and disadvantages of the entire setup.
Demos and slides can be found [here](https://github.com/rasmuskl/react-webpack-typescript).
## Abstract
React has been gaining popularity for single page apps but how does it fit into ASP.NET web apps? How can we use it in combination with Visual Studio without turning our regular workflow upside down?
At Templafy we recently migrated our existing Knockout.js frontend to React. As part of this journey, we had to decode all the node.js guides on using React and convert them into a working solution. In the end we settled on the combination of React, Webpack and TypeScript. This talk is a condensed version of our experiences.
In the session we explore what React and Webpack are, how they work and how they differ from the tools we usually use in ASP.NET. We will also have a brief introduction to TypeScript and what benefits it adds. After looking at these technologies individually we will look at how they can work together in an ASP.NET web app. This will also include a closer look at the development workflow with hot reloading and the advantages and disadvantages of the entire setup.
%20of%20my%20%22ASP.NET%20without%20Razor:%20React,%20Webpack%20and%20TypeScript%22%20talk%20at%20Microsoft%20in%20Lyngby%20in%20collaboration%20with%20Copenhagen%20.NET%20User%20Group.%0A%0AThe%20event%20had%20around%20260%20atteendees%20and%20the%20talk%20was%20a%20bit%20shorter%20this%20time,%20as%20I%20only%20had%20an%20hour%20(originally%20the%20talk%20was%20around%202%20hours).%0A%0AIt%20was%20a%202%20talk%20event%20with%20Anders%20Hejlsberg%20following%20my%20session%20with%20a%20great%20introduction%20to%20TypeScript%20and%20where%20it%20it%20is%20headed.%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/presentation-at-microsoft.jpg%22%20/%3E%0A%0ADemos%20and%20slides%20can%20be%20found%20%5Bhere%5D(https://github.com/rasmuskl/react-webpack-typescript).%0A%0A%23%23%20Abstract%0A%0AReact%20has%20been%20gaining%20popularity%20for%20single%20page%20apps%20but%20how%20does%20it%20fit%20into%20ASP.NET%20web%20apps?%20How%20can%20we%20use%20it%20in%20combination%20with%20Visual%20Studio%20without%20turning%20our%20regular%20workflow%20upside%20down?%0A%0AAt%20Templafy%20we%20recently%20migrated%20our%20existing%20Knockout.js%20frontend%20to%20React.%20As%20part%20of%20this%20journey,%20we%20had%20to%20decode%20all%20the%20node.js%20guides%20on%20using%20React%20and%20convert%20them%20into%20a%20working%20solution.%20In%20the%20end%20we%20settled%20on%20the%20combination%20of%20React,%20Webpack%20and%20TypeScript.%20This%20talk%20is%20a%20condensed%20version%20of%20our%20experiences.%0A%0AIn%20the%20session%20we%20explore%20what%20React%20and%20Webpack%20are,%20how%20they%20work%20and%20how%20they%20differ%20from%20the%20tools%20we%20usually%20use%20in%20ASP.NET.%20We%20will%20also%20have%20a%20brief%20introduction%20to%20TypeScript%20and%20what%20benefits%20it%20adds.%20After%20looking%20at%20these%20technologies%20individually%20we%20will%20look%20at%20how%20they%20can%20work%20together%20in%20an%20ASP.NET%20web%20app.%20This%20will%20also%20include%20a%20closer%20look%20at%20the%20development%20workflow%20with%20hot%20reloading%20and%20the%20advantages%20and%20disadvantages%20of%20the%20entire%20setup.)
React, Webpack, TypeScript presentation at Templafy 1 Mar 2017 3:00 PM (8 years ago)
Yesterday at Templafy in collaboration with Copenhagen .NET User Group I presented my talk: "ASP.NET without Razor: React, Webpack and TypeScript".
 Demos and slides can be found [here](https://github.com/rasmuskl/react-webpack-typescript).
## Abstract
React has been gaining popularity for single page apps but how does it fit into ASP.NET web apps? How can we use it in combination with Visual Studio without turning our regular workflow upside down?
At Templafy we recently migrated our existing Knockout.js frontend to React. As part of this journey, we had to decode all the node.js guides on using React and convert them into a working solution. In the end we settled on the combination of React, Webpack and TypeScript. This talk is a condensed version of our experiences.
In the session we explore what React and Webpack are, how they work and how they differ from the tools we usually use in ASP.NET. We will also have a brief introduction to TypeScript and what benefits it adds. After looking at these technologies individually we will look at how they can work together in an ASP.NET web app. This will also include a closer look at the development workflow with hot reloading and the advantages and disadvantages of the entire setup.
Demos and slides can be found [here](https://github.com/rasmuskl/react-webpack-typescript).
## Abstract
React has been gaining popularity for single page apps but how does it fit into ASP.NET web apps? How can we use it in combination with Visual Studio without turning our regular workflow upside down?
At Templafy we recently migrated our existing Knockout.js frontend to React. As part of this journey, we had to decode all the node.js guides on using React and convert them into a working solution. In the end we settled on the combination of React, Webpack and TypeScript. This talk is a condensed version of our experiences.
In the session we explore what React and Webpack are, how they work and how they differ from the tools we usually use in ASP.NET. We will also have a brief introduction to TypeScript and what benefits it adds. After looking at these technologies individually we will look at how they can work together in an ASP.NET web app. This will also include a closer look at the development workflow with hot reloading and the advantages and disadvantages of the entire setup.
.%0A%0A%23%23%20Abstract%0A%0AReact%20has%20been%20gaining%20popularity%20for%20single%20page%20apps%20but%20how%20does%20it%20fit%20into%20ASP.NET%20web%20apps?%20How%20can%20we%20use%20it%20in%20combination%20with%20Visual%20Studio%20without%20turning%20our%20regular%20workflow%20upside%20down?%0A%0AAt%20Templafy%20we%20recently%20migrated%20our%20existing%20Knockout.js%20frontend%20to%20React.%20As%20part%20of%20this%20journey,%20we%20had%20to%20decode%20all%20the%20node.js%20guides%20on%20using%20React%20and%20convert%20them%20into%20a%20working%20solution.%20In%20the%20end%20we%20settled%20on%20the%20combination%20of%20React,%20Webpack%20and%20TypeScript.%20This%20talk%20is%20a%20condensed%20version%20of%20our%20experiences.%0A%0AIn%20the%20session%20we%20explore%20what%20React%20and%20Webpack%20are,%20how%20they%20work%20and%20how%20they%20differ%20from%20the%20tools%20we%20usually%20use%20in%20ASP.NET.%20We%20will%20also%20have%20a%20brief%20introduction%20to%20TypeScript%20and%20what%20benefits%20it%20adds.%20After%20looking%20at%20these%20technologies%20individually%20we%20will%20look%20at%20how%20they%20can%20work%20together%20in%20an%20ASP.NET%20web%20app.%20This%20will%20also%20include%20a%20closer%20look%20at%20the%20development%20workflow%20with%20hot%20reloading%20and%20the%20advantages%20and%20disadvantages%20of%20the%20entire%20setup.)
Test Cloud Presentation at Mjølner event 12 Nov 2015 3:00 PM (9 years ago)
Mjølner was kind enough to invite Karl Krukow and me along with our evangelist Mike James to come and talk at their Xamarin seminar.
They have posted a blog post about the event [here](http://mjolner.dk/events/xamarin-videos-how-to-build-and-test-apps-with-xamarin/).
The talk that me and Karl did was a rehash of our [Evolve 2014 talk](/2015/06/18/xamarin-evolve-presentation/) from last year.
The presentation was recorded and is available on YouTube:
What is Xamarin.UITest? 30 Oct 2015 4:00 PM (9 years ago)
One of the projects I have been working on at Xamarin is leading development on our C# test framework Xamarin.UITest.
I recently wrote a guest post over on the Xamarin blog about some of the background and design that went into creating the framework. The Xamarin blog has been removed so I have moved the post here.
## What is Xamarin.UITest?
A key component of Xamarin Test Cloud is the development of test scripts to automate mobile UI testing. The Xamarin Test Cloud team started working on Xamarin.UITest in December of 2013 and released a public version at Xamarin Evolve in October, 2014. In this blog post, I'm going to share some thoughts and advice about the framework and our design decisions.
 What is Xamarin.UITest?
Xamarin.UITest is a C# test automation framework that enables testing mobile apps on Android and iOS. Mobile automation is far from an easy endeavor, and Xamarin.UITest aims to provide a suitable abstraction on top of the platform tools to let you focus on what to test. Tests are written locally using either physical devices or simulators/emulators and then submitted to Xamarin Test Cloud for more extensive testing across hundreds of devices.
Available from NuGet, there are two restrictions for non-Xamarin Test Cloud users: 1) they can only run on simulators/emulators and 2) the total duration of a single test run cannot exceed 15 minutes.
### A Simple Example
Here is a simple example of a test written with Xamarin.UITest:
```csharp
[Test]
public void MyFirstTest()
{
var app = ConfigureApp
.Android
.ApkFile("MyApkFile.apk")
.StartApp();
app.EnterText("NameField", "Rasmus");
app.Tap("SubmitButton");
}
```
First, we configure the app that we're going to be testing. Then we enter "Rasmus" into a text field and press a button.
The main abstraction in Xamarin.UITest is an app. This is the gateway for communicating with the app running on the device. There is an iOSApp, an AndroidApp, and an IApp interface containing all of the shared functionality between the platforms, allowing cross-platform app tests to be written against the IApp interface.
### Design Goals
Xamarin.UITest is designed with a few design goals in mind, which help focus our efforts and provide a level of consistency. Some of the goals are inspired by Mogens Heller Grabe and his Rebus project. Goals are only as good as the reasons that back them, so let's take a look at some of the goals for Xamarin.UITest and why we decided that each of them was important.
#### Discoverable
Part of the power of C# is amazing tools; for example, we have come to depend heavily on IntelliSense. One goal in designing Xamarin.UITest was to harness these tools and make as much functionality as possible discoverable through IntelliSense. In order to do this, you must minimize the number of entry points that the end user has to know about.
At the time of this writing, the only entry point for writing tests in Xamarin.UITest is the static ConfigureApp fluent interface. Once you have this entry point, everything else in the framework can be discovered through IntelliSense. The only exception is the TestEnvironment static class, which provides a bit of contextual information about the test environment that can be helpful when configuring the app.
#### Declarative
Mobile testing is hard. Platforms and tools are constantly changing and, as a result, the underlying framework often has to adapt. In addition to the rapid pace of change, the test has to perform on a wide range of devices with different sizes and processing power.
We built Xamarin.UITest with this in mind. We strive to provide a succinct interface for describing intent, such as the interactions you want performed or what information you are interested in.
A common issue in testing that's very evident in mobile testing is waiting: you tap a button and have to wait for the screen to change before you can interact with the next control. The easy solution is to use a Thread.Sleep call to wait just enough time, but what amount of time is “enough”? This leads to slow tests that wait too long or tests that are brittle because they're pushing the limits. A better solution would be wait for a change in the app. In Xamarin.UITest, one option is app.WaitForElement, which will continuously poll the app. However, waiting is an artifact of making the test work. The scenario we are trying to solve is to interact with two controls. Our solution for most gestures is to automatically wait if the element is not already present on the screen. In the best case, this alleviates the tester from worrying about details that are not important to the test. The only downside is that a failure will be a bit slower.
#### No Visible External Dependencies
In recent years, .NET has been greatly enhanced by technology such as NuGet, which allows us to create software that utilizes many other libraries, but there are still has a few problems. One of these problems is versioning, and a prime example is depending on a NuGet package that depends on a specific version of a popular package such as Newtonsoft.Json. This then restricts you in your own Newtonsoft.Json version and could possibly mismatch with other NuGet packages you want to use.
For Xamarin.UITest, our aim is to have no visible external dependencies. This doesn't mean that we code everything from the ground up; rather, we take care to not use any types from our dependencies in our public interface, so that we can use ILMerge (or ILRepack in our case) to combine everything into a single assembly with our dependencies internalized. In the case that we need something that is available on our public interface, we could open the framework up and provide a separate integration NuGet package. A nice example of this approach can also be seen in [Rebus](https://github.com/rebus-org/Rebus).
#### Helpful Errors
Errors happen. Mobile testing exercises many components and interacts with quite a few external systems, and there may be prerequisites or other environment settings that are not set up properly. In these cases, we often have no choice but to report the error, because our aim is to provide the best possible information about what went wrong. In addition, if we have any information that might help the user resolve the problem, we attempt to include this information in the error message as well.
### More Information
For more information, follow the tutorials in our documentation. Karl Krukow and I also did a presentation featuring a general overview of Xamarin Test Cloud, a demo of Xamarin.UITest, and a live stream of one of the Xamarin Test Cloud labs that you can watch [here](https://www.youtube.com/watch?v=PQMBCoVIABI).
What is Xamarin.UITest?
Xamarin.UITest is a C# test automation framework that enables testing mobile apps on Android and iOS. Mobile automation is far from an easy endeavor, and Xamarin.UITest aims to provide a suitable abstraction on top of the platform tools to let you focus on what to test. Tests are written locally using either physical devices or simulators/emulators and then submitted to Xamarin Test Cloud for more extensive testing across hundreds of devices.
Available from NuGet, there are two restrictions for non-Xamarin Test Cloud users: 1) they can only run on simulators/emulators and 2) the total duration of a single test run cannot exceed 15 minutes.
### A Simple Example
Here is a simple example of a test written with Xamarin.UITest:
```csharp
[Test]
public void MyFirstTest()
{
var app = ConfigureApp
.Android
.ApkFile("MyApkFile.apk")
.StartApp();
app.EnterText("NameField", "Rasmus");
app.Tap("SubmitButton");
}
```
First, we configure the app that we're going to be testing. Then we enter "Rasmus" into a text field and press a button.
The main abstraction in Xamarin.UITest is an app. This is the gateway for communicating with the app running on the device. There is an iOSApp, an AndroidApp, and an IApp interface containing all of the shared functionality between the platforms, allowing cross-platform app tests to be written against the IApp interface.
### Design Goals
Xamarin.UITest is designed with a few design goals in mind, which help focus our efforts and provide a level of consistency. Some of the goals are inspired by Mogens Heller Grabe and his Rebus project. Goals are only as good as the reasons that back them, so let's take a look at some of the goals for Xamarin.UITest and why we decided that each of them was important.
#### Discoverable
Part of the power of C# is amazing tools; for example, we have come to depend heavily on IntelliSense. One goal in designing Xamarin.UITest was to harness these tools and make as much functionality as possible discoverable through IntelliSense. In order to do this, you must minimize the number of entry points that the end user has to know about.
At the time of this writing, the only entry point for writing tests in Xamarin.UITest is the static ConfigureApp fluent interface. Once you have this entry point, everything else in the framework can be discovered through IntelliSense. The only exception is the TestEnvironment static class, which provides a bit of contextual information about the test environment that can be helpful when configuring the app.
#### Declarative
Mobile testing is hard. Platforms and tools are constantly changing and, as a result, the underlying framework often has to adapt. In addition to the rapid pace of change, the test has to perform on a wide range of devices with different sizes and processing power.
We built Xamarin.UITest with this in mind. We strive to provide a succinct interface for describing intent, such as the interactions you want performed or what information you are interested in.
A common issue in testing that's very evident in mobile testing is waiting: you tap a button and have to wait for the screen to change before you can interact with the next control. The easy solution is to use a Thread.Sleep call to wait just enough time, but what amount of time is “enough”? This leads to slow tests that wait too long or tests that are brittle because they're pushing the limits. A better solution would be wait for a change in the app. In Xamarin.UITest, one option is app.WaitForElement, which will continuously poll the app. However, waiting is an artifact of making the test work. The scenario we are trying to solve is to interact with two controls. Our solution for most gestures is to automatically wait if the element is not already present on the screen. In the best case, this alleviates the tester from worrying about details that are not important to the test. The only downside is that a failure will be a bit slower.
#### No Visible External Dependencies
In recent years, .NET has been greatly enhanced by technology such as NuGet, which allows us to create software that utilizes many other libraries, but there are still has a few problems. One of these problems is versioning, and a prime example is depending on a NuGet package that depends on a specific version of a popular package such as Newtonsoft.Json. This then restricts you in your own Newtonsoft.Json version and could possibly mismatch with other NuGet packages you want to use.
For Xamarin.UITest, our aim is to have no visible external dependencies. This doesn't mean that we code everything from the ground up; rather, we take care to not use any types from our dependencies in our public interface, so that we can use ILMerge (or ILRepack in our case) to combine everything into a single assembly with our dependencies internalized. In the case that we need something that is available on our public interface, we could open the framework up and provide a separate integration NuGet package. A nice example of this approach can also be seen in [Rebus](https://github.com/rebus-org/Rebus).
#### Helpful Errors
Errors happen. Mobile testing exercises many components and interacts with quite a few external systems, and there may be prerequisites or other environment settings that are not set up properly. In these cases, we often have no choice but to report the error, because our aim is to provide the best possible information about what went wrong. In addition, if we have any information that might help the user resolve the problem, we attempt to include this information in the error message as well.
### More Information
For more information, follow the tutorials in our documentation. Karl Krukow and I also did a presentation featuring a general overview of Xamarin Test Cloud, a demo of Xamarin.UITest, and a live stream of one of the Xamarin Test Cloud labs that you can watch [here](https://www.youtube.com/watch?v=PQMBCoVIABI).
Presentation at Xamarin Evolve 2014 17 Jun 2015 4:00 PM (9 years ago)
As part of my work for Xamarin, I was lucky enough to get the chance to present at the main stage at Xamarin Evolve last year with Karl Krukow.
Our talk was about mobile testing with [Xamarin Test Cloud](http://xamarin.com/test-cloud) and my part specifically was about the test framework I have been working on: [Xamarin.UITest](http://developer.xamarin.com/guides/testcloud/uitest/)
The presentation is available on YouTube - my part starts at around 21:30. Also there is our neat demo with live streaming from one of the actual Test Cloud labs at around 57:00.
Env Reboot Diaries - The First Day 29 Sep 2013 4:00 PM (11 years ago)
Today was the first day of my new job. I've always been a Windows user except for when using university computers - and my professional career has mainly consisted of .NET C# development. My new job is in a polyglot environment, the main language is Ruby - but there's also CoffeeScript and Clojure. I'll also be doing it on a Macbook Pro instead of my usual Windows machine. I thought it would be interesting to capture some of the thoughts as I go through learning a new OS and a new development stack. ## The Macbook Pro I spent most of the day setting up my temporary machine and doing some research for the first feature I'm assisting on. I was curious about how I'd like the Macbook Pro. I haven't had much luck with Apple products in the past. I've owned both an iPhone and an iPad and ended up selling both, usually due being annoyed with too few configuration options. Regarding the Macbook Pro, I think I might survive it. It's a nice piece of hardware, to be sure. I like the crisp display and the feel of both keyboard and trackpad are very good. The keyboard layout (Danish) will definitely take some getting used to, but I'm hoping it won't be much worse than learning `fn` key combinations on any other new laptop these days. Likes so far: * The virtual screens and navigating options are pleasant to work with. I've actually just been working on the Macbook without an external screen today. * The terminal. Tab completion etc seems more natural than both `cmd` and PowerShell. Will have to look at term replacements though, obviously. * Stronger package management. I've been using `homebrew` and `homebrew-cask` to install stuff. Installing Spotify with `homebrew cask install spotify` is a winner in my book. This has improved a bit on the Windows side of things with [Chocolatey](http://chocolatey.org/) though. Dislikes so far: * Having to enter my credit card information to install free apps from AppStore. * Also having to choose 3 security questions to install free apps - with crappy choices. * I'm not too keen on the dock yet either. But maybe it'll grow on me. ## Text Editor vs IDE I've been addicted to perfecting IDE use for quite some time. Give me Visual Studio and ReSharper and I'll slice and dice C# code with my hands behind my back. Tools like ReSharper are huge boosters - not just for writing code, but also for molding existing code into new shapes and even more importantly, for navigating, reading and understanding code. And while I am a huge fan - I've also come to realize that these tools sometimes become a prison. Introducing new technology that depends on some new file type into the Microsoft world more or less requires Visual Studio integration. In my experience, developers will be very reluctant to adopt it (myself included), if it doesn't have Intellisense for instance. So while I've considered starting out with Jetbrains' RubyMine, I've decided to try a text editor instead - at least for now. I actually thought I was going to pick Sublime Text, but in the end I decided to give vim a try. I've run through `vimtutor` tonight and plan to do it again tomorrow - and got a basic `.vimrc` config up and running. For now, I'm going to try and keep the number of plugins down - but have install [Vundle](https://github.com/gmarik/vundle) for managing plugins, the [solarized](https://github.com/altercation/vim-colors-solarized) theme and [vim-airline](https://github.com/bling/vim-airline) as an improved status bar.
My Git + PowerShell setup for .NET development 22 Sep 2013 4:00 PM (11 years ago)
 I've been using git for a couple of years and thought I would document my setup. Git's linux heritage shows and while it's not many tools that I use via a shell, it's actually a real breeze. So I've mainly been using it through PowerShell.
## Git
I run the plain [Git for Windows](http://msysgit.github.io/) installation.
My only comment for the installation is that I usually choose the option (not default) to use checkout-as-is, commit-as-is for line endings. I mainly work with .NET projects and prefer to keep my Windows line endings in the repository to avoid any problems.
### .gitattributes
The line endings configuration can give problems in a mixed team - and recently I've been using a `.gitattributes` file in the root of my repositories with the following content:
```
* -text
```
This will instruct git to not mess with any line endings in the repository across the team, regardless of the installation options, which is nice as long as you don't have a mix of platforms.
### .gitignore
I usually build my `.gitignore` file as needed - I always do `git status` before committing, so it's been quite a while since something has slipped by. My minimal `.gitignore` will usually look something like this:
```
bin
obj
*.csproj.user
*.suo
packages
```
Generally I prefer to use NuGet for all possible dependencies and avoid checking the binary files in to keep the overall repository size down.
### posh-git
I use posh-git to get a bit of contextual information about my repository and some nice tab completion.
I've been using git for a couple of years and thought I would document my setup. Git's linux heritage shows and while it's not many tools that I use via a shell, it's actually a real breeze. So I've mainly been using it through PowerShell.
## Git
I run the plain [Git for Windows](http://msysgit.github.io/) installation.
My only comment for the installation is that I usually choose the option (not default) to use checkout-as-is, commit-as-is for line endings. I mainly work with .NET projects and prefer to keep my Windows line endings in the repository to avoid any problems.
### .gitattributes
The line endings configuration can give problems in a mixed team - and recently I've been using a `.gitattributes` file in the root of my repositories with the following content:
```
* -text
```
This will instruct git to not mess with any line endings in the repository across the team, regardless of the installation options, which is nice as long as you don't have a mix of platforms.
### .gitignore
I usually build my `.gitignore` file as needed - I always do `git status` before committing, so it's been quite a while since something has slipped by. My minimal `.gitignore` will usually look something like this:
```
bin
obj
*.csproj.user
*.suo
packages
```
Generally I prefer to use NuGet for all possible dependencies and avoid checking the binary files in to keep the overall repository size down.
### posh-git
I use posh-git to get a bit of contextual information about my repository and some nice tab completion.
 posh-git is rather simple to install by following the instructions in the main [repository](https://github.com/dahlbyk/posh-git).
### gitk
Working in a shell environment is fine for many of the every day operations, sometimes a bit of GUI can be nice to get an overview. Git includes `gitk` which while a bit basic usually works just fine. I usually launch it with `gitk --all` to see all branches.
posh-git is rather simple to install by following the instructions in the main [repository](https://github.com/dahlbyk/posh-git).
### gitk
Working in a shell environment is fine for many of the every day operations, sometimes a bit of GUI can be nice to get an overview. Git includes `gitk` which while a bit basic usually works just fine. I usually launch it with `gitk --all` to see all branches.
 If you want a more advanced GUI for Git, you can either download [SourceTree](http://www.sourcetreeapp.com/) from Atlassian or [GitHub for Windows](http://windows.github.com/).
## PowerShell
My PowerShell setup mainly consists of my profile, which is loaded when PowerShell starts. On my system it's found under:
```
C:\Users\Rasmus\Documents\WindowsPowerShell\Microsoft.PowerShell_profile.ps1
```
You can however access it through PowerShell using `$PROFILE` variable. So you can easily edit it with:
```
notepad $PROFILE
```
After you've made changes to your profile, you'll have to reload it into the current PowerShell session with:
```
. $PROFILE
```
My full PowerShell profile is available in this [gist](https://gist.github.com/rasmuskl/3786798).
### General purpose aliases
I have two aliases set up that I use often, but are not entirely Git related. First off I have `np`:
```
set-alias -name np -value "C:\Program Files\Sublime Text 3\sublime_text.exe"
```
This is just always set up to open my current text editor whenever it's [Sublime Text](http://www.sublimetext.com/) or [Notepad++](http://notepad-plus-plus.org/) and used to do quick edits.
My other alias is `vsh`, which is just short for "Visual Studio here". What it'll do is to search recursively from the current folder and open the first solution it encounters. It'll give you a quick standard way to open your solution from the root of a repository where you generally want your shell most of the time anyway.
```powershell
function vsh() {
Write-Output "Opening first solution..."
$sln = (dir -in *.sln -r | Select -first 1)
Write-Output "Found $($sln.FullName)"
Invoke-Item $sln.FullName
}
```
If you want a more advanced GUI for Git, you can either download [SourceTree](http://www.sourcetreeapp.com/) from Atlassian or [GitHub for Windows](http://windows.github.com/).
## PowerShell
My PowerShell setup mainly consists of my profile, which is loaded when PowerShell starts. On my system it's found under:
```
C:\Users\Rasmus\Documents\WindowsPowerShell\Microsoft.PowerShell_profile.ps1
```
You can however access it through PowerShell using `$PROFILE` variable. So you can easily edit it with:
```
notepad $PROFILE
```
After you've made changes to your profile, you'll have to reload it into the current PowerShell session with:
```
. $PROFILE
```
My full PowerShell profile is available in this [gist](https://gist.github.com/rasmuskl/3786798).
### General purpose aliases
I have two aliases set up that I use often, but are not entirely Git related. First off I have `np`:
```
set-alias -name np -value "C:\Program Files\Sublime Text 3\sublime_text.exe"
```
This is just always set up to open my current text editor whenever it's [Sublime Text](http://www.sublimetext.com/) or [Notepad++](http://notepad-plus-plus.org/) and used to do quick edits.
My other alias is `vsh`, which is just short for "Visual Studio here". What it'll do is to search recursively from the current folder and open the first solution it encounters. It'll give you a quick standard way to open your solution from the root of a repository where you generally want your shell most of the time anyway.
```powershell
function vsh() {
Write-Output "Opening first solution..."
$sln = (dir -in *.sln -r | Select -first 1)
Write-Output "Found $($sln.FullName)"
Invoke-Item $sln.FullName
}
```
 ### Git aliases
I have two main aliases for interacting with Git, namely `ga` and `gco`.
My alias for adding everything to the staging area is `ga`. For a long time I'd use `git add .` usually and then `git add -A` whenever I also had deletes - but I'm happy with `ga` now. As a bonus it also does a `git status` so I'm forced to review what the heck I'm doing.
``` powershell
function ga() {
Write-Output "Staging all changes..."
git add -A
git status
}
```
After staging files I have to commit obviously. I got a bit annoyed with typing `git add -m "blah"` all the time and came up with `gco`. Besides being shorter, it has 2 little twists:
- If you add `-a` or `-amend` it'll do a `git commit --amend` for overwriting the last commit. Useful for fixing typoes or unsaved files that didn't make it into the commit.
- Under most circumstances you can leave out the surrounding quotes and it'll work just fine. So you can write `gco message` instead of `gco "message"`. If you're using special chars like apostrophes in your messages however, you still have to add the quotes.
``` powershell
function gco() {
param([switch]$amend, [switch]$a)
$argstr = $args -join ' '
$message = '"', $argstr, '"' -join ''
if ($amend -or $a) {
Write-Output "Amending previous commit with message: $message"
git commit -m $message --amend
} else {
Write-Output "Committing with message: $args"
git commit -m $message
}
}
```
I also have a `gca` alias, which is basically `gco -a` - but I don't use it often. You can grab it from the [profile gist](https://gist.github.com/rasmuskl/3786798).
### Git aliases
I have two main aliases for interacting with Git, namely `ga` and `gco`.
My alias for adding everything to the staging area is `ga`. For a long time I'd use `git add .` usually and then `git add -A` whenever I also had deletes - but I'm happy with `ga` now. As a bonus it also does a `git status` so I'm forced to review what the heck I'm doing.
``` powershell
function ga() {
Write-Output "Staging all changes..."
git add -A
git status
}
```
After staging files I have to commit obviously. I got a bit annoyed with typing `git add -m "blah"` all the time and came up with `gco`. Besides being shorter, it has 2 little twists:
- If you add `-a` or `-amend` it'll do a `git commit --amend` for overwriting the last commit. Useful for fixing typoes or unsaved files that didn't make it into the commit.
- Under most circumstances you can leave out the surrounding quotes and it'll work just fine. So you can write `gco message` instead of `gco "message"`. If you're using special chars like apostrophes in your messages however, you still have to add the quotes.
``` powershell
function gco() {
param([switch]$amend, [switch]$a)
$argstr = $args -join ' '
$message = '"', $argstr, '"' -join ''
if ($amend -or $a) {
Write-Output "Amending previous commit with message: $message"
git commit -m $message --amend
} else {
Write-Output "Committing with message: $args"
git commit -m $message
}
}
```
I also have a `gca` alias, which is basically `gco -a` - but I don't use it often. You can grab it from the [profile gist](https://gist.github.com/rasmuskl/3786798).
%20installation.%0A%0AMy%20only%20comment%20for%20the%20installation%20is%20that%20I%20usually%20choose%20the%20option%20(not%20default)%20to%20use%20checkout-as-is,%20commit-as-is%20for%20line%20endings.%20I%20mainly%20work%20with%20.NET%20projects%20and%20prefer%20to%20keep%20my%20Windows%20line%20endings%20in%20the%20repository%20to%20avoid%20any%20problems.%0A%0A%23%23%23%20.gitattributes%0A%0AThe%20line%20endings%20configuration%20can%20give%20problems%20in%20a%20mixed%20team%20-%20and%20recently%20I've%20been%20using%20a%20%60.gitattributes%60%20file%20in%20the%20root%20of%20my%20repositories%20with%20the%20following%20content:%0A%0A%60%60%60%0A*%20-text%0A%60%60%60%0A%0AThis%20will%20instruct%20git%20to%20not%20mess%20with%20any%20line%20endings%20in%20the%20repository%20across%20the%20team,%20regardless%20of%20the%20installation%20options,%20which%20is%20nice%20as%20long%20as%20you%20don't%20have%20a%20mix%20of%20platforms.%0A%0A%0A%23%23%23%20.gitignore%0A%0AI%20usually%20build%20my%20%60.gitignore%60%20file%20as%20needed%20-%20I%20always%20do%20%60git%20status%60%20before%20committing,%20so%20it's%20been%20quite%20a%20while%20since%20something%20has%20slipped%20by.%20My%20minimal%20%60.gitignore%60%20will%20usually%20look%20something%20like%20this:%0A%0A%60%60%60%0Abin%0Aobj%0A*.csproj.user%0A*.suo%0Apackages%0A%60%60%60%0A%0AGenerally%20I%20prefer%20to%20use%20NuGet%20for%20all%20possible%20dependencies%20and%20avoid%20checking%20the%20binary%20files%20in%20to%20keep%20the%20overall%20repository%20size%20down.%0A%0A%23%23%23%20posh-git%0A%0AI%20use%20posh-git%20to%20get%20a%20bit%20of%20contextual%20information%20about%20my%20repository%20and%20some%20nice%20tab%20completion.%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/wp-content/uploads/2013-09-23-20_29_45-poshgit-test-project-master.png%22%20/%3E%0A%0Aposh-git%20is%20rather%20simple%20to%20install%20by%20following%20the%20instructions%20in%20the%20main%20%5Brepository%5D(https://github.com/dahlbyk/posh-git).%0A%0A%23%23%23%20gitk%0A%0AWorking%20in%20a%20shell%20environment%20is%20fine%20for%20many%20of%20the%20every%20day%20operations,%20sometimes%20a%20bit%20of%20GUI%20can%20be%20nice%20to%20get%20an%20overview.%20Git%20includes%20%60gitk%60%20which%20while%20a%20bit%20basic%20usually%20works%20just%20fine.%20I%20usually%20launch%20it%20with%20%60gitk%20--all%60%20to%20see%20all%20branches.%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/wp-content/uploads/2013-09-23-21_27_26-gitk_-alphalaunch.png%22%20/%3E%0A%0AIf%20you%20want%20a%20more%20advanced%20GUI%20for%20Git,%20you%20can%20either%20download%20%5BSourceTree%5D(http://www.sourcetreeapp.com/)%20from%20Atlassian%20or%20%5BGitHub%20for%20Windows%5D(http://windows.github.com/).%0A%0A%0A%23%23%20PowerShell%0A%0AMy%20PowerShell%20setup%20mainly%20consists%20of%20my%20profile,%20which%20is%20loaded%20when%20PowerShell%20starts.%20On%20my%20system%20it's%20found%20under:%0A%0A%60%60%60%0AC:%5CUsers%5CRasmus%5CDocuments%5CWindowsPowerShell%5CMicrosoft.PowerShell_profile.ps1%0A%60%60%60%0A%0AYou%20can%20however%20access%20it%20through%20PowerShell%20using%20%60$PROFILE%60%20variable.%20So%20you%20can%20easily%20edit%20it%20with:%0A%0A%60%60%60%0Anotepad%20$PROFILE%0A%60%60%60%0A%0AAfter%20you've%20made%20changes%20to%20your%20profile,%20you'll%20have%20to%20reload%20it%20into%20the%20current%20PowerShell%20session%20with:%0A%0A%60%60%60%0A.%20$PROFILE%0A%60%60%60%0A%0AMy%20full%20PowerShell%20profile%20is%20available%20in%20this%20%5Bgist%5D(https://gist.github.com/rasmuskl/3786798).%0A%0A%23%23%23%20General%20purpose%20aliases%0A%0AI%20have%20two%20aliases%20set%20up%20that%20I%20use%20often,%20but%20are%20not%20entirely%20Git%20related.%20First%20off%20I%20have%20%60np%60:%0A%0A%60%60%60%0Aset-alias%20-name%20np%20-value%20%22C:%5CProgram%20Files%5CSublime%20Text%203%5Csublime_text.exe%22%0A%60%60%60%0A%0AThis%20is%20just%20always%20set%20up%20to%20open%20my%20current%20text%20editor%20whenever%20it's%20%5BSublime%20Text%5D(http://www.sublimetext.com/)%20or%20%5BNotepad++%5D(http://notepad-plus-plus.org/)%20and%20used%20to%20do%20quick%20edits.%0A%0AMy%20other%20alias%20is%20%60vsh%60,%20which%20is%20just%20short%20for%20%22Visual%20Studio%20here%22.%20What%20it'll%20do%20is%20to%20search%20recursively%20from%20the%20current%20folder%20and%20open%20the%20first%20solution%20it%20encounters.%20It'll%20give%20you%20a%20quick%20standard%20way%20to%20open%20your%20solution%20from%20the%20root%20of%20a%20repository%20where%20you%20generally%20want%20your%20shell%20most%20of%20the%20time%20anyway.%0A%0A%60%60%60powershell%0Afunction%20vsh()%20%7B%0A%20%20Write-Output%20%22Opening%20first%20solution...%22%0A%20%20%20%20$sln%20%3D%20(dir%20-in%20*.sln%20-r%20%7C%20Select%20-first%201)%0A%20%20%20%20Write-Output%20%22Found%20$($sln.FullName)%22%0A%20%20%20%20Invoke-Item%20$sln.FullName%0A%7D%0A%60%60%60%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/wp-content/uploads/2013-09-23-21_06_03-poshgit-alphalaunch-master.png%22%20/%3E%0A%0A%23%23%23%20Git%20aliases%0A%0AI%20have%20two%20main%20aliases%20for%20interacting%20with%20Git,%20namely%20%60ga%60%20and%20%60gco%60.%0A%0AMy%20alias%20for%20adding%20everything%20to%20the%20staging%20area%20is%20%60ga%60.%20For%20a%20long%20time%20I'd%20use%20%60git%20add%20.%60%20usually%20and%20then%20%60git%20add%20-A%60%20whenever%20I%20also%20had%20deletes%20-%20but%20I'm%20happy%20with%20%60ga%60%20now.%20As%20a%20bonus%20it%20also%20does%20a%20%60git%20status%60%20so%20I'm%20forced%20to%20review%20what%20the%20heck%20I'm%20doing.%0A%0A%60%60%60%20powershell%0Afunction%20ga()%20%7B%0A%20%20Write-Output%20%22Staging%20all%20changes...%22%0A%20%20%20%20git%20add%20-A%0A%20%20%20%20git%20status%0A%7D%0A%60%60%60%0A%0AAfter%20staging%20files%20I%20have%20to%20commit%20obviously.%20I%20got%20a%20bit%20annoyed%20with%20typing%20%60git%20add%20-m%20%22blah%22%60%20all%20the%20time%20and%20came%20up%20with%20%60gco%60.%20Besides%20being%20shorter,%20it%20has%202%20little%20twists:%0A%0A-%20If%20you%20add%20%60-a%60%20or%20%60-amend%60%20it'll%20do%20a%20%60git%20commit%20--amend%60%20for%20overwriting%20the%20last%20commit.%20Useful%20for%20fixing%20typoes%20or%20unsaved%20files%20that%20didn't%20make%20it%20into%20the%20commit.%0A-%20Under%20most%20circumstances%20you%20can%20leave%20out%20the%20surrounding%20quotes%20and%20it'll%20work%20just%20fine.%20So%20you%20can%20write%20%60gco%20message%60%20instead%20of%20%60gco%20%22message%22%60.%20If%20you're%20using%20special%20chars%20like%20apostrophes%20in%20your%20messages%20however,%20you%20still%20have%20to%20add%20the%20quotes.%0A%0A%60%60%60%20powershell%0Afunction%20gco()%20%7B%0A%20%20param(%5Bswitch%5D$amend,%20%5Bswitch%5D$a)%0A%0A%20%20%20%20$argstr%20%3D%20$args%20-join%20'%20'%0A%20%20%20%20$message%20%3D%20'%22',%20$argstr,%20'%22'%20-join%20''%0A%0A%20%20%20%20if%20($amend%20-or%20$a)%20%7B%0A%20%20%20%20%20%20Write-Output%20%22Amending%20previous%20commit%20with%20message:%20$message%22%0A%20%20%20%20%20%20%20%20git%20commit%20-m%20$message%20--amend%0A%20%20%20%20%7D%20else%20%7B%0A%20%20%20%20%20%20Write-Output%20%22Committing%20with%20message:%20$args%22%0A%20%20%20%20%20%20%20%20git%20commit%20-m%20$message%0A%20%20%20%20%7D%0A%7D%0A%60%60%60%0A%0AI%20also%20have%20a%20%60gca%60%20alias,%20which%20is%20basically%20%60gco%20-a%60%20-%20but%20I%20don't%20use%20it%20often.%20You%20can%20grab%20it%20from%20the%20%5Bprofile%20gist%5D(https://gist.github.com/rasmuskl/3786798).)
Joining Xamarin 13 Aug 2013 4:00 PM (11 years ago)
![]() After some 3 years working as an independent consultant I'm excited to announce that I'm joining [Xamarin](http://www.xamarin.com) in October. Working as a consultant has brought me many interesting experiences and may do so again some day, but for some time I've been looking for a company with the right profile to join. I've mainly been looking for a highly skilled team building exciting stuff without too much corporate overhead, with a great vision, where I could really make an impact. Xamarin seems to fit the bill perfectly.
## Xamarin Test Cloud
More specifically, I will be joining the Xamarin team in Århus responsible for the [Xamarin Test Cloud](http://xamarin.com/test-cloud) - a cloud platform for BDD-style UI automation testing Android and iOS apps on actual physical devices without having to deal with the devices yourself. The mobile device market has crazy fragmentation due to the number of OS versions, screen sizes, customizations and just sheer number of different models. [Nat Friedman](http://www.nat.org/) (Xamarin CEO) gave a nice overview of the problem in the Xamarin Evolve 2013 keynote this year ([video: The State of Mobile Testing](http://xamarin.com/evolve/2013#keynote-72:12)) and also proceeded to give an overview to the Xamarin Test Cloud ([video: Xamarin Test Cloud](http://xamarin.com/evolve/2013#keynote-80:44)).
## New challenges
First of all since I'm joining the Xamarin team in Århus and I live in Copenhagen, I will be spending quite a bit more time riding trains back and forth. It's important to be a part of the team and I've also planned to read up on tips for optimizing remote work - [Scott Hanselman](http://www.hanselman.com/) comes to mind, especially his tips on [video portals](http://www.hanselman.com/blog/VirtualCamaraderieAPersistentVideoPortalForTheRemoteWorker.aspx).
I'm currently investigating possible office spaces in Copenhagen for my remote work - suggestions are very welcome.
Besides working remotely my new main programming environment will no longer be .NET and C# in Visual Studio, but rather Ruby in some yet undecided editor on a Mac. It's always refreshing to try something new! But while I'll be writing Ruby, Xamarin does have a heavy investment in C#, so I'm sure my C# knowledge will come in handy anyway.
Exciting times.
After some 3 years working as an independent consultant I'm excited to announce that I'm joining [Xamarin](http://www.xamarin.com) in October. Working as a consultant has brought me many interesting experiences and may do so again some day, but for some time I've been looking for a company with the right profile to join. I've mainly been looking for a highly skilled team building exciting stuff without too much corporate overhead, with a great vision, where I could really make an impact. Xamarin seems to fit the bill perfectly.
## Xamarin Test Cloud
More specifically, I will be joining the Xamarin team in Århus responsible for the [Xamarin Test Cloud](http://xamarin.com/test-cloud) - a cloud platform for BDD-style UI automation testing Android and iOS apps on actual physical devices without having to deal with the devices yourself. The mobile device market has crazy fragmentation due to the number of OS versions, screen sizes, customizations and just sheer number of different models. [Nat Friedman](http://www.nat.org/) (Xamarin CEO) gave a nice overview of the problem in the Xamarin Evolve 2013 keynote this year ([video: The State of Mobile Testing](http://xamarin.com/evolve/2013#keynote-72:12)) and also proceeded to give an overview to the Xamarin Test Cloud ([video: Xamarin Test Cloud](http://xamarin.com/evolve/2013#keynote-80:44)).
## New challenges
First of all since I'm joining the Xamarin team in Århus and I live in Copenhagen, I will be spending quite a bit more time riding trains back and forth. It's important to be a part of the team and I've also planned to read up on tips for optimizing remote work - [Scott Hanselman](http://www.hanselman.com/) comes to mind, especially his tips on [video portals](http://www.hanselman.com/blog/VirtualCamaraderieAPersistentVideoPortalForTheRemoteWorker.aspx).
I'm currently investigating possible office spaces in Copenhagen for my remote work - suggestions are very welcome.
Besides working remotely my new main programming environment will no longer be .NET and C# in Visual Studio, but rather Ruby in some yet undecided editor on a Mac. It's always refreshing to try something new! But while I'll be writing Ruby, Xamarin does have a heavy investment in C#, so I'm sure my C# knowledge will come in handy anyway.
Exciting times.
![]()
Releasing my ReSharper Course Material 12 Jun 2013 4:00 PM (11 years ago)
 I've decided to release my ReSharper course material under the [Creative Commons Attribution 3.0 license](http://creativecommons.org/licenses/by/3.0/).
The material can be found at on [GitHub](http://github.com/rasmuskl/ReSharperCourse).
A short description of the course can be found in the git repository README (pasted below).
The precompiled exercises-PDF can be downloaded [here on GitHub](https://github.com/rasmuskl/ReSharperCourse/raw/master/Source/ReSharper%20Exercises.pdf).
# Introduction
This is my basic [ReSharper](http://www.jetbrains.com/resharper/) course material developed in 2012 - based on ReSharper 6.1, although a lot of the material is still relevant.
It should provide enough content for 4 to 6 hours of entertainment. The course focuses on progressivly harder exercises and hands-on experience over a lot of talk.
Exercises are generated through the ASP.NET MVC site found in `Source/CourseTasks`.
# Topics
- Why use ReSharper?
- Navigation
- Code Interaction
- Code Analysis
- Code Generation
- Refactoring
- Completion modes
- Refactoring combos
- Usage Inspection
- Solution Refactorings
- Move Code
- Navigating Hierarchies
- Inspect This
# Licensing
Course material is licensed under the Creative Commons Attribution-ShareAlike 3.0 Unported License.
For source code found in the Source folder - please check individual projects for license information (Rebus and BlogEngine.NET).
I've decided to release my ReSharper course material under the [Creative Commons Attribution 3.0 license](http://creativecommons.org/licenses/by/3.0/).
The material can be found at on [GitHub](http://github.com/rasmuskl/ReSharperCourse).
A short description of the course can be found in the git repository README (pasted below).
The precompiled exercises-PDF can be downloaded [here on GitHub](https://github.com/rasmuskl/ReSharperCourse/raw/master/Source/ReSharper%20Exercises.pdf).
# Introduction
This is my basic [ReSharper](http://www.jetbrains.com/resharper/) course material developed in 2012 - based on ReSharper 6.1, although a lot of the material is still relevant.
It should provide enough content for 4 to 6 hours of entertainment. The course focuses on progressivly harder exercises and hands-on experience over a lot of talk.
Exercises are generated through the ASP.NET MVC site found in `Source/CourseTasks`.
# Topics
- Why use ReSharper?
- Navigation
- Code Interaction
- Code Analysis
- Code Generation
- Refactoring
- Completion modes
- Refactoring combos
- Usage Inspection
- Solution Refactorings
- Move Code
- Navigating Hierarchies
- Inspect This
# Licensing
Course material is licensed under the Creative Commons Attribution-ShareAlike 3.0 Unported License.
For source code found in the Source folder - please check individual projects for license information (Rebus and BlogEngine.NET).
.%0A%0AThe%20material%20can%20be%20found%20at%20on%20%5BGitHub%5D(http://github.com/rasmuskl/ReSharperCourse).%0A%0AA%20short%20description%20of%20the%20course%20can%20be%20found%20in%20the%20git%20repository%20README%20(pasted%20below).%0A%0AThe%20precompiled%20exercises-PDF%20can%20be%20downloaded%20%5Bhere%20on%20GitHub%5D(https://github.com/rasmuskl/ReSharperCourse/raw/master/Source/ReSharper%2520Exercises.pdf).%0A%0A%23%20Introduction%0A%0AThis%20is%20my%20basic%20%5BReSharper%5D(http://www.jetbrains.com/resharper/)%20course%20material%20developed%20in%202012%20-%20based%20on%20ReSharper%206.1,%20although%20a%20lot%20of%20the%20material%20is%20still%20relevant.%20%0A%0AIt%20should%20provide%20enough%20content%20for%204%20to%206%20hours%20of%20entertainment.%20The%20course%20focuses%20on%20progressivly%20harder%20exercises%20and%20hands-on%20experience%20over%20a%20lot%20of%20talk.%0A%0AExercises%20are%20generated%20through%20the%20ASP.NET%20MVC%20site%20found%20in%20%60Source/CourseTasks%60.%0A%0A%23%20Topics%0A%0A-%20Why%20use%20ReSharper?%0A-%20Navigation%20%0A-%20Code%20Interaction%0A-%20Code%20Analysis%0A-%20Code%20Generation%0A-%20Refactoring%0A-%20Completion%20modes%0A-%20Refactoring%20combos%0A-%20Usage%20Inspection%0A-%20Solution%20Refactorings%0A-%20Move%20Code%0A-%20Navigating%20Hierarchies%0A-%20Inspect%20This%0A%0A%23%20Licensing%0A%0ACourse%20material%20is%20licensed%20under%20the%20Creative%20Commons%20Attribution-ShareAlike%203.0%20Unported%20License.%0A%0AFor%20source%20code%20found%20in%20the%20Source%20folder%20-%20please%20check%20individual%20projects%20for%20license%20information%20(Rebus%20and%20BlogEngine.NET).)
Microsoft DDC 2013 Reflections 26 Apr 2013 4:00 PM (11 years ago)
A few weeks ago, I attended and spoke at this years Danish Developer Conference by Microsoft. The conference was run in both Horsens and Copenhagen and both venues were cinemas. I gave a talk with Mads Kristensen with the topic of Visual Studio productivity tips. Mads covered plain Visual Studio and I gave a whirlwind tour of what productivity with ReSharper could look like. ## The venue I loved both venues, MegaScope in Horsens and Cinemaxx in Copenhagen, presenting in a cinema is just amazing. Forget everything about presentation resolutions and just fire away - Cinemaxx's projectors were 4K (4096 x 2304px). Having 60+ m2 of screen estate makes everything much simpler. Combined with comfortable seats it was really enjoyable. We had an entire cinema as a Speakers Lounge as well. ## My talk As previously mentioned, I gave my ReSharper whirlwind tour. The talk has very few slides and focuses on giving a quick overview of the most basic features in ReSharper. If you are looking specifically for my ReSharper slides, I have some old presentation blog posts containing a richer set. I think it will be the last time that I am going to give my basic ReSharper talk, unless specifically requested - since I have given it quite a few times now. I might be tempted to create a more advanced ReSharper talk at some point though. Maybe I will actually speak about some C# related stuff next time. ## Other talks I was generally happy with all the talks I saw, but I want to recommend 2 talks specifically, if you happen to get a chance to see them at a user group or at another conference: #### Advanced Unit Testing (Danish: Unit testing for viderekommende) [Mark Seemann](http://blog.ploeh.dk/) is a very experienced speaker and a passionate proponent of automated tests. This talk gives an introduction to some of the patterns to avoid brittle tests, especially in regards to test object construction and equality. In many regards it reflects some of the painful experiences I have gone through over the years. #### Bigger, Faster, Stronger: Optimizing ASP.NET 4 and 4.5 Applications [Mads Kristensen](http://madskristensen.net/) has given this talk so many times but it is better every time and it touches on so many helpful things to optimize your web pipeline from the server to the client. The talk is based around the [Web Developer Checklist](http://webdevchecklist.com/) - so if you can't see the talk live, at least take a look at the checklist.
Surviving no media keys on your new keyboard 18 Mar 2013 4:00 PM (12 years ago)
I've recently acquired a new keyboard, after using my trusty old Logitech for many years. I've come to rely on my media keys and the volume wheel for controlling Spotify or other apps.
My solution is to use [AutoHotKey](http://www.autohotkey.com) to bind the following combinations after a short conversation with [Mark](http://www.improve.dk) (although we don't entirely agree on the layout):
- Win + Numpad 4 - Previous track
- Win + Numpad 5 - Play / pause
- Win + Numpad 6 - Next track
- Win + Numpad 8 - Volume up
- Win + Numpad 2 - Volume down
- Win + Numpad 7 - Mute
Here's the script to add to AHK:
``` autohotkey
#Numpad4::Send {Media_Prev}
#Numpad5::Send {Media_Play_Pause}
#Numpad6::Send {Media_Next}
#Numpad2::Send {Volume_Down}
#Numpad7::Send {Volume_Mute}
#Numpad8::Send {Volume_Up}
```
... and on a final semi-unrelated note, I'll recommend my new mechanical keyboard - [Das Keyboard S Ultimate Silent](http://www.daskeyboard.com/model-s-ultimate-silent/). It's far from silent - but it's an awesome keyboard. The keys have a very nice feel as you're typing along and the keyboard itself is rather heavy (almost 2kg) and thus stay completely in place when typing.

%20to%20bind%20the%20following%20combinations%20after%20a%20short%20conversation%20with%20%5BMark%5D(http://www.improve.dk)%20(although%20we%20don't%20entirely%20agree%20on%20the%20layout):%0A%0A-%20Win%20+%20Numpad%204%20-%20Previous%20track%0A-%20Win%20+%20Numpad%205%20-%20Play%20/%20pause%0A-%20Win%20+%20Numpad%206%20-%20Next%20track%0A-%20Win%20+%20Numpad%208%20-%20Volume%20up%0A-%20Win%20+%20Numpad%202%20-%20Volume%20down%0A-%20Win%20+%20Numpad%207%20-%20Mute%0A%0AHere's%20the%20script%20to%20add%20to%20AHK:%0A%0A%60%60%60%20autohotkey%0A%23Numpad4::Send%20%7BMedia_Prev%7D%0A%23Numpad5::Send%20%7BMedia_Play_Pause%7D%0A%23Numpad6::Send%20%7BMedia_Next%7D%0A%23Numpad2::Send%20%7BVolume_Down%7D%0A%23Numpad7::Send%20%7BVolume_Mute%7D%0A%23Numpad8::Send%20%7BVolume_Up%7D%0A%60%60%60%0A%0A...%20and%20on%20a%20final%20semi-unrelated%20note,%20I'll%20recommend%20my%20new%20mechanical%20keyboard%20-%20%5BDas%20Keyboard%20S%20Ultimate%20Silent%5D(http://www.daskeyboard.com/model-s-ultimate-silent/).%20It's%20far%20from%20silent%20-%20but%20it's%20an%20awesome%20keyboard.%20The%20keys%20have%20a%20very%20nice%20feel%20as%20you're%20typing%20along%20and%20the%20keyboard%20itself%20is%20rather%20heavy%20(almost%202kg)%20and%20thus%20stay%20completely%20in%20place%20when%20typing.%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/mechanical_keyboard_hero.jpg%22%20classname%3D%22center%22%20/%3E)
Setting up Web Deploy 3.0 / MSDeploy 26 Sep 2012 4:00 PM (12 years ago)
I'm currently on the path of converting one of my sites from SFTP deployments to using [Web Deploy 3.0](http://www.iis.net/downloads/microsoft/web-deploy) and thought it might be interesting to document the process and the pitfalls that I run into. My approach is roughly based on [this guide](http://www.iis.net/learn/publish/using-web-deploy/configure-the-web-deployment-handler), but it wasn't a complete fit for me, so here we go.
## Motivation
So why would you want to use Web Deploy for deploying web sites? Compared to regular file copy or FTP deployments, Web Deploy offers the option of running a dedicated deployment service on your server, that is actually aware of IIS and can help you make your deployments as smooth as possible. In my case, my SFTP service had started to lock random assemblies recently, and since I'd been wanting upgrade to Web Deploy anyway, I thought now might be as good a time as any.
Web Deploy can do a bunch of things for you, such as syncing IIS sites (6, 7 and 8), deploying packages, archiving sites by offering a multitude of different providers. This post is dedicated to deploying a rather simple site that is already bin deployable.
## My setup
My setup is a remote server running Windows Server 2008 R2 with IIS 7.5 and a development environment on a Windows 7 Ultimate machine.
The site is an ASP.NET 4.0 mixed WebForms / MVC project. The application itself manages database migrations, so they're not in scope for the post either.
## Setup steps
1 - Created a dedicated deployment user for use with deployment. It's nice to know that everything is locked down, when you open up remote access.
2 - Installed Management Service role for my IIS in Server Manager.
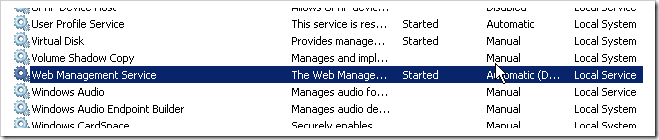
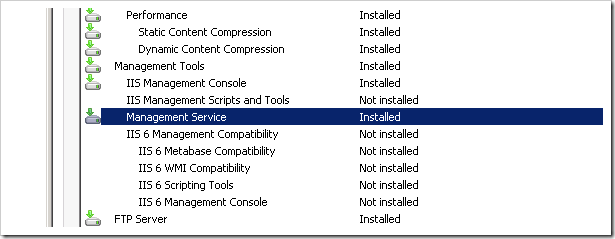 3 - Changed Web Management Service to Start automatically (delayed) and specified a specific deployment user.
3 - Changed Web Management Service to Start automatically (delayed) and specified a specific deployment user.
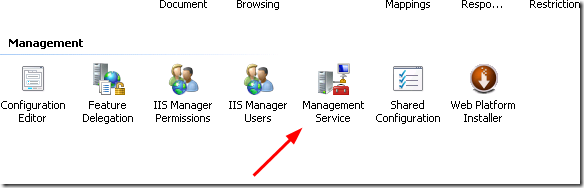
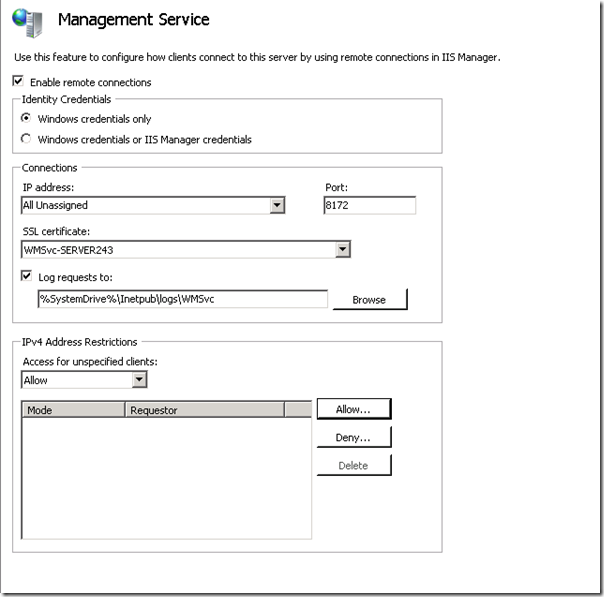
 4 - Configured Management Service within IIS.
4 - Configured Management Service within IIS.
 Like this:
Like this:
 5 - Created a new site in IIS. Gave the deployment user access to the site folder on the web server.
6 - Gave the deployment user access to the site through IIS Manager Permissions.
5 - Created a new site in IIS. Gave the deployment user access to the site folder on the web server.
6 - Gave the deployment user access to the site through IIS Manager Permissions.
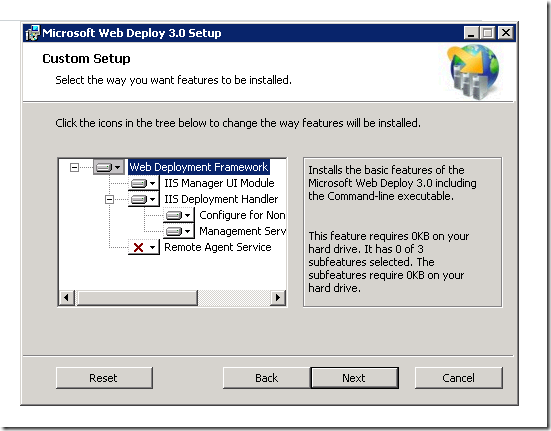
 7 - Installed Web Deploy 3.0 including IIS Deployment Handler (wasn't visible in the first custom install). Not using Platform installer. The IIS Deployment handler install option was not visible the first time I tried, because I hadn't installed the Management Service in IIS.
7 - Installed Web Deploy 3.0 including IIS Deployment Handler (wasn't visible in the first custom install). Not using Platform installer. The IIS Deployment handler install option was not visible the first time I tried, because I hadn't installed the Management Service in IIS.
 8 - The guide told me to add rules, but rules already existed in Management Service Delegation.
8 - The guide told me to add rules, but rules already existed in Management Service Delegation.
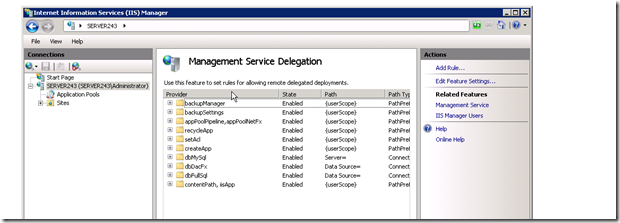
 (Already existing rules:)
(Already existing rules:)
 9 - Installed IIS on my local machine. Was rather freshly paved, so I hadn't yet. I'm guessing most of you can skip this step.
10 - Wasn't able to ‘Connect to Site' as mentioned in test guide - so I installed IIS Manager for Remote Administration v1.1 using Web Platform Installer.
9 - Installed IIS on my local machine. Was rather freshly paved, so I hadn't yet. I'm guessing most of you can skip this step.
10 - Wasn't able to ‘Connect to Site' as mentioned in test guide - so I installed IIS Manager for Remote Administration v1.1 using Web Platform Installer.
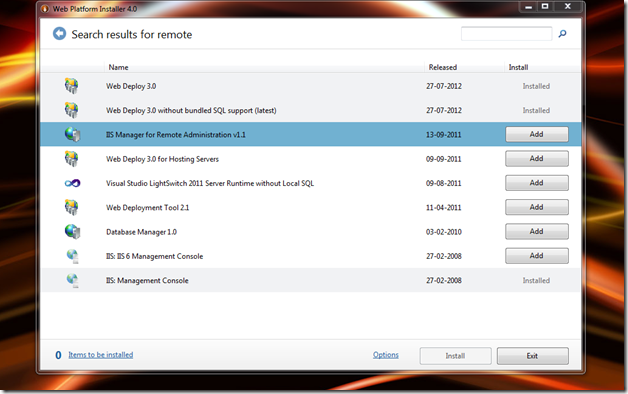 11 - Connected to the Site.
11 - Connected to the Site.
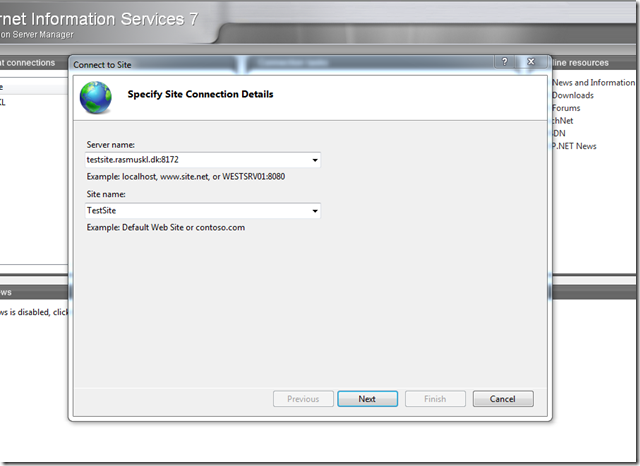 12 - Selected the site.
12 - Selected the site.
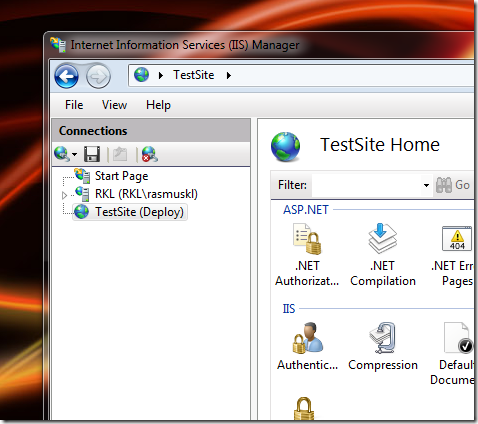 13 - ... aaaaand imported my application package that I'd created through Visual Studio.
13 - ... aaaaand imported my application package that I'd created through Visual Studio.
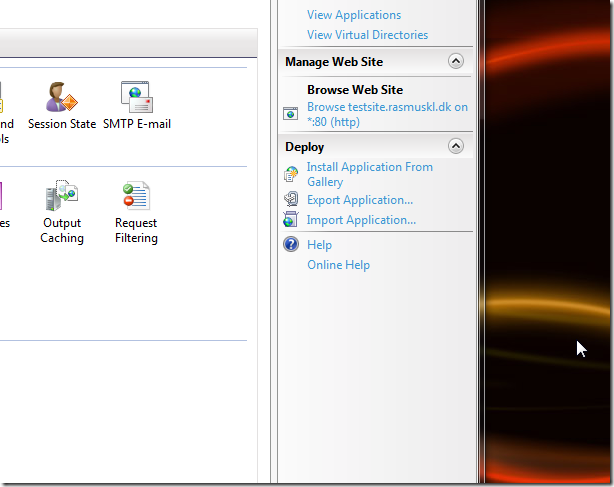 14 - Profit!
14 - Profit!
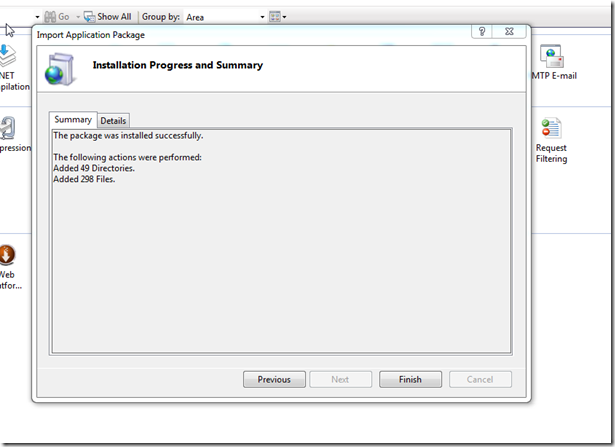 ## Conclusion
Now this is a rather crude picture guide. But hopefully it'll still be useful to some people. I know I'll check it next time I'm setting up Web Deploy.
My next goals are to adapt my rake scripts for the application to create the package on my TeamCity server and add one-click deployments directly from TeamCity.
## Conclusion
Now this is a rather crude picture guide. But hopefully it'll still be useful to some people. I know I'll check it next time I'm setting up Web Deploy.
My next goals are to adapt my rake scripts for the application to create the package on my TeamCity server and add one-click deployments directly from TeamCity.
%20and%20thought%20it%20might%20be%20interesting%20to%20document%20the%20process%20and%20the%20pitfalls%20that%20I%20run%20into.%20My%20approach%20is%20roughly%20based%20on%20%5Bthis%20guide%5D(http://www.iis.net/learn/publish/using-web-deploy/configure-the-web-deployment-handler),%20but%20it%20wasn't%20a%20complete%20fit%20for%20me,%20so%20here%20we%20go.%0A%20%20%0A%23%23%20Motivation%0A%20%20%0ASo%20why%20would%20you%20want%20to%20use%20Web%20Deploy%20for%20deploying%20web%20sites?%20Compared%20to%20regular%20file%20copy%20or%20FTP%20deployments,%20Web%20Deploy%20offers%20the%20option%20of%20running%20a%20dedicated%20deployment%20service%20on%20your%20server,%20that%20is%20actually%20aware%20of%20IIS%20and%20can%20help%20you%20make%20your%20deployments%20as%20smooth%20as%20possible.%20In%20my%20case,%20my%20SFTP%20service%20had%20started%20to%20lock%20random%20assemblies%20recently,%20and%20since%20I'd%20been%20wanting%20upgrade%20to%20Web%20Deploy%20anyway,%20I%20thought%20now%20might%20be%20as%20good%20a%20time%20as%20any.%0A%20%20%0AWeb%20Deploy%20can%20do%20a%20bunch%20of%20things%20for%20you,%20such%20as%20syncing%20IIS%20sites%20(6,%207%20and%208),%20deploying%20packages,%20archiving%20sites%20by%20offering%20a%20multitude%20of%20different%20providers.%20This%20post%20is%20dedicated%20to%20deploying%20a%20rather%20simple%20site%20that%20is%20already%20bin%20deployable.%0A%20%20%0A%23%23%20My%20setup%0A%20%20%0AMy%20setup%20is%20a%20remote%20server%20running%20Windows%20Server%202008%20R2%20with%20IIS%207.5%20and%20a%20development%20environment%20on%20a%20Windows%207%20Ultimate%20machine.%20%0A%20%20%0AThe%20site%20is%20an%20ASP.NET%204.0%20mixed%20WebForms%20/%20MVC%20project.%20The%20application%20itself%20manages%20database%20migrations,%20so%20they're%20not%20in%20scope%20for%20the%20post%20either.%0A%20%20%0A%23%23%20Setup%20steps%0A%20%20%0A1%20-%20Created%20a%20dedicated%20deployment%20user%20for%20use%20with%20deployment.%20It's%20nice%20to%20know%20that%20everything%20is%20locked%20down,%20when%20you%20open%20up%20remote%20access.%0A%20%20%0A2%20-%20Installed%20Management%20Service%20role%20for%20my%20IIS%20in%20Server%20Manager.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb_10.png%22%20/%3E%0A%20%20%0A3%20-%20Changed%20Web%20Management%20Service%20to%20Start%20automatically%20(delayed)%20and%20specified%20a%20specific%20deployment%20user.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/4_thumb.png%22%20/%3E%0A%20%20%0A4%20-%20Configured%20Management%20Service%20within%20IIS.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/1_thumb.png%22%20/%3E%0A%20%20%0ALike%20this:%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/2_thumb.png%22%20/%3E%0A%20%20%0A5%20-%20Created%20a%20new%20site%20in%20IIS.%20Gave%20the%20deployment%20user%20access%20to%20the%20site%20folder%20on%20the%20web%20server.%20%0A%20%20%0A6%20-%20Gave%20the%20deployment%20user%20access%20to%20the%20site%20through%20IIS%20Manager%20Permissions.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/5_thumb.png%22%20/%3E%0A%20%20%0A7%20-%20Installed%20Web%20Deploy%203.0%20including%20IIS%20Deployment%20Handler%20(wasn't%20visible%20in%20the%20first%20custom%20install).%20Not%20using%20Platform%20installer.%20The%20IIS%20Deployment%20handler%20install%20option%20was%20not%20visible%20the%20first%20time%20I%20tried,%20because%20I%20hadn't%20installed%20the%20Management%20Service%20in%20IIS.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/16_thumb.png%22%20/%3E%0A%20%20%0A8%20-%20The%20guide%20told%20me%20to%20add%20rules,%20but%20rules%20already%20existed%20in%20Management%20Service%20Delegation.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/15-out-of-order_thumb.png%22%20/%3E%0A%20%20%0A(Already%20existing%20rules:)%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/7_thumb.png%22%20/%3E%0A%20%20%0A9%20-%20Installed%20IIS%20on%20my%20local%20machine.%20Was%20rather%20freshly%20paved,%20so%20I%20hadn't%20yet.%20I'm%20guessing%20most%20of%20you%20can%20skip%20this%20step.%0A%20%20%0A10%20-%20Wasn't%20able%20to%20%E2%80%98Connect%20to%20Site'%20as%20mentioned%20in%20test%20guide%20-%20so%20I%20installed%20IIS%20Manager%20for%20Remote%20Administration%20v1.1%20using%20Web%20Platform%20Installer.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/9_thumb.png%22%20/%3E%0A%20%20%0A11%20-%20Connected%20to%20the%20Site.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/10_thumb.png%22%20/%3E%0A%20%20%0A12%20-%20Selected%20the%20site.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/11_thumb.png%22%20/%3E%0A%20%20%0A13%20-%20...%20aaaaand%20imported%20my%20application%20package%20that%20I'd%20created%20through%20Visual%20Studio.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/13_thumb.png%22%20/%3E%0A%20%20%0A14%20-%20Profit!%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/14_thumb.png%22%20/%3E%0A%20%20%0A%23%23%20Conclusion%0A%20%20%0ANow%20this%20is%20a%20rather%20crude%20picture%20guide.%20But%20hopefully%20it'll%20still%20be%20useful%20to%20some%20people.%20I%20know%20I'll%20check%20it%20next%20time%20I'm%20setting%20up%20Web%20Deploy.%0A%20%20%0AMy%20next%20goals%20are%20to%20adapt%20my%20rake%20scripts%20for%20the%20application%20to%20create%20the%20package%20on%20my%20TeamCity%20server%20and%20add%20one-click%20deployments%20directly%20from%20TeamCity.)
MOW2012: Exploring C# DSLs: LINQ, Fluent Interfaces and Expression Trees 18 Apr 2012 4:00 PM (13 years ago)
I gave my Exploring C# DSLs: LINQ, Fluent Interfaces and Expression Trees talk today at [Miracle Open World 2012](http://mow2012.dk) about C# Domain Specific Languages. The slides are now available [here](http://www.slideshare.net/rasmuskl/exploring-c-dsls-linq). ... and the demo source is available as a git repository on bitbucket [here](http://bitbucket.org/rasmuskl/mow2012dsltalk/). Note that some of the source is just mocked implementation, the goal was not really to show production level quality - but rather concepts. The quality of the few tests and commit messages reflect this.
Converting a Mercurial repository to Git (Windows) 11 Mar 2012 4:00 PM (13 years ago)
After going through the pain of (re-)discovering how to convert a Mercurial repository into a Git repository on Windows, I thought I'd share how easy it really is. I've bounced back and forth between Mercurial and Git a few times - my current preference is Git, mainly because I like Git's branching strategy a bit better - but really, they're both excellent choices. I still find the best analogy for comparing them is that [Git is MacGyver and Mercurial is James Bond](http://importantshock.wordpress.com/2008/08/07/git-vs-mercurial/). You can find quite a few [posts](http://arr.gr/blog/2011/10/bitbucket-converting-hg-repositories-to-git/) [describing](http://candidcode.com/2010/01/12/a-guide-to-converting-from-mercurial-hg-to-git-on-a-windows-client/) how to convert - but many of the steps mentioned in those guides are not needed if you have [TortoiseHg](http://tortoisehg.bitbucket.org/) installed, which most Windows Mercurial users do. ## Prerequisites As I already mentioned, this guide expects that you have [TortoiseHg](http://tortoisehg.bitbucket.org/) installed on your system. For the actual conversion, we're going to be using a Mercurial extension called [hggit](https://github.com/schacon/hg-git) that enables Mercurial to push and pull from Git repositories. You can either clone the [hggit](https://github.com/schacon/hg-git) repository on GitHub or grab a zipped version [here](https://github.com/schacon/hg-git/downloads). What we need is the **hggit** folder from the clone or zip file - put this some place handy and remember the path. ## Preparing the Git repository In this guide we're going to be pushing our repository to a local Git repository - so let's create a bare repository - this way you'll avoid Git complains about [pushing to a non-bare repository](http://gitready.com/advanced/2009/02/01/push-to-only-bare-repositories.html). Open a command prompt, create a directory for the new repository and from within the directory execute: `git init -bare` That's it - our Git repository is ready. Alternatively you could push directly to a Git repository on either [GitHub](http://www.github.com), [Bitbucket](http://www.bitbucket.org) or other provider. ## Enabling hggit in Mercurial Now we need to let Mercurial know about the hggit extension. This is done by adding it to the **.hgrc** or **mercurial.ini** file in your home directory (for me that'd be **c:\users\rasmuskl\mercurial.ini**). In the config file, find the **[extensions]** section - or add it at bottom if it's not already there. Then add a reference to the hggit extension followed by the path of the hggit folder: ``` hggit = c:\path\to\hggit ``` ## Converting the repository To convert the repository, simply open your command prompt, navigate to your Mercurial repository and do: `hg push c:\path\to\bare\git\repository` And you're done. You can now either clone the bare repository to a working directory - or push it to your GitHub or Bitbucket account.
Tips for decluttering Visual Studio 2010 27 Feb 2012 3:00 PM (13 years ago)
[Mogens Heller Grabe](http://mookid.dk/oncode/) wrote a [nice post](http://mookid.dk/oncode/archives/2725) about reducing the amount of clutter in your Visual Studio the other day - and I thought I'd chime in with a few tips.
## Hiding the Navigation bar
First up we have the navigation bar - which is taking up a line of your precious screen estate.
 To remove it, jump to:
Tools -> Options -> Text Editor -> All Languages
Uncheck ‘Navigation bar'. For extra bonus points, check ‘Line numbers'.
## Bringing back the Configuration Manager
The following tip I got from [Rasmus Wulff Jensen](http://www.rwj.dk/) when I mentioned that the only thing I really like from the standard Visual Studio toolbars is the ‘Configuration Manager' drop down that allows me to switch between Debug and Release builds. He showed me a neat trick to put it in the top toolbar.
Right click on the tool bar to bring up the tool bar selection.
To remove it, jump to:
Tools -> Options -> Text Editor -> All Languages
Uncheck ‘Navigation bar'. For extra bonus points, check ‘Line numbers'.
## Bringing back the Configuration Manager
The following tip I got from [Rasmus Wulff Jensen](http://www.rwj.dk/) when I mentioned that the only thing I really like from the standard Visual Studio toolbars is the ‘Configuration Manager' drop down that allows me to switch between Debug and Release builds. He showed me a neat trick to put it in the top toolbar.
Right click on the tool bar to bring up the tool bar selection.
 Choose ‘Customize'. Change the tab to ‘Commands' and move focus to the bottom of the list, like so:
Choose ‘Customize'. Change the tab to ‘Commands' and move focus to the bottom of the list, like so:
 The hit the ‘Add Command' button and go to the ‘Build' category. Scrolling to the bottom, you will find a command labeled ‘Solution Configurations'. Pick it.
The hit the ‘Add Command' button and go to the ‘Build' category. Scrolling to the bottom, you will find a command labeled ‘Solution Configurations'. Pick it.
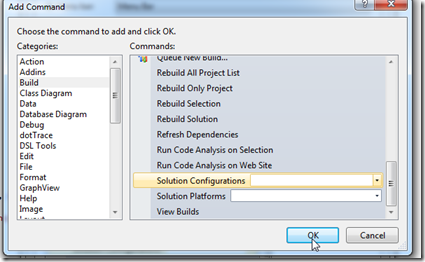 You now have an inline configuration manager on your top toolbar without taking up extra space. Same trick can be applied to any other commands.
You now have an inline configuration manager on your top toolbar without taking up extra space. Same trick can be applied to any other commands.
 ## Docking the Find dialog box
The ‘Find and Replace' dialog is probably one of the most used dialogs in Visual Studio - however with the default settings, you get a floating dialog that doesn't seem to want to go away after you're done using it.
## Docking the Find dialog box
The ‘Find and Replace' dialog is probably one of the most used dialogs in Visual Studio - however with the default settings, you get a floating dialog that doesn't seem to want to go away after you're done using it.
 If you dock it - like so:
If you dock it - like so:
 ... and unpin it, it will behave nicely and disappear when you're done searching or press ESC.
## Switch to a dark theme
This is more a matter of taste. Personally I've been using dark themes for Visual Studio forever. My eyes feel way more relaxed after a day of using a dark theme. My theory is that since computer monitors use [additive colors](http://en.wikipedia.org/wiki/Additive_color) (with white being a full blast mix of red, green and blue and black being no light), a dark theme simply emits way less light.
... and unpin it, it will behave nicely and disappear when you're done searching or press ESC.
## Switch to a dark theme
This is more a matter of taste. Personally I've been using dark themes for Visual Studio forever. My eyes feel way more relaxed after a day of using a dark theme. My theory is that since computer monitors use [additive colors](http://en.wikipedia.org/wiki/Additive_color) (with white being a full blast mix of red, green and blue and black being no light), a dark theme simply emits way less light.
 If you want, you can download my personal theme [here](/files/RKL-blue-theme-vs2010-2012-02-28.zip) (ReSharper specific). It's the same as I've previously posted, except I've adjusted it to work properly with Razor views too.
If you want, you can download my personal theme [here](/files/RKL-blue-theme-vs2010-2012-02-28.zip) (ReSharper specific). It's the same as I've previously posted, except I've adjusted it to work properly with Razor views too.
%20wrote%20a%20%5Bnice%20post%5D(http://mookid.dk/oncode/archives/2725)%20about%20reducing%20the%20amount%20of%20clutter%20in%20your%20Visual%20Studio%20the%20other%20day%20-%20and%20I%20thought%20I'd%20chime%20in%20with%20a%20few%20tips.%0A%20%20%0A%23%23%20Hiding%20the%20Navigation%20bar%0A%20%20%0AFirst%20up%20we%20have%20the%20navigation%20bar%20-%20which%20is%20taking%20up%20a%20line%20of%20your%20precious%20screen%20estate.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb_2.png%22%20/%3E%0A%20%20%0ATo%20remove%20it,%20jump%20to:%0A%20%20%0ATools%20-%26gt;%20Options%20-%26gt;%20Text%20Editor%20-%26gt;%20All%20Languages%0A%20%20%0AUncheck%20%E2%80%98Navigation%20bar'.%20For%20extra%20bonus%20points,%20check%20%E2%80%98Line%20numbers'.%0A%20%20%0A%23%23%20Bringing%20back%20the%20Configuration%20Manager%0A%20%20%0AThe%20following%20tip%20I%20got%20from%20%5BRasmus%20Wulff%20Jensen%5D(http://www.rwj.dk/)%20when%20I%20mentioned%20that%20the%20only%20thing%20I%20really%20like%20from%20the%20standard%20Visual%20Studio%20toolbars%20is%20the%20%E2%80%98Configuration%20Manager'%20drop%20down%20that%20allows%20me%20to%20switch%20between%20Debug%20and%20Release%20builds.%20He%20showed%20me%20a%20neat%20trick%20to%20put%20it%20in%20the%20top%20toolbar.%0A%20%20%0ARight%20click%20on%20the%20tool%20bar%20to%20bring%20up%20the%20tool%20bar%20selection.%20%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb_3.png%22%20/%3E%0A%20%20%0AChoose%20%E2%80%98Customize'.%20Change%20the%20tab%20to%20%E2%80%98Commands'%20and%20move%20focus%20to%20the%20bottom%20of%20the%20list,%20like%20so:%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb_4.png%22%20/%3E%0A%20%20%0AThe%20hit%20the%20%E2%80%98Add%20Command'%20button%20and%20go%20to%20the%20%E2%80%98Build'%20category.%20Scrolling%20to%20the%20bottom,%20you%20will%20find%20a%20command%20labeled%20%E2%80%98Solution%20Configurations'.%20Pick%20it.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb_5.png%22%20/%3E%0A%20%20%0AYou%20now%20have%20an%20inline%20configuration%20manager%20on%20your%20top%20toolbar%20without%20taking%20up%20extra%20space.%20Same%20trick%20can%20be%20applied%20to%20any%20other%20commands.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb_6.png%22%20/%3E%0A%20%20%0A%23%23%20Docking%20the%20Find%20dialog%20box%0A%20%20%0AThe%20%E2%80%98Find%20and%20Replace'%20dialog%20is%20probably%20one%20of%20the%20most%20used%20dialogs%20in%20Visual%20Studio%20-%20however%20with%20the%20default%20settings,%20you%20get%20a%20floating%20dialog%20that%20doesn't%20seem%20to%20want%20to%20go%20away%20after%20you're%20done%20using%20it.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb_7.png%22%20/%3E%0A%20%20%0AIf%20you%20dock%20it%20-%20like%20so:%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb_8.png%22%20/%3E%0A%20%20%0A...%20and%20unpin%20it,%20it%20will%20behave%20nicely%20and%20disappear%20when%20you're%20done%20searching%20or%20press%20ESC.%0A%20%20%0A%23%23%20Switch%20to%20a%20dark%20theme%0A%20%20%0AThis%20is%20more%20a%20matter%20of%20taste.%20Personally%20I've%20been%20using%20dark%20themes%20for%20Visual%20Studio%20forever.%20My%20eyes%20feel%20way%20more%20relaxed%20after%20a%20day%20of%20using%20a%20dark%20theme.%20My%20theory%20is%20that%20since%20computer%20monitors%20use%20%5Badditive%20colors%5D(http://en.wikipedia.org/wiki/Additive_color)%20(with%20white%20being%20a%20full%20blast%20mix%20of%20red,%20green%20and%20blue%20and%20black%20being%20no%20light),%20a%20dark%20theme%20simply%20emits%20way%20less%20light.%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb_9.png%22%20/%3E%0A%20%20%0AIf%20you%20want,%20you%20can%20download%20my%20personal%20theme%20%5Bhere%5D(/files/RKL-blue-theme-vs2010-2012-02-28.zip)%20(ReSharper%20specific).%20It's%20the%20same%20as%20I've%20previously%20posted,%20except%20I've%20adjusted%20it%20to%20work%20properly%20with%20Razor%20views%20too.)
Peer Reviews - Why bother? 2 Jan 2012 3:00 PM (13 years ago)
 Working with code is tricky business - the larger and more complex the code base, the more tricky. Ingraining micro-processes into your work day can help fix some of the issues, some of the broken windows that grow into almost any code base over time. Peer reviews is a great starting point.
There are many forms of peer review - but this post is mainly about informal check-in reviews. The process is simple: Any commit to the code repository must be signed off by another member of the team. Many argue that small commits are okay to go unchecked - but the size of a “small commit” grows in my experience. My counterargument is that a small commit will only take 30 seconds or less. Simply bring up the change set, go over the changes, discuss anything needed informally, then add "Review: <initials>" to the commit message and fire away.
## Benefits?
One of the first things you'll notice when you introduce peer reviews is **catching common commit mistakes**. These include small changes in files made while testing or debugging that were not meant to be committed, files that were not related to the current commit and, if your reviewer is alert, files missing from the commit.
Another small side effect is a **subconscious increase in code quality**. Knowing that someone else will review your code closely will increase the mental barrier to introducing hacks and other peculiarities that
Working with code is tricky business - the larger and more complex the code base, the more tricky. Ingraining micro-processes into your work day can help fix some of the issues, some of the broken windows that grow into almost any code base over time. Peer reviews is a great starting point.
There are many forms of peer review - but this post is mainly about informal check-in reviews. The process is simple: Any commit to the code repository must be signed off by another member of the team. Many argue that small commits are okay to go unchecked - but the size of a “small commit” grows in my experience. My counterargument is that a small commit will only take 30 seconds or less. Simply bring up the change set, go over the changes, discuss anything needed informally, then add "Review: <initials>" to the commit message and fire away.
## Benefits?
One of the first things you'll notice when you introduce peer reviews is **catching common commit mistakes**. These include small changes in files made while testing or debugging that were not meant to be committed, files that were not related to the current commit and, if your reviewer is alert, files missing from the commit.
Another small side effect is a **subconscious increase in code quality**. Knowing that someone else will review your code closely will increase the mental barrier to introducing hacks and other peculiarities that sometimes sneak into code.
While many developers focus more on writing self-documenting, readable code, getting another pair of eyes on the code is great for clarifying the intent of the code - uncovering small scale refactorings such as renames and extractions. The earlier you **uncover and discuss minor design issues** like these and further **aligning team coding styles**, the better shape the code base is likely to end up. Aligning coding styles across multiple teams is a hard task, any improvement is worth taking. Once in a while a peer review will uncover larger design issues and ultimately lead to discarding the code under review and going for a different solution. This is not always a pleasant experience, but it's **easier to kill your darlings when nudged in the right direction** by a colleague.
In line with the last paragraph, reviews also **often spur discussions about larger things like domain concepts and architecture** - it just seems to come up more when looking at concrete issues in the code base. Likewise, the reviewer is investing some of this time in the code and putting his name on it, thus **increasing shared code ownership** of the code.
Lastly, just seeing how other developers work can **give insight in other developers IDE and tool tricks**. Being a keyboard-junkie myself, I often find myself exchanging IDE / productivity tips during reviews.
## Conclusion
Information code reviews are, in my opinion, one of the cheaper ways to directly affect code quality - assuming it's taken seriously of course. You might notice that many of these benefits are the same as with pair programming - and they are. Pair programming is usually harder to get started on and not suited for all assignments, although most teams ought to do way more pair programming than they are. Peer review is broadly applicable. Try it with your team for a week or a month - if I'm wrong and nothing improves, I'll buy you a beer next time we meet :-)
)
Check your backups - unexpected SQL Server VSS backup 29 Nov 2011 3:00 PM (13 years ago)
Your backup is only as good as your last restore. I recently changed my backup strategy on my SQL Server 2008 from doing a full nightly backup to doing incremental nightly backups and only a full backup each week. SQL Server incremental backups base themselves on the last full backup. This is nice when you go to restore them since you will only need the full backup + the incremental backup, not any intermediary backups.
However, a few days back I wanted to check some queries on a larger dataset and decided to check my backups at the same time. Fetched full + incremental backups from the server and started the local restore:
``` sql
RESTORE DATABASE [testdb]
FROM DISK = N'C:\temp\full.wbak'
WITH FILE = 1, NORECOVERY, REPLACE
RESTORE DATABASE [testdb]
FROM DISK = N'C:\temp\incremental.bak'
WITH FILE = 1, RECOVERY
```
The first backup went through fine, but restoring the incremental backup resulted in the following error message:
This differential backup cannot be restored because the database has not been restored to the correct earlier state.
SQL Server refused to restore my incremental database - this is only supposed to happen if there has been another full backup in between. I double checked the backups I had fetched, checked that I had the set up the new backups correctly and that the old backup job was gone. Everything seemed fine.
I then explored the backup history a bit further with a query adjusted from the one found in [this](http://blog.sqlauthority.com/2010/11/10/sql-server-get-database-backup-history-for-a-single-database/) post:
``` sql
SELECT TOP 10
s.database_name,
m.physical_device_name,
s.backup_start_date
FROM msdb.dbo.backupset s
INNER JOIN msdb.dbo.backupmediafamily m ON s.media_set_id = m.media_set_id
WHERE s.database_name = DB_NAME() -- Remove this line for all the database
ORDER BY backup_start_date DESC
```
The result showed that there had indeed been backups in between my nightly runs:
 Further research revealed that backup devices with a GUID name are virtual backup devices and the times of backups matched the daily schedule of our bare metal system backup. Turns out that [R1Soft's backup software](http://www.r1soft.com/windows-cdp/) integrates with SQL Server's VSS writer service to perform backups when it finds databases on disk.
Disabling the VSS writer service returned the backups to a working state (VSS backup + my own incremental would also have worked). I did consider skipping my own nightly backups (since the VSS backup is super fast) and just using the R1Soft one, but decided against it for now - my own management is already set up and if I do need to restore, grabbing the backup from the external backup is much slower and more tedious than having it on disk already.
Further research revealed that backup devices with a GUID name are virtual backup devices and the times of backups matched the daily schedule of our bare metal system backup. Turns out that [R1Soft's backup software](http://www.r1soft.com/windows-cdp/) integrates with SQL Server's VSS writer service to perform backups when it finds databases on disk.
Disabling the VSS writer service returned the backups to a working state (VSS backup + my own incremental would also have worked). I did consider skipping my own nightly backups (since the VSS backup is super fast) and just using the R1Soft one, but decided against it for now - my own management is already set up and if I do need to restore, grabbing the backup from the external backup is much slower and more tedious than having it on disk already.
%20post:%0A%0A%60%60%60%20sql%0ASELECT%20TOP%2010%0As.database_name,%0Am.physical_device_name,%0As.backup_start_date%0AFROM%20msdb.dbo.backupset%20s%0AINNER%20JOIN%20msdb.dbo.backupmediafamily%20m%20ON%20s.media_set_id%20%3D%20m.media_set_id%0AWHERE%20s.database_name%20%3D%20DB_NAME()%20--%20Remove%20this%20line%20for%20all%20the%20database%0AORDER%20BY%20backup_start_date%20DESC%0A%60%60%60%0A%0AThe%20result%20showed%20that%20there%20had%20indeed%20been%20backups%20in%20between%20my%20nightly%20runs:%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb_1.png%22%20/%3E%0A%0AFurther%20research%20revealed%20that%20backup%20devices%20with%20a%20GUID%20name%20are%20virtual%20backup%20devices%20and%20the%20times%20of%20backups%20matched%20the%20daily%20schedule%20of%20our%20bare%20metal%20system%20backup.%20Turns%20out%20that%20%5BR1Soft's%20backup%20software%5D(http://www.r1soft.com/windows-cdp/)%20integrates%20with%20SQL%20Server's%20VSS%20writer%20service%20to%20perform%20backups%20when%20it%20finds%20databases%20on%20disk.%0A%0ADisabling%20the%20VSS%20writer%20service%20returned%20the%20backups%20to%20a%20working%20state%20(VSS%20backup%20+%20my%20own%20incremental%20would%20also%20have%20worked).%20I%20did%20consider%20skipping%20my%20own%20nightly%20backups%20(since%20the%20VSS%20backup%20is%20super%20fast)%20and%20just%20using%20the%20R1Soft%20one,%20but%20decided%20against%20it%20for%20now%20-%20my%20own%20management%20is%20already%20set%20up%20and%20if%20I%20do%20need%20to%20restore,%20grabbing%20the%20backup%20from%20the%20external%20backup%20is%20much%20slower%20and%20more%20tedious%20than%20having%20it%20on%20disk%20already.)
NHibernate Flushing and You 14 Jun 2011 4:00 PM (13 years ago)
Working with NHibernate, you will eventually have to know something about flushing. Flushing is the process of persisting the current session changes to the database. In this post, I will explain how flushing works in NHibernate, which options you have and what the benefits and disadvantages are. As you work with the NHibernate session, loading existing entities and attaching new entities, NHibernate will keep track of the objects that are associated with current session. When a flush is triggered, NHibernate will perform dirty checking; inspect the list of attached entities to determine what needs to be saved and which SQL statements are required to persist the changes. NHibernate offers several different flush modes that determine when a flush is triggered. The flush mode can be set using a property on the session (usually when opening the session). Out of the box NHibernate defaults to **FlushMode.Auto** which is a flush mode that offers a minimum of surprises while providing decent performance. Auto will flush changes to the database when a manual flush is performed (using ISession.Flush()), when a transaction is committed and when NHibernate deems that an auto flush is necessary to serve up-to-date results in response to queries. While the auto flush is convenient, it does cause a few disadvantages as well. To determine whether an auto flush is required before executing a query NHibernate has to inspect the entities attached to the session. This is clearly a performance overhead and unfortunately as application complexity (and thus likely session length, number of queries and number of attached entities) increases, the cost will be in the ballpark of O(q*e) - quadratic growth based on number of **q**ueries and **e**ntities. Furthermore auto flushes are not always easy to predict, especially in complex systems - this can lead to unexpected exceptions if using things like NHibernates merge and replicate features (a blog post all by itself). A better solution for bigger applications is **FlushMode.Commit**, this flush mode will flush on manual flushes and when transactions are committed. Avoiding auto flushes provides quite a few performance opportunities, it will potentially require fewer SQL statements (multiple changes to the same data), it will cause fewer round trips to the database and thus enable better batching. What you need to understand before changing your flush mode to FlushMode.Commit is that your queries may return stale results until you commit transactions. However, this is generally what people expect when working with transactions, so it is usually not a problem. In some cases, you might have to perform a manual flush, but it makes sense to reduce the number of these (since they defeat the benefit of the flush mode). NHibernate offers two more (usable) flush modes. **FlushMode.Always** will trigger a flush before every query and is thus generally not useful except for maybe some special edge cases. **FlushMode.Never** will cause the session to only flush when manually flushing - this can be useful to create a read-only session (better performance and more assurance that no flushes are performed). For read-only / bulk needs, it's also practical to look into IStatelessSession (low memory / performant for bulk operations) and ReadOnly on queries and criterias introduced in NHibernate 3.1.
Countdown timer 25 May 2011 4:00 PM (13 years ago)
I demoed a small app today at the Demo Dag session at Community Day.
The app was developed at an ANUG Code Dojo - and the purpose is simply to create timers that are a few pixels high either at the bottom or top of your screen - to be used for running Pomodoros or other timing needs - like an informal timer for a presentation.
I got a few requests for the app, so I've uploaded the source to Bitbucket [here](http://bitbucket.org/rasmuskl/countdown/downloads) (there's also a v. 0.1 zip file with an executable - if you don't want to build from source).
Bear in mind that this app was hacked together in a few hours (with the purpose of learning WPF actually - we got sidetracked) - so don't expect quality code or an excellent polished app. It has quirks - you have been warned :-)
 Enjoy.
Enjoy.
%20(there's%20also%20a%20v.%200.1%20zip%20file%20with%20an%20executable%20-%20if%20you%20don't%20want%20to%20build%20from%20source).%0A%20%20%0ABear%20in%20mind%20that%20this%20app%20was%20hacked%20together%20in%20a%20few%20hours%20(with%20the%20purpose%20of%20learning%20WPF%20actually%20-%20we%20got%20sidetracked)%20-%20so%20don't%20expect%20quality%20code%20or%20an%20excellent%20polished%20app.%20It%20has%20quirks%20-%20you%20have%20been%20warned%20:-)%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/image_thumb.png%22%20/%3E%0A%20%20%0AEnjoy.)
Slides from ANUG VS Launch Event 23 May 2010 4:00 PM (14 years ago)
I spoke last week about ReSharper 5 at [ANUG](http://www.anug.dk)'s Visual Studio 2010 launch event. Here are the slides from my presentation. The slides are in danish and probably won't make too much sense as most of my presentation was done demoing stuff - but they should give the gist of it. [Slides](/files/ReSharper-5-ANUG-VS-Launch.pptx) If you have any questions on my presentation, feel free to shoot me a mail here on the blog :-)
Slides from Miracle Open World 19 Apr 2010 4:00 PM (15 years ago)
Last week I gave two talks at MOW2010. Was an awesome conference and the 80% talks + 80% networking concept really held true. Hope to be going again next year - as speaker or otherwise. Here is the slides from my two talks. ## Increasing productivity with ReSharper This talk is about optimizing the mechanical part of your work. See how a keyboard-centric focus can speed up your work and how to navigate codebases easily independent of size. Visual Studio 2010 has introduced more advanced keyboard features, but ReSharper is still king, so it will be the main focus of the talk. While this session will contain a lot of fast-paced flashy keyboard shortcuts, it will also contain basic techniques and advice for you to get started with your own keyboard. [Slides](/files/Productivity-with-ReSharper.pptx) ## Practical ASP.NET MVC 2 ASP.NET MVC is the new kid on the Microsoft block. This talk will give you a short introduction to the framework and the new features in ASP.NET MVC 2. After the introduction, we will dig into some practical experiences and common situations of actually implementing a system using ASP.NET MVC. Detours will include other alternative open-source web frameworks and maybe even some JavaScript. [Slides](/files/Practical-ASP.NET-MVC.pptx)
Black / Blue Visual Studio 2010 + ReSharper 5 Theme 19 Apr 2010 4:00 PM (15 years ago)
I have been using black background in Visual Studio for as long I can remember. I started out using Rob Conery's black / orange TextMate theme, but last year I created my own black theme with a blueish style. Today at the [ANUG](http://www.anug.dk) code dojo we tweaked it to actually look alright with the changes in Visual Studio and especially ReSharper.
You can download the theme [here](/files/RKL-blue-theme-vs2010-2010-04-20.zip) if you want a nice black theme.
It looks like this:
 Selection:
Selection:
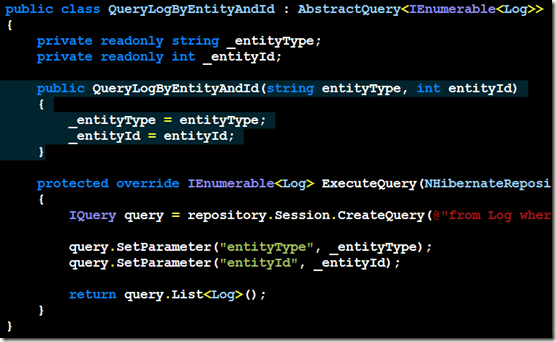 Subtle highlights of active identifier:
Subtle highlights of active identifier:
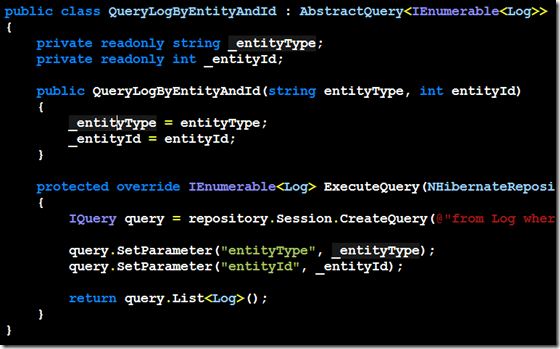 Enjoy :-)
Enjoy :-)
%20code%20dojo%20we%20tweaked%20it%20to%20actually%20look%20alright%20with%20the%20changes%20in%20Visual%20Studio%20and%20especially%20ReSharper.%0A%20%20%0AYou%20can%20download%20the%20theme%20%5Bhere%5D(/files/RKL-blue-theme-vs2010-2010-04-20.zip)%20if%20you%20want%20a%20nice%20black%20theme.%0A%20%20%0AIt%20looks%20like%20this:%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/BlackBlueVisualStudio2010ReSharper5Theme/7E978485/theme_thumb.png%22%20/%3E%20%0A%20%20%0ASelection:%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/BlackBlueVisualStudio2010ReSharper5Theme/428B42D0/image_thumb.png%22%20/%3E%20%0A%20%20%0ASubtle%20highlights%20of%20active%20identifier:%0A%20%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/BlackBlueVisualStudio2010ReSharper5Theme/517271EA/image_thumb.png%22%20/%3E%20%0A%20%20%0AEnjoy%20:-))
SOLID Presentation Slides 26 Oct 2009 4:00 PM (15 years ago)
A few weeks back I gave a talk in Odense .NET User Group ([ONUG](http://www.onug.dk)) on “Practical SOLID in C#” about object-orientation and the SOLID principles. Here is the slide deck for the presentation. [Download](/files/Solid-presentation.pptx)
Why AAA style mocking is better than Record / Playback 23 May 2009 4:00 PM (15 years ago)
If you've followed me on twitter for more than a couple of days, you will most probably have heard my grumbling each time I run into issues using record / playback mocking - so I thought I'd write a short post on my experiences with both and why I think that I keep bumping into issues with record / playback.
## Phases of a test
If you take a look at the normal flow of a test method without mocking, it will usually perform some kind of setup, then perform some action that invokes the code under test - and then at the end, make some assertions about the state of some component that you want verified. While some tests continue after this point, this is where you should stop if you're following the "one assert per test" rule - this is sort of the single responsibility principle for tests. This flow is also the inspiration for the AAA name - first you **Arrange **your test setup, then you **Act** upon the class under test - and then you **Assert** something about the state. Here's a simple example without mocking:
``` csharp
[Test]
public void CanRemoveCategories()
{
// Arrange
var collection = new CategoryCollection("test");
// Act
collection.RemoveCategory("test");
// Assert
Assert.That(collection.Count, Is.EqualTo(0));
}
```
This test is chronologically sound, it makes sense and it is easy to read - but then again, this is a state-based test, I said I was going to talk about behavioral tests - mock tests.
## Phase confusion
Many people find that mocking is rather difficult to understand and that it often very hard to read and understand. Since our tests act as an API-description for our code - and since we want to be able to figure out how to fix our failed tests - readability is important. Now, let's look at one of my tests from a Record / Playback point of view. I'm using Rhino Mocks as my mocking framework in this test:
``` csharp
[Test]
public void ShouldIgnoreRespondentsThatDoesNotExistRecordPlayback()
{
var guid = Guid.NewGuid();
IEventRaiser executeRaiser;
using(_mocks.Record())
{
Expect.Call(_view.Respondents).Return(new[] {guid.ToString()});
Expect.Call(_repository.GetById(guid)).Return(null);
_view.ExecuteOperation += null;
executeRaiser = LastCall.IgnoreArguments()
.Repeat.Any()
.GetEventRaiser();
Expect.Call(_view.OperationErrors = null)
.IgnoreArguments()
.Constraints(List.IsIn("Non-existant respondent: " + guid));
}
using(_mocks.Playback())
{
new BulkRespondentPresenter(_view, _repository);
executeRaiser.Raise(null, EventArgs.Empty);
}
}
```
Now, at a glance, can you tell me what this test is really doing? There's something with a view and a repository and we can probably deduce quite a bit from the test name. But it's rather hard to separate the different phases I talked about before **Arrange**, **Act** and **Assert**. Below, I've tried to annotate the test with the phases:
``` csharp
[Test]
public void ShouldIgnoreRespondentsThatDoesNotExistRecordPlayback()
{
// Arrange
var guid = Guid.NewGuid();
// Part of Act
IEventRaiser executeRaiser;
using(_mocks.Record())
{
// Arrange (or Assert?)
Expect.Call(_view.Respondents).Return(new[] {guid.ToString()});
Expect.Call(_repository.GetById(guid)).Return(null);
// Part of Act
_view.ExecuteOperation += null;
executeRaiser = LastCall.IgnoreArguments()
.Repeat.Any()
.GetEventRaiser();
// Assert
Expect.Call(_view.OperationErrors = null)
.IgnoreArguments()
.Constraints(List.IsIn("Non-existant respondent: " + guid));
}
using(_mocks.Playback())
{
// Arrange
new BulkRespondentPresenter(_view, _repository);
// Act
executeRaiser.Raise(null, EventArgs.Empty);
}
}
```
No wonder it's hard to read and understand. The phases are mixed all over - and the Asserts are in the middle of the test - this is nothing like the natural flow of the previous test without mocking. I usually like to have the phases separated in my test with comments as well, but it's just not possible in this test. I wrote this test up rather quickly, so there might be a better way of doing it that I am missing - if there is, please yell at me :-)
## Sorting out the confusion
AAA mocking, as the name suggests, is all about clearing out the confusion in that last test - it's about maintaining the original test flow. It just so happens also to have some other benefits, that I will get into later in the post. I've written the same test as above in an AAA style, this time with Moq, since I'm trying it out at the moment, but Rhino Mocks has similar syntax. Moq is pretty heavy on lambda expressions, but even if you haven't worked with those yet, I'm sure you will grasp the idea. If you want a general introduction to mocking with Moq, [Justin Etheredge](http://www.codethinked.com/) has a small [series](http://www.codethinked.com/post/2009/03/13/Beginning-Mocking-With-Moq-3-Part-1.aspx) about it.
``` csharp
[Test]
public void ShouldIgnoreRespondentsThatDoesNotExist()
{
// Arrange
var guid = Guid.NewGuid();
_viewMock.Setup(x => x.Respondents).Returns(new[] { guid.ToString() });
_repositoryMock.Setup(x => x.GetById(guid)).Returns(() => null);
// Act
_viewMock.Raise(x => x.ExecuteOperation += null, EventArgs.Empty);
// Assert
_viewMock.VerifySet(x => x.OperationErrors =
It.Is
Be Mindful Of Your Dependencies 10 May 2009 4:00 PM (15 years ago)
Dependencies are everywhere in your code, you cannot avoid them, without dependencies, your software would make no sense, it is the interaction and collaboration between the software entities that create the program. Now this statement doesn't mean that we should not worry about our dependencies - we just can't remove them completely. But as with almost any other aspect of good software development, we should be mindful of our dependencies. ## Coupling When a software entity depends on another, they are said to be coupled. Coupling ranges in degrees from totally decoupled over loosely coupled to tightly coupled. The tighter two software entities are coupled, the bigger risk that when one changes, the other will be forced to change as well. Why is this important? Because coupling is transitive (if A depends on B and B depends on C, A indirectly depends on C) and we would like to be able to change our program in the future. If you have a program where all components depend on each other and the coupling is high, a small change will often ripple through the system - either a) forcing you to change a bigger part of the system (potentially creating more ripples) or b) breaking the system in unexpected places. If not treated properly, these ripples can cause developers to loose confidence in their changes (what will I break this time?) and slow development down - maybe even to a halt. ## Cohesion Cohesion describes how related the responsibilities within a component are, how focused it is. This relates to the functionality within the component - a static utility class will often have rather low cohesion. But it also relates to the level of abstraction used within the component - again, a class that does both very high level operations and very low level operations will often have very low cohesion. Code with low cohesion will often be harder to understand, since it doing many different things. It will often be easier to reuse a component with high cohesion, since it will be more focused on doing a single task. ## Managing Dependencies So how do we manage dependencies? As mentioned, we can't get rid of them - but we can choose to decouple our software components from each other - and we can work to increase the cohesion of our components. Looking into the [Gang of Four book](http://www.amazon.com/Design-Patterns-Object-Oriented-Addison-Wesley-Professional/dp/0201633612), some basic advice is available: - Program to an interface, not an implementation. - Favor composition over inheritance. ## Interfaces Decoupling often involves programming to an interface instead of an implementation. Interfaces can help us break our dependency chains - looking at the example from before: If A depends on B and B depends on C - we can break the dependency chain by making an interface IB of B. Now A depends on IB instead. Interfaces, when used properly, can be seen as concepts and are thus more "stable" than an actual implementation. It is a contract that describes a set of properties for some object to fulfill. If you were to build a tall tower, would you prefer to have the core of the tower made of stable building blocks or instable ones? Having an interface also allows us to tweak other things, such as the granularity of access - the size of the surface on which A is dependant. If we reduce the size of the interface and thus the dependency, A's usage of B will be easier to control - and new concrete classes based on IB will probably be easier to implement and have higher cohesion too. ## Composition Another factor that can help us reduce coupling is to favor composition over inheritance. I like the analogy from the Gang of Four book where they talk about inheritance as white-box reuse, while composition is black-box reuse. What this means is that a sub-class will often be tightly coupled to the internals of the parent. In languages like C# and Java, single inheritance limits your options even further, once you start inheriting - and languages with multiple inheritance often suffer from other [problems](http://en.wikipedia.org/wiki/Diamond_problem). Composition on the other hand, is all about creating small units of focused behavior and then "weaving" this behavior into the desired functionality. With composition, different components are free to vary independent of each other - whereas this might cause combinatorial explosions in inheritance trees. This is not to say that inheritance is not useful, but it is often overused - composition is often a little harder to grasp at first (I know it took me a while), but it is a really powerful technique. ## Conclusion In this post I have discussed some of the basics about managing dependencies. It is on a reasonably low level, but will be the basis for some of my next posts on design principles and design patterns - since many of them build upon exactly this.
Code Quality and Software Entropy 30 Mar 2009 4:00 PM (16 years ago)
 Code is an odd thing, it can be beautiful, ugly, horrible, elegant, it can smell - some people even compare code to poetry. If you are a developer, you will know that there are an almost infinite number of ways that you can write a piece of code with the same functionality. The way chosen will affect the different qualities that the code - and thus the program as a whole - will exhibit. These qualities are things like performance, testability, robustness, security, scalability etc.
However, when developers talk about code quality (at least when I do) the main focus is often maintainability and flexibility. From my point of view, any software project is always decaying, especially if you have multiple people working on it, hacks are made, designs are twisted into fulfilling new responsibilities that their original creator didn't foresee or intend. Even with a clean design and a focus on maintaining high quality, the amount of code is almost always increasing with new functionality, as is the programs complexity. This is sometimes known as software entropy - chaos. If this entropy is ignored over longer periods of time, the technical debt incurred will keep increasing until the interest is so high that the project will grind to a halt - creating new features takes a long time and introduces many new and interesting bugs.
Maintainability is important on most projects, it often depends on the complexity of the program and the expected lifetime - so if you are doing prototypes or mock-ups, focusing on maintainability may not be beneficial, although in my experience, when management sees a really cool prototype, they often feel like building a project on top of it. Most software projects will have a rather long lifetime, often with multiple versions and a need to maintain the project even after it has shipped.
Obtaining high code quality is a craft, it requires discipline and continuous refactoring and improvement. This will be the main topic of my blog for a while, save the random posts about ReSharper or other intriguing things that may come up. Topics within this field off the top of my head: Unit testing, design principles (SOLID and others), design patterns, understanding and taming dependencies, inversion of control containers, simplicity and many more - ideas are welcome.
Code is an odd thing, it can be beautiful, ugly, horrible, elegant, it can smell - some people even compare code to poetry. If you are a developer, you will know that there are an almost infinite number of ways that you can write a piece of code with the same functionality. The way chosen will affect the different qualities that the code - and thus the program as a whole - will exhibit. These qualities are things like performance, testability, robustness, security, scalability etc.
However, when developers talk about code quality (at least when I do) the main focus is often maintainability and flexibility. From my point of view, any software project is always decaying, especially if you have multiple people working on it, hacks are made, designs are twisted into fulfilling new responsibilities that their original creator didn't foresee or intend. Even with a clean design and a focus on maintaining high quality, the amount of code is almost always increasing with new functionality, as is the programs complexity. This is sometimes known as software entropy - chaos. If this entropy is ignored over longer periods of time, the technical debt incurred will keep increasing until the interest is so high that the project will grind to a halt - creating new features takes a long time and introduces many new and interesting bugs.
Maintainability is important on most projects, it often depends on the complexity of the program and the expected lifetime - so if you are doing prototypes or mock-ups, focusing on maintainability may not be beneficial, although in my experience, when management sees a really cool prototype, they often feel like building a project on top of it. Most software projects will have a rather long lifetime, often with multiple versions and a need to maintain the project even after it has shipped.
Obtaining high code quality is a craft, it requires discipline and continuous refactoring and improvement. This will be the main topic of my blog for a while, save the random posts about ReSharper or other intriguing things that may come up. Topics within this field off the top of my head: Unit testing, design principles (SOLID and others), design patterns, understanding and taming dependencies, inversion of control containers, simplicity and many more - ideas are welcome.
%20the%20main%20focus%20is%20often%20maintainability%20and%20flexibility.%20From%20my%20point%20of%20view,%20any%20software%20project%20is%20always%20decaying,%20especially%20if%20you%20have%20multiple%20people%20working%20on%20it,%20hacks%20are%20made,%20designs%20are%20twisted%20into%20fulfilling%20new%20responsibilities%20that%20their%20original%20creator%20didn't%20foresee%20or%20intend.%20Even%20with%20a%20clean%20design%20and%20a%20focus%20on%20maintaining%20high%20quality,%20the%20amount%20of%20code%20is%20almost%20always%20increasing%20with%20new%20functionality,%20as%20is%20the%20programs%20complexity.%20This%20is%20sometimes%20known%20as%20software%20entropy%20-%20chaos.%20If%20this%20entropy%20is%20ignored%20over%20longer%20periods%20of%20time,%20the%20technical%20debt%20incurred%20will%20keep%20increasing%20until%20the%20interest%20is%20so%20high%20that%20the%20project%20will%20grind%20to%20a%20halt%20-%20creating%20new%20features%20takes%20a%20long%20time%20and%20introduces%20many%20new%20and%20interesting%20bugs.%0A%0AMaintainability%20is%20important%20on%20most%20projects,%20it%20often%20depends%20on%20the%20complexity%20of%20the%20program%20and%20the%20expected%20lifetime%20-%20so%20if%20you%20are%20doing%20prototypes%20or%20mock-ups,%20focusing%20on%20maintainability%20may%20not%20be%20beneficial,%20although%20in%20my%20experience,%20when%20management%20sees%20a%20really%20cool%20prototype,%20they%20often%20feel%20like%20building%20a%20project%20on%20top%20of%20it.%20Most%20software%20projects%20will%20have%20a%20rather%20long%20lifetime,%20often%20with%20multiple%20versions%20and%20a%20need%20to%20maintain%20the%20project%20even%20after%20it%20has%20shipped.%0A%0AObtaining%20high%20code%20quality%20is%20a%20craft,%20it%20requires%20discipline%20and%20continuous%20refactoring%20and%20improvement.%20This%20will%20be%20the%20main%20topic%20of%20my%20blog%20for%20a%20while,%20save%20the%20random%20posts%20about%20ReSharper%20or%20other%20intriguing%20things%20that%20may%20come%20up.%20Topics%20within%20this%20field%20off%20the%20top%20of%20my%20head:%20Unit%20testing,%20design%20principles%20(SOLID%20and%20others),%20design%20patterns,%20understanding%20and%20taming%20dependencies,%20inversion%20of%20control%20containers,%20simplicity%20and%20many%20more%20-%20ideas%20are%20welcome.)
ReSharper Series - Part 6: Find Usages 8 Mar 2009 4:00 PM (16 years ago)
This is the 6th post in my [ReSharper Series](/2009/01/10/resharper-series/) - this time we are going to look at how to find usages of particular code members in your code. While plain old text search can be useful sometimes, a structured search is really awesome for getting a good overview. In addition, the standard ReSharper setup on this feature is rather bad compared to what is possible, so a bit of UI tweaking (very simple) is also available.
## Find Usages
Find usages works on almost all code elements, be it classes, methods or variables, invoking it by pressing **Shift+F12** [IntelliJ: **Alt+F7**] will open a result window, which show the places in your project / solution where the element is used. Using the ASP.NET MVC source, in the Controller class, invoking Find Usages on the ModelState property:
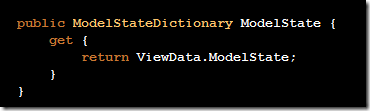 This gives us the following results window:
This gives us the following results window:
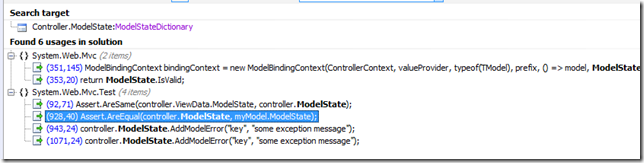 Usages are presented on a namespace level, showing the line of code that includes the given element. Double-clicking or hitting Enter on a line jumps to the file.
## Pimp My Search Results
While this results window is useful, you would often like slightly more information. In the options row of the Find Usages window, there is a group by drop down, which is set to Namespace as default - and most people I have seen using ReSharper never change this.
Usages are presented on a namespace level, showing the line of code that includes the given element. Double-clicking or hitting Enter on a line jumps to the file.
## Pimp My Search Results
While this results window is useful, you would often like slightly more information. In the options row of the Find Usages window, there is a group by drop down, which is set to Namespace as default - and most people I have seen using ReSharper never change this.
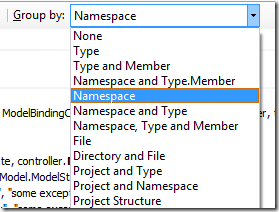 There are a lot of grouping options available, as shown above - I usually prefer the Namespace and Type option, giving me the same Namespace overview that I had before, but allowing me to see the names of the actual classes that use the element.
Another useful option is the Show Preview option, also found on the options row of the Find Usages window. This is disabled by default, but enabling it will show a preview of the code surrounding the selected line in the search results.
There are a lot of grouping options available, as shown above - I usually prefer the Namespace and Type option, giving me the same Namespace overview that I had before, but allowing me to see the names of the actual classes that use the element.
Another useful option is the Show Preview option, also found on the options row of the Find Usages window. This is disabled by default, but enabling it will show a preview of the code surrounding the selected line in the search results.
 Since I usually have my Find Usages window docked in the bottom (auto-hiding though) of my screen, I prefer setting the Show Preview to Right.
With these small tweaks, the Find Usages window now look like this:
Since I usually have my Find Usages window docked in the bottom (auto-hiding though) of my screen, I prefer setting the Show Preview to Right.
With these small tweaks, the Find Usages window now look like this:
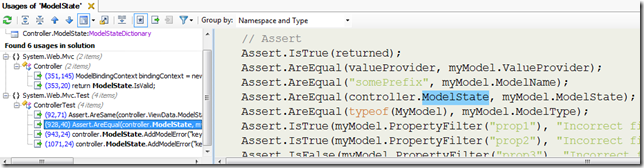 ## Go To Usage
Sometimes you are not interested in looking at the results of your search in the Find Usages window - you have your cursor at some code element and you want to navigate directly to a usage. Hitting **Alt+Shift+F12** [IntelliJ: **Ctrl+Alt+F7**] will bring up a code-completion-like-menu to quickly jump to a usage. Invoking this on the ModelState gives us the following result:
## Go To Usage
Sometimes you are not interested in looking at the results of your search in the Find Usages window - you have your cursor at some code element and you want to navigate directly to a usage. Hitting **Alt+Shift+F12** [IntelliJ: **Ctrl+Alt+F7**] will bring up a code-completion-like-menu to quickly jump to a usage. Invoking this on the ModelState gives us the following result:
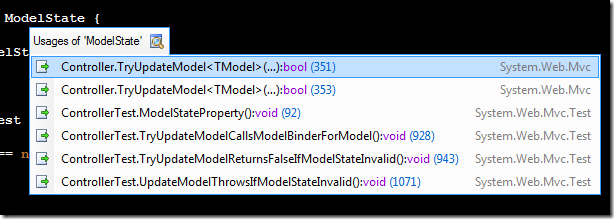 Selecting an item from the list jumps directly to usage. In a later post, we will explore more of these quick-navigation options from directly within the code editor.
Selecting an item from the list jumps directly to usage. In a later post, we will explore more of these quick-navigation options from directly within the code editor.
%20-%20this%20time%20we%20are%20going%20to%20look%20at%20how%20to%20find%20usages%20of%20particular%20code%20members%20in%20your%20code.%20While%20plain%20old%20text%20search%20can%20be%20useful%20sometimes,%20a%20structured%20search%20is%20really%20awesome%20for%20getting%20a%20good%20overview.%20In%20addition,%20the%20standard%20ReSharper%20setup%20on%20this%20feature%20is%20rather%20bad%20compared%20to%20what%20is%20possible,%20so%20a%20bit%20of%20UI%20tweaking%20(very%20simple)%20is%20also%20available.%0A%20%0A%23%23%20Find%20Usages%0A%20%0AFind%20usages%20works%20on%20almost%20all%20code%20elements,%20be%20it%20classes,%20methods%20or%20variables,%20invoking%20it%20by%20pressing%20**Shift+F12**%20%5BIntelliJ:%20**Alt+F7**%5D%20will%20open%20a%20result%20window,%20which%20show%20the%20places%20in%20your%20project%20/%20solution%20where%20the%20element%20is%20used.%20Using%20the%20ASP.NET%20MVC%20source,%20in%20the%20Controller%20class,%20invoking%20Find%20Usages%20on%20the%20ModelState%20property:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart8FindUsages_128DA/image_thumb_5.png%22%20/%3E%20%0A%20%0AThis%20gives%20us%20the%20following%20results%20window:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart8FindUsages_128DA/image_thumb_12.png%22%20/%3E%20%0A%20%0AUsages%20are%20presented%20on%20a%20namespace%20level,%20showing%20the%20line%20of%20code%20that%20includes%20the%20given%20element.%20Double-clicking%20or%20hitting%20Enter%20on%20a%20line%20jumps%20to%20the%20file.%20%0A%20%0A%23%23%20Pimp%20My%20Search%20Results%0A%20%0AWhile%20this%20results%20window%20is%20useful,%20you%20would%20often%20like%20slightly%20more%20information.%20In%20the%20options%20row%20of%20the%20Find%20Usages%20window,%20there%20is%20a%20group%20by%20drop%20down,%20which%20is%20set%20to%20Namespace%20as%20default%20-%20and%20most%20people%20I%20have%20seen%20using%20ReSharper%20never%20change%20this.%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart8FindUsages_128DA/image_thumb_7.png%22%20/%3E%20%0A%20%0AThere%20are%20a%20lot%20of%20grouping%20options%20available,%20as%20shown%20above%20-%20I%20usually%20prefer%20the%20Namespace%20and%20Type%20option,%20giving%20me%20the%20same%20Namespace%20overview%20that%20I%20had%20before,%20but%20allowing%20me%20to%20see%20the%20names%20of%20the%20actual%20classes%20that%20use%20the%20element.%0A%20%0AAnother%20useful%20option%20is%20the%20Show%20Preview%20option,%20also%20found%20on%20the%20options%20row%20of%20the%20Find%20Usages%20window.%20This%20is%20disabled%20by%20default,%20but%20enabling%20it%20will%20show%20a%20preview%20of%20the%20code%20surrounding%20the%20selected%20line%20in%20the%20search%20results.%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart8FindUsages_128DA/image_thumb_9.png%22%20/%3E%20%0A%20%0ASince%20I%20usually%20have%20my%20Find%20Usages%20window%20docked%20in%20the%20bottom%20(auto-hiding%20though)%20of%20my%20screen,%20I%20prefer%20setting%20the%20Show%20Preview%20to%20Right.%0A%20%0AWith%20these%20small%20tweaks,%20the%20Find%20Usages%20window%20now%20look%20like%20this:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart8FindUsages_128DA/image_thumb_11.png%22%20/%3E%0A%20%0A%23%23%20Go%20To%20Usage%0A%20%0ASometimes%20you%20are%20not%20interested%20in%20looking%20at%20the%20results%20of%20your%20search%20in%20the%20Find%20Usages%20window%20-%20you%20have%20your%20cursor%20at%20some%20code%20element%20and%20you%20want%20to%20navigate%20directly%20to%20a%20usage.%20Hitting%20**Alt+Shift+F12**%20%5BIntelliJ:%20**Ctrl+Alt+F7**%5D%20will%20bring%20up%20a%20code-completion-like-menu%20to%20quickly%20jump%20to%20a%20usage.%20Invoking%20this%20on%20the%20ModelState%20gives%20us%20the%20following%20result:%20%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart8FindUsages_128DA/image_thumb_4.png%22%20/%3E%20%0A%20%0ASelecting%20an%20item%20from%20the%20list%20jumps%20directly%20to%20usage.%20In%20a%20later%20post,%20we%20will%20explore%20more%20of%20these%20quick-navigation%20options%20from%20directly%20within%20the%20code%20editor.)
Craftsmanship In The Wild 6 Mar 2009 3:00 PM (16 years ago)
 I was out dining today and had an experience I simply had to share. It was a moderately expensive restaurant and they had cocktails as part of their menu.
As my after dinner cocktail, I chose a Mojito, which is actually a fairly difficult cocktail to make properly - at least if you want it to be as strong as it ought to be, while still masking the taste with the proper levels of sugar and mint.
I watched as the bartender mixed the drink - he didn't measure, but he was focused on the task at hand - he even tasted the drink elegantly with a straw to check its quality. The Mojito was extraordinary - perfect - it was so good that I felt like I really needed to order another one. However, this time, a girl, clearly an apprentice bartender wanted to make my next drink. She used the same ingredients but her focus was all around, she didn't sample the drink, just mixed everything approximately as she had been told. Watching the process, I wasn't surprised when the drink was a disappointment - it was too sweet and kind of watery.
As I asked for the bill, at the first bartender, I complimented his craftsmanship and mentioned that the second Mojito had not quite been what his had been - he immediately cut the cost of the second drink in half. He didn't even blink.
What kind of bartender do you want to be?
I was out dining today and had an experience I simply had to share. It was a moderately expensive restaurant and they had cocktails as part of their menu.
As my after dinner cocktail, I chose a Mojito, which is actually a fairly difficult cocktail to make properly - at least if you want it to be as strong as it ought to be, while still masking the taste with the proper levels of sugar and mint.
I watched as the bartender mixed the drink - he didn't measure, but he was focused on the task at hand - he even tasted the drink elegantly with a straw to check its quality. The Mojito was extraordinary - perfect - it was so good that I felt like I really needed to order another one. However, this time, a girl, clearly an apprentice bartender wanted to make my next drink. She used the same ingredients but her focus was all around, she didn't sample the drink, just mixed everything approximately as she had been told. Watching the process, I wasn't surprised when the drink was a disappointment - it was too sweet and kind of watery.
As I asked for the bill, at the first bartender, I complimented his craftsmanship and mentioned that the second Mojito had not quite been what his had been - he immediately cut the cost of the second drink in half. He didn't even blink.
What kind of bartender do you want to be?

ReSharper Series - Part 5: Generating Code 3 Mar 2009 3:00 PM (16 years ago)
Welcome to the 5th part of my [ReSharper Series](/2009/01/10/resharper-series/) - in this post we are going to take a look at how you can easily generate a lot of the fluff code that surrounds your real functionality.
While C# is a great language, there is a quite of bit of the code that you write every day that feels somewhat crufty. It is these standard things that we do a thousand times, like writing constructors, properties, backing fields to said properties (better with automatic properties - but you still often need a backing field). Luckily, ReSharper can help ease your pain - or at least let you focus on writing that core functionality - and not worry about the cost of adding another class (in terms of typing).
## Generating Class Members
We have already the power of **Alt+Enter** in one of the [earlier posts](/2009/01/21/resharper-series-part-1-the-power-of-alt-enter/) - and this a tool that most people I have seen use for creating new code. It can do stuff like implementing missing methods and assigning creating backing fields for you from constructor arguments. If we use it on our balance argument that is unused (gray), ReSharper offers the following options:
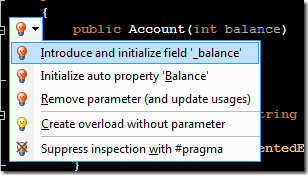 However, we might want more - we had to write the constructor ourselves - and we have to create the property afterwards. Let's introduce another shortcut - **Alt+Ins**. While **Alt+Enter** is a general purpose tool, **Alt+Ins** is focused on generating code. Use it anywhere in a class and you will be presented with the following options:
However, we might want more - we had to write the constructor ourselves - and we have to create the property afterwards. Let's introduce another shortcut - **Alt+Ins**. While **Alt+Enter** is a general purpose tool, **Alt+Ins** is focused on generating code. Use it anywhere in a class and you will be presented with the following options:
 Generating a **constructor** will bring up a dialog allowing you to select which members / properties you want to initialize from the constructor. **Read-only properties** / **Properties** will give quick options to create read-only properties from whatever backing fields you already have in your class. **Implementing missing members** will create any members not yet implemented from interfaces or abstract base classes. **Equality members** will implement Equals and the equality operators - `GetHashCode` included, based on the properties / fields you choose. **Formatting members** will introduce a `ToString` method that contains the values of whatever properties / fields you want.
The last one I didn't mention is the one I think is mostly underused - it is the **Delegating members** option. It is often useful in object oriented design to encapsulate another class and provide delegated methods for a number of the contained type's methods. The perfect example is when implementing the decorator pattern - this pattern, by design, requires you to delegate all the methods the contained type. This is a pain to do by hand. However, let's try using the delegating members option in my Account class, after adding a `List
Generating a **constructor** will bring up a dialog allowing you to select which members / properties you want to initialize from the constructor. **Read-only properties** / **Properties** will give quick options to create read-only properties from whatever backing fields you already have in your class. **Implementing missing members** will create any members not yet implemented from interfaces or abstract base classes. **Equality members** will implement Equals and the equality operators - `GetHashCode` included, based on the properties / fields you choose. **Formatting members** will introduce a `ToString` method that contains the values of whatever properties / fields you want.
The last one I didn't mention is the one I think is mostly underused - it is the **Delegating members** option. It is often useful in object oriented design to encapsulate another class and provide delegated methods for a number of the contained type's methods. The perfect example is when implementing the decorator pattern - this pattern, by design, requires you to delegate all the methods the contained type. This is a pain to do by hand. However, let's try using the delegating members option in my Account class, after adding a `List This brings up the following dialog:
This brings up the following dialog:
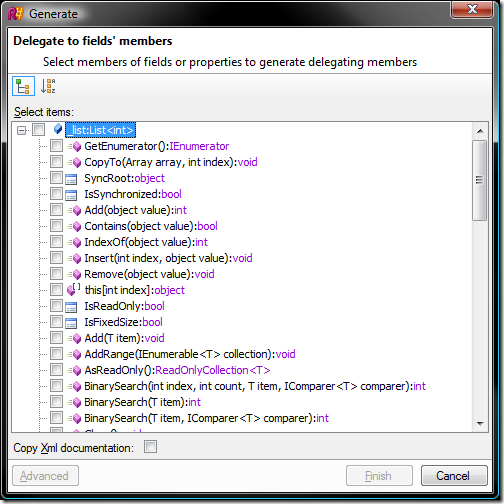 So basically, ReSharper lets me pick and choose any or all methods / properties that I want to directly delegate. For this class, maybe I need the Add and indexer methods, so I check them off and hit finish:
So basically, ReSharper lets me pick and choose any or all methods / properties that I want to directly delegate. For this class, maybe I need the Add and indexer methods, so I check them off and hit finish:
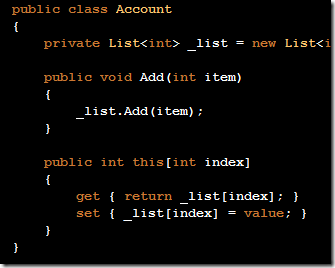 The code for delegating members is silly simple - and this is EXACTLY why we want to generate it in the first place. Generating delegating members let me focus on my intent of which options I want to expose from my class instead of the laborious task of typing out the code.
## Generating Files
As a final note in this post, I would like to introduce another usage of **Alt+Ins** which I have grown quite fond of - in the solution explorer, pressing the shortcut will allow you to add new files in a more lightweight way than the usual add file dialog:
The code for delegating members is silly simple - and this is EXACTLY why we want to generate it in the first place. Generating delegating members let me focus on my intent of which options I want to expose from my class instead of the laborious task of typing out the code.
## Generating Files
As a final note in this post, I would like to introduce another usage of **Alt+Ins** which I have grown quite fond of - in the solution explorer, pressing the shortcut will allow you to add new files in a more lightweight way than the usual add file dialog:
 Later, when we look at live templates, we will also see how to add your own file templates to this menu.
Later, when we look at live templates, we will also see how to add your own file templates to this menu.
%20-%20in%20this%20post%20we%20are%20going%20to%20take%20a%20look%20at%20how%20you%20can%20easily%20generate%20a%20lot%20of%20the%20fluff%20code%20that%20surrounds%20your%20real%20functionality.%0A%20%0AWhile%20C%23%20is%20a%20great%20language,%20there%20is%20a%20quite%20of%20bit%20of%20the%20code%20that%20you%20write%20every%20day%20that%20feels%20somewhat%20crufty.%20It%20is%20these%20standard%20things%20that%20we%20do%20a%20thousand%20times,%20like%20writing%20constructors,%20properties,%20backing%20fields%20to%20said%20properties%20(better%20with%20automatic%20properties%20-%20but%20you%20still%20often%20need%20a%20backing%20field).%20Luckily,%20ReSharper%20can%20help%20ease%20your%20pain%20-%20or%20at%20least%20let%20you%20focus%20on%20writing%20that%20core%20functionality%20-%20and%20not%20worry%20about%20the%20cost%20of%20adding%20another%20class%20(in%20terms%20of%20typing).%0A%20%0A%23%23%20Generating%20Class%20Members%0A%20%0AWe%20have%20already%20the%20power%20of%20**Alt+Enter**%20in%20one%20of%20the%20%5Bearlier%20posts%5D(/2009/01/21/resharper-series-part-1-the-power-of-alt-enter/)%20-%20and%20this%20a%20tool%20that%20most%20people%20I%20have%20seen%20use%20for%20creating%20new%20code.%20It%20can%20do%20stuff%20like%20implementing%20missing%20methods%20and%20assigning%20creating%20backing%20fields%20for%20you%20from%20constructor%20arguments.%20If%20we%20use%20it%20on%20our%20balance%20argument%20that%20is%20unused%20(gray),%20ReSharper%20offers%20the%20following%20options:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart5_127BE/image_thumb.png%22%20/%3E%20%0A%20%0AHowever,%20we%20might%20want%20more%20-%20we%20had%20to%20write%20the%20constructor%20ourselves%20-%20and%20we%20have%20to%20create%20the%20property%20afterwards.%20Let's%20introduce%20another%20shortcut%20-%20**Alt+Ins**.%20While%20**Alt+Enter**%20is%20a%20general%20purpose%20tool,%20**Alt+Ins**%20is%20focused%20on%20generating%20code.%20Use%20it%20anywhere%20in%20a%20class%20and%20you%20will%20be%20presented%20with%20the%20following%20options:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart5_127BE/image_thumb_1.png%22%20/%3E%20%0A%20%0AGenerating%20a%20**constructor**%20will%20bring%20up%20a%20dialog%20allowing%20you%20to%20select%20which%20members%20/%20properties%20you%20want%20to%20initialize%20from%20the%20constructor.%20**Read-only%20properties**%20/%20**Properties**%20will%20give%20quick%20options%20to%20create%20read-only%20properties%20from%20whatever%20backing%20fields%20you%20already%20have%20in%20your%20class.%20**Implementing%20missing%20members**%20will%20create%20any%20members%20not%20yet%20implemented%20from%20interfaces%20or%20abstract%20base%20classes.%20**Equality%20members**%20will%20implement%20Equals%20and%20the%20equality%20operators%20-%20%60GetHashCode%60%20included,%20based%20on%20the%20properties%20/%20fields%20you%20choose.%20**Formatting%20members**%20will%20introduce%20a%20%60ToString%60%20method%20that%20contains%20the%20values%20of%20whatever%20properties%20/%20fields%20you%20want.%0A%20%0AThe%20last%20one%20I%20didn't%20mention%20is%20the%20one%20I%20think%20is%20mostly%20underused%20-%20it%20is%20the%20**Delegating%20members**%20option.%20It%20is%20often%20useful%20in%20object%20oriented%20design%20to%20encapsulate%20another%20class%20and%20provide%20delegated%20methods%20for%20a%20number%20of%20the%20contained%20type's%20methods.%20The%20perfect%20example%20is%20when%20implementing%20the%20decorator%20pattern%20-%20this%20pattern,%20by%20design,%20requires%20you%20to%20delegate%20all%20the%20methods%20the%20contained%20type.%20This%20is%20a%20pain%20to%20do%20by%20hand.%20However,%20let's%20try%20using%20the%20delegating%20members%20option%20in%20my%20Account%20class,%20after%20adding%20a%20%60List%3Cint%3E%60%20-%20like%20so:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart5_127BE/image_thumb_3.png%22%20/%3E%20%0A%20%0AThis%20brings%20up%20the%20following%20dialog:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart5_127BE/image_thumb_4.png%22%20/%3E%20%0A%20%0ASo%20basically,%20ReSharper%20lets%20me%20pick%20and%20choose%20any%20or%20all%20methods%20/%20properties%20that%20I%20want%20to%20directly%20delegate.%20For%20this%20class,%20maybe%20I%20need%20the%20Add%20and%20indexer%20methods,%20so%20I%20check%20them%20off%20and%20hit%20finish:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart5_127BE/image_thumb_5.png%22%20/%3E%20%0A%20%0AThe%20code%20for%20delegating%20members%20is%20silly%20simple%20-%20and%20this%20is%20EXACTLY%20why%20we%20want%20to%20generate%20it%20in%20the%20first%20place.%20Generating%20delegating%20members%20let%20me%20focus%20on%20my%20intent%20of%20which%20options%20I%20want%20to%20expose%20from%20my%20class%20instead%20of%20the%20laborious%20task%20of%20typing%20out%20the%20code.%0A%20%0A%23%23%20Generating%20Files%0A%20%0AAs%20a%20final%20note%20in%20this%20post,%20I%20would%20like%20to%20introduce%20another%20usage%20of%20**Alt+Ins**%20which%20I%20have%20grown%20quite%20fond%20of%20-%20in%20the%20solution%20explorer,%20pressing%20the%20shortcut%20will%20allow%20you%20to%20add%20new%20files%20in%20a%20more%20lightweight%20way%20than%20the%20usual%20add%20file%20dialog:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart5_127BE/image_thumb_6.png%22%20/%3E%20%0A%20%0ALater,%20when%20we%20look%20at%20live%20templates,%20we%20will%20also%20see%20how%20to%20add%20your%20own%20file%20templates%20to%20this%20menu.)
Code Coverage - What You Need To Know 22 Feb 2009 3:00 PM (16 years ago)
People often talk about the percentage of code coverage they have from unit tests, whether it be actual coverage or the goal they or their project have set. Having a high coverage percentage is often seen as a quality, but code coverage is not really a metric that gives much value in itself. In this post I want to investigate the different types of code coverage that exists and address some of the problems with code coverage. ## Types of Code Coverage There are various forms of [code coverage](http://en.wikipedia.org/wiki/Code_coverage), not just the one we seem to always talk about. A short introduction to some of the existing coverage types: **Statement coverage** - How many percent of statements / lines have been covered? **Branch coverage** - How many percent of branches (control structures) have been covered? In the case of an if statement, has the expression evaluated to both true and false. There are variations of branch coverage that talk about more detailed decision coverage, like covering all permutations of true and false in an expression that contain stuff like **AND** and **OR**. **Path coverage** - How many percent of all possible paths have been covered? This may not sound too different from the two above, but it is actually much more complicated. An example could be a function with two simple if statements (**A** and **B**) after each other. To obtain full path coverage, you would have to get all four permutations of true and false in the two if statements (**A B -** **!A B -** **A !B -** **!A !B**) whereas in statement coverage you would only have to exercise the if statements in isolation. Mind you that this is the simple case - if statements with multiple sub expressions, nested ifs and loops are much worse. The coverage type we usually talk about is actually statement coverage - but as you can see from just looking at branch and path coverage, much is left to be desired. Coverage types like path coverage are also hard to measure, as many loops will have a near-infinite number of paths. Another thing that is very hard to measure with code coverage is multi-threaded behavior. It is definitely not caught in our statement coverage and if getting full path coverage is hard, consider getting full path coverage with multiple threads. ## One Problem - Test Quality The problem with using code coverage on its own is that code coverage tells you nothing about the quality of the tests that cover the code. Code coverage tells you how much of your code has actually been executed, but it tells you nothing about the asserts that were made in the tests - that is, it says nothing about the correctness of the code. The perfect example of this is writing a test with zero asserts (state or interaction). This test will produce a certain percentage of coverage, while ensuring nothing except that the code can successfully execute. While such sanity tests can be useful in some tricky cases with exceptions, this is often a worthless test - it has no quality whatsoever, it doesn't verify any intent of the programmer who wrote the code it is testing. The thing that is easy to sell about code coverage is that is is reasonably easy to measure. It is easy to set a percentage, a goal and then try to obtain this goal. 100% code coverage is a great goal - it might be unrealistic in most situations, but it is a good thing to strive towards. But if the tests suck or the programmers who write the tests become lazy the code coverage will be nothing but misleading. The problem with test quality is that measuring it is really really hard - at least programmatically. How can you even begin to measure how much this code matches the intent of the programmer. Usually the number of asserts that make sense for a given test match only a very low number of the values in the system. And even if we could measure test quality using a program, we might as well do away with the tests and just measure programmer intent versus the real program. The solution, to me, is discipline and good engineering principles. Code coverage can be really valuable to a team that treat their test code like production code, sharing ownership of the code and doing regular inspections / code reviews to ensure that the test quality is high. ## The Inverse Property One of the things I like best about code coverage is it's quality as an inverse property - that is, a tool that can specifically tell me which parts of my code that I have not tested. This is a clear signal that you need to be more careful when touching this code. This is also one of the reasons that I actually like to remove tests that either are very low quality or haven't kept up to date with the intent of the code they are testing. The ideal solution is to rewrite the tests to match the intent of the code / desired quality, but this is not always realistic. To me, such tests are more harmful than no tests at all - they give a false sense of security and will only confuse if anyone look at them. At least if there is no tests my coverage tool can tell me there is a problem in this part of the system. And while we are at it, it is actually amusing that some people treat test code like it is nowhere near production code and then the same people seem to think that it is blasphemy to delete even a single test. Treat your test code like your normal code, delete / rewrite it if it is obsolete or doesn't make sense. Maintaining code that doesn't add value to the system makes no sense. ## Conclusion Code coverage is a useful metric, but often not in isolation. If you use it then be aware of the implications of the way you're using it, increasing test quality is much more valuable to me than reaching a specific coverage percentage, although it is good to have some sort of goal. Write tests to verify intent, not to increase the coverage percent - use coverage to find the intents not covered.
ReSharper Series - Retrospective? 9 Feb 2009 3:00 PM (16 years ago)
Now, I've written the first 4 (7 really) parts of my [ReSharper Series](/2009/01/10/resharper-series/) - I was a bit curious if anyone is actually reading it - and if anyone is getting value from it? Personally I am learning quite a bit more than I already knew about ReSharper. So a few questions: - So, are the topics too basic? Too advanced? Too long posts? - Would it be better with screencasts? I feel it can be kind of hard to show the speed that you can obtain with ReSharper using simple screen shots. - Are there anything in particular you would like to hear about? Hear more about something that has already been mentioned? - Other suggestions? I am going away on ski vacation next week and then to Copenhagen for a few days after that (for the MDIP meeting), so there's probably not going to be any more posts until I get back in about 2 weeks. Hope to get a few useful comments (or mails) on this post.
ReSharper Series - Part 4: Moving Code 9 Feb 2009 3:00 PM (16 years ago)
Welcome to the 4th part of my [ReSharper Series](/2009/01/10/resharper-series/). Today we are going to look at one of my new favorite ways to use ReSharper - to move code around. We haven't dipped into refactoring really yet, and today isn't really going to be that much about it - this is moving code on a lower syntactic level - shortcuts to save that copy / paste. In addition, we are going to have a little bit of code navigation that plays well with this feature.
Furthermore, since many people use the VS binding mode in ReSharper, I am going to try and supply both binding sets in the future. I might even go back and change the previous posts at some point - today all the bindings I will show work for both binding modes though.
## Navigating Methods
The first small feature is navigation between members. Basically what it gives you is a way to quickly navigate between methods in your class. If you are in a method like so:
 Pressing **Alt+Arrow Down** will navigate to the next method, while using **Alt+Arrow Up** will send you to the method signature, like so:
Pressing **Alt+Arrow Down** will navigate to the next method, while using **Alt+Arrow Up** will send you to the method signature, like so:
 When at a method signature already, you can jump up and down between method signatures in the same way.
When at a method signature already, you can jump up and down between method signatures in the same way.
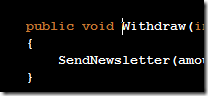 This comes in handy when moving methods, since you need to be at the method signature to do so.
## Moving Code
The shortcuts for moving code involve a lot of keys, but they are pretty easy to remember. You can move code over 2 axis, up/down and left/right. This is controlled using the arrow keys. To enable the move functionality, you need to hold down Alt, Ctrl and Shift.
## Moving Methods
Let us look at the first example. With our cursor placed on the method signature of the Withdraw method, we hold down Alt, Ctrl and Shift to enable movement. This will make the block of code we are moving turn a light cyan (with my color scheme at least):
This comes in handy when moving methods, since you need to be at the method signature to do so.
## Moving Code
The shortcuts for moving code involve a lot of keys, but they are pretty easy to remember. You can move code over 2 axis, up/down and left/right. This is controlled using the arrow keys. To enable the move functionality, you need to hold down Alt, Ctrl and Shift.
## Moving Methods
Let us look at the first example. With our cursor placed on the method signature of the Withdraw method, we hold down Alt, Ctrl and Shift to enable movement. This will make the block of code we are moving turn a light cyan (with my color scheme at least):
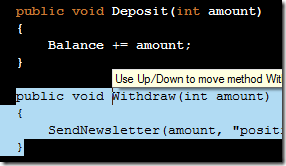 Hitting the move up shortcut (**Alt+Ctrl+Shift+Arrow Up**) sends our method above the Deposit method like so:
Hitting the move up shortcut (**Alt+Ctrl+Shift+Arrow Up**) sends our method above the Deposit method like so:
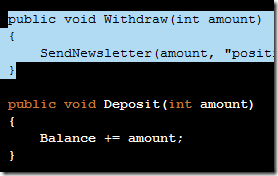 We can also move methods down using **Alt+Ctrl+Shift+Arrow Down**. Quite a bit easier than copy pasting it - and useful for reordering methods quickly if combined with the method navigation above.
## Moving Arguments
Now we can move quite a bit more than methods. Say we have a method call where we wanted to move the arguments. We can do so using **Alt+Ctrl+Shift+Arrow Left** and **Alt+Ctrl+Shift+Arrow Right**. Again, as we hold down Alt, Ctrl and Shift, the block we are about to move is highlighted:
We can also move methods down using **Alt+Ctrl+Shift+Arrow Down**. Quite a bit easier than copy pasting it - and useful for reordering methods quickly if combined with the method navigation above.
## Moving Arguments
Now we can move quite a bit more than methods. Say we have a method call where we wanted to move the arguments. We can do so using **Alt+Ctrl+Shift+Arrow Left** and **Alt+Ctrl+Shift+Arrow Right**. Again, as we hold down Alt, Ctrl and Shift, the block we are about to move is highlighted:
 And sending it left is easy:
And sending it left is easy:
 This also works for actual method signatures, just be aware that this *doesn't actually refactor your method* and change all the call sites for the method (although ReSharper can do this in it's refactor menu - look for the Change Signature refactoring).
## Moving Statements
When we are dealing with statements inside a method, it can some times be useful to reorder lines of code or move code in and out of control structures, so when we hold down Ctrl, Alt and Shift here it actually suggests that we can use all 4 directions.
This also works for actual method signatures, just be aware that this *doesn't actually refactor your method* and change all the call sites for the method (although ReSharper can do this in it's refactor menu - look for the Change Signature refactoring).
## Moving Statements
When we are dealing with statements inside a method, it can some times be useful to reorder lines of code or move code in and out of control structures, so when we hold down Ctrl, Alt and Shift here it actually suggests that we can use all 4 directions.
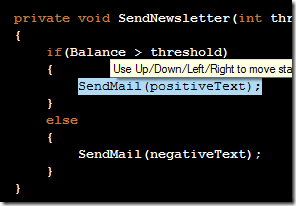 Moving up and down lets us maintain our level of scope, in this case, pressing **Alt+Ctrl+Shift+Arrow Down**, we would send the method call into the else branch:
Moving up and down lets us maintain our level of scope, in this case, pressing **Alt+Ctrl+Shift+Arrow Down**, we would send the method call into the else branch:
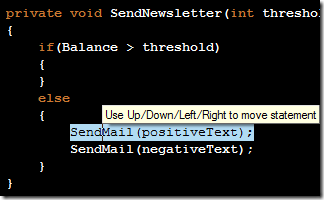 Repeating this would send it below the negativeText call. When we move left and right, we move in and out of scopes, thus if we press **Alt+Ctrl+Shift+Arrow Left**, we yank the statement all the way out of the entire if statement:
Repeating this would send it below the negativeText call. When we move left and right, we move in and out of scopes, thus if we press **Alt+Ctrl+Shift+Arrow Left**, we yank the statement all the way out of the entire if statement:
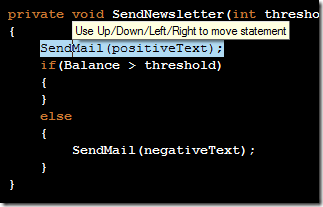 Again, if we move up and down here, we maintain our level of scope and thus do not re-enter the if statement unless we move the statement right.
Again, if we move up and down here, we maintain our level of scope and thus do not re-enter the if statement unless we move the statement right.
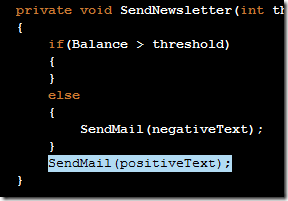 ## Reordering Expressions
The last short example is reordering expressions, this makes it easy to reorder expressions and move parts of them around. Like here:
## Reordering Expressions
The last short example is reordering expressions, this makes it easy to reorder expressions and move parts of them around. Like here:
 Moving Balance right would actually swap the two values.
Moving Balance right would actually swap the two values.
 ## Summary
What I have shown is some of the possibilities for moving code, but as always, play around with it - you can move quite a bit more - like fields and properties in your classes - possibly a lot more.
## Summary
What I have shown is some of the possibilities for moving code, but as always, play around with it - you can move quite a bit more - like fields and properties in your classes - possibly a lot more.
.%20Today%20we%20are%20going%20to%20look%20at%20one%20of%20my%20new%20favorite%20ways%20to%20use%20ReSharper%20-%20to%20move%20code%20around.%20We%20haven't%20dipped%20into%20refactoring%20really%20yet,%20and%20today%20isn't%20really%20going%20to%20be%20that%20much%20about%20it%20-%20this%20is%20moving%20code%20on%20a%20lower%20syntactic%20level%20-%20shortcuts%20to%20save%20that%20copy%20/%20paste.%20In%20addition,%20we%20are%20going%20to%20have%20a%20little%20bit%20of%20code%20navigation%20that%20plays%20well%20with%20this%20feature.%0A%20%0AFurthermore,%20since%20many%20people%20use%20the%20VS%20binding%20mode%20in%20ReSharper,%20I%20am%20going%20to%20try%20and%20supply%20both%20binding%20sets%20in%20the%20future.%20I%20might%20even%20go%20back%20and%20change%20the%20previous%20posts%20at%20some%20point%20-%20today%20all%20the%20bindings%20I%20will%20show%20work%20for%20both%20binding%20modes%20though.%0A%20%0A%23%23%20Navigating%20Methods%0A%20%0AThe%20first%20small%20feature%20is%20navigation%20between%20members.%20Basically%20what%20it%20gives%20you%20is%20a%20way%20to%20quickly%20navigate%20between%20methods%20in%20your%20class.%20If%20you%20are%20in%20a%20method%20like%20so:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb.png%22%20/%3E%20%0A%20%0APressing%20**Alt+Arrow%20Down**%20will%20navigate%20to%20the%20next%20method,%20while%20using%20**Alt+Arrow%20Up**%20will%20send%20you%20to%20the%20method%20signature,%20like%20so:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_1.png%22%20/%3E%0A%20%0AWhen%20at%20a%20method%20signature%20already,%20you%20can%20jump%20up%20and%20down%20between%20method%20signatures%20in%20the%20same%20way.%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_4.png%22%20/%3E%20%0A%20%0AThis%20comes%20in%20handy%20when%20moving%20methods,%20since%20you%20need%20to%20be%20at%20the%20method%20signature%20to%20do%20so.%0A%20%0A%23%23%20Moving%20Code%0A%20%0AThe%20shortcuts%20for%20moving%20code%20involve%20a%20lot%20of%20keys,%20but%20they%20are%20pretty%20easy%20to%20remember.%20You%20can%20move%20code%20over%202%20axis,%20up/down%20and%20left/right.%20This%20is%20controlled%20using%20the%20arrow%20keys.%20To%20enable%20the%20move%20functionality,%20you%20need%20to%20hold%20down%20Alt,%20Ctrl%20and%20Shift.%0A%20%0A%23%23%20Moving%20Methods%0A%20%0ALet%20us%20look%20at%20the%20first%20example.%20With%20our%20cursor%20placed%20on%20the%20method%20signature%20of%20the%20Withdraw%20method,%20we%20hold%20down%20Alt,%20Ctrl%20and%20Shift%20to%20enable%20movement.%20This%20will%20make%20the%20block%20of%20code%20we%20are%20moving%20turn%20a%20light%20cyan%20(with%20my%20color%20scheme%20at%20least):%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_5.png%22%20/%3E%0A%20%0AHitting%20the%20move%20up%20shortcut%20(**Alt+Ctrl+Shift+Arrow%20Up**)%20sends%20our%20method%20above%20the%20Deposit%20method%20like%20so:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_6.png%22%20/%3E%0A%20%0AWe%20can%20also%20move%20methods%20down%20using%20**Alt+Ctrl+Shift+Arrow%20Down**.%20Quite%20a%20bit%20easier%20than%20copy%20pasting%20it%20-%20and%20useful%20for%20reordering%20methods%20quickly%20if%20combined%20with%20the%20method%20navigation%20above.%0A%20%0A%23%23%20Moving%20Arguments%0A%20%0ANow%20we%20can%20move%20quite%20a%20bit%20more%20than%20methods.%20Say%20we%20have%20a%20method%20call%20where%20we%20wanted%20to%20move%20the%20arguments.%20We%20can%20do%20so%20using%20**Alt+Ctrl+Shift+Arrow%20Left**%20and%20**Alt+Ctrl+Shift+Arrow%20Right**.%20Again,%20as%20we%20hold%20down%20Alt,%20Ctrl%20and%20Shift,%20the%20block%20we%20are%20about%20to%20move%20is%20highlighted:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_7.png%22%20/%3E%20%0A%20%0AAnd%20sending%20it%20left%20is%20easy:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_8.png%22%20/%3E%20%0A%20%0AThis%20also%20works%20for%20actual%20method%20signatures,%20just%20be%20aware%20that%20this%20*doesn't%20actually%20refactor%20your%20method*%20and%20change%20all%20the%20call%20sites%20for%20the%20method%20(although%20ReSharper%20can%20do%20this%20in%20it's%20refactor%20menu%20-%20look%20for%20the%20Change%20Signature%20refactoring).%0A%20%0A%23%23%20Moving%20Statements%0A%20%0AWhen%20we%20are%20dealing%20with%20statements%20inside%20a%20method,%20it%20can%20some%20times%20be%20useful%20to%20reorder%20lines%20of%20code%20or%20move%20code%20in%20and%20out%20of%20control%20structures,%20so%20when%20we%20hold%20down%20Ctrl,%20Alt%20and%20Shift%20here%20it%20actually%20suggests%20that%20we%20can%20use%20all%204%20directions.%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_9.png%22%20/%3E%20%0A%20%0AMoving%20up%20and%20down%20lets%20us%20maintain%20our%20level%20of%20scope,%20in%20this%20case,%20pressing%20**Alt+Ctrl+Shift+Arrow%20Down**,%20we%20would%20send%20the%20method%20call%20into%20the%20else%20branch:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_10.png%22%20/%3E%20%0A%20%0ARepeating%20this%20would%20send%20it%20below%20the%20negativeText%20call.%20When%20we%20move%20left%20and%20right,%20we%20move%20in%20and%20out%20of%20scopes,%20thus%20if%20we%20press%20**Alt+Ctrl+Shift+Arrow%20Left**,%20we%20yank%20the%20statement%20all%20the%20way%20out%20of%20the%20entire%20if%20statement:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_11.png%22%20/%3E%20%0A%20%0AAgain,%20if%20we%20move%20up%20and%20down%20here,%20we%20maintain%20our%20level%20of%20scope%20and%20thus%20do%20not%20re-enter%20the%20if%20statement%20unless%20we%20move%20the%20statement%20right.%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_12.png%22%20/%3E%20%0A%20%0A%23%23%20Reordering%20Expressions%0A%20%0AThe%20last%20short%20example%20is%20reordering%20expressions,%20this%20makes%20it%20easy%20to%20reorder%20expressions%20and%20move%20parts%20of%20them%20around.%20Like%20here:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_14.png%22%20/%3E%20%0A%20%0AMoving%20Balance%20right%20would%20actually%20swap%20the%20two%20values.%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperSeriesPart4MovingCode_12A24/image_thumb_15.png%22%20/%3E%20%0A%20%0A%23%23%20Summary%0A%20%0AWhat%20I%20have%20shown%20is%20some%20of%20the%20possibilities%20for%20moving%20code,%20but%20as%20always,%20play%20around%20with%20it%20-%20you%20can%20move%20quite%20a%20bit%20more%20-%20like%20fields%20and%20properties%20in%20your%20classes%20-%20possibly%20a%20lot%20more.)
ReSharper Series - Part 3: Auto-completion / Intellisense 3 Feb 2009 3:00 PM (16 years ago)
This is the 3. part of my [ReSharper series](/2009/01/10/resharper-series/). Today we are going to have a look at how ReSharper helps you complete your code / show options while programming. I know I didn't know about some of these for a long time, maybe there's something new for you as well?
## Standard Symbol Completion
This is the basic intellisense that you are used to and the one that is automatically provided for you whenever you are typing. It contains everything that matches the prefix that you have written in the scope (class, object, etc) that is relevant - just like you are used to from normal Visual Studio intellisense.
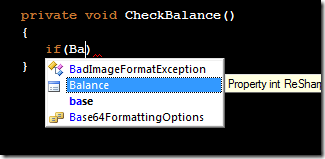 The keyboard shortcuts for enabling this type of completion is either **Ctrl+Space** or **Alt+Right Arrow**, with Ctrl+Space being the usual one. Now as I mentioned this is enabled when you are typing, but say you have returned to a line of code you were writing and it doesn't pop up on its own, this is the shortcut to be hitting.
## Import Completion
Remember in [part 1](/2009/01/21/resharper-series-part-1-the-power-of-alt-enter/) when I mentioned an easier way to import namespaces than typing out the full name and doing a quick fix (**Alt+Enter**)? Well this is it. With this auto-completion mode, you can as ReSharper to complete the names of types that are not imported yet, thus not requiring to type the full type name and getting the automatic import for free.
Say I wanted to use a LinkedList in my CheckBalance method shown above, the standard auto-completion isn't very helpful since I have not imported the collections namespace:
The keyboard shortcuts for enabling this type of completion is either **Ctrl+Space** or **Alt+Right Arrow**, with Ctrl+Space being the usual one. Now as I mentioned this is enabled when you are typing, but say you have returned to a line of code you were writing and it doesn't pop up on its own, this is the shortcut to be hitting.
## Import Completion
Remember in [part 1](/2009/01/21/resharper-series-part-1-the-power-of-alt-enter/) when I mentioned an easier way to import namespaces than typing out the full name and doing a quick fix (**Alt+Enter**)? Well this is it. With this auto-completion mode, you can as ReSharper to complete the names of types that are not imported yet, thus not requiring to type the full type name and getting the automatic import for free.
Say I wanted to use a LinkedList in my CheckBalance method shown above, the standard auto-completion isn't very helpful since I have not imported the collections namespace:
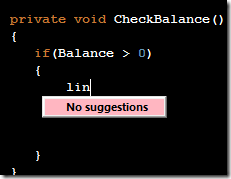 This doesn't really help me much. However, if you enable symbol import by pressing **Alt+Shift+Space** [IntelliJ: **Ctrl+Alt+Space**], this is what you get:
This doesn't really help me much. However, if you enable symbol import by pressing **Alt+Shift+Space** [IntelliJ: **Ctrl+Alt+Space**], this is what you get:
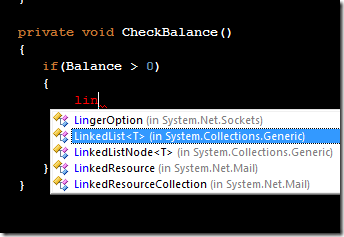 ReSharper will complete the common prefix and suggest type names in other namespaces. When using generic types I usually hit **<** at this point and type out the generic constraint. While writing this post I noticed that it was behaving oddly when completing types with multiple generic types, but it might just be me. Anyway it is a really helpful in addition to the basic intellisense that we usually use.
## Smart Completion
To be honest I hadn't looked at this completion mode until recently - but ReSharper actually also has a completion mode that tried to be clever about the type context of the expression you are currently writing. Since ReSharper knows the scope of the code you're writing and it has an idea about the current expression, what smart completion does it to filter the completion list to only show symbols that have the relevant type.
I find that I mostly use smart completion when I am writing method calls, especially if I am either messing in some code that I don't know that well (since the completion list is often much smaller) or if I know that there is only one possible completion. In the latter case, ReSharper will do the full complete when enabling the completion and proceed to the next parameter instantly.
If I have a method that takes a boolean for example, enabling smart completion will only suggest symbols that actually have the relevant type, like so:
ReSharper will complete the common prefix and suggest type names in other namespaces. When using generic types I usually hit **<** at this point and type out the generic constraint. While writing this post I noticed that it was behaving oddly when completing types with multiple generic types, but it might just be me. Anyway it is a really helpful in addition to the basic intellisense that we usually use.
## Smart Completion
To be honest I hadn't looked at this completion mode until recently - but ReSharper actually also has a completion mode that tried to be clever about the type context of the expression you are currently writing. Since ReSharper knows the scope of the code you're writing and it has an idea about the current expression, what smart completion does it to filter the completion list to only show symbols that have the relevant type.
I find that I mostly use smart completion when I am writing method calls, especially if I am either messing in some code that I don't know that well (since the completion list is often much smaller) or if I know that there is only one possible completion. In the latter case, ReSharper will do the full complete when enabling the completion and proceed to the next parameter instantly.
If I have a method that takes a boolean for example, enabling smart completion will only suggest symbols that actually have the relevant type, like so:
 The shortcut to use smart completion is **Ctrl+Alt+Space** [IntelliJ: **Ctrl+Shift+Space**]. I find that it is somewhat situational for me, but it is useful - I use the other two more though.
**Hint:** Out of personal opinion, I suggest that people using Visual Studio bindings remap these keys so that Import Completion become **Alt+Ctrl+Space** like in IntelliJ - I use it much more often and it's so much easier to hit this combination. Smart Completion could then be **Alt+Shift+Space**.
## Camel Humps
[Søren](http://www.publicvoid.dk) mentioned camel humps when I was talking about basic navigation in the last post - and this also holds true for all the auto-completions shown above. If you type upper case letters while completing, it will match camel humps in the list. For example, if I wanted to use a LinkedResourceCollection as seen in the symbol completion example, here's what I could do:
The shortcut to use smart completion is **Ctrl+Alt+Space** [IntelliJ: **Ctrl+Shift+Space**]. I find that it is somewhat situational for me, but it is useful - I use the other two more though.
**Hint:** Out of personal opinion, I suggest that people using Visual Studio bindings remap these keys so that Import Completion become **Alt+Ctrl+Space** like in IntelliJ - I use it much more often and it's so much easier to hit this combination. Smart Completion could then be **Alt+Shift+Space**.
## Camel Humps
[Søren](http://www.publicvoid.dk) mentioned camel humps when I was talking about basic navigation in the last post - and this also holds true for all the auto-completions shown above. If you type upper case letters while completing, it will match camel humps in the list. For example, if I wanted to use a LinkedResourceCollection as seen in the symbol completion example, here's what I could do:
 I find that this is mostly useful when you have types with long names that you use often.
## Case Sensitivity
Another thing you can do if you want more control over what is filtered in the completion lists is to enable case sensitive prefix matching in the ReSharper settings under IntelliSense -> Completion Behavior.
I find that this is mostly useful when you have types with long names that you use often.
## Case Sensitivity
Another thing you can do if you want more control over what is filtered in the completion lists is to enable case sensitive prefix matching in the ReSharper settings under IntelliSense -> Completion Behavior.
 This will force ReSharper to match the case as you are typing and it will only present symbols that actually match the case - this could potentially be useful if you don't prefix your instance fields (personally I prefer prefixing with underscore).
Without case sensitivity:
This will force ReSharper to match the case as you are typing and it will only present symbols that actually match the case - this could potentially be useful if you don't prefix your instance fields (personally I prefer prefixing with underscore).
Without case sensitivity:
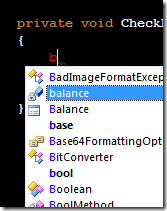 With case sensitivity:
With case sensitivity:
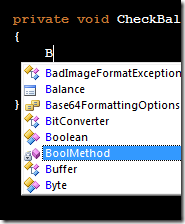
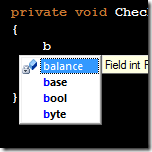 I haven't played around with case sensitivity enabled so much, generally I just accept having a longer result list and not being forced to case my identifiers.
## Summary
In this post I gave an introduction to the auto-completion modes of ReSharper, try them out and see what works for you, I especially recommend the import symbol completion if you are not already using it.
I haven't played around with case sensitivity enabled so much, generally I just accept having a longer result list and not being forced to case my identifiers.
## Summary
In this post I gave an introduction to the auto-completion modes of ReSharper, try them out and see what works for you, I especially recommend the import symbol completion if you are not already using it.
Crazy January 2 Feb 2009 3:00 PM (16 years ago)
What a great start on 2009, I only hope the rest of the year will be as eventful as this month. The highlights were: - Blogger of the month on danish MSDN Flash [newsletter](http://www.microsoft.com/danmark/msdn/nyhedsbreve/2009/januar2009.htm) [danish]. - Awarded the [MDIP](http://blogs.msdn.com/danielmf/archive/2008/04/23/mdip-microsoft-designated-information-provider.aspx) (Microsoft Designated Information Provider) title [danish] by [Daniel](http://blogs.msdn.com/danielmf/). - Was invited to join the core group of [Aarhus .NET User Group](htttp://www.anug.dk) [danish]. I am truly humbled by all these things, it's just great to know that someone out there thinks that my ramblings and crazy technical obsession is valuable. Anyway, back to the technical posts.
ReSharper Series - Part 2: Basic Navigation 26 Jan 2009 3:00 PM (16 years ago)
At part 2 of the [ReSharper series](/2009/01/10/resharper-series/), we will attempt to enable more "no mouse survival". We will take a look at navigating between files without using the mouse. This is also a great chance to mention that not all the stuff you will see here is exclusive ReSharper stuff, some times I will throw in some Visual Studio shortcuts - the essence is to increase productivity - not religiously using one product for everything. In addition I have been using the combination for so long that I am often confused what is what.
## Opening Files
ReSharper offers many ways of navigating between files based on what you need - and we are going to look at a few basic ones today.
The first one is called Go to Type and is activated through **Ctrl+T**[IntelliJ: **Ctrl+N**]. This will bring up the window shown below. Basically it's a quick search in all your classes.
 Most often, navigating types is what you want, but sometimes it can be useful to navigate files instead, especially for configuration files, NHibernate mappings and other special files. ReSharper has a Go to File shortcut that brings up the following window - **Ctrl+Shift+T** [IntelliJ: **Ctrl+Shift+N**]:
Most often, navigating types is what you want, but sometimes it can be useful to navigate files instead, especially for configuration files, NHibernate mappings and other special files. ReSharper has a Go to File shortcut that brings up the following window - **Ctrl+Shift+T** [IntelliJ: **Ctrl+Shift+N**]:
 Both of the search windows allow * wildcards, like in the below search where I wanted to find all the files that contain the word "Base":
Both of the search windows allow * wildcards, like in the below search where I wanted to find all the files that contain the word "Base":
 They also allow the use of the + wildcard to denote one or more characters...
They also allow the use of the + wildcard to denote one or more characters...
 ... and the ? wildcard to denote zero or one character:
... and the ? wildcard to denote zero or one character:
 ## Closing Files
Closing tabs in the visual studio editor is as easy as pressing **Ctrl+F4**. Not a ReSharper shortcut - but nice to know.
## Accessing the Solution Explorer
While ReSharper gives us a nice way of opening files by name, it can still be useful to bring out the good ol' Solution Explorer once in a while. There's two shortcuts for this. There is a standard Visual Studio shortcut which will bring up the Solution Explorer tool - **Alt+Ctrl+L**. This will open the tool in it's current configuration - like you left it.
Lets imagine that I am browsing the MVC source - standing in the ControllerBase file in the System.Web.Mvc project. In my Solution Explorer I browse to the MvcFutures project to see something. After leaving the Solution Explorer, pressing **Alt+Ctrl+L** will bring me to my last location again:
## Closing Files
Closing tabs in the visual studio editor is as easy as pressing **Ctrl+F4**. Not a ReSharper shortcut - but nice to know.
## Accessing the Solution Explorer
While ReSharper gives us a nice way of opening files by name, it can still be useful to bring out the good ol' Solution Explorer once in a while. There's two shortcuts for this. There is a standard Visual Studio shortcut which will bring up the Solution Explorer tool - **Alt+Ctrl+L**. This will open the tool in it's current configuration - like you left it.
Lets imagine that I am browsing the MVC source - standing in the ControllerBase file in the System.Web.Mvc project. In my Solution Explorer I browse to the MvcFutures project to see something. After leaving the Solution Explorer, pressing **Alt+Ctrl+L** will bring me to my last location again:
 However ReSharper also has a shortcut for bringing up the Solution Explorer - it is called Locate in Solution Explorer -** Alt+Shift+L**. Using this in the previous situation will actually track the current file and open the Solution Explorer with this file highlighted, as shown below:
However ReSharper also has a shortcut for bringing up the Solution Explorer - it is called Locate in Solution Explorer -** Alt+Shift+L**. Using this in the previous situation will actually track the current file and open the Solution Explorer with this file highlighted, as shown below:
 I actually find both shortcuts useful in different situations - but play around with it and see what works for you.
## Escaping Tools
Another quick Visual Studio tip - the Solution Explorer and other tools you might activate while coding are easy to deactivate again with a quick **Esc**. This will bring the focus back to the code editor.
I actually find both shortcuts useful in different situations - but play around with it and see what works for you.
## Escaping Tools
Another quick Visual Studio tip - the Solution Explorer and other tools you might activate while coding are easy to deactivate again with a quick **Esc**. This will bring the focus back to the code editor.
,%20we%20will%20attempt%20to%20enable%20more%20%22no%20mouse%20survival%22.%20We%20will%20take%20a%20look%20at%20navigating%20between%20files%20without%20using%20the%20mouse.%20This%20is%20also%20a%20great%20chance%20to%20mention%20that%20not%20all%20the%20stuff%20you%20will%20see%20here%20is%20exclusive%20ReSharper%20stuff,%20some%20times%20I%20will%20throw%20in%20some%20Visual%20Studio%20shortcuts%20-%20the%20essence%20is%20to%20increase%20productivity%20-%20not%20religiously%20using%20one%20product%20for%20everything.%20In%20addition%20I%20have%20been%20using%20the%20combination%20for%20so%20long%20that%20I%20am%20often%20confused%20what%20is%20what.%0A%20%0A%23%23%20Opening%20Files%0A%20%0AReSharper%20offers%20many%20ways%20of%20navigating%20between%20files%20based%20on%20what%20you%20need%20-%20and%20we%20are%20going%20to%20look%20at%20a%20few%20basic%20ones%20today.%20%0A%20%0AThe%20first%20one%20is%20called%20Go%20to%20Type%20and%20is%20activated%20through%20**Ctrl+T**%5BIntelliJ:%20**Ctrl+N**%5D.%20This%20will%20bring%20up%20the%20window%20shown%20below.%20Basically%20it's%20a%20quick%20search%20in%20all%20your%20classes.%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperEventDay2_A25E/image_thumb_4.png%22%20/%3E%20%0A%20%0AMost%20often,%20navigating%20types%20is%20what%20you%20want,%20but%20sometimes%20it%20can%20be%20useful%20to%20navigate%20files%20instead,%20especially%20for%20configuration%20files,%20NHibernate%20mappings%20and%20other%20special%20files.%20ReSharper%20has%20a%20Go%20to%20File%20shortcut%20that%20brings%20up%20the%20following%20window%20-%20**Ctrl+Shift+T**%20%5BIntelliJ:%20**Ctrl+Shift+N**%5D:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperEventDay2_A25E/image_thumb.png%22%20/%3E%20%0A%20%0ABoth%20of%20the%20search%20windows%20allow%20*%20wildcards,%20like%20in%20the%20below%20search%20where%20I%20wanted%20to%20find%20all%20the%20files%20that%20contain%20the%20word%20%22Base%22:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperEventDay2_A25E/image_thumb_1.png%22%20/%3E%20%0A%20%0AThey%20also%20allow%20the%20use%20of%20the%20+%20wildcard%20to%20denote%20one%20or%20more%20characters...%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperEventDay2_A25E/image_thumb_5.png%22%20/%3E%0A%20%0A...%20and%20the%20?%20wildcard%20to%20denote%20zero%20or%20one%20character:%20%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperEventDay2_A25E/image_thumb_6.png%22%20/%3E%20%0A%20%0A%23%23%20Closing%20Files%0A%20%0AClosing%20tabs%20in%20the%20visual%20studio%20editor%20is%20as%20easy%20as%20pressing%20**Ctrl+F4**.%20Not%20a%20ReSharper%20shortcut%20-%20but%20nice%20to%20know.%0A%20%0A%23%23%20Accessing%20the%20Solution%20Explorer%0A%20%0AWhile%20ReSharper%20gives%20us%20a%20nice%20way%20of%20opening%20files%20by%20name,%20it%20can%20still%20be%20useful%20to%20bring%20out%20the%20good%20ol'%20Solution%20Explorer%20once%20in%20a%20while.%20There's%20two%20shortcuts%20for%20this.%20There%20is%20a%20standard%20Visual%20Studio%20shortcut%20which%20will%20bring%20up%20the%20Solution%20Explorer%20tool%20-%20**Alt+Ctrl+L**.%20This%20will%20open%20the%20tool%20in%20it's%20current%20configuration%20-%20like%20you%20left%20it.%20%0A%20%0ALets%20imagine%20that%20I%20am%20browsing%20the%20MVC%20source%20-%20standing%20in%20the%20ControllerBase%20file%20in%20the%20System.Web.Mvc%20project.%20In%20my%20Solution%20Explorer%20I%20browse%20to%20the%20MvcFutures%20project%20to%20see%20something.%20After%20leaving%20the%20Solution%20Explorer,%20pressing%20**Alt+Ctrl+L**%20will%20bring%20me%20to%20my%20last%20location%20again:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperEventDay2_A25E/image_thumb_2.png%22%20/%3E%20%0A%20%0AHowever%20ReSharper%20also%20has%20a%20shortcut%20for%20bringing%20up%20the%20Solution%20Explorer%20-%20it%20is%20called%20Locate%20in%20Solution%20Explorer%20-**%20Alt+Shift+L**.%20Using%20this%20in%20the%20previous%20situation%20will%20actually%20track%20the%20current%20file%20and%20open%20the%20Solution%20Explorer%20with%20this%20file%20highlighted,%20as%20shown%20below:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReSharperEventDay2_A25E/image_thumb_3.png%22%20/%3E%20%0A%20%0AI%20actually%20find%20both%20shortcuts%20useful%20in%20different%20situations%20-%20but%20play%20around%20with%20it%20and%20see%20what%20works%20for%20you.%20%0A%20%0A%23%23%20Escaping%20Tools%0A%20%0AAnother%20quick%20Visual%20Studio%20tip%20-%20the%20Solution%20Explorer%20and%20other%20tools%20you%20might%20activate%20while%20coding%20are%20easy%20to%20deactivate%20again%20with%20a%20quick%20**Esc**.%20This%20will%20bring%20the%20focus%20back%20to%20the%20code%20editor.)
Testing a Visitor - Mocking and Test Readability 21 Jan 2009 3:00 PM (16 years ago)
The other day I was using TDD to write a visitor for an object graph at work. I often use mocks a lot and was using mocks in this particular batch of tests as well. However, in the end creating my own fake class turned out to be much better (in my opinion). Favoring state-based testing over interaction-based testing (sometimes) can really simplify the noise within a test and provide clarity.
What I wanted to test was that objects of the correct types were visited from the parent object and was thus producing a number of tests that look something like this:
``` csharp
private MockRepository mocks;
[SetUp]
public void Setup()
{
mocks = new MockRepository();
}
[Test]
public void ShouldVisitObject1BelowRootObject()
{
var rootObject = ObjectMother.Build
ReSharper Series - Part 1: The Power of Alt+Enter 20 Jan 2009 3:00 PM (16 years ago)
Woo, finally hit part 1 of the [ReSharper series](/2009/01/10/resharper-series/) and ready to start on the basics of ReSharper. Today we will look at the basic look and feel after you have installed ReSharper and fired up your Visual Studio. Learn one of the most basic commands.
The single thing you will probably use most in ReSharper is the quick-fix command - which is initiated using **Alt+Enter**. This is a context-based command which will suggest actions based on where your cursor is located. ReSharper provides different visual cues to alert you that an action is available. Lets look at a few examples of the versatility of this command.
## Implementing Missing Methods
Say I am implementing the standard Account class and want to check something with the balance when doing a withdrawal. As I write the code shown below, ReSharper will pop up a red light-bulb on the left of my method as my cursor is on it. This is ReSharper's way of telling me that an action is available.
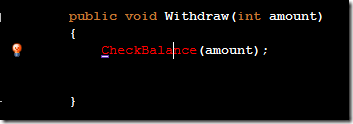 When you see a yellow or red light-bulb, pressing **Alt+Enter** brings up the action menu:
When you see a yellow or red light-bulb, pressing **Alt+Enter** brings up the action menu:
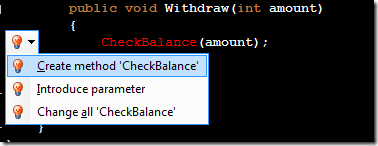 In this case, ReSharper is offering to create the missing method for me. Picking the default option by hitting the Enter key creates the new method with a default implementation:
In this case, ReSharper is offering to create the missing method for me. Picking the default option by hitting the Enter key creates the new method with a default implementation:
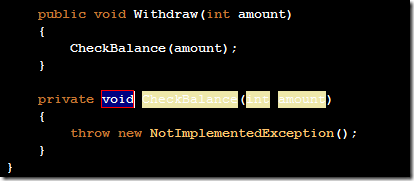 ReSharper will show these light yellow boxes for on our new method for things that we might want to change. They don't go too well with my color scheme, but the idea is that ReSharper suggests a return value, a method name and types/names of the arguments. It is easy to navigate between the yellow boxes using either Enter or Tab.
After all the yellow boxes have been resolved (just pressing Enter to go with the default) the whole exception line will be selected and we're ready to start implementing our method.
Errors like this will also often show up as red squigglies like the ones you know from Word.
## Removing Dead Code
Another thing you will probably notice after installing ReSharper is that some of your text turns gray like this:
ReSharper will show these light yellow boxes for on our new method for things that we might want to change. They don't go too well with my color scheme, but the idea is that ReSharper suggests a return value, a method name and types/names of the arguments. It is easy to navigate between the yellow boxes using either Enter or Tab.
After all the yellow boxes have been resolved (just pressing Enter to go with the default) the whole exception line will be selected and we're ready to start implementing our method.
Errors like this will also often show up as red squigglies like the ones you know from Word.
## Removing Dead Code
Another thing you will probably notice after installing ReSharper is that some of your text turns gray like this:
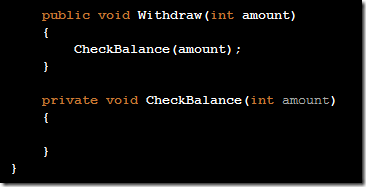 Gray text is ReSharper's way of letting us know we have dead or unused code. We are not using the amount argument for anything in the method and thus it can safely be removed. Placing our cursor on amount, another light-bulb pops up and gives us the following context menu:
Gray text is ReSharper's way of letting us know we have dead or unused code. We are not using the amount argument for anything in the method and thus it can safely be removed. Placing our cursor on amount, another light-bulb pops up and gives us the following context menu:
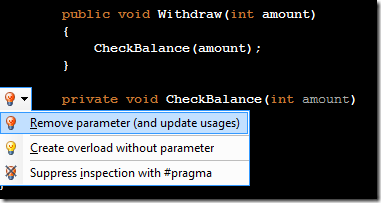 This is where we start benefiting from the fact that ReSharper knows the structure of our code. It is suggesting that we remove the parameter and update the usages. In this simple example, the only usage is the Withdraw method above, but this will actually work on much more advanced examples. Accepting the action with Enter removes the parameter and also changes the code in Withdraw method:
This is where we start benefiting from the fact that ReSharper knows the structure of our code. It is suggesting that we remove the parameter and update the usages. In this simple example, the only usage is the Withdraw method above, but this will actually work on much more advanced examples. Accepting the action with Enter removes the parameter and also changes the code in Withdraw method:
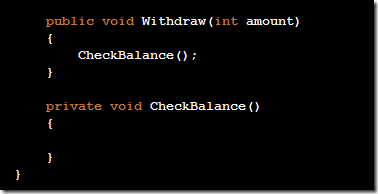 ReSharper also checks your import statements to see if you are importing namespaces that you are not using and suggests removing them like so:
ReSharper also checks your import statements to see if you are importing namespaces that you are not using and suggests removing them like so:
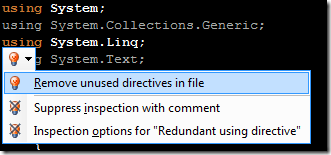 Later in the series, we will look at some of ReSharper's options for choosing namespaces to always import some often used namespaces and ignoring them when scanning for use.
## Importing Namespaces
When using types in namespaces that you have not imported, ReSharper will pop up a blue square to suggest an import like so:
Later in the series, we will look at some of ReSharper's options for choosing namespaces to always import some often used namespaces and ignoring them when scanning for use.
## Importing Namespaces
When using types in namespaces that you have not imported, ReSharper will pop up a blue square to suggest an import like so:
 No more writing using statements by hand. Recently I've started using ReSharper's auto-completion (will be visited one of the next parts) for this, but it's still a very useful feature, again using **Alt+Enter**.
## Hints and Suggestions
ReSharper also supports hints and suggestions, both are actually suggestions for changing something in your code, but hints are less obtrusive and won't show up when navigating between suggestions and not show up on the scrollbar in the code editor.
No more writing using statements by hand. Recently I've started using ReSharper's auto-completion (will be visited one of the next parts) for this, but it's still a very useful feature, again using **Alt+Enter**.
## Hints and Suggestions
ReSharper also supports hints and suggestions, both are actually suggestions for changing something in your code, but hints are less obtrusive and won't show up when navigating between suggestions and not show up on the scrollbar in the code editor.
 If we look at this bit of code, we notice that the `List
If we look at this bit of code, we notice that the `List Let us deal with the hint first. This hint is actually for us to use the C# 3.0 var keyword instead of our `List
Let us deal with the hint first. This hint is actually for us to use the C# 3.0 var keyword instead of our `List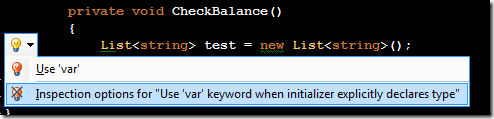 I usually don't like this hint so much, since I feel it sometimes reduces the readability of my code if I overuse the var keyword - luckily there is an option in the context menu to change the inspection options for the particular hint. Pressing Enter brings up the following dialog:
I usually don't like this hint so much, since I feel it sometimes reduces the readability of my code if I overuse the var keyword - luckily there is an option in the context menu to change the inspection options for the particular hint. Pressing Enter brings up the following dialog:
 Here I can set the severity of not using the var keyword when possible. Since I don't like it - I choose "Do not show" and press OK. Now the solid green line is gone. Proceeding to press **Alt+Enter** on the suggestion asks me if I want to use a collection initializer instead of calling the add method on the next line:
Here I can set the severity of not using the var keyword when possible. Since I don't like it - I choose "Do not show" and press OK. Now the solid green line is gone. Proceeding to press **Alt+Enter** on the suggestion asks me if I want to use a collection initializer instead of calling the add method on the next line:
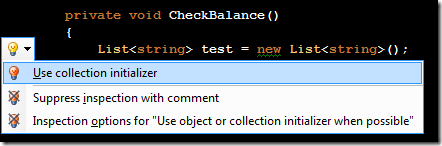 Accepting this removed the call to Add and uses the collection initializer - as expected.
Accepting this removed the call to Add and uses the collection initializer - as expected.
 ## Context Is King
This post shows some examples of how ReSharper uses the context of your code to suggest "intelligent" options. All examples in this post were resolved pressing **Alt+Enter**. Using this single key combination can save you a lot of writing and often even suggest things that you didn't think of. But remember to consider what it's suggestion (like the var keyword) instead of just doing everything blindly.
## Context Is King
This post shows some examples of how ReSharper uses the context of your code to suggest "intelligent" options. All examples in this post were resolved pressing **Alt+Enter**. Using this single key combination can save you a lot of writing and often even suggest things that you didn't think of. But remember to consider what it's suggestion (like the var keyword) instead of just doing everything blindly.
ReSharper Series - Part 0: Installation 16 Jan 2009 3:00 PM (16 years ago)
 Welcome to the 0. part of my ReSharper series - almost at the "real" ReSharper content now, but we just need to get the Resharper installation out of the way. It's not really that hard either.
## ReSharper Installation
This series is based on ReSharper 4.1 - as this is the newest version. You can download it directly from [here](http://www.jetbrains.com/resharper/download/index.html). Once you get past the installation, just fire up Visual Studio and it should present you with options to use either Visual Studio or IntelliJ bindings.
Welcome to the 0. part of my ReSharper series - almost at the "real" ReSharper content now, but we just need to get the Resharper installation out of the way. It's not really that hard either.
## ReSharper Installation
This series is based on ReSharper 4.1 - as this is the newest version. You can download it directly from [here](http://www.jetbrains.com/resharper/download/index.html). Once you get past the installation, just fire up Visual Studio and it should present you with options to use either Visual Studio or IntelliJ bindings. I've gone with the IntelliJ bindings for my setup, so this is what this series is going to be based on. I am using the Visual Studio bindings, and will provide information for both keyboard layouts in this series.
If you already installed ReSharper earlier and want to switch to either of the bindings, you can do so in the ReSharper Options in the General section:
 The first time you use some of the shortcut keys that clash with Visual Studios bindings, you will get a dialog like the one below:
The first time you use some of the shortcut keys that clash with Visual Studios bindings, you will get a dialog like the one below:
 I usually just check "Apply to all ReSharper shortcuts". Haven't had a problem with it yet. Then you should be set for starting up with ReSharper.
## Additional Suggestions
Other than installing ReSharper, I've found it helpful to print the cheatsheet from the JetBrains ReSharper [documentation page](http://www.jetbrains.com/resharper/documentation/index.html). It can be found [here](http://www.jetbrains.com/resharper/docs/ReSharper40DefaultKeymap2.pdf).
I also recommend picking up [Roy Osherove's](http://weblogs.asp.net/rosherove/) [Keyboard Jedi](http://weblogs.asp.net/rosherove/archive/2007/06/03/train-to-be-a-keyboard-master-with-keyboard-jedi.aspx) - pressing **Ctrl+Alt+Shift+F12** will disable the mouse in the application that currently has focus. I've found this to be a very healthy technique when figuring out how much you really use your mouse - and force you to look for those keyboard shortcuts. It sounds silly, but it can really change the way to work when the mouse is just not available. Just enable it one hour each day.
I usually just check "Apply to all ReSharper shortcuts". Haven't had a problem with it yet. Then you should be set for starting up with ReSharper.
## Additional Suggestions
Other than installing ReSharper, I've found it helpful to print the cheatsheet from the JetBrains ReSharper [documentation page](http://www.jetbrains.com/resharper/documentation/index.html). It can be found [here](http://www.jetbrains.com/resharper/docs/ReSharper40DefaultKeymap2.pdf).
I also recommend picking up [Roy Osherove's](http://weblogs.asp.net/rosherove/) [Keyboard Jedi](http://weblogs.asp.net/rosherove/archive/2007/06/03/train-to-be-a-keyboard-master-with-keyboard-jedi.aspx) - pressing **Ctrl+Alt+Shift+F12** will disable the mouse in the application that currently has focus. I've found this to be a very healthy technique when figuring out how much you really use your mouse - and force you to look for those keyboard shortcuts. It sounds silly, but it can really change the way to work when the mouse is just not available. Just enable it one hour each day.
.%20Once%20you%20get%20past%20the%20installation,%20just%20fire%20up%20Visual%20Studio%20and%20it%20should%20present%20you%20with%20options%20to%20use%20either%20Visual%20Studio%20or%20IntelliJ%20bindings.%20%3Cdel%3EI've%20gone%20with%20the%20IntelliJ%20bindings%20for%20my%20setup,%20so%20this%20is%20what%20this%20series%20is%20going%20to%20be%20based%20on.%3C/del%3E%20I%20am%20using%20the%20Visual%20Studio%20bindings,%20and%20will%20provide%20information%20for%20both%20keyboard%20layouts%20in%20this%20series.%0A%20%0AIf%20you%20already%20installed%20ReSharper%20earlier%20and%20want%20to%20switch%20to%20either%20of%20the%20bindings,%20you%20can%20do%20so%20in%20the%20ReSharper%20Options%20in%20the%20General%20section:%20%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ResharperEventDay0Installation_E3B3/image_thumb_1.png%22%20/%3E%20%0A%20%0AThe%20first%20time%20you%20use%20some%20of%20the%20shortcut%20keys%20that%20clash%20with%20Visual%20Studios%20bindings,%20you%20will%20get%20a%20dialog%20like%20the%20one%20below:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ResharperEventDay0Installation_E3B3/image_thumb_2.png%22%20/%3E%20%0A%20%0AI%20usually%20just%20check%20%22Apply%20to%20all%20ReSharper%20shortcuts%22.%20Haven't%20had%20a%20problem%20with%20it%20yet.%20Then%20you%20should%20be%20set%20for%20starting%20up%20with%20ReSharper.%0A%20%0A%23%23%20Additional%20Suggestions%0A%20%0AOther%20than%20installing%20ReSharper,%20I've%20found%20it%20helpful%20to%20print%20the%20cheatsheet%20from%20the%20JetBrains%20ReSharper%20%5Bdocumentation%20page%5D(http://www.jetbrains.com/resharper/documentation/index.html).%20It%20can%20be%20found%20%5Bhere%5D(http://www.jetbrains.com/resharper/docs/ReSharper40DefaultKeymap2.pdf).%0A%20%0AI%20also%20recommend%20picking%20up%20%5BRoy%20Osherove's%5D(http://weblogs.asp.net/rosherove/)%20%5BKeyboard%20Jedi%5D(http://weblogs.asp.net/rosherove/archive/2007/06/03/train-to-be-a-keyboard-master-with-keyboard-jedi.aspx)%20-%20pressing%20**Ctrl+Alt+Shift+F12**%20will%20disable%20the%20mouse%20in%20the%20application%20that%20currently%20has%20focus.%20I've%20found%20this%20to%20be%20a%20very%20healthy%20technique%20when%20figuring%20out%20how%20much%20you%20really%20use%20your%20mouse%20-%20and%20force%20you%20to%20look%20for%20those%20keyboard%20shortcuts.%20It%20sounds%20silly,%20but%20it%20can%20really%20change%20the%20way%20to%20work%20when%20the%20mouse%20is%20just%20not%20available.%20Just%20enable%20it%20one%20hour%20each%20day.)
ReSharper Series - Part -1: My Visual Studio Setup 12 Jan 2009 3:00 PM (16 years ago)
So it's time for part -1 in my [blog series](/2009/01/10/resharper-series/) about ReSharper. We're still in the negative parts, since we're not dealing with ReSharper yet, so much introduction to do. Today is going to be about my personal Visual Studio setup - and the source code setup for this series. I'll do a lot of screenshotting in the series, so you might as well see how my setup is.
## ASP.NET MVC Beta Source
I needed some source code for my examples. When we get to the navigation parts of the series, I'll need some actual code to explore and I wanted to use some publicly available code, so it would be possible for people to follow along in some of the examples if they wanted to. So I picked the ASP.NET MVC Beta Source code as my base for playing with Resharper. It can be downloaded [here](http://www.codeplex.com/aspnet/Release/ProjectReleases.aspx?ReleaseId=18764).
## Physical Setup
I run with a dual monitor setup at home with two Samsung monitors and find that is a real [productivity booster](http://www.codinghorror.com/blog/archives/001076.html). Highly recommended. My main monitor is a 22" wide-screen [Samsung 2253BW](http://www.samsung.com/us/consumer/detail/detail.do?group=computersperipherals&type=monitors&subtype=lcd&model_cd=LS22AQWJFV/XAA) and my secondary monitor is a 19" [Samsung SyncMaster 971p](http://www.samsung.com/dk/consumer/detail/detail.do?group=computersperipherals&type=computersperipherals&subtype=monitors&model_cd=LS19MBXXHV/EDC). I love the 22" wide-screen for it's size - and the 971p has a truly amazing contrast which is really nice for doing graphical work of any kind. I would post a photo, but my desk is too messy at the moment. Oh, and on the subject of multiple monitors, I highly recommend using [MultiMon](http://www.mediachance.com/free/multimon.htm) or [UltraMon](http://www.realtimesoft.com/ultramon/) for providing monitor-specific taskbars and hotkeys for moving windows between monitors.
## Visual Studio Layout
I prefer to work with a dark background when I'm coding, since monitors use [additive colors](http://en.wikipedia.org/wiki/Additive_color), having a white background simply emits way too much light and my eyes get tired more quickly. I happened to find a theme [Rob Conery](http://blog.wekeroad.com/) modified to look like the vibrant ink theme from [TextMate](http://macromates.com/). Robs version can be found [here](http://blog.wekeroad.com/blog/textmate-theme-for-visual-studio-take-2/). It looks like this (although I'm using Courier New instead of Consolas - old habit):
 You will also notice that all my windows are set to auto-hide. This discourages me from clicking on stuff with my mouse and I can easily bring up most of what I need with keyboard shortcuts anyway.
## AnkhSvn
While this is not really ReSharper related at all, I feel that I must mention the incredible (and free) [AnkhSvn](http://ankhsvn.open.collab.net/) add-in for managing subversion. I tried the first versions and it really sucked, but now that version 2 is out, it's really the best out there in my opinion.
You will also notice that all my windows are set to auto-hide. This discourages me from clicking on stuff with my mouse and I can easily bring up most of what I need with keyboard shortcuts anyway.
## AnkhSvn
While this is not really ReSharper related at all, I feel that I must mention the incredible (and free) [AnkhSvn](http://ankhsvn.open.collab.net/) add-in for managing subversion. I tried the first versions and it really sucked, but now that version 2 is out, it's really the best out there in my opinion.
%20about%20ReSharper.%20We're%20still%20in%20the%20negative%20parts,%20since%20we're%20not%20dealing%20with%20ReSharper%20yet,%20so%20much%20introduction%20to%20do.%20Today%20is%20going%20to%20be%20about%20my%20personal%20Visual%20Studio%20setup%20-%20and%20the%20source%20code%20setup%20for%20this%20series.%20I'll%20do%20a%20lot%20of%20screenshotting%20in%20the%20series,%20so%20you%20might%20as%20well%20see%20how%20my%20setup%20is.%0A%0A%23%23%20ASP.NET%20MVC%20Beta%20Source%0A%0AI%20needed%20some%20source%20code%20for%20my%20examples.%20When%20we%20get%20to%20the%20navigation%20parts%20of%20the%20series,%20I'll%20need%20some%20actual%20code%20to%20explore%20and%20I%20wanted%20to%20use%20some%20publicly%20available%20code,%20so%20it%20would%20be%20possible%20for%20people%20to%20follow%20along%20in%20some%20of%20the%20examples%20if%20they%20wanted%20to.%20So%20I%20picked%20the%20ASP.NET%20MVC%20Beta%20Source%20code%20as%20my%20base%20for%20playing%20with%20Resharper.%20It%20can%20be%20downloaded%20%5Bhere%5D(http://www.codeplex.com/aspnet/Release/ProjectReleases.aspx?ReleaseId%3D18764).%0A%0A%23%23%20Physical%20Setup%0A%0AI%20run%20with%20a%20dual%20monitor%20setup%20at%20home%20with%20two%20Samsung%20monitors%20and%20find%20that%20is%20a%20real%20%5Bproductivity%20booster%5D(http://www.codinghorror.com/blog/archives/001076.html).%20Highly%20recommended.%20My%20main%20monitor%20is%20a%2022%22%20wide-screen%20%5BSamsung%202253BW%5D(http://www.samsung.com/us/consumer/detail/detail.do?group%3Dcomputersperipherals%26amp;type%3Dmonitors%26amp;subtype%3Dlcd%26amp;model_cd%3DLS22AQWJFV/XAA)%20and%20my%20secondary%20monitor%20is%20a%2019%22%20%5BSamsung%20SyncMaster%20971p%5D(http://www.samsung.com/dk/consumer/detail/detail.do?group%3Dcomputersperipherals%26amp;type%3Dcomputersperipherals%26amp;subtype%3Dmonitors%26amp;model_cd%3DLS19MBXXHV/EDC).%20I%20love%20the%2022%22%20wide-screen%20for%20it's%20size%20-%20and%20the%20971p%20has%20a%20truly%20amazing%20contrast%20which%20is%20really%20nice%20for%20doing%20graphical%20work%20of%20any%20kind.%20I%20would%20post%20a%20photo,%20but%20my%20desk%20is%20too%20messy%20at%20the%20moment.%20Oh,%20and%20on%20the%20subject%20of%20multiple%20monitors,%20I%20highly%20recommend%20using%20%5BMultiMon%5D(http://www.mediachance.com/free/multimon.htm)%20or%20%5BUltraMon%5D(http://www.realtimesoft.com/ultramon/)%20for%20providing%20monitor-specific%20taskbars%20and%20hotkeys%20for%20moving%20windows%20between%20monitors.%0A%0A%23%23%20Visual%20Studio%20Layout%0A%0AI%20prefer%20to%20work%20with%20a%20dark%20background%20when%20I'm%20coding,%20since%20monitors%20use%20%5Badditive%20colors%5D(http://en.wikipedia.org/wiki/Additive_color),%20having%20a%20white%20background%20simply%20emits%20way%20too%20much%20light%20and%20my%20eyes%20get%20tired%20more%20quickly.%20I%20happened%20to%20find%20a%20theme%20%5BRob%20Conery%5D(http://blog.wekeroad.com/)%20modified%20to%20look%20like%20the%20vibrant%20ink%20theme%20from%20%5BTextMate%5D(http://macromates.com/).%20Robs%20version%20can%20be%20found%20%5Bhere%5D(http://blog.wekeroad.com/blog/textmate-theme-for-visual-studio-take-2/).%20It%20looks%20like%20this%20(although%20I'm%20using%20Courier%20New%20instead%20of%20Consolas%20-%20old%20habit):%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ResharperEventDay1MyVisualStudioSetup_D707/image_thumb.png%22%20/%3E%0A%0AYou%20will%20also%20notice%20that%20all%20my%20windows%20are%20set%20to%20auto-hide.%20This%20discourages%20me%20from%20clicking%20on%20stuff%20with%20my%20mouse%20and%20I%20can%20easily%20bring%20up%20most%20of%20what%20I%20need%20with%20keyboard%20shortcuts%20anyway.%0A%0A%23%23%20AnkhSvn%0A%0AWhile%20this%20is%20not%20really%20ReSharper%20related%20at%20all,%20I%20feel%20that%20I%20must%20mention%20the%20incredible%20(and%20free)%20%5BAnkhSvn%5D(http://ankhsvn.open.collab.net/)%20add-in%20for%20managing%20subversion.%20I%20tried%20the%20first%20versions%20and%20it%20really%20sucked,%20but%20now%20that%20version%202%20is%20out,%20it's%20really%20the%20best%20out%20there%20in%20my%20opinion.)
Reducing Check-In Friction (in Continuous Integration) 10 Jan 2009 3:00 PM (16 years ago)
In a [continuous integration](http://en.wikipedia.org/wiki/Continuous_Integration) environment, one of main motivations is to avoid big bang integrations, where multiple people and/or multiple teams build their part of the project and it is all fused together before release. The benefits of having an automated continuous build are huge, since problems become visible early. The build server polls the source control server and produces a build and runs the appropriate tests when new code is checked in.
 To have an efficient continuous integration environment, changes should be checked in often. Not checking in often results in more merge conflicts, less visibility of current project status) and reduced benefits from source control in general (less check-ins mean less chance of rolling back, bigger risk of loosing code). To encourage developers to check in their code often, it should be a non-event - it should be easy and not dangerous. However, continuous integration is all about visualizing build failure, where you use a simple tray application, [lava lamps](http://schneide.wordpress.com/2008/10/27/extreme-feedback-device-xfd-the-onoz-lamp/) or whatnot. So checking in something that doesn't work can cause some developer stress, rushing to fix the build.
When the build is broken, other developers can't check in or out (at least they shouldn't - they will either make the problems worse or get broken code), so you want to minimize the time the build is broken. It is useful to have some discipline about the process of checking in, like the "Check In Dance" described Jeremy Miller's [post](http://codebetter.com/blogs/jeremy.miller/archive/2005/07/25/129797.aspx). In general you want to make sure of the following:
- You have the latest bits from source control.
- The code can build successfully.
- Relevant tests pass (unit tests, maybe static analysis tools like FxCop)
Jeremy also describes notifying the team that a change is coming. While this might be a good idea for smaller teams, I find that it would be rather disturbing if you are part of a bigger team (10-20+ developers). In this case I would opt for a more optimistic check-in policy, assuming that check-ins won't happen at the same time or won't clash. It involves slightly more praying and can give some annoying conflicts sometimes though.
Reducing friction on the check-in process is important. To make check-in a non-event, it needs to be very simple for the developer. A good solution for this is often to have a "smoke-screen" to verify the quality of your code before checking in. If you look at the above steps, it is rather simple to collect them in a single build target that could be run easily by the developer. This will also increase developer confidence in not breaking the build, thus eliminating check-in fear and enabling often check-in.
You will want to make sure that the build target can be executed in a few minutes and that tools like FxCop use identical settings on developer machines and build server (personal experience). Another option is to use [pre-tested check-ins](http://www.jetbrains.com/teamcity/delayed_commit.html) if you are using TeamCity, but I find that the build target will serve the purpose just as well.
I hope you enjoyed the post. May your future builds be green.
To have an efficient continuous integration environment, changes should be checked in often. Not checking in often results in more merge conflicts, less visibility of current project status) and reduced benefits from source control in general (less check-ins mean less chance of rolling back, bigger risk of loosing code). To encourage developers to check in their code often, it should be a non-event - it should be easy and not dangerous. However, continuous integration is all about visualizing build failure, where you use a simple tray application, [lava lamps](http://schneide.wordpress.com/2008/10/27/extreme-feedback-device-xfd-the-onoz-lamp/) or whatnot. So checking in something that doesn't work can cause some developer stress, rushing to fix the build.
When the build is broken, other developers can't check in or out (at least they shouldn't - they will either make the problems worse or get broken code), so you want to minimize the time the build is broken. It is useful to have some discipline about the process of checking in, like the "Check In Dance" described Jeremy Miller's [post](http://codebetter.com/blogs/jeremy.miller/archive/2005/07/25/129797.aspx). In general you want to make sure of the following:
- You have the latest bits from source control.
- The code can build successfully.
- Relevant tests pass (unit tests, maybe static analysis tools like FxCop)
Jeremy also describes notifying the team that a change is coming. While this might be a good idea for smaller teams, I find that it would be rather disturbing if you are part of a bigger team (10-20+ developers). In this case I would opt for a more optimistic check-in policy, assuming that check-ins won't happen at the same time or won't clash. It involves slightly more praying and can give some annoying conflicts sometimes though.
Reducing friction on the check-in process is important. To make check-in a non-event, it needs to be very simple for the developer. A good solution for this is often to have a "smoke-screen" to verify the quality of your code before checking in. If you look at the above steps, it is rather simple to collect them in a single build target that could be run easily by the developer. This will also increase developer confidence in not breaking the build, thus eliminating check-in fear and enabling often check-in.
You will want to make sure that the build target can be executed in a few minutes and that tools like FxCop use identical settings on developer machines and build server (personal experience). Another option is to use [pre-tested check-ins](http://www.jetbrains.com/teamcity/delayed_commit.html) if you are using TeamCity, but I find that the build target will serve the purpose just as well.
I hope you enjoyed the post. May your future builds be green.
%26bodytext%3DIn%20a%20%5Bcontinuous%20integration%5D(http://en.wikipedia.org/wiki/Continuous_Integration)%20environment,%20one%20of%20main%20motivations%20is%20to%20avoid%20big%20bang%20integrations,%20where%20multiple%20people%20and/or%20multiple%20teams%20build%20their%20part%20of%20the%20project%20and%20it%20is%20all%20fused%20together%20before%20release.%20The%20benefits%20of%20having%20an%20automated%20continuous%20build%20are%20huge,%20since%20problems%20become%20visible%20early.%20The%20build%20server%20polls%20the%20source%20control%20server%20and%20produces%20a%20build%20and%20runs%20the%20appropriate%20tests%20when%20new%20code%20is%20checked%20in.%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/ReducingCheckInFriction_AEB9/image_thumb.png%22%20classname%3D%22right%22%20/%3E%0A%0ATo%20have%20an%20efficient%20continuous%20integration%20environment,%20changes%20should%20be%20checked%20in%20often.%20Not%20checking%20in%20often%20results%20in%20more%20merge%20conflicts,%20less%20visibility%20of%20current%20project%20status)%20and%20reduced%20benefits%20from%20source%20control%20in%20general%20(less%20check-ins%20mean%20less%20chance%20of%20rolling%20back,%20bigger%20risk%20of%20loosing%20code).%20To%20encourage%20developers%20to%20check%20in%20their%20code%20often,%20it%20should%20be%20a%20non-event%20-%20it%20should%20be%20easy%20and%20not%20dangerous.%20However,%20continuous%20integration%20is%20all%20about%20visualizing%20build%20failure,%20where%20you%20use%20a%20simple%20tray%20application,%20%5Blava%20lamps%5D(http://schneide.wordpress.com/2008/10/27/extreme-feedback-device-xfd-the-onoz-lamp/)%20or%20whatnot.%20So%20checking%20in%20something%20that%20doesn't%20work%20can%20cause%20some%20developer%20stress,%20rushing%20to%20fix%20the%20build.%0A%0AWhen%20the%20build%20is%20broken,%20other%20developers%20can't%20check%20in%20or%20out%20(at%20least%20they%20shouldn't%20-%20they%20will%20either%20make%20the%20problems%20worse%20or%20get%20broken%20code),%20so%20you%20want%20to%20minimize%20the%20time%20the%20build%20is%20broken.%20It%20is%20useful%20to%20have%20some%20discipline%20about%20the%20process%20of%20checking%20in,%20like%20the%20%22Check%20In%20Dance%22%20described%20Jeremy%20Miller's%20%5Bpost%5D(http://codebetter.com/blogs/jeremy.miller/archive/2005/07/25/129797.aspx).%20In%20general%20you%20want%20to%20make%20sure%20of%20the%20following:%0A%0A%20-%20You%20have%20the%20latest%20bits%20from%20source%20control.%0A%20-%20The%20code%20can%20build%20successfully.%0A%20-%20Relevant%20tests%20pass%20(unit%20tests,%20maybe%20static%20analysis%20tools%20like%20FxCop)%0A%0AJeremy%20also%20describes%20notifying%20the%20team%20that%20a%20change%20is%20coming.%20While%20this%20might%20be%20a%20good%20idea%20for%20smaller%20teams,%20I%20find%20that%20it%20would%20be%20rather%20disturbing%20if%20you%20are%20part%20of%20a%20bigger%20team%20(10-20+%20developers).%20In%20this%20case%20I%20would%20opt%20for%20a%20more%20optimistic%20check-in%20policy,%20assuming%20that%20check-ins%20won't%20happen%20at%20the%20same%20time%20or%20won't%20clash.%20It%20involves%20slightly%20more%20praying%20and%20can%20give%20some%20annoying%20conflicts%20sometimes%20though.%0A%0AReducing%20friction%20on%20the%20check-in%20process%20is%20important.%20To%20make%20check-in%20a%20non-event,%20it%20needs%20to%20be%20very%20simple%20for%20the%20developer.%20A%20good%20solution%20for%20this%20is%20often%20to%20have%20a%20%22smoke-screen%22%20to%20verify%20the%20quality%20of%20your%20code%20before%20checking%20in.%20If%20you%20look%20at%20the%20above%20steps,%20it%20is%20rather%20simple%20to%20collect%20them%20in%20a%20single%20build%20target%20that%20could%20be%20run%20easily%20by%20the%20developer.%20This%20will%20also%20increase%20developer%20confidence%20in%20not%20breaking%20the%20build,%20thus%20eliminating%20check-in%20fear%20and%20enabling%20often%20check-in.%0A%0AYou%20will%20want%20to%20make%20sure%20that%20the%20build%20target%20can%20be%20executed%20in%20a%20few%20minutes%20and%20that%20tools%20like%20FxCop%20use%20identical%20settings%20on%20developer%20machines%20and%20build%20server%20(personal%20experience).%20Another%20option%20is%20to%20use%20%5Bpre-tested%20check-ins%5D(http://www.jetbrains.com/teamcity/delayed_commit.html)%20if%20you%20are%20using%20TeamCity,%20but%20I%20find%20that%20the%20build%20target%20will%20serve%20the%20purpose%20just%20as%20well.%0A%0AI%20hope%20you%20enjoyed%20the%20post.%20May%20your%20future%20builds%20be%20green.)
ReSharper Series 9 Jan 2009 3:00 PM (16 years ago)
As I've mentioned earlier on twitter, I've been planning on doing a ReSharper series on my blog. The idea is to go over ReSharper one part at a time and find some new quirk or feature that I'd like to highlight. I have used ReSharper for a very long time, but want to dig even deeper and try to pass some of the knowledge as well. I have already learned a great deal more just researching for this series. We're going to start from the basics and go from installation over the basic features of ReSharper to some more advanced and exotic features. The whole event is going to have a strong focus on utilizing the keyboard as much as possible - surviving without your mouse. The reason for this is simply that I've found that in most cases, this will boost the productivity - once you really know keyboard shortcuts, I feel the keyboard just almost becomes a natural extension of your mind, allowing for very rapid work. I will be updating this post to serve as a reference and overview for the parts as I'm progressing. The number of posts is not decided yet, but suggestions and feedback is very welcome and will probably make me do more posts. Disclaimer: This blog is not affiliated with JetBrains. #### List of posts - [Part -2: Introduction & Motivation](/2009/01/10/resharper-series-part-minus-2-introduction-motivation/) - [Part -1: My Visual Studio Setup](/2009/01/13/resharper-series-part-minus-1-my-visual-studio-setup/) - [Part 0: Installation](/2009/01/17/resharper-series-part-0-installation/) - [Part 1: The Power of Alt+Enter](/2009/01/21/resharper-series-part-1-the-power-of-alt-enter/) - [Part 2: Basic Navigation](/2009/01/27/resharper-series-part-2-basic-navigation/) - [Part 3: Auto-completion / Intellisense](/2009/02/04/resharper-series-part-3-auto-completion-intellisense/) - [Part 4: Moving Code](/2009/02/10/resharper-series-part-4-moving-code/) - [Part 5: Generating Code](/2009/03/04/resharper-series-part-5-generating-code/) - [Part 6: Find Usages](/2009/03/09/resharper-series-part-6-find-usages/)
ReSharper Series - Part -2: Introduction & Motivation 9 Jan 2009 3:00 PM (16 years ago)
 This is the first and -2. part of my [ReSharper series](/2009/01/10/resharper-series/). -2 because it there's still a few parts until I hit real ReSharper content. The subject today will be a quick introduction to ReSharper and the motivation for using it - so why should we?
## What is ReSharper?
ReSharper is a Visual Studio add-in made by [JetBrains](http://www.jetbrains.com). In their words, ReSharper is:
> The most intelligent add-in to Visual Studio.
What it really amounts to is a lot of smart static analysis of your code, much like Visual Studio does already to provide you with IntelliSense and red squigglies when you make mistakes. What they do with this information is to provide context-based suggestions and generally reduce the number of keystrokes required to produce the most common code scenarios.
In addition to this, the static analysis information can be used to provide a structured way to refactor your code without resorting to error-prone search and replace techniques. Since ReSharper "knows" the structure of your code, it can provide much better support for stuff like renaming classes, extracting and moving functionality.
## Strengths
From my point of view and experience the main strength of ReSharper is it's context-awareness. This is what gives the intelligent and intuitive feel when using it. Since ReSharper provides a lot of functionality, filtering it by what is available (or reasonable) at this given point in the code is really valuable.
Besides context-awareness, I really love the navigation options provided by ReSharper. It allows me to navigate along different axis depending on what I'm looking for. Providing easy options for navigating according to usages (where is this method called from), inheritance trees (superclasses/interfaces/subclasses) or completely different files, depending on which aspects of the code I am exploring at the given moment.
Third is code-generation and refactoring. This is often mentioned as the main strength of ReSharper - this is mostly convenience, reducing the amount of manual work required to do refactoring and doing (mostly small-scale) code generation used to create the usual cruft code for classes, properties and such.
## Weaknesses
Seems odd to talk about weaknesses in this motivation post, but this isn't really weaknesses in ReSharper per se, but more things I still feel I'm missing. I actually feel that ReSharper is doing the job it is supposed to do quite well.
At the moment, ReSharper is the only real productivity add-in I use in Visual Studio - but I feel I'm missing features for basic text editor stuff, quick navigation in the current file (ReSharper provides some, but it can be heavy sometimes). It seems that the vim add-in [ViEmu](http://www.viemu.com/) might be some of what I'm looking for. Maybe after I'm done with this series.
This is the first and -2. part of my [ReSharper series](/2009/01/10/resharper-series/). -2 because it there's still a few parts until I hit real ReSharper content. The subject today will be a quick introduction to ReSharper and the motivation for using it - so why should we?
## What is ReSharper?
ReSharper is a Visual Studio add-in made by [JetBrains](http://www.jetbrains.com). In their words, ReSharper is:
> The most intelligent add-in to Visual Studio.
What it really amounts to is a lot of smart static analysis of your code, much like Visual Studio does already to provide you with IntelliSense and red squigglies when you make mistakes. What they do with this information is to provide context-based suggestions and generally reduce the number of keystrokes required to produce the most common code scenarios.
In addition to this, the static analysis information can be used to provide a structured way to refactor your code without resorting to error-prone search and replace techniques. Since ReSharper "knows" the structure of your code, it can provide much better support for stuff like renaming classes, extracting and moving functionality.
## Strengths
From my point of view and experience the main strength of ReSharper is it's context-awareness. This is what gives the intelligent and intuitive feel when using it. Since ReSharper provides a lot of functionality, filtering it by what is available (or reasonable) at this given point in the code is really valuable.
Besides context-awareness, I really love the navigation options provided by ReSharper. It allows me to navigate along different axis depending on what I'm looking for. Providing easy options for navigating according to usages (where is this method called from), inheritance trees (superclasses/interfaces/subclasses) or completely different files, depending on which aspects of the code I am exploring at the given moment.
Third is code-generation and refactoring. This is often mentioned as the main strength of ReSharper - this is mostly convenience, reducing the amount of manual work required to do refactoring and doing (mostly small-scale) code generation used to create the usual cruft code for classes, properties and such.
## Weaknesses
Seems odd to talk about weaknesses in this motivation post, but this isn't really weaknesses in ReSharper per se, but more things I still feel I'm missing. I actually feel that ReSharper is doing the job it is supposed to do quite well.
At the moment, ReSharper is the only real productivity add-in I use in Visual Studio - but I feel I'm missing features for basic text editor stuff, quick navigation in the current file (ReSharper provides some, but it can be heavy sometimes). It seems that the vim add-in [ViEmu](http://www.viemu.com/) might be some of what I'm looking for. Maybe after I'm done with this series.
.%20-2%20because%20it%20there's%20still%20a%20few%20parts%20until%20I%20hit%20real%20ReSharper%20content.%20The%20subject%20today%20will%20be%20a%20quick%20introduction%20to%20ReSharper%20and%20the%20motivation%20for%20using%20it%20-%20so%20why%20should%20we?%0A%20%0A%23%23%20What%20is%20ReSharper?%0A%20%0AReSharper%20is%20a%20Visual%20Studio%20add-in%20made%20by%20%5BJetBrains%5D(http://www.jetbrains.com).%20In%20their%20words,%20ReSharper%20is:%0A%0A%3E%20The%20most%20intelligent%20add-in%20to%20Visual%20Studio.%0A%0AWhat%20it%20really%20amounts%20to%20is%20a%20lot%20of%20smart%20static%20analysis%20of%20your%20code,%20much%20like%20Visual%20Studio%20does%20already%20to%20provide%20you%20with%20IntelliSense%20and%20red%20squigglies%20when%20you%20make%20mistakes.%20What%20they%20do%20with%20this%20information%20is%20to%20provide%20context-based%20suggestions%20and%20generally%20reduce%20the%20number%20of%20keystrokes%20required%20to%20produce%20the%20most%20common%20code%20scenarios.%20%0A%20%0AIn%20addition%20to%20this,%20the%20static%20analysis%20information%20can%20be%20used%20to%20provide%20a%20structured%20way%20to%20refactor%20your%20code%20without%20resorting%20to%20error-prone%20search%20and%20replace%20techniques.%20Since%20ReSharper%20%22knows%22%20the%20structure%20of%20your%20code,%20it%20can%20provide%20much%20better%20support%20for%20stuff%20like%20renaming%20classes,%20extracting%20and%20moving%20functionality.%0A%20%0A%23%23%20Strengths%0A%20%0AFrom%20my%20point%20of%20view%20and%20experience%20the%20main%20strength%20of%20ReSharper%20is%20it's%20context-awareness.%20This%20is%20what%20gives%20the%20intelligent%20and%20intuitive%20feel%20when%20using%20it.%20Since%20ReSharper%20provides%20a%20lot%20of%20functionality,%20filtering%20it%20by%20what%20is%20available%20(or%20reasonable)%20at%20this%20given%20point%20in%20the%20code%20is%20really%20valuable.%20%0A%20%0ABesides%20context-awareness,%20I%20really%20love%20the%20navigation%20options%20provided%20by%20ReSharper.%20It%20allows%20me%20to%20navigate%20along%20different%20axis%20depending%20on%20what%20I'm%20looking%20for.%20Providing%20easy%20options%20for%20navigating%20according%20to%20usages%20(where%20is%20this%20method%20called%20from),%20inheritance%20trees%20(superclasses/interfaces/subclasses)%20or%20completely%20different%20files,%20depending%20on%20which%20aspects%20of%20the%20code%20I%20am%20exploring%20at%20the%20given%20moment.%0A%20%0AThird%20is%20code-generation%20and%20refactoring.%20This%20is%20often%20mentioned%20as%20the%20main%20strength%20of%20ReSharper%20-%20this%20is%20mostly%20convenience,%20reducing%20the%20amount%20of%20manual%20work%20required%20to%20do%20refactoring%20and%20doing%20(mostly%20small-scale)%20code%20generation%20used%20to%20create%20the%20usual%20cruft%20code%20for%20classes,%20properties%20and%20such.%0A%20%0A%23%23%20Weaknesses%0A%20%0ASeems%20odd%20to%20talk%20about%20weaknesses%20in%20this%20motivation%20post,%20but%20this%20isn't%20really%20weaknesses%20in%20ReSharper%20per%20se,%20but%20more%20things%20I%20still%20feel%20I'm%20missing.%20I%20actually%20feel%20that%20ReSharper%20is%20doing%20the%20job%20it%20is%20supposed%20to%20do%20quite%20well.%0A%20%0AAt%20the%20moment,%20ReSharper%20is%20the%20only%20real%20productivity%20add-in%20I%20use%20in%20Visual%20Studio%20-%20but%20I%20feel%20I'm%20missing%20features%20for%20basic%20text%20editor%20stuff,%20quick%20navigation%20in%20the%20current%20file%20(ReSharper%20provides%20some,%20but%20it%20can%20be%20heavy%20sometimes).%20It%20seems%20that%20the%20vim%20add-in%20%5BViEmu%5D(http://www.viemu.com/)%20might%20be%20some%20of%20what%20I'm%20looking%20for.%20Maybe%20after%20I'm%20done%20with%20this%20series.)
Craftsmanship over Crap 5 Jan 2009 3:00 PM (16 years ago)
I was catching up on my blog reading ([ObjectMentor](http://blog.objectmentor.com/) to be more specific) when I found Uncle Bob's [post](http://blog.objectmentor.com/articles/2008/08/14/quintessence-the-fifth-element-for-the-agile-manifesto) on quintessence as the fifth element for the Agile Manifesto. His statement of "Craftsmanship over Crap" really rang true with me. We (software developers) like to compare our work to that of craftsmen and many people are starting to realize that maintainability is one of the cornerstones of writing good software. However, our software still keeps decaying, brilliant designs are mangled with hacks, quick bug fixes or just plain outdated with changing requirements. However, I challenge you, next time you go to fix that bug or that small change request that almost fits the current design, step back and think first. Spend those extra minutes considering if there is a way you can fix it, maybe even *improving* the current design. Don't go on an overengineering spree, just keep it simple and elegant. Then, when you're done, sit back and marvel at your work and smile. We've all made a quick hack, we will all do it again, but I promise you, those few extra minutes spent will be worth it in the long run. Technical debt has high interests. How often have you made a quick change while thinking (or even better made a comment) that you will come back and fix it later. How often have you forgotten? Actively thinking about this and being proud of the results is really good for my personal productivity. Ideally, if you always leave your code slightly better than you found it, it should resist decay very well. Challenge your team to join you in this quest. - Leave the code slightly better than you found it. - Write a regression test for a bug, so it's not reintroduced. - Don't live in a house with [broken windows](http://www.pragprog.com/the-pragmatic-programmer/extracts/software-entropy). - Write tests to gain the confidence to perform refactoring. - Be a craftsman. And to quote [J.P Boodhoo](http://blog.jpboodhoo.com/): '**Develop with Passion**'.
Evolution of Solutions - and Perceived Performance 19 Dec 2008 3:00 PM (16 years ago)
I entered a small competition yesterday and wanted to write a short post describing my progress and findings. The competition was rather simple, write a method that returns an array containing the numbers from 1 to 1000 in a random order.
My first solution was the naive LINQ solution.
``` csharp
public static int[] NaiveLinq(int max)
{
var random = new Random();
var query = from number in Enumerable.Range(1, max)
orderby random.Next()
select number;
return query.ToArray();
}
```
I reckoned that several people would post this solution, so I felt like doing something slightly more fancy - and since parallelization is so hot these days, why not do it with PLINQ instead, so it would actually be faster on multi-core systems. The change is really simple.
``` csharp
public static int[] PLinq(int max)
{
var random = new Random();
var query = from number in ParallelEnumerable.Range(1, max)
orderby random.Next()
select number;
return query.ToArray();
}
```
I benchmarked it (on my quad-core machine), and saw that the PLINQ solution was indeed faster - but only for rather big solutions, the overhead was simply too big in small instances of the problem (array size < 3000). This is not too well for a competition that is supposed to make arrays of size 1000. However, reluctant to ditch my parallel idea, I made a hybrid solution, which would use regular LINQ for small instances and PLINQ for big instances, based on my benchmark:
``` csharp
public static int[] GenerateUsingHybridLinq(int arrayLength)
{
var random = new Random();
// Use PLINQ if we're above the "very scientific" limit of 3000.
if (arrayLength >= 3000)
{
return (from i in ParallelEnumerable.Range(1, arrayLength)
orderby random.Next()
select i).ToArray();
}
return (from i in Enumerable.Range(1, arrayLength)
orderby random.Next()
select i).ToArray();
}
```
I posted this solution to the competition and decided I had spent enough time on it. However, it bugged me because I knew that the `Random` class in the .NET framework is not guaranteed to be thread-safe. It also bugged be that I was actually solving a shuffling problem by sorting. Shuffling can be solved in O(n) while sorting is O(n*log(n)). In addition I thought that the LINQ solutions were kind of dull.
So I decided to take a stab at solving it without resolving to sorting. Shuffling is a well known problem, so I implemented the [Fisher-Yates algorithm](http://en.wikipedia.org/wiki/Fisher-Yates_shuffle), often used for shuffling cards. It is actually a rather elegant algorithm.
``` csharp
public static int[] Generate()
{
Random random = new Random();
var numbers = new int[1000];
// Add sorted numbers to shuffle
for (var i = 0; i < 1000; i++)
numbers[i] = i + 1;
var last = numbers.Length;
while (last > 1)
{
// Select a random entry in the array to swap
var swap = random.Next(last);
// Decrease relevant end of array
last = last - 1;
// Swap numbers using XOR swap, we don't need no stinkin' temp variables
if (last != swap)
{
numbers[last] ^= numbers[swap];
numbers[swap] ^= numbers[last];
numbers[last] ^= numbers[swap];
}
}
return numbers;
}
```
I adjusted it a bit and finally found a place to make an ode to the awesomeness that is [XOR swap](http://en.wikipedia.org/wiki/Xor_swap_algorithm), swapping two values without using a temporary variable. Even though the algorithm was faster asymptotically, I was curious how it would venture against the sort-based LINQ solutions performance-wise. Here is the result:
 Note that both HLINQ and PLINQ use all 4 cores on my quad-core machine. I realize there's an overhead using LINQ, but I'm still impressed how much faster this simple little algorithm is.
I submitted my new solution, with a note to replace my hybrid solution, just before midnight, but unfortunately I think it might have been too late, it didn't seem to make the cut for the competition. At least my hybrid solution made it into the final round - and non-thread-safe Random surely won't be a problem for instances of size 1000 - since it will use regular LINQ for that.
Note that both HLINQ and PLINQ use all 4 cores on my quad-core machine. I realize there's an overhead using LINQ, but I'm still impressed how much faster this simple little algorithm is.
I submitted my new solution, with a note to replace my hybrid solution, just before midnight, but unfortunately I think it might have been too late, it didn't seem to make the cut for the competition. At least my hybrid solution made it into the final round - and non-thread-safe Random surely won't be a problem for instances of size 1000 - since it will use regular LINQ for that.
%0A%7B%0A%20%20%20%20var%20random%20%3D%20new%20Random();%0A%20%20%20%20var%20query%20%3D%20from%20number%20in%20Enumerable.Range(1,%20max)%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20orderby%20random.Next()%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20select%20number;%0A%20%20%20%20return%20query.ToArray();%0A%7D%0A%60%60%60%0A%0AI%20reckoned%20that%20several%20people%20would%20post%20this%20solution,%20so%20I%20felt%20like%20doing%20something%20slightly%20more%20fancy%20-%20and%20since%20parallelization%20is%20so%20hot%20these%20days,%20why%20not%20do%20it%20with%20PLINQ%20instead,%20so%20it%20would%20actually%20be%20faster%20on%20multi-core%20systems.%20The%20change%20is%20really%20simple.%0A%0A%60%60%60%20csharp%0Apublic%20static%20int%5B%5D%20PLinq(int%20max)%0A%7B%0A%20%20%20%20var%20random%20%3D%20new%20Random();%0A%20%20%20%20var%20query%20%3D%20from%20number%20in%20ParallelEnumerable.Range(1,%20max)%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20orderby%20random.Next()%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20select%20number;%0A%20%20%20%20return%20query.ToArray();%0A%7D%0A%60%60%60%0A%0AI%20benchmarked%20it%20(on%20my%20quad-core%20machine),%20and%20saw%20that%20the%20PLINQ%20solution%20was%20indeed%20faster%20-%20but%20only%20for%20rather%20big%20solutions,%20the%20overhead%20was%20simply%20too%20big%20in%20small%20instances%20of%20the%20problem%20(array%20size%20%3C%203000).%20This%20is%20not%20too%20well%20for%20a%20competition%20that%20is%20supposed%20to%20make%20arrays%20of%20size%201000.%20However,%20reluctant%20to%20ditch%20my%20parallel%20idea,%20I%20made%20a%20hybrid%20solution,%20which%20would%20use%20regular%20LINQ%20for%20small%20instances%20and%20PLINQ%20for%20big%20instances,%20based%20on%20my%20benchmark:%0A%0A%60%60%60%20csharp%0Apublic%20static%20int%5B%5D%20GenerateUsingHybridLinq(int%20arrayLength)%0A%7B%0A%20%20%20%20var%20random%20%3D%20new%20Random();%0A%20%20%20%20//%20Use%20PLINQ%20if%20we're%20above%20the%20%22very%20scientific%22%20limit%20of%203000.%0A%20%20%20%20if%20(arrayLength%20%3E%3D%203000)%0A%20%20%20%20%7B%0A%20%20%20%20%20%20%20%20return%20(from%20i%20in%20ParallelEnumerable.Range(1,%20arrayLength)%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20orderby%20random.Next()%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20select%20i).ToArray();%0A%20%20%20%20%7D%0A%20%20%20%20return%20(from%20i%20in%20Enumerable.Range(1,%20arrayLength)%0A%20%20%20%20%20%20%20%20%20%20%20%20orderby%20random.Next()%0A%20%20%20%20%20%20%20%20%20%20%20%20select%20i).ToArray();%0A%7D%0A%60%60%60%0A%0AI%20posted%20this%20solution%20to%20the%20competition%20and%20decided%20I%20had%20spent%20enough%20time%20on%20it.%20However,%20it%20bugged%20me%20because%20I%20knew%20that%20the%20%60Random%60%20class%20in%20the%20.NET%20framework%20is%20not%20guaranteed%20to%20be%20thread-safe.%20It%20also%20bugged%20be%20that%20I%20was%20actually%20solving%20a%20shuffling%20problem%20by%20sorting.%20Shuffling%20can%20be%20solved%20in%20O(n)%20while%20sorting%20is%20O(n*log(n)).%20In%20addition%20I%20thought%20that%20the%20LINQ%20solutions%20were%20kind%20of%20dull.%20%0A%0ASo%20I%20decided%20to%20take%20a%20stab%20at%20solving%20it%20without%20resolving%20to%20sorting.%20Shuffling%20is%20a%20well%20known%20problem,%20so%20I%20implemented%20the%20%5BFisher-Yates%20algorithm%5D(http://en.wikipedia.org/wiki/Fisher-Yates_shuffle),%20often%20used%20for%20shuffling%20cards.%20It%20is%20actually%20a%20rather%20elegant%20algorithm.%0A%0A%60%60%60%20csharp%0Apublic%20static%20int%5B%5D%20Generate()%0A%7B%0A%20%20%20%20Random%20random%20%3D%20new%20Random();%0A%20%20%20%20var%20numbers%20%3D%20new%20int%5B1000%5D;%0A%20%20%20%20//%20Add%20sorted%20numbers%20to%20shuffle%0A%20%20%20%20for%20(var%20i%20%3D%200;%20i%20%3C%201000;%20i++)%0A%20%20%20%20%20%20%20%20numbers%5Bi%5D%20%3D%20i%20+%201;%0A%20%20%20%20var%20last%20%3D%20numbers.Length;%0A%20%20%20%20while%20(last%20%3E%201)%0A%20%20%20%20%7B%0A%20%20%20%20%20%20%20%20//%20Select%20a%20random%20entry%20in%20the%20array%20to%20swap%0A%20%20%20%20%20%20%20%20var%20swap%20%3D%20random.Next(last);%0A%20%20%20%20%20%20%20%20//%20Decrease%20relevant%20end%20of%20array%0A%20%20%20%20%20%20%20%20last%20%3D%20last%20-%201;%0A%20%20%20%20%20%20%20%20//%20Swap%20numbers%20using%20XOR%20swap,%20we%20don't%20need%20no%20stinkin'%20temp%20variables%0A%20%20%20%20%20%20%20%20if%20(last%20!%3D%20swap)%0A%20%20%20%20%20%20%20%20%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20numbers%5Blast%5D%20%5E%3D%20numbers%5Bswap%5D;%0A%20%20%20%20%20%20%20%20%20%20%20%20numbers%5Bswap%5D%20%5E%3D%20numbers%5Blast%5D;%0A%20%20%20%20%20%20%20%20%20%20%20%20numbers%5Blast%5D%20%5E%3D%20numbers%5Bswap%5D;%0A%20%20%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%20%20return%20numbers;%0A%7D%0A%60%60%60%0A%0AI%20adjusted%20it%20a%20bit%20and%20finally%20found%20a%20place%20to%20make%20an%20ode%20to%20the%20awesomeness%20that%20is%20%5BXOR%20swap%5D(http://en.wikipedia.org/wiki/Xor_swap_algorithm),%20swapping%20two%20values%20without%20using%20a%20temporary%20variable.%20Even%20though%20the%20algorithm%20was%20faster%20asymptotically,%20I%20was%20curious%20how%20it%20would%20venture%20against%20the%20sort-based%20LINQ%20solutions%20performance-wise.%20Here%20is%20the%20result:%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/EvolutionofSolutionsandPerceivedPerforma_118/image_thumb.png%22%20/%3E%20%0A%0ANote%20that%20both%20HLINQ%20and%20PLINQ%20use%20all%204%20cores%20on%20my%20quad-core%20machine.%20I%20realize%20there's%20an%20overhead%20using%20LINQ,%20but%20I'm%20still%20impressed%20how%20much%20faster%20this%20simple%20little%20algorithm%20is.%0A%0AI%20submitted%20my%20new%20solution,%20with%20a%20note%20to%20replace%20my%20hybrid%20solution,%20just%20before%20midnight,%20but%20unfortunately%20I%20think%20it%20might%20have%20been%20too%20late,%20it%20didn't%20seem%20to%20make%20the%20cut%20for%20the%20competition.%20At%20least%20my%20hybrid%20solution%20made%20it%20into%20the%20final%20round%20-%20and%20non-thread-safe%20Random%20surely%20won't%20be%20a%20problem%20for%20instances%20of%20size%201000%20-%20since%20it%20will%20use%20regular%20LINQ%20for%20that.)
A WinDbg Debugging Journey - NHibernate Memory Leak 18 Dec 2008 3:00 PM (16 years ago)
*Disclaimer: This is not a stab at the NHibernate team. They are doing an awesome job, it might as well (and for a long time I thought it was) have been in my own code. In addition - the memory leak is already solved on the NHibernate trunk.*
## Introduction
A few weeks back, an ASP.NET application (using NHibernate 2.0.0.4000) I am running got under heavier load than usual. I had noted that the memory usage was slightly high earlier, but it had never been a real problem - this is all the server is doing. However, under heavier load, memory pressure started approaching 700-800mb and the dreaded OutOfMemoryException started appearing when doing big chunks of work.
To be honest, I have never done much memory debugging - learning opportunity! If you do a sweep of the web these days on .NET and debugging, you will no doubt find the blog of [Tess Ferrandez](http://blogs.msdn.com/tess/), who is an ASP.NET Escalation Engineer working at Microsoft. She has even done a lab series aptly named [buggy bits](http://blogs.msdn.com/tess/pages/net-debugging-demos-information-and-setup-instructions.aspx) that ease you through debugging and identifying various kinds of application problems.
After reading through her articles and watching her [TechEd presentation](http://blogs.msdn.com/tess/archive/2008/11/27/video-of-my-teched-presentation-of-common-issues-in-asp-net-and-how-to-debug-them-with-windbg.aspx) on the subject, I downloaded [WinDbg](http://www.microsoft.com/whdc/devtools/debugging/default.mspx), configured it as Tess had described and started experimenting. This blog post will describe my journey and hopefully help other solve similar problems.
## The Puzzle
The first thing I did was to grab a memory with adplus, one of the tools included with WinDbg. From my understanding, it stops the application momentarily and just writes the entire contents of memory to disk. This produced a huge .DMP file - a memory dump. My managed heap was at around 800mb at the time, but the dump file was slightly bigger.
Working with WinDbg is not your standard draggy-droppy windows application, it looks sort of like a console and you type bizarre command and it produces even more bizarre output for you to reason about. I started out using the `!eeheap -gc` command, which produces some basic information about your heaps.
 As you can see, my heap size was around 814mb. If you dig into the information (not all shown on screenshot), you will find that my garbage collectors generation 2 is much bigger than generation 0 and 1. (You can read more about garbage collection and generational garbage collection [here](http://en.wikipedia.org/wiki/Garbage_collection_(computer_science)).)
After looking at this, I fired off the `!dumpheap -stat` command to get an overview of the objects in the heap.
As you can see, my heap size was around 814mb. If you dig into the information (not all shown on screenshot), you will find that my garbage collectors generation 2 is much bigger than generation 0 and 1. (You can read more about garbage collection and generational garbage collection [here](http://en.wikipedia.org/wiki/Garbage_collection_(computer_science)).)
After looking at this, I fired off the `!dumpheap -stat` command to get an overview of the objects in the heap.
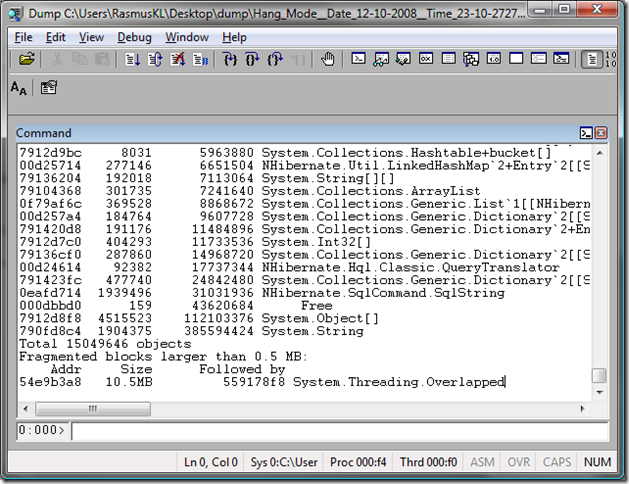 The output looked like that, the first column denoting the type of object, second is number of objects, third is the shallow size of the objects, that is, not including whatever it references - the fourth is the type name.
Now, the first time I looked at this, I noted the NHibernate objects but focused more on the 385mb of strings - usually, [SELECT isn't broken](http://www.pragprog.com/the-pragmatic-programmer/extracts/tips) - I was convinced this was a problem in my code. I dug a bit deeper but didn't really find much, partly because WinDbg isn't super easy. This lead me to find some other places in my code that needed StringBuilders, but this proved not to be the root cause (thanks anyway [Søren](http://www.publicvoid.dk/)).
Later, when thinking about the problem, it came to me that that maybe 1.9 million NHibernate SqlStrings was a wee bit too many. I decided to did deeper into this - I found the SqlString in my list and found that the type is denoted with 0eafd714. Now, !dumpheap can do more that just give you statistics, it can give you filtered lists using various arguments. I wanted to sample some instances of these SqlStrings to see where they were bounded, so I used the command `!dumpheap -mt 0eafd714`. This makes WinDbg give me a list of all the instances of the NHibernate SqlString - this is a very long list.
The output looked like that, the first column denoting the type of object, second is number of objects, third is the shallow size of the objects, that is, not including whatever it references - the fourth is the type name.
Now, the first time I looked at this, I noted the NHibernate objects but focused more on the 385mb of strings - usually, [SELECT isn't broken](http://www.pragprog.com/the-pragmatic-programmer/extracts/tips) - I was convinced this was a problem in my code. I dug a bit deeper but didn't really find much, partly because WinDbg isn't super easy. This lead me to find some other places in my code that needed StringBuilders, but this proved not to be the root cause (thanks anyway [Søren](http://www.publicvoid.dk/)).
Later, when thinking about the problem, it came to me that that maybe 1.9 million NHibernate SqlStrings was a wee bit too many. I decided to did deeper into this - I found the SqlString in my list and found that the type is denoted with 0eafd714. Now, !dumpheap can do more that just give you statistics, it can give you filtered lists using various arguments. I wanted to sample some instances of these SqlStrings to see where they were bounded, so I used the command `!dumpheap -mt 0eafd714`. This makes WinDbg give me a list of all the instances of the NHibernate SqlString - this is a very long list.
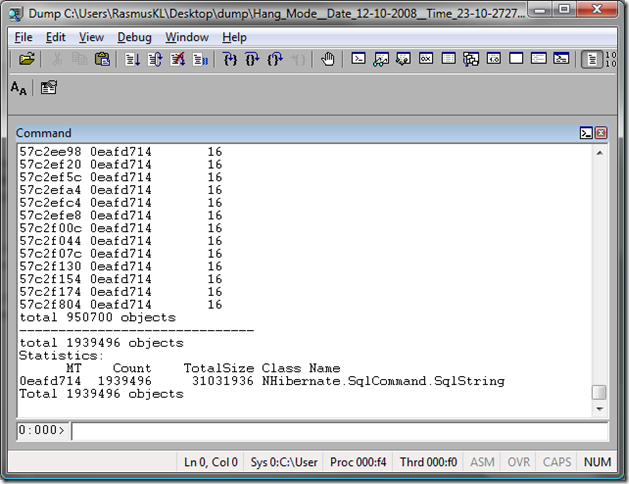 Now, the second column denotes the type, the third is the shallow object size and the first is what we are looking for - the instance address. I picked a few of them at random and used the !gcroot command to show where they were rooted. That is, give me the chain of references that lead to this object. An example is `!gcroot 57c2f130`, which produces the following output.
Now, the second column denotes the type, the third is the shallow object size and the first is what we are looking for - the instance address. I picked a few of them at random and used the !gcroot command to show where they were rooted. That is, give me the chain of references that lead to this object. An example is `!gcroot 57c2f130`, which produces the following output.
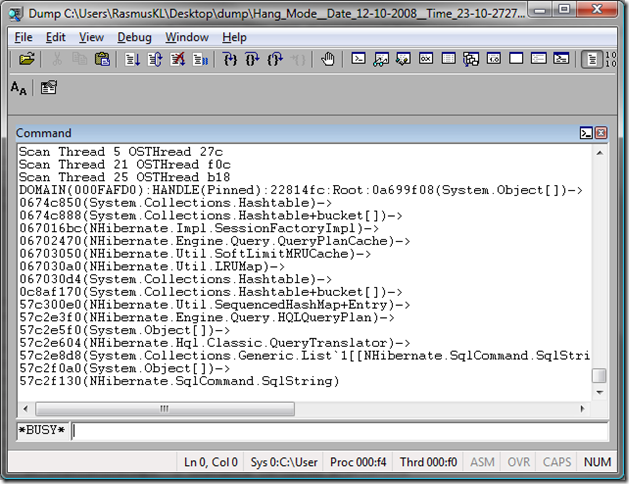 You can see the actual instance at the bottom and then follow the chain upwards. It seems this current SqlString is rooted in a QueryPlanCache in the NHibernate SessionFactory.
At this point I actually downloaded the NHibernate source and started looking around. Conceptually, the NHibernate SessionFactory keeps a cache of recent HQL queries, so it doesn't have to rebuild them. According to the source code, it would store the 128 most recently used queries.
Now WinDbg can actually tell you the "deep" size of an object, object size + objects it references. This is done using the !objsize command. Now this literally took several hours of processing, so I don't have a screenshot for the blog post, but executing `!objsize 067016bc` command should give me the memory size of my SessionFactory. According to my log file, it told me:
```
sizeof(067016bc) = 716798348 ( 0x2ab9798c) bytes (NHibernate.Impl.SessionFactoryImpl)
```
That is one **big** SessionFactory (~700mb). I dug further down the reference chain to try and figure out what was wrong with the cache. Remember I said that this cache was supposed to hold 128 queries. When I got to the hashtable in the cache and dumped it using the `!do 067030d4` command, it revealed the following:
You can see the actual instance at the bottom and then follow the chain upwards. It seems this current SqlString is rooted in a QueryPlanCache in the NHibernate SessionFactory.
At this point I actually downloaded the NHibernate source and started looking around. Conceptually, the NHibernate SessionFactory keeps a cache of recent HQL queries, so it doesn't have to rebuild them. According to the source code, it would store the 128 most recently used queries.
Now WinDbg can actually tell you the "deep" size of an object, object size + objects it references. This is done using the !objsize command. Now this literally took several hours of processing, so I don't have a screenshot for the blog post, but executing `!objsize 067016bc` command should give me the memory size of my SessionFactory. According to my log file, it told me:
```
sizeof(067016bc) = 716798348 ( 0x2ab9798c) bytes (NHibernate.Impl.SessionFactoryImpl)
```
That is one **big** SessionFactory (~700mb). I dug further down the reference chain to try and figure out what was wrong with the cache. Remember I said that this cache was supposed to hold 128 queries. When I got to the hashtable in the cache and dumped it using the `!do 067030d4` command, it revealed the following:
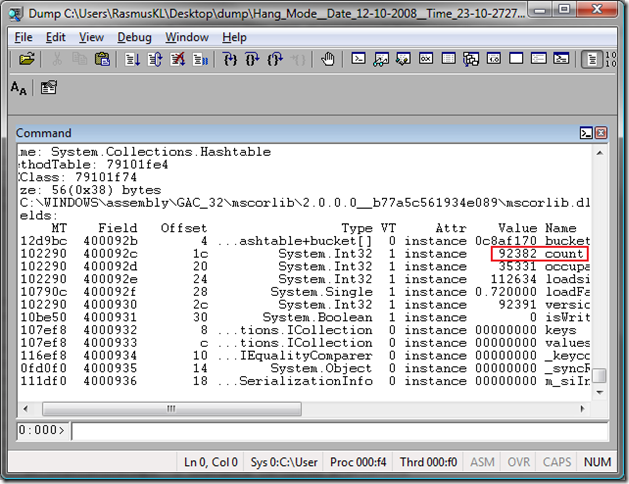 According to this, my cache contains 92000 queries. After digging around in the code, writing a few unit tests and getting some help from the NHibernate user group, I finally found out that it was a bug in the object indexer in the LRUMap, such that it didn't enforce the 128 limit properly.
It was a small innocent bug, but having a 700mb (and growing) hashtable hanging around in your system forever is not really that pleasant. I ended up writing a hack that used reflection to access the field that contained the cache and clearing it periodically. It is already fixed on the NHibernate trunk, but I haven't gotten around to updating yet.
Since implementing my clear hack, I haven't seen memory usages above 50mb.
## Conclusion
I've told my small debugging tale of how I got introduced to WinDbg and how it helped me track down a major issue in my application and reduce memory usage from ~800mb to ~50mb. It's a funky tool and can be quite scary at first, but if it helps me remove memory leaks, I am all for it. The second lesson learned is that sometimes - although I still won't look there first - SELECT is broken.
According to this, my cache contains 92000 queries. After digging around in the code, writing a few unit tests and getting some help from the NHibernate user group, I finally found out that it was a bug in the object indexer in the LRUMap, such that it didn't enforce the 128 limit properly.
It was a small innocent bug, but having a 700mb (and growing) hashtable hanging around in your system forever is not really that pleasant. I ended up writing a hack that used reflection to access the field that contained the cache and clearing it periodically. It is already fixed on the NHibernate trunk, but I haven't gotten around to updating yet.
Since implementing my clear hack, I haven't seen memory usages above 50mb.
## Conclusion
I've told my small debugging tale of how I got introduced to WinDbg and how it helped me track down a major issue in my application and reduce memory usage from ~800mb to ~50mb. It's a funky tool and can be quite scary at first, but if it helps me remove memory leaks, I am all for it. The second lesson learned is that sometimes - although I still won't look there first - SELECT is broken.
Postponing ReSharper Series 8 Dec 2008 3:00 PM (16 years ago)
I haven't written much lately, mostly because I was planning a series on ReSharper, which would be an event that ran for X days - with 1 post each day. I'm still going to do this, but my current workload doesn't allow me to work up enough posts to have a consistent buffer (plus I want to write it as I go) - so I'm postponing it officially - so I can feel alright about posting other stuff. :-)
Playing with XNA 3.0 8 Dec 2008 3:00 PM (16 years ago)
Visited my brother this weekend and we played some random [Tower Defense](http://www.towerdefence.net/) games for fun - and I had a lot of ideas for the game and knew that Microsofts game platform [XNA](http://msdn.microsoft.com/en-us/xna/default.aspx) was supposed to be really good.
I spent a few hours remembering how vectors worked, making a small game was an absolute breeze. The result so far is:
 The monsters walk the path and you can place 3 different kinds of towers that will attempt to eliminate them. I'm currently working on getting some level balance, as my current 5 levels are way too easy. Pondering putting it up on codeplex or some other site when it is more complete.
The monsters walk the path and you can place 3 different kinds of towers that will attempt to eliminate them. I'm currently working on getting some level balance, as my current 5 levels are way too easy. Pondering putting it up on codeplex or some other site when it is more complete.
 Stay tuned for more.
Stay tuned for more.
%20games%20for%20fun%20-%20and%20I%20had%20a%20lot%20of%20ideas%20for%20the%20game%20and%20knew%20that%20Microsofts%20game%20platform%20%5BXNA%5D(http://msdn.microsoft.com/en-us/xna/default.aspx)%20was%20supposed%20to%20be%20really%20good.%0A%20%0AI%20spent%20a%20few%20hours%20remembering%20how%20vectors%20worked,%20making%20a%20small%20game%20was%20an%20absolute%20breeze.%20The%20result%20so%20far%20is:%0A%20%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/PlayingwithXNA3.0_12C0D/image_thumb.png%22%20/%3E%0A%20%0AThe%20monsters%20walk%20the%20path%20and%20you%20can%20place%203%20different%20kinds%20of%20towers%20that%20will%20attempt%20to%20eliminate%20them.%20I'm%20currently%20working%20on%20getting%20some%20level%20balance,%20as%20my%20current%205%20levels%20are%20way%20too%20easy.%20Pondering%20putting%20it%20up%20on%20codeplex%20or%20some%20other%20site%20when%20it%20is%20more%20complete.%0A%0A%3Cimg%20src%3D%22https://rasmuskl.dk/WindowsLiveWriter/PlayingwithXNA3.0_12C0D/image_thumb_3.png%22%20/%3E%0A%0AStay%20tuned%20for%20more.)
Information Overload 16 Nov 2008 3:00 PM (16 years ago)
Ran into this at work today. Apparently our Team Foundation Server wanted to tell me something.
 I'm still not sure that I pressed the right button - what does Cancel do again?
I'm still not sure that I pressed the right button - what does Cancel do again?

Patterns: Iterator And .NET - Yield I Say! 10 Nov 2008 3:00 PM (16 years ago)
## Introduction
In this second post of my patterns and principles series, I aim to give an overview of the Iterator pattern, a pattern most of us .NET people have so integrated in our languages that we don't even think about it. But it is still useful to know the theory of the pattern and how it is integrated into the framework - the solution baked in allows for more variation than you'd think.
## The Theory
According to Gang of Four, the Iterator pattern's intent is to:
> Provide a way to access the elements of an aggregate object sequentially without exposing its underlying representation.
Basically what we want to do is abstract the traversal so we don't have to worry about it. The Iterator will provide us with a nice interface for getting the next object in our data structure, maintain state about how far we've already progressed in our traversal and tell us when we're done. Abstracting the traversal also makes it easier to change the actual traversal - like if you want to iterate over your data structure in reverse order.
Furthermore, encapsulating the traversal logic in an Iterator will often result in higher cohesion and lower coupling for client code. Higher cohesion because they can more clearly express their intent instead of worrying about iteration state and order - and lower coupling because they are not as tied to the actual implementation of the data structure being iterated. As a result, it is possible with Iterators to provide a uniform interface for traversing different data structures.
Iterators are also sometimes used as Generators, where they generate a series of values instead of actually iterating over an object structure. If implemented lazily, these can generate potentially infinite series like a never-ending stream of numbers or primes or whatever.
## How Does It Work In .NET?
One of the reasons we rarely think about the Iterator pattern is because it's so embedded into our languages. In the .NET world, an Iterator is actually called an Enumerator - and if we look in the framework documentation, we find an interface named `IEnumerator` that looks something like this (the generic version):
``` csharp
public interface IEnumerator
Design By Contract Preconditions With Expression Trees 5 Nov 2008 3:00 PM (16 years ago)
## Introduction
Seems like [Design by Contract](http://en.wikipedia.org/wiki/Design_by_contract) is [coming](http://channel9.msdn.com/pdc2008/TL51/) to C# 4.0, replacing the somewhat inadequate Debug.Assert, which is the only thing built into the framework at the moment. However, what are the options for today? In this post, I'll take a look at how to improve current precondition checking techniques using C# 3.0 expression trees.
## Design By What?
Design by contract is technique for strengthening the contracts for classes by adding 3 kinds of checks:
**Preconditions** - What the called method expects from the caller. This is usually various forms of checks on method arguments.
**Postconditions** - What the called method guarantees upon returning. Often guarantees about the return value.
**Invariants** - What is guaranteed by the class? That is, the class invariant should be true upon one of the objects methods and again when the method returns.
So why is this even important? One of the merits of Design by Contract are that it can communicate a whole lot about your classes to other people using or reading your code. but they can also be helpful to you, as they allow you to express your intent more clearly and will support the fail-fast principle of [defensive programming](http://en.wikipedia.org/wiki/Defensive_programming). The idea here is to produce the error as close to the source as possible.
Lets do a simple example to illustrate why this might be useful, consider the following two classes:
```csharp
public class Person
{
public Person(string name)
{
Name = name;
}
public string Name { get; set; }
}
public class Account
{
private Person _owner;
public Account(Person owner)
{
_owner = owner;
}
public string GetOwnerName()
{
return _owner.Name;
}
}
```
It seems that the writer of the Account class is implying that an Account object should have an owner - an instance of Person. However, there's nothing to stop a potential client from doing this:
```csharp
static void Main(string[] args)
{
var account = new Account(null);
Console.WriteLine(account.GetOwnerName());
}
```
This fails with a NullReferenceException in line 4 with the following stack trace:
```
DbCExpressionTrees.exe!DbCExpressionTrees.Account.GetOwnerName() Line 17 C#
DbCExpressionTrees.exe!DbCExpressionTrees.Program.Main(string[] args = {string[0]}) Line 13 + 0xa bytes C#
```
Now this example is very contrived, since it's blatantly obvious where the bug is. But still, consider if the call to GetOwnerName had been in a completely different layer of the application, maybe even minutes after the Account object had been created. I'm sure you've had your fun with your debugger tracking down errors like this, if you've done any moderate size programs - I know I have.
What we need is a way for the writer of the Account class to communicate a stronger contract on what he's expecting from his client. In an [ideal world](http://en.wikipedia.org/wiki/Eiffel_(programming_language)), this contract would be enforced at compile-time and not allow the program to compile if contracts were broken. A thing I've always wanted for situations like this is being able to specify arguments as non-nullable in C# - that is, give me an object of this type and NOT null - since this makes sense in a lot of situations. Anyway, the only way to get something resembling this today is using [Spec#](http://research.microsoft.com/SpecSharp/), but this is a research project and still under development. So we will have to settle for runtime checks for starters.
Returning to the fail-fast principle - why is this useful? Consider the following change to the Account constructor:
```csharp
public Account(Person owner)
{
if(owner == null)
throw new ArgumentNullException("owner");
_owner = owner;
}
```
Executing the client code from before, our program will now fail when trying to create the invalid Account object with the following stack trace - and a clearly readable exception message (that owner is not allowed to be null):
```
DbCExpressionTrees.exe!DbCExpressionTrees.Account.Account(DbCExpressionTrees.Person owner = null) Line 13 C#
DbCExpressionTrees.exe!DbCExpressionTrees.Program.Main(string[] args = {string[0]}) Line 12 + 0x17 bytes C#
```
The benefit here is that this stack trace points directly to the first offense against the "contract". Consider the differences in debugging time on the two examples. Examples like this could also be made for postconditions and invariants.
## Expression Trees
Okay, I admit it, I've been itching to play around with Expressions since C# 3.0 was released and especially with all the cool usages in ASP.NET MVC. Furthermore I'll often go to great lengths to avoid "magic strings" in favor of something more type-safe (and refactor-friendly). Also, I happened to stumble upon these two posts by [The Wandering Glitch](http://aabs.wordpress.com/2008/01/16/complex-assertions-using-c-30/)and [Søren Skovsbøll](http://skarpt.dk/blog/?p=14) where they experiment with Design By Contract and C# 3.0.
Realistically, I preconditions are only viable part of Design by Contract to implement in C# at the moment. While you can probably do crazy postcondition and invariant checking by using exotic things like IL injection or interceptors, I really don't think we'll see any really good solutions until the language provides better support. So I decided to see what I could do on preconditions.
Now, Søren and Andrew (the Glitch) used a general Requires method for defining their preconditions. Søren's looks like this:
``` csharp
public static void Require(this T obj, Expression Now the Requires function could probably be optimized (maybe some expression caching), but the difference is quite remarkable.
## Conclusion
In this post I've described some of the benefits with Design By Contract and defensive programming and tried to give some insight into using C# 3.0 Expression Trees for avoiding "magic strings" in our precondition checking.
Now the Requires function could probably be optimized (maybe some expression caching), but the difference is quite remarkable.
## Conclusion
In this post I've described some of the benefits with Design By Contract and defensive programming and tried to give some insight into using C# 3.0 Expression Trees for avoiding "magic strings" in our precondition checking.
Simple ASP.NET MVC Beta AJAX with jQuery! 4 Nov 2008 3:00 PM (16 years ago)
## Introduction
[ASP.NET MVC](http://www.asp.net/mvc/) is all the rage these days - and after Microsoft [announced](http://weblogs.asp.net/scottgu/archive/2008/09/28/jquery-and-microsoft.aspx) their partnership with the great folks over at [jQuery](http://www.jquery.com) and started shipping it - I knew I had to explore the whole AJAX experience again. I've still not played too much with the MVC framework, but I am working on switching a few projects over from WebForms - and I must say that the experience is quite different. So I've set out to do the smallest (simple) demo possible of ASP.NET MVC AJAX with jQuery - just to get (and give you) the flavor of it.
## The Story
I did play around with the [Microsoft AJAX Library](http://www.asp.net/ajax/) earlier, but found it too heavy-weight and never really liked the concept of UpdatePanels. It just seemed like too much server-side cruft and coupled with the rather complex WebForm lifecycle, it just didn't seem worth it. I must admit that this is a while ago and I haven't reinvestigated, but I doubt it has the grace and simplicity of jQuery. So I've been using jQuery since forever for various client-side snippets, but never really played around with the AJAX bits since it seemed kind of cumbersome with WebForms.
## Lets Get Started
Okay, so I grabbed the beta bits from the ASP.NET MVC and installed them on my machine and fired up a new ASP.NET MVC site:
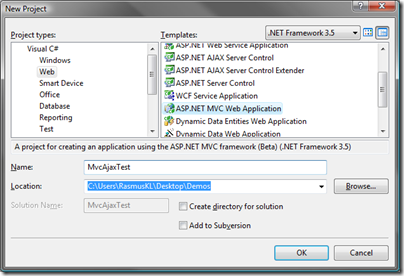 The solution now already contains a "Scripts" folder that contains Microsoft AJAX and jQuery. Continued to head into the Site.Master masterpage in Views/Shared to add jQuery. Now I'd caught the glimpse of blog posts mentioning intellisense for jQuery and found this [post](http://blogs.msdn.com/webdevtools/archive/2008/10/28/rich-intellisense-for-jquery.aspx) describing how to grab the vsdoc version of jQuery from the jQuery site and plug it in.
The solution now already contains a "Scripts" folder that contains Microsoft AJAX and jQuery. Continued to head into the Site.Master masterpage in Views/Shared to add jQuery. Now I'd caught the glimpse of blog posts mentioning intellisense for jQuery and found this [post](http://blogs.msdn.com/webdevtools/archive/2008/10/28/rich-intellisense-for-jquery.aspx) describing how to grab the vsdoc version of jQuery from the jQuery site and plug it in.
 Since this was just going to be a demo site, I decided to just use the documented version directly, but this proved to be a bad idea. I encountered a few different runtime JavaScript errors while using this version, more specifically related to the ajaxStart event function. The solution apparently involves a masterpage with the following added to the head section:
```csharp
<% if (false) { %>
<% } %>
```
The trick here is that Visual Studio will see the vsdoc version and grab documentation from there, but it will never actually load on your pages. As described in the before mentioned post, this will be fixed and in the future it should be enough to reference the original jQuery file and have the vsdoc version present. I also found that the intellisense was kind of flaky (not showing up) sometimes in nested functions, hopefully this will be fixed as well.
Next I grabbed the Index.aspx view in Views/Home and cleared out all the contents of the Content PlaceHolder and added a bit of HTML:
```html
Since this was just going to be a demo site, I decided to just use the documented version directly, but this proved to be a bad idea. I encountered a few different runtime JavaScript errors while using this version, more specifically related to the ajaxStart event function. The solution apparently involves a masterpage with the following added to the head section:
```csharp
<% if (false) { %>
<% } %>
```
The trick here is that Visual Studio will see the vsdoc version and grab documentation from there, but it will never actually load on your pages. As described in the before mentioned post, this will be fixed and in the future it should be enough to reference the original jQuery file and have the vsdoc version present. I also found that the intellisense was kind of flaky (not showing up) sometimes in nested functions, hopefully this will be fixed as well.
Next I grabbed the Index.aspx view in Views/Home and cleared out all the contents of the Content PlaceHolder and added a bit of HTML:
```html
 Now one of the great forces about jQuery is it's power to hook into the DOM using powerful selectors. This means that you can have your JavaScript almost completely separated from your HTML. I've often had several small jQuery files that would completely change the appearance of a page and add all kinds of fancy if they were included. This also makes it very easy to enable / disable effects and even test your page degradation for users who have JavaScript disabled (just remove your script reference). However, for simplicity, I've just included my jQuery directly in a script tag:
```html
```
Now I decided not to start doing JavaScript templating and return lots of JSON data. Instead I'm just going to pull a normal HTML page from the HomeController and append the data to the result div. Most of the magic is in the click function which registers a handler to grab the defined page /Home/AjaxHtml with the name entered in the textbox as parameter and to execute the updateResult function when the data comes back. After this it was time to add the action to the HomeController:
``` csharp
public ActionResult AjaxHtml(string name)
{
Thread.Sleep(3000);
return View("AjaxHtml", new { Name=name, Time=DateTime.Now });
}
```
Rather simple really. Just sleeps for a few seconds (to allow me to see the load on my local dev machine) and then renders a new view called AjaxHtml with a simple Dictionary containing the passed argument name and the current time as ViewModel. I also added a new View called AjaxHtml:
```csharp
<%@ Page Language="C#" AutoEventWireup="true"
CodeBehind="AjaxHtml.aspx.cs"
Inherits="MvcAjaxTest.Views.Home.AjaxHtml" %>
Ajax Call: <%= ViewData.Model %>
Now one of the great forces about jQuery is it's power to hook into the DOM using powerful selectors. This means that you can have your JavaScript almost completely separated from your HTML. I've often had several small jQuery files that would completely change the appearance of a page and add all kinds of fancy if they were included. This also makes it very easy to enable / disable effects and even test your page degradation for users who have JavaScript disabled (just remove your script reference). However, for simplicity, I've just included my jQuery directly in a script tag:
```html
```
Now I decided not to start doing JavaScript templating and return lots of JSON data. Instead I'm just going to pull a normal HTML page from the HomeController and append the data to the result div. Most of the magic is in the click function which registers a handler to grab the defined page /Home/AjaxHtml with the name entered in the textbox as parameter and to execute the updateResult function when the data comes back. After this it was time to add the action to the HomeController:
``` csharp
public ActionResult AjaxHtml(string name)
{
Thread.Sleep(3000);
return View("AjaxHtml", new { Name=name, Time=DateTime.Now });
}
```
Rather simple really. Just sleeps for a few seconds (to allow me to see the load on my local dev machine) and then renders a new view called AjaxHtml with a simple Dictionary containing the passed argument name and the current time as ViewModel. I also added a new View called AjaxHtml:
```csharp
<%@ Page Language="C#" AutoEventWireup="true"
CodeBehind="AjaxHtml.aspx.cs"
Inherits="MvcAjaxTest.Views.Home.AjaxHtml" %>
Ajax Call: <%= ViewData.Model %>``` The only thing to note about this is that I didn't use my normal masterpage for this page - since I'm only interested in passing this little tidbit of HTML back - not my entire page layout. Launching the application again, typing a name and hitting the link produces the following without a full page reload:
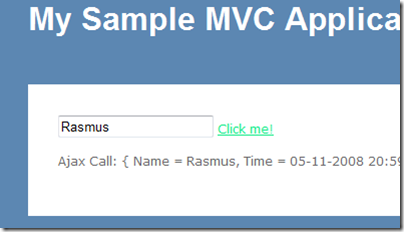 Additional clicks append further AJAX lines like so:
Additional clicks append further AJAX lines like so:
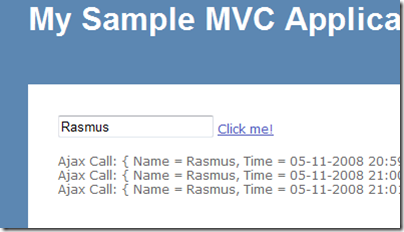 Obviously this could have been some other information posted - but this little sample contains both information from client-side (the name) and some data appended by the server (the timestamp).
## Load Indicator
Now, after doing all this, it didn't feel so impressive to click the link and wait for 3 seconds for another line of text to appear, so the obvious solution is to add some extra effects - and it's not like it's real AJAX [tm] if it ain't got a cool load indicator. So off I went to the kind people at [ajaxload.info](http://www.ajaxload.info/) where you can customize your own animated gif load indicator. I went with the shape called "Snake" with a nice blue MVC template-like color.
Adding the load indicator was a breeze really. I just threw the load indicator in an invisible image after the link:
```html
```
Note that I used the CSS style visibility: hidden instead of using display: none. Both work, but when using display: none, the space for the image is not reserved on the page, which caused a small annoying "jump" effect on my page as the load indicator appeared (and was a few pixels taller than the link text). With the visibility style, space is actually reserved for the image and the line doesn't jump.
All we have left is hooking the load indicator onto jQuerys AJAX call - for a simple scenario like this, the global AJAX events called ajaxStart and ajaxStop are just what we need. ajaxStart will run whenever an AJAX request is started and ajaxStop will run whenever one ends. So at the end of my script block (after the updateResult function), I added the following:
```js
$("#loading").ajaxStart(function() { $(this).css("visibility", "visible"); });
$("#loading").ajaxStop(function() { $(this).css("visibility", "hidden"); });
```
If we had used display: none instead, we could have used the jQuery functions show() and hide() instead of the whole CSS stunt, but I like this better. Firing up the browser and hitting the link now produces enough eye candy to distract my eyes from the 3 second wait:
Obviously this could have been some other information posted - but this little sample contains both information from client-side (the name) and some data appended by the server (the timestamp).
## Load Indicator
Now, after doing all this, it didn't feel so impressive to click the link and wait for 3 seconds for another line of text to appear, so the obvious solution is to add some extra effects - and it's not like it's real AJAX [tm] if it ain't got a cool load indicator. So off I went to the kind people at [ajaxload.info](http://www.ajaxload.info/) where you can customize your own animated gif load indicator. I went with the shape called "Snake" with a nice blue MVC template-like color.
Adding the load indicator was a breeze really. I just threw the load indicator in an invisible image after the link:
```html
```
Note that I used the CSS style visibility: hidden instead of using display: none. Both work, but when using display: none, the space for the image is not reserved on the page, which caused a small annoying "jump" effect on my page as the load indicator appeared (and was a few pixels taller than the link text). With the visibility style, space is actually reserved for the image and the line doesn't jump.
All we have left is hooking the load indicator onto jQuerys AJAX call - for a simple scenario like this, the global AJAX events called ajaxStart and ajaxStop are just what we need. ajaxStart will run whenever an AJAX request is started and ajaxStop will run whenever one ends. So at the end of my script block (after the updateResult function), I added the following:
```js
$("#loading").ajaxStart(function() { $(this).css("visibility", "visible"); });
$("#loading").ajaxStop(function() { $(this).css("visibility", "hidden"); });
```
If we had used display: none instead, we could have used the jQuery functions show() and hide() instead of the whole CSS stunt, but I like this better. Firing up the browser and hitting the link now produces enough eye candy to distract my eyes from the 3 second wait:

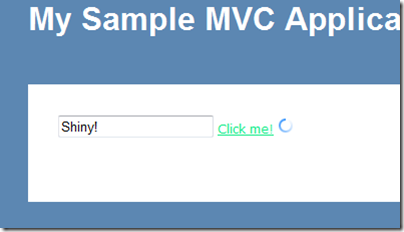 ## Resources
Now this is definitely only a beginning. You'd want to do some proper error handling and probably some more advanced scenarios.
If you want to find more information on ASP.NET MVC, you definitely want to go read / subscribe to some of these blogs: [ScottGu](http://weblogs.asp.net/Scottgu/), [Phil Haack](http://haacked.com/), [Rob Conery](http://blog.wekeroad.com/) (especially the Storefront series), [Stephen Walther](http://weblogs.asp.net/StephenWalther/) and many more.
As for more jQuery, there's been a storm of posts about this lately, which should be easy to find, but for documentation, nothing beats the plain ol' jQuery [documentation](http://docs.jquery.com/) or a personal favorite of mine for quick access: [visual jQuery](http://visualjquery.com/), a jQuery-optimized version of the jQuery docs.
## Conclusion
In this post I gave a quick introduction to the world of AJAX using jQuery with ASP.NET MVC. I really enjoy the model and simplicity. It just feels right - and finally I have control over my HTML. Hope it was useful for you as well.
## Resources
Now this is definitely only a beginning. You'd want to do some proper error handling and probably some more advanced scenarios.
If you want to find more information on ASP.NET MVC, you definitely want to go read / subscribe to some of these blogs: [ScottGu](http://weblogs.asp.net/Scottgu/), [Phil Haack](http://haacked.com/), [Rob Conery](http://blog.wekeroad.com/) (especially the Storefront series), [Stephen Walther](http://weblogs.asp.net/StephenWalther/) and many more.
As for more jQuery, there's been a storm of posts about this lately, which should be easy to find, but for documentation, nothing beats the plain ol' jQuery [documentation](http://docs.jquery.com/) or a personal favorite of mine for quick access: [visual jQuery](http://visualjquery.com/), a jQuery-optimized version of the jQuery docs.
## Conclusion
In this post I gave a quick introduction to the world of AJAX using jQuery with ASP.NET MVC. I really enjoy the model and simplicity. It just feels right - and finally I have control over my HTML. Hope it was useful for you as well.
Patterns and Principles - Getting Started 23 Oct 2008 4:00 PM (16 years ago)
## Introduction
Design patterns and principles are a fundamental thing in software development. Yet they're can be quite elusive and difficult to get into. As one of my goals with this blog is to further my own knowledge, as well as share it with others, I've wanted to do posts on basic object oriented principles and patterns. I believe that patterns is one of those things you grasp best when actively thinking about them - and thus to improve my own skillset on patterns, writing blog posts and thinking up good examples is a great way to go.
While this post is mostly an introduction to the series, my approach will definitely be a pragmatic one. I'm aiming to have two types of posts in this series, basic posts introducing specific design patterns or principle with up-to-date .NET examples and more advanced posts on the variations of the patterns and my own crazy experimentation with them. In any case, both types of posts should be brimming with examples if all goes as planned.
## Design Principles
Drops of distilled wisdom and experience. Most of these principles deal with increasing maintainability, testability, flexibility, reducing (unneeded) complexity and attaining high cohesion and low coupling. Allowing you to mitigate at least one of the inevitable three (death, taxes and changing requirements).
I personally see them as guidelines for thought, not golden rules, you might encounter situations where fewer of these principles may apply, as there's often trade-offs involved. However, keeping them in mind is a way to open your eyes to other solutions. In my experience, some of them are easier to be adamant about (DRY springs to mind), while some are more subjective considerations and best practices. I guess my point is that you should avoid following anything blindly without thought. Broaden your horizon, don't narrow it.
I'll not dig too deep into these, but rather give a short introduction in this.. uh, introduction post. Note that this is not an exhaustive list.
#### Single Responsibility Principle
Separation of Concerns. An object should have one and only one reason to change, thus increasing cohesion and avoiding coupled responsibilities. It ties into many of the other principles.
#### Open/Closed Principle
Your software entities should be closed for modification, but open for extension. Hard to explain briefly, but the gist is to be able to extend the system without modifying existing code (save for bugs). Examples could be: Avoiding dependencies on internal workings and down-casts to specific types.
#### The Interface Segregation Principle
Do cohesive, responsibility-based interfaces (think roles) instead of huge general interfaces. Your clients will then only depend on a minimal subset of your methods, instead of potentially depending on methods they're not using.
#### DRY
Don't Repeat Yourself. Duplication is bad, mkay? A good example of this is duplicate code, you'll always miss at least one spot when making changes later.
#### Dependency Inversion Principle
> "High level modules should not depend upon low level modules. Both should depend upon abstractions.".
Seeks to lower coupling in the system and increase testability. Applied through dependency injection and often IoC (Inversion of Control) containers.
#### Liskov Substitution Principle
Informally: When defining an interface or contract, the system should be able to use any (correct) implementation of it. That is, clients of the contract should not have to know the implementation details (or depend on them). Ties into Design by Contract.
#### Law of Demeter
Also known as the Principle of Least Knowledge. Don't talk to strangers. The law states that a method on an object should only call methods on itself, parameters passed in to the method, objects it created and composite objects. This means don't go dot, dot, doting yourself into the entire object tree.
#### Tell, Don't Ask
Aim to tell objects what to do instead of asking it about it's state and deciding what to do. The idea is that the object probably knows better than you. It also forces you to think about responsibilities.
#### YAGNI
You Aren't Gonna Need It. From Extreme Programming. Don't waste your time adding functionality based on what you think the future might bring. You will (most likely) be wrong. In addition, you will have to maintain this extra code and complexity. Variation of KISS (Keep It Simple, Stupid).
#### Favor Composition Over Inheritance
Inheritance is often over- and misused. Inheritance is an 'is-a relation' and is often used as a 'has-a relation' (composition). An advantage of composition is that composed objects can be replaced dynamically - and they can vary independently. Inheritance still has it's place in some cases though (Hint: When you have an 'is-a relation').
## Design Patterns
Design patterns are reusable solutions to recurring problems in software development. One of the best points about design patterns is that they allow developers to talk on a higher level, since they have a shared vocabulary of design techniques. Seeing pattern names in code can also communicate an intent that can otherwise be hard to see.
A lot of the same things from the design principles section apply here too. An UML diagram describing a design pattern is just one instance of the pattern - they're meant for inspiration and almost all patterns have several variation points.
I'll not even try to list design patterns yet, they come in all shapes and sizes, better save something for next time.
## Literature
While blog posts and other online sources are good for quick answers, nothing beats sitting down with a well-written book on a subject.
 [Design Patterns: Elements of Reusable Object-Oriented Software](http://www.amazon.com/Design-Patterns-Object-Oriented-Addison-Wesley-Professional/dp/0201633612/)
_Erich Gamma, Richard Helm, Ralph Johnson, John M. Vlissides_
If you've read anything about patterns, you will undoubtedly have heard of the GoF (Gang of Four) book, the often proclaimed Bible of Design Patterns. While this is a great book, especially as a reference catalogue of patterns when you want to look something up, I was kind of lost when I read it the first time. The book is rather abstract and it can be rather confusing for someone starting out with design patterns. I really think you should make it part of your book collection, but if you're starting out with patterns, I would recommend starting out with this book instead:
[Design Patterns: Elements of Reusable Object-Oriented Software](http://www.amazon.com/Design-Patterns-Object-Oriented-Addison-Wesley-Professional/dp/0201633612/)
_Erich Gamma, Richard Helm, Ralph Johnson, John M. Vlissides_
If you've read anything about patterns, you will undoubtedly have heard of the GoF (Gang of Four) book, the often proclaimed Bible of Design Patterns. While this is a great book, especially as a reference catalogue of patterns when you want to look something up, I was kind of lost when I read it the first time. The book is rather abstract and it can be rather confusing for someone starting out with design patterns. I really think you should make it part of your book collection, but if you're starting out with patterns, I would recommend starting out with this book instead:
 [Design Patterns Explained: A New Perspective on Object-Oriented Design](http://www.amazon.com/Design-Patterns-Explained-Perspective-Object-Oriented/dp/0321247140/)
_Alan Shalloway, James Trott_
This book was my personal eye-opener. It is somewhat more chatty than the GoF book, slightly less catalogue, slightly more "getting into object-oriented design". It's a great introduction to design patterns and the authors go to great lengths to not only describe the patterns, but to discover them by examining different solutions and quantifying the strengths and weaknesses. This is a great book for bridging the gap before GoF.
[Design Patterns Explained: A New Perspective on Object-Oriented Design](http://www.amazon.com/Design-Patterns-Explained-Perspective-Object-Oriented/dp/0321247140/)
_Alan Shalloway, James Trott_
This book was my personal eye-opener. It is somewhat more chatty than the GoF book, slightly less catalogue, slightly more "getting into object-oriented design". It's a great introduction to design patterns and the authors go to great lengths to not only describe the patterns, but to discover them by examining different solutions and quantifying the strengths and weaknesses. This is a great book for bridging the gap before GoF.
 [Refactoring: Improving the Design of Existing Code](http://www.amazon.com/Refactoring-Improving-Existing-Addison-Wesley-Technology/dp/0201485672/)
_Martin Fowler_
While refactoring is not design patterns per se, refactoring is a method to mold your code (or others code) towards some of the same goals as the ones presented by design patterns. It's all about improving the maintainability and flexibility of your software. Fowler does a fine job of explaining the reasons for the different refactorings, describing code smells and which tools to use to get rid of them. Another reason knowledge about refactoring is good is that often, you won't have the luxury (or curse) of working solely with your own code. Refactoring can be a great tool to unravel spaghetti code and gaining insight while (hopefully) adding tests to support it.
## Online Resources
If you want to get started reading more about patterns and principles, here's a few good links for getting started.
- [Object Mentor Published Articles](http://objectmentor.com/resources/publishedArticles.html)
- [Ward Cunningham's Wiki](http://c2.com/cgi/wiki?CategoryPattern)
## Conclusion
In this post, the first in a series of N, I gave a short introduction to design patterns and principles. I've outlined some recommended getting-started literature and hope to have sparked your interest. Next part will be a basic post describing the first pattern.
Note: I could have more sources in this post, but most of this post is tidbits from experience, opinion and a compilation of snippets from way too many sources. I'll list them in following posts, when we dig into the detail.
[Refactoring: Improving the Design of Existing Code](http://www.amazon.com/Refactoring-Improving-Existing-Addison-Wesley-Technology/dp/0201485672/)
_Martin Fowler_
While refactoring is not design patterns per se, refactoring is a method to mold your code (or others code) towards some of the same goals as the ones presented by design patterns. It's all about improving the maintainability and flexibility of your software. Fowler does a fine job of explaining the reasons for the different refactorings, describing code smells and which tools to use to get rid of them. Another reason knowledge about refactoring is good is that often, you won't have the luxury (or curse) of working solely with your own code. Refactoring can be a great tool to unravel spaghetti code and gaining insight while (hopefully) adding tests to support it.
## Online Resources
If you want to get started reading more about patterns and principles, here's a few good links for getting started.
- [Object Mentor Published Articles](http://objectmentor.com/resources/publishedArticles.html)
- [Ward Cunningham's Wiki](http://c2.com/cgi/wiki?CategoryPattern)
## Conclusion
In this post, the first in a series of N, I gave a short introduction to design patterns and principles. I've outlined some recommended getting-started literature and hope to have sparked your interest. Next part will be a basic post describing the first pattern.
Note: I could have more sources in this post, but most of this post is tidbits from experience, opinion and a compilation of snippets from way too many sources. I'll list them in following posts, when we dig into the detail.
BlogEngine.NET, TinyMCE And SyntaxHighlighter 20 Oct 2008 4:00 PM (16 years ago)
I went through my few posts the other day to put some tags on them using BlogEngine.NETs administration page, but as I finished and went to see the end result, TinyMCE had stripped my syntax highlighting. Apparently this is a known issue and there's a fix to have TinyMCE allow pre html tags to keep their name attribute (needed for syntaxhighlighter). The fix can be found on Scott Dougherty's page [here](http://www.scottdougherty.com/blog/post/Adding-SyntaxHighlighter-to-BlogEngineNET.aspx). Furthermore it seems that TinyMCE eats my indentation which is rather annoying. Scott's fix didn't solve this, so I'll have to either avoid online editing or find a fix for this as well. If you know, please let me know.
Ditching ActiveRecord For More NHibernate Love 14 Oct 2008 4:00 PM (16 years ago)
## Introduction
I had a project using an old version of [Castle ActiveRecord](http://www.castleproject.org/activerecord/index.html) and [NHibernate](http://www.hibernate.org/343.html) 1.2. Lately there's been a lot of interesting projects surrounding NHibernate and I've been wanting to make the switch away from the old version of ActiveRecord.
ActiveRecord is a thin layer on top of NHibernate that makes it easier to use and configure, especially through configuration using attributes on classes and properties (hence the [ActiveRecord](http://en.wikipedia.org/wiki/Active_record_pattern) name as seen in Ruby on Rails). However unless you build all the tools yourself, it can be quite the dependency hell to play around with all the new NHibernate toys. So I wanted to eradicate ActiveRecord from my reference list and upgrade NHibernate from 1.2. So I thought I'd share my experiences and some of the useful links I found along the way.
## Fluent NHibernate
One of the new things I wanted to try out for NHibernate was [Fluent NHibernate](http://code.google.com/p/fluent-nhibernate/), a refreshing new way of doing configuration using a fluent interface in C#. NHibernate is usually configured through XML files that look something like this:
```xml
Embedded Scripting Language? Boo! 6 Oct 2008 4:00 PM (16 years ago)
## Setting the stage
In a recent project, I've had the need to use an embedded scripting language. The main purpose was to give the end user a [DSL](http://en.wikipedia.org/wiki/Domain_Specific_Language) like feeling, while retaining the power of a full-fledged scripting language. For a long time the project has been using [IronPython](http://www.codeplex.com/Wiki/View.aspx?ProjectName=IronPython) to provide this, but recently I've run into a few problems and started searching for something new.
## Problems with IronPython
One of the strategies I've used is to have functions that return functions to provide a more humane syntax, like so:
```python
def TextWidth(width):
def f(xq, xs):
xs.SetTextWidth(width)
return f
```
The idea here is that the users script will create a function that will be called later in the correct context and have the inner function take other arguments. However, it does make the script files more verbose and it can be hard to read the functions when they get more complex. Also it's very hard to add extra arguments to a given script context, since you have to find all the functions called in this context and add the argument to the inner function.
Lately, I've been finding myself leaning more in the direction of Ayende's [anonymous base class](http://ayende.com/Blog/archive/2007/12/03/Implementing-a-DSL.aspx) approach. Basically, what you do is to provide a class that wraps the end user script and provides the scope of functions that can be called from the script. However, Python's [class mechanics](http://www.python.org/doc/2.5.2/tut/node11.html) lend themselves very badly to this method, because Python requires abundant amounts of self keywords.
Another idea I had using the anonymous base class approach was to separate the actual scripting logic from the API using the [bridge](http://en.wikipedia.org/wiki/Bridge_pattern) pattern. In pseudo-Python, it'd look something like this:
```python
def TextWidth(width):
impl.SetTextWidth(width)
```
I will probably write another post about this, but the main idea is to be able to swap the implementation of the script logic on runtime. One use of this could be to find more errors when new scripts are entered, by using a script logic implementation that performs extra validation on the arguments instead of actually performing the intended actions.
## Enter Boo
I've had my eye on [Boo](http://boo.codehaus.org/) for quite a while. It's an object oriented statically typed programming language that looks a lot like Python, written on the .NET framework. It's open source and was created in 2003 by [Rodrigo B. De Oliveira](http://blogs.codehaus.org/people/bamboo/). The really cool thing about Boo is the focus on extensibility. It's rather easy to insert extra steps into the Boo compiler if you want your own special macros or syntax.
So I grabbed the latest stable bits from [Boo distributions](http://dist.codehaus.org/boo/distributions/?C=M;O=D) (version 8.2), started up a new VS project and added a reference to Boo.
## Compiler or Interpreter?
As mentioned in Arron Washington [tutorial](http://boo.codehaus.org/Boo+as+an+embedded+scripting+language) on Boo as a scripting language, it's possible to either use the Boo compiler or the interactive interpreter. I went with the compiler. I don't have intimate knowledge of the differences between Boos compiler and interpreter, but usual trade-offs include things like speed, since you're running compiled code instead of traversing some form of the [abstract syntax tree](http://en.wikipedia.org/wiki/Abstract_syntax_tree).
One thing to keep in mind when using the compiler is that you can't unload the assemblies you create unless you unload the entire AppDomain. So unless you worry about AppDomain boundaries and have criteria for unloading your script AppDomain, memory usage will increase as you continue to compile different things. This problem is beyond the scope of this post, but [Google is your friend](http://www.google.com/search?q=assembly+unload+boundaries). As my application is an ASP.NET application that usually gets recycled rather often and because my scripts are semi-static, I've decided not to dig deeper into this. Maybe if circumstances change.
## Simple Example
As a simple example, the below snippet will load up the Boo compiler, compile a simple script where I inject some code into a class and call the method via the C# interface.
```csharp
namespace BooConsoleApp
{
public interface IRunnable
{
void Run();
}
public class Program
{
public static IRunnable CompileToRunnable(string source)
{
// Boo class we're injecting our code into
// A simple Test class implementing our IRunnable interface
var classDef = String.Format(
@"import BooConsoleApp
class Test(IRunnable):
def Run():
{0}", source);
var booCompiler = new BooCompiler();
// Compile to memory
booCompiler.Parameters.Pipeline = new CompileToMemory();
// Compile as library to avoid missing 'No entry point' error
booCompiler.Parameters.OutputType = CompilerOutputType.Library;
// Add our Boo code as input
booCompiler.Parameters.Input.Add(new StringInput("test", classDef));
// Compile the code
CompilerContext context = booCompiler.Run();
// Very basic compile error handling
if (context.Errors.Count > 0)
throw new Exception(context.Errors.ToString(true));
// Create the actual instance of our IRunnable
var runnable = context.GeneratedAssembly.CreateInstance("Test") as IRunnable;
return runnable;
}
public static void Main(string[] args)
{
// Compile our hello world
IRunnable runnable = CompileToRunnable("print 'hello world'");
// Run the program
runnable.Run();
Console.ReadLine();
}
}
}
```
And the output is as expected:
 ## Conclusion
In this post I gave a short primer on getting started with Boo as embedded scripting language. I hope to follow up with more advanced topics. Good luck on getting started with Boo until then.
## Conclusion
In this post I gave a short primer on getting started with Boo as embedded scripting language. I hope to follow up with more advanced topics. Good luck on getting started with Boo until then.
Upgrade, Fresh Start and Syntax Highlight Test 25 Sep 2008 4:00 PM (16 years ago)
I've upgraded my blog to BlogEngine 1.4.5 and deleted the few old posts I had. They weren't very interesting anyways. I've decided to use [syntaxhighlighter](http://code.google.com/p/syntaxhighlighter/) for code snippets, so this post will serve as a small test of this too. ```csharp public void HelloWorld() { Console.WriteLine("Hello World!"); } ``` Hope it works out right.