Die Dimensionen des Google-Rankings 9 Nov 2024 11:08 PM (5 months ago)
Die Rankingfaktoren bei Google sind über die Jahre immer mehrdimensionaler und vielfältiger geworden, was die die Suchmaschinenoptimierung immer komplexer erscheinen lässt. In diesem Artikel geht es um die Entwicklung der Ranking-Faktoren in der Suchmaschinenoptimierung (SEO) von der Dokumenten-Ebene hin zu Domain- und Urheber-Entitäten-Ebene. Zudem werden die drei Bewertungs-Dimensionen für das Google-Ranking erklärt und welche Ranking-Faktoren auf den Dokumenten-, Domain- und Urheber-Entitäten-Ebenen wirken.
Immer mehr Rankingfaktoren auf Meta-Ebene
Suchmaschinenoptimierung bestand früher in erster Linie aus der Optimierung einzelner Dokumente. Der Fokus von SEO lag lange Zeit auf der Dokumentenebene. Im Jahr 2009 begann Google mit dem Vince Update, auch Brand Update genannt, immer mehr Domain- bzw. sitewide Faktoren einzuführen.
- 2009: Vince Update (Brand Update): Bekannte Brand-Domains bekommen Rankingvorteile
- 2011: Panda Update: Content-Qualität als sitewide Faktor
- 2012: Google Exact Match Domain (EMD) Update
- 2014: Vorstellung von E-A-T in den Quality Rater Guidelines. Sitewide Content-Qualität zu Themen und Trust der Urheber (Publisher/Autor)
- 2021: Page Experience System: Die Page Experience ganzer Websitebereiche fließt in das Ranking mit ein.
- 2022: Helpful Content System: Bewertung von Content-Qualität über sitewide Qualifier
- 2018 bis heute: Diverse Core Updates: U.a. mit Schwerpunkt E-E-A-T
Dokumenten Relevanz Scoring vs. Entitäten- bzw. Domain-Qualitäts-Bewertung
Im Information-Retrieval-Prozess muss zwischen dem Scoring auf Dokumenten-Ebene und Bewertung der Domain, Website-Bereich, Thema oder Urheber-Entität unterschieden werden.
Das Scoring auf Dokumentenebene orientiert sich in erster Linie an der Suchanfrage und deren Suchintention und bewertet die Relevanz eines Inhalts zur Suchanfrage.
Bewertungen auf einer Meta-Ebene Suchanfragen-unabhängig sind. Sie bewerten die Qualität der Quelle generell oder bezogen auf ein Thema.
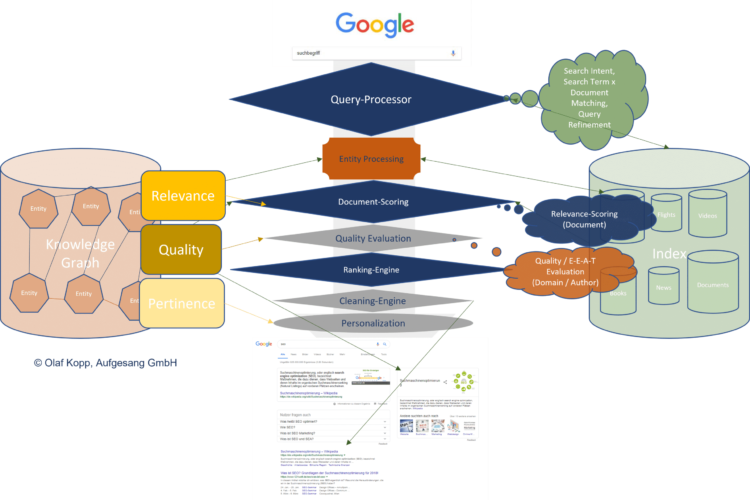
Mehr dazu im Beitrag Relevanz, Pertinenz und Qualität bei Suchmaschinen
Die Bedeutung des Ursprungs eines Inhalts wächst
Schon lange vor (E-)E-A-T hat Google versucht, die Bewertung der Quelle eines Inhalts in das Ranking mit einzubeziehen. Zu nennen ist z.B. das Vince-Update aus dem Jahr 2009, bei dem die Inhalte von Brands im Ranking bevorteilt wurden.
Über bereits lange beendete Projekte wie Knol oder Google+ hat Google versucht, Signale für eine Autoren-Bewertung über z.B. einen Social Graph und Nutzer-Bewertungen zu sammeln.
So findet man in den letzten 20 Jahren einige Google-Patente, die auf Content-Plattformen wie Knol oder soziale Netzwerke wie Google+ direkt oder indirekt verweisen. Auf einige werde ich im Verlauf des Artikels eingehen.
Den Ursprung bzw. den Autoren eines Inhalts nach den Kriterien von E-E-A-T zu bewerten, ist ein wichtiger Schritt und eine fundamentale Weiterentwicklung beim Ranking von Suchergebnissen.
Auch mit Blick auf die Fülle an KI-generiertem Content, aber auch klassischem Spam ist es ein wichtiger Schritt. Es macht für Google keinen Sinn, minderwertige Inhalte in den Suchindex zu übernehmen. Je mehr Inhalte Google indexiert und im Information-Retrieval-Prozess verarbeiten muss, desto mehr Rechenleistung wird benötigt.
E-E-A-T kann Google helfen, basierend auf Entitäten bzw. Domain- und Autoren-Ebene im Big Scale zu bewerten, ohne jeden einzelnen Inhalt crawlen zu müssen. Auf dieser Makro-Ebene lassen sich Inhalte gemäß der Urheber-Entität klassifizieren und mit mehr oder weniger Crawlingbudget ausstatten. Zudem kann Google über diesen Weg ganze Inhaltsgruppen von der Indexierung ausschließen.
Die drei Bewertungs-Dimensionen für das Google-Ranking
Für SEO ist es wichtig zu verstehen auf welchen Ebenen nach welchen Rankingfaktoren die Suchergebnisse ermittelt werden. Deswegen nachfolgend eine kurze Erläuterung der drei Dimensionen.
Zu unterscheiden ist nach Dokumentenspezifischen Rankingfaktoren und generelleren Meta-Faktoren.

Dokumenten-Level
Rankingfaktoren, die für die Bewertung der Relevanz verantwortlich sind. wirken in der Regel auf Dokumentenebene. Relevant ist etwas für Suchmaschinen wenn ein Dokument bzw. Inhalt in Bezug auf die Suchanfrage und deren Suchintention bedeutsam ist.
Die Relevanzbewertung auf Dokumentenebene findet durch den Ascorer / Muppet für das initiale Ranking und Superroot / Twiddler für das fortlaufende Reranking statt.

Hier einige der Rankingfaktoren, die auf Dokumentenebene angewandt werden:
- Keyword-Nutzung in Überschriften, Content und Seitentitel
- TF-IDF / BM25
- Interne und externe Verlinkung und Ankertexte
- Treffen der Suchintention
- Nutzersignale (Deeprank, RankEmbed BERT, Navboost)
- Passage Based Indexing
- Information Gain
- Helpful Content (E-E-A-T)
- Knowledge Based Trust (E-E-A-T)
Domain-Level
Domains sind digitale Repräsentanzen von Urheber-Entitäten. Auf Domain-Ebene gelten, aber auch Entitäten-unabhängige Rankingfaktoren. Von daher sollte man diese Dimension segmentiert betrachten. Sitewide- oder Domain-bezogene Rankingfaktoren können sowohl auf Gesamtdomain-Ebene, Website-Bereich-Ebene oder Themen-Ebene wirken und sind keine Relevanz- sondern Qualitätsfaktoren. Hier einige Rankingfaktoren auf Domain-Level:
- Top Level Domains (TLDs)
- Interne und externe Verlinkung und Ankertexte
- Content-Qualität im Gesamten oder pro Thema (E-E-A-T)
- Page Experience (Core Web Vitals)
- Domain-Alter
- Domain-Trust
- Entfernung zu Trust Seed Sites im Linkgraph (E-E-A-T)
- Transparenz zu den Autoren und Publisher (E-E-A-T)
- Topical Authority (E-E-A-T)
Urheber-Entitäten-Level
Die Bewertung von Urheber-Entitäten (Autoren, Organisationen) gemäß E-E-A-T ist ein relativ neue Dimension beim Google-Ranking. Es ist auch eine thematische oder generelle Qualitäts-Bewertung, die auch Domain unabhängig angewendet werden kann. Die Grundlage wurde 2013 durch das Hummingbird Update und den Knowledge Graph geschaffen. Mehr dazu findest du hier im Blog oder wenn du nach Olaf Kopp E-E-A-T googlest.
Rankingfaktoren zur Bewertung der Urheber-Entität sind u.a.
- Erfahrung des Autors
- Kookkurrenzen des Entitätsnamens mit thematisch relevanten Begriffen in Suchanfragen und Inhalten
- Sentiment um die Entität
- Anzahl an veröffentlichten Inhalten zu einem Thema
- Anteil an Inhalten innerhalb eines thematischen Dokumenten-Korpus
- Nennung der Entität in Best of und Award-Listen
- Brand Suchvolumen

Zusammenfassung
In der Suchmaschinenoptimierung ist es wichtig, zwischen dem Scoring auf Dokumentenebene und der Bewertung von Domain, Website-Bereich, Thema oder Urheber-Entität zu unterscheiden. Das Scoring auf Dokumentenebene bezieht sich auf die Suchanfrage und bewertet die Relevanz eines Inhalts zur Suchanfrage. Bewertungen auf einer Meta-Ebene sind unabhängig von der Suchanfrage und bewerten die Qualität der Quelle generell oder bezogen auf ein Thema.
Die Bewertung der Quelle eines Inhalts ist für Google schon lange ein wichtiger Ranking-Faktor. Mit E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) bewertet Google die Urheber-Entität eines Inhalts und ermöglicht es, Inhalte gemäß der Urheber-Entität zu klassifizieren und zu bewerten. Dies ist insbesondere wichtig angesichts der Fülle an KI-generiertem Content und klassischem Spam.
Es gibt drei Dimensionen, nach denen die Suchergebnisse ermittelt werden: Dokumenten-Level, Domain-Level und Urheber-Entitäten-Level. Dokumenten-Level bezieht sich auf die Bewertung der Relevanz eines Inhalts, Domain-Level auf die Bewertung von Qualitätsfaktoren und Urheber-Entitäten-Level auf die Bewertung der Urheber-Entität selbst. Es ist wichtig zu verstehen, auf welchen Ebenen nach welchen Rankingfaktoren die Suchergebnisse ermittelt werden.
Mehr dazu wie die Google-Suche heute funktionier in diesem Deep Dive

Der Beitrag Die Dimensionen des Google-Rankings erschien zuerst auf Aufgesang.









80+ Faktoren für eine E-E-A-T-Bewertung durch Google 5 Nov 2024 3:35 AM (5 months ago)
Im Jahr 2022 veröffentlichte ich erstmals eine Übersicht über E-E-A-T-Signale, die Google messen kann, um E-E-A-T für Domains, Unternehmen und Autoren zu bewerten. Ich hatte alle Signale aus verschiedenen Google-Quellen und Patenten recherchiert. Der Beitrag war der zweitbeliebteste Artikel von Search Engine Land im Jahr 2022.
Seitdem bin ich auf viele weitere Google-Patente gestoßen, die Hinweise auf andere mögliche E-E-A-T-Signale liefern. Deshalb ist es Zeit für ein Update. Ich konnte über 80 mögliche Signale aus mehr als 40 Quellen ermitteln. Alle Patente, auf die ich mich beziehe, befinden sich in der Datenbank meiner SEO Resesarch Suite.
Ich höre immer wieder, dass SEOs nicht glauben, dass E-E-A-T einen Einfluss auf das Ranking hat, und denken, dass es nur ein Modewort ist. Man muss verstehen, dass Google gerne PR-Claims wie „Hilfreicher Inhalt“ oder „E-E-A-T“ verwendet, um das Suchprodukt mit aussagekräftigen positiven Attributen zu versehen. Diese Namen sind nur eine Klammer oder eine Sammlung für viele einzelne Signale und Algorithmen, die unabhängig voneinander arbeiten.
Google muss Signale identifizieren und messen, um das E-E-A-T-Puzzle zusammenzusetzen und algorithmisch vertrauenswürdigere Ressourcen in den SERPs zu erreichen, um diese Qualitätsbewertung zu skalieren. Diese Qualitätsbewertung könnte auch eine wichtige Rolle bei der Auswahl von Ressourcen für die Schulung von LLMs spielen. Daher ist diese Forschung so wichtig für die Erweiterung des Wissens und die Grundlage für die Optimierung von E-E-A-T.
Weder in Google-Patenten noch im API-Leak oder in den Dokumenten des DOJ wird E-E-A-T ausdrücklich erwähnt. Bei meiner Recherche habe ich mich darauf konzentriert, Quellen zu finden, in denen Qualität, Vertrauen, Autorität und Fachwissen erwähnt werden.
Mehr über E-E-A-T erfahren Sie in meinem umfassenden Leitfaden.
Disclaimer:
Diese Zusammenfassung möglicher E-E-A-T-Faktoren, die Google als Signale für E-E-A-T heranziehen kann ist nicht als Tipp-Liste für SEOs zu verstehen, die diese manipulieren wollen. Die Beeinflussung von E-E-A-T ist nur bedingt durch SEO-Maßnahmen zu beeinflussen, da die aufgeführten Signale eher durch Marketing und PR zu beeinflussen sind. Vorab möchte ich klarstellen, dass die nachfolgend aufgeführten Faktoren für eine E-E-A-T-Bewertung großteils nicht durch Google bestätigt sind. Aber sie sind auch mehr als eine Meinung, da ich sie aus verschiedenen Google Patenten, Whitepapern und wissenschaftlichen Papieren aus de Hause Google recherchiert habe. Von daher ist es fundierter als vieles von dem was man in der Branche hört und liest. Die Quellen habe ich zu jedem Faktor angegeben, sodass Du Dich selbst tiefer einlesen kannst, wenn du magst.
Es gibt keinen einzigen zusammengefassten E-E-A-T-Score
Laut Google gibt es keinen einzelnen E-E-A-T-Score in den alle Signale zusammengefasst bzw. aufgerechnet werden. Ich kann mir vorstellen, dass Google durch viele verschiedene Algorithmen ein Gesamteindruck von E-E-A-T eines Autors, Publishers bzw. Website erhält. Dieser Gesamteindruck ist weniger als Score zu verstehen, sondern als Annäherung an Musterbild für eine Entität, die über E-E-A-T verfügt. Google könnte anhand von ausgewählten Muster-Entitäten die Algorithmen so trainieren, dass ein Benchmark-Muster für E-E-A-T entsteht. Je mehr die Entität sich über verschiedene Signale mit diesem Musterbild gleicht, desto höher die Qualität. Mehr dazu in den von mir bereits erwähnten weiterführenden Beiträgen.
Ranking-Dimensionen bei Google
Um die über 80 Signale klar zu strukturieren, habe ich beschlossen, die Signale in die von mir entwickelten Ranking-Dimensionen zu unterteilen:
- Document-Level
- Domain-Level
- Source Entity Level
Die Dimensionen der Google-Rankings haben sich im Laufe der Jahre zu einem komplexen und vielschichtigen System entwickelt. Früher konzentrierte sich die Suchmaschinenoptimierung hauptsächlich auf die Optimierung einzelner Dokumente.
In den letzten 15 Jahren hat Google zunehmend domain- und seitenweite Faktoren eingeführt.
Heute gibt es drei Bewertungsebenen: die Dokumentebene, die Domainebene und die Quellenebene. Relevanzbasierte Faktoren wie die Verwendung von Schlüsselwörtern und die Qualität der Inhalte werden auf Dokumentebene bewertet.
Auf der Domain-Ebene werden seitenweite Qualitätsfaktoren wie Linkprofil und E-E-A-T berücksichtigt.
Auf der Quellenebene wird die Qualität der Autoreneinheit anhand der E-E-A-T-Kriterien bewertet.
Diese mehrdimensionale Bewertung ermöglicht es Google, Inhalte umfassender zu klassifizieren und qualitativ hochwertige Suchergebnisse zu liefern.
Die in diesem Artikel behandelten Signale können in einen oder mehrere Qualitätsklassifikatoren integriert werden.

Klassifikatoren führen keine Bewertung durch und vergeben keine Punkte, sondern klassifizieren Quellentitäten, Domains und Dokumente in verschiedene Klassen wie Spam, schlecht, mittel oder gut. Wie Google bestätigt, gibt es also keine E-E-A-T-Bewertungen, sondern nur Klassen.
Überblick: Signale für eine E-E-A-T-Bewertung basierend auf Grundlagenforschung
Ich habe die folgenden über 80 E-E-A-T-Signale aus 47 Google-Patenten, dem Whitepaper „How Google fights Spam“ und den Quality Rater Guidelines sowie anderen Google-Aussagen recherchiert und zusammengestellt. Unterstützt wurde ich dabei vom AI Patent & Paper Analyzer aus der SEO Research Suite.
E-E-A-T auf Dokumentenebene (Bewertung der Dokumentqualität)
Fachwissen und Erfahrung:
-
- Originalität des Inhalts: Hoher Anteil an Originalinhalten im Vergleich zu kopierten Inhalten.
- Umfassende Themenabdeckung: Erfüllt sowohl Informations- als auch Navigationsabsichten.
- Relevanz für alternative Abfragen: Die Fähigkeit von Inhalten, sowohl für Erst- als auch für alternative Abfragen gerankt zu werden, kann auf Fachwissen und Autorität zu einem Thema hinweisen.
- Relevanz des Ankertextes: Kontextrelevanter Ankertext signalisiert Fachwissen.
- Grammatik und Layoutqualität: Saubere, professionelle Präsentation der Inhalte.
- Länge der Inhalte: Ausführliche Ressourcen, die Themen umfassend abdecken.
- Häufigkeit der Aktualisierungen: Regelmäßig aktualisierte Inhalte, um Relevanz und Genauigkeit zu gewährleisten.
- Vielfalt der Inhaltstypen (Text, Video, Bilder), die unterschiedliche Nutzerpräferenzen und Interaktionsmuster abdecken.
- Grammatik und Layoutqualität – Bewertung von Faktoren wie Grammatik und Layout, die auf Fachwissen und Professionalität hinweisen können.
- Zitate und externe ausgehende Links zu verlässlichen Quellen: Die Anzahl und Qualität der ausgehenden Links von einem Dokument zu anderen verlässlichen Quellen kann auf Fachwissen und Glaubwürdigkeit hinweisen. Saubere Linkprofile sind wichtig, um Vertrauenswürdigkeit zu schaffen.
- Ankertext und N-Gramme deuten darauf hin, dass kontextuell relevanter Ankertext in Links wichtig ist. Dies könnte auf Fachwissen zum Thema hinweisen.
- Entitätsbeziehungen: Der Nachweis klarer, genauer Beziehungen zwischen Entitäten in Inhalten kann auf Fachwissen und Glaubwürdigkeit hinweisen.
- Co-occurrence patterns: Das konsistente, relevante gemeinsame Auftreten verwandter Entitäten in Inhalten kann auf Fachwissen zu einem Thema hinweisen. Überprüfung der Anzahl der Vorkommen des Namens einer Entität in Ressourcen. Häufige, kontextuell angemessene Erwähnungen relevanter Entitäten können auf thematische Fachkenntnis hinweisen.
- Content Länge – Die Länge der Ressource wird berücksichtigt, was darauf hindeutet, dass umfassende, tiefgehende Inhalte bevorzugt werden.
-
- Abfrageunabhängiges Dokument zur langfristigen Benutzerbindung (wie CTR, Verweildauer)
- Hohe Klick-Raten im Vergleich zu anderen Ergebnissen für dieselbe Abfrage, was darauf hindeutet, dass die Seite als zuverlässiger angesehen wird.
- Konsistente Auswahl eines bestimmten Ergebnisses für eine Abfrage im Laufe der Zeit, was auf eine anhaltende Autorität in Bezug auf das Thema hindeutet.
- Zuordnung mehrerer verwandter Abfragen zu einer einzigen zuverlässigen Seite, was auf eine umfassende thematische Abdeckung hindeutet.
- Suchbegriff-Entitäts-Auswahlwerte: Diese berechneten Werte spiegeln wider, wie gut Ressourcen mit der Absicht der Benutzer für bestimmte Suchbegriffe und Entitäten übereinstimmen.
- Direkte URL-Eingaben: Steigerung der Messungen der Verweildauer für Ressourcen, auf die über eine direkte URL-Eingabe zugegriffen wird, da dies auf eine positive Qualitätsbewertung durch den Benutzer hindeutet. Dies könnte als Signal für Vertrauen und Autorität gewertet werden.
E-E-A-T auf Dokumentebene steht für hilfreiche Inhalte und kann auf die gesamte Website oder auf Website-Bereiche übertragen werden. Die Summe hochwertiger hilfreicher Inhalte wirkt sich also auf die Domain-Ebene aus.
E-E-A-T auf Domain-Ebene (Qualitätsbewertung für die gesamte Website oder für einen bestimmten Bereich der Website)
Vertrauenswürdigkeit:
-
- Domain-Reputation: Der Domainname wird als Merkmal für die Klassifizierung berücksichtigt.
- Verknüpfung mit verifizierten Geschäftsinformationen: Einheitliche Geschäftsdaten wie Adressen und Telefonnummern.
- Geringerer Bedarf an Schlussfolgerungen: Durch die direkte Bereitstellung verifizierter Informationen zeigen Unternehmen Transparenz und Vertrauenswürdigkeit.
- Saubere Linkprofile: Ausgehende Links zu maßgeblichen Quellen signalisieren Vertrauenswürdigkeit.
- Nähe zu vertrauenswürdigen Startseiten: Kurze Entfernungen in Link-Diagrammen zu maßgeblichen Seiten.
- Faktische Genauigkeit: Verwendung von Knowledge-Based Trust (KBT) zur Bewertung der Richtigkeit von Fakteninformationen.
- Vorhandensein unangemessener Inhalte: Negative Signale wirken sich auf die Vertrauenswürdigkeit der Domain aus.
- Konsistenz zwischen den Signalen: Übereinstimmung von Informationen über Links, Titel und Inhalte hinweg.
- Langfristige Nutzerbindung auf der gesamten Website: Klickrate und Verweildauer auf der gesamten Domain.
- Übereinstimmung zwischen Domain-Namen und Firmennamen: Domain-Namen, die mit Firmennamen übereinstimmen, deuten auf einen offiziellen oder autoritativen Status hin.
- Verwendung von https
Autorität:
-
- PageRank und Link-Vielfalt: Unterschiedliche, hochwertige Links von seriösen Quellen.
- Historische Daten: Langfristige Konsistenz bei Rankings und Website-Leistung.
- Netzwerk verwandter Dokumente: Verknüpfte, relevante Inhalte, die die Autorität erhöhen.
- Domainweite Qualität: Website-weite Bewertung der Autorität, nicht nur einzelner Seiten.
- Passendes themenspezifisches Vokabular: Verwendung relevanter Begriffe und Konzepte für bestimmte Themenbereiche.
- Gleichbleibend hohe Rankings: Anhaltende Leistung bei verschiedenen Abfragen.
- Alter der Domain und des Inhalts auf der gesamten Website
- Gleichbleibend hohe Rankings: Ressourcen, die bei verschiedenen Abfragetypen (anfänglich und alternativ) durchgehend hohe Rankings erzielen, können als zuverlässiger angesehen werden.
- Entitätsreferenzen: Ressourcen, die relevante Entitäten genau und umfassend abdecken, können als zuverlässiger angesehen werden.
- Beständigkeit bei der Identifizierung als Navigationsressource für bestimmte Themen im Laufe der Zeit, wodurch Vertrauen und Autorität aufgebaut werden.
- Markenbekanntheit: Anfragen, die direkt auf eine Website oder Marke verweisen, können auf deren Autorität und Vertrauenswürdigkeit in den Augen der Benutzer hinweisen
Expertise und Erfahrung (hilfreicher Inhalt)
-
- Thematischer Fokus und Originalität des Inhalts: Originalinhalte, die relevante Themen gründlich abdecken.
- Aktualität der Inhalte: Regelmäßige Aktualisierungen und zeitnahe Überarbeitungen der Inhalte.
- Relevanz der Kategorien: Starke Leistung in relevanten Inhaltskategorien.
- Breites vs. Nischeninteresse: Nachweis von Fachwissen in Nischen- und breiten Themenbereichen.
- Vorhandensein unangemessener Inhalte
- Breites vs. Nischeninteresse – Ob eine Website ein breites oder ein Nischeninteresse hat, das sich auf thematische Fachkenntnisse beziehen kann.
- Historische Daten: Die Verwendung historischer Daten zur Qualität der Website deutet darauf hin, dass die langfristige Reputation und Konsistenz in die E-E-A-T-Bewertungen einfließen. Die Verwendung früherer Leistungskennzahlen deutet darauf hin, dass etablierte Fachkenntnisse und Autorität im Laufe der Zeit geschätzt werden können.
- Relevanz des Inhalts für häufig oder selten gesuchte Themen. Dies könnte auf Fachwissen in bestimmten Themenbereichen hinweisen, insbesondere bei Nischen- oder Fachinhalten.
- Umfassende Themenabdeckung, die sowohl Informations- als auch Navigationsabsichten erfüllt und die Tiefe des Wissens demonstriert. Detaillierte, gut strukturierte Inhalte, die ein Thema gründlich abdecken. Durch die Untersuchung von Makro- und Mikrokontexten, um die Tiefe und Relevanz von Inhalten zu bestimmten Themen zu verstehen, was auf die Qualität der Inhalte hinweisen könnte.
- Erstmaliger Inhalt – Inhalte, die erstmals zu einem bestimmten Thema veröffentlicht werden, werden höher bewertet, was auf Fachwissen und Autorität hinweist.
- Passendes typisches Vokabular für den Themenbereich: Domainlisten mit unverwechselbaren Begriffen für verschiedene Themenbereiche deuten darauf hin, dass Suchmaschinen den thematischen Fokus und die Autorität der gesamten Website bewerten können. Die Berücksichtigung wichtiger Begriffe und relevanter Entitäten deutet darauf hin, dass der Inhalt Schlüsselkonzepte und -entitäten im Zusammenhang mit dem Thema gründlich abdecken sollte.
- Verhaltensmuster der Benutzer: Übergänge von Informations- zu Navigationsabfragen signalisieren Fachwissen.
- Abfrageunabhängige langfristige Benutzerbindung auf der gesamten Website oder in bestimmten Bereichen (CTR, Verweildauer)
- Relevanz der Kategorie: Das Patent verwendet kategoriespezifische Dauerwerte zur Bewertung von Websites. Eine gute Leistung in relevanten Kategorien könnte Fachwissen und Autorität in diesen Themen signalisieren.
- Konsistente Leistung über Kategorien hinweg: Websites, die in mehreren relevanten Kategorien gut abschneiden, können insgesamt als zuverlässiger und vertrauenswürdiger angesehen werden.
E-E-A-T auf der Ebene der Source-Entity-Ebene
Vertrauenswürdigkeit
- Authentifizierung von Mitwirkenden: Überprüfung der persönlichen Informationen von Erstellern von Inhalten.
- Reputations- und Glaubwürdigkeitsverlauf: Erfolgsbilanz bei der Bereitstellung korrekter Informationen.
- Stimmung bei Erwähnungen und Bewertungen: Konsensstimmungsbewertung für die Entität.
- Einfluss von Kollegen und Empfehlungen: Bewertungen oder Empfehlungen von angesehenen Autoren.
- Vertrauensbeziehungen zwischen Entitäten: Berechnung von Vertrauensrängen auf der Grundlage der wahrgenommenen Vertrauenswürdigkeit durch andere Entitäten, was auf ein Vertrauensnetzwerk hinweist, das mit Autorität und Fachwissen in Zusammenhang stehen könnte.
- Beitragsmetrik: Basierend auf kritischen Bewertungen und Ruhm-Rankings belohnt diese Metrik wahrscheinlich Entitäten und Inhaltsersteller, die in ihrem Bereich bedeutende Beiträge geleistet haben.
- Nachbarschaftsqualität: Die Qualität der verknüpften oder verwandten Entitäten beeinflusst die Bewertung einer Entität, was darauf hindeutet, dass maßgebliche Verbindungen die E-E-A-T-Signale verstärken. Die Berücksichtigung von Zugehörigkeiten zwischen Dokumenten deutet möglicherweise darauf hin, dass Inhalte von etablierten Autoren oder seriösen Quellen höher bewertet werden.
- Reputation und Glaubwürdigkeitsverlauf – Die Erfolgsbilanz einer Entität bei der Bereitstellung zuverlässiger und genauer Informationen beeinflusst ihre Autorenbewertung.
- Die Häufigkeit der Veröffentlichung hochwertiger Inhalte wird als Faktor zur Verbesserung der Reputationsbewertungen genannt.
- Verifizierte Referenzen: Bildungshintergrund, Berufserfahrung und andere verifizierte Referenzen werden als Faktoren für die Glaubwürdigkeit eines Autors beschrieben.
Autorität
- Referenzen der Entität in autoritativen Quellen: Häufigkeit und Genauigkeit der Erwähnungen in autoritativen Quellen.
- Preis-Metrik: Auszeichnungen oder Anerkennungen, die mit der Entität verbunden sind, signalisieren Autorität.
- Häufigkeit der Inhaltszitate: Wie oft werden die Inhalte einer Entität von anderen zitiert?
- Veröffentlichungshistorie: Umfang und Konsistenz der Inhaltsbeiträge im Laufe der Zeit.
- Beitragsmessung: Bedeutende Beiträge im Bereich der Entität, basierend auf kritischen Bewertungen.
- Markenbekanntheit: Abfragen, die sich speziell auf die Entität beziehen.
- Die Übereinstimmung von Ankertext und Firmennamen deutet auf Anerkennung und Autorität für diese Entität hin.
- Präsenz in autoritativen strukturierten Online-Datenbanken und Enzyklopädien könnte ein E-E-A-T-Signal sein.
- Zitierhäufigkeit: Wie oft der Inhalt einer Entität von anderen glaubwürdigen Quellen zitiert wird, trägt zu ihrem Autoren-Score bei und signalisiert Fachwissen und Vertrauenswürdigkeit.
- Langfristige Konsistenz: Die Integrität historischer Daten und die Konsistenz der Identität eines Autors über verschiedene Plattformen hinweg werden als Faktoren für die Authentifizierungsbewertung genannt.
- Bemerkenswerte Typ-Metrik: Diese kombiniert die globale Popularität mit der Bedeutung des Entitätstyps, was darauf hindeutet, dass bekannte Entitäten in prominenten Kategorien bevorzugt werden könnten.
- Preis-Metrik: Diese spiegelt die Anerkennung und Auszeichnungen wider, die mit einer Entität verbunden sind, und signalisiert möglicherweise Fachwissen und Leistung.
- Autor: Assoziationen mit Themen basierend auf der beanspruchten Autorenschaft und der Interaktion der Benutzer mit ihren Inhalten, was auf Fachwissen in bestimmten Bereichen hindeutet.
- Benutzersitzungsdaten: Durch die Einbeziehung von Benutzersitzungsknoten in ein Diagramm kann das System bewerten, wie eine Ressource in umfassendere Muster der Benutzerrecherche passt, was möglicherweise auf ihre Autorität innerhalb eines Themenbereichs hindeutet.
- Anzahl der zu einem Thema veröffentlichten Inhalte nach Quelle
- Beliebtheit der Quelle
- Anzahl der Backlinks/Verweise auf die Quelle
- Anteil des Inhalts, den eine Quelle zu einem thematischen Dokumentenkorpus beigetragen hat
Expertise und Erfahrung:
- Erstinstanzlicher Inhalt: Pionierinhalte zu einem bestimmten Thema.
- Themenrelevanz: Die Übereinstimmung der Expertise des Autors mit dem Inhaltsthema.
- Veröffentlichungshistorie – Das Volumen, die Konsistenz und die Vielfalt der inhaltlichen Beiträge einer Entität im Laufe der Zeit werden berücksichtigt und können auf Erfahrung und Fachwissen hinweisen.
- Relevanz des Themas: Die Bedeutung des Fachwissens eines Autors für den von ihm erstellten Inhalt.
- Zeit bis zur letzten Veröffentlichung zu einem Thema der Quellentität
Diese Übersicht ist ein guter Ausgangspunkt für die Orientierung. Ich wäre Dir sehr dankbar, wenn Du dieses Wissen teilst und mich motivieren kannst, diese Übersicht regelmäßig zu aktualisieren. Danke!
Wenn Du mehr zum Thema E-E-A-T erfahren willst und ich erst einmal einlesen willst empfehle ich Dir die folgenden Beiträge:
- E-A-T (Expertise, Autorität, Trust) erklärt: Einfluss auf die Google-Rankings & Bedeutung für SEO
- E-A-T-Optimierung: Wie optimiert man E-A-T bei Google?
- E-A-T: Klassifizierung von Websites über Vektorraumanalysen nach Autorität und Expertise
- E-A-T & thematische Marken-Positionierung als kritischer Erfolgsfaktor in der SEO
Der Beitrag 80+ Faktoren für eine E-E-A-T-Bewertung durch Google erschien zuerst auf Aufgesang.
Case Study: 1400% Sichtbarkeitssteigerung in 6 Monaten durch E-E-A-T der Source Entity 24 Sep 2024 4:00 AM (6 months ago)
In diesem Artikel möchte ich die Hintergründe, Durchführung und Ergebnisse eines Tests aufzeigen, der der Domain aufgesang.de einen Sichtbarkeits-Boost von über 1400% in 6 Monaten beschehrt hat. Diese Case Study gibt Hinweise darauf wie mächtig E-E-A-T der Source Entity wirken kann. Zudem gibt einige weitere interessante Beobachtungen, die ich rund um diesen Test machen konnte und die einige bisherige Theorien zu E-E-A-T in Frage stellen.


Hintergrund
Die Domain sem-deutschland.de gehörte mit zeitweise >5 Sichtbarkeitsindex bei Sistrix vor Dezember 2020 einige Jahre zu der sichtbarsten Agentur Webseiten im D-A-CH-Raum. Seit dem Core Update im Dezember 2020 verzeichnete die Domain bis zum August Core Update einen absteigenden Sichtbarkeitsverlauf meistens aufgrund der diverser Core Updates. Unsere zweite Agentur Domain aufgesang.de hatte bis zu diesem Jahr keinen großen Anspruch auf Rankings oder Sichtbarkeit und sollte in erster Linie den Brand-Traffic von Aufgesang bedienen. Ende letzten Jahres haben wir begonnen auch auf der aufgesang.de ein Fachwörter-Glossar aufzubauen, was in erster Linie SEO-Zielen verfolgt.

Im April habe ich mich dazu entschlossen einige ausgewählte Glossar-Beiträge von der sem-deutschland.de unverändert in das Glossar auf aufgesang.de zu übertragen. Alle dieser Beiträge haben gemeinsam, dass sie bis Ende 2020 Top 5 Rankings für Suchbegriffe >500 Suchanfragen pro Monat vorwiesen, dann aber aus den Top 10 rausgeflogen sind.
Bevor ich auf den Test und die Ergebnisse eingehe möchte ich die Theorie erläutern, die ich mit diesem Test stützen wollte.
Die Theorie für den Sichtbarkeits-Verlust
Wir können davon ausgehen, dass Google auf drei Ebenen oder Dimensionen Websites und Ergebnisse für das Ranking bewertet:
- Dokumenten-Ebene: Relevanz-Scoring auf Inhaltsebene nach klassischen IR-Scores z.B. nach BM25, TF-IDF, Nutzersignale …
- Domain-Ebene: Qualitätsbewertung auf seitenweiter oder Website-Bereichs-Ebene z.B. E-E-A-T. Die Domain ist digitale Repräsentanz der Source Enity.
- Source-Entity-Ebene: Als Source Entity bezeichne ich die Organisation/Publisher oder den Autor hinter den Inhalten einer Website. Für die Bewertung werden Brand-Signale genutzt wie Vorkommen und Suchmuster rund um die Brand, Brand Mentions, Kookkurrenzen aus Marke und Themen.
Mehr dazu im Beitrag Die Dimensionen des Google-Rankings
Die Source Enity Aufgesang ist aufgrund des Brand-Traffics, den sie erhält, mehr in Beziehung mit der Domain aufgesang.de als mit der Domain sem-deutschland.de.

aufgesang.de

aufgesang.de

sem-deutschland.de

sem-deutschland.de
Die Domain sem-deutschland.de wird mehr der Entität „Olaf Kopp“ zugeordnet als der Entität „Aufgesang“.

Hieran kann man gut erkennen, dass Google versucht Domains mit einer im Knowledge Graph erfassten Entität zusammenzubringen. Die Source Entity sem deutschland und die Domain sem-deutschland.de erhält selbst keine Brand-Signale, hängt damit etwas haltlos im Raum.
Meine Theorie war vor dem Umzug der Inhalte, dass die Brand-Stärke der Source Entity Aufgesang die gleichen Inhalte deutlich boostet und die alten Rankings für die identischen Inhalte auf der aufgesang.de wiederherstellt. Das wäre ein Hinweis auf den großen Einfluss von E-E-A-T der Source Entity auf das Ranking.
Um Zweifler an dieser Theorie etwas den Wind aus den Segeln zu nehmen, habe ich vorher natürlich das Backlinkprofil und Core Web Vitals der beiden Domains verglichen. Das Backlinkprofil von sem-deutschland.de war vor dem Umzug besser sowohl was Anzahl, als auch Qualität der Links. Wir haben seit 2010 durch die Veröffentlichung von Studien, Ebooks, Blogbeiträgen … viele hochkarätige Links für die sem-deutschland.de einsammeln können.


Auch die Core Web Vitals sind auf der sem-deutschland.de besser als die der aufgesang.de

Core Web Vitals aufgesag.de

Core Web Vitals sem-deutschland.de
Somit können diese beiden Faktoren schon mal asugeschlossen werden.
Das Test-Szenario
Ich habe 29 Inhalte ausgewählt, um sie unverändert im Zeitraum April bis August 2024 in das Glossar auf aufgesang.de umzuziehen. Die Artikel wurden in der Vergangenheit alle als relevant von Google bewertet und vor 2021 mit Top Rankings belohnt, haben mit der Zeit aber ihre Top 10 Positionen verloren.
Die alten URLs wurden per 301 weitergeleitet auf die neuen. Für die interne Verlinkung der Glossar-Beiträge nutzen wir bei beiden Domains WordPress Plugins für die automatische interne Verlinkung mit den Hauptkeywords als Ankertext. Der einzige Unterschied bei der Gestaltung der Glossar-Beiträge ist, dass auf aufgesang.de ich nicht als Autor genannt werde und auch keine Autorenboxen genutzt werden. Das sollte laut Theorie eigentlich ein Nachteil sein, aber die Ergebnisse zeigen, dass es sich überraschenderweise nicht als Nachteil herausgestellt hat.
Die Sichtbarkeits- und Ranking-Entwicklungen der einzelnen Inhalte überwache ich in mehreren Sistrix-Dashboards.
Ich möchte erwähnen, dass keine der gerade sehr gehypten Methoden wie Topical Mapping, Micro Semantics, Macro Semantics oder andere komplexe Ansätze bei der Produktion der Inhalte genutzt wurden. Die Relevanz-Optimierung wurde damals klassisch mittels TF-IDF-Analysen und W-Fragen-Recherche durchgeführt.
Die Testergebnisse
Die Domain aufgesang.de konnte seit April über 1400% an Sichtbarkeit zulegen. Die alten Rankings, die die Inhalte auf der sem-deutschland.de vor 2021 erreichen konnten sind nahezu alle wieder hergestellt und zum Teil sogar besser.




Betrachtet man die jetzige Gesamt-Sichtbarkeit beider Domains zusammen gab es einen Zuwachs von ca. 250% wobei erwähnt werden muss, dass August Core Update 2024 zum Teil zu einer Recovery bei der sem-deutschland.de geführt hat.

Sichtbarkeit der beiden Domains gestapelt
Fazit
Seit 2013 beschäftigt mich das Thema Entitäten- und Domain-spezifische Qualitätsbewertung. Schon bevor Google 2015 E-E-A-T in die Quality Rater Guidelines einführte hatte ich das Gefühl, dass es einflusstarke Rankingfaktoren gibt, die vor allem mit Digitalen Markenaufbau beeinflusst werden können. Mit E-E-A-T als Qualitäts- und Markenkonzept gab Google diesem Gefühl einen Namen.
Folgende Schlussfolgerungen möchte ich aus diesem Test ziehen:
- Die Vertrauenswürdigkeit und Autorität einer Seite hat einen sehr großen Einfluss auf Rankings, nicht nur für YMYL-Themen.
- Autorenboxen spielen keine große Rolle.
- Überraschenderweise scheint die Autorenschaft keine große Rolle zu spielen, sondern in erster Linie die Source Entity des Unternehmens oder Publishers selbst.
- E-E-A-T hängt vor allem von Brandbezogenen Makrofaktoren auf Domain- und Source-Entity-Ebene ab, weniger von den einzelnen Inhalten selbst. (siehe Grafik dazu)

Dieser Test gibt einen weiteren Hinweis, dass dieses „Gefühl“ nicht nur pure Theorie ist. Es gibt nur wenige Tests, die das Thema E-E-A-T und Brand-Einfluss auf das Ranking bisher untersucht haben. Dieser Test soll als eine der wenigen Case Studies dazu führen, dass die Sicherheit erhöht das Thema E-E-A-T mehr in den Fokus zu nehmen.
Mehr Details zu diesem Praxis-Case und mehr in unserem nächsten Webinar:

Der Beitrag Case Study: 1400% Sichtbarkeitssteigerung in 6 Monaten durch E-E-A-T der Source Entity erschien zuerst auf Aufgesang.
Digitaler Markenaufbau: Das Zusammenspiel aus (Online-)Branding & Customer Experience 7 Aug 2024 12:40 AM (8 months ago)
Digitaler Markenaufbau bzw. Branding ist eines der zentralen Themen im Online Marketing. Nachfolgend mehr zur wachsenden Bedeutung und zu den Merkmalen einer (digitalen) Marke, wie man über eine herausragende Customer Experience eine Marke aufbaut und wie man Branding digital messen kann.
Definition: Was ist digitaler Markenaufbau bzw. was ist Online-Branding?
Digitaler Markenaufbau oder Online-Branding beschreibt eine Methode des Brand-Managements. Beim digitalen Markenaufbau geht es um die Positionierung in einem oder mehreren thematischen Bereichen und Stärkung der Beziehung zwischen einer Marke mit potentiellen sowie bestehenden Kunden über die Customer Experience (Nutzererfahrung) mit digitalen Touchpoints.
Der Unterschied zum klassischen Branding bzw. Markenaufbau ist, dass beim digitalen Markenaufbau neben den Nutzern auch die Algorithmen der wichtigen digitalen Gatekeeper wie Suchmaschinen und soziale Netzwerke überzeugt werden müssen.
Markenaufbau bzw. Branding wird in den meisten Fällen durch digitale und analoge Touchpoints im Zusammenspiel gefördert.
Was sind mögliche Branding-Ziele?
Ziele von Markenaufbau und Branding sind
- der Aufbau und Verbesserung von Beziehungen mit potentiellen Kunden, bestehenden Kunden und Mitarbeitern sowie potentiellen Mitarbeitern (Employer Branding).
- der Ausbau und die Pflege von Beziehungen zu weiteren Stakeholdern wie Influencer und anderen Multiplikatoren.
- Positionierung der Marke als thematische Autorität.
- Bessere Sichtbarkeit und Auffindbarkeit im Internet bzw. bei den wichtigen Gatekeepern wie Google, Facebook …
Das Web 3.0 als logische Konsequenz aus dem Web 2.0
Das Web 2.0 mit den einhergehenden technischen Möglichkeiten hat es quasi jedem ermöglicht Inhalte online über eigene Websites, Blogs und Social Media Profile zu veröffentlichen. Das führt zwangsläufig zu einer Überschwemmung des Netz mit Information und Daten, wie die folgende Infografik eindrucksvoll demonstriert.

Das Web 3.0 und die digitale Marke
Gatekeeper im Netz wie Google und Facebook wollen und können diese Marken und Autoritäten im Netz über Graphen identifizieren. Dabei spielt es primär erst einmal keine Rolle, ob man sich offline schon eine Marke aufgebaut hat oder nicht. Entitäten spielen in dieser Betrachtung eine wichtige Rolle.
In der Semantik ist eine Entität eindeutig durch einen Identifier, einen Entitäts-Typ und bestimmten Eigenschaften gekennzeichnet.
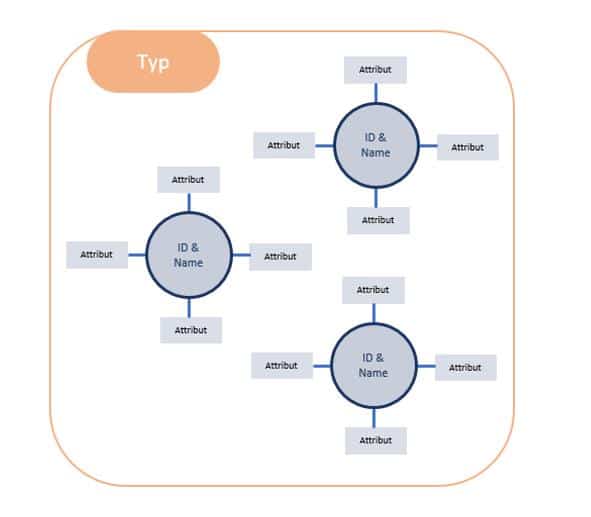
Der Zusammenhang von Entitäten und Marken
Entitäten sind in den meisten Fällen Teil mindestens einer Ontologie und können Personen, Bauwerke, Unternehmen etc. darstellen. Ontologien beschreiben das Umfeld in dem sich die Entitäten befinden. So ist Zalando eine Entität in des Entitätstyps Shop oder Händler und Teil der Ontologie z.B. Mode oder Mode-Shops und steht in Beziehung zu anderen Entitäten dieser Ontologien.
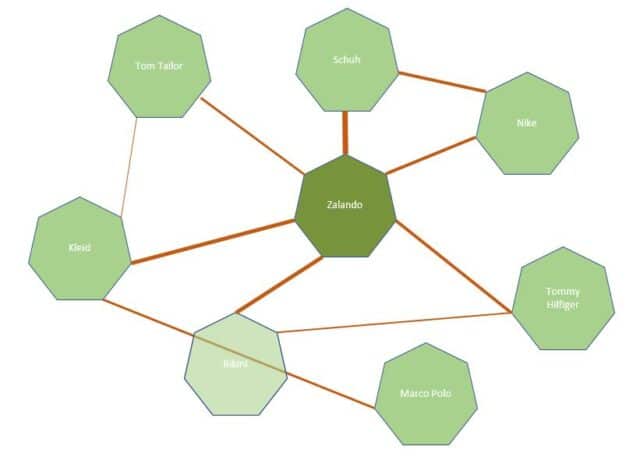
Beziehungen rund um die Entitaet Zalando
Starke digitale Marken sind im semantischen Web i.d.R. auch Entitäten mit hoher Relevanz mit vielen Schnittstellen zu anderen Entitäten in bestimmten thematischen Ontologien. Dies spielt auch für die Suchmaschinenoptimierung eine wichtige Rolle. Übertragen auf das Internet kann man Websites bzw. Domains als zentrales digitales Abbild einer Marke sehen.
Über Verlinkungen, Kookkurrenzen der Marke mit anderen Entitäten in Suchanfragen oder Online-Texten lassen sich Marken algorithmisch in Ontologien positionieren. Durch die Häufigkeit dieser Beziehungen bewerten hinsichtlich Autorität und Glaubwürdigkeit.
Mehr zum Thema Entitäten und Google findest Du in der ausführlichen Artikelreihe Semantische SEO: Entitäten, NLP & Semantik bei Suchmaschinen(Nur für Premium-Mitglieder) oder dem Einsteiger-Beitrag zum Thema Entitäten im Glossar.
Warum die digitale Marke im Online Marketing eine zentrale Rolle spielt
Es gibt mehrere Ursachen dafür, warum der Markenaufbau eine zentrale Rolle im (Online-)Marketing spielt.
- Die Marktlage in vielen Branchen.
- Die technische Entwicklung der wichtigsten Gatekeeper in Richtung des semantischen Web 3.0 .
- Die Bedeutung von vertrauenswürdigen und thematisch autoritären Quellen.
- Der Informations-Schock für Konsumenten
- Herausforderung zur automatischen Identifikation von vertrauenswürdigen und autoritären Anbietern und Informations-Quellen.
Unternehmen, die in der Vergangenheit nur auf das Performance-Marketing-Pferd gesetzt haben und Branding außer Acht gelassen haben, bekommen in vielen Bereichen Probleme sich im Internet zu behaupten. Dies ist begründet durch den über die Jahre gestiegenen Wettbewerbsdruck und das auf breiter Ebene gestiegene Know-How bzw. Ressourcen was Performance-Marketing angeht. Zudem befindet sich die Aufmerksamkeit für Werbeanzeigen im Sinkflug, nicht nur wegen den Ad-Blockern. Die Information muss zum Kontext des Nutzers passen, da sie sonst nicht durch das enge Aufmerksamkeits-Fenster des Nutzers durchkommt. Werbung als Touchpoint schafft das in in vielen Phasen der Customer Journey nicht.
Eine starke Marke kann Online-Marketing entscheidend zum Erfolg führen.
- Eine starke Marke kann zu besseren Abschlussraten bzw. Konversionsraten führen, da das Vertrauen in eine bekannte Marke größer ist.
- Das größere Vertrauen kann auch zu verbesserten Klickraten in den SERPs führen, was sich positiv auf das Google Ranking
- Etablierte Marken führen zugrößerer Kundenbindung und Loyalität, was sich in mehr wiederkehrenden Website-Besuchern und Kunden auswirken kann.
- Die Chance auf Verweise und Social Shares ist größer, da starke digitale Marken, aufgrund der Vertrauenswürdigkeiteher durch Multiplikatoren verlinkt, verwiesen bzw. Inhalte geteilt Das führt zu größerer Reichweite und besseren Rankings. Content-Marketing, SEO und PR wird einfacher.
- Marken, die sich in einem oder mehreren thematischen Bereichen als Autorität über die Domain etabliert haben,werden mit Inhalten eher bei Google gefunden als nicht etablierte Domains.
- Starke Marken profitieren, aufgrund der Popularität auch von besseren Klickraten bei derSuchmaschinenwerbung (SEA), was zur Verbesserung von Qualitätsfaktoren und damit geringeren Klickpreisen führt.
Zudem ist Marken-Traffic z.B. über Direktzugriffe oder Suchanfragen nach der Marke in Suchmaschinen zusammen mit den wiederkehrenden Besuchern der wertvollste Traffic.
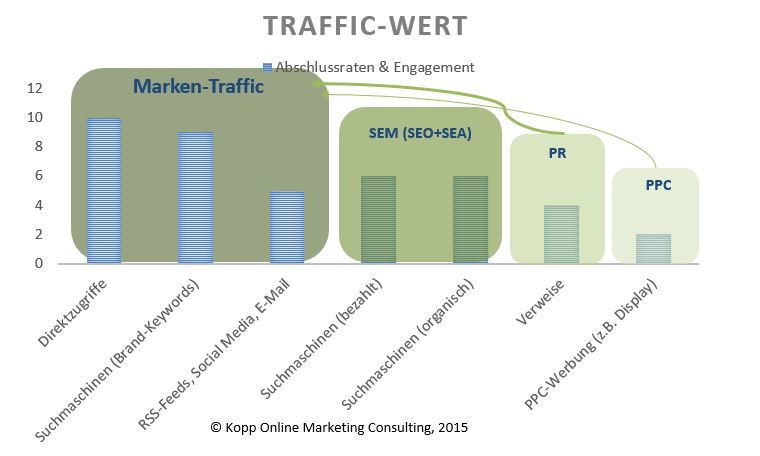
Je höher der Anteil der Marken-Traffics, desto höher sind in den meisten Fällen die Engagment-Kennzahlen wie z.B. Seitenaufrufe, durchschnittliche Aufenthaltsdauer, Absprungrate … die Loyalitäts-Kennzahlen wie z.B. der Anteil der wiederkehrenden Besucher und vor allem die Abschlussraten.
Somit gibt es einen direkten Wirkungszusammenhang zwischen der Markenstärke und der Performance.
Der Aufbau einer Marke folgt einem strategischen nachhaltigen Ansatz mit dem Ziel Kundenloyalität und Reputation zu verbessern, was die nachhaltige Positionierung im Markt fördert.
Performance-Marketing hingegen ist oft eher taktisch/operativ und folgt nur selten einer Strategie der Positionierung als Marke.
Der Aufbau einer digitalen Marke ist kritischer Erfolgsfaktor und rückt in das Zentrum des Online Marketings, wo bisher alleinig das Performance-Marketing stand. Deswegen lässt sich Performance-Marketing und Branding nicht mehr voneinander trennen wie im Beitrag Warum die Diskussion um Branding vs. Performance im Marketing überflüssig ist erläutert.
Über eine herausragende Customer-Experience entlang der Customer-Journey eine Marke aufbauen
Menschen bauen Beziehungen mit Marken auf, indem sie positive Gefühle bei der Interaktion mit verschiedenen Kontaktpunkten mit der Marke empfinden. Hier spielt die Nutzererfahrung bzw. User- oder Customer Experience mit diesen Touchpoints eine wichtige Rolle. Touchpoints können z.B. sein:
- Content
- Werbe-Anzeigen
- Kontakt mit dem Vertriebs-Mitarbeiter bzw. Verkäufer
- Kontakt mit dem Service-Mitarbeiter
- ein Angebot
- Bestellabwicklung
- die Erfahrung mit dem Produkt in der Anwendung
Typische digitale Touchpoints sind:
- organisches Suchergebnis
- Produktdetailseite im Shop
- Ratgeber-Content im Blog
- Google Ads Anzeige
- Social-Media-Post
- Social Media Anzeige
- Display-Anzeige
- Bestellabschlussseite im Shop
- Kontaktformular
- Whitepaper
- …
Die Touchpoints müssen je nach Kontext den Nutzers
- emotional ansprechend sein
- rational ansprechend sein
- funktional ansprechend sein
- erwartungskonform sein
Alle Punkte werden je nach Person bzw.Kontext dieser individuell empfunden und bewertet. So sollten Touchpoints so gestaltet sein die wichtigsten Zielgruppen oder Personas dementsprechend zu befriedigen. Zudem sollten möglichst viele Touchpoints entlang der Customer Journey des Nutzers ausgerichtet an seinen Bedürfnissen konsistent sein. Inkonsistenz und Widersprüche führen zu Verwirrung und Einschränkung der Nutzererfahrung.
Hier einige Beispiele:
Ein Nutzer der in einer Suchmaschine nach „rückenschmerzen“ googlet hat eine bestimmte Suchabsicht bzw. Suchinintention. Er sucht objektive Informationen wie z.B. einen Ratgeber-Beitrag oder Video. Ein erwartungskonformes Suchergebnis wäre ein umfassender Ratgeber zu Symptomen, Ursachen, Behandlungsmöglichkeiten … Eine Produktvorstellung für ein neues Rheuma-Mittel wäre hingegen kein erwartungskonformer Touchpoint.
Gerade bei Touchpoints die auf eine Pull-Mechnanismus setzen wie z.B. organische Suchergebnisse bzw. Suchmaschinenwerbung und die dementsprechenden Zielseiten sollten sehr fokussiert auf die Erwartungskonformität achten, da sonst die Nutzererfahrung und damit die Marken-Wahrnehmung leidet.
Ein Nutzer klickt auf eine Display-Anzeige, die ihm suggeriert ein kostenloses Produkt erwerben zu können. Auf der Landingpage wird klar, dass das Produkt nicht kostenfrei ist. Die Folge ist eine negative Nutzererfahrung, da nicht erwartungskonform.
Ein Nutzer besucht eine Website, die unendlich lange lädt. Er will sich weiter durch die Website navigieren und bricht irgendwann verzweifelt ab, da jede Interaktion mit der Website zu lange dauert. Die Folge ist eine schlecht Customer Experience aufgrund schlechter Funktionalität.
Das gleiche gilt für nicht funktionierende Anwendungen wie z.B. Konfiguratoren oder Tools.
Ein Mitarbeiter eines Unternehmens postet einen Beitrag bei Facebook, der im Widerspruch zu den bisher an anderen Touchpoints kommunizierten Werten des Unternehmens steht. Es kommt zu einer emotionalen Verunsicherung und im schlimmsten Fall zu einem Shitstorm. Sowohl auf der erwartungs als auch auf emotionaler Ebene führt diese Inkonsistenz zu einer schlechten Nutzererfahrung.
Die Customer Experience an den Touchpoints hat einen direkten Einfluss auf die Wahrnehmung der Marke. So können als positiv empfundene Touchpoints positiv für den Markenaufbau sein und umgekehrt.
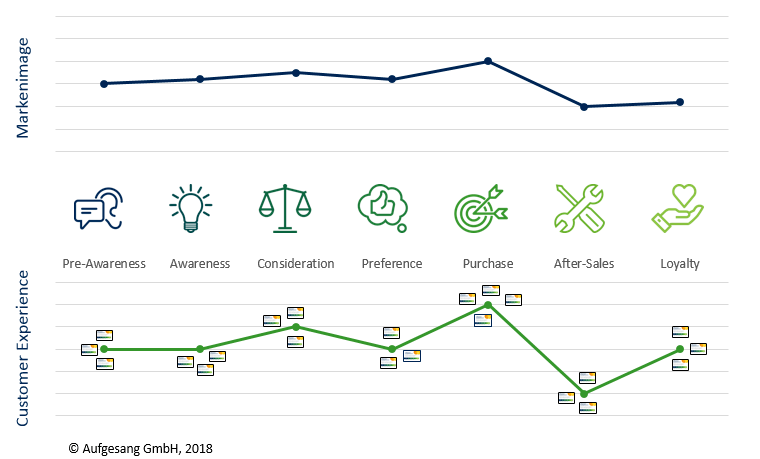
Der Einfluss der Customer Experience an Touchpoints auf das Markenimage
Es wird kein Unternehmen auf der Welt geben, das alle Touchpoints herausragend gestalten kann. Deswegen ist es wichtig im Rahmen des Touchpoint- und Customer Journey Managements die erfolgskritischsten Touchpoints zu identifizieren, um diese mit Fokus zu gestalten und zu optimieren.
Die verschiedenen Ebenen für das Branding und die Gestaltung von Touchpoints
Für den Markenaufbau ist es wichtig die Marke in einen für den Nutzer verständlichen und einheitlichen Kontext zu verorten. Dieser Kontext hat mehrere Ebenen.
- Die thematische Ebene
- Die emotionale Ebene
- Die Beziehungs-Ebene
- Die funktionale Ebene
Die thematische Ebene
Um eine thematische Autorität in den Köpfen der Nutzer zu werden bedarf einer thematischen Einordnung der Marke. Gerade für B2B-Unternehmen oder als Anbieter teurer und/oder komplexer Dienstleistungen un Produkte spielt diese Ebene neben der Beziehungs-Ebene eine besondere Rolle.
Der Nutzer muss verstehen in welchen thematischen Bereichen meine Marke als relevant einzuordnen ist. Hier spielen Kookkurrenzen, also die immer wieder vorkommende Nennung meiner Marke in Verbindung mit Begriffen eines bestimmten Themas eine große Rolle. Je häufiger die eigene Marke im Zusammenhang mit den jeweiligen thematischen Kontexten bzw. deren typischen Begrifflichkeiten genannt wird, desto mehr Autorität wird der Marke in den Themenbereichen zugesprochen. Man kann hier auch von thematischer Positionierung sprechen.
Gerade auch für die algorithmisch gestützte Identifikation von thematischen Autoritäten bzw. Brands wie z.B. bei Suchmaschinen wie Google sind Kookkurrenzen messbare und damit nützliche Signale.
Die emotionale Ebene
Die emotionale Ebene spielt im Marketing eine herausragende Rolle für Kaufentscheidungen. In unserem Podcast mit der Neuromarketing-Spezialistin Gesa Lischka spricht sie sogar davon, dass unsere Kauf- und Konsum-Entscheidungen bis zu 90% durch Emotionen bestimmt werden und die rationale Entscheidung eine dementsprechend kleine Rolle spielt.
Ich sehe das etwas differenzierter und würde nach dem Produkt bzw. der Dienstleistung unterscheiden wollen welchen Anteil die drei Ebenen jeweils an der Kaufentscheidung haben.
Die emotionale Ebene wird stark durch Erscheinung, Haptik und weitere audiovisuelle Eigenschaften des Touchpoints bestimmt. Ist allerdings auch eine sehr individuelle Wahrnehmung.
Die Beziehungs-Ebene
Die Nähe zu anderen Brands, sei es Unternehmen oder Personenmarken wie z.B. Influencer spielt eine wichtige Rolle beim Brand-Building. Die Beziehung zu anderen Marken stärkt das Vertrauen in die eigene Marke beim Nutzer. Es ist eine Bestätigung und stärkt die Beziehung bzw. Bindung. Damit ist diese Ebene ein Verstärker der Effekte, die aus den anderen Ebenen entstanden sind.
Auch Signale für die Beziehungs-Ebene können von Algorithmen für Identifikation einer Marke genutzt werden.
Aber auch die Beziehung zu Repräsentanten der Marke wie Servive- und Vertriebs-Mitarbeiter oder anderen menschlichen Kontaktpunkten beeinflussen die Customer Experience und damit die Wahrnehmung einer Marke.
Die funktionale Ebene
Die Nutzerfreundlichkeit und damit die User Experience auch als Customer Experience bezeichnet wird auch durch die Funktionalität eines möglichen Touchpoints beeinflusst. Eine herausragende funktionale UX bei der Nutzung einer Dienstleistung bzw. eines Produkts ist eine wichtige Vorraussetzung für die Kundenbindung.
Aber auch Touchpoints in der Pre-Purchase-Phase z.B. beim Ausfüllen eines Kontaktangebots, Zustandekommen eines ersten Beratungsgesprächs, Nutzung von Anwendungen und Content im Rahmen der Neukundenakquise wie z.B. die Erreichbarkeit. Mobilfreundlichkeit, Ladezeit einer Website sollten eine herausragende funktionale Nutzererfahrung bieten.
Merkmale und Kennzahlen einer Marke
Übertragen auf das Internet kann man Websites bzw. Domains als zentrales digitales Abbild einer Marke wichtige Merkmale zuordnen. Eine digitale Marke erkennt man daran, dass die Marken-Website im Vergleich zum Durchschnitt der anderen Websites im Themenbereich / Branche eine größere Popularität vorweist. Kennzahlen für eine überdurchschnittliche Popularität können z.B. folgende sein:
- Besucherzahlen
- Anzahl neuer Besucher
- Suchvolumen nach Markenbegriffen
- Suchvolumen navigationsorientierter Suchbegriffe bezogen auf die Domain und Marke
- Social-Spread, Social Buzz, Sichtbarkeit in sozialen Netzwerken
Eine weitere wichtige Eigenschaft von Marken als auch Autoritäten ist die Kundenbindung und Loyalität. Loyalitäts-Kennzahlen können sein:
- durchschnittliche Aufenthaltsdauer
- Absprungrate
- Anteil wiederkehrender Besucher
Die wohl wichtigste Eigenschaft einer Marke und Autoriät ist das entgegengebrachte Ansehen und Vertrauen, das man anhand folgender externer Reputations-Kennzahlen bewerten kann:
- Kookkurrenzen und Co-Citations
- Marken-Nennungen und Verlinkungen
Ein weiteres Anzeichen für Vertrauen in eine Marke bzw. Website sind Kennzahlen, die den Interaktionsgrad aufzeigen. Dafür können folgende Engagement-Kennzahlen herangezogen werden:
- Abschlussraten
- weitere Interaktionen mit der Website wie Downloads, Kommentare …
- Beziehung zu anderen Marken, Autoritäten und Influencern
- Anzahl Seitenaufrufe (Page Impressions)
Abschlussraten haben natürlich auch immer etwas mit Maßnahmen bei der Conversion- und Usability-Optimierung zu tun, aber Engagement hat auch immer etwas mit Vertrauen in eine Website und damit auch die Marke zu tun.
Tools und Methoden zur Messbarkeit des Markenaufbaus
Es gibt verschiedene Methoden den Erfolg des eigenen Markenaufbaus nachzuverfolgen. Insbesondere verschiedene Google-Tools geben einen guten Aufschluss darüber wie populär, thematisch positioniert und vernetzt eine Marke ist.
Google Trends
Über Google Trends lässt sich die Entwicklung der einer Marken-Nachfrage nachverfolgen. Hier zum Beispiel der Nachfrage-Verlauf nach den Automarken VW, Mercedes und Toyota in den letzten Jahren:
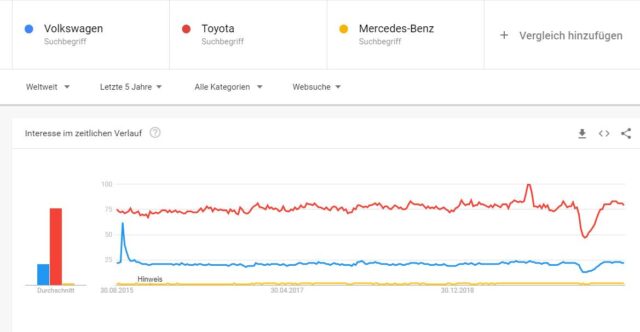
Google Trends eignet sich aber nur für Marken, die schon eine gewisse Popularität besitzen, da sonst keine Daten ausgegeben werden. Zudem ist es wichtig zu verstehen, dass sich Google Trends nicht als Tool zum direkten Wettbewerbsvergleich hinsichtlich der Popularität eignet, da die Y-Achse keine Vergleichsgröße darstellt. Mehr dazu in diesem Beitrag vom geschätzten Kollegen Tom Alby >>> 5 Gründe, warum Du Google Trends falsch verstehst.
Keyword Planer
Im Beitrag Warum E-A-T für das Ranking so wichtig ist und wie man E-A-T optimiert habe ich eine Methode erläutert wie man mit Hilfe des Keyword Planers die thematische Autorität einer Domain, also das digitale Abbild einer Marke ermitteln kann. Diese Methode ist nicht nur für SEOs interessant, sondern auch für Brand-Verantwortliche, da man erkennen kann in welchem thematischen Kontext die eigene Marke gegooglet wird bzw. mit welchen Begriffen die eigene Marke in Kookkurrenz gesucht wird.
Diese Methode lässt sich auch für den Wettbewerb durchführen.
Wenn man im Keyword-Planer über die Funktion „mit einer Website beginnen“ Keyword-Vorschläge abruft ergibt sich am Beispiel von zalando.de folgendes Bild:


Die Keyword sind nach einer durch Google undefinierten Relevanz sortiert. Überprüft man die ausgegebenen Keywords hinsichtlich dem Ranking wird klar, dass nahezu für alle dieser Keywords Zalando auf Top-Positionen rankt. Hier scheint eine thematische Autorität bzw. große Nähe zu bestimmten Themen und anderen Entitäten vorzuliegen.
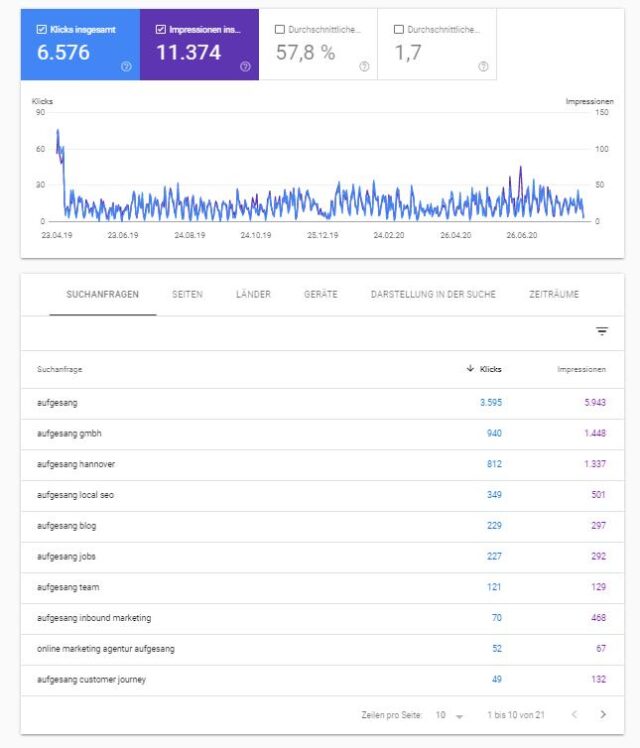
Google Search Console
Im Bericht „Leistung“ in der Search Console kann man sich maximal für die letzten 16 Monate die „Brand-Leistung“ im Zeitverlauf ansehen. Gerade mit Blick auf laufende oder gerade abgelaufene Branding-Kampagnen sehr spannend. Einfach den Bericht Leistung aufrufen, den gewünschten Zeitrahmen auswählen und als Suchanfrage die eigene Brand auswählen. Neben der Höhe des exakten Suchvolumens je Brand-Begriff in Form der Impressionen ist der zeitliche Verlauf spannend. Eine Marketing-Kampagne ,egal ob offline oder online, sollte hier Effekte zeigen.
Google Alerts
Über die Google Alerts lassen sich Brand-Nennungen online überwachen. Einfach einen Alert auf die eigene Brand anlegen und man wird per E-Mail informiert, sobald die eigene Marke genannt wird.
Media Monitoring Tools
Eine kostenpflichtige Alternative zu Google-Alerts sind Media-Monitoring-Tools. Da wir in unseren Beiträgen Test: 5 Mediamonitoring-Tools im Vergleich und Online-Media-Monitoring: Tools können mehr, als Kampagnen evaluieren genauer darauf eingegangen sind möchte ich an dieser Stelle bei diesem Verweis belassen.
Google Analytics
Um das Engagement mit den Touchpoints auf der eigenen Website messen zu können eignen sich Web-Analyse-Tools wie Google Analytics. Am Ende diesen Beitrags findest Du ein kostenloses von mir erstelltest Google-Analytics-Dashboard zur freien Verwendung, das ich bei Zeiten aktualisieren werde.
Verwandte Suchanfragen bei Google und Google Suggest
Die verwandten Suchanfragen bei Google und Google-Suggest eignen sich dafür ähnlich wie der Keyword-Planer die thematischen Kookkurrenzen mit der eigenen Brand im Auge zu behalten. So geben die verwandten Suchanfragen zu meiner Personenmarke einen realitätsnahes Abbild zu meiner Positionierung wieder. Man findet diese am Ende der ersten Suchergebnisseite bzw. beim Eintippen einer Suchanfrage.
Das Auflösen der Silos für konsistent herausragende Touchpoint für das Branding
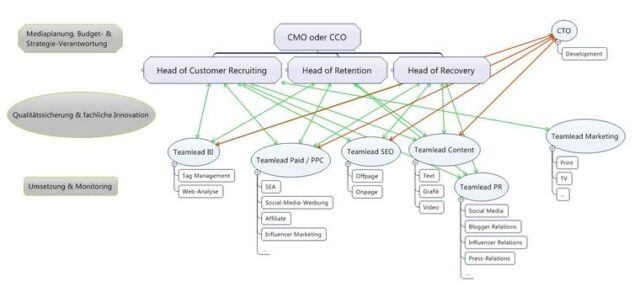
Wie in dem Beitrag Marketing wir haben ein Problem! Silos und fehlende Schnittstellen verhindern moderne Unternehmenskommunikation verhindern Silos in den meisten Unternehmen immer noch die konsistente Gestaltung und Verknüpfung der Touchpoints im Sinne des Brandings. So fallen Touchpoint hinsichtlich emotionalen, funktionale und thematischen Ebene häufig als auch der Nutzererfahrung unterschiedlich aus und verhindern die Wahrnehmung eines einheitlich positiven Markenbilds.
Unternehmen brauchen Strukturen, die es ermöglichen zumindest die wichtigsten Touchpoints innerhalb der Customer-Journey konsistent zu gestalten und miteinander sinnvoll zu verknüpfen.
So können die Customer-Journey-Phasen auch bei der Struktuierung eines Unternehmens als Grundlage dienen. So können die Fachabteilungen in der Hierarchie unterhalb einer Führung gemäß der einzelnen Customer-Journey-Phasen einsortiert werden.
Nutzerzentrierung in der Strukturierung des Marketings, © Michael Singer
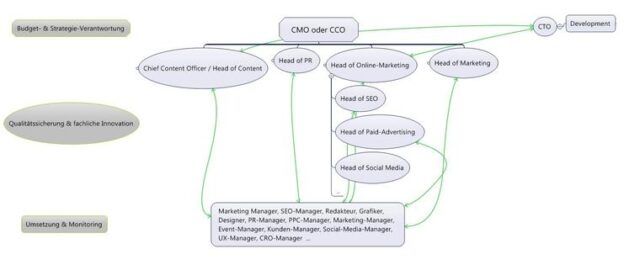
Oder sorgt für eine Auflösung der Silos in der Umsetzungs-Ebene und die Zusammenarbeit bei der Gestaltung der Touchpoints besser zu ermöglichen.
Auflösung der Silos im Marketing auf der Umsetzungs-Ebene, © Olaf Kopp
Digitaler Markenaufbau entlang der Customer-Journey im Zentrum des modernen (Online-)Marketings
Ich bin mir sicher, dass Markenaufbau bzw. Branding das zentrale Thema im Online Marketing ist. Der wichtigste Erfolgsfaktor für ein Unternehmen ist die positive Wahrnehmung der Marke offline und online, sowohl bei den Zielgruppen als auch bei den wichtigsten digitalen Gatekeepern und deren Bewertungs-Algorithmen.
In erster Linie funktioniert heute der Aufbau einer digitalen Marke bzw. Online-Branding nicht mehr wie früher über reichweitenorientierte Push Werbung. Push-Werbung schafft es nur noch bedingt echte Beziehungen aufzubauen.
Die „Marken-Awareness“ über diese Marketing-Form hat besonders im Internet stark nachgelassen.
Beziehungsaufbauende und stärkende Touchpoints entlang der Customer-Journey bzw. User-Journey sind vor allem Touchpoints wie Content, der Kontakt mit Mitarbeitern in Vertrieb, Service … und die Nutzererfahrung mit dem Angebot/Produkt. Push-Werbung kann im richtigen zeitlichen und örtlichen Kontext unterstützen. Hier hilft die Customer-Journey als zentrales strategisches Modell diese Touchpoints zu verorten.
Diese erfolgskritischen Touchpoints werden am besten initial je Zielgruppe in Customer-Journey-Management-Workshops entwickelt. Hierzu hat mein Kollege Ulf Hendrik Schrader einen Beitrag zu veröffentlicht >>> In 4 Schritten zu einem integrierten Online-Marketing entlang der Customer-Journey
Der Aufbau einer digitalen Marke wird kritischer Erfolgsfaktor und rückt auch in das Zentrum des Online Marketings, wo bisher alleinig das Performance-Marketing stand.
Weitere Quellen von mir zum Thema digitaler Markenaufbau
Der Beitrag Digitaler Markenaufbau: Das Zusammenspiel aus (Online-)Branding & Customer Experience erschien zuerst auf Aufgesang.
Google Helpful Content: Was wirklich wichtig ist! 13 Jul 2024 5:17 AM (9 months ago)
Seit dem ersten Helpful Content Update in 2022 macht sich die SEO-Welt Gedanken darüber wie man „hilfreiche Inhalte“ erstellen oder ihn dahingehend optimieren kann. Es werden Hypothesen aufgestellt, Analysen, Checklisten und Audits erstellt. Ich blicke auf die meisten dieser Ansätze mit etwas Skepzis, da die Analyse-Erkenntnisse oft den Fokus auf die Eigenschaften des Contents selbst haben und aus der Sicht eines Menschen und nicht einer Maschine bzw. Algorithmen hergeleitet werden. Google ist eine Maschine, kein Mensch!
Mein SEO-Mantra ist: „Think like an engineer, act like a human.“
Deswegen nähere ich mich in diesem Artikel dem Thema Helpful Content mit der Frage: Wie Google helpful content algorithmisch identifizieren kann und was sinnvoll ist.
Helpful Content, was ist das überhaupt?
Helpful Content ist eine Terminologie, die Google im Rahmen des ersten Hepful Content Updates im August 2022 eingeführt hat. Zuerst hatte Google angekündigt, dass es sich beim Helpful Content System, um einen „sitewide Classifier“ handelt. Später wurde bekannt, dass es auch für die Bewertung von einzelnen Dokumenten genutzt wird.
Our helpful content system is designed to better ensure people see original, helpful content written by people, for people, in search results, rather than content made primarily to gain search engine traffic.
Unsere zentralen Ranking-Systeme sind in erster Linie für den Einsatz auf Seitenebene konzipiert. Anhand verschiedener Signale und Systeme wird die Nützlichkeit der einzelnen Seiten ermittelt. Es gibt auch einige websiteweite Signale, die ebenfalls berücksichtigt werden.
Ich habe mich bereits im Rahmen des ersten Helpful Content Updates dazu geäußert, dass dieses Update nicht nur aufgrund des bedeutungschwangeren Titels vor allem ein PR-Update war. Meine Herleitung und Kritik kann man hier im Detail nachlesen.
Ein PR-Ziel von Google ist es Website-Betreiber dazu zu animieren Crawling, Indexierung und damit die Bewertung einfacher zu machen. Das war zumindest das Ziel der größten Updates wie z.B. die Umstellung auf Page Speed Update, Page Experience Update, Spam Update … Diese Updates haben eins gemeinsam. Sie implizieren durch den vielsagenden konkreten Titel eine Handlungsempfehlung und helfen damit Google beim Information Retrieval.
Ich hätte das Helpful Content System eher „User Satisfaction System“ genannt. Aber dazu später mehr.
Was ist hilfreich?
Um diese Frage zu beantworten, sollte man sich etwas mit den Information-Retrieval-Begriffen Relevanz, Pertinenz und Nützlichkeit beschäftigen. Wie in meinem Artikel „Relevanz, Pertinenz und Qualität bei Suchmaschinen“ beschrieben sind diese Begriffe wie folgt beschrieben:
Relevant ist etwas für Suchmaschinen wenn ein Dokument bzw. Inhalt in Bezug auf die Suchanfrage bedeutsam ist. Die Suchanfrage beschreibt die Situation und den Zusammenhang. Diese Relevanz ermittelt Google über Methodiken der Textanalyse, wie z.B. BM25, WDF*IDF bzw. TF-IDF, Word2Vec …
Pertinenz beschreibt die subjektive Bedeutsamkeit eines Dokuments für den Nutzer. Das bedeutet neben dem Match mit der Suchanfrage kommt eine subjektive Nutzerebene dazu.
Nützlichkeit schränkt neben den Bedingungen für Relevanz und Pertinenz die Ebene der Neuartigkeit mit ein.
Pertinenz und Nützlichkeit sind für mich die beiden Ebene, die für helpfulness stehen.
Objektive Relevanz an sich ist nicht wirklich hilfreich, da jeder Nutzer unterschiedliche Absichten, Wissensstände … hat. Für eine Suchmaschine gilt es herauszufinden, welche Inhalte Nutzer als hilfreich und nützlich empfinden. Daher ist der fokussierte Blick auf die Nutzer-Interaktion bzw. das Nutzerverhalten im ersten Schritt sinnvoller, anstatt die Beschaffenheit eines Inhalts zu bewerten.
Wie kann man algorithmisch helpfullness bzw. Pertinenz und Nützlichkeit messen?
Die Pertinenz und Nützlichkeit lässt sich über die Zufriedenheit der Nutzer mit dem Inhalts ermitteln. Die beste Methode, um die Zufriedenheit von Nutzern festzustellen ist die Messung und Interpretation des Nutzerverhaltens. Das gibt neben der Relevanz des Inhalts zur Suchanfrage einen besseren Aufschluss darüber, ob Nutzer einen Inhalt im jeweiligen Kontext wirklich hilfreich finden. Die Analyse von Dokumenten oder Inhalts-Eigenschaften sagt nur bedingt etwas darüber aus wie hilfreich ein Inhalt ein Suchergebnis ist, da der Nutzer hier nicht berücksichtigt wird.
Hierfür gibt es verschiedene mögliche Metriken, die aus dem Google API Leak hervorgehen:
- CTR (Click-Through Rate)
ctrWeightedImpressions: This attribute tracks the weighted impressions for calculating CTR.- Source: GoogleApi.ContentWarehouse.V1.Model.IndexingSignalAggregatorAdaptiveIntervalData
- Good Clicks
goodClicks: This attribute tracks the number of good clicks.lastGoodClickDateInDays: Indicates the date when the document received the last good click.- Source: GoogleApi.ContentWarehouse.V1.Model.QualityNavboostCrapsCrapsClickSignals
- Bad Clicks
badClicks: This attribute tracks the number of bad clicks.- Source: GoogleApi.ContentWarehouse.V1.Model.QualityNavboostCrapsCrapsClickSignals
- Long Clicks
lastLongestClicks: This attribute tracks the number of clicks that were the last and longest in related user queries.- Source: GoogleApi.ContentWarehouse.V1.Model.QualityNavboostCrapsCrapsClickSignals
- Short Clicks
- While there isn’t a direct attribute named „short clicks,“ the absence of long clicks or a high number of bad clicks could imply shorter interactions.
- Source: GoogleApi.ContentWarehouse.V1.Model.QualityNavboostCrapsCrapsClickSignals
Quelle: Google API Leak Analyzer
Weitere Faktoren, die ich aus Google Patenten recherchiert habe sind:
-
Click-Through Rate (CTR):
- Search Result Interaction: The percentage of users who click on a website link when it appears in search results.
- Ad Performance: CTR for advertisements displayed on the site.
-
Dwell Time:
- Average Time on Site: The average time users spend on the page after clicking a search result.
- Bounce Rate: The percentage of visitors who leave the site after viewing only one page.
-
Good Clicks and Bad Clicks:
- User Engagement Metrics: Metrics like page interactions (likes, shares, comments), bounce rates, and return visits.
- Viewing Time: Longer views are given higher relevance, indicating good clicks, while shorter views are given lower relevance, indicating bad clicks.
-
Long Clicks and Short Clicks:
-
Viewing Length: Measures the duration of time users spend viewing each document. Longer views (long clicks) are considered more relevant.
-
Weighting Functions: Applies continuous and discontinuous weighting functions to adjust relevance scores based on viewing time.
-
Patente:
-
-
- „Ranking Factors or Scoring Criteria“
- „Increased Importance of User Engagement Metrics“
- „User Engagement as a Ranking Factor“
-
Quelle: Database Research Assistant
Die Nützlichkeit lässt sich durch Suchmaschinen zusätzlich über einen Information Gain Score ermitteln.
Der Information Gain bzw. Informationsgewinn bezieht sich auf einen Score, der angibt, wie viele zusätzliche Informationen ein Dokument über die üblichen Informationen hinaus enthält, die in den von einem Nutzer zuvor angesehenen Dokumenten enthalten sind.
Dieser Wert hilft bei der Bestimmung, wie viele neue Informationen ein Dokument dem Benutzer im Vergleich zu dem, was der Benutzer bereits gesehen hat, bietet.
Mehr zum Information Gain findest du im Artikel Information Gain: Wie wird er berechnet? Welche Faktoren sind entscheidend?
Identifikation von hilfreichen Dokumenten-Eigenschaften, anhand der Nutzersignale
Eine weitere Möglichkeit ist über positive Nutzersignale in statistisch valider Menge vermeintliche Dokumenten-Eigenschaften oder Dokumenten-Muster zu identifzieren, die für Nutzer hilfreich sein könnten.
In dem Google Patent „Ranking Search Result Documents“ wird eine Methodik beschrieben, die aufgrund der vergangenen Nutzer-Interaktionen u.a. Eigenschaften der Suchanfragen mit Dokumenten Eigenschaften abgleicht.

Diese Methode würde allerdings viel Rechner-Ressourcen kosten. Zudem hätte eine solche Methodik immer einen größeren Zeitversatz zur Folge bis die Ergebnisse aussagekräftig sind.
Das Zusammenspiel aus initialen Ranking und Reranking
Um zu verstehen an welcher Stelle des Ranking Prozess helpful content ermittel wird ein kurzer Exkurs in Teile des Information Retrieval Prozess.

Im Ranking-Prozess gibt es drei Schritte:
- Dokumenten Scoring
- Quality Classification
- Reranking
Das Dokumenten Scoring ist für das initiale Ranking der Top-n Dokumente zuständig. Hier wird ein sogenannter Ascorer genutzt, um IR-Scores zu errechnen. Wie hoch das das n ist nur zu vermuten. Ich gehe hier aus Performance-Gründen von maximal wenigen hunderten Dokumenten aus.
Bei der Quality Classification spielen vor allem Signale mit Bezug zu E-E-A-T eine Rolle. Hier wird die Beschaffenheit der einzelnen Dokumente nicht bewertet, sondern seitenweite Klassifikatoren eingesetzt.
Beim Reranking werden sogenannte Twiddler eingesetzt.
Twiddlers are components within Google’s Superroot system designed to re-rank search results from a single corpus. They operate on ranked sequences rather than isolated results, making adjustments to the initial ranking provided by Ascorer. There are two types of Twiddlers: Predoc and Lazy.
- Predoc Twiddlers:
- Operation: Run on thin responses (initial search results with minimal information).
- Functions: Modify IR scores, reorder results, and perform remote procedure calls (RPCs).
- Use Case: Suitable for broad, initial adjustments and promoting results based on preliminary data.
- Lazy Twiddlers:
- Operation: Run on fat results (detailed document information).
- Functions: Reorder and filter results based on detailed content analysis.
- Use Case: Ideal for fine-tuning and filtering based on specific content attributes.
For more detailed information, you can refer to the „Twiddler Quick Start Guide“ here.
Quelle: Database Research Assistant
Diese Twiddler können laut dem API-Leak neben der Dokumenten-Ebene auch für die Bewertung auf Domain-Ebene genutzt werden.
Twiddlers are used in Google’s ranking and indexing processes to adjust the relevance and ranking of documents. They are essentially factors or signals that can be „twiddled“ or adjusted to fine-tune the search results. Here are some key points about twiddlers based on the provided documents:
-
-
Domain Classification:
- Twiddlers can be used to classify the domain of a document, which helps in understanding the context and relevance of the content.
- Source: „qualityTwiddlerDomainClassification“ – Google-Leak_API-Module_zusammengefasst
-
Spam Detection:
- Twiddlers play a role in identifying and mitigating spam. They can adjust the ranking of documents that are flagged by spam detection algorithms.
- Source: „spamBrainSpamBrainData“ – Google-Leak_API-Module_zusammengefasst
-
Content Quality:
- Twiddlers can influence the perceived quality of content by adjusting scores based on various quality signals.
- Source: „commonsenseScoredCompoundReferenceAnnotation“ – Google-Leak_API-Module_zusammengefasst
-
Shopping and Ads:
-
For e-commerce and shopping-related queries, twiddlers can adjust the relevance of shopping annotations and ads.
-
Source: „adsShoppingWebpxRawShoppingAnnotation“ – Google-Leak_API-Module_zusammengefasst
-
-
Quelle: Google API Leak Analyzer
Die Twiddler sind ein Teil von Googles Superroot für ein nachgelagerte Qualitätsbewertung im Sinne von u.a. auch helpfullness auf einer Dokumenten- und Domain-Ebene verantwortlich.
Quelle: Interne Google Präsentation „Ranking for Research“, November 2018
Für die Bewertung hinsichtlich Helpful Content machen objektive Rankingfaktoren, ausser Information Gain, keinen Sinn, da sie nicht den Nutzer im Fokus haben. Diese Faktoren werden vor allem beim initialen Ranking über den Ascorer berücksichtig.

Es macht Sinn, dass Google Helpful Content vor allem anhand der verschiedenen möglichen Nutzersignalen und einem Information Gain Score bewertet, der aber auch sehr personalisiert Nutzer individuell bewertet werden kann.
Helpful Content hat eine Korrelation mit dem Content, ist aber kausal zu den Nutzersignalen
Wie eingangs erwähnt bin ich skeptisch, was viele Analysen und Checklisten hinsichtlich Helpful Content angeht, weil ich denke, dass Google helpfullness vor allem aufgrund von Nutzersignalen bewertet und nicht aufgrund von Dokumenten-Eigenschaften. Sprich eine Analyse einzelner Inhalte hinsichtlich helpfullness ohne Einblick in Nutzerdaten zu haben halte ich für nur bedingt aussagekräftig.
Natürlich möchte man mit der Optimierung von Inhalten die Nutzersignale verbessern, aber am Schluss entscheidet der Nutzer, ob er/sie einen Inhalt hilfreich findet oder nicht und nicht der SEO, der bestimmte Eigenschaften eines Dokuments gemäß einer Checkliste optimiert.
Zudem ist die Entscheidung des Nutzers, ob er/sie einen Inhalt hilfreich findet abhängig von Thema und Kontext. Sprich die Empfehlungen zur Optimierung sind auch immer davon abhängig.
Es kann Korrelationen zwischen Dokumenten Eigenschaften zu Helpful Content geben, aber am Schluss besteht die Kausalität zu den Nutzersignalen.
Mit anderen Worten: Wenn man ein Content optimiert und sich die Nutzersignale nicht verbessern, wird dieser auch nicht hilfreicher. Google muss erst anhand der Nutzersignale lernen was hilfreich ist.

Interne Google Präsentation „Google is magical“, Oktober 2017
Diese These wird untermauert durch die Erkenntnnisse, die man aus dem Antitrust-Verfahren gegen Google ziehen konnte. Demnach ist das Verständnis / Qualität eines Inhalts nur aufgrund des Dokuments selbst nur bedingt abzuleiten.

Quelle: Interne Google Präsentation „Ranking for Research“ von November 2018
Der Wunsch nach einer Blaupause am besten in Form von Checklisten ist in der SEO-Branche groß. Deswegen bekommen sie auch immer große Aufmerksamkeit und sind populär. Sie hängen der Zeit aber hinterher, da sich das Bedürfnis und damit die helpfullness eines Inhalts je Suchanfrage sehr dynamisch sein kann.
Auch der Wunsch nach Klarheit,was z.B. Google Updates und mögliche Gründe für eine Abstrafung angeht ist groß. Deswegen sind Analysen der Google Updates auch sehr beliebt.
Aber wenn der Content King ist, sind Nutzersignale Queen und sie bestimmen am Schluss für wie hilfreich ein Inhalt von Google bewertet wird. Da die meisten Analysen hinsichtlich Core Updates und Helpful Content sich an den Eigenschaften von Dokumenten und Domains orientieren stellen sie maximal Korrelationen dar, aber keine Kausalitäten dar.
Eine Theorie wie z.B. Google wertet Websites wegen Affiliates-Links ab oder weil sie nicht die richtigen Entitäten oder Keywords erwähnen ist nicht sinnvoll. Google wertet Websites ab, weil die Nutzersignale nicht entsprechend sind und sie keinen Information Gain bieten, somit nicht den Nutzerbedürfnissen entsprechen und damit für viele Nutzer nicht hilfreich sind. Google wertet Seiten im Reranking nicht ab wegen bestimmter Dokumenten-Eigenschaften.
Für mich ist das Helpful Content System eher ein Rahmen, der alle genutzten Nutzersignale und darauf basierenden Bewertungssysteme zusammenfasst. Deswegen würde ich es eher „User Satisfaction System“ nennen.
Was ist Deine Meinung? Lass uns diskutieren!
Der Beitrag Google Helpful Content: Was wirklich wichtig ist! erschien zuerst auf Aufgesang.
Information Gain: Wie wird er berechnet? Welche Faktoren sind entscheidend? 12 Jul 2024 3:30 AM (9 months ago)
Information Gain ist einer der spannendsten Rankingfaktoren für moderne Suchmaschinen und damit SEO. Vielen Erklärungen zum Information Gain mangelt es an technologischer Tiefe und es fehlen Ansätze zur Optimierung des Information Gain.
Dieser Artikel soll einen tiefen Überblick über das Konzept, die Berechnung und SEO-Ansätze zur Optimierung auf Information Gain geben. Auch die Verbindung zum Phrase Based Indexing wird erläutert.
Diese Insights zum Information Gain basieren auf grundlegenden Kenntnissen der interessantesten Google-Patente zum Thema Information Gain.
Was versteht man unter Information Gain im Zusammenhang mit Information Retrieval und Suchmaschinen?
Der Information Gain bzw. Informationsgewinn bezieht sich auf einen Score, der angibt, wie viele zusätzliche Informationen ein Dokument über die üblichen Informationen hinaus enthält, die in den von einem Nutzer zuvor angesehenen Dokumenten enthalten sind.
Dieser Wert hilft bei der Bestimmung, wie viele neue Informationen ein Dokument dem Benutzer im Vergleich zu dem, was der Benutzer bereits gesehen hat, bietet.
Bei diesen Methoden werden die Daten aus den Dokumenten auf ein maschinelles Lernmodell angewendet, um eine Bewertung des Informationsgewinns zu generieren, die dazu beiträgt, dem Benutzer Dokumente so zu präsentieren, dass diejenigen mit einer höheren Bewertung der neuen Informationen bevorzugt werden.
Beim Information Retrieval und bei Suchmaschinen wird der Informationsgewinn verwendet, um die Relevanz und Effektivität von Dokumenten oder Begriffen zu bewerten, um die Ungewissheit über den Informationsbedarf der Nutzer zu verringern. Er hilft bei der Einstufung von Dokumenten und bei der Verbesserung des Sucherlebnisses insgesamt.
Ein größerer Informationsgewinn deutet auf eine Gruppe oder Gruppen von Stichproben mit geringerer Entropie und damit auf eine geringere (negative) Überraschung hin.

Welche Rolle spielt die Entropie beim Information Gain?
Die Entropie spielt eine entscheidende Rolle beim Informationsgewinn im Rahmen des Entscheidungsbaumlernens. Genauer gesagt ist die Entropie ein Maß für die Unreinheit oder Unsicherheit in einem Datensatz. Bei der Erstellung von Entscheidungsbäumen wird der Informationsgewinn verwendet, um zu bestimmen, welches Attribut die Daten am besten in verschiedene Klassen unterteilt. Der Informationsgewinn wird als die Verringerung der Entropie berechnet, die sich aus der Partitionierung der Daten auf der Grundlage eines bestimmten Attributs ergibt.
- Entropie: Misst die Unreinheit oder Zufälligkeit in Daten.
- Hohe Entropie: Die Daten sind sehr gemischt und die Klassen sind ungleichmäßig verteilt.
- Geringe Entropie: Die Daten sind einheitlicher und die Klassen sind gleichmäßig verteilt.
- Die Werte der maximalen Entropie ändern sich mit der Anzahl der Klassen (z. B. 2 Klassen: maximale Entropie ist 1, 4 Klassen: maximale Entropie ist 2).
- Hohe Entropie: Die Daten sind sehr gemischt und die Klassen sind ungleichmäßig verteilt.
Der Prozess der Ermittlung eines Information Gain Scores
Die Ermittlung einer Informationsbewertung kann in folgenden Schritten erfolgen:
- Identifizieren Sie bereits präsentierte Dokumente: Das System identifiziert eine Reihe von Dokumenten, die ein gemeinsames Thema haben und dem Benutzer bereits präsentiert wurden.
- Identifizierung neuer Dokumente: Anschließend werden neue Dokumente identifiziert, die dasselbe Thema haben, dem Benutzer aber noch nicht vorgelegt wurden.
- Bestimmen des Informationsgewinns: Für jedes neue Dokument wird ein Informationsgewinn-Score berechnet. Dieser Wert spiegelt die Menge an neuen Informationen in dem Dokument wider, die in den zuvor präsentierten Dokumenten nicht enthalten sind.
- Auswahl und Präsentation der Dokumente: Die Dokumente werden auf der Grundlage ihrer Informationsgewinnbewertung ausgewählt und dem Benutzer präsentiert. Die Auswahl und Präsentation kann in einer Rangfolge erfolgen, wobei die Dokumente mit höherem Informationsgewinn Vorrang haben.
- Verwendung in automatischen Assistenten: Der automatisierte Assistent kann diese Bewertungen nutzen, um dem Benutzer während einer interaktiven Sitzung effizientere, relevantere und nicht redundante Informationen zu liefern und so das allgemeine Benutzererlebnis zu verbessern.
- Anwendung des maschinellen Lernens: Der Informationsgewinn kann mithilfe eines maschinellen Lernmodells ermittelt werden, das semantische Darstellungen der Dokumente verarbeitet, um neue Informationen zu identifizieren.

Eine Suchschnittstelle zeigt Verweise auf Dokumente an, die nach ihrem Informationsgewinn geordnet sind. Über diese Schnittstelle kann der Benutzer Dokumente auswählen und aufrufen, von denen angenommen wird, dass sie die meisten zusätzlichen Informationen liefern, die der Benutzer noch nicht erhalten hat.

Abb. 4 zeigt eine Reihe von Dokumenten, die danach kategorisiert sind, ob der Benutzer sie angesehen hat oder nicht. Zu Beginn befinden sich alle Dokumente in einem ungesehenen Zustand. Wenn der Benutzer ein Dokument ansieht, wechselt es von der Gruppe der ungesehenen in die Gruppe der angesehenen Dokumente. Diese Klassifizierung ist dynamisch und wird aktualisiert, wenn der Benutzer mit weiteren Dokumenten interagiert.
Wie wird das maschinelle Lernmodell zur Ermittlung des Informationsgewinns trainiert?
Das maschinelle Lernmodell wird so trainiert, dass es einen Informationsgewinn erkennt, indem es zunächst eine Reihe von Dokumenten sammelt, die der Nutzer bereits angesehen hat. Diese Dokumente, die als erste Gruppe bezeichnet werden, haben ein gemeinsames Thema. Eine zweite Gruppe von Dokumenten, die noch nicht vom Benutzer angesehen wurden, aber dasselbe Thema haben, wird identifiziert. Um den Informationsgewinn für diese ungesehenen Dokumente zu ermitteln, werden Daten, die für die Dokumente kennzeichnend sind (z. B. ihr Inhalt, hervorstechende extrahierte Informationen oder semantische Darstellungen), sowohl aus der ersten als auch aus der zweiten Menge als Input für ein trainiertes maschinelles Lernmodell bereitgestellt.
Wie unterscheidet das maschinelle Lernmodell zwischen neuen und alten Informationen?
Das maschinelle Lernmodell unterscheidet zwischen neuen und alten Informationen durch einen Prozess, der die Erstellung eines Informationsgewinn-Scores für jedes Dokument beinhaltet. Der Informationsgewinn-Score misst die Menge an neuen Informationen, die ein Dokument im Vergleich zu den Dokumenten bietet, die der Nutzer bereits angesehen hat. Im Folgenden wird die Funktionsweise im Detail erläutert:
- Identifizierung der Dokumente: Das Modell identifiziert zunächst eine Menge von Dokumenten, die der Benutzer bereits angesehen hat (erste Menge), und eine weitere Menge von Dokumenten, die noch nicht angesehen wurden, aber zum selben Thema gehören (zweite Menge).
- Merkmalsextraktion: Für beide Dokumentensätze extrahiert das Modell Datenmerkmale wie den gesamten Inhalt, hervorstechende Informationen, semantische Repräsentationen (wie Einbettungen oder Merkmalsvektoren) usw.
-
- Gesamter Inhalt: Dies beinhaltet eine vollständige Inhaltsanalyse des Dokuments.
- Hervorstechende extrahierte Informationen: Die wichtigsten Informationen, die aus dem Dokument extrahiert wurden.
- Semantische Repräsentationen: Einschließlich Einbettungen, Merkmalsvektoren, Bag-of-Words-Darstellungen und Histogramme, die aus Wörtern/Phrasen im Dokument generiert werden.
- Gesamter Inhalt: Dies beinhaltet eine vollständige Inhaltsanalyse des Dokuments.
Für welche Bereiche könnte Information Gain in Suchmaschinen genutzt werden?
Informationsgewinn spielt in mehreren Bereichen von Suchmaschinen eine entscheidende Rolle, um das Auffinden und die Einstufung relevanter Dokumente zu verbessern. Hier sind die wichtigsten Bereiche, in denen Informationsgewinn genutzt wird:
Informationsgewinn kann in Suchmaschinen für verschiedene Schlüsselbereiche genutzt werden:
- Ranking von Suchergebnissen: Der Informationsgewinn kann dazu beitragen, die Suchergebnisse in eine Rangfolge zu bringen, indem bewertet wird, wie viele neue oder zusätzliche Informationen ein Dokument im Vergleich zu bereits angesehenen Dokumenten bietet. Dadurch werden die Suchergebnisse für den Benutzer relevanter und informativer.
- Redundante Informationen herausfiltern: Durch die Identifizierung und Förderung von Dokumenten mit hohem Informationsgewinn können Suchmaschinen überflüssige Dokumente herausfiltern. Dies trägt dazu bei, dem Nutzer vielfältigere und umfassendere Informationen zu präsentieren.
- Personalisierung von Empfehlungen: Der Informationsgewinn kann zur Personalisierung von Suchergebnissen auf der Grundlage früherer Interaktionen des Nutzers genutzt werden, um sicherzustellen, dass neu präsentierte Dokumente einen Mehrwert bieten und Wissen vermitteln, anstatt zu wiederholen, was der Nutzer bereits gesehen hat.
Beispiele für die Verwendung des Information Gain
Das Konzept des Informationsgewinns kann in verschiedenen Arten von Suchmaschinen und Empfehlungsmaschinen verwendet werden.
Die Bewertung des Informationsgewinns hilft bei der Identifizierung und Präsentation von Dokumenten, die das Wissen des Benutzers zu einem bestimmten Thema wahrscheinlich erweitern.
Wenn ein Benutzer beispielsweise ein Computerproblem behebt, könnten Dokumente, die der Benutzer zuvor angesehen hat, gängige Softwarelösungen abdecken. Neue Dokumente würden danach bewertet werden, wie viele zusätzliche, einzigartige Informationen sie enthalten. Ein Dokument, in dem die Behebung von Hardwareproblemen beschrieben wird, könnte eine höhere Punktzahl erhalten, wenn dieser Inhalt zuvor noch nicht behandelt wurde. Ziel ist es, die Dokumente auf der Grundlage ihres Potenzials, neue, wertvolle Informationen zu liefern, zu bewerten und zu präsentieren und so Redundanzen zu vermeiden und die Benutzerfreundlichkeit zu verbessern.

Eine automatische Assistentenschnittstelle zeigt eine Dialogsitzung zwischen einem Benutzer und dem Assistenten an. Die Schnittstelle zeigt Gesprächsabschnitte an, in denen der Assistent Informationen aus Dokumenten entsprechend ihrer Informationsgewinne präsentiert und so die Benutzerinteraktion verbessert.
Wie hängen der Information Gain mit Phrase based Indexing zusammen?
Der Informationsgewinn ist eng mit der phrasenbasierten Indexierung in Suchmaschinen verbunden, da beide Konzepte darauf abzielen, die Relevanz und Genauigkeit der Suchergebnisse zu verbessern.
Phrasenbasierte Indexierung (Phrase based indexing)
Die phrasenbasierte Indexierung ist eine Technik, die von Suchmaschinen verwendet wird, um das Auffinden relevanter Dokumente zu verbessern, indem Phrasen statt einzelner Wörter indexiert werden. Diese Methode hilft dabei, den Kontext und die Semantik von Benutzeranfragen genauer zu verstehen. Die wichtigsten Aspekte sind:
- Erkennung von Phrasen:
- Identifizierung und Indizierung allgemeiner Phrasen und Mehrwortausdrücke in Dokumenten.
- Phrasen sind informativer als einzelne Wörter, da sie den Kontext und die Bedeutung besser erfassen.
- Identifizierung und Indizierung allgemeiner Phrasen und Mehrwortausdrücke in Dokumenten.
- Gewichtung von Phrasen:
- Gewichtung von Phrasen auf der Grundlage ihrer Bedeutung und Häufigkeit.
- Häufig verwendete und hoch relevante Phrasen werden bei der Indexierung höher gewichtet.
- Gewichtung von Phrasen auf der Grundlage ihrer Bedeutung und Häufigkeit.
- Kontextbezogenes Verstehen:
- Durch die Konzentration auf Phrasen können Suchmaschinen den Kontext einer Suchanfrage besser verstehen, was zu relevanteren Suchergebnissen führt.
- Phrasen helfen bei der Unterscheidung zwischen verschiedenen Bedeutungen desselben Wortes in verschiedenen Kontexten.
- Durch die Konzentration auf Phrasen können Suchmaschinen den Kontext einer Suchanfrage besser verstehen, was zu relevanteren Suchergebnissen führt.
Verbindung zwischen Information Gain und phrasenbasierter Indexierung
Informationsgewinn und phrasenbasierte Indizierung sind bei der Verbesserung der Relevanz und Effektivität von Suchmaschinen eng miteinander verknüpft. Im Folgenden wird anhand der Dokumente erläutert, wie sie zusammenhängen:
1. Identifizierung guter Phrasen mit Hilfe des Informationsgewinns
Der Informationsgewinn wird als prädiktives Maß verwendet, um gute Phrasen aus einem großen Korpus zu identifizieren. Eine Phrase gilt als gut, wenn sie häufiger mit anderen signifikanten Phrasen vorkommt, als dies zufällig zu erwarten wäre. Dies hilft bei der Erstellung einer verfeinerten Liste von Phrasen, die wirklich relevant und nützlich sind.
- Kookkurrenzen und Vorhersage: Für jeden Satz berechnet das System die erwartete Häufigkeit des gemeinsamen Auftretens mit anderen Sätzen und vergleicht sie mit der tatsächlichen Häufigkeit des gemeinsamen Auftretens. Wenn die tatsächliche Rate einen Schwellenwert übersteigt, wird davon ausgegangen, dass die Phrase einen signifikanten Informationsgewinn aufweist, und sie wird in der Liste der guten Phrasen beibehalten.
- Schwellenwerte: In der Regel wird ein Schwellenwert für den Informationsgewinn zwischen 1,1 und 1,7 verwendet, um unverbundene Phrasen herauszufiltern und sicherzustellen, dass nur sinnvolle Verbindungen erhalten bleiben.
2. Pruning und Clustering auf der Grundlage des Informationsgewinns
Cluster von verwandten Phrasen werden auf der Grundlage hoher Informationsgewinnwerte identifiziert. Die Phrasen innerhalb eines Clusters sind miteinander verwandt und weisen signifikante Informationsbeziehungen auf. Nach der Identifizierung guter Phrasen verfeinert das System die Liste weiter, indem es Phrasen entfernt, die keine anderen guten Phrasen vorhersagen oder lediglich Erweiterungen anderer Phrasen sind.
- Ausschneiden unvollständiger Phrasen: Unvollständige Phrasen, die nur ihre Erweiterungen vorhersagen, werden entfernt, um sicherzustellen, dass nur Phrasen übrig bleiben, die einen wesentlichen Informationsgewinn bieten. Zum Beispiel würde „Präsident von“ entfernt werden, wenn es keine anderen eindeutigen Phrasen jenseits seiner Erweiterungen wie „Präsident der Vereinigten Staaten“ vorhersagt.
- Clustering verwandter Phrasen: Phrasen werden auf der Grundlage eines hohen Informationsgewinns zwischen ihnen geclustert. Dies hilft bei der Bildung semantisch sinnvoller Gruppen von Phrasen, die häufig zusammen verwendet werden, und verbessert die kontextuelle Relevanz der Suchergebnisse.
3. Verbesserung der Suchergebnisse durch Phrasenerweiterungen
Die phrasenbasierte Indexierung nutzt den Informationsgewinn von Phrasen, um die Suchergebnisse zu verbessern, indem sie Phrasenerweiterungen vorschlägt oder automatisch danach sucht.
- Erweiterung der Suchanfrage: Wenn ein Benutzer eine Teilphrase eingibt, kann das Suchsystem die Erweiterungen dieser Phrase mit dem höchsten Informationsgewinn verwenden, um die Suche vorzuschlagen oder durchzuführen. Zum Beispiel kann eine Abfrage nach „President of the United“ automatisch „President of the United States“ vorschlagen.
- Verringerung der Mehrdeutigkeit: Durch die Verwendung von Phrasen mit hohem Informationsgewinn reduziert das System die Mehrdeutigkeit und verbessert die Genauigkeit der Suchergebnisse, wodurch sichergestellt wird, dass die Benutzer die relevantesten Dokumente finden.
4. Annotation und Ranking von Dokumenten
Der Informationsgewinn wird genutzt, um Dokumente mit verwandten Phrasen zu annotieren, was das Ranking und die Relevanz der Suchergebnisse verbessert.
- Annotation: Dokumente werden mit Zählungen und Vektoren verwandter Phrasen kommentiert, was der Suchmaschine hilft, die primären und sekundären Themen des Dokuments zu verstehen. Diese strukturierten Daten werden verwendet, um Dokumente auf der Grundlage ihrer Relevanz für die Suchanfrage effektiver einzustufen.
- Einstufung nach verwandten Ausdrücken: Die Dokumente werden nicht nur nach dem Vorkommen von Suchphrasen, sondern auch nach dem Vorhandensein verwandter Phrasen mit hohem Informationsgewinn eingestuft. Dieser mehrschichtige Ansatz stellt sicher, dass Dokumente höher eingestuft werden, wenn sie das Thema umfassender abdecken.
Implikationen für SEO
Aus den untersuchten Google-Patenten lässt sich schließen, dass Informationsgewinn eine auf den einzelnen Nutzer ausgerichtete Methode ist, die ihm immer neue Informationen zu einem Thema liefert und Redundanzen vermeidet.
Die gängige Meinung in der SEO-Branche ist jedoch, dass der Informationsgewinn ein nutzerunabhängiger Rankingfaktor ist. Letztlich geht es darum, den einzelnen Nutzer mit neuen Informationen zu einem Thema in Bezug auf sein bereits erworbenes Wissen zufrieden zu stellen.
Für SEO bedeutet dies, dass man nicht nur Informationen aus den Inhalten, die bereits auf den vorderen Plätzen rangieren, sammeln sollte, sondern auch neue, einzigartige Informationen liefern sollte. Darüber hinaus sollten die Inhalte immer wieder mit neuen, einzigartigen Informationen ergänzt werden, um den Informationsgewinn zu erhalten.
Ein einfaches Kuratieren von Inhalten aus den Top-Rankings bringt in jedem Fall keinen Informationsgewinn.
Um sicherzustellen, dass die eigenen Inhalte möglichst vielen Nutzern einen Informationsgewinn bieten, muss man auf eigene Erfahrungen zurückgreifen und auch vorhersagen, welche Informationen für Nutzer zu einem Thema in Zukunft neu sein könnten.
Einige TF-IDF-Tools bieten die Möglichkeit, neben den Nachweisbegriffen auch eindeutige Begriffe anzuzeigen, die als Referenz für Aspekte genutzt werden können, um die Eindeutigkeit der Informationen zu gewährleisten.
Auch Nutzerumfragen können Hinweise darauf geben, welche Informationen noch nicht durch die bisher gerankten Dokumente abgedeckt sind.
Da die heutigen Google-Rankingsysteme nicht mehr nur begriffsbasiert sind, sondern auch Sätze und ganze Absätze für ein besseres Verständnis durch ein größeres Kontextfenster nutzen, sind TF-IDF-Analysen nicht optimal. SEOs sollten außerdem darauf achten, Texte klar zu strukturieren und semantisch verwandte Begriffe in der gleichen Nachbarschaft zu verwenden. So entstehen Abschnitte mit einer hohen Salienz für das jeweilige Thema.
Der Beitrag Information Gain: Wie wird er berechnet? Welche Faktoren sind entscheidend? erschien zuerst auf Aufgesang.
Shopping-Graph-Optimierung: Die Zukunft für Shop SEO / E-Commerce SEO 16 May 2024 6:24 AM (11 months ago)
Bei Ecommerce SEO standen bisher die Shop-Kategorieseiten im Mittelpunkt der Maßnahmen. Das könnte sich ändern! Die Präsenz von Google Shopping in Form von Product Grids, aber auch im Rahmen von SEO nimmt rasant zu. Damit rückt Google Shopping in den Fokus von Shop-SEO.
Googles semantische Datenbank hinter Shopping ist der Google Shopping Graph und die Optimierung des Shopping Graph sollte jeder SEO bei der Suchmaschinenoptimierung für Shops im Auge behalten.
Warum ist der Shopping Graph im Zeitalter von generativer KI und SGE so wichtig?
Anwendungen, die auf generativer KI basieren, werden das Such- und Rechercheverhalten vieler Nutzer verändern. Die Suche wird interaktiver, individueller, präziser und schneller.
Das bedeutet, dass Nutzer zukünftig weniger auf Suchergebnisse klicken werden und deutlich weniger Touchpoints benötigen, um sich auch über Produkte zu informieren.
Die Messy Middle wird durch eine hybride Suche mit generativer KI und klassischer Suche verkürzt.

Laut einer Studie von SERanking werden fast 26% der E-Commerce-Suchanfragen mit einer Snapshot AI Box in der SGE ausgeliefert. Damit gehört der E-Commerce zu den fünf am stärksten von der SGE betroffenen Branchen.

Die klassischen Suchergebnisse werden in vielen Fällen durch die SGE below the fold verdrängt. Prominenter Bestandteil bei produktbezogenen Suchanfragen sind Einblendungen aus dem Google Shopping Graph.

Laut einer Studie von ziptie ranken im E-Commerce-Sektor knapp 80% der Quellen für die SGE nicht in den Top 10 Suchergebnissen bei der jeweiligen Suchanfrage.

Das bedeutet, dass wir mit klassischer SEO nur bedingt weiterkommen. Man muss woanders ansetzen und nach meiner Meinung ist das der Shopping Graph.
Der Shopping Graph als Pendant zu Googles Knowledge Graph
Der Google Knowledge Graph ist seit 2012 Googles semantische Datenbank in der das Wissen der Welt über Entitäten (Knoten) und deren Beziehungen zueinander (Kanten) erfasst und verstanden wird.
Als Pendant zum Knowledge Graph baut Google mit Fokus auf Produkt-Entitäten den Shopping Graph nach dem gleichen Prinzip auf.

Der Google Shopping Graph ist eine umfangreiche, maschinenlernende Datenbank mit Milliarden von Produktlisten, die den Nutzern hilft, bestimmte Produkte zu finden.
- Der Google Shopping Graph ist eine Echtzeitdatenbank für Produkte und Verkäufer, die auf maschinellem Lernen basiert.
- Mit mehr als 35 Milliarden Produkten bietet der Shopping Graph eine riesige Auswahl an Produkten und deren Details wie Verfügbarkeit, Bewertungen, Materialien, Farben und Größen.
- Die Nutzer können nach bestimmten Kriterien nach Produkten suchen und der Shopping Graph durchsucht Milliarden von Listen und relevanten Daten im Web, um passende Optionen zu finden.
- Der Shopping Graph ermöglicht verschiedene Shopping-Funktionen wie „Shop the Look“ für Styling-Ideen und „Buying Guide“ für Kaufempfehlungen durch die Synthese von Informationen aus verschiedenen Quellen im Web.
- Mit dem Shopping Graph können Nutzer auf Google inspirierende Produkte finden und ihre Optionen auf der Grundlage aktueller Shopping-Informationen eingrenzen.
Auf welche Datenquellen stützt sich der Google Shopping Graph?
Um Anhaltspunkte für die Optimierung des Shopping Graph zu finden, muss man sich zunächst die Frage stellen, wo optimiert werden soll. Dazu muss man wissen, auf welchen Datenquellen die Informationen im Shopping Graph basieren.
Nach eigenen Angaben von Google stammen die Informationen im Shopping Graph aus folgenden Quellen:
- Youtube Videos
- Hersteller-Webseiten
- Online-Shops und Produktdetailseiten (PDPs)
- Google Merchant Center
- Google Manufacturer Center
- Produkt-Tests
- Produkt-Bewertungen
Genau an diesen Stellen sind Optimierungen für den Shopping Graph möglich.

Der Shopping Graph als E-Commerce-spezifische Ergänzung für RAG
RAG steht für „Retrieval-Augmented Generation“ und ist eine Technik in der künstlichen Intelligenz, speziell in der Verarbeitung natürlicher Sprache. RAG kombiniert zwei Hauptkomponenten: Information Retrieval und Generative Sprachmodelle.
Das Ziel von RAG ist es, die Qualität und Relevanz der von Sprachmodellen generierten Antworten zu verbessern, indem zusätzliche Informationen aus einer externen Datenquelle abgerufen und zur Antwortgenerierung genutzt werden.
So funktioniert RAG:
- Retrieval (Abruf): Zunächst wird eine Suchanfrage an eine externe Datenbank gestellt, um relevante Informationen zu finden. Dies kann eine Sammlung von Texten, Datenbanken, Graphen-Datenbanken oder jede andere Form von unstrukturierten und strukturierten Daten sein.
- Augmentation (Erweiterung): Die abgerufenen Informationen werden dann als Kontext in das generative Modell eingespeist, das daraufhin eine detaillierte und informierte Antwort generiert.

Mögliche Rolle des Shopping Graph im RAG-Kontext:
Der Google Shopping Graph kann eine wertvolle Informationsquelle für RAG-basierte Systeme sein, insbesondere in Anwendungen, die mit E-Commerce und Online-Shopping zu tun haben wie z.B. auch eine Suchmaschine.
Hier sind einige mögliche Rollen des Shopping Graphs in einem RAG-System:
- Verbesserung der Produktrecherche: Bei einer produktspezifischen Anfrage könnte ein RAG-System relevante Informationen aus dem Shopping Graph abrufen, um präzisere und kontextuell angemessenere Antworten zu generieren. Beispielsweise könnte es spezifische Produktempfehlungen, Verfügbarkeitsdaten oder Preisinformationen integrieren.
- Personalisierte Empfehlungen: Der Shopping Graph könnte genutzt werden, um personalisierte Shopping-Empfehlungen zu generieren, basierend auf den spezifischen Interessen und dem Verhalten des Nutzers, die in den Daten des Shopping Graphs gespeichert sind.
- Unterstützung interaktiver Anfragen: In einem interaktiven Chatbot-Szenario könnte der Shopping Graph helfen, auf Follow-up-Fragen zu antworten, indem er zusätzliche Produktdetails oder Alternativvorschläge liefert, die auf den ersten Empfehlungen basieren.
- Integration von Bewertungen und Rezensionen: Der Shopping Graph könnte auch genutzt werden, um Bewertungen und Rezensionen in die generierten Antworten einzubeziehen, was die Qualität und Nützlichkeit der Empfehlungen erhöhen würde.
Insgesamt kann der Shopping Graph durch seine reichen und strukturierten Informationen über Produkte und deren Beziehungen eine Schlüsselrolle in der Optimierung von RAG-basierten Systemen wie Googles SGE spielen.
Wie können produktbezogene Recherchen zukünftig ablaufen?
Sprachmodelle (LLMs) lernen anhand der Häufigkeit von vorkommenden Kookuurenzen, also im Kontext E-Commerce aus Co-Nennungen von Attributen mit dem jeweiligen Produkt. (siehe dazu auch meinen Beitrag LLM optimization: Can you influence generative AI outputs? )
Welche Attribute für eine Produkt-Entität wichtig ist, ergibt sich aus der Häufigkeit der Attribute, die in Prompts und Suchanfragen nachgefragt sind.
Wie bereits angesprochen werden zukünftige Produkt-Recherchen interaktiver und kontextueller. Durch Prompts lassen sich Anfragen viel mehr Kontextebenen mitgeben. Hier ein Beispiel für einen produktbezogenen Prompt.

Thema des Prompts sind Jogging Schuhe bzw. Laufschuhe. Kontexte sind
- Alter: mittleres Alter
- Gewicht: Übergewicht (Gewicht zu Größe)
- DIstanz: Mittelstrecke
- Größe: mittelgroße Person
- Frequenz: häufig
Bei diesem Prompt geben uns die unterschiedlichen KI-Systeme unterschiedliche Produkt-Empfehlungen aus:
ChatGPT schlägt konkrete Laufschuhmodelle vor und übersetzt den Kontext aus dem Prompt in entsprechende Attribute-Typen:
- Durability
- Foot Type
- Gait
- Fit
- Comfort

Googles Gemini schlägt im ersten Anlauf nur Laufschuh-Marken vor und übersetzt den Prompt in folgende Attribute:
- Cushioning
- Support
- Stability
- Running Style

Fragt man Gemini nach einer Konkretisierung der Schuh-Modelle werden folgende Schuhmodelle inkl. Bildern vorgeschlagen.
- Brooks Ghost 15
- Saucony Kinvara 14
- Asics Kayano 29
- Brooks Adrenaline GTS 23
- Hoka One One Bondi 8
- Saucony Triumph 20

Die Empfehlungen der beiden LLM sind ähnlich. So werden der Brooks Ghost, Asics Kayano, Hoka One Bondi und Saucony Triumph auch von ChatGPT empfohlen.
Meine Tests haben jedoch gezeigt, dass dies nicht immer der Fall ist und die Produktempfehlungen unterschiedlich ausfallen können. Das kann mit den unterschiedlichen Trainingsdaten zusammenhängen.
Warum werden diese Produkte von den LLMs vorgeschlagen und andere nicht?
Diese Produkte scheinen häufig in der Nähe von Attributen genannt zu werden, die im jeweiligen LLM übersetzt wurden.
Bei der Optimierung für den Shopping Graph sollte versucht werden, die relevanten Attribute möglichst in den oben genannten Datenquellen zu erwähnen.
Hier haben wir mit unserem Custom GPT für Textanalyse via Natural Language Processing die Herstellerbeschreibung der Laufschuhmarke Asics für die Modellreihe Asics Kayano analysiert.

Folgende Attribute konnten aus dem Hersteller-Text extrahiert werden:
- Alter/Lebensdauer: Der Schuh ist seit 27 Jahren der führende Laufschuh von ASICS.
- Beliebtheit: Er wird als eine der beliebtesten Laufschuhkollektionen der Welt bezeichnet.
- Zweck des Designs: Speziell für Langstreckenläufe entwickelt.
- Technologische Innovationen: Jedes Modell erhält die neuesten ASICS-Technologie-Innovationen.
- Stabilität: Entwickelt für Stabilität mit Unterstützung und Haltbarkeit im Hinterkopf.
- Geschlechtsspezifische Dämpfung: Verfügt über eine geschlechtsspezifische Dämpfung.
- Komfort: Bietet maximalen Komfort mit einer federnden, stützenden Sohle, die Schmerzen und Reibung bei langen Läufen verhindert.
- Verbesserung: Die Kollektion wird ständig verbessert und erweitert.
- Komfort: Beschrieben als federnd, sehr reaktionsfreudig und leicht zu kontrollieren.
Mit dem Chrome Add On Harpa.ai in Kombination mit Gemini habe ich dieses Youtube video hinsichtlich sub Entitäten und Attributen untersucht.



Das Laufschuh Modell wird hier mit den Attributen bequem, Training- und Wettkampfschuh, lange Distanz und einem bestimmten Obermaterial in Verbindung gebracht.
In dieser Art und Weise lassen sich alle möglichen Daten-Quellen untersuchen.
Je mehr die mit dem jeweiligen Produkt in Verbindung gebrachten Attribute den im Prompt angegeben Kontext und daraus vom LLM abgeleiteten Attributen gleichen desto eher besteht, die Möglichkeit, dass die Produkte in einer Antwort der generativen KI genannt werden.
Was können E-Commerce-Unternehmen daraus lernen?
Die Art und Weise, wie SEO im E-Commerce bisher funktioniert hat, wird sich aufgrund des veränderten Suchverhaltens durch generative KI wie SGE, ChatGPT, Copilot etc. ändern müssen.
Shop-Kategorieseiten werden immer weniger organischen Traffic anziehen und Nutzer werden immer mehr durch generative KI bzw. LLMs an Produkte herangeführt. In welchem Ausmaß diese Verschiebung stattfinden wird, ist unklar. Aber wir als SEOs sollten uns auf diesen hybriden Ansatz der Informationssuche vorbereiten und uns auch im E-Commerce mit Large Language Model Optimization beschäftigen, um nicht an Sichtbarkeit zu verlieren.
Das semantische Herzstück dafür ist für mich der Shopping Graph als Product Entity Database. Der Shopping Graph als semantische, Machine-Learning-basierte Datenbank enthält umfangreiche Produktinformationen und spielt eine zentrale Rolle bei der Zusammenführung von Nutzern und Produkten über spezifische Suchkriterien.
Optimierungsmöglichkeiten für den Shopping Graph ergeben sich aus verschiedenen Datenquellen wie YouTube-Videos, Herstellerwebseiten und Online-Shops bzw. der Gestaltung von Produktdetailseiten und Shopping-Feeds.
Schlussfolgerungen für die Zukunft von Shop-SEO
- Fokus auf Shopping-Graph-Optimierung: SEO-Strategien sollten sich auf die Optimierung innerhalb des Google Shopping Graph konzentrieren, da dieser zunehmend an Bedeutung gewinnt, insbesondere durch seine Integration in generative KI-Anwendungen und SGE.
- Anpassung an generative KI: Da generative KI das Suchverhalten verändert, indem sie Suchen beschleunigt und interaktiver macht, sollten SEO-Maßnahmen im E-Commerce darauf abzielen, in den Datenquellen des Shopping Graph präsent zu sein und die relevanten Attribute hervorzuheben.
- Neue Suchgewohnheiten berücksichtigen: Mit der Zunahme von KI-gestützten Tools wie Chatbots und SGE werden klassische Suchergebnisse immer seltener angeklickt. SEO- und Marketingstrategien müssen sich darauf einstellen, dass weniger Touchpoints nötig sind, um Nutzer zu erreichen und zu überzeugen.
- Optimierung auf Basis von Datenquellen: Effektive Optimierungsstrategien für den Shopping Graph sollten sich darauf konzentrieren, den Kontext und die Relevanz von Produkten in den primären Datenquellen für den Shopping Graph wie YouTube, Herstellerwebseiten und Produktbewertungen zu verbessern.
- Die Identifikation und das Verständnis von nutzer- und produktrelevanten Attributen wird in Zukunft immer wichtiger werden. Daher gewinnt die Longtail-Analyse von Suchanfragen und Prompts zunehmend an Bedeutung.
- Ein semantisches Verständnis rund um Entity-basierte Information-Retrieval-Systeme und ein technologisches Verständnis von LLMs wird zukünftig zu den Grundlagen der Suchmaschinenoptimierung gehören.
- SEOs müssen mehr in Konzepten, Entitäten, Attributen und Relationen denken und optimieren. Die Zeit der Keywords als zentraler Fokus neigt sich dem Ende zu.
Der Beitrag Shopping-Graph-Optimierung: Die Zukunft für Shop SEO / E-Commerce SEO erschien zuerst auf Aufgesang.
Die Google Suche: So funktioniert das Ranking der Suchmaschine heute 13 Feb 2024 4:52 AM (last year)
Google hat Informationen über seine Rankingsysteme veröffentlicht. Mit diesen Informationen, eigenen Überlegungen und Recherchen, z.B. in Google-Patenten und anderen Quellen, möchte ich in diesem Artikel die Puzzleteile zu einem Gesamtbild zusammenfügen.
Dabei gehe ich nicht im Detail auf die Ranking-Faktoren und deren Gewichtung ein, sondern eher auf die Funktionsweise.
Disclaimer: Einige Annahmen in diesem Artikel basieren auf meinen eigenen Gedanken und Hypothesen, die ich aus verschiedenen Quellen entwickelt habe.
Warum sollten sich SEOs mit der Funktionsweise von Suchmaschinen / Google beschäftigen?
Ich halte es nicht für sinnvoll, sich nur mit Rankingfaktoren und möglichen Optimierungsaufgaben zu beschäftigen, ohne zu verstehen, wie eine moderne Suchmaschine wie Google funktioniert. Es gibt viele Mythen und Spekulationen in der SEO-Branche, denen man blind folgt, wenn man keine eigenen Ranking-Erfahrungen hat. Um Mythen im Vorfeld beurteilen zu können, ist es hilfreich, sich mit der Technologie und der grundsätzlichen Funktionsweise von Google auseinanderzusetzen. Dieser Artikel soll dabei helfen und fasst meine Gedanken zu den Aussagen von Google, den Google-Patenten und dem Kartellverfahren gegen Google sowie den Aussagen von Pandu Nayak von Google zusammen.
Prozessschritte beim Information Retrieval, des Rankings und der Wissensentdeckung bei Google
Nach dem exzellenten Vortrag „How Google works: A Google Ranking Engineer’s Story“ von Paul Haahr unterscheidet Google folgende Prozessschritte:
Vor einer Suchanfrage
- Crawlen
- Analyse der gecrawlten Seiten
- Links extrahieren
- Inhalte extrahieren
- Semantik annotieren
- …
- Indexierung
Verarbeitung von Suchanfragen
- Suchanfragen verstehen
- Retrieval und Scoring
- Anpassungen nach dem Retrieval
Indexierung und Crawling
Indexierung und Crawling sind die Grundvoraussetzung für das Ranking, haben aber ansonsten nichts mit dem Ranking von Inhalten zu tun.
Google durchsucht das Internet jede Sekunde mit Hilfe von Bots. Diese Bots werden auch als Crawler bezeichnet. Die Google-Bots folgen Links, um neue Dokumente/Inhalte zu finden. Aber auch URLs, die nicht im HTML-Code angezeigt werden und vielleicht! Auch URLs, die direkt in den Chrome-Browser eingegeben werden, können von Google zum Crawlen verwendet werden.
Findet der Google Bot neue Links, werden diese in einem Scheduler gesammelt, damit sie später abgearbeitet werden können.
Domains werden mit unterschiedlicher Häufigkeit und Vollständigkeit gecrawlt oder es werden Domains unterschiedliche Crawling-Budgets zugewiesen. Bisher war der PageRank ein Indikator für die Crawling-Intensität einer Domain. Neben externen Links können auch die Veröffentlichungs- und Aktualisierungshäufigkeit sowie die Art der Website eine Rolle spielen. Nachrichtenseiten, die auf Google News erscheinen, werden in der Regel häufiger gecrawlt. Laut Google gibt es bis zu einer Anzahl von ca. 10.000 URLs keine Probleme mit dem Crawling. Mit anderen Worten: Die meisten Websites können problemlos vollständig gecrawlt werden.
Die Indexierung erfolgt in zwei Schritten.
Im ersten Schritt wird der reine html-Code mit einem Parser so aufbereitet, dass er ressourcenschonend in einen Index übertragen werden kann. Mit anderen Worten: Die erste indizierte Version des Inhalts ist eine reine html-Seite, die nicht gerendert wurde. Das spart Google Zeit beim Crawlen und damit bei der Indexierung.
In einem zweiten, späteren Schritt wird die indizierte html-Version mit einem Rendering versehen.
Der klassische Indexierungsprozess kann in zwei Teile unterteilt werden:
- Indexerstellung: Suchmaschinen durchforsten das Internet nach Dokumenten (Webseiten, PDFs usw.) und erstellen einen Index, eine umfangreiche Datenbank mit Wörtern, Sätzen und den dazugehörigen Dokumenten. Dieser Index ermöglicht es der Suchmaschine, Dokumente, die mit einer bestimmten Anfrage in Zusammenhang stehen, schnell aufzufinden.
- Dokument-Merkmale: Jedes Dokument im Index wird auf bestimmte Merkmale hin analysiert, wie z. B. das Vorhandensein und die Verteilung von Schlüsselwörtern, die Struktur des Dokuments (z. B. Titel, Überschriften und Links) und andere Signale, die auf seine Relevanz für bestimmte Themen oder Abfragen hinweisen könnten. Diese Merkmale können abfrageabhängig oder -unabhängig sein.
Welche Google-Indizes gibt es?
Bei Google kann grundsätzlich zwischen drei Arten von Indizes unterschieden werden.
Klassische Suchindizes
Der klassische Suchindex enthält alle Inhalte, die Google indexieren kann. Je nach Art des Inhalts unterscheidet Google auch zwischen den sogenannten vertikalen Indizes wie klassischer Dokumentenindex (Text), Bildindex, Videoindex, Flüge, Bücher, Nachrichten, Shopping, Finanzen. Der klassische Suchindex besteht aus Tausenden von Scherben, die Millionen von Websites enthalten. Aufgrund der Größe des Index ist es möglich, durch die parallele Abfrage der Websites in den einzelnen Shards sehr schnell die Top-n-Dokumente/Inhalte pro Shard zusammenzustellen.
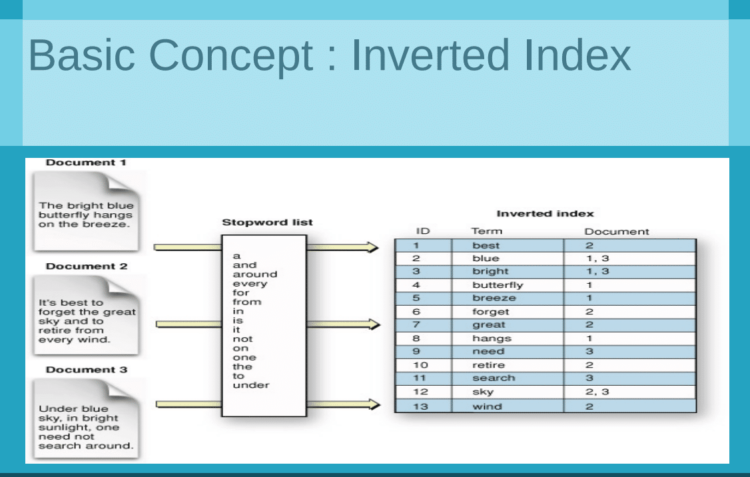
Quelle: https://datascience.stackexchange.com/questions/112544/how-does-google-indexes-text-documents
Knowledge Graph
Der Knowledge Graph ist der semantische Entitätsindex von Google. Alle Informationen über Entitäten und ihre Beziehungen zueinander werden im Knowledge Graph gespeichert. Google bezieht die Informationen über die Entitäten aus verschiedenen Quellen.
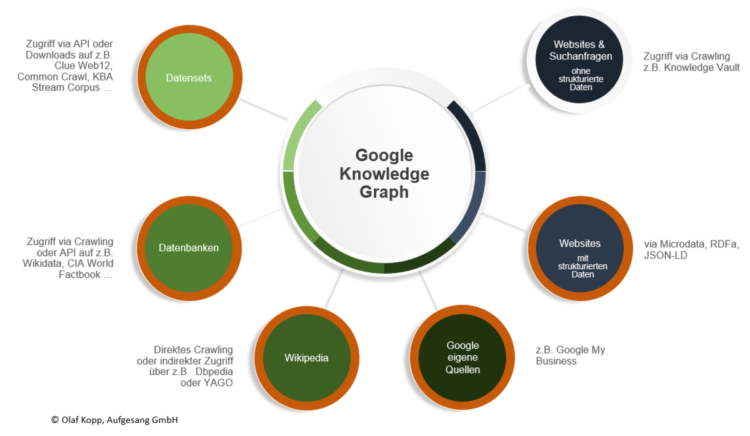
Mit Hilfe von Natural Language Processing (NLP) ist Google zunehmend in der Lage, unstrukturierte Informationen aus Suchanfragen und Online-Inhalten zu extrahieren, um Entitäten zu identifizieren oder Daten zu Entitäten zuzuordnen. Mit MUM kann Google dafür nicht nur Textquellen nutzen, sondern auch Bilder, Videos und Audios. Mehr Infos zu Natural Language Based Search hier.
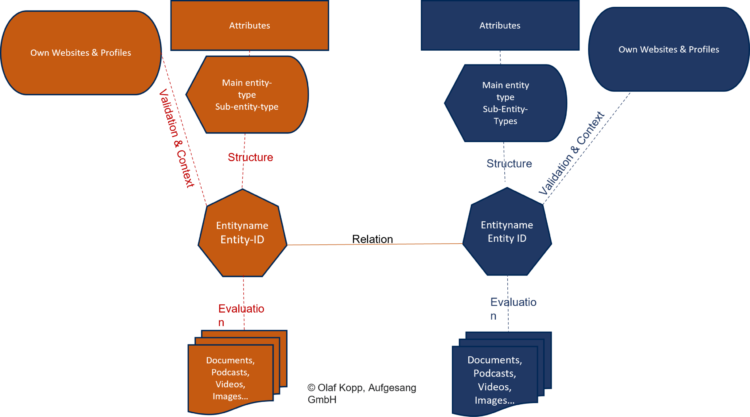
LLM, Vektor-Index und Vektor-Datenbank
Die neueste Art von Index, die Google zum Speichern und Verstehen von Informationen verwendet, sind Large Language Models (LLMs) und die dazugehörigen Vektordatenbanken. Seit der Einführung von BERT im Jahr 2018 verwendet Google LLMs, um Ähnlichkeitsberechnungen in Vektorräumen durchzuführen. Seit der Einführung von Rankbrain im Jahr 2015 verwendet Google Verfahren wie Word2Vec, um Wörter und andere Elemente in Vektoren umzuwandeln.
Google wird in Zukunft verstärkt Vektordatenbanken oder Vektorindizes für die Organisation und das Ranking verwenden.
Vektordatenbanken sind spezialisierte Datenbanken, die für die effiziente Speicherung, Suche und Verwaltung von Vektoren (Darstellungen von Daten in hochdimensionalen Räumen) konzipiert sind. Diese Vektoren können eine Vielzahl von Datentypen darstellen, z. B. Bilder, Text, Audio oder andere komplexe Datentypen, die in einen Vektorraum transformiert wurden.
Im Zusammenhang mit maschinellem Lernen und künstlicher Intelligenz (KI) werden Daten oft als Vektoren dargestellt, um Ähnlichkeiten und Beziehungen zwischen verschiedenen Datenelementen zu erkennen. Vektordatenbanken machen sich diesen Ansatz zunutze, um hochdimensionale Abfragen effizient zu unterstützen. Sie sind besonders nützlich für Anwendungen wie semantische Suchen, Empfehlungssysteme, Gesichtserkennung und andere KI-gesteuerte Funktionen.
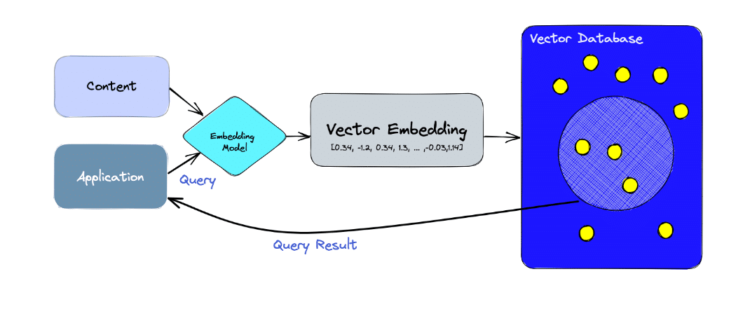
Quelle: https://www.pinecone.io/learn/vector-database/
Ein Hauptmerkmal von Vektordatenbanken ist ihre Fähigkeit, Ähnlichkeitssuchen durchzuführen. Das bedeutet, dass sie Datenelemente finden können, die einem bestimmten Beispiel oder einer Abfrage ähnlich sind, und zwar auf der Grundlage des Abstands zwischen Vektoren im hochdimensionalen Raum. Dieser Abstand kann mit verschiedenen Metriken gemessen werden, z. B. dem euklidischen Abstand oder der Kosinusähnlichkeit.
Vektordatenbanken bieten auch spezialisierte Indizierungs- und Speicherstrategien, um die Suche und den Abruf von hochdimensionalen Daten effizient zu gestalten. Sie können sowohl in der Cloud als auch vor Ort implementiert werden und unterstützen häufig skalierbare und verteilte Architekturen, um große Datensätze zu verarbeiten.
Hybride Lösungen aus KGs und LLMs
Bei der Organisation von Wissen gibt es derzeit einen Wettlauf zwischen Wissensgraphen auf der einen und großen Sprachmodellen (LLMs) auf der anderen Seite. Neuere Entwicklungen legen nahe, dass eine Kombination beider Systeme eine optimale Lösung darstellt. In Zukunft könnten Wissensvektorgraphen die Vorteile einer symbolischen semantischen Datenbank wie dem Knowledge Graph und hoch skalierbarer LLMs sein.
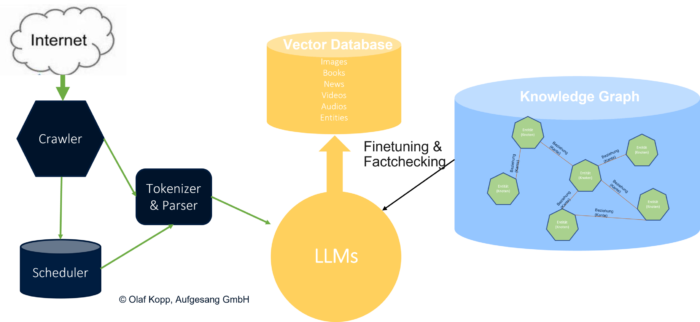
Die Grenzen von LLMs liegen in ihrem Mangel an Domänenwissen und führen zu veralteten oder ungenauen Antworten. Um dies zu beheben, wurde das Konzept der Retrieval-Augmented Generation (RAG) eingeführt, das LLMs mit externen Wissensdatenbanken anreichert. RAG steht jedoch vor praktischen Herausforderungen, wie der Komplexität der Datenverarbeitung und -integration.
Die vorgeschlagene Lösung beinhaltet die Verwendung von Vektordatenbanken für eine effiziente Informationsbeschaffung durch eine vektorielle Ähnlichkeitssuche. Trotz seiner Vorteile birgt dieser Ansatz eine Reihe von Herausforderungen, darunter die Nichttransitivität der Vektorähnlichkeit, die die genaue Suche nach relevanten Informationen erschwert.
Um diese Hindernisse zu überwinden, könnte das Konzept eines Wissensvektorgraphen als neuartige RAG-Architektur, die Vektordatenbanken mit Graphdatenbanken kombiniert, eine Lösung darstellen. Dieser Ansatz zielt darauf ab, eine nuanciertere und umfassendere Methode für die Verknüpfung von disparaten Wissensteilen bereitzustellen und dadurch die Fähigkeit des LLM zu verbessern, genaue und kontextbezogene Antworten zu generieren.
Quelle: https://medium.com/@johnson.h.kuan/from-rags-to-riches-helping-ai-connect-the-dots-with-a-knowledge-vector-graph-f9e8f91b06a4
Im Jahr 2024 stellte Google Exphormer vor: Scaling transformers for graph-structured data (Skalierung von Transformatoren für graph-strukturierte Daten), das die Welt der Graphen und Transformatoren zusammenbringt. Exphormer ist eine intelligente Lösung, mit der Transformatoren große Graphen verarbeiten können, ohne überfordert zu werden. Dies geschieht durch die Auswahl der zu berücksichtigenden Verbindungen unter Verwendung von so genannten „Expander-Graphen“. Diese sind besonders, weil sie gerade genug Verbindungen haben, um sicherzustellen, dass keine Informationen verloren gehen, aber nicht so viele, dass der Transformator ins Stocken gerät.
Das Exphormer-System bietet Skalierbarkeit durch die Einführung eines spärlichen Aufmerksamkeitsmechanismus, der speziell für Graphdaten entwickelt wurde. Es nutzt Expander-Graphen, die spärlich, aber gut verbunden sind, was eine effiziente Berechnung und Speichernutzung ermöglicht.
Die Suche-Revolution der Vektorsuche
Die Vektorsuche erfreut sich zunehmender Beliebtheit, da sie mit komplexen Objekten arbeiten kann, die als hochdimensionale Vektoren dargestellt werden.
Sie bietet einen tieferen Lernansatz, der die Semantik von Abfragen versteht, was für den Abgleich von Bedeutung und Absicht entscheidend ist. Die Vektorsuche kann verschiedene Datenformate wie Text, Bilder, Audio und Video durchsuchen, um den Kontext zu verstehen und schnell relevante Antworten zu liefern. Google könnte daher MUM im Jahr 2021 als leistungsstarkes neues Deep-Learning-System einführen.
Die Vektorsuche ermöglicht es den Nutzern, bei ihren Suchanfragen den Kontext zu berücksichtigen, so dass Relevanz und Kontext Hand in Hand gehen.
Die Nutzer können Informationen finden, die über eine spezifische Anfrage hinausgehen, und erhalten präzise und differenzierte Antworten, ohne lange Ergebnislisten durchsuchen zu müssen.
Die Implementierung der Vektorsuche kann eine Herausforderung darstellen, da sie die Integration verschiedener Komponenten wie eines großen Sprachmodells, einer Vektordatenbank und Frameworks erfordert. Die Vektorsuche bietet Google neuronale Pfade für den kognitiven Abruf und unterstützt kontextbezogene Entscheidungen.
Sie ermöglicht es Google, eine natürliche semantische Suche in Anwendungen zu integrieren, die Interaktion mit dem Nutzer zu verbessern und Informationen in Echtzeit bereitzustellen.
Embeddings
Deep Learning ist ein Bereich der Informatik, der Computern hilft, die Bedeutung von Daten auf einer tieferen Ebene zu „verstehen“, ähnlich der Funktionsweise unseres Gehirns. Deep Learning verwendet so genannte neuronale Netze, die die Funktionsweise des menschlichen Gehirns nachahmen sollen. Diese Netze bestehen aus mehreren Schichten, von der Eingabe (was Sie in den Computer eingeben) bis zur Ausgabe (was der Computer aus der Eingabe versteht oder vorhersagt).
Hier kommen die Embeddings ins Spiel. Wenn ein Computer ein Datenelement betrachtet, z.B. ein Foto eines Hundes, sieht er nicht „Hund“ wie wir. Stattdessen wandelt er das Foto in eine lange Liste von Zahlen um, die Embeddings genannt werden. Jede Zahl in dieser Liste steht für verschiedene Merkmale oder Aspekte des Fotos, z. B. ob ein Hund darauf zu sehen ist, ob der Himmel blau ist oder ob ein Baum im Hintergrund steht.
Stellen Sie sich vor, Sie würden versuchen, das Wesen eines Fotos nur mit Zahlen zu beschreiben. Genau das tun eingebettete Vektoren, aber in einer Form, die Computer verstehen und verarbeiten können. Diese Vektoren ermöglichen es Computern, verschiedene Datentypen zu vergleichen und zu durchsuchen, indem sie darauf achten, wie ähnlich sich ihre Zahlen sind, anstatt sich auf die exakten Wörter zu verlassen. Selbst wenn zwei Bilder für uns sehr unterschiedlich aussehen, kann der Computer feststellen, dass ihre Einbettungsvektoren sehr ähnlich sind, was bedeutet, dass sie viele Merkmale gemeinsam haben.
Kurz gesagt, Embeddings sind wie eine universelle Sprache für Computer, um alle Arten von Daten auf der Grundlage ihrer tatsächlichen Bedeutung zu verstehen und zu durchsuchen, und nicht nur auf der Grundlage dessen, was sie sagen oder oberflächlich betrachtet zu sein scheinen. Dies eröffnet völlig neue Möglichkeiten für die Suche und Organisation von Informationen, die bisher nicht möglich waren.
Embeddings sind eine Schlüsselkomponente beim Übergang von traditionellen lexikalischen Suchmethoden zu fortgeschrittenen semantischen Suchfunktionen, insbesondere beim Umgang mit unstrukturierten Daten wie Bildern, Videos und Audiodateien. Lexikalische Suchmaschinen wandeln strukturierten Text in durchsuchbare Begriffe um, aber dieser Ansatz reicht bei unstrukturierten Daten nicht aus, da für eine effiziente Indizierung und Abfrage ein Verständnis der den Daten innewohnenden Bedeutung erforderlich ist.
Deep Learning, ein Zweig des maschinellen Lernens, der sich auf Modelle konzentriert, die auf künstlichen neuronalen Netzen mit mehreren Verarbeitungsebenen basieren, ist entscheidend für die Extraktion der wahren Bedeutung aus unstrukturierten Daten. Diese neuronalen Netze ahmen die Struktur und Funktionsweise des menschlichen Gehirns nach und verfügen über Eingabe- und Ausgabeschichten sowie mehrere verborgene Schichten für die Datenverarbeitung.
Quelle: https://www.ibm.com/topics/neural-networks
Neuronale Netze wandeln unstrukturierte Daten in Embeddings oder Sequenzen von Gleitkommawerten um, die die Daten in einem mehrdimensionalen Raum darstellen. Während Menschen Vektoren in zwei oder drei Dimensionen leicht verstehen können, können die in neuronalen Netzen verwendeten Einbettungsvektoren Hunderte oder Tausende von Dimensionen haben, von denen jede einem Merkmal oder einer Eigenschaft der Daten entspricht.
Embeddings ermöglichen somit eine semantische Suche, indem sie das Wesen und die Merkmale unstrukturierter Daten erfassen und so präzisere und relevante Suchergebnisse auf der Grundlage der Bedeutung der Daten und nicht nur der übereinstimmenden Begriffe ermöglichen. Dieser Ansatz verbessert die Fähigkeit, große Mengen unstrukturierter Daten zu durchsuchen und zu analysieren, erheblich und ebnet den Weg für intelligentere und kontextbewusste Suchsysteme.
Die Google-Suche als Hybridsystem aus lexikalischer und semantischer Suche
Google arbeitet heute lexikalisch und entitätenbasiert. Je nachdem, wie klar Google die Verbindungen zwischen Entitäten in den Suchanfragen und Dokumenten erkennt, verwendet Google semantische oder lexikalische Ansätze zur Informationsgewinnung in Recall und Precision.
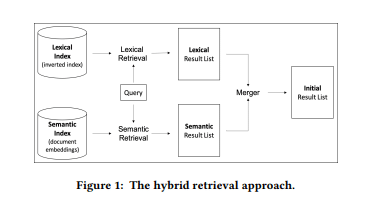
Die semantische Suche geht über den einfachen Abgleich von Schlüsselwörtern hinaus, indem sie die komplexen Beziehungen zwischen den Wörtern versteht und so die Bedeutung oder den Kontext der Anfrage und der Dokumente erfasst. Dies ist entscheidend, um relevante Dokumente zu finden, die nicht die exakten Suchbegriffe enthalten, aber im Kontext miteinander in Beziehung stehen.
Der Ansatz basiert auf der Prämisse, dass effektive semantische Modelle, insbesondere in den letzten Jahren, vor allem mit Hilfe von tiefen neuronalen Netzen entwickelt wurden. Diese Modelle sind in der Lage, die Nuancen der Sprache zu verstehen, einschließlich Synonyme, verwandte Begriffe und Kontext, die von lexikalischen Modellen oft übersehen werden.
Das semantische Retrievalmodell basiert auf tiefen neuronalen Netzen, die insbesondere Architekturen wie BERT (Bidirectional Encoder Representations from Transformers) nutzen. BERT und ähnliche Modelle werden mit großen Mengen von Textdaten trainiert, um komplexe Sprachmuster und Semantik zu verstehen.
Für den Retrievalprozess erzeugt das Modell Embeddings sowohl für Anfragen als auch für Dokumente. Diese Embeddings repräsentieren den semantischen Inhalt des Textes in einem hochdimensionalen Raum, in dem die semantische Ähnlichkeit zwischen einer Anfrage und einem Dokument gemessen werden kann, üblicherweise mit Hilfe der Kosinusähnlichkeit.
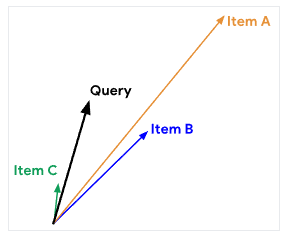
Verbesserter Recall: Durch die Erfassung der Bedeutung hinter den Wörtern kann der semantische Ansatz ein breiteres Spektrum relevanter Dokumente ausfindig machen, einschließlich solcher, die nicht genau die gleichen Schlüsselwörter wie die Suchanfrage enthalten. Dies ist besonders nützlich, um das Problem der Vokabularinkongruenz zu lösen, bei dem die Anfrage und die relevanten Dokumente unterschiedliche Begriffe zur Beschreibung desselben Konzepts verwenden.
Mehr zum semantischen Retrieval finden Sie in meiner Übersicht Most interesting Google Patents for semantic search.
Semantische Suche vs. Lexikalische Suche
Die lexikalische Suche basiert auf dem Prinzip, exakte Wörter oder Phrasen aus einer Suchanfrage mit denen in den Dokumenten zu vergleichen. Diese Methode ist einfach und schnell, hat aber mit Problemen wie Rechtschreibfehlern, Synonymen oder Polysemie (Wörtern mit mehreren Bedeutungen) zu kämpfen. Sie berücksichtigt auch nicht den Kontext oder die Bedeutung der Wörter, was zu irrelevanten Ergebnissen führen kann.
Im Gegensatz dazu verwendet die vektorbasierte semantische Ähnlichkeitssuche Techniken der natürlichen Sprachverarbeitung (Natural Language Processing, NLP), um die Bedeutung von Wörtern und ihre Beziehungen zueinander zu analysieren. Die Wörter werden als Vektoren in einem hochdimensionalen Raum dargestellt, wobei der Abstand zwischen den Vektoren ihre semantische Ähnlichkeit angibt. Diese Methode kann mit Rechtschreibfehlern, Synonymen und Mehrdeutigkeit umgehen und subtilere Wortbeziehungen wie Antonyme, Hypernyme und Meronyme erfassen, was zu genaueren und relevanteren Ergebnissen führt.
Der Einsatz der vektorbasierten semantischen Ähnlichkeitssuche ist jedoch mit Einschränkungen verbunden. Für das Training der NLP-Modelle sind große Datenmengen erforderlich, was rechenintensiv und zeitaufwändig ist. Bei kurzen Dokumenten oder Anfragen ohne ausreichenden Kontext zur Bestimmung der Wortbedeutung ist dieser Ansatz möglicherweise nicht so effektiv. In diesen Fällen könnte eine einfache lexikalische Suche geeigneter und effektiver sein.
Darüber hinaus kann der „Fluch der Dimensionalität“ die Leistung der vektorbasierten semantischen Ähnlichkeitssuche in bestimmten Szenarien beeinträchtigen. Kurze Dokumente können in einem Vektorraum für eine bestimmte Anfrage einen höheren Rang einnehmen, auch wenn sie nicht so relevant sind wie längere Dokumente. Dies liegt daran, dass kurze Dokumente in der Regel weniger Wörter enthalten, was bedeutet, dass ihre Wortvektoren im hochdimensionalen Raum näher am Abfragevektor liegen, was zu einem höheren Ähnlichkeitskoeffizienten führen kann, obwohl sie weniger Information oder Kontext enthalten.
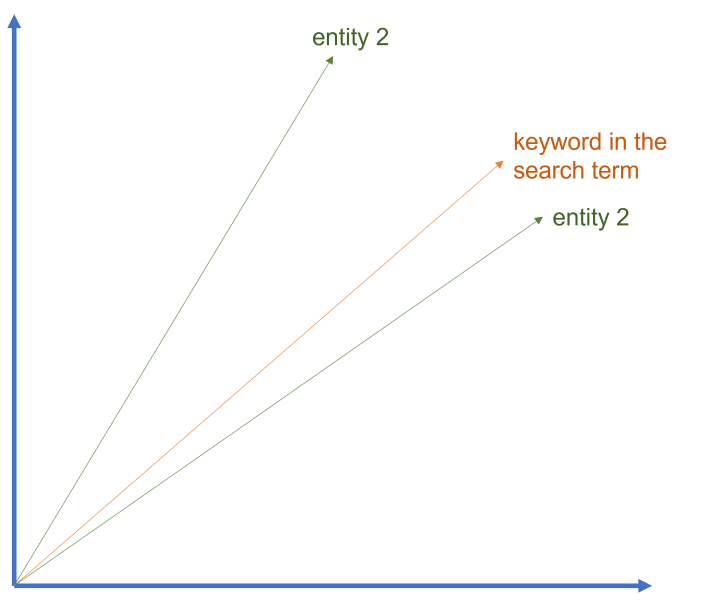
Zusammenfassend lässt sich sagen, dass sowohl die lexikalische Suche als auch die vektorielle semantische Ähnlichkeitssuche ihre Stärken und Schwächen haben. Je nach Art des Korpus, der Art der Abfragen und der verfügbaren Rechenressourcen kann der eine Ansatz besser geeignet sein als der andere. Um die besten Suchergebnisse zu erzielen, ist es entscheidend, die Unterschiede zwischen diesen beiden Methoden zu verstehen und sie mit Bedacht einzusetzen.
Klassifizierung von neuen Inhalten und Gewährleistung eines Information Gain
Wenn Google neue Inhalte entdeckt und crawlt, besteht der nächste Schritt darin, diese thematisch in einem thematischen Korpus zu klassifizieren. Dazu kann Google klassische Information-Retrieval-Methoden wie TF-IDF, semantische Methoden wie die Entity-Analyse oder Ähnlichkeitsberechnungen mittels Vektorraumanalyse verwenden. Inhalte, die einem bestimmten thematischen Muster entsprechen, können einem thematischen Korpus zugeordnet werden.
Ein häufiges Problem ergibt sich, wenn mehrere Dokumente zum gleichen Thema ähnliche Informationen enthalten. Wenn ein Benutzer beispielsweise nach Lösungen für ein Computerproblem sucht, werden ihm möglicherweise mehrere Dokumente vorgelegt, die ähnliche Schritte zur Fehlerbehebung oder Lösungen auflisten. Dies kann dazu führen, dass der Benutzer nach der Lektüre eines Dokuments in den nachfolgenden Dokumenten zum selben Thema wenig bis gar keine neuen Informationen findet. Diese Redundanz kann zu Ineffizienz und Frustration bei den Nutzern führen, die neue oder zusätzliche Informationen zu ihren Fragen oder Interessen suchen.
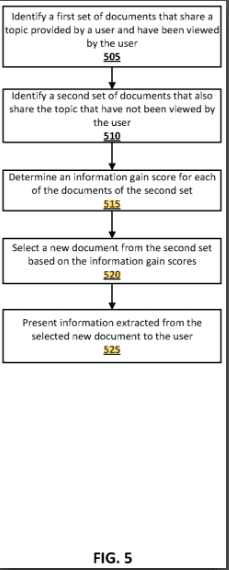 Das Google-Patent Contextual estimation of link information gain beschreibt Techniken zur Bestimmung eines Informationsgewinn-Scores für Dokumente, die für einen Nutzer von Interesse sind, und zur Präsentation von Informationen aus diesen Dokumenten auf der Grundlage ihres Informationsgewinn-Scores. Der Informationsgewinn eines Dokuments gibt an, welche zusätzlichen Informationen es enthält, die über das hinausgehen, was in den vom Nutzer zuvor angesehenen Dokumenten enthalten ist. Bei diesem Ansatz werden Modelle des maschinellen Lernens verwendet, um den Informationsgewinn von Dokumenten zu berechnen. Die Dokumente können den Nutzern dann in einer Weise zur Verfügung gestellt werden, die die potenziellen neuen Informationen widerspiegelt, die sie durch die Anzeige dieser Dokumente gewinnen könnten.
Das Google-Patent Contextual estimation of link information gain beschreibt Techniken zur Bestimmung eines Informationsgewinn-Scores für Dokumente, die für einen Nutzer von Interesse sind, und zur Präsentation von Informationen aus diesen Dokumenten auf der Grundlage ihres Informationsgewinn-Scores. Der Informationsgewinn eines Dokuments gibt an, welche zusätzlichen Informationen es enthält, die über das hinausgehen, was in den vom Nutzer zuvor angesehenen Dokumenten enthalten ist. Bei diesem Ansatz werden Modelle des maschinellen Lernens verwendet, um den Informationsgewinn von Dokumenten zu berechnen. Die Dokumente können den Nutzern dann in einer Weise zur Verfügung gestellt werden, die die potenziellen neuen Informationen widerspiegelt, die sie durch die Anzeige dieser Dokumente gewinnen könnten.
- Informationsgewinn-Score: Eine Metrik, die die neuen oder zusätzlichen Informationen quantifiziert, die ein Dokument im Vergleich zu dem liefert, was der Benutzer bereits gesehen hat. Dies hilft bei der Priorisierung der Dokumente, die dem Benutzer auf der Grundlage der Wahrscheinlichkeit, dass sie neue Erkenntnisse bieten, präsentiert werden.
- Anwendung des maschinellen Lernens: Die Verwendung von Modellen des maschinellen Lernens zur Analyse von Dokumenten und zur Berechnung ihrer Informationsgewinnwerte. Dabei wird der Inhalt neuer Dokumente mit dem früherer Dokumente verglichen, um die Neuartigkeit und Relevanz der darin enthaltenen Informationen zu bewerten.
- Benutzerzentrierte Dokumentendarstellung: Die Dokumente werden in eine Rangfolge gebracht und dem Benutzer auf der Grundlage ihrer Informationsgewinnwerte präsentiert. Auf diese Weise wird sichergestellt, dass den Nutzern mit größerer Wahrscheinlichkeit Dokumente angezeigt werden, die neue Erkenntnisse bieten, was die Effizienz und Effektivität der Informationsfindung erhöht.
- Dynamisches Ranking: Die Rangfolge der Dokumente kann aktualisiert werden, wenn der Benutzer weitere Dokumente ansieht. Diese Neueinstufung basiert auf neu berechneten Bewertungen des Informationsgewinns, wodurch sichergestellt wird, dass sich die Präsentation der Dokumente an die sich entwickelnden Informationen anpasst.
Die folgenden Faktoren können für die Bewertung des Informationsgewinns verwendet werden:
- Neuartigkeit des Inhalts: Dieser Faktor bewertet die Einzigartigkeit der Informationen in einem neuen Dokument im Vergleich zu den Informationen in den Dokumenten, die der Benutzer zuvor angesehen hat. Inhalte, die neue Konzepte, Daten oder Erkenntnisse enthalten, die der Nutzer zuvor noch nicht gelesen hat, erhalten eine höhere Punktzahl für den Informationsgewinn.
- Relevanz für die Benutzerabfrage: Die Relevanz des Inhalts eines Dokuments für die ursprüngliche Suchanfrage oder das geäußerte Interesse des Nutzers ist ein wichtiger Bewertungsfaktor. Dokumente, die den Informationsbedürfnissen oder der Suchabsicht des Nutzers am ehesten entsprechen, werden wahrscheinlich höher bewertet, da davon ausgegangen wird, dass sie dem Nutzer wertvollere Informationen bieten.
- Semantische Analyse: Der Einsatz semantischer Analysetechniken, wie z. B. die Verarbeitung natürlicher Sprache (NLP) und maschinelle Lernmodelle, ermöglicht ein tieferes Verständnis der Bedeutung und des Kontexts des Inhalts. Diese Analyse hilft bei der Identifizierung der semantischen Beziehungen zwischen dem neuen Dokument und den zuvor vom Benutzer angesehenen Dokumenten und trägt so zu einer genaueren Bewertung des Informationsgewinns bei.
- Verlauf der Benutzerinteraktion: Die Interaktionshistorie des Nutzers mit zuvor angesehenen Dokumenten, wie die mit einem Dokument verbrachte Zeit, die Beschäftigung mit dem Inhalt (z. B. Klicken auf Links, Ansehen eingebetteter Videos) und jegliches Feedback (z. B. Upvotes, Likes oder Kommentare), kann die Bewertung beeinflussen. Dokumente, die denen ähneln, mit denen der Benutzer in der Vergangenheit positiv interagiert hat, können eine höhere Punktzahl erhalten.
- Frische des Dokuments: Die Aktualität der in einem Dokument enthaltenen Informationen kann ebenfalls ein Faktor sein, insbesondere bei Themen, bei denen neue Entwicklungen häufig und bedeutend sind. Neuere Dokumente, die die neuesten Informationen oder Daten enthalten, können besser bewertet werden, da sie die aktuellsten Erkenntnisse liefern.
Informationsdichte: Die Dichte an wertvollen Informationen in einem Dokument, im Gegensatz zu Füllmaterial oder allgemein bekannten Fakten, kann sich auf die Bewertung des Informationsgewinns auswirken. Dokumente mit detaillierten Analysen, umfassenden Daten oder ausführlichen Erklärungen zu dem betreffenden Thema werden wahrscheinlich besser bewertet. - Autorität und Verlässlichkeit der Quelle: Die Glaubwürdigkeit und Autorität der Quelle eines Dokuments kann dessen Bewertung beeinflussen. Dokumente aus hoch angesehenen Quellen, die für ihre Genauigkeit und Gründlichkeit in der Materie bekannt sind, können höher bewertet werden, was den Mehrwert zuverlässiger Informationen widerspiegelt.
- Kontextbezogene und verhaltensbezogene Signale: Das System kann auch kontextbezogene Signale berücksichtigen, wie z. B. die aktuelle Aufgabe, den Standort oder die Tageszeit des Benutzers, und verhaltensbezogene Signale, wie z. B. die langfristigen Interessen oder das Informationskonsummuster des Benutzers. Diese Signale helfen dabei, den Informationsgewinn auf den spezifischen Kontext und die Präferenzen des Benutzers abzustimmen.
Verarbeitung von Suchanfragen
Die Magie der Interpretation von Suchbegriffen geschieht bei der Verarbeitung von Suchanfragen. Die folgenden Schritte sind hier wichtig:
Eingabe der Suchanfrage
- Benutzereingabe: Der Prozess beginnt, wenn ein Nutzer einen Suchbegriff oder eine Phrase in die Suchmaschine eingibt. Dies kann über eine Weboberfläche, Sprachsuche oder sogar über integrierte Suchfunktionen in anderen Anwendungen erfolgen.
- Normalisierung: Die Suchmaschine kann die Anfrage normalisieren, um eine einheitliche Verarbeitung zu gewährleisten. Dies kann die Umwandlung aller Zeichen in Kleinbuchstaben, das Entfernen unnötiger Satzzeichen und die Standardisierung von Leerzeichen beinhalten.
Verstehen von Abfragen
- Parsing: Die Suchmaschine analysiert die Anfrage, um ihre Struktur zu verstehen und die wichtigsten Schlüsselwörter, Operatoren (wie Anführungszeichen für exakte Übereinstimmungen oder Minuszeichen für Ausschlüsse) und andere Elemente zu identifizieren, die die Suche beeinflussen können.
- Erkennung von Absichten: Das Verstehen der Absicht des Nutzers ist entscheidend. Die Suchmaschine verwendet Techniken zur Verarbeitung natürlicher Sprache (NLP), um festzustellen, ob der Nutzer nach bestimmten Informationen sucht (Informationsabsicht), versucht, eine bestimmte Website zu erreichen (Navigationsabsicht), oder beabsichtigt, eine Aktion oder einen Kauf durchzuführen (Transaktionsabsicht).
- Kontextualisierung: Der Kontext der Abfrage wird ebenfalls berücksichtigt, z. B. der Standort des Nutzers, der Zeitpunkt der Abfrage, das verwendete Gerät und alle Personalisierungsfaktoren, die auf dem Suchverlauf und den Einstellungen des Nutzers basieren.
Erweiterung und Verfeinerung von Suchanfragen
- Synonymabgleich: Die Suchmaschine kann die Abfrage um Synonyme oder verwandte Begriffe erweitern, um die Suche auszuweiten und mehr potenziell relevante Dokumente zu erfassen.
Rechtschreibkorrektur und Vorschläge: Häufige Rechtschreib- oder Tippfehler werden automatisch korrigiert, und die Suchmaschine kann auch alternative Suchanfragen vorschlagen, wenn sie der Meinung ist, dass der Benutzer einen Fehler gemacht hat oder wenn es eine üblichere Formulierung für die Anfrage gibt. - Semantische Analyse: Fortgeschrittene Suchmaschinen führen eine semantische Analyse durch, um die Bedeutung hinter der Anfrage zu verstehen, nicht nur die einzelnen Begriffe. Dies beinhaltet die Erkennung von Entitäten (wie Namen von Personen, Orten oder Dingen) und deren Beziehungen, wodurch die Suchmaschine in die Lage versetzt wird, Ergebnisse abzurufen, die in einem semantischen Zusammenhang mit der Suchanfrage stehen.
- Vorhersage von Suchanfragen: Die Vorhersage, welche Suchanfragen ein Nutzer als Nächstes stellen könnte, ist für Google sowohl im Hinblick auf das Nutzererlebnis als auch auf die Effizienz bei der Bereitstellung von Suchergebnissen sehr interessant. Das Google-Patent „Identification and Issuance of Repeatable Queries“ beschreibt, wie dies funktionieren kann.
Personalisierung
- Nutzerprofil und Verlauf: Wenn der Nutzer eingeloggt ist oder die Suchmaschine Zugriff auf einen Verlauf der Interaktionen des Nutzers hat, kann sie die Verarbeitung der Suchanfrage auf der Grundlage dessen, was sie über die Vorlieben des Nutzers, frühere Suchen und angeklickte Ergebnisse weiß, anpassen.
- Lokalisierung: Die Suchmaschine berücksichtigt den Standort des Nutzers, um lokalisierte Ergebnisse zu liefern, was besonders wichtig für Suchanfragen ist, bei denen der geografische Kontext relevant ist (z. B. Restaurantsuche, Wettervorhersage).
Die Suchabsicht kann je nach Nutzer variieren und sich sogar im Laufe der Zeit ändern, während die lexikalisch-semantische Bedeutung gleich bleibt.
Bei bestimmten Suchanfragen wie offensichtlichen Rechtschreibfehlern oder Synonymen erfolgt eine automatische Verfeinerung der Anfrage im Hintergrund. Als Nutzer können Sie die Verfeinerung der Suchanfrage auch manuell auslösen, sofern Google nicht sicher ist, ob es sich um einen Tippfehler handelt. Bei der Suchanfrageverfeinerung wird eine Suchanfrage im Hintergrund umgeschrieben, um die Bedeutung besser interpretieren zu können.
Neben der Verfeinerung von Suchanfragen umfasst die Verarbeitung von Suchanfragen auch das Parsen von Suchanfragen, das es der Suchmaschine ermöglicht, die Suchanfrage besser zu verstehen. Suchanfragen werden so umgeschrieben, dass auch Suchergebnisse geliefert werden können, die nicht direkt mit der Suchanfrage selbst, sondern auch mit verwandten Suchanfragen übereinstimmen. Mehr dazu hier.
Die Verarbeitung von Suchanfragen kann nach dem klassischen schlagwortbasierten Term x Document Matching oder nach einem entitätsbasierten Ansatz erfolgen, je nachdem, ob Entitäten in der Suchanfrage vorkommen und bereits erfasst sind oder nicht.
Eine ausführliche Beschreibung der Suchanfrageverarbeitung finden Sie in dem Artikel Wie versteht Google Suchanfragen durch die Suchanfrageverarbeitung?
Ranking von Suchergebnissen
Das Google-Patent „Ranking Search Results“ gibt einige interessante Einblicke, wie Google heute Suchergebnisse bewerten könnte.
- Empfangen einer Suchanfrage: Eine Suchanfrage wird von einem Client-Gerät empfangen.
- Empfang von Suchergebnisdaten: Es werden Daten empfangen, die eine Vielzahl von Suchergebnis-Ressourcen zusammen mit den jeweiligen Anfangswerten für jede Ressource identifizieren.
- Identifizierung von Ressourcengruppen: Jede Suchergebnis-Ressource ist mit einer bestimmten Gruppe von Ressourcen verbunden.
- Bestimmen von Modifikationsfaktoren: Für jede Gruppe von Ressourcen wird ein gruppenbasierter Modifikationsfaktor bestimmt.
- Anpassen der Anfangswerte: Die Anfangsbewertung für jede Suchergebnisressource wird auf der Grundlage des gruppenspezifischen Modifikationsfaktors angepasst, um eine zweite Bewertung für jede Ressource zu generieren.
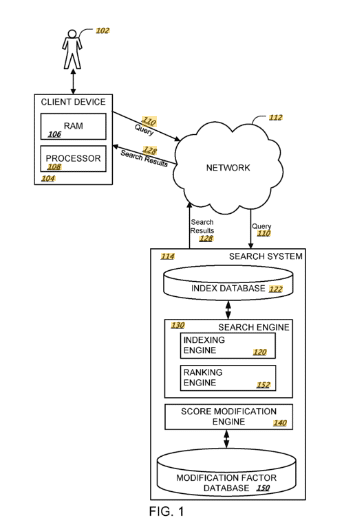
Zusätzliche Aspekte:
- Bereitstellen von Suchergebnissen: Die Suchergebnisse werden dem Client-Gerät zur Verfügung gestellt, wobei jedes Suchergebnis eine entsprechende Suchergebnis-Ressource identifiziert, die in einer Reihenfolge entsprechend der zweiten Punktezahl präsentiert wird.
- Weitere Anpassungen: Vor der Bereitstellung der Suchergebnisse an das Client-Gerät können weitere Anpassungen an den zweiten Punktwerten vorgenommen werden.
- Ressourcenspezifische Modifikationsfaktoren: Das Verfahren kann die Erzeugung eines ressourcenspezifischen Modifikationsfaktors für jede Suchergebnisressource auf der Grundlage der gruppenbasierten Modifikationsfaktoren beinhalten.
- Navigationsabfragen: Die Anpassungen der Punktzahlen können variieren, je nachdem, ob die Suchanfrage eine Navigation zu einer bestimmten Suchergebnisressource darstellt.
- Schwellenwerte: Die Methode umfasst die Erzeugung ressourcenspezifischer Modifikationsfaktoren, die darauf basieren, ob die anfänglichen Punktzahlen bestimmte Schwellenwerte überschreiten, wobei spezifische Formeln für die Berechnung dieser Faktoren bereitgestellt werden.
- Analyse wiederholter Klicks: Das Verfahren kann auch die Analyse wiederholter Klicks auf Gruppen von Ressourcen beinhalten, um den gruppenbasierten Modifikationsfaktor zu bestimmen, einschließlich der Zählung einmaliger und wiederholter Klicks und der Verwendung von Bruchteilen wiederholter Klicks bei der Berechnung der Modifikationsfaktoren.
Der Prozess der Identifizierung von Ressourcengruppen und der Anwendung gruppenbasierter Modifizierungsfaktoren deutet auf einen ausgeklügelten Ansatz für das Suchranking hin, der über die Analyse einzelner Seiten hinausgeht. Durch die Berücksichtigung der kollektiven Merkmale oder Verhaltensweisen, die mit Gruppen von Ressourcen verbunden sind, kann die Suchmaschine ihr Ranking so anpassen, dass es der Absicht des Nutzers besser entspricht und das Sucherlebnis insgesamt verbessert wird. Dieser Ansatz könnte auch dazu beitragen, die Herausforderungen im Zusammenhang mit der Vielfalt der Inhalte im Internet zu bewältigen und sicherzustellen, dass qualitativ hochwertige Ressourcen für die Nutzer besser sichtbar sind.
- Auf der Grundlage der Internetadresse: Eine Methode zur Identifizierung der Ressourcengruppe, zu der die einzelnen Suchergebnisressourcen gehören, ist die Verwendung der Internetadresse (URL) der Suchergebnisressource. Dies deutet darauf hin, dass die Kategorisierung auf der Domäne, der Subdomäne, dem Pfad oder anderen URL-Komponenten basieren könnte, die auf eine Gemeinsamkeit zwischen den Ressourcen hinweisen, wie z. B. die Zugehörigkeit zur selben Website, zum selben Thema oder zum selben Inhaltstyp.
- Gruppenspezifische Merkmale: Auch wenn in den bereitgestellten Zusammenfassungen nicht explizit darauf eingegangen wird, beinhaltet die Identifizierung von Ressourcengruppen wahrscheinlich die Analyse von Merkmalen, die die Einzigartigkeit oder Gemeinsamkeit der Gruppe definieren. Dazu könnten die Art des Inhalts (z. B. Blogbeiträge, Nachrichtenartikel, wissenschaftliche Arbeiten), das Thema (z. B. Technologie, Gesundheit, Finanzen) oder andere semantische oder strukturelle Merkmale gehören.
- Zweck der Gruppenidentifizierung: Die Identifizierung von Ressourcengruppen dient dem Zweck, gruppenbasierte Modifikationsfaktoren im Rankingprozess anzuwenden. Durch die Kategorisierung von Ressourcen in Gruppen kann das System Anpassungen an den anfänglichen Bewertungen der Suchergebnisse vornehmen, die auf dem Verhalten oder den Attributen basieren, die mit jeder Gruppe verbunden sind. Dies ermöglicht eine differenziertere und kontextabhängige Einstufung der Suchergebnisse, wodurch die Relevanz und Qualität der den Nutzern präsentierten Ergebnisse verbessert werden kann.
- Verwendung von gruppenbasierten Modifikationsfaktoren: Nach der Identifizierung der Gruppen beinhaltet die Methode die Bestimmung eines entsprechenden gruppenbasierten Änderungsfaktors für jede Gruppe von Ressourcen. Dieser Faktor wird verwendet, um die anfänglichen Punktzahlen der Suchergebnisressourcen anzupassen. Der Modifikationsfaktor kann durch verschiedene Metriken beeinflusst werden, wie z.B. das Engagement der Nutzer mit den Ressourcen der Gruppe, die Glaubwürdigkeit der Quellen innerhalb der Gruppe oder andere Qualitätsindikatoren.
- Verwendung von Metriken: Zur Bestimmung der Änderungsfaktoren werden wahrscheinlich verschiedene Metriken herangezogen, die die Interaktion der Nutzer mit den Ressourcen einer bestimmten Gruppe widerspiegeln. Dazu könnten Metriken wie Klickraten, Verweildauer auf Ressourcen, Absprungraten oder wiederholte Besuchsmuster gehören. Diese Metriken helfen dabei, den Wert, die Relevanz und die Qualität der Ressourcen innerhalb jeder Gruppe zu bewerten.
- Anpassung auf der Grundlage des Nutzerverhaltens: Eine spezifische Methode zur Bestimmung von Änderungsfaktoren beinhaltet die Analyse wiederholter Klicks auf eine bestimmte Gruppe von Ressourcen. Dies beinhaltet die Bestimmung der Anzahl der einmaligen und wiederholten Klicks auf die Ressourcen einer bestimmten Gruppe, die Erstellung eines Anteils der wiederholten Klicks auf der Grundlage dieser Zählungen und die Verwendung dieses Anteils zur Bestimmung des gruppenbasierten Änderungsfaktors. Dieser Ansatz legt nahe, dass das Engagement und die Interaktionsmuster der Nutzer eine wichtige Rolle bei der Anpassung der Rangfolge der Suchergebnisse spielen.
- Anwendung der Modifikationsfaktoren: Sobald diese gruppenbasierten Modifikationsfaktoren bestimmt sind, werden sie verwendet, um die anfänglichen Punktzahlen der Suchergebnisressourcen anzupassen. Der Anpassungsprozess beinhaltet die Anwendung des Modifikationsfaktors in einer Art und Weise, die die Gesamtqualität, die Relevanz oder den Grad der Nutzerzufriedenheit der Gruppe widerspiegelt. Dies könnte bedeuten, dass die Punktzahl von Ressourcen aus Gruppen mit hoher Glaubwürdigkeit oder hohem Engagement erhöht oder die Punktzahl von Ressourcen aus Gruppen mit geringerem Engagement oder geringerer Glaubwürdigkeit verringert wird.
- Dynamische Ranking-Anpassungen: Die Verwendung von Modifikationsfaktoren ermöglicht dynamische Anpassungen der Rangfolge von Suchergebnissen auf der Grundlage von Echtzeit- oder akkumulierten Nutzerinteraktionsdaten. Dieser dynamische Ansatz trägt dazu bei, den Nutzern die relevantesten und qualitativ hochwertigsten Suchergebnisse zu präsentieren und das Sucherlebnis insgesamt zu verbessern.
- Anpassung und Personalisierung: Obwohl nicht explizit erwähnt, könnte die Methodik zur Bestimmung der Änderungsfaktoren auch eine Anpassung oder Personalisierung der Suchergebnisse auf der Grundlage von benutzerspezifischem Verhalten oder Präferenzen ermöglichen, vorausgesetzt, dass Überlegungen zum Datenschutz und zur Zustimmung der Benutzer berücksichtigt werden.
- Qualitäts- und Relevanzverbesserung: Durch die Anpassung der Suchergebnisse auf der Grundlage von gruppenbasierten Modifikationsfaktoren zielt die Suchmaschine darauf ab, qualitativ minderwertige Ressourcen herabzustufen und qualitativ hochwertigere zu fördern, um sicherzustellen, dass die Nutzer mit größerer Wahrscheinlichkeit das finden, was sie suchen, und zwar ganz oben in den Suchergebnissen.
Anpassung der Anfangswerte
- Gruppenbasierte Modifikationsfaktoren: Die Anpassung der Anfangswerte beinhaltet die Anwendung von gruppenbasierten Modifikationsfaktoren, die durch die Analyse der Merkmale und Benutzerinteraktionsmetriken, die mit jeder Gruppe von Ressourcen verbunden sind, bestimmt werden. Diese Modifikationsfaktoren ermöglichen die Verfeinerung der Suchergebnisse über die ursprüngliche Bewertung hinaus, indem sie zusätzliche Dimensionen der Relevanz und Qualität berücksichtigen, die für Gruppen von Ressourcen spezifisch sind.
- Anpassungsprozess: Der Prozess der Anpassung der anfänglichen Scores kann eine Erhöhung oder Verringerung der Scores basierend auf dem gruppenspezifischen Modifikationsfaktor beinhalten. So können beispielsweise Ressourcen, die zu einer Gruppe mit hohem Nutzerengagement und hoher Nutzerzufriedenheit gehören, eine positive Anpassung erhalten, wodurch sich ihr Ranking in den Suchergebnissen erhöht. Umgekehrt könnten Ressourcen aus Gruppen mit niedrigeren Engagement- oder Zufriedenheitsmetriken nach unten angepasst werden.
- Dynamisches und kontextabhängiges Ranking: Die Anpassung der anfänglichen Punktzahlen mit Hilfe von gruppenbasierten Modifikationsfaktoren führt ein dynamisches und kontextbezogenes Element in den Ranking-Prozess ein. Dieser Ansatz ermöglicht es der Suchmaschine, die Rangfolge der Suchergebnisse auf der Grundlage aktueller Benutzerinteraktionstrends und der kollektiven Merkmale von Ressourcengruppen anzupassen, was zu einem relevanteren und personalisierten Sucherlebnis führen kann.
Implikationen und Überlegungen
- Verbesserte Relevanz und Qualität: Durch die Anpassung der anfänglichen Punktzahlen auf der Grundlage gruppenspezifischer Modifizierungsfaktoren will die Suchmaschine die Relevanz und Qualität der den Nutzern präsentierten Suchergebnisse verbessern. Diese Methode hilft bei der Priorisierung von Ressourcen, die nicht nur individuell relevant sind, sondern auch zu Gruppen gehören, die hohe Qualitäts- oder Engagement-Metriken aufweisen.
- Komplexität und Transparenz: Der Prozess der Anpassung der anfänglichen Punktzahlen erhöht die Komplexität des Suchalgorithmus und wirft Fragen bezüglich der Transparenz und der Fähigkeit von Webmastern auf, ihre Inhalte für die Sichtbarkeit in Suchmaschinen zu optimieren. Dies unterstreicht, wie wichtig es ist, qualitativ hochwertige und ansprechende Inhalte zu erstellen, die den Bedürfnissen der Nutzer entsprechen.
- Anpassungsfähigkeit an sich änderndes Nutzerverhalten: Dieser Ansatz ermöglicht der Suchmaschine eine schnellere Anpassung an sich ändernde Nutzergewohnheiten und -präferenzen, da gruppenbasierte Modifikationsfaktoren auf der Grundlage neuer Daten aktualisiert werden können, wodurch sichergestellt wird, dass die Suchergebnisse im Laufe der Zeit relevant und nützlich bleiben.
Das Patent erklärt auch eine Methodik, die das Ranking von Websites Dritter für Navigationsanfragen verhindert:
The patent also addresses the use of click data.
Durchführen einer Analyse der wiederholten Klicks
- Einmalige und wiederholte Klicks: Bei dieser Methode wird zwischen einmaligen Klicks und wiederholten Klicks auf Ressourcen innerhalb einer bestimmten Gruppe unterschieden. Ein einmaliger Klick ist definiert als ein Klick eines einzelnen Nutzers auf ein Suchergebnis, das eine Ressource in der Gruppe identifiziert und damit ein erstes Interesse signalisiert. Ein wiederholter Klick liegt hingegen vor, wenn derselbe Nutzer während verschiedener Suchsitzungen auf ein Suchergebnis klickt, das dieselbe Ressource oder Ressourcen innerhalb derselben Gruppe identifiziert, was auf anhaltendes Interesse oder Zufriedenheit mit der Ressource hindeutet.
- Berechnung der Repeat Click Fraction (RCF): Die Analyse der Klickwiederholung umfasst die Berechnung des Anteils der Klickwiederholung für eine bestimmte Gruppe von Ressourcen. Dieser Anteil wird durch das Verhältnis von wiederholten Klicks zu einmaligen Klicks auf die Ressourcen innerhalb der Gruppe bestimmt. Der RCF liefert ein quantitatives Maß für das Engagement und die Zufriedenheit der Nutzer, wobei davon ausgegangen wird, dass eine höhere Wiederholungsinteraktion einen höheren Wert oder eine höhere Relevanz der Ressourcen für die Nutzer anzeigt.
- Verwendung der RCF zur Bestimmung von Modifikationsfaktoren: Der Anteil der wiederholten Klicks wird dann verwendet, um den gruppenbasierten Änderungsfaktor zu bestimmen. Dieser Faktor passt die anfängliche Bewertung der Suchergebnisressourcen auf der Grundlage des durch den RCF angezeigten Grads der Benutzerinteraktion und -zufriedenheit an. Gruppen mit höheren RCFs können positive Anpassungen erhalten, was ihren höheren wahrgenommenen Wert für die Nutzer widerspiegelt, während Gruppen mit niedrigeren RCFs geringere Anpassungen erhalten können.
Auswirkungen der Analyse wiederholter Klicks
- Verbesserte Relevanz und Qualität: Durch die Einbeziehung der Analyse wiederholter Klicks in den Rankingprozess kann die Suchmaschine die Relevanz und Qualität von Ressourcen aus Nutzersicht genauer bewerten. Diese Methode ermöglicht eine dynamische Anpassung des Suchrankings auf der Grundlage des tatsächlichen Nutzerverhaltens, was zu einem zufriedenstellenderen Sucherlebnis führen kann.
- Dynamische Feedbackschleife: Durch die Analyse der wiederholten Klicks entsteht eine dynamische Feedbackschleife, in der die Interaktionen der Nutzer direkten Einfluss auf das Ranking der Ressourcen haben. Dadurch wird sichergestellt, dass die Suchmaschine auf die Bedürfnisse und Vorlieben der Nutzer eingeht und sich im Laufe der Zeit an das veränderte Nutzerverhalten anpasst.
- Balance zwischen Exploration und Nutzung: Die Methode schafft ein Gleichgewicht zwischen der Notwendigkeit der Exploration (Entdeckung neuer, relevanter Ressourcen) und der Notwendigkeit der Nutzung (Nutzung bekannter, wertvoller Ressourcen). Durch die Anpassung des Rankings auf der Grundlage wiederholter Klicks kann die Suchmaschine besser auf die unmittelbaren Bedürfnisse der Nutzer eingehen und gleichzeitig die Entdeckung neuer Inhalte fördern.
- Fairness und Vielfalt: Die Analyse wiederholter Klicks kann das Ranking hochinteressanter Ressourcen verbessern, erfordert aber auch Mechanismen, die Fairness und Vielfalt in den Suchergebnissen gewährleisten. Dies bedeutet, dass ein Gleichgewicht zwischen der Förderung häufig angeklickter Ressourcen und der Einbeziehung neuer oder weniger bekannter Ressourcen, die für die Suchanfrage ebenso relevant sein können, gefunden werden muss.
Google-Ranking-Systeme
Google unterscheidet hier zwischen den folgenden Rankingsystemen:
- KI-Ranking-Systeme
- Rankbrain
- BERT
- MUM
- Kriseninformationssysteme
- Deduplizierungssysteme
- System der exakten Übereinstimmung von Domänen
- Freshness-System
- System für hilfreiche Inhalte
- Linkanalysesysteme und PageRank
- Lokale Nachrichtensysteme
- Neuronaler Abgleich
- Systeme für ursprüngliche Inhalte
- Auf Entfernung basierende Herabstufungssysteme
- System für Seitenerfahrung
- Passage-Ranking-System
- Produktbewertungssystem
- System für verlässliche Informationen
- System für Seitenvielfalt
- Spam-Erkennungssystem
Ausgeschiedene Systeme
- Hummingbird (wurde weiter entwickelt)
- Mobile friendly ranking system (jetzt Teil des Page experience system)
- System für die Seitengeschwindigkeit (jetzt Teil des Systems für das Seitenerlebnis)
- Panda-System (Teil des Kernsystems seit 2015)
- Penguin-System (Teil des Kernsystems seit 2016)
- System für sichere Websites (jetzt Teil des Seitenerlebnissystems)
Diese Rankingsysteme werden in verschiedenen Prozessschritten der Google-Suche eingesetzt.
Deep Learning Modelle und andere Komponenten für das Ranking
Nach Aussagen von Googles Pandu Nayak im Rahmen des Kartellverfahrens 2023/2024 nutzt Google folgende Deep Learning-Modelle und -Komponenten für das Ranking.
- Rankbrain
- DeepRank
- RankEmbed BERT
- Navboost
- Tangram und Glue

Was ist Rankbrain?
Google RankBrain ist ein Algorithmus mit künstlicher Intelligenz, der Teil des Suchmaschinenalgorithmus von Google ist und Ende 2015 eingeführt wurde. Seine Hauptaufgabe besteht darin, Suchanfragen besser zu verstehen und die Suchergebnisse zu verbessern, insbesondere bei neuen, einzigartigen oder komplexen Anfragen, die Google bisher nicht kannte.
RankBrain nutzt maschinelles Lernen, um Muster in Suchanfragen zu erkennen und die Bedeutung hinter Wörtern zu verstehen. Es zielt darauf ab, die Absicht hinter einer Suchanfrage zu interpretieren, um relevantere Suchergebnisse zu liefern, selbst wenn die genauen Wörter der Anfrage nicht auf den Webseiten vorhanden sind. Dadurch ist RankBrain besonders effektiv bei der Bearbeitung vager oder mehrdeutiger Suchanfragen.
Eine interessante Eigenschaft von RankBrain ist seine Fähigkeit zur Selbstverbesserung. Es lernt kontinuierlich aus Suchanfragen und dem Klickverhalten der Nutzer, um seine Algorithmen zu verfeinern und die Genauigkeit der Suchergebnisse zu erhöhen.
Rankbrain wird nur auf die ersten 20-30 Dokumente angewandt und passt die anfänglichen Punktzahlen dieser Inhalte an. Da Rankbrain sehr teuer ist, wird es nur für eine Vorauswahl von Dokumenten mit den höchsten Anfangswerten verwendet.

Was ist Deeprank?
Google DeepRank wird oft mit RankBrain verwechselt oder in Verbindung mit RankBrain genannt, aber es ist wichtig, zwischen den beiden zu unterscheiden. Während RankBrain eine bekannte Komponente des Google-Algorithmus ist, die sich darauf konzentriert, Suchanfragen durch maschinelles Lernen zu verstehen, bezieht sich DeepRank speziell auf Googles Bemühungen, die Suchergebnisse zu verbessern, indem die Relevanz bestimmter Passagen einer Seite für eine Suchanfrage besser verstanden wird.
DeepRank ist kein separater Algorithmus, sondern vielmehr ein Teil des umfassenderen Suchalgorithmus von Google, der um das Jahr 2020 herum genauer vorgestellt wurde. Sein Schwerpunkt liegt auf der Fähigkeit, einzelne Passagen von Webseiten in den Suchergebnissen zu verstehen und zu bewerten, nicht nur die Seite als Ganzes. Das bedeutet, dass Google selbst dann, wenn ein kleiner Abschnitt einer Seite für eine Suchanfrage sehr relevant ist, diese Passage identifizieren und einstufen kann, so dass die Nutzer die beste Übereinstimmung mit ihren Suchanforderungen finden können, selbst wenn der Rest der Seite ein etwas anderes Thema behandelt.
Deeprank stärkt Rankbrain als unterstützenden Algorithmus. Während BERT das grundlegende KI-Modell ist, stützt sich Deeprank beim Ranking auf BERT.

Die Einführung dieser Technologie war ein großer Fortschritt für die Suchfunktionen von Google, da sie eine feinere Granularität beim Verständnis von Inhalten ermöglicht. Dies ist vor allem bei langen, detaillierten Seiten von Vorteil, bei denen bestimmte Passagen für eine Suchanfrage sehr relevant sein können, auch wenn die Seite ein breiteres Thema behandelt.
Was ist RankEmbed BERT?
RankEmbed BERT ist ein fortschrittlicher Algorithmus, der von Google verwendet wird, um die Relevanz und Genauigkeit von Suchergebnissen zu verbessern, indem die Sprache und der Kontext von Nutzeranfragen besser verstanden werden. Diese Technologie integriert die Fähigkeiten von BERT (Bidirectional Encoder Representations from Transformers), einem Deep-Learning-Algorithmus zur Verarbeitung natürlicher Sprache (Natural Language Processing, NLP), in den Ranking-Prozess von Google, wobei der Schwerpunkt auf dem Verständnis von Anfragen und Webseiteninhalten liegt.
Innerhalb des Ranking-Systems von Google trägt RankEmbed-BERT neben anderen fortschrittlichen Deep-Learning-Modellen wie RankBrain und DeepRank dazu bei, die endgültige Rangfolge der Suchergebnisse zu bestimmen. Es funktioniert insbesondere in der Phase der Neueinstufung nach dem ersten Aufruf der Ergebnisse. Das Modell wird anhand von Klick- und Abfragedaten trainiert und mit den Erkenntnissen menschlicher Bewerter über die Informationszufriedenheit (IS) verfeinert. Im Vergleich zu einfacheren Feedforward-Modellen wie RankBrain ist das Training von RankEmbed BERT rechenintensiver, was seine hochentwickelten Fähigkeiten zur Verbesserung der Relevanz und Genauigkeit von Suchergebnissen widerspiegelt.
Rankembed BERT wurde vor BERT veröffentlicht und dann mit BERT erweitert. Rankembed BERT wird ebenfalls mit Klick- und Suchdaten trainiert.

Was ist NavBoost?
NavBoost wurde entwickelt, um die Suchergebnisse für navigationsbezogene Suchanfragen zu verbessern. NavBoost konzentriert sich auf die Verbesserung des Nutzererlebnisses, indem es relevantere und genauere Ergebnisse für solche Suchanfragen liefert. NavBoost analysiert die Benutzerinteraktionen, einschließlich der Klicks, um die relevantesten Ergebnisse zu ermitteln. NavBoost speichert vergangene Klicks für Suchanfragen bis zu 13 Monate (18 Monate vor 2017), um seinen Entscheidungsprozess zu unterstützen.
NavBoost wird auch als „Glue“ bezeichnet, was alle Funktionen auf einer Suchmaschinenergebnisseite (SERP) umfasst, die nicht zu den Webergebnissen gehören, wie z. B. Klicks, Hover, Scrolling und Swipes. Dieses System erzeugt eine gemeinsame Metrik zum Vergleich von Suchergebnissen und Funktionen, was auf eine breitere Anwendung über reine Navigationsanfragen hinaus hindeutet. Der Algorithmus führt eine „Culling“-Funktion durch, um Suchergebnisse auf der Grundlage von Merkmalen wie Standort und Gerätetyp zu trennen und so die Relevanz der Suchergebnisse zu verbessern.
Wenn du tiefer in die Welt des maschinellen Lernens und des Rankings eintauchen möchten, lies meinen Überblick über Patente und Forschung im Bereich Deep Learning & Ranking von Marc Najork.
Wie arbeiten die unterschiedlichen Rankingsysteme zusammen?
Zunächst muss Google im Zuge einer Suchanfrage einen thematisch passenden Korpus von meist Tausenden von Dokumenten zusammenstellen. Aus diesen Tausenden von Dokumenten wählt Google dann einige Hundert Dokumente für ein spezielles Dokumentenscoring aus. Dazu verwendet Google Aktualitätssignale, Page Rank, Lokalisierungssignale…

Dann werden die Deep-Learning-Systeme für das Ranking verwendet.

Das Dokumentenscoring verwendet klassische Information-Retrieval-Signale und Faktoren wie Keywords, TF-IDF, interne und externe Links usw., um die objektive Relevanz eines Dokuments in Bezug auf die Suchanfrage zu bestimmen.
Das Ranking kann dann auf der Basis von Deep-Learning-Systemen erfolgen, die sowohl Nutzerdaten als auch Qualitätssignale oder Signale, die dem E-E-A-T-Konzept zugeordnet werden können, zum Training verwenden. Da diese Signale zur Erkennung von Relevanz-, Kompetenz-, Autoritäts- und Vertrauensmustern verwendet werden, erfolgt das Ranking mit einer zeitlichen Verzögerung.
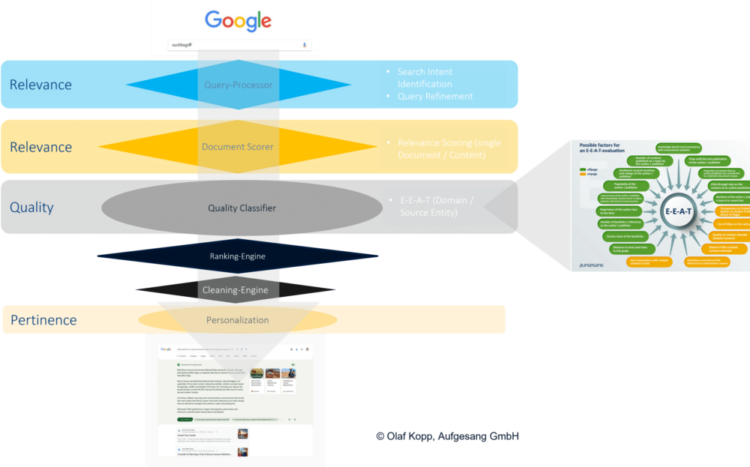
Anhand der Nutzerdaten kann festgestellt werden, welche Art von Inhalten die Nutzer bei einer Suchanfrage bevorzugen. Sind es lange, umfassende Inhalte oder eher kurze Checklisten, Anleitungen oder Definitionen? Daher ist es wichtig, die Suchintentionen nach Micro Intents zu klassifizieren. Siehe meine beiden Artikel How to use 12 micro intents for SEO and content journey mapping und Micro intents and their role in the customer journey.
Ich denke, dass ein iteratives Re-Ranking auf Basis von Nutzerdaten bereits nach wenigen Wochen möglich ist, je nachdem wie schnell Google genügend Nutzerdaten gesammelt hat. Beim Lernen aus E-E-A-T-Signalen dauert es länger, weil das Sammeln von Vertrauensmustern und das Trainieren der Algorithmen viel komplexer ist. Die Core Updates scheinen hier für das Ranking verantwortlich zu sein.
Nach meinem Verständnis bewertet Google auf drei verschiedenen Ebenen. (Mehr dazu im Artikel Die Dimensionen des Google-Rankings)
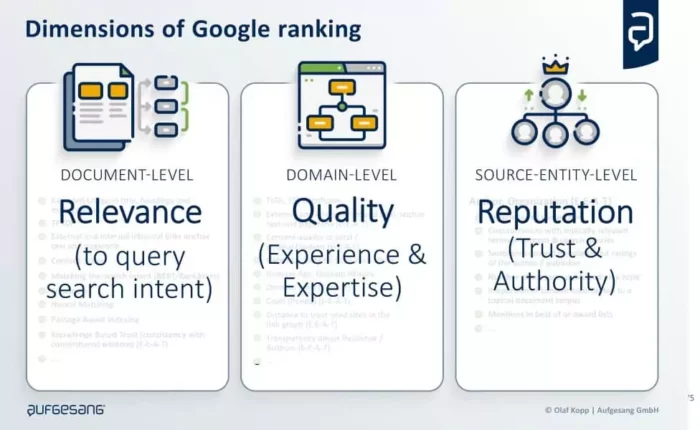
Dokumentenebene:
Auf der Dokumentebene wird der Inhalt hinsichtlich seiner Relevanz für die Suchabsicht bewertet.
Dies kann in mehreren Schritten geschehen. Zunächst wird der Inhalt anhand klassischer Information-Retrieval-Faktoren wie der Verwendung von Schlagwörtern im Fließtext, in Überschriften, Seitentiteln etc. verwendet, um ein Scoring zu erstellen. In einem zweiten Schritt wird der Inhalt auf Basis der Nutzersignale neu klassifiziert. Dazu können die Deep Learning Modelle und Komponenten verwendet werden.
Die Nutzersignale und die Eingaben der Qualitätsbewerter werden verwendet, um ein KI-Modell zu trainieren, das neue Relevanzattribute und damit Muster für das ursprüngliche Ranking identifiziert und die Reihenfolge der Ergebnisse entsprechend der Nutzersignale neu anpasst.
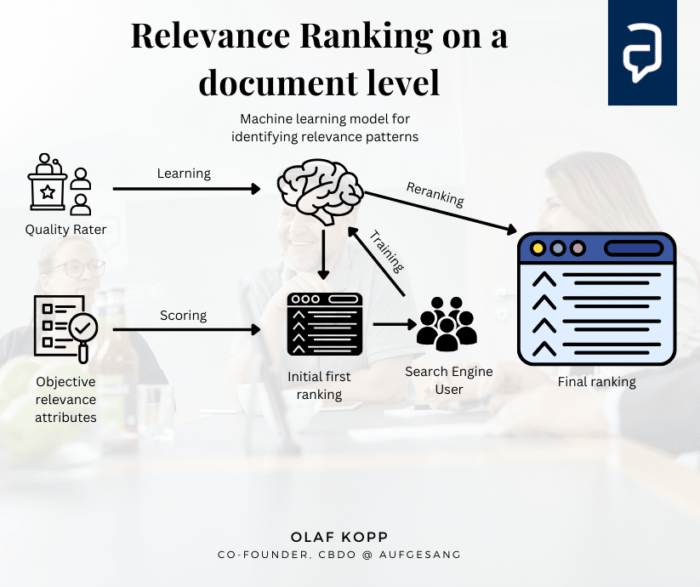
Abgleich von Suchanfrage und Dokumentmerkmalen
- Objektive, von der Suchanfrage unabhängige Bewertung der Relevanz: Dokumente werden danach bewertet, wie gut ihre Merkmale mit den Merkmalen der Suchanfrage übereinstimmen. Diese Bewertung kann komplexe Algorithmen umfassen, die die Häufigkeit und Position von Schlüsselwörtern im Dokument, die allgemeine thematische Relevanz des Dokuments und die Qualität des Inhalts berücksichtigen.
- Abfrageabhängige Ranking-Faktoren: Neben dem grundsätzlichen Matching berücksichtigt die Suchmaschine auch anfrageabhängige Faktoren wie den Standort des Nutzers, das verwendete Gerät, Personalisierungseinstellungen oder die Suchhistorie, die die Relevanz von Dokumenten für die jeweilige Anfrage beeinflussen können.
Nutzung früherer Interaktionen
- Lernen aus dem Nutzerverhalten: Verwendung von Aktionen, die mit Dokument- und Abfragemerkmalen verknüpft sind, auf der Grundlage früherer Interaktionen. Dies bedeutet, dass die Suchmaschine lernt, wie Benutzer in der Vergangenheit mit Dokumenten interagiert haben (Klickraten, Verweildauer auf einer Seite usw.), um vorherzusagen, welche Dokumente für eine bestimmte Anfrage relevanter oder nützlicher sein könnten.
- Anpassung der Rangfolge: Die Relevanzwerte und die Rangfolge der Dokumente können auf der Grundlage des gelernten Verhaltens angepasst werden, wobei Dokumente, die in der Vergangenheit ähnliche Suchanfragen beantwortet haben, bevorzugt werden.
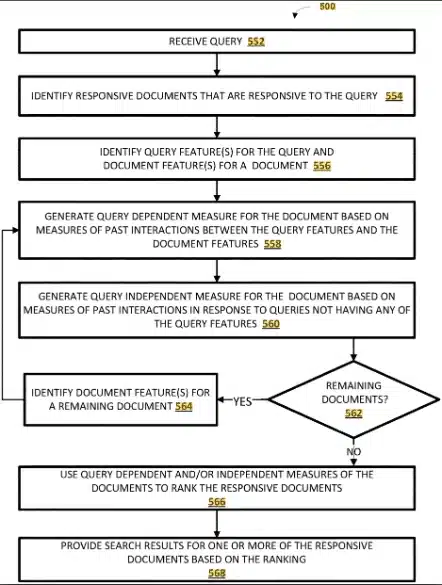
Ranking search result documents, US10970293B2
Die Signale der Nutzer, die Google erhält, werden verwendet, um die Ranking-Algorithmen zu trainieren, insbesondere die Algorithmen des maschinellen Lernens, die die Ergebnisse neu ordnen. Wie das genau funktioniert, können Sie in meiner Zusammenfassung des Patents Training a Ranking Model nachlesen.
Sitewide Website-Bereich und Domain-Ebene
Auf der Domain-Ebene werden Website-Bereiche oder ganze Domains nach Erfahrung und Expertise in ihrer Qualität eingestuft. Das Help Content System, https, Page Experience … können hier eine Rolle spielen.
Wie im Patent Website Representation Vectors beschrieben, können diese Websites dann in verschiedene Kompetenzstufen in Bezug auf bestimmte Themen klassifiziert werden.
Auch hier können Deep-Learning-Modelle eingesetzt werden, um Muster für qualitativ hochwertige Autoren und thematische Autorität zu erkennen.
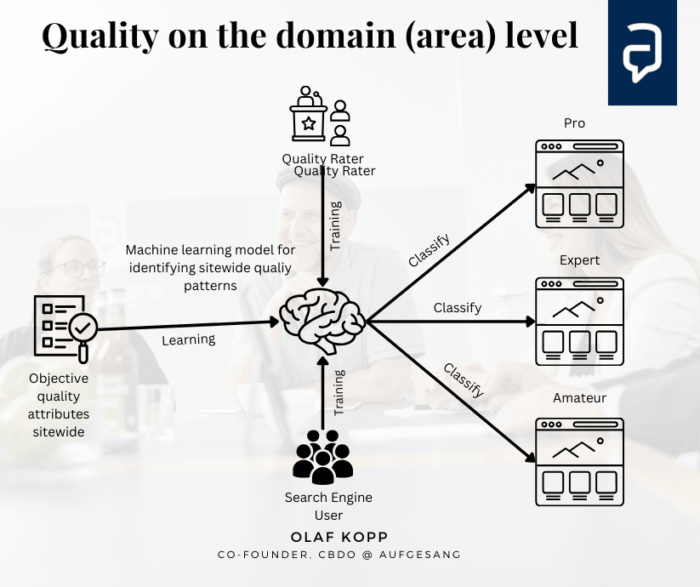
Source Entity Ebene
Auf dieser Ebene kann Google den Autor in Form von Organisationen und Autoren in Bezug auf Autorität und Reputation bewerten. In dem Artikel Die interessantesten Google-Patente und wissenschaftlichen Arbeiten auf E-E-A-T finden Sie viele fundierte Recherchen zu Patenten und wissenschaftlichen Arbeiten.
Die Eingaben der Qualitätsbewerter sowie objektive Signale für die Autorität einer Marke werden zum Lernen und Trainieren eines KI-Modells verwendet.
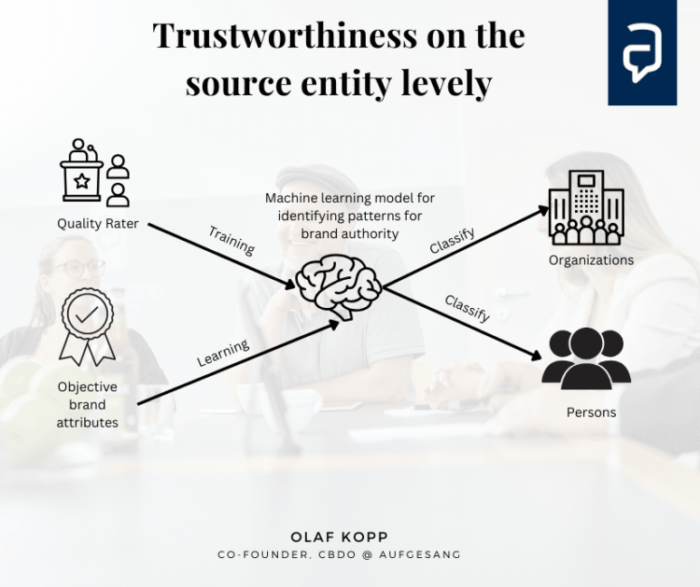
Eine Übersicht über mögliche Signale, insbesondere für die Auswertung auf Domänen- und Entitätsebene, finden Sie hier:
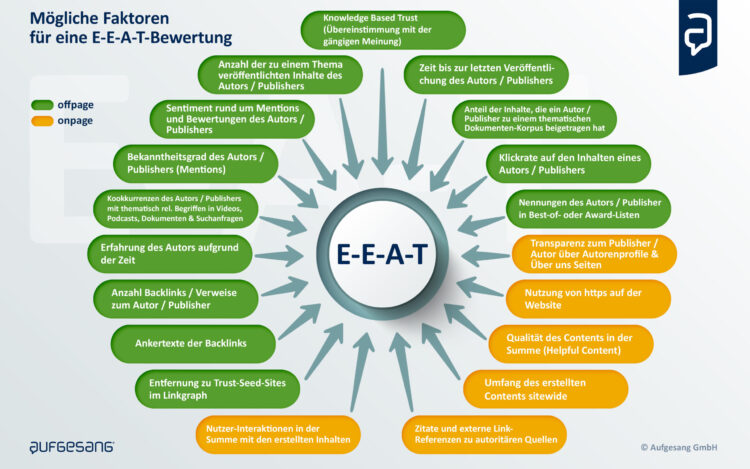
Schließlich versuche ich, die vielen Informationen von Google über die Funktionalität ihrer Suchmaschinen in ein Gesamtbild zu bringen.
Für die Interpretation von Suchanfragen, die Identifikation von Suchintentionen, das Query Refinement, das Query Parsing und das Search Term Document Matching ist ein Query Processor zuständig.
Der Entity Processor oder Semantic API bildet die Schnittstelle zwischen dem Knowledge Graph und dem klassischen Suchindex. Diese kann für Named Entity Recognition und Data Mining für den Knowledge Graph bzw. Knowledge Vault genutzt werden, z.B. über Natural Language Processing. Mehr dazu im Artikel „Natural Language Processing to build a semantic database„.
Für das Google-Ranking sind eine Scoring Engine, ein Entity- und Sitewide Qualifier und eine Ranking Engine zuständig. Bei den Rankingfaktoren unterscheidet Google zwischen anfrageabhängigen (z.B. Keywords, Proximity, Synonyme…) und anfrageunabhängigen Rankingfaktoren (z.B. PageRank, Sprache, Page Experience…). Ich würde noch zwischen dokumentbezogenen Rankingfaktoren und domänen- bzw. entitätsbezogenen Rankingfaktoren unterscheiden.
Bei der Scoring Engine findet eine Relevanzbewertung auf Dokumentenebene in Bezug auf die Suchanfrage statt. Beim Entity- und Sitewide-Qualifier geht es um die Bewertung des Herausgebers bzw. Autors sowie die Qualität des Inhalts insgesamt in Bezug auf Themen und UX der Website (Domains).
Die Ranking Engine fasst die Punkte aus der Scoring Engine und dem Entity- und Sitewide-Qualifier zusammen und erstellt ein Ranking der Suchergebnisse.
Eine Cleaning Engine sortiert doppelte Inhalte aus und bereinigt die Suchergebnisse von Inhalten, die einen Penalty erhalten haben.
Ein Personalization Layer schließlich berücksichtigt Faktoren wie die Suchhistorie oder bei regionalen Suchintentionen den Standort oder andere lokale Rankingfaktoren.
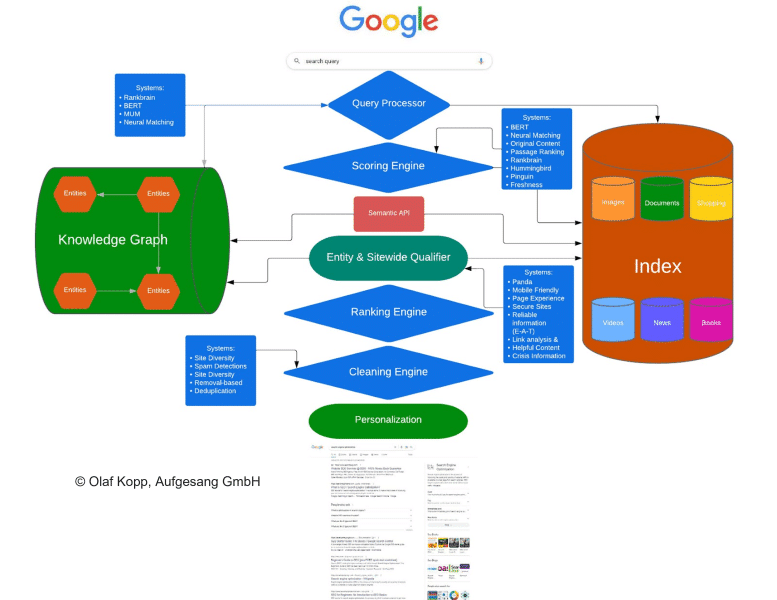
Mehr dazu wie die Google-Suche heute funktioniert:
Der Beitrag Die Google Suche: So funktioniert das Ranking der Suchmaschine heute erschien zuerst auf Aufgesang.
Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO 30 Nov 2023 1:12 PM (last year)
Google hat dieses Jahr viele Patente veröffentlicht und erneut veröffentlicht. Dieser Artikel behandelt die 11 interessantesten Google-Patente.
Die Recherche zu Google-Patenten ist eine der intelligentesten Möglichkeiten, moderne Suchmaschinen wie Google zu verstehen.
Ein Pionier der Google-Patentforschung war der unvergessliche Bill Slawski. Er verstarb im Sommer 2022 vorzeitig. Er inspirierte mich dazu, selbst zu Google-Patente zu recherchieren und meine eigenen Gedanken und Theorien aus Google-Patenten zu verfassen.
Spiegeln die Patente die tatsächlichen Praktiken von Google wider?
Nur weil Google eine Patentanmeldung einreicht und veröffentlicht, ist das keine Garantie dafür, dass die beschriebenen Methoden in der Google-Suche implementiert werden. Um zu beurteilen, ob Google eine Methodik oder Technologie für überzeugend genug hält, um sie in der Praxis anzuwenden, kann man prüfen, ob das Patent nicht nur in den USA, sondern auch in anderen Ländern angemeldet ist. Ein Anspruch auf Patentpriorität in anderen Ländern muss innerhalb von 12 Monaten nach der Erstanmeldung geltend gemacht werden.
In diesem Artikel gehe ich nur auf Google-Patente ein, die auch außerhalb der USA veröffentlicht werden.
Auch wenn ein Patent nicht direkt in die Praxis umgesetzt wird, ist die Prüfung der Patente von Google wertvoll. Es bietet Einblicke in die Themen und Herausforderungen, auf die sich die Produktentwickler von Google konzentrieren.
Die folgenden Patente sind nicht nach Priorität sortiert.
Search result filters from resource content
Die Google-Suche wird mit mehr Filtern zur Verfeinerung der Suche noch intelligenter. Dieses neue Patent könnte eine Grundlage für die Filtermethodik sein.
Kennung:US11797626B2
Länder: USA, China, Europa, Russland
Erscheinungsdatum: Oktober 2023
Das Patent beschreibt ein System zur Verbesserung des Sucherlebnisses durch die dynamische Generierung von Suchabfragefiltern, die auf den Inhalt von Ressourcen (wie Webseiten) zugeschnitten sind, die für die Suchanfrage eines Benutzers relevant sind. Ziel dieses Ansatzes ist es, die Relevanz und Vielfalt der Suchmöglichkeiten zu verbessern.
Konzeptübersicht:
- Datenverarbeitung: Das System beginnt mit der Analyse der Suchanfrage eines Benutzers, um relevante Ressourcen wie Webseiten oder Dokumente zu identifizieren.
- Schlüsselwortextraktion: Nach der Identifizierung relevanter Ressourcen werden Schlüsselbegriffe aus deren Inhalt extrahiert. Diese Schlüsselwörter spiegeln die Hauptthemen oder Themen innerhalb der Ressourcen wider. Beispielsweise könnte eine Suche nach „besten Smartphones 2023“ Schlüsselwörter wie „Akkulaufzeit“, „Kameraqualität“ und „5G-Unterstützung“ ergeben.
- Filterauswahl: Das System verfeinert diese extrahierten Schlüsselwörter zu einer Reihe von Abfragefiltern. Es verwendet Kriterien wie Diversität und Differenzschwellen, um sicherzustellen, dass jeder Filter eine einzigartige Perspektive auf die Suchergebnisse bietet. Folglich werden Filter wie „Beste Kamerahandys“, „5G-Smartphones“ und „Telefone mit langer Akkulaufzeit“ gebildet, die jeweils auf unterschiedliche Teilmengen der Suchergebnisse verweisen.
- Benutzerinteraktion: Diese Abfragefilter werden dem Benutzer dann zusammen mit seinen Suchergebnissen angezeigt. Mit dieser Funktion können Benutzer ihre Suche basierend auf bestimmten Interessen weiter verfeinern. Die Filter sind dynamisch und ändern sich als Reaktion auf die Suchanfrage und den Inhalt der aktuell verfügbaren Ressourcen. Beispielsweise würde bei der Smartphone-Suche die Auswahl des Filters „Beste Kamerahandys“ die Ergebnisse eingrenzen, um sich auf Telefone mit überlegener Kameraqualität zu konzentrieren.
Zusammenfassend bietet dieses System ein verfeinertes, benutzerorientiertes Sucherlebnis, indem es Suchanfragen verarbeitet, relevante Schlüsselwörter extrahiert, verschiedene Filter erstellt und eine dynamische Benutzerinteraktion mit diesen Filtern ermöglicht.
SEO-Implikationen
Für SEO-Profis ist es wichtig, die Nuancen dieser dynamischen Suchfiltersysteme zu verstehen. Es unterstreicht die Notwendigkeit, abwechslungsreiche, reichhaltige und relevante Inhalte zu erstellen, die gut auf die potenziellen Suchfilter abgestimmt sind. Diese Ausrichtung ermöglicht es Websites, sich effektiv in den Suchergebnissen zu positionieren und gezielt auf die unterschiedlichen Interessen und Suchanfragen der Nutzer einzugehen.
- Schwerpunkt auf vielfältigen und relevanten Inhalten: SEO-Strategien müssen sich auf die Entwicklung von Inhalten konzentrieren, die ein breites Spektrum relevanter Themen innerhalb eines bestimmten Bereichs abdecken. Dieser Ansatz beeinflusst wahrscheinlich die dynamischen Filter, die eine Suchmaschine generieren könnte, und verbessert dadurch die Sichtbarkeit der Website.
- Keyword-Optimierungn: Ein tiefes Verständnis der relevantesten und vielfältigsten Schlüsselwörter in einer bestimmten Domain ist heute wichtiger denn je. Diese Schlüsselwörter beeinflussen wahrscheinlich die Suchfilter und sind somit ein Schlüsselfaktor dafür, wie Inhalte entdeckt und eingestuft werden.
- Ausrichtung an der Benutzerabsicht: SEO-Bemühungen sollten auf ein genaues Verständnis und die Erfüllung der Benutzerabsichten ausgerichtet sein. Da sich Suchmaschinen zunehmend darauf konzentrieren, mithilfe von Filtern dynamisch auf Benutzerabsichten einzugehen, wird die Ausrichtung auf diese Absichten zu einer strategischen Notwendigkeit.
- Bleiben Sie auf dem Laufenden über neue Trends: Es ist von entscheidender Bedeutung, über neue Schlüsselwörter und Trends in einer bestimmten Domain auf dem Laufenden zu bleiben. Diese neuen Elemente könnten schnell in die dynamischen Filter integriert werden und sich auf die Relevanz der Suchergebnisse auswirken.
- Verbesserung des Benutzerengagements: Websites sollten danach streben, umfassende und vielfältige Informationen anzubieten. Dies bindet Benutzer nicht nur effektiver ein, sondern wirkt sich möglicherweise auch darauf aus, wie sie in den gefilterten Suchergebnissen angezeigt werden, und beeinflusst dadurch ihre allgemeine Suchsichtbarkeit.
Evaluating an Interpretation for a Search Query
Für Suchmaschinen ist es von entscheidender Bedeutung, die Bedeutung und Absicht einer Suchanfrage zu erkennen. Dieses Patent könnte Teil der Methodik sein.
Das Patent enthält insbesondere einen Verweis auf BERT (Bidirektionale Encoderdarstellungen von Transformers), was darauf hindeutet, dass diese Methodik im Zusammenhang mit der Anwendung von BERT in Suchalgorithmen relevant sein könnte.
Kennung:US20230334045A1
Länder: USA, China, Südkorea, Europa
Erscheinungsdatum: Oktober 2023
Das Patent beschreibt ein System und eine Methode zur Bewertung der Genauigkeit menschlicher Interpretationen von Suchanfragen, die zwei unterschiedliche Modelle umfassen:
- Erstes Modell: Dieses Modell wird anhand eines Datensatzes trainiert, der historische Suchanfragen, ihre menschlichen Interpretationen und von Menschen zugewiesene Bezeichnungen enthält, die die Genauigkeit dieser Interpretationen anzeigen. Seine Hauptfunktion besteht darin, zunächst die Genauigkeit einer menschlichen Interpretation einer Suchanfrage zu bestimmen.
- Zweites Modell: Aufbauend auf der Erstbewertung des ersten Modells integriert dieses Modell zusätzliche Faktoren wie zeitbezogene und Cluster-Merkmale der Suchanfrage. Seine Aufgabe besteht darin, ein endgültiges Urteil über die Genauigkeit der menschlichen Interpretation der Suchanfrage zu fällen.
Das Google-Patent befasst sich mit dem Konzept der Gruppierung oder Clusterung von Suchanfragen, einem Schlüsselaspekt seiner Methodik zur Bewertung von Interpretationen von Suchanfragen.
Das Patent beinhaltet das Konzept der Suchabsicht, auch wenn der Begriff „Suchabsicht“ möglicherweise nicht ausdrücklich erwähnt wird. Der Fokus des Patents auf die Genauigkeit menschlicher Interpretationen von Suchanfragen beinhaltet von Natur aus das Erkennen des beabsichtigten Zwecks oder Ziels des Benutzers hinter seiner Suchanfrage, was den Kern der Suchabsicht ausmacht. Hier ist ein Überblick darüber, wie das Patent implizit die Suchabsicht berücksichtigt:
Menschliche Interpretation von Suchanfragen:
Die Bewertung der Genauigkeit menschlicher Interpretationen von Suchanfragen durch das System erfordert grundsätzlich ein Verständnis der beabsichtigten Bedeutung oder des beabsichtigten Ziels des Benutzers. Dieses Verständnis ist von zentraler Bedeutung für das Konzept der Suchabsicht.
Verfeinerungen der Suchanfrage:
Das Patent diskutiert die Identifizierung nachfolgender Suchanfragen als Verfeinerungen früherer Suchanfragen. Dieser Prozess ist untrennbar mit der Suchabsicht verbunden, da Benutzer ihre Suche häufig verfeinern, wenn die ersten Ergebnisse ihre Absicht nicht vollständig erfüllen, was zu Anpassungen ihrer Abfragen führt, um präzisere Ergebnisse zu erzielen.
Zeit- und Clusterfunktionen:
Durch die Berücksichtigung von Zeit- und Clustermerkmalen im Bewertungsprozess befasst sich das System indirekt mit dem Kontext und den Nuancen der Suchabsicht. Beispielsweise kann der Zeitpunkt der Abfragen oder deren Gruppierung innerhalb bestimmter Themencluster Aufschluss über die angestrebten Ziele der Nutzer geben.
Trainingsdatensatz mit vom Menschen bewerteten Etiketten:
Die Einbeziehung menschlicher Interpretationen und ausgewerteter Bezeichnungen für frühere Suchanfragen in den Trainingsdatensatz weist darauf hin, dass das System aus früheren Fällen lernt, in denen menschliches Urteilsvermögen zum Verständnis der Absicht hinter einer Suchanfrage genutzt wurde.
Vektorsatzdarstellungen und Distanzalgorithmen:
Die Verwendung von Vektorsatzdarstellungen und Distanzalgorithmen beim Parsen und Gruppieren von Abfragen hängt mit dem Verständnis der Suchabsicht zusammen. Diese Technologien helfen dabei, die semantischen Bedeutungen und Feinheiten von Abfragen zu verstehen, die für die Erkennung der Benutzerabsichten von entscheidender Bedeutung sind.
SEO-Implikationen:
- Schwerpunkt auf genauer Abfrageinterpretation: SEO-Strategien sollten die Ausrichtung von Inhalten auf die wahrscheinlichen Interpretationen von Suchanfragen durch Benutzer priorisieren. Das Verstehen und Abgleichen der erwarteten Interpretationen der Benutzeranfragen ist für eine effektive Suchmaschinenoptimierung von entscheidender Bedeutung.
- Bedeutung von Kontext und Zeitlichkeit: Es ist wichtig, dass Inhalte unter Berücksichtigung des zeitlichen Kontexts und einer möglichen Häufung von Themen oder Schlüsselwörtern optimiert werden. Dieser Ansatz stellt sicher, dass der Inhalt relevant bleibt und basierend auf neuen Trends und zeitkritischen Abfragen genau indiziert wird.
- Anpassung an Suchverfeinerungen: Die Optimierung von Websites für verfeinerte Suchen ist wichtig, da diese Verfeinerungen auf anfängliche Missverständnisse oder Fehlinterpretationen durch Suchmaschinen hinweisen können. Ein Fokus auf die Beantwortung verfeinerter Suchanfragen kann die Relevanz und Genauigkeit einer Website in den Suchergebnissen verbessern.
- Nutzung natürlicher Sprachverarbeitung (NLP): Mit der Integration von Methoden wie BERT in Suchmaschinen wird die Einbeziehung von NLP-Strategien in die Inhaltserstellung immer wichtiger. Diese Angleichung an die Abfrageinterpretationsmethoden von Suchmaschinen kann die Sichtbarkeit und Relevanz einer Website in den Suchergebnissen verbessern.
Generative summaries for search results
Dieses Patent ist das einzige in dieser Liste, was bisher nur in US veröffentlicht wurde. Aufgrund der Nähe zu SGE habe ich es hier dennoch mit aufgenommen.
Kennung:US11769017B1
Länder: USA
Erscheinungsdatum: 26. September 2023

Dieses Google-Patent beschäftigt sich mit der Verwendung von großen Sprachmodellen (LLMs) zur Generierung von natürlichsprachigen Zusammenfassungen in Antwort auf Suchanfragen.
Das Patent beschreibt eine Methode, die die selektive Verwendung eines großen Sprachmodells (LLM) zur Generierung von natürlichsprachigen (NL) Zusammenfassungen in Antwort auf Benutzeranfragen beinhaltet. Es führt die Idee ein, zusätzliche Inhalte über die Anfrage hinaus mithilfe des LLM zu verarbeiten, um genauere und kontextbewusstere NL-Zusammenfassungen zu generieren. Das Ziel ist es, Ungenauigkeiten sowie Über- oder Unterbeschreibungen der generierten Zusammenfassungen zu reduzieren.
Prozess:
- Verarbeitung zusätzlicher Inhalte, einschließlich Suchergebnis-Dokumenten, die auf die Anfrage reagieren.
- Generierung von Zusammenfassungen basierend auf verschiedenen zusätzlichen Inhalten, um die Relevanz für den Benutzer zu erhöhen.
- Überarbeitung von Zusammenfassungen basierend auf Benutzerinteraktion mit den Suchergebnissen.
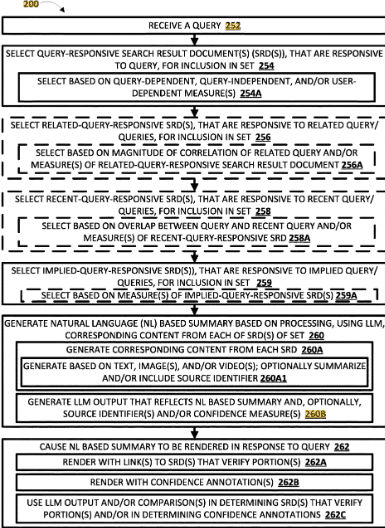
Faktoren:
- Unterschiedliche Verarbeitung von zusätzlichem Inhalt für verschiedene Anfragen.
- Berücksichtigung des Kontext des Nutzers mit bestimmten Inhalten.
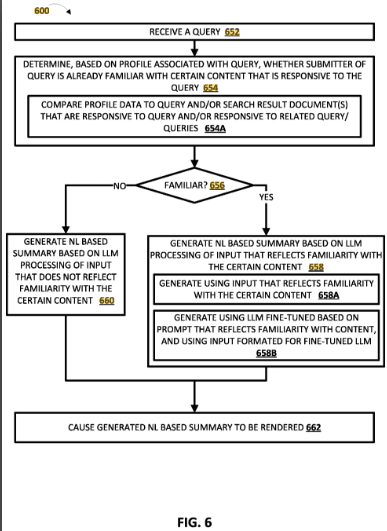
Die Methoden aus diesem Patent nutzen LLMs, um bessere, genauere und benutzerfreundlichere natürlichsprachige Zusammenfassungen in Reaktion auf Suchanfragen zu generieren. Dies wird erreicht, indem zusätzliche Inhalte, einschließlich Suchergebnis-Dokumenten, in die Generierung einbezogen werden. Dadurch können Ungenauigkeiten reduziert und die Relevanz für den Benutzer verbessert werden.
Auswirkungen auf SEO
Dieses Patent könnte erhebliche Auswirkungen auf die Suchmaschinenoptimierung (SEO) haben, da es die Art und Weise verändert, wie Suchergebnisse zusammengefasst und präsentiert werden. SEO-Experten müssen möglicherweise ihre Strategien anpassen, um sicherzustellen, dass ihre Inhalte in den generierten Zusammenfassungen berücksichtigt werden und die Benutzererfahrung verbessert wird. Mehr dazu im Artikel Sind LLMO oder GAIO die Zukunft von SEO? . Es wird auch wichtig sein, die Benutzerfamiliarität mit Inhalten zu berücksichtigen, um relevantere Zusammenfassungen zu generieren.
Providing search results based on a compositional query
Google entwickelt die Suche immer mehr zu einer Entitäten basierten Suchmaschine. Daher ist es von entscheidender Bedeutung, relevante Ergebnisse nach Einheiten zu liefern. Dieses Patent könnte ein Teil des Puzzles sein, um Entitäten und ihre Beziehungen besser zu verstehen.
Kennung:US11762933B2
Länder: USA, Europa, China
Erscheinungsdatum: September 2023
Das Patent beschreibt eine Technik zur Bereitstellung von Suchergebnissen basierend auf kompositorischen Abfragen. Diese Methode umfasst das Erkennen von Entitätstypen und ihren Beziehungen innerhalb der Abfrage, das Lokalisieren von Knoten innerhalb eines Wissensgraphen und das Bewerten von Attributwerten, um die resultierenden Entitätsreferenzen zu ermitteln. Dieses System ist in der Lage, Abfragen zu verwalten, die relative Beziehungen zwischen verschiedenen Entitätstypen beinhalten, und bietet so Suchergebnisse, die aussagekräftiger und kontextbezogener sind.
Kompositionsabfragen, wie sie im Patent und allgemein im Bereich der Suche und des Informationsabrufs beschrieben werden, umfassen Abfragen, die mehrere Entitätstypen und deren Wechselbeziehungen umfassen. Im Gegensatz zu Abfragen, die sich auf ein einzelnes Schlüsselwort oder eine einzelne Entität konzentrieren, zielen kompositorische Abfragen darauf ab, Ergebnisse basierend auf der Beziehung verschiedener Entitäten in der Abfrage zueinander zu interpretieren und zu generieren.
Hier eine Übersicht:
- Mehrere Entitätstypen: Kompositionsabfragen enthalten Verweise auf mindestens zwei verschiedene Entitätstypen. Eine Entität bezieht sich hier auf alles, was eindeutig, einzigartig und genau definiert ist, wie eine Person, ein Ort, ein Objekt, ein Konzept usw.
- Relative Beziehungen: Die Entitäten in diesen Abfragen sind durch eine Form relativer Beziehungen verknüpft. Bei diesen Beziehungen kann es sich um räumliche, zeitliche oder andere Arten von Verbindungen handeln, die die Entitäten gezielt auf sinnvolle Weise miteinander verbinden.
SEO-Implikationen:
- Komplexe Abfragebearbeitung: SEO-Experten sollten beachten, dass Suchmaschinen wahrscheinlich zu einer ausgefeilteren Handhabung von Suchanfragen übergehen, bei denen es um das Zusammenspiel verschiedener Entitäten geht. Diese Entwicklung erfordert ein tieferes Verständnis dafür, wie Inhalte für diese komplexen Abfragestrukturen optimiert werden können.
- Optimierung des Wissensgraphen: Angesichts des Fokus des Patents auf die Verwendung eines Wissensgraphen ist es zwingend erforderlich, Inhalte so zu optimieren, dass sie in diesen Graphen genau erkannt und kategorisiert werden. Eine effektive Integration in Wissensgraphen kann die Sichtbarkeit und Relevanz von Inhalten erheblich verbessern.
- Entitätsanerkennung: Es ist von entscheidender Bedeutung, Inhalte so zu strukturieren, dass Suchmaschinen die verschiedenen Entitäten und ihre Beziehungen leicht erkennen und kategorisieren können. Eine klare und logische Organisation von Informationen kann die Auffindbarkeit und Relevanz des Inhalts bei Suchanfragen mit mehreren Entitäten verbessern.
- Kontextbezogene Relevanz: SEO-Strategien sollten vorrangig darauf achten, sicherzustellen, dass Inhalte kontextuell relevant sind. Dabei muss die Fähigkeit der Suchmaschine berücksichtigt werden, die Attribute verschiedener Entitäten zu verstehen und zu vergleichen und so die Inhaltsstrategie mit den erweiterten Interpretationsfähigkeiten der Suchmaschine in Einklang zu bringen.
Contextualizing knowledge panels
Knowledge Panels sind das Fenster zum Google Knowledge Graph und den gespeicherten Entitäten. Die Bereitstellung relevanter und korrekter Informationen für die einzelnen Unternehmen ist von entscheidender Bedeutung. Diese Panels sind in Standardsuchergebnisse integriert und bieten eine umfassende Informationsquelle.
In diesem Patent werden Methoden zur Bewältigung dieser Aufgabe erörtert.
Kennung:US11720577B2
Länder: USA, Japan, Südkorea, China, Deutschland, Europa
Letztes Erscheinungsdatum: August 2023
Das Patent konzentriert sich auf Methoden, Systeme und Geräte zur Verbesserung von Suchmaschinenergebnissen durch die Einbindung von Wissenspanels, die kontextbezogene Informationen zu Suchanfragen bereitstellen. Diese Wissenspanels werden basierend auf der Identifizierung von Entitäten (wie Sängern, Schauspielern, Musikern) und Kontextbegriffen in Benutzersuchanfragen generiert.
- Entitätsidentifikation: Das System identifiziert Entitäten, auf die in einer Suchabfrage verwiesen wird.
- Kontextbegriffe: Es identifiziert auch Kontextbegriffe, die diesen Entitäten zugeordnet sind.
- Wissenspanels: Basierend auf diesen Identifikationen werden Wissenspanels generiert, die relevante Fakten und Informationen über die Entität im Kontext der Suchanfrage bereitstellen.
- Ranking und Auswahl: Das System weist verschiedenen Wissenselementen basierend auf ihrer Relevanz für die Kontextbegriffe Rangbewertungen zu und wählt die relevantesten für die Anzeige aus.
Ziel der Wissenspanels ist es, das Benutzererlebnis zu verbessern, indem relevantere, kontextbezogene Informationen direkt in den Suchergebnissen bereitgestellt werden.
Der Inhalt von Knowledge Panels ändert sich dynamisch basierend auf den in der Suchabfrage enthaltenen Kontextbegriffen.
Das System verwendet einen ausgefeilten Ranking-Mechanismus, um die relevantesten anzuzeigenden Wissenselemente zu ermitteln.
Dieses Patent unterstreicht die sich weiterentwickelnde Natur von Suchmaschinen hin zu einer kontextbewussteren und benutzerorientierten Informationsbeschaffung, die für SEO-Praktiker von entscheidender Bedeutung ist, um sie zu verstehen und sich daran anzupassen.
Implikationen für SEO
- Fokus auf entitätsbasierter Optimierung: SEO-Strategien sollten die Bedeutung von Entitäten und ihrem Kontext bei der Inhaltserstellung berücksichtigen.
- Rich-Content-Erstellung: Die Erstellung von Inhalten, die Entitäten und ihre zugehörigen Aspekte umfassend abdecken, kann die Chancen erhöhen, in Wissenspanels vorgestellt zu werden.
- Keyword-Strategie: Durch die Integration relevanter Kontextbegriffe neben primären Keywords kann die Sichtbarkeit des Inhalts verbessert werden.
- Benutzerabsicht verstehen: SEO-Bemühungen sollten auf dem Verständnis der Benutzerabsicht und der kontextbezogenen Verwendung von Suchbegriffen ausgerichtet sein.
Systems and methods for using document activity logs to train Machine-Learned models for determining document relevance
Benutzerinteraktion und Benutzerprotokolle sind eine wichtige Quelle für die Optimierung der maschinellen Lernalgorithmen von Google, die für die Ranking-Ergebnisse verantwortlich sind. Dieses Patent beschreibt Techniken zur Bewältigung dieser Aufgabe.
Kennung:US20230267277A1
Länder: Vereinigte Staaten, WIPO
Letztes Erscheinungsdatum: 24. August 2023
Hinweis: Dieses Patent hat den Status schwebend. Dies bedeutet, dass es heute nicht verwendet wird, aber in Zukunft verwendet werden könnte.
Das Patent beschreibt Systeme und Methoden zum Trainieren eines maschinell erlernten semantischen Matching-Modells unter Verwendung von Dokumentaktivitätsprotokollen, um die Dokumentrelevanz zu bestimmen. Dieser Ansatz ist besonders nützlich für Umgebungen wie Cloud-Speicher oder private Dokumentenspeicher, in denen der Zugriff auf Inhaltsdaten oder Benutzerinteraktionsdaten begrenzt ist.
Diese Methode ist in Szenarien von Vorteil, in denen herkömmliche Datenquellen wie Benutzerinteraktionsdaten oder vollständiger Dokumentinhalt nicht verfügbar sind.
Verfahren:
- Datenerfassung: Besorgen Sie sich zwei Dokumente zusammen mit den jeweiligen Aktivitätsprotokollen.
- Bestimmung der Beziehungsbezeichnung: Bestimmen Sie anhand der Aktivitätsprotokolle eine Beziehungsbezeichnung, die angibt, ob die Dokumente miteinander verbunden sind.
- Semantische Ähnlichkeitsbewertung: Geben Sie die Dokumente in das Modell ein, um einen semantischen Ähnlichkeitswert zu erhalten, der die geschätzte semantische Ähnlichkeit zwischen ihnen darstellt.
- Modelltraining: Bewerten Sie eine Verlustfunktion, die den Unterschied zwischen der Beziehungsbezeichnung und dem semantischen Ähnlichkeitswert bewertet. Ändern Sie die Modellparameter basierend auf dieser Verlustfunktion.
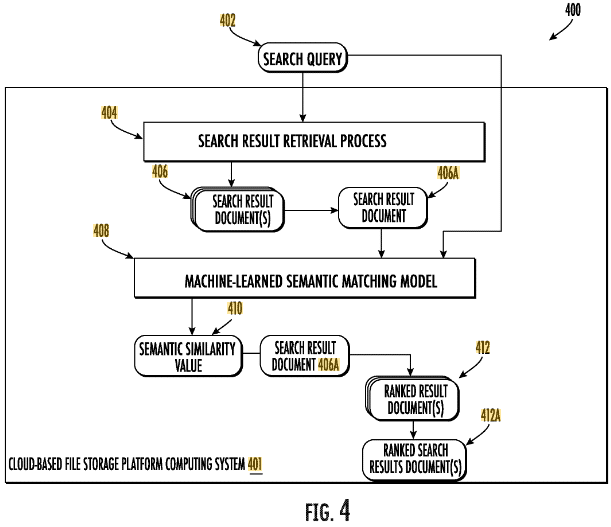
Faktoren:
- Dokumentaktivitätsprotokolle: Dazu gehören Zugriffszeitstempel und Arten von Interaktionen (z. B. Bearbeiten, Teilen).
- Beziehungsbezeichnungen: Werden basierend auf der Zeitdifferenz zwischen den Zugriffen auf die Dokumente generiert.
- Semantischer Ähnlichkeitswert: Eine Ausgabe des Modells, die schätzt, wie ähnlich zwei Dokumente sind.
- Verlustfunktion: Wird verwendet, um das Modell durch Vergleich der Beziehungsbezeichnung mit dem semantischen Ähnlichkeitswert zu verfeinern.
Implikationen für SEO
- Schwerpunkt auf Benutzerinteraktion: SEO-Strategien müssen sich möglicherweise stärker auf die Benutzerinteraktion mit Dokumenten konzentrieren, da diese Daten die Dokumentenrelevanz beeinflussen können.
- Über Schlüsselwörter hinaus: Die Relevanz von Inhalten könnte durch Benutzerverhalten und Dokumentinteraktionen bestimmt werden, nicht nur durch Schlüsselwörter.
- Private und Cloud-Dokumente: SEO für private oder in der Cloud gespeicherte Dokumente hängt möglicherweise mehr davon ab, wie auf diese Dokumente zugegriffen und wie sie verwendet werden, als von herkömmlichen On-Page-Faktoren.
- Prädiktive Modellierung: Das Verstehen und Vorhersagen des Benutzerverhaltens könnte ein wichtiger Bestandteil von SEO-Strategien werden.
Query composition system
Suchergebnisse sind immer kontextbezogener. Eine bessere Erkennung des Kontexts einer Suchanfrage und des Benutzers führt zu besseren Suchergebnissen und einem besseren Benutzererlebnis. Dieses Patent ist eine Lösung, um diese Herausforderung zu meistern.
Kennung:US20230244657A1
Länder: USA, China, WIPO, Russland
Letztes Veröffentlichungsdatum: 3. August 2023
Hinweis: Dieses Patent hat den Status schwebend. Dies bedeutet, dass es heute nicht verwendet wird, aber in Zukunft verwendet werden könnte.
Das Patent konzentriert sich auf Methoden, Systeme und Geräte zur Generierung von Daten, die Kontextcluster und Kontextclusterwahrscheinlichkeiten beschreiben. Diese Cluster werden basierend auf Abfrageeingaben und dem mit jeder Abfrageeingabe verknüpften Kontext gebildet.
Das Patent beschreibt ein System, das den Suchabfrageprozess durch die Verwendung von Kontextclustern vereinfacht. Diese Cluster werden basierend auf dem Kontext und Inhalt früherer Abfragen gebildet. Wenn ein Benutzer eine Suche startet, präsentiert das System relevante Kontextcluster, sodass der Benutzer eine Abfrage auswählen kann, ohne sie eingeben zu müssen.
Das System zielt darauf ab, das Benutzererlebnis zu verbessern, indem es kontextrelevante Suchvorschläge bereitstellt, ohne dass der Benutzer Zeichen der Suchabfrage eingeben muss.
Verfahren
- Datenverarbeitung und Gruppierung: Das System greift auf Abfragedaten mehrerer Benutzer zu und gruppiert diese Abfragen basierend auf ihrem Eingabekontext und Inhalt in Kontextclustern.
- Bestimmung der Kontextcluster-Wahrscheinlichkeit: Für jeden Kontextcluster wird eine Wahrscheinlichkeit berechnet, die die Wahrscheinlichkeit angibt, dass eine zu diesem Cluster gehörende Abfrageeingabe von einem Benutzer ausgewählt wird.
- Reaktion auf ein Benutzerereignis: Beim Empfang eines Hinweises auf ein Benutzerereignis (z. B. Zugriff auf eine Suchmaschine) wählt das System einen Kontextcluster basierend auf dem Kontext des Benutzergeräts und den berechneten Wahrscheinlichkeiten aus.
- Anzeige und Auswahl: Der ausgewählte Kontextcluster wird dem Benutzer dann zur Auswahl angezeigt, gefolgt von einer Liste von Abfragen innerhalb dieses Clusters für weitere Eingaben.
Faktoren
- Eingabekontext: Beinhaltet Faktoren wie Standort, Datum und Uhrzeit sowie Benutzerpräferenzen.
- Inhalt der Abfrageeingaben: Der tatsächliche Inhalt, der von jeder Abfrageeingabe beschrieben wird.
- Kontext-Cluster-Wahrscheinlichkeit: Eine Metrik, die die Wahrscheinlichkeit angibt, dass eine Abfrageeingabe aus einem Cluster vom Benutzer ausgewählt wird.
Implikationen für SEO
- Konzentrieren Sie sich auf Kontextrelevanz: SEO-Strategien sollten Inhalte priorisieren, die mit Benutzerkontexten wie Ort und Zeit übereinstimmen.
- Verbessertes Verständnis der Benutzerabsicht: Das Verständnis der wahrscheinlichen Kontextcluster kann dabei helfen, Inhalte genauer an die Benutzerabsicht anzupassen.
- Anpassung an abfragelose Suchen: SEO muss sich an Szenarien anpassen, in denen Benutzern Vorschläge gemacht werden, bevor sie eine Abfrage eingeben, wobei die Bedeutung der Einbeziehung in relevante Kontextcluster betont wird.
Combining parameters of multiple search queries that share a line of inquiry
Dieses Patent zeigt einmal mehr, wie wichtig für Google der individuelle Kontext eines Nutzers ist. Hierauf liegt der Fokus.
Kennung:US11762848B2
Länder: USA, China
Letztes Veröffentlichungsdatum: 19. September 2023
Das Patent konzentriert sich auf die Verbesserung der Suchabfrageverarbeitung. Es stellt eine Methode zum Generieren einer kombinierten Suchabfrage vor, die auf den Parametern einer aktuellen Suchabfrage und einer oder mehreren vorherigen Abfragen desselben Benutzers basiert, sofern diese Abfragen eine gemeinsame Anfragelinie haben.
Das Patent beschreibt eine Methode zur Optimierung des Online-Sucherlebnisses durch die intelligente Kombination mehrerer verwandter Suchanfragen zu einer einzigen, effektiveren Suchanfrage. Dieser Ansatz nutzt semantische Analyse und Benutzerinteraktion, wodurch möglicherweise Redundanzen in Suchergebnissen reduziert und die Relevanz der abgerufenen Informationen erhöht werden.
Im Wesentlichen deutet dieses Patent auf einen deutlichen Wandel hin zu einem differenzierteren, kontextbewussten Suchprozess hin, der SEO-Strategien mit Schwerpunkt auf semantischer Relevanz und Benutzerabsicht neu gestalten könnte.
Verfahren
- Identifizierung einer gemeinsamen Anfragelinie: Das System erkennt, wenn zwei oder mehr Suchanfragen eines Benutzers semantisch verwandt sind und somit eine gemeinsame Anfragelinie haben.
- Kombinieren von Suchabfragen: Sobald eine gemeinsame Suchlinie eingerichtet ist, formuliert das System eine kombinierte Suchabfrage, die Parameter sowohl der aktuellen als auch der vorherigen Abfragen enthält.
- Benutzerinteraktion und Feedback: Benutzer können mit den Suchparametern oder Ergebnissen interagieren, um die kombinierte Suchabfrage zu verfeinern.
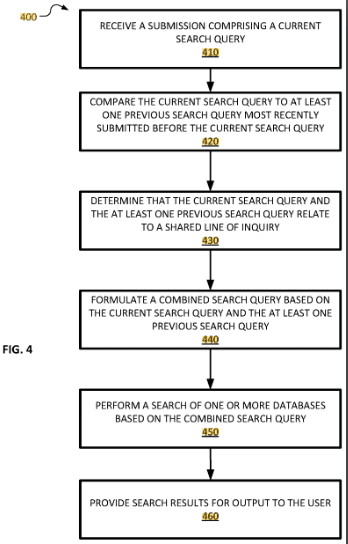
Faktoren
- Semantische Ähnlichkeit: Das System verwendet semantische Ähnlichkeit, die durch die Einbettung von Abfragen in den latenten Raum und die Berechnung der Abstände zwischen diesen Einbettungen gemessen wird, um festzustellen, ob Abfragen miteinander verbunden sind.
- Verknüpfung von Grammatiken und Heuristiken: Das System kann auch Verknüpfungsgrammatiken oder Heuristiken verwenden, um verwandte Abfragen zu identifizieren, insbesondere in Sprachsuchszenarien.
- Stateful Research-Modus: Benutzer werden möglicherweise aufgefordert, in einen Stateful Research-Modus zu wechseln, der es dem System ermöglicht, frühere Abfragen für die Formulierung kombinierter Abfragen zu verwenden.
Implikationen für SEO
- Verstärkter Fokus auf semantische Relevanz: SEO-Strategien müssen möglicherweise mehr Wert auf semantische Relevanz und Kontext legen, da das Patent darauf hinweist, dass Google sich zunehmend auf das Verstehen und Verknüpfen semantisch verwandter Abfragen konzentriert.
- Long-Tail-Keyword-Optimierung: Die Möglichkeit, Abfragen zu kombinieren, deutet auf eine mögliche Verlagerung hin zu Long-Tail-Keywords und konversationelleren Abfrageformaten hin.
- Inhaltsstrukturierung: Inhalte müssen möglicherweise so strukturiert werden, dass sie sich nahtlos in eine Reihe verwandter Suchanfragen einfügen und so ihre Chancen erhöhen, in einem kombinierten Suchszenario gefunden zu werden.
- Optimierung der Sprachsuche: Durch die Verwendung von Verknüpfungsgrammatiken wird die Optimierung für die Sprachsuche immer wichtiger, da das System gesprochene Abfragen im Laufe der Zeit verknüpfen kann.
Presenting search result information
Auf den ersten Blick erscheint dieses Patent etwas verwirrend, da es um die Verwendung von Inhalten, Markups und Anmerkungen vom Gerät des Benutzers geht. Vor allem aber zeigt es, dass Suchmaschinen wie Google in Zukunft hochgradig personalisierte Suchergebnisse liefern könnten.
Kennung:US20230244657A1
Länder: USA, China, WIPO, Russland
Letztes Veröffentlichungsdatum: 3. Oktober 2023
Im Mittelpunkt des Patents steht eine Methode zur Darstellung computergenerierter Suchergebnisse. Dabei geht es darum, eine Suchanfrage zu erhalten, mehrere Suchergebnisse zu identifizieren, diese Ergebnisse mithilfe von Inhalten aus einem oder mehreren Web-Notizbüchern in eine Rangfolge zu bringen und diese dann in der Rangliste aufgeführten Ergebnisse zur Präsentation bereitzustellen.
Das Patent beschreibt eine Methode zur Verbesserung der Genauigkeit und Relevanz von Suchergebnissen durch die Einbindung von Inhalten aus Web-Notizbüchern. Dieser Ansatz ermöglicht ein personalisierteres und kontextbezogeneres Sucherlebnis, da die Rangfolge der Suchergebnisse durch benutzergenerierte Inhalte und Anmerkungen in Webnotizbüchern beeinflusst wird.
Web-Notizbücher, auf die im Google-Patent Bezug genommen wird, sind digitale Sammlungen von Inhalten, die Benutzer aus verschiedenen Webquellen erstellen und zusammenstellen. Diese Notizbücher können eine Reihe von Inhaltstypen wie Textauszüge, Bilder und möglicherweise Benutzeranmerkungen oder Metadaten enthalten. Zu den wichtigsten Merkmalen und Einsatzmöglichkeiten von Web-Notizbüchern gehören:
- Inhaltsaggregation: Benutzer schneiden Inhalte aus verschiedenen Webseiten aus oder wählen sie aus und fassen diese Informationen an einem einzigen Ort zusammen. Dies kann zum persönlichen Nachschlagen, zur Recherche oder zum Teilen mit anderen dienen.
- Benutzeranmerkungen und Metadaten: Zusätzlich zu den ausgeschnittenen Inhalten können Benutzer dem Inhalt dieser Notizbücher eigene Anmerkungen, Kommentare oder Metadaten hinzufügen. Dies könnte Kontext oder persönliche Einblicke in die gesammelten Informationen liefern.
- Themenorientierte Sammlungen: Web-Notizbücher konzentrieren sich häufig auf bestimmte Themen oder Themen. Beispielsweise könnte ein Benutzer ein Web-Notizbuch über „nachhaltige Gartenpraktiken“ oder „Ressourcen für die Webentwicklung“ erstellen.
- Teilbarkeit und Zugänglichkeit: Diese Notizbücher können privat sein oder mit einer ausgewählten Gruppe von Benutzern geteilt oder sogar öffentlich gemacht werden. Dies ermöglicht den Austausch kuratierter Informationen und Erkenntnisse.
- Dynamischer Charakter: Im Gegensatz zu statischen Lesezeichen können Web-Notizbücher kontinuierlich aktualisiert und bearbeitet werden, was sie zu einer dynamischen Ressource zum Sammeln und Organisieren von Webinhalten macht.
Suchmaschinenintegration: Wie aus dem Patent hervorgeht, können Inhalte in Web-Notizbüchern verwendet werden, um Suchmaschinenergebnisse zu beeinflussen. Die Suchmaschine könnte die Relevanz des Inhalts in diesen Notizbüchern für eine bestimmte Suchanfrage berücksichtigen und sie möglicherweise zur Verfeinerung und Personalisierung der Suchergebnisse verwenden.
Verfahren
- Empfangen einer Suchanfrage: Die Methode beginnt mit dem Empfang einer Suchanfrage von einem Client-Computer.
- Identifizieren von Suchergebnissen: Anschließend werden mehrere Suchergebnisse als Reaktion auf die Anfrage identifiziert.
- Ranking mithilfe von Web-Notizbüchern: Die Suchergebnisse werden anhand der Inhalte in Web-Notizbüchern eingestuft. Dazu gehört die Prüfung, ob Titel, Überschriften, ausgeschnittene Inhalte, Metadaten oder Benutzeranmerkungen in den Web-Notizbüchern einen Bezug zur Suchanfrage haben. Wenn ja, erhöht sich das Ranking der referenzierten Suchergebnisse.
- Bereitstellung geordneter Ergebnisse: Abschließend werden die geordneten Suchergebnisse zur Präsentation auf dem Client-Computer bereitgestellt.
Faktoren
- Inhalt von Web-Notizbüchern: Der Inhalt von Web-Notizbüchern spielt eine entscheidende Rolle für das Ranking. Es umfasst Titel, Überschriften, ausgeschnittene Inhalte, Metadaten und Benutzeranmerkungen.
- Backlink-Analyse: Der Prozess kann auch die Analyse von Backlinks umfassen, die den Suchergebnissen entsprechen.
- Benutzeridentität: Die Auswahl von Web-Notizbüchern für das Ranking kann auf der Identität des Benutzers basieren, der die Suchanfrage initiiert.
- Snippet-Informationen: Teil des Prozesses ist die Generierung von Snippet-Informationen durch die Identifizierung von Teilen von Dokumenten in Web-Notizbüchern, die mit den Suchergebnissen verknüpft sind.
Implikationen für SEO
- Bedeutung von benutzergenerierten Inhalten: SEO-Strategien müssen möglicherweise den Schwerpunkt auf benutzergenerierte Inhalte legen, da Web-Notizbücher das Suchranking beeinflussen.
- Personalisierung und Kontext: Es gibt einen Trend hin zu stärker personalisierten und kontextbezogenen Suchergebnissen, weshalb es für SEO wichtig ist, sich auf diese Aspekte zu konzentrieren.
- Verschiedene Inhaltstypen: Die Einbeziehung verschiedener Inhaltstypen wie Metadaten, Anmerkungen und ausgeschnittene Inhalte könnte für SEO wichtiger werden.
Multi source extraction and scoring of short query answers
Die Ausgabe direkter Antworten in den SERPs nimmt immer mehr zu. Ein Beispiel hierfür sind die Informationen, die direkt aus dem Knowledge Graph ausgegeben werden, sowie Featured Snippets und die Antworten in den Snapshot AI Boxen bei SGE. Dieses Patent zeigt Methoden zur Generierung und Auswahl solcher direkter Antworten.
Kennung:US20230342411A1
Länder: USA, Europa, WIPO, Südkorea
Letztes Veröffentlichungsdatum: 26. Oktober 2023
Das Patent konzentriert sich auf die Verbesserung der Qualität von Kurzantworten, die von Suchmaschinen bereitgestellt werden. Es stellt eine Methode zum Generieren und Bewerten dieser Kurzantworten auf der Grundlage mehrerer Quellen vor, anstatt sich auf ein einzelnes Suchergebnis mit dem höchsten Rang zu verlassen.
Das Patent beschreibt eine Methode zur Verbesserung der Zuverlässigkeit und Genauigkeit von Kurzantworten in Suchmaschinenergebnissen. Dies geschieht durch die Bewertung einer Kandidatenpassage anhand anderer Kontextpassagen aus unterschiedlichen Suchergebnissen, wodurch ein höheres Maß an Genauigkeit und Relevanz gewährleistet wird.
Verfahren
- Empfangen von Abfragedaten: Der Prozess beginnt damit, dass die Suchmaschine die Suchabfrage eines Benutzers empfängt.
- Generieren von Suchergebnissen: Es werden mehrere Suchergebnisse generiert, die jeweils eine Passage enthalten, die sich auf die Suchanfrage bezieht.
- Auswählen von Passagen: Es wird eine Reihe von Passagen ausgewählt, darunter eine Kandidatenpassage aus einem Suchergebnis mit dem höchsten Rang und zusätzliche Kontextpassagen aus anderen Ergebnissen.
- Bewertung der Kandidatenpassage: Die Kandidatenpassage wird anhand der Kontextpassagen bewertet, um eine Genauigkeitsbewertung zu erhalten.
- Anzeigeentscheidung: Basierend auf der Genauigkeitsbewertung wird die Kandidatenpassage entweder als Kurzantwort in den Suchergebnissen angezeigt oder nicht.
Faktoren
- Genauigkeitsbewertung: Die Entscheidung, eine kurze Antwort anzuzeigen, hängt von der Genauigkeitsbewertung ab, die mit einem vorgegebenen Schwellenwert verglichen wird.
- Konsens mit Kontextpassagen: Der Genauigkeitswert wird aus dem Grad der Übereinstimmung zwischen der Kandidatenpassage und den Kontextpassagen abgeleitet.
- Qualität der Kurzantwort: Die Qualität und Zuverlässigkeit der Kurzantwort werden durch diesen Multi-Source-Ansatz verbessert.
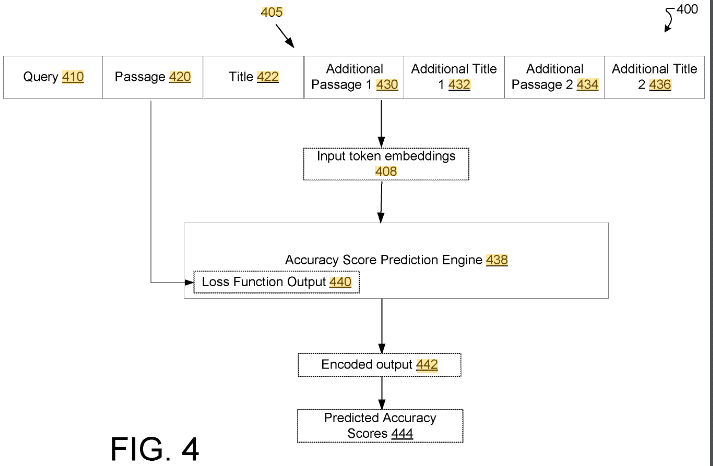
Implikationen für SEO
Für SEO deutet dieses Patent auf eine Verlagerung hin zu Inhalten hin, die nicht nur relevant, sondern auch kontextuell korrekt und konsensorientiert sind. SEO-Strategien müssen sich möglicherweise mehr auf die Bereitstellung umfassender, abgerundeter Inhalte konzentrieren, die mit dem breiteren Kontext eines Themas übereinstimmen, anstatt nur auf Schlüsselwörter oder Phrasen mit dem höchsten Rang abzuzielen. Dies könnte dazu führen, dass der Schwerpunkt stärker auf gründlicher Recherche, vielfältigen Inhaltsperspektiven und der Genauigkeit der auf Webseiten präsentierten Informationen liegt.
Wie man SEO grundlegend lernt und welche Bedeutung Patente für SEO haben
Viele SEOs stürzen sich daher direkt in die Umsetzung der Optimierung, weil sie sich Ideen aus Blogs, Social Media, YouTube… von SEO-Hacks holen, ohne die theoretischen Grundlagen zu kennen.
Deshalb empfehle ich jedem, der sich mit SEO beschäftigt, sich zunächst mit den Grundlagen des Crawlings, der Indexierung und des Information Retrievals vertraut zu machen.
Der nächste Schritt besteht darin, die Grundlagen moderner Suchmaschinentechnologien wie die Verarbeitung und Einbettung natürlicher Sprache zu verstehen.
Wir wollen für technische Systeme optimieren, uns aber nicht mit der Technik auseinandersetzen?
Das ergibt für mich keinen Sinn.
Ich empfehle jedem, der es mit SEO ernst meint, folgende Punkte zu beachten:
- Verstehen Sie moderne Suchmaschinentechnologie
- Grundlagen Information Retrieval
- Grundlagen der semantischen Suche / Entitäten
- Grundlagen der Verarbeitung natürlicher Sprache
- Grundlagen Embeddings
- Sammeln Sie Erfahrungen mit Projekten
Die bloße Suche nach praktischen Erfahrungen, ohne die wissenschaftlichen Grundlagen zu kennen und die Technik zu verstehen, führt oft dazu, die Dinge sehr subjektiv zu betrachten. Die Kenntnis der Technologie und der wissenschaftlichen Grundlagen ist wie eine rationale Ebene, die als Gegenkontrolle zu unseren subjektiven Theorien fungiert. So sind Sie besser davor geschützt, jedem Hype zu folgen.
Die Google-Sprecher im Kontext der Suche sind nur teilweise sichtbar, insbesondere wenn es um das Ranking der Suchergebnisse geht. Die Informationen sind oft ungenau und unklar. Dies ist verständlich, da Google eine Manipulation der Suchergebnisse verhindern möchte.
Wir brauchen also andere Informationsquellen, die uns tiefere Einblicke ermöglichen. Die Patentforschung ist fortgeschritten. Als Anfänger sollten Sie sich zunächst auf die oben genannten Schritte konzentrieren.
Dann können Sie mit der Patentrecherche fortfahren. Sie müssen die Grundlagen verstehen, wenn Sie Google-Patente verstehen wollen.
Unabhängig davon, ob ein Patent in die Praxis umgesetzt wird, ist es sinnvoll, sich mit Google-Patenten zu befassen, da Sie so ein Gefühl für die Probleme und Herausforderungen bekommen, mit denen Produktentwickler bei Google konfrontiert sind.
Ausführlichere Zusammenfassungen der Google-Patente finden Sie in meinem Blog. Ich füge fast jede Woche neue Patente hinzu. https://www.kopp-online-marketing.com/interesting-google-patents
Der Beitrag Die 11 interessantesten Google-Patente aus dem Jahr 2023 und die Auswirkungen auf SEO erschien zuerst auf Aufgesang.
Sind LLMO, GAIO oder GEO die Zukunft von SEO? 4 Oct 2023 12:46 AM (last year)
Seit der Vorstellung von generativer KI in Form von ChatGPT, BARD oder SGE erobern Large Language Models (LLMs) die Welt und finden den Weg auch in die Suchmaschinen. SEOs diskutieren weltweit über die Möglichkeit, KI-Ausgaben via Large Language Model Optimization (LLMO), Generative Engine Optimization (GEO) oder Generative AI Optimization (GAIO) proaktiv zu beeinflussen.
Einige SEOs sprechen sogar von der Zukunft von SEO. Dieser Artikel soll die zukünftige Bedeutung von LLM-Optimierung (LLMO) im Kontext SEO behandeln und auch den Blick aus der Data Science Perspektive kritisch einbeziehen.
Was ist LLM-Optimization (LLMO) / Generative AI Optimization (GAIO) / Generative Engine Optimization (GEO)?
GAIO, GEO bzw. LLMO haben zum Ziel, dass Unternehmen ihre Marken und Produkte in den Outputs der führenden Large Language Models (LLM) wie z.B. GPT und Google Bard prominent zu positionieren, da diese Modelle zukünftig viele Kaufentscheidungen beeinflussen können.
Wenn man beispielsweise im Bing Chat nach dem besten Laufschuh für einen Läufer mit 96 Kilogramm mit einer Laufleistung von 20 Kilometern pro Woche sucht werden Schuhmodelle der Marken Brooks, Saucony, Hoka und New Balance vorgeschlagen.
Fragt man Bing Chat nach Autos, die sicher, familienfreundlich und groß genug zum Einkaufen und Reisen sind, werden Automodelle der Marken KIA, Toyota, Hyundai und Chevrolet vorgeschlagen.
Der Ansatz möglicher Verfahren wie der LLM-Optimierung zielt darauf ab, bei entsprechenden transaktionsorientierten Fragestellungen bestimmte Marken und Produkte zu bevorzugen.
Wie kommen solche Empfehlungen zustande?
Die Vorschläge von Bing Chat und anderen generativen KI-Tools berücksichtigen immer den gegebenen Kontext. Als Quelle für die Empfehlungen nutzt die KI in der Regel neutrale Sekundärquellen wie Fachzeitschriften, Nachrichtenseiten, Webseiten von Verbänden und öffentlichen Einrichtungen sowie Blogs. Die Ausgabe der generativen KI basiert auf der Ermittlung statistischer Häufigkeiten. Je häufiger Wörter in den Quelldaten hintereinander vorkommen, desto wahrscheinlicher ist es, dass das gesuchte Wort in der Ausgabe das richtige ist. Wörter, die in den Trainingsdaten häufig zusammen vorkommen, sind sich statistisch ähnlicher oder semantisch näher verwandt.
Welche Marken und Produkte in einem bestimmten Kontext genannt werden, kann durch die Funktionsweise von LLMs erklärt werden.
Wie funktionieren Large Language Models (LLMs)?
Moderne transformatorbasierte LLMs wie GPT oder BARD basieren auf statistischen Auswertungen von Kookkurrenzen zwischen Tokens oder Wörtern. Dazu werden Texte und Daten für die maschinelle Verarbeitung in Tokens zerlegt und über Vektoren in semantischen Räumen positioniert. Vektoren können auch ganze Wörter (Word2Vec), Entitäten (Node2Vec) und Attribute sein.
Der semantische Raum wird in der Semantik auch als Ontologie bezeichnet. Da LLMs mehr auf Statistik als auf Semantik basieren, sind sie nicht wirklich Ontologien. Durch die Menge der Daten nähert sich die KI jedoch einem semantischen Verständnis an.
Die semantische Nähe kann durch den euklidischen Abstand oder den Kosinuswinkel im semantischen Raum bestimmt werden.
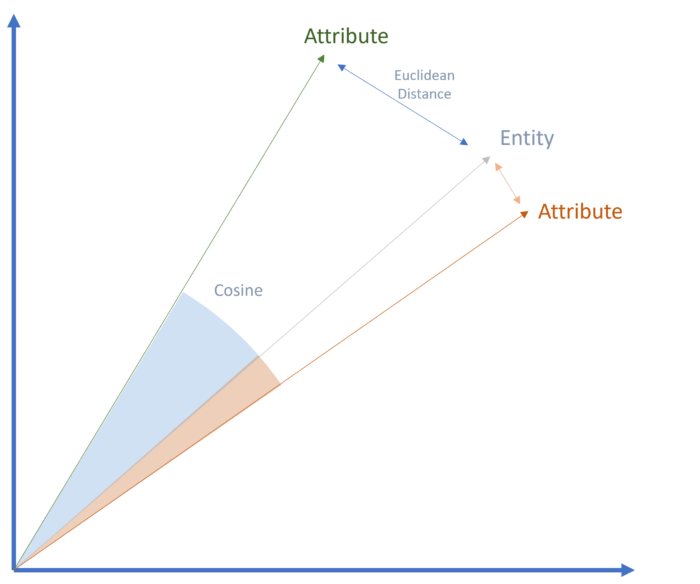
Semantische Nähe im Vektorraum
Wenn eine Entität häufig in Verbindung mit bestimmten anderen Entitäten oder Eigenschaften in den Trainingsdaten genannt wird, besteht eine hohe statistische Wahrscheinlichkeit für eine semantische Beziehung.
Die Methode dieser Verarbeitung wird als transformatorbasiertes Natural Language Processing bezeichnet. NLP beschreibt einen Prozess, natürliche Sprache in eine maschinenverständliche Form zu transformieren, die eine Kommunikation zwischen Mensch und Maschine ermöglicht. NLP besteht aus den Bereichen Natural Language Understanding (NLU) und Natural Language Generation (NLG).
Beim Training von LLMs liegt der Schwerpunkt auf NLU und bei der Ausgabe von KI-generierten Ergebnissen auf NLG.
Die Identifikation von Entitäten durch Named Entity Extraction spielt sowohl für das semantische Verständnis als auch für die Bedeutung einer Entität innerhalb einer thematischen Ontologie eine besondere Rolle.
Durch die häufige Kookkurrenz bestimmter Wörter rücken diese Vektoren im semantischen Raum näher zusammen. Die semantische Nähe nimmt zu und die Wahrscheinlichkeit der Zugehörigkeit steigt.
Über NLG werden die Ergebnisse entsprechend der statistischen Wahrscheinlichkeit ausgegeben.
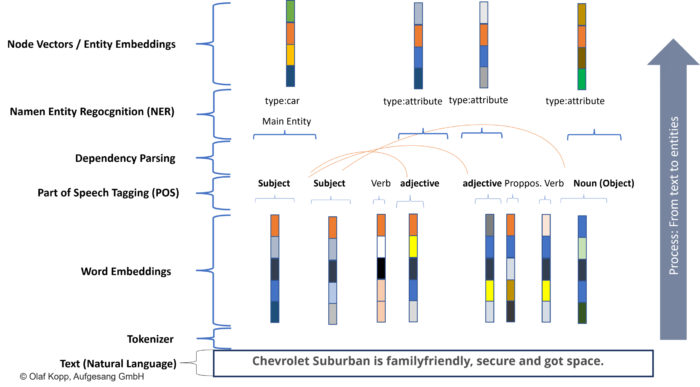
Transformer basiertes NLP: Vom Text zum Node Vektor
Wird z.B. der Chevrolet Suburban häufig im Zusammenhang im Kontext mit Familie und Sicherheit genannt, kann das LLM diese Entität mit bestimmten Attributen wie sicher oder familiengerecht assoziieren. Es besteht eine hohe statistische Wahrscheinlichkeit, dass dieses Automodell mit diesen Attributen in Zusammenhang steht.
Lassen sich die Ergebnisse von generativer KI proaktiv beeinflussen?
Auf diese Frage habe ich noch keine schlüssigen Antworten gehört, sondern nur unhaltbare Spekulationen. Um der Antwort näher zu kommen, ist es sinnvoll, sich der Frage aus der Sicht der Data Science zu nähern. Also von Leuten, die sich mit der Funktionsweise von Large Language Modellen auskennen.
Ich habe dazu 3 Data Science Experten aus meinem Netzwerk befragt:
“Theoretically, it’s certainly possible, and it cannot be ruled out that political actors or states might go to such lengths. Frankly, I actually assume some do. However, from a purely practical standpoint, for business marketing, I don’t see this as a viable way to intentionally influence the „opinion“ or perception of an AI, unless it’s also influencing public opinion at the same time, for instance through traditional PR or branding.
With commercial large language models, it is not publicly disclosed what training data is used, nor how it is filtered and weighted. Moreover, commercial providers utilize alignment strategies to ensure the AI’s responses are as neutral and uncontroversial as possible, irrespective of the training data. Ultimately, one would have to ensure that over 50% of the statements in the training data reflect the desired sentiment, which in the extreme case means flooding the net with posts and texts, hoping they get incorporated into the training data.” Kai Spriestersbach, Applied AI Researcher and SEO Veteran
“It’s theoretically possible to influence an LLM through a synchronized effort of content, PR, and mentions, the data science mechanics will underscore the increasing challenges and diminishing rewards of such an approach.
The endeavor’s complexity, when analyzed through the lens of data science, becomes even more pronounced and arguably unfeasible.
1)Data Density and Distribution: The training datasets for LLMs encompass a representative sample of the internet, spread across diverse domains. To exert influence, new content would need to become a significant portion of this distribution, which is statistically improbable given the sheer volume of existing data.
2)Statistical Significance: Even if your content achieved virality, its representation in the entire dataset might still be statistically insignificant. Altering an LLM’s outputs would require your content to outweigh existing patterns, which means not just adding new data but overshadowing established data points.
3)Network Diffusion Dynamics: PR and mentions, from a data science perspective, would fall under network diffusion models. Your content would need a nearly unprecedented diffusion rate to permeate the vast network of references that influence LLMs. This involves not just direct mentions but multiple layers of references and back-references, a complex and challenging feature.
4)Temporal Factors: Time series analysis in data science underscores the importance of persistence. Short-lived trends, even if they achieve peak virality, decay in significance over time. For enduring influence on LLMs, the content’s prominence should persist across multiple temporal checkpoints. u
5) Model Regularization and Overfitting: LLMs use regularization techniques to avoid overfitting to specific patterns or anomalies in training data. This means that even if your content becomes a noticeable data point, the model might interpret it as an outlier and reduce its weight during training.
6)Feedback Loops and System Dynamics: An unintended consequence could be the introduction of feedback loops. As content tries to influence the model, and the model’s output influences future content, you risk creating an echo chamber that might distort information rather than enriching it.
7) Economic Cost vs. Information Gain: From a data economics perspective, the cost of injecting and sustaining such content prominence far exceeds the potential information gain for the LLM. The diminishing returns on added content make the endeavor increasingly resource-intensive with limited tangible benefits.
8) Model Update Latency: LLMs aren’t continuously trained. They undergo versioned updates, and influencing one version doesn’t guarantee influence on subsequent versions. The latency between your efforts and the next model iteration could nullify or dilute your influence.”
Barbara Lampl, CEO & Lead Data Strategist
“The dynamics between LLMs and systems like ChatGPT and SEO ultimately remain the same at the end of the equation. Only the perspective of optimization will switch to another tool, that is in fact nothing more than a better interface for classical information retrieval systems.
The models are trained on large crawls of the web (for example https://commoncrawl.org/). The crucial issue of these crawls is to cover as many relevant contexts for users as possible, through which the model learns to correctly assess them and provide the generative basis for the subsequent reinforcement learning layer.
ChatGPT fine-tuning process (https://openai.com/blog/chatgpt)
The reinforcement learning layer generates an appropriate response based on the learned contexts and prompt patterns. The probability that traditional information retrieval systems (e.g. google or bing) are used for additional crawls to target qualitative content and known domains like wikipedia or github are collected holistically is the only way to ensure relevance continuously from user perspective. The training of these LLMs and the use in traditional information retrieval systems like google and bing is known to all since the implementation of BERT.
Google BERT implementation changes the way how information retrieval understands queries and contexts (https://blog.google/products/search/search-language-understanding-bert/)
With this in mind user input targets already for a longer time the needed crawling focus for LLM models to target the relevant contexts for incoming searches. The probability that the LLM model uses corresponding content from the crawl for training increases with the findability of the respective document on the web and in search engines to provide consistency and quality. LLM systems are great systems to compute similarity but not as good in provide facts or solve logical tasks. For solving logical tasks, training data in the form of prompts is needed. To provide better answers for facts and to support them with sources, the latest developments are driving to close the loop. RAG (retrieval-augmented generation) uses external data stores as context to provide better, more up-to-date answers that you can rely on because they include the appropriate relevant sources in the answer.
This is done with the help of search engines. Here is an example with the new ChatGPT Bing Beta feature:
Data storage sources from bing:
- https://www.menshealth.com/grooming/g21347829/best-electric-razor-men/#
- https://shavercheck.com/best-electric-razor/
- https://www.healthline.com/health/best-electric-shaver-for-men#A-quick-look-at-the-best-electric-shavers
- https://www.gq.com/story/best-electric-shavers#:~:text=The%20Longstanding%20Fan%20Favorite%3A%20Panasonic,Head
- https://www.gq-magazine.co.uk/gallery/best-electric-shavers#:~:text=What%27s%20the%20best%20electric%20shaver,sharp%20NanoTech%20blades
From my prompt, a corresponding search query was derived, which added appropriate relevant content from Bing as context, and from which ChatGPT then generated a response with appropriate summarized sources (Bing API). This leads to two optimizations, on the one hand ChatGPT and on the other in the field of SEO. On the ChatGPT side: the users prompts and the search queries and results generated from them can be used both to drive a more relevant crawl and thus train the LLM and to train the reinforcement learning layer with appropriate prompts to continuously increase the quality of the overall system as it is used. As before, the bottleneck remains the human-performed labeling and ranking of the prompts and responses for the reinforcement learning step. On the other side, we have the classic SEO mechanics: more relevant and discoverable content leads to a higher probability of being part of the crawl and LLM training to include your constructed context. How much impact your content will have on the LLM is hard to measure because the shifting data points of your tokens in the given context are calculated in contrast to all other tokens and documents in the corpus/crawl. Maybe you have luck and change a context, but alone the fact that your brand is known inside of a context and part of the vocabulary of the model is a great achievement. The RAG mechanics also lead to better ranking content being used as the basis for higher quality responses. This is exactly where optimization potential exists, as suitable targets can be identified and the content of these can be matched with the answer.
The end result is not a truly new approach to SEO, but merely a new perspective. Which search engines are in the focus and are used by systems like ChatGPt or BARD, how to include the prompt generated keywords into the keyword research process, how to target the relevant pages that are used as data storage / context and place fitting content and how content must be structured to get the best possible mention in a timely manner as a response. This leads at the end to the same optimizations as known with a light slide of the perspective and underlying discovery and research process. In the end, it’s an optimization for a hybrid metasearch engine with a natural language user interface that summarizes the results for you.”
Philip Ehring, Head of Business Intelligence


Zusammengefasst kann man folgende Punkte aus Data Science Sicht festhalten:
- Bei großen kommerziellen Sprachmodellen ist die Trainingsdatenbasis nicht öffentlich, und es werden Ausrichtungsstrategien angewendet, um neutrale und unkontroverse Antworten zu gewährleisten. Um die gewünschte Meinung in der KI zu verankern, müsste mehr als 50% der Trainingsdaten diese Meinung reflektieren, was extrem aufwendig wäre zu beeinflussen.
- Es ist sehr schwer, aufgrund der enormen Datenmenge und statistischen Signifikanz eine bedeutende Wirkung zu erzielen.
- Die Dynamik der Netzwerkverbreitung, zeitliche Faktoren, Modell-Regularisierung, Feedback-Schleifen und ökonomische Kosten stellen Hindernisse dar.
- Zudem erschwert die Verzögerung bei Modellupdates die Beeinflussung.
- Aufgrund der großen Anzahl der Kookkurrenzen, die man erzeugen müsste, ist es je nach Markt nur mit größerem Engagement in PR und Marketing möglich, die Ausgaben einer generativen KI hinsichtlich der eigenen Produkte und Marke zu beeinflussen.
- Ein weitere Herausforderung ist die Identifikation der Quellen, die als Trainingsdaten für die LLMs genutzt werden.
- Die Dynamik zwischen LLMs und Systemen wie ChatGPT bzw. BARD und SEO bleibt konsistent. Die einzige Änderung liegt in der Optimierungsperspektive, die sich auf eine bessere Schnittstelle für klassisches Information Retrieval verlagert.
- Das Finetuning von ChatGPT beinhaltet eine Verstärkungslernschicht, die Antworten auf der Grundlage gelernter Kontexte und Aufforderungen generiert.
- Traditionelle Suchmaschinen wie Google und Bing werden verwendet, um qualitativ hochwertige Inhalte und Domains wie Wikipedia oder GitHub zu finden. Die Integration von Modellen wie BERT in diese Systeme ist ein Fortschritt. Googles BERT verändert die Art und Weise, wie Information Retrieval Nutzeranfragen und Kontexte versteht.
- Prompts stehen im Mittelpunkt der Webcrawls für LLMs. Die Wahrscheinlichkeit, dass ein LLM Inhalte aus einem Crawl für das Training verwendet, wird durch die Auffindbarkeit des Dokuments im Web beeinflusst.
- Während LLMs sich durch die Berechnung von Ähnlichkeiten auszeichnen, sind sie nicht so gut darin, sachliche Antworten zu geben oder logische Aufgaben zu lösen. Um dieses Problem zu lösen, nutzt Retrieval-Augmented Generation (RAG) externe Datenspeicher, um bessere und fundiertere Antworten zu liefern.
- Die Integration von Web Crawling bietet einen doppelten Nutzen: Verbesserung der Relevanz und des Trainings von ChatGPT und Verbesserung der Suchmaschinenoptimierung. Eine Herausforderung bleibt die menschliche Kennzeichnung und Einstufung von Prompts und Antworten für das Reinforcement Learning.
- Die Bedeutung von Inhalten im LLM-Training wird durch ihre Relevanz und Auffindbarkeit beeinflusst. Die Auswirkung spezifischer Inhalte auf ein LLM ist schwer zu quantifizieren, aber die Wiedererkennung der eigenen Marke in einem bestimmten Kontext ist ein mögliches Ziel.
- Die RAG-Methodik verbessert auch die Qualität der Antworten durch die Verwendung von höher eingestuften Inhalten. Dies stellt eine Optimierungsmöglichkeit dar, indem der Inhalt auf potenzielle Antworten abgestimmt wird.
- Es geht darum, zu verstehen, welche Suchmaschinen von Systemen wie ChatGPT priorisiert werden, die von Prompts generierten Schlüsselwörter in die Recherche einzubeziehen, relevante Seiten für den Inhalt auszuwählen und den Inhalt für eine optimale Erwähnung in den Antworten zu strukturieren.
- Letztlich geht es um die Optimierung für eine hybride Metasuchmaschine mit einer natürlichsprachlichen Schnittstelle, die die Ergebnisse für die Nutzer zusammenfasst.
Wie könnten die Trainingsdaten für die LLMs ausgewählt werden?
Hier gibt es zwei mögliche Ansätze. E-E-A-T und Ranking.
Es ist davon auszugehen, dass die Anbieter der bekannten LLMs nur Quellen als Trainingsdaten verwenden, die einen gewissen Qualitätsstandard erfüllen und vertrauenswürdig sind.
Das E-E-A-T-Konzept von Google würde eine Möglichkeit bieten, diese Quellen zu selektieren. In Bezug auf die Entitäten kann Google den Knowledge Graph für das Factchecking und das Finetuning des LLM nutzen.
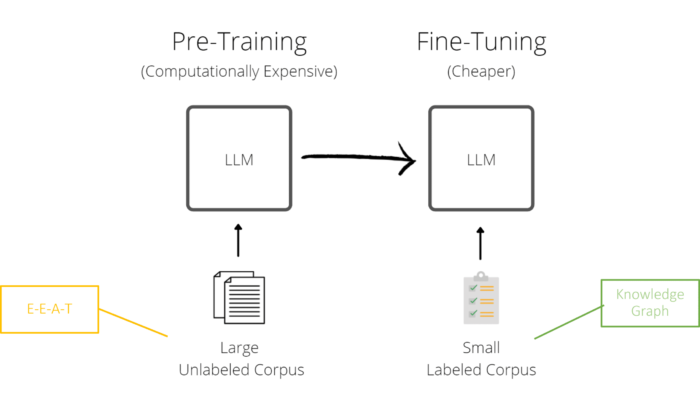
E-E-A-T und Knowledge Graph und LLMs
Der zweite Ansatz ist wie von Philip Ehring die Auswahl der Trainingsdaten anhand von Relevanz und Qualität ermittelt durch den eigentlichen Ranking-Prozess. Also vorne rankende Inhalte zu den entsprechenden Queries und Prompts werden automatisch für das Training der LLMs herangezogen. Dieser Ansatz geht davon aus, dass das Information Retrieval Rad nicht neu erfunden werden muss und Suchmaschinen auf die etablierten Bewertungs-Verfahren aufsetzen, um Trainingsdaten auszuwählen. Das würde dann neben der Relevanz-Bewertung auch E-E-A-T beinhalten. Mehr dazu in dem Beitrag Die Dimensionen des Google-Rankings
Allerdings haben Tests bei Bing Chat und SGE bisher keine klaren Korrelationen zwischen den in den KI-Antworten und den referenzierten Quellen und den Rankings aufgezeigt.
Schlussfolgerung
Ob sich LLM-Optimierung bzw. GAIO tatsächlich als legitime Strategie zur Beeinflussung von LLMs im Sinne der eigenen Ziele durchsetzen wird, steht in den Sternen.
Von Seiten der Data Science gibt es Skepsis. Einige SEOs glauben daran.
Sollte dies der Fall sein, ergeben sich folgende Ziele, die es zu erreichen gilt:
- Etablierung der eigenen Medien über E-E-A-T als Trainingsdatenquelle
- Generierung von Erwähnungen der eigenen Marke und Produkte in qualifizierten Medien
- Erzeugung von Kookkurrenzen der eigenen Marke mit anderen relevanten Entitäten und Attributen in qualifizierten Medien
- Teil des Knowledge Graph werden
Welche Maßnahmen dafür zu ergreifen sind, habe ich in dem Artikel How to improve E-A-T for websites and entities erläutert.
Die Chancen, mit LLM-Optimierung erfolgreich zu sein, steigen mit der Größe des Marktes. Je nischiger ein Markt ist, desto einfacher ist es, sich als Marke im jeweiligen thematischen Kontext zu positionieren. Dadurch sind auch weniger Kookkurrenzen in den qualifizierten Medien notwendig, um mit den relevanten Attributen und Entitäten in den LLMs assoziiert zu werden. Je größer der Markt, desto schwieriger, da viele Marktteilnehmer über große PR- und Marketingressourcen verfügen und eine lange Historie aufgebaut haben.
GAIO oder LLM-Optimierung benötigt deutlich mehr Ressourcen als klassisches SEO, um die öffentliche Wahrnehmung und damit die LLMs zu beeinflussen und muss strategisch gut durchdacht sein. An dieser Stelle möchte ich auf mein Konzept des Digital Authority Management verweisen. Mehr dazu im Artikel Digital Authority Management: Eine neue Disziplin im Zeitalter von SGE und E-E-A-T.
Sollte sich die LLM-Optimierung als sinnvolle SEO-Strategie herausstellen, werden große Marken aufgrund ihrer PR- und Marketingressourcen zukünftig deutliche Vorteile bei der Positionierung in Suchmaschinen und in den Ergebnissen von generativer KI haben.
GAIO oder LLMO sehe ich nicht als die Zukunft von SEO, aber man sollte die Entwicklungen und Möglichkeiten aufmerksam beobachten.
Eine andere Perspektive ist, dass man in der Suchmaschinenoptimierung weitermachen kann wie bisher, da gut rankende Inhalte auch gleichzeitig für das Training der LLMs genutzt werden kann. Dort sollte man dann zusätzlich auf Kookkurrenzen zwischen Marken/Produkten und Attributen bzw. anderen Entitäten achten und darauf optimieren.
Welcher dieser Ansätze die Zukunft für SEO sein wird ist nicht klar und wird sich erst zeigen wenn SGE endgültig eingeführt wird und sich abzeichnet welche Tools und Sprachmodelle sich durchsetzen werden.
Der Beitrag Sind LLMO, GAIO oder GEO die Zukunft von SEO? erschien zuerst auf Aufgesang.