StressFree Webmin theme version 2.09 released 1 Dec 2010 6:50 PM (15 years ago)
This update to the Webmin theme includes a patch from Alon Swartz (from the TurnKey Linux project) that fixes a bug in the display of menu icons. Also included are new icons for the LDAP Client module.
The updated theme can be downloaded from here.









Tuning Ubuntu's software RAID 22 Apr 2010 7:04 PM (15 years ago)
Recently I encountered an issue where the read/write performance of Ubuntu's software RAID configuration was relatively poor. Fortunately, others have encountered this problem and have documented a potential cause and solution here:
The short story is that Ubuntu uses some very conservative defaults for RAID caching. Whilst this may ensure reliable behavior across a range of hardware, it does mean that for many read/write performance will be lacklustre. The solution to this problem is to define a more aggressive caching options on any software RAID partitions that are in use.
Setting the stripe_cache_size and read ahead caches
The following example assumes that the Ubuntu server has two software-based RAID-5 partitions, /dev/md0 (the root partition) and /dev/md1 (the /var partition).
Set the stripe_cache_size and read ahead caches in the /etc/rc.local script. In the example below the stripe_cache_size is set to 8192, and the read ahead cache 4096:
#!/bin/sh -e
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
# Make sure that the script will "exit 0" on success or any other
# value on error.
#
# In order to enable or disable this script just change the execution bits.
#
# By default this script does nothing.
# Tune the RAID5 configuration
echo 8192 > /sys/block/md0/md/stripe_cache_size
echo 8192 > /sys/block/md1/md/stripe_cache_size
blockdev --setra 4096 /dev/md0
blockdev --setra 4096 /dev/md1
exit 0
Restart Ubuntu to apply these settings.
Note: It is possible to apply these changes without a restart by executing each directive at the command line.
The pages linked to above explain how to test the influence of these cache changes. In general I have found that the parameters given in the example above have improved performance without influencing the reliability of the system, or the data stored on it.
Bluestreak and the birth of a collaboration kernel 7 Jan 2010 12:11 AM (16 years ago)
Successful Architecture, Engineering and Construction (AEC) collaboration depends on the timely dissemination of relevant information throughout the project team. This task is made difficult by the number of collaboration interactions that occur and the diverse range of digital tools used to support them. To improve this process it is proposed that a collaboration kernel could weave together these disparate interactions and tools. This will create a more productive and efficient collaboration environment by allowing design discussion, issues and decisions to be efficiently and reliably exchanged between team members and the digital tools they currently use. This article describes how Project Bluestreak, a messaging service from Autodesk Labs, can be transformed into an effective collaboration kernel. To guide this transformation, the principles of the Project Information Cloud have been used to evaluate the existing service and identify areas for future development. These fundamental digital collaboration principles are derived from lessons learnt in the formation of the World Wide Web. When these principles are embodied within a digital collaboration tool, they have demonstrated an ability to improve the timely delivery of relevant information to members of the project team.
Seamless collaboration within a fragmented digital environment
A successful AEC digital collaboration environment brings multiple parties together so that they can productively work towards a satisfactory and achievable design outcome. During this process participants must engage in a variety of interactions between team members and the digital models used to describe the design. These interactions, and the technologies commonly used to enable them, are summarised in the following diagram and table.
Note: The term 'model' refers to a CAD or BIM digital model that represents the proposed design. Digital models play an important role in the collaboration process as they communicate ideas, impose restrictions and can be manipulated to reflect a participant's opinion.

Person to person | |
Purpose | Productive conversations between design participants are critical for the success of any design project. The intention of these interactions is to present, question and debate all aspects of the design. |
Nature | Given the non-linear and bi-directional nature of conversation, the ideas and data communicated are generally fluid and unstructured. To be most effective, the tools used should not introduce latency as this can result in a disjointed conversation. During these exchanges it should be possible for participants to easily reference media such as photographs, documents, diagrams and digital models. |
Enabling technologies | The most common person to person interactions during a design project are physical meetings and telephone conversations. In cases where participants are geographically distributed, Internet-based voice and video conferencing technologies are supplanting these 'traditional' tools. Email, and to a lesser extent instant messaging, are also commonly used in situations where person to person interactions are limited in scope, or do not warrant the interruption of a real-time meeting. |
Person to group | |
Purpose | Individuals must be able to efficiently and reliably communicate information about the design to the project team, such as its status, data and any associated decisions or questions. |
Nature | This interaction is uni-directional because a group cannot directly add to a conversation. If a recipient of a person to group message responds this spawns a new person to person, or person to group interaction. Person to group interactions typically have a specific topic, but the supporting media referenced during the exchange varies depending on the subject and its context. |
Enabling technologies | Email is the most prevalent digital means of communication between a participant and the project team. Messaging systems and discussion forums embedded within project extranets, company intranets or the public Internet are also used. However compared to email their industry adoption is limited. Many document management systems include support for person to group interactions, but this is typically a secondary and underused piece of functionality. |
Person to model | |
Purpose | A participant interacts with the model to understand the design, express new ideas and review the contributed work of others. If the participant cannot efficiently comprehend or manipulate the model, their ability to take part in the broader design discussion is significantly impacted. |
Nature | The nature of this interaction depends on the role and technical ability of the individual. It is common for the majority of an AEC project team to be unable to modify the model. For these participants the model simply communicates the design state, whereas those capable of modifying the model can reshape it to reflect their own opinion, or that of others. |
Enabling technologies | The primary interface between the individual and a digital model is the CAD/BIM software used to create it. Given the complexity and cost of this software, more accessible formats such as DWF and 3D PDF have been developed to allow the entire project team to experience and provide feedback on the model. |
Model to model | |
Purpose | To simplify and distribute the overall process, a design is typically developed using more than one digital model. It is important that these distinct models can be efficiently and consistently integrated so that the team can comprehend the overall design. |
Nature | Given the technical complexity of this task, the flow of data in a model to model interaction typically goes in one direction. This involves extracting the data present in one or more digital models and merging it into a primary 'master' model. |
Enabling technologies | Technologies for model to model interaction vary in complexity, capability and industry penetration. The most common means of consolidation is the manual importing of data from standard digital model formats such as IFC or DWG. Unfortunately, incompatibilities between different CAD/BIM implementations mean such interactions can lead to inconsistent data. Many CAD/BIM tools have functionality for collaboratively editing digital models, but uptake is limited due to their operational complexity and the limitations imposed. |
Model to group | |
Purpose | The overall design needs to be distributed amongst the project team for review and eventual construction. The information conveyed by the model is raw data related to the current state of the design, rather than personal opinion. |
Nature | Given the physical and technical distribution of a project team, it is usually impractical for a group to interact with a digital model in real-time. To compensate, snapshots of the model's design state are created and communicated in a manner that all interested parties can consume. Given its revision-centric nature, the information transfer between model and group is uni-directional. If group members wish to respond to the information conveyed they must establish a new person to person, person to group or person to model interaction. |
Enabling technologies | In larger projects, document management systems such as Buzzsaw, ProjectWise and Aconex are commonly used to ensure the project team is informed of changes to the digital model and supporting documentation. Many of these tools are integrated into CAD/BIM software so that the interaction between model and group is seamless. In smaller projects the cost and complexity of these systems cannot be justified, so manual file transfers using FTP or web servers are often used to distribute the model. |
Given these diverse functional requirements it is understandable that no single technology is capable of satisfying the digital collaboration needs of a project team. This poses a problem because participants stand the greatest chance of receiving timely and relevant data when the digital experience is well integrated. Unfortunately the boundaries between two or more collaboration tools generate inefficiencies, confusion and data loss due to the inability of many digital tools to collaborate with each other. As a consequence, using two or more digital collaboration tools can often lead to the following issues:
- Lack of Process Integration: The decisions or actions taken in one tool are often not reflected in others. In an ideal world, design decisions made during an email exchange would automatically generate outstanding to-do items within the digital model and have the document management service (DMS) notify the team of forthcoming design revisions. When interacting with the digital model or DMS later in the project, this same trail of messages can be used to understand the motivations and justification behind a design element. Currently these actions currently cannot be automatically undertaken, because a simple means of passing messages between the various collaboration tools used by the team does not yet exist.
- No Identity Management: Collaboration tools do not generally use the same system for identifying users or recording information about them. This forces participants to create numerous virtual identities and maintain a record of those used by the team. This becomes problematic when reviewing a series of design decisions that have been made in unison with multiple collaboration tools. For example, a project team using email to exchange thoughts between participants, BIM to develop the digital model and a document management service to distribute the outcomes employs the following identity systems:
Interaction
Software
Identity System
Person to model
BIM software
Account on the local operating system. e.g. COMPANY\username
Person to person
Email
Globally unique email address. e.g. participant.name@company.com
Model to team
Document management service (DMS)
DMS-specific user account. e.g. participant_name
With three different identity systems, tracking a design decision from conception (email) to its finalisation (in the DMS) becomes a complex process. Questioning a design decision is no easier because the participant must first identify who it is they need to talk to, and from there discern that person's virtual identity relative to the collaboration tool being used to conduct the interaction.
- Functional and Data Repetition: The lack of messaging or identity integration between collaboration tools results in the repetition of functionality and data-entry tasks. Common information such as the identities of team members, their project roles and general interests cannot be easily shared or consumed by applications. Similarly, common collaboration functionality used by multiple applications must be continually reimplemented rather than being reused. This occurs because utilising functionality present in third-party applications is difficult, and not all participants have access to the relevant software dependencies. This situation is akin to early desktop computing where system-wide functionality such as copy, paste and printing did not exist. Once this shared functionality was introduced, the capability and productivity of desktop computing was improved because all involved could rely on the presence and consistent behaviour of these familiar tools.
Using a collaboration kernel to integrate collaboration interactions
In an ideal world, the various collaboration interactions which occur during a project would be supported by a single, tightly integrated software application. This 'digital collaboration swiss army knife' would promote an efficient and cohesive collaboration environment by reliably recording and seamlessly communicating relevant design information throughout the team. Unfortunately a universal AEC digital collaboration tool is impractical, both now and in the foreseeable future, because of the complications which arise from bundling so much functionality into a single tool that will be used by a diverse audience. Rather than trying to reinvent the perfect wheel, a more practical approach is needed that provides a means for existing digital tools to exchange design discussion, issues and decisions. This will relieve the integration and replication issues that currently exist without having to start from scratch. The most efficient and reliable means of solving this problem is to establish a collaboration kernel that can act as an intermediary between the disparate tools. This Internet-centric service would in effect become the project's digital post office, overseeing the exchange of messages that support, summarise and promote the collaboration interactions taking place within the project team. A collaboration kernel's presence would be subtle, but its influence on collaboration would be significant. For example, consider the following hypothetical scenario set in the not too distant future:
Pam the project manager reviewed the client's email. The design of the entrance foyer for their multi-storey commercial development needed to be enlarged to accommodate more activities than originally projected. This was not a simple task because the layout of the ground floor was tight, so allocating more space meant sacrificing something else. In her email client she highlighted the email, pressed the New Task button and from the list of names assigned it to Andy the architect. She wrote a quick summary of the task ahead:
"From Pam to Andy: Tomorrow can you identify an alternative foyer design based on the criteria listed in this email?"
She pressed the 'Create Task' button and left work for the evening. As she left, the email client uploaded a copy of the email to the architecture practice's internal server where Andy could access it. It then passed Pam's message, along with a link to the relevant email, to the collaboration kernel which would ensure the task would be brought to Andy's attention the next morning.
The next morning Andy arrived in the office and logged into the Practice's Intranet. His personalised homepage checked in with the collaboration kernel, which promptly returned the task Pam had assigned to him. Andy read the message and followed the link to the referenced email. Being newly assigned to the project he was not fully aware of previous design decisions associated with the foyer. To provide some background he queried the collaboration kernel for all the design interactions related to that specific part of the building. The service returned a chronological history showing who had been involved in the design of this aspect and what input had been recorded. The breakdown revealed two particularly active design periods which included references to early 3D models and preliminary spacial renderings. Reviewing this work and the associated discussions, Andy quickly came to terms with the design concepts and issues at work within this part of the building. He opened the project's Building Information Model (BIM), but before starting work on the revision made the following note in the modelling tool's work-log:
"From Andy to everyone: I am spending this morning redeveloping the entrance foyer as per Pam's instructions."
He attached Pam's task to this note and saved it to the work-log. Behind the scenes the BIM software published the message to the collaboration kernel. The kernel broadcast the message to everyone in the team so that they could be forewarned of the changes afoot.
Meanwhile in another part of town Leny the lighting consultant was finalising the design of the building's ground floor lighting. That morning he had received a phone call from the client requesting a change to some of the fittings, but the proposed foyer changes had not been mentioned. His lighting simulation software displayed a notification from one of the architects:
"From Andy: I am spending this morning redeveloping the entrance foyer as per Pam's instructions."
Lenny could not access Pam's referenced instructions as he worked in another office, but he got the feeling this could affect his lighting design. He contacted Andy over instant messaging, and very quickly they identified the change would be a problem and that they should have a telephone conversation to discuss a practical way forward. After the telephone call Lenny quickly made a couple of notes about the conversation and what changes they had both agreed to make to their respective digital models:
"From Lenny to everyone: Andy and I have just discussed the proposed changes to the foyer and have come to an agreement that will suit the client's needs and code requirements."
"From Lenny to Andy: If you redesign the east side of the foyer as discussed I will be in a position to make the relevant lighting design changes this afternoon."
These notes were published to the collaboration kernel where they were distributed to everyone in the team. The second note was addressed to Andy so that his computer would remind him of Lenny's plans.
Andy spent the morning modifying the digital model to include the revised foyer design. On completion he published the revised model to the project's document management system (DMS) for review. On committing the change he wrote a quick summary of what design aspects had been modified:
"From Andy: This revision to this foyer design takes into account the changes to capacity requested by the client. Accommodating this extra space required changes to the surrounding design, which is forcing Lenny to redesign aspects of the lighting."
News of this change and the accompanying note where automatically published to the collaboration kernel by the DMS. Team members tracking this particular model where then automatically notified of Andy's change by the collaboration kernel. Lenny was one of these people, and on receiving this news he downloaded the revised model for checking against his updated lighting design. After confirming there were no conflicts and the design met code requirements he published a note via the collaboration kernel:
"From Lenny to Andy and Pam: I have reviewed Andy's proposed foyer changes alongside my revised lighting layout. Everything checks out, and as far as I am concerned everything can proceed."
The collaboration kernel delivered the message to Pam to her mobile phone via SMS. She was tied up on the construction site in meetings most of the day, but had been keeping half an eye on Andy and Lenny's activity. She sent an SMS message in reply:
"From Pam to Andy and Leny: Good progress. When I get back to the office I will have the client to review both changes."
The SMS went to a service that automatically forwarded incoming messages from approved numbers to the collaboration kernel for distribution amongst the team.
Establishing a collaboration kernel and attaining this level of integration between the various digital tools in use will take a significant amount of time and resources. Fortunately the early foundations of this cohesive environment may already be in place. For example one promising collaboration kernel candidate is Project Bluestreak, a web-based messaging tool from Autodesk Labs.
The untapped potential of Bluestreak
Autodesk Labs' Project Bluestreak is a Web-based tool for exploring the applicability and usefulness of various 'Web 2.0' and social networking concepts within the context of design collaboration. Whilst unique for Autodesk, this is not the first time these technology concepts have been applied within the AEC industry. For example Vuuch and Kalexo are two established and functionally richer products. However, Autodesk is a dominant and pervasive presence throughout the world of digital design. Therefore if Bluestreak testing proves successful, aspects of it could permeate through their entire software portfolio. This would significantly benefit the workflow of Autodesk's customers, and ultimately influence the direction of collaboration within the industry. In the shorter-term, a key differentiator between Bluestreak and its contemporaries is the support pledged to third-party application development on the platform. Of late, developer ecosystems that leverage information and relationships stored within larger, parent networks have achieved significant business traction. SalesForce's AppExchange and Facebook's Application Directory are prominent examples of this strategy. In both cases, large numbers of independently developed applications have flourished thanks to the popularity of the underlying core service. A collaboration-centric application ecosystem would not garner the same levels of developer or media attention, but within the context of the AEC industry would still be a powerful platform. For Autodesk such an endeavour would add considerable value to their product line, whilst for third-party collaboration tool vendors it would significantly ease development and distribution costs.

When viewed alongside the concept of a collaboration kernel, Bluestreak in its current form is a lost opportunity. Instead of a standalone website, the service should be repositioned as a social messaging service that will be integrated across Autodesk's software portfolio. This would be a strong move as it would expose the service to a broad audience and position it as a viable collaboration kernel. Internally this would benefit Autodesk as it would allow their various development groups to leverage this collaboration-centric functionality via a set of Application Programming Interfaces (API). Once standardised, these same APIs could be publicly exposed to enable third-party application integration, or entirely new collaboration experiences. Third-party software vendors would be eager to build on this platform as it would simplify development and provide a direct, sanctioned link to Autodesk's applications and customer network. Whilst this strategy may sound simple, transforming Bluestreak into a viable collaboration kernel will not be straightforward. The service shows promise but it needs a considerable amount of redevelopment before it can adequately meet this challenge. Rather than blindly working towards this goal, a more productive approach is to analyse Bluestreak's theoretical performance relative to the collaboration principles set down by the Project Information Cloud. This process will identify a set of functional improvements that are required before it can effectively meet the demands of operating as a collaboration kernel.
A Bluestreak in the Project Information Cloud
The intention of a collaboration kernel is to improve the timeliness and relevancy of information delivered to project participants. To achieve this, the kernel must provide a set of common functionality that can be easily leveraged by other AEC software tools. This will efficiently improve the capability of these tools and allow team members to participate in an integrated and consistent collaboration environment. But what functionality does such a kernel require and how will this ensure the collaboration experience is improved?
One solution to this problem is to apply the principles of the Project Information Cloud to the design of the collaboration kernel. The Project Information Cloud is a proposal for an integrated collaboration environment where a project's digital history is readily accessible to those involved (see Using Project Information Clouds to Preserve Design Stories within the Digital Architecture Workplace). The principles of this environment have been derived from the World Wide Web, which in a relatively short space of time has proven to be a very successful and versatile medium for digital collaboration.
The seven principles of the Project Information Cloud are:
- Comprehension: Is the system relatively easy to understand and use by both developers and participants within a project team? Technology should facilitate streamlined and reliable collaboration interactions instead of being an unfortunate necessity.
- Modularity: Can the functionality of the system be extended or replicated by a third-party without interrupting the overall experience of the project team? The concept of a collaboration kernel implies that the extra functionality required to achieve each collaboration interaction can be seamlessly 'bolted on'.
- Decentralisation: Can the collaboration interactions reliably occur without the presence of a central, mediating body? Likewise can one or more parties leave the project team without effecting the consistent flow of information?
- Ubiquity: Can the entire project team access the system from the digital tools that they commonly use? Reliable interaction with the collaboration environment should not require specialised tools that are dependent on a specific software vendor.
- Situational Awareness: Is the system capable of gathering and responding to external information generated by other systems within the project team? A system that stands alone is of marginal value as a collaboration tool.
- Context Sensitivity: Does the system understand the hierarchy and ongoing activities within the project team, and can it tailor its operations and user-interfaces accordingly? AEC project teams are complex and constantly changing. Collaboration systems that cannot adapt during these context shifts are at best a hindrance, and at worst a liability.
- Dynamic Semantics: Can the system's categorisation system change over time so that participants record and navigate information in a way that relates to the current state of the project? No two projects are identical, and as they evolve the vocabulary used to describe the design and associated activities needs to keep pace with this change.
The ability of a collaboration tool to satisfy these principles can be visually illustrated on a seven point spider diagram. Analysing a tool's performance in this manner is a simple yet effective means of identifying its strengths and weaknesses relative to other collaboration technologies. The rating system employed by this spider diagram is illustrated below and described in the following table.

Comprehension | |
0 - Enigma | The purpose, processes and outcomes of the collaboration tool are impossible to understand. |
1 | One or two aspects of the tool's purpose, processes and outcomes are somewhat understood by a few users. |
2 | After significant amount of effort, the tool's purpose, processes and outcomes can be understood by the minority of users. |
3 | After some effort, the purpose, processes and outcomes of the tool can be largely understood by the majority of users. |
4 - Obvious | The purpose, processes and outcomes of the tool are readily understood by all users. |
Modularity | |
0 - Sculpture | The tool is made from a single, large component whose functionality cannot be extended or replicated. |
1 | The tool is made from a single, large component, but with significant effort minor functional aspects can be extended or replicated. |
2 | Parts of the tool are modular and with significant effort some its functionality can be extended or replicated. |
3 | The majority of the tool is modular and with some effort most of its functionality can be extended or replicated. |
4 - Lego | The tool is completely modular and with minimal effort all of its functionality can be extended or replicated. |
Ubiquity | |
0 - Exclusive | The tool is only used by a single party and employs non-standard, proprietary technologies and data formats. |
1 | The tool has some industry use, but it is not readily available and employs non-standard, proprietary technologies and data formats. |
2 | The tool is readily available, but not widely used and generally employs non-standard, proprietary technologies and data formats. |
3 | The tool is readily available and widely used, but it generally employs non-standard, proprietary technologies and data formats. |
4 - Universal | The tool is readily available, widely used and employs freely accessible technologies with standardised data formats. |
Decentralisation | |
0 - Monolith | The tool in its entirety is bound to a single location and cannot be moved or used anywhere else. |
1 | The tool is based in one location, but with significant effort it can be deployed to and used in multiple locations. |
2 | The tool relies on some centralised components, but with moderate effort it can be deployed to and used in multiple locations. |
3 | The tool has a few centralised components that do not stop it from easily being deployed to and used in multiple locations. |
4 - Mesh | The tool's components are distributed and replicated, which presents no single point of failure and allows its use from anywhere. |
Situational Awareness | |
0 - Isolationist | The tool is isolated from the outside world and its processes and interface cannot respond to changes in this environment. |
1 | With significant effort the tool can monitor a few external resources so that its processes or interface can respond to changes in them. |
2 | With moderate effort the tool can monitor some external resources so that its processes or interface can respond to changes in them. |
3 | With minimal effort the tool can monitor a large number of external resources and can automatically respond to changes in them. |
4 - Hive mind | The tool is deeply intertwined with its surrounding environment and its processes and interface automatically responds to changes in it. |
Context Sensitivity | |
0 - Oblivious | The tool has no understanding of the project situation and its processes and interface only operate one way. |
1 | The tool has no understanding of the project situation, but with significant effort, its processes and interface can be tuned. |
2 | The tool has a very limited understanding of the project situation, but with moderate effort, its processes and interface can be tuned. |
3 | The tool has a limited understanding of the project situation, and in response can change some processes and interface aspects. |
4 - Aware | The tool has a strong understanding of the project situation, and in response automatically changes its processes and interface. |
Dynamic Semantics | |
0 - Meaningless | The tool employs no semantic system to organise the data it collects or transfers. |
1 | The tool employs a single semantic system that cannot be modified without considerable effort or planning. |
2 | The tool employs a single semantic system that can be modified with minimal effort or planning. |
3 | The tool employs multiple semantic systems specific to the user and their context, but modifying them requires considerable effort. |
4 - Expressive | The tool employs multiple semantic systems specific to the user and their context, and if need be they can be easily modified. |
How each of these Project Information Cloud principles is embodied within collaboration tools currently used by the AEC industry is illustrated in the following diagrams. In this diagrammatic analysis an ideal digital collaboration tool would form a perfect heptagon, but in each case one or more areas are found to be lacking.

These same principles can be applied to Bluestreak to identify its collaboration strengths and weaknesses. Adequately satisfying these principles will ensure the service has a strong chance of performing well as a collaboration kernel. Bluestreak's immediate and long-term ability to satisfy the principles of the Project Information Cloud are illustrated in the following diagram and proceeding text.

Comprehension
Bluestreak is currently easy to understand because it has only just been released and therefore lacks functionality or historical 'cruft'. Given this spartan beginning, the greatest challenge facing Bluestreak's developers is identifying what functionality does not need to be added. This is important because a collaboration kernel should be concise so that those using it have a clear understanding of what services it provides and why. A limited scope will help to ensure the Bluestreak platform is easily adopted by developers and end-users appreciate its role in collaboration. This strategy has been very successful for Twitter, which has flourished thanks to the ease by which developers and users alike have understood what it has to offer and how to leverage it to achieve their desired results.

The difficultly ahead for Bluestreak is that becoming a successful collaboration kernel requires it integrate with a diverse range of AEC tools in a number of ways (as illustrated by the diagram above). This integration breaks down into three forms:
- Components: Autodesk and third-parties will build components on top of the Bluestreak API that will form a critical part of its web interface and functionality.
- Web Service API: For basic operations many Autodesk and third-party web applications will interact with Bluestreak using a set of web service functions. Web services are a ubiquitous and accessible means of exchanging data between different systems, but these same properties makes it an inefficient means of programming complex tasks.
- Client API Libraries: Learning a set of low-level web services and writing custom code poses a significant learning curve and development hurdle. To ease this burden Autodesk needs to provide a set of software libraries which allow developers to reliably and quickly perform a set of complex Bluestreak operations using only a few lines of code.
To improve the comprehension of developers and users it is important that these three integration points are well designed and documented. A developer should not be expected to understand the entire Bluestreak platform if all they wish to do is achieve quick results using a Client API library. In contrast, the experience of the end-user should be such that they are unaware these even interfaces exist. To them Bluestreak should be as transparent as possible so that collaboration across different applications appears to "just work".
Modularity
Bluestreak's capacity to be modular hinges on its API which will allow third-parties to develop new components. As this API is currently not publicly available judgement cannot be passed on its success. However, it is promising that Bluestreak's own file upload component has been developed using a subset of it. Beyond allowing independent parties to add new functionality, a well documented and public API can be reimplemented by other collaboration systems such as ProjectWise, Aconex and Vuuch. If these services reimplemented the API then, at least in theory, Bluestreak components would be able to integrate with, or run inside of these other services. The benefit of this modularity is that a 'killer application' written on top of the Bluestreak API would not necessarily be restricted to Autodesk's collaboration environment. In the programming world cross-platform APIs and runtime environments are popular and powerful platforms. These range from fully portable programming runtimes such as Java, to ports of traditional APIs like WINE, which enables Windows applications run unmodified on other operating systems.

A diagram illustrating the relationship between the Bluestreak service, its API and various Autodesk and third-party applications.
Beyond the as yet unreleased API, Bluestreak employs OpenID which is an open standard for authenticating to websites. This is currently limited to Autodesk's own OpenID provider, but a future iteration could permit third-party OpenID services to be used, for example Google, Yahoo or an internal corporate account. Enabling authentication modularity in this manner lowers barriers to entry, as potential collaborators will not necessarily have to create a new online identity to participate in an online conversation.
Decentralisation
Like most web applications, Bluestreak cannot be installed onto a private server and migrating data stored on it to another service is not straightforward. This may suffice for a consumer application, but it poses a significant problem in the context of the AEC industry. Companies require reliable systems that adhere to entrenched processes and policies. Therefore to be successful Bluestreak must be decentralised so that it can be run 'in-house' or integrated into other systems.
The first step in this process would be to offer Bluestreak as a standalone application that can be installed on a local server. This sounds straightforward, but in practice it would require significant changes to the way Bluestreak is designed and implemented. An isolated copy of Bluestreak is of limited value if it cannot "talk" to other Bluestreak installations. For example if architects and engineers cannot exchange information because they are running different Bluestreak instances, then the service as a whole is of limited collaboration value. Unfortunately enabling this level of reliable and timely data exchange is fraught with challenges. Google Wave captured headlines due to its rich user-interface, but ultimately its long-term success hinges on the ability of the Wave Federation Protocol to allow users on different Wave servers to seamlessly collaborate in near real-time. A viable option would be for Autodesk to follow Novell's lead and implement the Wave Federation Protocol within Bluestreak. This would solve the decentralisation problem, however this would be a complex, costly and inherently risky undertaking.
Ubiquity
Bluestreak shows promise as a collaboration kernel because it is built on ubiquitous technologies and places minimal restrictions on what can be exchanged. Being a Javascript-based web application, it can be accessed from any standards compliant web browser with an Internet connection. Likewise, when using the tool participants are free to exchange whatever data their team can readily access, instead of being forced into specific formats.
Micro-blogging is one area where Bluestreak could enhance its ubiquity. Micro-blogging is a promising AEC collaboration medium (see Using micro-blogging to record architectural design conversation alongside the BIM), but the implementation within Bluestreak is hamstrung by its isolation and inconsistencies. There is currently no means of posting a message without visiting the Bluestreak website, and for no discernible reason 'status' and 'group' messages have different maximum lengths - 150 vs 250 characters respectively. A more ubiquitous approach would be to implement an existing, albeit immature, micro-blogging standard such as StatusNet (formerly Laconi.ca). Extending an established platform would allow Bluestreak to leverage this existing functionality and community. Project teams would then be able to use desktop or mobile-based software clients rather than just the Bluestreak website. From the perspective of decentralisation, initiatives like StatusNet also allow different micro-blogging systems to exchange messages. These federated micro-blogging solutions are simpler than Google's Wave Federation Protocol, and could prove 'good enough' for the purposes of digital design collaboration.
Beyond the promotion of ubiquitous formats and processes, the concept of Bluestreak needs to become ubiquitous across Autodesk's software line. Similar to Ray Ozzie's Mesh initiative within Microsoft, Bluestreak should be portrayed as a collaboration umbrella that touches upon all aspects of Autodesk's activities. Conversations currently taking part within the Bluestreak web application need to be brought to the 3D CAD and BIM tools where the majority of design development, analysis and documentation is taking place. For example, when using Revit an architect should be able to review and participate in Bluestreak discussions without leaving the application. Then when the model is exported to DWF for sending to the contractor, relevant aspects of that discussion could be embedded within the file to preserve its context relative to the overall design process.
Situational Awareness
Currently Bluestreak depends on manual data input and there is no way of externally monitoring the discussion taking place within it. This is a considerable shortcoming because collaboration takes place over multiple communication channels. A successful collaboration kernel should make the team aware of the activities taking place on these other channels instead of being oblivious to them. The API could significantly boost situational awareness by allowing components to pull data from external services, or push data into Bluestreak. Examples of potential components are:
- Changes: An agent that monitors files in a third-party document management service and informs the team when modifications take place. Most project documentation will not reside within Bluestreak, so knowing it has changed and to what degree is an important consideration during collaboration.
- Progress: An agent that parses the project manager's Microsoft Project file or shared calendar and alerts the team of significant events. The project timeline is continually evolving and those involved cannot be expected to maintain it in multiple locations. Monitoring a project's timeline also ensures the collaboration service satisfies the principle of context sensitivity.
- External Activity: An agent monitors an external email account, collaboration tool, or web service for information contributed by a third-party. A sub-contractor may not warrant full Bluestreak project membership, but they could be provided an email address for submitting information and questions. The component could then automatically monitor this email account and publish correspondence to Bluestreak.
Situational awareness is a two-way street, so beyond acting as a data sponge, Bluestreak should expose data to trusted third-parties. Presently users can manually monitor conversations via the website, or elect to have all status/group messages emailed to them. Both of these options are problematic because for many team members Bluestreak will not form a part of their daily workflow. As a result most will not visit the website regularly and will soon ignore, or disable, email notifications. These attention issues cannot be resolved by Bluestreak alone. Instead it must work towards exposing its data and functionality to applications that are regularly used by the team. A prime example of this is that a large portion of Twitter use takes place within third-party tools. Similar results can only be achieved by Bluestreak if it exposes the collaboration interactions it records in machine readable formats (RSS, XML, JSON) that can be parsed by other software used within the project team.
Context Sensitivity
Bluestreak's only nod towards context sensitivity is the use of groups to divide people and conversations. In the future it needs to make better use of the contextual information within a project so that participants can easily navigate, filter and target collaboration interactions. For example project teams have clearly defined, hierarchical relationships that reflect the roles and expertise of each participant. A collaboration kernel that successfully leverages this knowledge will be more able to deliver timely and relevant information to the team. Bluestreak users have profiles, but these lack expertise or fields of interest which would help to bring relevant messages to their attention. Alternatively this information could identify people within the team who are the most capable of resolving a specific design problem.
Beyond filtering and highlighting conversations, context is a useful means of stopping information from reaching participants in the first place. In its current form, a Bluestreak project is like working with a group of people in a large auditorium - anybody can say or hear anything. Whilst fine for general situations, when large numbers of people or sensitive data is involved it becomes important that certain interactions occur in private. At present multiple Bluestreak groups can be created to achieve this, but practically this is unwieldy. A more flexible approach would be to allow messages to be addressed to people within the team based on their profile's meta-data or the project's hierarchical structure. This could be achieved by combining micro-blogging's address (@) and subject (#) syntax at the beginning of a message. For example, a message beginning with @#architect would signify it should be brought to the attention of architects within the team. This same mechanism could be extended to specific phases in the project (@#construction), or fields of interest (@#concept). Borrowing again from micro-blogging, a leading 'd' character (for Direct Message) would signify that the message was intended for a restricted audience. Whilst this syntax is simple, it is compatible with micro-blogging standards and can be clearly presented by software agents.
Dynamic Semantics
At present Bluestreak lacks any means for categorising contributed content. When navigating or searching large amounts of AEC collaboration data this soon becomes a problem because the content of many messages does not reflect its subject matter. For example a discussion centered around "indoor and outdoor flow" maybe conceptual (the floor layout), or specific (the detailing of a door). Micro-blogging services like Twitter have demonstrated that semantics can be embedded within messages via hash (#) tags which Bluestreak could easily support. Components could then be developed using the API that allows the project's semantic structure to be visualised and navigated.
Embedding hash tags within messages is a flexible means of publishing semantics, but participants must also be able to retrospectively apply meaning to content. For example a project's taxonomy will initially focus on conceptual ideas, but as the design is refined, so too will the semantics used to describe it. Semantics are also relative depending on the perspective of the participant, therefore it must be possible to assign multiple semantic layers to content. Achieving this semantic flexibility requires users possess the ability to manually re-categorise any content. To assist in this process the collaboration kernel itself should infer meaning based on a message's context and any assigned relationships.
Applied Semantics
Within Bluestreak users should be able to tag any content that has been contributed so it can be referenced by other data. In a distributed environment embedding new semantic information within existing content is problematic because these changes must be replicated across the team. A more efficient means of solving this problem is to assign all content published to Bluestreak a globally unique URL. These simple URL references can then be categorised multiple times using an existing bookmarking/tagging service such as Delicious, or a native Bluestreak tool.
Inferred Semantics
Beyond manual tagging, semi-intelligent agents could categorise collaboration data based on where and when it was created and what it is related to. This would require Bluestreak to be integrated into other software so that information can be automatically included from this environment. For example, an architect using Revit may identify and highlight an issue with the design's foundations. On posting the issue to Bluestreak using a tool built into Revit, relevant meta-data such as the components affected (foundations), materials used (concrete) and the model's revision details (revision #432) would be included automatically.
Conclusion
A collaboration kernel communicates key design ideas, issues and decisions between the disparate digital tools used by the AEC industry. If it became as digitally prevalent as copy and paste is today, such a service would be an efficient and reliable median between the various collaboration interactions which occur. By helping to weave together these various communication channels, the collaboration kernel would improve the timeliness and relevancy of information delivered to members of the project team. The principles of the Project Information Cloud proved very useful in isolating the key characteristics of a collaboration kernel and its benefit to information flow within the team. Using these principles to assess Bluestreak identified a set of changes that would allow it to better fill the role of collaboration kernel. By implementing these changes and integrating the service across its line of software products, Autodesk could be the first to establish a collaboration kernel, and in doing so ultimately improve the AEC industry's overall collaboration capability.
Synchronise two SilverStripe CMS instances 8 Dec 2009 3:40 PM (16 years ago)
This script allows you to operate two distinct, fully functional SilverStripe instances and have the content of one synchronised with the other. When running a content management system in a corporate environment it is useful to have an internal 'development' site and a public 'production' site. SilverStripe has a couple of caching options, namely StaticPublisher and StaticExporter, but these generate static HTML files that cannot be easily modified by content editors.
This approach allows the development and production SilverStripe servers to be easily synchronised, but in between times, content editors are free to make different changes at each end. This is useful when internally the content of the website is undergoing significant change, but during this time the production website content must be 'maintained'.
i.e. You are not forced to 'freeze' your production website, or push internal changes out before they have been properly vetted.
The script copies the local SilverStripe MySQL database (sans page revisions) to the production site and synchronises the assets/Uploads directory.
Note: Page revisions are not sent to the production site because this takes a significant amount of time and bandwidth. Considering these revisions are stored on the internal development server, storing them in both locations is not necessary.
A flow diagram of the actions that take place during this synchronisation process is provided below.

This script assumes that SilverStripe's StaticPublisher caching mechanism is enabled on both local and remote sites, otherwise the sync process will fail.
Requirements
- The script requires SSH, MySQL and RSync, awk, and grep on both servers to function correctly.
- For the email notifications to work, either sendmail or postfix will need to be running locally so that the mail command can deliver notifications.
- For the script run without SSH prompting for passwords, key-based authentication between the two servers will need to be configured. (The key should not have a password.)
- The local MySQL user needs to be able to access two databases:
- Read-only access to the local SilverStripe database.
- All permissions to an empty database where the script can make a copy of the SilverStripe database and strip the page revisions from.
Configuration
The sssync.sh script pulls configuration information from a supplied config file. Below is an example configuration file that lists the various options that should be tuned to your environment.
config
# The local directory where the SilverStripe website is installed
Local_SilverStripe_Directory /var/www
# The local temp directory which the script has write access to
Local_Temp_Directory /tmp
# The local MySQL user (must have write permissions to temp database)
Local_MySQL_User localuser
# The local MySQL password
Local_MySQL_Password localpassword
# The local MySQL hostname
Local_MySQL_Host localhost
# The local MySQL port
Local_MySQL_Port 3306
# The local (primary) MySQL database
Local_MySQL_Database silverstripe
# The local temporary database used to store a revisionless version of the site
Local_MySQL_TempDatabase silverstripe_tmp
# The local user who owns the cache files
Local_User www
# The local group who owns the cache files
Local_Group www
# The remote SSH username
Remote_SSH_User remoteuser
# The remote SSH hostname
Remote_SSH_Host remote.host.name
# The remote SSH port
Remote_SSH_Port 22
# The remote directory where the SilverStripe website is installed
Remote_SilverStripe_Directory /var/www
# The remote directory where backups of the website and database are stored
Remote_Backup_Directory /var/backup/silverstripe
# The remote MySQL username
Remote_MySQL_User remoteuser
# The remote MySQL password
Remote_MySQL_Password remotepassword
# The remote MySQL hostname
Remote_MySQL_Host localhost
# The remote MySQL port
Remote_MySQL_Port 3306
# The remote MySQL database
Remote_MySQL_Database silverstripe
# The remote user who owns the cache files
Remote_User www
# The remote group who owns the cache files
Remote_Group www
# The email address(es) of recipients for sssync email
Recipient_Email_Address notify@user
# The sssync from email address
From_Email_Address sssync@domain.com
# The SMTP server (assumes the Heirloom Mailx utility is used)
SMTP_Server smtp.server.com
The sssync.sh script
The sssync.sh script performs all the described synchronisation functions. Copy and paste the following into a file on your local server named sssync.sh. Make sure you mark it as executable (chmod 777).
sssync.sh (this file can be downloaded from here)
#!/bin/sh
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# A copy of the GNU General Public License is available at
# <http://www.gnu.org/licenses/>.
#
#
###########################################################
# sssync - SilverStripe Site Sync #
###########################################################
#
# Author: David Harrison
# Date: 9 December 2009
#
# This script synchronises a remote SilverStripe installation
# with a local copy. It is assumed that SilverStripe's caching
# mechanism is enabled.
# For SSH authentication to occur without a password prompt,
# SSH keys should be generated to allow password-less login.
#
# ---------------------------------------------------------
#############################################
# Variables pulled from the supplied config #
#############################################
# Local website directory
localSSDir=`awk '/^Local_SilverStripe_Directory/{print $2}' $1`
# Local temp directory
tempDir=`awk '/^Local_Temp_Directory/{print $2}' $1`
# Local MySQL configuration
localMySQLUser=`awk '/^Local_MySQL_User/{print $2}' $1`
localMySQLPassword=`awk '/^Local_MySQL_Password/{print $2}' $1`
localMySQLHost=`awk '/^Local_MySQL_Host/{print $2}' $1`
localMySQLPort=`awk '/^Local_MySQL_Port/{print $2}' $1`
localMySQLDatabase=`awk '/^Local_MySQL_Database/{print $2}' $1`
localMySQLTempDatabase=`awk '/^Local_MySQL_TempDatabase/{print $2}' $1`
# Remote SSH configuration
remoteSSHUser=`awk '/^Remote_SSH_User/{print $2}' $1`
remoteSSHHost=`awk '/^Remote_SSH_Host/{print $2}' $1`
remoteSSHPort=`awk '/^Remote_SSH_Port/{print $2}' $1`
# Remote directories
remoteSSDir=`awk '/^Remote_SilverStripe_Directory/{print $2}' $1`
remoteBackupDir=`awk '/^Remote_Backup_Directory/{print $2}' $1`
# Remote MySQL configuration
remoteMySQLUser=`awk '/^Remote_MySQL_User/{print $2}' $1`
remoteMySQLPassword=`awk '/^Remote_MySQL_Password/{print $2}' $1`
remoteMySQLHost=`awk '/^Remote_MySQL_Host/{print $2}' $1`
remoteMySQLPort=`awk '/^Remote_MySQL_Port/{print $2}' $1`
remoteMySQLDatabase=`awk '/^Remote_MySQL_Database/{print $2}' $1`
# The email options - email requires sendmail or postfix running locally
emailRecipient=`awk '/^Recipient_Email_Address/{print $2}' $1`
fromAddress=`awk '/^From_Email_Address/{print $2}' $1`
smtpServer=`awk '/^SMTP_Server/{print $2}' $1`
# The sendEmail function delivers an email notification.
# This function assumes the Heerloom mailx utility is installed on the system.
# It takes the following parameters:
# 1- Subject
# 2- Message
sendEmail() {
echo "Sending email to $emailRecipient:"
echo " Subject - ${1}"
echo " Message - ${2}"
echo ${2} | mail -s "${1}" -S "smtp=$smtpServer" -r $fromAddress $emailRecipient
}
# The buildStripVersionsSQL function constructs a temporary SQL file that contains
# commands for removing the revisions from the temp database.
#
# Note: If you have custom page types include the relevant SQL statements below
buildStripVersionsSQL() {
echo "DELETE FROM ErrorPage_versions;" > ${tempDir}/sssync.sql
echo "DELETE FROM GhostPage_versions;" >> ${tempDir}/sssync.sql
echo "DELETE FROM RedirectorPage_versions;" >> ${tempDir}/sssync.sql
echo "DELETE FROM SiteTree_versions;" >> ${tempDir}/sssync.sql
echo "DELETE FROM VirtualPage_versions;" >> ${tempDir}/sssync.sql
}
# The cleanTemp function removes the temporary error file.
cleanTemp() {
rm ${tempDir}/sssync.err
}
# The rollBackChanges function restores the file and database backup of the remote website.
rollBackChanges() {
echo "Rolling back the remote file changes"
ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"tar -xzf ${remoteBackupDir}/html.tgz -C ${remoteSSDir}"
echo "Rolling back the remote database changes"
ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"mysql -u ${remoteMySQLUser} -h ${remoteMySQLHost} -p${remoteMySQLPassword} \
-P ${remoteMySQLPort} \
${remoteMySQLDatabase} < ${remoteBackupDir}/backup.sql"
}
echo
echo "--------------------------------------------"
echo "| SilverStripe Sync process initiated |"
echo "--------------------------------------------"
echo
echo "Local SilverStripe directory: ${localSSDir}"
echo "Temporary directory: ${tempDir}"
echo "--------------------------------------------"
echo
logger "Initiating sssync script..."
echo "Rebuilding the local SilverStripe cache"
cd ${localSSDir}
sapphire/sake dev/buildcache flush=1 > ${tempDir}/sssync.err 2>&1
chown -R $localUser:$localGroup cache
localCacheRebuilt=`tail ${tempDir}/sssync.err | grep "== Done! =="`
cleanTemp
if [ "${localCacheRebuilt}" != "== Done! ==" ]
then
echo
echo "** Error rebuilding the SilverStripe cache - Exiting **"
echo
sendEmail "Error rebuilding local SilverStripe cache"\
"There was an error rebuilding the SilverStripe cache. \
The sync process was not undertaken."
exit
fi
#############################################
# Create a local, revisionless SS database #
#############################################
echo "Creating a temporary, revisionless database"
mysqldump -C -u ${localMySQLUser} -p${localMySQLPassword} -h ${localMySQLHost} -P ${localMySQLPort} ${localMySQLDatabase} | \
mysql -u ${localMySQLUser} -p${localMySQLPassword} -h ${localMySQLHost} -P ${localMySQLPort} ${localMySQLTempDatabase} > ${tempDir}/sssync.err 2>&1
# Create the SQL file to pass to the temp database
buildStripVersionsSQL
# Stip the versions from the temp database
mysql -u ${localMySQLUser} -p${localMySQLPassword} -h ${localMySQLHost} -P ${localMySQLPort} ${localMySQLTempDatabase} \
< ${tempDir}/sssync.sql > ${tempDir}/sssync.err 2>&1
# Remove the temporary SQL file
rm ${tempDir}/sssync.sql
localDBCreated=$(cat ${tempDir}/sssync.err)
cleanTemp
if [ "${localDBCreated}" != "" ]
then
echo
echo "** Error creating a revisionless database - Exiting **"
echo
sendEmail "Error creating revisionless database"\
"There was an error creating a revisionless version of the local database. \
The sync process was not undertaken."
exit
fi
#############################################
# Before performing the sync, make a backup #
#############################################
echo "Moving HTML backup ${remoteBackupDir}/html.tgz to ${remoteBackupDir}/html.tgz.old"
ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"mv ${remoteBackupDir}/html.tgz ${remoteBackupDir}/html.tgz.old"
echo "Moving SQL backup ${remoteBackupDir}/backup.sql to ${remoteBackupDir}/backup.sql.old"
ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"mv ${remoteBackupDir}/backup.sql ${remoteBackupDir}/backup.sql.old"
echo "Creating backup of the remote website"
remoteBackupMade=`ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"tar -czf ${remoteBackupDir}/html.tgz -C ${remoteSSDir} ."`
echo "Creating backup of the remote database"
remoteBackupMade="${remoteBackupMade}`ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"mysqldump -u ${remoteMySQLUser} -h ${remoteMySQLHost} -P ${remoteMySQLPort} -p${remoteMySQLPassword} \
${remoteMySQLDatabase} > ${remoteBackupDir}/backup.sql"`"
if [ "${remoteBackupMade}" != "" ]
then
echo
echo "** Error creating remote backup - Exiting **"
echo
echo "Moving the old remote backups into place"
ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"mv ${remoteBackupDir}/html.tgz.old ${remoteBackupDir}/html.tgz"
ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"mv ${remoteBackupDir}/backup.sql.old ${remoteBackupDir}/backup.sql"
sendEmail "Error creating remote backup"\
"There was an error creating a backup of the remote website files or database. \
The sync process was not undertaken."
exit
fi
# Variable to hold sync failure flag
syncFailure="false"
##############################################
# Perform the synchronisation of file assets #
##############################################
echo "Synchronising remote website assets/Uploads directory with local copy"
remoteFileSync=`rsync -aqz --delete -e "ssh -p ${remoteSSHPort}" ${localSSDir}/assets/Uploads/ \
${remoteSSHUser}@${remoteSSHHost}:${remoteSSDir}/assets/Uploads/`
if [ "${remoteFileSync}" != "" ]
then
syncFailure="true"
echo
echo "** Error synchronising website assets/Uploads - Rolling back changes **"
echo
sendEmail "Error synchronising website assets/Uploads"\
"There was an error synchronising the remote website's asset directory. \
The sync process was rolled back."
fi
##############################################
# Synchronise the local and remote databases #
##############################################
echo "Synchronising the remote database with the local (temp) database"
mysqldump -C -u ${localMySQLUser} -p${localMySQLPassword} -h ${localMySQLHost} \
-P ${localMySQLPort} ${localMySQLTempDatabase} | \
ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"mysql -u ${remoteMySQLUser} -h ${remoteMySQLHost} -p${remoteMySQLPassword} \
-P ${remoteMySQLPort} ${remoteMySQLDatabase}" > ${tempDir}/sssync.err 2>&1
remoteMySQLSync=$(cat ${tempDir}/sssync.err)
cleanTemp
if [ "${remoteMySQLSync}" != "" ]
then
syncFailure="true"
echo
echo "** Error synchronising the MySQL databases - Rolling back changes **"
echo
sendEmail "Error synchronising the MySQL databases"\
"There was an error synchronising the two MySQL databases. \
The sync process was rolled back."
fi
if [ "${syncFailure}" == "true" ]
then
echo
echo "** Error synchronising the SilverStripe site - Rolling back & exiting **"
echo
# Roll back the file and database changes
rollBackChanges
sendEmail "Error synchronising the remote website"\
"There was an error performing the synchronisation process. \
The sync process was rolled back."
exit
fi
##############################################
# Rebuild the remote SilverStripe web cache #
##############################################
echo "Rebuilding the remote SilverStripe cache"
ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"cd ${remoteSSDir}; sapphire/sake dev/buildcache flush=1" > ${tempDir}/sssync.err 2>&1
ssh ${remoteSSHUser}@${remoteSSHHost} -p ${remoteSSHPort} \
"chown -R $remoteUser:$remoteGroup ${remoteSSDir}/cache"
remoteCacheRebuilt=`tail ${tempDir}/sssync.err | grep "== Done! =="`
cleanTemp
if [ "${remoteCacheRebuilt}" != "== Done! ==" ]
then
echo
echo "** Error rebuilding the remote SilverStripe cache - Rolling back changes **"
echo
# Roll back the file and database changes
rollBackChanges
sendEmail "Error rebuilding the remote SilverStripe cache"\
"There was an error rebuilding the remote SilverStripe cache."
exit
fi
sendEmail "SilverStripe was successfully synchronised"\
"Congratulations, the remote website was synchronised without any issues."
logger "sssync script completed"
echo
echo "------------------------------------------------"
echo "SilverStripe was successfully synchronised"
echo "=============================="
echo
Running the script
Assuming your configuration file is in the same directory as the sssync.sh script, run the sync process with the following command:
./sssync.sh config
Assuming the requirements have been met and sync process takes place without error, the following output should be generated:
--------------------------------------------
| SilverStripe Sync process initiated |
--------------------------------------------
Local SilverStripe directory: /var/www
Temporary directory: /var/backup/sssync
------------------------------------------
Rebuilding the local SilverStripe cache
Creating a temporary, revisionless database
Moving HTML backup /var/backup/silverstripe/html.tgz to /var/backup/silverstripe/html.tgz.old
Moving SQL backup /var/backup/silverstripe/backup.sql to /var/backup/silverstripe/backup.sql.old
Creating backup of the remote website
Creating backup of the remote database
Synchronising remote website assets/Uploads directory with local copy
Synchronising the remote database with the local (temp) database
Rebuilding the remote SilverStripe cache
Sending email to recipient@user.com:
Subject - SilverStripe was successfully synchronised
Message - Congratulations, the remote website was synchronised without any issues.
------------------------------------------------
SilverStripe was successfully synchronised
==============================
It is possible to have multiple configuration files and store them in a different directory to the sssync.sh script. For example:
./ssync.sh /etc/sssync/production
./ssync.sh /etc/sssync/testing
The above commands will execute the sync process using the "production" and "testing" configuration files stored in the /etc/sssync directory.
Handling error pages
The sssync.sh script only synchronises the assets/Uploads directory as this is where file and image uploads are stored by default. SilverStripe error pages are stored in the root of the assets directory which is not synchronised. If an error page is changed, make sure it is republished using the SilverStripe admin interface.
StressFree Webmin theme version 2.05 released 18 Oct 2009 2:36 PM (16 years ago)
This update is minor but addresses a few issues:
- Adds a Javascript patch submitted by Rob Shinn that adds sidebar support for multiple servers.
- Fixes the missing footer link back to the module index bug.
- Also included is compressed Javascript and CSS files which should slightly reduce load times.
The updated theme can be downloaded from here.
Integrating Google Site Search into SilverStripe 15 Sep 2009 12:32 AM (16 years ago)
SilverStripe is an excellent, user-friendly content management system but its internal search functionality is, to put it kindly, useless. Fortunately with Google Site Search you can embed a Google-powered custom search engine into your SilverStripe site. Doing so requires a paid Site Search account, pricing for which starts at $100/year.
This tutorial explains how to integrate this Google Site Search XML feed into your SilverStripe site. Doing so has a number of benefits over the standard means of integrating Site Search, namely:
- No Javascript is required to display results within the SilverStripe site.
- The user is not taken to a separate, Google operated website to view results.
- The look and feel is consistent with the rest of the SilverStripe site.
- Multiple Site Search engines can be integrated into a single SilverStripe site.
- Site Search results pages are integrated into SilverStripe's management console.
Note: To integrate Site Search into SilverStripe using the described method a Site Search plan must be purchased as this provides results in XML. The free, advertising supported, Site Search engine does not provide search results in XML and cannot be used.
Loading XML data from an external source
Before the search page can be added to SilverStripe we need a reliable means of loading XML content. This is complicated by the fact many Web hosts disable PHP's built in URL fetcher (fopen) with the following php.ini directive:
allow_url_fopen = Off
Assuming it is installed, the cURL can get around this restriction, hence the XmlLoader helper library includes both methods (cURL is used by default in search.php).
Create a XmlLoader.php file in your SilverStripe's mysite/code directory with the following contents:
mysite/code/XmlLoader.php
<?php
class XmlLoader {
public function pullXml($url, $parameters, $useCurl) {
$urlString = $url."?".$this->buildParamString($parameters);
if ($useCurl) {
return simplexml_load_string($this->loadCurlData($urlString));
} else {
return simplexml_load_file($urlString);
}
}
private function loadCurlData($urlString) {
if ($urlString == -1) {
echo "No url supplied<br/>"."/n";
return(-1);
}
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $urlString);
curl_setopt($ch, CURLOPT_TIMEOUT, 180);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$data = curl_exec($ch);
curl_close($ch);
return $data;
}
private function buildParamString($parameters) {
$urlString = "";
foreach ($parameters as $key => $value) {
$urlString .= urlencode($key)."=".urlencode($value)."&";
}
if (trim($urlString) != "") {
$urlString = preg_replace("/&$/", "", $urlString);
return $urlString;
} else {
return (-1);
}
}
}
?>
With the helper library in place to load the XML, it is now time to implement the SilverStripe "search" page type and logic. Create a search.php file in your SilverStripe's mysite/code directory with the following contents:
mysite/code/search.php
<?php
require_once 'XmlLoader.php';
class Search extends Page {
static $db = array(
'GoogleSearchId' => 'Text',
'NoResults' => 'HTMLText',
);
static $has_one = array(
);
function getCMSFields() {
$fields = parent::getCMSFields();
$fields->addFieldToTab('Root.Content.Main', new TextField(
'GoogleSearchId', 'Google Site Search ID'), 'Content');
$fields->addFieldToTab('Root.Content.Main', new HtmlEditorField(
'NoResults', 'No results message'), 'Content');
# Remove the content field
$fields->removeFieldFromTab("Root.Content.Main","Content");
return $fields;
}
}
class Search_Controller extends Page_Controller {
function SearchForm() {
$input = array_merge($_GET, $_POST);
$query = $input['q'];
$output = "<form class=\"search\" action=\"/search/results\"><fieldset>";
$output .= "<input type=\"text\" size=\"40\" name=\"q\" value=\"$query\"/>";
$output .= "<input type=\"hidden\" name=\"p\" value=\"1\"/>";
$output .= "<input type=\"submit\" value=\"Search\"/>";
$output .= "</fieldset></form>";
return $output;
}
function SearchResults() {
$output = "";
$input = array_merge($_GET, $_POST);
$page = isset($input['p']) ? $input['p'] : '1';
$query = $input['q'];
$perPage = 10;
if ($page < 1) { $page = 1; }
$xml = $this->getGoogleSearchResults($this->GoogleSearchId, $perPage, $page, $query);
$results = $this->parseGoogleSearchResults($xml);
$totalResults = $this->getResultCount($xml);
$output .= $this->getFormattedResults($results);
if (count($results) == 0) {
// Show no results message
$output .= $this->NoResults;;
} else {
// Append paging
$output .= $this->getPagingForResults($totalResults, $query, $perPage, $page);
}
return $output;
}
private function getGoogleSearchResults($googleId, $perPage, $page, $query) {
$startingRecord = ($page - 1) * $perPage;
$url = "http://www.google.com/search";
$parameters = array();
$parameters["client"] = "google-csbe";
$parameters["output"] = "xml_no_dtd";
$parameters["num"] = $perPage;
$parameters["cx"] = $googleId;
$parameters["start"] = $startingRecord;
$parameters["q"] = $query;
$XmlLoader = new XmlLoader();
return $XmlLoader->pullXml($url, $parameters, true);
}
private function parseGoogleSearchResults($xml) {
$results = array();
$attr["title"] = $xml->xpath("/GSP/RES/R/T");
$attr["url"] = $xml->xpath("/GSP/RES/R/U");
$attr["desc"] = $xml->xpath("/GSP/RES/R/S");
foreach($attr as $key => $attribute) {
$i = 0;
foreach($attribute as $element) {
$results[$i][$key] = (string)$element;
$i++;
}
}
return $results;
}
private function getFormattedResults($results) {
$output = "";
if (count($results) > 0) {
$output .= "<ul class=\"results\">";
foreach($results as $i => $result) {
$title = "";
$url = "";
$desc = "";
foreach($result as $key => $value) {
if ($key == "title") {
$title = $value;
}
if ($key == "url") {
$url = $value;
}
if ($key == "desc") {
$desc = $value;
}
$output .= "<li><a href=\"$url\">$title</a><p>";
$output .= str_replace("<br>", "<br/>", $desc);
$output .= "</p></li>\n";
}
$output .= "</ul>";
}
return $output;
}
private function getResultCount($xml) {
$totalResults = 0;
$count = $xml->xpath("/GSP/RES/M");
foreach($count as $value) {
$totalResults = $value;
}
return $totalResults;
}
private function getPagingForResults($totalResults, $query, $perPage, $page) {
$maxPage = ceil($totalResults/$perPage);
if ($totalResults > 1) {
$output = "<div class=\"searchPaging\"><p>";
for($pageNum = 1; $pageNum <= $maxPage; $pageNum++) {
if ($pageNum == $page) {
$output .= " <strong>$pageNum</strong> ";
} else {
$output .= " <a href=\"".$this->AbsoluteLink()."results?q=$query&p=$pageNum\">$pageNum</a> ";
}
}
$output .= "</p></div>";
}
return $output;
}
}
?>
This file defines a search page type with two fields, a Google Search Id and an HTML field that is displayed if no search results are found. As this page does not have any content of its own the default SilverStripe content field is also disabled to avoid confusion.
With the backend logic in place it is time to implement the templates. The templates themselves will vary from site to site, but the examples given are good starting points. There are two templates, one which simply displays the search box and a second that displays the results.
Create a Search.ss file in your SilverStripe's mysite/templates/Layout directory with the following contents:
mysite/templates/Layout/Search.ss
<% if Menu(2) %>
<div class="pageWithMenu">
<% end_if %>
<div class="page">
<% if Menu(2) %>
<div class="content contentStandard">
<% else %>
<div class="content contentFull">
<% end_if %>
<h1>$Title</h1>
<div class="contentWrapper">
$SearchForm
<div class="clear"><!-- --></div>
</div>
</div>
<% if Menu(2) %>
<div id="sidepanel">
<% include SideBar %>
</div>
<div class="clear"><!-- --></div>
</div>
<% end_if %>
Now create the results page named Search_results.ss in your SilverStripe's mysite/templates/Layout directory with the following contents:
mysite/templates/Layout/Search_results.ss
<% if Menu(2) %>
<div class="pageWithMenu">
<% end_if %>
<div class="page">
<% if Menu(2) %>
<div class="content contentStandard">
<% else %>
<div class="content contentFull">
<% end_if %>
<h1>$Title</h1>
<div class="contentWrapper">
$SearchForm
<div id="searchResults">
$SearchResults
</div>
</div>
<div class="clear"><!-- --></div>
</div>
</div>
<% if Menu(2) %>
<div id="sidepanel">
<% include SideBar %>
</div>
<div class="clear"><!-- --></div>
</div>
<% end_if %>
Note: The content of these two files will vary depending on your site. In the above example a SideBar include file is used to load the secondary menu.
With the backend logic and template files in place it is time to rebuild the SilverStripe database so that the new page type can be recognised. Enter the following (modified) URL into your browser: http://yourwebsite/dev/build?flush=all
All going well the rebuild command will execute correctly. If it does browse to the administration section of your site and create a 'search' page type.
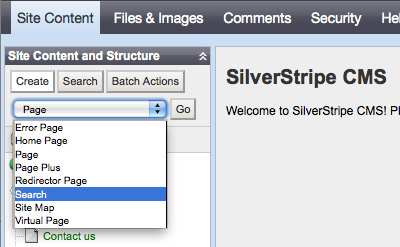
The search page type in the create menu
On the search page enter your relevant Google Search Id and Results Not Found message. For the page URL use /search as this is hard coded into the search.php file. It is possible to change this URL (or use a dynamic one) but for the purposes of this tutorial it is not necessary.
Note: You can get your Google Search Id from the Google Search administration console, or it can be found within the embed URL used in the Javascript or external search forms.
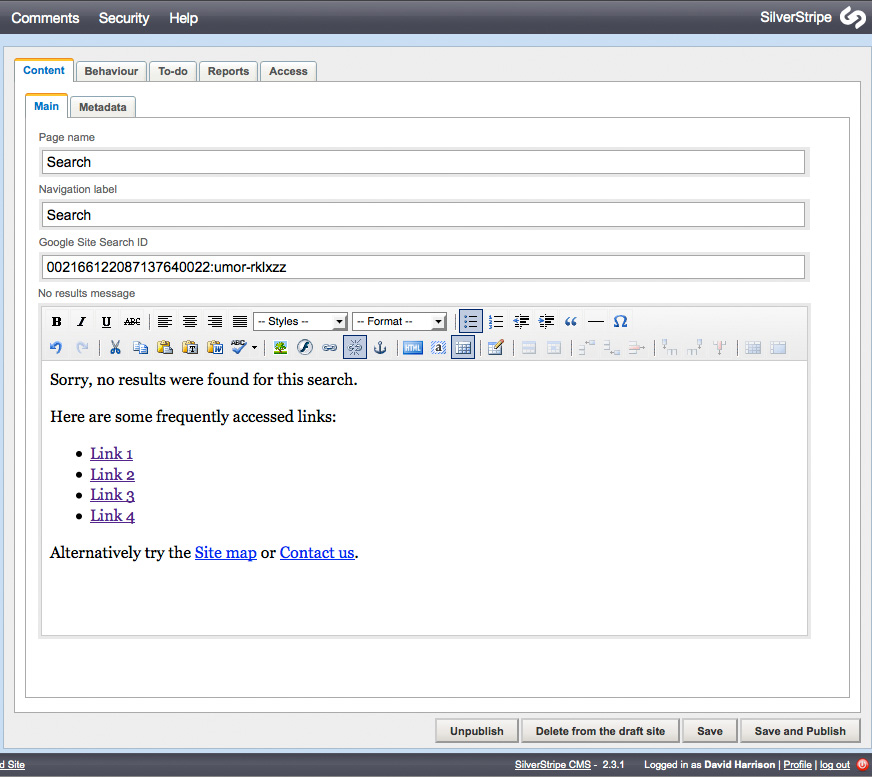
Once published open the page and try a search. Assuming your code and settings are correct the Google search results should be displayed within your SilverStripe page. Now all there is left for you to do is style the results.
For an example of this technique at work, checkout the Parliamentary Counsel Office's search interface which is implemented using the method just described.
StressFree Webmin theme version 2.04 released 12 Sep 2009 2:48 AM (16 years ago)
In what is hopefully the last update in a while the StressFree Webmin theme version 2.04 is available. This release applies some spit and polish to the previous release by fixing a few browser bugs, internationalising strings and adding some missing images/styles.
One more thing, if you do not like the new "Installed Modules" menu system you can change back to the old system by editing the theme-stressfree/config file and setting the old_menu parameter to 1.
The updated theme can be downloaded from here.
StressFree Webmin theme version 2.03 released 10 Sep 2009 2:23 AM (16 years ago)
Version 2.03 of the StressFree Webmin theme is a significant overhaul of the underlying HTML, Perl and CSS code. Here is a rundown of the new/changed features:
- By default menus are organised by installed services with a menu for 'Unused Modules'.
- The Javascript-based curved borders code has been replaced with pure CSS/images.
- The theme should work correctly in Internet Explorer 6, 7 and 8.
- Various graphical refinements including better looking tabs.
- A "View Logs" link like that found in the default Webmin theme.
- A large number of new icons for various modules.
The revised theme can be downloaded from here.
NOTE: This is a significant upgrade so please make sure that after installing you clear your browser cache, proxy cache (if used) and Google Gears (if used).
To refresh the Google Gears cache you must open the Google Gears settings panel and remove the Webmin server from the list of allowed sites. This will delete all the cached files but it will mean you will need to re-enable Google Gears for the site.
%3C/a%3E%3C/div%3E%0A%3Cp%3E%3Cstrong%3ENOTE:%20%3C/strong%3EThis%20is%20a%20significant%20upgrade%20so%20please%20make%20sure%20that%20after%20installing%20you%20clear%20your%20browser%20cache,%20proxy%20cache%20(if%20used)%20and%20Google%20Gears%20(if%20used).%3C/p%3E%0A%3Cp%3ETo%20refresh%20the%20Google%20Gears%20cache%20you%20must%20open%20the%20Google%20Gears%20settings%20panel%20and%20remove%20the%20Webmin%20server%20from%20the%20list%20of%20allowed%20sites.%20This%20will%20delete%20all%20the%20cached%20files%20but%20it%20will%20mean%20you%20will%20need%20to%20re-enable%20Google%20Gears%20for%20the%20site.%3C/p%3E%0A%3C!--break--%3E%20%20%3C/div%3E%0A%0A%3Cul%3E%0A%0A%20%20%20%20%20%20%3Cli%3E%0A%20%20%20%20%20%20%3Ca%20href%3D%22https://www.stress-free.co.nz/tech/webmin%22%3Ewebmin%3C/a%3E%20%20%20%20%3C/li%3E%0A%20%20%0A%3C/ul%3E)
StressFree Webmin theme version 2.01 released 4 Sep 2009 11:30 PM (16 years ago)
Version 2.01 of the StressFree Webmin theme fixes a compatibility error with Webmin 1.480. All users of Webmin 1.480 or higher should upgrade to this version of the theme to avoid display errors. Along with this compatibility fix a few extra service icons have been added.
The revised theme can be downloaded from here.
USB devices with VMWare Server 2.0 on Ubuntu 16 Aug 2009 9:17 PM (16 years ago)
One of the nice features of VMWare Server 2.0 is that it supports the forwarding of USB devices to virtual machines. Unfortunately when it comes to Linux the VMWare team have leveraged an old method (/proc/bus/usb) for scanning the USB bus which newer distributions, such as Ubuntu Server 8.04 no longer support.
To resolve this problem the "old" method for scanning for USB devices must be enabled in the underlying operating system. In the case of Ubuntu Server 8.04 this is a case of editing the file /etc/init.d/mountdevsubfs.sh and uncommenting the following section:
#
# Magic to make /proc/bus/usb work
#
mkdir -p /dev/bus/usb/.usbfs
domount usbfs "" /dev/bus/usb/.usbfs -obusmode=0700,devmode=0600,listmode=0644
ln -s .usbfs/devices /dev/bus/usb/devices
mount --rbind /dev/bus/usb /proc/bus/usb
Reboot the server and /proc/bus/usb should be functional once more.
Activating a USB device within a virtual machine
Once the underlying USB subsystem is configured the USB device needs to be associated with a virtual machine. For this to occur the virtual machine must have the USB Controller added to its virtual hardware configuration. If the controller is not already part of the virtual machine's configuration shutdown the VM, add the device and restart.
Assuming there are USB devices attached to the server, once the virtual machine boots a small USB icon will appear within the VMWare web management console. Click on the icon and select the relevant USB device to attach it to the running virtual machine.
All going well the USB device will appear within the virtual machine as an accessible device. VMWare Server remembers this selection, so the next time the virtual machine (or server itself) is restarted the USB device will automatically be attached to the running VM.
![]()
Suggestions For Improving Your Research Process 21 Jul 2009 9:43 PM (16 years ago)
Below is a presentation I gave today to a group of Honors students at Victoria University's School of Architecture and Design. The presentation covers what I have learnt during my time doing my PhD and the mistakes I made, especially around the research process.
The primary message of the presentation is that research is by no means easy and when things get difficult you need to focus on MUPPET:
Motivate - Eureka moments only take you so far.
Undertake - Write something every (other) day.
Plan - Conciously identify your rainbow (objective), horse (process) and cart (interest).
Ponder - Understand how your actions relate to the research.
Exchange - Talk to everyone (relevant) about your research.
Test - Continually evaluate what you have done and where you are going.
VMWare Server 2.0 optimisations 19 Jul 2009 12:42 AM (16 years ago)
VMWare Server 2.0 is emerging as a capable, zero cost alternative to VMWare ESX when used in combination with Ubuntu Server 8.04LTS. Unfortunately "out of the box" performance can be a little disappointing, especially when running guest Windows virtual machines. What follows are a few system tweaks that can improve performance without hampering overall system stability. I have not come up with these myself, instead they are pruned from the following pages:
- VMWare FAQ: I need more performance out of my VMware environment
- VMWare Communities: Performance tuning in Server 2.0
- Ubuntu Server Installation with VMware Server
Kernel parameters
In addition to the default Ubuntu Server kernel parameters, the following should be appended to the end of /etc/sysctl.conf.
vm.swappiness=0
vm.overcommit_memory=1
vm.dirty_background_ratio=5
vm.dirty_ratio=10
vm.dirty_expire_centisecs=1000
dev.rtc.max-user-freq=1024
Once added reboot the server to ensure their application is successful and permanent.
Create an in-memory temp drive
In the host's /tmp directory create a new directory named vmware (e.g. /tmp/vmware). This will be used as the mount point for a tmpfs (in-memory) partition for storing VM related, temporary files.
Edit /etc/fstab and add the /tmp/vmware partition to your list of mount points:
tmpfs /tmp/vmware tmpfs defaults,size=100% 0 0
Now if you execute the following command the tmpfs filesystem will be mounted at /tmp/vmware:
sudo mount /tmp/vmware
If successful, reboot the Ubuntu server to ensure the tmpfs partition is mounted at boot time.
VMWare Server configuration
Edit the /etc/vmware/config file and ensure the following configuration declarations are set:
prefvmx.minVmMemPct = "100"
prefvmx.useRecommendedLockedMemSize = "TRUE"
mainMem.partialLazySave = "TRUE"
mainMem.partialLazyRestore = "TRUE"
tmpDirectory = "/tmp/vmware"
mainMem.useNamedFile = "FALSE"
sched.mem.pshare.enable = "FALSE"
MemTrimRate = "0"
MemAllowAutoScaleDown = "FALSE"
These configuration declarations instruct VMWare Server to keep all virtual machines in memory and not to write unused blocks to disk. It also sets the temporary directory to the newly created tmpfs partition at /tmp/vmware.
Restart the VMWare Server process (sudo /etc/init.d/vmware restart) or reboot the server for these changes to take effect. The net result should be notably smoother virtual machine performance, especially when it comes to Windows guests.
Virtual machine tips
- Always use fully allocated disk images.
- Do not use snapshots as they are approximately 20% slower.
- Always install the VMWare Tools package.
- If running Linux make sure the kernel is compiled for running within a VM, or is using the correct boot time parameters.
![]()
Be2camp presentation on architectural micro-blogging 15 May 2009 2:34 AM (16 years ago)
Below is the slide presentation I will (hopefully) present at tonight's Be2camp North un-conference. Basically the presentation graphically summarises my recent blog post on the use of micro-blogging within architectural collaboration.
The conference is in Liverpool and I am in New Zealand, so if the technology gods are not in a good mood things may go pear shaped very quickly...
Using micro-blogging to record architectural design conversation alongside the BIM 11 May 2009 2:16 AM (16 years ago)

The majority of professionals within the architecture, engineering and construction (AEC) industry use the telephone and email to collaborate on immediate design problems. Unfortunately there is a disconnection between this communication and the underlying Building Information Model (BIM) where the agreed upon architectural solution is recorded. As a consequence it is difficult for a person interacting solely with the BIM to take part or learn from this external conversation because they are often oblivious to it taking place. Micro-blogging is an emerging, Internet-based communication medium that may provide the common thread to tie these disparate sources of project information together. It will achieve this through enabling the issues and outcomes discussed during architectural conversations to be quickly recorded by any member of the project team. Those working on the BIM will be able to actively monitor and search across these conversations to keep up to date with the project’s state and help solve new design problems.
Unlike blogging and instant messaging, micro-blogging can communicate simple messages between groups of people using mobile phones or any Internet connected device. These conversations are published online so they can be referenced in further design discussion, or indexed for searching alongside other sources of project information. For adoption to occur the technology must be integrated within the BIM toolset so that being part of this conversation is a natural extension of the digital workspace. Current micro-blogging services such as Twitter, lack this integration and have not (yet) been tailored to meet the specific demands of architectural collaboration. A focused implementation would likely improve architectural collaboration because micro-blogging embodies many of the principles of the Project Information Cloud. Its qualities of simplicity, ubiquity, decentralisation, modularity, awareness, context sensitivity and evolving semantics make it a promising collaboration medium, and one that could move the AEC industry towards the goal of hyperlinked practice.
What is micro-blogging?
Micro-blogging is an emerging Internet-based communication medium that could significantly improve the timeliness and accessibility of architectural collaboration discussion. Made popular by the Twitter web service, conceptually it is a combination of some of the best features of email, text messaging (SMS), blogging, and instant messaging (IM). The result has the flexibility of email, the ubiquity of SMS and the immediacy of IM, whilst its content can be browsed, referenced or indexed like a traditiona blog. Through this “best of bread” combination, micro-blogging creates a text-based communication platform that can be accessed by any network connected device. The technology has proven adept at conveying news and discussion amongst clusters of individuals who share common interests, for example debating the 2008 US election. Currently adoption is centered around public sites such as Twitter and Tumblr, but efforts are underway to inject the technology into business through initiatives such as Yammer.
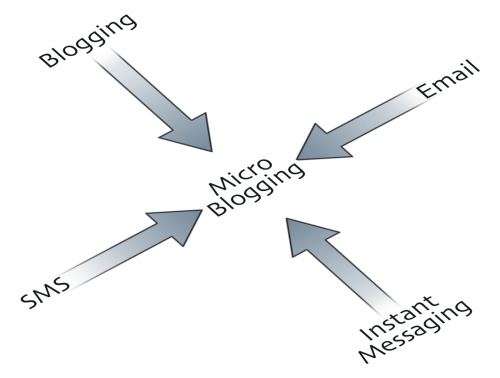
At a practical level, micro-blogging is the publishing of a short text message to an Internet service responsible for notifying other users and publishing the message on the Web. The concise nature of these messages (~140 characters) allows them to be produced and consumed by almost any device connected to a cellular network or the Internet. This means taking part in design discussion is not limited to a specific device or context, and as such collaborators are free to participate at a time and place of their choosing. Whilst reaching a broad audience is important, the technology also attempts to solve the communication overload which plagues contemporary communication tools. Ironically this overload stems from their primary benefit; the immediate, unfiltered and low-cost access the telephone, facsimile and email provide. The underlying issue with these tools being the assumption that a recipient is either interested in, or the most relevant receiver of the message, question or data conveyed. For decision making within large groups this becomes unwieldy as it relies on everyone maintains a strong understanding of the team’s dynamic and knowledge distribution. In contrast micro-blogging encourages participants to explicitly state their interests by 'subscribing' to other’s accounts, or ‘tracking’ keywords as they are published. This enables collaborators to control the quantity and type of information received, and as a consequence indicates to others who and what the person is interested in.
i.e. I am interested in receiving messages from these people, and monitoring conversations taking part within the broader group around these topics.
How can micro-blogging improve architectural collaboration?
An evolved, AEC-specific micro-blogging platform could in the long-term prove as influential to architectural collaboration as the facsimile or email. The technology will not replace other communication tools, in fact for direct or complex interactions the telephone and email will always be the preferred tool of choice. Instead micro-blogging will form a digital conversation layer around the BIM where collaboration issues and outcomes can be monitored and discussed by the entire project team. This will benefit architectural collaboration by improving the timeliness and accessibility of information related to project decisions and current issues. From the point of view of the building life-cycle, micro-blog content will help preserve a history of the design and construction process, supporting what is recorded within the BIM.
Conventional collaboration tools assume the conversation initiator knows who should take part, and that those selected can participate at that time using the chosen medium. For example teleconferences are limited to those invited on the call at that time, whilst email involves only those explicitly included, or carbon copied, into the conversation. The collaboration exchanges in both cases are self contained, with outcomes requiring manual dissemination throughout the project team. In comparison recipients of micro-blog messages are not explicitly defined, instead they are inferred through a social networking and search-based syndication process. A recipient may have expressed an interest in receiving some (or all) of the author’s messages, or alternatively may have configured real-time searches for particular keywords. Relevant messages can be delivered to almost any network connected digital device, allowing a team member to monitor or participate in design conversation from any location.
Beyond exposing internal conversations to the broader design team, an added architectural collaboration benefit is that micro-blogging produces HTML artifacts. Each message generates a corresponding HTML document that has a unique address (URI), links to further information, the author’s details and the date of publication. These documents become part of the project’s knowledge base, and can be browsed, referenced or indexed using existing web browsers and search engines. From the collaboration perspective this is important because it enables knowledge reuse, and new members can familiarise themselves with the project’s design history. This is significant improvement over contemporary communication tools whose content cannot be easily referenced by, or stored alongside, other project data such as the BIM.
The following hypothetical scenario illustrates how micro-blogging could be used in practice to improve architectural collaboration. This scenario illustrates nine pieces of functionality that a dedicated AEC micro-blogging platform should enable in order to best satisfy a team’s collaboration needs:
- Seamless Integration with BIM applications.
- Rich searching of project content.
- Hyperlinking to supporting digital media.
- Significance derived through identity and meta-data.
- Prompting for micro-blog entries on key events.
- Monitoring of content for important events or topics.
- Publishing to shared messaging channels.
- Delivery of messages to a preferred device.
- Integration with digital cameras and GPS devices.
"Kelly was helping John, one of the Practice's directors make design alterations to a large office development in order for it to meet the client’s requirements. Prior to an element being modified in the Building Information Model (BIM) the program would list relevant design discussion drawn from the project team's micro-blogs. This worked by Kelly selecting part of the model and asking the search tool to find micro-blogs that had linked to, or included tags relating to, this particular area of the building. Kelly had ordered this information by significance, so in this case content published by her direct supervisors was listed above that of others such as the quantity surveyor. Whilst most of this was unimportant, Kelly often came across micro-blogs published during the briefing process or on-site that highlighted issues she was unaware of. In this instance there were no obvious problems, so Kelly repositioned the wall element within the BIM and saved the changes. As the application registered this as a significant change she was prompted to record a micro-blog entry explaining what she had done and why. Kelly dutifully entered that she moved the wall to satisfy the client, and supported her claim with a link to the change request within the project's document repository. She described the change and her message was automatically tagged "#change-alert" so that everyone who mattered within the project would receive the update.
John meanwhile was running late to the project’s weekly site meeting. His cellphone beeped with the arrival of Kelly's SMS micro-blog message, that let him know the design change had been made and the updated plans were available. As usual the 'idealised' design process had gone out the door months ago, and now the client wanted the internal wall moved only after its construction had begun. Arriving onsite he found the foreman had also received the message and had downloaded the updated plans to his laptop. However on inspecting what was already built they soon came to the conclusion the change would not work due to the existence of a heating pipe that was not in Kelly’s BIM. Needing a compromise, John used his smart-phone to take photographs of the problem, which he posted to his micro-blog along with a few ideas Kelly could explore. At this point Richard, the building services engineer chimed in with a micro-blog that the pipe was a late addition by the client, and that clear access to it was very important. Richard had moved on to a new job, but he had kept tracking the project for any messages about services just in case a problem like this were to occur. John and the foreman had a brief teleconference with Richard to discuss alternatives. Prior to leaving the site John used his cellphone to post a micro-blog stating he had discussed the problem with Richard and requested an up to date services model for Kelly. He would not get back to the office for a while, but by then he hoped Kelly would have at least received and digested the revised services layout from Richard.”
Micro-blogging within the Project Information Cloud
Successful architectural collaboration involves understanding the decisions, compromises and assumptions which occurred during the creation of the built form and its digital representations. The Project Information Cloud is an Internet-centric knowledge network formed around a BIM in order to improve collaboration and data capture within distributed projects. It is the loosely coupled, digital space where these exchanges and associated data can be recorded, shared and referenced to each other or relevant project information. There is a need for such a construct because BIM’s centralised and controlling nature cannot adequately record or properly represent these unstructured data streams. Whereas Intranets consolidate ownership and control, a Project Information Cloud’s goal is to enable seamless collaboration across organisational and contextual borders. Given this ambition the Project Information Cloud is not a single technology, but a set of principles that can be applied to the development of architectural collaboration tools. Tools that embody these principles will improve the timeliness and accessibility of relevant project information, and in the long-term enable the goal of Hyperlinked Practice.
The seven principles of the Project Information Cloud are:
- Simple - The collaboration technology is easily to understand and capable of being used by the widest audience, for example architects, clients and contractors. This simplicity should extend beyond that of the user interface into the collaboration metaphors and technical architecture employed. Collaboration is most effective when participants comprehend how their tools help facilitate and empower their role within the project team.
- Ubiquitous - The collaboration technology should be readily available and cost-effective to use in a variety of contexts, from design office to construction site. The concept of ubiquity should extend beyond the prevalence of the physical device or software tool to the ability of a broad number people to utilise it. Simple software that is well understood and available to all is ultimately a more powerful collaboration tool than complex tools which only a limited number of participants can understand or access.
- Decentralised - Contributed collaboration data should not be dependent on a single, centralised system for its continued existence or be 'owned' by a single party. On leaving a team participants should be able to easily make digital copies of the design conversation they have participated in. Whilst productive within a closed environment, centralised collaboration structures promote control and restrict conversation, which in a distributed team leads to friction and confusion.
- Modular - It should be possible to add or remove functionality from collaboration end points, i.e. the software participants use to interact with each other, without breaking the compatibility or reliability of the overall communication system. Likewise participants should not be forced to use specific software in order to take part in digital conversations. Similar to how any certified telephone can be used to make phone calls, successful digital collaboration should emphasise interoperability.
- Information Aware - Collaboration systems should assume that they are part of a larger ecosystem and strive to integrate with this environment as much as possible. Integration should include the ability for the tools themselves to automatically seek out and classify relevant digital information from sources within the team and externally. In modern, attention starved workplaces, the more independently a digital tool can operate within a collaboration ecosystem, the more valuable it becomes to the end-user.
- Context Sensitive - Information should be presented in a manner that is relevant to the collaboration situation and people consuming it. The sheer quantity of digital data in an architectural project can confuse or overwhelm design conversation if not managed properly. To compensate digital collaboration tools should strive to act as intelligent information brokers to ensure design conversation between participants remains coherent and distinct from a project’s background noise.
- Evolving Semantics - Collaboration data should be unbounded by a rigid structure so that those taking part are free to convey any architectural concept. Contemporary collaboration tools such as BIM employ rich, but rigid, semantic models which ultimately prove less versatile than tools which communicate simple, unstructured data. Highly structured data formats cause a great deal of collaboration friction if the consuming tools are not fully compatible, or the concepts conveyed are not comprehensively supported.
If a digital collaboration tool fails to satisfy one or more of these principles the likelihood of it playing a productive role within the Project Information Cloud is reduced. This argument is supported by the limited adoption prior digital architectural collaboration initiatives that have failed to satisfy many of the principles outlined. Consequently these tools have imposed high technical barriers to entry, or have exhibited collaboration shortcomings when deployed within distributed project teams. For example BIM is unquestionably a very powerful architectural productivity tool, but for enabling collaboration within a project team it is weak in many of the described areas. As a result project teams have turned to simpler, more ubiquitous technologies such as PDF, DWF and email to exchange data about a BIM within the project team.
Micro-blogging embodies many of the principles of the Project Information Cloud and therefore stands to become a productive architectural collaboration platform. This is in part because it has evolved as a response to the complexities witnessed in the first wave of Internet-based communication and collaboration initiatives. Whilst simplicity and ubiquity are key factors in its initial success, its ability to satisfy the other principles of the Project Information Cloud are growing with time.
Simple
Publishing 140 character plain text messages is simple to implement, and premise that a person “follows” others or “tracks” ideas is easily understood by a broad audience. With this conceptual foundation in place users and developers have been free to utilise and expand on the concept in a multitude of ways. For example the prevalent use of hyperlinking within micro-blog content has enabled a variety referencing and multimedia capabilities not present in the original implementation. Here rather than introducing complexity to solve new problems, the application of another simple concept, the hyperlink, has enabled sophisticated outcomes. Further examples in simplicity can be found in the evolutionary use of characters such as @ and # to represent reply and topic fields within micro-blogs. Whereas many technologies have added complexity to enable such functionality, recording this information within the message has ensured micro-blogging remained simple.
Ubiquitous
The simple conceptual and technical characteristics of micro-blogging enables its content to be produced or consumed on almost any network connected digital device. This platform ubiquity ensures micro-blogging is accessible to the broadest possible audience in terms of technical ability, network availability or workplace context. From a collaboration perspective this is important because it gives all potential participants the opportunity to passively monitor or actively take part in project discussion. At a technical level micro-blogging has also leveraged ubiquitous communication protocols such as HTML, RSS and XMPP to output a user’s message stream. This has enabled the rapid growth of a broad micro-blogging ecosystem, complete with external services that consume and add value to the underlying data. For example conventional search engines can crawl a micro-blog’s HTML content, whilst newer ‘live‘ search and trend services can monitor XMPP output in near real-time. The benefit of this ubiquity is two fold; the service can integrate with existing infrastructure, and developers can efficiently add functionality using well understood technologies.
Decentralised
Whilst the decentralisation of micro-blogging is in its preliminary stages, if successful it will enable greater levels of scalability, privacy and flexibility. Twitter is currently the most popular micro-blogging implementation, but due to its centralised nature, it is also notorious for its unreliability due in large part to scalability issues. In response decentralisation and cross-platform interoperability are paramount objectives for “second generation” micro-blogging platforms such as Laconica.
"The model I am trying to follow is email. You have different servers that have different domains... But they are all interconnected, and as long as they are speaking the same simple protocol they work pretty well.”
Evan Prodromou, Developer of Laconica, FLOSS Weekly, Episode 37
Initiatives such as this have led to the OpenMicroBlogging specification, which along with OAuth and YADIS establish protocols for the discovery and creation of micro-blogs. Whilst at this time it is unlikely Twitter will adopt all of these standards, their existence will ensure competition and interoperability will be strong within the micro-blogging market.
Modular
The concept and technologies behind micro-blogging are relatively simple and as a consequence the number of implementations of different types is steadily growing. Besides Twitter other examples of independently produced micro-blogging platforms include Jaiku, Laconica, Tumblr, Yammer and FriendFeed. Whilst at this time interoperability between these disparate systems is inconsistent, standards like OpenMicroBlogging, OAuth and YADIS are beginning to enable it. Micro-blogging has also demonstrated its modularity through the rapid and diverse growth of the client software which interacts with the service. Through hyperlinks and semantic syntax (@ and #) developers have been able to add new layers of functionality onto micro-blogging without breaking backwards compatibility. The first and most prevalent of these is the widespread use of URL shortening services such as TinyURL to make long hyperlinks micro-blog friendly (i.e. < 20 characters). Beyond simple URLs, micro-blogging specific photo sharing sites such as TwitPic make it easy for client software to upload and display images within standard messages. From an architectural collaboration perspective this is powerful as the majority of design problems are visual in nature, making communication using only 140 characters difficult.
Information Aware
The most powerful property of micro-blogging is its emphasis on live, customised data streams that are generated based on user lists (follow) and keywords (track). As a result micro-blogging clients are inherently information aware because their purpose is to monitor and clearly display an ever changing conversation space. However evolutionary improvements still need to be made to these interfaces to better manage the continual flow of data and minimise the risk of information overload. Beyond consumption, micro-blogs expose data as HTML, RSS and XMPP streams so that other information aware tools can collect, present and act on this information. For example Yahoo Pipes can aggregate multiple micro-blogs, perform complex operations on the data, (filter, manipulate, etc.) and output the result as a new RSS feed. Finally the simple and ubiquitous nature of micro-blogging is helping it become a medium for third-party applications to publish messages such as event notifications. An early but unique example of this is Tweet-a-Watt, an Internet connected electricity monitor that automatically publishes a building’s daily power consumption to Twitter.
Context Sensitive
The growing use of @ and # characters to identify people and topics is allowing more contextual information beyond creation time to be recorded within a micro-blog message. Emphasis has now shifted to the development of intelligent clients and services that can interrogate and represent these contextual nuances to users in more meaningful ways. For example micro-blog streams are unthreaded, but many clients can recreate message threads through the weaving relevant person, topic and creation time meta-data. Whilst still in its early stages, services like FriendFriend use such techniques to facilitate “real-time conversation”, loosely threaded discussions derived from micro-blog content. Beyond real-time conversation is the eventual integration of micro-blogging content with other digital activities such as the creation of a shared document or digital model. Although no concrete examples have yet to emerge, it is only a matter of time before micro-blogging is integrated within applications such as these to create powerful results.
Evolving Semantics
Micro-blogging has no predefined semantic structure, but the recording of meta-data within a message via hash tags has occurred through a process of community acceptance. Initially these tags have been used to aid in search and to identify semantic trends within micro-blogging communities, for example the hashtags.org service for Twitter. Whilst hash tags have given micro-blogging a flexible semantic mechanism, the drawback is that including tags within a message reduces the space available for content. A consequence of this trade-off is that micro-blogs form shallow, but broad semantic structures with only a limited number of explicit relationships formed between tags. For example a micro-blog message on CAD may apply the explicit tag #revit or #microstation, but the more generic #cad tag may be omitted for the purposes of brevity. This reduces the navigability of the semantic structure because many of the required higher-level links between terms and associated content is omitted. To counter this shortcoming “micro-blog thesauruses” may emerge to allow people to browse micro-blog semantic trees using implicit (rather than explicit) relationships.
Why the AEC Industry needs a dedicated platform
Micro-blogging adheres to the Project Information Cloud’s principles, but consumer micro-blogging services do not satisfy the AEC industry’s operational requirements. Although a consumer service such as Twitter could theoretically be used by a project team, adoption would be mixed and the outcome unsatisfactory. For broad adoption an AEC-specific micro-blogging solution must integrate with existing workflows, respect the team hierarchy, store information securely and operate reliably within distributed environments.
BIM/CAD integration
AEC professionals spend a good portion of their workday interacting with BIM and CAD models. If micro-blogging is to gain acceptance in this field it needs to seamlessly integrate with the tools used to interact with these models and the accompanying workflows. Given this emphasis, to be of most value in the collaboration process micro-blog content needs to be presented alongside the source material. For example displaying and searching for relevant micro-blog content within the BIM or CAD model viewers and editors is an important integration point. Likewise to preserve the workflow, functionality should be provided to create micro-blog messages from within the BIM and CAD applications themselves. This should include the prompting for updates on significant events, and the ability to create and link to screen captures or 3D models when composing a message.
Comprehension of the project team hierarchy
Unlike consumer micro-blogging services a system targeted at AEC professionals needs to comprehend and respect the hierarchical nature of project teams. Rather than placing the onus on the user to manually identify and create these relationships the basic network should be maintained within a project template. Managers would create this template using a tool that lets them map the working and security relationships between project participants. By maintaining this hierarchy it allows the people and topics followed by a user to be automatically updated as the composition of the project team changes. This would save people time by keeping them informed of developments, and in the process expose them to new sources of information within the team.
Context-level security
The AEC industry is a litigious environment and as a consequence any micro-blogging solution used within it must be capable of restricting access to published content. Currently the security options offered by Twitter, or even the business-centric Yammer, are limited in that content can only be restricted at a user-level. For example whilst it is possible to mark a message stream as private, once another user is granted read access they can read every piece of content published by this account. However project teams are distributed and dynamic, so a finer grained, context-level access control system is required that filters access to specific parts of a message stream. For example an external consultant joining a micro-blog conversation should only be able to view messages posted by team members relating to that specific project. Additionally it may be necessary for the project administrators to filter access to users based on specific topics or periods of time. This would enable the consultant’s access to be limited further to messages published between a defined period of time about specific aspects of the design. From a practical perspective this context-level security would be applied at the micro-blog servers as this would allow the client software to operate unchanged.
Decentralised implementation
Architecture projects are temporary collaborations between multiple organisations so it cannot be assumed that all parties will be using the same micro-blogging system. For an AEC-specific implementation to be successful it needs to allow participants to seamlessly collaborate whilst using different micro-blogging services. As discussed earlier this is an important principle of the Project Information Cloud and a primary goal of second-generation micro-blogging platforms. To consistently apply the project hierarchy and context-level security settings across micro-blogging services the relevant information would need to be exchanged. In theory an AEC micro-blog system could operate without this data transfer, but if it were to occur the benefit to the end-user experience would be considerable.
Digital collaboration-fact, not fiction
Although the architectural collaboration example and AEC specific requirements may seem far fetched, much of the functionality highlighted already exists. Therefore implementing a working, AEC-specific micro-blogging collaboration system is more a case of putting the right pieces together than inventing a new wheel. The following examples illustrate how these functional characteristics exist today, and hint at how an AEC-specific implementation may operate in the future.
1. Seamless Integration with BIM applications
There are many standalone desktop micro-blogging applications (for example Thwirl and Spaz), but some developers are taking the concept further by integrating into the desktop itself. MoodBlast and Twitterific are two examples where the line between micro-blogging and traditional desktop functionality is blurred.
For example when browsing the Web, pressing a hot-key combination will display a MoodBlast message window and pre-fill it with the browser's current URL. When the message is submitted the URL is automatically shortened and the result posted to a variety of micro-blogging systems. Likewise Twitterific regularly displays new content published to your social network so that you can be updated of events while working. Mechanisms such as these could easily be included within BIM applications to allow users to publish and consume micro-blogging content alongside project model data.
2. Rich searching of project content
Building search indexes from micro-blog messages is technically relatively simple given the problem of searching Web content has existed for some time. Unfortunately the message size restrictions limits the quantity of meta-data that can be associated, and as a consequence it is unlikely search relevancy can be improved. However Twitter Search has been able to include unique search parameters such as ‘attitude’, which is made possible by micro-blogging’s real-time, conversational nature. Yet to be fully exploited is the search potential derived from the social network formed through micro-blogging’s acts of following and being followed by others. In a distributed team the ability to ask, “who do I know that may know the answer to this question?” is in many ways more useful than “what is the answer to this question?”
3. Hyperlinking to supporting digital media
Given the limited payload size for a micro-blog message it is very common to include a hyperlinks to external Internet resources. This capability and the resulting obfuscation caused by URL shortening leads to the crafting of messages which succinctly convey what is important about the included link. For example, “The revised ground floor plan showing the realigned internal wall (PDF): http://aecurl.com/GEDJ32”. From a comprehension and search standpoint this is an efficient process as it encourages resources to be described rather than having them exist as anonymous files. Currently for internal documents this process is not as simple as it should be, but services like TwitDoc hint at how this process can be made easier for AEC professionals.
4. Significance derived through identity and meta-data
Unlike the majority of conventional Web content, the current assumption with a micro-blog is that like email it is published by a specific person. This provides a strong mechanism for identifying reliable information as the source and recipients of the message can easily be identified. Likewise by constructing a map of references between micro-blogs and hyerlinked URLs it is possible to quickly identify significant project events and resources. This technique, known as PageRank, is common in search engines, but in a real-time micro-blogging environment it can be used to identify emerging 'flash points'. Two services that demonstrate this functionality are Twitterurls and Twitlinks, both of which monitor and display popular trends, media and hyperlinks published to Twitter.
5. Prompting for micro-blog entries on key events
Like a traditional diary, a micro-blog gains more value as a historical record of events the more frequently it is used. Integrating the technology into productivity tools such as BIM will assist in this adoption process, but to foster regular submissions the tool should proactively seek input. A basic example of a proactive micro-blogging mechanism is the Yammer Time Firefox plug-in for the Yammer service. However whilst a time-based approach would meet with some success, a mechanism activated on key events would be more efficient and less obtrusive. For example saving a BIM after changing identified elements, or crossing an overall model change threshold, could trigger a request for a micro-blog justification.
6. Monitoring of content for important events or topics
Micro-blogs are time-sensitive records and one of their most important characteristics is their ability to display the “real-time” status of a distributed discussion. The most powerful demonstration of this has been Twitter’s trending and tracking functions which allow users to easy monitor events or topics within the broader community. TweetDeck provides a dashboard-like interface where a subset of this dynamic information can be easily monitored and acted upon.
Such functionality would be useful to a project manager wishing to keep on top of issues as they could monitor the project stream for trends and specific “problem” keywords. If successful in some situations this may see a shift from reactive to proactive decision making based on issues detected at an early stage of development.
7. Publishing to shared messaging channels
A significant portion of architectural collaboration micro-blog content would not be targeted at a specific person, but instead concern a particular topic. Applying of hash tags to messages would ensure the content was received by relevant people via micro-blogging’s tracking mechanism. The role of a dedicated AEC service would be to make using and tracking these hash tags as simple and automated as possible. One example could be the syndication of project hash tags to desktop clients so that instead of working from memory participants could choose “messaging channels” from a list. This way a team member could follow the project’s conceptual design (#concept) and development (#devel) channels without having to remember the correct hash tag(s) to use.
8. Delivery of messages to a preferred device
The design of micro-blogging services and their ~140 character limitation is to ensure they can be delivered to any network connected device. From an AEC collaboration perspective this characteristic is important because it cannot be assumed project team members will have Internet connectivity. Whilst adoption of Internet-capable smart-phones is growing, the majority of the workforce still uses “traditional” cellular devices and desktops with fixed Internet connections. As a consequence the ability to deliver or publish important micro-blog notifications via SMS is a significant capability should a design problem be identified.
9. Integration with digital cameras and GPS devices
Camera and GPS equipped smart-phones such as the iPhone and Blackberry are pushing the boundaries of micro-blogging client applications. Software like Tweetie and TweetGenius make it simple for photos taken using a smart-phone to be uploaded to a micro-blog along with accompanying GPS data. From an AEC perspective this capability is very useful during construction as the process shortens the feedback loop between the site and office. For example onsite progress or problems are typically recorded using a digital camera, and the resulting images are emailed or physically taken back to the office. Either process takes time and there is no guarantee that the images will make their way into the project’s knowledge base or distributed throughout the team. In contrast a micro-blogging application on a smart-phone can upload a photo and instantly include a reference to it within the project’s message stream.
Conclusion
A correctly implemented, AEC-specific micro-blogging implementation could become a powerful and valuable architectural collaboration mechanism. Success hinges on the service embracing the principles of the Project Information Cloud and respecting the workflows and operational requirements of AEC professionals. Implementing the service would not be a simple task, but the functional groundwork has already been laid in the broader micro-blogging ecosystem.
Google O3D may finally bring 3D to the Web 22 Apr 2009 3:23 AM (16 years ago)

Today Google released a very early preview of O3D, a cross-platform, open source plug-in that enables OpenGL accelerated graphics within Web browsers. Delivering 3D graphics within browsers is not a new thing, (remember VRML?) but what makes this initiative promising is that it works on all platforms and is backed by Google. Performance-wise O3D seems very snappy when compared to alternatives such as Flash 3D. As a result some of the initial demonstrations are very impressive, and it hints at a future where Google Earth and SketchUp leave their desktop roots behind to become pure web applications.
From an architectural collaboration perspective O3D is valuable for a number of reasons. Firstly in a review situation it would mean remote clients can experience 3D designs without having to download, install and learn a separate "viewer" application. Likewise within an intranet such functionality would be valuable when navigating a project or company knowledge base. Whereas at the moment textual (web) data is quite distinct from 3D models, in a O3D-enabled future the two could be seamlessly intertwined in a variety of powerful ways. Finally by freely distributing 3D capabilities to everyone with a browser O3D opens up the possibility for new types of 3D-centric web applications that allow all design team participants to more effectively communicate ideas with one and other. For examples of these potential markets checkout the section 'Where will Dragonfly land?' in my earlier 'Autodesk Dragonfly emerges from its larvae' post. The people behind O3D's demo applications seem to appreciate this fact too, because the "Interiors" demo showcases such a tool (i.e. it 'copies' Project DragonFly).
A 3D, Google Trends view of the Earth in O3D
I have not yet created or rendered content using O3D, but if I get the chance there is a significant amount of developer documentation online. Anybody with web development experience should feel at home because the rendering engine is initiated and controlled using Javascript. This is a great choice, not only does it make the technology accessible, but it means 3D can be integrated into "traditional" web applications using standard Javascript event handlers. For example if you were creating a web-based CAD application you could create the majority of the user-interface using standard HTML/Javascript and leave O3D to handle just the rendering of the model window(s). Such an approach also means developers who already have already created 3D web applications in Flash and HTML could leverage O3D without being completely rewritten.
Overall O3D comes across as a very powerful and surprisingly polished early preview. Google are obviously very serious about 3D in the browser, and this implementation seems to be the most promising yet.
%20but%20what%20makes%20this%20initiative%20promising%20is%20that%20it%20works%20on%20all%20platforms%20and%20is%20backed%20by%20Google.%C2%A0Performance-wise%20O3D%20seems%20very%20snappy%20when%20compared%20to%20alternatives%20such%20as%20Flash%203D.%20As%20a%20result%20some%20of%20the%20%3Ca%20href%3D%22http://code.google.com/apis/o3d/docs/samplesdirectory.html%22%3Einitial%20demonstrations%3C/a%3E%20are%20very%20impressive,%20and%20it%20hints%20at%20a%20future%20where%20Google%20Earth%20and%20SketchUp%20leave%20their%20desktop%20roots%20behind%20to%20become%20pure%20web%20applications.%3C/p%3E%0A%3Cdiv%3E%0A%0A%0A%3C/div%3E%0A%3C!--break--%3E%0A%3Cp%3EFrom%20an%20architectural%20collaboration%20perspective%20O3D%20is%20valuable%20for%20a%20number%20of%20reasons.%20Firstly%20in%20a%20review%20situation%20it%20would%20mean%20remote%20clients%20can%20experience%203D%20designs%20without%20having%20to%20download,%20install%20and%20learn%20a%20separate%20%22viewer%22%20application.%20Likewise%20within%20an%20intranet%20such%20functionality%20would%20be%20valuable%20when%20navigating%20a%20project%20or%20company%20knowledge%20base.%20Whereas%20at%20the%20moment%20textual%20(web)%20data%20is%20quite%20distinct%20from%203D%20models,%20in%20a%20O3D-enabled%20future%20the%20two%20could%20be%20seamlessly%20intertwined%20in%20a%20variety%20of%20powerful%20ways.%20Finally%20by%20freely%20distributing%203D%20capabilities%20to%20everyone%20with%20a%20browser%20O3D%20opens%20up%20the%20possibility%20for%20new%20types%20of%203D-centric%20web%20applications%20that%20allow%20all%20design%20team%20participants%20to%20more%20effectively%20communicate%20ideas%20with%20one%20and%20other.%20For%20examples%20of%20these%20potential%20markets%20checkout%20the%20section%20'Where%20will%20Dragonfly%20land?'%20in%20my%20earlier%20'%3Ca%20href%3D%22https://www.stress-free.co.nz/autodesk_dragonfly_emerges_from_its_larvae%22%3EAutodesk%20Dragonfly%20emerges%20from%20its%20larvae%3C/a%3E'%20post.%20The%20people%20behind%20O3D's%20demo%20applications%20seem%20to%20appreciate%20this%20fact%20too,%20because%20the%20%22Interiors%22%20demo%20showcases%20such%20a%20tool%20(i.e.%20it%20'copies'%20Project%20DragonFly).%3C/p%3E%0A%3Cdiv%3E%3Cimg%20src%3D%22https://www.stress-free.co.nz/sites/default/files/u63/o3d_trends.jpg%22%20alt%3D%22%22%20width%3D%22400%22%20height%3D%22361%22%20/%3E%3Cbr%20/%3EA%203D,%20Google%20Trends%20view%20of%20the%20Earth%20in%20O3D%3C/div%3E%0A%3Cp%3EI%20have%20not%20yet%20created%20or%20rendered%20content%20using%20O3D,%20but%20if%20I%20get%20the%20chance%20there%20is%20a%20significant%20amount%20of%20%3Ca%20href%3D%22http://code.google.com/apis/o3d/docs/devguideintro.html%22%3Edeveloper%20documentation%3C/a%3E%20online.%C2%A0Anybody%20with%20web%20development%20experience%20should%20feel%20at%20home%20because%20the%20rendering%20engine%20is%20%3Ca%20href%3D%22http://code.google.com/apis/o3d/docs/devguidechap01.html%22%3Einitiated%20and%20controlled%3C/a%3E%20using%20Javascript.%20This%20is%20a%20great%20choice,%20not%20only%20does%20it%20make%20the%20technology%20accessible,%20but%20it%20means%203D%20can%20be%20integrated%20into%20%22traditional%22%20web%20applications%20using%20standard%20Javascript%20event%20handlers.%20For%20example%20if%20you%20were%20creating%20a%20web-based%20CAD%20application%20you%20could%20create%20the%20majority%20of%20the%20user-interface%20using%20standard%20HTML/Javascript%20and%20leave%20O3D%20to%20handle%20just%20the%20rendering%20of%20the%20model%20window(s).%20Such%20an%20approach%20also%20means%20developers%20who%20already%20have%20already%20created%203D%20web%20applications%20in%20Flash%20and%20HTML%20could%20leverage%20O3D%20without%20being%20completely%20rewritten.%3C/p%3E%0A%3Cp%3EOverall%20O3D%20comes%20across%20as%20a%20very%20powerful%20and%20surprisingly%20polished%20early%20preview.%20Google%20are%20obviously%20very%20serious%20about%203D%20in%20the%20browser,%20and%20this%20implementation%20seems%20to%20be%20the%20most%20promising%20yet.%3C/p%3E%0A%3Cp%3E%C2%A0%3C/p%3E%20%20%3C/div%3E%0A%0A%3Cul%3E%0A%0A%20%20%20%20%20%20%3Cli%3E%0A%20%20%20%20%20%20%3Ca%20href%3D%22https://www.stress-free.co.nz/thesis%22%3Ethesis%3C/a%3E%20%20%20%20%3C/li%3E%0A%20%20%20%20%20%20%3Cli%3E%0A%20%20%20%20%20%20%3Ca%20href%3D%22https://www.stress-free.co.nz/tech/google%22%3Egoogle%3C/a%3E%20%20%20%20%3C/li%3E%0A%20%20%20%20%20%20%3Cli%3E%0A%20%20%20%20%20%20%3Ca%20href%3D%22https://www.stress-free.co.nz/tech/autodesk%22%3Eautodesk%3C/a%3E%20%20%20%20%3C/li%3E%0A%20%20%20%20%20%20%3Cli%3E%0A%20%20%20%20%20%20%3Ca%20href%3D%22https://www.stress-free.co.nz/tech/dragonfly%22%3Edragonfly%3C/a%3E%20%20%20%20%3C/li%3E%0A%20%20%0A%3C/ul%3E)